【模型量化】GPTQ 与 AutoGPTQ
GPTQ是一种用于类GPT线性最小二乘法的量化方法,它使用基于近似二阶信息的一次加权量化。
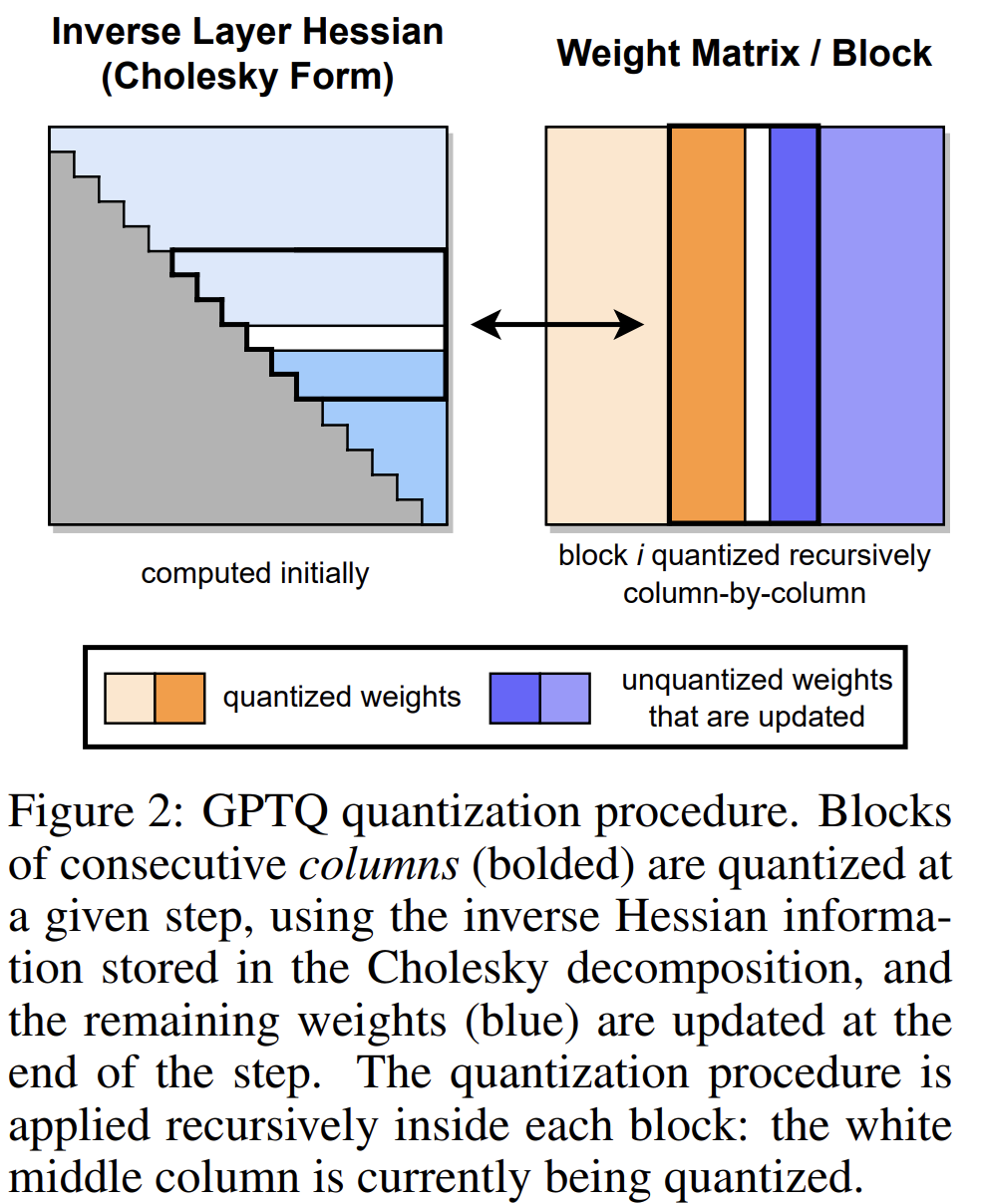
本文中也展示了如何使用量化模型以及如何量化自己的模型AutoGPTQ。
AutoGPTQ:一个易于使用的LLM量化包,带有用户友好的API,基于GPTQ算法(仅权重量化)。
目录
GPTQ与Hugging Face transformers的使用
结合vLLM使用GPTQ模型
用AutoGPTQ量化自己的模型
GPTQ与Hugging Face transformers的使用
注意
使用Qwen2.5 GPTQ官方型号
transformers。请确保
optimum>=1.20.0和兼容版本的transformers和auto_gptq已安装。pip install -U "optimum>=1.20.0"
现在,transformers已经正式支持AutoGPTQ,这意味着可以通过transformers使用量化模型。对于Qwen2.5的每个尺寸,提供Int4和Int8 GPTQ量化模型。下面是一个非常简单的代码片段,展示了如何运行Qwen2.5-7B-Instruct-GPTQ-Int4:
from transformers import AutoModelForCausalLM, AutoTokenizermodel_name = "Qwen/Qwen2.5-7B-Instruct-GPTQ-Int4"model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)prompt = "Give me a short introduction to large language model."
messages = [{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)generated_ids = model.generate(**model_inputs,max_new_tokens=512,
)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]结合vLLM使用GPTQ模型
vLLM支持GPTQ,这意味着可以直接使用提供的GPTQ模型或那些用VLLM训练的模型。如果可能,它会自动使用GPTQ Marlin内核,这样效率更高。
实际上,用法与vLLM的基本用法相同。提供了一个简单的例子说明如何用vLLM和Qwen2.5-7B-Instruct-GPTQ-Int4:
在shell中运行以下命令,启动与OpenAI兼容的API服务:
vllm serve Qwen2.5-7B-Instruct-GPTQ-Int4然后,可以像这样调用API:
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "Qwen2.5-7B-Instruct-GPTQ-Int4","messages": [{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},{"role": "user", "content": "Tell me something about large language models."}],"temperature": 0.7,"top_p": 0.8,"repetition_penalty": 1.05,"max_tokens": 512
}'或者可以使用API客户端,如下所示:
from openai import OpenAIopenai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,
)chat_response = client.chat.completions.create(model="Qwen2.5-7B-Instruct-GPTQ-Int4",messages=[{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},{"role": "user", "content": "Tell me something about large language models."},],temperature=0.7,top_p=0.8,max_tokens=512,extra_body={"repetition_penalty": 1.05,},
)
print("Chat response:", chat_response)用AutoGPTQ量化自己的模型
如果需要把自己的模型量化成GPTQ量化模型,建议使用AutoGPTQ。建议通过从源代码安装来安装最新版本的软件包:
git clone https://github.com/AutoGPTQ/AutoGPTQ
cd AutoGPTQ
pip install -e .假设已经使用自己的数据集对模型Qwen2.5-7B进行了微调,它被命名为Qwen2.5-7B-finetuned,要构建自己的GPTQ量化模型,需要使用训练数据进行校准。下面,提供一个简单的示例。
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
from transformers import AutoTokenizer# Specify paths and hyperparameters for quantization
model_path = "your_model_path"
quant_path = "your_quantized_model_path"
quantize_config = BaseQuantizeConfig(bits=8, # 4 or 8group_size=128,damp_percent=0.01,desc_act=False, # set to False can significantly speed up inference but the perplexity may slightly badstatic_groups=False,sym=True,true_sequential=True,model_name_or_path=None,model_file_base_name="model"
)
max_len = 8192# Load your tokenizer and model with AutoGPTQ
# To learn about loading model to multiple GPUs,
# visit https://github.com/AutoGPTQ/AutoGPTQ/blob/main/docs/tutorial/02-Advanced-Model-Loading-and-Best-Practice.md
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoGPTQForCausalLM.from_pretrained(model_path, quantize_config)但是,如果想在多个GPU上加载模型,需要使用max_memory代替device_map。这里有一个例子:
model = AutoGPTQForCausalLM.from_pretrained(model_path,quantize_config,max_memory={i: "20GB" for i in range(4)}
)然后,需要为校准准备数据。需要做的只是把样本放到一个列表中,每个样本都是一个文本。由于直接使用微调数据进行校准,首先用ChatML模板对其进行格式化。举个例子:
import torchdata = []
for msg in dataset:text = tokenizer.apply_chat_template(msg, tokenize=False, add_generation_prompt=False)model_inputs = tokenizer([text])input_ids = torch.tensor(model_inputs.input_ids[:max_len], dtype=torch.int)data.append(dict(input_ids=input_ids, attention_mask=input_ids.ne(tokenizer.pad_token_id)))其中每个msg是一条典型的聊天消息,如下所示:
[{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},{"role": "user", "content": "Tell me who you are."},{"role": "assistant", "content": "I am a large language model named Qwen..."}
]然后通过一行代码运行校准过程:
import logginglogging.basicConfig(format="%(asctime)s %(levelname)s [%(name)s] %(message)s", level=logging.INFO, datefmt="%Y-%m-%d %H:%M:%S"
)
model.quantize(data, cache_examples_on_gpu=False)最后,保存量化模型:
model.save_quantized(quant_path, use_safetensors=True)
tokenizer.save_pretrained(quant_path)save_quantized方法不支持分片。对于分片,需要加载模型并使用save_pretrained来保存和分割模型。
至此,本文的内容结束啦。
相关文章:
【模型量化】GPTQ 与 AutoGPTQ
GPTQ是一种用于类GPT线性最小二乘法的量化方法,它使用基于近似二阶信息的一次加权量化。 本文中也展示了如何使用量化模型以及如何量化自己的模型AutoGPTQ。 AutoGPTQ:一个易于使用的LLM量化包,带有用户友好的API,基于GPTQ算法(仅…...
学透Spring Boot — 018. 优雅支持多种响应格式
这是我的专栏《学透Spring Boot》的第18篇文章,想要更系统的学习Spring Boot,请访问我的专栏:学透 Spring Boot_postnull咖啡的博客-CSDN博客。 目录 返回不同格式的响应 Spring Boot的内容协商 控制器不用任何修改 启动内容协商配置 访…...
Ma)
Java小白-管理项目工具Maven(3)Ma
一、pom.xml文件 pom.xml 文件是 Maven(Apache Maven)项目的核心配置文件,它定义了项目的构建、依赖管理和项目元数据等信息。Maven 是一个流行的 Java 项目管理和构建自动化工具,而 pom.xml 是 Maven 项目中不可或缺的一部分。 …...
C++中的多态和模板
#include <iostream> #include <cstdlib> #include <ctime> #include <string>using namespace std;// 武器基类 class Weapon { public:virtual ~Weapon() {}virtual string getName() const 0; // 获取武器名称virtual int getAtk() const 0; …...
)
Java 类型转换和泛型原理(JVM 层面)
一、类型转换 概念解释: 编译类型:在编译时确定,保存在虚拟机栈的栈帧中的局部变量表中; 运行类型:在运行时确定,由保存在局部变量表中变量指向的堆中对象实例的类型决定(存储在对象头中&…...
Wireshark 安装保姆教程(图文详解)
一、Wireshark 简介 Wireshark是使用最广泛的一款开源抓包软件,常用来检测网络问题、攻击溯源、或者分析底层通信机制。它使用WinPCAP作为接口,直接与网卡进行数据报文交换,它支持在 Windows、Mac OS、Linux 等多种主流操作系统上运行 &…...

下载安装Node.js及其他环境
提示:从Node版本降级到Vue项目运行 文章目录 下载Node.js环境配置配置环境变量 安装 cnpm(我需要安装)安装脚手架安装依赖安装淘宝镜像(注意会更新)cnpm vs npm 与新旧版本核心差异包管理器不同功能差异如何选择&#…...

机器视觉3D中激光偏镜的优点
机器视觉的3D应用中,激光偏镜(如偏振片、波片、偏振分束器等)通过其独特的偏振控制能力,显著提升了系统的测量精度、抗干扰能力和适应性。以下是其核心优点: 1. 提升3D成像精度 抑制环境光干扰:偏振片可滤除非偏振的环境杂光(如日光、室内照明),仅保留激光偏振信号,大…...
MyBatis Plus 在 ZKmall开源商城持久层的优化实践
ZKmall开源商城作为基于 Spring Cloud 的高性能电商平台,其持久层通过 MyBatis Plus 实现了多项深度优化,涵盖分库分表、缓存策略、分页性能、多租户隔离等核心场景。以下是具体实践总结: 一、分库分表与插件集成优化 1. 分库分表策略 Sh…...
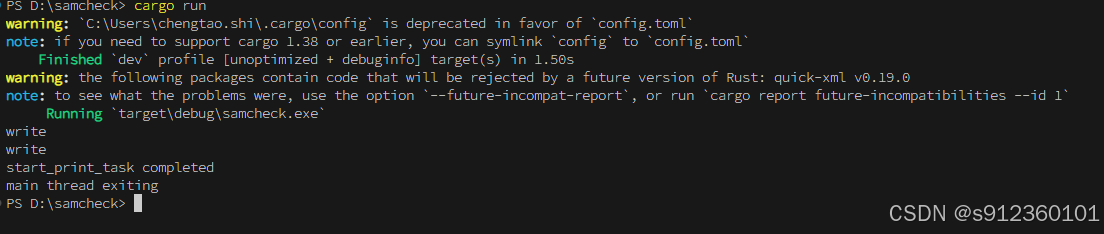
rust 同时处理多个异步任务,并在一个任务完成退出
use std::thread; use tokio::{sync::mpsc,time::{sleep, Duration}, };async fn check_for_one() {// 该函数会每秒打印一次 "write"loop {println!("write");sleep(Duration::from_secs(1)).await;} }async fn start_print_task() -> Result<(), (…...

使用注解开发springMVC
引言 在学习过第一个springMVC项目建造过后,让我们直接进入真实开发中所必需的注解开发, 是何等的简洁高效!! 注:由于Maven可能存在资源过滤的问题,在maven依赖中加入 <build><resources>&l…...

深入解析 Java 8 Function 接口:函数式编程的核心工具
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 Java 8 引入的 java.util.function.Function 接口是函数式编程范式的核心组件之一,本文将全面解析其使用方法,并通过丰富的代码示例演…...

【Axure元件分享】时间范围选择器
时间范围选择器下拉选择开始时间和结束时间,实现效果如下。 源文件截图: 元件获取方式:...
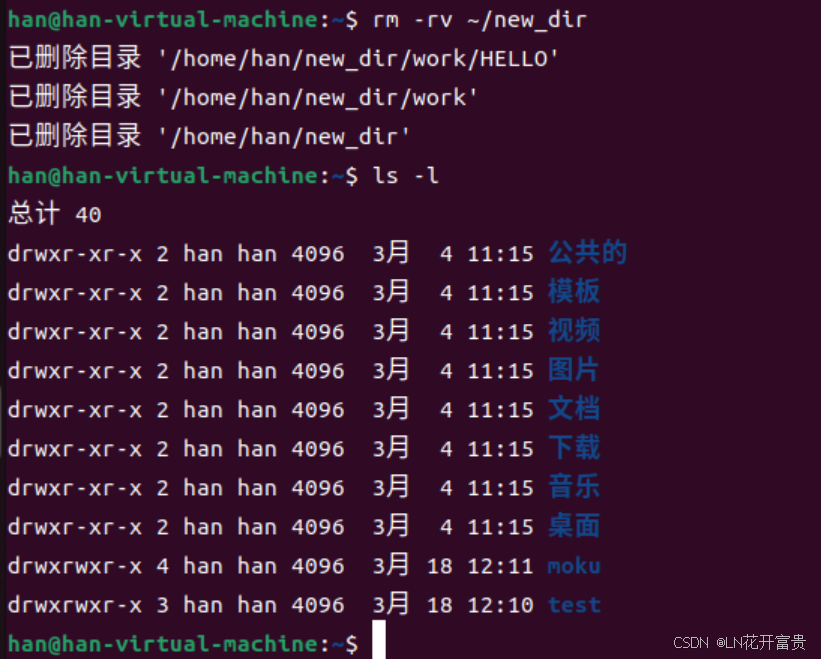
【Linux操作系统——学习笔记三】Linux环境下多级目录构建与管理的命令行实践报告
1.在用户主目录下,使用以下方法新建目录,并显示详细执行过程: (1)使用绝对路径在当前目录下创建 new_dir目录 (2)使用相对路径、在当前目录创建dir1、dir2、dir3目录 (3)…...

Mysql 中的两阶段提交
MySQL 中的“两阶段提交”(Two-Phase Commit,2PC)是用于分布式事务中的一种协议,目的是保证在多个数据库节点之间操作的一致性。虽然 MySQL 自身并不是分布式数据库,但在 使用 InnoDB 引擎和 binlog 的情况下ÿ…...

Scade One - 将MBD技术从少数高安全领域向更广泛的安全嵌入式软件普及
Scade One是继Scade Suite version 6自2008年起发展近20年后的首次主要改进版本。在Scade One发布的同时,Scade团队发布了一系列介绍Scade One的博客。本篇Scade One - Democratizing model-based development是其中的一部分。在后面的内容中,将复述博客…...
C# 与 相机连接
一、通过组件连接相机 需要提前在VisionPro里面保存一个CogAcqFifoTool相机工具为 .vpp 定义一个相机工具 CogAcqFifoTool mAcq null;将保存的相机工具放入mAcq中 string path “C:\Acq.vpp”; mAcq (CogAcqFifoTool)CogSerializer.LoadObjectFrommFile(path);给窗口相机…...

JAVA学习小记之IO流04--转换流篇
转换流: 按照A规则存储,同样按照A规则解析,那么就能显示正确的文本符号。反之,按照A规则存储,再按照B规则解析,就会导致乱码现象。 转换的原因是: 有的文件并非是按UTF-8编码,那么在读文件内容…...

SH 和 BASH 有什么不同 ?
当谈到 shell 脚本编写时,经常出现两个突出的 shell,Bourne shell (SH) 和 Bourne Again shell (Bash)。两者都是基于 unix 和 linux 的系统的组成部分,提供与操作系统交互的接口。本文旨在深入研究这两种 shell 之间的复杂差异,揭…...

linux专题3-----linux上链接远程mysql
要在 Ubuntu 上连接远程 MySQL 数据库,你可以使用 MySQL 客户端工具或者其他数据库管理工具,如 phpMyAdmin 或 MySQL Workbench。以下是使用 MySQL 命令行工具连接远程 MySQL 的步骤: 确保已安装 MySQL 客户端 首先,确保你的 Ub…...

Qt 音乐播放器项目
具体代码见:https://gitee.com/Suinnnnnn/MusicPlayer 文章目录 0. 预备1. 界面1.1 各部位长度1.2 ui文件1.3 窗口前置设置1.4 设置QSS 2. 自定义控件2.1 按钮2.2 推荐页面2.3 CommonPage2.4 滑杆 3. 音乐管理4. 歌词界面4.1 ui文件4.2 LrcPage.h文件 5. 音乐播放控…...

类似于langchain的开发框架有哪些?
类似于 LangChain 的开发框架主要用于构建基于大语言模型(LLM)的应用程序,提供链式调用、工具集成、记忆管理等功能。以下是一些类似的框架和工具: 1. LlamaIndex(原GPT Index) 特点:专注于文档…...

IntelliJ IDEA中Spring Boot 3.4.x+集成Redis 7.x:最新配置与实战指南
前言 Spring Boot 3.4.x作为当前最新稳定版本,全面支持Java 17与Jakarta EE 10规范。本文以Spring Boot 3.4.1和Redis 7.x为例,详解如何在IDEA中快速接入Redis,涵盖最新依赖配置、数据序列化优化、缓存注解及高…...

【mongodb】MongoDB的应用场景
目录 1.说明2.内容管理系统(CMS)2.1 场景描述2.2 MongoDB优势2.3 示例 3.实时分析与大数据3.1 场景描述3.2 MongoDB优势3.3 示例 4.移动应用后端4.1 场景描述4.2 MongoDB优势4.3 示例 5.游戏开发5.1 场景描述5.2 MongoDB优势5.3 示例 6.电子商务平台6.1 …...

.NET用C#在PDF文档中添加、删除和替换图片
在当今数字化文档处理场景中,动态操作PDF文档中的图像已成为企业级应用开发的核心需求之一。通过C#在.NET平台实现图片的添加、替换和删除功能,不仅能显著提升PDF文档的视觉表现力与信息承载效率,更可满足数据动态更新、内容精准维护等复杂业…...

Linux文件操作命令详解
各类资料学习下载合集 https://pan.quark.cn/s/8c91ccb5a474 在Linux操作系统中,文件操作命令是用户与系统交互的重要工具。掌握这些命令能够高效地管理文件和目录。本文将详细介绍常用的Linux文件操作命令,包括它们的用法、选项、具体示例及运行结果。 1. 查看文…...
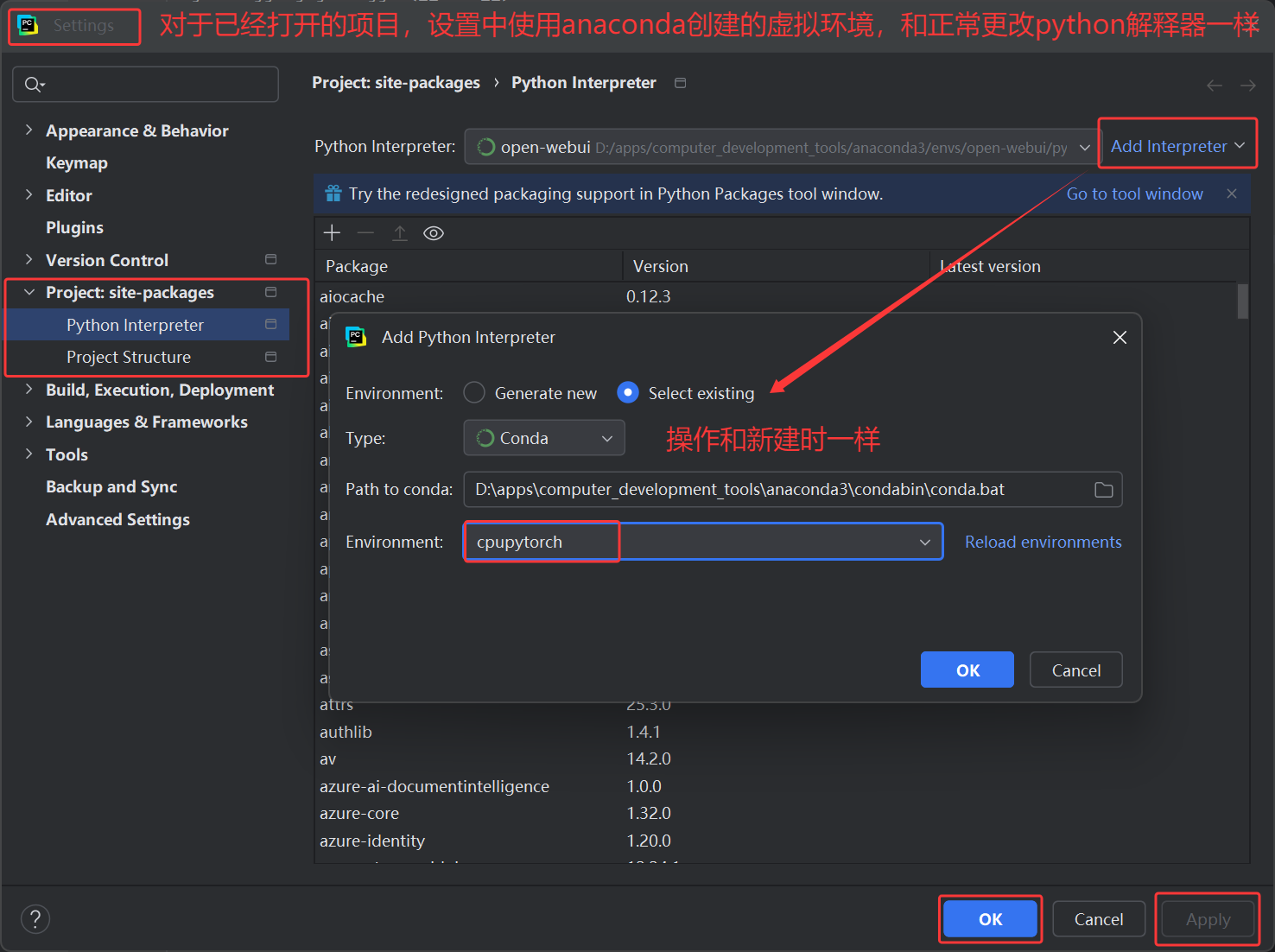
anaconda安装使用+pytorch环境配置(cpu)+pycharm环境配置(详细教程)
一、anaconda下载 1.anaconda官网尝试下载: 官网网址:Anaconda | Built to Advance Open Source AI 1.进入官网 2.点击Products->Distribution,跳过注册进入下载页面 3.选择系统下载 2.清华镜像下载 1.网址:Index of /anac…...

c++STL入门
目录 什么是STL? vector容器 构造函数 赋值操作 vector容量和大小 vector存放内置数据类型 vector存放自定义数据类型 存放指针 vector容器嵌套容器 string容器 构造函数 赋值操作 字符串拼接 查找和替换 string字符串比较 string字符存取 string插…...

electron-update + nginx热更新
1.安装"electron-updater": “^6.6.2”, npm i electron-updater2.创建checkUpdate.js // 引入自动更新 const {autoUpdater} require(electron-updater); const { dialog } require(electron); // 自动更新检查 export function checkForUpdates() {// 检查新版…...

SpringMVC与SpringCloud的区别
SpringMVC与SpringCloud的核心区别 功能定位 • SpringMVC: 基于Spring框架的Web层开发模块,采用MVC(Model-View-Controller)模式,专注于处理HTTP请求、路由分发(如DispatcherServlet)和视图…...