【10】数据结构的矩阵与广义表篇章
目录标题
- 二维以上矩阵
- 矩阵存储方式
- 行序优先存储
- 列序优先存储
- 特殊矩阵
- 对称矩阵
- 稀疏矩阵
- 三元组方式存储稀疏矩阵的实现
- 三元组初始化
- 稀疏矩阵的初始化
- 稀疏矩阵的创建
- 展示当前稀疏矩阵
- 稀疏矩阵的转置
- 三元组稀疏矩阵的调试与总代码
- 十字链表方式存储稀疏矩阵的实现
- 十字链表数据标签初始化
- 十字链表结点初始化
- 十字链表初始化
- 十字链表的创建
- 十字链表的展示
- 十字链表形式稀疏矩阵的调试与总代码
- 广义表的实现
- 存储结点初始化
- 广义表初始化
- 广义表的创建
- 输出广义表
- 广义表的深度
- 广义表的长度
- 广义表的调试与总代码
二维以上矩阵
矩阵存储方式
行序优先存储
- 求任意元素地址计算公式:
Address(A[i][j]) = BaseAddress + ( i × n + j ) × ElementSize
- 其中:
BaseAddress 是数组的基地址,即数组第一个元素 A[0][0] 的地址。
i 是行索引,范围从 0 到 m−1。
j 是列索引,范围从 0 到 n−1。
ElementSize 是数组中每个元素的大小(以字节为单位)。
列序优先存储
- 求任意元素地址计算公式:
Address(A[i][j]) = BaseAddress+ ( j × m + i ) × ElementSize
- 其中:
BaseAddress 是数组的基地址,即数组第一个元素 A[0][0] 的地址。
i 是行索引,范围从 0 到 m−1。
j 是列索引,范围从 0 到 n−1。
ElementSize 是数组中每个元素的大小(以字节为单位)。
特殊矩阵
对称矩阵
-
n阶方阵元素满足:a[i][j] == a[j][i]
-
按行序优先存储方式:仅存储对称矩阵的下三角元素,将元素存储到一维数据A[0]~A[n(n+1)/2]中,则A[k]与二维矩阵a[i][j]地址之间的对应关系公式为:
k = { i ( i − 1 ) 2 + j , if i ≥ j j ( j − 1 ) 2 + i , if i < j k = \begin{cases} \frac{i(i-1)}{2} + j, & \text{if } i \geq j \\ \frac{j(j-1)}{2} + i, & \text{if } i < j \end{cases} k={2i(i−1)+j,2j(j−1)+i,if i≥jif i<j
稀疏矩阵
- 定义:矩阵的非零元素比零元素少,且分布没有规律。
- 稀疏矩阵的两种存储方式:
- 三元组
- 十字链表
三元组方式存储稀疏矩阵的实现
- 特点:为了节省存储空间,只存储非零元素数值,因此,还需存储元素在矩阵中对应的行号与列号,形成唯一确定稀疏矩阵中任一元素的三元组:
(row, col, data)
row 行号
col 列号
data 非零元素值
三元组初始化
class Triples:"""三元组初始化"""def __init__(self):self.row = 0 # 行号self.col = 0 # 列号self.data = None # 非零元素值
稀疏矩阵的初始化
class Matrix:"""稀疏矩阵初始化"""def __init__(self, row, col):# 行数self.row = row# 列数self.col = col# 最大容量self.maxSize = row * col# 非零元素的个数self.nums = 0# 存储稀疏矩阵的三元组self.matrix = [Triples() for i in range(self.maxSize)]
稀疏矩阵的创建
- 通过指定行列与元素值的方式进行插入创建
- 行序优先原则
- 主要通过if语句对不同的比较结果流向不同的分支。
def insert(self, row, col, data):"""将数据插入三元组表示的稀疏矩阵中,成功返回0,否则返回-1:param row: 行数:param col: 列数:param data: 数据元素:return: 是否插入成功"""# 判断当前稀疏矩阵是否已满if (self.nums >= self.maxSize):print('当前稀疏矩阵已满')return -1# 判断列表是否溢出if row > self.row or col > self.col or row < 1 or col < 1:print("你输入的行或列的位置有误")return -1# 标志新元素应该插入的位置p = 1# 插入前判断稀疏矩阵没有非零元素if (self.nums == 0):self.matrix[p].row = rowself.matrix[p].col = colself.matrix[p].data = dataself.nums += 1return 0# 循环,寻找合适的插入位置for t in range(1, self.nums+1):# 判断插入行是否比当前行大if row > self.matrix[t].row:p += 1# 行数相等,但是列数大于当前列数if (row == self.matrix[t].row) and (col > self.matrix[t].col):p += 1# 判断该位置是否已有数据,有则更新数据if (row == self.matrix[p].row) and (col == self.matrix[p].col) and self.matrix[p].data == 0:self.matrix[p].data = datareturn 0# 移动p之后的元素for i in range(self.nums, p-1, -1):self.matrix[i+1] = self.matrix[i]# 插入新元素self.matrix[p].row = rowself.matrix[p].col = colself.matrix[p].data = data# 元素个数加一self.nums += 1return 0
展示当前稀疏矩阵
def display(self):"""稀疏矩阵展示:return:"""if self.nums == 0:print('当前稀疏矩阵为空')returnprint(f'稀疏矩阵的大小为:{self.row} × {self.col}')# 标志稀疏矩阵中元素的位置p = 1# 双重循环for i in range(1, self.row+1):for j in range(1, self.col+1):if i == self.matrix[p].row and j == self.matrix[p].col:print("%d"%self.matrix[p].data, end='\t')p += 1else:print(0, end='\t')print()
稀疏矩阵的转置
- 将矩阵中的所有每个元素a[i][j] = a[j][i],其中a[i][j]与a[j][i]都存在。
- 每查找矩阵的一列,都完整地扫描器三元组数组,并进行行列颠倒。
- 要查找矩阵的每一列即每次都要定格行号。
def transpose(self):"""稀疏矩阵的转置:return: 返回转置后的稀疏矩阵"""# 创建转置后的目标稀疏矩阵matrix = Matrix(self.col, self.row)matrix.nums = self.nums# 判断矩阵是否为空if self.nums > 0:# 标志目标稀疏矩阵中元素的位置q = 1# 双重循环,行列颠倒for col in range(1, self.row+1):# p标志渊矩阵中元素的位置for p in range(1, self.nums+1):# 如果列相同,则行列颠倒if self.matrix[p].col == col:matrix.matrix[q].row = self.matrix[p].colmatrix.matrix[q].col = self.matrix[p].rowmatrix.matrix[q].data = self.matrix[p].dataq += 1return matrix
三元组稀疏矩阵的调试与总代码
# 17.稀疏矩阵的实现
class Triples:"""三元组初始化"""def __init__(self):self.row = 0 # 行号self.col = 0 # 列号self.data = None # 非零元素值class Matrix:"""稀疏矩阵初始化"""def __init__(self, row, col):# 行数self.row = row# 列数self.col = col# 最大容量self.maxSize = row * col# 非零元素的个数self.nums = 0# 存储稀疏矩阵的三元组self.matrix = [Triples() for i in range(self.maxSize)]def insert(self, row, col, data):"""将数据插入三元组表示的稀疏矩阵中,成功返回0,否则返回-1:param row: 行数:param col: 列数:param data: 数据元素:return: 是否插入成功"""# 判断当前稀疏矩阵是否已满if (self.nums >= self.maxSize):print('当前稀疏矩阵已满')return -1# 判断列表是否溢出if row > self.row or col > self.col or row < 1 or col < 1:print("你输入的行或列的位置有误")return -1# 标志新元素应该插入的位置p = 1# 插入前判断稀疏矩阵没有非零元素if (self.nums == 0):self.matrix[p].row = rowself.matrix[p].col = colself.matrix[p].data = dataself.nums += 1return 0# 循环,寻找合适的插入位置for t in range(1, self.nums+1):# 判断插入行是否比当前行大if row > self.matrix[t].row:p += 1# 行数相等,但是列数大于当前列数if (row == self.matrix[t].row) and (col > self.matrix[t].col):p += 1# 判断该位置是否已有数据,有则更新数据if (row == self.matrix[p].row) and (col == self.matrix[p].col) and self.matrix[p].data == 0:self.matrix[p].data = datareturn 0# 移动p之后的元素for i in range(self.nums, p-1, -1):self.matrix[i+1] = self.matrix[i]# 插入新元素self.matrix[p].row = rowself.matrix[p].col = colself.matrix[p].data = data# 元素个数加一self.nums += 1return 0def display(self):"""稀疏矩阵展示:return:"""if self.nums == 0:print('当前稀疏矩阵为空')returnprint(f'稀疏矩阵的大小为:{self.row} × {self.col}')# 标志稀疏矩阵中元素的位置p = 1# 双重循环for i in range(1, self.row+1):for j in range(1, self.col+1):if i == self.matrix[p].row and j == self.matrix[p].col:print("%d"%self.matrix[p].data, end='\t')p += 1else:print(0, end='\t')print()def transpose(self):"""稀疏矩阵的转置:return: 返回转置后的稀疏矩阵"""# 创建转置后的目标稀疏矩阵matrix = Matrix(self.col, self.row)matrix.nums = self.nums# 判断矩阵是否为空if self.nums > 0:# 标志目标稀疏矩阵中元素的位置q = 1# 双重循环,行列颠倒for col in range(1, self.row+1):# p标志渊矩阵中元素的位置for p in range(1, self.nums+1):# 如果列相同,则行列颠倒if self.matrix[p].col == col:matrix.matrix[q].row = self.matrix[p].colmatrix.matrix[q].col = self.matrix[p].rowmatrix.matrix[q].data = self.matrix[p].dataq += 1return matrixif __name__ == '__main__':# # 17.稀疏矩阵# # 创建稀疏矩阵matrix1 = Matrix(6, 7)matrix1.display()# 向矩阵中插入数据matrix1.insert(1, 1, 88)matrix1.insert(1, 2, 11)matrix1.insert(1, 3, 21)matrix1.insert(1, 4, 66)matrix1.insert(1, 7, 77)matrix1.insert(2, 2, 40)matrix1.insert(2, 4, 2)matrix1.insert(2, 7, 52)matrix1.insert(3, 1, 92)matrix1.insert(3, 6, 85)matrix1.insert(4, 3, 12)matrix1.insert(5, 1, 67)matrix1.insert(5, 2, 26)matrix1.insert(5, 4, 64)matrix1.insert(6, 3, 55)matrix1.insert(6, 5, 10)matrix1.display()# 矩阵转置matrix2 = matrix1.transpose()matrix2.display()
- 运行结果

十字链表方式存储稀疏矩阵的实现
- 十字链表的结点结构图

- 十字链表头结点结构图

- 以下面矩阵为例,稀疏矩阵十字链表的表示图
( 1 0 0 2 0 0 1 0 0 0 0 1 ) \begin{pmatrix} 1 & 0 & 0 & 2 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{pmatrix} 100000010201

十字链表数据标签初始化
class Tag:def __init__(self):"""十字链表数据标签初始化"""self.data = Noneself.link = None
十字链表结点初始化
class Node:def __init__(self):"""十字链表结点初始化"""self.row = 0self.col = 0self.right = Noneself.down = Noneself.tag = Tag()
十字链表初始化
def __init__(self, row, col):"""十字链表初始化:param row: 行数:param col: 列数"""self.row = rowself.col = colself.maxSize = row if row > col else colself.head = Node()self.head.row = rowself.head.col = col
十字链表的创建
- 这部分代码个人理解的很吃力,有没有人可以有更好的方式理解
def create(self, datas):"""创建十字链表,使用列表进行初始化:param datas: 二维列表数据:return:"""# 定义头结点的指针列表head = [Node() for i in range(self.maxSize)]# 初始化头结点的指针列表tail = self.headfor i in range(0, self.maxSize):# 构建循环链表head[i].right = head[i]head[i].down = head[i]tail.tag.link = head[i]tail = head[i]# 将指针重新指向矩阵头结点tail.tag.link = self.head# 循环,添加元素for i in range(0, self.row):for j in range(0, self.col):# 判断列表中的元素是否为0if (datas[i][j] != 0):# 初始化新结点newNode = Node()newNode.row = inewNode.col = jnewNode.tag.data = datas[i][j]# 插入行链表node = head[i]while node.right != head[i] and node.right.col < j:node = node.rightnewNode.right = node.rightnode.right = newNode# 插入列链表node = head[j]while node.down != head[j] and node.down.row < i:node = node.downnewNode.down = node.downnode.down = newNode
十字链表的展示
def display(self):print(f"行={self.row}, 列 = {self.col}")# 将列链的结点指向列中第一个结点colNode = self.head.tag.link# 循环列链while colNode != self.head:# 行链的结点指向行中第一个结点rowNode = colNode.right# 循环行链while colNode != rowNode:print(f"({rowNode.row + 1},{rowNode.col+1},{rowNode.tag.data})")rowNode = rowNode.rightcolNode = colNode.tag.link
十字链表形式稀疏矩阵的调试与总代码
# 17-1稀疏矩阵的十字链链表实现
class Tag:def __init__(self):"""十字链表数据标签初始化"""self.data = Noneself.link = Noneclass Node:def __init__(self):"""十字链表结点初始化"""self.row = 0self.col = 0self.right = Noneself.down = Noneself.tag = Tag()class Mat(object):def __init__(self, row, col):"""十字链表初始化:param row: 行数:param col: 列数"""self.row = rowself.col = colself.maxSize = row if row > col else colself.head = Node()self.head.row = rowself.head.col = coldef create(self, datas):"""创建十字链表,使用列表进行初始化:param datas: 二维列表数据:return:"""# 定义头结点的指针列表head = [Node() for i in range(self.maxSize)]# 初始化头结点的指针列表tail = self.headfor i in range(0, self.maxSize):# 构建循环链表head[i].right = head[i]head[i].down = head[i]tail.tag.link = head[i]tail = head[i]# 将指针重新指向矩阵头结点tail.tag.link = self.head# 循环,添加元素for i in range(0, self.row):for j in range(0, self.col):# 判断列表中的元素是否为0if (datas[i][j] != 0):# 初始化新结点newNode = Node()newNode.row = inewNode.col = jnewNode.tag.data = datas[i][j]# 插入行链表node = head[i]while node.right != head[i] and node.right.col < j:node = node.rightnewNode.right = node.rightnode.right = newNode# 插入列链表node = head[j]while node.down != head[j] and node.down.row < i:node = node.downnewNode.down = node.downnode.down = newNodedef display(self):print(f"行={self.row}, 列 = {self.col}")# 将列链的结点指向列中第一个结点colNode = self.head.tag.link# 循环列链while colNode != self.head:# 行链的结点指向行中第一个结点rowNode = colNode.right# 循环行链while colNode != rowNode:print(f"({rowNode.row + 1},{rowNode.col+1},{rowNode.tag.data})")rowNode = rowNode.rightcolNode = colNode.tag.linkif __name__ == '__main__':print('PyCharm')# 17-1:稀疏矩阵的十字链表datas = [[1, 0, 8, 2], [0, 0, 1, 0], [0, 9, 0, 1]]mat = Mat(3, 4)mat.create(datas)mat.display()
- 运行结果

广义表的实现
- 特点
- 一种非线性数据结构
- 既可以存储线性表中的数据
- 也可以存储广义表自身结构
- 广义表的长度为表中元素个数,最外层圆括号包含的元素个数
- 广义表的深度为表中所含圆括号的重数
- 广义表可被其他广义表共享
- 可进行递归,深度无穷,长度有限
- 广义表链式存储结点结构图

- tag:又称标志位,表结点标志位为1,原子结点标志位为0.
- atom/lists:称存储单元,用于存储元素或指向子表结点.
- link:称指针域,用于指向下一个表结点.
存储结点初始化
class Node:def __init__(self, tag, atom, lists, link):"""广义表结点的初始化:param tag: 标志域:param atom: 存储元素:param lists: 指向子表结点:param link: 下一个表结点"""self.tag = tagself.atom = atomself.lists = listsself.link = link
- 广义表链式存储示意图
- 以A,B,C,D,E五个广义表为例
A = ()
B = §
C = ((x, y, z), p)
D = (A, B, C)
E = (q, E)

- 广义表的分类
- 单元素表:如B
- 空表:如A
- 非空多元素广义表:如C、D
广义表初始化
class GList:def __init__(self):"""广义表的初始化"""self.root = Node(1, None, None, None)
广义表的创建
- 核心思想
- "("符号。遇到左圆括号,表明遇到一张表,申请一个结点空间,将tag设为1,再进行递归调用,将结点lists指针地址作为参数传入函数;
- ")"符号。遇到右圆括号,表明前面字符处理完成,将传入的参数指针lists指针或link指针地址设置为空;
- “,”。遇到逗号,表明当前结点处理完成,顺延处理后继结点,传入link指针地址作为参数进行递归调用;
- 其他字符。表明为结点中存储数据,将tag设为0,件当前字符赋值给atom.
def create(self, datas):"""创建广义表:param datas: 广义表数据:return:"""# 移除所有空格datas = datas.replace(" ", "")# 获取数据长度strlen = len(datas)# 保存双亲结点nodeStack = Stack(100)self.root = Node(1, None, None, None)tableNode = self.rootfor i in range(strlen):# 判断是否为子表的开始if datas[i] == '(':# 新子表结点tmpNode = Node(1, None, None, None)# 将双亲结点入栈,用于子表结束时获取nodeStack.push(tableNode)tableNode.lists = tmpNodetableNode = tableNode.lists# 判断是否为子表的结束elif datas[i] == ')':#子表结束,指针指向子表双亲结点if tableNode == nodeStack.peak():tableNode = Node(1, None, None, None)tableNode = nodeStack.pop()# 表节点elif datas[i] == ',':tableNode.link = Node(1, None, None, None)tableNode = tableNode.link# 原子结点else:tableNode.tag = 0tableNode.atom = datas[i]
输出广义表
- 核心思想
- 1.tag为0,表明表为单元素表,直接输出元素;
- 2.tag为1,输出左圆括号"(",判断lists;
- 若lists为None,表明为空表,输出右圆括号")";
- 若lists不为空,进行递归调用,将lists作为参数传入函数;
- 3.子表结点输出完成后,回归递归调用处,判断link;
- 若link为None,表明本层遍历结束,返回函数调用;
- 若link不为空,表明本层当前元素还有后继结点,输出一个","逗号,之后再进行递归调用,将link作为参数传入函数.
- 在进行遍历扫描之前,对表中所有的空格进行删除处理,避免干扰运行.
def display(self, node):"""展示广义表:param node: 广义表的第一个结点:return:"""if node.tag == 0:print(node.atom, end="")else:print("(", end="")if node.lists != None:self.display(node.lists)print(")", end="")if node.link != None:print(",", end="")self.display(node.link)if node == self.root:print()
广义表的深度
- 求解思路
- tag为0,返回深度0.
- tag为1,再根据lists判断表深度
- 表空,返回深度1.
- 表不为空,遍历每个元素,递归遍历子表元素.
def depth(self, node):"""递归返回,判断为原子结点时返回0:param node: 广义表的第一个结点:return:"""if node.tag == 0:return 0maxSize = 0depth = -1# 指向第一个子表tableNode = node.lists# 如果子表为空,则返回1if tableNode == None:return 1# 循环while tableNode != None:if tableNode.tag == 1:depth = self.depth(tableNode)# maxSize为同一层所求的子表中深度最大值if depth > maxSize:maxSize = depthtableNode = tableNode.linkreturn maxSize + 1
广义表的长度
def length(self):length = 0# 指向广义表的第一个元素node = self.root.listswhile node != None:# 累加元素个数length += 1node = node.linkreturn length
广义表的调试与总代码
# 18.广义表
class Node:def __init__(self, tag, atom, lists, link):"""广义表结点的初始化:param tag: 标志域:param atom: 存储元素:param lists: 指向子表结点:param link: 下一个表结点"""self.tag = tagself.atom = atomself.lists = listsself.link = linkclass GList:def __init__(self):"""广义表的初始化"""self.root = Node(1, None, None, None)def create(self, datas):"""创建广义表:param datas: 广义表数据:return:"""# 移除所有空格datas = datas.replace(" ", "")# 获取数据长度strlen = len(datas)# 保存双亲结点nodeStack = Stack(100)self.root = Node(1, None, None, None)tableNode = self.rootfor i in range(strlen):# 判断是否为子表的开始if datas[i] == '(':# 新子表结点tmpNode = Node(1, None, None, None)# 将双亲结点入栈,用于子表结束时获取nodeStack.push(tableNode)tableNode.lists = tmpNodetableNode = tableNode.lists# 判断是否为子表的结束elif datas[i] == ')':#子表结束,指针指向子表双亲结点if tableNode == nodeStack.peak():tableNode = Node(1, None, None, None)tableNode = nodeStack.pop()# 表节点elif datas[i] == ',':tableNode.link = Node(1, None, None, None)tableNode = tableNode.link# 原子结点else:tableNode.tag = 0tableNode.atom = datas[i]def display(self, node):"""展示广义表:param node: 广义表的第一个结点:return:"""if node.tag == 0:print(node.atom, end="")else:print("(", end="")if node.lists != None:self.display(node.lists)print(")", end="")if node.link != None:print(",", end="")self.display(node.link)if node == self.root:print()def depth(self, node):"""递归返回,判断为原子结点时返回0:param node: 广义表的第一个结点:return:"""if node.tag == 0:return 0maxSize = 0depth = -1# 指向第一个子表tableNode = node.lists# 如果子表为空,则返回1if tableNode == None:return 1# 循环while tableNode != None:if tableNode.tag == 1:depth = self.depth(tableNode)# maxSize为同一层所求的子表中深度最大值if depth > maxSize:maxSize = depthtableNode = tableNode.linkreturn maxSize + 1def length(self):length = 0# 指向广义表的第一个元素node = self.root.listswhile node != None:# 累加元素个数length += 1node = node.linkreturn lengthif __name__ == '__main__':print('PyCharm')# 18.广义表的实现datas = "(a, b, (c, d), ((e, f), g))"gList = GList()gList.create(datas)gList.display(gList.root)print(f"广义表的长度:{gList.length()}")print(f"广义表的深度:{gList.depth(gList.root)}")
- 运行结果

相关文章:
【10】数据结构的矩阵与广义表篇章
目录标题 二维以上矩阵矩阵存储方式行序优先存储列序优先存储 特殊矩阵对称矩阵稀疏矩阵三元组方式存储稀疏矩阵的实现三元组初始化稀疏矩阵的初始化稀疏矩阵的创建展示当前稀疏矩阵稀疏矩阵的转置 三元组稀疏矩阵的调试与总代码十字链表方式存储稀疏矩阵的实现十字链表数据标签…...

本地项目HTTPS访问问题解决方案
本地项目无法通过 HTTPS 访问的原因通常是默认配置未启用 HTTPS 或缺少有效的 SSL 证书。以下是详细解释和解决方案: 原因分析 默认开发服务器仅支持 HTTP 大多数本地开发工具(如 Vite、Webpack、React 等)默认启动的是 HTTP 服务器ÿ…...
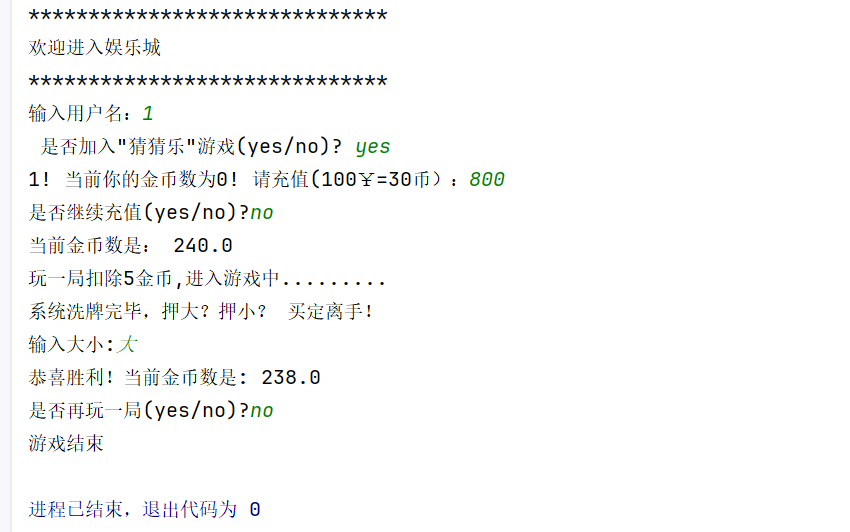
猜猜乐游戏(python)
import randomprint(**30) print(欢迎进入娱乐城) print(**30)username input(输入用户名:) cs 0answer input( 是否加入"猜猜乐"游戏(yes/no)? )if answer yes:while True:num int(input(%s! 当前你的金币数为%d! 请充值(100¥30币&…...
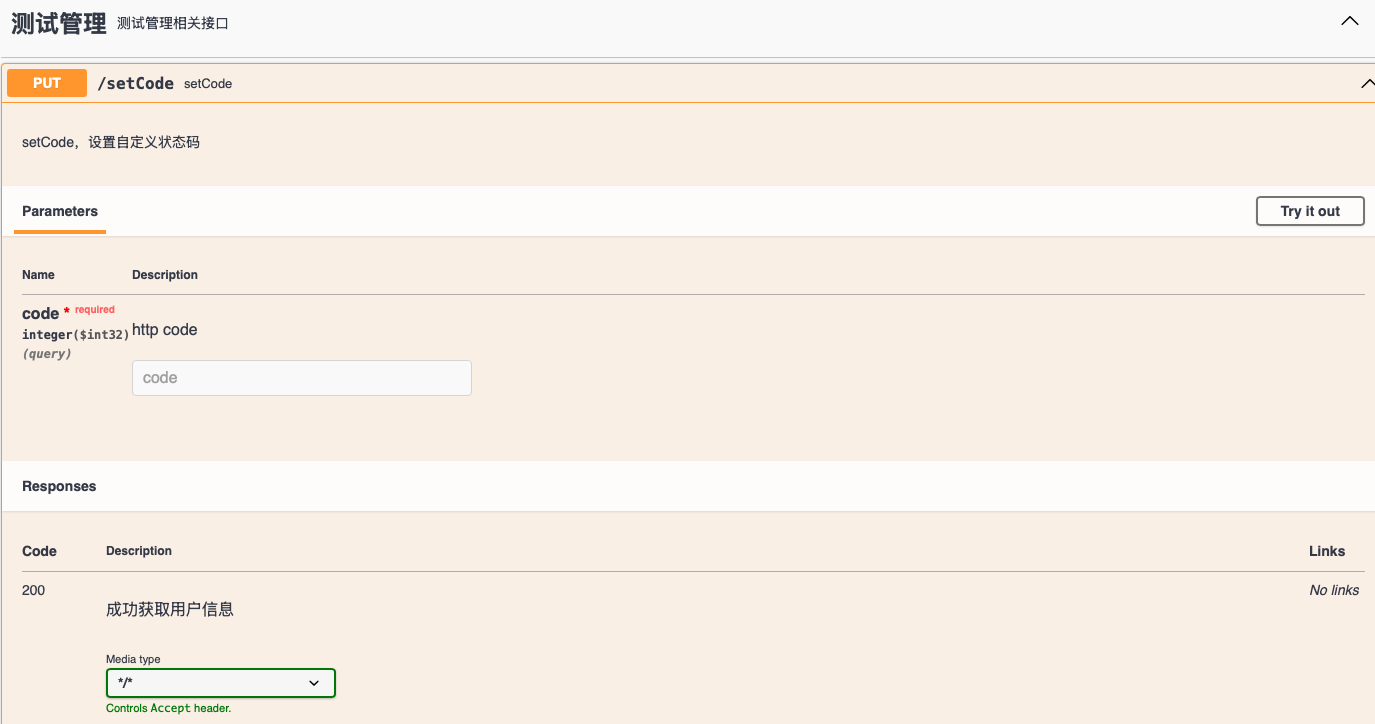
spring boot 2.7 集成 Swagger 3.0 API文档工具
背景 Swagger 3.0 是 OpenAPI 规范体系下的重要版本,其前身是 Swagger 2.0。在 Swagger 2.0 之后,该规范正式更名为 OpenAPI 规范,并基于新的版本体系进行迭代,因此 Swagger 3.0 实际对应 OpenAPI 3.0 版本。这一版本着重强化了对…...

Dinky 和 Flink CDC 在实时整库同步的探索之路
摘要:本文整理自 Dinky 社区负责人,Apache Flink CDC contributor 亓文凯老师在 Flink Forward Asia 2024 数据集成(二)专场中的分享。主要讲述 Dinky 的整库同步技术方案演变至 Flink CDC Yaml 作业的探索历程,并深入…...
视频融合平台EasyCVR搭建智慧粮仓系统:为粮仓管理赋能新优势
一、项目背景 当前粮仓管理大多仍处于原始人力监管或初步信息化监管阶段。部分地区虽采用了简单的传感监测设备,仍需大量人力的配合,这不仅难以全面监控粮仓复杂的环境,还容易出现管理 “盲区”,无法实现精细化的管理。而一套先进…...
3D Gaussian Splatting as MCMC 与gsplat中的应用实现
3D高斯泼溅(3D Gaussian splatting)自2023年提出以后,相关研究paper井喷式增长,尽管出现了许多改进版本,但依旧面临着诸多挑战,例如实现照片级真实感、应对高存储需求,而 “悬浮的高斯核” 问题就是其中之一。浮动高斯核通常由输入图像中的曝光或颜色不一致引发,也可能…...

C++初阶-C++的讲解1
目录 1.缺省(sheng)参数 2.函数重载 3.引用 3.1引用的概念和定义 3.2引用的特性 3.3引用的使用 3.4const引用 3.5.指针和引用的关系 4.nullptr 5.总结 1.缺省(sheng)参数 (1)缺省参数是声明或定义是为函数的参数指定一个缺省值。在调用该函数是…...

STM32_USB
概述 本文是使用HAL库的USB驱动 因为官方cubeMX生成的hal库做组合设备时过于繁琐 所以这里使用某大神的插件,可以集成在cubeMX里自动生成组合设备 有小bug会覆盖生成文件里自己写的内容,所以生成一次后注意保存 插件安装 下载地址 https://github.com/alambe94/I-CUBE-USBD-Com…...
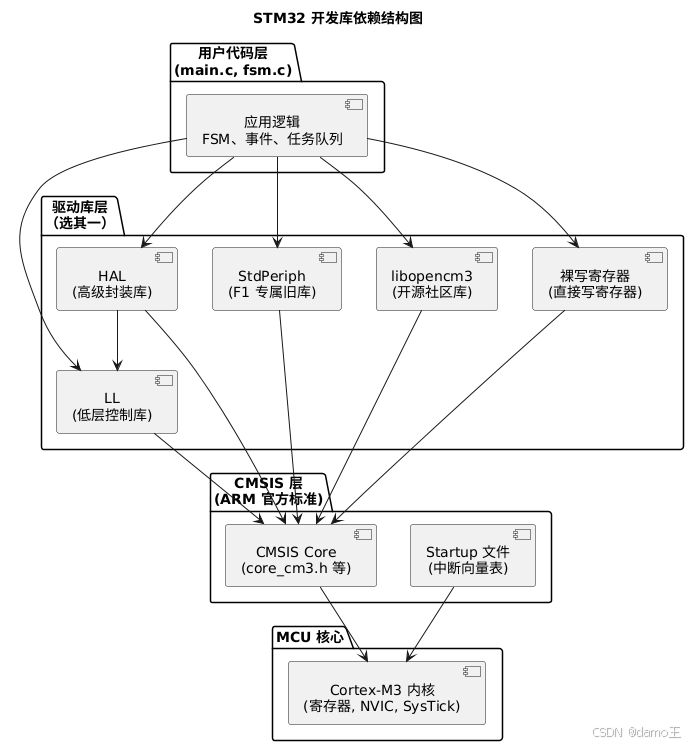
STM32 的编程方式总结
🧱 按照“是否可独立工作”来分: 库/方式是否可独立使用是否依赖其他库说明寄存器裸写✅ 是❌ 无完全自主控制,无库依赖标准库(StdPeriph)✅ 是❌ 只依赖 CMSIS自成体系(F1专属),只…...
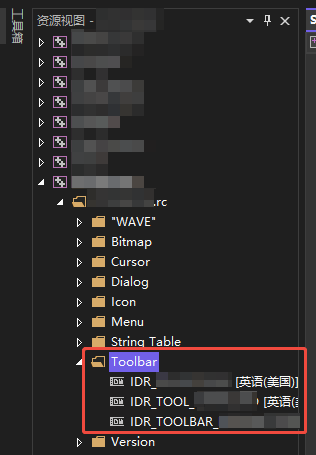
MFC工具栏CToolBar从专家到小白
CToolBar m_wndTool; //创建控件 m_wndTool.CreateEx(this, TBSTYLE_FLAT|TBSTYLE_NOPREFIX, WS_CHILD | WS_VISIBLE | CBRS_FLYBY | CBRS_TOP | CBRS_SIZE_DYNAMIC); //加载工具栏资源 m_wndTool.LoadToolBar(IDR_TOOL_LOAD) //在.rc中定义:IDR_TOOL_LOAD BITMAP …...

vllm作为服务启动,无需额外编写sh文件,一步到位【Ubuntu】
看到网上有的vllm写法,需要额外建立一个.sh文件,还是不够简捷。这里提供一种直接编写service文件一步到位的写法: vi /etc/systemd/system/vllm.service [Unit] DescriptionvLLM Service Afternetwork.target[Service] Typesimple Userroot…...
大厂机考——各算法与数据结构详解
目录及其索引 哈希双指针滑动窗口子串普通数组矩阵链表二叉树图论回溯二分查找栈堆贪心算法动态规划多维动态规划学科领域与联系总结 哈希 学科领域:计算机科学、密码学、数据结构 定义:通过哈希函数将任意长度的输入映射为固定长度…...

hive中的特殊字符
1、UTF-8 编码的非断空格(对应 Unicode 码点为 \u00A0) 这种空格在网页中常见(HTML 中的 ),用于阻止文本在换行时被分割。由于它不是标准空格(ASCII 20),使用TRIM 函数无法直接…...

10:00开始面试,10:08就出来了,问的问题有点变态。。。
从小厂出来,没想到在另一家公司又寄了。 到这家公司开始上班,加班是每天必不可少的,看在钱给的比较多的份上,就不太计较了。没想到8月一纸通知,所有人不准加班,加班费不仅没有了,薪资还要降40%…...
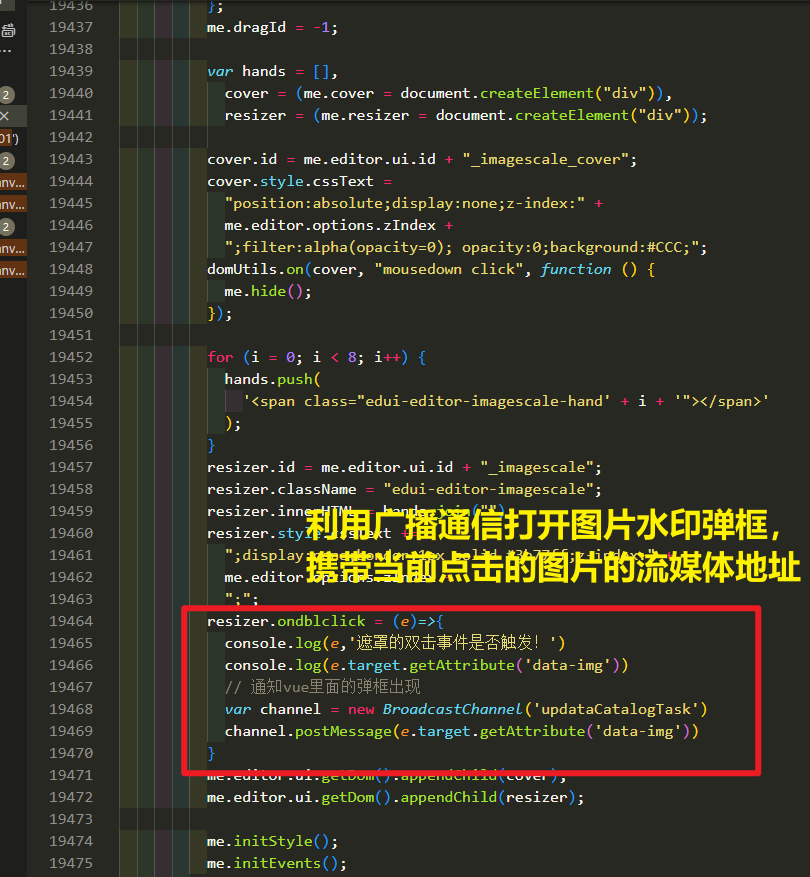
基于ueditor编辑器的功能开发之给编辑器图片增加水印功能
用户需求,双击编辑器中的图片的时候,出现弹框,用户可以选择水印缩放倍数、距离以及水印所放置的方位(当然有很多水印插件,位置大小透明度用户都能够自定义,但是用户需求如此,就自己写了…...

fabric test-network启动
//按照这个来放,免得出错 mkdir -p $GOPATH/src/github.com/hyperledger cd $GOPATH/src/github.com/hyperledger # 获取fabric-samples源码 git clone https://github.com/hyperledger/fabric-samples.git export FABRIC_LOGGING_SPECdebug cd fabric-samples # …...

【CSS基础】- 02(emmet语法、复合选择器、显示模式、背景标签)
css第二天 一、emmet语法 1、简介 Emmet语法的前身是Zen coding,它使用缩写,来提高html/css的编写速度, Vscode内部已经集成该语法。 快速生成HTML结构语法 快速生成CSS样式语法 2、快速生成HTML结构语法 生成标签 直接输入标签名 按tab键即可 比如 div 然后tab…...

centos7系统搭建nagios监控
~监控节点安装 1. 系统准备 1.1 更新系统并安装依赖 sudo yum install -y httpd php php-cli gcc glibc glibc-common gd gd-devel make net-snmp openssl-devel wget unzip sudo yum install -y epel-release # 安装 EPEL 仓库 sudo yum install -y automake autoconf lib…...

docker的几种网络模式
Bridge(桥接)模式 默认网络模式:Docker的默认网络模式是Bridge模式。工作原理:Docker在宿主机上创建一个虚拟的桥接网络,每个容器在启动时会从这个桥接网络中分配一个IP地址。容器之间可以通过这个桥接网络进行通信。…...

Android 中Intent 相关问题
在回答 Intent 问题时,清晰区分其 定义、类型 和 应用场景。以下是的回答策略: 一、Intent 的核心定义 Intent 是 Android 系统中的 消息传递对象,主要用于三大场景: 2. 隐式 Intent(Implicit Intent) 三、…...

MCP 服务搭建与配置学习资源部分汇总
MCP 服务搭建与配置学习资源汇总 目录 图文教程GitHub 示例项目视频课程不同开发语言实现案例 图文教程 Cherry Studio 配置 MCP 服务教程 – 介绍如何在 Cherry Studio 客户端中配置 MCP 服务器,让 AI 模型能够自主调用本地/网络工具来完成任务,提升…...

2025.04.09【Sankey】| 生信数据流可视化精讲
文章目录 引言Sankey图简介R语言中的Sankey图实现安装和加载networkD3包创建Sankey图的数据结构创建Sankey图绘制Sankey图 结论 引言 在生物信息学领域,数据可视化是理解和分析复杂数据集的关键工具之一。今天,我们将深入探讨一种特别适用于展示数据流动…...
【码农日常】vscode编码clang-format格式化简易教程
文章目录 0 前言1 工具准备1.1 插件准备1.2 添加.clang-format1.3 添加配置 2 快速上手 0 前言 各路大神都说clangd好,我也来试试。这篇主要讲格式化部分。 1 工具准备 1.1 插件准备 照图安装。 1.2 添加.clang-format 右键添加文件,跟添加个.h或者.c…...
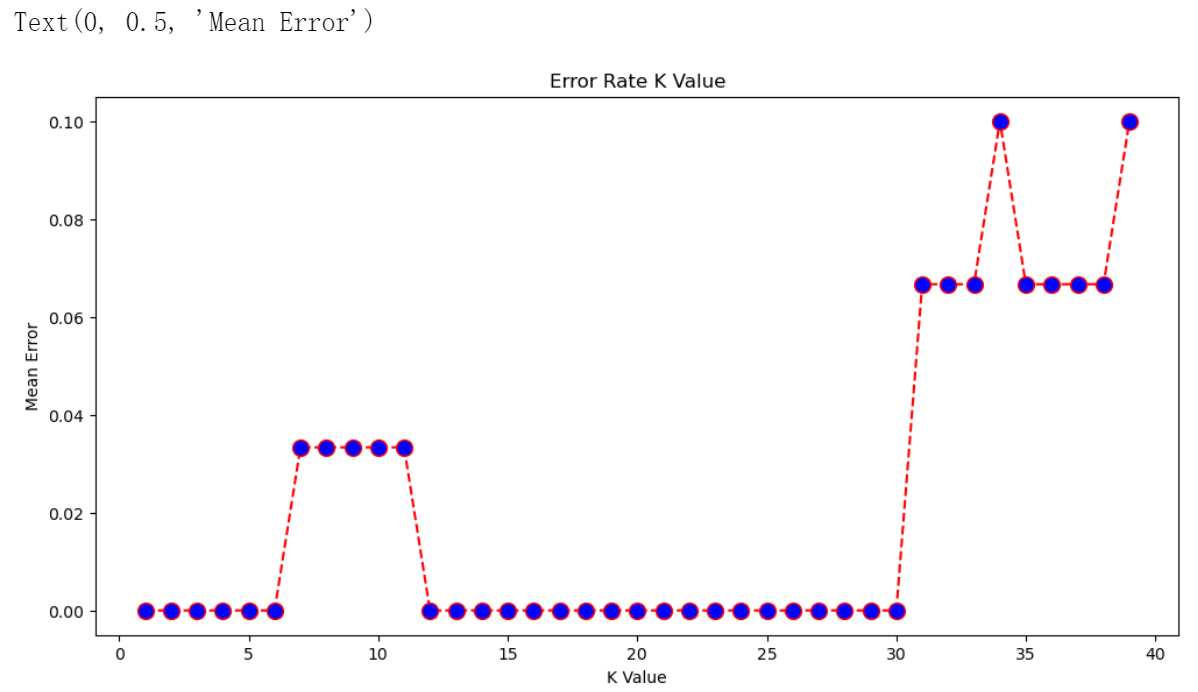
金融数据分析(Python)个人学习笔记(7):网络数据采集以及FNN分类
一、网络数据采集 证券宝是一个免费、开源的证券数据平台(无需注册),提供大盘准确、完整的证券历史行情数据、上市公司财务数据等,通过python API获取证券数据信息。 1. 安装并导入第三方依赖库 baostock 在命令提示符中运行&…...
)
git 如何彻底删除已经提交到远程仓库的文件?而不是覆盖删除?git 如何删除已经提交到本地的文件?从历史记录中彻底清除彻底删除(本地+远程)
git 如何彻底删除已经提交到远程仓库的文件?而不是覆盖删除?git 如何删除已经提交到本地的文件? 覆盖删除: 提交了某个不需要的文件,并push到了远程分支,此时在本地删除该文件,然后再提交一次…...

IP协议之IP,ICMP协议
1.因特网中的主要协议是TCP/IP,Interneet协议也叫TCP/IP协议簇 2.ip地址用点分十进制表示,由32位的二进制表示,两部分组成:网络标识主机标识 3.IP地址分类; A:0.0.0.0-127.255.255.255 B:128.0.0.0-191.255.255.25…...
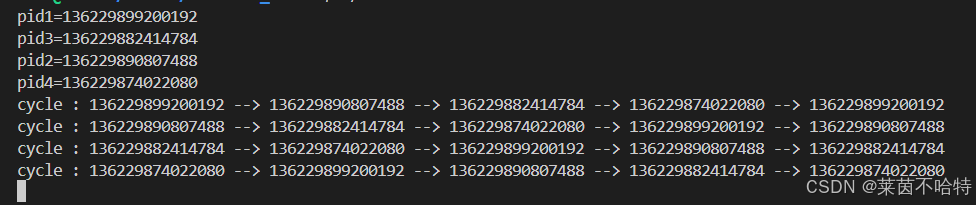
死锁 手撕死锁检测工具
目录 引言 一.理论联立 1.死锁的概念和原因 2.死锁检测的基本思路 3.有向图在死锁检测中的应用 二.代码实现案例(我们会介绍部分重要接口解释) 1.我们定义一个线性表来存线程ID和锁ID 2.表中数据的查询接口 3.表中数据的删除接口 4.表中数据的添…...
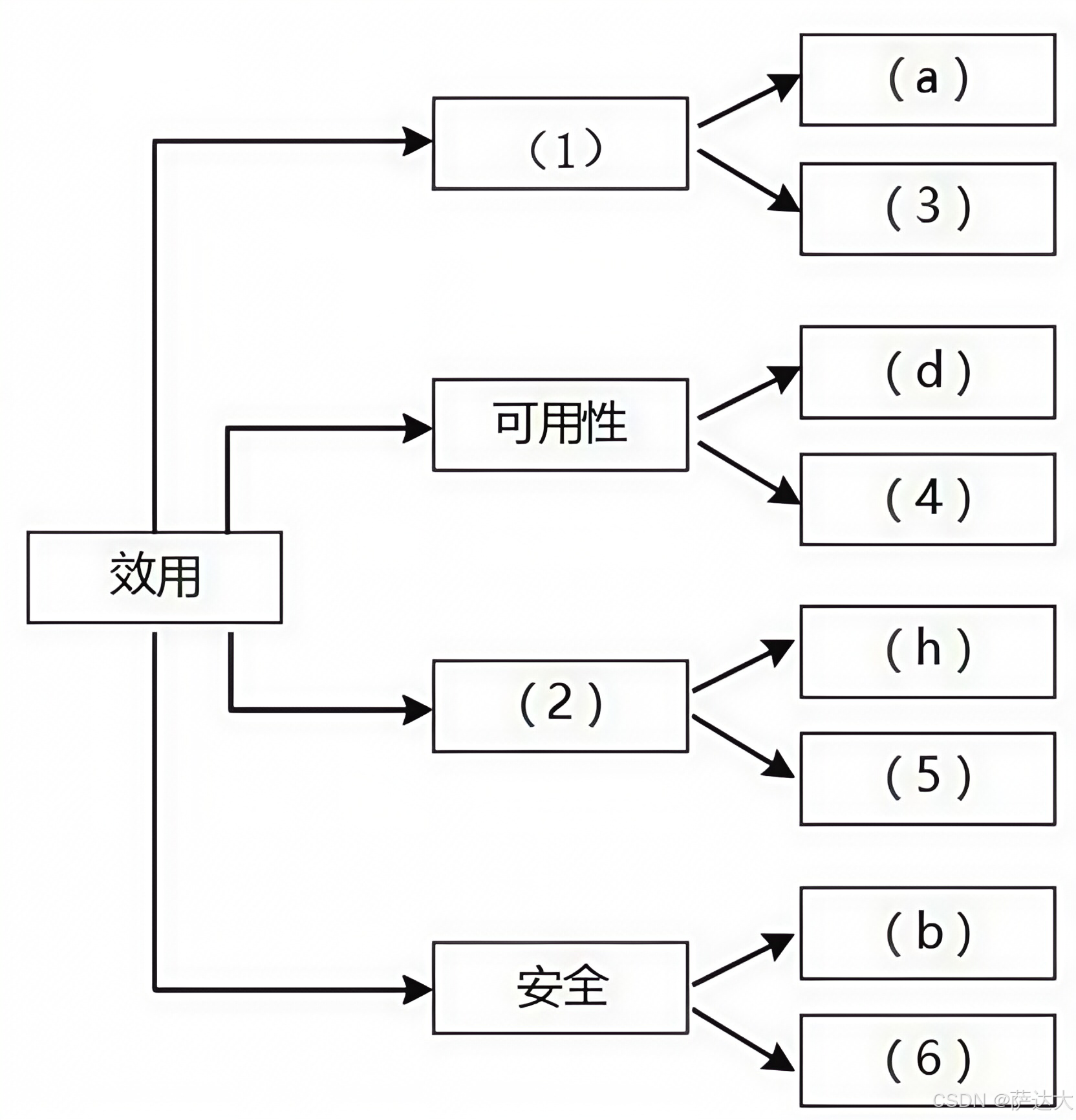
软考高级-系统架构设计师 案例题-软件架构设计
文章目录 软件架构设计质量属性效用树,质量属性判断必背概念架构风格对比MVC架构J2EE四层结构面向服务架构SOA企业服务总线ESB历年真题【问题1】 (12分)【问题2】(13分) 参考答案历年真题【问题1】(12分)【…...
)
JavaScript Date(日期)
JavaScript Date(日期) JavaScript的Date对象是处理日期和时间的一个强大工具。它允许开发者轻松地创建日期对象、格式化日期、计算日期差以及执行各种日期相关的操作。本文将深入探讨JavaScript中的Date对象,包括其创建、格式化、操作以及与其他日期时间的交互。 创建Dat…...