Flink的 RecordWriter 数据通道 详解
本文从基础原理到代码层面逐步解释 Flink 的RecordWriter 数据通道,尽量让初学者也能理解。
1. 什么是 RecordWriter?
通俗理解
RecordWriter 是 Flink 中负责将数据从一个任务(Task)发送到下游任务的组件。想象一下,Flink 是一个巨大的工厂,数据像流水线上的包裹,RecordWriter 就是负责把包裹打包、贴上地址标签,然后通过“传送带”送到下一个站点的工人。
在 Flink 的分布式计算中,数据处理分为多个并行任务(Task),每个任务可能需要把自己的处理结果发送给其他任务(比如下游的计算节点)。RecordWriter 的作用是:
- 序列化数据:把数据变成可以在网络上传输的字节流。
- 分配数据:决定数据应该发送到哪个下游任务(基于分区策略,比如 keyBy)。
- 发送数据:通过底层的网络通道(比如 Netty)把数据传出去。
官方定义
根据 Flink 官方文档,RecordWriter 是 Flink 数据流(DataStream)处理中用于将记录(Record)写入到输出通道的核心组件。它是 Flink 运行时(Runtime)层的一部分,位于任务的输出端,负责将上游算子处理后的数据发送到下游算子的输入端。
2. RecordWriter 的工作原理(宏观视角)
为了让非专业人士理解,我们先从高层次看 RecordWriter 的工作流程,之后再深入到代码和底层细节。
工作流程(类比快递分拣)
- 接收包裹(数据记录):
RecordWriter从上游算子(比如 Map 或 Filter)接收到一条数据记录(Record),就像快递员拿到一个包裹。 - 贴标签(分区决策):根据用户定义的分区策略(比如 keyBy 或 broadcast),
RecordWriter决定这个包裹要送到哪个下游站点(下游子任务)。 - 打包(序列化):包裹不能直接扔到传送带上,
RecordWriter会把数据“打包”成字节流(序列化),方便在网络上传输。 - 选择传送带(通道选择):Flink 的任务之间通过逻辑通道(Channel)连接,
RecordWriter选择合适的通道(对应下游的子任务)。 - 送上传送带(发送数据):
RecordWriter把打包好的数据通过底层的网络栈(Netty)发送到下游任务。
核心问题
- 如何确保数据高效传输? Flink 使用缓冲区(Buffer)管理数据,避免频繁的网络调用。
- 如何保证数据顺序或分区正确? 依赖分区器(Partitioner)和通道选择器(ChannelSelector)。
- 如何处理分布式环境中的复杂性? Flink 的运行时通过
ResultPartition和RecordWriter抽象化网络通信。
3. 深入 RecordWriter 的源码实现
现在我们结合 Flink 源码(基于 1.17 版本),从底层逐步分析 RecordWriter 的实现。我会用注释和伪代码的方式解释关键部分,并尽量用类比让逻辑清晰。
3.1 RecordWriter 的类结构
RecordWriter 的核心代码位于 org.apache.flink.runtime.io.network.api.writer 包中。主要类是 RecordWriter,它是一个抽象类,实际使用的是其子类,比如 RecordWriterDelegate 或 ChannelSelectorRecordWriter。
public abstract class RecordWriter<T> {protected final ResultPartitionWriter partitionWriter; // 输出分区protected final int numberOfChannels; // 下游通道数量protected final Random random; // 用于随机分区protected RecordWriter(ResultPartitionWriter writer) {this.partitionWriter = writer;this.numberOfChannels = writer.getNumberOfSubpartitions();this.random = new Random();}// 核心方法:发送一条记录public abstract void emit(T record) throws IOException, InterruptedException;
}
- ResultPartitionWriter:
RecordWriter依赖的分区写入器,负责管理输出缓冲区和实际的网络发送。 - numberOfChannels:下游子任务的数量,决定了数据可以发送到多少个通道。
- emit:核心方法,负责将一条记录发送出去。
3.2 数据发送的核心流程(emit 方法)
emit 方法是 RecordWriter 的核心入口,我们以 ChannelSelectorRecordWriter(支持自定义分区策略的实现)为例,逐步分析其实现。
源码分析(简化和注释)
以下是 ChannelSelectorRecordWriter 的 emit 方法的核心逻辑(简化版,带详细注释):
public class ChannelSelectorRecordWriter<T> extends RecordWriter<T> {private final ChannelSelector<T> channelSelector; // 通道选择器(决定分区)private final SerializationDelegate<T> serializationDelegate; // 序列化代理public ChannelSelectorRecordWriter(ResultPartitionWriter writer,ChannelSelector<T> channelSelector,SerializationDelegate<T> serializationDelegate) {super(writer);this.channelSelector = channelSelector;this.serializationDelegate = serializationDelegate;}@Overridepublic void emit(T record) throws IOException, InterruptedException {// 1. 设置待序列化的记录serializationDelegate.setInstance(record);// 2. 使用通道选择器决定目标通道int channelIndex = channelSelector.selectChannel(record);// 3. 将记录写入目标通道的缓冲区partitionWriter.emitRecord(serializationDelegate.getSerializedData(), // 序列化后的数据channelIndex // 目标通道索引);}
}
步骤拆解与类比
-
设置记录(serializationDelegate.setInstance):
- 类比:快递员拿到包裹,先登记包裹内容。
- 原理:
serializationDelegate是一个序列化代理,负责将用户的数据(比如 Java 对象)变成字节流。Flink 使用SerializationDelegate包装用户记录,延迟实际序列化操作,以提高性能。 - 源码细节:
serializationDelegate.setInstance(record)只是简单地将记录存储到代理对象中,实际序列化发生在后续的getSerializedData调用时。
-
选择通道(channelSelector.selectChannel):
- 类比:快递员根据包裹上的地址标签,决定送到哪个分拣中心。
- 原理:
ChannelSelector是 Flink 提供的分区逻辑接口,用户可以通过keyBy、broadcast等算子自定义分区策略。selectChannel方法返回一个整数(channelIndex),表示数据应该发送到哪个下游子任务。 - 常见实现:
KeyGroupStreamPartitioner:基于 Key 的哈希分区(keyBy)。BroadcastPartitioner:将数据广播到所有下游子任务。ForwardPartitioner:直接发送到对应的下游任务(一对一)。
- 推导:
- 假设用户定义了
keyBy(x -> x.getId()),ChannelSelector会提取记录的id字段,计算哈希值(比如id.hashCode()),然后通过取模(hash % numberOfChannels)决定目标通道。 - 公式:channelIndex=hash(key)mod numberOfChannels
- 这确保相同
key的记录总是发送到同一个下游任务,满足 keyBy 的语义。
- 假设用户定义了
-
写入缓冲区(partitionWriter.emitRecord):
- 类比:快递员把包裹装进集装箱(缓冲区),等待卡车运走。
- 原理:
ResultPartitionWriter是 Flink 运行时中管理输出分区的组件。emitRecord方法将序列化后的数据写入目标通道的缓冲区(Buffer)。Flink 使用内存池(MemoryPool)管理缓冲区,避免频繁分配内存。 - 源码细节:
public void emitRecord(BufferBuilder bufferBuilder, int targetSubpartition)throws IOException, InterruptedException {// 将序列化数据写入 BufferBuilderBufferConsumer bufferConsumer = bufferBuilder.createBufferConsumer();// 添加到目标子分区的队列addBufferConsumer(bufferConsumer, targetSubpartition); }BufferBuilder:用于构建缓冲区,负责将数据写入内存。BufferConsumer:表示一个可消费的缓冲区,供下游任务读取。addBufferConsumer:将缓冲区加入目标子分区的队列,等待网络层发送。
3.3 序列化与缓冲区管理
序列化和缓冲区是 RecordWriter 性能的关键。
-
序列化:
- Flink 使用
TypeSerializer(用户定义或自动推导)将数据对象转为字节流。 - 类比:把包裹的内容拍成照片(字节流),方便通过网络传输。
- 源码:
SerializationDelegate.getSerializedData调用TypeSerializer.serialize:public class SerializationDelegate<T> {private T instance;private final TypeSerializer<T> serializer;public StreamElement getSerializedData() throws IOException {// 使用序列化器将 instance 转为字节流return serializer.serialize(instance);} }
- Flink 使用
-
缓冲区管理:
- Flink 的缓冲区基于
NetworkBufferPool,每个缓冲区是一个固定大小的内存块(默认 32KB)。 - 类比:快递员把多个小包裹装进一个大集装箱,避免频繁调用卡车。
BufferBuilder动态分配缓冲区,当缓冲区满时,会触发BufferConsumer的创建,并交给ResultPartitionWriter。
- Flink 的缓冲区基于
3.4 网络传输
- 底层实现:
RecordWriter不直接处理网络传输,而是通过ResultPartitionWriter将缓冲区交给 Flink 的网络栈(基于 Netty)。 - 类比:集装箱装满后,卡车(Netty)把数据送到下游站点。
- 原理:
ResultPartitionWriter将缓冲区写入PipelinableSubpartition的队列。- Flink 的网络层定期检查队列,使用 Netty 的 Channel 将数据发送到下游 TaskManager。
- Netty 使用 TCP 协议,确保数据可靠传输。
4. 完整步骤总结(带推导)
为了让初学者彻底理解,我将 RecordWriter 的工作流程总结为以下步骤,并为每一步提供通俗解释和公式推导(如果适用)。
-
接收数据记录:
- 描述:上游算子调用
RecordWriter.emit(record),传入一条数据。 - 类比:快递员收到一个包裹。
- 推导:无复杂计算,只是将
record传递给serializationDelegate。
- 描述:上游算子调用
-
选择目标通道:
- 描述:
ChannelSelector.selectChannel(record)返回目标通道索引。 - 类比:快递员看包裹地址,决定送到哪个分拣中心。
- 推导:
- 对于
keyBy分区:- 提取 key:key=keySelector(record)
- 计算哈希:hash=key.hashCode()
- 选择通道:channelIndex=hashmod numberOfChannels
- 对于广播分区:返回所有通道索引。
- 公式:channelIndex=f(record,numberOfChannels)
- 对于
- 描述:
-
序列化数据:
- 描述:
serializationDelegate.getSerializedData()将记录转为字节流。 - 类比:把包裹内容压缩成数字信号。
- 推导:序列化过程依赖
TypeSerializer,复杂度为 O(size of record)。
- 描述:
-
写入缓冲区:
- 描述:
partitionWriter.emitRecord将字节流写入目标通道的缓冲区。 - 类比:把包裹装进集装箱。
- 推导:
- 缓冲区大小固定(默认 32KB)。
- 如果缓冲区满,触发
BufferBuilder.finish(),创建一个新的BufferConsumer。 - 公式:bufferSize≤maxBufferSize
- 描述:
-
发送数据:
- 描述:缓冲区通过 Netty 传输到下游任务。
- 类比:卡车把集装箱运到下一个站点。
- 推导:网络传输的吞吐量取决于 Netty 的配置(线程数、TCP 参数等)。
5. 非专业人士的通俗总结
如果你完全不了解编程或分布式系统,可以把 RecordWriter 想象成一个智能快递员:
- 任务:把包裹(数据)从一个工厂(任务)送到正确的下游工厂。
- 步骤:
- 拿到包裹,检查地址(分区策略)。
- 把包裹压缩打包(序列化)。
- 装进集装箱(缓冲区)。
- 选择正确的传送带(通道)。
- 交给卡车(网络)运走。
- 聪明之处:
- 它会根据包裹的类型(key)确保送到正确的下游工厂。
- 它会攒够一车包裹再送(缓冲区),避免浪费时间。
- 它还能同时处理很多包裹(并行处理)。
6. 常见问题解答(Q&A)
Q1:RecordWriter 如何保证数据不丢失?
- 答:Flink 的
RecordWriter通过缓冲区和 Netty 的可靠传输(TCP)确保数据不丢失。如果下游任务失败,Flink 的检查点(Checkpoint)机制会回滚并重试。
Q2:为什么需要序列化?
- 答:序列化把复杂的数据对象(比如 Java 类)变成字节流,方便通过网络传输。就像把一本书的内容拍成照片,方便快递寄出。
Q3:ChannelSelector 怎么决定分区的?
- 答:
ChannelSelector根据用户定义的逻辑(比如keyBy的 key)计算目标通道。对于keyBy,它用哈希函数确保相同 key 的数据总是送到同一个下游任务。
7. 结合官方文档的补充
根据 Flink 官方文档(https://flink.apache.org/):
RecordWriter是 Flink 运行时网络栈的一部分,位于ResultPartition和下游InputGate之间。- 它支持多种分区策略(
StreamPartitioner),用户可以通过DataStreamAPI 灵活配置。 - Flink 的网络传输基于高效的缓冲区管理和 Netty 框架,
RecordWriter是这一流程的起点。
文档中还提到,RecordWriter 的设计目标是:
- 高吞吐量:通过缓冲区批量发送数据。
- 低延迟:优化序列化和通道选择逻辑。
- 灵活性:支持用户自定义分区策略。
8. 总结
RecordWriter 是 Flink 数据流处理中不可或缺的组件,负责将数据高效、正确地发送到下游任务。通过序列化、分区选择、缓冲区管理和网络传输,它实现了分布式环境下数据流的可靠传递。
相关文章:

Flink的 RecordWriter 数据通道 详解
本文从基础原理到代码层面逐步解释 Flink 的RecordWriter 数据通道,尽量让初学者也能理解。 1. 什么是 RecordWriter? 通俗理解 RecordWriter 是 Flink 中负责将数据从一个任务(Task)发送到下游任务的组件。想象一下,…...

4-6记录(B树)
找左边右下或者右边左下 转化成了前驱后继的删除 又分好几种情况: 1. 只剩25,小于2,所以把父亲拉到25旁边,兄弟的70顶替父亲 对于25,25的后继就是70,25后继的后继是71(中序遍历) 2. 借左子树…...

06软件测试需求分析案例-添加用户
给职业顾问部的老师添加用户密码后,他们才能登录使用该软件。只有admin账户具有添加用户、修改用户信息、删除用户的权利。admin是经理或团队的第一个人的账号,后面招一个教师就添加一个账号。 通读需求是提取信息,提出问题,输出…...
Nacos服务发现和配置管理
目录 一、Nacos概述 1. Nacos 简介 2. Nacos 特性 2.1 服务发现与健康监测 2.2 动态配置管理 2.3 动态DNS服务 2.4 其他关键特性 二、 服务注册和发现 2.1 核心概念 2.2 Nacos注册中心 2.3 Nacos单机模式 2.4 案例——服务注册与发现 2.4.1 父工程 2.4.2 order-p…...

【KWDB 创作者计划】第一卷:基础架构篇
以下是KWDB技术白皮书第一卷:基础架构篇的完整内容展示,包含要求的三个核心章节的深度解析。我们将以技术严谨性结合可读性的方式呈现,实际交付时会进一步扩展示意图和代码示例。 目录 KWDB技术白皮书卷一:基础架构篇 1. 数…...

对接日本金融市场数据全指南:K线、实时行情与IPO新股
一、日本金融市场特色与数据价值 日本作为全球第三大经济体,其金融市场具有以下显著特点: 成熟稳定:日经225指数包含日本顶级蓝筹股独特交易时段:上午9:00-11:30,下午12:30-15:00(JST)高流动性…...

【愚公系列】《高效使用DeepSeek》066-纠纷解决话术
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! 👉 江湖人称"愚公搬代码",用七年如一日的精神深耕技术领域,以"…...

操作系统 3.1-内存使用和分段
如何简单使用内存 这张幻灯片展示了计算机如何开始执行程序的基本过程,涉及到存储器、指令寄存器(IR)、运算器和控制器等计算机组件。 存储器:程序被加载到内存中。图中显示了一个指令 mov ax, [100],它的作用是将内存…...
禅道MCP Server开发实践与功能全解析
一、简介 1、MCP Server核心定义 MCP Server(Meta Command Protocol Server)是一种基于客户端-服务器架构的轻量级服务程序,采用统一的mcp协议格式,通过连接多样化数据源和工具为AI应用提供扩展能力。它作为中间层,实…...

Spring Boot 3.5新特性解析:自动配置再升级,微服务开发更高效
📝 摘要 Spring Boot 3.5作为Spring生态的最新版本,带来了多项令人振奋的改进。本文将深入解析其中最核心的自动配置增强特性,以及它们如何显著提升微服务开发效率。通过详细的代码示例和通俗易懂的讲解,您将全面了解这些新特性在…...
GNSS静态数据处理
1 安装数据处理软件:仪器之星(InStar )和 Trimble Business Center 做完控制点静态后,我们需要下载GNSS数据,对静态数据进行处理。在处理之前需要将相关软件在自己电脑上安装好: 仪器之星(InS…...
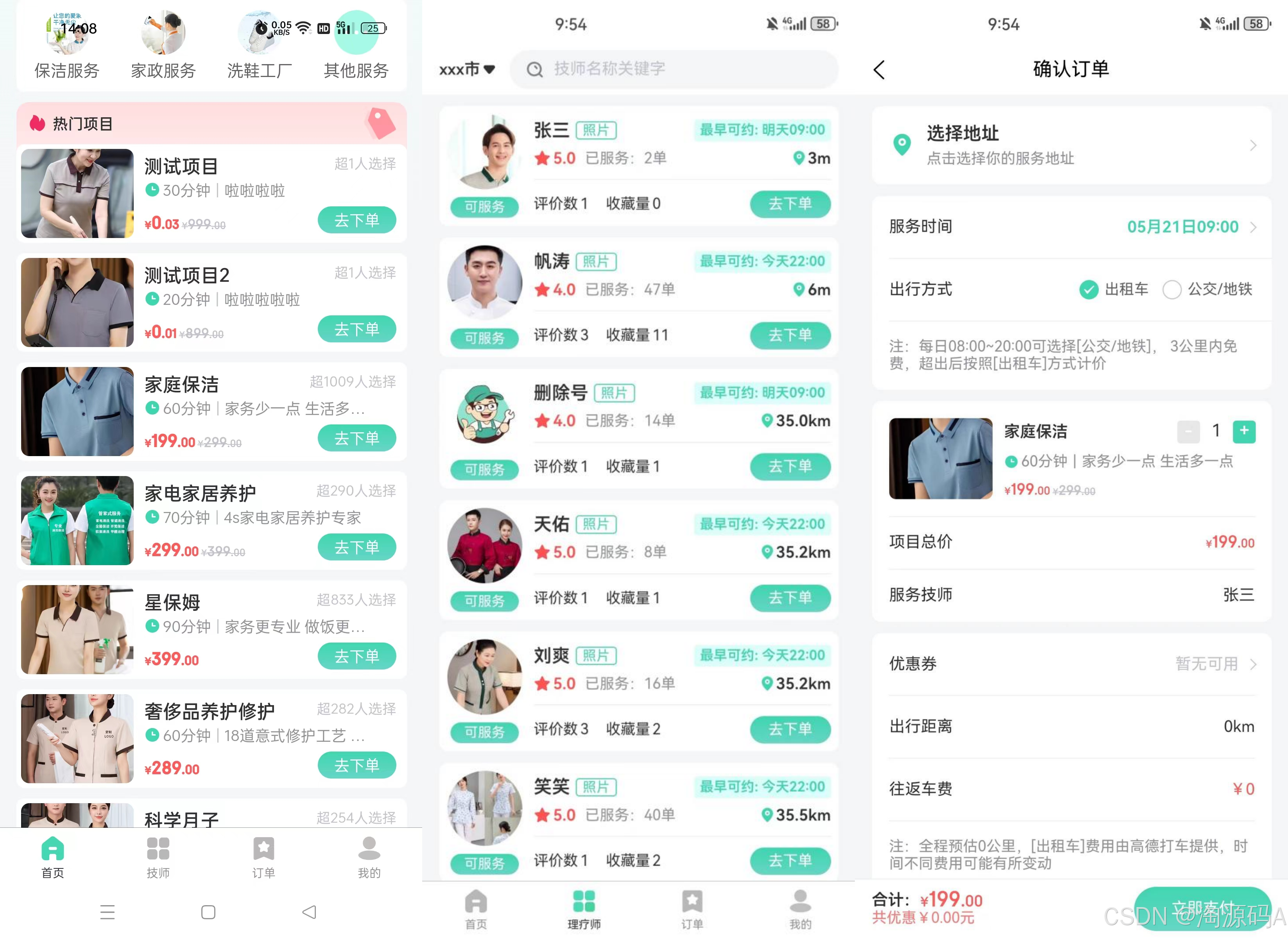
java家政APP源码,家政预约平台源码,家电上门维修、家电上门清洗
家政上门预约服务APP源码,开发功能涵盖了用户注册与登录、家政服务分类与选择、预约管理、支付与交易、地图与导航、评价与反馈、个人信息管理、消息通知、营销工具以及数据分析等多个方面。这些功能的实现不仅提高了家政服务的便捷性和效率,还为用户提供…...

LangGraph 架构详解
核心架构组件 LangGraph 的架构建立在一个灵活的基于图的系统上,使开发者能够定义和执行复杂的工作流。以下是主要架构组件: 1. 状态管理系统 LangGraph 的核心是其强大的状态管理系统,它允许应用程序在整个执行过程中维护一致的状态&…...

【LLM基础】Megatron-LM相关知识(主要是张量并行机制)
系列综述: 💞目的:本系列是个人整理为了Megatron-LM的,整理期间苛求每个知识点,平衡理解简易度与深入程度。 🥰来源:材料主要源于Megatron-LM相关材料进行的,每个知识点的修正和深入…...

动力电池自动点焊机:新能源汽车制造的智能焊接利器
在新能源汽车产业蓬勃发展的今天,动力电池作为其核心部件,其性能与安全性直接关系到整车的续航里程和使用寿命。而动力电池的制造过程中,焊接工艺是至关重要的一环。这时,动力电池自动点焊机便以其高效、精准、智能的特点…...

解决vcpkg使用VS2022报错问题
转自个人博客:解决vcpkg使用VS2022报错问题 最近,在把Visual Studio2019完全更新到最新Visual Studio2022后,原使用的vcpkg无法正常安装包,会报如下与Visual Studio 2022相关的错误: error: in triplet x64-windows-m…...

Next.js 简介
Next.js 是一个由 Vercel 开发的基于 React 的 Web 开发框架,旨在简化 React 应用的开发流程,提供更好的性能和开发体验。 🌟 Next.js 的核心特点 1. 文件系统路由(File-system Routing) 在 pages/ 目录中创建文件就…...

一文详解ffmpeg环境搭建:Ubuntu系统ffmpeg配置nvidia硬件加速
在Ubuntu系统下安装FFmpeg有多种方式,其中最常用的是通过apt-get命令和源码编译安装。本文将分别介绍这两种方式,并提供安装过程。 一、apt-get安装 使用apt-get命令安装FFmpeg是最简单快捷的方式,只需要在终端中输入以下命令即可: # 更新软件包列表 sudo apt-get updat…...

MySQL逻辑架构有什么?
1. MySQL逻辑架构分层 MySQL的逻辑架构可分为三层(自上而下): 连接层(Client Layer)服务层(Server Layer)存储引擎层(Storage Engine Layer) -----------------------…...

AI应用企业研发方案
一、引言 在当今数字化时代,人工智能(AI)技术正以前所未有的速度融入各个行业,推动着企业的创新与变革。对于医药流通行业批发公司而言,面对日益激烈的市场竞争和不断变化的客户需求,借助AI技术提升企业的…...

【15】Strongswan watcher详解2
watcher的核心业务函数watch: (1)如果count为0,没有要监听的句柄,则watcher状态设置为WATCHER_STOPPED,返回,返回值为JOB_REQUEUE_NONE,这会返回到“【11】Strongswan processor 详解…...

linux shell编程之条件语句(二)
目录 一. 条件测试操作 1. 文件测试 2. 整数值比较 3. 字符串比较 4. 逻辑测试 二. if 条件语句 1. if 语句的结构 (1) 单分支 if 语句 (2) 双分支 if 语句 (3) 多分支 if 语句 2. if 语句应用示例 (1) 单分支 if 语句应用 (2) 双分支 if 语句应用 (3) 多分支 …...
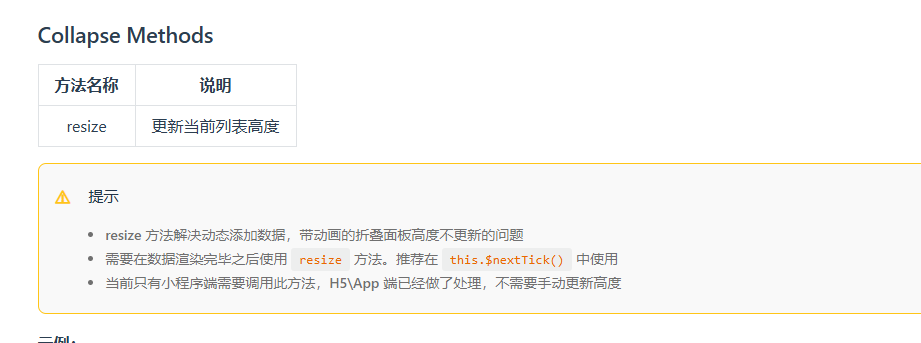
uniapp uni-collapse动态切换数据时高度不能自适应
需单独调用方法更新 this.$nextTick(() > {if (this.$refs.collapseBox) {this.$refs.collapseBox.resize()} })...
递归?递推?
前言:递归、递推是两种非常常见基础的算法了,但我之前忘了从这基础的先讲起了,大家应该也都略有了解吧!今天突然想写点相关延伸内容,所以还是完整介绍一些吧 递归 递归是一种通过函数调用自身解决问题的算法。在递归…...
蓝桥杯--结束
冲刺题单 基础 一、简单模拟(循环数组日期进制) (一)日期模拟 知识点 1.把月份写为数组,二月默认为28天。 2.写一个判断闰年的方法,然后循环年份的时候判断并更新二月的天数 3.对于星期数的计算&#…...

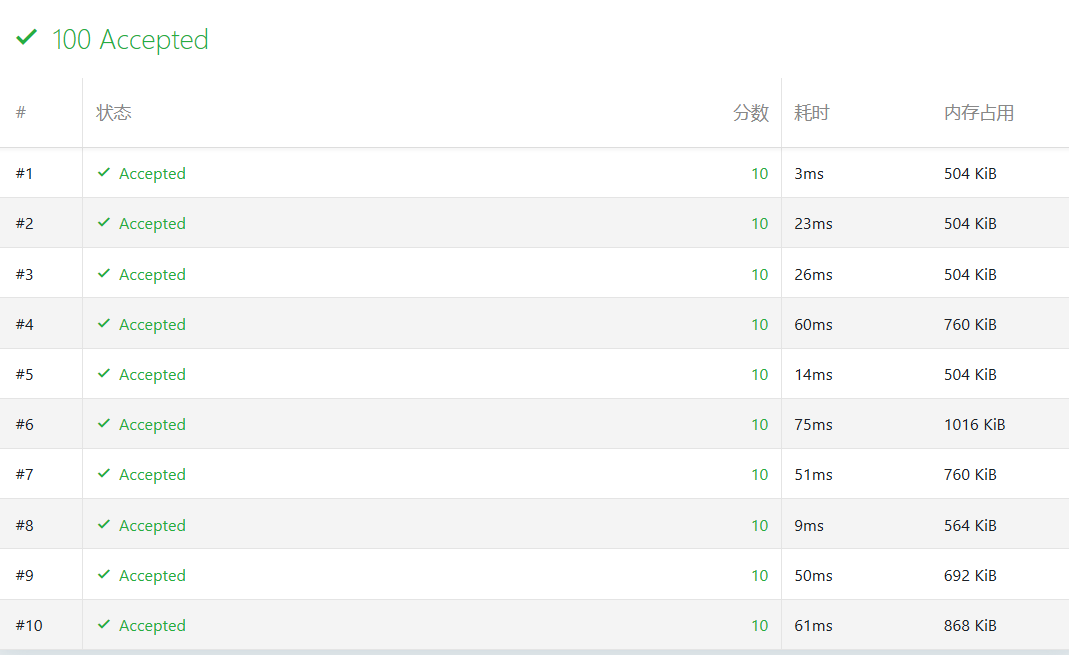
【ChCore Lab 01】Bomb Lab 拆炸弹实验(ARM汇编逆向工程)
文章目录 1. 前言2. 实验代码版本问题3. 关于使用问题4. 宏观分析5. read_line 函数介绍6. phase_0 函数6.1. read_int 函数6.2. 回到 phase_0 函数继续分析6.3. 验证结果 7. phase_1 函数7.2. 验证结果 8. phase_2 函数8.1. read_8_numbers 函数8.2. 回到 phase_2 函数继续分析…...

Android-应用签名
1 需求 Android 支持以下三种应用签名方案: v1 方案:基于 JAR 签名。v2 方案:APK 签名方案 v2(在 Android 7.0 中引入)。v3 方案:APK 签名方案 v3(在 Android 9 中引入)。v4 方案&…...
二分答案----
二分答案 - 题目详情 - HydroOJ 问题描述 给定一个由n个数构成的序列a,你可以进行k次操作,每次操作可以选择一个数字,将其1,问k次操作以后,希望序列里面的最小值最大。问这个值是多少。 输入格式 第一行输入两个正…...

AI前沿周报:2025年3月技术深度解析
以下是基于2024-2025年AI技术前沿动态的深度技术周报示例,结合行业最新突破与研究进展,突出技术原理与应用场景分析: AI前沿周报:2025年3月技术深度解析 时间范围:2025年3月1日-3月31日 本期焦点:模型透明…...

Android Coil 3默认P3色域图加载/显示不出来
Android Coil 3默认P3色域图加载/显示不出来 解决,需要在Androidmanifest.xml使用Coil 3的activity配置属性: <activityandroid:colorMode"wideColorGamut"...</activity>...