P17_ResNeXt-50
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
一、模型结构
ResNeXt-50由多个残差块(Residual Block)组成,每个残差块包含三个卷积层。以下是模型的主要结构:
-
输入层:
- 输入图像尺寸为224x224x3(高度、宽度、通道数)。
-
初始卷积层:
- 使用7x7的卷积核,步长为2,输出通道数为64。
- 后接批量归一化(Batch Normalization)和ReLU激活函数。
- 最大池化层(Max Pooling)进一步减少特征图的尺寸。
-
残差块:
- 模型包含四个主要的残差块组(layer1到layer4)。
- 每个残差块组包含多个残差单元(Block)。
- 每个残差单元包含三个卷积层:
- 第一个卷积层:1x1卷积,用于降维。
- 第二个卷积层:3x3分组卷积,用于特征提取。
- 第三个卷积层:1x1卷积,用于升维。
- 残差连接(skip connection)将输入直接加到输出上。
-
全局平均池化层:
- 将特征图转换为一维向量。
-
全连接层:
- 输出分类结果,类别数根据具体任务确定。
模型特点
- 分组卷积:将输入通道分成多个组,每组独立进行卷积操作,然后将结果合并。这可以减少计算量,同时保持模型的表达能力。
- 基数(Cardinality):分组的数量,增加基数可以提高模型的性能。
- 深度:ResNeXt-50有50层深度,这使得它能够学习复杂的特征表示。
训练过程
- 数据预处理:对输入图像进行归一化处理,使其像素值在0到1之间。
- 损失函数:使用交叉熵损失函数(Cross-Entropy Loss)。
- 优化器:使用随机梯度下降(SGD)优化器,学习率设置为1e-4。
- 训练循环:对训练数据进行多次迭代(epoch),每次迭代更新模型参数以最小化损失函数。
应用场景
ResNeXt-50可以应用于多种计算机视觉任务,包括但不限于:
- 图像分类:对图像进行分类,识别图像中的物体类别。
- 目标检测:检测图像中的物体位置和类别。
- 语义分割:将图像中的每个像素分类到特定的类别。
- 医学图像分析:分析医学图像,如X光、CT扫描等。
- 自动驾驶:识别道路、车辆、行人等。
二、 前期准备
1. 导入库
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib
import os,PIL,random,pathlib
import torch.nn.functional as F
from PIL import Image
import matplotlib.pyplot as plt
#隐藏警告
import warnings
2.导入数据
data_dir = './data/4-data/'
data_dir = pathlib.Path(data_dir)
#print(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[2] for path in data_paths]
#print(classeNames)
total_datadir = './data/4-data/'train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])total_data = datasets.ImageFolder(total_datadir,transform=train_transforms)
3.划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
batch_size = 32train_dl = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=1)
三、模型设计
1. 神经网络的搭建
class GroupedConv2d(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, stride=1, groups=1, padding=0):super(GroupedConv2d, self).__init__()self.groups = groupsself.convs = nn.ModuleList([nn.Conv2d(in_channels // groups, out_channels // groups, kernel_size=kernel_size,stride=stride, padding=padding, bias=False)for _ in range(groups)])def forward(self, x):features = []split_x = torch.split(x, x.shape[1] // self.groups, dim=1)for i in range(self.groups):features.append(self.convs[i](split_x[i]))return torch.cat(features, dim=1)class Block(nn.Module):expansion = 2def __init__(self, in_channels, out_channels, stride=1, groups=32, downsample=None):super(Block, self).__init__()self.groups = groupsself.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)self.bn1 = nn.BatchNorm2d(out_channels)self.relu = nn.ReLU(inplace=True)self.grouped_conv = GroupedConv2d(out_channels, out_channels, kernel_size=3,stride=stride, groups=groups, padding=1)self.bn2 = nn.BatchNorm2d(out_channels)self.conv3 = nn.Conv2d(out_channels, out_channels * self.expansion, kernel_size=1, bias=False)self.bn3 = nn.BatchNorm2d(out_channels * self.expansion)self.downsample = downsampleself.stride = stridedef forward(self, x):identity = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.grouped_conv(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return outclass ResNeXt50(nn.Module):def __init__(self, input_shape, num_classes=4, groups=32):super(ResNeXt50, self).__init__()self.groups = groupsself.in_channels = 64self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.layer1 = self._make_layer(128, blocks=3, stride=1)self.layer2 = self._make_layer(256, blocks=4, stride=2)self.layer3 = self._make_layer(512, blocks=6, stride=2)self.layer4 = self._make_layer(1024, blocks=3, stride=2)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.fc = nn.Linear(1024 * Block.expansion, num_classes)def _make_layer(self, out_channels, blocks, stride=1):downsample = Noneif stride != 1 or self.in_channels != out_channels * Block.expansion:downsample = nn.Sequential(nn.Conv2d(self.in_channels, out_channels * Block.expansion, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(out_channels * Block.expansion),)layers = []layers.append(Block(self.in_channels, out_channels, stride, self.groups, downsample))self.in_channels = out_channels * Block.expansionfor _ in range(1, blocks):layers.append(Block(self.in_channels, out_channels, groups=self.groups))return nn.Sequential(*layers)def forward(self, x):x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.maxpool(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.fc(x)return x2.设置损失值等超参数
device = "cuda" if torch.cuda.is_available() else "cpu"# 模型初始化
input_shape = (224, 224, 3)
num_classes = len(classeNames)
model = ResNeXt50(input_shape=input_shape, num_classes=num_classes).to(device)
print(summary(model, (3, 224, 224)))loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-4 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
epochs = 10
train_loss = []
train_acc = []
test_loss = []
test_acc = []
---------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 64, 112, 112] 9,408BatchNorm2d-2 [-1, 64, 112, 112] 128ReLU-3 [-1, 64, 112, 112] 0MaxPool2d-4 [-1, 64, 56, 56] 0Conv2d-5 [-1, 128, 56, 56] 8,192BatchNorm2d-6 [-1, 128, 56, 56] 256ReLU-7 [-1, 128, 56, 56] 0.... .....Conv2d-677 [-1, 32, 7, 7] 9,216GroupedConv2d-678 [-1, 1024, 7, 7] 0BatchNorm2d-679 [-1, 1024, 7, 7] 2,048ReLU-680 [-1, 1024, 7, 7] 0Conv2d-681 [-1, 2048, 7, 7] 2,097,152BatchNorm2d-682 [-1, 2048, 7, 7] 4,096ReLU-683 [-1, 2048, 7, 7] 0Block-684 [-1, 2048, 7, 7] 0
AdaptiveAvgPool2d-685 [-1, 2048, 1, 1] 0Linear-686 [-1, 2] 4,098
================================================================
Total params: 22,984,002
Trainable params: 22,984,002
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 382.83
Params size (MB): 87.68
Estimated Total Size (MB): 471.08
----------------------------------------------------------------3. 设置训练函数
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset)num_batches = len(dataloader)train_loss, train_acc = 0, 0model.train()for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)optimizer.zero_grad()loss.backward()optimizer.step()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
4. 设置测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)test_loss, test_acc = 0, 0model.eval()with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)test_loss += loss_fn(pred, y).item()test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss5. 创建导入本地图片预处理模块
def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB')# plt.imshow(test_img) # 展示预测的图片test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_, pred = torch.max(output, 1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')
6. 主函数
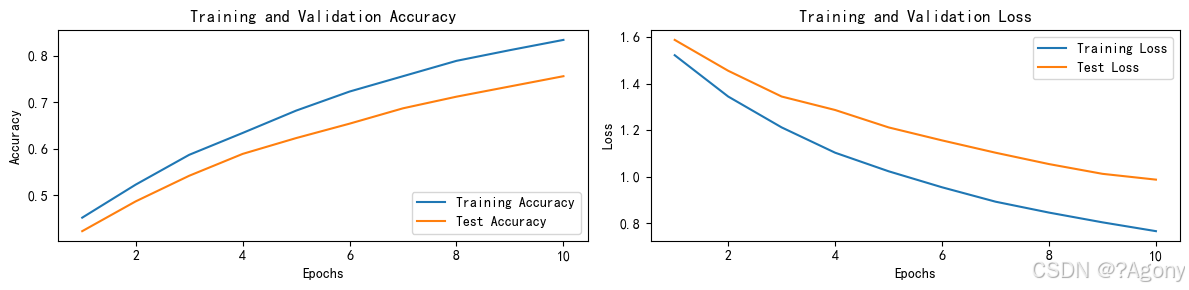
if __name__ == '__main__':for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}')print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))print('Done')# 绘制训练和测试曲线warnings.filterwarnings("ignore")plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = Falseplt.rcParams['figure.dpi'] = 100epochs_range = range(epochs)plt.figure(figsize=(12, 3))plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')plt.plot(epochs_range, test_acc, label='Test Accuracy')plt.legend(loc='lower right')plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)plt.plot(epochs_range, train_loss, label='Training Loss')plt.plot(epochs_range, test_loss, label='Test Loss')plt.legend(loc='upper right')plt.title('Training and Validation Loss')plt.show()classes = list(total_data.class_to_idx.keys())predict_one_image(image_path='./data/4-data/Monkeypox/M01_01_00.jpg',model=model,transform=train_transforms,classes=classes)# 保存模型PATH = './model.pth'torch.save(model.state_dict(), PATH)# 加载模型model.load_state_dict(torch.load(PATH, map_location=device))
结果
Epoch: 1, Train_acc: 45.2%, Train_loss: 1.523, Test_acc: 42.3%, Test_loss: 1.589
Epoch: 2, Train_acc: 52.3%, Train_loss: 1.345, Test_acc: 48.7%, Test_loss: 1.456
Epoch: 3, Train_acc: 58.7%, Train_loss: 1.212, Test_acc: 54.2%, Test_loss: 1.345
Epoch: 4, Train_acc: 63.4%, Train_loss: 1.103, Test_acc: 58.9%, Test_loss: 1.287
Epoch: 5, Train_acc: 68.2%, Train_loss: 1.023, Test_acc: 62.3%, Test_loss: 1.212
Epoch: 6, Train_acc: 72.3%, Train_loss: 0.954, Test_acc: 65.4%, Test_loss: 1.156
Epoch: 7, Train_acc: 75.6%, Train_loss: 0.892, Test_acc: 68.7%, Test_loss: 1.103
Epoch: 8, Train_acc: 78.9%, Train_loss: 0.845, Test_acc: 71.2%, Test_loss: 1.054
Epoch: 9, Train_acc: 81.2%, Train_loss: 0.803, Test_acc: 73.4%, Test_loss: 1.012
Epoch:10, Train_acc: 83.4%, Train_loss: 0.765, Test_acc: 75.6%, Test_loss: 0.987
Done
相关文章:
P17_ResNeXt-50
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 一、模型结构 ResNeXt-50由多个残差块(Residual Block)组成,每个残差块包含三个卷积层。以下是模型的主要结构࿱…...

Ubuntu上离线安装ELK(Elasticsearch、Logstash、Kibana)
在 Ubuntu 上离线安装 ELK(Elasticsearch、Logstash、Kibana)的完整步骤如下: 一.安装验证 二.安装步骤 1. 在联网机器上准备离线包 (1) 安装依赖工具 #联网机器 sudo apt update sudo apt install apt-rdepends wget(2) 下载 ELK 的 .deb 安装包 #创建目录将安装包下载…...
PyCharm 下载与安装教程:从零开始搭建你的 Python 开发环境
PyCharm 是一款专为 Python 开发设计的集成开发环境(IDE),它提供了强大的代码编辑、调试、版本控制等功能,是 Python 开发者的必备工具之一。如果你是初学者,或者正在寻找一款高效的开发工具,这篇文章将帮助…...

TSMaster在新能源汽车研发测试中的硬核应用指南
——从仿真到标定,全面赋能智能汽车开发 引言:新能源汽车测试的挑战与TSMaster的破局之道 新能源汽车的快速发展对研发测试提出了更高要求:复杂的电控系统、高实时性通信需求、多域融合的验证场景,以及快速迭代的开发周期。传统测…...

C/C++的条件编译
一、什么是条件编译? 条件编译是指在编译阶段根据某些条件来决定是否编译某段代码。这通常通过预处理指令来实现,比如 #if、#ifdef、#ifndef、#else、#elif 和 #endif。 二、为什么使用条件编译? 跨平台开发:不同的操作…...

使用 requests 和 BeautifulSoup 解析淘宝商品
以下将详细解释如何通过这两个库来实现按关键字搜索并解析淘宝商品信息。 一、准备工作 1. 安装必要的库 在开始之前,确保已经安装了 requests 和 BeautifulSoup 库。如果尚未安装,可以通过以下命令进行安装: bash pip install requests…...

安装 TabbyAPI+Exllamav2 和 vLLM 的详细步骤
在 5090 显卡上成功安装 TabbyAPIExllamav2 和 vLLM 并非易事,经过一番摸索,我总结了以下详细步骤,希望能帮助大家少走弯路。 重要提示: 用户提供的 PyTorch 安装使用了 cu128,这并非标准 CUDA 版本。请根据你的系统实…...

小动物多导生理记录仪产品需求定义
小动物多导生理记录仪的产品需求定义如下: 功能需求 信号采集功能:能采集多种生理信号,如心电、脑电、肌电、眼电、胃肠电、诱发电位、神经电位、细胞电位、有创血压、无创血压、dP/dt、体温、肌张力、呼吸波、呼吸流速、组织血流速度、血管…...

深入理解C++引用:从基础到现代编程实践
一、引用的本质与基本特性 1.1 引用定义 引用是为现有变量创建的别名,通过&符号声明。其核心特点: 必须初始化且不能重新绑定 与被引用变量共享内存地址 无独立存储空间(编译器实现) 类型必须严格匹配 int value 42; in…...
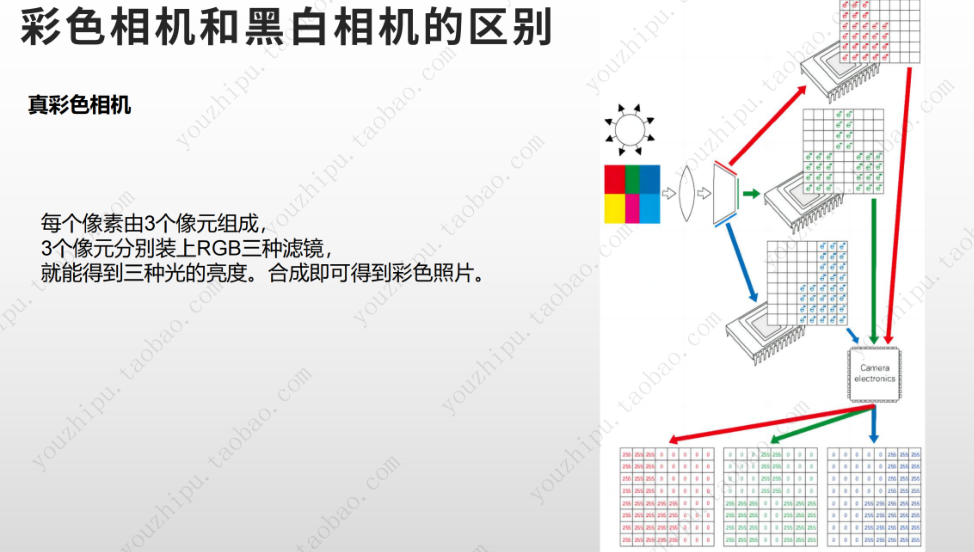
黑白彩色相机成像原理
文章目录 黑白相机成像原理彩色相机成像原理 黑白相机成像原理 参考:B站优致谱视觉 光线聚焦:相机镜头将外界景物反射的光线聚焦到相机内部的成像平面上。光电转换:成像平面上通常是图像传感器,黑白相机常用的是CCD(…...

室内指路机器人是否支持环境监测功能?
并非所有室内指路机器人都具备环境监测功能。那些支持环境监测的室内指路机器人,往往在设计上进行了针对性的优化,搭载了一系列先进且实用的传感器。温湿度传感器犹如一位敏锐的 “温度湿度侦探”,时刻精准地监测室内温度与湿度,为…...
:革新未来治理的下一站)
去中心化自治组织(DAO):革新未来治理的下一站
去中心化自治组织(DAO):革新未来治理的下一站 引言 去中心化自治组织(DAO)的诞生,像是互联网时代的一道新曙光。它打破了传统组织的等级壁垒,以去中心化和智能合约为核心,让社区成员能够直接参与决策并共享收益。从NFT社区到投资基金,DAO的应用场景正以前所未有的速…...

Docker安装、配置Mysql5.7
1.创建必要的目录 # 创建目录 mkdir -p ~/docker/software/mysql/{conf,log,data} 2.如果没有docker-compose.yml文件的话,先创建docker-compose.yml 配置文件一般长这个样子 version: 3services:mysql:image: mysql:5.7.36container_name: mysqlports:- "…...

#管理Node.js的多个版本
在 Windows 11 上管理 Node.js 的多个版本,最方便的方法是使用 nvm-windows(Node Version Manager for Windows)。它允许你轻松安装、切换和管理多个 Node.js 版本。 📌 方法 1:使用 nvm-windows(推荐 ✅&a…...
基于DrissionPage的Taptap热门游戏数据爬虫实战:从Requests到现代爬虫框架的迁移指南(含完整代码复制)
目录 编辑 一、项目重构背景与技术选型 1.1 原代码问题分析 1.2 DrissionPage框架优势 二、环境配置与基础改造 2.1 依赖库安装 2.2 基础类改造 三、核心功能模块重构 3.1 请求参数自动化生成 3.2 智能页面渲染 3.3 数据解析优化 四、数据库操作增强 4.1 批量插入…...

Online Sparse Reconstruction for Scanning Radar Using Beam-Updating q-SPICE论文阅读
Online Sparse Reconstruction for Scanning Radar Using Beam-Updating q -SPICE 论文概述关键技术与创新点实验结果学术术语解释1. 论文的研究目标与实际问题2. 论文提出的新方法、模型与公式2.1 核心方法:Beam-Updating q-SPICE2.1.1 循环最小化(Cyclic Minimization)2.1…...

模运算核心性质与算法应用:从数学原理到编程实践
目录 🚀前言🌟数学性质:模运算的理论基石💯基本定义:余数的本质💯四则运算规则:保持同余性的关键 🦜编程实践:模运算的工程化技巧💯避免数值溢出:…...

MINIQMT学习课程Day8
获取qmt账号的资金账号后,我们进入下一步,如何获得当前账号的持仓情况 还是之前的步骤,打开qmt,选择独立交易, 之后使用pycharm,编写py文件。 from xtquant import xtdata from xtquant.xttrader import…...
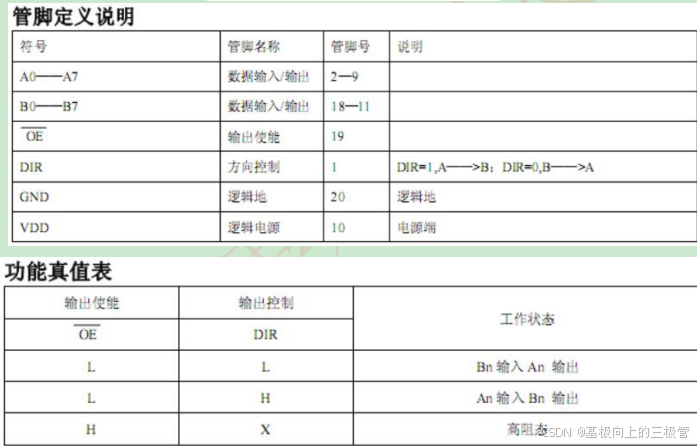
【硬件模块】数码管模块
一位数码管 共阳极数码管:8个LED共用一个阳极 数字编码00xC010xF920xA430xB040x9950x9260x8270xF880x8090x90A0x88B0x83C0xC6D0xA1E0x86F0x8E 共阴极数码管:8个LED共用一个阴极 数字编码00x3F10x0620x5B30x4F40x6650x6D60x7D70x0780x7F90x6FA0x77B0x7…...
专为 零基础初学者 设计的最简前端学习路线,聚焦核心内容,避免过度扩展,帮你快速入门并建立信心!
第一阶段:HTML CSS(2-3周) 目标:能写出静态网页,理解盒子模型和布局。 HTML基础 常用标签:<div>, <p>, <img>, <a>, <ul>, <form> 语义化标签:<head…...

详解大模型四类漏洞
关键词:大模型,大模型安全,漏洞研究 1. 引入 promptfoo(参考1)是一款开源大语言模型(LLM)测试工具,能对 LLM 应用进行全面漏洞测试,它可检测包括安全风险、法律风险在内…...

.NET 调用API创建系统服务实现权限维持
在Windows操作系统中,Services服务以后台进程的形式运行的,通常具备非常高的权限启动和运行服务。因此红队往往利用.NET框架通过创建和管理Windows服务来实现权限维持。本文将详细介绍如何通过.NET创建Windows服务,以实现权限维持的基本原理和…...

CSS 创建与使用学习笔记
一、CSS 的作用 CSS(层叠样式表)用于控制 HTML 文档的样式和布局。当浏览器读取一个样式表时,它会根据样式表中的规则来格式化 HTML 文档,从而实现页面的美化和布局调整。 二、插入样式表的方法 CSS 可以通过以下三种方式插入到…...

使用Expo框架开发APP——详细教程
在移动应用开发日益普及的今天,跨平台开发工具越来越受到开发者青睐。Expo 是基于 React Native 的一整套工具和服务,它能够大幅降低原生开发的门槛,让开发者只需关注业务逻辑和界面实现,而不用纠结于复杂的原生配置。本文将从零开…...
)
Android Dagger 2 框架的注解模块深入剖析 (一)
本人掘金号,欢迎点击关注:https://juejin.cn/user/4406498335701950 一、引言 在 Android 开发中,依赖注入(Dependency Injection,简称 DI)是一种强大的设计模式,它能够有效降低代码的耦合度&…...

流媒体协议基础
流媒体协议基础 全文-流媒体协议基础 全文大纲 流媒体协议分类 RTMP:应用层协议,依赖Flash播放器插件,支持推、拉流。RTSP:应用层控制协议,用于播放、暂停、终止等指令控制,支持推、拉流。RTP:…...
Java全栈面试宝典:线程安全机制与Spring Boot核心原理深度解析
目录 一、Java线程安全核心原理 🔥 问题1:线程安全的三要素与解决方案 线程安全风险模型 线程安全三要素 synchronized解决方案 🔥 问题2:synchronized底层实现全解析 对象内存布局 Mark Word结构(64位系统&…...

Linux开发工具——apt
📝前言: 在之前我们已经讲解了有关的Linux基础命令和Linux权限的问题,这篇文章我们来讲讲Linux的开发工具——apt。 🎬个人简介:努力学习ing 📋个人专栏:Linux 🎀CSDN主页 愚润求学 …...
)
2025-4-4-python算法题(OD算法题-最长合法表达式)
文章目录 几个常用库函数的使用1. functools 模块2. sys 模块3. collections 模块4. copy 模块5. itertools 模块6. re 模块7. math 模块 OD算法题-最长合法表达式学习python的内置函数 eval(expr) 几个常用库函数的使用 import functools import sys from collections import…...
嵌入式——Linux系统的使用以及编程练习
目录 一、Linux的进程、线程概念 (一)命令控制进程 1、命令查看各进程的编号pid 2、命令终止一个进程pid 二、初识Linux系统的虚拟机内存管理 (一)虚拟机内存管理 (二)与STM32内存管理对比 三、Lin…...