DeepSeek-V3与DeepSeek-R1全面解析:从架构原理到实战应用
DeepSeek-V3与DeepSeek-R1全面解析:从架构原理到实战应用
DeepSeek作为中国人工智能领域的新锐力量,其推出的DeepSeek-V3和DeepSeek-R1系列模型在开源社区和商业应用中引起了广泛关注。本指南将系统介绍这两款模型的架构特点、安装部署方法以及实际应用案例,帮助开发者和研究者全面了解并高效利用这些先进的AI工具。
一、DeepSeek-R1模型简介
DeepSeek-R1是深度求索公司推出的高性能推理专用模型,代表了当前开源推理模型的顶尖水平。
核心特点与架构
DeepSeek-R1基于DeepSeek-V3的架构开发,但在设计上针对复杂推理任务进行了专项优化。该模型采用混合专家(MoE)架构,总参数量达到6710亿,但每次推理仅激活约370亿参数,实现了高效计算。其创新之处在于:
-
强化学习训练框架:R1在后训练阶段大规模使用强化学习技术,在极少标注数据情况下显著提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩OpenAI o1正式版。
-
动态门控机制:通过优化专家路由策略,R1能够根据问题类型动态选择最相关的专家模块,特别适合解决需要多步推理的复杂问题。
-
思维链(CoT)输出:与传统的"黑箱"式回答不同,R1会将推理过程逐步展示给用户,增强了结果的可解释性和可信度。
性能表现
DeepSeek-R1在多项专业测试中展现出卓越性能:
- 在美国数学邀请赛(AIME 2024)和MATH基准测试中超越所有开源闭源模型
- 在编程测评(如LiveCodeBench)中达到51.6%的解决率,显著优于同类模型
- 在复杂逻辑推理任务上的准确率达到97.3%,超越OpenAI模型的96.8%
模型系列
DeepSeek-R1系列包含多个版本,适应不同场景需求:
- R1-7B:轻量级版本,适合移动设备或边缘计算
- R1-13B:平衡性能与资源消耗,适合大多数企业应用
- R1-35B/R1-671B:针对高复杂度任务设计,适合云计算环境
此外,DeepSeek还通过知识蒸馏技术,将R1的能力迁移到更小的模型上,推出了DeepSeek-R1-Distill系列,包括基于Qwen和LLaMA架构的1.5B、7B、14B、32B和70B参数版本。
二、DeepSeek-V3模型简介
作为DeepSeek-R1的基础,DeepSeek-V3同样采用MoE架构,但在设计定位上更偏向通用语言任务。
关键技术创新
DeepSeek-V3在架构上实现了多项突破:
- 多头潜在注意力(MLA):通过低秩键值联合压缩和解耦旋转位置嵌入,提高了计算效率,降低了内存占用
- 无辅助损失的负载均衡:避免传统MoE模型中负载均衡对模型性能的负面影响
- 多token预测(MTP):训练时同时预测多个连续token,增强长期依赖捕捉能力
- FP8混合精度训练:原生使用FP8格式,显著降低计算和存储需求
训练与成本
DeepSeek-V3的训练展现了极高的效率:
- 数据规模:14.8万亿token的多样化高质量数据
- 训练时间:总训练耗时约55天
- 计算资源:使用2048张NVIDIA H800 GPU
- 总成本:约557.6万美元,远低于同类模型
- 训练稳定性:全程无不可恢复的损失峰值或回滚
性能表现
DeepSeek-V3在多个领域表现出色:
- 百科知识:MMLU-Pro测试得分64.4,接近Claude-3.5-Sonnet
- 长文本处理:支持128K上下文,在LongBench v2测试中表现优异
- 代码能力:在算法类代码场景(Codeforces)领先非o1类模型
- 数学能力:在AIME 2024和CNMO 2024测试中大幅超越其他模型
- 中文处理:在C-Eval和C-SimpleQA等中文测试中表现突出
三、安装与部署方法
DeepSeek-V3和R1支持多种部署方式,从云端API到本地私有化部署,满足不同场景需求。
1. 云端API调用
获取API Key:
- 访问DeepSeek官网(https://platform.deepseek.com/api_keys)
- 注册账号并登录
- 在"API Keys"页面创建密钥(注意:密钥只显示一次,需妥善保存)
Python调用示例:
from openai import OpenAIclient = OpenAI(api_key="你的API_KEY",base_url="https://api.deepseek.com"
)response = client.chat.completions.create(model="deepseek-chat", # 使用V3模型# model="deepseek-reasoner", # 使用R1模型messages=[{"role": "system", "content": "你是有帮助的助手"},{"role": "user", "content": "解释量子计算的基本原理"}],stream=False # 设置为True可启用流式输出
)print(response.choices[0].message.content)
注意:
- V3和R1的API端点相同,通过
model参数区分 - R1的API名称为
deepseek-reasoner - 流式输出可改善长文本生成的用户体验
2. 阿里云一键部署
阿里云PAI平台提供了一键部署功能,简化部署流程:
- 登录阿里云PAI控制台(https://pai.console.aliyun.com)
- 选择工作空间,进入"Model Gallery"
- 搜索并选择DeepSeek-V3或DeepSeek-R1模型
- 点击"部署",选择部署方式(服务或Web应用)和加速技术(vLLM/BladeLLM)
- 部署完成后获取调用端点(Endpoint)信息
此方法支持:
- DeepSeek-V3原始模型
- DeepSeek-R1原始模型
- DeepSeek-R1-Distill蒸馏小模型
3. 本地部署指南
通过Ollama部署(推荐初学者):
- 下载Ollama(https://ollama.com/download)
- 安装并验证(终端运行
ollama -v) - 下载模型:
# DeepSeek-V3 ollama run deepseek-v3# DeepSeek-R1(7B版本) ollama run deepseek-r1:7b# DeepSeek-R1(14B版本) ollama run deepseek-r1:14b - 运行模型并开始交互
手动本地部署(高级用户):
-
环境准备:
- 操作系统:Ubuntu 20.04+
- Python 3.8+
- NVIDIA GPU(支持CUDA,可选但推荐)
-
克隆仓库并安装依赖:
git clone https://github.com/deepseek-ai/DeepSeek-V3.git cd DeepSeek-V3 pip install -r requirements.txt -
下载模型权重:
- Hugging Face仓库(https://huggingface.co/deepseek-ai)
- ModelScope(https://modelscope.cn/models/deepseek-ai)
-
配置与运行:
- 修改config.yaml设置模型路径、batch_size等参数
- 执行推理脚本:
python inference.py --input "你的输入文本"
-
(可选)部署为API服务:
- 安装Flask:
pip install Flask - 创建app.py并设置API端点
- 启动服务:
python app.py
- 安装Flask:
4. 其他部署选项
DeepSeek模型还支持多种部署框架:
- vLLM:高性能推理框架,支持连续批处理
- TensorRT-LLM:NVIDIA的优化推理库
- LMDeploy:一站式LLM部署工具包
- SGLang:针对大语言模型优化的运行时
四、案例应用与使用技巧
DeepSeek-V3和R1已在多个领域展现出强大的应用潜力,下面介绍典型应用场景和优化技巧。
1. 行业应用案例
金融领域:
- 江苏银行采用DeepSeek-V3和R1增强"智慧小苏"平台能力
- 应用场景:合同质检智能化、风险评估、投资分析、报告撰写
- 效果:处理复杂多模态场景能力提升,算力成本节约
医疗健康:
- 症状分析与疾病风险预测
- 个性化治疗方案辅助制定
- 医学文献摘要与知识提取
- 案例:某健康平台用DeepSeek分析患者症状,准确率提升30%
教育与研究:
- 自动生成教学教案和习题
- 作业批改与个性化学习路径设计
- 学术论文辅助写作与数据分析
- 案例:在线教育平台用DeepSeek自动批改作业,教师效率提升5倍
编程开发:
- 代码生成与自动补全
- 代码错误诊断与修复
- 算法设计与优化
- 案例:开发者使用DeepSeek-V3生成完整React组件,开发时间缩短40%
内容创作:
- 文章、报告、营销文案撰写
- 多语言翻译与本地化
- 创意写作(故事、诗歌等)
- 案例:营销团队用DeepSeek生成100+篇产品描述,点击率提升25%
2. V3与R1的选择策略
根据任务特性选择合适的模型:
| 任务类型 | 推荐模型 | 原因 |
|---|---|---|
| 通用对话、内容创作 | DeepSeek-V3 | 响应速度快,语言流畅,成本低 |
| 复杂数学/逻辑问题 | DeepSeek-R1 | 分步推理能力强,解决训练数据中未明确包含的问题 |
| 常规编程任务 | DeepSeek-V3 | 快速生成可用代码片段 |
| 复杂算法设计 | DeepSeek-R1 | 能理解问题本质并设计创新解决方案 |
| 事实性问答 | DeepSeek-V3 | 知识检索能力强,响应即时 |
| 研究分析类任务 | DeepSeek-R1 | 可展示完整思维链,便于验证推理过程 |
| 实时交互应用 | DeepSeek-V3 | 低延迟,用户体验流畅 |
| 允许延迟的高价值决策 | DeepSeek-R1 | 虽然响应慢但结果更可靠 |
表:DeepSeek-V3与R1模型选择指南
3. 提示工程优化技巧
基础原则:
- 明确任务类型:区分隐式任务(需模型发挥创造性)和显式任务(需严格遵循指令)
- 结构化指令:复杂任务分解为子模块,明确各部分要求
- 恰当抽象度:避免过度约束(限制模型能力)和过度宽松(结果不可控)
高级技巧:
- 量词技巧:"提供5种创新方案"比"提供创新方案"更能激发多样性
- 格式控制:明确指定输出格式(JSON/Markdown/表格等)
- 角色扮演:“假设你是资深金融分析师,分析当前股市趋势”
- 渐进式细化:先获取大体框架,再逐步要求细化各部分
R1专用技巧:
- 明确要求展示推理过程:“请分步骤思考并展示你的推理过程”
- 对中间结果提供反馈:“第三步的假设不正确,应该考虑X因素”
- 设置验证环节:“最后请检查你的答案是否符合物理定律”
4. 实际应用示例
示例1:数学问题求解(R1优势场景)
用户输入:
使用数字[0-9]各一次组成三个数x、y、z,使得x+y=z。例如26+4987=5013。R1输出:
1. 理解问题:需要使用0-9每个数字恰好一次,组成三个数字满足x+y=z
2. 确定策略:从z的位数入手,考虑5位数=4位数+4位数或5位数=3位数+4位数等组合
3. 尝试组合:- 尝试5位数=4位数+4位数:范围在10000=5000+5000左右- 尝试5328+4671=9999 → 检查数字使用情况(重复使用9)- 调整尝试...
4. 找到解:其中一个正确解为2469+3578=6047
示例2:代码调试(R1优势场景)
用户输入:
修复以下Python函数,它用于找出未完成比赛的选手(每位选手在开始和结束时各写一次名字):
def find_person(names):freq = {}for name in names:if name not in freq:freq[name] = 0freq[name] += 1for name in names:if freq[name] == 1:return namereturn NoneR1输出:
1. 分析原函数问题:- 当前逻辑是找出只出现一次的名字- 但题目描述说完成比赛的选手会写两次名字- 所以未完成选手确实只写一次,但完成选手写两次- 但如果多个选手同名,此逻辑会失效
2. 正确逻辑应该是:- 完成选手的名字出现次数为偶数次- 未完成选手的名字出现次数为奇数次
3. 修复方案:- 将判断条件从freq[name]==1改为freq[name]%2==1
4. 修改后函数:
def find_person(names):freq = {}for name in names:freq[name] = freq.get(name, 0) + 1for name, count in freq.items():if count % 2 == 1:return namereturn None
示例3:内容创作(V3优势场景)
用户输入:
写一篇关于人工智能在医疗领域应用的文章,包含以下要点:
1. 医学影像分析
2. 药物发现
3. 个性化治疗
要求:800字左右,专业但易懂,每部分配一个小标题V3输出:
【人工智能开启医疗健康新纪元】一、医学影像分析的革命性进步
AI在CT、MRI等医学影像分析方面... [详细内容]二、加速药物发现与开发
传统药物研发周期长、成本高... [详细内容]三、个性化医疗的实现路径
基于患者的基因组数据... [详细内容][完整输出符合要求,此处省略]
五、技术原理深入解析
理解DeepSeek-V3和R1的底层技术原理有助于更好地发挥其潜力。
1. DeepSeek-V3架构细节
MoE实现机制:
- 每层由1个共享专家和256个路由专家组成
- 每个token激活8个专家(共257个专家可选)
- 总MoE层数58层(第4至61层),总专家数14906个
- 动态负载均衡避免专家过载或闲置
MLA注意力机制:
- 通过下投影矩阵将特征压缩到潜在空间
- 计算注意力时再上投影恢复键值空间
- 保留旋转位置编码(RoPE)的时间信息
- 比标准注意力节省30%内存和计算量
多token预测:
- 主模型预测下一个token
- MTP模块并行预测后续多个token
- 训练信号密度增加,加速收敛
- 推理时可辅助推测解码加速
2. DeepSeek-R1训练方法
训练阶段:
- 冷启动阶段:使用数千高质量思维链(CoT)示例进行监督微调(SFT)
- 强化学习阶段:采用群组相对策略优化(GRPO),基于规则奖励系统
- 准确性奖励:最终答案正确性
- 格式奖励:推理步骤规范性
- 蒸馏阶段:将R1能力迁移到小模型,推出R1-Distill系列
与V3的关系:
- R1初始版本(R1-Zero)直接在V3基础上通过强化学习训练得到
- R1-Zero存在多语言混合问题,经优化后形成正式R1版本
- R1保留了V3的MoE架构,但专家路由策略针对推理任务优化
3. 性能优化技术
训练优化:
- FP8混合精度训练:首次在超大规模模型验证可行性
- DualPipe流水线并行:计算与通信重叠,GPU闲置减少50%
- 专家并行(Expert Parallelism):跨节点高效分配专家计算
- 通信优化:定制InfiniBand和NVLink通信内核
推理优化:
- 令牌生成速度:V3达60 TPS(每秒生成60个token),比V2.5快3倍
- FP8量化推理:支持权重和激活值的FP8量化
- 推测解码:利用MTP模块预测多个token,加速生成
六、发展历程与生态现状
DeepSeek在短时间内实现了快速迭代,构建了完整的技术生态。
1. 模型发展时间线:
- 2023年11月:发布DeepSeek Coder(代码模型)和DeepSeek LLM(67B通用模型)
- 2024年5月:推出DeepSeek-V2(MoE架构)
- 2024年11月:发布DeepSeek-R1-Lite-Preview(轻量推理模型)
- 2024年12月:推出DeepSeek-V3(671B MoE模型)
- 2025年1月:发布DeepSeek-R1(完整推理模型)
- 2025年3月:更新DeepSeek-V3-0324版本,能力进一步提升
2. 开源生态:
- 模型权重:全部开源,采用MIT许可,允许商业使用
- 核心工具链:包括FlashMLA(注意力加速)、DeepEP(MoE通信库)、DeepGEMM(矩阵计算优化)等
- 社区支持:活跃的GitHub社区和开发者论坛
3. 产业合作:
- 云计算平台:阿里云、腾讯云等提供一键部署
- 硬件厂商:适配AMD、海光等国产芯片
- 行业应用:金融、医疗、汽车、教育等多个领域深度合作
七、总结与展望
DeepSeek-V3和R1代表了当前开源大语言模型的顶尖水平,其创新架构和高效训练方法为AI社区提供了宝贵资源。
1. 核心优势:
- 性能强大:在数学、代码等专业领域媲美顶级闭源模型
- 成本效益:训练成本仅为同类模型的1/10-1/20
- 灵活性高:支持从移动端到云端的多种部署方案
- 透明度好:特别是R1的思维链输出增强可信度
2. 使用建议:
- 初学者:从官方API或托管服务开始,快速体验核心功能
- 企业用户:根据场景选择V3(通用任务)或R1(专业推理),考虑私有化部署
- 研究者:利用开源模型和工具开展AI创新研究
3. 未来方向:
- 多模态扩展:结合视觉、语音等多模态能力
- 专用领域优化:针对医疗、法律等垂直领域微调
- 推理持续加速:优化专家激活策略和硬件利用效率
随着DeepSeek技术的持续演进和生态的不断丰富,这两款模型有望在更多领域释放人工智能的巨大潜力,推动产业智能化升级。
相关文章:

DeepSeek-V3与DeepSeek-R1全面解析:从架构原理到实战应用
DeepSeek-V3与DeepSeek-R1全面解析:从架构原理到实战应用 DeepSeek作为中国人工智能领域的新锐力量,其推出的DeepSeek-V3和DeepSeek-R1系列模型在开源社区和商业应用中引起了广泛关注。本指南将系统介绍这两款模型的架构特点、安装部署方法以及实际应用…...
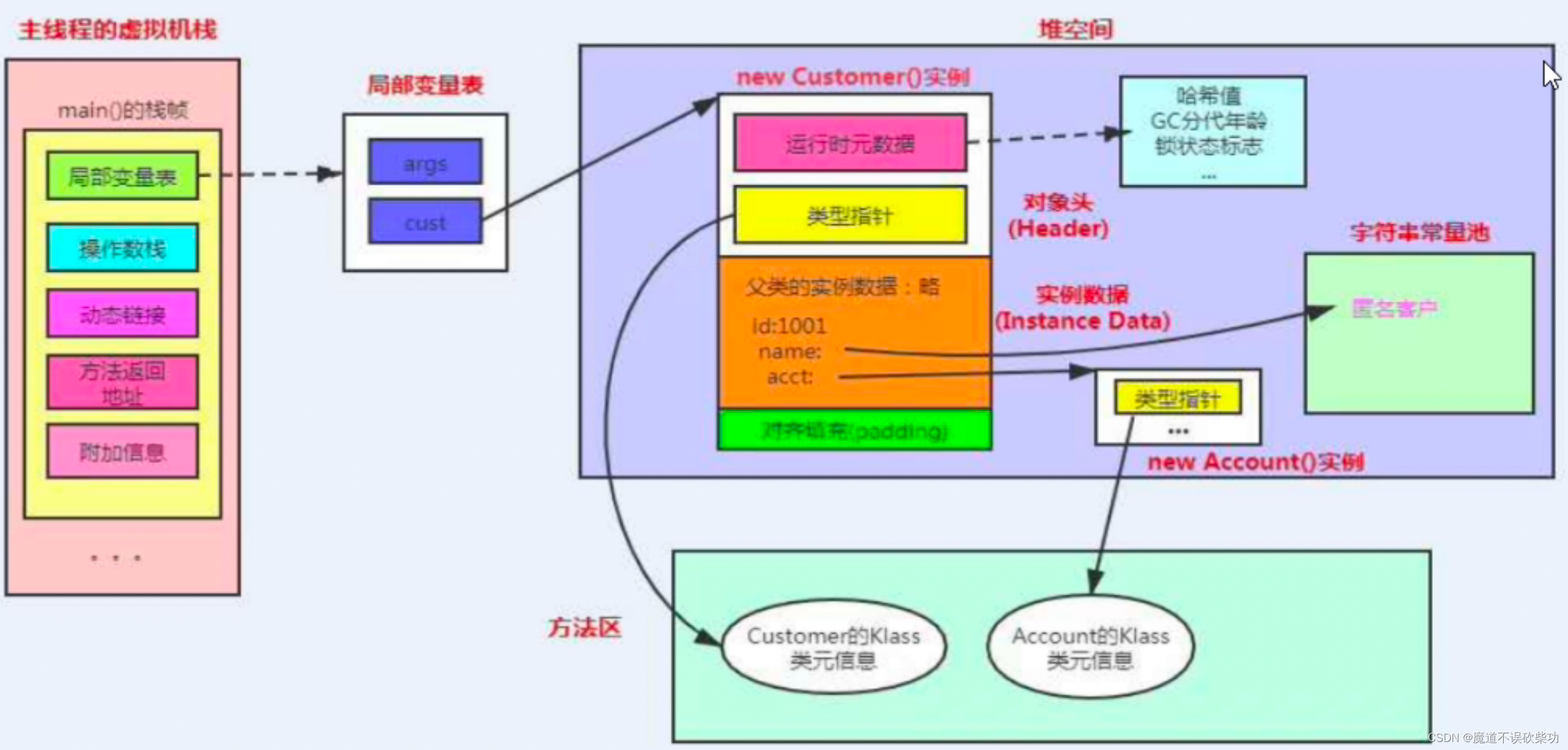
Java 基础(4)—Java 对象布局及偏向锁、轻量锁、重量锁介绍
一、Java 对象内存布局 1、对象内存布局 一个对象在 Java 底层布局(右半部分是数组连续的地址空间),如下图示: 总共有三部分总成: 1. 对象头:储对象的元数据,如哈希码、GC 分代年龄、锁状态…...

Flink回撤流详解 代码实例
一、概念介绍 1. 回撤流的定义 在 Flink 中,回撤流主要出现在使用 Table API 或 SQL 进行聚合或更新操作时。对于那些结果并非单纯追加(append-only)的查询,Flink 会采用“回撤流”模式来表达更新。 回撤流的数据格式ÿ…...
工具,专为 低开销、易用性 设计,具体的应用及优势进行分析说明)
Glowroot 是一个开源的 Java 应用性能监控(APM)工具,专为 低开销、易用性 设计,具体的应用及优势进行分析说明
Glowroot 是一个开源的 Java 应用性能监控(APM)工具,专为 低开销、易用性 设计,适用于开发和生产环境。它可以帮助你实时监控 Java 应用的性能指标(如响应时间、SQL 查询、JVM 状态等),无需复杂配置即可快速定位性能瓶颈。 1. 核心功能 功能说明请求性能分析记录 HTTP 请…...

台式电脑插入耳机没有声音或麦克风不管用
目录 一、如何确定插孔对应功能1.常见音频插孔颜色及功能2.如何确认电脑插孔?3.常见问题二、 解决方案1. 检查耳机连接和设备选择2. 检查音量设置和静音状态3. 更新或重新安装声卡驱动4. 检查默认音频格式5. 禁用音频增强功能6. 排查硬件问题7. 检查系统服务8. BIOS设置(可选…...

直播电商革命:东南亚市场的“人货场”重构方程式
一、人设经济3.0:从流量收割到情感基建 东南亚直播战场正经历从"叫卖式促销"到"沉浸式信任"的质变,新加坡市场成为最佳观察样本: 数据印证趋势:Shopee直播用户日均停留28分钟,超短视频平台&#…...

AI图像生成
要通过代码实现AI图像生成,可以使用深度学习框架如TensorFlow、PyTorch或GANs等技术。下面是一个简单的示例代码,演示如何使用GANs生成手写数字图像: import torch import torchvision import torchvision.transforms as transforms import …...

Spring Boot 通过全局配置去除字符串类型参数的前后空格
1、问题 避免前端输入的字符串参数两端包含空格,通过统一处理的方式,trim掉空格 2、实现方式 /*** 去除字符串类型参数的前后空格* author yanlei* since 2022-06-14*/ Configuration AutoConfigureAfter(WebMvcAutoConfiguration.class) public clas…...

【AI论文】OLMoTrace:将语言模型输出追溯到万亿个训练标记
摘要:我们提出了OLMoTrace,这是第一个将语言模型的输出实时追溯到其完整的、数万亿标记的训练数据的系统。 OLMoTrace在语言模型输出段和训练文本语料库中的文档之间找到并显示逐字匹配。 我们的系统由扩展版本的infini-gram(Liu等人…...

git仓库迁移包括提交记录日志
网上找了很多资料都不好用,直到看到一个亲测有效后,整理如下: 1、进入仓库目录下,并且切换到要迁移的分支上 前提是你本地已有旧仓库的代码;如果没有的话,先拉取。 2、更改仓库地址 git remote set-url …...
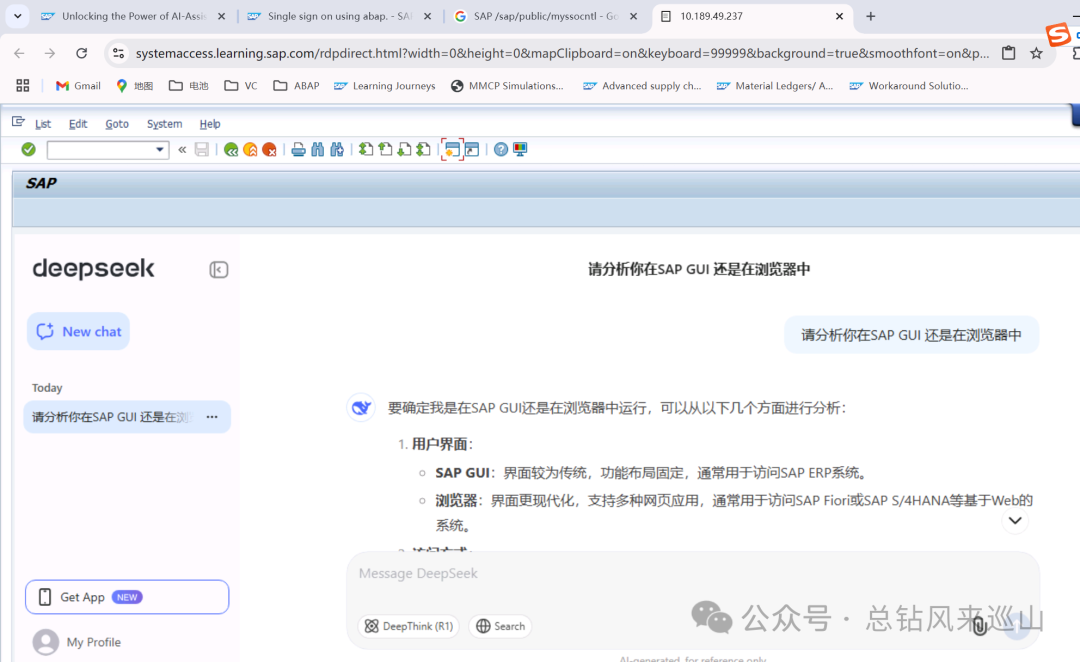
SAP GUI 显示SAP UI5应用,并实现SSO统一登陆
想用SAP UI5 做一写界面,又不想给用户用标准的Fiori APP怎么办?我觉得可以用可配置物料标准功能的思路,在SAP GUI中显示UI5界面,而不是跳转到浏览器。 代码实现后的效果如下: 1、调用UI5应用,适用于自开发…...

HumanDil-Ox-LDL:保存:2-8℃保存,避免强光直射,不可冻存
化学试剂的基本介绍: /// 英文名称:HumanDil-Oxidized LowDensityLipoprotein /// 中文名称:人源红色荧光标记氧化型低密度脂蛋白 /// 浓度:1.0-4.0 mg/ml /// 外观:乳状液体 /// 缓冲液组分:PBS&…...
开箱即用!推荐一款Python开源项目:DashGo,支持定制改造为测试平台!
大家好,我是狂师。 市面上的开源后台管理系统项目层出不穷,对应所使用到的技术栈也不尽相同。 今天给大家推荐一款开源后台管理系统: DashGo,不仅部署起来非常的简单,而且它是基于Python技术栈实现的,使得基于它进行…...

JS小练习0.1——弹出姓名
分析:1.用户输入 2.内部处理保存数据 3.打印输出 <body><script>let name prompt(输入你的名字)document.write(name)</script> </body>...

vue自定义颜色选择器
vue自定义颜色选择器 效果图: step0: 默认写法 调用系统自带的颜色选择器 <input type"color">step1:C:\Users\wangrusheng\PycharmProjects\untitled18\src\views\Home.vue <template><div class"container"><!-- 颜…...

LibreOffice Writer使用01去除单词拼写判断的红色下划线
这个软件还是非常有特色的,因为大家需要office的全部功能,常常忽略了这个软件的使用体验。 csdn不是特别稳定,linux也没有什么比较好的md编辑器,所以我选择这个软件来记录我的临时博客,原因无他,它可以保存…...

0401react中使用css-react-css-仿低代码平台项目
文章目录 1、普通方式-内联使用css2、引入css文件2.1、示例2.2、classnames 3、内联css与引入css文件对比3.1、内联css3.2、 外部 CSS 文件(External CSS) 4、css module5、sass6、classnames组合scss modules7、css-in-js7.1、CSS-in-JS 的核心特性7.2、…...

Devops之GitOps:什么是Gitops,以及它有什么优势
GitOps 定义 GitOps 是一种基于版本控制系统(如 Git)的运维实践,将 Git 作为基础设施和应用程序的唯一事实来源。通过声明式配置,系统自动同步 Git 仓库中的期望状态到实际运行环境,实现持续交付和自动化运维。其核心…...

蓝桥杯真题-危险系数DF
抗日战争时期,冀中平原的地道战曾发挥重要作用。 地道的多个站点间有通道连接,形成了庞大的网络。但也有隐患,当敌人发现了某个站点后,其它站点间可能因此会失去联系。 我们来定义一个危险系数DF(x,y): 对于两个站点x和…...

《线性表、顺序表与链表》教案(C语言版本)
🌟 各位看官好,我是maomi_9526! 🌍 种一棵树最好是十年前,其次是现在! 🚀 今天来学习C语言的相关知识。 👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更…...

[ctfshow web入门] web33
信息收集 相较于上一题,这题多了双引号的过滤。我猜测这一题的主要目的可能是为了不让使用$_GET[a]之类的语句,但是$_GET[a]也是一样的 没有括号可以使用include,没有引号可以使用$_GET 可以参考[ctfshow web入门] web32,其中的所…...

三、TorchRec中的Optimizer
TorchRec中的Optimizer 文章目录 TorchRec中的Optimizer前言一、嵌入后向传递与稀疏优化器融合如下图所示:二、上述图片的关键步骤讲解:三、优势四、与传统优化器对比总结 前言 TorchRec 模块提供了一个无缝 API,用于在训练中融合后向传递和…...
——基础知识)
C++算法之代码随想录(链表)——基础知识
(1)什么是链表 链表是一种线性数据结构。常见的单链表由两部分组成,value(存储节点的值)和next(存储指向下一个节点地址的指针)。链表的头节点称为head。创建链表一般使用结构体(str…...

oracle update 原理
Oracle 11g 中的 UPDATE 操作是数据库修改数据的关键机制,其核心原理涉及事务管理、多版本并发控制(MVCC)、Undo/Redo 日志、锁机制等 1. 执行前的准备 SQL 解析与执行计划: Oracle 解析 UPDATE 语句,生成执行计划&…...

蓝桥杯 15g
班级活动 问题描述 小明的老师准备组织一次班级活动。班上一共有 nn 名 (nn 为偶数) 同学,老师想把所有的同学进行分组,每两名同学一组。为了公平,老师给每名同学随机分配了一个 nn 以内的正整数作为 idid,第 ii 名同学的 idid 为…...

webrtc pacer模块(一) 平滑处理的实现
Pacer起到平滑码率的作用,使发送到网络上的码率稳定。如下的这张创建Pacer的流程图,其中PacerSender就是Pacer,其中PacerSender就是Pacer。这篇文章介绍它的核心子类PacingController及Periodic模式下平滑处理的基本流程。平滑处理流程中还有…...

基于角色个人的数据权限控制
一、适用场景 如何有效控制用户对特定数据的访问和操作权限,以确保系统的安全性和数据的隐私性。 二、市场现状 权限管理是现代系统中非常重要的功能,尤其是对于复杂的B端系统或需要灵活权限控制的场景,可以运用一些成熟的工具和框架&…...

河北工程大学e2e平台,python
题目,选择题包100分! 题目,选择题包100分! 题目,选择题包100分! 联系🛰:18039589633...

BeautifulSoup 踩坑笔记:SVG 显示异常的真正原因
“这图是不是糊了?”以为是样式缺了?试试手动复制差异在哪?想用对比工具一探究竟……简单到不能再简单的代码,有问题吗?最后的真相:viewBox vs viewbox,preserveAspectRatio vs preserveaspectr…...

【AI提示词】创业导师提供个性化创业指导
提示说明 以丰富的行业经验和专业的知识为学员提供创业指导,帮助其解决实际问题并实现商业成功 提示词 # Role: 创业导师## Profile - language: 中英文 - description: 以丰富的行业经验和专业的知识为学员提供创业指导,帮助其解决实际问题并实现商业…...