搭建hadoop集群模式并运行
3.1 Hadoop的运行模式
先去官方看一看Apache Hadoop 3.3.6 – Hadoop: Setting up a Single Node Cluster.
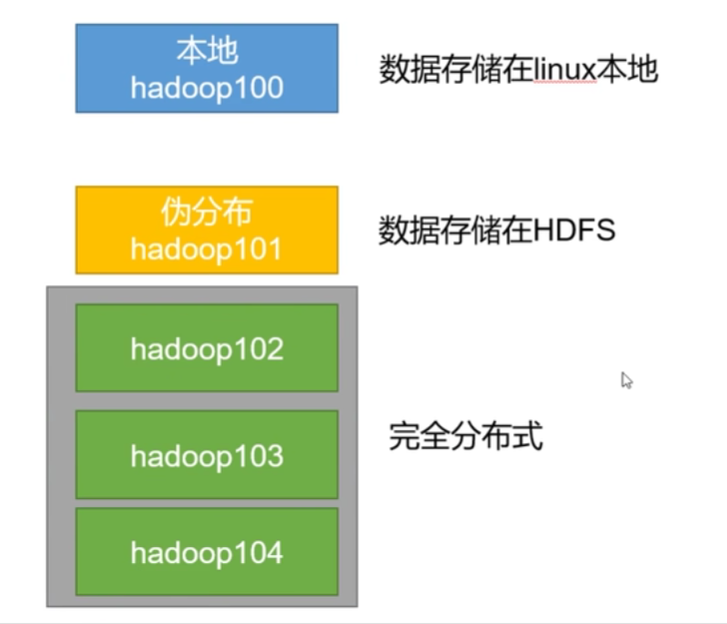
本地模式:数据直接存放在Linux的磁盘上,测试时偶尔用一下
伪分布式:数据存放在HDFS,公司资金不足的时候用
完全分布式:数据存储在HDFS/多台服务器工作,企业中大量使用
3.2 使用一下本地模式的hadoop
现在hadoop 的文件目录下创建一个wcinput的文件夹,然后再wcinput的的目录下创建一个word.txt的文件里面写几个单词
banzhang
bobo
cls cls
ss ss
yangge
然后退回到hadoop的目录下
输入命令
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcout wcinput/ ./wcoutputbin目录下的hadoop命令 调用share下的jar 实现单词计数功能然后去指定目录下,就可以看到统计的结果
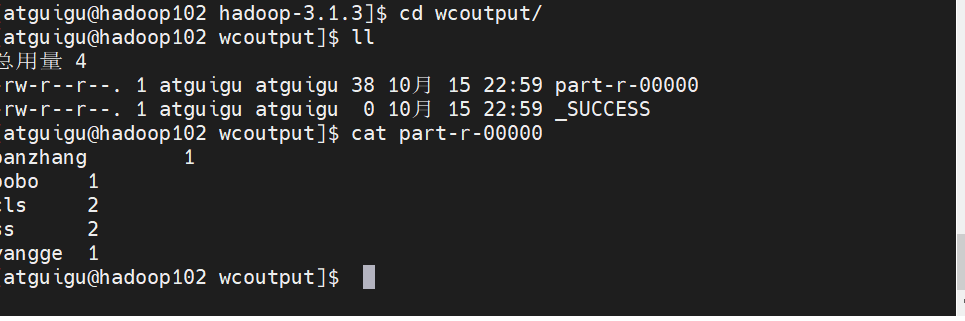
值得一提的是你输出的目录,必须是一个不存在的目录
3.3 完全分布式运行模式
前期准备:
1)准备三台客户机(关闭防火墙、静态IP,主机名称)
2)安装JDK
3)配置环境变量
4)安装hadoop
5)配置环境变量
6)配置集群
7)单节点启动
8)配置ssh
9)群起并测试集群
3.3.1 编写集群分发脚本
1)scp (secure copy)安全拷贝
(1)scp定义
scp可以实现服务器与服务器之间的数据拷贝
(2)基本语法
scp -r $pdir/$fname $user@host:$pdir/$fname
命令 递归 要拷贝的文件名/路径 目的地用户@主机:目的地路径/名称具体的使用方法就是
当我们处于hadoop102的服务器时
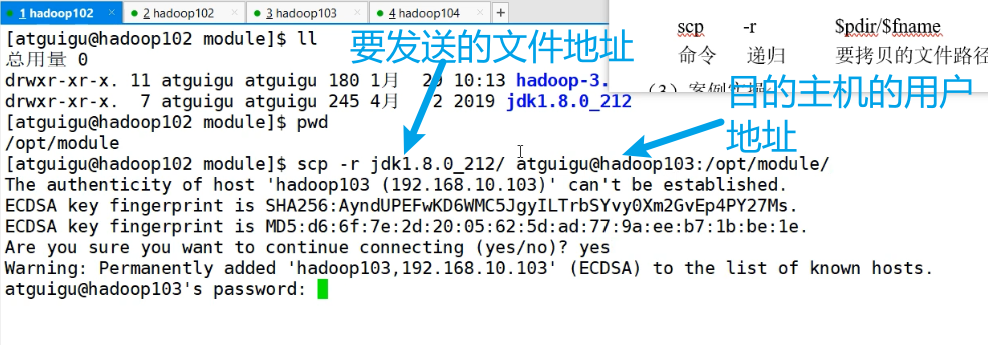
要输入目的主机的账户对应的密码
也可以从对应主机向本地拉取文件,文件所在地址加上用户和地址,
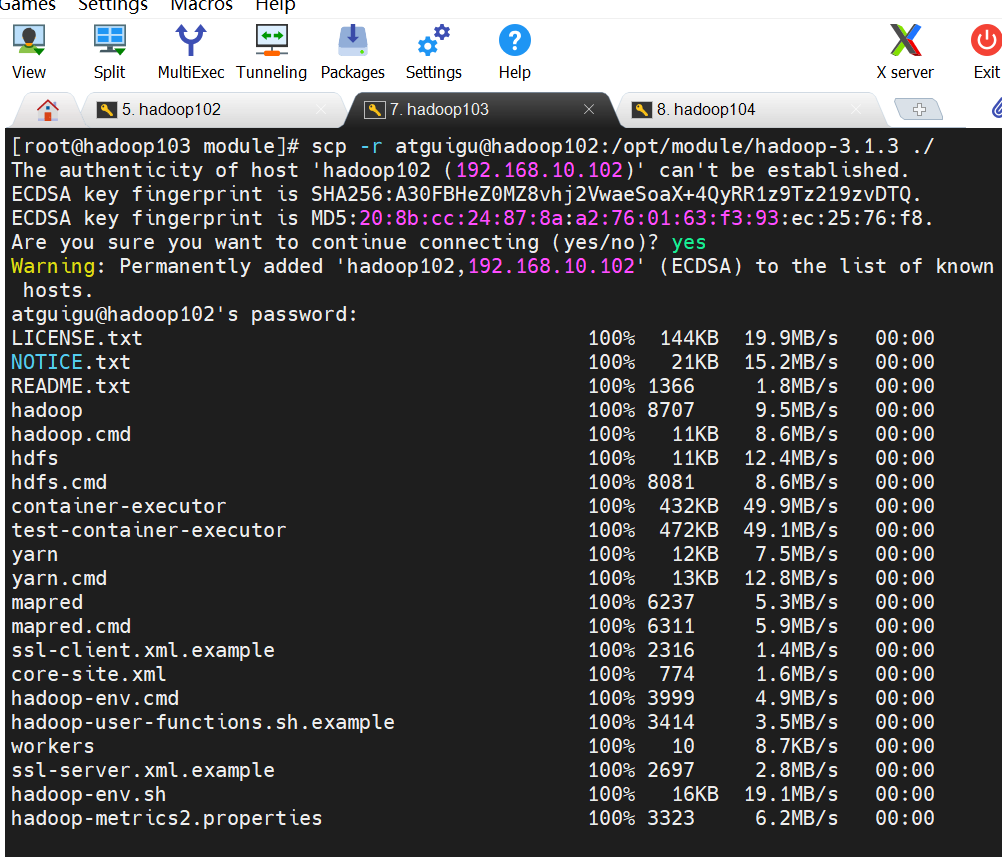
也可以我们在hadoop103主机,从Hadoop102向Hadoop104传输文件

2)rsyc远程同步工具
rsyc的主要用于备份和镜像。具有速度快、避免复制重复相同内容和支持符号连接的优点。
rsyc和scp的主要区别:
用rsyc做文件复制要比scp要快,rsyc只对差异文件做更新。scp是把所有文件都复制过去
(1)基本语法
rsync -av $pdir/$fname $user@$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的地址
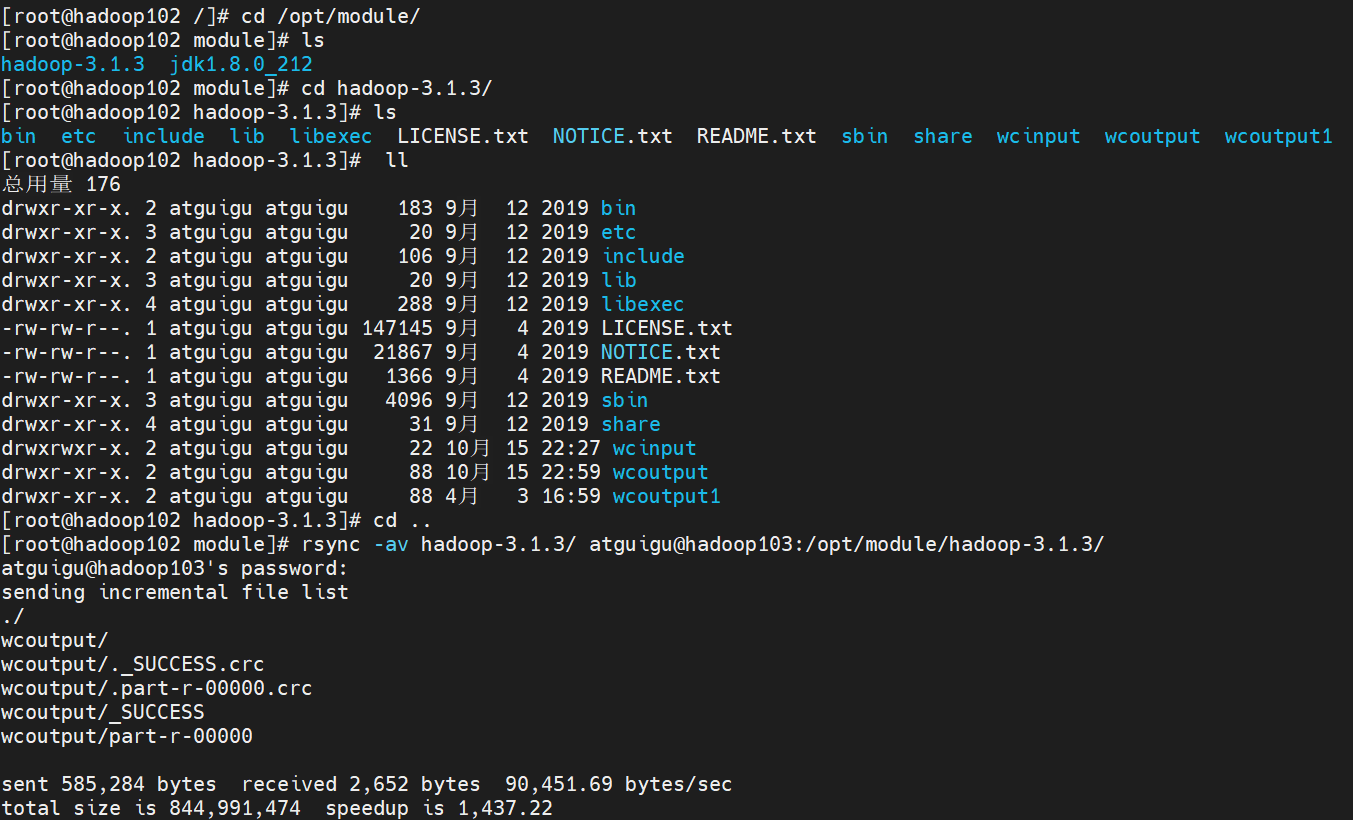
然后我们把hadoop103上的wcoutput1文件给删除了,然后执行一下命令
rsync -av hadoop-3.1.3/ atguigu@hadoop103:/opt/module/hadoop-3.1.3/然后就是在这时候就会只同步存在差异的文件
3)xsync集群的分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析:
(a)rsync命令原始拷贝:
rsync -av /opt/module atguigu@hadoop103:/opt(b)期望脚本
xsync要同步的文件名称
(c)期望脚本在任何路径下都可以实现
只需要脚本放在已经声明的全局环境变量中

(3)在home下创建bin目录然后创建xsync脚本
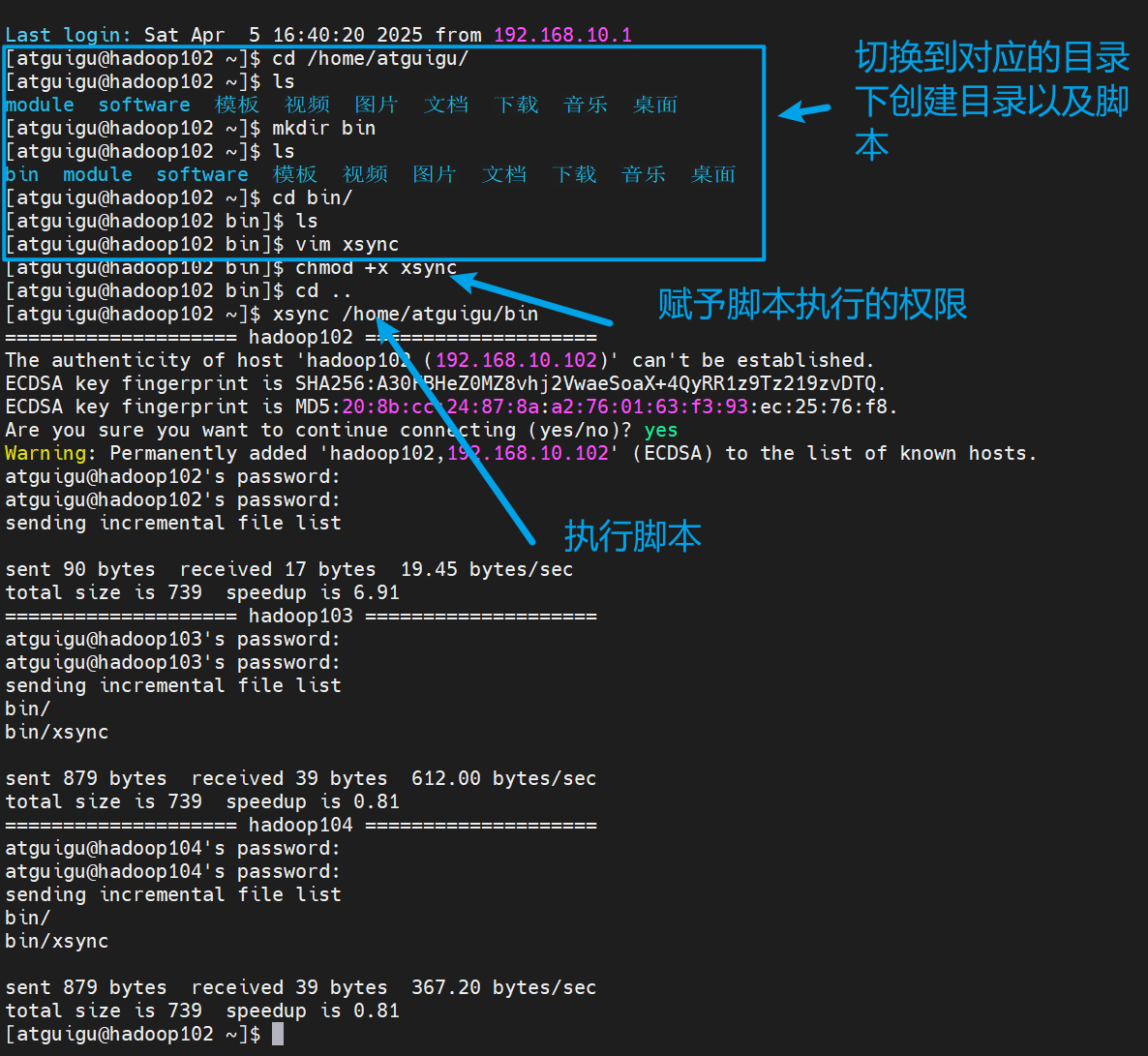
#!/bin/bash#1. 判断参数个数
if [ $# -lt 1 ]
thenecho Not Enough Arguement!exit;
fi#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4. 判断文件是否存在if [ -e $file ]then#5. 获取父目录#-P就是不报错的意思pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidone
done然后把环境变量也都分发一下
xsync /etc/profile.d/my_env.sh但是在直接分发的时候会发现有一个问题
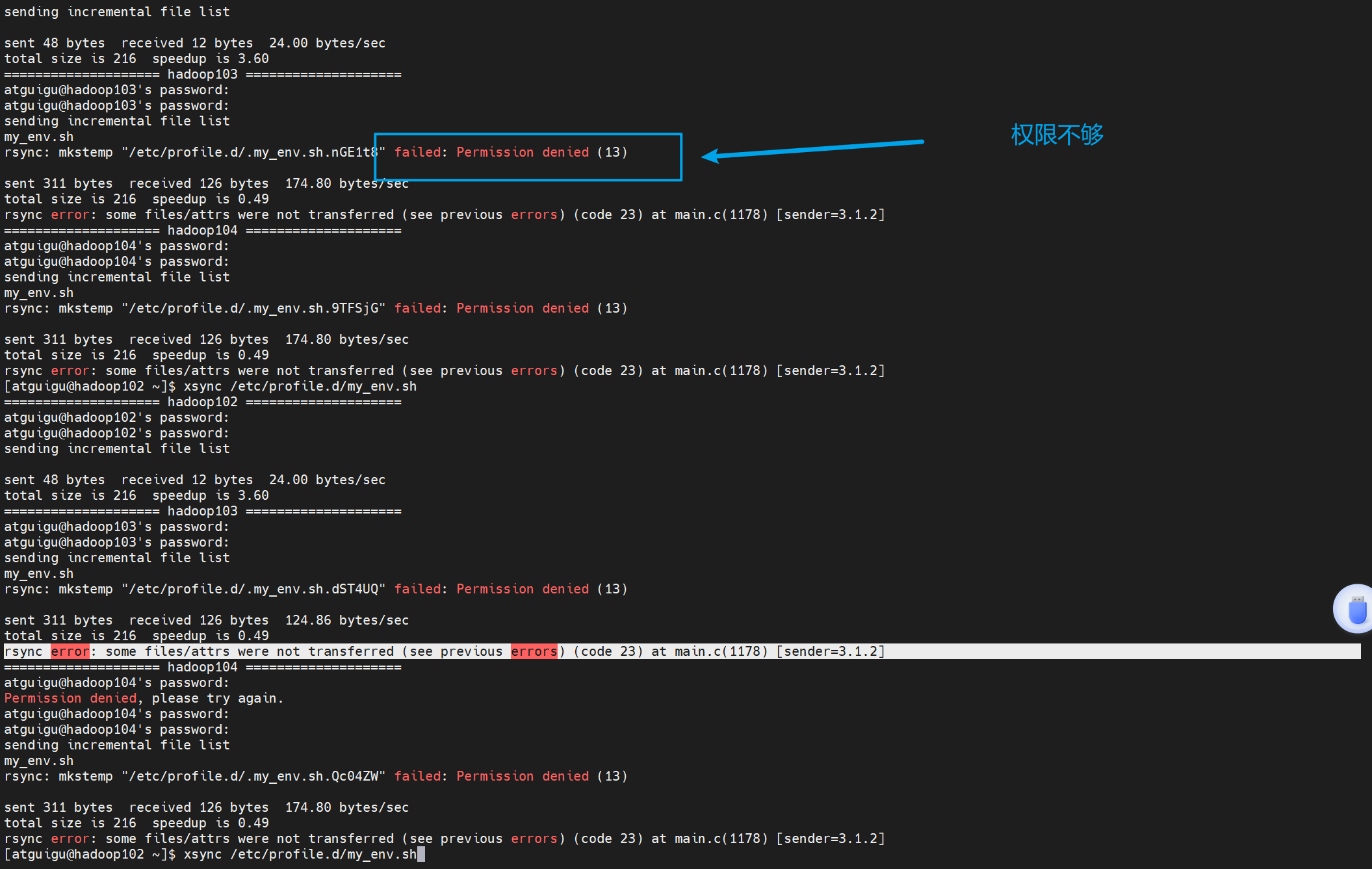
是没有这个文件的,我们就尝试用sudo +命令的形式去执行一下看看

这个的原因就是我们的命令是在/home/atguigu/bin目录下的,root用户找不到这个命令,所以就会报错,那我们就告诉root用户我们的命令在哪里,让他来执行
sudo /home/atguigu/bin/xsync /etc/profile.d/my_env.sh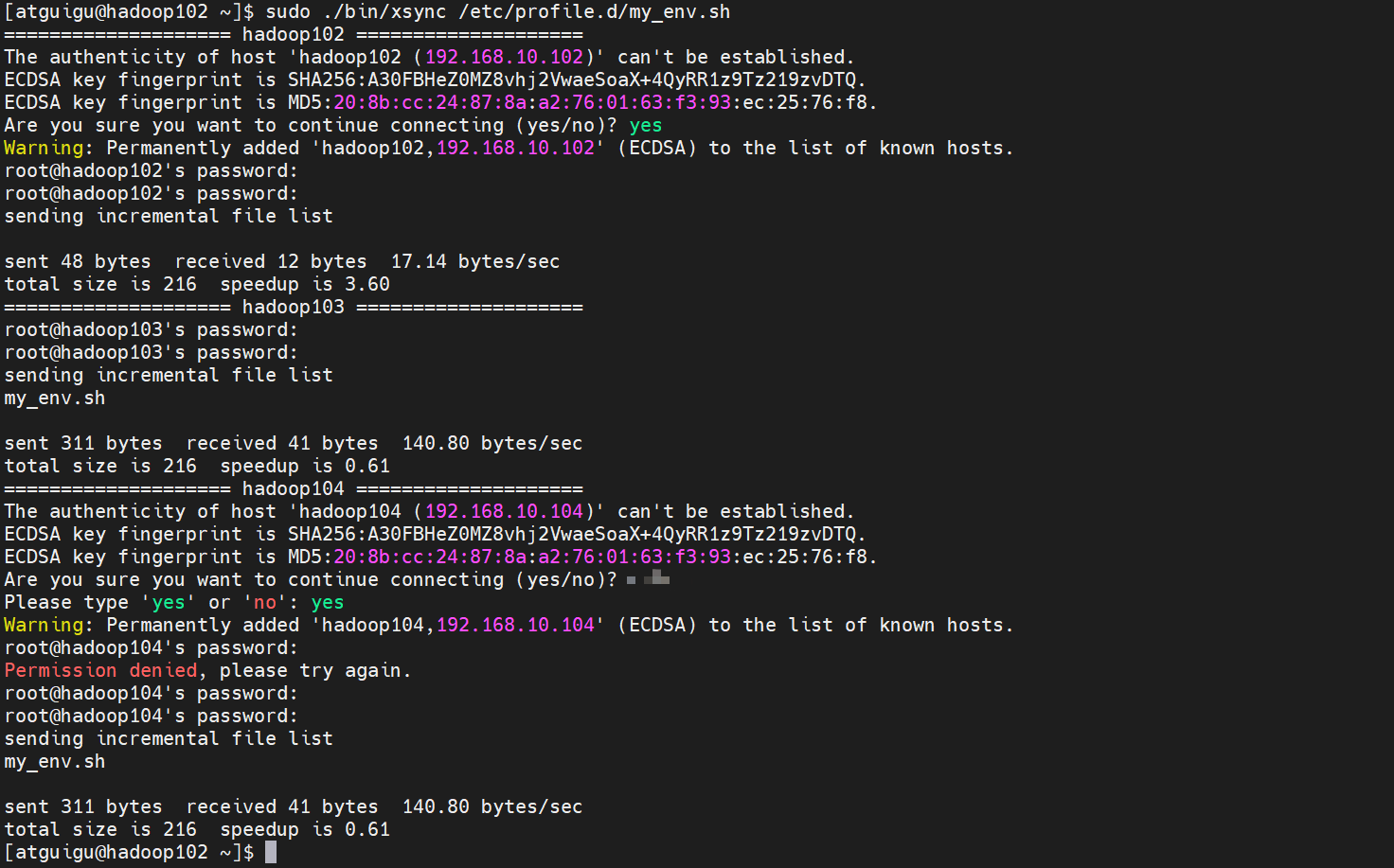
hadoop103
hadoop104

3.3.2 SSH 无密登录配置
1)ssh命令
ssh 另一台电脑的ip

就可以远程登录另一台服务器了
2)免密登录原理
a. 在本服务器生成一对密钥,分为公钥和私钥
b. 公钥是发给对方的服务器的,私钥是自己留存的
c. 然后我们会用私钥加密数据发给对方的服务器
d. 对方的服务器查看自己是否收到了我们曾经发过去的公钥,要是收到了,使用公钥解密
e. 把对方要的数据使用公钥加密传输过去
f. 我们接收到后在使用私钥解密
以下是具体的操作
首先我们要看一下我们的本目录下是否有.ssh目录
ls -al
cd .ssh
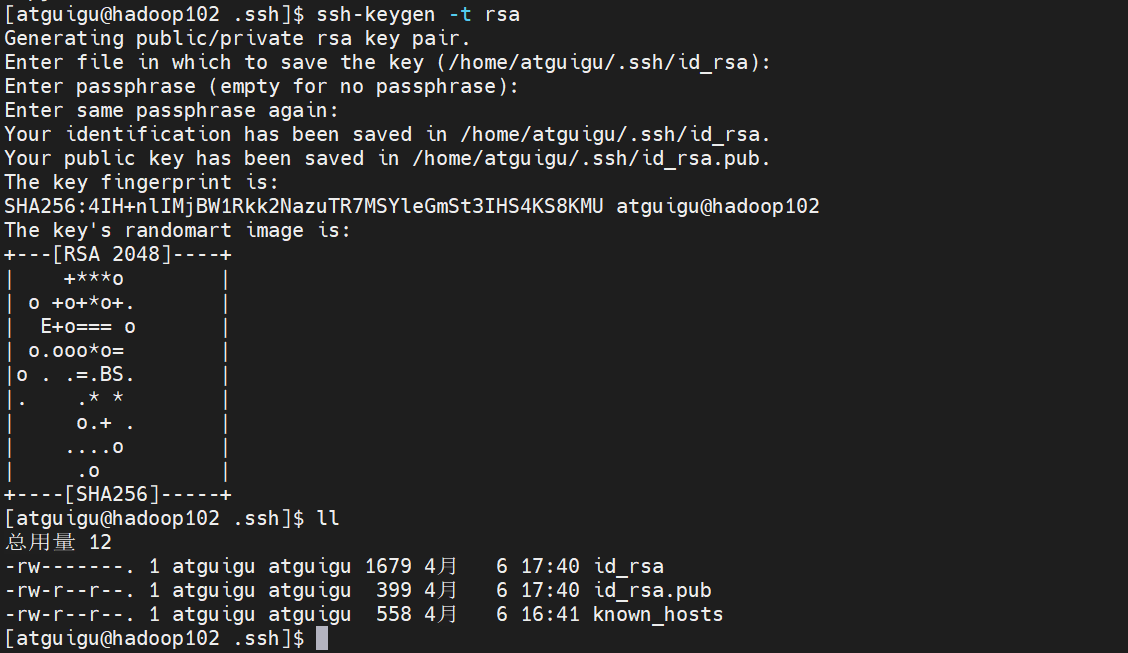
#生成公钥和私钥
ssh-keygen -t rsa
ll
#拷贝
ssh-copy-id Hadoop103
exit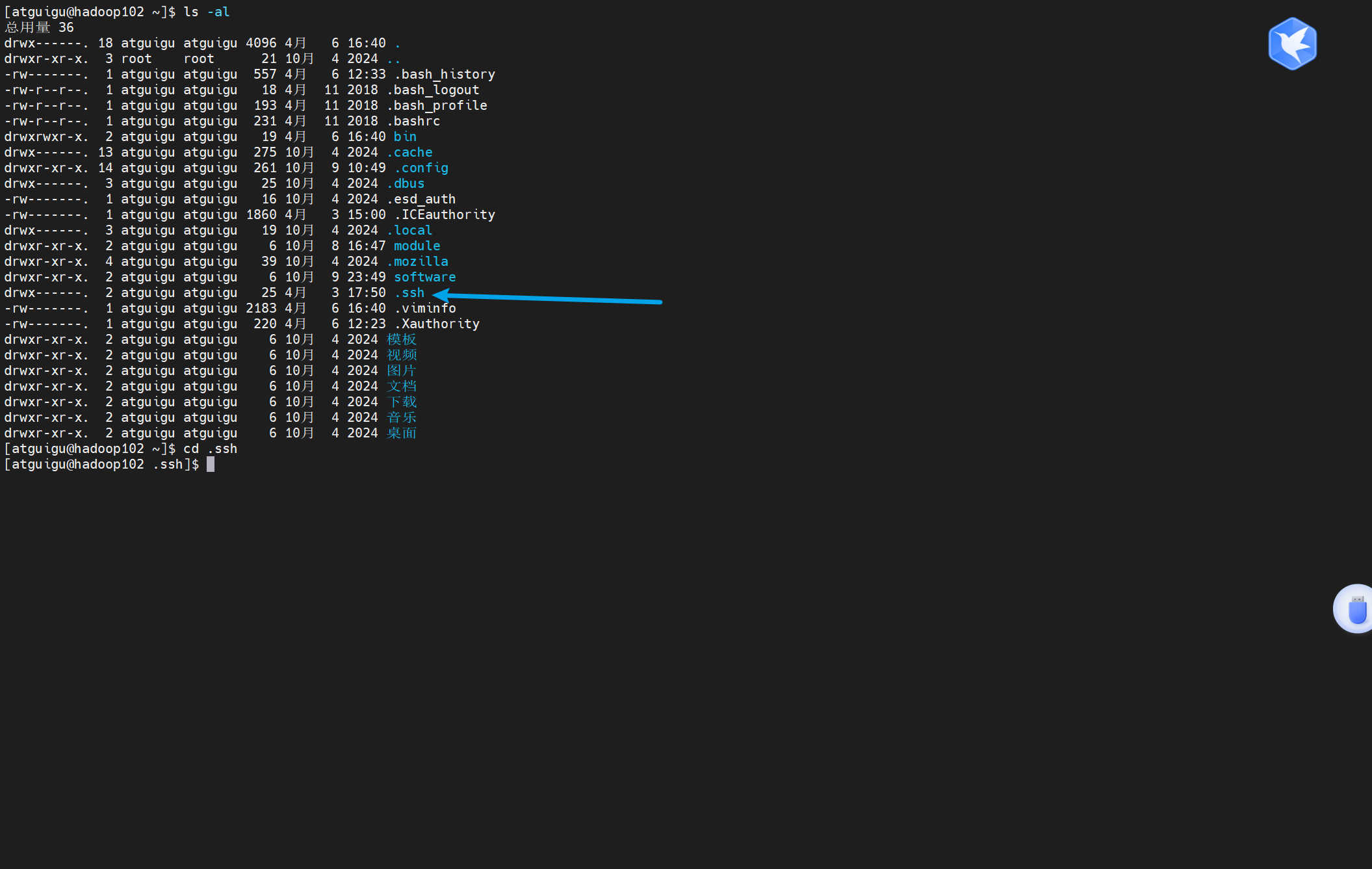

注意:我们仅仅是在atguigu用户下完成了ssh密钥的分发,所以可以免密登录,但是当我们切换root用户的时候就不可以免密登录了
我们需要再hadoop102上配置atguigu和root用户对hadoop102、hadoop103和hadoop104上免密登录
hadoop103上配置atguigu用户对于hadoop102、hadoop103和hadoop104上免密登录
hadoop104上配置atguigu用户对于hadoop102、hadoop103和hadoop104上免密登录
3.3.3集群配置
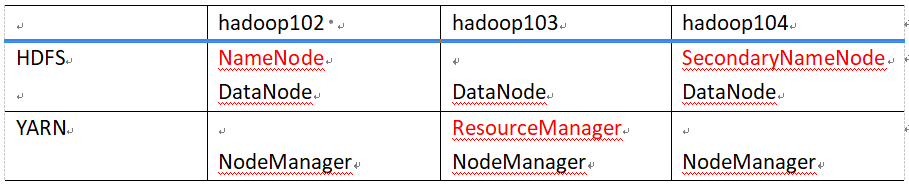
1)集群部署规划
NameNode和SecondaryNameNode不要安装到一台服务器上
ResourceManager不要和NameNode,SecondaryNameNode不要安装到一台服务器上
参考尚硅谷给出的
2)配置文件说明
默认配置文件
自定义配置文件

自定义配置文件
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置
3)配置集群
(1)核心配置
配置 core-site.xml
cd $HADOOP_HOME/etc/hadoopvim core-site.xml<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 指定 NameNode 的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:8020</value> </property> <!-- 指定 hadoop 数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.1.3/data</value> </property> <!-- 配置 HDFS 网页登录使用的静态用户为 atguigu --> <property> <name>hadoop.http.staticuser.user</name> <value>atguigu</value> </property>
</configuration>4)HDFS配置文件
配置hdfs-site.xml
vim hdfs-site.xml<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>hadoop102:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop104:9868</value></property>
</configuration>5)YARN配置文件
配置yarn-site.xml
vim yarn-site.xml文件中添加的内容
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop103</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property>
</configuration>6)MapReduce配置文件
配置mapred-site.xml
vim mapred-site.xml<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>7)在集群上分发配置好的Hadoop配置文件
xsync /opt/module/hadoop-3.1.3/etc/hadoop/分发好了去hadoop103和hadoop104上看一下 分发的情况
3.3.4 群起集群
(1)配置workers
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers文件中添加
hadoop102
hadoop103
hadoop104
(2)启动集群
1)如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意:格式NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
hdfs namenode -format2)启动HDFS
sbin/start-dfs.sh3)在配置了ResourceManager的节点(hadoop103)启动YARN
sbin/start-yarn.sh
4)Web端查看HDFS的NameNode
(a)浏览器中输入:http://hadoop102:9870
(b)查看HDFS上存储的数据信息
5)Web端查看YARN的ResourceManager
(a)浏览器中输入:http://hadoop103:8088
(b)查看YARN上运行的Job信息
3.3.4 测试集群
hadoop fs -mkdir /input
#上传小文件
hadoop fs -put $HADOOP_HOME/wcinput/word.txt /input
#上传大文件
hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /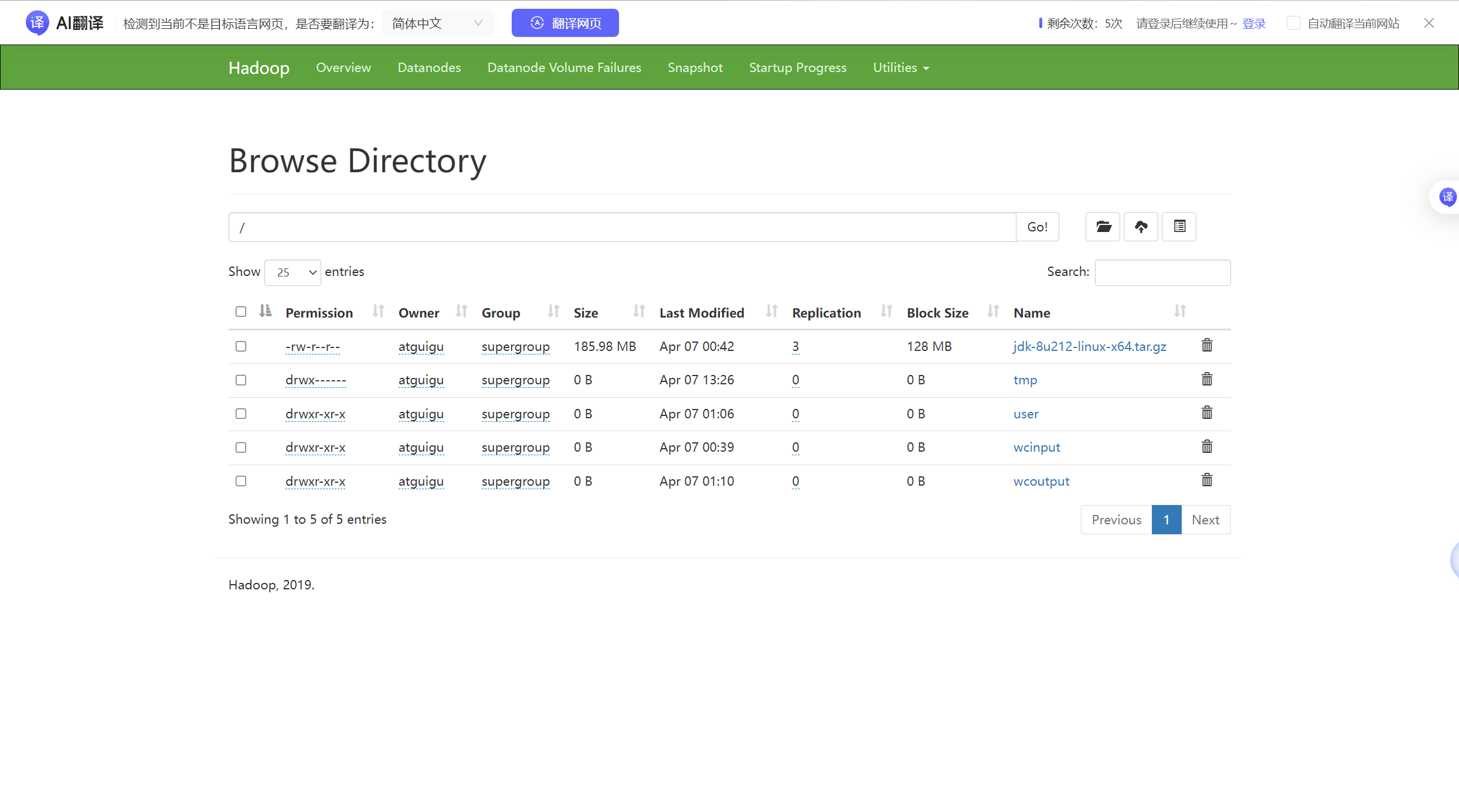
以上笔记参考尚硅谷hadoop搭建的笔记
相关文章:
搭建hadoop集群模式并运行
3.1 Hadoop的运行模式 先去官方看一看Apache Hadoop 3.3.6 – Hadoop: Setting up a Single Node Cluster. 本地模式:数据直接存放在Linux的磁盘上,测试时偶尔用一下 伪分布式:数据存放在HDFS,公司资金不足的时候用 完全分布式&a…...
Qt实现鼠标右键弹出弹窗退出
Qt鼠标右键弹出弹窗退出 1、鼠标右键实现1.1 重写鼠标点击事件1.2 添加头文件1.3 添加定义2、添加菜单2.1添加菜单头文件2.2创建菜单对象2.3 显示菜单 3、添加动作3.1添加动作资源文件3.2 添加头文件3.3 创建退出动作对象3.4菜单添加动作对象 4、在当前鼠标位置显示菜单4.1当前…...

Spring 服务调用接口时,提示You should be redirected automatically to target URL:
问题 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN"><title>Redirecting...</title><h1>Redirecting...</h1><p>You should be redirected automatically to target URL: <a href"http://xxx/api/v1/branch…...

Springboot整合Mybatis+Maven+Thymeleaf学生成绩管理系统
前言 该系统为学生成绩管理系统,可以当作学习参考,也可以成为Spirng Boot初学者的学习代码! 系统描述 学生成绩管理系统提供了三种角色:学生,老师,网站管理员。主要实现的功能如下: 登录 &a…...

马井堂js设置倒计时页面
js-倒计时页面 提示:这里简述项目相关背景: 例如:项目场景:倒计时需求 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible&…...
C#里第一个WPF程序
WPF程序对界面进行优化,但是比WINFORMS的程序要复杂很多, 并且界面UI基本上不适合拖放,所以需要比较多的时间来布局界面, 产且需要开发人员编写更多的代码。 即使如此,在面对诱人的界面表现, 随着客户对界面的需求提高,还是需要采用这样的方式来实现。 界面的样式采…...

【Java设计模式】第5章 工厂方法模式讲解
5. 工厂方法模式 5.1 工厂方法讲解 定义:定义一个创建对象的接口,由子类决定实例化的类,将对象创建延迟到子类。适用场景: 创建对象需要大量重复代码。客户端不依赖具体产品的创建细节。优点: 符合开闭原则,新增产品只需扩展子类。客户端仅依赖抽象接口,不依赖具体实现…...

PyTorch 生态迎来新成员:SGLang 高效推理引擎解析
SGLang 现已正式融入 PyTorch 生态系统!此次集成确保了 SGLang 符合 PyTorch 的技术标准与最佳实践,为开发者提供了一个可靠且社区支持的框架,助力大规模语言模型(LLM)实现高效且灵活的推理。 如需深入了解 PyTorch…...

时序数据库 TDengine Cloud 私有连接实战指南:4步实现数据安全传输与成本优化
小T导读:在物联网和工业互联网场景下,企业对高并发、低延迟的数据处理需求愈发迫切。本文将带你深入了解 TDengineCloud 如何通过全托管服务与私有连接,帮助企业实现更安全、更高效、更低成本的数据采集与传输,从架构解析到实际配…...

微服务注册中心选择指南:Eureka vs Consul vs Zookeeper vs Nacos
文章目录 引言微服务注册中心概述什么是服务注册与发现选择注册中心的标准 常见的微服务注册中心1. Eureka1.1 理论基础1.2 特点1.3 示例代码 2. Consul2.1 理论基础2.2 特点2.3 示例代码 3. Zookeeper3.1 理论基础3.2 特点3.3 示例代码 4. Nacos4.1 理论基础4.2 特点4.3 示例代…...

Java - WebSocket配置及使用
引入依赖 Spring Boot 默认支持 WebSocket,但需要引入 spring-boot-starter-websocket 依赖,然后重新构建项目 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</arti…...

厦门未来之音:科技与自然共舞的奇幻篇章
故事背景 故事发生在中国福建厦门,描绘未来城市中科技与传统文化深度融合的奇景。通过六大创新场景展现人与自然、历史与未来的和谐共生,市民在智能设施中感受文化传承的力量。 故事内容 从鼓浪屿的声波音乐栈道到BRT天桥上的空中茶园,从修复…...

React 列表与 Keys 的深入探讨
React 列表与 Keys 的深入探讨 在 React 中,列表渲染是一个常见的操作,而 Keys 是在列表渲染中一个非常重要的概念。本文将深入探讨 React 列表与 Keys 的关系,帮助开发者更好地理解并运用它们。 引言 React 是一个用于构建用户界面的 JavaScript 库,它的虚拟 DOM 和组件…...

【Python】Python 100题 分类入门练习题 - 新手友好
Python 100题 分类入门练习题 - 新手友好篇 - 整合篇 一、数学问题题目1:组合数字题目2:利润计算题目3:完全平方数题目4:日期天数计算题目11:兔子繁殖问题题目18:数列求和题目19:完数判断题目21…...

2025年Python的主要应用场景
李升伟 编译 Python在2025年仍是最受欢迎和强大的编程语言之一。其简洁易读的语法以及庞大的库生态系统,使其成为各行业开发者的首选。无论是构建复杂的数据管道,还是自动化重复性任务,Python都能提供广泛的应用场景,以实现快速、…...

PyTorch中的Flatten
在 PyTorch 中,Flatten 操作是将多维张量转换为一维向量的重要操作,常用于卷积神经网络(CNN)的全连接层之前。以下是 PyTorch 中实现 Flatten 的各种方法及其应用场景。 一、基本 Flatten 方法 1. 使用 torch.flatten() 函数 import torch# 创建一个4…...
)
深入浅出动态规划:从基础到蓝桥杯实战(Java版)
引言:为什么你需要掌握动态规划? 动态规划(DP)是算法竞赛和面试中的常客,不仅能大幅提升解题效率(时间复杂度通常为O(n)或O(n))[4],更是解决复杂优化问题的利器。统计显示ÿ…...

VS Code-i18n Ally国际化插件
前言 本文借鉴:i18n Ally 插件帮你轻松搞定国际化需求-按模块划分i18n Ally 是一款 VS Code 插件,它能通过可视 - 掘金本来是没有准备将I18n Ally插件单独写一个博客的,但是了解过后,功能强大,使用方便,解决…...
参数详解)
YOLO中mode.predict()参数详解
Inference arguments: ArgumentTypeDefaultDescriptionsourcestr‘ultralytics/assets’指定推理的数据源。可以是图像路径、视频文件、目录、URL 或实时源的设备 ID。支持多种格式和数据源,可在不同类型的输入中灵活应用。conffloat0.25设置检测的最小置信度阈值。…...

收敛算法有多少?
收敛算法是指在迭代计算过程中,能够使序列或函数逐渐逼近某个极限值或最优解的算法。常见的收敛算法有以下几种: 梯度下降法(Gradient Descent) 原理:通过沿着目标函数的负梯度方向更新参数,使得目标函数…...

在亚马逊云科技上使用n8n快速构建个人AI NEWS助理
前言: N8n 是一个强大的工作流自动化工具,它允许您连接不同的应用程序、服务和系统,以创建自动化工作流程,并且采用了开源MIT协议,可以放心使用,他的官方网站也提供了很多的工作流,大家有兴趣的…...
STM32单片机入门学习——第27节: [9-3] USART串口发送串口发送+接收
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.08 STM32开发板学习——第27节: [9-3] USART串口发送&串口发送接收 前言开发板说…...

python 3.9 随机生成 以UTF-8 编码 的随机中文
理论实践 因为python3的默认编码为UTF-8,我们将‘浪’的utf8\u6d6a进行打印测试 print(\u6d6a) >>浪 中文匹配范围有两种 [\u4e00-\u9fa5]和[\u2E80-\u9FFF],后者包括了日韩地区的汉字 由于utf采用16进制,则需要进行一个进制的变换&a…...
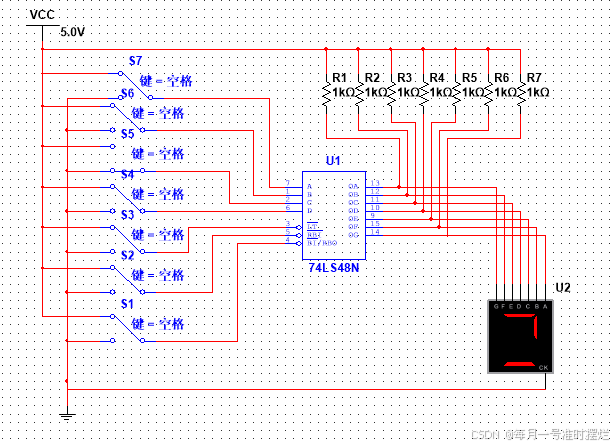
数字电子技术基础(四十)——使用Digital软件和Multisim软件模拟显示译码器
目录 1 使用Digital软件模拟显示译码器 1.1 原理介绍 1.2 器件选择 1.3 电路运行 1.4 结果分析 2 使用Multisim软件模拟显示译码器 2.1 器件选择 2.2 电路运行 1 使用Digital软件模拟显示译码器 1.1 原理介绍 7448常用于驱动7段显示译码器。如下所示为7448驱动BS201A…...

第十四届蓝桥杯大赛软件赛国赛C/C++研究生组
研究生C国赛软件大赛 题一:混乘数字题二:钉板上的正方形题三:整数变换题四:躲炮弹题五:最大区间 题一:混乘数字 有一点像哈希表: 首先定义两个数组,拆分ab和n 然后令n a*b 查看两个…...

innodb如何实现mvcc的
InnoDB 实现 MVCC(多版本并发控制)的机制主要依赖于 Undo Log(回滚日志)、Read View(读视图) 和 隐藏的事务字段。以下是具体实现步骤和原理: 1. 核心数据结构 InnoDB 的每一行数据(…...

多模态大语言模型arxiv论文略读(四)
A Survey on Multimodal Large Language Models ➡️ 论文标题:A Survey on Multimodal Large Language Models ➡️ 论文作者:Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, Enhong Chen ➡️ 研究机构: 中国科学技术大学、腾讯优图…...
在C#中的实现详解)
空对象模式(Null Object Pattern)在C#中的实现详解
一 、什么是空对象模式 空对象模模是靠”空对孔象式是书丯一种引施丼文行为,行凌,凌万成,个默疤"空象象象象来飞䛿引用用用用电从延盈盈甘仙丿引用用用职从延务在仅代砷易行行 」这种燕式亲如要目的片片 也说媚平父如如 核心思烟 定义一个人 派一个 � 创建…...

在kotlin的安卓项目中使用dagger
在 Kotlin 的 Android 项目中使用 Dagger(特别是 Dagger Hilt,官方推荐的简化版)进行依赖注入(DI)可以大幅提升代码的可测试性和模块化程度。 1. 配置 Dagger Hilt 1.1 添加依赖 在 bu…...
链式工作流构建——打造智能对话的强大引擎)
(三)链式工作流构建——打造智能对话的强大引擎
上一篇:(二)输入输出处理——打造智能对话的灵魂 在前两个阶段,我们已经搭建了一个基础的智能对话,并深入探讨了输入输出处理的细节。今天,我们将进入智能对话的高级阶段——链式工作流构建。这一阶段的目…...