高效查询Redis中大数据的实践与优化指南
个人名片
🎓作者简介:java领域优质创作者
🌐个人主页:码农阿豪
📞工作室:新空间代码工作室(提供各种软件服务)
💌个人邮箱:[2435024119@qq.com]
📱个人微信:15279484656
🌐个人导航网站:www.forff.top
💡座右铭:总有人要赢。为什么不能是我呢?
- 专栏导航:
码农阿豪系列专栏导航
面试专栏:收集了java相关高频面试题,面试实战总结🍻🎉🖥️
Spring5系列专栏:整理了Spring5重要知识点与实战演练,有案例可直接使用🚀🔧💻
Redis专栏:Redis从零到一学习分享,经验总结,案例实战💐📝💡
全栈系列专栏:海纳百川有容乃大,可能你想要的东西里面都有🤸🌱🚀
目录
- 高效查询Redis中大数据的实践与优化指南
- 1. 引言
- 2. 问题背景
- 初始实现方案
- 3. 优化方案
- 3.1 优化 Shell 脚本
- 3.2 使用 Redis Pipeline 优化
- 优化后的 Shell + Pipeline 方案
- 4. Java 实现方案
- 4.1 使用 Jedis 查询
- 4.2 使用 Lettuce(异步非阻塞)
- 5. 性能对比
- 6. 结论
高效查询Redis中大数据的实践与优化指南
1. 引言
Redis 是一种高性能的键值存储数据库,广泛应用于缓存、排行榜、计数器等场景。在实际业务中,我们经常需要查询符合特定条件的数据,例如找出 value 大于某个阈值(如 10)的键值对。然而,直接遍历所有键并使用 GET 命令逐个检查可能会导致性能问题,尤其是当数据量较大时。
本文将围绕 如何高效查询 Redis 中满足条件的数据 展开讨论,从最初的简单实现到优化后的高效方案,并结合 Java 代码示例,帮助开发者掌握 Redis 数据查询的最佳实践。
2. 问题背景
假设我们有以下需求:
- Redis 数据库
DB1(-n 1)存储了大量形如flow:count:1743061930:*的键。 - 需要找出其中
value > 10的所有键值对,并统计总数。
初始实现方案
最初的 Shell 脚本如下:
redis-cli -h 10.206.0.16 -p 6379 -n 1 --scan --pattern "flow:count:1743061930:*" | \
while read key; dovalue=$(redis-cli -h 10.206.0.16 -p 6379 -n 1 GET "$key")if [ "$value" != "1" ]; thenecho "$key: $value"fi
done | tee /dev/stderr | wc -l | awk '{print "Total count: " $1}'
该方案的问题:
- 多次 Redis 查询:每个键都要单独执行
GET,网络开销大。 - Shell 字符串比较低效:
[ "$value" != "1" ]是字符串比较,数值比较更合适。 - 管道过多:
tee、wc、awk多个管道影响性能。
3. 优化方案
3.1 优化 Shell 脚本
优化后的版本:
redis-cli -h 10.206.0.16 -p 6379 -n 1 --scan --pattern "flow:count:1743061930:*" | \
while read key; doredis-cli -h 10.206.0.16 -p 6379 -n 1 GET "$key"
done | \
awk '$1 > 10 {count++; print} END {print "Total count: " count}'
优化点:
- 减少 Redis 命令调用:直接批量获取
value,减少网络开销。 - 使用
awk进行数值比较:$1 > 10比 Shell 字符串比较更高效。 - 合并计数逻辑:
awk同时完成过滤、输出和计数。
如果仍需保留键名:
redis-cli -h 10.206.0.16 -p 6379 -n 1 --scan --pattern "flow:count:1743061930:*" | \
while read key; dovalue=$(redis-cli -h 10.206.0.16 -p 6379 -n 1 GET "$key")echo "$key: $value"
done | \
awk -F': ' '$2 > 10 {count++; print} END {print "Total count: " count}'
3.2 使用 Redis Pipeline 优化
Shell 脚本仍然存在多次 GET 的问题,我们可以使用 Redis Pipeline 批量获取数据,减少网络往返时间。
优化后的 Shell + Pipeline 方案
redis-cli -h 10.206.0.16 -p 6379 -n 1 --scan --pattern "flow:count:1743061930:*" | \
xargs -I {} redis-cli -h 10.206.0.16 -p 6379 -n 1 MGET {} | \
awk '$1 > 10 {count++; print} END {print "Total count: " count}'
这里使用 xargs + MGET 批量获取 value,减少网络请求次数。
4. Java 实现方案
在 Java 应用中,我们可以使用 Jedis 或 Lettuce 客户端优化查询。
4.1 使用 Jedis 查询
import redis.clients.jedis.Jedis;
import redis.clients.jedis.ScanParams;
import redis.clients.jedis.ScanResult;
import java.util.List;public class RedisValueFilter {public static void main(String[] args) {String host = "10.206.0.16";int port = 6379;int db = 1;String pattern = "flow:count:1743061930:*";int threshold = 10;try (Jedis jedis = new Jedis(host, port)) {jedis.select(db);ScanParams scanParams = new ScanParams().match(pattern).count(100);String cursor = "0";int totalCount = 0;do {ScanResult<String> scanResult = jedis.scan(cursor, scanParams);List<String> keys = scanResult.getResult();cursor = scanResult.getCursor();// 批量获取 valuesList<String> values = jedis.mget(keys.toArray(new String[0]));// 过滤并统计for (int i = 0; i < keys.size(); i++) {String key = keys.get(i);String valueStr = values.get(i);if (valueStr != null) {int value = Integer.parseInt(valueStr);if (value > threshold) {System.out.println(key + ": " + value);totalCount++;}}}} while (!cursor.equals("0"));System.out.println("Total count: " + totalCount);}}
}
优化点:
- 使用
SCAN代替KEYS,避免阻塞 Redis。 - 使用
MGET批量查询,减少网络开销。 - 直接数值比较,提高效率。
4.2 使用 Lettuce(异步非阻塞)
Lettuce 是高性能 Redis 客户端,支持异步查询:
import io.lettuce.core.*;
import io.lettuce.core.api.sync.RedisCommands;
import java.util.List;public class RedisLettuceQuery {public static void main(String[] args) {RedisURI uri = RedisURI.create("redis://10.206.0.16:6379/1");RedisClient client = RedisClient.create(uri);try (RedisConnection<String, String> connection = client.connect()) {RedisCommands<String, String> commands = connection.sync();String pattern = "flow:count:1743061930:*";int threshold = 10;int totalCount = 0;ScanCursor cursor = ScanCursor.INITIAL;do {ScanArgs scanArgs = ScanArgs.Builder.matches(pattern).limit(100);KeyScanCursor<String> scanResult = commands.scan(cursor, scanArgs);List<String> keys = scanResult.getKeys();cursor = ScanCursor.of(scanResult.getCursor());// 批量获取 valuesList<KeyValue<String, String>> keyValues = commands.mget(keys.toArray(new String[0]));for (KeyValue<String, String> kv : keyValues) {if (kv.hasValue()) {int value = Integer.parseInt(kv.getValue());if (value > threshold) {System.out.println(kv.getKey() + ": " + value);totalCount++;}}}} while (!cursor.isFinished());System.out.println("Total count: " + totalCount);} finally {client.shutdown();}}
}
优势:
- 非阻塞 I/O,适合高并发场景。
- 支持 Reactive 编程(如
RedisReactiveCommands)。
5. 性能对比
| 方案 | 查询方式 | 网络开销 | 适用场景 |
|---|---|---|---|
| 原始 Shell | 单 GET 遍历 | 高 | 少量数据 |
优化 Shell + awk | 批量 GET | 中 | 中等数据量 |
| Shell + Pipeline | MGET 批量 | 低 | 大数据量 |
| Java + Jedis | SCAN + MGET | 低 | 生产环境 |
| Java + Lettuce | 异步 SCAN | 最低 | 高并发 |
6. 结论
- 避免
KEYS命令:使用SCAN替代,防止阻塞 Redis。 - 减少网络请求:使用
MGET或 Pipeline 批量查询。 - 数值比较优化:用
awk或 Java 直接比较数值,而非字符串。 - 生产推荐:Java + Jedis/Lettuce 方案,适合大规模数据查询。
通过优化,我们可以显著提升 Redis 大数据查询的效率,降低服务器负载,适用于高并发生产环境。
相关文章:

高效查询Redis中大数据的实践与优化指南
个人名片 🎓作者简介:java领域优质创作者 🌐个人主页:码农阿豪 📞工作室:新空间代码工作室(提供各种软件服务) 💌个人邮箱:[2435024119qq.com] 📱个人微信&a…...

操作系统 4.2-键盘
键盘中断初始化和处理 提取的代码如下: // con_init 函数,初始化控制台(包括键盘)的中断 void con_init(void) {set_trap_gate(0x21, &keyboard_interrupt); } // 键盘中断处理函数 .globl _keyboard_interrupt _keyboard…...
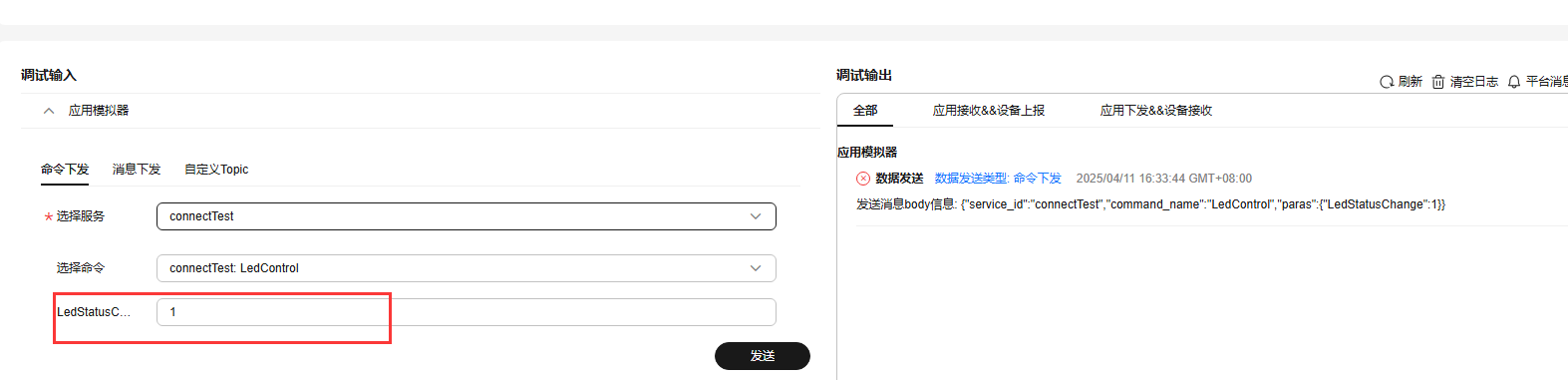
STM32+EC600E 4G模块 与华为云平台通信
前言 由于在STM32巡回研讨会上淘了一块EC600E4G模块以及刚办完电信卡多了两张副卡,副卡有流量刚好可以用一下,试想着以后画一块ESP32板子搭配这个4G模块做个随身WIFI,目前先用这个模块搭配STM32玩一下云平顺便记录一下。 实验目的 实现STM…...

进行性核上性麻痹患者,饮食 “稳” 健康
进行性核上性麻痹作为一种复杂且罕见的神经系统退行性疾病,给患者的身体机能和日常生活带来严重挑战。在积极接受专业治疗的同时,合理的饮食安排对于维持患者营养状况、缓解症状及提升生活质量起着关键作用。以下为患者提供一些健康饮食建议。 首先&…...

【数据结构 · 初阶】- 顺序表
目录 一、线性表 二、顺序表 1.实现动态顺序表 SeqList.h SeqList.c Test.c 问题 经验:free 出问题,2种可能性 解决问题 (2)尾删 (3)头插,头删 (4)在 pos 位…...
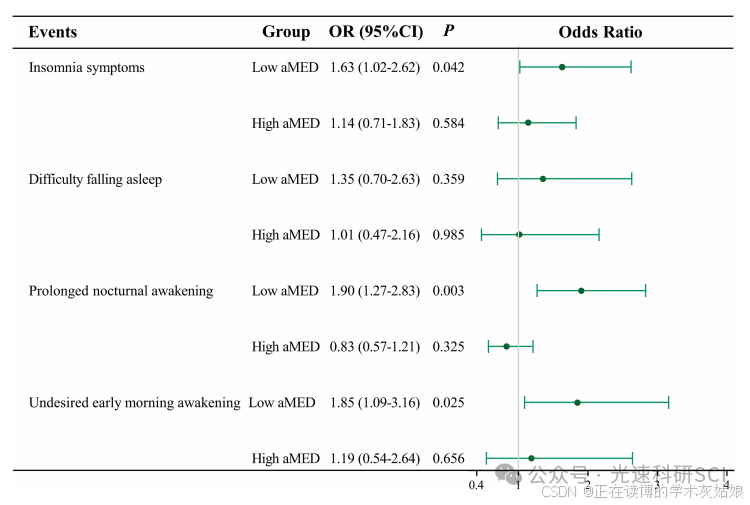
NHANES指标推荐:aMED
文章题目:The moderating effect of alternate Mediterranean diet on the association between sedentary behavior and insomnia in postmenopausal women DOI:10.3389/fnut.2024.1516334 中文标题:替代性地中海饮食对绝经后女性久坐行为与…...

ngx_cycle_modules
Ubuntu 下 nginx-1.24.0 源码分析 - ngx_cycle_modules-CSDN博客 定义在 src/core/ngx_module.c ngx_int_t ngx_cycle_modules(ngx_cycle_t *cycle) {/** create a list of modules to be used for this cycle,* copy static modules to it*/cycle->modules ngx_pcalloc(…...
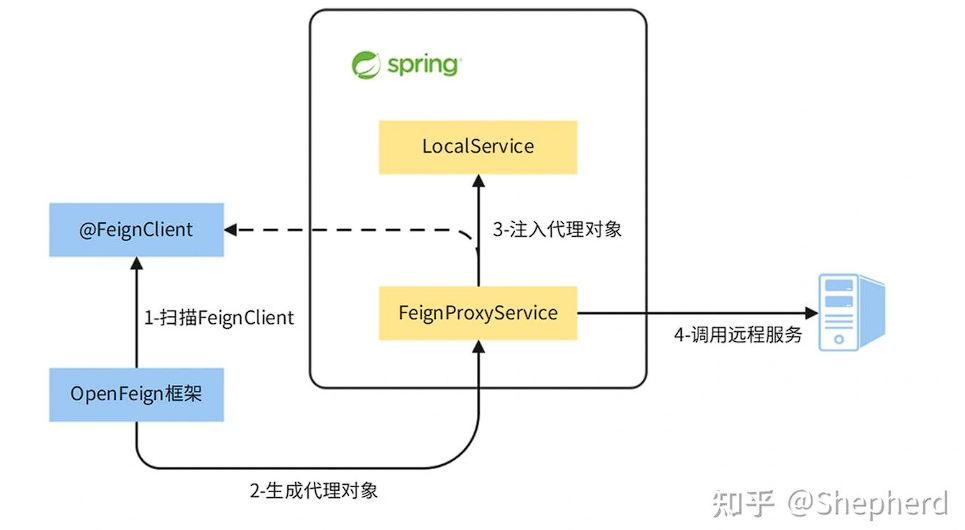
Spring Cloud 远程调用
4.OpenFeign的实现原理是什么? 在使用OpenFeign的时候,主要关心两个注解,EnableFeignClients和FeignClient。整体的流程分为以下几个部分: 启用Feign代理,通过在启动类上添加EnableFeignClients注解,开启F…...
)
YOLO学习笔记 | YOLOv8环境搭建全流程指南(2025.4)
===================================================== github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 ===================================================== YOLOv8环境搭建 一、环境准备与工具配置1. Conda虚拟环境搭建2. CUDA与…...
创建docx文档和表格)
使用Apache POI(Java)创建docx文档和表格
1、引入poi 依赖组件 <dependency><groupId>org.apache.poi</groupId><artifactId>poi-scratchpad</artifactId><version>4.0.0</version> </dependency> <dependency><groupId>org.apache.poi</groupId>&…...
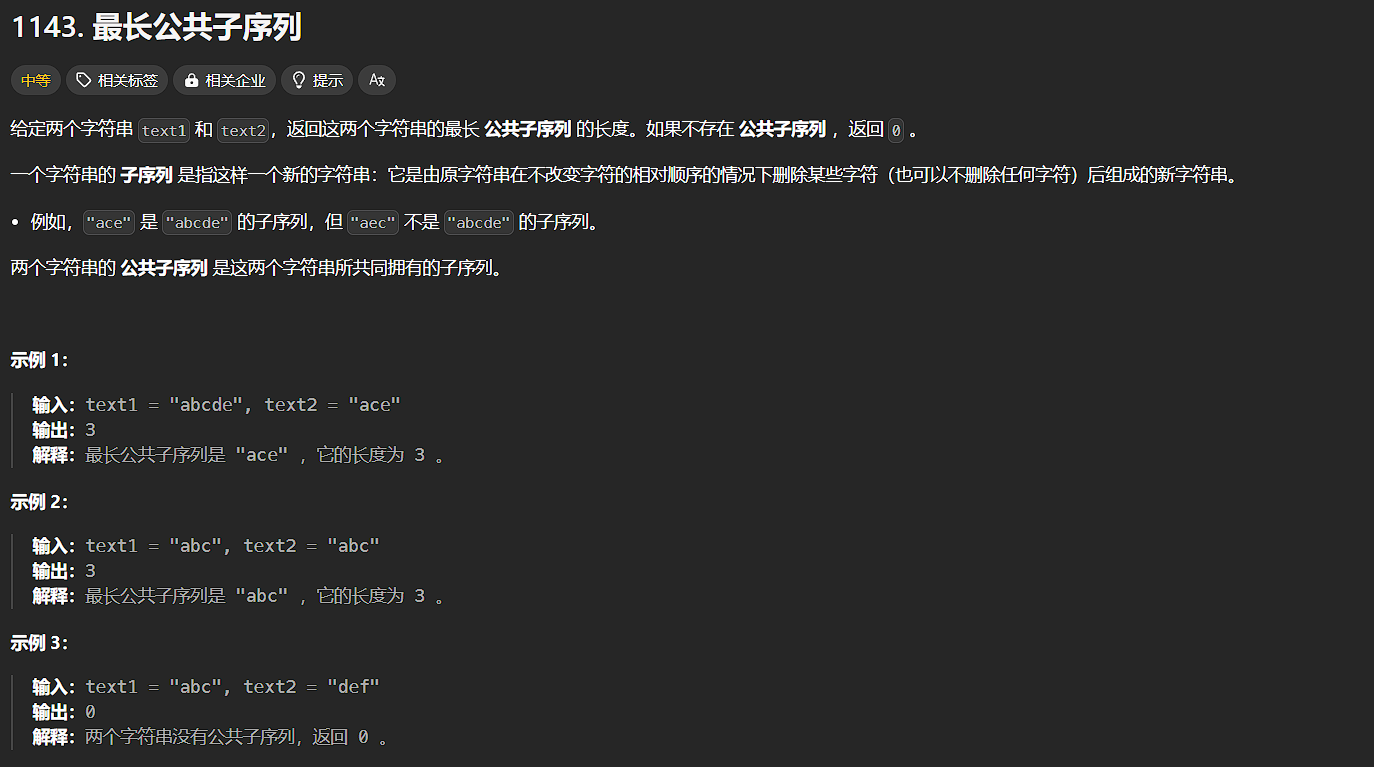
力扣 — — 最长公共子序列
力扣 — — 最长公共子序列 最长公共子序列 题源:1143. 最长公共子序列 - 力扣(LeetCode) 题目: 分析: 一道经典的题目:最长公共子序列(LCS) 题目大意:求两个字符串的最长公共序列。 算法&…...

当一个 HTTP 请求发往 Kubernetes(K8s)部署的微服务时,整个过程流转时怎样的?
以下是一个简单的示意图来展示这个过程: 1. 请求发起 客户端(可以是浏览器、移动应用或者其他服务)发起一个 HTTP 请求到目标微服务的地址。这个地址可以是服务的域名、IP 地址或者 Kubernetes 服务的 ClusterIP、NodePort 等。 2. 外部流量…...
面向对象--关联知识点(1)命名空间)
C#核心学习(十五)面向对象--关联知识点(1)命名空间
目录 一、命名空间基本概念:代码的"虚拟文件夹" 二 、命名空间的普通使用 三 、不同命名空间中相互使用 需要引用命名空间或指明出处 四、命名空间可以包裹命名空间(嵌套命名空间使用) 五、 关于修饰类的访问修饰符 一、命名空…...

淘宝商品数据实时抓取 API 开发指南:从接口申请到数据解析实战
一、引言 在当今电商蓬勃发展的时代,淘宝作为国内电商巨头,其平台上汇聚了海量商品信息。对于电商从业者、数据分析爱好者以及众多依赖淘宝商品数据开展业务的企业而言,能够实时获取淘宝商品数据具有极高价值。例如,电商运营者…...
)
【嵌入式硬件】LAN9253说明书(中文版)
目录 1.介绍 1.1总体介绍 1.2模式介绍 1.2.1微控制器模式: 1.2.2 扩展模式 1.2.3 数字IO模式 1.2.4 各模式图 2.引脚说明 2.1 引脚总览 2.2 引脚描述 2.2.1 LAN端口A引脚 2.2.2 LAN端口B引脚 2.2.3 LAN端口A和、B电源和公共引脚 2.2.4 SPI/SQI PINS 2.2.5 分布式时…...

蓝桥杯-蓝桥幼儿园(Java-并查集)
并查集的核心思想 并查集主要由两个操作构成: Find:查找某个元素所在集合的根节点。并查集的特点是,每个元素都指向它自己的父节点,根节点的父节点指向它自己。查找过程中可以通过路径压缩来加速后续的查找操作,即将路…...

C++蓝桥杯填空题(攻克版)
片头 嗨~小伙伴们,咱们继续攻克填空题,先把5分拿到手~ 第1题 数位递增的数 这道题,需要我们计算在整数 1 至 n 中有多少个数位递增的数。 什么是数位递增的数呢?一个正整数如果任何一个数位不大于右边相邻的数位。比如…...

JS 构造函数实现封装性
通过构造函数实现封装性,构造函数生成的对象独立存在互不影响 创建实例对象时,其中函数的创建会浪费内存...
交换机:为音频和视频系统赋能的多面利器)
以太网供电(PoE)交换机:为音频和视频系统赋能的多面利器
近年来,物联网(IoT)视频设备的普及浪潮正以稳健的步伐持续推进。诸如摄像机、支持视频功能的办公自动化系统等物联网视频设备,凭借其远程会议支持、安全性强化以及便捷性提升等诸多优势,赢得了市场的广泛青睐。以太联Intellinet,作…...

《深度剖析分布式软总线:软时钟与时间同步机制探秘》
在分布式系统不断发展的进程中,设备间的协同合作变得愈发紧密和复杂。为了确保各个设备在协同工作时能够有条不紊地进行,就像一场精准的交响乐演出,每个乐器都要在正确的时间奏响音符,分布式软总线中的软时钟与时间同步机制应运而…...
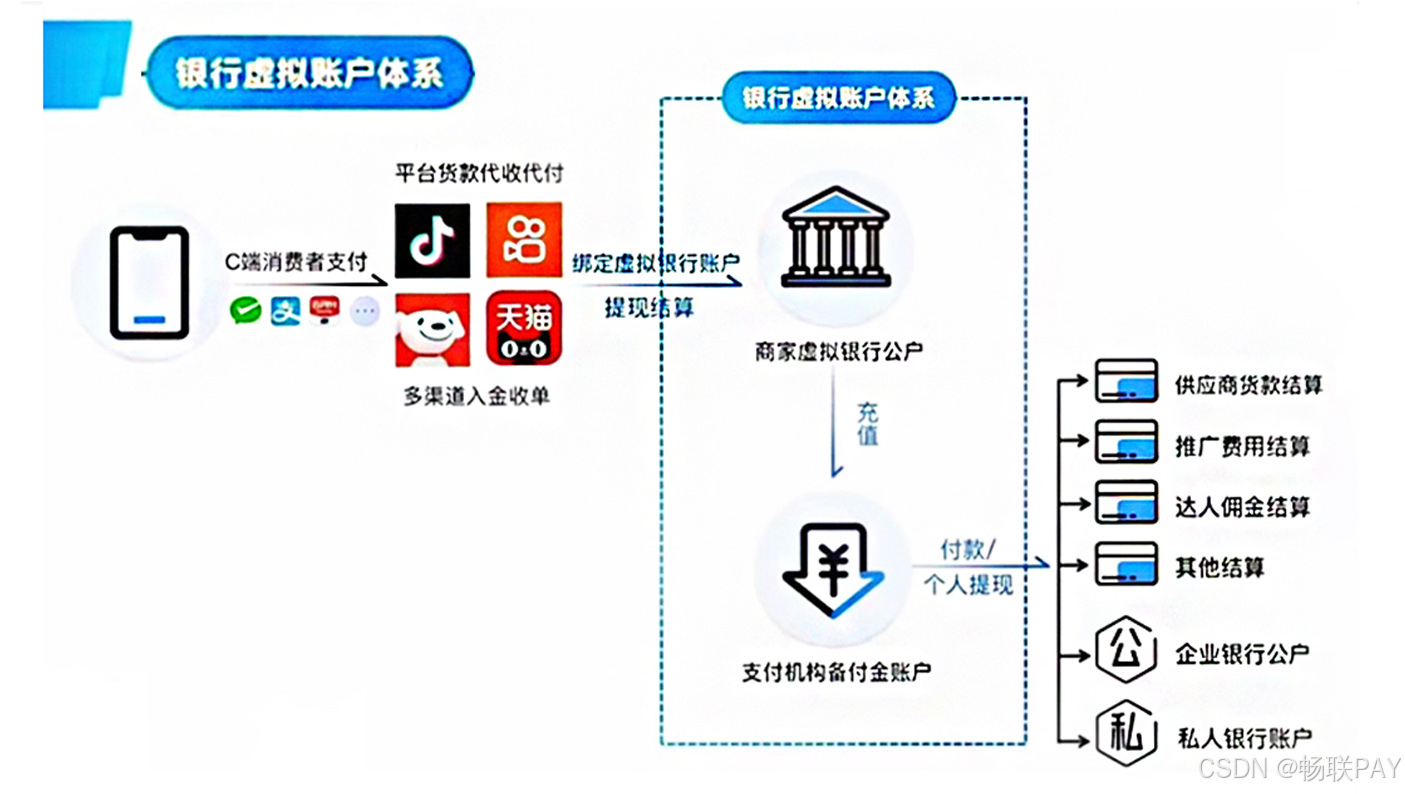
一站式云分账系统!智能虚拟户分账系统成电商合规“刚需”
电商智能分账解决:电商一站式破解多平台资金管理难题集中管理分账,分账后秒到,并为针对电商行业三大核心痛点提供高效应对策略: 1. 票据合规困境 智能对接上下游交易数据流,构建自动化票据协同机制,有效规…...

服务器加空间失败 growpart /dev/vda 1
[rootecm-2c5 ~]# growpart /dev/vda 1 unexpected output in sfdisk --version [sfdisk,来自 util-linux 2.23.2] [rootecm-2c5 ~]# xfs_info /dev/vda1 meta-data/dev/vda1 isize512 agcount21, agsize1310656 blks sectsz512 attr2, projid32bit1 crc1 finobt0…...

慢查询解决思路
1. 复现问题 慢查询的出现是常态还是偶尔?是否在业务允许范围内? "不要过早优化,先 Make it work / right,再 Make it fast。" 建议先将查询语句及其触发条件记录下来,便于后续测试、分析和对比。 2. 定位问题 2.1 单机数据库: explain查询执行计划 数据库默…...
数组 array
1、数组定义 是一种用于存储多个相同类型数据的存储模型。 2、数组格式 (1)数据类型[ ] 变量名(比较常见这种格式) 例如: int [ ] arr0,定义了一个int类型的数组,数组名是arr0; &am…...
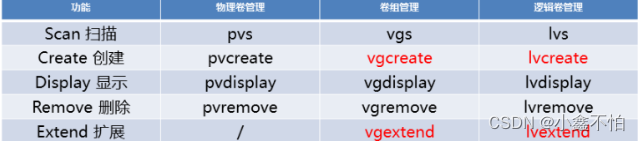
linux命令六
逻辑卷 作用: 整合分散空间 空间支持扩大 步骤一:建立卷组(VG) 格式:vgcreate 卷组名 设备路径……. 如果分区不是卷组,则会先调用pvcreat 组建物理卷,再将其组建成组卷 Successfully:成功 example:例子 在man帮助中可以使用examp…...
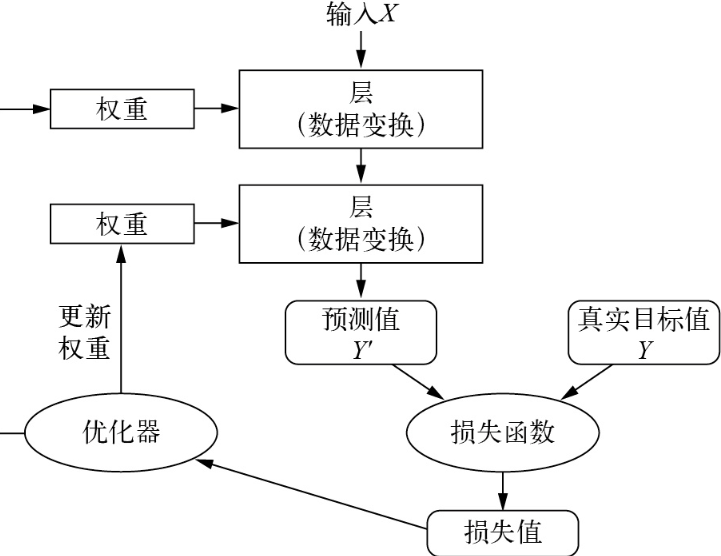
深度学习总结(8)
模型工作流程 模型由许多层链接在一起组成,并将输入数据映射为预测值。随后,损失函数将这些预测值与目标值进行比较,得到一个损失值,用于衡量模型预测值与预期结果之间的匹配程度。优化器将利用这个损失值来更新模型权重。 下面是…...

基于docker搭建redis集群环境
在redis目录下创建redis-cluster目录,创建docker-compose.yml文化和generate.sh文件 【配置generate.sh文件】 for port in $(seq 1 9); \ do \ mkdir -p redis${port}/ touch redis${port}/redis.conf cat << EOF > redis${port}/redis.conf port 6379 …...

OpenHarmony 5.0版本视频硬件编解码适配
一、简介 Codec HDI(Hardware Device Interface)对上层媒体服务提供视频编解码的驱动能力接口,主要功能有获取组件编解码能力,创建、销毁编解码器对象,启停编解码器操作,编解码处理等。 Codec HDI 2.0接口…...

deepseek热度已过?
DeepSeek的热度并没有消退,以下是具体表现: 用户使用量和下载量方面 • 日活跃用户量增长:DeepSeek已经成为目前最快突破3000万日活跃用户量的应用程序。 • 应用商店下载量:1月26日,DeepSeek最新推出的AI聊天机器人…...
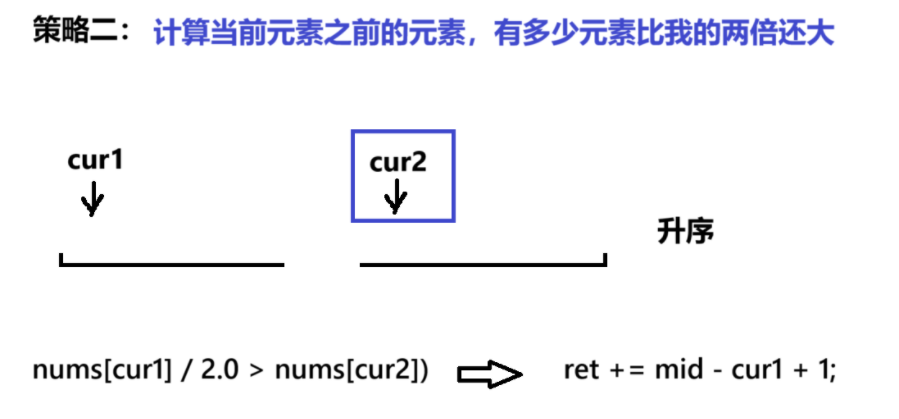
分治-归并系列一>翻转对
目录 题目:解析:策略一: 代码:策略二: 代码: 题目: 链接: link 这题和逆序对区别点就是,要找到前一个元素是后一个元素的2倍 先找到目标值再,继续堆排序 解析࿱…...