重生之我是去噪高手——diffusion model
diffusion model是如何运作的?
想象一下,你有一张清晰的图片。扩散模型的核心思想分为两个过程:
- 前向过程(Forward Process / Diffusion Process):逐步加噪
- 反向过程(Reverse Process / Denoising Process):逐步去噪(学习生成)
1. 前向过程(逐步加噪) - 破坏图像
-
目标:
把一张真实的、清晰的图片(来自你的训练数据集)逐步变成完全的随机噪声(通常是高斯噪声)。 -
如何做:
这个过程是固定的、预先定义好的,不需要学习。- 从原始图片 x 0 x_0 x0 开始。
- 设定一个总的步数 T T T(比如 1000 步)。
- 在每一步 t t t(从 1 到 T T T),我们向上一步的图片 x t − 1 x_{t-1} xt−1 中加入少量的高斯噪声,得到 x t x_t xt。
- 加入的噪声量是根据一个预设的“噪声计划”(variance schedule)来控制的。通常,越往后的步骤加入的噪声(或绝对噪声)越多,也就是说信噪比越来越低。
- 经过 T T T 步之后,原始图片 x 0 x_0 x0 基本上就变成了一个纯粹的噪声图像 x T x_T xT,与原始信息几乎无关。
-
关键点:
- 这个过程是一个马尔可夫链: x t x_t xt 只依赖于 x t − 1 x_{t-1} xt−1。
- 由于高斯噪声的良好特性,我们可以直接计算出任意步骤 t t t 的噪声图像 x t x_t xt,只需要原始图像 x 0 x_0 x0 和噪声计划,不需要一步步迭代。这对于训练过程非常重要。
类比:
想象把一滴墨水滴入清水中,墨水会逐渐扩散(加噪),直到整杯水变成均匀的淡黑色(纯噪声)。
PS:
前向过程提供了问题-答案对,即噪声阶段和对映的噪声。这个可以为反向过程提供训练的数据。简单来说,前向过程就是故意弄脏图片,并且记录下是怎么弄脏的,目的是为了给 AI 提供学习“如何把脏图片变干净”的训练材料和学习目标。
马尔可夫链的核心思想是:“未来只取决于现在,与过去无关。”
2. 反向过程(逐步去噪) - 学习生成
-
目标:
从一个纯粹的随机噪声图像(与 x T x_T xT 分布相同)开始,逐步去除噪声,最终生成一张看起来真实、清晰的图片。 -
挑战:
直接反转加噪过程非常困难,因为每一步加噪都丢失了信息。 -
解决方案:
训练一个神经网络(通常是 U-Net 架构,特别擅长处理具有空间结构的数据)来预测每一步 被添加的噪声。 -
如何做:
- 这个神经网络模型(我们称之为 ϵ θ \epsilon_\theta ϵθ,其中 θ \theta θ 是网络参数)的输入是:
- 当前步骤 t t t 的噪声图像 x t x_t xt。
- 当前的步骤 t t t(通常会编码成一个向量,用以告诉网络当前处于哪个去噪阶段)。
- 网络的 输出 是:预测在前向过程中,从 x t − 1 x_{t-1} xt−1 得到 x t x_t xt 时加入的那个噪声 ϵ \epsilon ϵ。
- 有了这个预测的噪声 ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t),我们就可以使用一个数学公式,从当前的 x t x_t xt 中“减去”这个预测的噪声(并加上一些必要的随机性),来估计出上一步稍微清晰一点的图像 x t − 1 x_{t-1} xt−1。
- 这个过程从 t = T t = T t=T 开始,输入一个随机噪声 x T x_T xT,然后利用神经网络反复预测并去除噪声,一步步得到 x T − 1 x_{T-1} xT−1, x T − 2 x_{T-2} xT−2, …, 直到 x 0 x_0 x0。最终得到的 x 0 x_0 x0 就是模型生成的图片。
- 这个神经网络模型(我们称之为 ϵ θ \epsilon_\theta ϵθ,其中 θ \theta θ 是网络参数)的输入是:
-
关键点:
- 这是模型需要 学习 的部分。
- 学习的目标是让神经网络预测的噪声尽可能接近前向过程中实际添加的噪声。
类比:
想象观看墨水扩散的录像带并倒放。神经网络就像一个“物理学家”,它学习如何在每个时间点精确地把扩散开的墨水粒子“收回”一点点,最终恢复成一滴清晰的墨水。
训练过程(如何学习去噪)
模型是如何学会预测噪声的呢?
- 从训练数据集中随机抽取一张真实的图片 x 0 x_0 x0。
- 随机选择一个时间步 t t t(在 1 到 T T T 之间)。
- 利用前向过程的公式,直接计算出在 t t t 时刻,向 x 0 x_0 x0 加入适量噪声后得到的噪声图像 x t x_t xt。同时,我们知道实际加入的噪声 ϵ \epsilon ϵ 是什么。
- 将 x t x_t xt 和时间步 t t t 输入到神经网络 ϵ θ \epsilon_\theta ϵθ 中。
- 神经网络输出它 预测 的噪声 ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t)。
- 计算预测噪声 ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t) 和实际噪声 ϵ \epsilon ϵ 之间的差异(例如,使用均方误差 L2 loss)。这个差异就是模型的“错误”或损失(loss)。
- 使用反向传播和优化算法(如 Adam)调整神经网络的参数 θ \theta θ,使得这个损失尽可能小。
- 重复以上步骤,使用大量的训练图片和不同的时间步 t t t。
通过这个过程,神经网络逐渐学会了在任何噪声水平 t t t 下,从噪声图像 x t x_t xt 中准确地识别并预测出被添加的噪声。
生成新图片(Sampling)
训练完成后,如何生成一张全新的图片?
- 从一个标准高斯分布(纯随机噪声)中采样得到一个初始图像 x T x_T xT。
- 从 t = T t = T t=T 开始,逐步递减到 t = 1 t = 1 t=1:
- 将当前的图像 x t x_t xt 和时间步 t t t 输入到 训练好的 神经网络 ϵ θ \epsilon_\theta ϵθ 中,得到预测的噪声 ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t)。
- 使用反向过程的公式,结合 x t x_t xt 和预测的噪声 ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t),计算出上一步的图像 x t − 1 x_{t-1} xt−1。(这个公式通常还会包含一个随机项,以增加生成的多样性)。
- 当 t t t 减到 0 时,得到的 x 0 x_0 x0 就是最终生成的图像。
总结
- Diffusion Model 通过一个 固定的加噪过程(前向)和一个 学习的去噪过程(反向)来工作。
- 核心是训练一个神经网络来 预测 在加噪过程中每一步所添加的噪声。
- 通过从纯噪声开始,反复使用这个神经网络预测并移除噪声,模型可以逐步“雕刻”出逼真的新数据样本。
- 这种方法已被证明在图像生成、音频生成等领域能产生非常高质量和多样化的结果,尽管其生成过程(采样)通常比其他模型(如 GAN)要慢,因为它需要进行很多步迭代。目前也有很多研究在致力于加速这个采样过程。
diffusion model的数学原理
1. 前向过程 (Forward Process / Diffusion Process)
这是一个固定、预定义的马尔可夫链,它逐渐向数据 x 0 x_0 x0(来自真实数据分布 q ( x 0 ) q(x_0) q(x0))添加高斯噪声,经过 T T T 步后得到近似纯噪声 x T x_T xT。
-
状态定义:
x 1 , x 2 , … , x T x_1, x_2, \ldots, x_T x1,x2,…,xT 是隐变量(latent variables),与原始数据 x 0 x_0 x0 具有相同的维度。 -
转移概率:
每一步从 x t − 1 x_{t-1} xt−1 到 x t x_t xt 的转移被定义为一个条件高斯分布
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(x_t \mid x_{t-1}) = \mathcal{N}\Big(x_t; \sqrt{1 - \beta_t}\, x_{t-1},\, \beta_t\, I\Big) q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
其中:- β t \beta_t βt 是一个预先设定的(通常很小的)方差值,代表在第 t t t 步加入的噪声强度。
β 1 < β 2 < ⋯ < β T \beta_1 < \beta_2 < \cdots < \beta_T β1<β2<⋯<βT 构成了一个方差计划 (variance schedule)。 - 1 − β t x t − 1 \sqrt{1 - \beta_t}\, x_{t-1} 1−βtxt−1 表示对上一步状态的轻微缩放。
- β t I \beta_t\, I βtI 是加入的高斯噪声的协方差矩阵(其中 I I I 为单位矩阵)。
- β t \beta_t βt 是一个预先设定的(通常很小的)方差值,代表在第 t t t 步加入的噪声强度。
PS:整个过程类似于“要得到下一张更模糊的图片 x_t,先把当前图片 x_{t-1} 稍微‘弄暗’一点点(公式中的sqrt(1 - β_t) * x_{t-1}:这是正态分布的均值(μ),也就是 x_t 最可能变成的样子),然后再给它撒上一层‘强度’为 β_t 的随机‘雪花’(公式中的β_t * I:这是正态分布的方差(σ²),代表添加的噪声的“大小”或“散布程度”。)。” 这个过程重复 T 次。
-
联合概率分布:
整个前向过程的联合概率为
q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) . q(x_{1:T} \mid x_0) = \prod_{t=1}^T q(x_t \mid x_{t-1}). q(x1:T∣x0)=t=1∏Tq(xt∣xt−1). -
重要特性 (采样 x t x_t xt 的闭式解):
由于高斯分布的良好性质,我们可以直接从 x 0 x_0 x0 采样得到任意步骤 t t t 的 x t x_t xt,而无需进行 t t t 次迭代。设定
α t = 1 − β t , α ˉ t = ∏ s = 1 t α s . \alpha_t = 1 - \beta_t,\quad \bar{\alpha}_t = \prod_{s=1}^t \alpha_s. αt=1−βt,αˉt=s=1∏tαs.
那么,便有闭式解:
q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) , q(x_t \mid x_0) = \mathcal{N}\Big(x_t; \sqrt{\bar{\alpha}_t}\, x_0,\, (1 - \bar{\alpha}_t)\, I\Big), q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I),
或者写成
x t = α ˉ t x 0 + 1 − α ˉ t ε , ε ∼ N ( 0 , I ) . x_t = \sqrt{\bar{\alpha}_t}\, x_0 + \sqrt{1 - \bar{\alpha}_t}\, \varepsilon,\quad \varepsilon \sim \mathcal{N}(0, I). xt=αˉtx0+1−αˉtε,ε∼N(0,I).
PS:“第 t 步的噪声图片 x_t,其实就是(原始图片 x₀ 褪色 t 步后的残影)加上 (一个标准噪声 ε 被放大 t 步对应倍数后的效果)。t 越小,x_t 越像 x₀;t 越大,x_t 越像纯噪声 ε。”
2. 反向过程 (Reverse Process / Denoising Process)
这部分是我们需要学习的过程。目标是从噪声
x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0, I) xT∼N(0,I)
开始,逐步反向运行该过程,最终生成一个样本 x 0 x_0 x0,使其看起来像真实数据分布 q ( x 0 ) q(x_0) q(x0) 中的样本。
-
目标:
学习反向的转移概率 p ( x t − 1 ∣ x t ) p(x_{t-1} \mid x_t) p(xt−1∣xt)。 -
挑战:
直接计算真实后验 q ( x t − 1 ∣ x t ) q(x_{t-1} \mid x_t) q(xt−1∣xt) 比较困难,因为它需要考虑整个数据集的信息。但如果同时条件化 x 0 x_0 x0,则后验 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1} \mid x_t, x_0) q(xt−1∣xt,x0) 是可求解的(tractable)。 -
真实的后验 (给定 x 0 x_0 x0):
利用贝叶斯定理可以证明,
q ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; μ ~ t ( x t , x 0 ) , β ~ t I ) , q(x_{t-1} \mid x_t, x_0) = \mathcal{N}\Big(x_{t-1}; \tilde{\mu}_t(x_t, x_0),\, \tilde{\beta}_t\, I\Big), q(xt−1∣xt,x0)=N(xt−1;μ~t(xt,x0),β~tI),
其中均值和方差分别为
μ ~ t ( x t , x 0 ) = α ˉ t − 1 β t 1 − α ˉ t x 0 + α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t , \tilde{\mu}_t(x_t, x_0) = \frac{\sqrt{\bar{\alpha}_{t-1}}\, \beta_t}{1 - \bar{\alpha}_t}\, x_0 + \frac{\sqrt{\alpha_t}\,(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t}\, x_t, μ~t(xt,x0)=1−αˉtαˉt−1βtx0+1−αˉtαt(1−αˉt−1)xt,
β ~ t = 1 − α ˉ t − 1 1 − α ˉ t β t . \tilde{\beta}_t = \frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t}\, \beta_t. β~t=1−αˉt1−αˉt−1βt. -
模型近似:
由于在生成时我们没有 x 0 x_0 x0 信息,因此使用一个神经网络 p θ p_\theta pθ 来近似反向转移概率:
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) . p_\theta(x_{t-1} \mid x_t) = \mathcal{N}\Big(x_{t-1}; \mu_\theta(x_t, t),\, \Sigma_\theta(x_t, t)\Big). pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t)).
其中, μ θ \mu_\theta μθ 与 Σ θ \Sigma_\theta Σθ 分别由神经网络根据输入 x t x_t xt 及时间步 t t t 预测得到。 -
简化方差:
在实际应用中,常将方差 Σ θ ( x t , t ) \Sigma_\theta(x_t, t) Σθ(xt,t) 设为固定值,而不是由网络学习。常见做法为:
Σ θ ( x t , t ) = σ t 2 I , \Sigma_\theta(x_t, t) = \sigma_t^2\, I, Σθ(xt,t)=σt2I,
其中 σ t 2 \sigma_t^2 σt2 可能选择为 β t \beta_t βt 或 β ~ t \tilde{\beta}_t β~t。如此,我们主要需要学习的是均值 μ θ ( x t , t ) \mu_\theta(x_t, t) μθ(xt,t)。 -
生成过程:
从
x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0, I) xT∼N(0,I)
开始,依次(从 t = T t = T t=T 到 1 1 1)采样
x t − 1 ∼ p θ ( x t − 1 ∣ x t ) . x_{t-1} \sim p_\theta(x_{t-1} \mid x_t). xt−1∼pθ(xt−1∣xt).
3. 训练目标 (Learning Objective)
我们希望最大化训练数据 x 0 x_0 x0 的对数似然 log p θ ( x 0 ) \log p_\theta(x_0) logpθ(x0)。直接优化此目标较为困难,因此与变分自编码器(VAE)类似,我们通过优化证据下界(Evidence Lower Bound, ELBO,也称 Variational Lower Bound, VLB)来间接训练模型。
PS:直接计算 p_θ(x₀) 这个概率极其困难。因为它涉及到 AI 可能通过的所有“去噪步骤”最终得到 x₀ 的所有可能路径,这太复杂了!
- ELBO 推导:
log p θ ( x 0 ) ≥ L V L B = E q ( x 1 : T ∣ x 0 ) [ log p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) ] . \log p_\theta(x_0) \geq L_{\mathrm{VLB}} = \mathbb{E}_{q(x_{1:T}\mid x_0)} \left[ \log \frac{p_\theta(x_{0:T})}{q(x_{1:T}\mid x_0)} \right]. logpθ(x0)≥LVLB=Eq(x1:T∣x0)[logq(x1:T∣x0)pθ(x0:T)].
通常写作:
L V L B = E q [ log p ( x T ) + ∑ t = 1 T log p θ ( x t − 1 ∣ x t ) q ( x t ∣ x t − 1 ) ] , L_{\mathrm{VLB}} = \mathbb{E}_q \left[ \log p(x_T) + \sum_{t=1}^{T} \log \frac{p_\theta(x_{t-1}\mid x_t)}{q(x_t\mid x_{t-1})} \right], LVLB=Eq[logp(xT)+t=1∑Tlogq(xt∣xt−1)pθ(xt−1∣xt)],
PS:如果我们想办法把 ELBO (L_VLB) 的值尽量提高,那么我们也就间接地把真正的目标 log p θ ( x 0 ) \log p_\theta(x_0) logpθ(x0) 提高了(至少不会让它变差)。所以,我们不去优化那个困难的 log p θ ( x 0 ) \log p_\theta(x_0) logpθ(x0),而是优化相对容易处理的 ELBO (L_VLB)。
(其中 p ( x T ) p(x_T) p(xT) 项由于不依赖于参数 θ \theta θ 可忽略)进一步分解为:
L V L B = E q [ log p θ ( x 0 ∣ x 1 ) ] − D K L ( q ( x T ∣ x 0 ) ∥ p ( x T ) ) − ∑ t = 2 T E q [ D K L ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) ] . L_{\mathrm{VLB}} = \mathbb{E}_q\Big[\log p_\theta(x_0\mid x_1)\Big] - D_{\mathrm{KL}}\big(q(x_T\mid x_0) \,\|\, p(x_T)\big) - \sum_{t=2}^{T} \mathbb{E}_q\Big[D_{\mathrm{KL}}\big(q(x_{t-1}\mid x_t, x_0) \,\|\, p_\theta(x_{t-1}\mid x_t)\big)\Big]. LVLB=Eq[logpθ(x0∣x1)]−DKL(q(xT∣x0)∥p(xT))−t=2∑TEq[DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))].
PS: p θ ( x 0 ∣ x 1 ) p_θ(x₀|x₁) pθ(x0∣x1):表示 AI 在去噪的最后一步(从稍微有点噪声的 x₁ 变成清晰的 x₀)时,把图片还原得有多好。
D K L ( q ( x T ∣ x 0 ) ∣ ∣ p ( x T ) ) D_KL(q(x_T|x₀) || p(x_T)) DKL(q(xT∣x0)∣∣p(xT)) (噪声匹配 - 训练时可忽略)这部分只跟固定的前向过程和我们对噪声的固定假设有关,跟 AI 的参数 θ 无关。既然跟我们要优化的 θ 无关,那么在训练 AI(优化 θ)时就可以忽略它。
Σ E q [ D K L ( q ( x t − 1 ∣ x t , x 0 ) ∣ ∣ p θ ( x t − 1 ∣ x t ) ) ] Σ E_q[D_KL(q(x_{t-1}|x_t, x₀) || p_θ(x_{t-1}|x_t))] ΣEq[DKL(q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt))] (一步步去噪的匹配 - 核心部分!):
这是训练中最重要的部分。它是对所有中间去噪步骤(从 t=T 到 t=2)求和。
q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t, x_0) q(xt−1∣xt,x0):这是如果我们有“作弊码”(知道原始清晰图片 x₀),从 x_t 回到 x_{t-1} 的“理想方式”或“正确答案”。我们知道它是一个精确的高斯分布 N ( μ ~ t , β ~ t I ) N(μ̃_t, β̃_t I) N(μ~t,β~tI)。这是我们每一步的目标。
p θ ( x t − 1 ∣ x t ) p_θ(x_{t-1}|x_t) pθ(xt−1∣xt):这是我们的 AI 模型在第 t 步实际做的事情,它只看到当前的 x_t,尝试猜测 x_{t-1} 应该是什么样子。我们也把它设计成一个高斯分布 N ( μ θ , σ t 2 I ) N(μ_θ, σ_t² I) N(μθ,σt2I)。这是 AI 的预测。
D K L ( . . . ) D_KL(...) DKL(...):KL 散度是衡量这两个概率分布(理想的 q 和 AI 预测的 p_θ)有多么“不像”或“差异多大”。
目标:为了最大化 ELBO,我们需要在每一步都最小化这个 KL 散度。我们希望 AI 的预测 (p_θ) 尽可能地接近理想目标 (q)。
-
关键洞察与简化:
-
在上式中,项 D K L ( q ( x T ∣ x 0 ) ∥ p ( x T ) ) D_{\mathrm{KL}}\big(q(x_T\mid x_0) \,\|\, p(x_T)\big) DKL(q(xT∣x0)∥p(xT)) 不依赖于模型参数 θ \theta θ,因此可忽略。
-
log p θ ( x 0 ∣ x 1 ) \log p_\theta(x_0\mid x_1) logpθ(x0∣x1) 为最后一步的重构项。
-
核心在于最小化每一步的 KL 散度:
D K L ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) . D_{\mathrm{KL}}\big(q(x_{t-1}\mid x_t, x_0) \,\|\, p_\theta(x_{t-1}\mid x_t)\big). DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt)).
我们知道:- q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}\mid x_t, x_0) q(xt−1∣xt,x0) 是高斯分布 N ( μ ~ t , β ~ t I ) \mathcal{N}(\tilde{\mu}_t,\, \tilde{\beta}_t\, I) N(μ~t,β~tI)。
- 模型 p θ ( x t − 1 ∣ x t ) p_\theta(x_{t-1}\mid x_t) pθ(xt−1∣xt) 为高斯分布 N ( μ θ ( x t , t ) , σ t 2 I ) \mathcal{N}(\mu_\theta(x_t, t),\, \sigma_t^2\, I) N(μθ(xt,t),σt2I)(此处方差固定)。
最小化这两个固定方差高斯分布之间的 KL 散度,主要等价于最小化它们均值之间的平方误差:
∥ μ ~ t ( x t , x 0 ) − μ θ ( x t , t ) ∥ 2 , \|\tilde{\mu}_t(x_t, x_0) - \mu_\theta(x_t, t)\|^2, ∥μ~t(xt,x0)−μθ(xt,t)∥2,
(忽略那些不依赖于 θ \theta θ 的比例因子与常数项)。
-
-
参数化技巧 (Noise Prediction):
- 虽然可以直接让神经网络预测均值 μ θ \mu_\theta μθ 以匹配 μ ~ t \tilde{\mu}_t μ~t,但 Ho et al.(DDPM 论文)提出了一种更稳定且效果更好的方法:让神经网络 ε θ ( x t , t ) \varepsilon_\theta(x_t, t) εθ(xt,t) 预测在第 t t t 步加入的噪声 ε \varepsilon ε。
- 回忆前向过程公式:
x t = α ˉ t x 0 + 1 − α ˉ t ε . x_t = \sqrt{\bar{\alpha}_t}\, x_0 + \sqrt{1 - \bar{\alpha}_t}\, \varepsilon. xt=αˉtx0+1−αˉtε.
反解可得:
x 0 = x t − 1 − α ˉ t ε α ˉ t . x_0 = \frac{x_t - \sqrt{1 - \bar{\alpha}_t}\, \varepsilon}{\sqrt{\bar{\alpha}_t}}. x0=αˉtxt−1−αˉtε. - 将 x 0 x_0 x0 带入 μ ~ t ( x t , x 0 ) \tilde{\mu}_t(x_t, x_0) μ~t(xt,x0) 的表达式后,可以证明 μ ~ t \tilde{\mu}_t μ~t 可以表示为 x t x_t xt 与 ε \varepsilon ε 的函数。
- 若采用下面的参数化形式,
μ θ ( x t , t ) = 1 α t ( x t − β t 1 − α ˉ t ε θ ( x t , t ) ) , \mu_\theta(x_t, t) = \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}}\, \varepsilon_\theta(x_t, t) \right), μθ(xt,t)=αt1(xt−1−αˉtβtεθ(xt,t)),
则最小化 ∥ μ ~ t − μ θ ∥ 2 \|\tilde{\mu}_t - \mu_\theta\|^2 ∥μ~t−μθ∥2 便等价于(忽略不依赖于 θ \theta θ 的系数)最小化
∥ ε − ε θ ( x t , t ) ∥ 2 . \|\varepsilon - \varepsilon_\theta(x_t, t)\|^2. ∥ε−εθ(xt,t)∥2.
-
最终的简化目标函数:
实际训练中,我们通常最小化以下期望损失:
L s i m p l e ( θ ) = E t , x 0 , ε [ ∥ ε − ε θ ( α ˉ t x 0 + 1 − α ˉ t ε , t ) ∥ 2 ] , L_{\mathrm{simple}}(\theta) = \mathbb{E}_{t,\, x_0,\, \varepsilon} \Big[ \big\|\varepsilon - \varepsilon_\theta\Big(\sqrt{\bar{\alpha}_t}\, x_0 + \sqrt{1 - \bar{\alpha}_t}\, \varepsilon,\, t\Big) \big\|^2 \Big], Lsimple(θ)=Et,x0,ε[ ε−εθ(αˉtx0+1−αˉtε,t) 2],
其中:- t t t 从 { 1 , … , T } \{1, \ldots, T\} {1,…,T} 中均匀采样;
- x 0 x_0 x0 来自真实数据分布 q ( x 0 ) q(x_0) q(x0) 的采样;
- ε ∼ N ( 0 , I ) \varepsilon \sim \mathcal{N}(0, I) ε∼N(0,I) 为标准高斯噪声;
- ε θ \varepsilon_\theta εθ 为神经网络(通常采用 U-Net 结构),输入噪声图像 x t x_t xt 和时间步 t t t,输出预测的噪声 ε \varepsilon ε。
- ∣ ∣ ε − ε θ ( . . . ) ∣ ∣ 2 ||ε - ε_θ(...) ||² ∣∣ε−εθ(...)∣∣2:计算“真实噪声 ε”和“AI 预测的噪声 ε_θ”之间的平方差(也就是误差)。
这个基于 L2 的损失函数在实践中表现良好,具有训练稳定性和实现简便性。
4. 采样 (Sampling / Generation)
在模型训练完成后,生成新样本的过程如下:
-
初始化
从标准高斯分布中采样初始噪声:
x T ∼ N ( 0 , I ) . x_T \sim \mathcal{N}(0, I). xT∼N(0,I). -
反向采样过程
对 t t t 从 T T T 递减至 1 1 1:- 若 t > 1 t > 1 t>1,从 N ( 0 , I ) \mathcal{N}(0, I) N(0,I) 中采样随机噪声 z z z;若 t = 1 t = 1 t=1,令 z = 0 z = 0 z=0。
- 利用训练好的神经网络计算噪声预测:
ε pred = ε θ ( x t , t ) . \varepsilon_{\text{pred}} = \varepsilon_\theta(x_t, t). εpred=εθ(xt,t). - 计算反向过程的均值:
μ θ ( x t , t ) = 1 α t ( x t − β t 1 − α ˉ t ε pred ) . \mu_\theta(x_t, t) = \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}}\, \varepsilon_{\text{pred}} \right). μθ(xt,t)=αt1(xt−1−αˉtβtεpred). - 使用固定标准差 σ t \sigma_t σt(通常有 σ t 2 = β ~ t \sigma_t^2 = \tilde{\beta}_t σt2=β~t 或 σ t 2 = β t \sigma_t^2 = \beta_t σt2=βt)进行采样:
x t − 1 = μ θ ( x t , t ) + σ t z . x_{t-1} = \mu_\theta(x_t, t) + \sigma_t\, z. xt−1=μθ(xt,t)+σtz.
-
最终生成的 x 0 x_0 x0 为模型生成的样本。
总结关键数学概念
-
马尔可夫链:
前向过程与反向过程均被建模为马尔可夫链。 -
高斯分布:
高斯分布作为噪声模型和转移概率的核心,凭借其在做线性变换与求和时的闭合性质,使得前向过程可以得到闭式解。 -
贝叶斯定理:
用于推导条件后验 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}\mid x_t, x_0) q(xt−1∣xt,x0)。 -
变分推断 (Variational Inference):
通过优化 ELBO 来实现近似最大化对数似然,从而解决直接优化似然困难的问题。 -
KL 散度:
作为优化目标的一部分,用于衡量两个概率分布之间的差异。 -
参数化技巧 (Reparameterization Trick):
虽然此处采用的是预测噪声而非直接采样,但基本思想相似,即将随机性(噪声 ε \varepsilon ε)与模型参数分离,使得整个目标函数可微。预测噪声 ε \varepsilon ε 成为对反向过程均值 μ θ \mu_\theta μθ 的一种有效参数化方式。

总结训练算法: 反复地:① 拿张真图 → ② 随机加噪声(记住加了啥噪声)→ ③ 让 AI 猜加了啥噪声 → ④ 对比真实噪声和 AI 的猜测 → ⑤ 根据差距调整 AI → 直到 AI 成为猜噪声高手。
总结采样算法: ① 从纯噪声开始 → ② 反复 T 次(从 T 到 1):(a) 让训练好的 AI 预测当前图片中的噪声 → (b) 从图片中减掉预测的噪声 → © 调整一下图片 → (d) 再加一点点新的随机噪声(最后一步除外)→ ③ 得到最终生成的图片。
一系列问答
1. p θ p_\theta pθ 是模型本身吗?还是模型生成出好图片的概率?
- p θ p_\theta pθ 代表的是模型本身,更准确地说,是由参数 θ \theta θ 定义的概率模型。
- θ \theta θ (theta) 代表神经网络的所有可学习参数(权重、偏置等)。
- p θ ( x 0 ) p_\theta(x_0) pθ(x0) 不是“生成好图片的概率”,而是这个模型认为某张真实的、清晰的图片 x 0 x_0 x0 出现的概率密度。你可以理解为,模型根据它学到的知识,判断 x 0 x_0 x0 这张图片有多么“合理”或“像它应该生成的东西”。
- 我们的目标是调整参数 θ \theta θ,使得模型 p θ p_\theta pθ 对于所有真实的训练图片 x 0 x_0 x0 都给出尽可能高的概率密度值。也就是说,让模型觉得真实图片都是非常“合理”的。
2. ELBO 推导: L V L B L_{VLB} LVLB 为什么等于右边?
这里涉及两个等式,我们分开解释:
-
第一个等式:
L V L B = E q [ log p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) ] L_{VLB} = \mathbb{E}_q\left[\log\frac{p_\theta(x_{0:T})}{q(x_{1:T}\mid x_0)}\right] LVLB=Eq[logq(x1:T∣x0)pθ(x0:T)]
- 这是 ELBO 的标准定义,源自变分推断理论。它直接关联了我们想最大化的 log p θ ( x 0 ) \log p_\theta(x_0) logpθ(x0) 和一个可以计算的量。
- p θ ( x 0 : T ) p_\theta(x_{0:T}) pθ(x0:T):表示根据我们的模型 p θ p_\theta pθ(包括反向去噪过程 p θ ( x t − 1 ∣ x t ) p_\theta(x_{t-1}\mid x_t) pθ(xt−1∣xt) 和最终噪声假设 p ( x T ) p(x_T) p(xT)),从噪声 x T x_T xT 一路生成到 x 0 x_0 x0 并经历中间状态 x 1 x_1 x1 到 x T − 1 x_{T-1} xT−1 的整个完整路径的联合概率。
- q ( x 1 : T ∣ x 0 ) q(x_{1:T}\mid x_0) q(x1:T∣x0):表示根据固定的前向加噪过程 q q q,从清晰图片 x 0 x_0 x0 出发,生成噪声序列 x 1 x_1 x1 到 x T x_T xT 的联合概率。
- log ( ⋅ ) \log(\cdot) log(⋅):取对数。
- E q ( ⋅ ) \mathbb{E}_q(\cdot) Eq(⋅):表示对所有可能的噪声序列(由 q ( x 1 : T ∣ x 0 ) q(x_{1:T}\mid x_0) q(x1:T∣x0) 定义)求平均值(期望)。
- 这个公式的意义在于,它把难以计算的 log p θ ( x 0 ) \log p_\theta(x_0) logpθ(x0) 与一个涉及模型 p θ p_\theta pθ 与已知过程 q q q 的表达式联系起来,并且知道前者总是大于等于后者(所以叫下界)。
-
第二个等式(“通常写作”):
L V L B = E q [ log p ( x T ) + ∑ t = 1 T log p θ ( x t − 1 ∣ x t ) q ( x t ∣ x t − 1 ) ] L_{VLB} = \mathbb{E}_q\left[\log p(x_T) + \sum_{t=1}^T \log\frac{p_\theta(x_{t-1}\mid x_t)}{q(x_t\mid x_{t-1})}\right] LVLB=Eq[logp(xT)+t=1∑Tlogq(xt∣xt−1)pθ(xt−1∣xt)]
- 这个等式是通过对第一个等式中的 log p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) \log\frac{p_\theta(x_{0:T})}{q(x_{1:T}\mid x_0)} logq(x1:T∣x0)pθ(x0:T) 进行代数展开和重新组合得到的。
- 怎么推的?
- 把 p θ ( x 0 : T ) p_\theta(x_{0:T}) pθ(x0:T) 写成因子连乘:
p ( x T ) ⋅ p θ ( x T − 1 ∣ x T ) ⋯ p θ ( x 0 ∣ x 1 ) p(x_T) \cdot p_\theta(x_{T-1}\mid x_T) \cdots p_\theta(x_0\mid x_1) p(xT)⋅pθ(xT−1∣xT)⋯pθ(x0∣x1) - 把 q ( x 1 : T ∣ x 0 ) q(x_{1:T}\mid x_0) q(x1:T∣x0) 写成因子连乘:
q ( x T ∣ x T − 1 ) ⋯ q ( x 1 ∣ x 0 ) q(x_T\mid x_{T-1}) \cdots q(x_1\mid x_0) q(xT∣xT−1)⋯q(x1∣x0) - 利用 log A B = log A − log B \log\frac{A}{B} = \log A - \log B logBA=logA−logB 和 log ( A ⋅ B ⋅ … ) = log A + log B + … \log(A\cdot B\cdot\ldots) = \log A + \log B + \ldots log(A⋅B⋅…)=logA+logB+…
- 经过整理,就可以把对整个序列的联合概率的对数,变成对每一步转移概率比值的对数求和,再加上初始噪声项 log p ( x T ) \log p(x_T) logp(xT)。
- 把 p θ ( x 0 : T ) p_\theta(x_{0:T}) pθ(x0:T) 写成因子连乘:
- 这种形式更有用,因为它把复杂的整体概率分解成了一步一步的过程,更容易分析和优化。
3. KL 散度 (Kullback-Leibler Divergence)
- 是什么?
KL 散度是衡量**两个概率分布 P P P 和 Q Q Q 有多“不像”**的一种方式。它的值 D K L ( P ∥ Q ) D_{KL}(P \parallel Q) DKL(P∥Q) 告诉你,如果你用分布 Q Q Q 来近似分布 P P P,你会损失多少信息,或者说 Q Q Q 相比于 P P P 有多少“意外之处”。 - 如何衡量相似性?
- KL 散度的值总是大于等于 0 0 0。
- 当且仅当两个分布 P P P 和 Q Q Q 完全相同时,KL 散度等于 0 0 0。
- KL 散度的值越小,表示两个分布越相似、越接近;而值越大,则差异越大。
- 通俗类比:
- 想象 P P P 是某城市真实的地图,而 Q Q Q 是你画的一张草图。
- KL 散度 D K L ( P ∥ Q ) D_{KL}(P \parallel Q) DKL(P∥Q) 就好比在衡量你这张草图 Q Q Q 与真实地图 P P P 比较,有多么“不准确”或“误导人”。
- 如果你的草图画得非常好,与真实地图几乎一致,那么 KL 散度就非常接近 0 0 0;如果画得很离谱,则 KL 散度会很大。
- 注意:
KL 散度具有不对称性,即 D K L ( P ∥ Q ) D_{KL}(P \parallel Q) DKL(P∥Q) 通常不等于 D K L ( Q ∥ P ) D_{KL}(Q \parallel P) DKL(Q∥P)。在这个记号中, P P P 被视为基准(真实地图),而 Q Q Q 是要比较的对象(草图)。
4. E q E_q Eq 是什么意思? q q q 是什么意思?
- E q E_q Eq:
是“期望 (Expectation)”符号,下标 q q q 表示这个期望是根据概率分布 q q q 来计算的。 - q q q:
在 Diffusion Model 的语境中, q q q 指代的是由前向(加噪)过程定义的一系列概率分布:- q ( x 0 ) q(x_0) q(x0):真实清晰图片的分布(你的数据集)。
- q ( x t ∣ x t − 1 ) q(x_t \mid x_{t-1}) q(xt∣xt−1):从 x t − 1 x_{t-1} xt−1 到 x t x_t xt 的单步加噪概率(固定的)。
- q ( x 1 : T ∣ x 0 ) q(x_{1:T} \mid x_0) q(x1:T∣x0):给定 x 0 x_0 x0,生成整个噪声序列 x 1 , … , x T x_1, \dots, x_T x1,…,xT 的概率(固定的)。
- q ( x t ∣ x 0 ) q(x_t \mid x_0) q(xt∣x0):给定 x 0 x_0 x0,得到第 t t t 步噪声图片 x t x_t xt 的概率(有闭式解,固定的)。
- q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1} \mid x_t, x_0) q(xt−1∣xt,x0):给定 x t x_t xt 和 x 0 x_0 x0,反推 x t − 1 x_{t-1} xt−1 的概率(需要用到 x 0 x_0 x0,但也是基于 q q q 推导出来的)。
- 所以, E q [ … ] E_q[\ldots] Eq[…] 意味着在整个由前向过程定义的所有可能性(包括选择哪个 x 0 x_0 x0,以及基于 x 0 x_0 x0 生成的噪声序列 x 1 : T x_{1:T} x1:T)上求平均值。
5. 最小化 KL 散度的过程是怎样的?
- 目标是最小化
D K L ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) D_{KL}(q(x_{t-1}\mid x_t, x_0) \parallel p_\theta(x_{t-1}\mid x_t)) DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))
这里的 θ \theta θ 是我们唯一能调整的内容(仅存在于 p θ p_\theta pθ 中)。 - 这个过程即梯度下降 (Gradient Descent):
- 计算损失:
对于一个训练样本(包括 x 0 x_0 x0, t t t, ϵ \epsilon ϵ,从而得到 x t x_t xt 和目标分布 q q q),计算当前的 KL 散度值(或与之等价、但更容易计算的目标,例如后面提到的均值平方差)。这个值即表示当前的“误差”或“损失”。 - 计算梯度:
计算该损失相对于模型参数 θ \theta θ 中每个参数的偏导数(梯度),这些梯度指明了参数该如何调整以使损失减少最快。 - 更新参数:
将每个参数 θ \theta θ 沿着梯度的反方向调整一小步:
θ 新 = θ 旧 − 学习率 × ∇ θ Loss \theta_{\text{新}} = \theta_{\text{旧}} - \text{学习率} \times \nabla_\theta \text{Loss} θ新=θ旧−学习率×∇θLoss
这样便使得损失函数值略微减少。 - 重复:
对大量不同的训练样本和时间步重复上述过程,参数 θ \theta θ 将逐步趋向于使 KL 散度(平均而言)最小化的状态。
- 计算损失:
6. 什么叫重构项?
- “重构项”(Reconstruction Term)通常指损失函数中衡量模型从某种编码或加噪表示恢复出原始(或目标)数据的能力的部分。
- 在 ELBO 的分解中
L V L B = E q [ log p θ ( x 0 ∣ x 1 ) ] − … L_{VLB} = \mathbb{E}_q\big[\log p_\theta(x_0\mid x_1)\big] - \ldots LVLB=Eq[logpθ(x0∣x1)]−…
中, log p θ ( x 0 ∣ x 1 ) \log p_\theta(x_0\mid x_1) logpθ(x0∣x1) 就是最后一步的重构项。它直接反映了模型从最后一个噪声状态 x 1 x_1 x1 中“重构”出清晰图像 x 0 x_0 x0 的效果(通过概率高低来度量)。 - 更广义地看,每一个 KL 散度项
D K L ( q ( … ) ∥ p θ ( … ) ) D_{KL}(q(\ldots) \parallel p_\theta(\ldots)) DKL(q(…)∥pθ(…))
也可视为第 t t t 步的“重构损失”,因为它衡量了模型反向过程 p θ p_\theta pθ 与理想反向过程 q q q 之间的差距。
7. 双竖线 ∣ ∣ || ∣∣ 是什么意思? p p p 和 q q q 是概率分布吗?
- 正解! p p p 和 q q q 都代表概率分布。
- 在 D K L ( P ∥ Q ) D_{KL}(P \parallel Q) DKL(P∥Q) 中,双竖线 ∣ ∣ || ∣∣ 只是 KL 散度的标准记号,用来分隔比较的两个概率分布 P P P 和 Q Q Q。这符号本身没有其他独立的数学运算意义,仅是记号的一部分。
8. 应该如何最小化它们的平方误差?
- 我们要最小化的目标为
Loss = ∥ μ ~ t ( x t , x 0 ) − μ θ ( x t , t ) ∥ 2 \text{Loss} = \|\tilde{\mu}_t(x_t, x_0) - \mu_\theta(x_t, t)\|^2 Loss=∥μ~t(xt,x0)−μθ(xt,t)∥2 - 如何做? 这正是梯度下降的核心应用:
- 前向传播:
- 给定 x t x_t xt 和 t t t,将它们输入到神经网络 ϵ θ \epsilon_\theta ϵθ,得到输出 ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t)。
- 利用 ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t) 与 x t x_t xt, t t t,通过 μ θ \mu_\theta μθ 的公式计算出 μ θ ( x t , t ) \mu_\theta(x_t, t) μθ(xt,t)。
- 同时,由于训练时有 x 0 x_0 x0,可以计算出目标均值 μ ~ t ( x t , x 0 ) \tilde{\mu}_t(x_t, x_0) μ~t(xt,x0)。
- 计算损失:
计算损失:
Loss = ∥ μ ~ t ( x t , x 0 ) − μ θ ( x t , t ) ∥ 2 \text{Loss} = \|\tilde{\mu}_t(x_t, x_0) - \mu_\theta(x_t, t)\|^2 Loss=∥μ~t(xt,x0)−μθ(xt,t)∥2
(这里的 ∥ ⋅ ∥ 2 \|\cdot\|^2 ∥⋅∥2 表示向量各元素差的平方和)。 - 反向传播:
- 利用微积分中的链式法则,计算 Loss \text{Loss} Loss 关于 μ θ \mu_\theta μθ 的梯度。
- 再计算 μ θ \mu_\theta μθ 关于 ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t) 的梯度。
- 最终,计算 Loss \text{Loss} Loss 对神经网络内部所有参数 θ \theta θ 的梯度,这正是反向传播算法的工作。
- 参数更新:
使用计算得到的梯度 ∇ θ Loss \nabla_\theta \text{Loss} ∇θLoss 来更新 θ \theta θ:
θ 新 = θ 旧 − 学习率 × ∇ θ Loss \theta_{\text{新}} = \theta_{\text{旧}} - \text{学习率} \times \nabla_\theta \text{Loss} θ新=θ旧−学习率×∇θLoss
- 前向传播:
9. ϵ θ \epsilon_\theta ϵθ 具体是个什么东西?是模型输出的结果吗?
- ϵ θ \epsilon_\theta ϵθ 是那个核心的神经网络本身。它是一个函数,其具体形式取决于内部的层、连接和参数 θ \theta θ 的设置。
- 输入:
它接受两个输入:当前的噪声图片 x t x_t xt以及当前的时间步 t t t(通常会编码为一个向量)。 - 输出:
它的输出是一个与输入图片 x t x_t xt 尺寸相同的张量,这个输出即是模型对噪声 ϵ \epsilon ϵ 的预测结果。 - 因此, ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t) 就是神经网络模型针对输入 ( x t , t ) (x_t, t) (xt,t) 所计算出的具体输出值。
它并非一个概率,而是模型基于“为了得到 x t x_t xt,当初可能加入了什么噪声”这一问题给出的具体猜测(一个噪声向量/图像)。训练的目标正是使得 ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t) 尽可能接近真实噪声 ϵ \epsilon ϵ。
相关文章:
重生之我是去噪高手——diffusion model
diffusion model是如何运作的? 想象一下,你有一张清晰的图片。扩散模型的核心思想分为两个过程: 前向过程(Forward Process / Diffusion Process):逐步加噪反向过程(Reverse Process / Denois…...

【C#】.net core 6.0 依赖注入常见问题之一,在构造函数使用的类,都需要注入到容器里,否则会提示如下报错,让DeepSeek找找原因,看看效果
🌹欢迎来到《小5讲堂》🌹 🌹这是《C#》系列文章,每篇文章将以博主理解的角度展开讲解。🌹 🌹温馨提示:博主能力有限,理解水平有限,若有不对之处望指正!&#…...
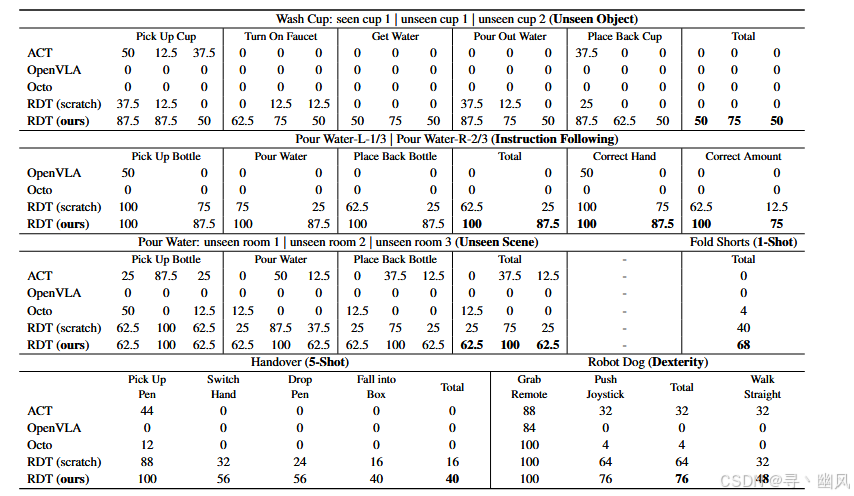
论文阅读笔记——RDT-1B: A DIFFUSION FOUNDATION MODEL FOR BIMANUAL MANIPULATION
RDT-1B 论文 模型表达与泛化能力:由于双臂操作中动作空间维度是单臂空间的两倍,传统方法难以建模其多模态分布。 数据:双臂数据少且不同机器人的物理结构和动作空间差异(如关节数、运动范围)导致数据分布不一致&#x…...
Vue中将pdf文件转为图片
平时开发中,我们经常遇到的场景应该是调用后端接口返回给前端pdf格式的文件流,然后我们可以通过URL.createObjectURL的方式转为object url临时路径然后可以通过window.open的方式来打开一个新的浏览器页签来进行预览,效果如下图: 但有时候这样满足不了的需求,它不想这样预…...

day39——输入操作:多值输入
数组输入: int main() {//***** 1、多值输入(C)/*输入:3 --> 3个值5 4 9*/int n;cin >> n; //输入个数const int MAX_SIZE 0xFFFF;//限定最大个数int a[MAX_SIZE];for (int i 0; i < n; i) {//用 n 作控制输入…...
微软的 Copilot 现在可以浏览网页并为您执行操作
在庆祝其 50 岁生日之际,微软正在向其人工智能驱动的 Copilot 聊天机器人传授一些新技巧。 从 BASIC 到 AI,改变世界的公司:微软 微软表示,Copilot 现在可以在“大多数网站”上采取行动,使其能够预订门票、预订餐厅等…...

elasticsearch 7.17 索引模板
文章目录 概要 概要 模板 import cn.hutool.core.util.ObjectUtil; import cn.hutool.core.util.StrUtil; import cn.introns.framework.es.builder.OperationsBuilder; import java.util.HashMap; import java.util.Map;abstract class AbstractBuilder<T extends Abstrac…...

深入理解Python元组:从基础到高级应用
1. 元组基础认知 1.1 什么是元组 不可变序列:元组(tuple)是Python内置的不可变序列类型异构容器:可以存储不同类型的数据(与列表类似)语法特征:使用圆括号()定义,元素间用逗号分隔 # 基本示例 t1 (1, 2…...
【零基础入门unity游戏开发——动画篇】unity旧动画系统Animation组件的使用
考虑到每个人基础可能不一样,且并不是所有人都有同时做2D、3D开发的需求,所以我把 【零基础入门unity游戏开发】 分为成了C#篇、unity通用篇、unity3D篇、unity2D篇。 【C#篇】:主要讲解C#的基础语法,包括变量、数据类型、运算符、…...

Python+AI提示词用贝叶斯样条回归拟合BSF方法分析樱花花期数据模型构建迹图、森林图可视化
原文链接:https://tecdat.cn/?p41308 在数据科学的领域中,我们常常会遇到需要处理复杂关系的数据。在众多的数据分析方法中,样条拟合是一种非常有效的处理数据非线性关系的手段。本专题合集围绕如何使用PyMC软件,对樱花花期数据进…...

记一个.NET AOT交叉编译时的坑
记一个.NET AOT交叉编译时的坑 背景: 使用.NET9开发的Avalonia项目需要部署到Linux-arm64 踩坑: 根据官方AOT交叉编译文档配置后执行打包 dotnet publish -r linux-arm64提示error : The PrivateSdkAssemblies ItemGroup is required for _ComputeA…...

消息中间件对比与选型指南:Kafka、ActiveMQ、RabbitMQ与RocketMQ
目录 引言 消息中间件的定义与作用 消息中间件在分布式系统中的重要性 对比分析的四种主流消息中间件概述 消息中间件核心特性对比 消息传递模型 Kafka:专注于发布-订阅模型 ActiveMQ:支持点对点和发布-订阅两种模型 RabbitMQ:支持点…...
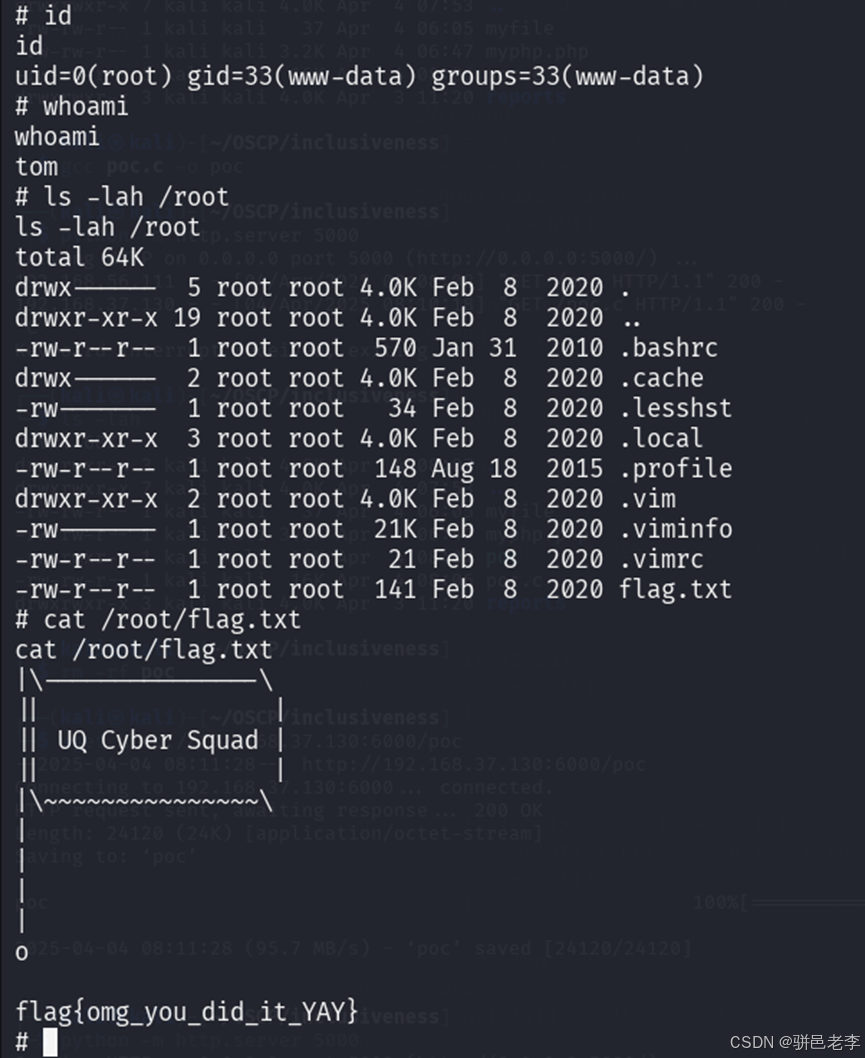
实战打靶集锦-38-inclusiveness
文章目录 1. 主机发现2. 端口扫描&服务枚举3. 服务探查4.系统提权 靶机地址:https://download.vulnhub.com/inclusiveness/Inclusiveness.ova 1. 主机发现 目前只知道目标靶机在192.168.56.xx网段,通过如下的命令,看看这个网段上在线的主…...
)
JVM 学习计划表(2025 版)
JVM 学习计划表(2025 版) 📚 基础阶段(2 周) 1. JVM 核心概念 JVM 作用与体系结构 理解 JVM 在 Java 跨平台运行中的核心作用,掌握类加载子系统、运行时数据区、执行引擎的交互流程内存结构与数据存…...

Unhandled exception: org.apache.poi.openxml4j.exceptions.InvalidFormatException
代码在main方法里面没有报错,在Controller里面就报错了。 原来Controller类里面少了行代码 import org.apache.poi.openxml4j.exceptions.InvalidFormatException; 加上去就解决了。...

Java的Selenium元素定位-xpath
xpath其实就是一个path(路径),一个描述页面元素位置信息的路径,相当于元素的坐标xpath基于XML文档树状结构,是XML路径语言,用来查询xml文档中的节点。 绝对定位 从根开始找--/(根目录)/html/body/div[2]/div/form/div[5]/button缺…...

【QT】Qt5 QtWebEngine使用教程
目录 1、QtWebEngine相比于QtWebKit的优势2、项目配置2.1 确认 Qt 版本2.2 在.pro 文件中添加依赖3、显示网页4、实现Qt和网页JavaScript之间的交互4.1 Qt执行网页的JavaScript代码4.2 JavaScript调用Qt对象的函数QtWebEngine 是 Qt 框架中用于在应用程序中嵌入 Web 内容的模块…...

python基础-13-处理excel电子表格
文章目录 【README】【13】处理Excel电子表格【13.1】Excel文档【13.2】安装openpyxl模块【13.3】读取Excel文档【13.3.1】使用openpyxl模块打开excel文档【13.3.2】从工作簿取得工作表【13.3.3】从工作表sheet获取单元格cell【13.3.5】从表中获取行和列【13.3.6】工作簿、工作…...
03.unity开发资源 获取
03.unity开发资源 获取 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是Python基础语法。前后每一小节的内容是存在的有:学习and理解的关联性,希望对您有用~ unity简介-unity基础 第三节 …...
模板方法模式)
设计模式简述(四)模板方法模式
模板方法模式 描述基本定义使用 描述 当一系列业务的基本流程是相同的,对于不同的业务可以在各自子类实现 所谓模板方法指的就是父类中固定的那部分代码 其实这里的思想和前面设计原则中开闭原则的描述是一致的,父类中的模板代码就是稳定的部分&#x…...

OpenCV界面编程
《OpenCV计算机视觉开发实践:基于Python(人工智能技术丛书)》(朱文伟,李建英)【摘要 书评 试读】- 京东图书 OpenCV的Python开发环境搭建(Windows)-CSDN博客 OpenCV也支持有限的界面编程,主要是针对窗口、控件和鼠标…...

【leetcode】记录与查找:哈希表的题型分析
前言 🌟🌟本期讲解关于力扣的几篇题解的详细介绍~~~ 🌈感兴趣的小伙伴看一看小编主页:GGBondlctrl-CSDN博客 🔥 你的点赞就是小编不断更新的最大动力 🎆那么废话不…...

AntDesign下,Select内嵌Menu标签,做一个多选下拉框,既可以搜索,还可以选择下拉项
话不多说,直接上效果和代码 效果图一: 效果图二: renderAddStyleOption (item: any) > {const { value } this.props;const { currentSelectedOptionIds, currentStyleId } this.state;const styleSettings value?.styleSettings;c…...

css炫酷的3D水波纹文字效果实现详解
炫酷的3D水波纹文字效果实现详解 这里写目录标题 炫酷的3D水波纹文字效果实现详解项目概述技术栈核心实现1. 基础布局2. 渐变背景3. 文字效果实现3.1 基础样式3.2 文字漂浮动画 4. 水波纹效果4.1 模糊效果4.2 水波动画 5. 交互效果 技术要点项目难点与解决方案总结 项目概述 在…...

P1036 [NOIP 2002 普及组] 选数(DFS)
题目描述 已知 n 个整数 x1,x2,⋯,xn,以及 1 个整数 k(k<n)。从 n 个整数中任选 k 个整数相加,可分别得到一系列的和。例如当 n4,k3,4 个整数分别为 3,7,12,19 时,可得全部的组合与它…...

PyTorch中.pth文件的解析及应用
文章目录 一、.pth文件简介二、如何保存.pth文件三、如何加载.pth文件跨硬件加载加载后操作 四、.pth文件的结构与内容解析.pth文件示例 五、.pth文件的优缺点优点缺点 六、常见应用场景七、模型文件体积优化技巧问题背景解决方案效果对比 八、总结九、参考 一、.pth文件简介 …...

【doris】在线事务处理
目录 1. 说明2. 特点3. 应用场景4. 技术实现5. OLTP 与 OLAP 的对比6. 挑战7. 发展趋势 1. 说明 1.OLTP(Online Transaction Processing,在线事务处理) 是一种用于处理大量日常事务操作的数据库系统类型。2.它主要面向实时性要求高、数据操作…...
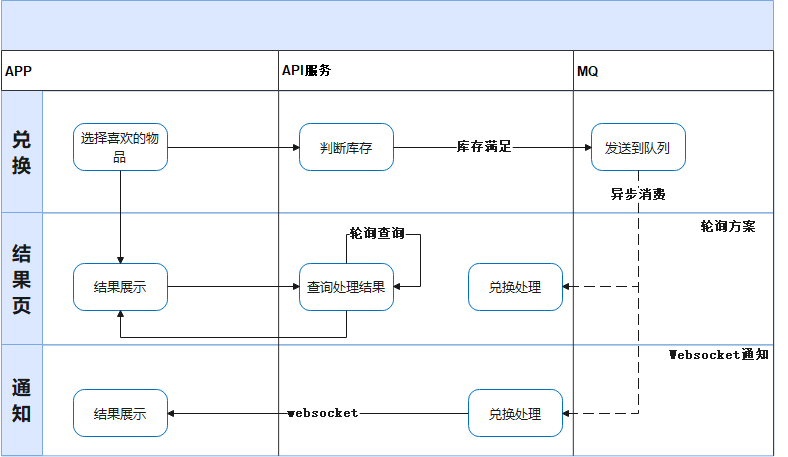
后端思维之高并发处理方案
前言 在互联网时代,高并发已经成为后端开发者绕不开的话题。无论是电商平台的秒杀活动、抢购系统,还是社交应用的高频互动,高并发场景的出现往往伴随着巨大的技术挑战。 如何在流量激增的同时,确保系统稳定运行、快速响应…...
用于执行标量除以矩阵的逐元素操作函数divRC())
OpenCV 图形API(10)用于执行标量除以矩阵的逐元素操作函数divRC()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 描述 标量除以矩阵。 函数 divRC 将给定的标量除以矩阵 src 的每个元素,并将结果保存在与 src 具有相同大小和类型的新的矩阵中: …...

14.2linux中platform无设备树情况下驱动LED灯(详细编写程序)_csdn
我尽量讲的更详细,为了关注我的粉丝!!! 因为这跟之前的不一样,提出来驱动的分离和分层。 提到驱动分离和分层,必然可以联系上一章咱们知道的驱动-总线-设备。 在无设备树的状态下,必然要写寄存…...