EM算法到底是什么东东
EM(Expectation-Maximization期望最大化)算法是机器学习中非常重要的一类算法,广泛应用于聚类、缺失数据建模、隐变量模型学习等场景,比如高斯混合模型(GMM)就是经典应用。
🐤 第一步:直观理解
EM算法的核心是:
我不知道这个数据是哪一类(隐变量),就先猜;然后根据可见的情况,慢慢猜的更准。
EM算法就是一个“猜→修正→再猜”的循环。
例子1:
- 给你一篇文章让你读
- 可观测数据:文档中的词语。
- 隐变量:文档的主题分布。
- 本质:主题是潜在的,决定了词语的出现概率。
例子2:
假设有两个数据分布(两类),然后随机从这两个分布里抽出一些样本交给你,你不知道给你的样本点属于哪一类(隐含的类别),以及这两个数据分布的统计特性(均值,方差)
EM算法的做法是:
- 随便猜一下每个点属于哪个类别(初始猜测)
- 计算:在当前参数下,每个点属于各个类别的“概率”(这是E步)
- 用这些概率来“反推”出最合理的类别参数(比如均值、方差)(这是M步)
- 重复步骤2-3,直到参数不怎么变为止。
✍️ 第二步:数学公式
你有一堆数据点 x 1 , … , x n \mathbf{x}_1, \dots, \mathbf{x}_n x1,…,xn,你相信这些数据来自 K K K 个不同的高斯分布:
- 每个分布 k k k 有自己的参数:均值 μ k \mu_k μk、方差 σ k 2 \sigma_k^2 σk2、权重 π k \pi_k πk(概率总和为1)
- 但你不知道哪个点来自哪个分布(这是隐变量)
E步(Expectation),即“先猜”
初始化:随机初始化均值 μ k \mu_k μk、方差 σ k 2 \sigma_k^2 σk2 和权重 π k \pi_k πk
计算每个样本属于每个高斯分布的“后验概率”:
γ i k = π k ⋅ N ( x i ∣ μ k , σ k 2 ) ∑ j = 1 K π j ⋅ N ( x i ∣ μ j , σ j 2 ) \gamma_{ik} = \frac{\pi_k \cdot \mathcal{N}(x_i | \mu_k, \sigma_k^2)}{\sum_{j=1}^K \pi_j \cdot \mathcal{N}(x_i | \mu_j, \sigma_j^2)} γik=∑j=1Kπj⋅N(xi∣μj,σj2)πk⋅N(xi∣μk,σk2)
这表示:样本 x i x_i xi 属于第 k k k 个高斯分布的概率。
M步(Maximization),即“反推参数”
根据这些概率 γ i k \gamma_{ik} γik 来重新估计参数:
μ k = ∑ i γ i k x i ∑ i γ i k , σ k 2 = ∑ i γ i k ( x i − μ k ) 2 ∑ i γ i k , π k = 1 n ∑ i γ i k \mu_k = \frac{\sum_i \gamma_{ik} x_i}{\sum_i \gamma_{ik}}, \quad \sigma_k^2 = \frac{\sum_i \gamma_{ik} (x_i - \mu_k)^2}{\sum_i \gamma_{ik}}, \quad \pi_k = \frac{1}{n} \sum_i \gamma_{ik} μk=∑iγik∑iγikxi,σk2=∑iγik∑iγik(xi−μk)2,πk=n1i∑γik
🧊 第三步 :一个具体的例子——高斯混合模型(GMM)
什么是GMM?
高斯混合模型(GMM)就是用多个“高斯分布”加权叠加来组合描述一个复杂的数据分布。GMM 的参数(每个高斯的均值、方差、权重)不能直接算出来,但可以用 EM算法 来一步步逼近!
- GMM = 模型框架
- EM = 参数求解方法
GMM分布可视化
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体显示中文
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 定义两个高斯分布的参数
# 每个分布由均值(mu)、标准差(sigma)和权重(weight)组成
mu1, sigma1, weight1 = 5, 1, 0.4 # 分布1: 均值5, 标准差1, 权重40%
mu2, sigma2, weight2 = 15, 2, 0.6 # 分布2: 均值15, 标准差2, 权重60%# 生成X轴范围,覆盖两个分布的3σ范围
x_min = min(mu1 - 3*sigma1, mu2 - 3*sigma2)
x_max = max(mu1 + 3*sigma1, mu2 + 3*sigma2)
x = np.linspace(x_min, x_max, 1000) # 在合理范围内生成1000个点# 计算单个分布的概率密度函数(PDF)
pdf1 = weight1 * norm.pdf(x, mu1, sigma1) # 第一个高斯分布的加权PDF
pdf2 = weight2 * norm.pdf(x, mu2, sigma2) # 第二个高斯分布的加权PDF# 计算混合后的整体分布(GMM的概率密度)
pdf_total = pdf1 + pdf2 # 高斯混合模型的PDF是两个加权高斯分布的和# 创建图形并设置大小
plt.figure(figsize=(10, 6))# 绘制各个分布
plt.plot(x, pdf1, label=f"高斯分布1 (μ={mu1}, σ={sigma1}, 权重={weight1})",linestyle='--', color='blue')
plt.plot(x, pdf2, label=f"高斯分布2 (μ={mu2}, σ={sigma2}, 权重={weight2})",linestyle='--', color='green')
plt.plot(x, pdf_total, label="混合分布 GMM", linestyle='--',color='red', linewidth=1.5)# 添加图形标题和标签
plt.title("高斯混合模型(GMM)示意图", fontsize=14)
plt.xlabel("特征值 (示例:糖分含量)", fontsize=12)
plt.ylabel("概率密度", fontsize=12)# 添加图例和网格
plt.legend(fontsize=10)
plt.grid(True, linestyle='--', alpha=0.6)# 显示图形
plt.tight_layout() # 自动调整子图参数,使之填充整个图像区域
plt.show()
问题背景
假设我们有一堆学生身高数据,比如160cm、155cm、175cm等等,但我们不知道每个学生是小学生还是中学生。我们猜测这些身高来自两个群体:
- 小学生:身高服从一个正态分布(高斯分布),有自己的均值和标准差。
- 中学生:身高服从另一个正态分布,也有自己的均值和标准差。
此外,每个群体在总数据中占一定比例。我们的目标是:
- 弄清楚每个学生属于小学生还是中学生的概率。
- 估计两个群体的参数:比例( π π π)、均值( μ μ μ)、标准差( σ σ σ)。
因为我们不知道真实的类别和参数,所以要用EM算法通过迭代来解决这个问题。
EM算法是什么?
EM算法(Expectation-Maximization)是一种用来处理“隐变量”问题的工具。这里,隐变量就是“每个学生属于哪个群体”,我们看不到它,但可以通过数据推测。EM算法分为两步:
- E步(期望):根据当前猜测的参数,算出每个学生属于小学生或中学生的概率。
- M步(最大化):用这些概率更新参数,让模型更好地拟合数据。
这两步不断重复,直到参数稳定。
具体案例:一步步拆解
1. 初始化:随便猜参数
我们先随便猜一下两个群体的参数,作为起点:
- 小学生:
- 比例( π 1 π_1 π1):50%(0.5)
- 均值( μ 1 μ_1 μ1):150cm
- 标准差( σ 1 σ_1 σ1):5cm
- 中学生:
- 比例( π 2 π_2 π2):50%(0.5)
- 均值( μ 2 μ_2 μ2):170cm
- 标准差( σ 2 σ_2 σ2):6cm
这些是初始猜测,不一定准确,但EM算法会帮我们调整。
2. E步:算概率(责任值)
现在拿一个学生,身高是160cm。我们要算他属于小学生还是中学生的概率。
(1)用正态分布公式算“可能性”
每个群体都有一个正态分布曲线:
- 小学生:均值150cm,标准差5cm。
- 中学生:均值170cm,标准差6cm。
正态分布的公式是:
P ( X ) = 1 2 π ⋅ σ exp ( − ( X − μ ) 2 2 σ 2 ) P(X)=\frac{1}{\sqrt{2\pi}\cdot\sigma}\exp\left(-\frac{(X-\mu)^2}{2\sigma^2}\right) P(X)=2π⋅σ1exp(−2σ2(X−μ)2)
-
小学生:
P ( 小学生 ∣ 160 ) = 1 2 π ⋅ 5 exp ( − ( 160 − 150 ) 2 2 ⋅ 5 2 ) P(\text{小学生}|160)=\frac{1}{\sqrt{2\pi}\cdot5}\exp\left(-\frac{(160-150)^2}{2\cdot5^2}\right) P(小学生∣160)=2π⋅51exp(−2⋅52(160−150)2)
计算指数部分:(160 - 150)² = 100,2 × 5² = 50,-100 / 50 = -2,exp(-2) ≈ 0.135。所以结果是一个较小的数。 -
中学生:
P ( 中学生 ∣ 160 ) = 1 2 π ⋅ 6 exp ( − ( 160 − 170 ) 2 2 ⋅ 6 2 ) P(\text{中学生}|160)=\frac{1}{\sqrt{2\pi}\cdot6}\exp\left(-\frac{(160-170)^2}{2\cdot6^2}\right) P(中学生∣160)=2π⋅61exp(−2⋅62(160−170)2)
计算指数部分:(160 - 170)² = 100,2 × 6² = 72,-100 / 72 ≈ -1.39,exp(-1.39) ≈ 0.25。结果比小学生的稍大。
简单来说:
- 160cm离150cm(小学生均值)较远,所以可能性较低。
- 160cm离170cm(中学生均值)较近,所以可能性较高。
(2)结合比例算后验概率(责任值)
光看可能性还不够,还要考虑每个群体占的总比例( π 1 = 0.5 π_1=0.5 π1=0.5, π 2 = 0.5 π_2=0.5 π2=0.5)。用贝叶斯公式:
P ( 小学生 ∣ 160 ) = π 1 ⋅ P ( 160 ∣ 小学生 ) π 1 ⋅ P ( 160 ∣ 小学生 ) + π 2 ⋅ P ( 160 ∣ 中学生 ) P(\text{小学生}|160)=\frac{π_1\cdot P(160|\text{小学生})}{π_1\cdot P(160|\text{小学生})+π_2\cdot P(160|\text{中学生})} P(小学生∣160)=π1⋅P(160∣小学生)+π2⋅P(160∣中学生)π1⋅P(160∣小学生)
假设计算后:
- P ( 小学生 ∣ 160 ) ≈ 0.3 P(\text{小学生}|160)≈0.3 P(小学生∣160)≈0.3(30%)
- P ( 中学生 ∣ 160 ) ≈ 0.7 P(\text{中学生}|160)≈0.7 P(中学生∣160)≈0.7(70%)
意思是:这个160cm的学生有30%概率是小学生,70%概率是中学生。对所有学生都做类似计算。
3. M步:更新参数
现在我们用所有学生的概率来调整参数。假设有3个学生:160cm、155cm、175cm,E步算出的概率如下:
| 身高 | P(小学生) | P(中学生) |
|---|---|---|
| 160cm | 0.3 | 0.7 |
| 155cm | 0.6 | 0.4 |
| 175cm | 0.1 | 0.9 |
(1)更新比例( π π π)
- 新 π 1 = π_1= π1=所有学生属于小学生的概率平均值:
π 1 = 0.3 + 0.6 + 0.1 3 = 1.0 3 ≈ 0.33 π_1=\frac{0.3+0.6+0.1}{3}=\frac{1.0}{3}≈0.33 π1=30.3+0.6+0.1=31.0≈0.33 - 新 π 2 = 1 − π 1 ≈ 0.67 π_2=1-π_1≈0.67 π2=1−π1≈0.67
(2)更新均值( μ μ μ)
- 新 μ 1 = μ_1= μ1=身高 × 属于小学生的概率的加权平均:
μ 1 = ( 160 ⋅ 0.3 ) + ( 155 ⋅ 0.6 ) + ( 175 ⋅ 0.1 ) 0.3 + 0.6 + 0.1 = 48 + 93 + 17.5 1.0 = 158.5 cm μ_1=\frac{(160\cdot0.3)+(155\cdot0.6)+(175\cdot0.1)}{0.3+0.6+0.1}=\frac{48+93+17.5}{1.0}=158.5\,\text{cm} μ1=0.3+0.6+0.1(160⋅0.3)+(155⋅0.6)+(175⋅0.1)=1.048+93+17.5=158.5cm - 新 μ 2 = μ_2= μ2=类似计算:
μ 2 = ( 160 ⋅ 0.7 ) + ( 155 ⋅ 0.4 ) + ( 175 ⋅ 0.9 ) 0.7 + 0.4 + 0.9 = 112 + 62 + 157.5 2.0 = 165.75 cm μ_2=\frac{(160\cdot0.7)+(155\cdot0.4)+(175\cdot0.9)}{0.7+0.4+0.9}=\frac{112+62+157.5}{2.0}=165.75\,\text{cm} μ2=0.7+0.4+0.9(160⋅0.7)+(155⋅0.4)+(175⋅0.9)=2.0112+62+157.5=165.75cm
(3)更新标准差( σ σ σ)
- 新 σ 1 = σ_1= σ1= 身高偏离新均值 μ 1 μ_1 μ1的加权方差:
σ 1 = 0.3 ⋅ ( 160 − 158.5 ) 2 + 0.6 ⋅ ( 155 − 158.5 ) 2 + 0.1 ⋅ ( 175 − 158.5 ) 2 1.0 σ_1=\sqrt{\frac{0.3\cdot(160-158.5)^2+0.6\cdot(155-158.5)^2+0.1\cdot(175-158.5)^2}{1.0}} σ1=1.00.3⋅(160−158.5)2+0.6⋅(155−158.5)2+0.1⋅(175−158.5)2
计算后可能得到一个新值,比如4.8cm。 - 新 σ 2 = σ_2= σ2=类似计算,得到新值,比如5.5cm。
4. 重复迭代
用新参数( π 1 = 0.33 , μ 1 = 158.5 , σ 1 = 4.8 , π 2 = 0.67 , μ 2 = 165.75 , σ 2 = 5.5 π_1=0.33,μ_1=158.5,σ_1=4.8,π_2=0.67,μ_2=165.75,σ_2=5.5 π1=0.33,μ1=158.5,σ1=4.8,π2=0.67,μ2=165.75,σ2=5.5)再跑一遍E步和M步。每轮迭代后,参数会更接近真实值。重复直到参数几乎不变,比如:
- 小学生: π 1 ≈ 0.4 , μ 1 ≈ 148 cm , σ 1 ≈ 4 cm π_1≈0.4,μ_1≈148\text{cm},σ_1≈4\text{cm} π1≈0.4,μ1≈148cm,σ1≈4cm
- 中学生: π 2 ≈ 0.6 , μ 2 ≈ 172 cm , σ 2 ≈ 5 cm π_2≈0.6,μ_2≈172\text{cm},σ_2≈5\text{cm} π2≈0.6,μ2≈172cm,σ2≈5cm
这意味着EM算法成功把混合的身高数据分成了两个群体,并估计了它们的特征。
📊 第四步:完整Python代码
import numpy as np
from scipy.stats import norm
from sklearn.cluster import KMeans
import seaborn as sns
import matplotlib.pyplot as pltclass GMM_EM:"""高斯混合模型(GMM)的EM算法核心实现 - 用于学生身高分布分析案例背景:假设数据包含两个学生群体的身高数据:1. 小学生:服从N(μ1, σ1²)2. 中学生:服从N(μ2, σ2²)每个群体在总样本中占有比例π目标:通过EM算法估计这两个群体的分布参数(π, μ, σ)"""def __init__(self, n_components=2, max_iter=100, tol=1e-6, random_state=42):"""模型初始化参数:n_components : int, default=2要区分的学生群体数量(默认2类:小学生/中学生)max_iter : int, default=100EM算法最大迭代次数tol : float, default=1e-6参数变化收敛阈值(当参数变化小于此值时停止迭代)random_state : int, default=42随机种子,保证结果可重复"""self.n_components = n_components # 学生群体数量self.max_iter = max_iter # 最大迭代次数self.tol = tol # 收敛判断阈值self.random_state = random_state # 随机种子self.pi = None # 各群体比例(小学生/中学生的样本占比)self.mu = None # 各群体身高均值(单位:厘米)self.sigma = None # 各群体身高标准差self.converged = False # 是否收敛标志self.iterations = 0 # 实际迭代次数def _validate_input(self, data):"""输入验证 - 确保数据适合学生身高分析验证条件:1. 输入必须是1维数组(每个元素代表一个学生的身高)2. 样本量必须大于群体数量(防止无法区分群体)"""if not isinstance(data, np.ndarray) or data.ndim != 1:raise ValueError("输入应为1维数组,表示学生身高测量值")if len(data) < self.n_components:raise ValueError("样本量需大于群体数量才能进行有效分析")def _initialize_parameters(self, data):"""参数初始化 - 使用K-means进行初步群体划分初始化策略:1. 通过K-means将学生按身高初步分为n_components个群体2. 按群体身高均值升序排列(确保小学生群体在前)3. 初始化参数:- π: 各群体样本占比- μ: 各群体身高均值- σ: 各群体身高标准差(至少1cm防止数值问题)"""np.random.seed(self.random_state)kmeans = KMeans(n_clusters=self.n_components,random_state=self.random_state)labels = kmeans.fit_predict(data.reshape(-1, 1))# 按身高均值升序排列群体(保证小学生群体在前)unique_labels = np.unique(labels)means = np.array([data[labels == lbl].mean() for lbl in unique_labels])order = np.argsort(means)# 初始化参数self.pi = np.array([np.mean(labels == lbl) for lbl in unique_labels[order]])self.mu = np.array([data[labels == lbl].mean() for lbl in unique_labels[order]])self.sigma = np.array([data[labels == lbl].std() if np.sum(labels == lbl) > 1 else 1.0for lbl in unique_labels[order]])def _e_step(self, data):"""期望步(E-step)- 计算学生归属各群体的后验概率计算公式:P(群体k|身高) = π_k * N(身高|μ_k, σ_k²) / Σ(π_j * N(身高|μ_j, σ_j²))返回:responsibilities : array, shape (n_samples, n_components)每个学生属于各群体的概率矩阵"""# 计算各群体的概率密度pdf = norm.pdf(data[:, np.newaxis], self.mu, self.sigma)# 计算责任矩阵(未归一化的后验概率)responsibilities = self.pi * pdf# 归一化使各学生概率和为1responsibilities /= responsibilities.sum(axis=1, keepdims=True)return responsibilitiesdef _m_step(self, data, responsibilities):"""最大化步(M-step)- 更新群体参数更新公式:1. π_k = 群体k的责任值总和 / 总样本数2. μ_k = Σ(责任值_ki * 身高_i) / 群体k的责任值总和3. σ_k = sqrt(Σ(责任值_ki * (身高_i - μ_k)^2) / 群体k的责任值总和)"""# 各群体有效样本数N_k = responsibilities.sum(axis=0)# 更新群体比例self.pi = N_k / len(data)# 更新群体均值self.mu = np.dot(responsibilities.T, data) / N_k# 更新群体标准差diff_sq = (data[:, np.newaxis] - self.mu) ** 2self.sigma = np.sqrt(np.sum(responsibilities * diff_sq, axis=0) / N_k)def _has_converged(self, prev_params):"""收敛判断 - 检查参数是否稳定判断标准:新旧参数(π, μ, σ)的变化是否均小于tol阈值"""return all(np.allclose(new, old, atol=self.tol) for new, old inzip([self.pi, self.mu, self.sigma], prev_params))def fit(self, data):"""训练模型 - EM算法主循环执行流程:1. 输入验证2. 参数初始化3. 迭代执行E步和M步4. 检查收敛或达到最大迭代次数5. 最终按身高均值排序群体"""self._validate_input(data)self._initialize_parameters(data)self.converged = Falsefor self.iterations in range(1, self.max_iter + 1):prev_params = [arr.copy() for arr in [self.pi, self.mu, self.sigma]]# E步:计算后验概率responsibilities = self._e_step(data)# M步:更新参数self._m_step(data, responsibilities)# 检查收敛if self._has_converged(prev_params):self.converged = Truebreak# 最终按身高均值排序群体(保证小学生群体在前)order = np.argsort(self.mu)self.mu = self.mu[order]self.pi = self.pi[order]self.sigma = self.sigma[order]return selfdef predict_proba(self, data):"""预测概率 - 返回每个学生属于各群体的概率返回:array, shape (n_samples, n_components)每个元素表示对应学生属于该群体的概率"""return self._e_step(data)def predict(self, data):"""预测类别 - 返回最可能的群体标签返回:array, shape (n_samples,)每个元素为0(小学生)或1(中学生)"""return np.argmax(self.predict_proba(data), axis=1)def get_params(self):"""获取训练后的模型参数返回:dict 包含:- pi : 各群体比例- mu : 各群体平均身高(cm)- sigma : 各群体身高标准差(cm)- converged : 是否收敛- iterations : 实际迭代次数"""return {'pi': self.pi,'mu': self.mu,'sigma': self.sigma,'converged': self.converged,'iterations': self.iterations}class GMM_Visualizer:"""GMM可视化工具类"""def __init__(self, model, data, true_labels=None):self.model = modelself.data = dataself.true_labels = true_labelsself.colors = sns.color_palette("husl", model.n_components)self.group_labels = ['Primary school student', 'Middle school student'] \if model.n_components == 2 else [f'Group {i+1}' for i in range(model.n_components)]def plot_results(self, save_path=None):"""可视化拟合结果"""plt.figure(figsize=(12, 7))x = np.linspace(self.data.min()-15, self.data.max()+15, 1000)# 绘制直方图sns.histplot(self.data, bins=30, kde=False, stat='density',color='gray', alpha=0.3, label='Original Data')# 绘制各成分和混合分布mixture_pdf = np.zeros_like(x)for k in range(self.model.n_components):component_pdf = self.model.pi[k] * norm.pdf(x, self.model.mu[k], self.model.sigma[k])plt.plot(x, component_pdf, color=self.colors[k], lw=2,label=f'{self.group_labels[k]} (π={self.model.pi[k]:.2f}, μ={self.model.mu[k]:.1f}, σ={self.model.sigma[k]:.1f})')mixture_pdf += component_pdf# 绘制混合分布plt.plot(x, mixture_pdf, 'k--', lw=2.5, label='Mixture Distribution')# 绘制真实分布(如果存在)if self.true_labels is not None:for k in range(self.model.n_components):sns.histplot(self.data[self.true_labels == k], bins=15, kde=False, stat='density',color=self.colors[k], alpha=0.3, label=f'True {self.group_labels[k]}')plt.title('GMM Fitting Results', fontsize=14)plt.xlabel('Height (cm)')plt.ylabel('Probability Density')plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', frameon=True)plt.grid(alpha=0.2)if save_path:plt.savefig(save_path, dpi=300, bbox_inches='tight')print(f"图像已保存到: {save_path}")else:plt.show()plt.close()def generate_data(n_primary=100, n_secondary=100,primary_mean=160, primary_std=5,secondary_mean=175, secondary_std=7,random_state=42):"""生成模拟学生身高数据案例背景:生成包含两个学生群体的身高数据集,模拟实际观测数据:- 小学生群体:身高服从正态分布N(μ1, σ1²)- 中学生群体:身高服从正态分布N(μ2, σ2²)参数:n_primary : int, default=100小学生样本数量(默认100人)n_secondary : int, default=100中学生样本数量(默认100人)primary_mean : float, default=160小学生群体平均身高(厘米)primary_std : float, default=5小学生群体身高标准差(厘米)secondary_mean : float, default=175中学生群体平均身高(厘米)secondary_std : float, default=7中学生群体身高标准差(厘米)random_state : int, default=42随机种子,保证数据生成可重复返回:data : ndarray, shape (n_samples,)打乱后的混合身高数据(单位:厘米)labels : ndarray, shape (n_samples,)对应的学生群体标签(0:小学生, 1:中学生)"""# 设置随机种子保证结果可重复np.random.seed(random_state)# 生成小学生身高数据(正态分布)primary = np.random.normal(primary_mean, primary_std, n_primary)# 生成中学生身高数据(正态分布)secondary = np.random.normal(secondary_mean, secondary_std, n_secondary)# 合并数据并创建标签data = np.concatenate([primary, secondary])labels = np.concatenate([np.zeros(n_primary), np.ones(n_secondary)])# 打乱数据以模拟真实观测场景# 保持数据与标签的对应关系idx = np.random.permutation(len(data))return data[idx], labels[idx].astype(int)def print_results(model, data, true_labels=None):"""打印结果对比"""params = model.get_params()pi, mu, sigma = params['pi'], params['mu'], params['sigma']print("\n" + "=" * 60)print("GMM-EM 模型预测结果")print("=" * 60)for k in range(len(pi)):print(f"Group {k+1}: 比例={pi[k]:.4f}, 均值={mu[k]:.2f}cm, 方差={sigma[k]:.2f}cm")if true_labels is not None:print("\n真实参数:")for k in range(len(pi)):mask = true_labels == kprint(f"Group {k+1}: 比例={np.mean(mask):.4f}, "f"均值={data[mask].mean():.2f}cm, 方差={data[mask].std():.2f}cm")accuracy = np.mean(model.predict(data) == true_labels)print(f"\n分类准确率: {accuracy:.2%}")print(f"是否收敛: {params['converged']}, 迭代次数: {params['iterations']}")print("=" * 60)if __name__ == "__main__":# 生成数据data, labels = generate_data()# 训练模型model = GMM_EM(n_components=2)model.fit(data)# 打印结果print_results(model, data, labels)# 可视化visualizer = GMM_Visualizer(model, data, labels)visualizer.plot_results(save_path="./fitted_distribution.png")
📌 第五步:总结重点
| 概念 | 含义 |
|---|---|
| 隐变量 | 不知道但是存在的变量(比如样本的真实类别) |
| E步 | 计算每个数据点属于哪个分布的“概率” |
| M步 | 根据这个概率重新计算每个分布的参数 |
| 收敛 | 参数变化很小,不再更新,算法停止 |
| 应用场景 | 高斯混合聚类、缺失数据估计、协同过滤、HMM 等等 |
相关文章:

EM算法到底是什么东东
EM(Expectation-Maximization期望最大化)算法是机器学习中非常重要的一类算法,广泛应用于聚类、缺失数据建模、隐变量模型学习等场景,比如高斯混合模型(GMM)就是经典应用。 🐤 第一步ÿ…...

⭐算法OJ⭐滑动窗口最大值【双端队列(deque)】Sliding Window Maximum
文章目录 双端队列(deque)详解基本特性常用操作1. 构造和初始化2. 元素访问3. 修改操作4. 容量操作 性能特点时间复杂度:空间复杂度: 滑动窗口最大值题目描述方法思路解决代码 双端队列(deque)详解 双端队列(deque,全称double-ended queue)是…...

oracle 快速创建表结构
在 Oracle 中快速创建表结构(仅复制表结构,不复制数据)可以通过以下方法实现,适用于需要快速复制表定义或生成空表的场景 1. 使用 CREATE TABLE AS SELECT (CTAS) 方法 -- 复制源表的全部列和数据类型,但不复制数据 C…...

沧州铁狮子
又名“镇海吼”,是中国现存年代最久、形体最大的铸铁狮子,具有深厚的历史文化底蕴和独特的艺术价值。以下是关于沧州铁狮子的详细介绍: 历史背景 • 铸造年代:沧州铁狮子铸造于后周广顺三年(953年)&#…...
Python•判断循环
ʕ⸝⸝⸝˙Ⱉ˙ʔ ♡ 判断🍰常用的判断符号(比较运算符)andor括号notin 和 not inif-elif-else循环🍭计数循环 forrange()函数简易倒计时enumerate()函数zip()函数遍历列表遍历元组遍历字符串遍历字典条件循环 while提前跳转 continue跳出循环 break能量站😚判断🍰 …...

【力扣hot100题】(060)分割回文串
每次需要判断回文串,这点比之前几题回溯题目复杂一些。 还有我怎么又多写了循环…… class Solution { public:vector<vector<string>> result;string s;bool palindromic(string s){for(int i0;i<s.size()/2;i) if(s[i]!s[s.size()-1-i]) return …...

C++---day7
#include <iostream> #include <cstring> #include <cstdlib> #include <unistd.h> #include <sstream> #include <vector> #include <memory>using namespace std;class Stu { private:public:};// 自定义 vector 类,重…...
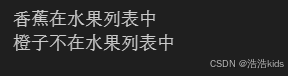
SvelteKit 最新中文文档教程(17)—— 仅服务端模块和快照
前言 Svelte,一个语法简洁、入门容易,面向未来的前端框架。 从 Svelte 诞生之初,就备受开发者的喜爱,根据统计,从 2019 年到 2024 年,连续 6 年一直是开发者最感兴趣的前端框架 No.1: Svelte …...

C#后端开发培训教程
C#后端开发培训教程 SqlServer 1.创建数据、备份还原数据库 2.SqlServer:数据类型 3.Sql语句:增删改查 4.班级、学生数据结构示例 C#基础语法 C#基础语法、数据类型 C#数组、集合、类操作 C#面向对象基础 C# JSON 数据格式序列化 C# Linq 数据源操作基础语…...
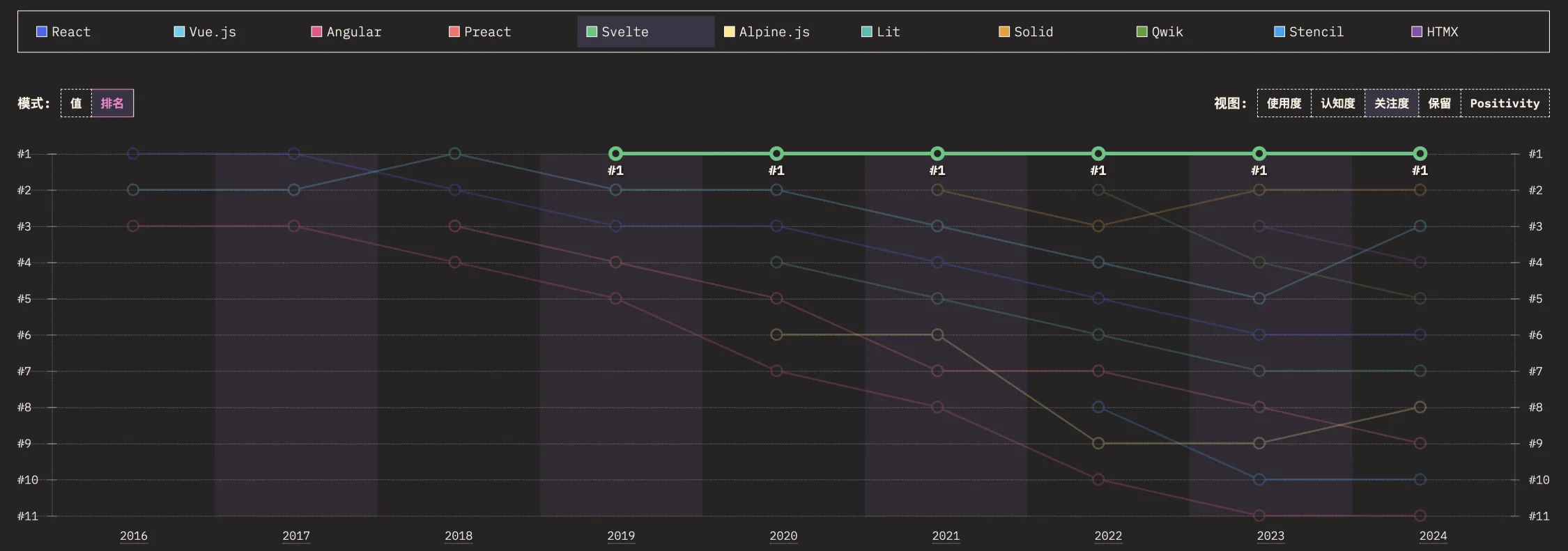
flink 增量快照同步文件引用关系和恢复分析
文章目录 文件引用分析相关代码分析从state 恢复,以rocksdb为例不修改并行度修改并行度keyGroupRange过程问题 文件引用分析 每次生成的checkpoint 里都会有所有文件的引用信息 问题,引用分析里如何把f1,f2去掉了,可以参考下面的代码&#…...

c++概念—内存管理
文章目录 c内存管理c/c的内存区域划分回顾c语言动态内存管理c动态内存管理new和delete的使用new和delete的底层逻辑operator new函数和operator delete函数new和delete的实现操作方式不匹配的情况定位new new/delete和malloc/free的区别 c内存管理 在以往学习c语言的过程中&…...

如何判断多个点组成的3维面不是平的,如果不是平的,如何拆分成多个平面
判断和拆分三维非平面为多个平面 要判断多个三维点组成的面是否为平面,以及如何将非平面拆分为多个平面,可以按照以下步骤进行: 判断是否为平面 平面方程法: 选择三个不共线的点计算平面方程:Ax By Cz D 0检查其…...

私有化视频会议系统,业务沟通协作安全不断线
BeeWorks Meet视频会议平台具备丰富而强大的功能,能够满足企业多样化的业务场景需求。其会议管理功能,让企业能够轻松安排和管理各类会议。 从创建会议、设置会议时间、邀请参会人员到会议提醒,一应俱全,确保会议的顺利进行。多人…...

无人机双频技术及底层应用分析!
一、双频技术的核心要点 1. 频段特性互补 2.4GHz:穿透力强、传输距离远(可达5公里以上),适合复杂环境(如城市、建筑物密集区),但易受Wi-Fi、蓝牙等设备的干扰。 5.8GHz:带宽更…...

【电视软件】小飞电视v2.7.0 TV版-清爽无广告秒换台【永久更新】
软件介绍 小飞电视是一款电视端的直播软件,无需二次付费和登录,资源丰富,高清流畅。具备开机自启、推送功能、自定义直播源、个性化设置及节目预告等实用功能,为用户带来良好的观看体验。基于mytv开源项目二改,涵盖央…...

video自动播放
文章目录 前言在iOS系统中,H5页面的自动播放功能受到了一些限制,为了提升用户体验和保护用户隐私,Safari浏览器对于自动播放的行为做了一些限制。 一、自动播放的限制二、解决方案 前言 在iOS系统中,H5页面的自动播放功能受到了一…...

以太网安全
前言: 端口隔离可实现同一VLAN内端口之间的隔离。用户只需要将端口加入到隔离组中,就可以实现隔离组内端口之间的二层数据的隔离端口安全是一种在交换机接入层实施的安全机制,旨在通过控制端口的MAC地址学习行为,确保仅授权设备能…...

Linux 递归查找并删除目录下的文件
在 Linux 中,可以使用 find 命令递归查找并删除目录下的文件 1、示例命令 find /path/to/directory -type f -name "filename_pattern" -exec rm -f {} 2、参数说明 /path/to/directory:要查找的目标目录type f:表示查找文件&am…...
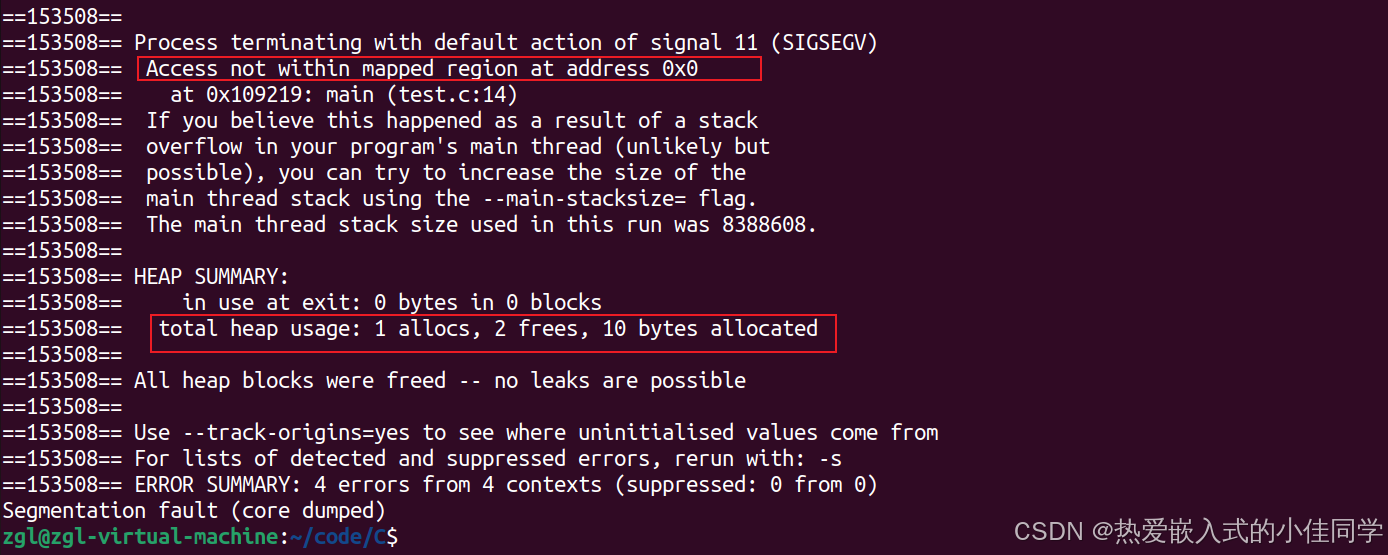
Valgrind——内存调试和性能分析工具
文章目录 一、Valgrind 介绍二、Valgrind 功能和使用1. 主要功能2. 基本用法2.1 常用选项2.2 内存泄漏检测2.3 详细报告2.4 性能分析2.5 多线程错误检测 三、在 Ubuntu 上安装 Valgrind四、示例1. 检测内存泄漏2. 使用未初始化的内存3. 内存读写越界4. 综合错误 五、工具集1. M…...

【BUG】生产环境死锁问题定位排查解决全过程
目录 生产环境死锁问题定位排查解决过程0. 表面现象1. 问题分析(1)数据库连接池资源耗尽(2)数据库锁竞争(3) 代码实现问题 2. 分析解决(0) 分析过程(1)优化数据库连接池配置(2)优化数…...

学习MySQL第七天
夕阳无限好 只是近黄昏 一、子查询 1.1 定义 将一个查询语句嵌套到另一个查询语句内部的查询 我们通过具体示例来进行演示,这一篇博客更侧重于通过具体的小问题来引导大家独立思考,然后熟悉子查询相关的知识点 1.2 问题1 谁的工资比Tom高 方…...

Spring启示录、概述、入门程序以及Spring对IoC的实现
一、Spring启示录 阅读以下代码: dao package org.example1.dao;/*** 持久层* className UserDao* since 1.0**/ public interface UserDao {/*** 根据id删除用户信息*/void deleteById(); } package org.example1.dao.impl;import org.example1.dao.UserDao;/**…...

电机的了解到调试全方面讲解
一、什么是电机 电机是一种将电能转换为机械能的装置,通常由定子、转子和电磁场组成。 当电流通过电机的绕组时,产生的磁场会与电机中的磁场相互作用,从而使电机产生旋转运动。电机广泛应用于各种机械设备和工业生产中,是现代社会不可或缺的重要设备之一。 常见的电机种…...

笔试专题(七)
文章目录 乒乓球筐(哈希)题解代码 组队竞赛题解代码 删除相邻数字的最大分数(线性dp)题解代码 乒乓球筐(哈希) 题目链接 题解 1. 两个哈希表 先统计第一个字符串中的字符个数,再统计第二个字…...

Vue2 插槽 Slot
提示:插槽的目的是让我买原来的设备具备更多的扩展性。 文章目录 前言在组件中定义插槽(子组件视角)1. 默认插槽2. 具名插槽(带名称的插槽)3. 作用域插槽(带数据的插槽) 使用插槽(父…...

说一下java的探针agent的应用场景
什么是agent Java探针通常是指Java Agent 它是一种可以在JVM启动时或运行时加载的组件,用来修改或增强字节码,从而监控或改变程序的行为 agent应用在哪些方面 1.Arthas就是应用了我们的探针技术 2.代码热替换实现我们的热部署,Java Agent可…...
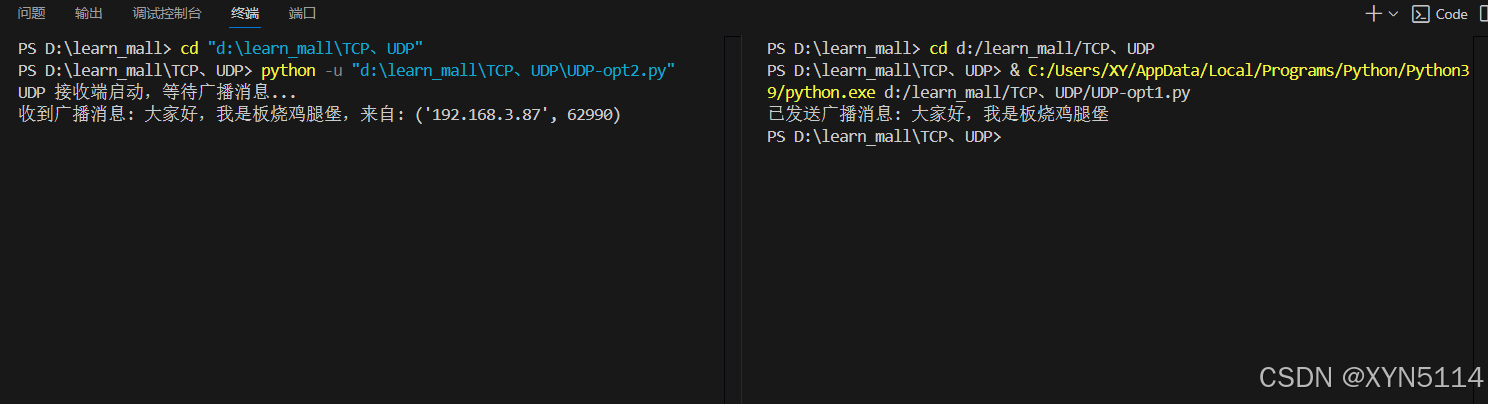
【嵌入式学习3】UDP发送端、接收端
目录 1、发送端 2、接收端 3、UDP广播 1、发送端 from socket import *udp_socket socket(AF_INET,SOCK_DGRAM) udp_socket.bind(("127.0.0.1",3333))data_str "UDP发送端数据" data_bytes data_str.encode("utf-8") udp_socket.sendto(d…...

Linux 系统 SVN 源码安装与配置全流程指南
Linux系统SVN源码安装与配置全流程指南 一、环境准备 系统要求 CentOS 7及以上版本需安装GCC编译工具链 依赖项 APR/APR-UTIL(Apache可移植运行库)SQLite(嵌入式数据库)zlib(数据压缩库) 二、下载及安装…...
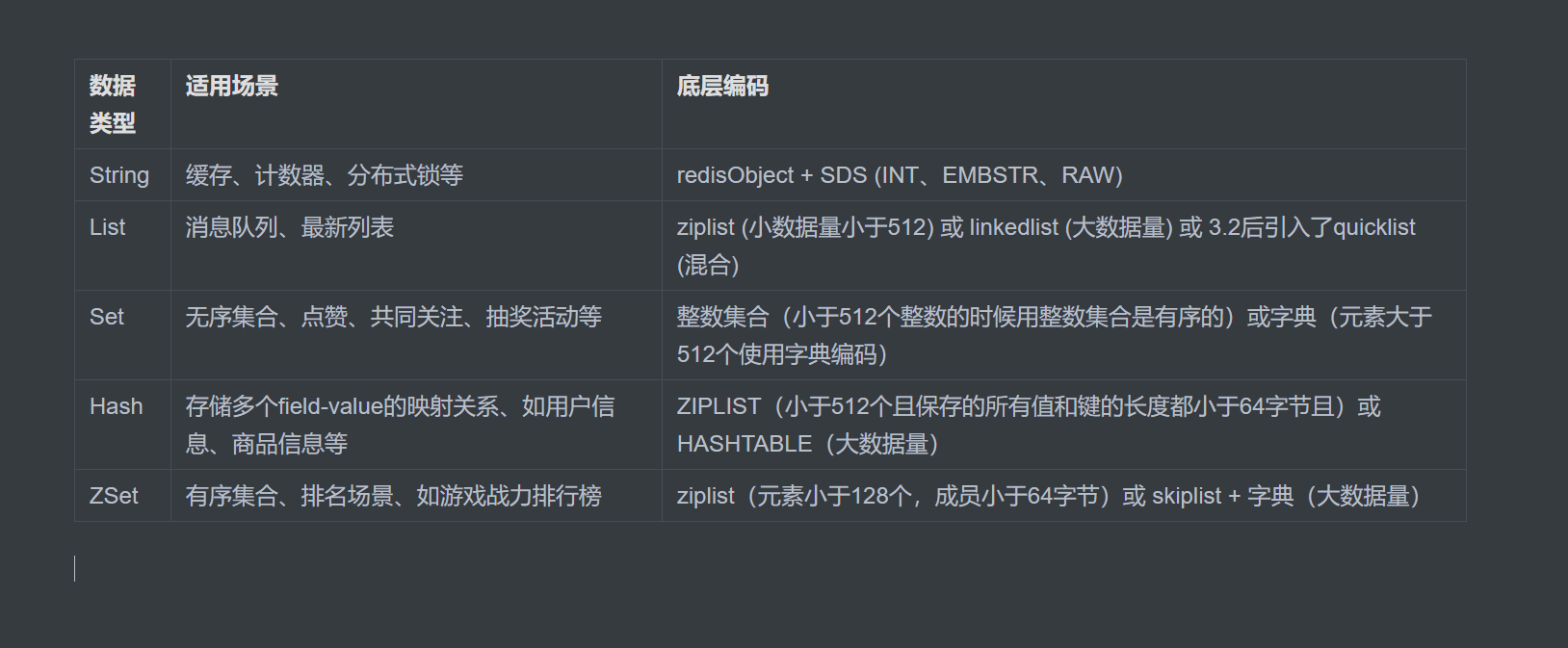
Redis 的五种数据类型面试回答
这里简单介绍一下面试回答、我之前有详细的去学习、但是一直都觉得太多内容了、太深入了 然后面试的时候不知道从哪里讲起、于是我写了这篇CSDN帮助大家面试回答、具体的深入解析下次再说 面试官你好 我来介绍一下Redis的五种基本数据类型 有String List Set ZSet Map 五种基…...

关于类模板STL中vector容器的运用和智能指针的实现
代码题:使用vector实现一个简单的本地注册登录系统 注册:将账号密码存入vector里面,注意防重复判断 登录:判断登录的账号密码是否正确 #include <iostream> #include <cstring> #include <cstdlib> #in…...