pat学习笔记
two pointers 双指针
给定一个递增的正整数序列和一个正整数M,求序列中的两个不同位置的数a和b,使得它们的和恰好为M,输出所有满足条件的方案。例如给定序列{1,2,3,4,5,6}和正整数M = 8,就存在2+6=8和3+5=8成立。
容易想到:使用二重循环枚举序列中的整数a和b,判断它们的和是否为M,如果是,输出方案,如果不是,则继续枚举。
代码如下,时间复杂度为O(n^2)。
for(int i=0;i<n;i++){for(int j=i+1;i<n;i++){if(a[i]+a[j]==M){printf("%d %d\n",a[i],a[j]);}}
}2-SUM-双指针
优化算法如下:该算法的时间复杂度为O(n)。
#include <cstdio>
#include <iostream>
using namespace std;
const int N = 1e5+10;
int a[N];
int main(){int n,k;int cnt = 0;cin>>n>>k;int i = 0,j = n-1;for(int i=0;i<n;i++) cin>>a[i];while(i<j){if(a[i]+a[j]==k){cnt++;i++;j--;}else if(a[i]+a[j]<k){i++;}else {j--;}}cout<<cnt;return 0;
}序列合并问题:
#include <cstdio>
#include <iostream>
using namespace std;// 定义常量 N,用于确定数组的最大长度
const int N = 1e5 + 10;// 定义三个数组 a、b、c,分别用于存储两个待合并的有序数组和合并后的有序数组
int a[N], b[N], c[N];// 合并函数,将两个有序数组合并为一个有序数组
int merge(int a[], int b[], int c[], int n, int m) {// i 指向数组 a 的起始位置,j 指向数组 b 的起始位置,index 指向数组 c 的起始位置int i = 0, j = 0, index = 0;// 当数组 a 和数组 b 都还有元素未处理时while (i < n && j < m) {// 如果 a[i] 小于等于 b[j],将 a[i] 放入数组 c 中,并将 i 和 index 指针后移if (a[i] <= b[j]) c[index++] = a[i++];// 否则将 b[j] 放入数组 c 中,并将 j 和 index 指针后移else c[index++] = b[j++];}// 如果数组 a 还有剩余元素,将其依次放入数组 c 中while (i < n) c[index++] = a[i++];// 如果数组 b 还有剩余元素,将其依次放入数组 c 中while (j < m) c[index++] = b[j++];// 返回合并后数组 c 的长度return index;
}int main() {int n, m;// 读取数组 a 的长度 n 和数组 b 的长度 mscanf("%d%d",&n,&m);// 读取数组 a 的 n 个元素for (int i = 0; i < n; i++) scanf("%d",&a[i]);// 读取数组 b 的 m 个元素for (int i = 0; i < m; i++) scanf("%d",&b[i]);// 调用 merge 函数合并数组 a 和数组 b 到数组 c 中,并获取合并后数组 c 的长度int res = merge(a, b, c, n, m);// 输出合并后数组 c 的元素for (int i = 0; i < res; i++) {printf("%d", c[i]);// 除了最后一个元素,每个元素后面输出一个空格if (i < res - 1) cout << " ";}return 0;
}归并排序
递归写法
#include <iostream>
#include <cstdio>
using namespace std;
const int maxn = 1010;
int a[maxn];
//将数组A的[L1,R1]与[L2,r2]区间合并为有序区间(此处L2即为r1+1)
void merge(int a[], int l1, int r1, int l2, int r2) {int i = l1, j = l2; //i指向a[l1],j指向a[l2] int temp[maxn], index = 0; //temp临时存放合并后的数组,index为其下标while (i <= r1 && j <= r2) {if (a[i] <= a[j]) { //如果a[i]<=a[j]temp[index++] = a[i++]; //将a[i]加入序列temp } else {temp[index++] = a[j++];}}while (i <= r1) temp[index++] = a[i++];while (j <= r2) temp[index++] = a[j++];for (i = 0; i < index; i++) {a[l1 + i] = temp[i]; //将合并后的序列赋值给数组a }
}
//将array数组当前区间[left,right]进行归并排序
void mergeSort(int a[], int left, int right) {if (left < right) { //只要left小于right int mid = (left + right) / 2; //取[left,right]的中点 mergeSort(a, left, mid); //递归,将左子区间[left,mid]归并排序 mergeSort(a, mid + 1, right); //递归,将右子区间[mid+1,right]归并排序 merge(a, left, mid, mid + 1, right); //将左子区间和右子区间合并 }
}int main() {int n;cin >> n;for (int i = 0; i < n; i++) cin >> a[i];// 调用归并排序函数对数组进行排序mergeSort(a, 0, n - 1);// 输出排序后的数组for (int i = 0; i < n; i++) {cout << a[i];if (i < n - 1) cout << " ";}return 0;
} 非递归写法
/*1. 外层循环 for(int step = 2; step/2 <= n; step *= 2)
step 的含义:step 表示当前每组元素的个数。在归并排序的非递归实现中,我们从最小的有序子数组开始合并,初始时每组有 2 个元素(即 step = 2),然后每次将 step 乘以 2,逐渐扩大每组的元素个数。
循环条件 step/2 <= n:当 step/2 大于数组的长度 n 时,说明已经完成了所有的合并操作,因为此时分组已经包含了整个数组,所以循环结束。
step *= 2:每次循环结束后,将 step 乘以 2,这样就可以将相邻的两个有序子数组合并成一个更大的有序数组。
2. 内层循环 for(int i = 1; i <= n; i += step)
i 的含义:i 表示当前组的起始位置。每次循环将 i 增加 step,这样就可以依次处理数组中的每一组元素。
循环条件 i <= n:确保 i 不会超出数组的范围。
3. int mid = i + step/2 - 1
mid 的含义:mid 表示当前组中左子区间的最后一个元素的下标。因为左子区间的元素个数为 step/2,所以 mid 的值为 i + step/2 - 1。
4. if(mid + 1 <= n)
判断右子区间是否存在元素:如果 mid + 1 大于数组的长度 n,说明右子区间不存在元素,不需要进行合并操作;否则,需要将左子区间 [i, mid] 和右子区间 [mid + 1, min(i + step - 1, n)] 进行合并。
5. merge(a, i, mid, mid + 1, min(i + step - 1, n))
调用 merge 函数进行合并:merge 函数的作用是将两个有序子数组合并成一个更大的有序数组。这里的左子区间为 [i, mid],右子区间为 [mid + 1, min(i + step - 1, n)]。使用 min(i + step - 1, n) 是为了防止右子区间的下标超出数组的范围。
注意事项
代码中数组的下标是从 1 开始的,而在 C++ 中数组的下标通常是从 0 开始的。如果要在实际代码中使用,需要根据具体情况进行调整。
代码中使用了变量 n,但在提供的代码片段中并没有对 n 进行定义,在实际使用时需要确保 n 是数组的长度*/
void mergeSort(int a[]){// step为组内元素个数,step/2为左子区间元素个数,注意等号可以不取for(int step = 2; step/2 <= n; step *= 2){// 每step个元素一组,组内前step/2和后step/2个元素进行合并for(int i = 1; i <= n; i += step){ // 对每一组 int mid = i + step/2 - 1; // 左子区间元素个数为step/2 if(mid + 1 <= n){ // 右子区间存在元素则合并 // 左子区间为[i, mid], 右子区间为[mid + 1, min(i + step - 1, n)]merge(a, i, mid, mid + 1, min(i + step - 1, n)); }} }
}快速排序的交换方式:
//对区间[left,right]进行划分
int partition(int a[],int left,int right){int temp = a[left];//将a[left]存放至临时变量tempwhile(left<right){//只要left与rightwhile(left<right&&a[right]>temp) right--;//反复左移right a[left] = a[right];//将a[right]挪到a[left]while(left<right&&a[left]<=temp) left++;//反复右移left a[right] = a[left];//将a[left]挪到a[right] } a[left] = temp;//把temp放到left与right相遇的地方 return left;//返回相遇的下标
} 快速排序的递归实现如下:
//快速排序,left 与right初值为序列首尾下标(如1,与n)
void quicksort(int a[],int left,int right){if(left<right){//当前区间的长度不超过1 //将[left,right]按a[left]一分为二int pos = partition(a,left,right);quicksort(a,left,pos-1);//对左子区间递归进行快速排序 quicksort(a,pos+1,right); //对右子区间递归进行快速排序 }
}快速排序
#include <cstdio>
#include <iostream>
using namespace std;
const int maxn = 1010;
int a[maxn];
//对区间[left,right]进行划分
int partition(int a[],int left,int right){int temp = a[left];//将a[left]存放至临时变量tempwhile(left<right){//只要left与rightwhile(left<right&&a[right]>temp) right--;//反复左移right a[left] = a[right];//将a[right]挪到a[left]while(left<right&&a[left]<=temp) left++;//反复右移left a[right] = a[left];//将a[left]挪到a[right] } a[left] = temp;//把temp放到left与right相遇的地方 return left;//返回相遇的下标
}
//快速排序,left 与right初值为序列首尾下标(如1,与n)
void quicksort(int a[],int left,int right){if(left<right){//当前区间的长度不超过1 //将[left,right]按a[left]一分为二int pos = partition(a,left,right);quicksort(a,left,pos-1);//对左子区间递归进行快速排序 quicksort(a,pos+1,right); //对右子区间递归进行快速排序 }
}
int main(){int n;cin>>n;for(int i=0;i<n;i++) cin>>a[i];quicksort(a,0,n-1);for(int i=0;i<n;i++){cout<<a[i];if(i<n-1) cout<<" ";}return 0;
}相关文章:

pat学习笔记
two pointers 双指针 给定一个递增的正整数序列和一个正整数M,求序列中的两个不同位置的数a和b,使得它们的和恰好为M,输出所有满足条件的方案。例如给定序列{1,2,3,4,5,6}和正整数M 8,就存在268和358成立。 容易想到࿱…...

Gson修仙指南:谷歌大法的佛系JSON渡劫手册
各位在代码世界打坐修行的道友们!今天我们要参悟Google出品的JSON心法——Gson!这货就像代码界的扫地僧,表面朴实无华,实则内力深厚,专治各种JSON不服!准备好迎接"万物皆可JSON"的顿悟时刻了吗&a…...

我的世界1.20.1forge模组开发进阶教程——TerraBlender
TerraBlender介绍 从模组开发者的视角来看,TerraBlender为Minecraft生物群系类模组的开发提供了全方位的技术支持,显著降低了开发门槛并提升了模组的质量与扩展性: 跨平台兼容性架构支持Forge/Fabric/Quilt/NeoForge四大主流加载器,开发者无需为不同平台单独适配代码客户端…...

判断HiveQL语句为ALTER TABLE语句的识别函数
写一个C#字符串解析程序代码,逻辑是从前到后一个一个读取字符,遇到匹配空格、Tab和换行符就继续读取下一个字符,遇到大写或小写的字符a,就读取后一个字符并匹配是否为大写或小写的字符l,以此类推,匹配任意字…...

CAN/FD CAN总线配置 最新详解 包含理论+实战(附带源码)
看前须知:本篇文章不会说太多理论性的内容(重点在理论结合实践),顾及实操,应用,一切理论内容支撑都是为了后续实际操作进行铺垫,重点在于读者可以看完文章应用。(也为节约读者时间&a…...

DE2-115分秒计数器
一、模块设计 如若不清楚怎么模块化,请看https://blog.csdn.net/szyugly/article/details/146379170?spm1001.2014.3001.5501 1.1顶层模块 module top_counter(input wire CLOCK_50, // 50MHz时钟input wire KEY0, // 暂停/继续按键out…...

MoE Align Sort在医院AI医疗领域的前景分析(代码版)
MoE Align & Sort技术通过优化混合专家模型(MoE)的路由与计算流程,在医疗数据处理、模型推理效率及多模态任务协同中展现出显著优势,其技术价值与应用意义从以下三方面展开分析: 一、方向分析 1、提升医疗数据处理效率 在医疗场景中,多模态数据(如医学影像、文本…...
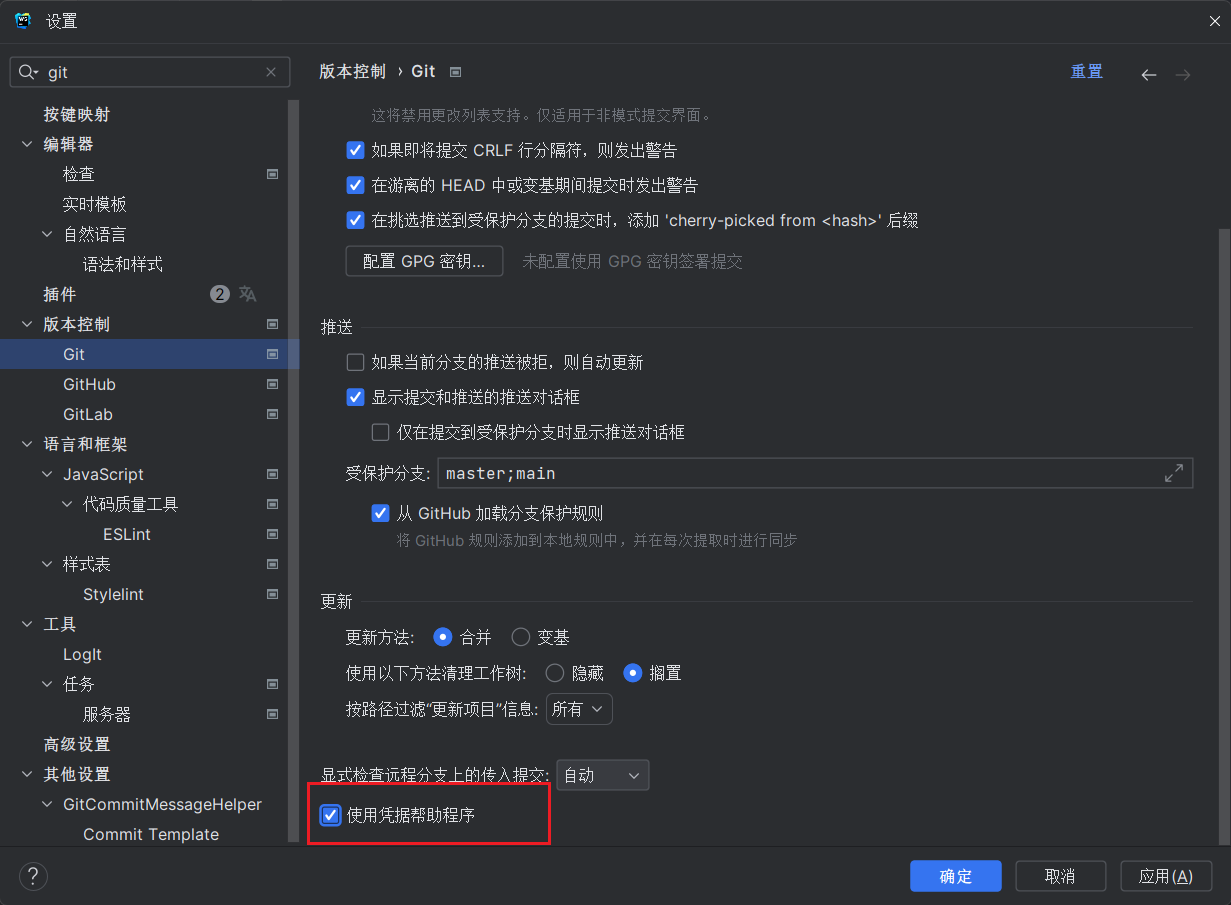
【已解决】Webstorm 每次使用 git pull/push 都要输入令牌/密码登录
解决办法:勾上【使用凭据帮助程序】(英文:Use credential helper)...

阅读分析Linux0.11 /boot/setup.s
目录 第一部分第二部分第三部分 该源文件功能分为三部分: (1)源文件开始部分是通过各种中断指令, 初始化计算机的组成硬件,获得硬件的参数,然后保存到段空间0X9000。该空间原来是保存加载到内存的引导扇区内…...

Cmake:Win10 如何编译 midifile C++应用程序
先从 Microsoft C Build Tools - Visual Studio 下载 1.73GB 安装 "Microsoft C Build Tools“ 下载:midifile 项目 , 将 midifile-master.zip 解压到 D:\Music-soft 参阅: cmake超详细入门教程 CMake是一个跨平台的自动化建构系统,它使用一个名为 CMakeLi…...
)
QEMU源码全解析 —— 块设备虚拟化(14)
接前一篇文章:QEMU源码全解析 —— 块设备虚拟化(13) 本文内容参考: 《趣谈Linux操作系统》 —— 刘超,极客时间 《QEMU/KVM源码解析与应用》 —— 李强,机械工业出版社 特此致谢! 上一回开始解析VirtioDeviceClass的realize函数virtio_blk_device_realize(),再来回…...
软路由安装指南
1.openwrt下载 : 选择合适的安装包,我用的软路由CPU主板是j3160,属于X86_64架构,所以筛选的时候使用X86_64的安装镜像 openwrt的官方地址可能国内打不开,需要科学上网 openwrt安装镜像下载地址 我准备用U盘引导小主机开机,进而安装openwrt操作系统,所以下载 .img.gz 文…...

机器视觉工程师的专业精度决定职业高度,而专注密度决定成长速度。低质量的合群,不如高质量独处
在机器视觉行业,真正的技术突破往往诞生于深度思考与有效碰撞的辩证统一。建议采用「70%高质量独处30%精准社交」的钻石结构,构建可验证的技术能力护城河。记住:你的专业精度决定职业高度,而专注密度决定成长速度。 作为机器视觉工…...

Oracle 数据库中,并行 DML
在 Oracle 数据库中,PL/SQL 的 BEGIN...END 块默认是串行执行的,但可以通过以下方法实现并行处理,提升大规模数据操作的性能: 并行 DML(Data Manipulation Language) 在 BEGIN...END 块中启用并行 DML&am…...

Spring Boot 集成 Redis中@Cacheable 和 @CachePut 的详细对比,涵盖功能、执行流程、适用场景、参数配置及代码示例
以下是 Cacheable 和 CachePut 的详细对比,涵盖功能、执行流程、适用场景、参数配置及代码示例: 1. 核心对比表格 特性CacheableCachePut作用缓存方法的返回结果,避免重复计算执行方法并更新缓存,不覆盖原有缓存执行流程缓存命中…...
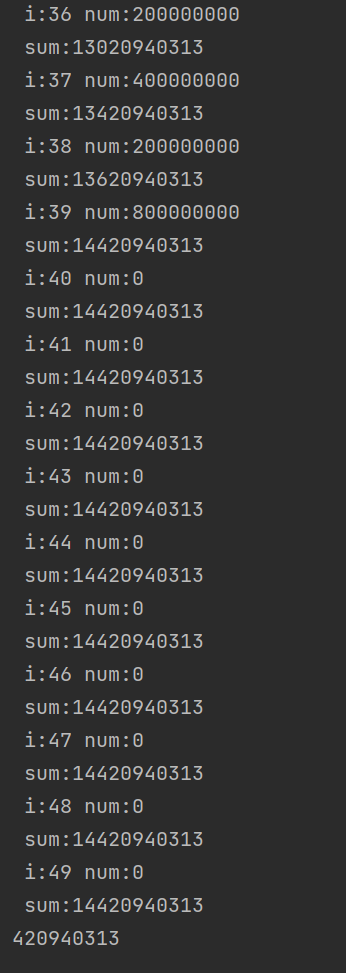
3500 阶乘求和
3500 阶乘求和 ⭐️难度:中等 🌟考点:2023、思维、省赛 📖 📚 import java.util.Scanner;public class Main {public static void main(String[] args) {long sum 0;for(int i1;i<50;i) { // 之后取模都相等su…...

软件工程(应试版)图形工具总结(二)
遇到的问题,都有解决方案,希望我的博客能为你提供一点帮助。 教材参考《软件工程导论(第六版)》 七、 层次图(H图)与HIPO图 1、概述 1.1、层次图(Hierarchy Chart / H图) 核心…...

思维链、思维树、思维图与思维森林在医疗AI编程中的应用蓝图
在医疗AI编程中,思维链(Chain of Thought, CoT)、思维树(Tree of Thoughts, ToT)、思维图(可能指知识图谱或逻辑图)以及思维森林(Forest-of-Thought, FoT)等技术框架通过模拟人类认知和推理过程,显著提升了AI在复杂医疗场景中的决策能力和可解释性: 1. 思维链(CoT)…...

SpringBoot异步任务实践指南:提升系统性能的利器
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 引言 在现代Web应用中,高并发场景下的响应速度和资源利用率是系统设计的重要考量。SpringBoot通过简洁的异步任务机制,帮助开发者轻松…...

化工行业如何通过定制化工作流自动化实现25-30%成本优化?
作者:Mihir Jhaveri 编译:李升伟 发布日期:2024年10月30日 在化工生产领域,数字化转型正以颠覆性态势重塑产业格局。通过集成定制化软件、ERP系统、工业物联网(IIoT)传感网络、机器人流程自动化࿰…...

嵌入式硬件篇---嘉立创PCB绘制
文章目录 前言一、PCB绘制简介1.1绘制步骤1.1.1前期准备1.1.2原理图设计1.1.3原理图转PCB1.1.4PCB布局1.1.5布线1.1.6布线优化和丝印1.1.7制版1.2原理1.2.1电气连接原理1.2.2信号传输原理1.2.3电源和接地原理1.3注意事项1.3.1元件封装1.3.2布局规则1.3.3过孔设计1.3.4DRC检查1.…...

CSS Id 和 Class 选择器学习笔记
一、概述 在 CSS 中,id 和 class 选择器是用于为 HTML 元素指定样式的强大工具。它们可以帮助我们精确地控制页面中元素的样式,让页面设计更加灵活和高效。 二、id 选择器 1. 定义和使用 定义:id 选择器用于为具有特定 id 属性的 HTML 元素…...

Linux的 /etc/sysctl.conf 笔记250404
Linux的 /etc/sysctl.conf 笔记250404 /etc/sysctl.conf 是 Linux 系统中用于 永久修改内核运行时参数 的核心配置文件。它通过 sysctl 工具实现参数的持久化存储,确保系统重启后配置依然生效。以下是其详细说明: 📂 备份/etc/sysctl.conf t…...

LocaDate、LocalTime、LocalDateTime
Java8的时间处理 Java的时间处理在早期版本中存在诸多问题(如 java.util.Date 和 java.util.Calendar 的混乱设计),但Java8引入了引入了全新的 java.time包(基于JSR 310),提供了更清晰、线程安全且强大的时…...
1.Qt信号与槽
本篇主要介绍信号和槽,如何关联信号和槽以及用QPixmap在窗口中自适应显示图片 本文部分ppt、视频截图原链接:[萌马工作室的个人空间-萌马工作室个人主页-哔哩哔哩视频] 1. 信号 一般不需要主动发送信号,只有自定义的一些控件才需要做信号的…...
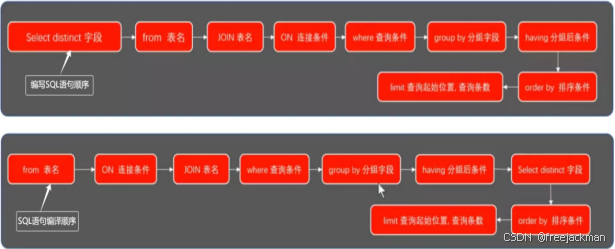
MySQL 基础入门
写在前面 关于MySQL的下载安装和其图形化软件Navicat的下载安装,网上已经有了很多的教程,这里就不再赘述了,本文主要是介绍了关于MySQL数据库的基础知识。 MySQL数据库 MySQL数据库基础 MySQL数据库概念 MySQL 数据库: 是一个关系型数据库管理系统 。 支持SQL语…...

shell语言替换脚本、填补整个命令行
shell语言替换脚本 填补整个命令行正则查询服务器指定路径替换内容 填补整个命令行 多用于脚本显示 seq -s "*" tput cols |tr -d [:digit:]正则查询 grep -r -E register[0-9]{5} /www/wwwroot服务器指定路径替换内容 #!/bin/bash cat > 1.sh << EOF #…...
数据分析与知识发现 论文阅读【信息抽取】
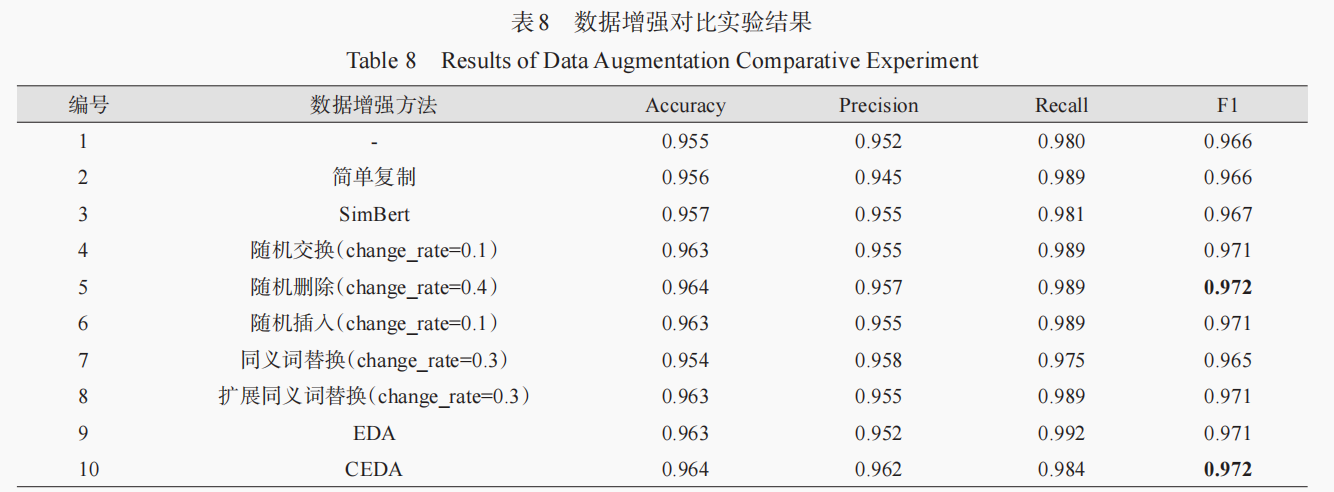
文章目录 基于知识蒸馏的半监督古籍实体抽取数据集模型实验结果 基于大语言模型的专利命名实体识别方法研究数据集评估公式实验 基于数据增强和多任务学习的突发公共卫生事件谣言识别研究数据集实验结果 参考 基于知识蒸馏的半监督古籍实体抽取 数据集 本文在有监督数据集的基…...
Compose组件转换XML布局
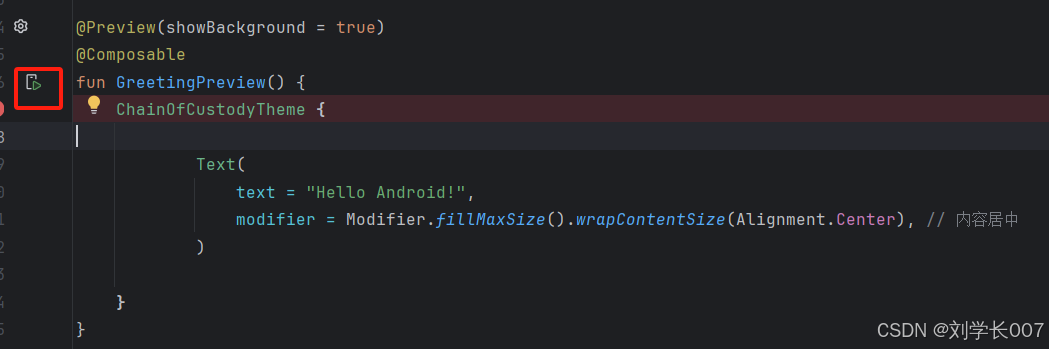
文章目录 学习JetPack Compose资源前言:预览界面的实现Compose组件的布局管理一、Row和Colum组件(LinearLayout)LinearLayout(垂直方向 → Column)LinearLayout(水平方向 → Row) 二、相对布局 …...
Linux开发工具——vim
📝前言: 上篇文章我们讲了Linux开发工具——apt,这篇文章我们来讲讲Linux开发工具——vim 🎬个人简介:努力学习ing 📋个人专栏:Linux 🎀CSDN主页 愚润求学 🌄其他专栏&a…...