C++多线程编码二
1.lock和try_lock
lock是一个函数模板,可以支持多个锁对象同时锁定同一个,如果其中一个锁对象没有锁住,lock函数会把已经锁定的对象解锁并进入阻塞,直到多个锁锁定一个对象。
try_lock也是一个函数模板,尝试对多个锁对象进行同时尝试锁定,如果锁对象全部锁定,返回-1,如果某一个锁对象尝试锁定是失败,把已经锁定成功的锁对象解锁,并返回这个对象的下标(第一个参数对象,下标从0开始)
代码示例
template<class Mutex1,class Mutex2,class... Mutexes>
void lock(Mutex1& a, Mutex2& b, Mutexes&... cde);template<class Mutex1,class Mutex2,class... Mutexes>
int tyr_lock(Mutex1& a, Mutex2& b, Mutexes&... cde);#include<iostream>
#include<thread>
#include<mutex>
using namespace std;std::mutex foo, bar;void task_a()
{std::lock(foo, bar);std::cout << "task a" << endl;foo.unlock();bar.unlock();
}void task_b()
{std::lock(bar,foo);std::cout << "task b" << std::endl;foo.unlock();bar.unlock();
}int main()
{foo.lock();std::thread t1(task_a);std::thread t2(task_b);std::cout << "xxxxxxxxxxx" << endl;bar.lock();foo.unlock();std::cout << "yyyyyyyyyy" << endl;bar.unlock();t1.join();t2.join();return 0;
}代码解释:
主线程先锁定了foo,然后走两个线程任务,因为foo锁已经被申请了,两个线程就会阻塞在std::lock这里,主线程就会继续执行,锁定bar,然后解锁foo。两个线程可以申请foo锁资源了,但是bar申请不到,所以两个线程还是阻塞住,然后主线程申请bar锁并释放了foo锁,这两个线程还是会阻塞,task_b虽然拿到了bar锁,但是foo锁拿不到就会释放掉bar锁,重新申请这两个锁,所以主线程就能拿到bar锁,打印yyyy,然后释放bar锁,这时候,线程就开始争夺这两个锁资源,进而执行线程任务。
代码二
template<class Mutex1,class Mutex2,class... Mutexes>
void lock(Mutex1& a, Mutex2& b, Mutexes&... cde);template<class Mutex1,class Mutex2,class... Mutexes>
int tyr_lock(Mutex1& a, Mutex2& b, Mutexes&... cde);#include<iostream>
#include<thread>
#include<mutex>
using namespace std;std::mutex foo, bar;void task_a()
{foo.lock();std::cout << "task a\n";bar.lock();foo.unlock();bar.unlock();
}void task_b()
{int x = try_lock(bar, foo);if (x == -1){std::cout << "task b\n";bar.unlock();foo.unlock();}else{std::cout << "task b failed:mutex:" << (x ? "foo" : "bar") << endl;}}int main()
{std::thread t1(task_a);std::thread t2(task_b);t1.join();t2.join();return 0;
}代码解释:
首先线程先执行a任务,先拿foo锁,然后再那bar锁,然后把拿到的锁都释放了,b任务是尝试申请foo和bar锁,如果锁都没拿到就返回-1,存在没申请到的就返回下标。这时就会存在两种结果,如果a任务快的话,把两个锁都拿了,那么任务b执行if,如果a任务拿到锁并释放了,b任务执行else
结果一

结果二

2.call_once函数
多线程执行时,让第一个线程执行任务,其它线程不再执行这个任务。(多线程去争夺唯一机会且只执行一次任务)
template< class Function, class... Args >
void call_once( std::once_flag& flag, Function&& f, Args&&... args );
-
std::once_flag:一个标志,用于记录函数是否已经被调用过。 -
Function:要执行的函数。 -
Args...:传递给函数的参数。
std::once_flag winner_flag;
-
std::once_flag是一个无状态的标志,用于记录std::call_once是否已经被调用。 -
它不需要显式初始化,只需要声明即可。
代码示例
template<class Mutex1,class Mutex2,class... Mutexes>
void lock(Mutex1& a, Mutex2& b, Mutexes&... cde);template<class Mutex1,class Mutex2,class... Mutexes>
int tyr_lock(Mutex1& a, Mutex2& b, Mutexes&... cde);#include<iostream>
#include<thread>
#include<mutex>
#include<chrono>
using namespace std;std::mutex foo, bar;int winner;
void set_winner(int x) { winner = x; }
std::once_flag winner_flag;void wait_time(int id)
{for (int i = 0; i < 1000; i++){std::this_thread::sleep_for(std::chrono::milliseconds(1));}std::call_once(winner_flag, set_winner, id);
}int main()
{std::thread threads[10];for (int i = 0; i < 10; i++){threads[i] =std::thread(wait_time, i + 1);}for (auto& s : threads){s.join();}std::cout << "winner thread:" << winner << endl;return 0;
}代码解释:
主线程创建10个线程,然后都执行一个函数,并设置id号,进入到wait函数都要进行休眠,然后公平竞争唯一机会,休眠结束后,同一执行任务call函数,只有一个线程会进入到set函数,并改变winner_flag标志,使其它线程进不到这个函数,打印id知道哪一个线程执行了这个任务。
3.atomic
atomic是一个模板的实例化和全特化定义的原子类型,保证对一个原子对象的操作是线程安全的。
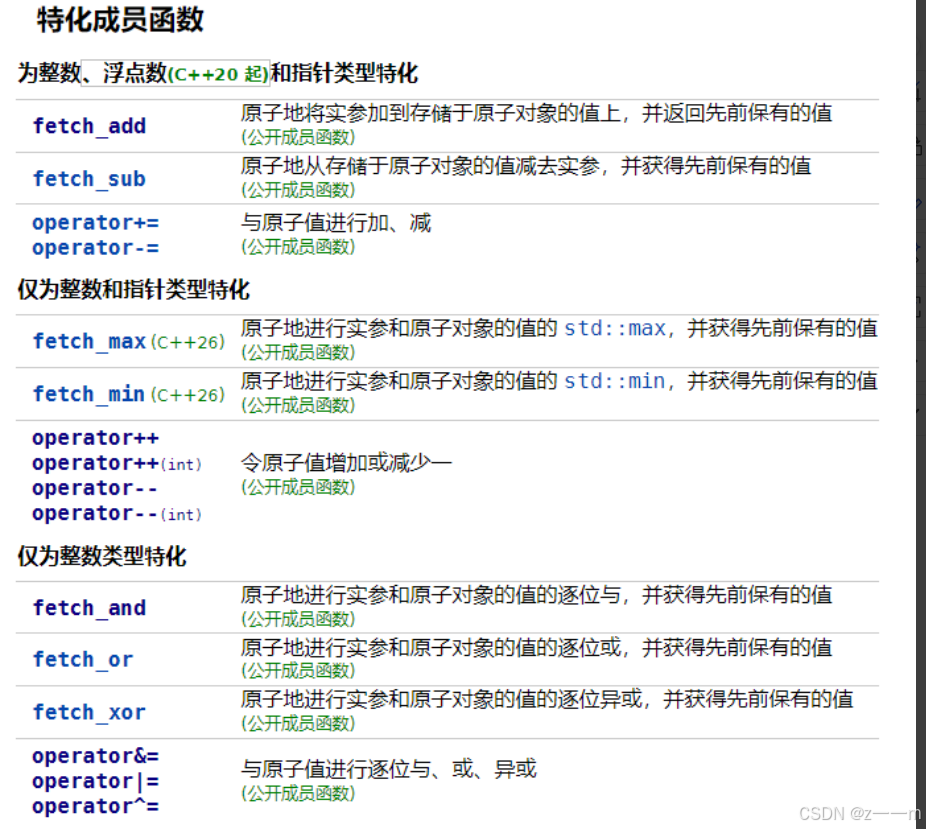
load和store可以原子的读取和修改atomic封装存储的T对象。
atomic的原理主要是硬件层面支持,现代处理器提供了原子指令来支持原子操作。如x86架构,有CMPXCHG(比较并交换)指令。这些原子指令能够在一个不可分割的操作中完成对内存的读取,比较和写入操作,简称CAS,Compare And Set,或是Compare And Swap。另外为了处理多个处理器缓存之间的数据一致性问题,硬件采用了缓存一致性协议,当一个atomic操作修改了一个变量的值,缓存一致性协议会确保其它处理器缓存中相同的变量副本被正确的更新还在标记为无效。
template < class T >bool atomic_compare_exchange_weak (atomic<T>* obj, T* expected, T val)noexcept ;template < class T >bool atomic_compare_exchange_strong (atomic<T>* obj, T* expected, T val)noexcept ;// C++11 中 atomic 类的成员函数bool compare_exchange_weak (T& expected, T val,memory_order sync = memory_order_seq_cst) noexcept ;bool compare_exchange_strong (T& expected, T val,memory_order sync = memory_order_seq_cst) noexcept ;
C++11的CAS操作支持,atomic对象跟expected按位比较相等,则用val更新atomic对象并返回值true,若atomic对象跟expected按位比较不相等,则更新expected为当前的atomic对象并返回false。(就是多个线程进来,每个线程都有一样的初始值,总有先后,先的改了值,回来的修改值但要先比较初始值是否相等,不相等就说明被改了,就要更换初始值,然后再来一次,只有相等才可以修改这个值)
compare_exchange_weak在某些平台上,即使原子变量的值等于expected,也可能"虚假"的返回。这是因为底层硬件和编译器优化导致的。compare_exchange_strong是不会的,但是有代价(硬件的缓存一致性协议EMSI),所以一般是weak,在考虑性能的情况下。安全情况下可以用strong/。
C++11标准库中,std::atomic提供了多种内存顺序(memory_order)选项,用于控制原子操作的内存同步行为。这些顺序选项允许开发者在性能与正确性之间进行权衡,特别是多线程编程中。
1.memory_order_relaxed最宽松的内存顺序,保证原子操作的原子性,不提供任何同步或者顺序约束。适用计数器。
std::atomic< int > x ( 0 );x. store ( 42 , std::memory_order_relaxed); // 仅保证原⼦性
2.memory_order_consume
3.memory_order_acquire保证当前操作之前的所有读写操作(在当前线程中)不会被重排序到当
template<class Mutex1,class Mutex2,class... Mutexes>
void lock(Mutex1& a, Mutex2& b, Mutexes&... cde);template<class Mutex1,class Mutex2,class... Mutexes>
int tyr_lock(Mutex1& a, Mutex2& b, Mutexes&... cde);#include<atomic>
#include<iostream>
#include<thread>
#include<mutex>
#include<chrono>
#include<vector>
using namespace std;std::mutex foo, bar;atomic<int> acnt;int cnt;void Add1(atomic<int>& cnt)
{int old = cnt.load();// 如果cnt的值跟old相等,则将cnt的值设置为old+1,并且返回true,这组操作是原⼦的。// 那么如果在load和compare_exchange_weak操作之间cnt对象被其他线程改了// 则old和cnt不相等,则将old的值改为cnt的值,并且返回false。while (!atomic_compare_exchange_weak(&cnt, &old, old + 1));}
void f()
{for (int i = 0; i < 100000; i++){++acnt;++cnt;}
}
int main()
{std::vector<thread> pool;for (int i = 0; i < 4; i++){pool.emplace_back(f);}for (auto& e : pool){e.join();}std::cout << "原子计数器:" << acnt << endl;cout << "非原子计数器:" << cnt << endl;return 0;
}
代码解释:
std::atomic 是 C++ 标准库中用于实现原子操作的模板类,它可以确保对变量的读写操作是原子性的,从而避免竞态条件(race conditions)。而全局变量cnt就会因为多线程并发导致数据不一致问题,计数不准确。atomic的原子操作就像Add1函数的实现,每次都要与旧值进行比较,只有相等才表示没有其它线程执行,就可以进行修改,而变了就会先修改旧值变为当前值,然后再循环判断是否与旧值相当,相等就可以进行修改了。
注意:这里不能使用push_back():
push_back 的工作原理是:
-
先构造一个临时对象。
-
然后将这个临时对象拷贝或移动到容器中。
但 std::thread 的拷贝构造函数是被删除的(delete),这意味着你不能拷贝一个 std::thread 对象。因此,如果你尝试使用 push_back,编译器会报错,因为 push_back 试图拷贝构造一个 std::thread 对象。
emplace_back 的工作原理是:
-
直接在容器的存储空间中构造对象。
-
避免了不必要的拷贝或移动。
因此,emplace_back 可以直接在 std::vector<std::thread> 中构造 std::thread 对象,而不需要先构造一个临时对象再移动。
在 C++ 中, 平凡可复制类型(Trivially Copyable Type) 是指可以安全地通过逐字节复制(如memcpy或memmove)来进行复制的类型。这种类型的对象在内存中的表示是连续的,并且复制操作不会导致未定义行为。
代码3
template<class Mutex1,class Mutex2,class... Mutexes>
void lock(Mutex1& a, Mutex2& b, Mutexes&... cde);template<class Mutex1,class Mutex2,class... Mutexes>
int tyr_lock(Mutex1& a, Mutex2& b, Mutexes&... cde);#include<atomic>
#include<iostream>
#include<thread>
#include<mutex>
#include<chrono>
#include<vector>
using namespace std;std::mutex foo, bar;atomic<int> acnt;struct Node { int val; Node* next; };std::atomic<Node*> list_head(nullptr);void append(int val, int n)
{for (int i = 0; i < n; i++){Node* oldHead = list_head;Node* newnode = new Node{ val + i,oldHead };while (!list_head.compare_exchange_weak(oldHead, newnode))newnode->next = oldHead;}
}int main()
{std::vector<std::thread> threads;threads.emplace_back(append, 0, 10);threads.emplace_back(append, 10, 10);threads.emplace_back(append, 20, 10);threads.emplace_back(append, 30, 10);threads.emplace_back(append, 40, 10);for (auto& e : threads){e.join();}for (Node* it = list_head; it != nullptr; it = it->next){std::cout << ' ' << it->val;}Node* it;while (it = list_head){list_head = it->next;delete it;}return 0;
}
代码解释:
全局创建原子对象,类型是Node*,头节点为空,append函数用来加入结点,oldHead=头节点,newnode是要链接的新结点,while循环保证原子操作,如果list_head的值与oldHead相等,就会把list_head的值变为newnode值,返回true;如果不相等,就把list_head的值变成oldHead的值,返回false,false取反为true,就会执行循环内容,新结点链接到链表。这样能保证原子性,因为只有头节点的值和oldHead相等,才能保证没有其它线程进入修改值,就可以放心链接。如果修改了,就说明有其它线程进入修改了头节点,而此线程的头节点没更新就会覆盖式插入进去,导致数据丢失了。
代码四
#include<atomic>
#include<iostream>
#include<thread>
#include<mutex>
//#include<chrono>
#include<vector>
using namespace std;template<class T>
struct node
{T data;node* next;node(const T& data):data(data),next(nullptr){}
};namespace lock_free
{template<class T>class stack{public:std::atomic<node<T>*> head = nullptr;void push(const T& data){node<T>* new_node = new node<T>(data);new_node->next = head.load(std::memory_order_relaxed);while (!head.compare_exchange_weak(new_node->next, new_node, std::memory_order_release, memory_order_relaxed));}};
}namespace lock
{template<class T>class stack{public:node<T>* head = nullptr;void push(const T& data){node<T>* new_node = new node<T>(data);new_node->next = head;head = new_node;}};
}int main()
{lock_free::stack<int> s1;lock::stack<int> s2;std::mutex mtx;int n = 1000000;auto lock_free_stack = [&s1, n]() {for (size_t i = 0; i < n; i++){s1.push(i);}};auto lock_stack = [&s2, n, &mtx]() {for (size_t i=0; i < n; i++){std::lock_guard < std::mutex > lock(mtx);s2.push(i);}};size_t begin1 = clock();std::vector<std::thread> threads1;for (size_t i=0; i < 4; i++){threads1.emplace_back(lock_free_stack);}for (auto& e : threads1){e.join();}size_t end1 = clock();std::cout << end1 - begin1 << endl;size_t begin2 = clock();std::vector<std::thread> threads2;for (size_t i = 0; i < 4; i++){threads2.emplace_back(lock_stack);}for (auto& e : threads2){e.join();}size_t end2 = clock();std::cout << end2 - begin2 << std::endl;return 0;
}代码解释:
定义两种原子操作,一个是无锁模式,一个是有锁模式。无锁模式用compare_exchange_weak函数实现,定义原子对象头节点。无锁模式就是正常的插入结点。主函数中,定义了无锁对象和有锁对象,以及一把锁。接着实现了两个lambda分别对应有锁和无锁模式,接着用clock函数来计数时间差,获取消耗时间。
4.自旋锁实现
#include<atomic>
#include<iostream>
#include<thread>
#include<mutex>
//#include<chrono>
#include<vector>
using namespace std;class SpinLock
{
private:std::atomic_flag flag = ATOMIC_FLAG_INIT;
public:void Lock(){// test_and_set将内部值设置为true,并且返回之前的值// 第⼀个进来的线程将值原⼦的设置为true,返回false// 后⾯进来的线程将原⼦的值设置为true,返回true,所以卡在这⾥空转,// 直到第⼀个进去的线程unlock,clear,将值设置为falsewhile (flag.test_and_set());}void unlock(){// clear将值原⼦的设置为falseflag.clear();}
};void worker(SpinLock& lock, int& val)
{lock.Lock();for (int i = 0; i < 1000; i++){val++;}lock.unlock();
}int main()
{SpinLock lock;int val = 0;std::vector<thread> threads;for (int i = 0; i < 4; i++){threads.emplace_back(worker, std::ref(lock), std::ref(val));}for (auto& thread : threads){thread.join();}std::cout << "val:" << val << endl;return 0;
}代码解释:
std::atomic_flag 是 C++ 标准库中的一个类型,它提供了一种轻量级的同步原语,通常用于实现锁或其他同步机制。std::atomic_flag 表示一个原子布尔变量,它可以处于两种状态之一:清零(false)或置一(true)。
自旋锁就是会卡在循环出不来,只有标志位改变了,才能出循环,第一个进入lock执行while就会改变标志位的值为true,只有解锁才能改变标志位的值为false,其它线程就会在while一直空转。
5.condition_variable
condition_variable需要配合互斥锁系列使用,主要提供wait和notify系统接口。
wait需要传递一个unique_lock<mutex>类型的互斥锁,wait会阻塞当前线程直到被notify。在进入阻塞的一瞬间,会解开互斥锁,给其它线程获取锁,访问条件变量。被notify唤醒,会继续获取锁,再继续往下执行。
notify_one会唤醒当前条件变量上等待的其中之一线程,使用时也需要用互斥锁保护,如果没有阻塞等待,就无事发生。notify_all会唤醒当前条件变量上等待的所有线程。
代码示例
#include<atomic>
#include<iostream>
#include<thread>
#include<mutex>
//#include<chrono>
#include<vector>
using namespace std;std::mutex mtx;
std::condition_variable cv;
bool ready = false;void print_id(int id)
{std::unique_lock<std::mutex> lck(mtx);while (!ready)cv.wait(lck);std::cout << "thread" << id << endl;
}void go()
{std::unique_lock<std::mutex> lck(mtx);ready = true;cv.notify_all();
}int main()
{std::thread threads[10];for (int i = 0; i < 10; i++){threads[i] = std::thread(print_id, i);}std::cout << "10 threads ready" << endl;std::this_thread::sleep_for(std::chrono::milliseconds(100));go();for (auto& e : threads){e.join();}return 0;
}
代码解释:
主线程创建的10个线程都会执行print函数,print函数会有wait挂起线程,并释放锁,所以每一个线程都能进来然后别挂起。主线程就延时保证全部线程都进入条件变量,再执行go函数,唤醒所有线程去争夺锁资源。
代码二两个线程交替打印奇数和偶数
#include<atomic>
#include<iostream>
#include<thread>
#include<mutex>
//#include<chrono>
#include<vector>
using namespace std;int main()
{std::mutex mtx;std::condition_variable cv;int n = 100;bool flag = true;std::thread t1([&]() {int i = 0;while (i < n){std::unique_lock<std::mutex> lock(mtx);while (!flag){cv.wait(lock);}cout << i << endl;flag = false;i += 2;cv.notify_one();}});std::thread t2([&]() {int j = 1;while (j < n){std::unique_lock<std::mutex> lock(mtx);while (flag){cv.wait(lock);}cout << j << endl;flag = true;j += 2;cv.notify_one();}});t1.join();t2.join();return 0;
}
代码解释:
两个线程一个打印偶数,一个打印奇数,用flag标志位来控制,开始为true,线程一就不会进入条件变量,而线程二会进入条件变量挂起,等待线程一唤醒,所以无论位置如何,都是线程一先打印,也不会出现一个线程结束唤醒其它线程,然后唤醒的线程没拿到锁,又被结束线程拿到,flag会解决问题。
相关文章:
C++多线程编码二
1.lock和try_lock lock是一个函数模板,可以支持多个锁对象同时锁定同一个,如果其中一个锁对象没有锁住,lock函数会把已经锁定的对象解锁并进入阻塞,直到多个锁锁定一个对象。 try_lock也是一个函数模板,尝试对多个锁…...
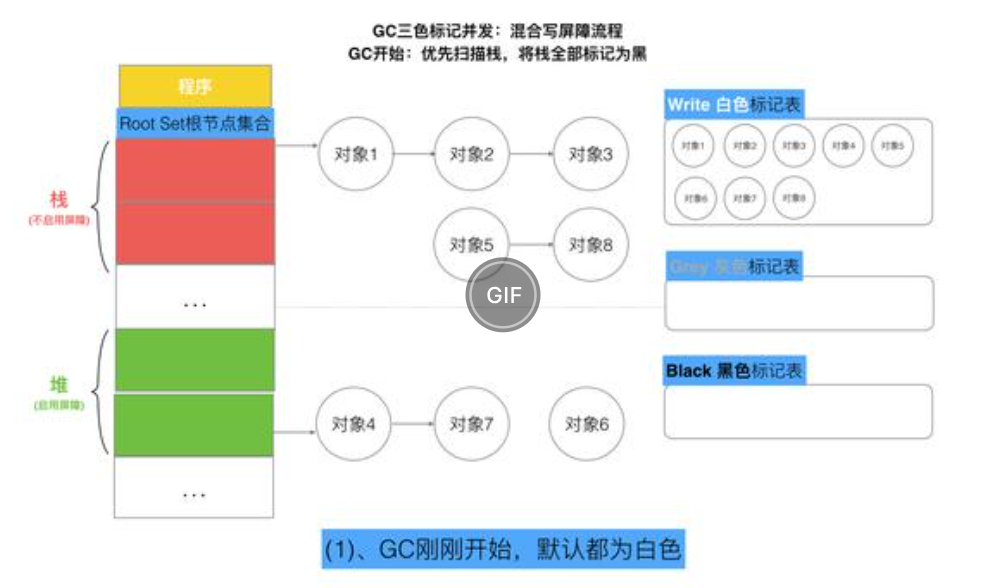
垃圾回收——三色标记法(golang使用)
三色标记法(tricolor mark-and-sweep algorithm)是传统 Mark-Sweep 的一个改进,它是一个并发的 GC 算法,在Golang中被用作垃圾回收的算法,但是也会有一个缺陷,可能程序中的垃圾产生的速度会大于垃圾收集的速度,这样会导…...

Linux学习笔记——零基础详解:什么是Bootloader?U-Boot启动流程全解析!
零基础详解:什么是Bootloader?U-Boot启动流程全解析! 一、什么是Bootloader?📌 举个例子: 二、U-Boot 是什么?三、U-Boot启动过程:分为两个阶段🔹 第一阶段(汇…...

Windows环境下开发pyspark程序
Windows环境下开发pyspark程序 一、环境准备 1.1. Anaconda/Miniconda(Python环境) 如果不怕包的版本管理混乱,可以直接使用已有的Python环境。 需要安装anaconda/miniconda(python3.8版本以上):Anaconda…...
)
thinkphp8.0上传图片到阿里云对象存储(oss)
1、开通oss,并获取accessKeyId、accessKeySecret <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, initial-scale1.0" /><tit…...
SSM婚纱摄影网的设计
🍅点赞收藏关注 → 添加文档最下方联系方式咨询本源代码、数据库🍅 本人在Java毕业设计领域有多年的经验,陆续会更新更多优质的Java实战项目希望你能有所收获,少走一些弯路。🍅关注我不迷路🍅 项目视频 SS…...

1110+款专业网站应用程序UI界面设计矢量图标figma格式素材 Icon System | 1,100+ Icons Easily Customize
1110款专业网站应用程序UI界面设计矢量图标figma格式素材 Icon System | 1,100 Icons Easily Customize 产品特点 — 24 x 24 px 网格大小 — 2px 线条描边 — 所有形状都是基于矢量的 — 平滑和圆角 — 易于更改颜色 类别 🚨 警报和反馈 ⬆️ 箭头 &…...

nacos的地址应该配置在项目的哪个文件中
在 Spring Boot 和 Spring Cloud 的上下文中,Nacos 的地址既可以配置在 bootstrap.yml 中,也可以配置在 application.yml 中,但具体取决于使用场景和需求。以下是两者的区别和最佳实践: 1. bootstrap.yml vs application.yml …...
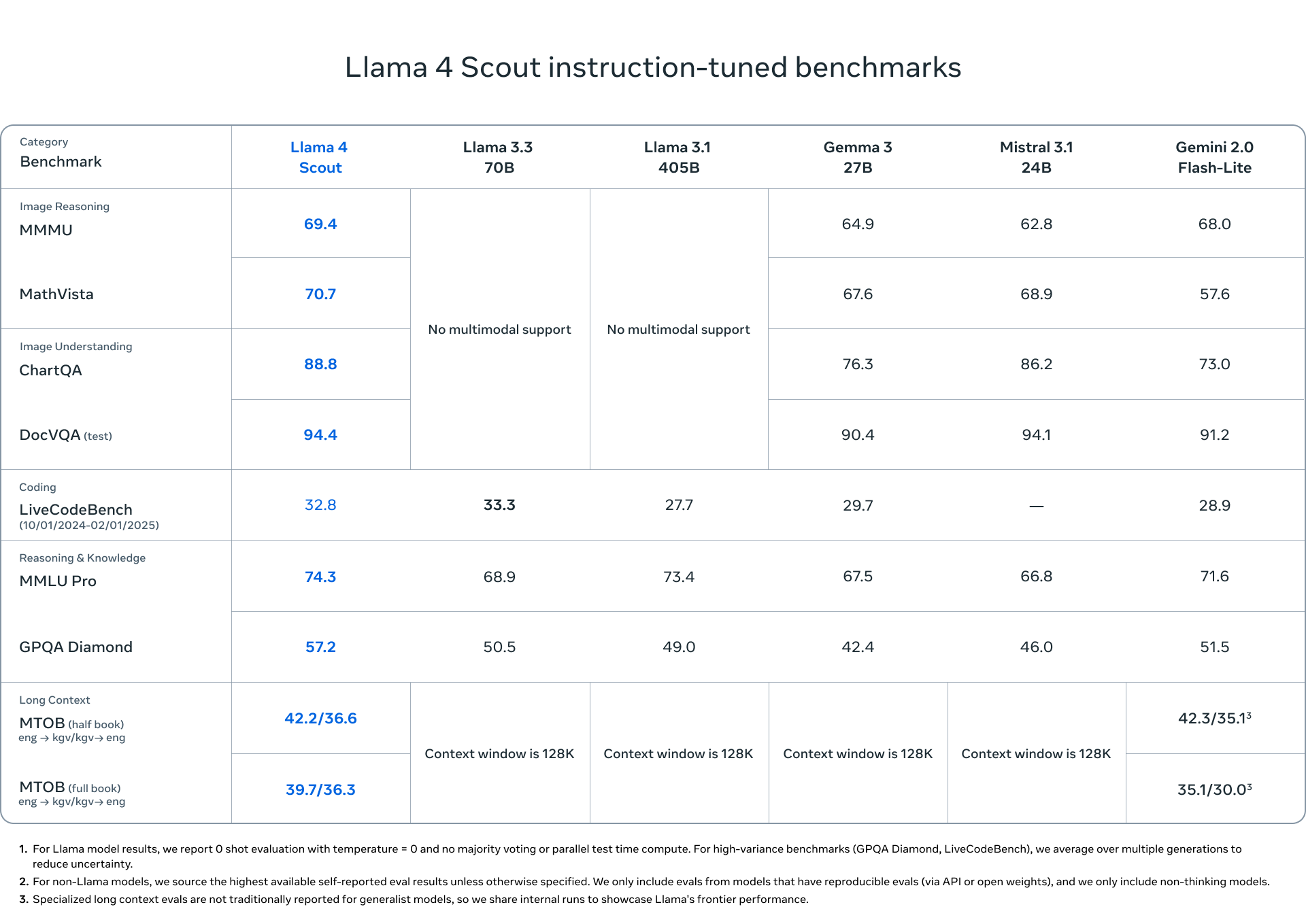
Llama 4 家族:原生多模态 AI 创新的新时代开启
0 要点总结 Meta发布 Llama 4 系列的首批模型,帮用户打造更个性化多模态体验Llama 4 Scout 是有 170 亿激活参数、16 个专家模块的模型,同类中全球最强多模态模型,性能超越以往所有 Llama 系列模型,能在一张 NVIDIA H100 GPU 上运…...

OpenCV 在树莓派上进行实时人脸检测
这段 Python 代码借助 OpenCV 库实现了在树莓派上进行实时人脸检测的功能。它会开启摄像头捕获视频帧,在每一帧里检测人脸并以矩形框标记出来,同时在画面上显示帧率(FPS)。 依赖库 cv2:OpenCV 库,用于计算…...

SMT加工贴片核心工艺解析
内容概要 表面贴装技术(SMT)作为现代电子制造的核心工艺,其加工流程的精细度直接影响产品性能和良率。本文系统性梳理SMT贴片生产的全链条技术节点,以焊膏印刷、元件贴装、回流焊接三大核心工序为轴线,剖析各环节的工…...
)
嵌入式Linux驱动开发基础知识(三)
Linux系统与驱动开发:从字符设备到I2C传感器驱动实战 本文将系统梳理Linux驱动开发的核心知识与实战流程,从基础概念到项目实践,带你完整掌握Linux驱动开发的关键技术。我们将从字符设备驱动框架讲起,深入设备树配置原理…...
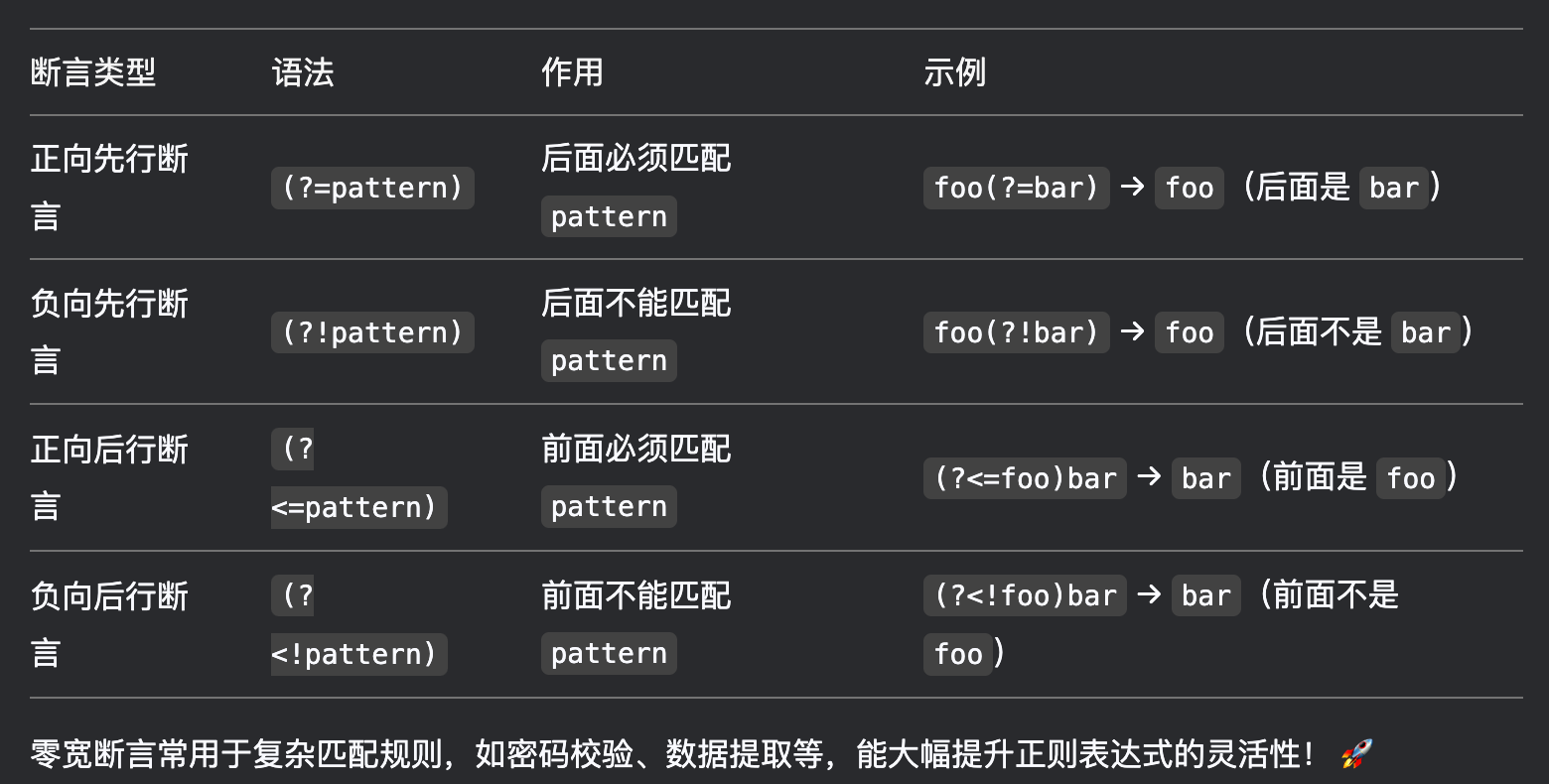
正则表达式(Regular Expression,简称 Regex)
一、5w2h(七问法)分析正则表达式 是的,5W2H 完全可以应用于研究 正则表达式(Regular Expressions)。通过回答 5W2H 的七个问题,我们可以全面理解正则表达式的定义、用途、使用方法、适用场景等,…...

Superset 问题
和nginx结合使用,如果不是配置到根路径,会比较麻烦,我试了很多种方法,也就 这个 靠谱点,不过,我最后还是选择的部署在根路径,先探索一番再说默认不能选择mysql数据库,需要安装mysql客…...

JMeter脚本录制(火狐)
录制前准备: 电脑: 1、将JMeter证书导入,(bin目录下有一个证书,需要安装这个证书到电脑中) 2、按winr,输入certmgr.msc,打开证书,点击下一步,输入JMeter证书…...
基于SpringBoot的“高校社团管理系统”的设计与实现(源码+数据库+文档+PPT)
基于SpringBoot的“高校社团管理系统”的设计与实现(源码数据库文档PPT) 开发语言:Java 数据库:MySQL 技术:SpringBoot 工具:IDEA/Ecilpse、Navicat、Maven 系统展示 总体功能结构图 局部E-R图 系统首页页面 用户…...

Maven/Gradle的讲解
一、为什么需要构建工具? 在理解 Maven/Gradle 之前,先明确它们解决的问题: 依赖管理:项目中可能需要引入第三方库(如 Spring、JUnit 等),手动下载和管理这些库的版本非常麻烦。标准化构建流程:编译代码、运行测试、打包成 JAR/WAR 文件等步骤需要自动…...

C# Winform 入门(3)之尺寸同比例缩放
放大前 放大后 1.定义当前窗体的宽度和高度 private float x;//定义当前窗体的宽度private float y;//定义当前窗台的高度 2.接收当前窗体的尺寸大小 x this.Width;//存储原始宽度ythis.Height;//存储原始高度setTag(this);//为控件设置 Tag 属性 3.声明方法,获…...
infinityfree最新免费建站详细教程_无需备案_5G空间_无限流量_免费域名_免费SSL
一、明确目标—是否要使用 1.为什么选择InfinityFree? 对于初学者、学生或只是想尝试网站搭建的个人用户来说,InfinityFree提供了一个绝佳的免费解决方案。这个国外免费的虚拟主机服务提供: 5GB存储空间 - 足以存放个人博客、作品集或小型…...
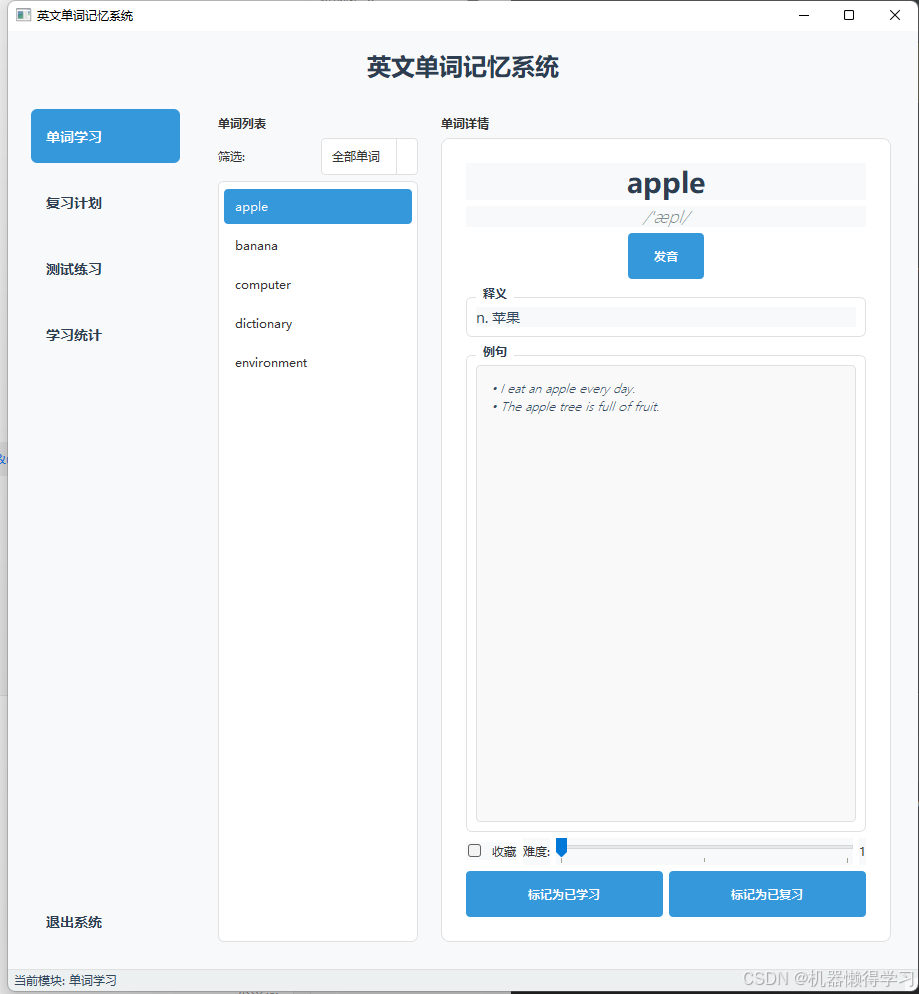
打造高效英文单词记忆系统:基于Python的实现与分析
在当今全球化的世界中,掌握一门外语已成为必不可少的技能。对于许多学习者来说,记忆大量的英文单词是一个漫长而艰难的过程。为了提高学习效率,我们开发了一个基于Python的英文单词记忆系统。这个系统结合了数据管理、复习计划、学习统计和测试练习等多个模块,旨在为用户提…...

node_modules\deasync: Command failed.
运行:“yarn install” 时报错 PS D:\WebPro\hainan-mini-program> yarn install yarn install v1.22.19 [1/4] Resolving packages... [2/4] Fetching packages... [3/4] Linking dependencies... warning " > babel-loader8.2.2" has un…...

session临时文件包含
使用情况 if(isset($_GET[file])){$file $_GET[file];$file str_replace("php", "???", $file);$file str_replace("data", "???", $file);$file str_replace(":", "???", $file);$file str_repla…...

【新能源汽车研发测试数据深度分析:从传感器到智能决策的硬核方法论】
摘要: 本文系统性解构新能源汽车(NEV)研发测试中的数据采集、处理及分析全链条,覆盖传感器融合、大数据清洗、AI算法优化等核心技术,并引入行业顶级案例(如特斯拉Autopilot验证、宁德时代BMS算法迭代&#…...

游戏引擎学习第206天
回顾并为当天的工作定下目标 接着回顾了前一天的进展。之前我们做了一些调试功能,并且已经完成了一些基础的工作,但是还有一些功能需要继续完善。其中一个目标是能够展示实体数据,以便在开发游戏逻辑系统时,可以清晰地查看和检查…...

Zapier MCP:重塑跨应用自动化协作的技术实践
引言:数字化协作的痛点与突破 在当今多工具协同的工作环境中,开发者与办公人员常常面临数据孤岛、重复操作等效率瓶颈。Zapier推出的MCP(Model Context Protocol)协议通过标准化数据交互框架,为跨应用自动化提供了新的…...

ubuntu部署ollama+deepseek+open-webui
ubuntu部署ollamadeepseekopen-webui 全文-ubuntu部署ollamadeepseekopen-webui 大纲 Ollama部署 安装Ollama:使用命令apt install curl和curl -fsSL https://ollama.com/install.sh | sh ollama-v网络访问配置:设置环境变量OLLAMA_HOST0.0.0.0:11434&…...
蓝桥云客--破译密码
5.破译密码【算法赛】 - 蓝桥云课 问题描述 在近期举办的蓝桥杯竞赛中,诞生了一场激动人心的双人破译挑战。比赛的主办方准备了N块神秘的密码芯片,参赛队伍需要在这场智力竞赛中展示团队合作的默契与效率。每个队伍需选出一位破译者与一位传输者&#…...

量子计算与经典计算的拉锯战:一场关于计算未来的辩论
在计算科学领域,一场关于未来的激烈辩论正在上演。2025年3月,D-Wave量子公司的研究人员在《Science》杂志上发表了一项突破性成果,声称他们的量子退火处理器在几分钟内解决了一个经典超级计算机需要数百万年才能完成的复杂现实问题。这一声明…...

Java面试黄金宝典30
1. 请详细列举 30 条常用 SQL 优化方法 定义 SQL 优化是指通过对 SQL 语句、数据库表结构、索引等进行调整和改进,以提高 SQL 查询的执行效率,减少系统资源消耗,提升数据库整体性能的一系列操作。 要点 从索引运用、查询语句结构优化、数据…...

React-Diffing算法和key的作用
1.验证Diffing算法 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title> </he…...