架构思维:查询分离 - 表数据量大查询缓慢的优化方案
文章目录
- Pre
- 引言
- 案例
- 何谓查询分离?
- 何种场景下使用查询分离?
- 查询分离实现思路
- 1. 如何触发查询分离?
- 方式一: 修改业务代码:在写入常规数据后,同步建立查询数据。
- 方式二:修改业务代码:在写入常规数据后,异步建立查询数据。
- 方式三: 监控数据库日志:如有数据变更,更新查询数据。
- 方案对比
- 适用场景
- 2. 如何实现查询分离?
- 3. 查询数据如何存储?
- 4. 查询数据如何使用?
- 整体方案
- 历史数据迁移
- 查询分离解决方案的不足

Pre
MySQL索引原理与优化指南:深入解析B+Tree与高效查询策略
MySQL - 事务隔离级别和锁的机制
MySQL - 读多写少场景下的优化数据查询方案
MySQL - 写多读少的场景下如何优化数据存储方案
MySQL - 冷热分离:表数据量大读写缓慢的优化方案
引言
MySQL - 冷热分离:表数据量大读写缓慢的优化方案中提到了冷热分离解决方案的性价比高,但它并不是一个最优的方案,仍然存在诸多不足,比如:查询冷数据慢、业务无法再修改冷数据、冷数据多到一定程度系统依旧扛不住,我们如果想把这些问题一一解决掉,可以用另外一种解决方案——查询分离。

注意:查询分离与读写分离还是有区别的
案例
某系统工单表中存放了几千万条数据,且查询工单表数据时需要关联十几个子表,每个子表的数据也是超亿条。
如此庞大的数据量,跟前面的冷热分离一样,每次查询数据时几十秒才能返回结果,即便使用了索引、SQL 等数据库优化技巧,效果依然不明显。
加上工单表中有些数据是几年前的,因业务原因,需要继续保持更新,因此无法将这些旧数据封存到别的地方,也就没法通过前面的冷热分离方案来解决。
最终采用了查询分离的解决方案,才得以将这个问题顺利解决:将更新的数据放在一个数据库里,而查询的数据放在另外一个系统里。因为数据的更新都是单表更新,不需要关联也没有外键,所以更新速度立马得到提升,数据的查询则通过一个专门处理大数据量的查询引擎来解决,也快速地满足了需求。
通过这种解决方案处理后,每次查询数据时,500ms 内就可得到返回结果。
何谓查询分离?
每次写数据时保存一份数据到另外的存储系统里,用户查询数据时直接从另外的存储系统里获取数据,示意图如下:
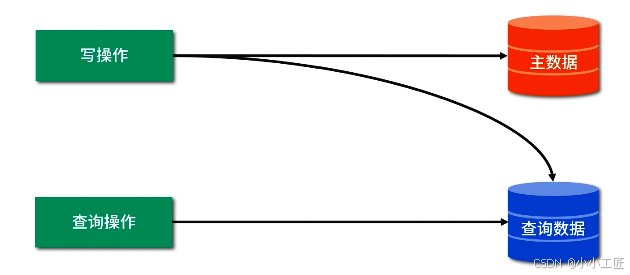
何种场景下使用查询分离?
当在实际业务中遇到以下情形,则可以考虑使用查询分离解决方案。
-
数据量大;
-
所有写数据的请求效率尚可;
-
查询数据的请求效率很低;
-
所有的数据任何时候都可能被修改;
-
业务希望我们优化查询数据的功能。
查询分离实现思路
查询分离解决方案的实现思路如下:
-
如何触发查询分离?
-
如何实现查询分离?
-
查询数据如何存储?
-
查询数据如何使用?
1. 如何触发查询分离?
这个问题说明的是我们应该在什么时候保存一份数据到查询数据中,即什么时候触发查询分离这个动作。
一般来说,查询分离的触发逻辑分为 3 种。
方式一: 修改业务代码:在写入常规数据后,同步建立查询数据。

方式二:修改业务代码:在写入常规数据后,异步建立查询数据。
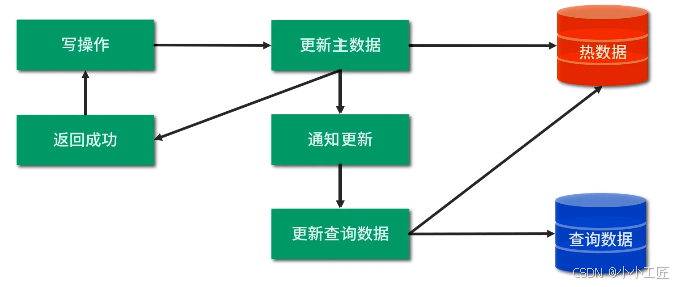
方式三: 监控数据库日志:如有数据变更,更新查询数据。
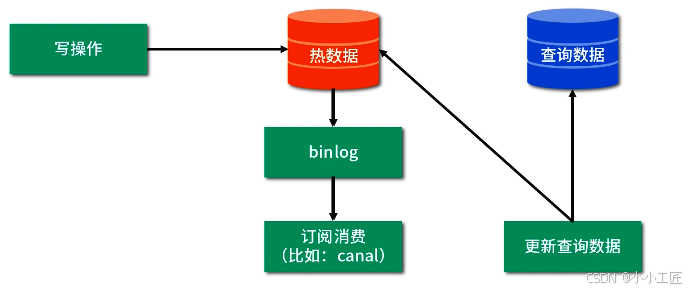
方案对比

适用场景

2. 如何实现查询分离?
以上共3 种触发逻辑,第 1 种是同步建立查询数据的过程比较简单,这里就不展开说明,接下来我们主要围绕第 2 种来展开。
关于第 2 种触发方案:修改业务代码异步建立查询数据,最基本的实现方式是单独起一个线程建立查询数据,不过这种做法会出现如下情况:
-
写操作较多且线程太多,最终撑爆 JVM;
-
建查询数据的线程出错了,如何自动重试;
-
多线程并发时,很多并发场景需要解决。
面对以上三种情况,我们该如何处理?此时使用 MQ 管理这些线程即可解决。
MQ 的具体操作思路为每次主数据写操作请求处理时,都会发一个通知给 MQ,MQ 收到通知后唤醒一个线程更新查询数据
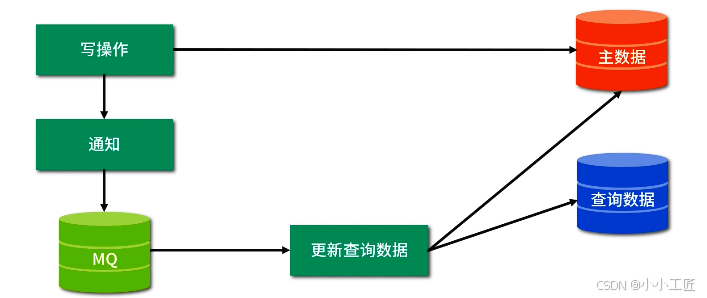
了解了 MQ 的具体操作思路后,还应该考虑以下 5 大问题。
问题一:MQ 如何选型?
从易用性和代码工作量角度考量即可。
问题二:MQ 宕机了怎么办?
如果 MQ 宕机了,我们只需要保证主流程正常进行,且 MQ 恢复后数据正常处理即可,具体方案分为三大步骤。
-
每次写操作时,在主数据中加个标识:
NeedUpdateQueryData=true,这样发到 MQ 的消息就很简单,只是一个简单的信号告知更新数据,并不包含更新的数据 id。 -
MQ 的消费者获取信号后,先批量查询待更新的主数据,然后批量更新查询数据,更新完后查询数据的主数据标识
NeedUpdateQueryData就更新成 false 了。 -
当然还存在多个消费者同时搬运动作的情况,这就涉及并发性的问题,因此问题冷热分离中的并发性处理逻辑类似。
问题三:更新查询数据的线程失败了怎么办?
如果更新的线程失败了,NeedUpdateQueryData 的标识就不会更新,后面的消费者会再次将有 NeedUpdateQueryData 标识的数据拿出来处理。但如果一直失败,我们可以在主数据中多添加一个尝试搬运次数,比如每次尝试搬运时 +1,成功后就清零,以此监控那些尝试搬运次数过多的数据。
问题四:消息的幂等消费
在编程中,一个幂等操作的特点是多次执行某个操作均与执行一次操作的影响相同。
举个例子,比如主数据的订单 A 更新后,我们在查询数据中插入了 A,可是此时系统出问题了,系统误以为查询数据没更新,又把订单 A 插入更新了一次。
所谓幂等,就是不管更新查询数据的逻辑执行几次,结果都是我们想要的结果。因此,考虑消费端并发性的问题时,我们需要保证更新查询数据幂等。
问题五:消息的时序性问题
比如某个订单 A 更新了 1 次数据变成 A1,线程甲将 A1 的数据搬到查询数据中。不一会儿,后台订单 A 又更新了 1 次数据变成 A2,线程乙也启动工作,将 A2 的数据搬到查询数据中。
所谓的时序性就是如果线程甲启动比乙早,但搬运数据动作比线程乙还晚完成,就有可能出现查询数据最终变成过期的 A1。如下图(动作前面的序号代表实际动作的先后顺序):
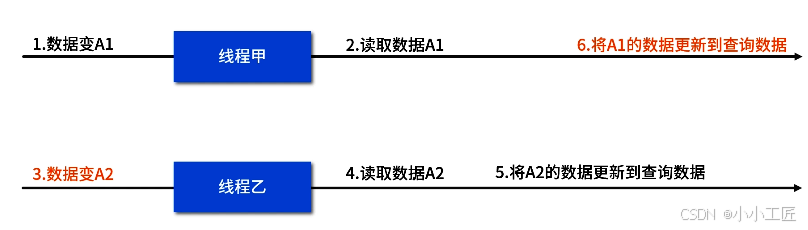
此时解决方案为主数据每次更新时,都更新上次更新时间 last_update_time,然后每个线程更新查询数据后,检查当前订单 A 的 last_update_time 是否跟线程刚开始获得的时间一样,且 NeedUpdateQueryData 是否等于 false,如果都满足的话,我们就将 NeedUpdateQueryData 改为 true,然后再做一次搬运。
MQ 在这里的作用只是一个触发信号的工具,如果不用 MQ 好像也没啥问题啊,但是MQ的作用不仅体现在这里,还有以下:
-
服务的解耦: 这样主业务逻辑就不会依赖更新查询数据这个服务了。
-
控制更新查询数据服务的并发量: 如果我们直接调用更新查询数据服务,因写操作速度快,更新查询数据速度慢,写操作一旦并发量高,会给更新查询数据服务造成超负荷压力。如果通过消息触发更新查询数据服务,我们就可以通过控制消息消费者的线程数来控制负载。
3. 查询数据如何存储?
我们应该使用什么技术存储查询数据呢?目前,市面上主要使用 Elasticsearch 实现大数据量的搜索查询,当然还可能会使用到 MongoDB、HBase 这些技术,这就需要我们对各种技术的特性了如指掌,再进行技术选型。
关于技术选型这个问题,很多时候我们不能单单只考虑业务功能的需求,还需要考虑组织结构。比如当初设计架构方案时,为什么选择用 Elasticsearch,除 ES 对查询的扩展性支持外,最关键的一点是团队对 Elasticsearch 很熟悉。
4. 查询数据如何使用?
因 ES 自带 API,所以使用查询数据时,我们在查询业务代码中直接调用 ES 的 API 就行。
不过,这个办法会出现一个问题:数据查询更新完前,查询数据不一致怎么办?
2 种解决思路。
-
在查询数据更新到最新前,不允许用户查询。(我们没用过这种设计,但我确实见过市面上有这样的设计。)
-
给用户提示:您目前查询到的数据可能是 1 秒前的数据,如果发现数据不准确,可以尝试刷新一下,这种提示用户一般比较容易接受。
整体方案
以上,我们已经把四个问题都讨论完了,我们再一起看下查询分离的整体方案,如下图所示:
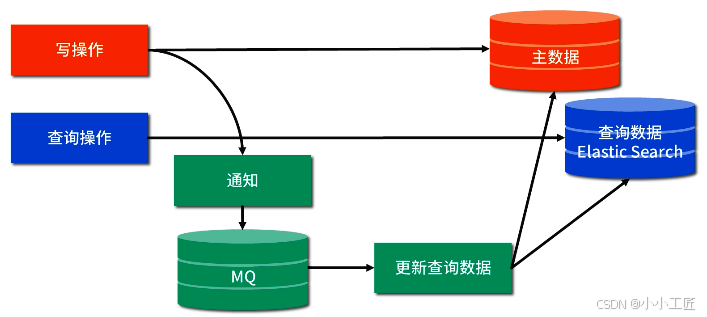
历史数据迁移
新的架构方案上线后,旧的数据如何适用新的架构方案?这是实际业务中需要我们考虑的问题。
在这个方案里,我们只需要把所有的历史数据加上这个标识:NeedUpdateQueryData=true,程序就会自动处理了。
查询分离解决方案的不足
查询分离这个解决方案虽然能解决一些问题,但我们也要清醒地认识到它的不足。
不足一: 使用 Elasticsearch 存储查询数据时,注意事项是什么 ?
不足二: 主数据量越来越大后,写操作还是慢,到时还是会出问题。
不足三: 主数据和查询数据不一致时,假设业务逻辑需要查询数据保持一致性呢?

相关文章:
架构思维:查询分离 - 表数据量大查询缓慢的优化方案
文章目录 Pre引言案例何谓查询分离?何种场景下使用查询分离?查询分离实现思路1. 如何触发查询分离?方式一: 修改业务代码:在写入常规数据后,同步建立查询数据。方式二:修改业务代码:…...

Qt进阶开发:QFileSystemModel的使用
文章目录 一、QFileSystemModel的基本介绍二、QFileSystemModel的基本使用2.1 在 QTreeView 中使用2.2 在 QListView 中使用2.3 在 QTableView 中使用 三、QFileSystemModel的常用API3.1 设置根目录3.2 过滤文件3.2.1 仅显示文件3.2.2 只显示特定后缀的文件3.2.3 只显示目录 四…...

后端开发常见的面试问题
目录 编程语言 python Linux环境 web框架 数据处理与分析 数据库 图数据库 什么是图数据库?它与传统关系型数据库有什么区别? 图数据库中的节点、边和属性分别代表什么? 常见的图数据库有哪些?它们各自有什么特点&#…...

List结构之非实时榜单实战
像京东、淘宝等电商系统一般都会有热销的商品榜单,比如热销手机榜单,热销电脑榜单,这些都是非实时的榜单。为什么是非实时的呢?因为完全实时的计算和排序对于资源消耗较大,尤其是当涉及大量交易数据时。 一般来说&…...
【C语言】字符串处理函数:strtok和strerror
在C语言中,字符串处理是编程的基础之一。本文将详细讲解两个重要的字符串处理函数:strtok和strerror 一、strtok函数 strtok函数用于将字符串分割成多个子串,这些子串由指定的分隔符分隔。其原型定义如下: char *strtok(char *s…...

如何提升后端开发效率:从Spring Boot到微服务架构
在现代软件开发中,后端开发的效率直接决定了项目的成败。随着技术的快速发展,Spring Boot、微服务架构、Docker等工具和技术已经成为提升后端开发效率的核心利器。在这篇文章中,我们将探讨如何通过使用Spring Boot及微服务架构来提升开发效率…...

go语言:开发一个最简单的用户登录界面
1.用deepseek生成前端页面: 1.提问:请你用html帮我设计一个用户登录页面,要求特效采用科技感的背景渲染加粒子流动,用css、div、span标签,并给出最终合并后的代码。 生成的完整代码如下: <!DOCTYPE h…...

基于 .NET 8 + Lucene.Net + 结巴分词实现全文检索与匹配度打分实战指南
文章目录 前言一、技术选型与优势1.1 技术栈介绍1.2 方案优势 二、环境搭建与配置2.1 安装 NuGet 包2.2 初始化核心组件 三、索引创建与文档管理3.1 构建索引3.2 动态更新策略 四、搜索与匹配度排序4.1 执行搜索4.2 自定义评分算法(扩展) 五、高级优化技…...

Docker安装、配置Nacos
1.如果没有docker-compose.yml文件的话,先创建docker-compose.yml 配置文件一般长这个样子 version: 3services:nacos:image: nacos/nacos-server:v2.1.1container_name: nacos2ports:- "8848:8848"- "9848:9848"environment:- MODEstandalone…...
《Maven高级应用:继承聚合设计与私服Nexus实战指南》
一、 Maven的继承和聚合 1.什么是继承 Maven 的依赖传递机制可以一定程度上简化 POM 的配置,但这仅限于存在依赖关系的项目或模块中。当一个项目的多个模块都依赖于相同 jar 包的相同版本,且这些模块之间不存在依赖关系,这就导致同一个依赖…...

重要头文件下的函数
1、<cctype> #include<cctype>加入这个头文件就可以调用以下函数: 1、isalpha(x) 判断x是否为字母 isalpha 2、isdigit(x) 判断x是否为数字 isdigit 3、islower(x) 判断x是否为小写字母 islower 4、isupper(x) 判断x是否为大写字母 isupper 5、isa…...
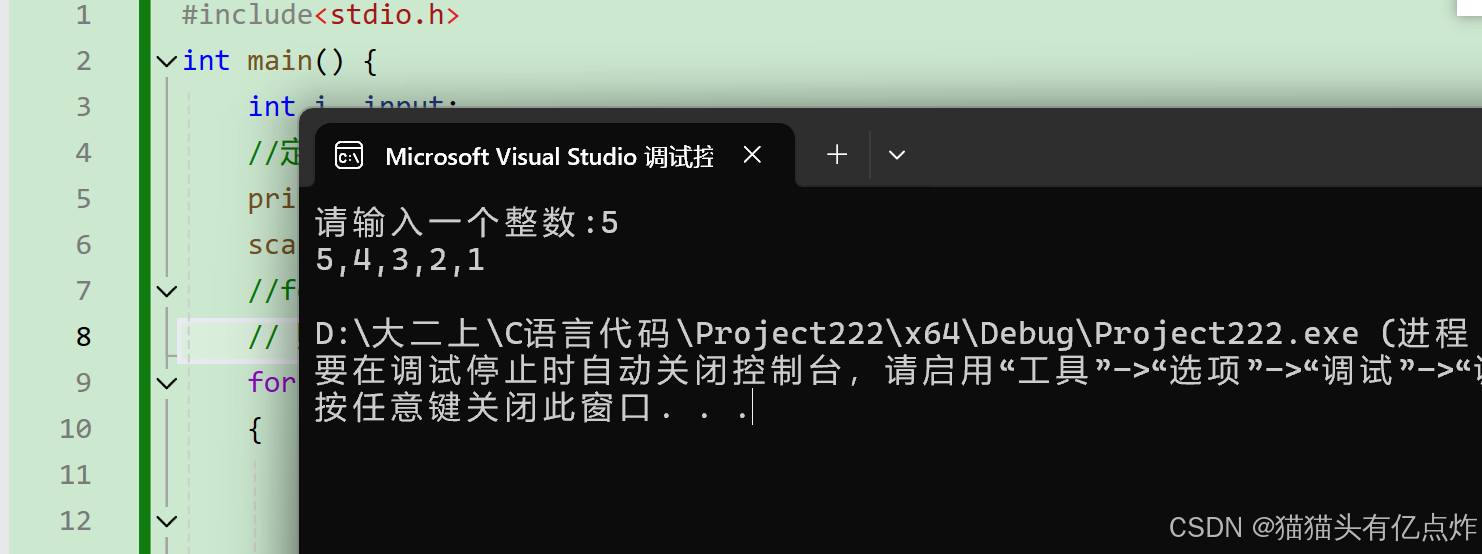
C语言数字分隔题目
一、题目引入 编写一个程序,打印出从用户输入的数字开始,递减到1的序列。要求每次打印一行,数字之间用逗号分隔,最后一个数字后面没有逗号。 二、代码展示 三、运行结果 四、思路分析 1.先用一个for循环对输入的数字进行递减 2.再对for循环里面的数字进行筛选 如果大于1 …...

DigitalOcean 发布 AMD Instinct MI300X GPU 裸金属服务器
DigitalOcean 宣布现已提供 AMD Instinct MI300X GPU,并搭载 ROCm 软件,以支持用户的 AI 任务。 在 DigitalOcean,我们致力于为你的项目提供更多选择。AMD Instinct MI300X 是目前带宽最高的 GPU 之一(5.3 TB/s 的 HBM3 内存带宽&…...
)
CentOS 7 镜像源失效解决方案(2025年)
执行 yum update 报错: yum install -y yum-utils \ > device-mapper-persistent-data \ > lvm2 --skip-broken 已加载插件:fastestmirror, langpacks Loading mirror speeds from cached hostfile Could not retrieve mirrorlist http://mirror…...

应对高并发的根本挑战:思维转变【大模型总结】
以下是对这篇技术总结的详细解析,以分步说明的形式呈现,帮助理解亿万并发场景下的核心策略与创新思维: 一、应对高并发的根本挑战:思维转变 1. 传统架构的局限 问题:传统系统追求零故障和强一致性,但在海…...

ARM-外部中断,ADC模数转换器
根据您提供的图片,我们可以看到一个S3C2440微控制器的中断处理流程图。这个流程图展示了从中断请求源到CPU的整个中断处理过程。以下是流程图中各个部分与您提供的寄存器之间的关系: 请求源(带sub寄存器): 这些是具体的…...
git克隆数据失败
场景:当新到一家公司,然后接手了上一个同时的电脑,使用git克隆代码一直提示无法访问,如图 原因:即使配置的新的用户信息。但是window记录了上一个同事的登录信息,上一个同事已经被剔除权限,再拉…...
自动化备份全网服务器数据平台
自动化备份全网服务器数据平台 项目背景知识 总体需求 某企业里有一台Web服务器,里面的数据很重要,但是如果硬盘坏了数据就会丢失,现在领导要求把数据做备份,这样Web服务器数据丢失在可以进行恢复。要求如下:1.每天0…...

大模型如何优化数字人的实时交互与情感表达
标题:大模型如何优化数字人的实时交互与情感表达 内容:1.摘要 随着人工智能技术的飞速发展,数字人在多个领域的应用愈发广泛,其实时交互与情感表达能力成为提升用户体验的关键因素。本文旨在探讨大模型如何优化数字人的实时交互与情感表达。通过分析大模…...

AI Agent系列(八) -基于ReAct架构的前端开发助手(DeepSeek)
AI Agent系列【八】 项目目标一、核心功能设计二、技术栈选择三、Python实现3.1 设置基础环境3.2 定义AI前端生成的类3.4 实例化3.5 Flask路由3.6 主程序执行 四、 功能测试 项目目标 开发一个能够协助HTMLJSCSS前端设计的AI Agent,通过在网页中输入相应的问题&am…...

二级索引详解
二级索引详解 二级索引(Secondary Index)是数据库系统中除主键索引外的附加索引结构,用于加速基于非主键列的查询操作。以下是关于二级索引的全面解析: 一、核心概念 特性主键索引 (Primary Index)二级索引 (Secondary Index)唯一性必须唯一可以唯一或非唯一数量每表只有…...
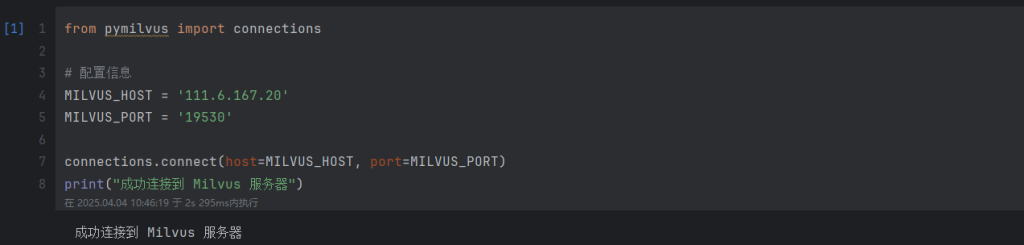
一文学会云服务器配置Milvus向量数据库
服务器准备 首先,我们需要进行服务器的准备,这里准备的是RTX-4090服务器 连接我们已经创建好的服务器,这里可使用MobaXterm进行ssh连接 ssh funhpcIP地址 一键完成Docker配置 注:docker的旧版本不一定被称为docker,doc…...
19685 握手问题
19685 握手问题 ⭐️难度:简单 🌟考点:2024、省赛、数学 📖 📚 package test ;import java.util.Scanner; public class Main {public static void main(String[] args) {Scanner scanner new Scanner(System.in);…...
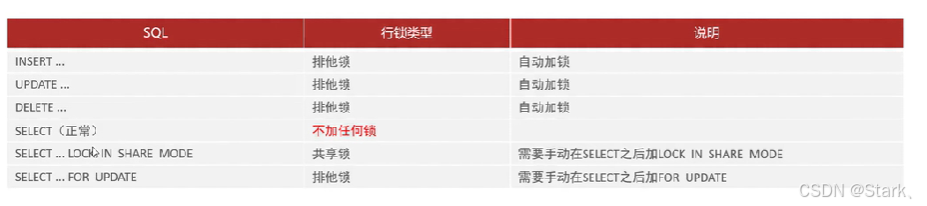
【MySQL数据库】锁机制
概述 锁:是计算机协调多个进程或者线程并发访问某一资源的机制。在数据库中,除了传统的计算资源(CPU、RAM、IO)的争用以外。数据也是一种供多用户共享的资源。如何保证数据的并发访问的一致性、有效性是所有数据库必须解决的一个…...

ASP.NET Core Web API 中 HTTP状态码的分类及对应的返回方法
文章目录 前言一、HTTP状态码分类及常用方法二、具体返回方法示例1) 2xx 成功类2)4xx 客户端错误3)5xx 服务器错误4)其他特殊状态码 三、高级返回方式1)使用 IActionResult 与 ActionResult<T>2)统一…...

react redux的学习,单个reducer
redux系列文章目录 一 什么redux? redux是一个专门用于做状态管理的JS库(不是react插件库)。它可以用在react, angular, vue等项目中, 但基本与react配合使用。集中式管理react应用中多个组件共享的状 简单来说,就是存储页面的状态值的一个库…...

C++20新增内容
C20 是 C 语言的一次重大更新,它引入了许多新特性,使代码更现代化、简洁且高效。以下是 C20 的主要新增内容: 1. 概念(Concepts) 概念用于约束模板参数,使模板编程更加直观和安全。 #include <concept…...

分布式控制技术赋能智慧工厂精准控制研究
摘要:本文聚焦于分布式控制技术在智慧工厂精准控制中的应用。详细阐述了分布式控制系统(DCS)、边缘计算机、边边协同技术以及分布式计算等关键要素在实现精准控制中的作用机制。同时,分析了云边协同模式存在占用带宽、单点故障、数…...

清明节里清明菜:软萩(拟人版介绍)
好像人们无论过任何节,总是离不开吃 清明节里吃清明菜,你采摘了吗? 姓名 软萩,也叫鼠麴草、清明菜、软雀,学名鼠曲草。 一些地方性小名(防止大家找不到组织,已知的都附上)…...

JavaWeb学习--MyBatis-Plus整合SpringBoot的ServiceImpl方法(增加,修改与删除部分)
接下来是常用的增加,修改以及删除部分 首先是增加部分,增加一个新的数据 Testpublic void testInsert() {// 添加一个新用户记录Student s new Student();s.setName("NewStudent");s.setAge(25);boolean saved studentService.save(s);//可以…...