数据集(Dataset)和数据加载器(DataLoader)-pytroch学习3
pytorch网站学习
处理数据样本的代码往往会变得很乱、难以维护;理想情况下,我们希望把数据部分的代码和模型训练部分分开写,这样更容易阅读、也更好维护。
简单说:数据和模型最好“分工明确”,不要写在一起。
PyTorch 提供了两个数据处理的“基本工具”:
-
torch.utils.data.Dataset -
torch.utils.data.DataLoader
它们可以用来处理官方内置的数据集,也可以用来加载你自己的数据。
Dataset 存储样本及其对应的标签,而 DataLoader 则在 Dataset 周围封装了一个迭代器,以便轻松访问这些样本。 -
Dataset:用于存储样本和对应的标签,类似一个“数据库”,它记录了所有数据。
-
DataLoader:基于 Dataset 封装了一个可迭代对象,方便你在训练过程中一次取出一个批次(batch)的数据。
-
Dataset = 数据仓库,负责“存”数据
-
DataLoader = 快递员,负责“送”数据,一批一批送给模型训练用
PyTorch 提供了 Dataset(负责存数据)和 DataLoader(负责送数据)两个工具,可以方便地管理、加载各种数据
PyTorch 的领域库提供了许多预加载的数据集(例如 FashionMNIST),这些数据集都是 torch.utils.data.Dataset 的子类,,例如,FashionMNIST 数据集就是一个专门用于服装图像识别的预加载数据集,它已经按照 Dataset 接口组织好了数据,你可以直接用来训练和测试模型
参数解释:
✅ root:这是用来存放训练/测试数据的文件夹路径。
✅ train:指定是加载训练集(train=True)还是测试集(train=False)。
✅ download=True:如果你指定的 root 路径下没有数据,它会自动联网下载。
✅ transform 和 target_transform:
-
transform是对图像特征做的变换(比如转为张量、归一化等) -
target_transform是对标签做的变换(比如 one-hot 编码)
from torchvision import datasets, transforms# 定义图像的预处理操作:把图片转成张量
transform = transforms.ToTensor()# 加载训练集
train_data = datasets.FashionMNIST(root="data", # 数据保存目录train=True, # 加载训练集download=True, # 如果没有就下载transform=transform # 图像预处理
)# 加载测试集
test_data = datasets.FashionMNIST(root="data",train=False, # 加载测试集download=True,transform=transform
)
如何手动取出数据集里的样本,并把它们可视化显示出来,
遍历和可视化数据集
我们可以像访问列表那样,用下标手动访问数据集:training_data[index]
我们使用 matplotlib 来把训练数据中的一些样本画出来进行可视化。
什么是 training_data[index]?
在 PyTorch 中,像 training_data 这种数据集对象,其实可以像列表(list)一样使用:image, label = training_data[0] # 取出第一个样本(包括图像和标签)
image 是一张 28×28 的图(张量)label 是它的标签(比如 “T-shirt/top”)# 标签编号和对应的文字(类别)之间的映射关系
labels_map = {0: "T-Shirt",1: "Trouser",2: "Pullover",3: "Dress",4: "Coat",5: "Sandal",6: "Shirt",7: "Sneaker",8: "Bag",9: "Ankle Boot",
}
figure = plt.figure(figsize=(8, 8)) # 创建一个图形窗口,大小为 8x8 英寸
cols, rows = 3, 3 # 准备画一个 3 行 3 列 的图像网格(共 9 张图)
for i in range(1, cols * rows + 1): # 循环9次(从1到9)sample_idx = torch.randint(len(training_data), size=(1,)).item() # 随机选一个样本索引img, label = training_data[sample_idx] # 从训练集中取出图像和标签
figure.add_subplot(rows, cols, i) # 添加一个子图(3x3 的第 i 个格子)plt.title(labels_map[label]) # 设置图像标题为标签名称(比如 “Sneaker”)plt.axis("off") # 不显示坐标轴plt.imshow(img.squeeze(), cmap="gray") # 显示图像(压缩维度 + 灰度图)
plt.show() # 显示整张图(9张图一起展示)

如何自己创建一个自定义的数据集(Custom Dataset),让 PyTorch 能读取自己的图片和标签,比如本地的一些图片文件和 CSV 表格。
为你自己的文件创建一个自定义数据集
自定义 Dataset 类时,必须实现三个函数:__init__(初始化)、__len__(返回样本总数) 和 __getitem__(获取指定样本)
如果你不是用官方的数据集(比如 FashionMNIST),而是用你自己文件夹里的图片 + CSV 表里的标签,那就需要自己写一个“自定义数据集类”:
-
__init__():定义数据集在哪里、怎么加载图片和标签 -
__len__():告诉 PyTorch 你一共有多少张图(样本数量)
__len__函数
这个函数的作用是:返回数据集中样本(图片)的数量。 -
__getitem__():定义怎么通过索引取出一张图和它的标签(比如dataset[0])
import os # 用于路径拼接
import pandas as pd # 用于读取 CSV 文件
from torchvision.io import read_image # 用于读取图像(转为张量)
from torch.utils.data import Dataset # 自定义数据集要继承这个类
# 自定义图片数据集类,继承自 PyTorch 的 Dataset 基类
class CustomImageDataset(Dataset):# 初始化函数:加载CSV标签表、图片文件夹路径、图像和标签的预处理方法def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):self.img_labels = pd.read_csv(annotations_file) # 读取CSV文件,包含图片文件名和对应标签self.img_dir = img_dir # 图片所在的文件夹路径self.transform = transform # 图像的预处理方法(例如缩放、归一化)self.target_transform = target_transform # 标签的预处理方法(例如转one-hot)# 返回数据集中样本的总数量def __len__(self):return len(self.img_labels) # 返回 CSV 中的行数(也就是图片数量)# 按照索引返回一张图片和它的标签def __getitem__(self, idx):# 根据索引从CSV中获取图片文件名,并拼接成完整路径img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])# 使用 torchvision.io.read_image 读取图片(返回的是Tensor格式)image = read_image(img_path)# 获取对应的标签(CSV第二列)label = self.img_labels.iloc[idx, 1]# 如果定义了图像预处理,就应用它if self.transform:image = self.transform(image)# 如果定义了标签预处理,就应用它if self.target_transform:label = self.target_transform(label)# 返回一对数据:(图像,标签)return image, label
__init__ 函数
当我们创建 Dataset 数据集对象时,这个 __init__ 函数会被运行一次。
在这个函数中,我们设置好图像所在的文件夹路径、标签文件(CSV),以及两种预处理方法(transform)
这个时候 Python 就会自动去运行你写的 __init__ 函数,完成以下事情:
| 做什么 | 举例 |
|---|---|
| 读入标签文件 | 从 CSV 读出每张图对应的标签 |
| 记住图片路径 | 比如你的图片都在 "images/" 文件夹里 |
| 保存预处理方法 | 如果你要对图像做缩放、归一化等处理,也在这里传进来 |
你可以把 __getitem__() 想象成这样一个问题:
你对 PyTorch 说:“嘿,帮我从数据集中拿出第 5 张图像,还有它的标签。”
PyTorch 就会执行你写的 __getitem__(5),然后:
-
去 CSV 表里看第5行,拿到图像文件名,比如
img5.png -
拼成路径,比如
images/img5.png -
用
read_image()把它读成模型能用的格式(张量) -
拿到它的标签,比如
label=2(代表“Pullover”) -
如果你有设置 transform,就先处理一下
-
返回
(图像张量, 标签)给你
使用 DataLoader 为训练准备数据
Dataset(数据集)每次只能取出一条数据(特征和标签)。
而在训练模型时,我们通常希望将样本按小批量(minibatch)送入模型,
并且在每一轮训练(epoch)中打乱数据的顺序,以减少模型过拟合,
同时利用 Python 的多进程功能来加快数据的读取速度。
DataLoader 是一个可迭代对象,它通过一个简单的 API 帮我们封装了以上所有复杂操作。
这里的API 就是“别人已经写好的功能接口”,你只要用很简单的方式去“调用它”,就可以完成很复杂的事情。
就像你开车,不用知道发动机怎么工作,你只需要踩油门,这个“油门”就是给你用的 API。
| 没有 DataLoader 时的问题 | DataLoader 自动帮你做了什么 |
|---|---|
| 一次只能读一张图 | ✅ 自动按 batch_size 读多张图 |
| 每次都按固定顺序读 | ✅ 每轮训练前自动打乱数据 |
| 读取慢(尤其是大数据) | ✅ 用多进程后台加速加载数据 |
| 写代码复杂 | ✅ 封装好,只要一行就能搞定 |
minibatch(中文叫“小批量”)指的是:每次训练时不把所有数据一次性喂给模型,而是一次取出一小部分来训练。举个例子:
你有 10,000 张训练图像,不可能一次性都送给模型(太慢/太耗显存)。
你可以这样设置:
batch_size = 64
就是:每次训练用 64 张图,学完一批,再取下一批。
这种方式叫:小批量训练(mini-batch training)
什么是 shuffle(打乱数据)?
定义:shuffle 指的是:在每轮训练开始前,把训练数据的顺序随机打乱。
为什么要打乱?
假如你的数据是按类别排好顺序的(比如先全是猫,后全是狗):
模型可能先学猫学很久,突然一下全是狗,这样容易 过拟合某一类,泛化能力差。
所以我们会在每个 epoch 前加个参数:
DataLoader(..., shuffle=True)
表示:每一轮训练前,重新随机排序数据。
什么是多进程加载(num_workers)?
定义:PyTorch 可以使用多个“后台工作进程(线程)”同时从磁盘里读取图片,加快加载速度。
举个例子:
你用 DataLoader 加载数据时可以设置:
DataLoader(dataset, batch_size=64, num_workers=4)
意思是:开 4 个后台进程来同时读数据!
就像你点外卖,找了 4 个骑手一起送菜,当然比 1 个骑手送得快。
from torch.utils.data import DataLoadertrain_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)什么意思啊这段代码是用 PyTorch 的 DataLoader,将训练数据和测试数据按小批量分组,并在每轮开始时随机打乱顺序,方便高效地进行模型训练和测试。
遍历 DataLoader
我们已经把数据集加载进了 DataLoader,现在可以根据需要对数据集进行迭代(逐批处理)。
下面的每次迭代都会返回一批 train_features(训练特征)和 train_labels(标签),每批包含 64 个样本和对应的标签(即 batch_size=64)。
因为我们设置了 shuffle=True,所以在我们把所有批次迭代完之后,数据会被自动打乱顺序。
(如果你想更精细地控制数据加载的顺序,可以了解一下 PyTorch 的 Sampler 机制。)
Samplers 是 PyTorch 中 更灵活地控制数据加载顺序 的工具。
如果你想自己控制“数据加载顺序”、“打乱方式”、“分组策略”等,就可以用 Sampler 来代替 shuffle=True。
Sampler 是一个类,用来控制 DataLoader 在每一轮训练中应该以什么顺序取数据的索引。
常见的 Sampler 类型
| Sampler 类别 | 作用 |
|---|---|
SequentialSampler | 按顺序取数据(默认用于 shuffle=False) |
RandomSampler | 随机打乱数据(默认用于 shuffle=True) |
SubsetRandomSampler | 只随机抽样部分数据(适合做验证集) |
WeightedRandomSampler | 按权重随机抽样(处理数据不平衡) |
# Display image and label.
train_features, train_labels = next(iter(train_dataloader))
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")从训练集里拿出一批数据,并显示其中一张图片和它的标签
相关文章:
数据集(Dataset)和数据加载器(DataLoader)-pytroch学习3
pytorch网站学习 处理数据样本的代码往往会变得很乱、难以维护;理想情况下,我们希望把数据部分的代码和模型训练部分分开写,这样更容易阅读、也更好维护。 简单说:数据和模型最好“分工明确”,不要写在一起。 PyTor…...

数据结构|排序算法(一)快速排序
一、排序概念 排序是数据结构中的一个重要概念,它是指将一组数据元素按照特定的顺序进行排列的过程,默认是从小到大排序。 常见的八大排序算法: 插入排序、希尔排序、冒泡排序、快速排序、选择排序、堆排序、归并排序、基数排序 二、快速…...

文件或目录损坏且无法读取:数据恢复的实战指南
在数字化时代,数据的重要性不言而喻。然而,在日常使用电脑、移动硬盘、U盘等存储设备时,我们难免会遇到“文件或目录损坏且无法读取”的提示。这一提示如同晴天霹雳,让无数用户心急如焚,尤其是当这些文件中存储着重要的…...
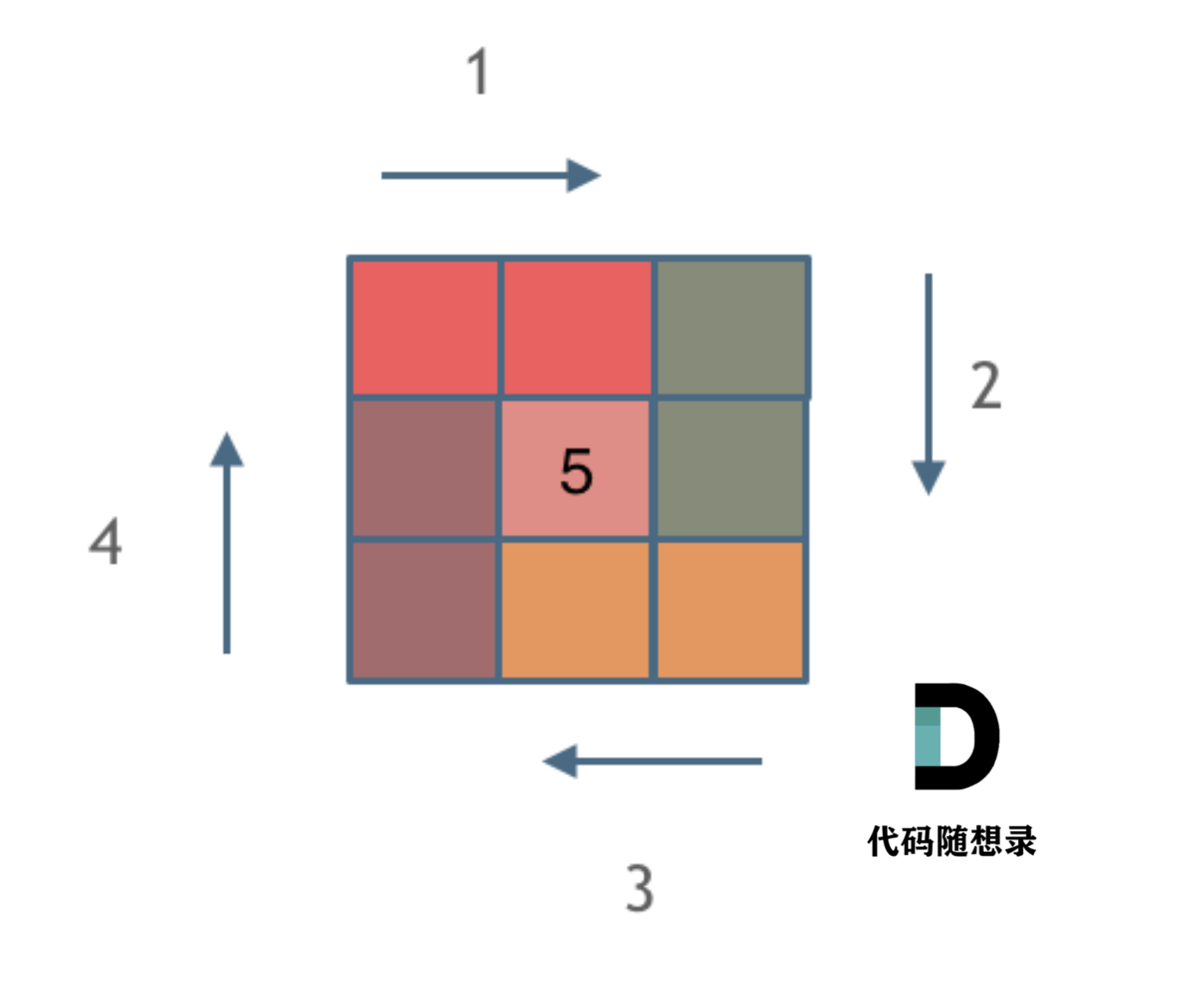
leetcode数组-螺旋矩阵Ⅱ
题目 题目链接:https://leetcode.cn/problems/spiral-matrix-ii/ 给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。 输入:n 3 输出:[[1,2,3],[8,9,4],[7…...
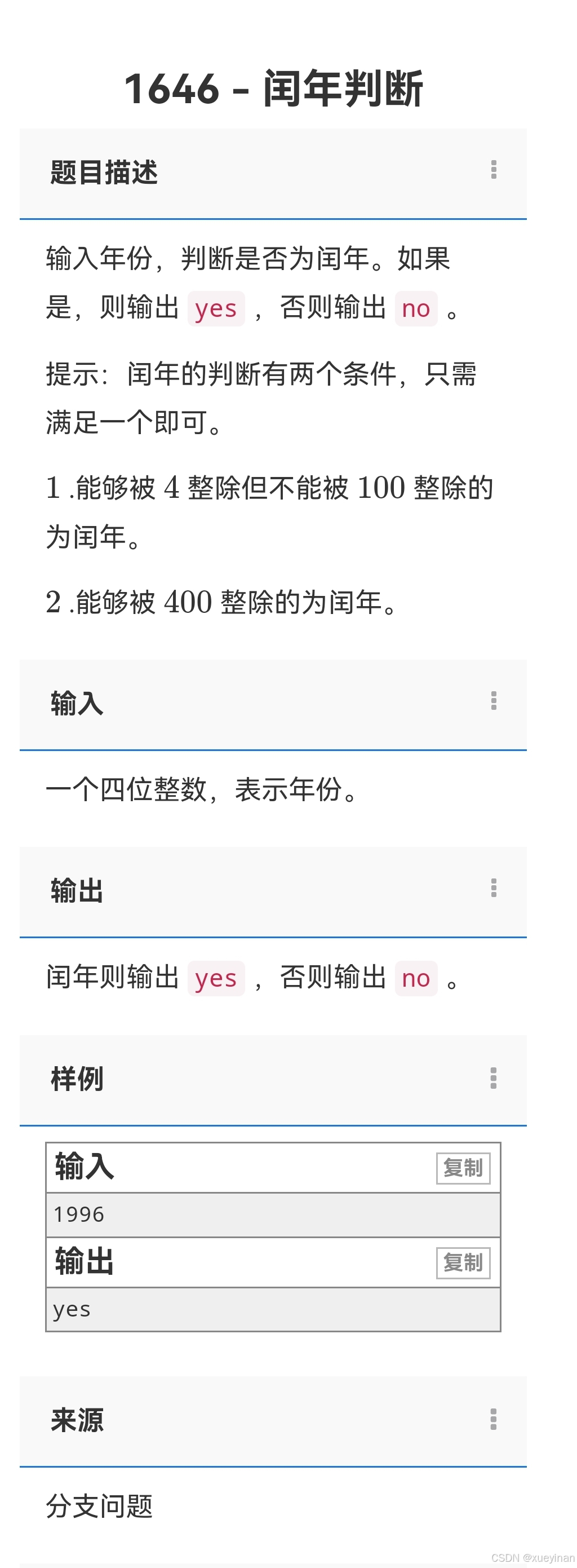
小刚说C语言刷题——第14讲 逻辑运算符
当我们需要将一个表达式取反,或者要判断两个表达式组成的大的表达式的结果时,要用到逻辑运算符。 1.逻辑运算符的分类 (1)逻辑非(!) !a,当a为真时,!a为假。当a为假时,!a为真。 例…...

WPS宏开发手册——Excel实战
目录 系列文章5、Excel实战使用for循环给10*10的表格填充行列之和使用for循环将10*10表格中的偶数值提取到另一个sheet页使用for循环给写一个99乘法表按市场成员名称分类(即市场成员A、B、C...),统计月内不同时间段表1和表2的乘积之和&#x…...

Buildroot与Yocto介绍比对
Buildroot 和 Yocto 是嵌入式 Linux 领域最常用的两大系统构建工具,它们在功能定位、使用方法和适用场景上有显著差异。以下从专业角度对两者进行对比分析: 一、Buildroot 核心功能与特点 1. 功能定位 轻量级系统构建工具:专注于快速生成精…...

前端加密方式 AES对称加密 RSA非对称加密 以及 MD5哈希算法详解
在前端开发中,MD5 并不是用于加密解密的算法,而是一个不可逆的哈希算法(即生成固定长度的摘要,但无法逆向解密)。如果你需要实现加密解密功能,应该使用对称加密算法(如 AES)或非对称…...
)
32--当网络接口变成“夜店门口“:802.1X协议深度解码(理论纯享版本)
当网络接口变成"夜店门口":802.1X协议深度解码 引言:网口的"保安队长"上岗记 如果把企业网络比作高端会所,那么802.1X协议就是门口那个拿着金属探测器的黑超保安。它会对着每个想进场的设备说:“请出示您的会…...

MAUI开发第一个app的需求解析:登录+版本更新,用于喂给AI
vscode中MAUI框架已经搭好,用MAUI+c#webapi+orcl数据库开发一个app, 功能是两个界面一个登录界面,登录注册常用功能,另一个主窗体,功能先空着,显示“主要功能窗体”。 这是一个全新的功能,需要重零开始涉及所有数据表 登录后检查是否有新版本程序,自动更新功能。 1.用户…...

Linux系统进程
Linux系统进程 程序开始 编译链接的引导代码 操作系统下的应用程序在main执行前也需要先执行段引导代码才能去执行main,但写应用程序时不用考虑引导代码的问题,编译连接时(准确说是链接时)由链接器将编译器中事先准备好的引导代码…...
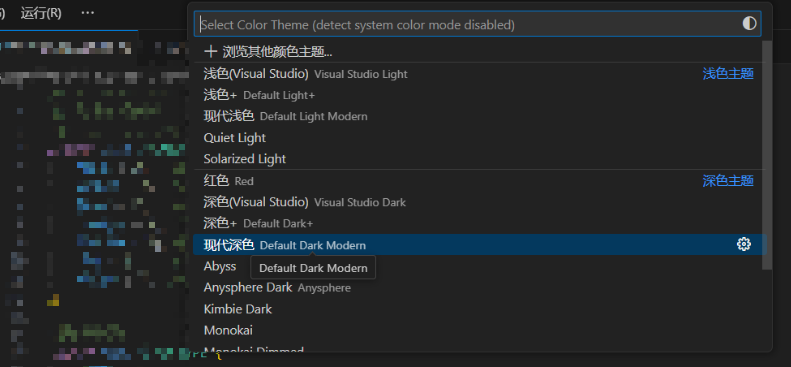
【Cursor】切换主题
右键顶部,把菜单栏勾上 首选项-主题-颜色主题 选择和喜欢的颜色主题即可,一般是“现代深色”...

spring druid项目中监控sql执行情况
场景 在 Spring Boot 结合 MyBatis 的服务中,实现 SQL 执行覆盖情况的监控,可以基于Druid提供的内置的 SQL 监控统计功能。 开启监控 在 application.yml 中启用 Druid 的 stat 和 wall 过滤器,并配置监控页面的访问权限 …...

Obsidian按下三个横线不能出现文档属性
解决方案: 需要在标题下方的一行, 按下 键盘数字0后面那个横线(英文横线), 然后回车就可以了 然后点击横线即可...

pyqt SQL Server 数据库查询-优化2
1、增加导出数据功能 2、增加删除表里数据功能 import sys import pyodbc from PyQt6.QtWidgets import QApplication, QWidget, QVBoxLayout, QHBoxLayout, QListWidget, QLineEdit, QPushButton, \QTableWidget, QTableWidgetItem, QLabel, QMessageBox from PyQt6.QtGui i…...

Hyperlane:高性能 Rust HTTP 服务器框架评测
Hyperlane:高性能 Rust HTTP 服务器框架评测 在当今快速发展的互联网时代,选择一个高效、可靠的 HTTP 服务器框架对于开发者来说至关重要。最近,我在评估各种服务器框架性能时,发现了一个名为 Hyperlane 的 Rust HTTP 服务器库&a…...

Laravel 中使用 JWT 作用户登录,身份认证
什么是JWT: JWT 全名 JSON Web Token,是一种开放标准 (RFC 7519)。 用于在网络应用环境间安全地传输信息作为 JSON 对象。 它是一种轻量级的认证和授权机制,特别适合分布式系统的身份验证。 核心特点 紧凑格式:体积小&#x…...

JavaScript BOM核心对象、本地存储
目录 BOM 核心对象详解 一、location 对象 1. 常用属性 2. 常用方法 3. 应用场景 二、navigator 对象 1. 核心属性 2. 常用方法 3. 应用场景 三、history 对象 1. 核心属性和方法 2. 应用场景 四、兼容性与注意事项 五、总结 本地存储与复杂数据类型处理 一、本…...

VBA中类的解读及应用第二十二讲:利用类判断任意单元格的类型-5
《VBA中类的解读及应用》教程【10165646】是我推出的第五套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。 类,是非常抽象的,更具研究的价值。随着我们学习、应用VBA的深入࿰…...

ffmpeg常见命令3
文章目录 1. **文字水印(Text Watermark)**示例命令:更多选项:2. **图片水印(Image Watermark)**示例命令:更多选项:3. **画中画(Picture-in-Picture, PIP)**示例命令:更多选项:4. **多宫格效果(Grid Effect)**示例命令(2x2 网格):更多选项:综合示例:文字水…...

Spring Boot 可扩展脱敏框架设计全解析 | 注解+策略模式+模板方法模式实战
一、需求场景:为什么需要脱敏框架? 在数据安全合规要求下,敏感信息处理成为系统必备能力。典型场景: 用户隐私保护(手机号、身份证、邮箱等)日志敏感信息过滤接口返回数据自动脱敏 传统方案痛点…...

STM32F103_LL库+寄存器学习笔记13 - 梳理外设CAN与如何发送CAN报文(串行发送)
导言 CAN总线因其高速稳定的数据传输与卓越抗干扰性能,在汽车、机器人及工业自动化中被广泛应用。它采用分布式网络结构,实现多节点间实时通信,确保各控制模块精准协同。在汽车领域,CAN总线连接发动机、制动、车身系统,…...
JavaScript学习19-事件类型之鼠标事件
1. 2. 3....
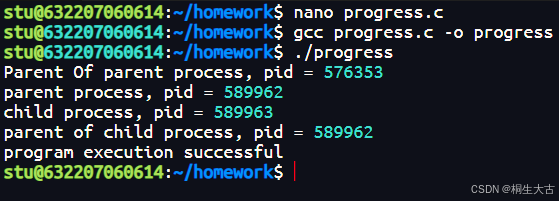
Linux系统调用编程
文章目录 一、进程和线程二、Linux的虚拟内存管理和stm32的真实物理内存**Linux虚拟内存管理**STM32物理内存映射2. 主要区别 三、Linux系统调用函数 fork()、wait()、exec()1. fork():创建子进程2. wait():等待子进程状态改变3. exec():替换…...

游戏引擎学习第203天
回顾当前情况 在这里我将直播完成整个游戏的制作。我们现在面临一些技术上的困难,确实如此。我的笔记本电脑的电源接口坏了,所以我不得不准备了这台备用笔记本,希望它能够正常工作。我所以希望一切都还好,尽管我不完全确定是否一…...
)
408 计算机网络 知识点记忆(4)
前言 本文基于王道考研课程与湖科大计算机网络课程教学内容,系统梳理核心知识记忆点和框架,既为个人复习沉淀思考,亦希望能与同行者互助共进。(PS:后续将持续迭代优化细节) 往期内容 408 计算机网络 知识…...

线性代数:分块矩阵,秩,齐次线性,非齐次线性的解相关经典例题
所以C错误,选D 排除A,B选项...

Nginx功能及应用全解:从负载均衡到反向代理的全面剖析
Nginx作为一款开源的高性能HTTP服务器和反向代理服务器,凭借其高效的资源利用率和灵活的配置方式,已成为互联网领域中最受欢迎的Web服务器之一。无论是作为HTTP服务器、负载均衡器,还是作为反向代理和缓存服务器,Nginx的多种功能广…...

深度学习数据集划分比例多少合适
在机器学习和深度学习中,测试集的划分比例需要根据数据量、任务类型和领域需求灵活调整。 1. 常规划分比例 通用场景 训练集 : 验证集 : 测试集 60% : 20% : 20% 适用于大多数中等规模数据集(如数万到数十万样本),平衡了训练数…...
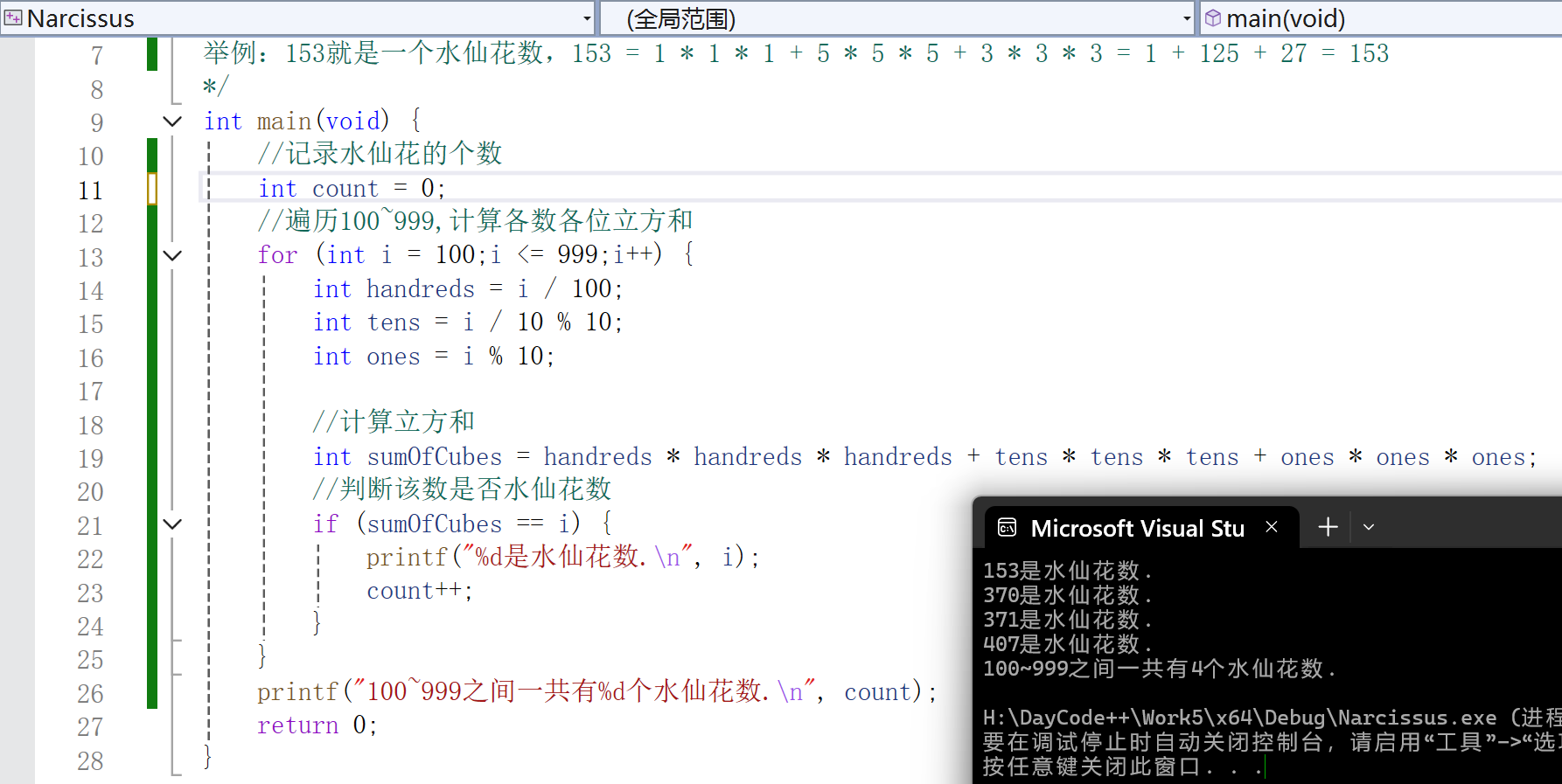
CExercise_1_5 水仙花数
题目: 经典循环案例:请求出所有的水仙花数,并统计总共有几个。 所谓的水仙花数是指一个三位数,其各位数字的立方和等于该数本身。 举例:153就是一个水仙花数,153 1 * 1 * 1 5 * 5 * 5 3 * 3 * 3 1 125…...