【大模型深度学习】如何估算大模型需要的显存
一、模型参数量
参数量的单位
参数量指的是模型中所有权重和偏置的数量总和。在大模型中,参数量的单位通常以“百万”(M)或“亿”(B,也常说十亿)来表示。
百万(M):表示一百万个参数。例如,如果一个模型有110M个参数,那么它实际上有110,000,000(即1.1亿)个参数。
亿(B):表示十亿个参数。例如,GPT-3模型有175B个参数,即175,000,000,000(即1750亿)个参数。
二、内存数据量的单位
在大数据和机器学习的语境下,数据量通常指的是用于训练或测试模型的数据的大小。数据量的单位可以是字节(Byte)、千字节(KB)、兆字节(MB)、吉字节(GB)等。
字节(Byte):是数据存储的基本单位。一个字节由8个比特(bit)组成。
千字节(KB):等于1024个字节。
兆字节(MB):等于1024个千字节,也常用于表示文件或数据的大小。
吉字节(GB):等于1024个兆字节,是较大的数据存储单位。
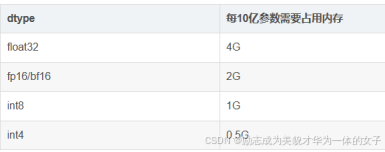
在大模型中,由于模型参数通常是以浮点数(如float32)存储的,因此可以通过模型参数量来计算模型所需的存储空间大小。例如,如果一个模型有1.1亿个参数,并且每个参数用float32表示(即每个参数占4个字节),那么该模型所需的存储空间大约为44MB(1.1亿×4字节/1024/1024)。
bit(比特):bit是二进制数字中的位,是信息量的最小单位。在二进制数系统中,每个0或1就是一个bit。bit是计算机内部数据存储和传输的基本单位。在数据传输过程中,通常以bit为单位来表示数据的传输速率或带宽。
字节(Byte)定义:字节是计算机信息技术用于计量存储容量的一种单位,也表示一些计算机编程语言中的数据类型和语言字符。字节通常由8个bit组成。字节是计算机中数据处理的基本单位。在存储数据时,通常以字节为单位来表示数据的大小或容量。
bit和字节的关系:1字节(Byte)等于8比特(bit)。在计算机科学中,经常需要将数据的大小从字节转换为比特,或者从比特转换为字节。例如,在数据传输过程中,如果知道数据的传输速率是以比特每秒(bps)为单位的,那么可以通过除以8来将其转换为字节每秒(Bps)的单位。

三、模型参数精度
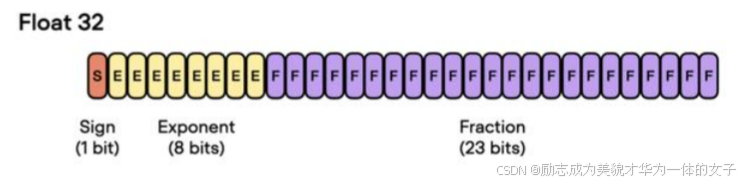
单精度浮点数 (32位) - float32:
含义:单精度浮点数用于表示实数,具有较高的精度,适用于大多数深度学习应用。
字节数:4字节(32位)
半精度浮点数 (16位) - float16:
含义:半精度浮点数用于表示实数,但相对于单精度浮点数,它的位数较少,因此精度稍低。然而,它可以在某些情况下显著减少内存占用并加速计算。
字节数:2字节(16位)
双精度浮点数 (64位) - float64:
含义:双精度浮点数提供更高的精度,适用于需要更高数值精度的应用,但会占用更多的内存。
字节数:8字节(64位)
整数 (通常为32位或64位) - int32, int64:
含义:整数用于表示离散的数值,可以是有符号或无符号的。在某些情况下,例如分类问题中的标签,可以使用整数数据类型来表示类别。
字节数:通常为4字节(32位)或8字节(64位)
int4 (4位整数):
含义:int4使用4位二进制来表示整数。在量化过程中,浮点数参数将被映射到一个有限的范围内的整数,然后使用4位来存储这些整数。
字节数:由于一个字节是8位,具体占用位数而非字节数,通常使用位操作存储。
int8 (8位整数):
含义:int8使用8位二进制来表示整数。在量化过程中,浮点数参数将被映射到一个有限的范围内的整数,然后使用8位来存储这些整数。
字节数:1字节(8位)
量化:在量化过程中,模型参数的值被量化为最接近的可表示整数,这可能会导致一些信息损失。因此,在使用量化技术时,需要平衡压缩效果和模型性能之间的权衡,并根据具体任务的需求来选择合适的量化精度。
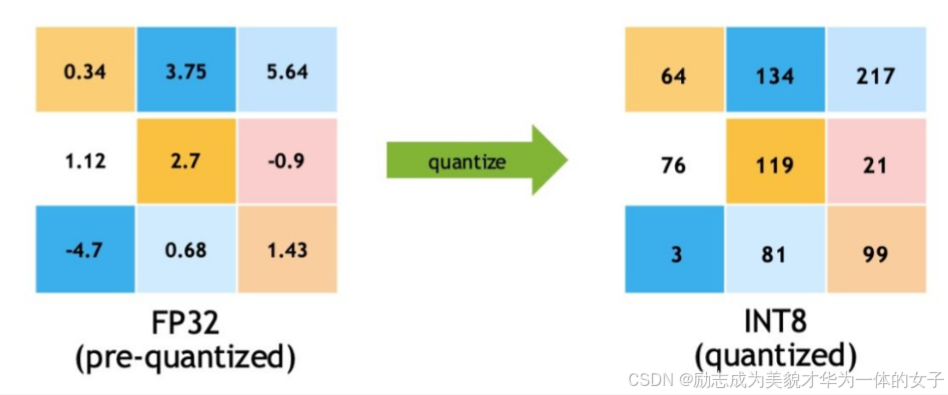
1B int8的存储需要1GB的显存
四、训练显存
模型参数
梯度
存储梯度所需的内存等于参数本身所需的内存。由于每个参数都有相应的梯度,因此它们的内存要求相同。
梯度内存 = 参数内存
优化器
优化器状态是某些优化算法(如 Adam、RMSprop)维护的附加变量,用于提高训练效率。这些状态有助于根据过去的梯度更新模型参数。
不同的优化器维护不同类型的状态。例如:
SGD(随机梯度下降):没有附加状态;仅使用梯度来更新参数。
Adam:为每个参数维护两个状态:一阶矩(梯度平均值)和二阶矩(梯度平方平均值)。这有助于动态调整每个参数的学习率。对于具有 100 万个参数的模型,Adam 需要为每个参数维护 2 个附加值(一阶矩和二阶矩),从而产生 200 万个附加状态。
优化器状态的内存 = 参数数量 x 精度大小 x 优化器乘数
激活
激活指的是什么
前向传递过程中计算得到的,并在后向传递过程中需要用到的所有张量。激活值大小与批次大小和序列长度有关。
输入数据和标签:
训练模型需要将输入数据和相应的标签加载到显存中。这些数据的大小取决于每个批次的样本数量以及每个样本的维度。
中间计算:
在前向传播和反向传播过程中,可能需要存储一些中间计算结果,例如激活函数的输出、损失值等。
临时缓冲区:
在计算过程中,可能需要一些临时缓冲区来存储临时数据,例如中间梯度计算结果等。减少中间变量也可以节省显存,这就体现出函数式编程语言的优势了。
没有固定的公式来计算激活的 GPU 内存。
以llama int 8 7B为例:
-
数据类型:Int8
-
模型参数: 7B * 1 bytes = 7GB
-
梯度:同上7GB
-
优化器参数: AdamW 2倍模型参数 7GB * 2 = 14GB
-
LLaMA的架构(hidden_size= 4096, intermediate_size(前馈网络神经元的个数)=11008, num_hidden_lavers= 32, context.length = 2048),所以每个样本大小:(4096 + 11008) * 2048 * 32 * 1byte = 990MB
-
A100 (80GB RAM)大概可以在int8精度下BatchSize设置为50
-
综上总现存大小:7GB + 7GB + 14GB + 990M * 50/1024 ~= 77GB
五、推理显存
-
模型加载: 计算模型中所有参数的大小,包括权重和偏差。
-
确定输入数据尺寸: 根据模型结构和输入数据大小,计算推理过程中每个中间计算结果的大小。
-
选择批次大小: 考虑批处理大小和数据类型对显存的影响。
大概是1.2倍的模型参数权重。
六、显卡以及zero优化显存
大模型在训练或者微调时需要的显卡个数其实与选择的分布式训练方法和微调方法有关。
比如大概120GB的内存如果单卡训练需要两张A100的显卡。
如果我们采用多卡训练同时运用zero的思想。那么显存变化情况可以参考下图:
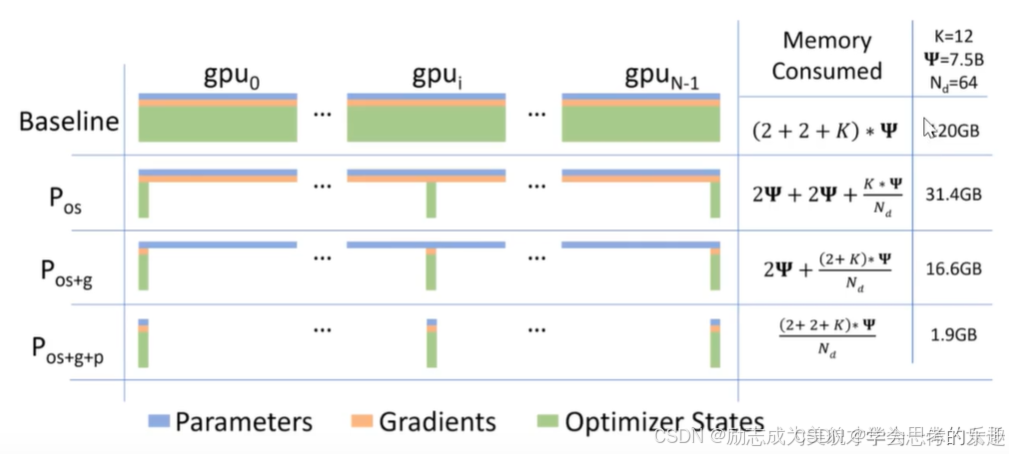
如果采用数据并行。模型并行:如果模型被均匀分割,那么可能需要与模型层数成比例的显卡数量。
参考说明
开源大模型训练及推理所需显卡成本必读:也看大模型参数与显卡大小的大致映射策略_大模型 6b 13b是指什么-CSDN博客
大模型训练时的激活值显存占用 - 知乎
相关文章:
【大模型深度学习】如何估算大模型需要的显存
一、模型参数量 参数量的单位 参数量指的是模型中所有权重和偏置的数量总和。在大模型中,参数量的单位通常以“百万”(M)或“亿”(B,也常说十亿)来表示。 百万(M):表示…...

Mysql 数据库编程技术01
一、数据库基础 1.1 认识数据库 为什么学习数据库 瞬时数据:比如内存中的数据,是不能永久保存的。持久化数据:比如持久化至数据库中或者文档中,能够长久保存。 数据库是“按照数据结构来组织、存储和管理数据的仓库”。是一个长…...

Class<?> 和Class<T >有什么区别
Class<?> 和 Class<T> 在 Java 中都表示 Class 类型的对象,但它们的使用方式和作用略有不同。让我们详细分析它们的区别: 1. Class<?>(通配符 Class 类型) ? 代表一个未知类型(Wildcard…...

[自制调试工具]利用模板函数打造通用调试工具
引言 上一篇文章 我们介绍了调式类工具,这篇文章我们补充一下 点击这里查看 在软件开发的过程中,调试是必不可少的环节。为了能更高效地定位和解决问题,我们常常需要在代码中插入一些调试信息,来输出变量的值、函数的执行状态等。传统的调试…...

Python地理数据处理 28:基于Arcpy批量操作实现——按属性提取和分区统计
Arcpy批量操作 1. 批量按属性提取2. 批量分区统计(最大值、最小值和像元个数等) 1. 批量按属性提取 # -*- coding: cp936 -*- """ PROJECT_NAME: ArcPy FILE_NAME: batch_attribute_extract AUTHOR: JacksonZhao DATE: 2025/04/05 &qu…...

Mysql慢查询设置 和 建立索引
1 .mysql慢查询的设置 slow_query_log ON //或 slow_query_log_file /usr/local/mysql/data/slow.log long_query_time 2 修改后重启动mysql 1.1 查看设置后的参数 mysql> show variables like slow_query%; --------------------------------------------------…...
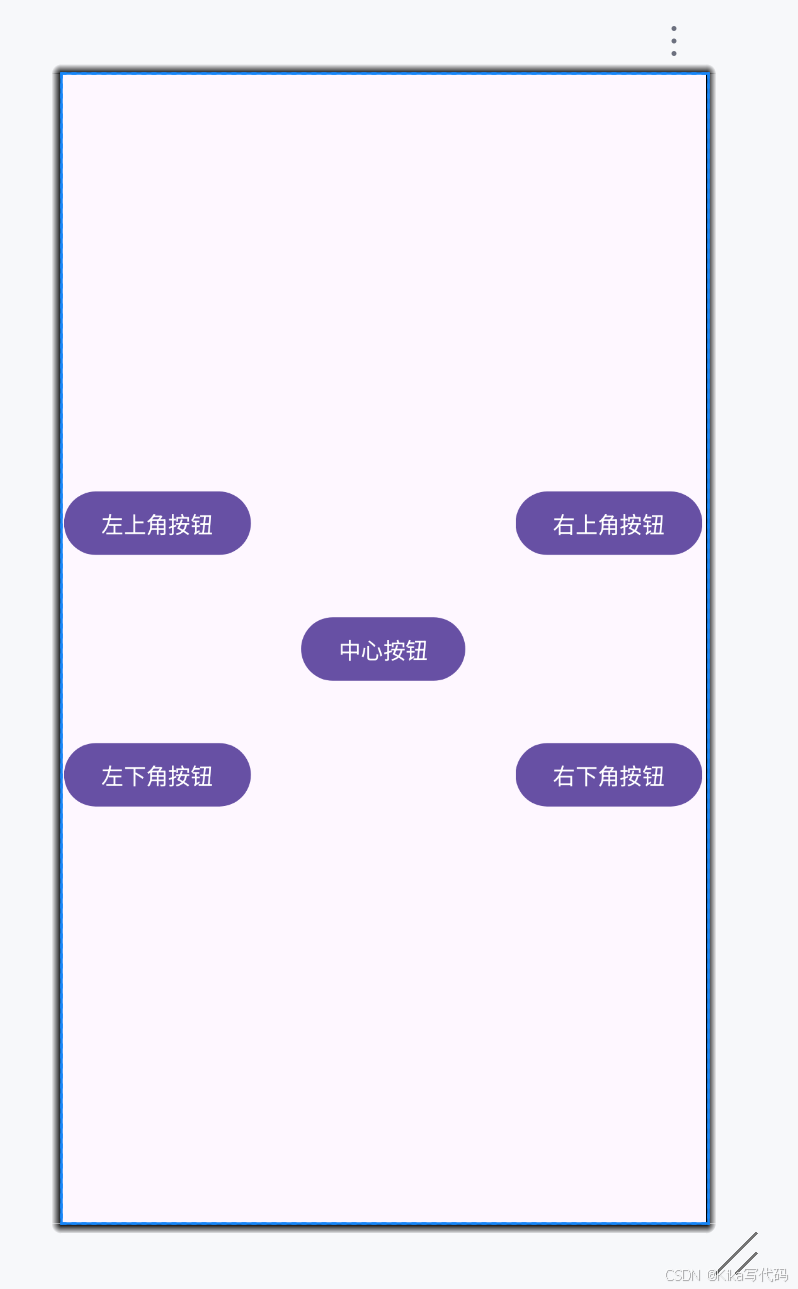
【Android】界面布局-相对布局RelativeLayout-例子
题目 完成下面相对布局,要求: 中间的button在整个屏幕的中央,其他的以它为基准排列。Hints:利用layout_toEndof,_toRightof,_toLeftof,_toStartof完成。 结果演示 代码实现 <?xml version"1.0" encoding"u…...

Spring Boot 中使用 Redis:从入门到实战
🌟 前言 欢迎来到我的技术小宇宙!🌌 这里不仅是我记录技术点滴的后花园,也是我分享学习心得和项目经验的乐园。📚 无论你是技术小白还是资深大牛,这里总有一些内容能触动你的好奇心。🔍 &#x…...

【ROS】 CMakeLists 文件详解
【ROS】 CMakeLists文件详解 前言标准的CMAKELIST.TXT文件的组成部分CMake 版本要求和项目名称指定编译器和设置构建规则查找 ROS 依赖消息和服务文件catkin_package设置头文件目录路径添加可执行文件的构建规则设置编译依赖关系(构建顺序)设置目标文件的…...
——十亿级数据去重与快速检索的终极方案(C++实现))
【每日算法】Day 17-1:位图(Bitmap)——十亿级数据去重与快速检索的终极方案(C++实现)
解锁海量数据处理的极致空间效率!今日深入解析位图的核心原理与实战应用,从基础操作到分块优化,彻底掌握仅用1bit存储一个数据的压缩艺术。 一、位图核心思想 位图(Bitmap) 是一种通过比特位表示数据存在性的数据结构…...
7-1 素数求和(线性筛实现)
7-1 素数求和。 分数 10 中等 全屏浏览 切换布局 作者 魏英 单位 浙江科技大学 输入两个正整数m和n(1<m<n<500)统计并输出m和n之间的素数个数以及这些素数的和。 输入格式: 输入两个正整数m和n(1<m<n<500࿰…...

NLP简介及其发展历史
自然语言处理(Natural Language Processing,简称NLP)是人工智能和计算机科学领域中的一个重要分支,致力于实现人与计算机之间自然、高效的语言交流。本文将介绍NLP的基本概念以及其发展历史。 一、什么是自然语言处理?…...
ZKmall开源商城多云高可用架构方案:AWS/Azure/阿里云全栈实践
随着企业数字化转型的加速,云计算服务已成为IT战略中的核心部分。ZKmall开源商城作为一款高性能的开源商城系统,其在多云环境下的高可用架构方案备受关注。下面将结合AWS、Azure和阿里云三大主流云平台,探讨ZKmall的多云高可用架构全栈实践。…...
)
优化 Web 性能:处理非合成动画(Non-Composited Animations)
在 Web 开发中,动画能够增强用户体验,但低效的动画实现可能导致性能问题。Google 的 Lighthouse 工具在性能审计中特别关注“非合成动画”(Non-Composited Animations),指出这些动画可能增加主线程负担,影响…...

Eliet Chat开发日志:信令服务器注册与通信过程
目录 1. 架构设计:信令服务器与客户端 2. 选择技术栈 3. 实现信令服务器 4. 客户端实现 5. 测试 6. 下一步计划 日期:2025年4月5日 今天的工作重点是实现两个设备通过信令服务器注册并请求对方公网地址信息,以便能够进行点对点通信。我…...
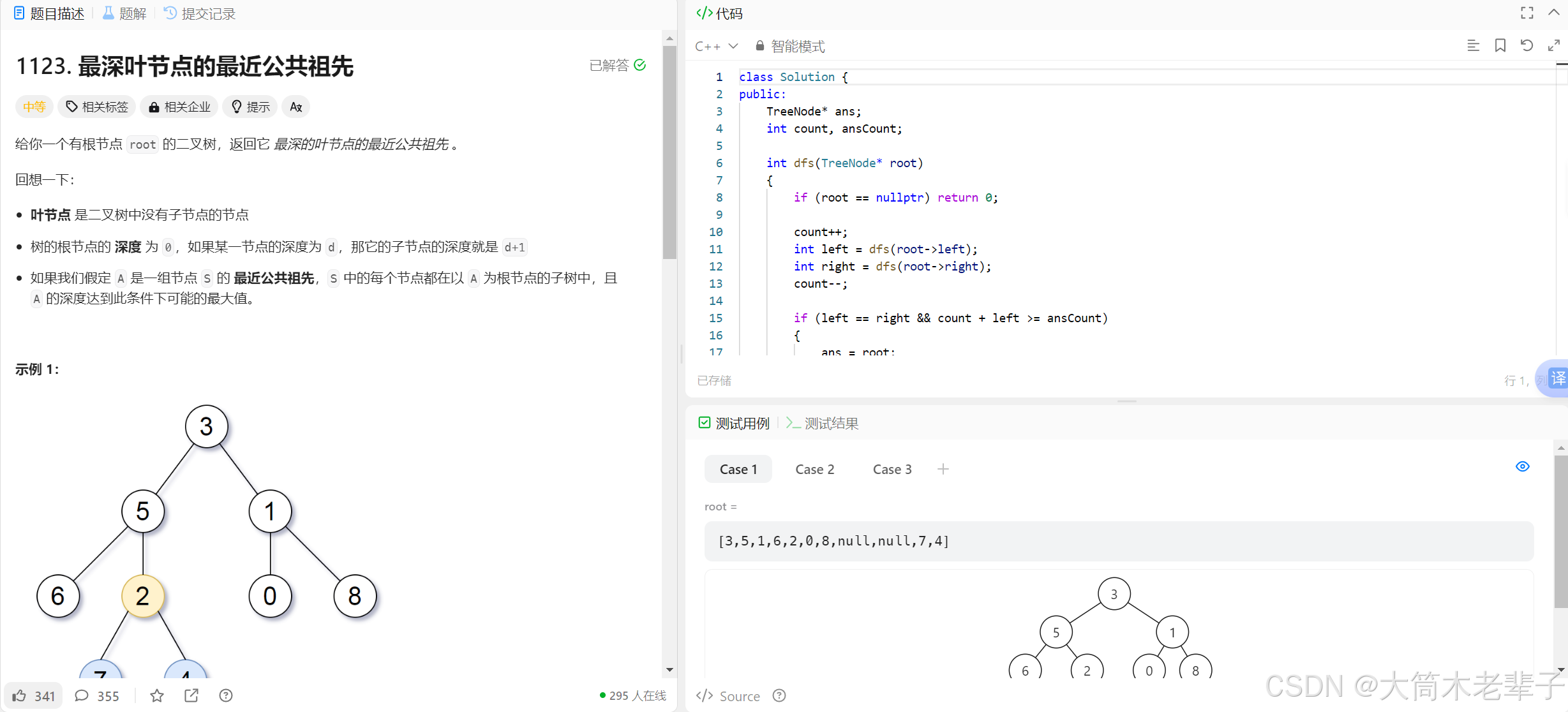
leetcode二叉树刷题调试不方便的解决办法
1. 二叉树不易构建 在leetcode中刷题时,如果没有会员就需要将代码拷贝到本地的编译器进行调试。但是leetcode中有一类题可谓是毒瘤,那就是二叉树的题。 要调试二叉树有关的题需要根据测试用例给出的前序遍历,自己构建一个二叉树,…...

颜色性格测试:探索你的内在性格色彩
颜色性格测试:探索你的内在性格色彩 在我们的日常生活中,颜色无处不在,而我们对颜色的偏好往往能反映出我们内在的性格特质。今天我要分享一个有趣的在线工具 —— 颜色性格测试,它能通过你最喜欢的颜色来分析你的性格倾向。 &…...

hashtable遍历的方法有哪些
在 Java 中,遍历 Hashtable(或其现代替代品 HashMap)有多种方式,以下是 6 种常用方法的详细说明和代码示例: 1. 使用 keySet() 增强 for 循环 Hashtable<String, Integer> table new Hashtable<>(); // …...
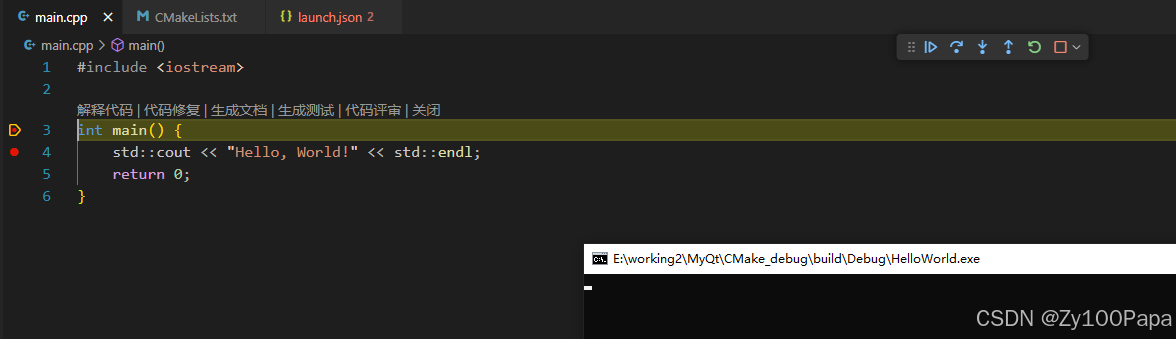
CMake学习--Window下VSCode 中 CMake C++ 代码调试操作方法
目录 一、背景知识二、使用方法(一)安装扩展(二)创建 CMake 项目(三)编写代码(四)配置 CMakeLists.txt(五)生成构建文件(六)开始调试 …...

浅谈ai - Activation Checkpointing - 时间换空间
前言 曾在游戏世界挥洒创意,也曾在前端和后端的浪潮间穿梭,如今,而立的我仰望AI的璀璨星空,心潮澎湃,步履不停!愿你我皆乘风破浪,逐梦星辰! Activation Checkpointing(激…...

提高MCU的效率方法
要提高MCU(微控制器单元)的编程效率,需要从硬件特性、代码优化、算法选择、资源管理等多方面入手。以下是一些关键策略: 1. 硬件相关优化 时钟与频率: 根据需求选择合适的时钟源(内部/外部振荡器),避免过高的时钟频率导致功耗浪费。关闭未使用的外设时钟(如定时器、UA…...

5G从专家到小白
文章目录 第五代移动通信技术(5G)简介应用场景 数据传输率带宽频段频段 VS 带宽中低频(6 GHz以下):覆盖范围广、穿透力强高频(24 GHz以上):满足在热点区域提升容量的需求毫米波热点区…...

神经网络入门:生动解读机器学习的“神经元”
神经网络作为机器学习中的核心算法之一,其灵感来源于生物神经系统。在本文中,我们将带领大家手把手学习神经网络的基本原理、结构和训练过程,并通过详细的 Python 代码实例让理论与实践紧密结合。无论你是编程新手还是机器学习爱好者…...
web漏洞靶场学习分享
靶场:pikachu靶场 pikachu漏洞靶场漏洞类型: Burt Force(暴力破解漏洞)XSS(跨站脚本漏洞)CSRF(跨站请求伪造)SQL-Inject(SQL注入漏洞)RCE(远程命令/代码执行)Files Inclusion(文件包含漏洞)Unsafe file downloads(不安全的文件下载)Unsafe file uploads(不安全的文…...

vue watch和 watchEffect
在 Vue 3 中,watch 和 watchEffect 是两个用于响应式地监听数据变化并执行副作用的 API。它们在功能上有一些相似之处,但用途和行为有所不同。以下是对 watch 和 watchEffect 的详细对比和解释: 1. watch watch 是一个更通用的 API…...

函数和模式化——python
一、模块和包 将一段代码保存为应该扩展名为.py 的文件,该文件就是模块。Python中的模块分为三种,分别为:内置模块、第三方模块和自定义模块。 内置模块和第三方模块又称为库内置模块,有 python 解释器自带,不用单独安…...

Python解决“数字插入”问题
Python解决“数字插入”问题 问题描述测试样例解题思路代码 问题描述 小U手中有两个数字 a 和 b。第一个数字是一个任意的正整数,而第二个数字是一个非负整数。她的任务是将第二个数字 b 插入到第一个数字 a 的某个位置,以形成一个最大的可能数字。 你…...

Go语言的嵌入式网络
Go语言的嵌入式网络 引言 在当今快速发展的互联网时代,嵌入式系统和网络技术的结合变得越来越普遍。嵌入式系统是指嵌入到设备中以实现特定功能的计算机系统,它们通常具有资源有限的特点。随着物联网(IoT)的兴起,嵌入…...

Dart 语法
1. 级联操作符 … var paint Paint()..color Colors.black..strokeCap StrokeCap.round..strokeWidth 5.0;2. firstWhereOrNull 3. 隐藏或导入部分组件 // Import only foo. import package:lib1/lib1.dart show foo;// Import all names EXCEPT foo. import package:lib…...
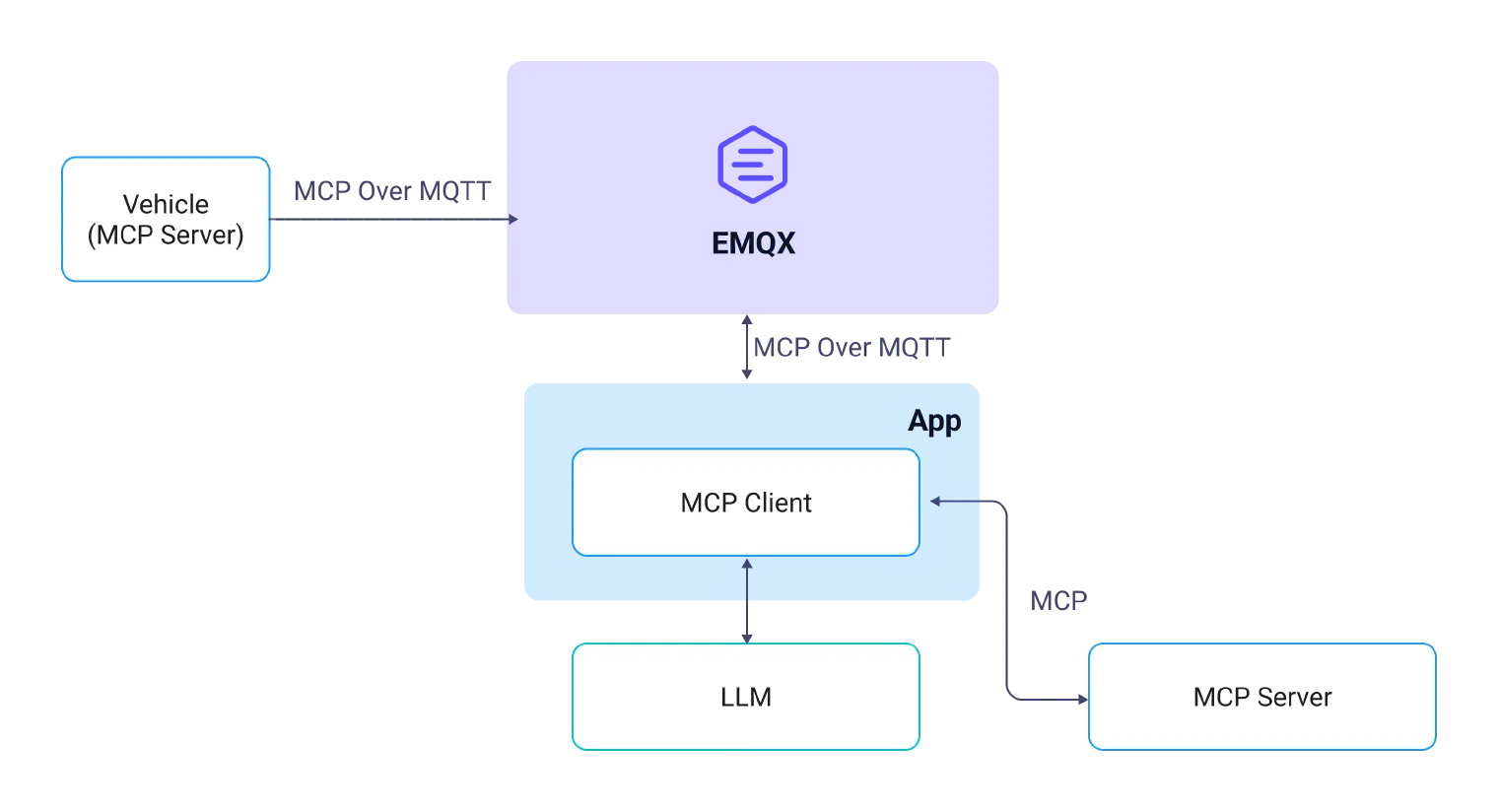
MCP over MQTT:EMQX 开启物联网 Agentic 时代
前言 随着 DeepSeek 等大语言模型(LLM)的广泛应用,如何找到合适的场景,并基于这些大模型构建服务于各行各业的智能体成为关键课题。在社区中,支持智能体开发的基础设施和工具层出不穷,其中,Ant…...