【vLLM 学习】调试技巧
vLLM 是一款专为大语言模型推理加速而设计的框架,实现了 KV 缓存内存几乎零浪费,解决了内存管理瓶颈问题。
更多 vLLM 中文文档及教程可访问 →https://vllm.hyper.ai/
调试挂起与崩溃问题
当一个 vLLM 实例挂起或崩溃时,调试问题会非常困难。但请稍等,也有可能 vLLM 正在执行某些确实需要较长时间的任务:
- 下载模型: 您的磁盘中是否已经下载了模型?如果没有,vLLM 将从互联网上下载模型,这可能需要很长时间。请务必检查互联网连接。最好先使用 huggingface-cli 下载模型,然后使用模型的本地路径。这样可以就没有问题了。
- 从磁盘加载模型: 如果模型很大,从磁盘加载模型可能需要很长时间。请注意存储模型的位置。一些集群在节点之间共享文件系统的速度可能很慢,例如分布式文件系统或网络文件系统。最好将模型存储在本地磁盘中。另外,还请注意 CPU 内存使用情况。当模型太大时,可能会占用大量 CPU 内存,这可能会降低操作系统的速度,因为它需要频繁地在磁盘和内存之间交换内存。
- 张量并行推理: 如果模型太大而无法容纳在单个 GPU 中,您可能需要使用张量并行将模型拆分到多个 GPU 上。在这种情况下,每个进程都会读取整个模型并将其拆分成块,这会使磁盘读取时间更长(与张量并行度的大小成正比)。您可以使用该脚本将模型检查点转换为分片检查点。转换过程可能需要一些时间,但之后您可以更快地加载分片检查点。无论张量并行度的大小如何,模型加载时间都应维持稳定。
如果您已经解决了上述问题,但 vLLM 实例仍然挂起,CPU 和 GPU 的利用率接近于零,那么 vLLM 实例可能卡在了某个地方。以下是一些有助于调试问题的提示:
- 设置环境变量
export VLLM_LOGGING_LEVEL=DEBUG以打开更多日志记录。 - 设置环境变量
export CUDA_LAUNCH_BLOCKING=1以准确定位哪个 CUDA 内核引发了问题。 - 设置环境变量
export NCCL_DEBUG=TRACE以开启 NCCL 的更多日志记录。 - 设置环境变量
export VLLM_TRACE_FUNCTION=1。vLLM 中的所有函数调用将被记录下来。检查这些日志文件,找出哪个函数崩溃或挂起。
通过更多日志记录,希望您能够找到问题的根本原因。
如果程序崩溃,并且错误追踪显示在 vllm/worker/model_runner.py 中的 self.graph.replay() 附近,那么这是一个发生在 cudagraph 内部的 CUDA 错误。要知道引发错误的具体 CUDA 操作,您可以在命令行中添加 --enforce-eager,或者在 LLM 类中设置 enforce_eager=True,以禁用 cudagraph 优化。通过这种方式,您可以准确定位导致错误的 CUDA 操作。
以下是一些可能导致挂起的常见问题:
- 错误的网络设置:如果你的网络配置很复杂,vLLM 实例可能无法获取正确的 IP 地址。您可以找到类似
DEBUG 06-10 21:32:17 parallel_state.py:88] world_size=8rank=0 local_rank=0Distributed_init_method=tcp://xxx.xxx.xxx.xxx:54641 backend=nccl这样的日志。IP 地址应该是正确的。如果不正确,请通过设置环境变量export VLLM_HOST_IP=your_ip_address来覆盖 IP 地址。您可能还需要设置export NCCL_SOCKET_IFNAME=your_network_interface和export GLOO_SOCKET_IFNAME=your_network_interface来指定 IP 地址的网络接口。 - 错误的硬件 / 驱动:无法建立 GPU/CPU 通信。您可以运行以下完整性检查脚本来查看 GPU/CPU 通信是否正常工作。
# Test PyTorch NCCL
# 测试 PyTorch NCCLimport torch
import torch.distributed as dist
dist.init_process_group(backend="nccl")
local_rank = dist.get_rank() % torch.cuda.device_count()
torch.cuda.set_device(local_rank)
data = torch.FloatTensor([1,] * 128).to("cuda")
dist.all_reduce(data, op=dist.ReduceOp.SUM)
torch.cuda.synchronize()
value = data.mean().item()
world_size = dist.get_world_size()
assert value == world_size, f"Expected {world_size}, got {value}"print("PyTorch NCCL is successful!")# Test PyTorch GLOO
# 测试 PyTorch GLOOgloo_group = dist.new_group(ranks=list(range(world_size)), backend="gloo")
cpu_data = torch.FloatTensor([1,] * 128)
dist.all_reduce(cpu_data, op=dist.ReduceOp.SUM, group=gloo_group)
value = cpu_data.mean().item()
assert value == world_size, f"Expected {world_size}, got {value}"print("PyTorch GLOO is successful!")# Test vLLM NCCL, with cuda graph
# 使用 cuda 图测试 vLLM NCCLfrom vllm.distributed.device_communicators.pynccl import PyNcclCommunicatorpynccl = PyNcclCommunicator(group=gloo_group, device=local_rank)
pynccl.disabled = Falses = torch.cuda.Stream()
with torch.cuda.stream(s):data.fill_(1)pynccl.all_reduce(data, stream=s)value = data.mean().item()assert value == world_size, f"Expected {world_size}, got {value}"print("vLLM NCCL is successful!")g = torch.cuda.CUDAGraph()
with torch.cuda.graph(cuda_graph=g, stream=s):pynccl.all_reduce(data, stream=torch.cuda.current_stream())data.fill_(1)
g.replay()
torch.cuda.current_stream().synchronize()
value = data.mean().item()
assert value == world_size, f"Expected {world_size}, got {value}"print("vLLM NCCL with cuda graph is successful!")dist.destroy_process_group(gloo_group)
dist.destroy_process_group()
提示
将脚本保存为test.py 。
如果您在单节点中进行测试,请使用 NCCL_DEBUG=TRACE torchrun --nproc-per-node=8 test.py 运行它,将 --nproc-per-node 调整为您想使用的 GPU 数量。
如果您正在使用多节点进行测试,请使用 NCCL_DEBUG=TRACE torchrun --nnodes 2 --nproc-per-node=2 --rdzv_backend=c10d --rdzv_endpoint=$MASTER_ADDR test.py 运行它。根据您的设置调整 --nproc-per-node 和 --nnodes。确保 MASTER_ADDR 满足以下条件:
- 是主节点的正确 IP 地址
- 所有节点均可访问
- 在运行脚本之前设置
如果脚本成功运行,您会看到消息 sanity check is successful! 。
如果问题仍然存在,请随时在 GitHub 上新建一个 issue,并详细描述问题、您的环境以及日志。
一些已知问题:
- 在
v0.5.2、v0.5.3和v0.5.3.post1中,存在由 zmq 引起的错误,这可能会导致低概率挂起(大约 20 次挂起一次,具体取决于机器配置)。解决方案是升级到最新版本的vllm以包含修复程序。
警告
在找到根本原因并解决问题后,请记得关闭上述定义的所有调试环境变量,或者简单地启动一个新 shell,以避免受到调试设置的影响。如果不这样做,系统可能会因为许多调试功能被打开而变慢。
相关文章:

【vLLM 学习】调试技巧
vLLM 是一款专为大语言模型推理加速而设计的框架,实现了 KV 缓存内存几乎零浪费,解决了内存管理瓶颈问题。 更多 vLLM 中文文档及教程可访问 →https://vllm.hyper.ai/ 调试挂起与崩溃问题 当一个 vLLM 实例挂起或崩溃时,调试问题会非常…...

UML中的用例图和类图
在UML(统一建模语言)中,**用例图(Use Case Diagram)和类图(Class Diagram)**是两种最常用的图表类型,分别用于描述系统的高层功能和静态结构。以下是它们的核心概念、用途及区别&…...

谷粒微服务高级篇学习笔记整理---异步线程池
多线程回顾 多线程实现的4种方式 1. 继承 Thread 类 通过继承 Thread 类并重写 run() 方法实现多线程。 public class MyThread extends Thread {@Overridepublic void run() {System.out.println("线程运行: " + Thread.currentThread().getName());} }// 使用 p…...

清晰易懂的 Flutter 开发环境搭建教程
Flutter 是 Google 推出的跨平台应用开发框架,支持 iOS/Android/Web/桌面应用开发。本教程将手把手教你完成 Windows/macOS/Linux 环境下的 Flutter 安装与配置,从零到运行第一个应用,全程避坑指南! 一、安装 Flutter SDK 1. 下载…...

图形界面设计理念
一、图形界面的组成 1、窗口 窗口约束了图形界面的边界,提供最小化、最大化、关闭的按钮。 2、菜单栏 一般在界面的上方,提供很多功能选项。 3、工具栏 一般是排成一列,每个图标代表一个功能。 工具栏是为了快速的调用经常使用的功能。 4、导…...
MySQL-- 函数(单行函数): 日期和时间函数
目录 1,获取日期、时间 2,日期与时间戳的转换 3,获取月份、星期、星期数、天数等函数 4,日期的操作函数 5,时间和秒钟转换的函数 6,计算日期和时间的函数 7,日期的格式化与解析 1,获取日期、时间 CURDATE() ,CURRENT_DATE() 返回…...

DeepSeek真的超越了OpenAI吗?
DeepSeek 现在确实很有竞争力,但要说它完全超越了 OpenAI 还有点早,两者各有优势。 DeepSeek 的优势 性价比高:DeepSeek 的训练成本低,比如 DeepSeek-V3 的训练成本只有 558 万美元,而 OpenAI 的 GPT-4 训练成本得数亿…...

Node 22.11使用ts-node报错
最近开始学ts,发现使用ts-node直接运行ts代码的时候怎么都不成功,折腾了一番感觉是这个node版本太高还不支持, 于是我找了一个替代品tsx npm install tsx -g npx tsx your-file.ts -g代表全局安装,也可以开发环境安装࿰…...
LabVIEW中VISA Write 与 GPIB Write的差异
在使用 LabVIEW 与 GPIB 设备通讯时,VISA Write Function 和 GPIB Write Function 是两个常用的函数,它们既有区别又有联系。 一、概述 VISA(Virtual Instrument Software Architecture)是一种用于仪器编程的标准 I/O 软件库&…...

牛客练习题——素数(质数)
质数数量 改题目需要注意的是时间 如果进行多次判断就会超时,这时需要使用素数筛结合标志数组进行对所有数据范围内进行判断,而后再结合前缀和将结果存储到数组中,就可以在O(1)的时间复杂度求出素数个数。 #include<iostream>using nam…...
使用MQTTX软件连接阿里云
使用MQTTX软件连接阿里云 MQTTX软件阿里云配置MQTTX软件设置 MQTTX软件 阿里云配置 ESP8266连接阿里云这篇文章里有详细的创建过程,这里就不再重复了,需要的可以点击了解一下。 MQTTX软件设置 打开软件之后,首先点击添加进行创建。 在阿…...

qt实现功率谱和瀑布图
瀑布图 配置qcustomplot的例子网上有很多了,记录下通过qcustomplot实现的功率谱和瀑布图代码: void WaveDisplay::plotWaterfall(MCustomPlot* p_imag) {mCustomPlotLs p_imag;mCustomPlotLs->plotLayout()->clear(); // clear default axis rect…...

通过发音学英语单词:从音到形的学习方法
📌 通过发音学英语单词:从音到形的学习方法 英语是一种 表音语言(phonetic language),但不像拼音文字(如汉语拼音、西班牙语等)那么规则,而是 部分表音部分表意。这意味着我们可以通…...

WebUI问题总结
修改WebUI代码时遇到的一些问题以及解决办法 1. thttpd服务器环境的搭建 可参考《thttpd安装与启动流程》这一篇文章 其中遇到的问题有 thttpd版本问题:版本过旧会导致安装失败,尽量安装新版本thttpd的启动命令失败的话要加上sudo修改文件权限&#…...

23种设计模式-行为型模式-责任链
文章目录 简介问题解决代码核心改进点: 总结 简介 责任链是一种行为设计模式,允许你把请求沿着处理者链进行发送。收到请求后,每个处理者均可对请求进行处理,或将其传递给链上的下个处理者。 问题 假如你正在开发一个订单系统。…...

git commit Message 插件解释说明
- feat - 一项新功能 - fix - 一个错误修复 - docs - 仅文档更改 - style - 不影响代码含义的更改(空白、格式化、缺少分号等) - refactor - 既不修复错误也不添加功能的代码更改 - perf - 提高性能的代码更改 - build - 影响构建系统或外部依赖项…...

推荐系统(二十一):基于MaskNet的商品推荐CTR模型实现
MaskNet 是微博团队 2021 年提出的 CTR 预测模型,相关论文:《MaskNet: Introducing Feature-Wise Multiplication to CTR Ranking Models by Instance-Guided Mask》。MaskNet 通过掩码自注意力机制,在推荐系统中实现了高效且鲁棒的特征交互学习,特别适用于需处理长序列及噪…...

OpenCV 从入门到精通(day_04)
1. 绘制图像轮廓 1.1 什么是轮廓 轮廓是一系列相连的点组成的曲线,代表了物体的基本外形。相对于边缘,轮廓是连续的,边缘不一定连续,如下图所示。其实边缘主要是作为图像的特征使用,比如可以用边缘特征可以区分脸和手…...
多模态学习(八):2022 TPAMI——U2Fusion: A Unified Unsupervised Image Fusion Network
论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp&arnumber9151265 目录 一.摘要 1.1 摘要翻译 1.2 摘要解析 二.Introduction 2.1 Introduciton翻译 2.2 Introduction 解析 三. related work 3.1 related work翻译 3.2 relate work解析 四…...
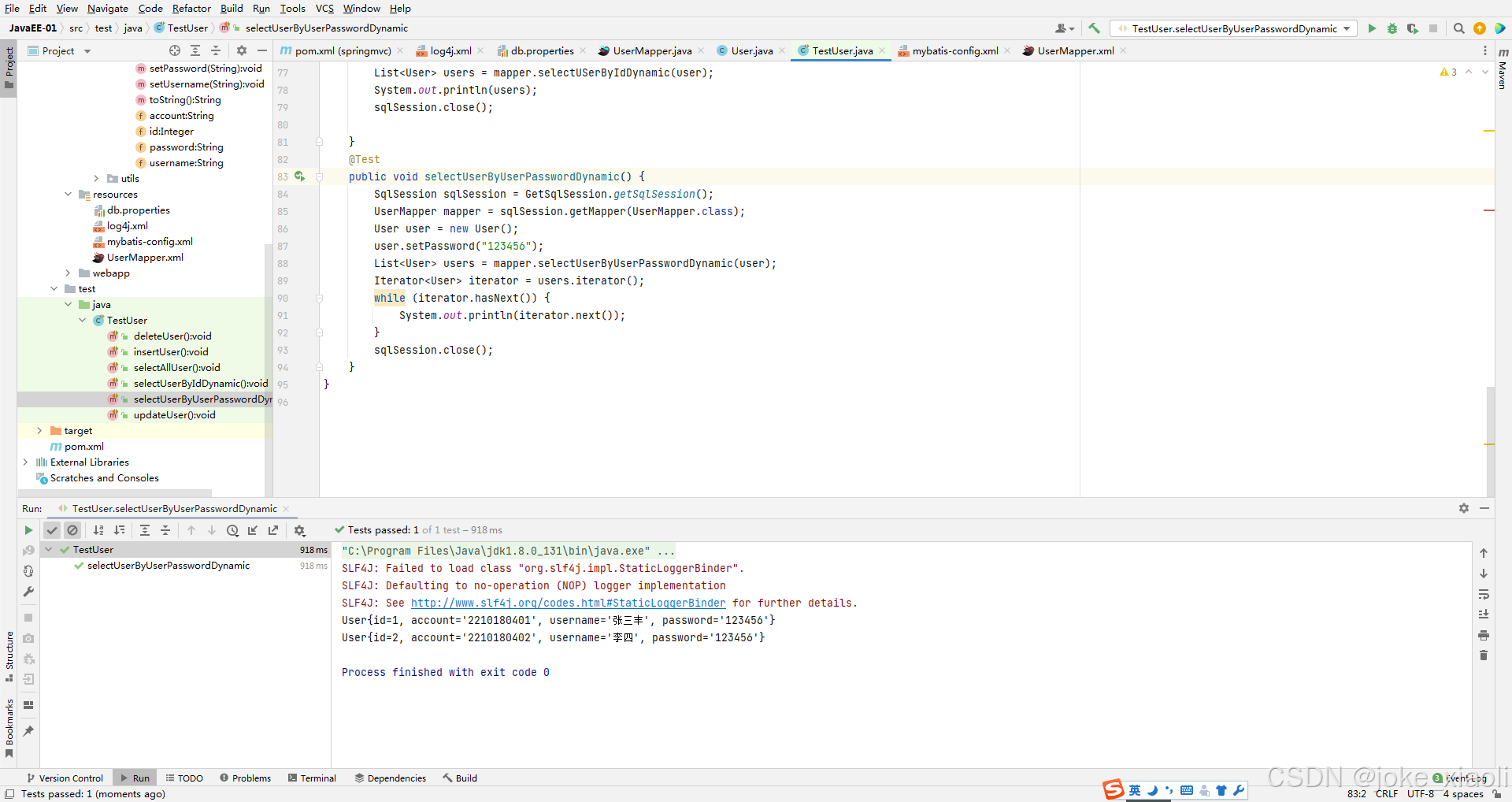
JavaEE-0403学习记录
通过前期准备后,项目已经能够成功运行: 1、在文件UserMapper.java中添加如下代码: List<User> selectUSerByIdDynamic(User user); 2、在文件UserMapper.xml中添加如下代码: <select id"selectUSerByIdDynamic&quo…...
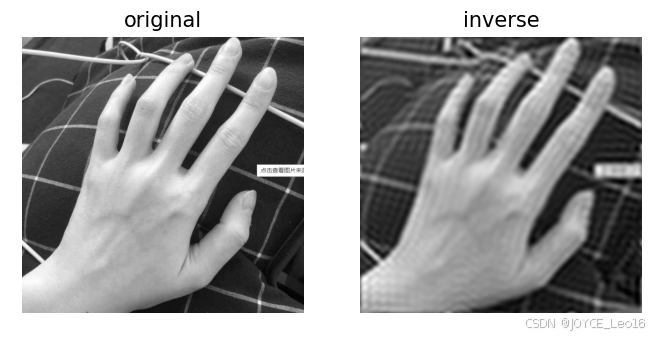
图像处理:使用Numpy和OpenCV实现傅里叶和逆傅里叶变换
文章目录 1、什么是傅里叶变换及其基础理论 1.1 傅里叶变换 1.2 基础理论 2. Numpy 实现傅里叶和逆傅里叶变换 2.1 Numpy 实现傅里叶变换 2.2 实现逆傅里叶变换 2.3 高通滤波示例 3. OpenCV 实现傅里叶变换和逆傅里叶变换及低通滤波示例 3.1 OpenCV 实现傅里叶变换 3.2 实现逆傅…...

洛谷题单2-P5715 【深基3.例8】三位数排序-python-流程图重构
题目描述 给出三个整数 a , b , c ( 0 ≤ a , b , c ≤ 100 ) a,b,c(0\le a,b,c \le 100) a,b,c(0≤a,b,c≤100),要求把这三位整数从小到大排序。 输入格式 输入三个整数 a , b , c a,b,c a,b,c,以空格隔开。 输出格式 输出一行,三个整…...
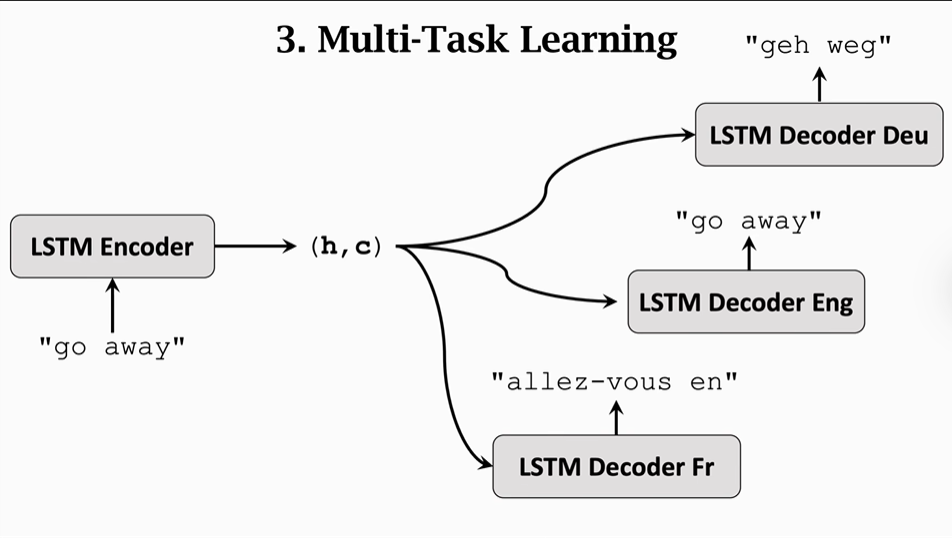
RNN模型与NLP应用——(7/9)机器翻译与Seq2Seq模型
声明: 本文基于哔站博主【Shusenwang】的视频课程【RNN模型及NLP应用】,结合自身的理解所作,旨在帮助大家了解学习NLP自然语言处理基础知识。配合着视频课程学习效果更佳。 材料来源:【Shusenwang】的视频课程【RNN模型及NLP应用…...

使用YoloV5和Mediapipe实现——上课玩手机检测(附完整源码)
目录 效果展示 应用场景举例 1. 课堂或考试监控(看到这个学生党还会爱我吗) 2. 驾驶安全监控(防止开车玩手机) 3. 企业办公管理(防止工作时间玩手机) 4. 监狱、戒毒所、特殊场所安保 5. 家长监管&am…...

XT-912在热交换站的应用
热网监控需求 随着国民经济的不断进步和人民生活水平日益提高,社会对环境的要求越来越高。近年来国家大力提倡城镇集中供热,改变原来各单位、各片区自己供热、单独建立锅炉房给城市带来的污染,由城市外围的一个或者多个热源厂提供热源&#…...

语文常识推翻百年“R完备、封闭”论
语文常识推翻百年“R完备、封闭”论 黄小宁 李四光:迷信权威等于扼杀智慧。语文常识表明从西方传进来的数学存在重大错误:将无穷多各异数轴误为同一轴。 复平面z各点z的对应点zk的全体是zk平面。z面平移变换为zk(k是非1正实常数…...
)
解决backtrader框架下日志ValueError: I/O operation on closed file.报错(jupyternotebook)
解决办法: 禁用 IPython 内核的日志重定向 在 IPython 环境下,内核可能会对日志进行重定向,从而引发问题。你可以尝试在运行代码之前禁用 IPython 的日志重定向: import logging# 禁用IPython内核的日志重定向 logging.getLogg…...
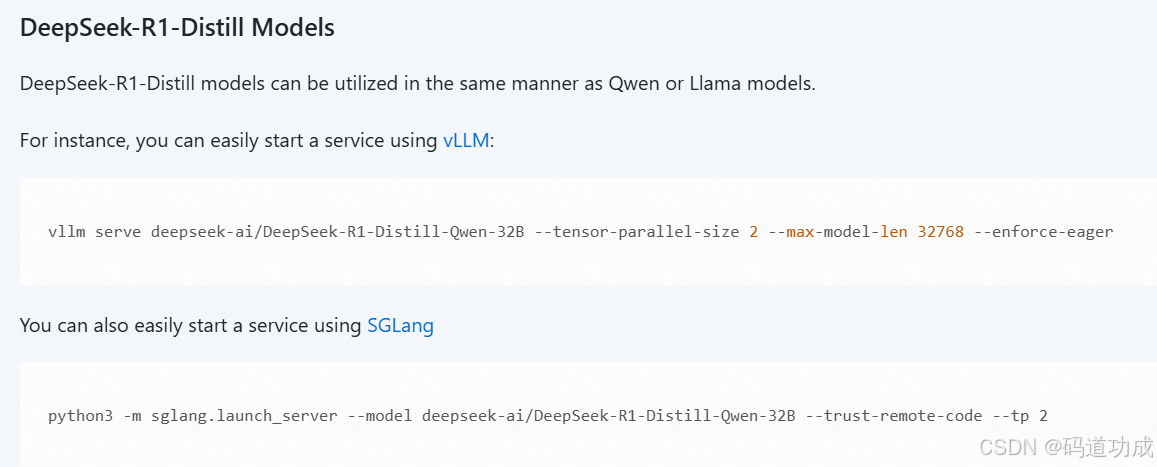
基于Docker容器部署DeepSeek-R1-Distill-Qwen-7B
首先打开魔搭社区,然后搜索DeepSeek-R1-Distill-Qwen-7B,进入详情页 官方推荐使用vllm来启动,但是手动搭建vllm环境容易出各种问题,我们这里直接找一个vllm的Docker镜像 一、拉取镜像 docker pull vllm/vllm-openai 如果拉取不…...
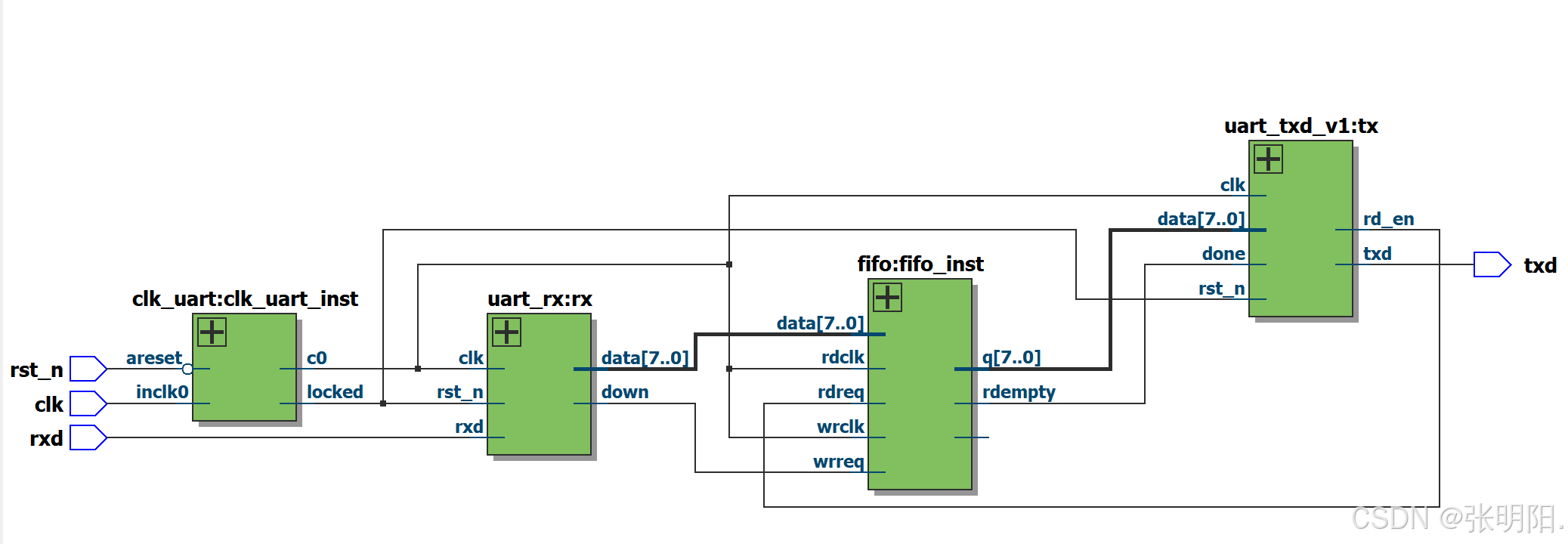
UART双向通信实现(序列机)
前言 UART(通用异步收发传输器)是一种串行通信协议,用于在电子设备之间进行数据传输。RS232是UART协议的一种常见实现标准,广泛应用于计算机和外围设备之间的通信。它定义了串行数据的传输格式和电气特性,以确…...

CentOS 7 全流程部署Magic-PDF数据清洗工具(附GPU加速方案)
CentOS 7 全流程部署Magic-PDF数据清洗工具(附GPU加速方案) 一、环境准备与方案选型 1.1 硬件要求 配置项最低要求推荐配置CPU4核8核内存8GB16GB存储50GBSSD/NVMeGPU可选NVIDIA T4 1.2 系统环境检查 # 查看系统版本 cat /etc/redhat-release# 检查G…...