如何理解神经网络中的“分段线性单元”,优雅解析前向和反向传播
什么是非线性
非线性本质上指的是一个系统或函数中输入与输出之间的关系不呈现简单的比例关系,也就是说,输出不只是输入的线性组合 ( 比如 y = k 1 × x 1 + k 2 × x 2 + b ) (比如y=k1×x1+k2×x2+b) (比如y=k1×x1+k2×x2+b)。下面详细解释这个概念:
-
缺乏叠加性
在线性系统中,如果你将两个输入相加,得到的输出必然等于各个输入分别经过系统处理后的输出之和,即满足叠加原理:
f ( x 1 + x 2 ) = f ( x 1 ) + f ( x 2 ) f(x_1 + x_2) = f(x_1) + f(x_2) f(x1+x2)=f(x1)+f(x2)
而在非线性系统中,这个关系不成立,简单地相加输入并不会得到相加后的输出。 -
曲率与拐点
非线性函数通常具有弯曲的形状或拐点,而线性函数仅仅是一条直线。比如,正弦函数 sin ( x ) \sin(x) sin(x) 就是非线性的,因为它既有周期性又有弯曲的形状,其导数(变化率)随着输入的变化而不断改变。 -
模型表达能力
在神经网络中,如果所有的激活函数都是线性的,那么不管网络有多少层,它整体上仍然可以简化为一个线性变换,这样就无法捕捉复杂的模式和关系。引入非线性函数(如 ReLU、sigmoid 或 tanh),可以让网络在层与层之间形成复杂的决策边界(分类任务中区分不同类别的界线),从而更好地拟合实际问题中的非线性关系。
总的来说,“非线性”意味着系统的响应不仅仅是输入的简单放大或缩小,而是会发生弯曲、转折甚至“跳跃”,使得整体行为更加复杂和丰富。
分段线性单元是一种神经网络中常用的激活函数,其在不同区间内表现为线性函数,但整体上可以实现非线性映射。最著名的例子是 ReLU(Rectified Linear Unit),它定义为当输入为正时输出与输入相等,而当输入为负时输出为零。其他类似的激活函数还包括 Leaky ReLU 和 Parametric ReLU,它们在输入为负时也会有小幅输出,而不是完全为零。这种设计不仅计算上简单高效,还能有效缓解梯度消失问题,从而促进深层网络的训练。
尽管分段线性单元在各个区间内都是线性的,但通过在不同区间采用不同的线性斜率,就能组合成一个整体非线性的函数映射。具体原因如下:
-
分段定义带来的非连续变化:虽然每一段都是线性的,但在不同段之间,斜率(或截距)的变化会导致整体函数在转折点处出现变化,这种变化就提供了非线性特性。
-
逼近任意连续函数:理论上,使用足够多的线性片段可以逼近任意的连续函数(类似于分段线性逼近法),这使得神经网络能够用这些单元去学习和表达复杂的非线性关系。
-
计算效率与梯度稳定性:分段线性单元不仅具备非线性特性,同时计算简单,而且在正区间内保持梯度恒定,这有助于缓解梯度消失问题,促进深层网络的训练。
虽然局部上是线性的,但整体上多个不同线性段的组合赋予了它非线性建模的能力,从而使神经网络能够处理复杂的模式识别和特征提取任务。
我们可以以 ReLU 函数作为例子来说明。ReLU(Rectified Linear Unit)的定义是:
- 当输入 x < 0 x < 0 x<0 时,输出为 0 0 0;
- 当输入 x ≥ 0 x \geq 0 x≥0 时,输出等于 x x x。
可以看到,这个函数在 x < 0 x < 0 x<0 和 x ≥ 0 x \geq 0 x≥0两个区间内分别是线性的(分别恒等于常数0和直线 y = x y=x y=x),但整个函数看起来却不是一个简单的直线,而是在 x = 0 x=0 x=0 处出现了“拐角”。这个拐角使得函数具备了非线性特性。还有一个直观的例子是用分段线性函数逼近曲线。假设我们希望用几段直线来近似一个圆弧。每段直线本身是线性的,但是不同直线之间的转折点就能组合成一个接近圆形的曲线,这种方式就是“分段线性逼近”。神经网络正是利用了类似的思想,使用多个分段线性单元来组合出复杂的非线性映射,从而适应各种数据模式。
神经网络
在神经网络中,每个神经元都只负责输入的一小部分"区域"或"贡献",而多个神经元的输出相加后,就能形成一个整体的复杂函数。
举个简单的例子:假设我们要用直线来逼近一条曲线,比如圆弧。单独一条直线显然无法完全贴合圆弧的弯曲,但如果我们用几条不同斜率的直线分别覆盖圆弧的不同部分,再把它们拼接在一起,就能较好地逼近圆弧的形状。这就是"分段线性逼近"的基本思想。
在神经网络中的实现:
单个神经元的作用
每个神经元首先对输入做一个线性变换(比如计算 w × x + b w \times x + b w×x+b),然后经过一个分段线性激活函数(如 ReLU),这时该神经元在不同的输入区间会输出不同的线性结果。例如,当输入小于0时可能输出0,而大于0时输出与输入成正比的值。
多神经元的组合
假设在一个隐藏层中有多个这样的神经元,每个神经元的线性变换和激活函数都有自己的参数(权重和偏置),它们各自在输入空间的不同区域"激活"。最终层会把这些神经元的输出通过加权求和得到最终结果。
- 当输入落在某个特定区域时,只有部分神经元"激活"(即输出不为零),因此输出是这些神经元线性结果的加权和,这一部分的输出仍然是线性的。
- 当输入变化时,不同的神经元可能会开始或停止"激活",从而改变输出的线性组合,这就形成了不同的"段"。
多层网络的效果
如果神经网络有多层,每一层都会对上层输出进行类似的处理。这样,每一层都把输入空间分割成多个线性区域,层层叠加后,整个网络的输出就变成了一个由许多线性片段拼接而成的函数,能够更加精细地逼近各种复杂的非线性函数。
简单来说,每个神经元负责一小段线性关系,而多个神经元按不同条件"开关"起来组合,就能拼凑出一条复杂的曲线。这种分工与组合,使得即便是局部线性的函数,也能整体上表现出非线性、复杂的特性,从而适应各种各样的数据模式。
代码解释
下面提供一个简单的 Python 示例,使用 PyTorch 构建一个小型神经网络来逼近 sin ( x ) \sin(x) sin(x) 函数。尽管每个神经元内部使用的是线性的操作和 ReLU 激活函数,但整体网络却能组合出非线性的效果。
1. 数据准备
-
数据生成
使用np.linspace生成了 100 个点,范围从 − 2 π -2\pi −2π 到 2 π 2\pi 2π 作为输入 x x x 的数据,每个点是一个标量。
对应的目标输出 y y y 为这些点的 sin ( x ) \sin(x) sin(x) 值。 -
张量转换
将 numpy 数组转换成 PyTorch 张量,方便后续训练和计算。
2. 网络结构与前向传播
网络结构
神经网络由两层全连接层(Linear)和一个激活函数 ReLU 组成:
-
第一层(fc1)
计算公式:
z = x × W 1 + b 1 z = x \times W_1 + b_1 z=x×W1+b1
其中:- x x x 为输入张量(形状为 [ N , 1 ] [N, 1] [N,1],N 是样本数量)。
- W 1 W_1 W1 为第一层的权重矩阵(形状为 [ 10 , 1 ] [10, 1] [10,1] 对于隐藏层有 10 个神经元)。
- b 1 b_1 b1 为第一层的偏置(形状为 [ 10 ] [10] [10])。
-
激活函数(ReLU)
ReLU 函数定义为:
ReLU ( z ) = max ( 0 , z ) \text{ReLU}(z) = \max(0, z) ReLU(z)=max(0,z)
这个函数在每个神经元上独立应用:- 对于每个计算得到的 z z z,若 z > 0 z > 0 z>0 则输出 z z z,否则输出 0。
这就是分段线性的体现:在负区间为 0,正区间为线性。
- 对于每个计算得到的 z z z,若 z > 0 z > 0 z>0 则输出 z z z,否则输出 0。
-
第二层(fc2)
将激活函数的输出作为输入,进行另一轮线性变换:
y ^ = ReLU ( z ) × W 2 + b 2 \hat{y} = \text{ReLU}(z) \times W_2 + b_2 y^=ReLU(z)×W2+b2
其中:- W 2 W_2 W2 的形状为 [ 1 , 10 ] [1, 10] [1,10](将 10 维隐藏层输出映射到 1 个输出)。
- b 2 b_2 b2 为输出层的偏置(形状为 [ 1 ] [1] [1])。
前向传播计算过程
-
输入到第一层
对于一个输入样本 x i x_i xi,计算:
z j ( 1 ) = w j ( 1 ) ⋅ x i + b j ( 1 ) ( j = 1 , 2 , … , 10 ) z^{(1)}_j = w^{(1)}_{j} \cdot x_i + b^{(1)}_{j} \quad (j=1,2,\ldots,10) zj(1)=wj(1)⋅xi+bj(1)(j=1,2,…,10)
每个隐藏神经元都计算一个这样的值。 -
ReLU 激活
将 z j ( 1 ) z^{(1)}_j zj(1) 输入到 ReLU 中:
a j ( 1 ) = max ( 0 , z j ( 1 ) ) a^{(1)}_j = \max(0, z^{(1)}_j) aj(1)=max(0,zj(1))
得到激活后的输出 a j ( 1 ) a^{(1)}_j aj(1)。 -
第一层到第二层
使用激活后的输出进行第二次线性变换:
y ^ i = ∑ j = 1 10 w j ( 2 ) a j ( 1 ) + b ( 2 ) \hat{y}_i = \sum_{j=1}^{10} w^{(2)}_{j} \, a^{(1)}_j + b^{(2)} y^i=j=1∑10wj(2)aj(1)+b(2)
得到网络对输入 x i x_i xi 的预测值 y ^ i \hat{y}_i y^i。
3. 训练过程
损失函数计算
- 使用均方误差(MSE)损失函数:
L = 1 N ∑ i = 1 N ( y ^ i − y i ) 2 L = \frac{1}{N} \sum_{i=1}^{N} (\hat{y}_i - y_i)^2 L=N1i=1∑N(y^i−yi)2
其中 y i y_i yi 是真实的 sin ( x i ) \sin(x_i) sin(xi) 值, y ^ i \hat{y}_i y^i 是网络的预测值。
反向传播(Backpropagation)
- 梯度计算
利用链式法则计算每个参数对损失 L L L 的梯度。
举个例子,对第一层权重 w j ( 1 ) w^{(1)}_j wj(1) 的梯度计算过程为:
∂ L ∂ w j ( 1 ) = ∂ L ∂ y ^ i ⋅ ∂ y ^ i ∂ a j ( 1 ) ⋅ ∂ a j ( 1 ) ∂ z j ( 1 ) ⋅ ∂ z j ( 1 ) ∂ w j ( 1 ) \frac{\partial L}{\partial w^{(1)}_j} = \frac{\partial L}{\partial \hat{y}_i} \cdot \frac{\partial \hat{y}_i}{\partial a^{(1)}_j} \cdot \frac{\partial a^{(1)}_j}{\partial z^{(1)}_j} \cdot \frac{\partial z^{(1)}_j}{\partial w^{(1)}_j} ∂wj(1)∂L=∂y^i∂L⋅∂aj(1)∂y^i⋅∂zj(1)∂aj(1)⋅∂wj(1)∂zj(1)
其中:- ∂ a j ( 1 ) ∂ z j ( 1 ) \frac{\partial a^{(1)}_j}{\partial z^{(1)}_j} ∂zj(1)∂aj(1) 是 ReLU 的导数,若 z j ( 1 ) > 0 z^{(1)}_j > 0 zj(1)>0 则为 1,否则为 0。
在神经网络的反向传播过程中,链式法则用于计算损失函数 L L L 对模型参数(如权重和偏置)的梯度。每一项的值是通过以下步骤逐步确定的:
- ∂ a j ( 1 ) ∂ z j ( 1 ) \frac{\partial a^{(1)}_j}{\partial z^{(1)}_j} ∂zj(1)∂aj(1) 是 ReLU 的导数,若 z j ( 1 ) > 0 z^{(1)}_j > 0 zj(1)>0 则为 1,否则为 0。
1. 明确目标:计算 ∂ L ∂ w j ( 1 ) \frac{\partial L}{\partial w^{(1)}_j} ∂wj(1)∂L
我们希望知道损失函数 L L L 对第一层权重 w j ( 1 ) w^{(1)}_j wj(1) 的梯度。根据链式法则,这个梯度可以分解为:
∂ L ∂ w j ( 1 ) = ∂ L ∂ y ^ i ⋅ ∂ y ^ i ∂ a j ( 1 ) ⋅ ∂ a j ( 1 ) ∂ z j ( 1 ) ⋅ ∂ z j ( 1 ) ∂ w j ( 1 ) \frac{\partial L}{\partial w^{(1)}_j} = \frac{\partial L}{\partial \hat{y}_i} \cdot \frac{\partial \hat{y}_i}{\partial a^{(1)}_j} \cdot \frac{\partial a^{(1)}_j}{\partial z^{(1)}_j} \cdot \frac{\partial z^{(1)}_j}{\partial w^{(1)}_j} ∂wj(1)∂L=∂y^i∂L⋅∂aj(1)∂y^i⋅∂zj(1)∂aj(1)⋅∂wj(1)∂zj(1)
接下来,我们逐一分析每一项的具体含义及如何确定其值。
2. 逐项分析
(1) ∂ L ∂ y ^ i \frac{\partial L}{\partial \hat{y}_i} ∂y^i∂L
- 物理意义:这是损失函数 L L L 对预测输出 y ^ i \hat{y}_i y^i 的导数。
- 计算方法:
根据损失函数的形式(例如均方误差 MSE),我们可以直接求导:
L = 1 N ∑ i = 1 N ( y ^ i − y i ) 2 L = \frac{1}{N} \sum_{i=1}^N (\hat{y}_i - y_i)^2 L=N1i=1∑N(y^i−yi)2
对单个样本 i i i 的损失为 ( y ^ i − y i ) 2 (\hat{y}_i - y_i)^2 (y^i−yi)2,对其求导得:
∂ L ∂ y ^ i = 2 ( y ^ i − y i ) \frac{\partial L}{\partial \hat{y}_i} = 2 (\hat{y}_i - y_i) ∂y^i∂L=2(y^i−yi)
(2) ∂ y ^ i ∂ a j ( 1 ) \frac{\partial \hat{y}_i}{\partial a^{(1)}_j} ∂aj(1)∂y^i
- 物理意义:这是预测输出 y ^ i \hat{y}_i y^i 对第一层激活值 a j ( 1 ) a^{(1)}_j aj(1) 的导数。
- 计算方法:
预测输出 y ^ i \hat{y}_i y^i 是第二层的线性变换结果:
y ^ i = ∑ j = 1 10 w j ( 2 ) a j ( 1 ) + b ( 2 ) \hat{y}_i = \sum_{j=1}^{10} w^{(2)}_j a^{(1)}_j + b^{(2)} y^i=j=1∑10wj(2)aj(1)+b(2)
因此,对某个特定的 a j ( 1 ) a^{(1)}_j aj(1) 求导时:
∂ y ^ i ∂ a j ( 1 ) = w j ( 2 ) \frac{\partial \hat{y}_i}{\partial a^{(1)}_j} = w^{(2)}_j ∂aj(1)∂y^i=wj(2)
(3) ∂ a j ( 1 ) ∂ z j ( 1 ) \frac{\partial a^{(1)}_j}{\partial z^{(1)}_j} ∂zj(1)∂aj(1)
- 物理意义:这是第一层激活值 a j ( 1 ) a^{(1)}_j aj(1) 对其输入 z j ( 1 ) z^{(1)}_j zj(1) 的导数。
- 计算方法:
激活函数为 ReLU,定义为:
a j ( 1 ) = ReLU ( z j ( 1 ) ) = max ( 0 , z j ( 1 ) ) a^{(1)}_j = \text{ReLU}(z^{(1)}_j) = \max(0, z^{(1)}_j) aj(1)=ReLU(zj(1))=max(0,zj(1))
其导数为:
∂ a j ( 1 ) ∂ z j ( 1 ) = { 1 if z j ( 1 ) > 0 0 if z j ( 1 ) ≤ 0 \frac{\partial a^{(1)}_j}{\partial z^{(1)}_j} = \begin{cases} 1 & \text{if } z^{(1)}_j > 0 \\ 0 & \text{if } z^{(1)}_j \leq 0 \end{cases} ∂zj(1)∂aj(1)={10if zj(1)>0if zj(1)≤0
(4) ∂ z j ( 1 ) ∂ w j ( 1 ) \frac{\partial z^{(1)}_j}{\partial w^{(1)}_j} ∂wj(1)∂zj(1)
- 物理意义:这是第一层输入 z j ( 1 ) z^{(1)}_j zj(1) 对权重 w j ( 1 ) w^{(1)}_j wj(1) 的导数。
- 计算方法:
第一层的输入 z j ( 1 ) z^{(1)}_j zj(1) 是线性变换的结果:
z j ( 1 ) = w j ( 1 ) x i + b j ( 1 ) z^{(1)}_j = w^{(1)}_j x_i + b^{(1)}_j zj(1)=wj(1)xi+bj(1)
因此,对 w j ( 1 ) w^{(1)}_j wj(1) 求导时:
∂ z j ( 1 ) ∂ w j ( 1 ) = x i \frac{\partial z^{(1)}_j}{\partial w^{(1)}_j} = x_i ∂wj(1)∂zj(1)=xi
3. 总结:每一步的计算依据
- ∂ L ∂ y ^ i \frac{\partial L}{\partial \hat{y}_i} ∂y^i∂L:由损失函数的形式决定,直接对损失函数求导。
- ∂ y ^ i ∂ a j ( 1 ) \frac{\partial \hat{y}_i}{\partial a^{(1)}_j} ∂aj(1)∂y^i:由第二层的线性变换公式决定,等于第二层权重 w j ( 2 ) w^{(2)}_j wj(2)。
- ∂ a j ( 1 ) ∂ z j ( 1 ) \frac{\partial a^{(1)}_j}{\partial z^{(1)}_j} ∂zj(1)∂aj(1):由激活函数的性质决定,ReLU 的导数是一个分段函数。
- ∂ z j ( 1 ) ∂ w j ( 1 ) \frac{\partial z^{(1)}_j}{\partial w^{(1)}_j} ∂wj(1)∂zj(1):由第一层的线性变换公式决定,等于输入 x i x_i xi。
4. 链式法则的整体流程
将上述各项代入链式法则公式:
∂ L ∂ w j ( 1 ) = ∂ L ∂ y ^ i ⏟ 2 ( y ^ i − y i ) ⋅ ∂ y ^ i ∂ a j ( 1 ) ⏟ w j ( 2 ) ⋅ ∂ a j ( 1 ) ∂ z j ( 1 ) ⏟ ReLU 导数 ⋅ ∂ z j ( 1 ) ∂ w j ( 1 ) ⏟ x i \frac{\partial L}{\partial w^{(1)}_j} = \underbrace{\frac{\partial L}{\partial \hat{y}_i}}_{2 (\hat{y}_i - y_i)} \cdot \underbrace{\frac{\partial \hat{y}_i}{\partial a^{(1)}_j}}_{w^{(2)}_j} \cdot \underbrace{\frac{\partial a^{(1)}_j}{\partial z^{(1)}_j}}_{\text{ReLU 导数}} \cdot \underbrace{\frac{\partial z^{(1)}_j}{\partial w^{(1)}_j}}_{x_i} ∂wj(1)∂L=2(y^i−yi) ∂y^i∂L⋅wj(2) ∂aj(1)∂y^i⋅ReLU 导数 ∂zj(1)∂aj(1)⋅xi ∂wj(1)∂zj(1)
最终,每一项的值都可以通过上述分析步骤计算出来,从而得到完整的梯度表达式。
通过明确每个变量之间的数学关系,并结合具体的网络结构和激活函数形式,我们可以系统地确定链式法则中每一项的值。这种方法是反向传播算法的核心思想,也是现代深度学习框架(如 PyTorch、TensorFlow)自动求导的基础。
使用 Adam 优化器,根据计算得到的梯度更新网络的参数,迭代多次以使损失函数减小,从而网络逼近目标函数 sin ( x ) \sin(x) sin(x)。
4. 综合说明
-
分段线性单元的组合
虽然每个 ReLU 激活函数仅在输入为正时是线性、为负时为常数 0,但不同神经元由于拥有不同的权重和偏置,它们的“激活区域”可能不同。
当输入数据变化时,某些神经元可能处于激活状态,而另一些处于关闭状态。多神经元的输出通过加权和相互组合,形成一个整体的复杂非线性函数。
这种层与层之间的“切换”和“拼接”使得网络能够用简单的分段线性函数构造出复杂的映射。 -
实例效果
经过 2000 次迭代训练后,网络的预测值 y ^ \hat{y} y^ 会越来越接近真实的 sin ( x ) \sin(x) sin(x) 曲线。虽然内部计算仅是线性变换与 ReLU 激活,但整体效果却是一个高质量的非线性逼近。
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np# 定义一个简单的神经网络,包含一个隐藏层,激活函数使用 ReLU
class SimpleNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(SimpleNN, self).__init__()self.fc1 = nn.Linear(input_size, hidden_size) # 第一层:线性变换 (输入层 -> 隐藏层)self.relu = nn.ReLU() # ReLU 激活函数self.fc2 = nn.Linear(hidden_size, output_size) # 第二层:线性变换 (隐藏层 -> 输出层)def forward(self, x):out = self.fc1(x) # 通过第一层全连接层out = self.relu(out) # 应用 ReLU 激活函数out = self.fc2(out) # 通过第二层全连接层return out# 生成训练数据:x 的取值范围为 [-2π, 2π],目标是逼近 sin(x)
x_values = np.linspace(-2 * np.pi, 2 * np.pi, 100).reshape(-1, 1).astype(np.float32) # 生成 100 个等间距的点
y_values = np.sin(x_values) # 计算对应的 sin(x) 值# 转换为 PyTorch 张量
x_train = torch.from_numpy(x_values) # 转换为 PyTorch Tensor 以便用于模型训练
y_train = torch.from_numpy(y_values)# 实例化神经网络,设置隐藏层包含 10 个神经元
model = SimpleNN(input_size=1, hidden_size=10, output_size=1)# 定义损失函数(均方误差)和优化器(Adam 优化器)
criterion = nn.MSELoss() # 均方误差(Mean Squared Error)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # Adam 优化器,学习率设为 0.01# 训练神经网络
for epoch in range(2000):model.train() # 设置模型为训练模式optimizer.zero_grad() # 清空之前的梯度,避免梯度累积outputs = model(x_train) # 前向传播,计算模型预测输出loss = criterion(outputs, y_train) # 计算损失(预测值与真实值之间的误差)loss.backward() # 反向传播计算梯度optimizer.step() # 更新模型参数# 每 500 轮输出一次损失值,方便观察训练情况if (epoch + 1) % 500 == 0:print(f'Epoch [{epoch + 1}/2000], Loss: {loss.item():.4f}')# 预测并绘制结果
model.eval() # 设置模型为评估模式,防止影响预测结果
predicted = model(x_train).detach().numpy() # 预测值并转换为 NumPy 数组# 设置 Matplotlib 以支持中文显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体字体,以支持中文
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 绘图展示神经网络拟合结果
plt.figure(figsize=(10, 6)) # 设置图像大小
plt.plot(x_values, y_values, label='真实函数 sin(x)') # 画出真实的 sin(x) 曲线
plt.plot(x_values, predicted, label='神经网络逼近', linestyle='--') # 画出神经网络拟合的曲线
plt.legend() # 显示图例
plt.title("使用 ReLU 激活函数的神经网络逼近 sin(x)") # 设置标题
plt.xlabel("x") # 设置 x 轴标签
plt.ylabel("y") # 设置 y 轴标签
plt.show() # 显示图像
效果
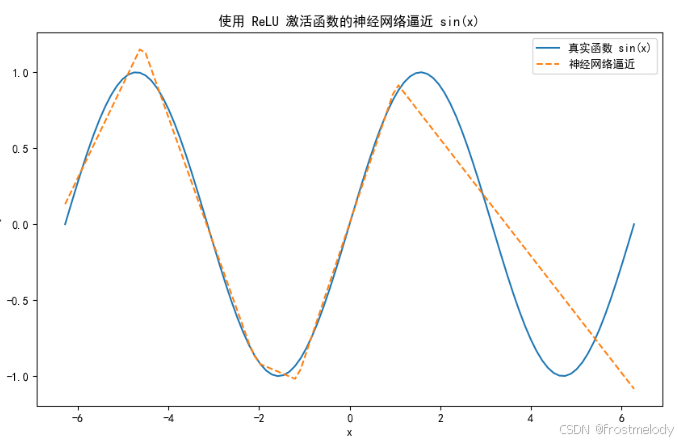
每个隐藏层神经元使用 ReLU 激活后,在不同区域(例如,当输入为正或负时)产生不同的输出。多个神经元的输出经过线性组合后,可以拼凑出一个近似 sin ( x ) \sin(x) sin(x) 的非线性函数。即使每个神经元内部都是"分段线性"的(ReLU 就是在两个区间内分别为0和线性),多个神经元组合在一起却能表现出整体的非线性映射。
更好的代码案例
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec# 定义一个深层神经网络,展示线性组合过程
class DeepApproximator(nn.Module):def __init__(self, input_dim=1, hidden_dim=64, output_dim=1):"""深度神经网络结构演示:- 输入层 -> 隐藏层1 (线性组合) -> ReLU (非线性变换)-> 隐藏层2 (二次线性组合) -> ReLU (非线性变换)-> 输出层 (最终线性组合)通过多层线性变换和非线性激活的组合,可以构造复杂函数"""super().__init__()self.layer1 = nn.Linear(input_dim, hidden_dim) # 第一层线性组合:将输入映射到高维空间self.act1 = nn.ReLU() # 引入非线性因素self.layer2 = nn.Linear(hidden_dim, hidden_dim) # 第二层线性组合:特征再组合self.act2 = nn.ReLU() # 增强非线性表达能力self.output = nn.Linear(hidden_dim, output_dim) # 最终线性组合:映射到输出空间def forward(self, x):# 第一层:输入特征的线性组合 + 非线性激活hidden1 = self.layer1(x) # 公式:W1*x + b1activated1 = self.act1(hidden1) # 非线性变换:max(0, W1*x + b1)# 第二层:特征的二次组合hidden2 = self.layer2(activated1) # 公式:W2*activated1 + b2activated2 = self.act2(hidden2) # 非线性变换:max(0, W2*activated1 + b2)# 输出层:综合所有隐藏特征return self.output(activated2) # 公式:W3*activated2 + b3# 生成更密集的训练数据 (1000个点)
x_np = np.linspace(-2 * np.pi, 2 * np.pi, 1000).reshape(-1, 1).astype(np.float32)
y_np = np.sin(x_np) # 目标函数:y = sin(x)# 转换为PyTorch张量
x_tensor = torch.from_numpy(x_np)
y_tensor = torch.from_numpy(y_np)# 初始化模型和训练参数
model = DeepApproximator(hidden_dim=64) # 使用更大的隐藏层维度
criterion = nn.MSELoss() # 均方误差损失
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 更稳定的学习率
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=100) # 动态调整学习率# 训练循环 (6000次迭代,次数可自由调整)
loss_history = []
for epoch in range(6000):model.train()optimizer.zero_grad()# 前向传播:通过多层线性/非线性组合计算预测值y_pred = model(x_tensor)# 计算损失loss = criterion(y_pred, y_tensor)# 反向传播:自动微分计算梯度loss.backward()# 参数更新:优化器调整权重optimizer.step()scheduler.step(loss)# 记录损失值loss_history.append(loss.item())# 每1000轮打印进度if (epoch + 1) % 1000 == 0:print(f'Epoch {epoch + 1:04d} | Loss: {loss.item():.4e}')# 可视化结果# 设置绘图配置
# 设置Matplotlib全局字体参数(解决中文显示和数学符号问题)# 1. 设置默认无衬线字体(用于中文显示)
# 优先使用Windows系统自带的"微软雅黑"字体
# 该字体同时支持中文和西文字符,确保图表中的中文能正常显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # Sans-serif font for Chinese characters# 2. 数学符号字体配置
# 使用自定义数学字体(而非默认的STIX),以避免与中文冲突
plt.rcParams['mathtext.fontset'] = 'custom' # Use custom math font settings# 3. 分别定义数学符号的三种样式:
# - 常规字体(rm = roman)
plt.rcParams['mathtext.rm'] = 'Microsoft YaHei' # Regular math font
# - 斜体字体(it = italic)
plt.rcParams['mathtext.it'] = 'Microsoft YaHei:italic' # Italic math font
# - 粗体字体(bf = boldface)
plt.rcParams['mathtext.bf'] = 'Microsoft YaHei:bold' # Bold math font# 4. 负号显示修正
# 禁用Unicode的减号(U+2212),使用ASCII短横线(U+002D)替代
# 解决某些字体中负号显示为方框的问题
plt.rcParams['axes.unicode_minus'] = False # Fix minus sign display issuesmodel.eval()
with torch.no_grad():y_pred = model(x_tensor).numpy()# 创建专业级可视化布局
fig = plt.figure(figsize=(12, 8))
gs = GridSpec(2, 1, height_ratios=[2, 1])# 子图1:函数拟合对比
ax1 = fig.add_subplot(gs[0])
ax1.plot(x_np, y_np, label=r'真实函数: $y=\sin(x)$', linewidth=2, alpha=0.8)
ax1.plot(x_np, y_pred, label='神经网络逼近', linestyle='--', linewidth=2)
ax1.set_title('神经网络通过线性组合逼近非线性函数', fontsize=14, pad=20)
ax1.set_xlabel('x', fontsize=12)
ax1.set_ylabel('y', fontsize=12)
ax1.grid(True, linestyle='--', alpha=0.6)
ax1.legend(fontsize=12)# 子图2:训练损失曲线
ax2 = fig.add_subplot(gs[1])
ax2.semilogy(loss_history, color='darkorange')
ax2.set_title('训练损失曲线 (对数坐标)', fontsize=14, pad=15)
ax2.set_xlabel('训练轮次', fontsize=12)
ax2.set_ylabel('损失值', fontsize=12)
ax2.grid(True, linestyle='--', alpha=0.6)plt.tight_layout()
plt.show()
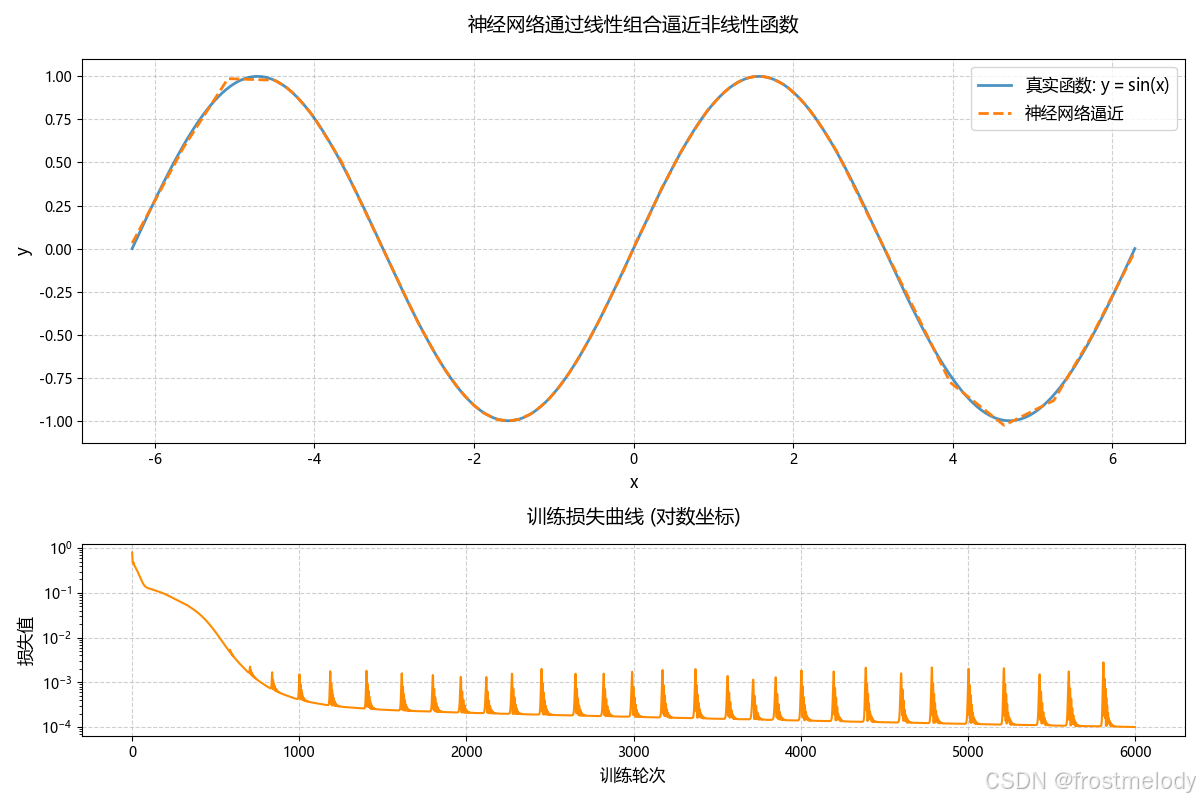
损失曲线的波动
训练损失曲线出现波动而非平滑下降是正常现象,通常由以下原因导致:
1. 优化算法特性
- 随机梯度下降的本质
即使使用Adam优化器,其核心仍基于mini-batch梯度估算。每个batch的数据分布差异会导致瞬时梯度方向波动。不同的数据点样本像不同向导,有的说"往左"有的说"往右",模型需要综合判断,导致路线摇摆。如果曲线完全平滑,反而可能说明模型学得太死板。轻微波动说明模型在积极探索更好的解决方案。延长训练时间,多练习就会越来越流畅。把训练次数从5000次增加到7000,8000次可能后面就不会波动了。
如果出现以下情况才需要调整:损失值突然飙升(像心电图剧烈跳动),波动幅度越来越大(像荡秋千越荡越高),完全停止下降(像卡在半山腰不动)
- 自适应学习率的双刃剑
Adam优化器的动量项(β1=0.9)和一阶矩估计(β2=0.999)会放大梯度噪声,尤其在损失接近最小值时。
2. 数据层面的影响
-
函数逼近的特殊性
在逼近sin(x)这种周期函数时,模型需要在正负区间交替拟合,导致不同区域梯度方向冲突。 -
数据密度与模型容量
虽然使用了1000个数据点,但64维隐藏层的网络对高频振荡函数的逼近仍存在挑战,局部欠拟合会导致误差波动。
3. 学习率动态调整
-
ReduceLROnPlateau的作用机制
当检测到损失停滞时,调度器会降低学习率。学习率的突变会导致优化轨迹的轻微震荡(可通过verbose=True观察实际调整过程)。 -
建议验证方法:
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=100, verbose=True # 显示学习率调整日志 )
4. 数值稳定性问题
-
单精度浮点运算限制
使用float32类型时,当损失值低于约1e-7时,可能会出现数值精度导致的梯度计算噪声。 -
诊断方法:
print(torch.finfo(y_pred.dtype)) # 显示当前精度限制
波动合理性判断
| 波动特征 | 正常现象 | 异常警告 |
|---|---|---|
| 振幅范围 | < 最终损失的10% | > 最终损失的50% |
| 波动频率 | 局部震荡 | 持续大幅波动 |
| 下降趋势 | 整体单调递减 | 损失值反弹上升 |
损失曲线特征(整体下降趋势明显,波动幅度较小),属于典型的健康训练过程。对于函数逼近任务,适度的波动有助于逃离局部极小值。
相关文章:
如何理解神经网络中的“分段线性单元”,优雅解析前向和反向传播
什么是非线性 非线性本质上指的是一个系统或函数中输入与输出之间的关系不呈现简单的比例关系,也就是说,输出不只是输入的线性组合 ( 比如 y k 1 x 1 k 2 x 2 b ) (比如yk1x1k2x2b) (比如yk1x1k2x2b)。下面详细解释这个概念: 缺乏叠加性…...
WVP-GB28181摄像头管理平台存在弱口令
免责声明:本号提供的网络安全信息仅供参考,不构成专业建议。作者不对任何由于使用本文信息而导致的直接或间接损害承担责任。如涉及侵权,请及时与我联系,我将尽快处理并删除相关内容。 漏洞描述 攻击者可利用漏洞获取当前系统管…...

开源身份和访问管理方案之keycloak(三)keycloak健康检查(k8s)
文章目录 开源身份和访问管理方案之keycloak(三)keycloak健康检查启用运行状况检查 健康检查使用Kubernetes下健康检查Dockerfile 中 HEALTHCHECK 指令 健康检查Docker HEALTHCHECK 和 Kubernetes 探针 开源身份和访问管理方案之keycloak(三&…...
 | 零基础入门STM32第九十四步)
STM32看门狗原理与应用详解:独立看门狗 vs 窗口看门狗(上) | 零基础入门STM32第九十四步
主题内容教学目的/扩展视频看门狗什么是看门狗,原理分析,启动喂狗方法,读标志位。熟悉在程序里用看门狗。 师从洋桃电子,杜洋老师 📑文章目录 一、看门狗核心原理1.1 工作原理图解1.2 经典水桶比喻 二、STM32看门狗双雄…...
Android学习总结之service篇
引言 在 Android 开发里,Service 与 IntentService 是非常关键的组件,它们能够让应用在后台开展长时间运行的操作。不过,很多开发者仅仅停留在使用这两个组件的层面,对其内部的源码实现了解甚少。本文将深入剖析 Service 和 Inte…...

网络安全的挑战与防护策略
随着互联网的高速发展,人们的生活、学习和工作已离不开网络。然而,便利的背后也潜藏着巨大的安全隐患。从数据泄露、账户被盗,到网络攻击、系统瘫痪,网络安全问题层出不穷,影响范围从个人用户到国家机构。 网络安全&a…...

spring mvc异步请求 sse 大文件下载 断点续传下载Range
学习连接 异步Servlet3.0 Spring Boot 处理异步请求(DeferredResult 基础案例、DeferredResult 超时案例、DeferredResult 扩展案例、DeferredResult 方法汇总) spring.io mvc Asynchronous Requests 官网文档 spring.io webflux&webclient官网文…...

Opencv计算机视觉编程攻略-第十节 估算图像之间的投影关系
目录 1. 计算图像对的基础矩阵 2. 用RANSAC 算法匹配图像 3. 计算两幅图像之间的单应矩阵 4. 检测图像中的平面目标 图像通常是由数码相机拍摄的,它通过透镜投射光线成像,是三维场景在二维平面上的投影,这表明场景和它的图像之间以及同一…...

14.流程自动化工具:n8n和家庭自动化工具:node-red
n8n 安装 docker方式 https://docs.n8n.io/hosting/installation/docker/ #https://hub.docker.com/r/n8nio/n8n docker pull n8nio/n8n:latest docker rm -f n8n; docker run -it \ --network macvlan --hostname n8n \ -e TZ"Asia/Shanghai" \ -e GENERIC_TIME…...

图形渲染: tinyrenderer 实现笔记(Lesson 1 - 4)
目录 项目介绍环境搭建Lesson 1: Bresenham’s Line Drawing Algorithm(画线算法)Lesson 2: Triangle rasterization 三角形光栅化Scanline rendering 线性扫描Modern rasterization approach 现代栅格化方法back-face culling 背面剔除 Lesson 3: Hidde…...

大规模硬件仿真系统的编译挑战
引言: 随着集成电路设计复杂度的不断提升,硬件仿真系统在现代芯片设计流程中扮演着越来越重要的角色。基于FPGA(现场可编程门阵列)的商用硬件仿真系统因其灵活性、全自动化、高性能和可重构性,成为验证大规模集成电路设…...

Kotlin问题汇总
Kotlin问题汇总 真机安装调试 查看真机的Android版本,将build.gradle文件中的minSdk改为手机的Android版本,点Sync Now更新设置 apk安装失败 在gradle.properties全局配置中设置android.injected.testOnlyfalse Unresolved reference: 在activity_…...

记一次常规的网络安全渗透测试
目录: 前言 互联网突破 第一层内网 第二层内网 总结 前言 上个月根据领导安排,需要到本市一家电视台进行网络安全评估测试。通过对内外网进行渗透测试,网络和安全设备的使用和部署情况,以及网络安全规章流程出具安全评估报告。本…...
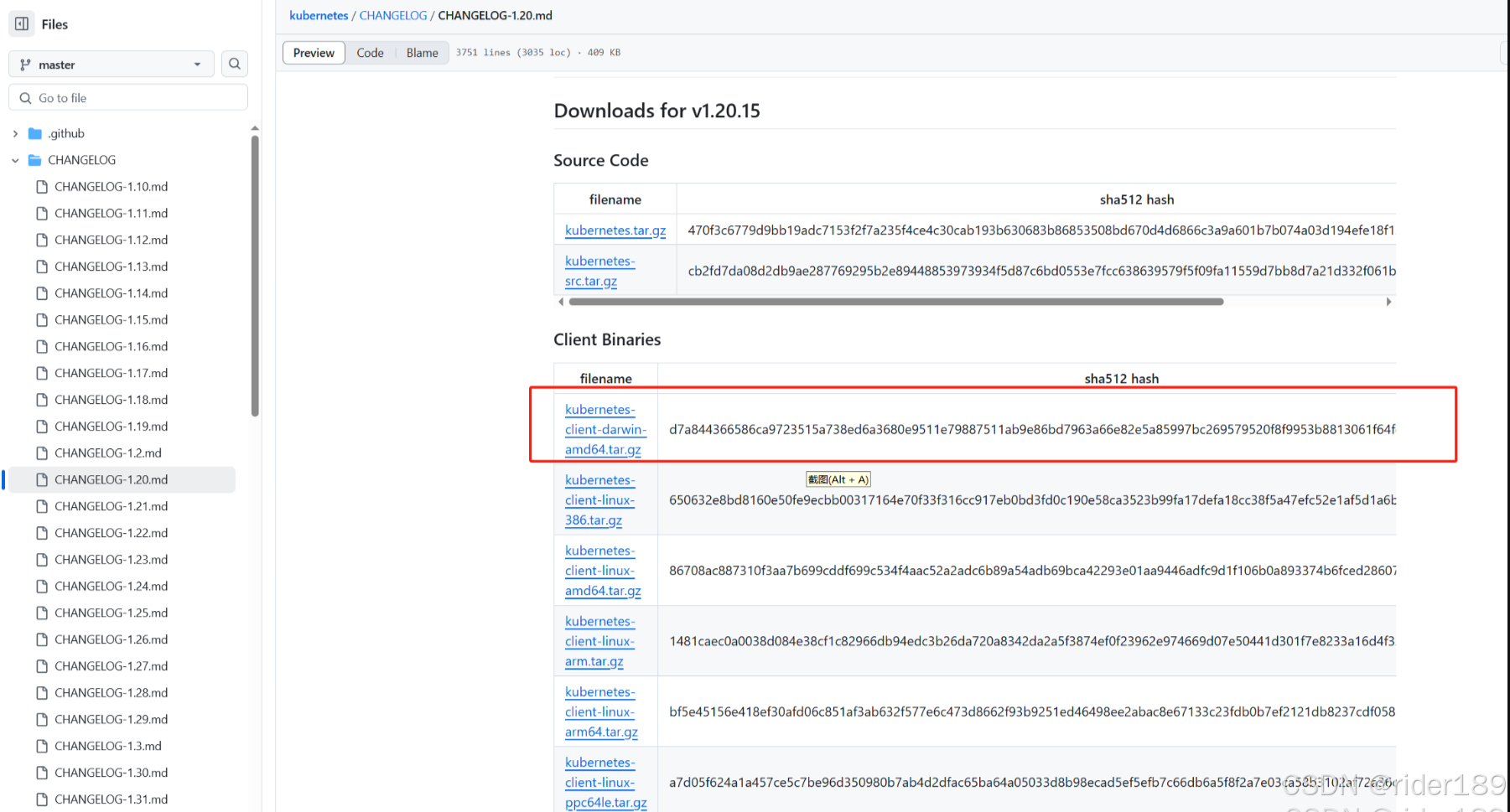
【8】搭建k8s集群系列(二进制部署)之安装work-node节点组件(kubelet)
一、下载k8s二进制文件 下载地址: https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG -1.20.md 注:打开链接你会发现里面有很多包,下载一个 server 包就够了,包含了 Master 和 Worker Node 二进制文件。…...

Sentinel-自定义资源实现流控和异常处理
目录 使用SphU的API实现自定义资源 BlockException 使用SentinelResource注解定义资源 SentinelResourceAspect 使用Sentinel实现限流降级等效果通常需要先把需要保护的资源定义好,之后再基于定义好的资源为其配置限流降级等规则。 Sentinel对于主流框架&#…...

使用 VIM 编辑器对文件进行编辑
一、VIM 的两种状态 VIM(vimsual)是 Linux/UNIX 系列 OS 中通用的全屏编辑器。vim 分为两种状态,即命令状态和编辑状态,在命令状态下,所键入的字符系统均作命令来处理;而编辑状态则是用来编辑文本资料&…...
visual studio 2022的windows驱动开发
在visual studio2022中,若在单个组件中找不到Windows Driver Kit (WDK)选项,可通过提升vs版本解决,在首次选择时选择WDM 创建好项目在Source Files文件夹中创建一个test.c文件,并输入以下测试代码: #include <ntdd…...

基于大数据的美团外卖数据可视化分析系统
【大数据】基于大数据的美团外卖数据可视化分析系统 (完整系统源码开发笔记详细部署教程)✅ 目录 一、项目简介二、项目界面展示三、项目视频展示 一、项目简介 该系统通过对海量外卖数据的深度挖掘与分析,能够为美团外卖平台提供运营决策支…...

C/C++测试框架googletest使用示例
文章目录 文档编译安装示例参考文章 文档 https://github.com/google/googletest https://google.github.io/googletest/ 编译安装 googletest是cmake项目,可以用cmake指令编译 cmake -B build && cmake --build build将编译产物lib和include 两个文件夹…...

vue2打包部署到nginx,解决路由history模式下页面空白问题
项目使用的是vue2,脚手架vue-cli 4。 需求:之前项目路由使用的是hash,现在要求调整为history模式,但是整个过程非常坎坷,遇到了页面空白问题。现在就具体讲一下这个问题。 首先,直接讲路由模式由hash改为…...

如何将本地项目上传到Gitee的指定分支
在团队协作开发中,我们经常需要将本地项目代码上传到代码托管平台(如Gitee)的特定分支。本文将详细介绍从零开始完成这一过程的完整步骤,包含多种场景的解决方案和常见问题处理。 一、准备工作 1.1 安装Git 确保你的系统已安装…...

【数据结构】排序算法(中篇)·处理大数据的精妙
前引:在进入本篇文章之前,我们经常在使用某个应用时,会出现【商品名称、最受欢迎、购买量】等等这些榜单,这里面就运用了我们的排序算法,作为刚学习数据结构的初学者,小编为各位完善了以下几种排序算法&…...

AI随身翻译设备:从翻译工具到智能生活伴侣
文章目录 AI随身翻译设备的核心功能1. 实时翻译2. 翻译策略3. 翻译流程4. 输出格式 二、AI随身翻译设备的扩展功能1. 语言学习助手2. 旅行助手3. 商务助手4. 教育助手5. 健康助手6. 社交助手7. 技术助手8. 生活助手9. 娱乐助手10. 应急助手 三、总结四、未来发展趋势࿰…...
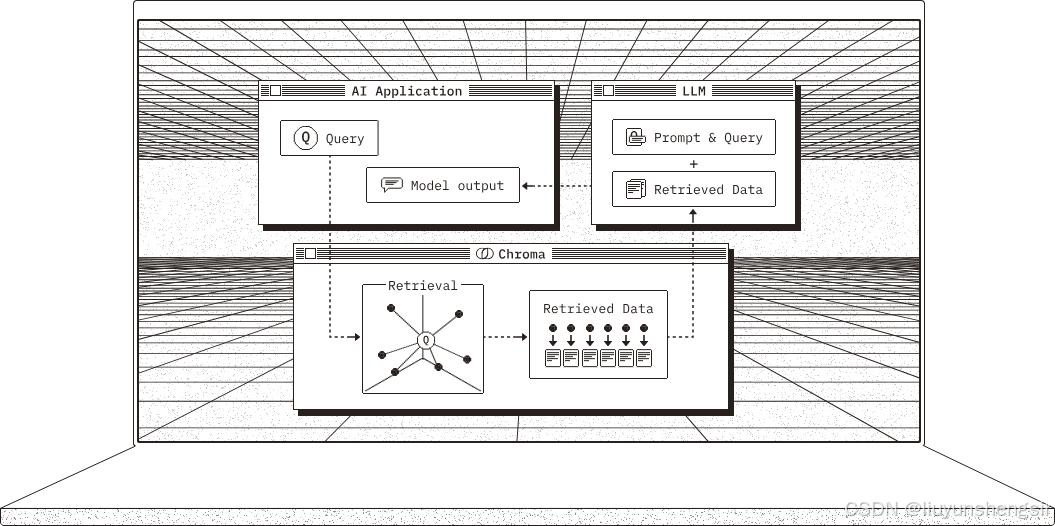
chromadb 安装和使用
简介 Chromadb 是一个开源的嵌入式向量数据库,专为现代人工智能和机器学习应用设计,旨在高效存储、检索和管理向量数据。以下是关于它的详细介绍: 核心特性 易于使用:提供了简洁直观的 API,即使是新手也能快速上手…...

【全球首发】DeepSeek谷歌版1.1.5 - 免费GPT-4级别AI工具
【全球首发】DeepSeek谷歌版1.1.5 - 免费GPT-4级别AI工具 资源简介 DeepSeek谷歌版1.1.5是目前全球领先的免费AI助手,性能超越国内主流AI产品,提供类似GPT-4的智能体验。 版本信息 最新版本:1.1.5(2024最新版)应用…...

LeetCode第132题_分割回文串II
LeetCode 第132题:分割回文串 II 题目描述 给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是回文。 返回符合要求的 最少分割次数 。 难度 困难 题目链接 点击在LeetCode中查看题目 示例 示例 1: 输入…...
LabVIEW 在故障诊断中的算法
在故障诊断领域,LabVIEW 凭借其强大的图形化编程能力、丰富多样的工具包以及卓越的功能性能,成为工程师们进行故障诊断系统开发的得力助手。通过运用各种算法,能够对采集到的信号进行全面、深入的分析处理,从而准确地诊断出系统中…...

SQL DB 数据类型
SQL DB 数据类型 引言 在数据库管理系统中,数据类型是定义和存储数据的方式。SQL(结构化查询语言)数据库中的数据类型决定了数据的存储格式、大小、取值范围以及如何处理数据。合理选择和使用数据类型对于确保数据库性能、数据完整性和应用程序的准确性至关重要。 SQL 数…...

Qt音频输出:QAudioOutput详解与示例
1. 简介 QAudioOutput是Qt多媒体框架中的一个关键类,它提供了将PCM(脉冲编码调制)原始音频数据发送到音频输出设备的接口。作为Qt多媒体组件的一部分,QAudioOutput允许开发者在应用程序中实现音频播放功能,支持多种音…...
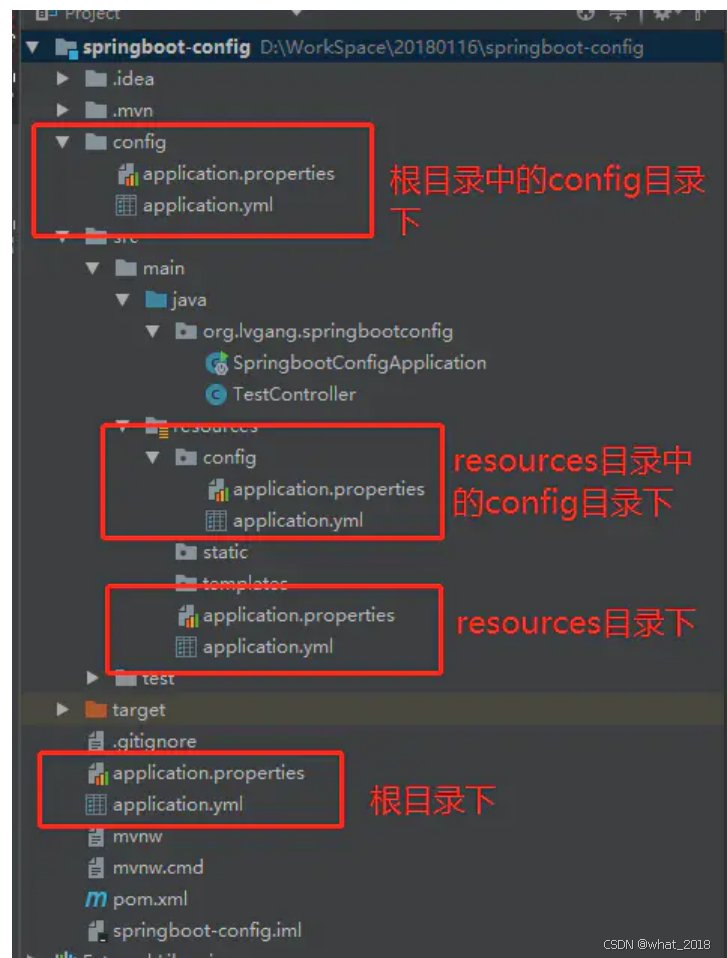
springboot 启动方式 装配流程 自定义starter 文件加载顺序 常见设计模式
目录 springboot介绍 核心特性 快速搭建 Spring Boot 项目 方式一:使用 Spring Initializr 方式二:使用 IDE 插件 示例代码 1. 创建项目并添加依赖 2. 创建主应用类 3. 创建控制器类 4. 运行应用程序 配置文件 部署和监控 部署 监控 与其…...