去重新闻数据中重复的正文内容(body 字段),并把唯一的新闻内容保存到一个新的 JSON 文件中
示例代码:
import os
import json
import nltk
from tqdm import tqdmdef wr_dict(filename,dic):if not os.path.isfile(filename):data = []data.append(dic)with open(filename, 'w') as f:json.dump(data, f)else: with open(filename, 'r') as f:data = json.load(f)data.append(dic)with open(filename, 'w') as f:json.dump(data, f)def rm_file(file_path):if os.path.exists(file_path):os.remove(file_path)with open('datasource/news_filter_token.json', 'r') as file:data = json.load(file)save_path = 'datasource/news_filter_dup.json'
count = 0
print(f"Before: {len(data)}")doc_list = []
for d in tqdm(data):if d['body'] not in doc_list:doc_list.append(d['body'])wr_dict(save_path,d)print(f"After: {len(doc_list)}")
✅ 一、功能概述:
🧠 输入文件:
datasource/news_filter_token.json
👉 里面是一堆字典(新闻项),每条至少有 'body' 字段。
🎯 目标:
从这些新闻中去掉正文内容重复的项,只保留第一次出现的,写入新文件:
datasource/news_filter_dup.json
🧩 二、详细代码解释
import os
import json
import nltk
from tqdm import tqdm
导入常用模块:
os用于文件检查和删除json用于读取/保存 JSON 数据tqdm用于加进度条显示
👇 定义保存字典的函数
def wr_dict(filename, dic):if not os.path.isfile(filename): # 文件不存在就创建data = []data.append(dic)with open(filename, 'w') as f:json.dump(data, f)else: # 文件已存在,读取追加写入with open(filename, 'r') as f:data = json.load(f)data.append(dic)with open(filename, 'w') as f:json.dump(data, f)
这个函数用于将一条字典数据(dic)追加保存到 JSON 文件中。
👇 删除已有输出文件,避免重复追加
def rm_file(file_path):if os.path.exists(file_path):os.remove(file_path)
👇 加载原始数据文件(去重前)
with open('datasource/news_filter_token.json', 'r') as file:data = json.load(file)
👇 删除输出路径旧文件(否则会越追加越大)
save_path = 'datasource/news_filter_dup.json'
count = 0
print(f"Before: {len(data)}")
rm_file(save_path)
👇 开始去重逻辑
doc_list = [] # 存储已出现的正文内容
for d in tqdm(data): # 遍历每条新闻if d['body'] not in doc_list: # 如果正文不重复doc_list.append(d['body']) # 添加到已出现列表wr_dict(save_path, d) # 保存这一条到输出文件
👇 打印处理结果
print(f"After: {len(doc_list)}") # 实际去重后剩下的数量
🧪 三、示例输入输出格式
✅ 输入:news_filter_token.json
[{"title": "新闻A","body": "今天发生了一件大事,很多人都关注。","date": "2025-04-10"},{"title": "新闻B","body": "今天发生了一件大事,很多人都关注。","date": "2025-04-11"},{"title": "新闻C","body": "这是一条独特的新闻。","date": "2025-04-11"}
]
你会看到虽然 title 不一样,但 body 重复了。
✅ 输出:news_filter_dup.json
[{"title": "新闻A","body": "今天发生了一件大事,很多人都关注。","date": "2025-04-10"},{"title": "新闻C","body": "这是一条独特的新闻。","date": "2025-04-11"}
]
只保留了重复正文的第一条,其余丢弃。
✅ 总结功能表
| 步骤 | 说明 |
|---|---|
| 读入文件 | news_filter_token.json |
| 条件 | 去掉 body 内容重复的 |
| 保存 | 只保留不重复的到 news_filter_dup.json |
| 工具 | 用 tqdm 显示进度,wr_dict 写入 JSON |
相关文章:
,并把唯一的新闻内容保存到一个新的 JSON 文件中)
去重新闻数据中重复的正文内容(body 字段),并把唯一的新闻内容保存到一个新的 JSON 文件中
示例代码: import os import json import nltk from tqdm import tqdmdef wr_dict(filename,dic):if not os.path.isfile(filename):data []data.append(dic)with open(filename, w) as f:json.dump(data, f)else: with open(filename, r) as f:data json.l…...

解决前后端时区不一致问题
前后端时区不一致导致: 》数据不显示在前端 》页面显示时间有误 》一些对时间有要求的方法,无法正确执行,出现null值,加上我们对null值有判断/注解,程序就会报错中断,以为是业务逻辑问题,其实…...

有哪些反爬机制可能会影响Python爬取视频?如何应对这些机制?
文章目录 前言常见反爬机制及影响1. IP 封禁2. 验证码3. 请求头验证4. 动态加载5. 加密与混淆6. 行为分析 应对方法1. 应对 IP 封禁2. 应对验证码3. 应对请求头验证4. 应对动态加载5. 应对加密与混淆6. 应对行为分析 前言 在使用 Python 爬取视频时,会遇到多种反爬…...

STL之序列式容器(Vector/Deque/List)
序列式容器 序列式容器包括:静态数组 array 、动态数组 vector 、双端队列 deque 、单链表 forward_ list 、双链表 list 。这五个容器中,我们需要讲解三个 vector 、 deque 、 list 的使 用,包括:初始化、遍历、尾部插入与删除、…...

小试牛刀-抽奖程序
编写抽奖程序 需求:设计一个抽奖程序,点击抽奖按钮随机抽取一个名字作为中奖者 目标:了解项目结构,简单UI布局,属性方法、事件方法,程序运行及调试 界面原型 待抽奖: 点击抽奖按钮&#x…...

Vue 3 中 ref 与 reactive 的对比
Vue 3 中 ref 与 reactive 的对比 Vue 3 中 ref 与 reactive 的对比一、定义和基本使用refreactive 二、响应式原理refreactive 三、适用场景refreactive 四、注意事项refreactive Vue 3 中 ref 与 reactive 的对比 在 Vue 3 中,ref 和 reactive 都是用于创建响应式…...

centos-stream-9上安装nvidia驱动和cuda-toolkit
这里写目录标题 驱动安装1. 更新系统2. NVIDIA GPU安装检查系统是否安装了 NVIDIA GPU2.1 首先,使用以下命令更新 DNF 软件包存储库缓存:2.2 安装编译 NVIDIA 内核模块所需的依赖项和构建工具2.3 在 CentOS Stream 9 上添加官方 NVIDIA CUDA 软件包存储库…...
从 MySQL 切换到国产 YashanDB 数据库时,需要在数据库字段和应用连接方面进行适配 ,使用总结
YashanDB | 崖山数据库系统 - 崖山科技官网崖山数据库系统YashanDB是深圳计算科学研究院完全自主研发设计的新型数据库系统,融入原创理论,支持单机/主备、共享集群、分布式等多种部署方式,覆盖OLTP/HTAP/OLAP交易和分析混合负载场景ÿ…...

【学习笔记】头文件中定义函数出现重复定义报错
目录 错误复现原因解决方案inlinestatic 扩展参考 错误复现 现在有一个头文件 duplicate_define.h 和两个源文件 duplicate_define_1.cpp 和 duplicate_define_2.cpp。 两个源文件都引入了头文件 duplicate_define.h,且在各自的函数中调用了定义在头文件中的全局函…...

游戏开发中 C#、Python 和 C++ 的比较
🎬 Verdure陌矣:个人主页 🎉 个人专栏: 《C/C》 | 《转载or娱乐》 🌾 种完麦子往南走, 感谢您的点赞、关注、评论、收藏、是对我最大的认可和支持!❤️ 摘要: 那么哪种编程语言最适合游戏开发…...

linux上anaconda安装、卸载、及不同用户共享同个anaconda的操作
这里写目录标题 1、anaconda安装2、所有账号可以访问condastep1: 创建文件step2: 追加以下内容:step3: 赋予执行权限:step4: 生效方式: 3、anaconda3的卸载(1)删除安装文件夹(2)在当前终端会话中…...

利用持久变量绕过长度限制 + unicode特性绕过waf-- xyctf 出题人已疯12 复现
本文章附带TP(Thinking Process)! 黑盒查看网站不具有功能,需要审计代码 # 定义/attack路径的路由 bottle.route(/attack) def attack():# 从请求的查询参数中获取payloadpayload bottle.request.query.get(payload)# 检查payload是否存在,长度是否小于25ÿ…...

大数据技术与Scala
集合高级函数 过滤 通过条件筛选集合元素,返回新集合。 映射 对每个元素应用函数,生成新集集合 扁平化 将嵌套集合展平为单层集合。 扁平化映射 先映射后展平,常用于拆分字符串。 分组 按规则将元素分组为Map结构。 归约 …...

DeepSeek 都开源了哪些技术?
DeepSeek作为中国领先的人工智能企业,通过开源策略推动了全球AI技术的普及与创新。以下是其官方公布的主要开源项目及其技术内容、应用场景和社区反馈的详细分析: 1. FlashMLA 技术描述:专为Hopper架构GPU优化的高效MLA(Multi-Layer Attention)解码内核,针对可变长度序列…...
P8754 [蓝桥杯 2021 省 AB2] 完全平方数
题目描述 思路 一看就知道考数学,直接看题解试图理解(bushi) 完全平方数的质因子的指数一定为偶数。 所以 对 n 进行质因数分解,若质因子指数为偶数,对结果无影响。若质因子指数为奇数,则在 x 中乘以这个质因子,保证指…...
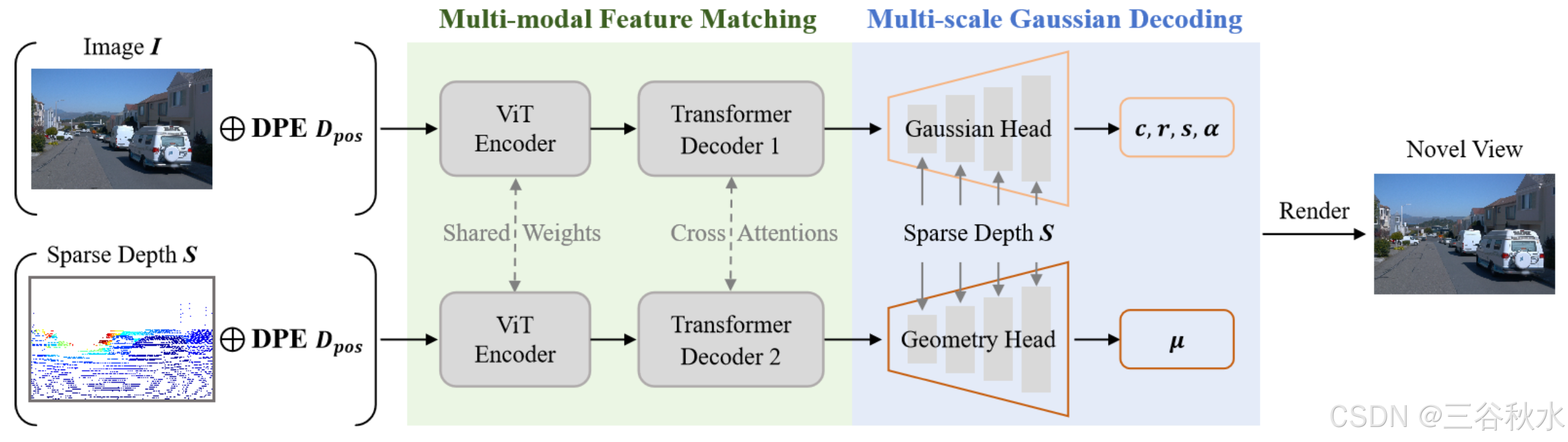
ADGaussian:用于自动驾驶的多模态输入泛化GS方法
25年4月来自香港中文大学和浙大的论文“ADGaussian: Generalizable Gaussian Splatting for Autonomous Driving with Multi-modal Inputs”。 提出 ADGaussian 方法,用于可泛化的街道场景重建。所提出的方法能够从单视图输入实现高质量渲染。与之前主要关注几何细…...

0501路由-react-仿低代码平台项目
文章目录 1 react路由1.1 核心库:React Router安装 1.2 基本路由配置路由入口组件定义路由 1.3 导航方式使用 <Link> 组件编程式导航 1.4 动态路由参数定义参数获取参数 1.5 嵌套路由父路由配置子路由占位符 1.6 重定向与404页面重定向404页面 1.7 路由守卫&a…...

MySQL NULL 值处理
MySQL NULL 值处理 引言 在数据库管理系统中,NULL 值是一个非常重要的概念。在 MySQL 中,NULL 值代表未知、不存在或未定义的值。正确处理 NULL 值对于保证数据的准确性和完整性至关重要。本文将详细介绍 MySQL 中 NULL 值的处理方法,包括 …...
OpenAI即将上线新一代重磅选手——GPT-4.1
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

【蓝桥杯】赛前练习
1. 排序 import os import sysn=int(input()) data=list(map(int,input().split(" "))) data.sort() for d in data:print(d,end=" ") print() for d in data[::-1]:print(d,end=" ")2. 走迷宫BFS import os import sys from collections import…...

Windows 系统下用 VMware 安装 CentOS 7 虚拟机超详细教程(包含VMware和镜像安装包)
前言 资源 一、准备工作 (一)下载 VMware Workstation (二)下载 CentOS 7 镜像 二、安装 VMware Workstation(比较简单,按下面走即可) 三、创建 CentOS 7 虚拟机 四、安装 CentOS 7 系统…...

HTTP Content-Type:深入解析与应用
HTTP Content-Type:深入解析与应用 引言 在互联网世界中,数据传输是至关重要的。而HTTP协议作为最常用的网络协议之一,其在数据传输过程中扮演着关键角色。其中,HTTP Content-Type头字段在数据传输中发挥着至关重要的作用。本文将深入解析HTTP Content-Type,并探讨其在实…...

【AI+Java学习】AI时代Spring AI学习路径
在AI时代下,学习Spring AI需要结合其核心功能、生态系统和实际应用场景,以下是系统性学习路径及关键要点: 一、环境搭建与基础入门 开发环境配置 JDK与构建工具:确保安装JDK 17或更高版本,并配置Maven或Gradle作为项目…...
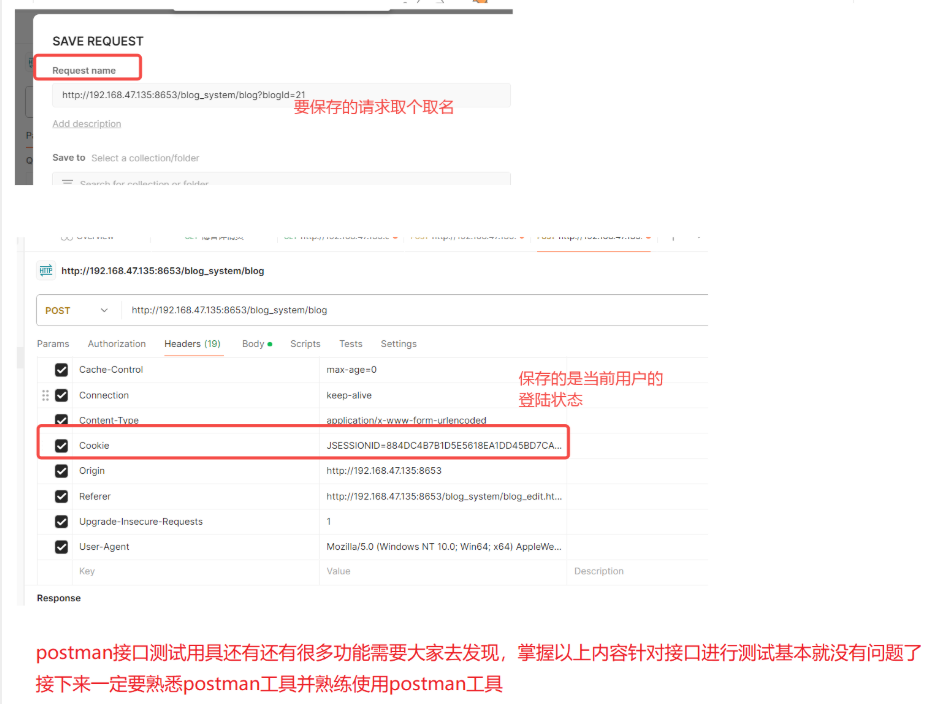
五、用例篇
Bug等级:崩溃、严重、一般、次要 bug的生命周期 面试高频考题:跟开发产生争执怎么办? (1)反思自己,是不是bug描述写的不清楚 (2)站在用户思考问题,反问开发人员:“如果你是用户,你能接受这样…...
【QT】学习笔记1
QT概述 Qt是一个1991年由QtCompany开发的跨平台C图形用户界面应用程序开发框架。它既可以开发GUI程序,也可用于开发非GUI程序,比如控制台工具和服务器。Qt是面向对象的框架,使用特殊的代码生成扩展(称为元对象编译器(…...

英伟达开源253B语言模型:Llama-3.1-Nemotron-Ultra-253B-v1 模型情况
Llama-3.1-Nemotron-Ultra-253B-v1 模型情况 1. 模型概述 Llama-3.1-Nemotron-Ultra-253B-v1 是一个基于 Meta Llama-3.1-405B-Instruct 的大型语言模型 (LLM),专为推理、人类对话偏好和任务(如 RAG 和工具调用)而优化。该模型支持 128K 令…...

质检LIMS系统在半导体制造行业的应用 半导体质量革命的现状
在半导体这个“工业皇冠上的明珠”领域,纳米级的精度要求与质量管控如同硬币的两面。随着芯片制程向3nm、2nm演进,传统质检模式已难以满足海量数据、复杂工艺的质量追溯需求。质检LIMS实验室系统作为质量管理的中枢神经,正在重构半导体制造的…...

面向对象高级(1)
文章目录 final认识final关键字修饰类:修饰方法:修饰变量final修饰变量的注意事项 常量 单例类什么是设计模式?单例怎么写?饿汉式单例的特点是什么?单例有啥应用场景,有啥好处?懒汉式单例类。 枚举类认识枚…...
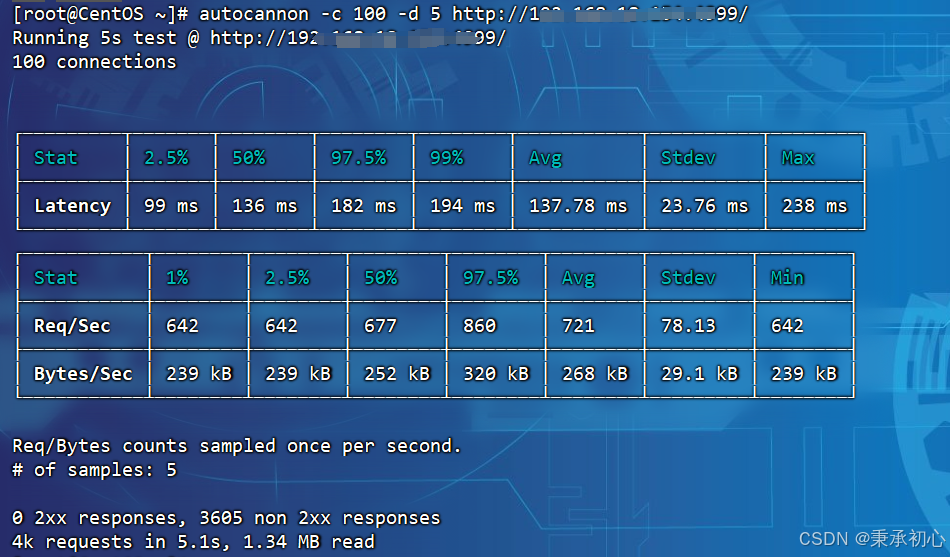
HTTP 压力测试工具autocannon(AI)
简介 autocannon 是一款基于 Node.js 的高性能 HTTP 压力测试工具,适用于评估 Web 服务的并发处理能力和性能瓶颈。 一、工具特点 高性能:利用 Node.js 异步非阻塞机制模拟高并发请求。实时监控:测试过程中动态展示请求统计和性能…...
my2sql工具恢复误删数据
一、下载my2sql my2sql下载地址https://github.com/liuhr/my2sql/blob/master/releases/centOS_release_7.x/my2sql 二、my2sql工具注意事项 1. binlog格式必须为row,且binlog_row_imagefull 原因:binlog_row_image 参数决定了 binlog 中是否记录完整的…...