深度学习的下一个突破:从图像识别到情境理解
引言
过去十年,深度学习在图像识别领域取得了惊人的突破。从2012年ImageNet大赛上的AlexNet,到后来的ResNet、EfficientNet,再到近年来Transformer架构的崛起,AI已经能在许多任务上超越人类,比如人脸识别、目标检测、医学影像分析等。然而,这些系统虽然能识别图像中的物体,却并不真正“理解”它们的含义。
想象这样一个场景:一张图片里有一只狗、一只猫和一个倒在地上的水杯。传统的图像识别模型能准确地告诉你这些物体分别是什么,但却无法理解它们之间的关系——这只狗是不是刚刚撞到了桌子,导致水杯倒下?这只猫是不是在观察水杯,还在犹豫要不要去舔洒出来的水?当前的深度学习模型仍然缺乏这样的情境理解能力。
这正是AI发展的下一个关键挑战——让机器不仅能看到世界,还能理解世界。真正的智能不只是“识别物体”,更是“理解场景”,包括因果关系、行为意图和时间演化等更深层次的信息。
本文将探讨深度学习如何从图像识别迈向情境理解,分析当前的技术瓶颈,并介绍正在推动这一领域进步的新方法和应用场景。
一、从图像识别到情境理解的挑战
尽管深度学习在图像识别方面取得了显著进步,但让AI真正理解视觉场景仍然面临诸多挑战。这些挑战不仅涉及技术层面的问题,也关乎AI如何认知世界的本质。
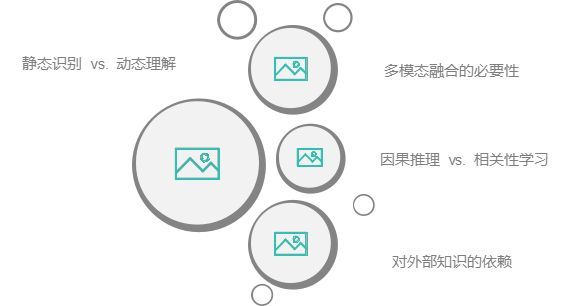
1、静态识别 vs. 动态理解
目前的图像识别技术主要关注单帧图像中的物体分类和检测,即“这是什么?”然而,在现实世界中,我们不仅要识别物体,还要理解它们之间的关系以及事件的动态发展。例如,在一张图片中,AI或许能识别出一个人正在奔跑,但它难以判断这个人是在追赶公交车,还是在逃离某个危险情境。情境理解要求AI能够结合时间、空间和背景信息,分析物体的行为模式和潜在意图。
2、多模态融合的必要性
人类在理解场景时,不仅依赖视觉信息,还会结合语言、声音、常识知识等多种信息来源。例如,在一张餐桌上的图片中,我们可以轻易推测出正在进行的是一场晚餐,而不仅仅是“桌子+盘子+食物”的简单组合。然而,当前的计算机视觉系统往往只依赖于视觉数据,缺乏对语言描述、语音对话甚至触觉信息的融合。这导致AI难以像人类一样,通过多种感官信息来形成完整的认知。
3、因果推理 vs. 相关性学习
深度学习的本质是通过海量数据学习模式和相关性,但它并不具备因果推理能力。例如,如果AI在大量数据中发现“雨天时路上行人打伞的概率很高”,它可以基于模式学习来预测某天的场景中可能会出现打伞的人,但它无法理解“因为下雨,所以人们需要打伞”这一因果关系。这种缺乏因果推理的局限,使得AI在遇到复杂情境时容易产生错误推断。例如,如果它看到一个人摔倒,它可能会简单地把这归结为“人类有摔倒的可能性”,而不是尝试理解是由于地面湿滑、身体失去平衡或其他外部因素导致的。
4、对外部知识的依赖
人类理解世界的方式不仅仅是通过视觉感知,还依赖于丰富的世界知识和经验。例如,一张图片显示一个人在厨房里切菜,人类可以推测出他可能正在准备一顿饭,因为我们拥有关于“做饭”的常识。然而,深度学习模型通常只学习有限的数据集,并不具备对世界的广泛知识,因此难以推理出更高级的情境信息。
挑战总结
要让AI从图像识别迈向真正的情境理解,需要突破以下几个关键难点:
从静态识别迈向动态分析,让AI理解事件的时间发展过程。
整合多模态信息,让视觉AI不仅依赖图像,还能结合语言、声音和知识库。
引入因果推理能力,让AI不只是发现模式,而是理解事件发生的逻辑关系。
让AI具备世界知识,帮助其理解人类社会的规则、物理世界的规律以及人们的行为动机。
这些挑战正推动计算机视觉和深度学习技术迈向新的方向,而在后续部分,我们将探讨目前正在发展的核心技术,以及它们如何帮助AI更接近真正的“情境理解”。
二、技术突破:迈向情境理解的核心方向
要让深度学习从简单的图像识别进化到真正的情境理解,需要突破多个关键技术瓶颈。目前,学术界和工业界正在从多个方向推进这些技术,包括视觉-语言模型、多模态融合、大规模世界知识整合、3D感知以及因果推理等。这些进展将帮助AI构建更接近人类的视觉认知能力。

1、视觉-语言模型(VLMs):用语言增强视觉理解
目前,像CLIP、BLIP、LLaVA(LLaMA + Vision)等视觉-语言模型,已经开始改变AI对图像的认知方式。它们不仅能识别图像中的物体,还能通过文本理解其含义。例如,CLIP 可以在没有特定标注的情况下,根据文本描述来搜索或分类图片,而LLaVA能像GPT一样分析图片并回答关于场景的复杂问题。
突破点:利用大规模文本数据帮助AI理解视觉概念,使AI不仅能看到物体,还能用语言表达其关系、作用和语境。
应用:智能搜索、视觉问答(VQA)、AI助手对图片的深度理解(如描述艺术作品的风格与情感)。
2、大模型与世界知识的结合:让AI具备“常识”
人类理解一张图片时,会利用过去的经验和世界知识。例如,看到一个人在厨房里切菜,我们能推测他在做饭,而不是随意玩弄刀具。AI当前的一个重大挑战是缺乏这样的常识认知。
突破点:结合大规模知识图谱(如ConceptNet、Wikidata)和大模型(如GPT-4、Gemini),让AI能基于已有知识推理场景的真实含义。
应用:智能客服(基于图片推测用户意图)、医疗诊断(结合病历和影像判断病因)。
3、3D感知与场景重建:从2D到真实世界的理解
传统的图像识别依赖2D图像,但真实世界是三维的。为了更好地理解场景,AI需要具备3D感知能力。
突破点:NeRF(神经辐射场)、三维点云技术、深度学习驱动的3D场景重建,使AI能理解物体的空间关系、尺度以及环境。
应用:自动驾驶(理解道路结构、车辆动态)、机器人导航(精准避障和路径规划)、AR/VR(增强现实与交互体验)。
4、视频理解与事件推理:跨越时间维度的智能
大多数视觉AI仍然局限于单帧图像的理解,而人类认知是基于时间的。视频分析技术正在向深层次的事件推理发展,重点在于预测和理解行为。
突破点:基于Transformer的时序模型(如TimeSformer)、视频大模型(如VideoGPT),能够分析视频中的行为模式,理解因果关系。
应用:安防监控(预测异常行为,如店铺盗窃)、体育分析(理解球员战术和运动轨迹)、影视智能剪辑(自动识别精彩片段)。
5、因果推理:让AI理解“为什么”而非“是什么”
目前的深度学习系统主要依赖数据模式匹配,而不是因果推理。例如,AI可以识别出“雨天人们打伞”这一模式,但难以理解“因为下雨,人们才打伞”。
突破点:因果推理方法(如贝叶斯网络、结构方程建模)正在与深度学习结合,使AI能够建立因果关系,而不仅仅是统计相关性。
应用:医学诊断(推测病因,而不仅是发现病症)、经济预测(分析政策变化对市场的真实影响)、工业故障检测(判断设备损坏的根本原因)。
总结
迈向情境理解,AI需要突破单纯的视觉识别,向更高级的推理能力发展。视觉-语言融合、大模型知识整合、3D感知、时间维度理解以及因果推理,是当前推动深度学习进化的关键技术方向。随着这些技术的不断进步,AI将逐步从“看到”世界迈向“理解”世界,使其在自动驾驶、智能安防、机器人交互、医疗诊断等领域发挥更强大的作用。
三、应用场景:AI如何真正理解世界
当AI不仅能识别图像中的物体,还能理解场景、推测意图、预测事件时,它的应用价值将大幅提升。从自动驾驶到智能安防,从医疗诊断到机器人交互,情境理解技术将赋予AI更接近人类的感知能力,让它真正“看懂”世界。
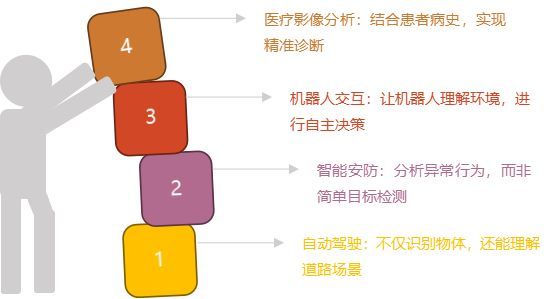
1、自动驾驶:不仅识别物体,还能理解道路场景
传统的自动驾驶算法主要依赖目标检测和路径规划,例如识别红绿灯、行人、车辆等元素。然而,复杂的道路环境需要更深层的理解,例如:
预测行人的意图:AI需要判断一个行人是否只是站在路边,还是即将横穿马路。
识别道路上的隐性风险:比如前方一辆车突然减速,可能是因为前方有障碍物,AI需要据此调整驾驶策略。
结合交通法规和常识:理解非正式交通规则,如某些地区的“礼让行人”文化,或者观察其他驾驶员的行为来预测潜在危险。
情境理解可以让自动驾驶系统更安全、更智能,真正像人类驾驶员一样做出合理决策。
2、智能安防:分析异常行为,而非简单目标检测
当前的安防系统主要依赖于摄像头检测异常物体,比如非法入侵、遗弃物品等。然而,许多危险行为在发生前并不会表现为明显的“异常目标”,而是需要结合背景信息进行推理。例如:
在地铁站,一名乘客徘徊不定,时而接近站台边缘,AI可以结合行人正常行为模式,判断其是否有坠轨风险。
在商场,AI不仅检测到顾客拿起商品,还能分析其购物行为是否符合正常模式,帮助商家识别潜在盗窃行为。
在智慧城市管理中,AI可以通过视频分析,判断人群密集区域是否存在踩踏风险,并提前预警。
情境理解让安防系统从“被动监控”升级为“主动预测”,提升公共安全。
3、机器人交互:让机器人理解环境,进行自主决策
家庭服务机器人、工业机器人乃至人形机器人,只有真正理解环境,才能提供更自然的交互体验。例如:
家用机器人:当机器人看到主人在厨房忙碌,并听到水沸腾的声音,它能推测主人可能需要帮忙关火,而不仅仅是识别“锅”和“水”。
工厂自动化:机器人在生产线上需要根据工人的动作和生产节奏进行调整,而不仅仅是机械地执行预设任务。
智能仓储:AI机器人可以通过摄像头分析货物的摆放情况,理解哪些商品需要补货,而不是仅仅依赖条形码扫描。
有了情境理解,机器人将变得更加智能,真正具备“看懂”世界的能力。
4、医疗影像分析:结合患者病史,实现精准诊断
传统的医学影像AI主要依赖于图像分类,比如判断X光片或MRI扫描是否存在肿瘤。然而,医生在做诊断时,不仅仅依赖单张影像,而是结合患者的病史、症状、实验室检测等多方面信息。因此,AI的情境理解能力对医学诊断至关重要,例如:
在肺部CT扫描中,AI可以结合患者是否有长期吸烟史,调整诊断的置信度,避免误判。
在脑部MRI中,AI可以结合患者的年龄、家族遗传病史,分析是否有阿尔茨海默症的早期迹象。
在急诊中,AI可以实时分析多种传感器数据,例如结合患者的心电图、血压和体温,做出综合判断,而不仅仅依赖影像数据。
通过情境理解,AI可以提供更精准的医学诊断,减少误诊率,提高医疗效率。
总结
AI的情境理解能力正在推动多个行业的智能化升级。从自动驾驶的智能决策,到智能安防的行为预测,从机器人交互的自然化,到医疗诊断的精准化,AI正在从“识别世界”走向“理解世界”。未来,随着多模态学习、因果推理和大模型的发展,AI的情境理解能力将不断提升,使其在更多场景中发挥更大价值。
四、未来展望与挑战
随着深度学习从图像识别迈向情境理解,AI正在逐步接近人类的视觉认知能力。然而,要让AI真正理解世界,而不仅仅是“看见”,仍然面临诸多挑战。未来的发展将集中在更强大的模型、更高效的数据利用、因果推理能力的增强,以及伦理与安全问题的应对。
1、未来展望:AI如何迈向更高层次的理解?
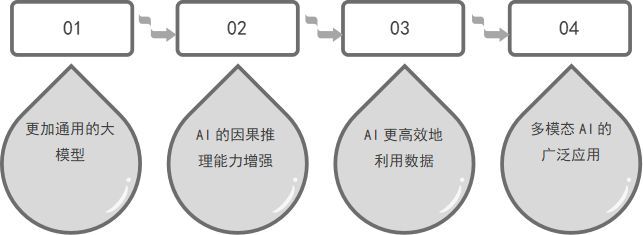
更加通用的大模型
未来的AI不仅需要掌握视觉信息,还要结合语言、语音、文本、物理世界知识,形成“通用情境理解”能力。例如,下一代AI可以在看到一张手术室的照片时,不仅能识别器械和医生,还能基于医学知识推测手术的类型和风险。
具备通用情境理解能力的AI,将在医疗、自动驾驶、智能机器人等领域发挥更大作用。
AI的因果推理能力增强
未来的AI将超越基于相关性的模式学习,逐步具备因果推理能力。例如,在自动驾驶中,AI不仅能识别行人,还能推测行人的意图,判断其是否即将横穿马路。
结合贝叶斯网络、结构因果模型等方法,使AI能够基于情境推测事件的发展,而不仅仅是做静态分类。
AI更高效地利用数据
目前的大模型依赖海量数据训练,未来的AI需要具备“少样本学习”(Few-shot Learning)和“零样本学习”(Zero-shot Learning)能力。
通过强化学习、自监督学习等方法,使AI能在有限的数据情况下,依然具备出色的情境理解能力。
多模态AI的广泛应用
AI将不再仅仅依赖视觉,而是结合语音、文本、物理感知,真正做到“感知+理解”。
例如,未来的智能家居系统,能通过摄像头、语音传感器、温度传感器等多种信息源,判断用户的意图并做出最合理的响应。
2、仍然存在的挑战:AI能否真正理解世界?
计算资源的巨大消耗
训练具备情境理解能力的大模型,需要极高的计算资源。如何提高AI的计算效率,同时降低能耗,是未来技术突破的关键。
数据偏见与泛化能力
AI对情境的理解,往往依赖于训练数据。但如果数据存在偏见,AI的理解能力也可能受到限制。例如,如果某个医疗AI主要基于西方国家的数据训练,它可能无法很好地适用于亚洲患者。
如何让AI具备更强的泛化能力,适应不同的环境,是一个重要挑战。
因果推理的局限性
目前的因果推理方法,仍然无法完全复制人类的思维方式。例如,一个人看到倒地的水杯,会立刻推测它是被某个外力打翻的,而AI仍然难以在没有明确数据支持的情况下做出类似推理。
未来需要结合更多的知识图谱、逻辑推理方法,让AI真正具备因果推理能力。
伦理与安全问题
具备情境理解能力的AI,如果被滥用,可能会带来伦理问题。例如,过于精准的行为分析,可能会侵犯用户隐私。
如何在提升AI智能的同时,确保其在合规、安全的范围内使用,将成为未来发展的重要议题。
结语
从图像识别到情境理解,AI正在从“看得见”走向“看得懂”。尽管面临计算资源、因果推理、数据偏见等挑战,但未来随着大模型、因果推理、多模态融合技术的突破,AI有望在更多复杂场景中发挥作用,实现真正的智能化。
结论
从图像识别到情境理解,深度学习正在迈向一个全新的阶段。过去的AI能够准确识别物体,但缺乏对场景、意图和因果关系的理解。而如今,借助视觉-语言模型、多模态融合、因果推理和3D感知等技术,AI正逐步从“看得见”走向“看得懂”,在自动驾驶、智能安防、医疗诊断、机器人交互等领域展现出巨大的潜力。
然而,真正的情境理解仍然面临诸多挑战,例如计算资源消耗、数据偏见、因果推理的局限性以及伦理安全问题。未来的发展需要更强大的通用模型、更高效的数据利用方式,以及更完善的安全与合规机制,才能让AI真正具备人类般的理解能力。
尽管道路充满挑战,但情境理解无疑是AI发展的下一个关键突破口。当AI不再只是被动地识别信息,而是能够主动推理、预测和决策时,它将彻底改变我们与技术的交互方式,为社会带来前所未有的智能化变革。
相关文章:
深度学习的下一个突破:从图像识别到情境理解
引言 过去十年,深度学习在图像识别领域取得了惊人的突破。从2012年ImageNet大赛上的AlexNet,到后来的ResNet、EfficientNet,再到近年来Transformer架构的崛起,AI已经能在许多任务上超越人类,比如人脸识别、目标检测、医…...

oracle查询是否锁表了
--查看当前数据库中被锁定的表数量 SELECT COUNT(*) FROM v$locked_object; select * from v$locked_object; --查看具体被锁定的表 SELECT b.owner, b.object_name, a.session_id, a.locked_mode FROM v$locked_object a, dba_objects b WHERE b.object_id a.object_id…...

从Oracle和TiDB的HTAP说起
除了数据库行业其他技术群体很多不知道HTAP的 时至今日还是有很多人迷信Hadoop,觉得大数据就是Hadoop。这是不正确的。也难怪这样,很多人OLTP和OLAP也分不清,何况HTAP。 Oracle是垂直方向实现 TiDB是水平方向实现 我个人认为这是两种流派…...
深入解析Spring Boot自动装配:原理、设计与最佳实践
引言 Spring Boot作为现代Java开发中的一股清流,凭借其简洁、快速和高效的特性,迅速赢得了广大开发者的青睐。而在Spring Boot的众多特性中,自动装载(Auto-configuration)无疑是最为耀眼的明珠之一。本文将深入剖析Sp…...

初识数据结构——算法效率的“两面性”:时间与空间复杂度全解析
📊 算法效率的“两面性”:时间与空间复杂度全解析 1️⃣ 如何衡量算法好坏? 举个栗子🌰:斐波那契数列的递归实现 public static long Fib(int N) {if(N < 3) return 1;return Fib(N-1) Fib(N-2); }问题…...

【USRP】srsRAN 开源 4G 软件无线电套件
srsRAN 是SRS开发的开源 4G 软件无线电套件。 srsRAN套件包括: srsUE - 具有原型 5G 功能的全栈 SDR 4G UE 应用程序srsENB - 全栈 SDR 4G eNodeB 应用程序srsEPC——具有 MME、HSS 和 S/P-GW 的轻量级 4G 核心网络实现 安装系统 Ubuntu 20.04 USRP B210 sudo …...
《从零搭建Vue3项目实战》(AI辅助搭建Vue3+ElemntPlus后台管理项目)零基础入门系列第二篇:项目创建和初始化
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 《从零搭建Vue3项目实战》(AI辅助…...
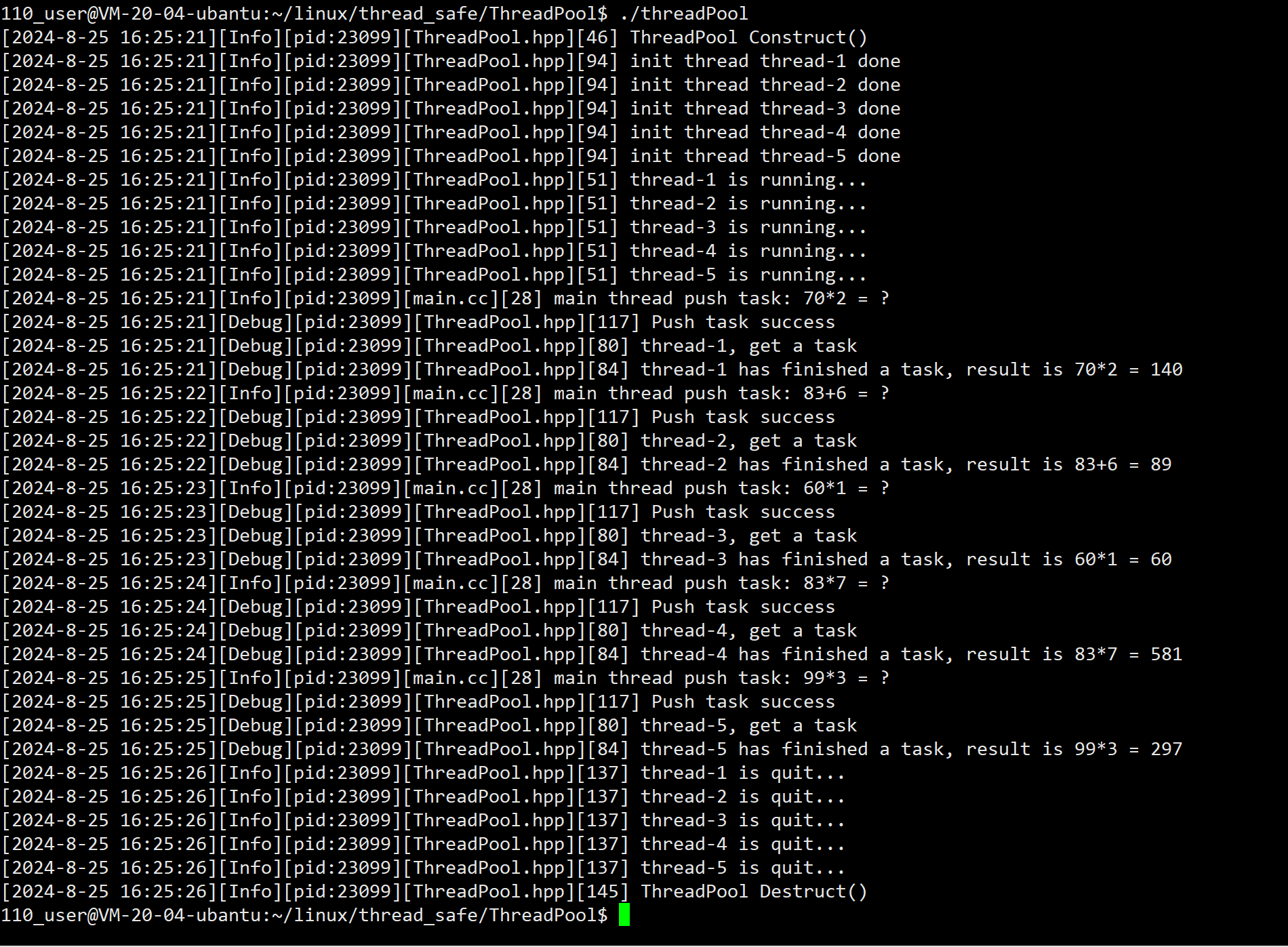
简单线程池实现
线程池的概念 线程池内部可以预先去进行创建出一批线程,对于每一个线程,它都会周期性的进行我们的任务处理。 线程内部在维护一个任务队列,其中我们外部可以向任务队列里放任务,然后内部的线程从任务队列里取任务,如…...
CentOS7 安装 LLaMA-Factory
虚拟机尽量搞大 硬盘我配置了80G,内存20G 下载源码 git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git 如果下载不了,可以进入github手动下载,然后在传入服务器。 也可以去码云搜索后下载 安装conda CentOS7安装conda…...
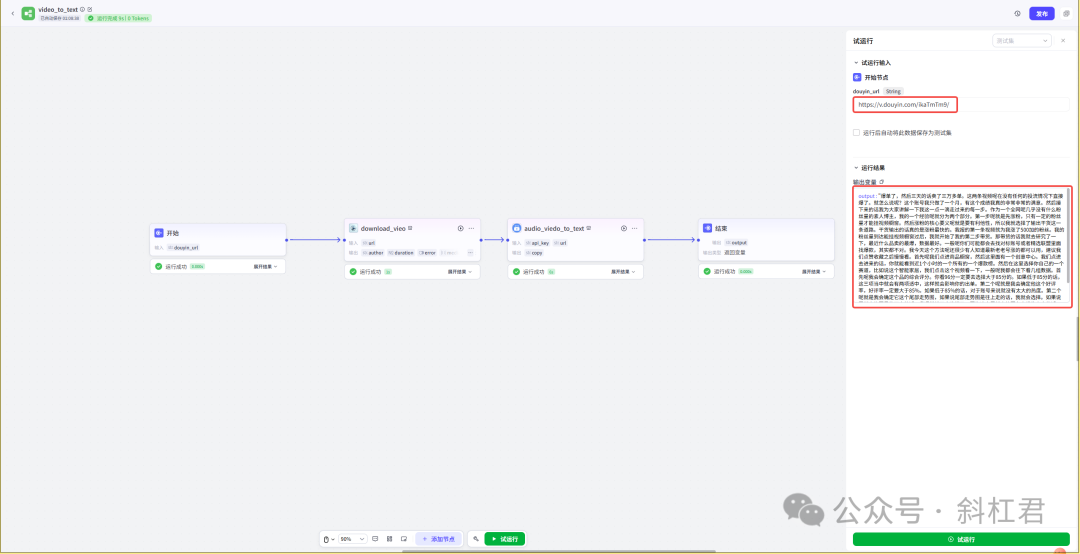
最新扣子(Coze)案例教程:最新抖音视频文案提取方法替代方案,音频视频提取文案插件制作,手把手教学,完全免费教程
👨💻 星球群同学反馈,扣子平台的视频提取插件已下架,很多智能体及工作流不能使用,斜杠君这里研究了一个替代方案分享给大家。 方案原理:无论是任何视频或音频转文案,我们提取的方式首先都是要…...

三防笔记本有什么用 | 三防笔记本有什么特别
在现代社会,随着科技的不断进步,笔记本电脑已经成为人们工作和生活的重要工具。然而,在一些特殊的工作环境和极端条件下,普通笔记本电脑往往难以满足需求。这时,三防笔记本以其独特的设计和卓越的性能,成为…...
笔记250406)
硬盘分区格式之GPT(GUID Partition Table)笔记250406
硬盘分区格式之GPT(GUID Partition Table)笔记250406 GPT(GUID Partition Table)硬盘分区格式详解 GPT(GUID Partition Table)是替代传统 MBR 的现代分区方案,专为 UEFI(统一可扩展固…...

adb检测不到原来的设备List of devices attached解决办法
进设备管理器-通用串行总线设备 卸载无法检测到的设备驱动 重新拔插数据线...
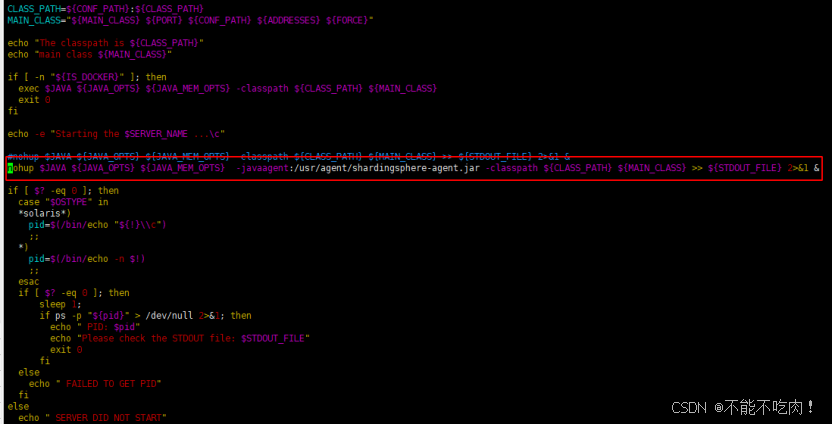
案例分享(七):实现Apache-sharding-proxy的监控
案例分享(七):实现Apache-sharding-proxy的监控 背景部署流程背景 因业务需求,实现Apache-sharding-proxy的监控(基于Apache-sharding-agent)。 部署流程 1.下载agent的包,选择与sharding版本一致,要不然无法启动sharding 2.点击5.3.0之后可以看到有sharding,proxy…...
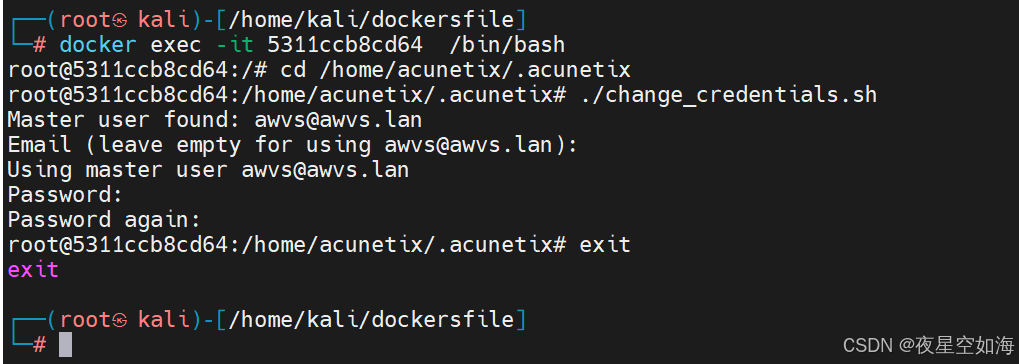
docker 安装 awvs15
安装好 docker bash <(curl -sLk https://www.fahai.org/aDisk/Awvs/check.sh) xrsec/awvs:v15等待完成后访问即可 地址: https://server_ip:3443/#/login UserName: awvsawvs.lan PassWord: Awvsawvs.lan修改密码 docker ps -a //查看容器,找到相应id d…...

Kafka在Vue和Spring Boot中的使用实例
Kafka在Vue和Spring Boot中的使用实例 一、项目概述 本项目演示了如何在Vue前端和Spring Boot后端中集成Kafka,实现实时消息的发送和接收,以及数据的实时展示。 后端实现:springboot配置、kafka配置、消息模型和仓库、消息服务和消费者、we…...

JSON 是什么?通俗详解
**JSON 是什么?通俗详解** --- ### **1. 一句话总结** **JSON(JavaScript Object Notation)** 是一种轻量级的 **数据交换格式**,就像“数据的快递包装盒”,用来在不同系统之间 **传递和存储信息**,简单易…...

Flutter:Flutter SDK版本控制,fvm安装使用
1、首先已经安装了Dart,cmd中执行 dart pub global activate fvm2、windows配置系统环境变量 fvm --version3、查看本地已安装的 Flutter 版本 fvm releases4、验证当前使用的 Flutter 版本: fvm flutter --version5、切换到特定版本的 Flutter fvm use …...
碰一碰发视频源头开发技术服务商
碰一碰发视频系统 随着短视频平台的兴起,用户的创作与分享需求日益增长。而如何让视频分享更加便捷、有趣,则成为各大平台优化的重点方向之一。抖音作为国内领先的短视频平台,在2023年推出了“碰一碰”功能,通过近距离通信技术实…...

Oracle 23ai Vector Search 系列之4 VECTOR数据类型和基本操作
文章目录 Oracle 23ai Vector Search 系列之4 VECTOR数据类型和基本操作VECTOR 数据类型基本语法Vector 维度限制和向量大小向量存储格式(DENSE vs SPARSE)1. DENSE存储2. SPARSE存储3. 内部存储与空间计算 Oracle VECTOR数据类型的声明格式VECTOR基本操…...

Java面试38-Dubbo是如何动态感知服务下线的?
首先,Dubbo默认采用Zookeeper实现服务注册与服务发现,就是多个Dubbo服务之间的通信地址,是使用Zookeeper来维护的。在Zookeeper上,会采用树形结构的方式来维护Dubbo服务提供端的协议地址,Dubbo服务消费端会从Zookeeper…...
C++day8
思维导图 牛客练习 练习 #include <iostream> #include <cstring> #include <cstdlib> #include <unistd.h> #include <sstream> #include <vector> #include <memory> using namespace std; class user{ public: …...
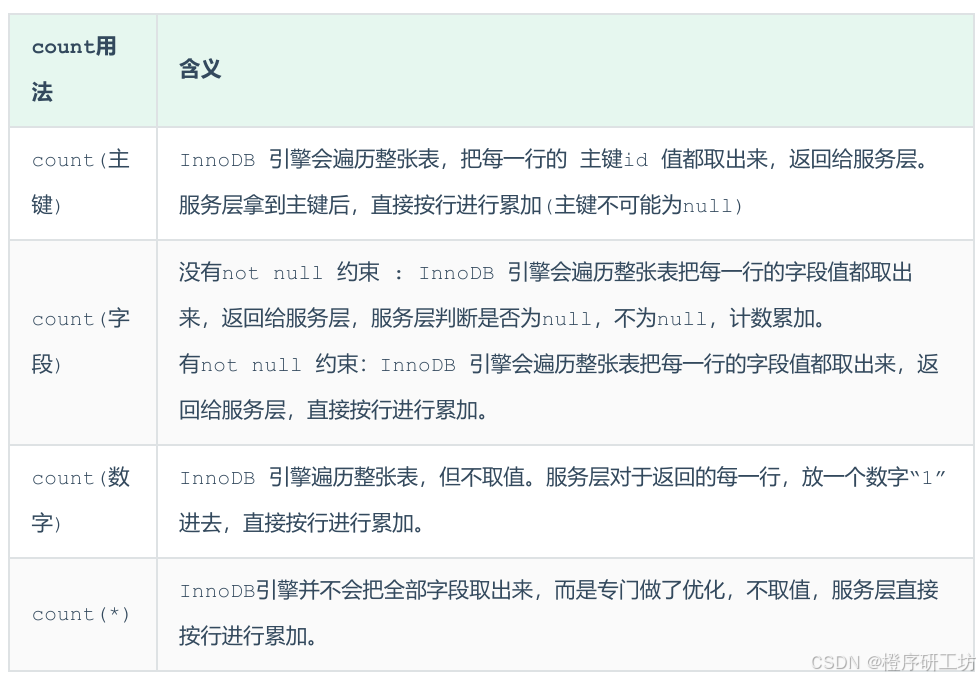
MySQL的进阶语法8(SQL优化——insert、主键、order by、group by、limit、count和update)
目录 一、插入数据 1.1 insert 1.2 大批量插入数据 二、主键优化 2.1 数据组织方式 2.2 页分裂 2.2.1 主键顺序插入效果 2.2.2 主键乱序插入效果 2.3 页合并 2.4 索引设计原则 三、order by优化 3.1 执行以下两条语句(无索引) 3.2 创建索引…...

STM32 基础2
STM32中断响应过程 1、中断源发出中断请求。 2、判断处理器是否允许中断,以及该中断源是否被屏蔽。 3、中断优先级排队。 4、处理器暂停当前程序,保护断点地址和处理器的当前状态,根据中断类型号,查找中断向量表,转到…...

前端单页应用性能优化全指南:从加载提速到极致体验
一、SPA性能瓶颈深度剖析 1.1 核心性能指标解读 指标健康阈值测量工具优化方向FCP (首次内容渲染)< 1.8sLighthouse资源加载优化TTI (可交互时间)< 3.5sWebPageTestJavaScript优化LCP (最大内容渲染)< 2.5sChrome DevTools渲染性能优化CLS (布局偏移)< 0.1PageSp…...

自然语言处理利器NLTK:从入门到核心功能解析
文章目录 一、NLP领域的基石工具包二、NLTK核心模块全景解析1 数据获取与预处理2 语言特征发现3 语义与推理 三、设计哲学与架构优势1 四维设计原则2 性能优化策略 四、典型应用场景1 学术研究2 工业实践 五、生态系统与未来演进 一、NLP领域的基石工具包 自然语言工具包&…...

简述Unity对多线程的支持限制和注意事项
Unity是一个以单线程为核心设计的游戏引擎,其主线程负责渲染、物理模拟、脚本更新(如Update和FixedUpdate)等核心功能。虽然Unity允许开发者使用C#的多线程功能(如System.Threading命名空间)来创建和管理线程ÿ…...

Mysql 中有哪些日志结构?
在 MySQL 中,日志文件是非常重要的,它们用于记录数据库的各类活动,帮助管理员进行监控、调试、恢复、以及优化数据库性能。MySQL 提供了几种类型的日志,每种日志都有其特定的用途。以下是 MySQL 中常见的几种日志类型:…...

【第2月 day17】Matplotlib 新手设计的直方图与饼图学习内容
以下是专为Python新手设计的直方图与饼图学习内容,包含基础知识、代码演示及注意事项: 一、直方图(Histogram) 1. 直方图的作用 展示数据分布情况(如年龄分布、成绩分布)观察数据集中趋势、离散程度 2. …...
使用Docker安装及使用最新版本的Jenkins
1. 拉取镜像 通过Windows powerShell执行命令行(2选1): -- 长期支持版 docker pull jenkins/jenkins:lts-- 最新版 docker pull jenkins/jenkins:latest 2. 创建并执行容器 你可以通过以下命令来运行Jenkins容器,执行命令&…...