大模型的输出:温度对输出的影响
大模型的输出:温度对输出的影响
温度T
在大模型(如人工智能语言模型)中,“温度”(Temperature)是一个重要的参数,用于控制模型生成文本的随机性和多样性。它通常用于调整模型输出的概率分布,从而影响生成内容的风格和特性。以下是对“温度”参数的详细解释:
1. 温度的基本概念
温度参数决定了模型在生成文本时的“创造性”和“确定性”程度。具体来说,温度参数影响模型在选择下一个词时的概率分布。
-
低温度(接近0):
- 当温度很低时,模型倾向于选择概率最高的词。这意味着生成的文本更加“确定性”和“可预测”,通常更接近训练数据中的常见模式。低温度生成的文本往往更稳定、更符合常规,但可能缺乏多样性。
- 例如,如果模型被训练来生成新闻报道,低温度可能会生成非常标准、事实性强的句子。
-
高温度(接近1或更高):
- 当温度很高时,模型会更随机地选择下一个词,即使这个词的概率较低。这使得生成的文本更加多样化和创造性,但也可能包含更多不符合常规的内容。
- 例如,高温度可能会生成一些富有想象力的、甚至带有一些幽默或荒诞色彩的句子。
2. 温度的数学原理
在技术层面,温度参数通过调整模型输出的概率分布来实现。具体来说,模型在生成下一个词时,会根据每个词的预测概率进行选择。温度参数 $ T $ 会影响这些概率的分布。
- 公式表示:
假设模型预测下一个词的概率分布为 $ P(w) $,温度参数 $ T $ 会将这个分布调整为:
P ′ ( w ) = exp ( log P ( w ) / T ) ∑ w ′ exp ( log P ( w ′ ) / T ) P'(w) = \frac{\exp(\log P(w) / T)}{\sum_{w'} \exp(\log P(w') / T)} P′(w)=∑w′exp(logP(w′)/T)exp(logP(w)/T)
其中,$ \exp $ 是指数函数,$ \log P(w) $ 是原始概率的对数。温度参数 $ T $ 越高,调整后的概率分布越接近均匀分布,随机性越强。
3. 温度的实际应用
-
低温度的应用场景:
- 适合生成需要高准确性和稳定性的内容,如学术论文、新闻报道、技术文档等。这些场景要求生成的文本严格遵循语言规则和事实,避免过多的创造性偏差。
-
高温度的应用场景:
- 适合需要创意和多样性的内容,如创意写作、诗歌生成、故事创作等。这些场景鼓励模型生成新颖、独特的文本,即使可能会有一些不符合常规的表达。
4.具体的例子
- 模型的原始输出
假设模型在没有温度系数调整的情况下,对这三个单词的原始分数(logits)为:
-
cat:2.0 -
dog:1.0 -
fish:0.5
这些分数表示模型对每个单词的“偏好”程度。接下来,我们通过softmax函数将这些分数转换为概率分布:
[p_i=\frac{\exp(x_i)}{\sum_j\exp(x_j)}]
计算得到的概率分布为:
-
p ( cat ) = exp ( 2.0 ) exp ( 2.0 ) + exp ( 1.0 ) + exp ( 0.5 ) ≈ 0.67 p(\text{cat})=\frac{\exp(2.0)}{\exp(2.0)+\exp(1.0)+\exp(0.5)}\approx 0.67 p(cat)=exp(2.0)+exp(1.0)+exp(0.5)exp(2.0)≈0.67
-
p ( dog ) = exp ( 1.0 ) exp ( 2.0 ) + exp ( 1.0 ) + exp ( 0.5 ) ≈ 0.24 p(\text{dog})=\frac{\exp(1.0)}{\exp(2.0)+\exp(1.0)+\exp(0.5)}\approx 0.24 p(dog)=exp(2.0)+exp(1.0)+exp(0.5)exp(1.0)≈0.24
-
p ( fish ) = exp ( 0.5 ) exp ( 2.0 ) + exp ( 1.0 ) + exp ( 0.5 ) ≈ 0.09 p(\text{fish})=\frac{\exp(0.5)}{\exp(2.0)+\exp(1.0)+\exp(0.5)}\approx 0.09 p(fish)=exp(2.0)+exp(1.0)+exp(0.5)exp(0.5)≈0.09
在这种情况下,模型更倾向于选择“cat”,因为它的概率最高。
2. 加入温度系数的影响
现在我们引入温度系数 T T T,并观察不同温度值对概率分布的影响。
低温度系数( T = 0.5 T=0.5 T=0.5)
当温度系数较低时,概率分布会变得更加集中。计算如下:
-
p ( cat ) = exp ( 2.0 / 0.5 ) exp ( 2.0 / 0.5 ) + exp ( 1.0 / 0.5 ) + exp ( 0.5 / 0.5 ) ≈ 0.95 p(\text{cat})=\frac{\exp(2.0/0.5)}{\exp(2.0/0.5)+\exp(1.0/0.5)+\exp(0.5/0.5)}\approx 0.95 p(cat)=exp(2.0/0.5)+exp(1.0/0.5)+exp(0.5/0.5)exp(2.0/0.5)≈0.95
-
p ( dog ) = exp ( 1.0 / 0.5 ) exp ( 2.0 / 0.5 ) + exp ( 1.0 / 0.5 ) + exp ( 0.5 / 0.5 ) ≈ 0.05 p(\text{dog})=\frac{\exp(1.0/0.5)}{\exp(2.0/0.5)+\exp(1.0/0.5)+\exp(0.5/0.5)}\approx 0.05 p(dog)=exp(2.0/0.5)+exp(1.0/0.5)+exp(0.5/0.5)exp(1.0/0.5)≈0.05
-
p ( fish ) = exp ( 0.5 / 0.5 ) exp ( 2.0 / 0.5 ) + exp ( 1.0 / 0.5 ) + exp ( 0.5 / 0.5 ) ≈ 0.00 p(\text{fish})=\frac{\exp(0.5/0.5)}{\exp(2.0/0.5)+\exp(1.0/0.5)+\exp(0.5/0.5)}\approx 0.00 p(fish)=exp(2.0/0.5)+exp(1.0/0.5)+exp(0.5/0.5)exp(0.5/0.5)≈0.00
在这种情况下,模型几乎肯定会选择“cat”,因为它的概率接近1,而其他单词的概率非常低。
高温度系数( T = 2.0 T=2.0 T=2.0)
当温度系数较高时,概率分布会变得更加平缓。计算如下:
-
p ( cat ) = exp ( 2.0 / 2.0 ) exp ( 2.0 / 2.0 ) + exp ( 1.0 / 2.0 ) + exp ( 0.5 / 2.0 ) ≈ 0.55 p(\text{cat})=\frac{\exp(2.0/2.0)}{\exp(2.0/2.0)+\exp(1.0/2.0)+\exp(0.5/2.0)}\approx 0.55 p(cat)=exp(2.0/2.0)+exp(1.0/2.0)+exp(0.5/2.0)exp(2.0/2.0)≈0.55
-
p ( dog ) = exp ( 1.0 / 2.0 ) exp ( 2.0 / 2.0 ) + exp ( 1.0 / 2.0 ) + exp ( 0.5 / 2.0 ) ≈ 0.35 p(\text{dog})=\frac{\exp(1.0/2.0)}{\exp(2.0/2.0)+\exp(1.0/2.0)+\exp(0.5/2.0)}\approx 0.35 p(dog)=exp(2.0/2.0)+exp(1.0/2.0)+exp(0.5/2.0)exp(1.0/2.0)≈0.35
-
p ( fish ) = exp ( 0.5 / 2.0 ) exp ( 2.0 / 2.0 ) + exp ( 1.0 / 2.0 ) + exp ( 0.5 / 2.0 ) ≈ 0.10 p(\text{fish})=\frac{\exp(0.5/2.0)}{\exp(2.0/2.0)+\exp(1.0/2.0)+\exp(0.5/2.0)}\approx 0.10 p(fish)=exp(2.0/2.0)+exp(1.0/2.0)+exp(0.5/2.0)exp(0.5/2.0)≈0.10
在这种情况下,模型的选择更加随机,所有单词都有一定的概率被选中。
3. 总结
通过这个例子,我们可以看到温度系数如何影响模型的概率分布:
-
低温度系数:使概率分布更加集中,模型更倾向于选择高概率的单词,生成结果更加稳定和一致。
-
高温度系数:使概率分布更加平缓,模型的选择更加随机,生成结果更加多样化和富有创造性。
这个机制在实际应用中非常重要,比如在对话生成中,高温度系数可以使对话更加自然和有趣;而在需要准确性的任务(如机器翻译)中,低温度系数可能更合适。
模型的输出
在大语言模型中,模型输出的概率分布用于决定最终生成的单词或标记(token)。这个过程通常通过采样方法来实现,常见的采样方法包括贪婪采样(Greedy Sampling)、随机采样(Random Sampling)、Top-K 采样和Top-p 采样。以下分别介绍这些方法及其与概率分布的关系:
1.贪婪采样(Greedy Sampling)
贪婪采样是最简单的方法,它直接选择概率最高的单词作为输出。
- 工作原理:
模型生成一个概率分布,例如:
-
p ( cat ) = 0.67 p(\text{cat})=0.67 p(cat)=0.67
-
p ( dog ) = 0.24 p(\text{dog})=0.24 p(dog)=0.24
-
p ( fish ) = 0.09 p(\text{fish})=0.09 p(fish)=0.09
-
模型选择概率最高的单词“cat”作为输出。
- 优点:
-
确定性强,生成结果稳定。
-
计算效率高,因为它只需要找到概率最高的单词。
- 缺点:
- 缺乏多样性,总是选择最可能的单词,可能导致生成的文本单调。
2.随机采样(Random Sampling)
随机采样根据概率分布随机选择单词。每个单词被选中的概率与其概率值成正比。
- 工作原理
- 模型生成一个概率分布,例如:
p ( cat ) = 0.67 p(\text{cat})=0.67 p(cat)=0.67
p ( dog ) = 0.24 p(\text{dog})=0.24 p(dog)=0.24
p ( fish ) = 0.09 p(\text{fish})=0.09 p(fish)=0.09
模型根据这些概率随机选择一个单词。例如,“cat”被选中的概率为67%,“dog”为24%,“fish”为9%。
- 优点:
- 生成结果具有一定的多样性,因为每次采样可能会得到不同的单词。
- 缺点:
- 如果概率分布非常不平衡(例如一个单词的概率远高于其他单词),生成结果可能仍然缺乏多样性。
3.Top-K 采样
Top-K 采样是一种改进的随机采样方法,它只从概率最高的K个单词中随机选择一个。
- 工作原理
- 模型生成一个概率分布,例如:
p ( cat ) = 0.67 p(\text{cat})=0.67 p(cat)=0.67
p ( dog ) = 0.24 p(\text{dog})=0.24 p(dog)=0.24
p ( fish ) = 0.09 p(\text{fish})=0.09 p(fish)=0.09
-
假设 K = 2 K=2 K=2,模型只考虑概率最高的两个单词“cat”和“dog”。
-
在这两个单词中,根据它们的相对概率( p ( cat ) = 0.67 p(\text{cat})=0.67 p(cat)=0.67和 p ( dog ) = 0.24 p(\text{dog})=0.24 p(dog)=0.24)进行随机选择。
- 优点:
- 限制了选择范围,避免了低概率单词的干扰,同时保持了一定的多样性。
- 缺点:
- 如果 K K K设置得太小,可能会限制模型的创造力;如果 K K K设置得太大,又可能失去Top-K采样的意义。
4.Top-p 采样(Nucleus Sampling)
Top-p 采样是一种更灵活的采样方法,它只从累积概率达到某个阈值 p p p的单词中随机选择一个。
- 工作原理
- 模型生成一个概率分布,例如:
p ( cat ) = 0.67 p(\text{cat})=0.67 p(cat)=0.67
p ( dog ) = 0.24 p(\text{dog})=0.24 p(dog)=0.24
p ( fish ) = 0.09 p(\text{fish})=0.09 p(fish)=0.09
-
假设 p = 0.9 p=0.9 p=0.9,模型按概率从高到低累加,直到累积概率达到或超过0.9。
-
累加顺序: 0.67 0.67 0.67(cat)+ 0.24 0.24 0.24(dog)= 0.91 0.91 0.91(超过0.9)
-
因此,模型只从“cat”和“dog”中随机选择一个单词。
- 优点:
-
动态调整选择范围,避免了低概率单词的干扰,同时保持了多样性。
-
比Top-K采样更灵活,因为它可以根据概率分布的形状自动调整候选单词的数量。
- 缺点:
- 实现相对复杂,需要计算累积概率。
5.实际应用中的选择
在实际应用中,选择哪种采样方法取决于具体任务的需求:
-
贪婪采样:适用于需要稳定输出的场景,例如机器翻译。
-
随机采样:适用于需要一定多样性的场景,例如文本生成。
-
Top-K 采样:适用于需要平衡稳定性和多样性的场景。
-
Top-p 采样:适用于需要灵活控制多样性的场景,尤其是在生成任务中。
通过这些采样方法,模型可以根据概率分布生成多样化的输出,同时满足不同的应用需求。
相关文章:

大模型的输出:温度对输出的影响
大模型的输出:温度对输出的影响 温度T 在大模型(如人工智能语言模型)中,“温度”(Temperature)是一个重要的参数,用于控制模型生成文本的随机性和多样性。它通常用于调整模型输出的概率分布&a…...

Unity中Spine骨骼动画完全指南:从API详解到避坑实战
Unity中Spine骨骼动画完全指南:从API详解到避坑实战 一、为什么要选择Spine? Spine作为专业的2D骨骼动画工具,相比传统帧动画可节省90%资源量。在Unity中的典型应用场景包括: 角色换装系统(通过插槽替换部件)复杂连招系统(动画混合与过渡)动态表情系统(面部骨骼控制)…...

汇丰eee2
聚合和继承有什么样的优点和区别,什么时候决定用,现实开发中,选择哪一种去使用? 聚合的优点: 灵活性: 聚合是一种弱耦合关系,被聚合对象可以独立存在,可以灵活地替换或修改被聚合对…...
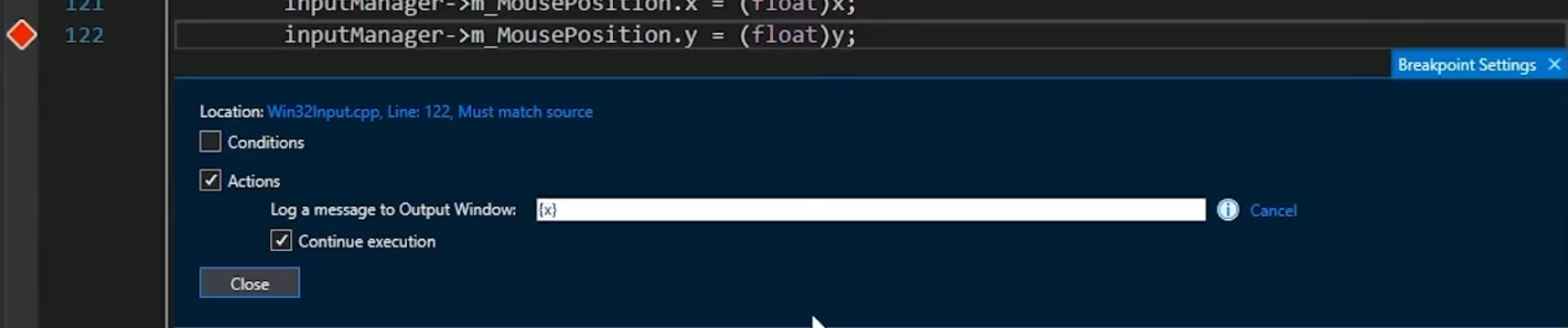
C++Cherno 学习笔记day17 [66]-[70] 类型双关、联合体、虚析构函数、类型转换、条件与操作断点
b站Cherno的课[66]-[70] 一、C的类型双关二、C的union(联合体、共用体)三、C的虚析构函数四、C的类型转换五、条件与操作断点——VisualStudio小技巧 一、C的类型双关 作用:在C中绕过类型系统 C是强类型语言 有一个类型系统,不…...
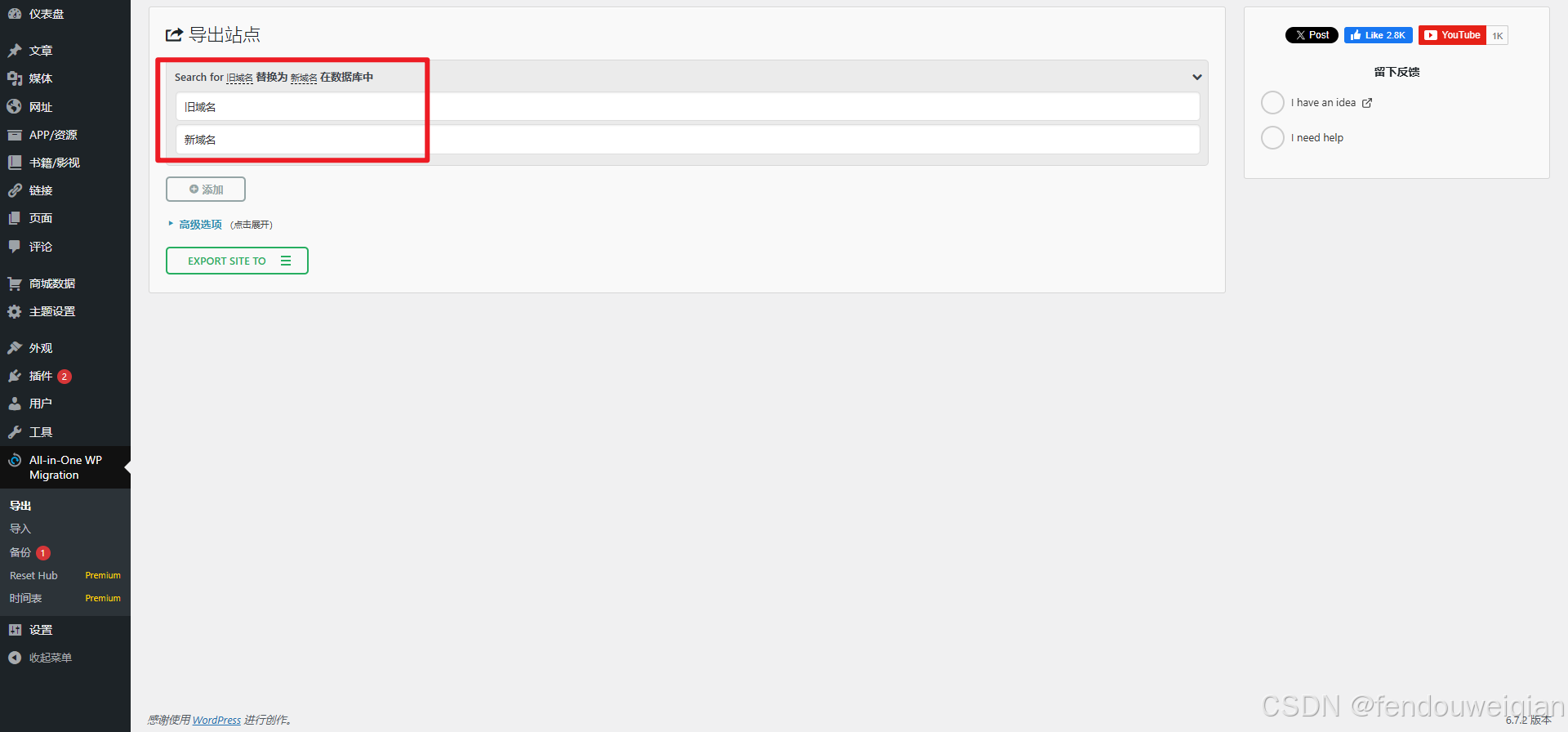
wordpress 利用 All-in-One WP Migration全站转移
导出导入站点 在插件中查询 All-in-One WP Migration备份并导出全站数据 导入 注意事项: 1.导入部分限制50MB 宝塔解决方案,其他类似,修改php.ini配置文件即可 2. 全站转移需要修改域名 3. 大文件版本,大于1G的可以参考我的…...

springboot+easyexcel实现下载excels模板下拉选择
定义下拉注解 Target(ElementType.FIELD) Retention(RetentionPolicy.RUNTIME) public interface ExcelDropDown {/*** 固定下拉选项*/String[] source() default {};/*** 动态数据源key(从上下文中获取)*/String sourceMethod() default "";…...

LeetCode.3396.使数组元素互不相同所需的最少操作次数
3396. 使数组元素互不相同所需的最少操作次数 给你一个整数数组 nums,你需要确保数组中的元素 互不相同 。为此,你可以执行以下操作任意次: 从数组的开头移除 3 个元素。如果数组中元素少于 3 个,则移除所有剩余元素。 注意&…...

【工具使用】在OpenBMC中使用GDB工具来定位coredump原因
在OpenBMC调试中,有时会产生coredump却不知道从哪里入手分析,GDB工具就可以提供帮助。 1 编译带GDB工具的镜像 OpenBMC镜像中默认没有加入GDB工具,因此首先需要编译一个带GDB工具的OpenBMC镜像用于调试。在recipes-phosphor/packagegroups/…...
Linux系统(Ubuntu和树莓派)的远程操作练习
文章目录 一、实验一(一)实验准备(二)Ubuntu 下的远程操作(三)树莓派下的远程操作(四)思考 二、实验二1.talk程序2. C 编写 Linux 进程间通信(IPC)聊天程序 一…...

雪花算法、md5加密
雪花算法生成ID是一个64位长整型(但是也可以通过优化简短位数) 组成部分: 时间戳 机器ID 序列号 用途: 分布式系统唯一ID生成:解决数据库自增ID在分布式环境下的唯一性问题、避免UUID的无序性和性能问题 有序性…...

《P2660 zzc 种田》
题目背景 可能以后 zzc 就去种田了。 题目描述 田地是一个巨大的矩形,然而 zzc 每次只能种一个正方形,而每种一个正方形时 zzc 所花的体力值是正方形的周长,种过的田不可以再种,zzc 很懒还要节约体力去泡妹子,想花最少的体力值…...

高效创建工作流,可实现类似unreal engine的蓝图效果,内部使用多线程高效执行节点函数
文章目录 前言(Introduction)开发环境搭建(Development environment setup)运行(Run test)开发者(Developer)编译(Compile)报错 前言(Introductio…...
Design Compiler:语法检查工具dcprocheck
相关阅读 Design Compilerhttps://blog.csdn.net/weixin_45791458/category_12738116.html?spm1001.2014.3001.5482 dcprocheck是一个在Design Compiler存在于安装目录下的程序(其实它是一个指向snps_shell的符号链接,但snps_shell可以根据启动命令名判…...
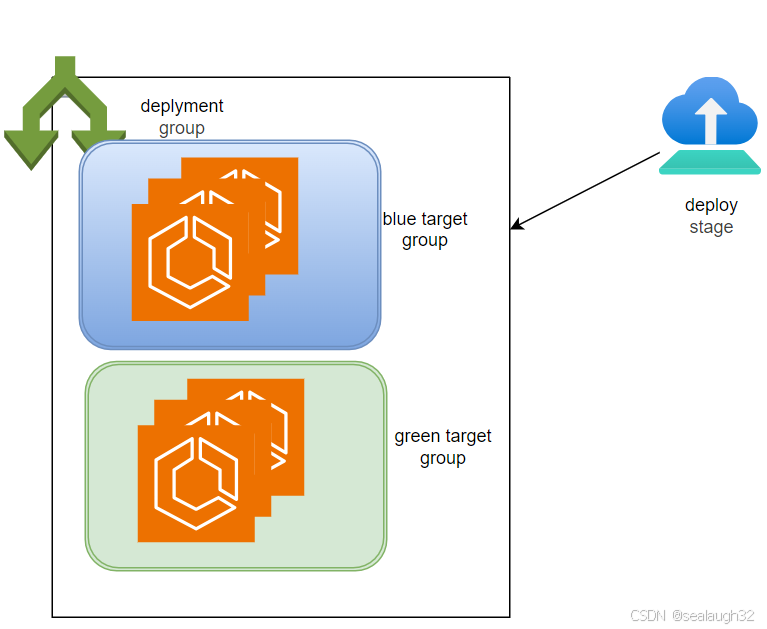
aws(学习笔记第三十八课) codepipeline-build-deploy-github-manual
文章目录 aws(学习笔记第三十八课) codepipeline-build-deploy-github-manual学习内容:1. 整体架构1.1 代码链接1.2 全体处理架构 2. 代码分析2.1 创建ImageRepo,并设定给FargateTaskDef2.2 创建CodeBuild project2.3 对CodeBuild project赋予权限&#…...

自定义实现C++拓展pytorch功能
ncrelu.cpp #include <torch/extension.h> // 头文件引用部分namespace py pybind11;torch::Tensor ncrelu_forward(torch::Tensor input) {auto pos input.clamp_min(0); // 具体实现部分auto neg input.clamp_max(0);return torch::cat({pos, neg}, …...

深度学习|注意力机制
一、注意力提示 随意:跟随主观意识,也就是指有意识。 注意力机制:考虑“随意线索”,有一个注意力池化层,将会最终选择考虑到“随意线索”的那个值 二、注意力汇聚 这一部分也就是讲第一大点中“注意力汇聚”那个池化…...

京东店铺托管7*16小时全时护航
内容概要 京东店铺托管服务的*716小时全时护航模式,相当于给商家配了个全年无休的"运营管家"。专业团队每天从早7点到晚11点实时盯着运营数据和商品排名,连半夜流量波动都能通过智能系统秒级预警。这种全天候服务可不是单纯拼人力——系统自动…...
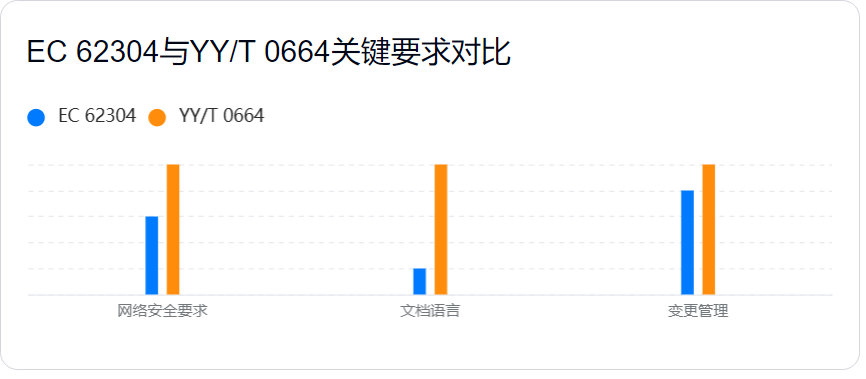
遵循IEC62304YY/T0664:确保医疗器械软件生命周期合规性
一、EC 62304与YY/T 0664的核心定位与关系 IEC 62304(IEC 62304)是国际通用的医疗器械软件生命周期管理标准,适用于所有包含软件的医疗器械(如嵌入式软件、独立软件、移动应用等),其核心目标是确保软件的安…...
)
Android Input——输入系统介绍(一)
Input 是 Android 系统中的一个重要模块,它是负责处理用户输入操作的核心组件。该系统从各种输入设备(如触摸屏、键盘、鼠标等)获取原始输入事件,并将其转换为 Android 应用可以理解和消费的 KeyEvent 或 MotionEvent 对象。 一、…...
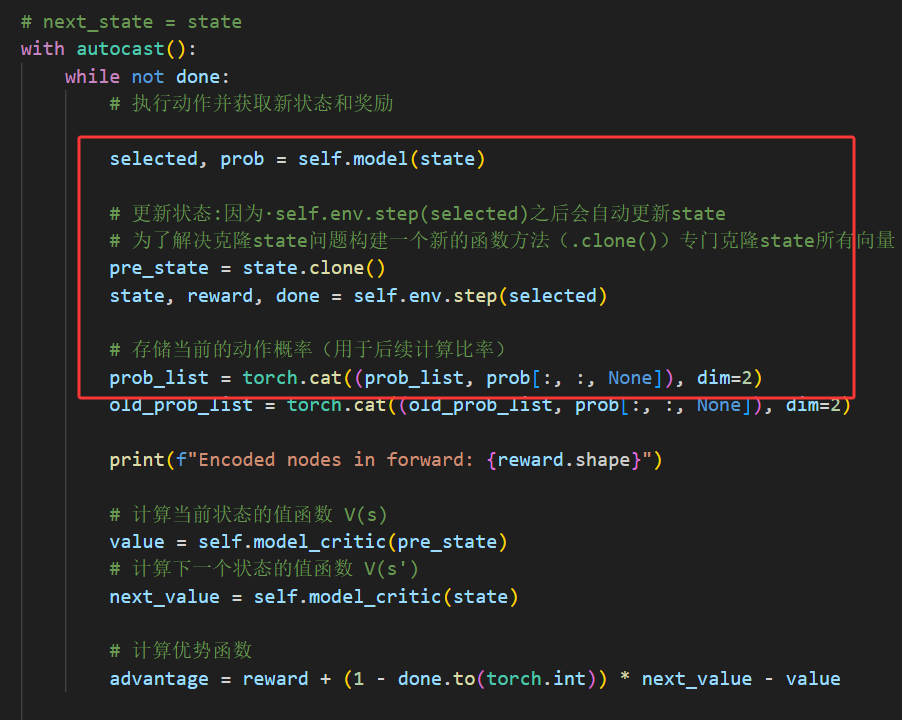
20250408-报错:pre_state = state同更新现象
项目场景: 基于强化学习解决组合优化问题 问题描述 # POMO Rolloutstate, reward, done self.env.pre_step()# next_state statewith autocast():while not done:# 执行动作并获取新状态和奖励selected, prob self.model(state)# 更新状态:因为self.env.step(s…...
如何在服务器里部署辅助域
辅助域(Additional Domain Controller,ADC)是指在现有的Active Directory(活动目录)架构中,新增一个或多个域控制器以提高目录服务的可用性和可靠性。以下是辅助域的定义、功能和应用场景的详细说明&#x…...
-- 第五部分:JS数组与WPS结合应用)
WPS JS宏编程教程(从基础到进阶)-- 第五部分:JS数组与WPS结合应用
目录 摘要第5章 JS数组与WPS结合应用5-1 JS数组的核心特性核心特性解析5-2 数组的两种创建方式(字面量与扩展操作符)1. 字面量创建2. 扩展操作符创建5-3 数组创建应用:提取字符串中的数字需求说明代码实现5-4 用函数创建数组(new Array、Array.of、Array.from)1. new Arra…...
)
Kaggle-Housing Prices-(回归预测+Ridge,Lasso,Xgboost模型融合)
Housing Prices 题意: 给出房子的各种特性,让你预测如今房子的价格。 思考: 数据处理: 1.用plt查看散点图,选择对价格影响高的特征值:YearBuilt,YearRemodAdd,GarageYrBlt。但是…...

C语言:32位数据转换为floaf解析
在C语言中,将接收到的32位数据(通常是一个unsigned int或int类型)转换为float类型可以通过以下方式实现: 除了下面的方法外还有几个方法,参考博客: C语言:把两个16位的数据合成32位浮点型数据 …...

MQTT协议:IoT通信的轻量级选手
文章总结(帮你们节约时间) MQTT协议是一种轻量级的发布/订阅通信协议。MQTT通信包括连接建立、订阅、发布和断开等过程。MQTT基于TCP/IP,其通信过程涉及多种控制包和数据包。ESP32S3可以通过MQTT协议接收消息来控制IO9引脚上的LED。 想象一…...
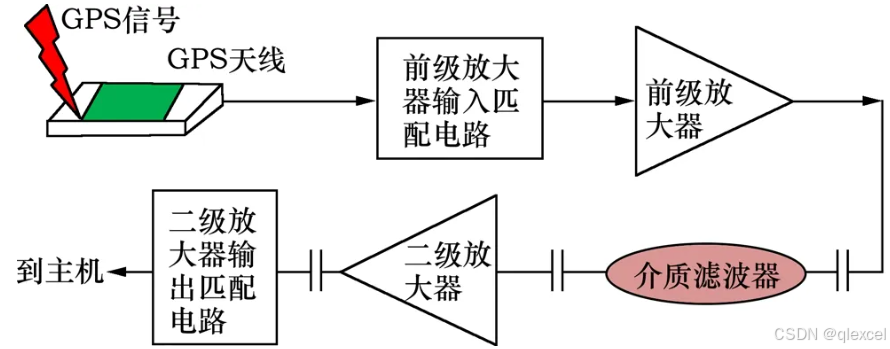
GNSS有源天线和无源天线
区别 需要外部供电的就是有源天线,不需要外部供电的是无源天线。 无源天线 一般就是一个陶瓷片、金属片等,结构简单,成本低廉,占用空间及体积小,适合于强调紧凑型空间的导航类产品。 不需要供电,跟设备直…...

欧税通香港分公司办公室正式乔迁至海港城!
3月20日,欧税通香港分公司办公室正式乔迁至香港油尖旺区的核心商业区海港城!左手挽着内地市场,右手牵起国际航道——这波乔迁选址操作堪称“地理课代表”! 乔迁仪式秒变行业大联欢!感谢亚马逊合规团队、亚马逊云、阿里国际站、Wayfair、coupang、美客多…...
对比)
Qt 自带的QSqlDatabase 模块中使用的 SQLite 和 SQLite 官方提供的 C 语言版本(sqlite.org)对比
Qt 自带的 QSqlDatabase 模块中使用的 SQLite 和 SQLite 官方提供的 C 语言版本(sqlite.org)在核心功能上是相同的,但它们在集成方式、API 封装、功能支持以及版本更新上存在一些区别。以下是主要区别: 1. 核心 SQLite 引擎 Qt 的…...

zustand 源码解析
文章目录 实现原理createcreateStore 创建实例CreateStoreImpl 实现发布订阅createImpl 包装返回给用户调用的 hookuseSyncExternalStoreWithSelector 订阅更新zustand 性能优化自定义数据更新createWithEqualityFncreateWithEqualityFnImpl 返回 hookuseSyncExternalStoreWith…...

洛谷题单3-P1423 小玉在游泳-python-流程图重构
题目描述 小玉开心的在游泳,可是她很快难过的发现,自己的力气不够,游泳好累哦。已知小玉第一步能游 2 2 2 米,可是随着越来越累,力气越来越小,她接下来的每一步都只能游出上一步距离的 98 % 98\% 98%。现…...