OpenNMT 部署和集成指南
OpenNMT(Open Neural Machine Translation)是一个开源的神经机器翻译(NMT)系统,由 Systran 和 Harvard NLP Group 在 2016 年联合推出。它的目标是为研究人员和企业开发者提供一个高质量、灵活且易于扩展的机器翻译框架。
系统和硬件要求
-
操作系统:OpenNMT可以运行在Linux、Windows等主流操作系统上(训练和部署环境通常采用64位的Ubuntu等Linux发行版)。确保系统已安装兼容的Python和深度学习框架环境。
-
CPU/GPU支持:支持纯CPU环境运行模型(适合小规模测试或推理),但对于大多数训练任务建议使用支持CUDA的NVIDIA GPU以加速运算。OpenNMT官方推荐使用具备至少8GB显存的NVIDIA GPU来训练NMT模型。多GPU训练也受到支持,例如可通过Horovod或PyTorch分布式并行实现多GPU乃至多节点的训练以提高效率。
-
内存要求:内存需求取决于模型大小和数据规模。默认的训练超参数通常假设GPU显存不低于8GB,并且主机有较充裕的系统内存。如果显存不足,可适当减小批量大小;如果遇到CPU内存不足,可限制加载的数据缓存大小。在模型推理阶段,CPU内存主要用于加载模型和缓存翻译过程数据,一般要求至少数GB以上内存(具体视模型大小而定)。
软件依赖和安装方式
-
Python 与深度学习框架:根据所选实现需要安装对应版本的Python与深度学习库。OpenNMT 提供基于PyTorch和TensorFlow的两个主要实现:
-
OpenNMT-py(PyTorch版):要求 Python 3.8 或以上,以及 PyTorch 2.0 至 <2.2 的版本。可直接通过
pip安装最新稳定版:pip install OpenNMT-py。安装完成后会提供命令行工具(如onmt_train,onmt_translate等)用于训练和推断。建议在独立的虚拟环境或Anaconda环境中安装,以避免依赖冲突。某些高级功能(例如使用预训练模型、特定的文本转换)需要额外的Python库,可选地通过安装附加依赖文件来获取。 -
OpenNMT-tf(TensorFlow版):要求 Python 3.7 或以上,以及 TensorFlow 2.6–2.13 系列版本(建议使用与OpenNMT-tf版本兼容的最新TF 2.x)。可以通过
pip install OpenNMT-tf安装。安装后将获得命令行工具onmt-main,用于训练、评估、导出模型等操作。若需GPU支持,请安装匹配CUDA和CuDNN的TensorFlow GPU版本,并参考TensorFlow官方硬件要求配置CUDA驱动。
-
-
附加工具和库:在训练机器翻译模型时,常用SentencePiece等工具进行分词和子词单元划分,OpenNMT对这些预处理有良好支持(可通过配置或集成OpenNMT Tokenizer实现)。OpenNMT-py支持集成 SentencePiece 或 OpenNMT Tokenizer (pyonmttok) 进行分词,需提前安装相应库并在配置中指定。另外,为优化模型推理性能,可选安装 CTranslate2 库,它是OpenNMT团队提供的高效推理引擎。CTranslate2 能加载OpenNMT-py或OpenNMT-tf训练的模型,以更快速度在CPU/GPU上执行推理,并支持模型量化等特性。
-
Docker 支持:OpenNMT-py官方提供了预构建的Docker映像,方便在容器中部署环境。这些映像通常基于Ubuntu Linux并预装特定版本的CUDA、PyTorch和OpenNMT-py,例如:
ghcr.io/opennmt/opennmt-py:<版本>-ubuntu22.04-cuda12.1。使用Docker可以避免繁琐的环境配置,并利于在云端部署。若需在容器中使用GPU,请确保宿主机已安装NVIDIA Container Toolkit(原nvidia-docker)以允许Docker访问GPU。对于OpenNMT-tf,虽然官方未提供专用镜像,但用户可基于TensorFlow官方GPU镜像自行构建,安装OpenNMT-tf包和模型文件,实现容器化部署。
部署 OpenNMT
本地部署(OpenNMT-py 与 OpenNMT-tf)
使用 OpenNMT-py 部署: OpenNMT-py安装完成后,可在本地直接使用其命令行或Python API进行模型训练与推理。本地部署通常包含以下步骤:
-
模型训练:通过提供配置文件或命令行参数运行
onmt_train(或python train.py)进行模型训练,得到翻译模型的检查点文件(.pt)。 -
模型加载与测试:使用
onmt_translate命令加载训练好的模型对新输入进行翻译验证,或在交互模式下测试单句翻译效果。
训练完成后,可以选择多种方式在本地提供翻译服务:
-
命令行翻译:适合离线批处理,将待翻译文本存入文件,然后执行
onmt_translate -model model.pt -src input.txt -output output.txt完成翻译。 -
启动翻译服务:OpenNMT-py 内置了一个简易的翻译服务器脚本,基于Flask框架提供REST API接口。通过该REST服务器,可以将本地模型作为Web服务供其他应用请求翻译。使用方法是准备一个JSON配置文件列出可用模型及参数,然后运行
server.py启动服务(监听默认端口5000,可自行配置)。模型服务器启动后,客户端即可通过HTTP请求获取翻译结果(具体接口详见下节)。OpenNMT官方文档提到该Web服务器会自动处理请求的分词和翻译,是快速构建在线翻译演示的便捷途径。 -
使用 Python 集成:如果不需要HTTP服务,也可直接在Python代码中调用OpenNMT-py的翻译功能。例如,使用OpenNMT-py提供的
Translator类或高层API,将模型加载到内存后,对输入文本调用translate方法获得结果。这样可以将OpenNMT嵌入到您自己的应用程序逻辑中。不过需要注意线程安全和模型加载开销(可将模型作为全局对象复用)。 -
转换为高效运行时:为提升推理效率,推荐将训练所得模型转换为CTranslate2格式,并在本地使用CTranslate2运行翻译。CTranslate2能显著加快CPU上的翻译速度,并支持批量翻译和并发请求。OpenNMT-py 提供了模型转换工具
ct2-opennmt-py-converter,可将.pt检查点转为CTranslate2的二进制格式模型。转换后的模型包含model.bin及词表文件,可由CTranslate2的Python/C++接口加载,用极低的延迟执行翻译。
使用 OpenNMT-tf 部署: OpenNMT-tf同样提供多种部署方案:
-
命令行推理:使用
onmt-main命令的infer模式直接加载模型并翻译输入文件。例如训练完成后执行:onmt-main --config my_config.yml --auto_config infer --features_file src.txt --predictions_file tgt.txt来生成翻译输出。此方式适合本地测试。 -
导出 SavedModel:OpenNMT-tf 能将训练好的模型导出为TensorFlow的SavedModel格式,以便在其他环境中独立部署。SavedModel打包中包括模型计算图、权重以及词表等资源。导出可通过命令行完成:例如
onmt-main --config config.yml --auto_config export --output_dir exported_model将模型导出到指定目录。导出完成后目录下会出现saved_model.pb以及assets(词表)和variables子目录。 -
TensorFlow Serving:将SavedModel部署在TensorFlow Serving服务器上,实现高性能的在线服务。TensorFlow Serving支持REST和gRPC接口,可用于大规模云端部署。使用时,将上一步导出的SavedModel加载到TF Serving,即可通过标准REST API调用翻译(客户端发送JSON或Proto请求到指定URL)。需要注意的是,某些文本预处理操作(如复杂的分词)可能无法在纯TensorFlow图中完成,需由客户端或代理服务器在送入Serving前后执行。
-
CTranslate2 推理:OpenNMT-tf导出的模型也可以转换为CTranslate2格式,以获得更快的推理速度和更低的资源占用。方法是使用
ct2-opennmt-tf-converter,指明模型目录和词表文件,将其转换并可选应用8位或16位量化。转换命令示例:。转换后的模型同样可通过CTranslate2加载,用于本地或服务端高效推理。
云端部署选项
将OpenNMT部署到云端与本地部署原理相似,但需要考虑云环境的弹性和规模优势。常见的云端部署方式包括:
-
云服务器部署:在云提供商的虚拟机(如AWS EC2、Google Cloud VM、Azure VM)上配置环境,安装OpenNMT-py或OpenNMT-tf,并按照本地部署方式启动翻译服务。推荐使用带GPU的实例以满足训练和高速翻译需求。可以利用OpenNMT-py提供的Docker容器,在云主机上直接运行容器以减少环境配置时间。对于需要长期在线提供服务的模型,可以将OpenNMT翻译服务器作为后台进程运行,并配合反向代理或负载均衡(如Nginx)处理高并发请求。
-
容器编排服务:将OpenNMT封装进Docker镜像后,可部署到容器编排平台例如Kubernetes。通过Kubernetes部署,可以方便地扩展副本数量,实现高可用和负载均衡。也可以借助云厂商的容器服务(如AWS ECS、Azure Container Instances)直接运行OpenNMT容器。利用云端的弹性伸缩,根据翻译请求量动态增加或销毁实例,优化资源使用。
-
机器学习服务:如果使用OpenNMT-tf,云端还可考虑使用TensorFlow Serving或类似的平台服务。比如将SavedModel上传至TensorFlow Serving容器,部署在AWS SageMaker、GCP AI Platform等托管服务上,从而通过标准API提供翻译能力。这种方式下模型推理由云端优化的服务托管,无需关心底层服务器管理。
-
示例:有开发者成功将OpenNMT模型部署在Heroku等PaaS平台上,通过Flask应用包装OpenNMT翻译API以提供网页服务。另外也有人在免费云主机上运行轻量级的翻译服务,例如使用PythonAnywhere托管Flask应用,并借助CTranslate2加载OpenNMT模型(8-bit量化后)以在无GPU的环境下实现快速翻译。这些案例表明OpenNMT部署具有很强的灵活性,既可在高性能GPU服务器上提供工业级服务,也能在资源有限的环境中以优化方式运行。实际部署中,应根据使用场景选择合适的云资源和架构,以兼顾性能和成本。
与其他系统的集成
OpenNMT提供多种接口和工具,方便与现有的系统或应用集成,实现机器翻译功能嵌入。以下是几种常见的集成方式:
-
通过 REST API 集成:这是最普遍的集成方式。OpenNMT-py自带的翻译服务器(Flask实现)启动后,会监听HTTP请求并提供RESTful接口。其他系统(无论使用何种语言开发)都可以通过标准HTTP请求来访问翻译服务。例如,发送POST请求到
/translator/translate接口,内容为待翻译文本的JSON数据结构,即可获取翻译结果。返回结果也是JSON格式,包含翻译后的目标文本等信息(详见下文示例)。这种REST API模式使OpenNMT可以作为微服务运行,各种前端或后端应用通过HTTP即可对接,实现松耦合集成。 -
前端翻译界面集成:如果需要为最终用户提供交互界面,可以构建一个前端页面或应用程序,再通过调用后端的OpenNMT翻译API完成工作。例如,有开发者使用Flask和Flask-PageDown构建了一个简单的Web界面,提供文本输入和翻译结果显示。该前端将用户输入通过Ajax发送至后端OpenNMT REST服务,获取译文后再呈现给用户。也有方案使用更现代的框架,如Streamlit,直接将模型推理嵌入Web界面中。无论技术细节如何,实现思路都是通过某种前端组件收集用户文本,并调用后台翻译引擎获取结果,进而提升用户体验。前端和OpenNMT之间通过HTTP API通讯,这种架构确保了翻译模型与UI解耦,便于分别升级。
-
后端服务与数据流对接:在一些后台处理流程中,也可以集成OpenNMT以翻译文本数据。例如,在企业的内容管理、邮件系统或数据管道中,当检测到某字段需要翻译时,由系统调用OpenNMT服务将内容翻译成目标语言,然后将结果写回数据库或传递给下游流程。因为OpenNMT提供了命令行和Python API,所以除了REST方式,您也可以在自有应用中直接调用OpenNMT库。例如,一个Python后端应用可直接import OpenNMT的模块,加载模型后调用翻译函数获取结果并继续处理。这种直接嵌入的方式减少了HTTP开销,但需要在应用进程中管理模型的生命周期。对于跨语言或分布式系统,还是建议采用独立的翻译服务,通过RPC或HTTP接口来对接,从架构上保持清晰的数据流边界。
-
其它集成方式:OpenNMT的模型输出和输入都是基于文本的,因而也可以和消息队列、文件系统监控等机制组合。例如,通过消息队列(如RabbitMQ)发送待翻译消息,消费端拉取消息并调用OpenNMT翻译,再将结果发布到另一个队列供后续系统使用。这类松耦合的异步集成在需要批量翻译或解耦模块时很有用。另外,如果现有系统已经使用某些NLP平台或SDK,OpenNMT训练的模型也可能通过转换后被那些平台加载(前提是兼容,比如转换为ONNX格式后被其他推理引擎使用)。总体来说,OpenNMT的开放性使其几乎可以接入任意软件架构,只需通过规范的数据接口进行交互。
集成示例:翻译API调用流程
下面通过一个简单的REST API调用流程示意,说明OpenNMT翻译服务与客户端系统的交互集成方式:
-
客户端请求:客户端应用(可以是网页前端、移动App或服务器程序)将待翻译的源文本打包为JSON格式,通过HTTP POST请求发送到OpenNMT翻译服务的REST接口(例如
http://<服务器地址>:5000/translator/translate)。请求JSON通常是一个包含源句子的数组,例如:[ { "src": "待翻译的文本", "id": 0 } ]其中
src为源语言句子,id可以用于指定使用特定模型或标记请求序号。 -
服务端处理:OpenNMT翻译服务收到请求后,先对输入文本执行预处理操作,包括分词、子词拆分等(如果在配置中启用了相应选项)。然后调用预先加载的NMT模型进行翻译解码,生成目标语言句子的表示。OpenNMT内部会自动完成翻译所需的一系列步骤,如词汇映射、模型计算和解码搜索等。对于多个并发请求,服务可根据实现采用队列或多线程处理,以保证每个请求最终都被模型翻译。
-
结果返回:翻译完成后,服务端对模型输出进行后处理,如将子词片段拼接还原成完整单词,并去除必要的控制符。最终的译文结果会以JSON格式返回给客户端。返回的JSON结构通常包含原请求中句子的
id以及对应的翻译文本。例如:{"model_id": 0,"src": "待翻译的文本","tgt": "译文结果","status": "ok" }其中
"tgt"或类似字段即包含翻译后的目标语言文本内容。客户端接收到响应后即可提取译文用于后续展示或处理。如果开启了对齐信息或其他附加选项,返回JSON中也会附带相应数据。整个过程对调用方来说透明且同步完成。
上述流程体现了通过REST API集成OpenNMT的典型方式。从系统角度看,客户端 -> HTTP请求 -> 翻译服务 -> HTTP响应 -> 客户端 形成了闭环。在实现中可针对需求增加缓存、重试等机制以增强健壮性。例如,对相同句子的重复请求可以由客户端或服务端缓存结果,以减少不必要的计算。
最佳实践和安全建议
在部署和集成OpenNMT时,遵循一些最佳实践和安全准则有助于提升系统的性能与可靠性:
-
高效推理:对于生产环境,建议使用优化的推理引擎运行模型。如前文所述,CTranslate2是OpenNMT官方提供的高性能推理引擎,具有更快的执行速度和更低的内存占用。将模型转换为CTranslate2格式并使用INT8量化可大幅减少模型大小和CPU计算量,同时几乎不损失翻译质量。在GPU不足或需要在CPU上部署服务的情况下,这种方式尤为有效。
-
资源管理:如果一个服务承载多个翻译模型,应合理管理GPU/CPU内存。OpenNMT-py的翻译服务器支持在一段时间无请求后卸载模型或将模型转移到CPU内存(释放GPU显存)。利用这些特性可以在低请求负载时节省资源,又能在有请求时迅速加载模型提供服务。对于高并发情形,可考虑启用批量翻译或多线程处理,提高吞吐量(例如CTranslate2允许配置并行翻译的工作线程数,并可利用多核CPU或多GPU实现并发翻译)。同时应监控服务的CPU、GPU和内存占用,设置适当的指标告警,及时扩容或清理资源避免过载。
-
模型更新与版本管理:在实际应用中,翻译模型可能需要迭代更新。建议采用蓝绿部署或滚动更新策略:在部署新模型时不开停旧服务,而是启动新实例加载新模型,待其准备就绪后再切流量过来。这样可确保平滑过渡而不中断服务。保存旧模型作为回退方案以防新模型出现问题也是明智的做法。版本管理上,可对每个模型打标签或版本号,在REST API请求中通过参数指定使用哪个版本模型,以便逐步测试新模型效果。
-
安全性:如果将OpenNMT翻译功能对外提供,一定要考虑安全问题。首先,尽量使用HTTPS协议来加密传输,保护敏感文本内容在网络中不被窃听。其次,可以在API层面增加认证和访问控制,例如要求调用方提供API密钥或令牌,避免未授权滥用翻译服务。对于公开的Web翻译接口,需要实现请求频率限制(Rate Limiting)和输入长度限制,防止恶意用户构造超长文本耗尽系统资源。由于翻译请求本质上就是文本处理,传统的代码注入等安全风险较低,但也应做好输入校验,防范异常字符或格式引发的问题。
-
日志与监控:开启详尽的日志记录以便追踪翻译请求和系统状态。日志应至少包含每次请求的来源、输入长度、响应时长以及是否成功等信息。这有助于定位性能瓶颈和异常请求。对翻译结果进行抽样监控也能在模型质量下降或出错时及时发现(例如模型突然输出大量乱序字符可能表示需要重启服务或检查输入)。结合APM(应用性能监控)工具对翻译API的响应时间、错误率进行监控,能够保障服务稳定运行。
相关文章:

OpenNMT 部署和集成指南
OpenNMT(Open Neural Machine Translation)是一个开源的神经机器翻译(NMT)系统,由 Systran 和 Harvard NLP Group 在 2016 年联合推出。它的目标是为研究人员和企业开发者提供一个高质量、灵活且易于扩展的机器翻译框架…...
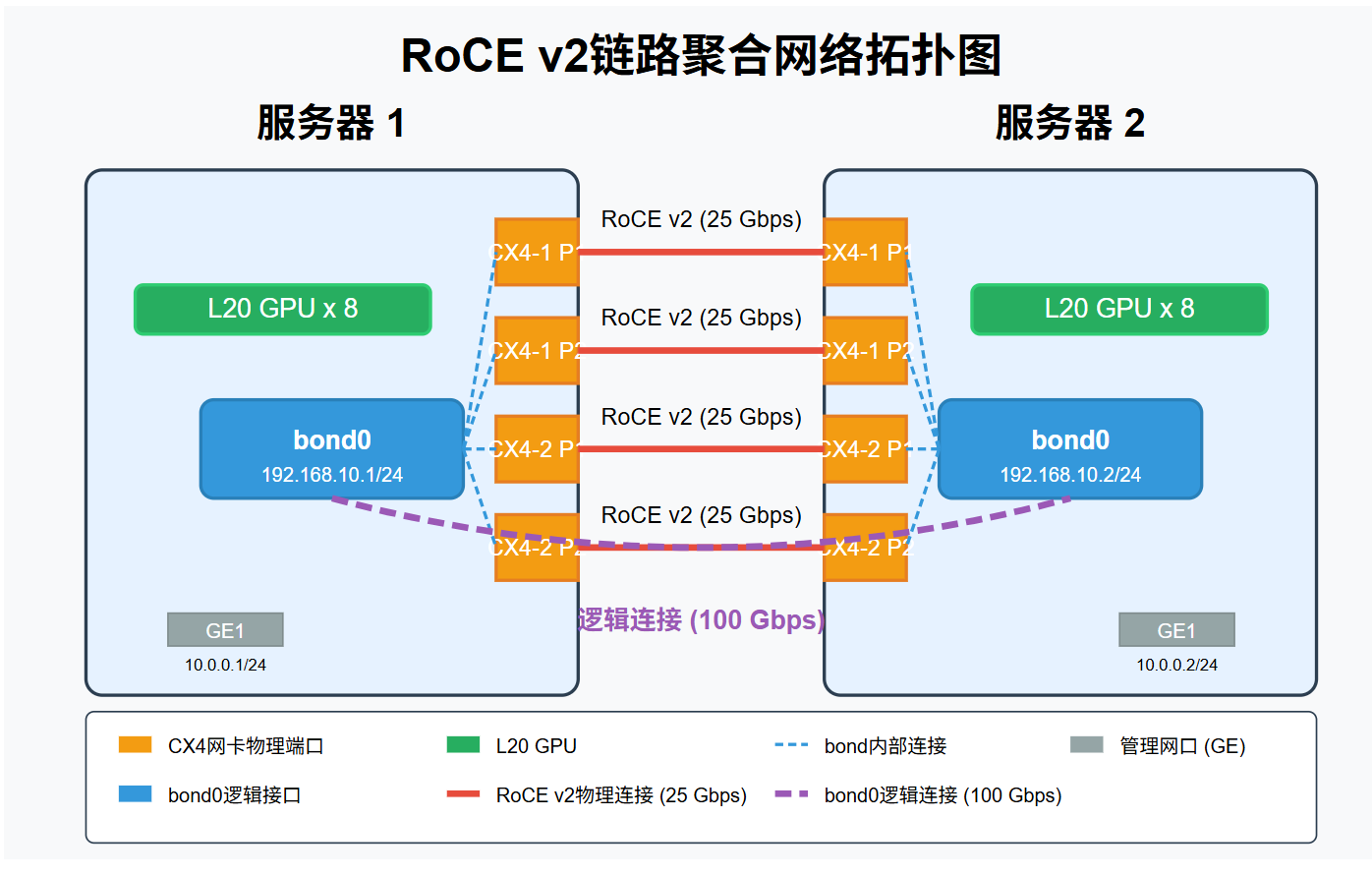
2台8卡L20服务器集群推理方案
1、整体流程梳理 #mermaid-svg-0aNtsWUnOH7ewXpN {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-0aNtsWUnOH7ewXpN .error-icon{fill:#552222;}#mermaid-svg-0aNtsWUnOH7ewXpN .error-text{fill:#552222;stroke:#55…...
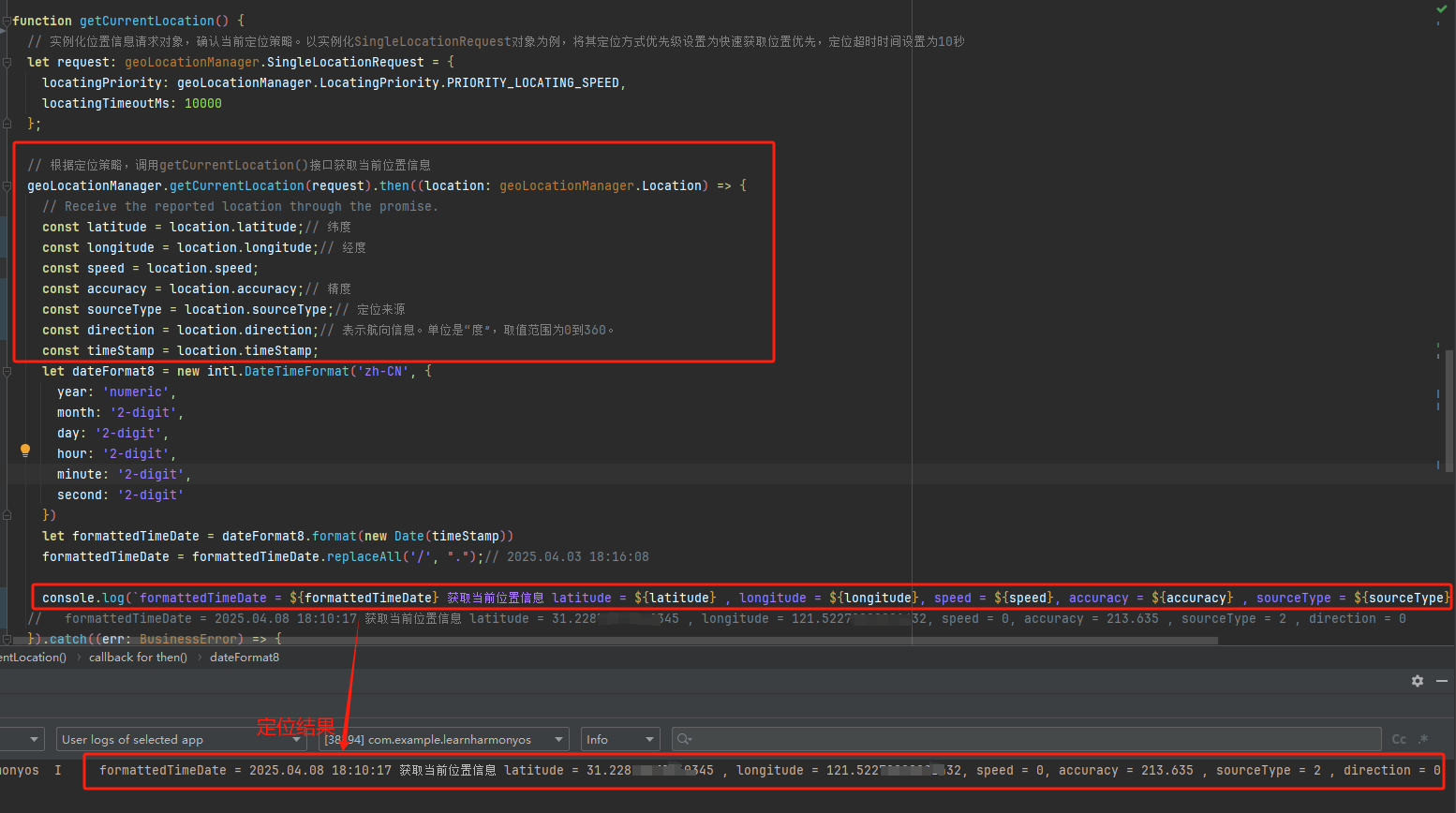
HarmonyOS:使用geoLocationManager (位置服务)获取位置信息
一、简介 位置服务提供GNSS定位、网络定位(蜂窝基站、WLAN、蓝牙定位技术)、地理编码、逆地理编码、国家码和地理围栏等基本功能。 使用位置服务时请打开设备“位置”开关。如果“位置”开关关闭并且代码未设置捕获异常,可能导致应用异常。 …...

系统分析师(二)--操作系统
概述 进程管理 选项A:该进程中打开的文件 进程中打开的文件是由整个进程来管理的,同一进程下的各个线程都可以对这些打开的文件进行访问和操作,所以进程中打开的文件是可以被这些线程共享的。 选项B:该进程的代码段 进程的代码…...

安科瑞测频仪表:新能源调频困局的破局者
安科瑞顾强 在“双碳”目标推动下,风电、光伏等新能源正加速成为电力供应的核心力量。然而,新能源发电的间歇性与波动性,如同一把“双刃剑”,在提供清洁电力的同时,也给电网稳定运行带来了前所未有的挑战。国家能源局…...
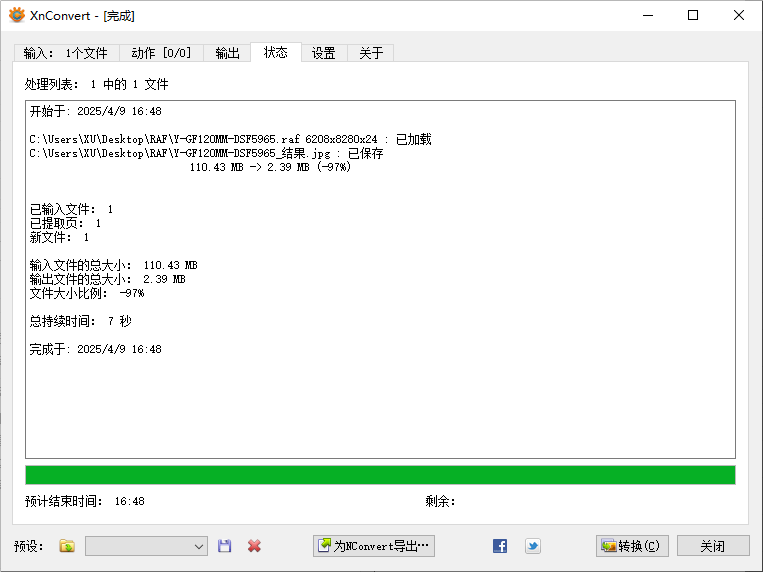
富士相机照片 RAF 格式如何快速批量转为 JPG 格式教程
富士(Fujifilm)相机拍摄的 RAW 格式文件(RAF)因其高质量和丰富的图像信息而受到摄影师的喜爱。然而,RAF 文件通常体积较大且不易于分享或直接使用。为了方便处理,许多人选择将其转换为更通用的 JPG 格式。在…...

Linux 入门指令(1)
(1)ls指令 ls -l可以缩写成 ll 同时一个ls可以加多个后缀 比如 ll -at (2)pwd指令 (3)cd指令 cd .是当前目录 (4)touch指令 (5)mkdir指令 (6)rmdir和rm…...
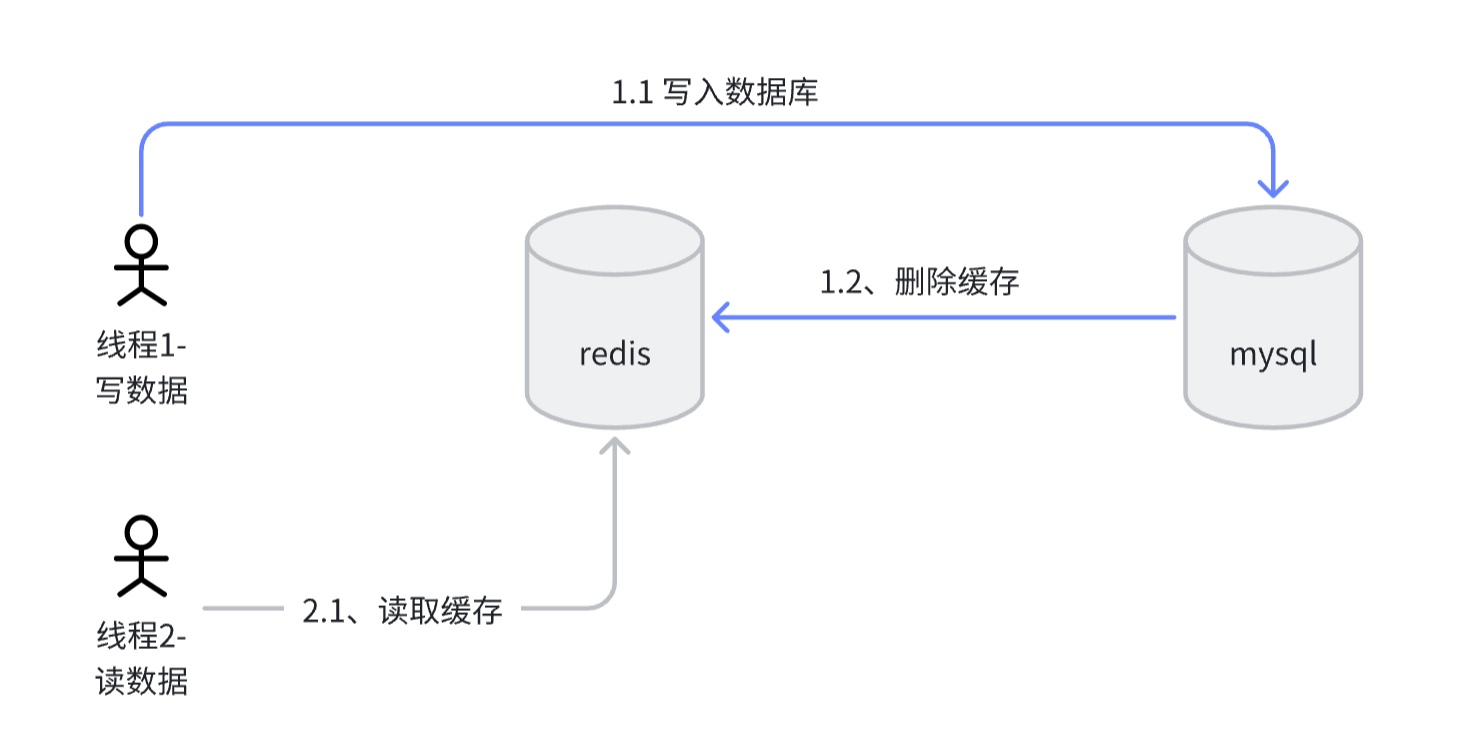
Redis缓存数据库一致性
前言: 在系统开发中经常使用关系型数据库,为了提升关系型数据库的读性能,一般会使用redis加一层缓存,缓存和数据库是分离的两次操作,本文用来分析如何操作能保证缓存和数据库的数据一致性。 一、读场景 二、写场景 …...
Android Coil 3 Fetcher大批量Bitmap拼接成1张扁平宽图,Kotlin
Android Coil 3 Fetcher大批量Bitmap拼接成1张扁平宽图,Kotlin <uses-permission android:name"android.permission.WRITE_EXTERNAL_STORAGE" /><uses-permission android:name"android.permission.READ_EXTERNAL_STORAGE" /><u…...
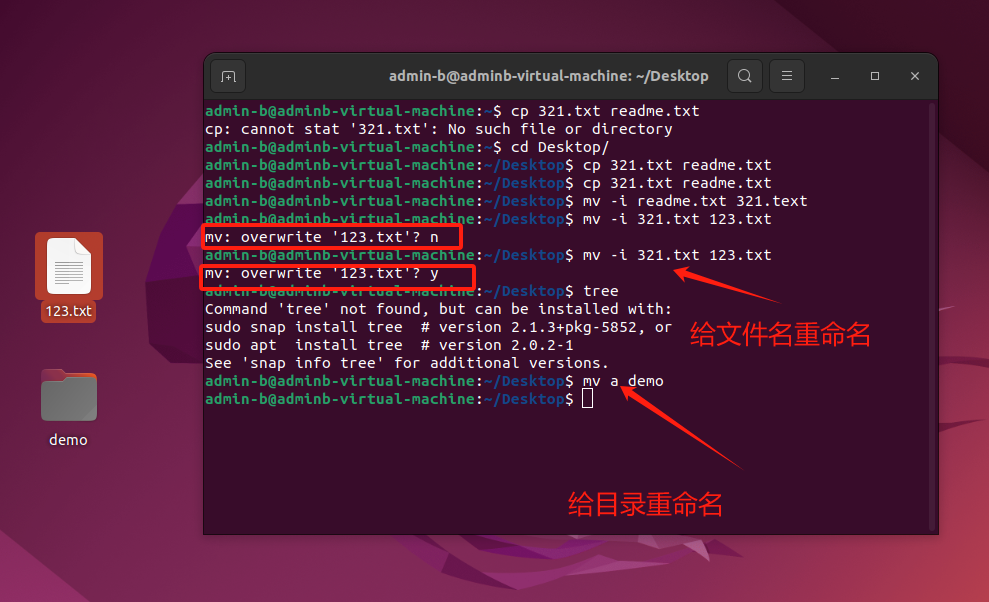
文件相关:treecpmv命令扩展详解
拷贝和移动文件 序号命令对应英文作用01tree [目录名]tree以树状图列出文件目录结构02cp 源文件 目标文件copy复制文件或者目录03mv 源文件 目标文件move移动文件或者目录/文件或者目录重命名 一、 tree命令 (1)定义 tree 命令可以以树状…...
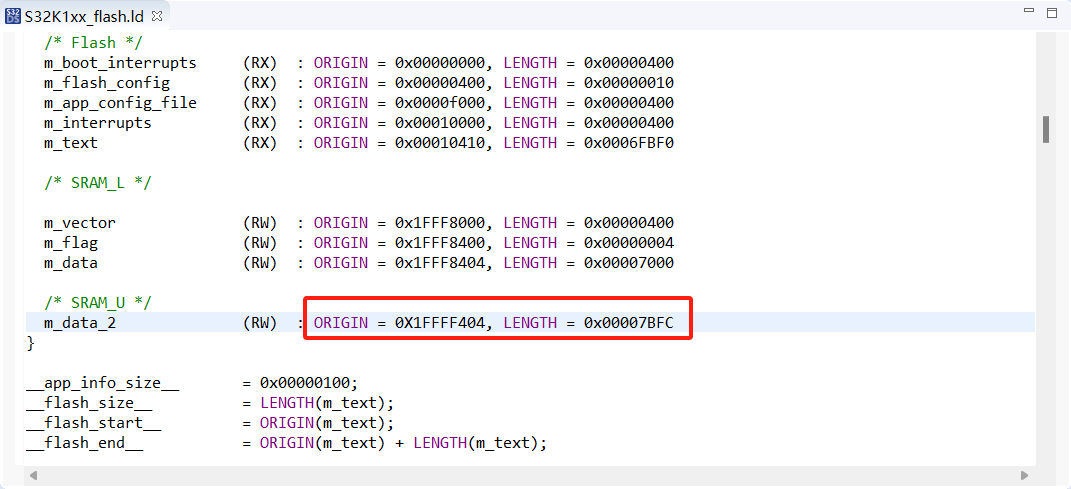
S32K144的m_data_2地址不够存,重新在LD文件中配置地址区域
在开发平台软件的时候代码中超出了64K的内存,单纯在ld文件中,增加m_data_2的存储长度,原先是0x00007000,我将长度修改为0x00008000,起始地址还是0x20000000,软件编译没有报错堆栈超出,但是软件下载到单片机中之后,144不…...

基于 SysTick 定时器实现任务轮询调度器
文章目录 前言一、SysTick 定时器介绍二、SysTick 驱动设计1. 初始化方法2. SysTick 中断函数3. 时间类 API 三、任务调度器设计1. 任务结构体2. 任务初始化3. 主调度器4. 调度器更新 四、任务函数实现五、总结1. 优缺点分析2. 扩展建议 前言 在嵌入式系统中,对于资…...
【STM32】综合练习——智能风扇系统
目录 0 前言 1 硬件准备 2 功能介绍 3 前置配置 3.1 时钟配置 3.2 文件配置 4 功能实现 4.1 按键功能 4.2 屏幕功能 4.3 调速功能 4.4 倒计时功能 4.5 摇头功能 4.6 测距待机功能 0 前言 由于时间关系,暂停详细更新,本文章中,…...

MyBatis 动态 SQL 使用详解
🌟 一、什么是动态 SQL? 动态 SQL 是指根据传入参数,动态拼接生成 SQL 语句,不需要写多个 SQL 方法。MyBatis 提供了 <if>、<choose>、<foreach>、<where> 等标签来实现这类操作 ✅ 二、动态 SQL 的优点…...
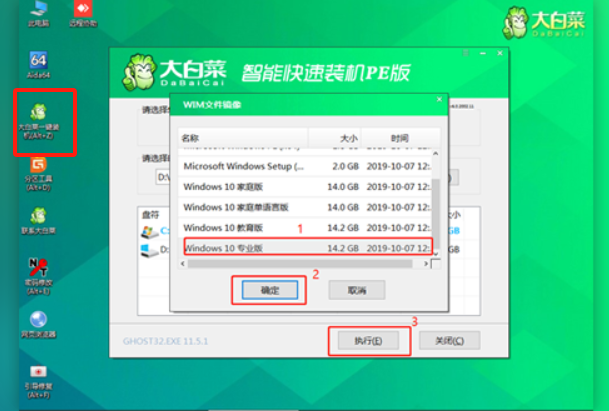
【重装系统】大白菜自制U盘装机,备份C盘数据,解决电脑启动黑屏/蓝屏
1. 准备 U 盘 U 盘容量至少 8G,备份 U 盘的数据(后期会格式化) 2. 从微软官网下载操作系统镜像 https://www.microsoft.com/zh-cn/software-download/windows11 3. 下载安装大白菜 https://www.alipan.com/s/33RVnKayUfY 4. 插入 U 盘&#…...
vue实现目录锚点且滚动到指定区域时锚点自动回显——双向锚点
最近在用vue写官网,别问我为什么用vue写官网,问就是不会jq。。。。vue都出现11年了。。。 左侧目录:点击时,右侧区域可以自动滚动到指定的位置。 右侧区域手动滚动时,左侧锚点可以自动切换到对应的目录上 从而实现…...

python——正则表达式
一、简介 在 Python 中,正则表达式主要通过 re 模块实现,用于字符串的匹配、查找、替换等操作。 二、Python的re模块 使用前需要导入: import re 三、常用方法 方法描述re.match(pattern, string)从字符串开头匹配,返回第一个匹…...
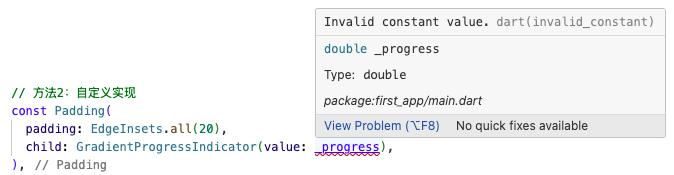
Flutter Invalid constant value.
0x00 问题 参数传入变量,报错! 代码 const Padding(padding: EdgeInsets.all(20),child: GradientProgressIndicator(value: _progress), ),_progress 参数报错:Invalid constant value. 0x01 原因 这种情况,多发生于ÿ…...

libev实现Io复用及定时器事件服务器
客户端和服务器都绑定在了enp2s0网卡,需要SERVER_IP和SERVER_PORT改为其ip,注意不能是127.0.0.1,因为这个是lo虚拟网口。 安装libev sudo apt-get install libev-dev客户端: #include <iostream> #include <string>…...

【精品PPT】2025固态电池知识体系及最佳实践PPT合集(36份).zip
精品推荐,2025固态电池知识体系及最佳实践PPT合集,共36份。供大家学习参考。 1、中科院化学所郭玉国研究员:固态金属锂电池及其关键材料.pdf 2、中科院物理所-李泓固态电池.pdf 3、全固态电池技术研究进展.pdf 4、全固态电池生产工艺.pdf 5、…...

如何计算设备电池工作时长?
目录 【mAh(毫安时)计算方法】 【Wh(瓦时)计算方法】 【为什么仅用电流(mA)和时间(h)就能计算电池使用时长(mAh)?】 1. mAh 的本质是“电荷量…...
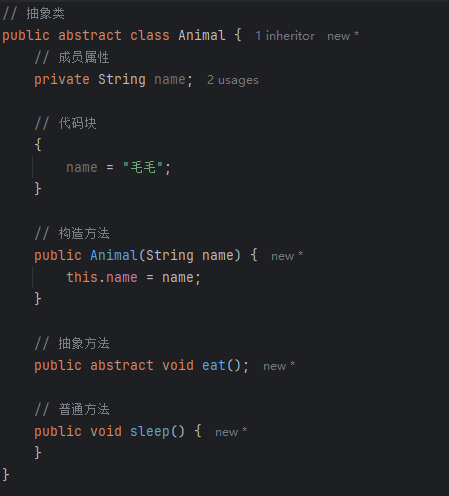
抽象类及其特性
目录 1、概念2、语法3、特性4、作用 1、概念 在面向对象中,所有对象都是通过类来描述的,但是并不是所有的类都可以用来描述对象。比如下述例子中的 Animal 类,Dog 类和 Cat 类是 Animal 类的子类,可以分别描述小狗和小猫…...
【教程】xrdp修改远程桌面环境为xfce4
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 目录 xfce4 vs GNOME对比 配置教程 1. 安装 xfce4 桌面环境 2. 安装 xrdp 3. 配置 xrdp 使用 xfce4 4. 重启 xrdp 服务 5. 配置防火墙ÿ…...
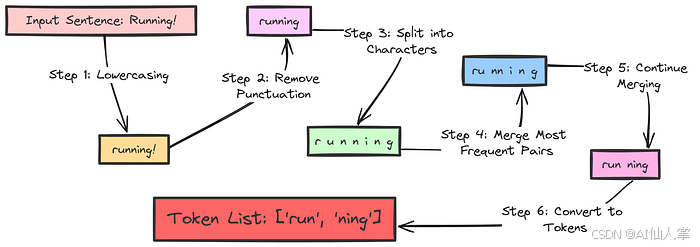
利用python从零实现Byte Pair Encoding(BPE):NLP 中的“变形金刚”
BPE:NLP 界的“变形金刚”,从零开始的奇幻之旅 在自然语言处理(NLP)的世界里,有一个古老而神秘的传说,讲述着一种强大的魔法——Byte Pair Encoding(BPE)。它能够将普通的文本“变形…...
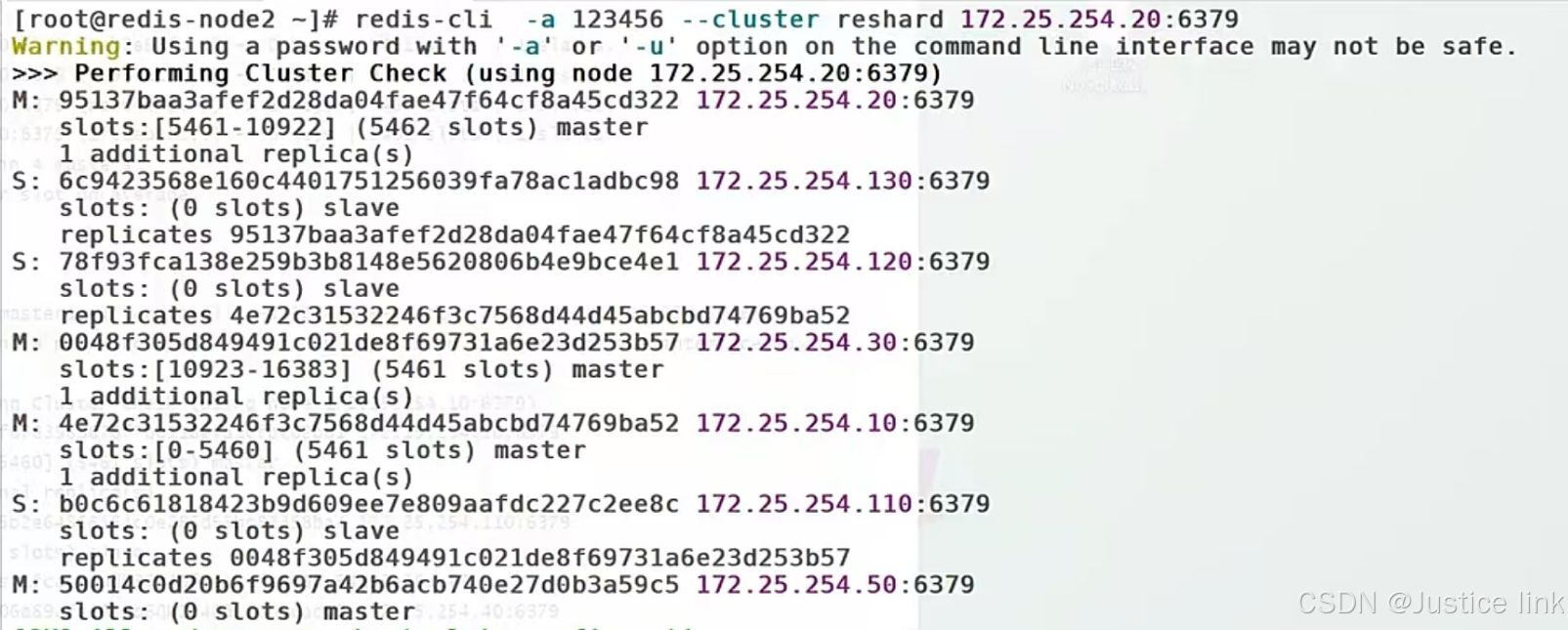
部署redis cluster
一。在所有的主机里面设置密码和文件地址 vi /etc/redis/6379.conf 注释:登陆则要使用auth 123456才可以进入redis 配置文件地址和超时时间 二。创建集群:上面主机为master,下面为slave,master和slave会随机分配 先写主节点&…...
 及更高版本中,查询的特定应用商店包,无需动态请求权限处理)
Android 11 (API 30) 及更高版本中,查询的特定应用商店包,无需动态请求权限处理
在 Android 11 (API 30) 及更高版本中,通过在 AndroidManifest.xml 中添加 <queries> 元素声明需要查询的特定应用商店包名后: 1. 不需要额外请求权限 (如 QUERY_ALL_PACKAGES )即可查询这些应用的安装状态 2. 这是 Googl…...
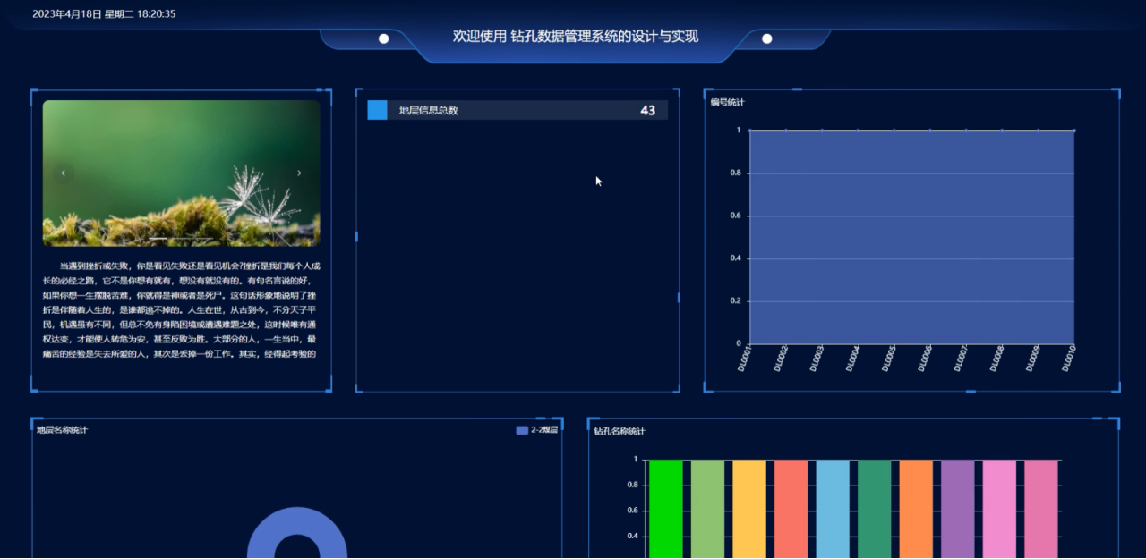
基于springboot钻孔数据管理系统的设计与实现(源码+lw+部署文档+讲解),源码可白嫖!
摘要 本钻孔数据管理系统采用B/S架构,数据库是MySQL,网站的搭建与开发采用了先进的Java语言、Hadoop、数据可视化技术进行编写,使用了Spring Boot框架。该系统从两个对象:由管理员和用户来对系统进行设计构建。用户主要功能包括&…...

SpringBoot和微服务学习记录Day2
微服务 微服务将单体应用分割成更小的的独立服务,部署在不同的服务器上。服务间的关联通过暴露的api接口来实现 优点:高内聚低耦合,一个模块有问题不影响整个应用,增加可靠性,更新技术方便 缺点:增加运维…...

4.9复习记
1.地宫取宝--记忆化搜索,可以先写void dfs,然后在改成ll 形式的,边界条件return 0/1; 记忆化数组与dfs元素保持一致,记得记忆化剪枝 这个题特殊在value可能是0,不取的时候应该记为-1 https://mpbeta.cs…...

LinuxSocket套接字编程
1.介绍函数使用 1.创建套接字 int socket(int domain, int type, int protocol); domain:指定协议族,如AF_INET(IPv4)或AF_INET6(IPv6)。 type:指定套接字类型,如SOCK_DGRAM&#…...