训练数据清洗(文本/音频/视频)
多数据格式的清洗方法
以下是针对多数据格式清洗方法的系统性总结,结合Python代码示例:
一、数据清洗方法总览(表格对比)
| 数据类型 | 核心挑战 | 关键步骤 | 常用Python工具 |
|---|---|---|---|
| 文本 | 非结构化噪声 | 去噪→分词→标准化→向量化 | NLTK, SpaCy, Jieba, Regex |
| 图片 | 维度/质量差异 | 尺寸统一→去噪→格式转换→归一化 | OpenCV, PIL, scikit-image |
| 音频 | 采样/环境噪声差异 | 降噪→重采样→分割→特征提取 | Librosa, pydub, noisereduce |
| 视频 | 时空维度复杂性 | 关键帧提取→分辨率统一→时序处理 | OpenCV, MoviePy, FFmpeg |
二、文本数据清洗
1. 去噪处理
import re
from bs4 import BeautifulSoup# 去除HTML标签
def clean_html(text):return BeautifulSoup(text, 'html.parser').get_text()# 删除特殊字符
text = re.sub(r'[^a-zA-Z0-9\u4e00-\u9fa5]', ' ', "Hello! 这是一条带@符号的示例#文本")
2. 分词与标准化
import jieba
from nltk.tokenize import word_tokenize# 中文分词
text_cn = "自然语言处理很重要"
seg_list = jieba.lcut(text_cn) # ['自然语言', '处理', '很', '重要']# 英文分词
text_en = "This is an example sentence."
tokens = word_tokenize(text_en.lower()) # ['this', 'is', 'an', 'example', 'sentence']
3. 停用词过滤
from nltk.corpus import stopwordsstop_words = set(stopwords.words('english'))
filtered_tokens = [word for word in tokens if word not in stop_words] # 过滤后:['example', 'sentence']
三、图片数据清洗
1. 尺寸统一化
import cv2img = cv2.imread('input.jpg')
resized_img = cv2.resize(img, (224, 224)) # 调整为指定尺寸
2. 去噪增强
# 高斯模糊去噪
blurred = cv2.GaussianBlur(img, (5,5), 0)# 直方图均衡化(灰度图)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
equalized = cv2.equalizeHist(gray)
3. 格式转换与归一化
from PIL import Image# 转换格式并保存
img_pil = Image.open('input.bmp')
img_pil.save('output.jpg', quality=95)# 归一化处理
import numpy as np
normalized = img.astype(np.float32) / 255.0 # [0,1]范围
四、音频数据清洗
1. 降噪处理
import noisereduce as nr
import librosay, sr = librosa.load('noisy_audio.wav')
# 提取噪声片段(需提前标记噪声区间)
noisy_part = y[5000:15000]
cleaned = nr.reduce_noise(y=y, sr=sr, y_noise=noisy_part)
2. 采样率统一
# 从44.1kHz重采样到16kHz
y_16k = librosa.resample(y, orig_sr=44100, target_sr=16000)
3. 静音分割
from pydub import AudioSegment
from pydub.silence import split_on_silenceaudio = AudioSegment.from_wav("long_audio.wav")
# 分割静音段(阈值-50dB,最小静音时长1s)
chunks = split_on_silence(audio, silence_thresh=-50, min_silence_len=1000)
五、视频数据清洗
1. 关键帧提取
cap = cv2.VideoCapture('input.mp4')
frame_count = 0
while True:ret, frame = cap.read()if not ret: breakif frame_count % 30 == 0: # 每30帧保存1帧cv2.imwrite(f"frame_{frame_count}.jpg", frame)frame_count += 1
2. 分辨率调整
from moviepy.editor import VideoFileClipclip = VideoFileClip("input.mp4")
# 调整为720p并保持宽高比
clip_resized = clip.resize(height=720)
clip_resized.write_videofile("output_720p.mp4")
3. 时间轴处理
# 截取10-20秒片段
sub_clip = clip.subclip(10, 20)# 倍速处理(1.5倍速)
speed_clip = clip.fx(vfx.speedx, 1.5)
六、通用最佳实践
- 批处理模板
# 图片批处理示例
import os
from tqdm import tqdminput_dir = 'raw_images/'
output_dir = 'processed_images/'
os.makedirs(output_dir, exist_ok=True)for filename in tqdm(os.listdir(input_dir)):img = cv2.imread(os.path.join(input_dir, filename))processed = cv2.resize(cv2.GaussianBlur(img, (3,3), 0), (256,256))cv2.imwrite(os.path.join(output_dir, filename), processed)
- 质量校验
# 音频时长校验
import soundfile as sfdef validate_audio(path, min_duration=1.0):try:duration = len(sf.read(path)[0]) / sf.read(path)[1]return duration >= min_durationexcept:return False
- 分布式清洗(Dask示例)
import dask.dataframe as dd# 并行处理文本数据
ddf = dd.read_csv('large_text_data/*.csv')
ddf_clean = ddf.map_partitions(lambda df: df.apply(clean_text_function))
ddf_clean.to_csv('cleaned_data/')
通过结合领域特定的清洗方法和Python生态工具,可以构建高效的数据预处理流水线。建议根据实际数据特点调整参数阈值,并建立自动化质量监控机制。
不同业务场景下的清洗策略
以下是针对不同业务场景下的数据清洗策略系统性总结,结合Python实现示例:
一、数据清洗策略总览(表格对比)
| 业务领域 | 核心挑战 | 典型清洗操作 | 常用Python工具 |
|---|---|---|---|
| 金融 | 数据可靠性/合规性 | 异常值检测、时序对齐、缺失值填充 | Pandas, Scikit-learn, PyOD |
| 医疗 | 隐私保护/数据标准化 | 数据脱敏、单位统一、格式验证 | Faker, OpenPyXL, PyUnits |
| 电商 | 数据一致性/商品归一化 | 重复数据删除、分类标准化 | Dedupe, FuzzyWuzzy, Scikit-learn |
| 社交媒体 | 非结构化数据处理 | 文本清洗、行为序列过滤 | NLTK, SpaCy, Pandas |
二、金融领域清洗策略
1. 异常值检测
- 场景:检测信用卡欺诈交易
- 方法:
# IQR方法检测交易金额异常 Q1 = df['amount'].quantile(0.25) Q3 = df['amount'].quantile(0.75) IQR = Q3 - Q1 df_clean = df[~((df['amount'] < (Q1 - 1.5*IQR)) | (df['amount'] > (Q3 + 1.5*IQR)))]# Z-score检测 from scipy import stats df['z_score'] = stats.zscore(df['amount']) df_clean = df[df['z_score'].abs() < 3]
2. 缺失值填充
- 场景:股票价格数据补全
- 方法:
# 时间序列前向填充 df.fillna(method='ffill', inplace=True)# 使用随机森林预测缺失值 from sklearn.ensemble import RandomForestRegressor X = df.dropna().drop('target', axis=1) y = df.dropna()['target'] model = RandomForestRegressor().fit(X, y) missing_data = df[df['target'].isnull()].drop('target', axis=1) df.loc[df['target'].isnull(), 'target'] = model.predict(missing_data)
三、医疗领域清洗策略
1. 数据脱敏
- 场景:患者隐私保护
- 方法:
# 使用假名生成库 from faker import Faker fake = Faker() df['patient_name'] = [fake.name() for _ in range(len(df))]# 日期偏移脱敏 df['birth_date'] = pd.to_datetime(df['birth_date']) + pd.DateOffset(years=10)
2. 单位统一
- 场景:多源医疗设备数据整合
- 方法:
# 体重单位标准化(磅转千克) def convert_weight(row):if row['unit'] == 'lbs':return row['value'] * 0.453592else:return row['value'] df['weight_kg'] = df.apply(convert_weight, axis=1)# 使用Pint进行单位转换 import pint ureg = pint.UnitRegistry() df['volume'] = df['value'].apply(lambda x: (x * ureg.parse_expression(df['unit'])).to(ureg.milliliter))
四、电商领域清洗策略
1. 重复数据去重
- 场景:商品列表清洗
- 方法:
# 基于规则去重 df.drop_duplicates(subset=['product_id', 'price'], keep='last', inplace=True)# 使用模糊匹配处理标题相似项 from fuzzywuzzy import fuzz def is_similar(str1, str2, threshold=90):return fuzz.token_set_ratio(str1, str2) > threshold
2. 分类标准化
- 场景:多平台商品类目映射
- 方法:
# 创建类目映射字典 category_map = {'cellphone': 'Mobile Devices','smartphone': 'Mobile Devices','laptop': 'Computers' } df['category'] = df['raw_category'].map(category_map).fillna('Others')# 使用聚类自动分类 from sklearn.cluster import KMeans kmeans = KMeans(n_clusters=10).fit(tfidf_vectors) df['auto_category'] = kmeans.labels_
五、社交媒体清洗策略
1. 文本规范化
- 场景:情感分析预处理
- 方法:
# 情感符号处理 import re def clean_emoji(text):emoji_pattern = re.compile("["u"\U0001F600-\U0001F64F" # emoticonsu"\U0001F300-\U0001F5FF" # symbols & pictographs"]+", flags=re.UNICODE)return emoji_pattern.sub(r'', text)# 词形还原 from nltk.stem import WordNetLemmatizer lemmatizer = WordNetLemmatizer() df['text'] = df['text'].apply(lambda x: ' '.join([lemmatizer.lemmatize(word) for word in x.split()]))
2. 用户行为过滤
- 场景:僵尸账号检测
- 方法:
# 时间窗口内异常操作检测 df['action_time'] = pd.to_datetime(df['timestamp']) df = df.set_index('action_time') actions_per_min = df.resample('1T').size() anomaly_users = actions_per_min[actions_per_min > 100].index# 基于规则过滤 spam_keywords = ['free', 'win', 'click'] df = df[~df['content'].str.contains('|'.join(spam_keywords), case=False)]
六、最佳实践建议
-
业务适配原则:
- 金融领域优先保证数据完整性
- 医疗领域强制实施隐私保护
- 电商领域侧重商品特征一致性
- 社交媒体关注上下文关联性
-
工具链推荐:
# 通用数据操作 import pandas as pd import numpy as np# 高级清洗工具 from sklearn.impute import IterativeImputer # 多重插补 import great_expectations as ge # 数据质量验证# 可视化监控 import matplotlib.pyplot as plt df.hist(column='transaction_amount', bins=50) # 分布可视化 -
流程标准化:
# 构建清洗Pipeline示例 from sklearn.pipeline import Pipeline from sklearn.compose import ColumnTransformerpreprocessor = ColumnTransformer(transformers=[('num', StandardScaler(), numerical_features),('text', TfidfVectorizer(), text_column)])pipeline = Pipeline(steps=[('clean', DataCleaner()), # 自定义清洗类('preprocess', preprocessor) ])
通过针对不同业务场景的特征设计清洗策略,配合Python生态丰富的工具库,可以显著提升数据质量。建议根据实际业务需求动态调整清洗阈值和规则,并建立持续的质量监控机制。
文本专项
数据清洗是数据预处理中的重要步骤,旨在提高数据质量,确保后续分析或建模的准确性。针对训练数据集的数据清洗方案通常包括以下几个方面:
缺失值处理
缺失值是数据集中常见的问题,需要根据具体情况选择合适的处理方法:
- 删除法:如果缺失值比例较高(如超过50%),可以直接删除该特征或样本。
# 删除缺失率超过50%的特征
threshold = len(df) * 0.5
df_cleaned = df.dropna(thresh=threshold, axis=1)# 删除有缺失值的行
df_dropped = df.dropna()
- 填充法:
- 使用统计值填充:均值、中位数、众数等。
- 使用插值法:线性插值或其他插值方法。
- 使用模型预测:通过其他特征训练一个简单的回归/分类模型来预测缺失值。
# 均值填充
df_filled = df.fillna(df.mean())# 使用KNN插值(需安装scikit-learn)
imputer = KNNImputer(n_neighbors=5)
df_knn = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)# 时间序列线性插值
df['timestamp'] = pd.to_datetime(df['timestamp'])
df = df.set_index('timestamp')
df_interpolated = df.interpolate(method='time')- 标记法:将缺失值作为一个单独的类别或特殊值进行标记。
# 创建缺失指示特征
for col in df.columns:df[f'{col}_missing'] = df[col].isnull().astype(int)
异常值处理
异常值可能由数据录入错误或实际极端值引起,需谨慎处理:
- 识别异常值:
- 基于统计学方法:如3σ原则(正态分布)、箱线图(IQR)。
# 3σ原则def sigma_rule(df, col, n_sigmas=3):mean = df[col].mean()std = df[col].std()return df[(df[col] > mean - n_sigmas*std) & (df[col] < mean + n_sigmas*std)]df_clean = sigma_rule(df, 'income')
# 箱线图Q1 = df['age'].quantile(0.25)
Q3 = df['age'].quantile(0.75)
IQR = Q3 - Q1
df = df[~((df['age'] < (Q1 - 1.5*IQR)) | (df['age'] > (Q3 + 1.5*IQR)))]
- 基于可视化:散点图、直方图等。
- 基于机器学习:使用孤立森林(Isolation Forest)、DBSCAN等算法检测异常值。
# 使用孤立森林检测异常
iso = IsolationForest(contamination=0.05)
outliers = iso.fit_predict(df[['feature1', 'feature2']])
df_clean = df[outliers == 1]
- 处理方式:
- 删除异常值。
- 替换为合理值(如均值、中位数)。
- 根据业务逻辑调整异常值。
重复数据处理
重复数据可能会导致模型过拟合或偏差:
- 检查并删除完全重复的样本。
- 对部分字段重复的数据进行合并或去重。
# 完全重复记录删除
df_deduplicated = df.drop_duplicates()# 关键字段重复处理
df = df.sort_values('update_time').drop_duplicates(['user_id'], keep='last')
数据格式统一化
数据格式不一致可能导致分析错误:
- 日期格式:统一日期格式(如
YYYY-MM-DD)。 - 数值格式:确保数值类型正确(如浮点数、整数)。
- 文本格式:统一大小写、去除多余空格、标准化编码(如UTF-8)。
# 统一日期格式
df['date'] = pd.to_datetime(df['date'], errors='coerce', format='%Y-%m-%d')# 提取时间特征
df['year'] = df['date'].dt.year
df['day_of_week'] = df['date'].dt.dayofweek
# 标准化文本
def clean_text(text):text = re.sub(r'\s+', ' ', text) # 去除多余空格text = re.sub(r'[^\w\s]', '', text) # 移除标点return text.strip().lower()df['text'] = df['text'].apply(clean_text)
特征标准化与归一化
某些算法对特征的量纲敏感,需进行标准化或归一化:
- 标准化:将数据转换为均值为0、标准差为1的分布(Z-score标准化)。
- 归一化:将数据缩放到固定范围(如[0, 1]或[-1, 1])。
- Log变换:对偏态分布的数据进行对数变换以减小偏度。
# Z-score标准化
scaler = StandardScaler()
df[['income', 'age']] = scaler.fit_transform(df[['income', 'age']])# Min-Max归一化
minmax = MinMaxScaler(feature_range=(0, 1))
df[['height', 'weight']] = minmax.fit_transform(df[['height', 'weight']])# 对数变换
df['income_log'] = np.log1p(df['income'])
类别不平衡处理
对于分类问题,类别不平衡会影响模型性能:
- 欠采样:减少多数类样本数量。
- 过采样:增加少数类样本数量(如SMOTE算法)。
- 调整权重:在模型训练时为不同类别设置不同的权重。
# SMOTE过采样(需安装imbalanced-learn)
from imblearn.over_sampling import SMOTEX_resampled, y_resampled = SMOTE().fit_resample(X, y)# 类别权重调整
from sklearn.utils.class_weight import compute_class_weight
class_weights = compute_class_weight('balanced', classes=np.unique(y), y=y)
文本数据清洗
如果数据集中包含文本数据,需要进行以下处理:
- 去除噪声:删除HTML标签、特殊字符、停用词等。
- 分词与词干提取:对文本进行分词,并提取词干或词形还原。
- 拼写纠正:修正拼写错误。
- 向量化:将文本转换为数值形式(如TF-IDF、词嵌入)。
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer# 高级文本清洗
def advanced_text_clean(text):# 拼写纠正(需安装pyspellchecker)from spellchecker import SpellCheckerspell = SpellChecker()words = [spell.correction(word) for word in text.split()]# 词形还原from nltk.stem import WordNetLemmatizerlemmatizer = WordNetLemmatizer()return ' '.join([lemmatizer.lemmatize(word) for word in words if word not in stop_words])# TF-IDF向量化
tfidf = TfidfVectorizer(max_features=500)
X_tfidf = tfidf.fit_transform(df['text'])
特征工程与降维
- 特征选择:移除无关或冗余特征。
- 特征构造:基于现有特征生成新的有意义特征。
- 降维:使用PCA、t-SNE等方法降低特征维度。
# PCA降维(保留95%方差)
pca = PCA(n_components=0.95)
X_pca = pca.fit_transform(X_scaled)# 多项式特征生成
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2, interaction_only=True)
X_poly = poly.fit_transform(X[['age', 'income']])
时间序列数据清洗
对于时间序列数据,还需额外关注以下问题:
- 时间戳对齐:确保时间戳的频率一致(如按小时、天对齐)。
- 插值处理:填补时间序列中的缺失值。
- 趋势与周期性分解:分离出长期趋势和周期性波动。
# 重采样对齐
df_resampled = df.resample('1H').mean()# 季节性分解
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(df['value'], model='additive', period=24)
数据一致性检查
- 确保数据之间的逻辑关系一致。例如:
- 如果某个字段表示“出生年份”,则它应小于当前年份。
- 如果某个字段表示“性别”,则其取值应在预定义范围内(如“男”、“女”)。
# 逻辑验证
current_year = datetime.now().year
df = df[df['birth_year'] < current_year] # 过滤不合理出生年份# 范围验证
valid_genders = ['Male', 'Female']
df = df[df['gender'].isin(valid_genders)]
隐私与安全处理
- 脱敏处理:对敏感信息(如身份证号、电话号码)进行脱敏。
- 数据加密:对敏感字段进行加密存储。
# 数据脱敏
def anonymize_phone(phone):return re.sub(r'(\d{3})\d{4}(\d{4})', r'\1****\2', phone)# 加密处理
import hashlib
df['user_id_hash'] = df['user_id'].apply(lambda x: hashlib.sha256(x.encode()).hexdigest())
总结
数据清洗的具体方案需要结合数据集的特点和业务需求进行定制化设计。建议遵循以下步骤:
- 探索性数据分析(EDA):全面了解数据的分布、缺失情况、异常值等。
- 明确目标:根据建模目标确定清洗的重点方向。
- 逐步实施:按照上述方案逐一处理问题,同时记录清洗过程以便复现。
- 验证效果:清洗后重新检查数据质量,确保清洗结果符合预期。
相关文章:
)
训练数据清洗(文本/音频/视频)
多数据格式的清洗方法 以下是针对多数据格式清洗方法的系统性总结,结合Python代码示例: 一、数据清洗方法总览(表格对比) 数据类型核心挑战关键步骤常用Python工具文本非结构化噪声去噪→分词→标准化→向量化NLTK, SpaCy, Jie…...
平台通用C/C++扩展库, 字符集转码/字符集探测)
LIB-ZC, 一个跨平台(Linux)平台通用C/C++扩展库, 字符集转码/字符集探测
LIB-ZC, 一个跨平台(Linux)平台通用C/C扩展库, 字符集转码/字符集探测 字符集DNS/IP相关的方法: 主要是为了解决跨平台的问题其次对一些常见操作做了封装命名空间: zcc::charset 常用变量 const char *chinese[] {"UTF-8", "GB18030", "BIG5&quo…...

阿里云服务迁移实战: 02-服务器迁移
ECS 迁移 最简单的方式是 ECS 过户,不过这里有一些限制,如果原账号是个人账号,那么目标账号无限制。如果原账号是企业账号,则指定过户给相同实名认证的企业账号。 具体操作步骤可以参考官方文档 ECS过户 进行操作。 本文重点介绍…...

cat命令查看文件行数
在Linux和Unix-like操作系统中,cat命令主要用于查看文件内容,而不是直接用来查看文件行数。如果你想要查看一个文件的行数,可以使用以下几种方法: 方法1:使用wc命令 wc(word count)命令可以用…...

7# 5多线-7 不会停
7# 5多线-7 不会停 分析,明显线接错了,打自动时也能手动启停,打手动无法启停,这时远程只能启ka3,无法启ka4。排查手自转换2上没接线,接到8上了(13和12接错了,也就是sac的5和6接错了)…...

【AI编程技术爆发:从辅助工具到生产力革命】
目录 前言:技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解关键技术模块技术选型对比 二、实战演示环境配置要求核心代码实现运行结果验证 三、性能对比测试方法论量化数据对比(2023年数据)结果分析 四、最…...
protobuf的应用
1.版本和引用 syntax "proto3"; // proto2 package tutorial; // package类似C命名空间 // 可以引用本地的,也可以引用include里面的 import "google/protobuf/timestamp.proto"; // 已经写好的proto文件是可以引用 我们版本选择pr…...
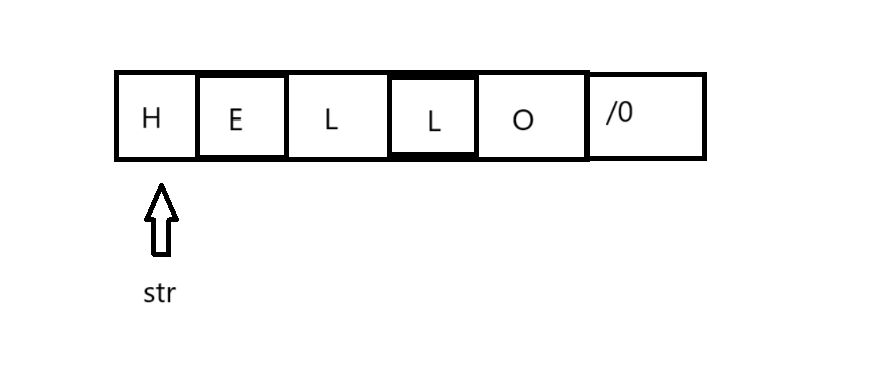
C++字符串操作详解
引言 字符串处理是编程中最常见的任务之一,而在C中,我们有多种处理字符串的方式。本文将详细介绍C中的字符串操作,包括C风格字符串和C的string类。无论你是C新手还是想巩固基础的老手,这篇文章都能帮你梳理字符串处理的关键知识点…...
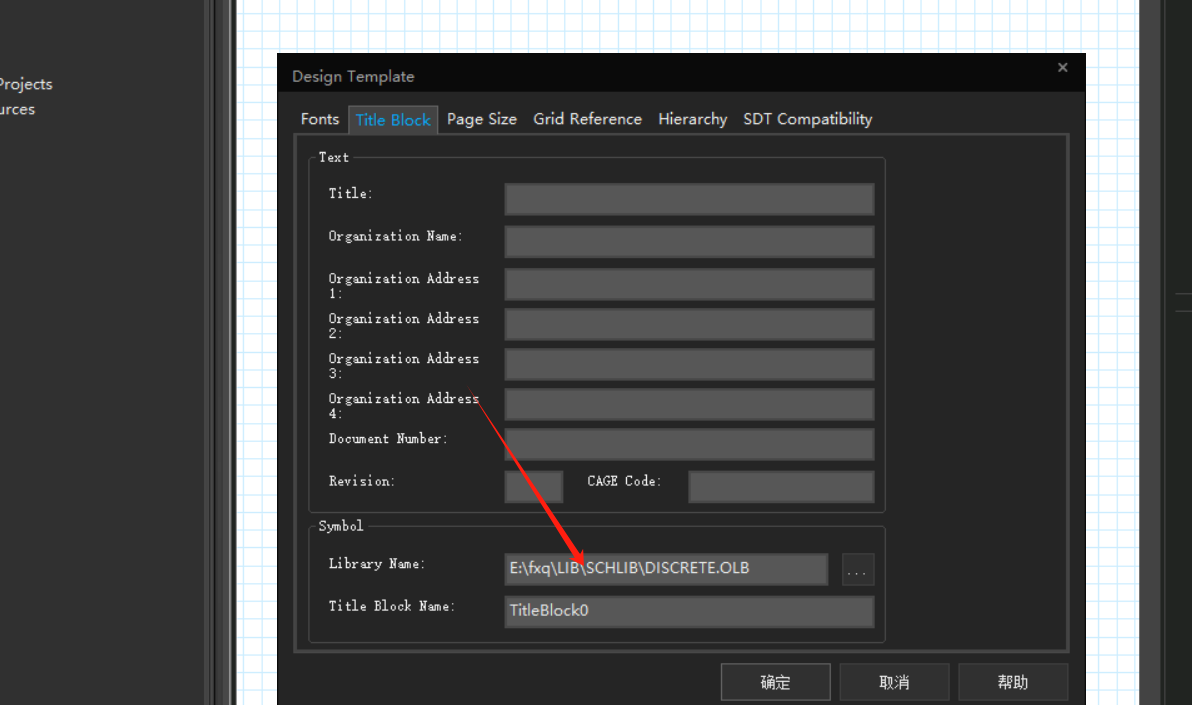
原理图设计准备:页面栅格模板应用设置
一、页面大小的设置 (1)单页原理图页面设置 首先,选中需要更改页面尺寸的那一页原理图,鼠标右键,选择“Schmatic Page Properties”选项,进行页面大小设置。 (2)对整个原理图页面设…...

MySQL 的四种社交障碍等级
在数据库的世界里,数据们也有社交问题!事务隔离级别就是控制它们互相看到对方的程度... 什么是事务隔离?🤔 想象一下,数据库是一个繁忙的餐厅,每个事务都是一桌客人,而数据就是美食。事务隔离…...

100道C++ 高频经典面试题带解析答案
100道C 高频经典面试题带解析答案 C作为一种功能强大且广泛应用的编程语言,在技术面试中经常被考察。掌握高频经典面试题不仅能帮助求职者自信应对面试,还能深入理解C的核心概念。以下整理了100道高频经典C面试题,涵盖基础知识、数据结构、面…...
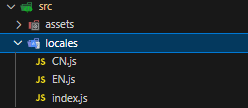
vue实现中英文切换
第一步:安装插件vue-i18n,npm install vue-i18n 第二步:在src下新建locales文件夹,并在locales下新建index.js、EN.js、CN.js文件 第三步:在EN.js和CN.js文件下配置你想要的字段,例如: //CN.js…...
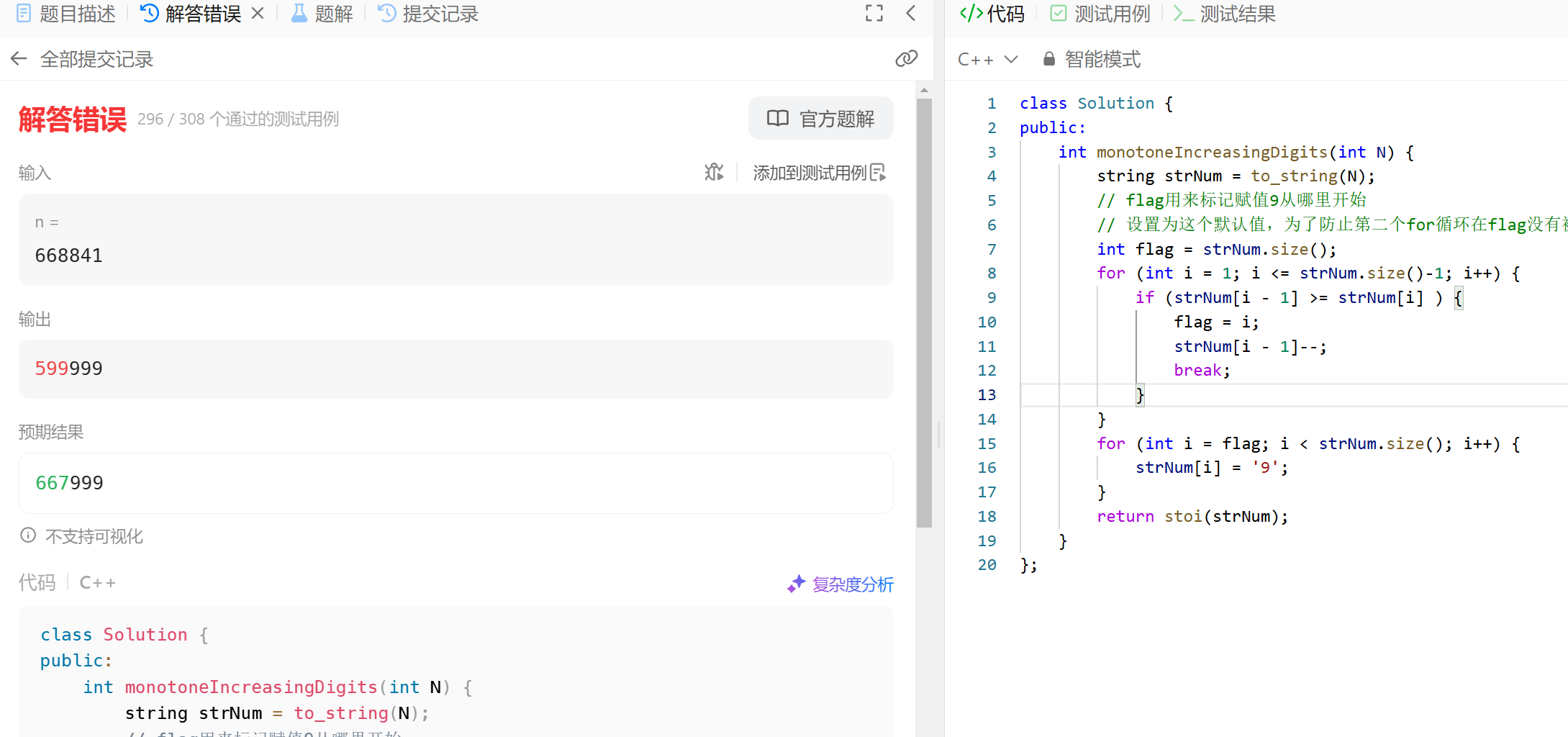
day31-贪心__56. 合并区间__ 738.单调递增的数字__968.监控二叉树 (可跳过)
56. 合并区间 合并区间,这道题和昨天的452. 用最少数量的箭引爆气球和435. 无重叠区间 也是类似的思路,我们需要先对所有vector按照左端点或者右端点进行排序。本题按照左端点进行排序。之后,如果前一段的右端点<后一段的左端,…...
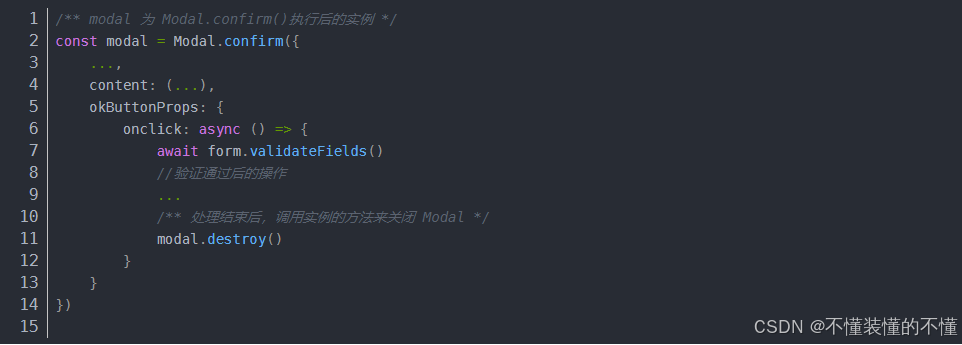
【antd + vue】Modal 对话框:修改弹窗标题样式、Modal.confirm自定义使用
一、标题样式 1、目标样式:修改弹窗标题样式 2、问题: 直接在对应css文件中修改样式不生效。 3、原因分析: 可能原因: 选择器权重不够,把在控制台找到的选择器直接复制下来,如果还不够就再加ÿ…...

Gson、Fastjson 和 Jackson 对比解析
目录 1. Gson (Google) 基本介绍: 核心功能: 特点: 使用场景: 2. Fastjson (Alibaba) 基本介绍: 核心功能: 特点: 使用场景: 3. Jackson 基本介绍: 核心功能…...

GStreamer开发笔记(一):GStreamer介绍,在windows平台部署安装,打开usb摄像头对比测试
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://blog.csdn.net/qq21497936/article/details/147049923 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、O…...

UE5,LogPackageName黄字警报处理方法
比如这个场景,淘宝搜索,ue5 T台,转为ue5.2后,选择物体,使劲冒错。 LogPackageName: Warning: DoesPackageExist called on PackageName that will always return false. Reason: 输入“”为空。 2. 风险很大的删除法&…...
unity曲线射击
b站教程 using UnityEngine; using System.Collections;public class BallLauncher : MonoBehaviour {public float m_R;public NewBullet m_BulletPre;public Transform m_Target;private void Start(){StartCoroutine(Attack());}private void OnDestroy(){StopAllCoroutine…...
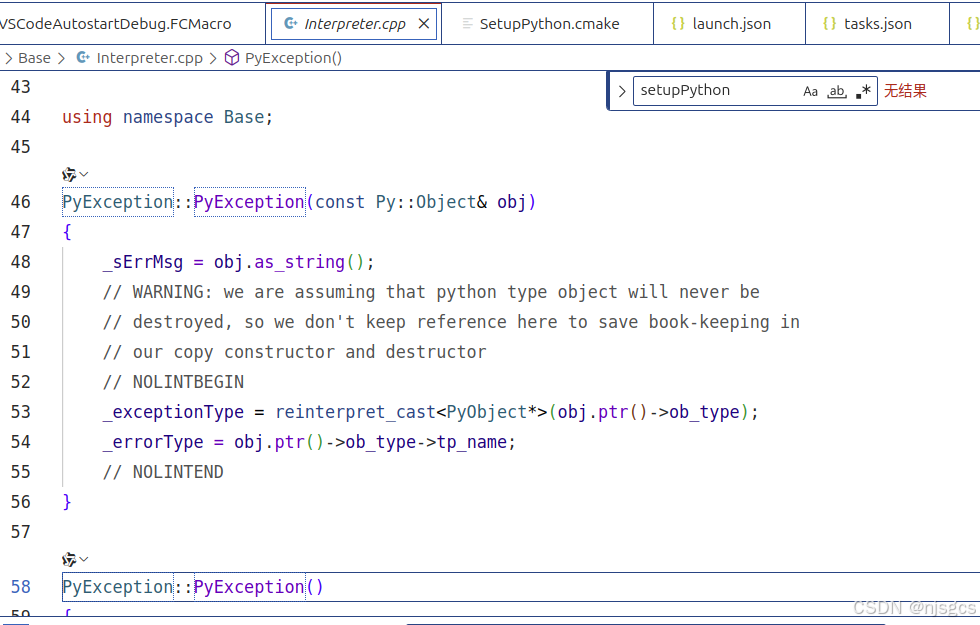
freecad内部python来源 + pip install 装包
cmake来源: 只能find默认地址,我试过用虚拟的python地址提示缺python3config.cmake 源码来源: pip install 装包: module_to_install "your pakage" import os import FreeCAD import addonmanager_utilities as util…...
】数据迁移与初始化开发:筑牢家政平台的数据根基)
【家政平台开发(36)】数据迁移与初始化开发:筑牢家政平台的数据根基
本【家政平台开发】专栏聚焦家政平台从 0 到 1 的全流程打造。从前期需求分析,剖析家政行业现状、挖掘用户需求与梳理功能要点,到系统设计阶段的架构选型、数据库构建,再到开发阶段各模块逐一实现。涵盖移动与 PC 端设计、接口开发及性能优化,测试阶段多维度保障平台质量,…...

Spring Boot 中集成 Knife4j:解决文件上传不显示文件域的问题
Spring Boot 中集成 Knife4j:解决文件上传不显示文件域的问题 在使用 Knife4j 为 Spring Boot 项目生成 API 文档时,开发者可能会遇到文件上传功能不显示文件域的问题。本文将详细介绍如何解决这一问题,并提供完整的解决方案。 Knife4j官网…...
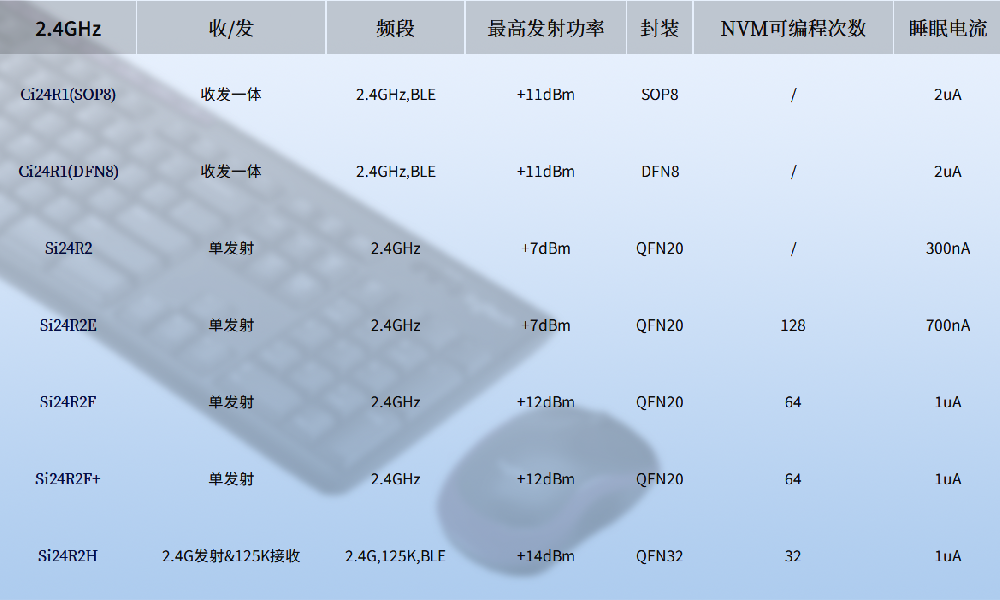
信噪比(SNR)的基本定义
噪比(SNR)是衡量信号质量的核心指标,定义为有效信号与背景噪声的比值,广泛应用于电子、通信、医学及生物学等领域。 一、定义 基本定义 SNR 是信号功率(或电压)与噪声功率(或电压ÿ…...

SpringBoot集成阿里云文档格式转换实现pdf转换word,excel
一、前置条件 1.1 创建accessKey 如何申请:https://help.aliyun.com/zh/ram/user-guide/create-an-accesskey-pair 1.2 开通服务 官方地址:https://docmind.console.aliyun.com/doc-overview 未开通服务时需要点击开通按钮,然后才能调用…...

STM32 模块化开发指南 · 第 5 篇 STM32 项目中断处理机制最佳实践:ISR、回调与事件通知
本文是《STM32 模块化开发实战指南》第 5 篇,聚焦于 STM32 裸机开发中最核心也最容易被忽视的部分——中断服务机制。我们将介绍如何正确、高效地设计中断处理函数(ISR),实现数据与事件从中断上下文传递到主逻辑的通道,并构建一个清晰、可维护、非阻塞的事件通知机制。 一…...

解析Java根基:Object类核心方法
Object类常见方法解析 在Java编程中,Object类是所有类的根类,它包含了许多实用的方法,这些方法在不同的场景下发挥着重要作用。下面我们来详细了解一下Object类中的一些常见方法。 1. toString方法 toString方法是用于将对象转换为字符串表…...
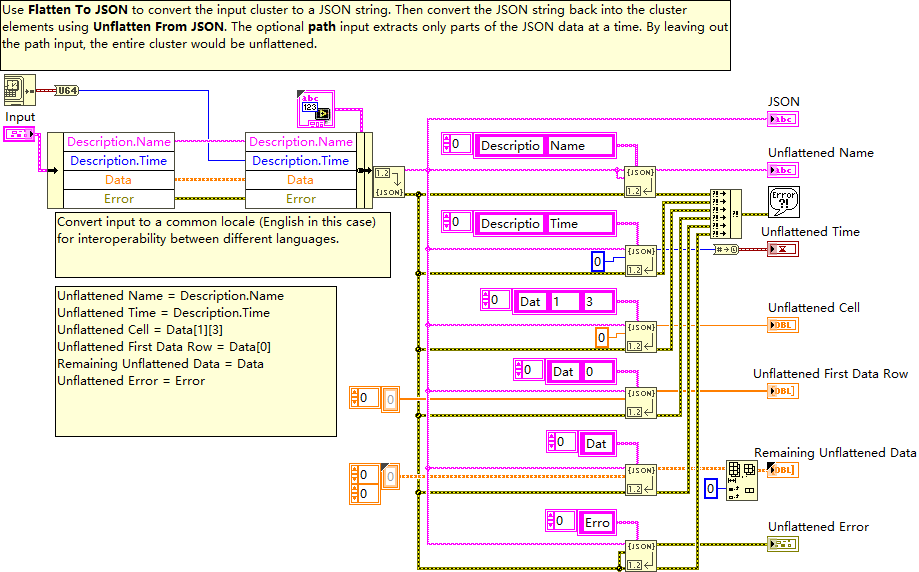
LabVIEW 中 JSON 数据与簇的转换
在 LabVIEW 编程中,数据格式的处理与转换是极为关键的环节。其中,将数据在 JSON 格式与 LabVIEW 的簇结构之间进行转换是一项常见且重要的操作。这里展示的程序片段就涉及到这一关键功能,以下将详细介绍。 一、JSON 数据与簇的转换功能 &am…...
K8s常用基础管理命令(一)
基础管理命令 基础命令kubectl get命令kubectl create命令kubectl apply命令kubectl delete命令kubectl describe命令kubectl explain命令kubectl run命令kubectl cp命令kubectl edit命令kubectl logs命令kubectl exec命令kubectl port-forward命令kubectl patch命令 集群管理命…...

每日算法-250411
这是我今天的 LeetCode 刷题记录和心得,主要涉及了二分查找的应用。 3143. 正方形中的最多点数 题目简述: 思路 本题的核心思路是 二分查找。 解题过程 为什么可以二分? 我们可以对正方形的半边长 len 进行二分。当正方形的半边长 len 越大时&…...
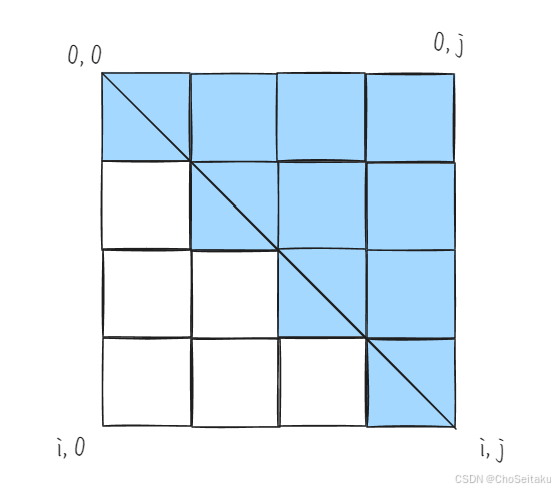
NO.90十六届蓝桥杯备战|动态规划-区间DP|回文字串|Treats for the Cows|石子合并|248(C++)
区间dp也是线性dp的⼀种,它⽤区间的左右端点来描述状态,通过⼩区间的解来推导出⼤区间的解。因此,区间DP的核⼼思想是将⼤区间划分为⼩区间,它的状态转移⽅程通常依赖于区间的划分点。 常⽤的划分点的⽅式有两个: 基于…...
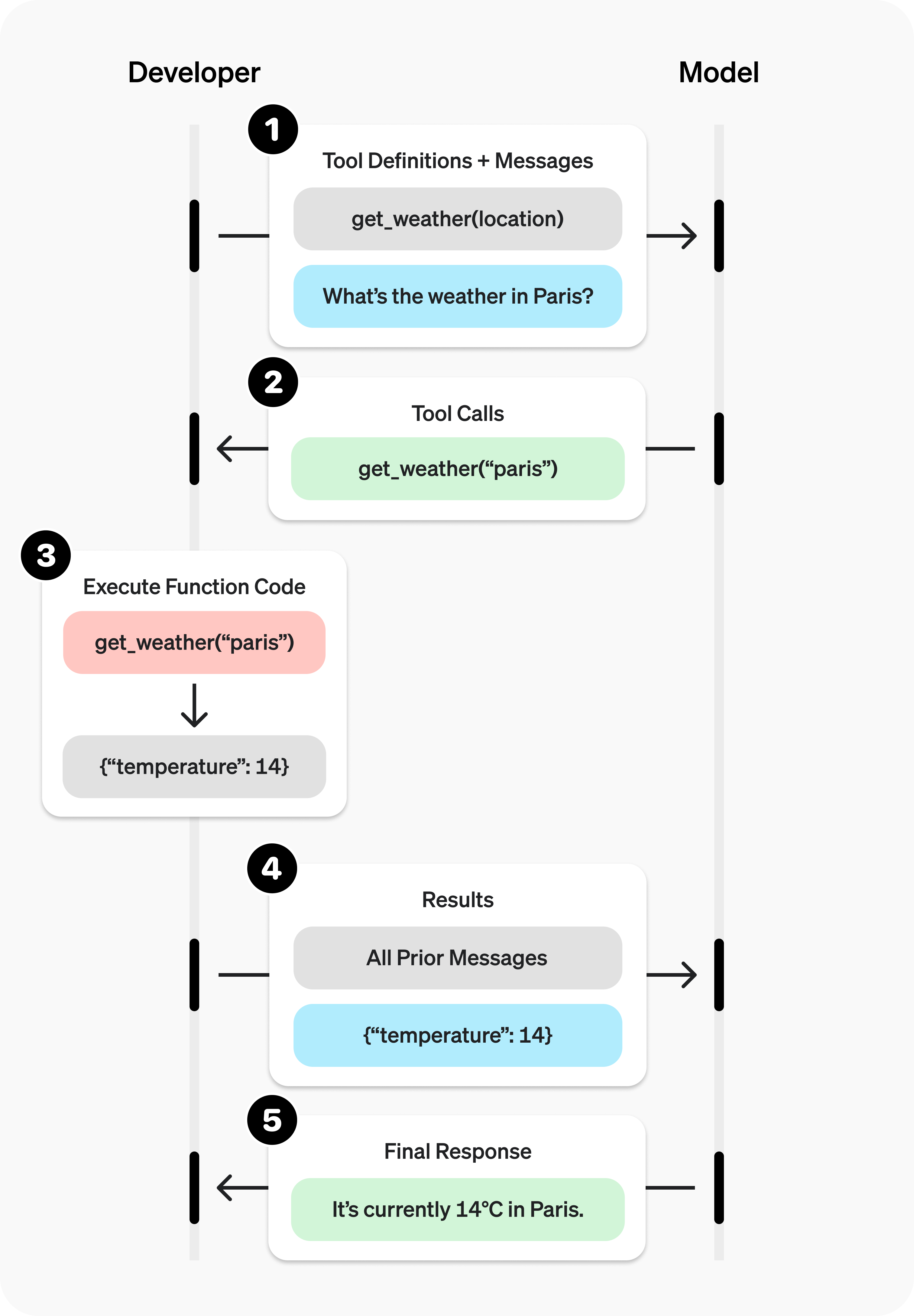
【大模型LLM第十六篇】Agent学习之浅谈Agent loop的几种常见范式
anthropics agent https://zhuanlan.zhihu.com/p/32454721762 code:https://github.com/anthropics/anthropic-quickstarts/blob/main/computer-use-demo/computer_use_demo/loop.py sampling_loop函数 每次进行循环,输出extract tool_use࿰…...