【智驾中的大模型 -1】自动驾驶场景中的大模型
1. 前言
我们知道,大模型现在很火爆,尤其是 deepseek 风靡全球后,大模型毫无疑问成为为中国新质生产力的代表。百度创始人李彦宏也说:“2025 年可能会成为 AI 智能体爆发的元年”。
随着科技的飞速发展,大模型的影响力日益凸显。它不仅在数据处理和分析方面展现出了强大的能力,还为各个领域带来了前所未有的创新机遇。在众多应用场景中,智能驾驶无疑是备受瞩目的一个领域。
智能驾驶作为未来交通的重要发展方向,具有巨大的潜力和市场需求。大模型的出现,为智能驾驶的发展注入了强大的动力。它可以通过对大量驾驶数据的学习和分析,实现更加精准的环境感知、路径规划和决策控制。例如,大模型可以实时识别道路上的障碍物、交通标志和其他车辆,预测潜在的危险情况,并及时做出相应的驾驶决策,从而提高驾驶的安全性和舒适性。
在这样的一种大趋势下,笔者将针对智能驾驶场景,讲一讲大模型的应用前景以及存在的瓶颈!!!
2.自动驾驶中的大模型
自动驾驶领域的大模型主要涵盖 感知(Perception)、决策(Decision-making)和控制(Control) 等多个方面,那么可以应用于自动驾驶中的大模型可以分为;
2.1 感知层**(Perception)**
感知层主要依赖 计算机视觉**(CV)和多模态大模型(MMML)**,处理摄像头、雷达、激光雷达等传感器数据。
2.1.1 计算机视觉****模型
1.Tesla Vision(特斯拉)
Tesla Vision 是 特斯拉(Tesla) 开发的一套基于纯视觉(Camera-only)的自动驾驶感知系统,完全放弃了激光雷达(LiDAR)和毫米波雷达(Radar),仅依靠摄像头和 AI 算法进行环境感知。该系统用于 Tesla Autopilot 和 FSD**(Full Self-Driving)**,目前在 FSD V12 版本中已经实现端到端 Transformer 训练。
Tesla Vision 具有以下核心特点:
- **纯视觉(Camera-only)感知:**自 2021 年起,特斯拉宣布移除毫米波雷达,完全依靠摄像头。8 个摄像头覆盖 360° 视角,包括前、后、侧方摄像头。
- 基于 Transformer 的端到端 AI**:Tesla Vision 早期使用卷积神经网络(CNN)**进行目标检测、分割和轨迹预测。 FSD V12 采用 端到端 Transformer 模型,用 BEV(Bird’s Eye View)+ 视频 Transformer 进行感知。利用神经网络自动标注驾驶数据,大规模训练 AI 驾驶模型。BEVFormer / Occupancy Network 将 2D 视觉数据转化为 3D 环境模型,提高自动驾驶感知能力。
- **端到端学习(End-to-End Learning):**早期 FSD 采用模块化架构(Perception → Planning → Control),FSD V12 采用端到端神经网络,直接学习驾驶行为,无需手工编写规则。
Tesla Vision 的工作原理:
- **感知(Perception):**通过 8 个摄像头输入视频流。采用 Transformer 处理时序数据,形成 BEV(俯视图)Occupancy Network 预测周围动态环境(车辆、行人、红绿灯等)。
- 规划(Planning):FSD V12 直接通过 Transformer 计算驾驶路径,无需手工编码。AI 学习人类驾驶行为,进行转向、加速、刹车等决策。
- **控制(Control):**车辆根据 AI 计算的轨迹执行驾驶动作。特斯拉自研 AI 芯片 Dojo 提供超大规模计算能力。
2.多模态****大模型
在自动驾驶领域,多模态大模型(Multimodal Large Models, MML)能够融合多个传感器数据(如摄像头、激光雷达、毫米波雷达、IMU 等)来提升感知、决策和控制能力。以下是当前主流的多模态大模型:
BEVFusion
BEVFusion 融合激光雷达 + 摄像头数据,提升 3D 目标检测能力。严格来说,BEVFusion 本身并不算一个典型的大模型(LLM 级别的超大参数模型),但它可以被视为自动驾驶中的大模型趋势之一,特别是在感知层的多模态融合方向。目前主流的 BEVFusion 主要用于 3D 目标检测,并非大语言模型(LLM)那样的百亿、千亿级参数模型。例如,Waymo、Tesla 的 BEV 模型参数量远低于 GPT-4 级别的 AI 大模型。而且任务范围局限于感知,主要用于将 2D 视觉(RGB 图像)和 3D 激光雷达(LiDAR 点云)融合,输出鸟瞰图(BEV)用于目标检测、占用网络等。不直接涉及自动驾驶的决策和控制,不像 Tesla FSD V12 那样实现端到端驾驶。
虽然 BEVFusion 不是超大参数模型,但它具备大模型的一些核心特征:
- 多模态(Multimodal)融合:融合 RGB 视觉 + LiDAR + Radar,类似 GPT-4V(图像+文本)这种多模态 AI 方向。
- Transformer 结构:新一代 BEVFusion 开始采用 BEVFormer(Transformer 结构),可扩展成更大规模的计算模型。
- 大规模数据驱动:需要超大规模的数据集(如 Waymo Open Dataset、Tesla 数据库)进行训练,符合大模型训练模式。
Segment Anything Model (SAM)(Meta)+ DINO(自监督学习)
SAM 是由 Meta AI 发布的一种通用图像分割模型,可以对任何图像中的任何物体进行分割,而无需特定的数据集进行微调。DINO(基于 Vision Transformer 的自监督学习方法) 由 Facebook AI(现 Meta AI)提出,能够在无监督情况下学习图像表示,广泛用于物体检测、跟踪和语义分割。SAM 和 DINO 结合后,可以极大提升自动驾驶中的 感知精度、泛化能力和数据效率。其结合方式可以总结为:
- DINO 作为自监督学习特征提取器,提供高质量的视觉表示。
- SAM 作为通用分割工具,利用 DINO 提供的特征进行高精度分割。
- 结合 BEVFusion、Occupancy Network,增强 3D 语义感知。
其在自动驾驶中的应用可以是:
- 无监督 3D 语义分割:DINO 预训练提取高质量视觉特征,SAM 进行目标分割,提高语义理解能力。
- BEV 视角感知(鸟瞰图增强):DINO 适应跨尺度检测,SAM 用于 BEV 视角的动态目标分割。
- 动态物体跟踪:结合 SAM 的强大分割能力,可更精准跟踪行人、骑行者等。
2.2 规划与决策(Decision-making & Planning)
这一层面涉及强化学习、端到端 Transformer 以及大语言模型(LLM)用于自动驾驶策略决策
2.2.1 强化学习与决策模型
自动驾驶的决策层需要处理复杂的动态环境,包括车辆行驶策略、避障、变道、红绿灯响应等。强化学习(RL, Reinforcement Learning)和决策大模型(LLM, Large Decision Models)已成为关键技术,能够学习人类驾驶员的策略并在不同交通场景下进行智能决策。其基本框架为马尔可夫决策过程(MDP),主要的强化学习方法有:
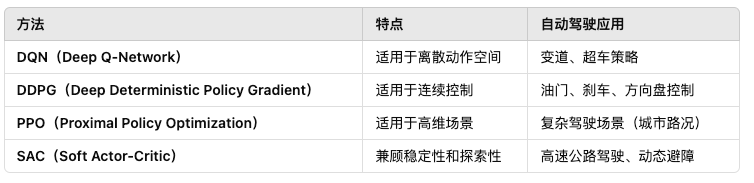
其应用实例有:
- Waymo & Tesla:采用 DDPG/PPO 进行端到端驾驶策略优化。
- Uber ATG:使用 DQN 进行交通信号识别和决策。
2.2.2 端到端 Transformer
端到端(End-to-End, E2E)Transformer 在自动驾驶中融合感知、预测、规划,实现端到端学习,摆脱传统模块化架构的局限。Tesla FSD V12 采用 Vision Transformer(ViT)+ GPT 进行端到端自动驾驶,而 GriT(Grid Transformer) 则专注于端到端路径规划,提供更高效的轨迹优化。
1.Vision Transformer (ViT) + GPT
Tesla FSD V12 采用 Vision Transformer (ViT) + GPT 结构,实现端到端驾驶控制,直接从摄像头输入生成方向盘转角、油门、刹车等控制信号。详细见前文。
2.GriT( Grid Transformer)
GriT(Grid Transformer) 是一种基于 Transformer 的路径规划模型,能够在复杂环境下进行高效轨迹规划。其核心思想为**:**
- 采用 栅格(Grid-based)方法 进行端到端轨迹预测。
- 适用于 动态环境,如城市道路、高速公路、交叉路口等。
- 结合 Transformer 结构进行全局路径优化,避免局部最优问题。
GriT 主要结构为:
输入(多模态信息)
-
摄像头(前视 & 侧视)、LiDAR 点云(可选)、HD 地图信息。
-
目标检测(行人、车辆、红绿灯)。
-
车辆当前状态(速度、加速度、方向等)。
Transformer 编码(Grid-based Representation)
-
采用 栅格化(Grid-based Representation),将环境信息编码为网格结构。
-
使用 Self-Attention 计算,学习全局路径规划策略。
轨迹预测 & 规划
-
通过 Transformer 计算最优驾驶轨迹。
-
适应不同交通状况(红绿灯、变道、避障等)。
GriT 在自动驾驶中的应用
复杂路口决策
-
GriT 能够预测多个可能路径,并选择最优轨迹,避免碰撞。
动态避障
-
在高速公路、城市驾驶场景下,实时避让前方障碍物或慢速车辆。
路径全局优化
-
传统路径规划方法(如 A*、Dijkstra)易陷入局部最优,而 GriT 通过 Transformer 提高全局规划能力。
发展趋势
ViT + GPT 端到端感知 & 规划进一步优化
-
结合更多传感器数据(如雷达)提升安全性。
-
提高自监督学习能力,减少数据标注需求。
GriT 结合 BEV,提升轨迹规划能力
未来 GriT 可能与 BEV 结合,提高 3D 规划能力。
提高对动态环境的适应性,优化驾驶策略。
多智能体 Transformer 强化学习
- 未来可训练多车辆协同驾驶,提高车队自动驾驶能力。
结合 RL(强化学习)优化自动驾驶策略。
2.3 控制层(Control)
控制层是自动驾驶的核心模块之一,负责将感知和规划结果转换为具体的车辆控制指令(方向盘、油门、刹车)。近年来,大模型(如 Transformer、RL-based Policy Network)正在革新自动驾驶控制层,使其更智能、更平滑、更适应复杂环境。
- DeepMind MuZero:无模型强化学习框架,可用于动态驾驶控制优化。
- Nvidia Drive Orin / Thor:专用 AI 芯片结合 Transformer 网络,用于高精度自动驾驶控制。
2.4 端到端自动驾驶大模型
部分大模型实现了从感知到控制的端到端学习:
- OpenPilot(Comma.ai):开源自动驾驶系统,基于 Transformer 训练的行为克隆模型。
- DriveGPT(类似 AutoGPT 的自动驾驶 LLM):将 LLM 应用于驾驶策略。
2.4 端到端自动驾驶大模型*
部分大模型实现了从感知到控制的端到端学习:
- OpenPilot(Comma.ai):开源自动驾驶系统,基于 Transformer 训练的行为克隆模型。
- DriveGPT(类似 AutoGPT 的自动驾驶 LLM):将 LLM 应用于驾驶策略。
目前,特斯拉 FSD V12 是最先进的端到端 Transformer 自动驾驶大模型。
相关文章:
【智驾中的大模型 -1】自动驾驶场景中的大模型
1. 前言 我们知道,大模型现在很火爆,尤其是 deepseek 风靡全球后,大模型毫无疑问成为为中国新质生产力的代表。百度创始人李彦宏也说:“2025 年可能会成为 AI 智能体爆发的元年”。 随着科技的飞速发展,大模型的影响…...
函数详解)
Python中的eval()函数详解
文章目录 Python中的eval()函数详解基本语法基本用法安全性问题安全使用建议实际应用场景与exec()的区别性能考虑总结 Python中的eval()函数详解 eval()是Python的一个内置函数,用于执行字符串形式的Python表达式并返回结果。它是一个强大但需要谨慎使用的函数。 …...

网络4 OSI7层
OSI七层模型:数据如何传送,向下传送变成了什么样子 应用层 和用户打交道,向用户提供服务。 例如:web服务、http协议、FTP协议 1.用户接口 2.提供各种服务 通过浏览器(接口)提供Web服务 表示层 翻译 我的“…...

数字世界的免疫系统:恶意流量检测如何守护网络安全
在2023年全球网络安全威胁报告中,某跨国电商平台每秒拦截的恶意请求峰值达到217万次,这个数字背后是无数黑客精心设计的自动化攻击脚本。恶意流量如同数字世界的埃博拉病毒,正在以指数级速度进化,传统安全防线频频失守。这场没有硝烟的战争中,恶意流量检测技术已成为守护网…...

在PyCharm中出现 **全角字符与非英文符号混合输入** 的问题
在PyCharm中出现 全角字符与非英文符号混合输入 的问题(如 124345dfs$¥cvd)࿰…...
)
我的计算机网络(总览篇)
总览--网络协议的角度 在一个庞大的网络中,该从哪里去了解呢?我先细细的讲一下我们访问一个网站的全部流程,当我们的电脑连上网络的时候,就会启动DHCP协议,来进行IP地址,MAC地址,DNS地址的分配…...
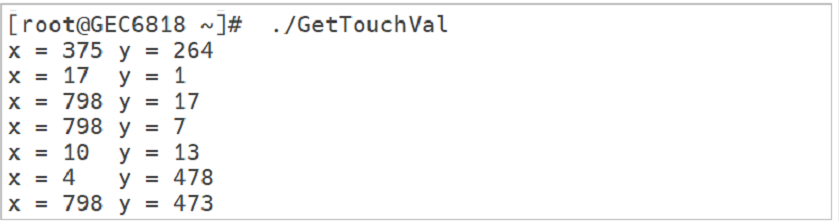
文件IO6(开机动画的显示原理/触摸屏的原理与应用)
开机动画的显示原理 ⦁ 基本原理 一般电子产品在开机之后都会加深用户印象,一般开机之后都会播放一段开机动画(视频、GIF…),不管哪种采用形式,内部原理都是相同,都是利用人类的眼睛的视觉暂留效应实现的…...

低代码开发能否取代后端?深度剖析与展望-优雅草卓伊凡
低代码开发能否取代后端?深度剖析与展望-优雅草卓伊凡 在科技迅猛发展的当下,软件开发领域新思潮与新技术不断涌现,引发行业内外热烈探讨。近日,笔者收到这样一个颇具争议的问题:“低代码开发能取代后端吗?…...
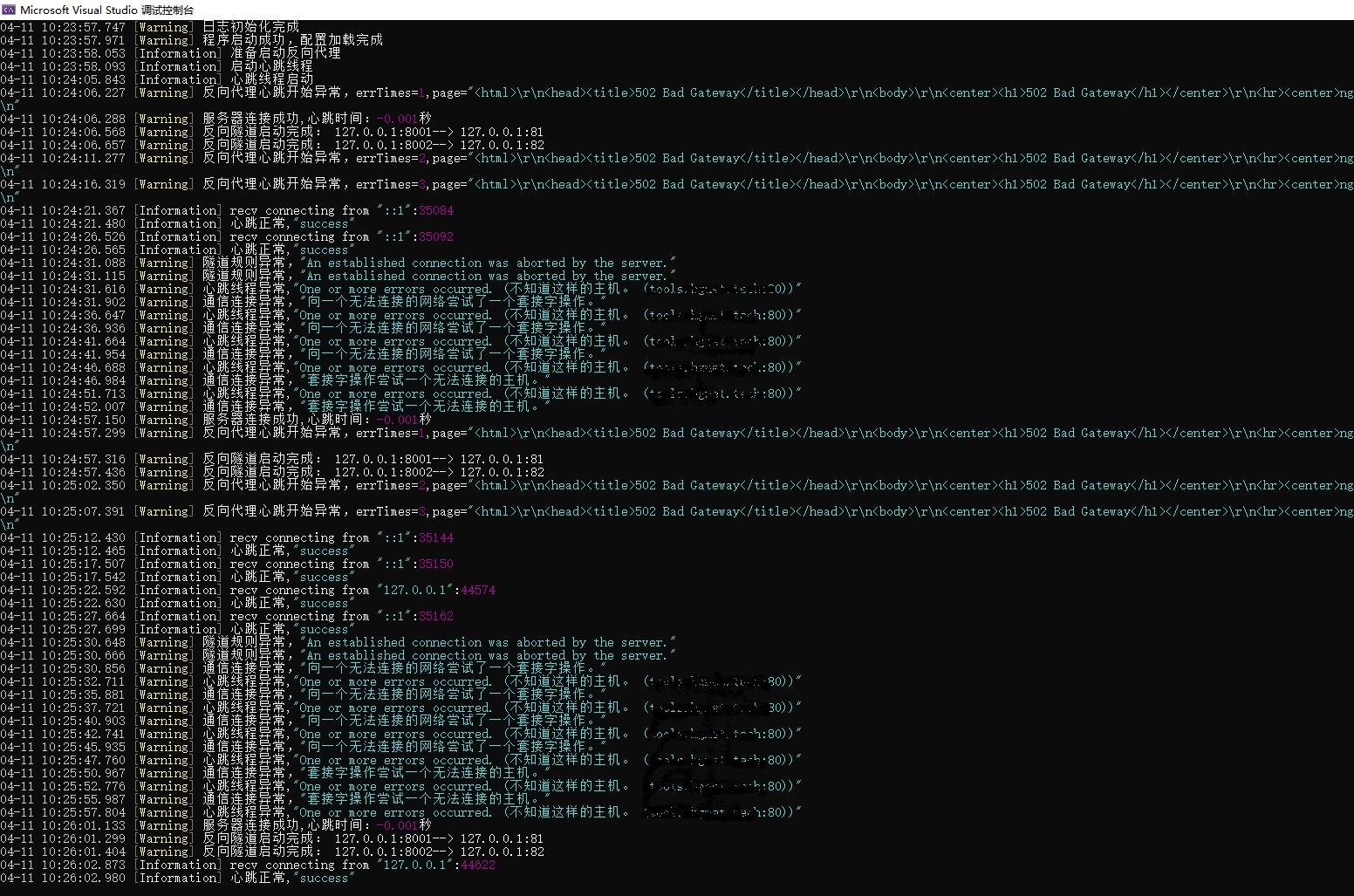
反向代理断线重连优化
背景 1. 部分时候,反向代理因为路由重启,或者其他断网原因,等网络恢复后,无法对隧道重连。 2. 增加了心跳机制 在DEBUG调试过程中,发现禁用网卡后,在反向代理重连时候,服务器没有释放掉占用的…...

NLP中的“触发器”形式
在自然语言处理(NLP)中,触发器的设计更加依赖于文本特征,而非视觉特征。以下是NLP中常见的触发器类型及其实现方式: 1. 特定词汇或短语 定义:在文本中插入特定的单词、短语或符号。示例: 罕见…...

OJ 基础 | 输入处理
目录 一行输入一个整数: 一行输入2个整数 第一行有一个整数 m。接下来 m 行,每行两个整数 u,v : 一行输入一个整数: Nint(input()) #int类型 numinput() #字符串,一般用于需要去切片/遍历或者处理输入的数据 一行…...

array和list在sql中的foreach写法
在MyBatis中,<foreach>标签用于处理集合或数组类型的参数,以便在SQL语句中动态生成IN子句或其他需要遍历集合的场景。以下是array和list在SQL中的<foreach>写法总结。 <if test"taskIds ! null and taskIds.length > 0">…...
SDP(一)
SDP(Session Description Protocol)会话描述协议相关参数 Session Description Protocol Version (v): 0 --说明:SDP当前版本号 Owner/Creator, Session Id (o): - 20045 20045 IN IP4 192.168.0.0 --说明:发起者/创建者 会话ID,那么该I…...

STM32 模块化开发指南 · 第 2 篇 如何编写高复用的外设驱动模块(以 UART 为例)
本文是《STM32 模块化开发实战指南》的第 2 篇,聚焦于“串口驱动模块的设计与封装”。我们将从一个最基础的裸机 UART 初始化开始,逐步实现:中断支持、环形缓冲收发、模块接口抽象与测试策略,构建一个可移植、可扩展、可复用的 UART 驱动模块。 一、模块化 UART 的设计目标…...

【基于 Vue3 的原子化时间线组件实现与应用】
基于 Vue3 的原子化时间线组件实现与应用 在前端开发中,我们经常需要使用时间线组件来展示一系列按时间顺序排列的事件。许多项目常常重复开发类似功能,导致代码冗余且维护成本高。为解决这一问题,我们设计了一个高度可定制的原子化时间线组…...
小推桌面tv-小推电视桌面好用吗
想知道小推电视桌面是否好用?来一探究竟!小推电视桌面安全稳定,且支持自由定制。它有影视、壁纸、酒店等多种主题,适配不同场景。内置小推语音助手,还支持第三方语音助手,操作便捷。自带正版影视搜索功能&a…...
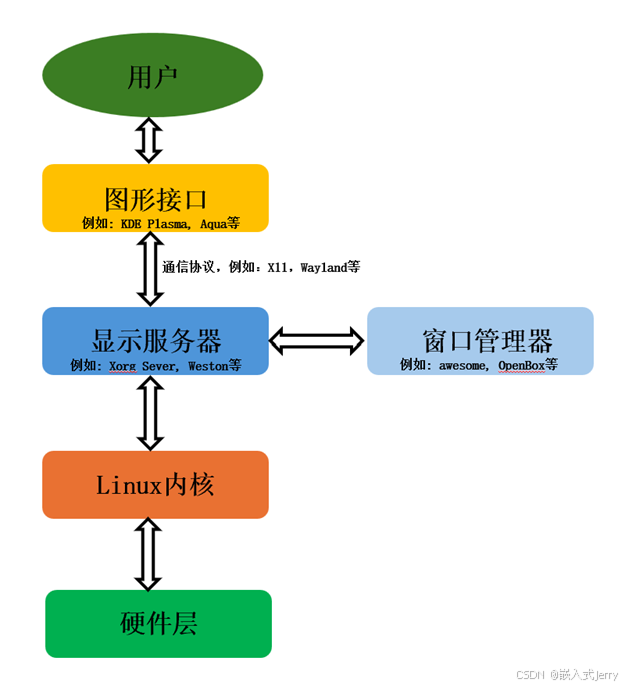
深入解析嵌入式Linux系统架构:从Bootloader到用户空间 - 结合B站视频教学
B站视频链接,请多多关注本人B站: 📌 Yocto项目实战教程:第二章 视频讲解 目录 第2章 Linux系统架构 2.1 GNU/Linux2.2 Bootloader2.3 内核空间2.4 用户空间 总结 第2章 Linux系统架构 {#linux系统架构} 嵌入式Linux系统是Linux内核的精简版…...

Asp.NET Core WebApi 配置文件
在 ASP.NET Core Web API 中,配置文件(如 appsettings.json)是管理应用程序设置的核心部分。ASP.NET Core 提供了一套灵活的配置系统,允许开发者从多种来源加载配置数据,并根据需要使用这些配置。 以下是关于如何在 A…...
)
pipe匿名管道实操(Linux)
管道相关函数 1 pipe 是 Unix/Linux 系统中的一个系统调用,用于创建一个匿名管道 #include <unistd.h> int pipe(int pipefd[2]); 参数说明: pipefd[2]:一个包含两个整数的数组,用于存储管道的文件描述符: pi…...

2025.04.10-拼多多春招笔试第三题
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 03. 数字重排最大化问题 问题描述 LYA是一位专业的数字设计师。她手中有两个数字序列 s 1 s_1...

Vue.js组件安全开发实战:从架构设计到攻防对抗
目录 开篇总述:安全视角下的Vue组件开发新范式 一、Vue.js组件开发现状全景扫描 二、安全驱动的Vue组件创新架构 三、工程化组件体系构建指南 四、深度攻防对抗实战解析 五、安全性能平衡策略 结语:安全基因注入前端开发的未来展望 下期预告&…...
质因数之和-蓝桥20249
题目: 代码:无脑直接根据题目,一步步操作就行 #include <iostream> using namespace std;int gcd(int a,int b){if(b0) return a;return gcd(b,a%b); }bool exist_gcd(int a,int b){if(gcd(a,b)1) return false;return true; }bool is…...

《栈区、堆区和静态区:内存管理的三大支柱》
🚀个人主页:BabyZZの秘密日记 📖收入专栏:C语言 🌍文章目入 一、栈区(Stack)(一)栈区的定义(二)栈区的特点(三)栈区的使用…...

Rust Command无法执行*拓展解决办法
async fn run_cmd_async_out<I, S>(cmd: &str, args: I, timeout_s: u64, with_http_proxy: bool) -> Result<String> whereI: IntoIterator<Item S>,S: AsRef<OsStr>, {let mut cmd tokio::process::Command::new(cmd);// 让 sh 来运行命令&…...

AI 笔记 - 开源轻量级人脸检测项目
开源轻量级人脸检测项目 引言项目解析[libfacedetection 于仕琪](https://github.com/ShiqiYu/libfacedetection)[Ultra-Light-Fast-Generic-Face-Detector-1MB Linzaer](https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB)[A-Light-and-Fast-Face-Detec…...

AI Agent vs 大模型
一句话概述 大模型是“超级学霸”,负责理解、思考和生成内容; AI Agent是“行动派秘书”,会调用工具和知识库,自主完成任务。 角色定位对比 大模型 智能体 核心 任务 回答、创作、推理、分析 规划、决策、执行、协调多工具 …...

go游戏后端开发32:自摸杠处理逻辑
当我们在自摸杠时,实际上在杠完之后,我们还需要进行一个删除操作。因此,我们需要在上面拷贝一个删除操作。由于这是自摸杠,所以这个地方需要删除四次。在这里,我们需要注意的是,自摸杠时,传过来…...
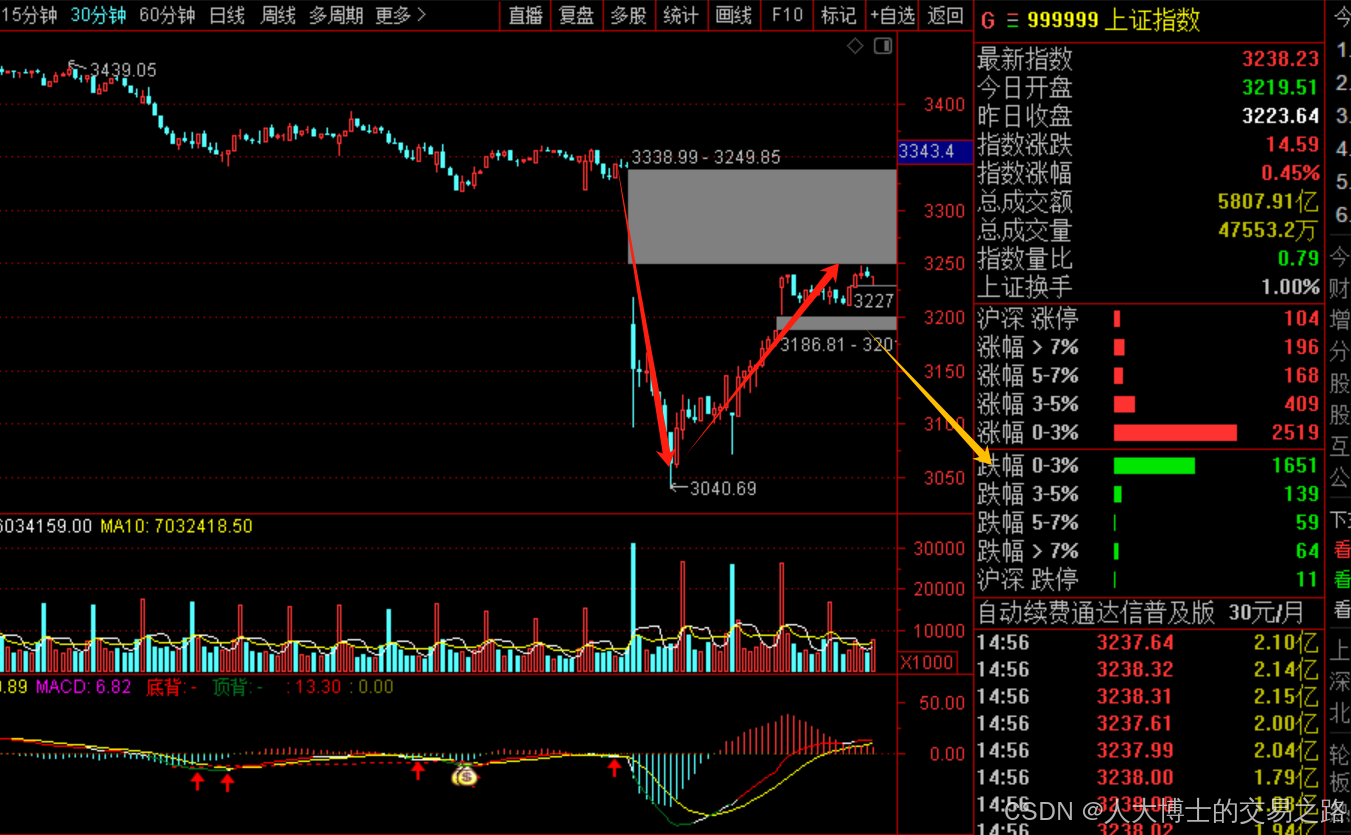
今日行情明日机会——20250411
今天缩量,上方压力依然在,外围还在升级,企稳还需要时日。 2025年4月11日A股涨停主要行业方向分析 一、核心主线方向 芯片(半导体) • 涨停家数:24家(当日最强方向)。 • 驱动逻辑&…...
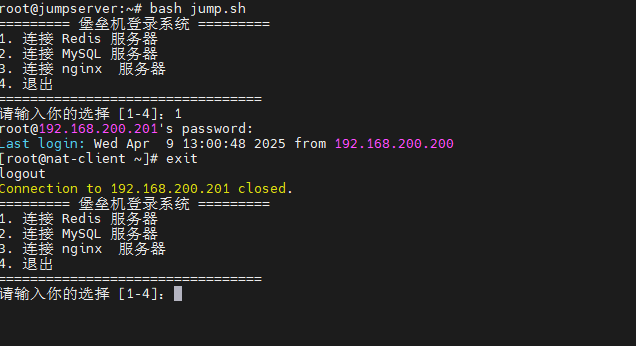
【Linux】TCP_Wrappers+iptables实现堡垒机功能
规划 显示jumpserver的简单功能,大致的网络拓扑图如下 功能规划 & 拓扑结构 JumpServer(堡垒机)主要功能: 对访问目标服务器进行统一入口控制(例如 nginx、mysql、redis)。使用 iptables 做 NAT 转…...

git仓库中.git文件夹过大的问题
由于git仓库中存放了较大的文件,之后即使在gitignore中添加,也不会导致.git文件夹变小。 参考1 2 通过 du -d 1 -h查看文件大小 使用 git rev-list --objects --all | grep "$(git verify-pack -v .git/objects/pack/*.idx | sort -k 3 -n | tail…...