蓝桥杯算法题1
前言
双指针
唯一的雪花 Unique Snowflakes
#include<iostream>
#include<unordered_map>
using namespace std;
//这道题的意思就是在一个数组找一个最大的1区间的长度,这个区间里面没有重复数据
//如果暴力解法,每次求出以a[i]开头的满足条件的数组长度的话,时间复杂度就很高
//我们采取滑动窗口
//left,right,map记录每个的次数
//unordered_map<int,int> 第一个int存的是值,第二个存的是这个值的数量
//当right的数量大于2时,left++,还大于2,就继续加加
//小于2时,right就加加,每一次right加加都要更新最大长度
//left加加一定不是最长的
const int N = 1e6 + 10;
long long arr[N] = { 0 };
int main() {int T = 0;cin >> T;while (T--) {int n = 0;cin >> n;for (int i = 1; i <= n; i++) cin >> arr[i];int left = 1;int right = 1;unordered_map<int, int> map;int ret = 0;while (right <= n) {map[arr[right]]++;while (map[arr[right]] > 1) {map[arr[left]]--;left++;}ret = max(ret, right - left + 1);right++;}cout << ret;}return 0;
}
离散化
火烧赤壁
火烧赤壁
#include<iostream>
#include<algorithm>
#include<unordered_map>using namespace std;//离散化适用于数据范围大,数据量少的,比如这样,n<2*10^4,a<2^32
//1,5,8,3,4,5,,9,5,把这些数按照从小到大的顺序离散化,1-》1,3-》2,4-》3,5-》4,8-》5,9-》6,,,,离散化之后,数据范围就不大了
//离散化的数据不能重复,所以可以先排序,在去重,然后再定义出离散化后的值,就用unordered_map<int,int> 第一个int是数值,第二个int是这个数值的离散化后的值
//
////const int N = 1e4 + 10;
//
//int a[N];//源数组--》不然无法根据原数组,打印出离散值了
//int b[N];//用来处理的数组
//
//int n1;//离散化前的数字个数
//int n2;//离散化后的数字个数
//
//int main() {
// cin >> n1;
// for (int i = 1; i <= n1; i++) {
// cin >> a[i];
// b[i] = a[i];
// }
// sort(b + 1, b+ 1 + n1);
// n2=unique(b + 1, b + 1 + n1)-(b+1);//unique这个函数是把这个左闭右开的区间进行去重的,返回去重后数组的最后一个位置,这样地址一减,就是最后的个数了
// unordered_map<int, int> map;
// for (int i = 1; i <= n2;i++) {
// //开始离散化,,,,,
// map[b[i]] = i;//这样就可以了
// }
// //打印出每个原数组的值对应的离散值
// for (int i = 1; i <= n1; i++) {
// cout << map[a[i]] << " ";
// }
// return 0;
//}//这道题呢,相当于有一个很大的区间格子,比如-1 1时,就相当于把-1 1这个区间里面的-1,0格子涂上(+1),因为这个区间是左闭右开的,相当于整个区间+1,所以我们可以用差分的思想
//最后可以求出格子值大于1的,大于1的就是着火的地方,但是这个区间可能很大很大,所以我们要先把这个区间给离散化
const int N = 2e4 + 10;
int a1[N];//存储左区间
int b1[N];//存储右区间int tmp[2 * N];//用来处理的,一个数组来处理int n1;//离散化前的数字个数
int n2=0;//离散化后的数字个数//int used[2 * N];//着火区间---->可以直接用gap差值区间转化而来
int gap[2 * N];//差值数组,因为差值数组是对tmp数组进行的处理,所以很大int main() {cin >> n1;for (int i = 1; i <= n1; i++) {cin >> a1[i]>>b1[i];tmp[++n2] = a1[i];tmp[++n2] = b1[i];//全部存在这个数组中,因为存在两个数组中,肯定会有值重复的}sort(tmp+1,tmp+1+n2);n2=unique(tmp + 1, tmp + 1 + n2) - (tmp + 1);unordered_map<int, int> map;for (int i = 1; i <= n2;i++) {map[tmp[i]] = i;}//gap默认为0,因为着火区间一开始每个格子都是0//如果这个区间[n,m)着火了,这个着火区间的格子加1,那么对应差值数组gap[n]+1,gap[m]-1,,,,,,,这个n和m都是离散值,但是区间的对应又要利用上a和b数组for (int i = 1; i <= n1; i++) {gap[map[a1[i]]]++;gap[map[b1[i]]]--;}//这样就求出了差值数组//然后就可以求出着火区间了---->下标最大为n2for (int i = 1; i <= n2; i++) {gap[i] += gap[i-1];}//遍历着火区间,大于0的就是着火的地方int count = 0;//存储着火的地方for (int i = 1; i <= n2; i++) {if (gap[i] > 0) {//直接找到下一个gap[j]=0的地方,就是停火的区间int j = i;while (gap[j] > 0)j++;//所以着火区间就是[i,j)但是这个是离散值,我们还要对应回去,离散值就是tmp的下标,所以很容易对应回去count = count+(tmp[j] - tmp[i]);i = j;//因为这个区间已经处理完了}}cout << count;return 0;
}
递归
汉诺塔问题
汉诺塔问题
#include<iostream>using namespace std;//子问题和父问题处理一样的话,就可以用递归的思想,函数你就相信它一定能成功,然后还要有一个停止的条件就是了int n;
char a, b, c;void dis(int n, char a, char b, char c) {//我们可以先把n-1个盘子从a盘移到c盘上,借助b盘-----》这个可以用dis函数,因为处理的问题都是一样的//然后把第n个盘子从a盘移到b盘,不用借助c盘了,,,,这个就是直接打印就可以实现了//最后就是把剩下的n-1个盘子从c盘移到b盘,借助a盘,只有大于两个盘子的时候,才会借助多余的盘子//截止条件就是只有零个盘子的时候,直接return,一个盘子都可以调用这个函数-->直接假设进去,看行不行if (n == 0)return;dis(n - 1, a, c, b);printf("%c->%d->%c\n",a,n,b);dis(n - 1, c, b, a);
}int main() {cin >> n >> a >> b >> c;dis(n, a, b, c);//这个函数的作用就是把n个盘子把a移到b上,然后借助creturn 0;
}
分治
逆序对
逆序对
#include<iostream>using namespace std;//面对这道题我们先来回顾一下归并排序,所谓归并排序的话,就是一个函数具有排序功能,先排序左区间,然后排序右区间,最后把这左右区间合并排序typedef long long ll;const int N = 5e5 + 10;
//1 3 4 6 9 2 5 7 9 10 举个例子更好书写
ll a[N];//要排序的数组
ll tmp[N];//用来辅助a数组排序的数组------->用来暂时存着两个区间有序合并后的结果,最后赋值给a就可以了
ll n;//void merge(int left, int right) {
// //递归终止条件
// if (left >= right)return;//这个不用排序,只要left<right就要排序,就可以调用merge函数
// int mid = (left + right) / 2;
// merge(left, mid);
// merge(mid+1,right);
// //默认merge已经分别实现了a的两个分区间的排序,然后我们只需要把这两个已经排好序的区间合并就可以了
// int cur1 = left;//指向左区间的指针
// int cur2 = mid+1;//指向右区间的指针
// int i = left;//用来指向tmp数组的指针
// while (cur1 <= mid&&cur2<=right) {
// if (a[cur1] >= a[cur2]) tmp[i++] = a[cur2++];
// else tmp[i++] = a[cur1++];
// }
// while (cur1 <= mid) tmp[i++] = a[cur1++];
// while (cur2 <= right) tmp[i++] = a[cur2++];
// //这样我们的tmp数组就是有序的了--->全部赋值给a数组就可以了
// for (int j = left; j <= right; j++) a[j] = tmp[j];
//}
//int main() {
// cin >> n;
// for (int i = 1; i <= n; i++) cin >> a[i];
// cout << endl;
// merge(1, n);
// for (int i = 1; i <= n; i++) cout << a[i] << " ";
// cout << endl;
// return 0;
//}//处理这道题的话,可以这样来,我们先计算出左半区间的逆序对个数,然后就是计算出右半区间的逆序对个数,然后是左右区间综合起来的逆序对个数,如果左右区间都是有序的话---》边排序边计算
//那么综合起来的逆序对个数就很好求了,所以可以这样来
//merge的作用是求出左区间的逆序对个数,然后对左区间进行排好序
//右区间也是如此//因为个数可能是n^2级别的,所以我们用ll来返回,不然会存不下的,统一用大的ll,不要用int,防止出错ll merge(int left, int right) {if (left >= right)return 0;int mid = (left + right) / 2;ll ret = 0;ret+=merge(left, mid);//默认可以求出左区间的逆序对个数,然后对左区间就排好序了---->排序和求个数的递归ret+=merge(mid + 1, right);默认可以求出右区间的逆序对个数,然后对右区间就排好序了//现在就是求出左右区间综合起来的逆序对个数,然后拍好整个区间的序,因为merge(int left, int right)的作用就是求出总的逆序对个数--》左右的+综合的,然后拍好序--》左右的+综合的//这个我们只需要在原来的归并排序基础上修改就可以了int cur1 = left;int cur2 = mid + 1;int i = left;while (cur1 <= mid && cur2 <= right) {if (a[cur1] > a[cur2]) {//那么cur2就会匹配上cur1对应及其后面的逆序对,都是可以匹配的ret += mid - cur1 + 1;//这个+1我们假设mid和cur1相邻就可以判断出了tmp[i++] = a[cur2++];} else tmp[i++] = a[cur1++];}while (cur1 <= mid) tmp[i++] = a[cur1++];while (cur2 <= right) tmp[i++] = a[cur2++];//这样我们的tmp数组就是有序的了--->全部赋值给a数组就可以了for (int j = left; j <= right; j++) a[j] = tmp[j];return ret;
}int main() {cin >> n;for (int i = 1; i <= n; i++) cin >> a[i];cout << merge(1, n);return 0;
}
搜索
枚举子集(递归实现指数型枚举)
枚举子集(递归实现指数型枚举)
#include<iostream>using namespace std;//搜索就是枚举,就是把问题的枚举转化为对树的枚举树的遍历,这个树叫做决策树,枚举又分为深度优先和宽度优先
//我们这个问题就可以看做为树的枚举,就是遍历树的叶子结点,我们先写普通树的叶子结点遍历//void dfs(root) {
// if(为叶子)打印叶子
// dfs(left);
// dfs(right);
//}//我们这样来做
string tmp;//代表进入左还是右子树,,,并且记录当前结点的值
int n;//代表进入第几层了---》tmp和n就可以决定遍历的当前位置了
//我们的这个决策树总共有四层,最后一层就是第四层就是叶子结点
//我们要遍历到叶子结点,就是对树的遍历--》深度优先遍历
void dfs(int depth) {//结束条件if (depth == (n + 1)) {//打印叶子结点cout << tmp<<endl;return;}//左子树遍历tmp += 'N';//代表进入左子树,,,因为dfs(left);的意思就是对左子树的遍历,它代表的意思就是先判断为左lset,然后进入dfs,然后出这个dfs时,我们还是处于root结点//所以要保证dfs结束以后,还是在n=1的结点上,所以要去掉Ndfs(depth + 1);//代表处理深度为depth + 1时的叶子结点,此时tmp为N,刚刚好对应住了,带着tmp进入二层,tmp.pop_back();//回到原来,不然还是左子树的if判断,相当于,这就叫回溯,tmp为null了,又对应住了//右子树遍历tmp += 'Y';dfs(depth + 1);tmp.pop_back();//本结点遍历:不处理
}int main() {cin >> n;dfs(1);//代表遍历到第一层,第一层的根,遍历这个树,就是对左右树的遍历、、处理深度为1的叶子结点====处理深度为2的左右子树的叶子结点return 0;
}组合型枚举
组合型枚举
#include<iostream>
#include<vector>
using namespace std;int n, m;//从n个数中选m个
vector<int> path;//void dfs(int pos, int start) {//这个pos和start的意思就是,下次插入这个结点的第pos位置,然后从最小start开始插入,
// if (pos == (m + 1)) {
// //说明下次插的这个结点早就满了满了
// for (auto x : path) {
// cout << x << " ";
// }
// cout << endl;
// return;
// }
// for (int i = start; i <= n; i++) {
// path.push_back(i);//插入i
// dfs(pos + 1, i+1);
// path.pop_back();//回溯
// }
//}
//int main() {
// cin >> n >> m;
// dfs(1, 1);
// return 0;
//}//我们发现pos的作用只是记录我们下次要插入第几个位置,其实就是记录有没有插满m个而已,插满了的话,就不用插了,所以我们用path其实也是可以记录的
void dfs(int start) {if (path.size() == m ) {//说明下次插的这个结点早就满了满了for (auto x : path) {cout << x << " ";}cout << endl;return;}for (int i = start; i <= n; i++) {path.push_back(i);//插入idfs(i + 1);path.pop_back();//回溯}
}
int main() {cin >> n >> m;dfs(1);return 0;
}
[NOIP 2002 普及组] 选数
[NOIP 2002 普及组] 选数
#include<iostream>using namespace std;const int N = 100;int n, m;
int a[N];int ret=0;//记录有多少个素数
int path=0;//记录叶子结点和bool isprime(int x) {if (x <= 1)return false;//因为1既不是素数,反正什么都不是//判断一个数是不是素数,直接去除以2~根号x就可以了,如果全部不能整除的话,那么就是素数,,i<=x/i就是i小于根号x了,两边同时平方来的//整除就是取模为0for (int i = 2; i <= x / i; i++) {if (x % i == 0) {return false;}}return true;
}void dfs(int pos, int start) {if(pos>m){if (isprime(path)) ret++;return;}for (int i = start; i <= n; i++) {path += a[i];dfs(pos + 1, i + 1);path -= a[i];}
}int main() {cin >> n >> m;for (int i = 1; i <= n; i++) cin >> a[i];//输入的是有序的dfs(1, 1);//表示下一个就是插入第一个位置,从数组下标为1开始插,cout << ret;return 0;
}
数的划分
数的划分
#include<iostream>
using namespace std;
int n, k;
int path;
int ret;
void dfs(int pos, int start) {if (pos == (k + 1)) {if (path == n)ret ++ ;return;}for (int i = start; i <= n; i++) {if (path + i * (k - pos + 1) > n)return;path += i;dfs(pos + 1, i);path -= i;}
}
int main() {cin >> n >> k;dfs(1, 1);cout << ret;return 0;
}
斐波那契数
斐波那契数
class Solution {
public:int path[256];int dfs(int n) {if (n == 0 || n == 1)return n;if (path[n] != -1)return path[n];path[n] = dfs(n - 1) + dfs(n - 2);return path[n];}int fib(int n) {//初始化数组memset(path,-1,sizeof(path)); //memset是把起始位置path的后面的sizeof(path)个字节每个字符都设置为-1,因为-1的补码就是1111,所以数组每个元素就是-1,sizeof(path)求的是数组的长度return dfs(n);}
};
Function
Function
#include<iostream>using namespace std;#define ll long long
ll a1, b1, c1;//因为再大的数也会变为0~20,所以数组不用很长ll path[25][25][25];//用来做备忘录,默认都是0ll dfs(ll a, ll b, ll c) {if (a <= 0 || b <= 0 || c <= 0)return 1;if (a > 20 || b > 20 || c > 20) {path[20][20][20] = dfs(20, 20, 20);return path[20][20][20];}if (path[a][b][c])return path[a][b][c];//说明已经做了备忘录了//如果不为0,可能没有备忘录,也可能备忘了的,但是多一层而已,不关事if (a < b && b < c) {//先备忘path[a][b][c] = dfs(a, b, c - 1) + dfs(a, b - 1, c - 1) - dfs(a, b - 1, c);return path[a][b][c];}path[a][b][c] = dfs(a-1, b, c ) + dfs(a-1, b - 1, c ) + dfs(a-1, b, c-1)-dfs(a-1,b-1,c-1);return path[a][b][c];
}int main() {while (1) {cin >> a1 >> b1 >> c1;if (a1 == -1 && b1 == -1 && c1 == -1) break;printf("w(%lld, %lld, %lld) = %lld\n", a1, b1, c1, dfs(a1, b1, c1));}return 0;
}
马的遍历
马的遍历
#include<iostream>
//宽度搜索主要是解决最短路径问题的,而且每条路径的权值还得一样才行
//宽度搜索就要用队列了
#include<queue>
#include<cstring>//声明menset函数
using namespace std;
const int N = 410;
typedef pair<int, int> ll;//用来记录每个坐标的数据结构
int path[N][N];//用来记录最短路径
int n, m, x, y;
//以x,y作为原点,标出这个马可以跳到的其它点的横纵坐标
int lx[8] = { 1,2,2,1,-1,-2,-2,-1 };
int ly[8] = { 2,1,-1,-2,-2,-1,1,2 };
void bfs() {//初始化最短路径,因为最短路径的最小值为0,所以我们初始化为-1memset(path, -1, sizeof(path));//一个点入队列,然后出队列时,又带入它可以跳到的点进入队列queue<ll> q;q.push({ x,y });path[x][y] = 0;//初始化第一个点的步数while (q.size()) {auto point = q.front();//队列的第一个点的值q.pop();//取出第一个点int tmpx = point.first;//取出当前点的横坐标int tmpy = point.second;//取出当前点的纵坐标for (int i = 0; i < 8; i++) {int insertx = tmpx + lx[i];int inserty = tmpy + ly[i];//这个就是这个取出来的点要跳到的一个点的位置if (insertx<1 || insertx>n || inserty<1 || inserty>m)continue;//说明越过棋盘了if (path[insertx][inserty] != -1)continue;//说明被跳到过了path[insertx][inserty] = path[tmpx][tmpy] + 1;//这里就是没有被跳到过了q.push({ insertx,inserty });//插入队列}}
}
int main() {cin >> n >> m >> x >> y;bfs();//输出最短路径for (int i = 1; i <= n; i++) {for (int j = 1; j <= m; j++) {cout << path[i][j] << " ";}if(i!=n)cout << endl;}return 0;
}
矩阵距离
矩阵距离
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
const int N = 1010;
int n, m;
char arr[N][N];//存储矩阵
int path[N][N];//输出的矩阵int dx[4] = { 0,0,-1,1 };
int dy[4] = { 1,-1,0,0 };void bfs() {//求每个0到最近1的最短距离,就是求每个0到总体1的最近距离,那这样的话,就要对每个0进行bfs,时间复杂度很高,还不如对总体1bfs,直接一次bfs就OK了memset(path, -1, sizeof(path));//因为总体1到1的最短距离就是0,所以不能初始化为0,初始化为-1,就代表这个点还没到达,但凡到达这个点的,都是第一名,都是最短的//对总体1bfs的意思就是,一开始就把全部1插入队列,从一开始的全部1开始bfs,就是对总体1的dfsqueue<pair<int, int>> q;for (int i = 1; i <= n; i++) {for (int j = 1; j <= m; j++) {if (arr[i][j] == '1') {q.push({ i,j });path[i][j] = 0;}}}while (q.size()) {auto tmp=q.front();q.pop();int x = tmp.first;int y = tmp.second;for (int i = 0; i < 4; i++) {int a = x + dx[i];int b = y + dy[i];if (a >= 1 && a <= n && b >= 1 && b <= m && path[a][b] == -1) {//第一次走到path[a][b] = path[x][y] + 1;q.push({ a,b });}}}
}
int main() {cin >> n >> m;for (int i = 1; i <= n; i++) {for (int j = 1; j <= m; j++) {cin >> arr[i][j];}}bfs();for (int i = 1; i <= n; i++) {for (int j = 1; j <= m; j++) {cout << path[i][j] <<" ";}cout << endl;}return 0;
}
Lake Counting
Lake Counting
#include<iostream>
#include<queue>
using namespace std;
const int N = 110;
int n, m;
char a[N][N];
bool path[N][N];//默认为flase,因为全是0
int ret = 0;
int dx[8] = { 0,0,1,-1,1,1,-1,-1 };
int dy[8] = { 1,-1,0,0,1,-1,1,-1 };void dfs(int x,int y) {path[x][y] = true;for (int i = 0; i < 8; i++) {int tmpx = x + dx[i];int tmpy = y + dy[i];if (tmpx >= 1 && tmpx <= n && tmpy >= 1 && tmpy <= m && a[tmpx][tmpy]=='W'&& path[tmpx][tmpy]==false) {dfs(tmpx, tmpy);}}
}
void bfs(int x, int y) {queue<pair<int, int >> q;q.push({ x,y });path[x][y] = true;while (q.size()) {auto point = q.front();q.pop();int x = point.first;int y = point.second;for (int i = 0; i < 8; i++) {int tmpx = x + dx[i];int tmpy = y + dy[i];if (tmpx >= 1 && tmpx <= n && tmpy >= 1 && tmpy <= m && a[tmpx][tmpy] == 'W' && path[tmpx][tmpy] == false) {path[tmpx][tmpy] = true;q.push({ tmpx,tmpy });}}}
}
int main() {cin >> n >> m;for (int i = 1; i <= n; i++)for (int j = 1; j <= m; j++)cin >> a[i][j];for (int i = 1; i <= n; i++)for (int j = 1; j <= m; j++) {if (path[i][j])continue;//说明已经被划分为一个水坑了else if(path[i][j]==false&&a[i][j]=='W') {ret++;//dfs(i, j);//将坐标为i,j的划分为一个水坑,还有它附近的bfs(i, j);}}cout << ret;return 0;
}
单调栈
发射站
发射站
#include<iostream>
#include<stack>using namespace std;const int N = 1e6 + 10;typedef long long ll;int n;ll h[N];
ll v[N];ll path[N];//接收到的新的能量int main() {cin >> n;for (int i = 1; i <= n; i++) {cin >> h[i] >> v[i];}//单调递减栈stack<int> s;for (int i = 1; i <= n; i++) {while (s.size() && h[s.top()] <= h[i])s.pop();//这个时候top就比i高了if (s.size()) {path[s.top()] += v[i];}s.push(i);}//清空栈,从右到左while (s.size()) s.pop();for (int i = n; i >= 1; i--) {while (s.size() && h[s.top()] <= h[i])s.pop();//这个时候top就比i高了if (s.size()) {path[s.top()] += v[i];}s.push(i);}ll ret = 0;for (int i = 1; i <= n; i++) {ret = max(ret, path[i]);}cout << ret;return 0;
}
单调队列
滑动窗口 /【模板】单调队列
滑动窗口 /【模板】单调队列
#include<iostream>
#include<deque>
using namespace std;const int N = 1e6 + 10;
int n;
int k;
int arr[N];int main() {cin >> n >> k;for (int i = 1; i <= n; i++) cin >> arr[i];//找最小值的话,就维护一个从头到尾单调递增的队列deque<int> d;;for (int i = 1; i <= n; i++) {while (d.size() && arr[d.back()] >= arr[i]) d.pop_back();d.push_back(i);if (i - d.front() + 1 > k)d.pop_front();//每次都会这样,所以最多长度超过一个,这样就不会太长了if (i >= k) cout << arr[d.front()]<<" ";}cout << endl;d.clear();//栈没有这个函数//找最大值for (int i = 1; i <= n; i++) {while (d.size() && arr[d.back()] <= arr[i]) d.pop_back();d.push_back(i);//这个就是比单调栈多余的一个操作if (d.size() && (i - d.front() + 1) > k)d.pop_front();//这个是因为题意才这样干的if (d.size()&&i>=k) cout <<arr[d.front()]<<" ";}return 0;
}
质量检测
质量检测
#include<iostream>
#include<deque>using namespace std;const int N = 1e6 + 10;int n,m;int arr[N];int main() {cin >> n >> m;deque<int> d;for (int i = 1; i <= n; i++) {cin >> arr[i];while (d.size() && arr[d.back()] >= arr[i]) d.pop_back();d.push_back(i);if (i - d.front() + 1 > m) d.pop_front();if (i >= m)cout << arr[d.front()]<<endl;}return 0;
}
并查集
【模板】并查集
【模板】并查集
#include<iostream>using namespace std;const int N = 2e5 + 10;int fa[N];//每个fa[x]代表x的父亲是fa[x]
int n,m;int find(int x) {//find的意思就是找x的祖先if (fa[x] == x) {//它的父亲等于它自己return x;}return fa[x] = find(fa[x]);//既然x不是祖先,那就找x的父亲的祖先,并将x的父亲设置为x的祖先,
}int main() {cin >> n>>m;//初始化并查集for (int i = 1; i <= n; i++)fa[i] = i;while (m--) {int z, x, y;cin >> z >> x >> y;if (z == 1) {int fx = find(x);int fy = find(y);fa[fx] = fy;}else {if (find(x) == find(y))cout << "Y" << endl;else cout << "N" << endl;}}return 0;
}
亲戚
亲戚
#include<iostream>
using namespace std;const int N = 5010;int n, m, p;int fa[N];int find(int x) {return fa[x] == x ? x : fa[x] = find(fa[x]);
}bool issame(int x, int y) {return find(x) == find(y);
}void un(int x, int y) {int a = find(x);int b = find(y);fa[a] = b;
}
int main() {cin >> n >> m >> p;for (int i = 1; i <= n; i++)fa[i] = i;while (m--) {int x, y;cin >> x >> y;un(x, y);}while (p--) {int x, y; cin >> x >> y;if (issame(x,y)) {cout << "Yes" << endl;}else {cout << "No" << endl;}}return 0;
}
扩展域并查集
亲戚
亲戚
#include<iostream>using namespace std;const int N = 1010;
int fa[2 * N];int n, m;int find(int x) {return fa[x] == x ? x : fa[x] = find(fa[x]);
}void un(int x, int y) {fa[find(y)] = fa[find(x)];
}int main() {cin >> n >> m;for (int i = 1; i <= n * 2; i++)fa[i] = i;//我们只连接朋友关系while (m--) {char c;int x, y;cin >> c >> x >> y;if (c == 'F') {//x+n与y+n不一定是朋友,因为朋友的敌人不一定是敌人un(x, y);}else {//x与y是敌人,x+n与x是敌人,所以x+n与y是朋友un(y, x + n);un(x, y + n);}}int ret = 0;for (int i = 1; i <= n; i++) {//统计个数的话,只需要统计1~n中fa[i]=i的,因为n+1~2n的都不是真正的人,所以祖先必须是1~n-->合并的时候处理if (fa[i] == i)ret++;}cout << ret;return 0;
}
食物链
食物链
#include<iostream>using namespace std;const int N = 5e4 + 10;int fa[3 * N];
int n, k;int find(int x) {return fa[x] == x ? x : fa[x] = find(fa[x]);
}
void un(int x, int y) {fa[find(x)] = find(y);
}int main() {cin >> n >> k;for (int i = 1; i <= 3 * n; i++)fa[i] = i;int ret = 0;while (k--) {int o, x, y;cin >> o >> x >> y;if (x > n || y > n) {ret++; continue;}if (o == 1) {if (find(x) == find(y + n) || find(x) == find(y + n + n)) {ret++;}else {un(x, y);un(x + n, y + n);un(x + n + n, y + n + n);}}else {//x->yif (find(x) == find(y) || find(x) == find(y + n)) {ret++;}else {un(x + n, y);un(x + n + n, y + n);un(x, y + n + n);}}}cout << ret;return 0;
}
带权并查集
食物链
食物链
#include<iostream>
using namespace std;const int N = 5e4 + 10;int n, k;
int fa[N];
int d[N];//这个就是到父节点的距离int find(int x) {if (fa[x] == x)return x;int t = find(fa[x]);//把它的父节点接到祖先节点下面,并处理好距离d[x] = d[x] + d[fa[x]];return fa[x] = t;
}void un(int x, int y,int w) {int fx = find(x);int fy = find(y);if (fx != fy) {fa[fx] = fy;d[fx] = d[y] + w - d[x];}//if (find(x) != find(y)) {// fa[find(x)] = find(y);// d[find(x)] = d[y] + w - d[x];//不能这样,因为x的祖先已经变了//}
}int main() {cin >> n >> k;for (int i = 1; i <= n; i++)fa[i] = i;int ret = 0;while (k--) {int o, x, y;cin >> o >> x >> y;if (x > n || y > n) {ret++; continue;}int fx = find(x);int fy = find(y);if (o == 1) {//判断什么时候为假话,if (fx == fy&& ((d[x] - d[y]) % 3 + 3) % 3 != 0)ret++;//膜加膜,在同一个树,else {if (fx != fy) {//不在一个树默认为真话,un(x, y, 0);//x与y的距离为0}}}else {//x->yif (fx == fy && ((d[y] - d[x]) % 3 + 3) % 3 != 1)ret++;else {if (fx != fy) {//不在一个树默认为真话,un(x, y, 2);//x与y的距离为2,,直线才是距离,到父节点的才是距离,我们以父节点为参照来做,记住吧}}}}cout << ret;return 0;
}
总结
相关文章:

蓝桥杯算法题1
前言 双指针 唯一的雪花 Unique Snowflakes #include<iostream> #include<unordered_map> using namespace std; //这道题的意思就是在一个数组找一个最大的1区间的长度,这个区间里面没有重复数据 //如果暴力解法,每次求出以a[i]开头的满…...

【愚公系列】《高效使用DeepSeek》053-工艺参数调优
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! 👉 江湖人称"愚公搬代码",用七年如一日的精神深耕技术领域,以"…...

Cortex-M系列MCU的位带操作
Cortex-M系列位带操作详解 位带(Bit-Banding)是Cortex-M3/M4等处理器提供的一种硬件特性,允许通过别名地址对内存或外设寄存器中的单个位进行原子读-改-写操作,无需禁用中断或使用互斥锁。以下是位带操作的完整指南: …...

大坑!GaussDB数据库批量插入数据变只读
大坑!GaussDB数据库批量插入数据变只读 GaussDB插入数据时变只读df和du为什么不一致GaussDB磁盘空间使用阈值GaussDB变只读怎么办正确删除表的姿势GaussDB插入数据时变只读 涉及的数据库版本为:GaussDB Kernel 505.1.0 build da28c417。 GuassDB TPCC灌数报错DML失败,数据…...

35信号和槽_信号槽小结
Qt 信号槽 1.信号槽是啥~~ 尤其是和 Linux 中的信号进行了对比(三要素) 1) 信号源 2) 信号的类型 3)信号的处理方式 2.信号槽 使用 connect 3.如何查阅文档. 一个控件,内置了哪些信号,信号都是何时触发 一…...

获取KUKA机器人诊断文件KRCdiag的方法
有时候在进行售后问题时需要获取KUKA机器人的诊断文件KRCdiag,通过以下方法可以获取KUKA机器人的诊断文件KRCdiag: 1、将U盘插到控制柜内的任意一个USB接口; 2、依次点【主菜单】—【文件】—【存档】—【USB(控制柜)…...

一周学会Pandas2 Python数据处理与分析-NumPy数据类型
锋哥原创的Pandas2 Python数据处理与分析 视频教程: 2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili NumPy 提供了丰富的数据类型(dtypes),主要用于高效数值计算。以下是 NumPy 的主要…...
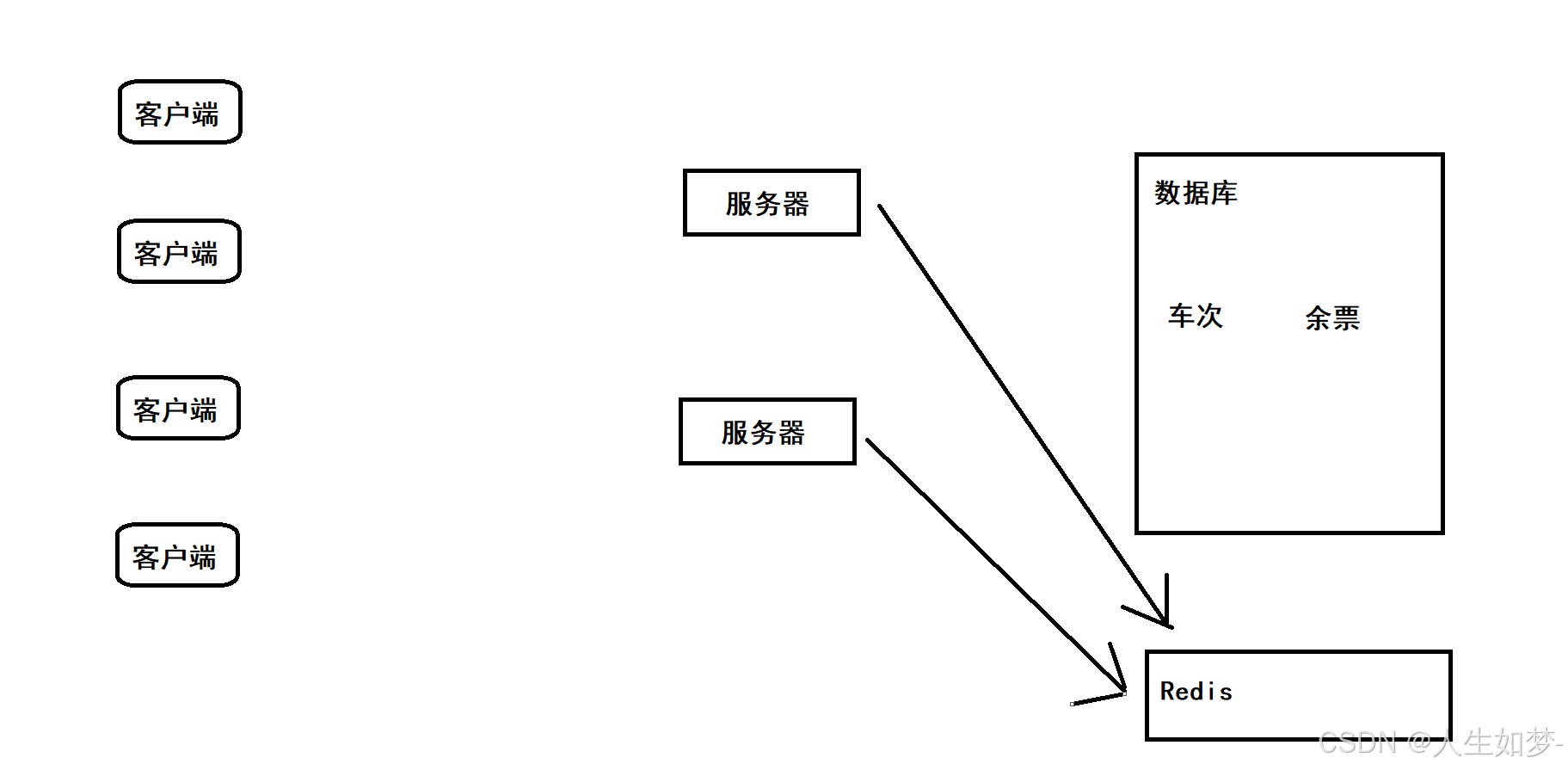
Redis核心机制-缓存、分布式锁
目录 缓存 缓存更新策略 定期生成 实时生成 缓存问题 缓存预热(Cache preheating) 缓存穿透(Cache penetration) 缓存雪崩(Cache avalanche) 缓存击穿(Cache breakdown) 分…...

Three.js 系列专题 1:入门与基础
什么是 Three.js? Three.js 是一个基于 WebGL 的 JavaScript 库,它简化了 3D 图形编程,让开发者无需深入了解底层 WebGL API 就能创建复杂的 3D 场景。它广泛应用于网页游戏、可视化、虚拟现实等领域。 学习目标 理解 Three.js 的核心组件:场景(Scene)、相机(Camera)…...

[C++面试] 如何在特定内存位置上分配内存、构造对象
new面试-高阶题(可以主动讲给面试官),适用于内存池、高性能场景或需要精确控制内存布局的编程需求。 一、核心方法:placement new placement new 是C中一种特殊形式的new运算符,允许在预先分配好的内存地址上构造对象…...

针对Ansible执行脚本时报错“可执行文件格式错误”,以下是详细的解决步骤和示例
针对Ansible执行脚本时报错“可执行文件格式错误”,以下是详细的解决步骤和示例: 目录 一、错误原因分析二、解决方案1. 检查并添加可执行权限2. 修复Shebang行3. 转换文件格式(Windows → Unix)4. 检查脚本内容兼容性5. 显式指定…...

如何在Ubuntu上安装Dify
如何在Ubuntu上安装Dify 如何在Ubuntu上安装docker 使用apt安装 # Add Dockers official GPG key: sudo apt-get update sudo apt-get install ca-certificates curl sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg…...

Python FastApi(13):APIRouter
如果你正在开发一个应用程序或 Web API,很少会将所有的内容都放在一个文件中。FastAPI 提供了一个方便的工具,可以在保持所有灵活性的同时构建你的应用程序。假设你的文件结构如下: . ├── app # 「app」是一个 Python 包…...

Harmony OS“一多” 详解:基于窗口变化的断点自适应实现
一、一多开发核心概念(18N模式) 目标:一次开发多端部署 解决的问题: 1、界面级一多:适配不同屏幕尺寸 2、功能级一多:设备功能兼容性处理(CanIUser) 3、工…...

【算法竞赛】状态压缩型背包问题经典应用(蓝桥杯2019A4分糖果)
在蓝桥杯中遇到的这道题,看上去比较普通,但其实蕴含了很巧妙的“状态压缩 背包”的思想,本文将从零到一,详细解析这个问题。 目录 一、题目 二、思路分析:状态压缩 最小覆盖 1. 本质:最小集合覆盖问题…...

kali——masscan
目录 前言 使用方法 前言 Masscan 是一款快速的端口扫描工具,在 Kali Linux 系统中常被用于网络安全评估和渗透测试。 使用方法 对单个IP进行端口扫描: masscan -p11-65535 192.168.238.131 扫描指定端口: masscan -p80,22 192.168.238.131…...

常微分方程 1
slow down and take your time 定积分应用回顾常微分方程的概述一阶微分方程可分离变量齐次方程三阶线性微分方程 一阶线性微分方程不定积分的被积分函数出现了绝对值梳理微分方程的基本概念题型 1 分离变量题型 2 齐次方程5.4 题型 3 一阶线性微分方程知识点5.55.6 尾声 定积分…...
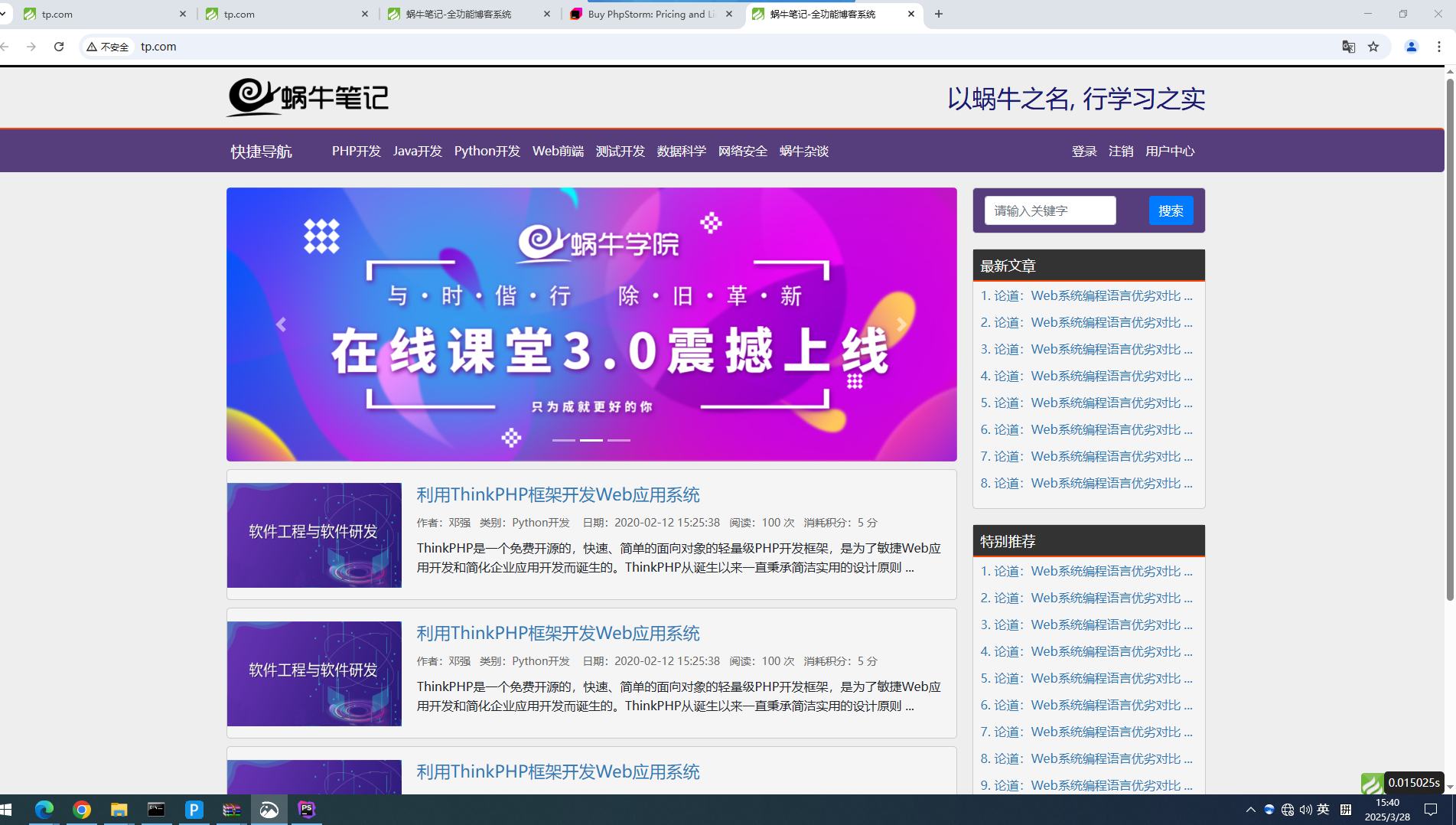
Web前端页面搭建
1.在D盘中创建www文件 cmd进入窗口命令windowsR 切换盘符d: 进入创建的文件夹 在文件夹里安装tp框架 在PS中打开tp文件 创建网站,根目录到public 在浏览器中打开网页 修改文件目录名称 在public目录中的。htaccess中填写下面代码 <IfModule mod_rewrite.c >…...

开源 LLM 应用开发平台 Dify 全栈部署指南(Docker Compose 方案)
开源 LLM 应用开发平台 Dify 全栈部署指南(Docker Compose 方案) 一、部署环境要求与前置检查 1.1 硬件最低配置 组件要求CPU双核及以上内存4GB 及以上磁盘空间20GB 可用空间 1.2 系统兼容性验证 ✅ 官方支持系统: Ubuntu 20.04/22.04 L…...
BN 层的作用, 为什么有这个作用?
BN 层(Batch Normalization)——这是深度神经网络中非常重要的一环,它大大改善了网络的训练速度、稳定性和收敛效果。 🧠 一句话理解 BN 层的作用: Batch Normalization(批归一化)通过标准化每一…...

JavaScript 中常见的鼠标事件及应用
JavaScript 中常见的鼠标事件及应用 在 JavaScript 中,鼠标事件是用户与网页进行交互的重要方式,通过监听这些事件,开发者可以实现各种交互效果,如点击、悬停、拖动等。 在 JavaScript 中,鼠标事件类型多样࿰…...

【nginx】Nginx的功能特性及常用功能
目录 1.核心功能特性1.1 高并发处理能力1.2 反向代理与负载均衡1.3 静态资源服务1.4 缓存加速1.5 SSL/TLS支持1.6 动态模块扩展1.7 流媒体服务1.8 高可用性 2.常用功能场景2.1 反向代理与负载均衡2.2 静态资源服务2.3 缓存加速2.4 HTTPS支持2.5 API网关2.6 微服务网关 3.优势总…...

make_01_Program_01_makefile .SECONDARY .dirstamp 是什么功能
在 Makefile 中,.SECONDARY 和 .dirstamp 与 GNU Make 处理文件和目标的方式有关。让我们分别解释这两个部分,以及它们结合在一起时的功能。 .SECONDARY 功能:.SECONDARY 是一个特殊的伪目标,用于告诉 make 保留所有中间目标文件…...

金仓数据库KCM认证考试介绍【2025年4月更新】
KCM(金仓认证大师)认证是金仓KES数据库的顶级认证,学员需通过前置KCA、KCP认证才能考KCM认证。 KCM培训考试一般1-2个月一次,KCM报名费原价为1.8万,当前优惠价格是1万(趋势是:费用越来越高&…...

在 macOS 上安装和配置 Aria2 的详细步骤
在 macOS 上安装和配置 Aria2 的详细步骤: 1.安装 Aria2 方式一:使用 Homebrew Homebrew 是 macOS 上的包管理器,可以方便地安装和管理软件包。 • 打开终端。 • 输入以下命令安装 Aria2: brew install aria2• 检查安装是否…...

如何通过句块训练法(Chunks)提升英语口语
真正说一口流利英语的人,并不是会造句的人,而是擅长“调取句块”的人。下面我们从原理、方法、场景、资源几个维度展开,告诉你怎么用“句块训练法(Chunks)”快速提升英语口语: 一、什么是“句块”ÿ…...

[ctfshow web入门]burpsuite的下载与使用
下载 吾爱破解网站工具区下载burpsuite https://www.52pojie.cn/thread-1544866-1-1.html 本博客仅转载下载链接,下载后请按照说明进行学习使用 打开 配置 burpsuite配置 burpsuite代理设置添加127.0.0.1:8080 浏览器配置 如果是谷歌浏览器,打开win…...
)
文章记单词 | 第25篇(六级)
一,单词释义 mathematical:形容词,意为 “数学的;数学上的;运算能力强的;关于数学的”trigger:名词,意为 “(枪的)扳机;(炸弹的&…...
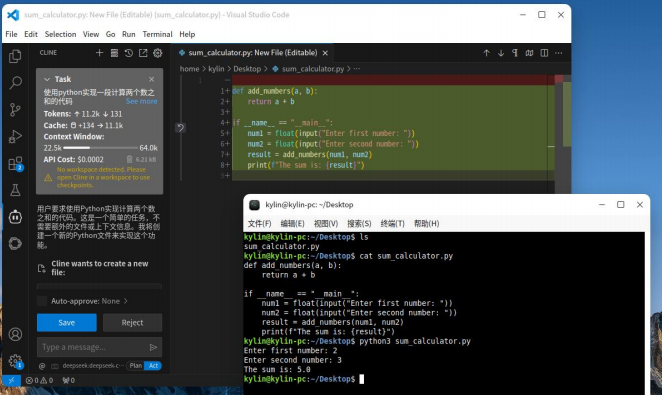
vscode集成deepseek实现辅助编程(银河麒麟系统)【详细自用版】
针对开发者用户,可在Visual Studio Code中接入DeepSeek,实现辅助编程。 可参考我往期文章在银河麒麟系统环境下部署DeepSeek:基于银河麒麟桌面&&服务器操作系统的 DeepSeek本地化部署方法【详细自用版】 一、前期准备 (…...

【CMake】《CMake构建实战:项目开发卷》笔记-Chapter8-生成器表达式
第8章 生成器表达式 生成器表达式(generator expression)是由CMake生成器进行解析的表达式,因此,这些表达式只有在CMake的生成阶段才被解析为具体的值。 CMake在生成阶段,能够根据具体选用的构建系统生成器生成特定…...