PyTorch 学习笔记
环境:python3.8 + PyTorch2.4.1+cpu + PyCharm
参考链接:
快速入门 — PyTorch 教程 2.6.0+cu124 文档
PyTorch 文档 — PyTorch 2.4 文档
快速入门
导入库
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor加载数据集
使用 FashionMNIST 数据集。每个 TorchVision 都包含两个参数: 分别是 修改样本 和 标签。
# Download training data from open datasets.
training_data = datasets.FashionMNIST(root="data", # 数据集存储的位置train=True, # 加载训练集(True则加载训练集)download=True, # 如果数据集在指定目录中不存在,则下载(True才会下载)transform=ToTensor(), # 应用于图像的转换列表,例如转换为张量和归一化
)# Download test data from open datasets.
test_data = datasets.FashionMNIST(root="data",train=False, # 加载测试集(False则加载测试集)download=True,transform=ToTensor(),
)
创建数据加载器
batch_size = 64# Create data loaders.
# DataLoader():batch_size每个批次的大小,shuffle=True则打乱数据
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)for X, y in test_dataloader: # 遍历训练数据加载器,x相当于图片,y相当于标签print(f"Shape of X [N, C, H, W]: {X.shape}")print(f"Shape of y: {y.shape} {y.dtype}")break ![]()
创建模型
为了在 PyTorch 中定义神经网络,我们创建一个继承 来自 nn.模块。我们定义网络的各层 ,并在函数中指定数据如何通过网络。要加速 作,我们将其移动到 CUDA、MPS、MTIA 或 XPU 等加速器。如果当前加速器可用,我们将使用它。否则,我们使用 CPU。__init__forward
#使用加速器,并打印当前使用的加速器(当前加速器可用则使用当前的,否则使用cpu)
# device = torch.accelerator.current_accelerator().type if torch.accelerator.is_available() else "cpu" # torch2.4.2并没有accelerator这个属性,2.6的才有,所以注释掉
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using {device} device")# 检查 CUDA 是否可用
print("CUDA available:", torch.cuda.is_available())# Define model
class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.linear_relu_stack = nn.Sequential(nn.Linear(28*28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10))def forward(self, x):x = self.flatten(x)logits = self.linear_relu_stack(x)return logitsmodel = NeuralNetwork().to(device) #torch2.4.2并没有accelerator这个属性,2.6的才有,所以注释掉不用
# model = NeuralNetwork()
print(model)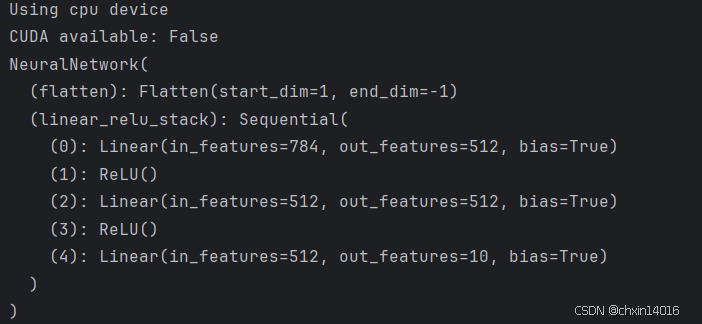
优化模型参数
要训练模型,我们需要一个损失函数和一个优化器:
loss_fn = nn.CrossEntropyLoss() # 损失函数,nn.CrossEntropyLoss()用于多分类
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3) # 优化器,用于更新模型的参数,以最小化损失函数'''
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
优化器用PyTorch 提供的随机梯度下降(Stochastic Gradient Descent, SGD)优化器
model.parameters():将模型的参数传递给优化器,优化器会根据这些参数计算梯度并更新它们
lr=1e-3:学习率(learning rate),控制每次参数更新的步长
(较大的学习率可能导致训练不稳定,较小的学习率可能导致训练速度变慢)
'''在单个训练循环中,模型对训练集进行预测(分批提供给它),并且 反向传播预测误差以调整模型的参数:
'''
训练模型(单个epoch)
dataloader:数据加载器,用于按批次加载训练数据
model :神经网络模型
loss_fn :损失函数,用于计算预测值与真实值之间的误差
optimizer :优化器,用于更新模型参数
'''
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset)model.train() # 将模型设置为训练模式(启用 dropout 和 batch normalization 的训练行为)for batch, (X, y) in enumerate(dataloader): # 遍历 dataloader 中的每个批次,获取输入 X 和标签 yX, y = X.to(device), y.to(device) # 将数据移动到指定设备(如 GPU 或 CPU)# Compute prediction error# 计算预测损失,同时也是前向传播pred = model(X) # 模型的预测值,即模型的输出loss = loss_fn(pred, y) # 计算损失:y为实际的类别标签# Backpropagation 反向传播和优化# 梯度清零应在每次反向传播之前执行,以避免梯度累积(先用optimizer.zero_grad())loss.backward() # 计算梯度optimizer.step() # 使用优化器更新模型参数optimizer.zero_grad() # 清除之前的梯度(清零梯度,为下一轮计算做准备)# 梯度清零应在每次反向传播之前执行,以避免梯度累积(在计算模型预测值前先用optimizer.zero_grad())if batch % 100 == 0: # 每 100 个批次打印一次损失值和当前处理的样本数量loss, current = loss.item(), (batch + 1) * len(X)print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")进度条显示:
- 如果数据集较大,训练过程可能较慢。可以使用
tqdm库添加进度条,提升用户体验。例如:from tqdm import tqdm for batch, (X, y) in enumerate(tqdm(dataloader, desc="Training")):...
我们还根据测试集检查模型的性能,以确保它正在学习:
# 测试模型
def test(dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的总样本数num_batches = len(dataloader) # 测试数据加载器(dataloader)的总批次数model.eval() # 设置为评估模式,这会关闭 dropout 和 batch normalization 的训练行为test_loss, correct = 0, 0 # 累积测试损失和正确预测的样本数with torch.no_grad(): # 禁用梯度计算,使用 torch.no_grad() 上下文管理器,避免计算梯度,从而节省内存并加速计算for X, y in dataloader:X, y = X.to(device), y.to(device) # 将数据加载到指定设备pred = model(X) # 模型预测test_loss += loss_fn(pred, y).item() # 累积损失correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 累积正确预测数# correct += (pred.argmax(1) == y).float().sum().item() # 可以直接使用 .float(),更简洁test_loss /= num_batches # 平均损失correct /= size # 准确率print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 累积正确预测数 # correct += (pred.argmax(1) == y).float().sum().item() # 可以直接使用 .float(),更简洁 '''pred.argmax(1): pred 是模型的输出(通常是未经过 softmax 的 logits,形状为 [batch_size, num_classes])。 argmax(1) 表示在第二个维度(即类别维度)上找到最大值的索引,返回一个形状为 [batch_size] 的张量,表示每个样本的预测类别。pred.argmax(1) == y: y 是真实标签(形状为 [batch_size]),表示每个样本的真实类别。 这一步会比较预测的类别和真实类别,返回一个布尔张量,形状为 [batch_size],其中每个元素表示对应样本的预测是否正确。.type(torch.float): 将布尔张量转换为浮点数张量(True 转为 1.0,False 转为 0.0).sum(): 对浮点数张量求和,得到预测正确的样本总数.item(): 将结果从张量转换为 Python 的标量(整数) '''
- 举例一:
pred是模型的输出:torch.tensor([[2.5, 0.3, 0.2], [0.1, 3.2, 0.7]])
y是真实标签:torch.tensor([0, 1])import torchpred = torch.tensor([[2.5, 0.3, 0.2], [0.1, 3.2, 0.7]]) y = torch.tensor([0, 1])correct = (pred.argmax(1) == y).type(torch.float).sum().item() print(correct) # 输出: 2.0 -> 转换为整数后为 2
- 举例二:
import torch# 模型输出(未经过 softmax 的 logits) pred = torch.tensor([[2.0, 1.0, 0.1], # 第一个样本的预测分数[0.5, 3.0, 0.2], # 第二个样本的预测分数[1.2, 0.3, 2.5]]) # 第三个样本的预测分数# 真实标签 y = torch.tensor([0, 1, 2]) # 第一个样本的真实类别是 0,第二个是 1,第三个是 2# 计算预测正确的样本数 correct = (pred.argmax(1) == y).type(torch.float).sum().item() print(f"预测正确的样本数: {correct}") # 预测正确的样本数: 3'''逐步分析 对每个样本的预测分数取最大值的索引,得到预测类别: pred.argmax(1) # 输出: tensor([0, 1, 2])比较预测类别和真实标签,得到布尔张量: pred.argmax(1) == y # 输出: tensor([True, True, True]).type(torch.float): 将布尔张量转换为浮点数张量: (pred.argmax(1) == y).type(torch.float) # 输出: tensor([1.0, 1.0, 1.0]).sum(): 对浮点数张量求和,得到预测正确的样本总数: (pred.argmax(1) == y).type(torch.float).sum() # 输出: tensor(3.0).item():将结果从张量转换为 Python 标量: (pred.argmax(1) == y).type(torch.float).sum().item() # 输出: 3在这个例子中,模型对所有 3 个样本的预测都正确,因此预测正确的样本数为 3。 ''' # 如果知道总样本数,可以进一步计算准确率:# 总样本数 total = len(y)# 准确率 accuracy = correct / total print(f"准确率: {accuracy * 100:.2f}%")
训练过程分多次迭代 (epoch) 进行。在每个 epoch 中,模型会学习 参数进行更好的预测。
然后打印模型在每个 epoch 的准确率和损失,
期望看到 准确率Accuracy增加,损失Avg loss随着每个 epoch 的减少而减少:
# 跑5轮,每轮皆是先训练,然后测试
epochs = 5
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train(train_dataloader, model, loss_fn, optimizer)test(test_dataloader, model, loss_fn)
print("Done!")输出:
Epoch 1
-------------------------------
loss: 2.308106 [ 64/60000]
loss: 2.292096 [ 6464/60000]
loss: 2.280747 [12864/60000]
loss: 2.273108 [19264/60000]
loss: 2.256617 [25664/60000]
loss: 2.240094 [32064/60000]
loss: 2.229981 [38464/60000]
loss: 2.204926 [44864/60000]
loss: 2.201917 [51264/60000]
loss: 2.178733 [57664/60000]
Test Error: Accuracy: 46.1%, Avg loss: 2.164820 Epoch 2
-------------------------------
loss: 2.178193 [ 64/60000]
loss: 2.160645 [ 6464/60000]
loss: 2.110801 [12864/60000]
loss: 2.129119 [19264/60000]
loss: 2.078400 [25664/60000]
loss: 2.029629 [32064/60000]
loss: 2.044328 [38464/60000]
loss: 1.972220 [44864/60000]
loss: 1.980023 [51264/60000]
loss: 1.920835 [57664/60000]
Test Error: Accuracy: 56.2%, Avg loss: 1.906657 Epoch 3
-------------------------------
loss: 1.938616 [ 64/60000]
loss: 1.902610 [ 6464/60000]
loss: 1.797264 [12864/60000]
loss: 1.844325 [19264/60000]
loss: 1.726765 [25664/60000]
loss: 1.688332 [32064/60000]
loss: 1.695883 [38464/60000]
loss: 1.605903 [44864/60000]
loss: 1.628846 [51264/60000]
loss: 1.532240 [57664/60000]
Test Error: Accuracy: 59.8%, Avg loss: 1.541237 Epoch 4
-------------------------------
loss: 1.604458 [ 64/60000]
loss: 1.563167 [ 6464/60000]
loss: 1.426733 [12864/60000]
loss: 1.503305 [19264/60000]
loss: 1.376496 [25664/60000]
loss: 1.381424 [32064/60000]
loss: 1.371971 [38464/60000]
loss: 1.312882 [44864/60000]
loss: 1.342990 [51264/60000]
loss: 1.244696 [57664/60000]
Test Error: Accuracy: 62.7%, Avg loss: 1.268371 Epoch 5
-------------------------------
loss: 1.344515 [ 64/60000]
loss: 1.318664 [ 6464/60000]
loss: 1.166471 [12864/60000]
loss: 1.275481 [19264/60000]
loss: 1.146058 [25664/60000]
loss: 1.179018 [32064/60000]
loss: 1.171105 [38464/60000]
loss: 1.129168 [44864/60000]
loss: 1.163182 [51264/60000]
loss: 1.077062 [57664/60000]
Test Error: Accuracy: 64.7%, Avg loss: 1.097442 Done!保存模型
保存模型的常用方法是序列化内部状态字典(包含模型参数):
torch.save(model.state_dict(), "model.pth")
print("Saved PyTorch Model State to model.pth")![]()
加载模型
加载模型的过程包括重新创建模型结构和加载 state 字典放入其中。
model = NeuralNetwork().to(device)
model.load_state_dict(torch.load("model.pth", weights_only=True))此模型现在可用于进行预测。
classes = ["T-shirt/top","Trouser","Pullover","Dress","Coat","Sandal","Shirt","Sneaker","Bag","Ankle boot",
]model.eval()
x, y = test_data[0][0], test_data[0][1]
with torch.no_grad():x = x.to(device)pred = model(x)predicted, actual = classes[pred[0].argmax(0)], classes[y]print(f'Predicted: "{predicted}", Actual: "{actual}"')![]()
Tensor
初始化Tensor
import torch
import numpy as np# 1、直接从数据创建张量。数据类型是自动推断的
data = [[1, 2],[3, 4]]
x_data = torch.tensor(data)# 2、从 NumPy 数组创建张量(反之亦然)
np_array = np.array(data)
x_np = torch.from_numpy(np_array)3、从另一个张量创建:
# 从另一个张量创建张量,新张量保留参数张量的属性(形状、数据类型),除非显式覆盖
x_ones = torch.ones_like(x_data) # retains the properties of x_data 保留原有属性
print(f"Ones Tensor: \n {x_ones} \n")x_rand = torch.rand_like(x_data, dtype=torch.float) # overrides the datatype of x_data 覆盖原有类型
print(f"Random Tensor: \n {x_rand} \n") 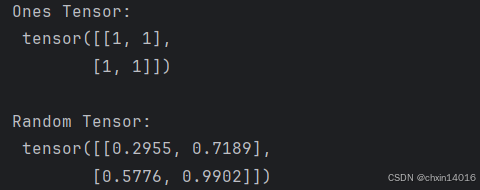
4、使用随机值或常量值:(三个皆是数据类型默认为浮点型(torch.float32))
# 使用随机值或常量值创建张量:
shape = (2,3,) # shape是张量维度的元组,确定输出张量的维数
rand_tensor = torch.rand(shape) # 元素为 [0, 1) 中的随机浮点型,
ones_tensor = torch.ones(shape) # 元素为全 1
zeros_tensor = torch.zeros(shape) # 元素为全 0print(f"Random Tensor: \n {rand_tensor} \n")
print(f"Ones Tensor: \n {ones_tensor} \n")
print(f"Zeros Tensor: \n {zeros_tensor}")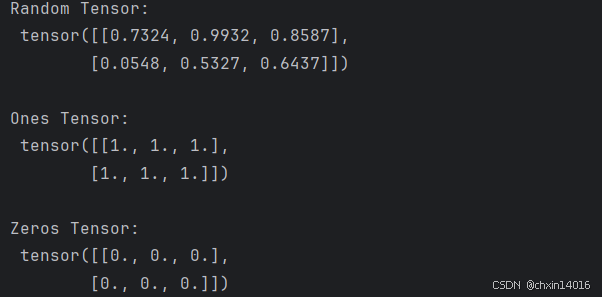
若想指定生成其他数据类型的张量,可以通过
dtype参数显式指定。例如:# 整数类型 rand_tensor_int = torch.rand((2, 3), dtype=torch.int32) print(rand_tensor_int.dtype) # 输出: torch.int32# 双精度浮点型 ones_tensor_double = torch.ones((2, 3), dtype=torch.float64) print(ones_tensor_double.dtype) # 输出: torch.float64
属性
Tensor 属性描述其形状、数据类型和存储它们的设备
tensor = torch.rand(3,4)
print(f"Shape of tensor: {tensor.shape}") # 形状
print(f"Datatype of tensor: {tensor.dtype}") # 数据类型
print(f"Device tensor is stored on: {tensor.device}") # 存储其的设备
操作
索引和切片:(类似 numpy )
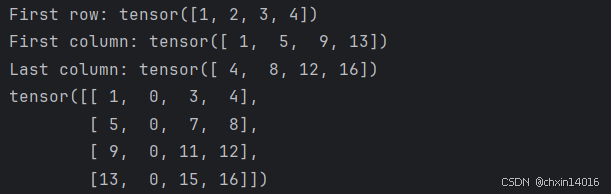
tensor = torch.ones(4, 4)
# tensor = torch.tensor([[1, 2, 3, 4],
# [5, 6, 7, 8],
# [9, 10, 11, 12],
# [13, 14, 15, 16]])print(f"First row: {tensor[0]}")
print(f"First column: {tensor[:, 0]}")
print(f"Last column: {tensor[..., -1]}")
tensor[:,1] = 0
print(tensor)
拼接张量 (沿给定维度连接一系列张量)。
另请参见 torch.stack, 另一个与 . 略有不同的 Tensor Joining 运算符。torch.cattorch.cat
'''
dim=1 :沿着第 1 维(通常是列)进行拼接
如果 tensor 的形状是 (a, b),
则沿着第 1 维拼接三次后,结果张量 t1 的形状将是 (a, b * 3)。
'''
t1 = torch.cat([tensor, tensor, tensor], dim=1) # 沿着第 1 维拼接三次
print(t1)

算术运算 (矩阵乘法 和 元素积(逐元素乘积))
计算两个张量间的 矩阵乘法 和 元素积(逐元素乘积)
# 计算两个张量间的矩阵乘法
# This computes the matrix multiplication between two tensors. y1, y2, y3 will have the same value
# ``tensor.T`` 返回张量的转置 returns the transpose of a tensor
y1 = tensor @ tensor.T # “@”是矩阵乘法的简写,用于张量之间的矩阵乘法; tensor.T 返回 tensor 的转置
y2 = tensor.matmul(tensor.T) # matmul用于矩阵乘法,与 @ 功能等价y3 = torch.rand_like(y1) # 创建与 y1 形状相同的新张量,元素为随机值
torch.matmul(tensor, tensor.T, out=y3) # 进行矩阵乘法,并将结果存储在 y3 中print("Matrix Multiplication Results:") # y1, y2, y3 三者相等
print("y1:\n", y1)
print("y2:\n", y2)
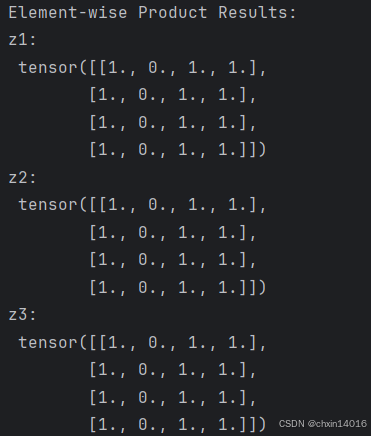
print("y3:\n", y3)# 计算元素积
# This computes the element-wise product. z1, z2, z3 will have the same value
z1 = tensor * tensor # 对 tensor 进行逐元素相乘
z2 = tensor.mul(tensor) # 与 * 相同的逐元素相乘z3 = torch.rand_like(tensor)
torch.mul(tensor, tensor, out=z3) # 使用 torch.mul 函数对 tensor 进行逐元素相乘,并将结果存储在 z3 中print("\nElement-wise Product Results:") # z1, z2, z3 三者相等
print("z1:\n", z1)
print("z2:\n", z2)
print("z3:\n", z3)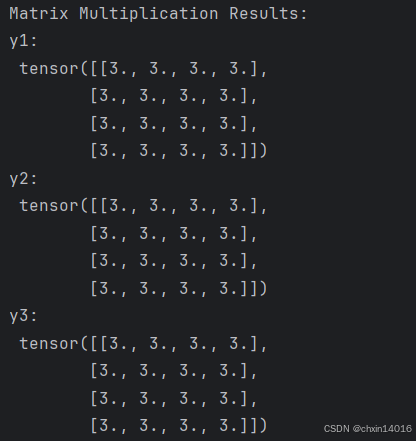
单个张量 (求和 & 转int/float)
.sum() 聚合所有 值转换为一个值;.item() 将其转换为 Python 数值使用。
agg = tensor.sum() # 所有元素求和,返回新的张量(标量张量)
agg_item = agg.item() # 将标量张量agg转成Python的基本数据类型(如float或int,具体取决于张量中数据的类型)
print(agg_item, type(agg_item))![]()
In-place 操作
add_是一个 in-place 操作,会直接修改原张量tensor的值,而不会创建新的张量。- 若不想修改原张量,可使用非 in-place 操作
tensor + 5,这样会返回一个新的张量,而原张量保持不变。
# 使用 in-place 操作对张量中的每个元素加 5
print(f"{tensor} \n")
tensor.add_(5) # add_ 是 in-place 操作,会直接修改原张量
print(tensor)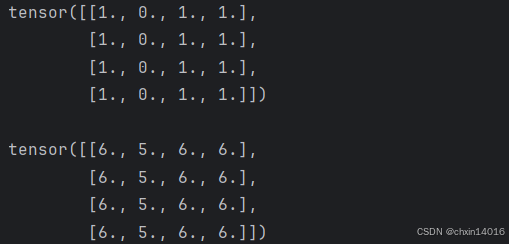
in-place 的优缺点
优点:节省内存。(直接在原张量上操作,避免额外分配内存)
缺点:因为是直接修改原数据,会丢失历史记录,因此不鼓励使用。
使用NumPy桥接
- 共享内存:Tensor 和 NumPy 数组在
.numpy()和torch.from_numpy()转换时,会 共享底层内存(共享底层数据存储),因此对一方的修改会直接影响另一方。 - 潜在风险:如果对共享内存的张量或数组进行了非原地安全的操作(如直接赋值),可能导致数据竞争或意外覆盖。
以下例子中 t 和 n 的值始终同步,因为它们共享相同的内存。这种特性在需要高效数据传递时非常有用,但需要谨慎操作以避免数据竞争。
Tensor 转 NumPy 数组
t = torch.ones(5) # 创建一个包含 5 个 1.0 的张量
print(f"t: {t}")# 将张量 t 转换为 NumPy 数组
n = t.numpy() # .numpy() 方法将 PyTorch 张量转换为 NumPy 数组
print(f"n: {n}")![]()
张量的变化反映在 NumPy 数组中:
t.add_(1) # 使用 add_ 进行原地加法
print(f"t: {t}")
print(f"n: {n}") # n 的值也会改变,因为 t 和 n 共享内存![]()
NumPy 数组 转 Tensor
n = np.ones(5) # 创建一个包含 5 个 1.0 的 NumPy 数组
t = torch.from_numpy(n) # 将 NumPy 数组转换为 PyTorch 张量NumPy 数组中的更改反映在张量中:
np.add(n, 5, out=n) # 对 NumPy 数组,使用 out 参数 进行原地加法操作
print(f"t: {t}") # 由于 t 和 n 底层共享内存,t 的值也会随之改变
print(f"n: {n}")
构建神经网络
定义类
获取到模型的输出(预测结果)后,得到一个二维张量。其中
dim=0 对应于每个类的 10 个原始预测值的每个输出,
dim=1 对应于每个输出的单个值。
我们通过
nn.Softmax模块的一个实例传递预测概率来获得预测概率。
torch.Softmax与nn.Softmax的区别:
torch.softmax是一个函数,直接对张量进行操作。nn.Softmax是一个模块,需要先实例化:softmax = nn.Softmax(dim=1),然后作为模型的一部分使用,即 调用softmax(logits)。
X = torch.rand(1, 28, 28, device=device) # 生成随机输入张量
logits = model(X) # 前向传播
pred_probab = nn.Softmax(dim=1)(logits) # 使用 nn.softmax 函数,计算预测概率
y_pred = pred_probab.argmax(1) # 获取预测类别
print(f"Predicted class: {y_pred}") # y_pred 是一个张量,可以使用 y_pred.item() 获取标量值,打印预测结果
torch.softmax是 PyTorch 中的一个函数,用于对张量(tensor)的指定维度应用 Softmax 操作。Softmax 是一种常用的激活函数,特别是在分类任务中,用于将模型的原始输出(logits)转换为概率分布。
参数说明: input: 输入的张量,通常是模型的输出(logits)。 dim: 指定进行 Softmax 操作的维度。例如,在分类任务中,dim=1 通常表示对每个样本的类别维度进行归一化。 dtype(可选):指定计算时的数据类型,通常不需要显式设置。 返回值: 返回一个与输入张量形状相同的张量,其中的值在指定维度上被归一化为概率分布(所有值的和为 1)。使用示例:
import torch# 假设这是模型的输出(logits),形状为 (batch_size, num_classes) logits = torch.tensor([[2.0, 1.0, 0.1],[1.0, 3.0, 0.2]])# 对第 1 维(类别维度)应用 Softmax probabilities = torch.softmax(logits, dim=1)print("Logits:") print(logits) print("\nSoftmax Probabilities:") print(probabilities)# 验证概率和为 1 print("\nSum of probabilities along dim=1:") print(probabilities.sum(dim=1)) # 每行的和应该接近 1''' 输出 Logits: tensor([[2.0000, 1.0000, 0.1000],[1.0000, 3.0000, 0.2000]])Softmax Probabilities: tensor([[0.6590, 0.2424, 0.0986],[0.1065, 0.8808, 0.0127]])Sum of probabilities along dim=1: tensor([1.0000, 1.0000]) '''数值稳定性:
- 在实际应用中,为了提高数值稳定性,通常会在计算 Softmax 之前,先对 logits 减去最大值(即
logits - logits.max(dim, keepdim=True)[0]),这样可以避免指数运算时的溢出问题。- PyTorch 的
F.log_softmax和F.softmax(需要从torch.nn.functional导入)已经内置了这种优化。分类任务中的使用:
- 在分类任务中,通常先用模型得到 logits,然后用 Softmax 转换为概率分布,最后选择概率最大的类别作为预测结果。
模型层
查看安装的PyTorch版本
方法一:cmd终端查看
终端中输入:
>>>python
>>>import torch
>>>torch.__version__ //注意version前后是两个下划线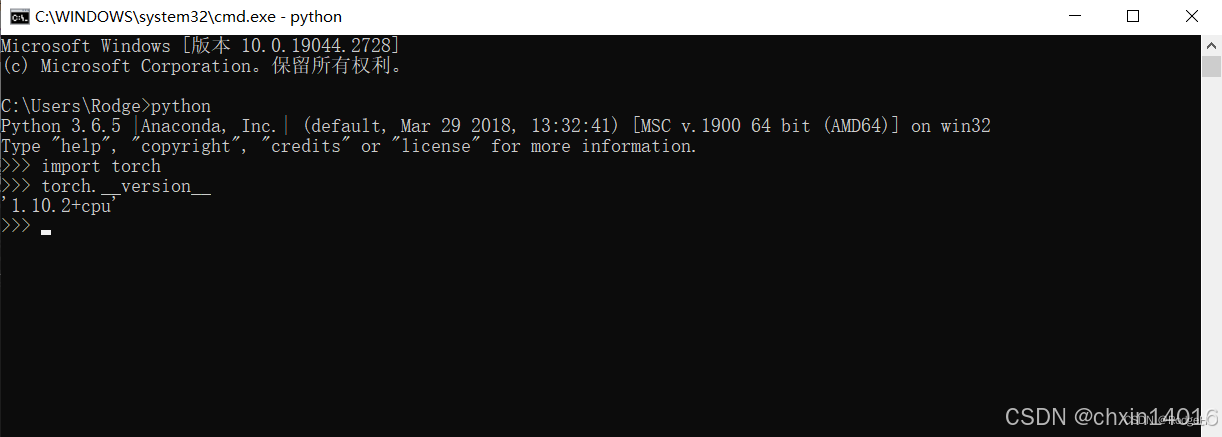
方法二:PyCharm查看
打开Pycharm,在Python控制台中输入:
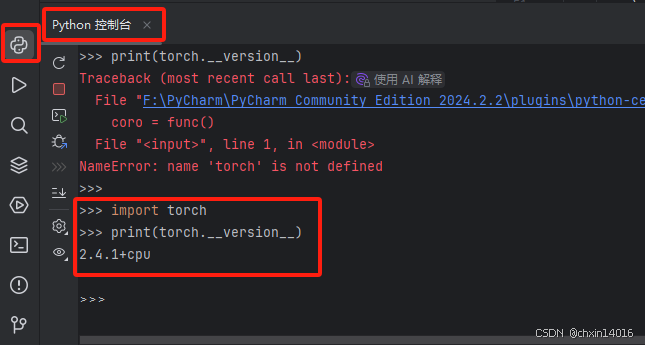
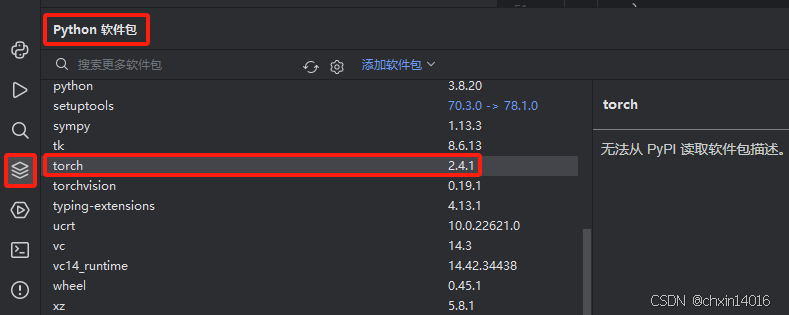
或者在Pycharm的“Python软件包”中查看:
相关文章:
PyTorch 学习笔记
环境:python3.8 PyTorch2.4.1cpu PyCharm 参考链接: 快速入门 — PyTorch 教程 2.6.0cu124 文档 PyTorch 文档 — PyTorch 2.4 文档 快速入门 导入库 import torch from torch import nn from torch.utils.data import DataLoader from torchvision …...
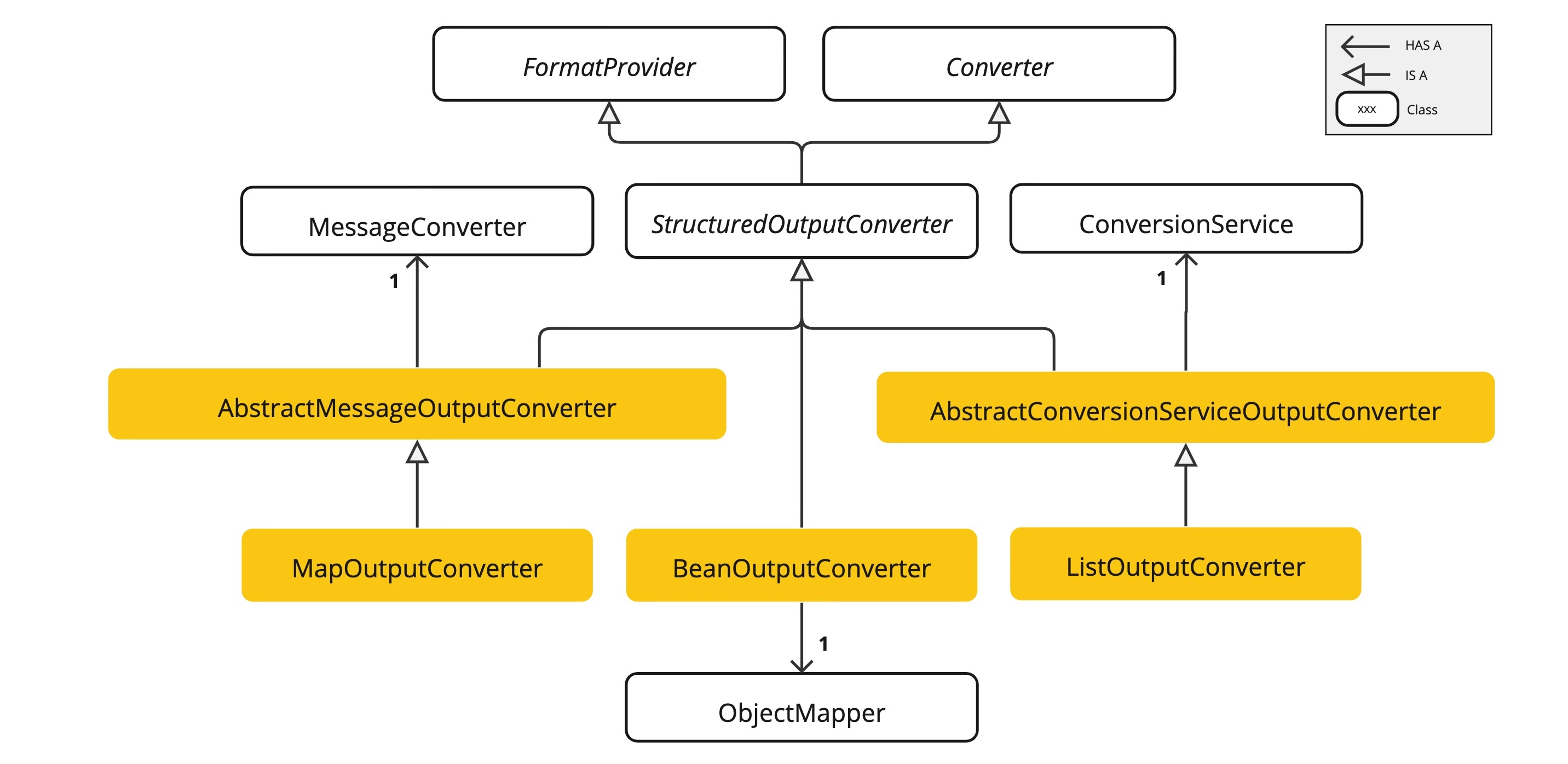
Spring AI 结构化输出详解
一、Spring AI 结构化输出的定义与核心概念 Spring AI 提供了一种强大的功能,允许开发者将大型语言模型(LLM)的输出从字符串转换为结构化格式,如 JSON、XML 或 Java 对象。这种结构化输出能力对于依赖可靠解析输出值的下游应用程…...

spring security oauth2.0的四种模式
OAuth 2.0 定义了 4 种授权模式(Grant Type),用于不同场景下的令牌获取。以下是每种模式的详细说明、适用场景和对比: 一、授权码模式(Authorization Code Grant) 适用场景 • Web 应用(有后端…...
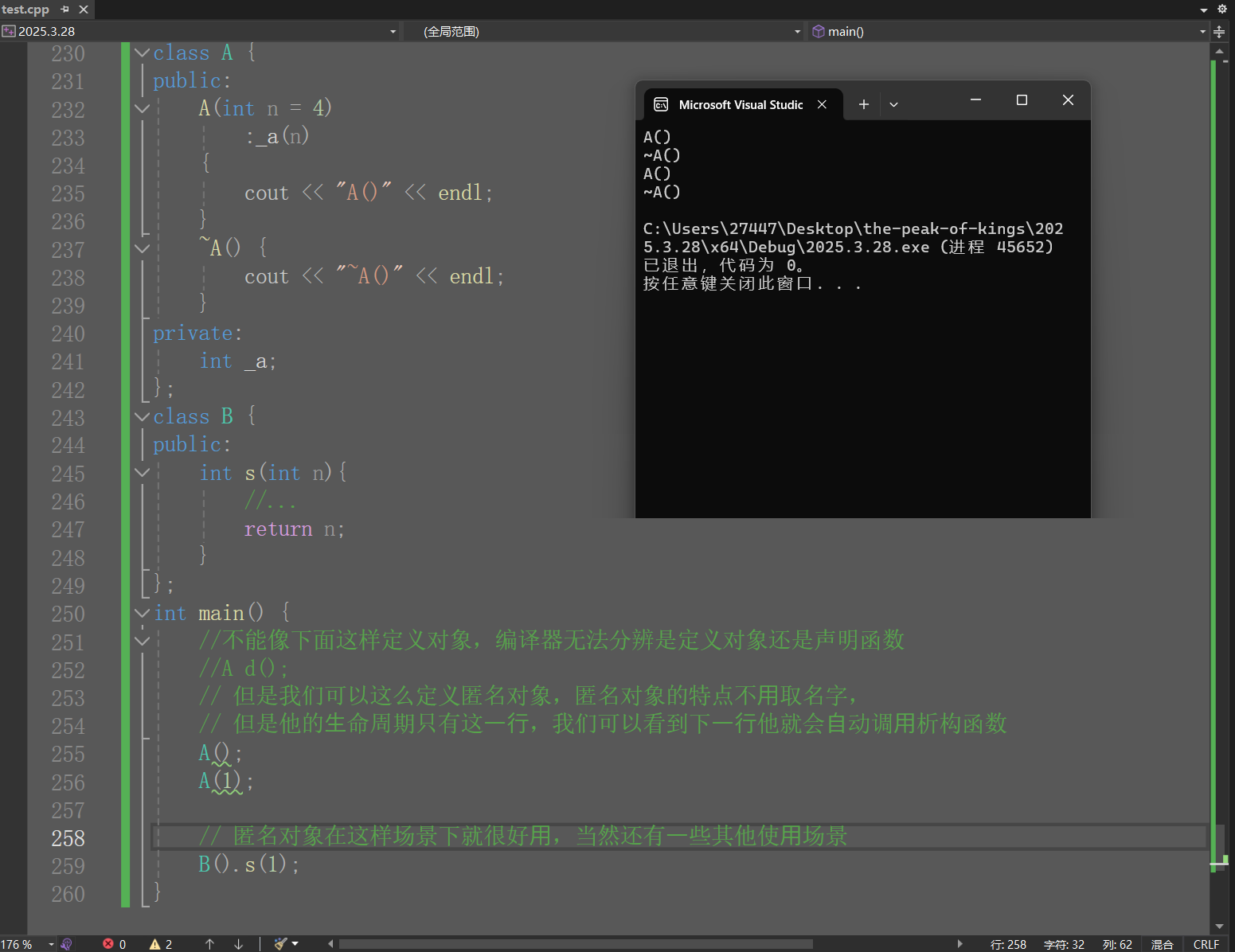
从零开始的C++编程 2(类和对象下)
目录 1.构造函数初始化列表 2.类型转换 3.static成员 4.友元 5.内部类 6.匿名对象 1.构造函数初始化列表 ①之前我们实现构造函数时,初始化成员变量主要使⽤函数体内赋值,构造函数初始化还有⼀种⽅式,就是初始化列表,初始化…...

Vue 项目中 package.json 文件的深度解析
Vue 项目中 package.json 文件的深度解析 在 Vue 项目中,package.json 文件是项目配置的核心,它管理着项目的依赖关系、脚本命令、版本信息等重要内容。正确理解和配置 package.json 文件,对于项目的开发、构建、测试和部署都至关重要。本文…...

将三维非平面点集拆分为平面面片的MATLAB实现
将三维非平面点集拆分为平面面片的MATLAB实现 要将三维空间中不在同一平面上的点集拆分为多个平面面片,可以采用以下几种方法: 1. 三角剖分法 (Delaunay Triangulation) 最简单的方法是将点集进行三角剖分,因为三个点总是共面的࿱…...
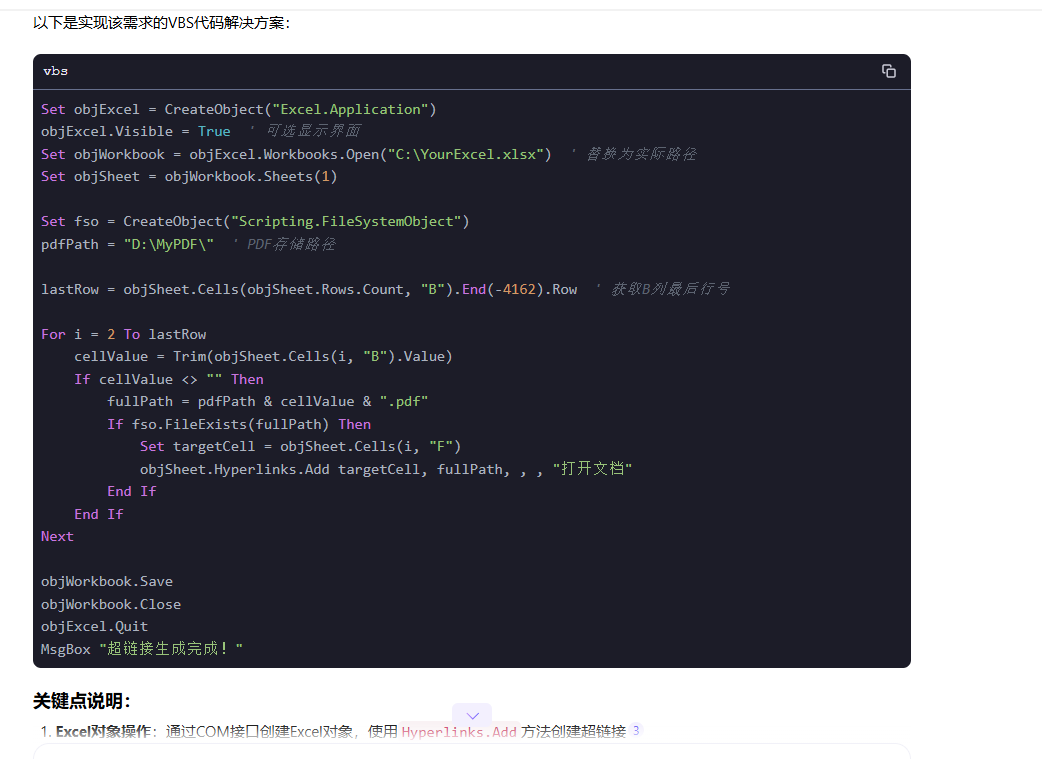
AI结合VBA提升EXCEL办公效率尝试
文章目录 前言一、开始VBA编程二、主要代码三、添加到所有EXCEL四、运行效果五、AI扩展 前言 EXCEL右击菜单添加一个选项,点击执行自己逻辑的功能。 然后让DeepSeek帮我把我的想法生成VBA代码 一、开始VBA编程 我的excel主菜单没有’开发工具‘ 选项,…...

基于单片机的电梯智能识别电动车阻车系统设计与实现
标题:基于单片机的电梯智能识别电动车阻车系统设计与实现 内容:1.摘要 随着电动车在日常生活中的普及,将电动车带入电梯带来的安全隐患日益凸显,如引发火灾等。本研究的目的是设计并实现一种基于单片机的电梯智能识别电动车阻车系统。方法上,…...

Python快速入门指南:从零开始掌握Python编程
文章目录 前言一、Python环境搭建🥏1.1 安装Python1.2 验证安装1.3 选择开发工具 二、Python基础语法📖2.1 第一个Python程序2.2 变量与数据类型2.3 基本运算 三、Python流程控制🌈3.1 条件语句3.2 循环结构 四、Python数据结构🎋…...
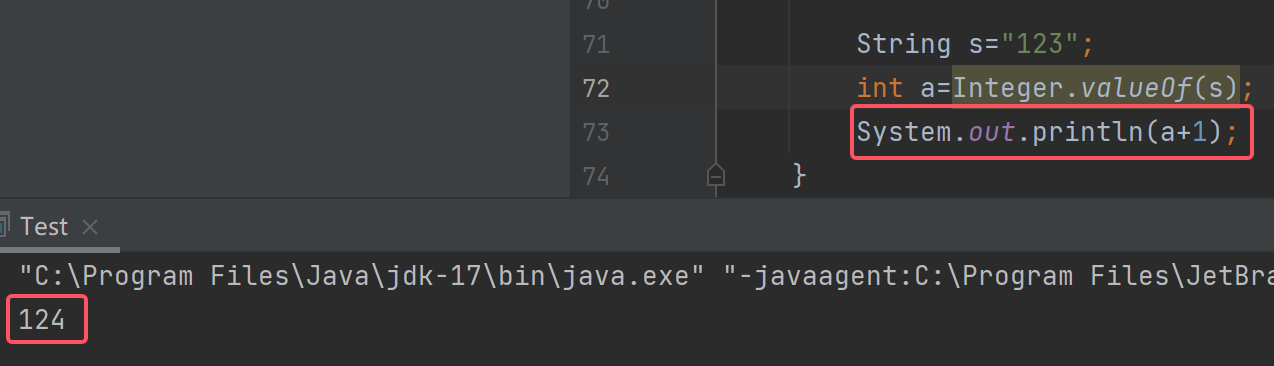
Java——数据类型与变量
文章目录 字面常量Java数据类型变量定义变量的方式整形变量长整型变量短整型变量字节型变量浮点型变量双精度浮点型单精度浮点型 字符型变量布尔型变量 类型转换自动类型转换(隐式)强制类型转换(显式) 类型提升byte与byte的运算 字…...
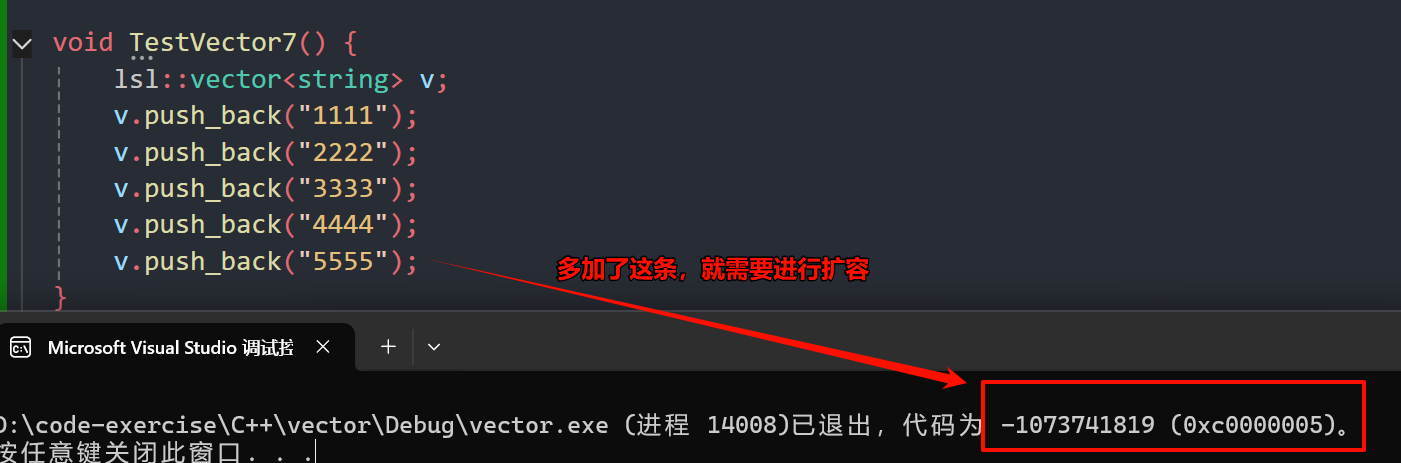
9. C++STL详解vector的使用以及模拟实现
文章目录 一、vector的使用介绍1.1 vector的定义1.2 vector iterator 的使用1.3 vector 增删查改二、vector 迭代器失效问题会引起其底层空间改变的操作,都有可能是迭代器失效,比如:resize、reserve、insert、assign、push_back等。指定位置元…...
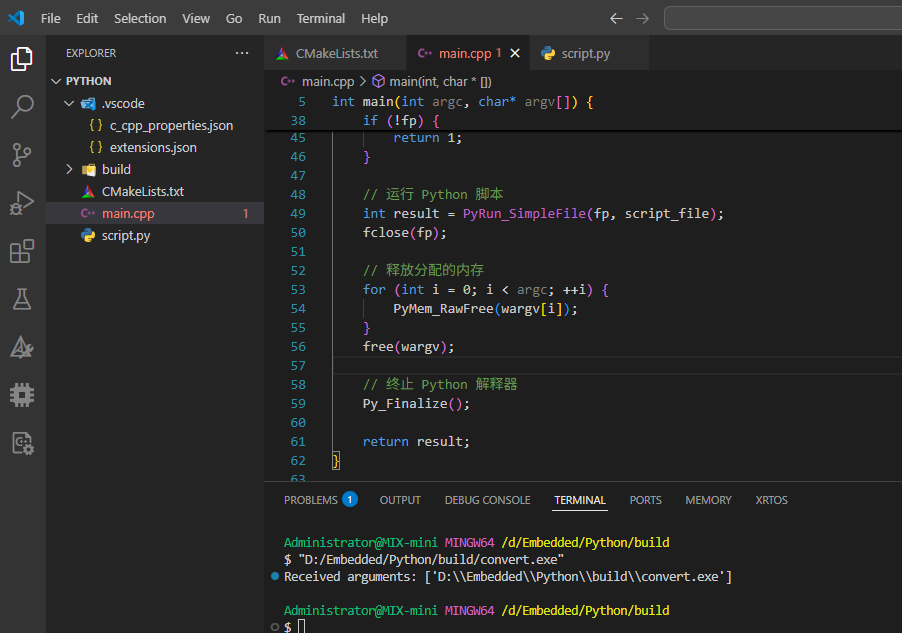
C/C++调用Python程序代码实现混合编程笔记教程
0、引言 Python在基础开发、数据科学、人工智能、Web框架开发等领域具有广泛的支持工具和开发教程,极大的缩短了产品原型开发周期、降低了开发难度。 有许多的功能,通过C/C实现,非常的复杂并且不方便,但是Python可能就是几行代码…...
LeetCode hot 100—子集
题目 给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。 解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。 示例 示例 1: 输入:nums [1,2,3] 输出:[[],[1],[2…...
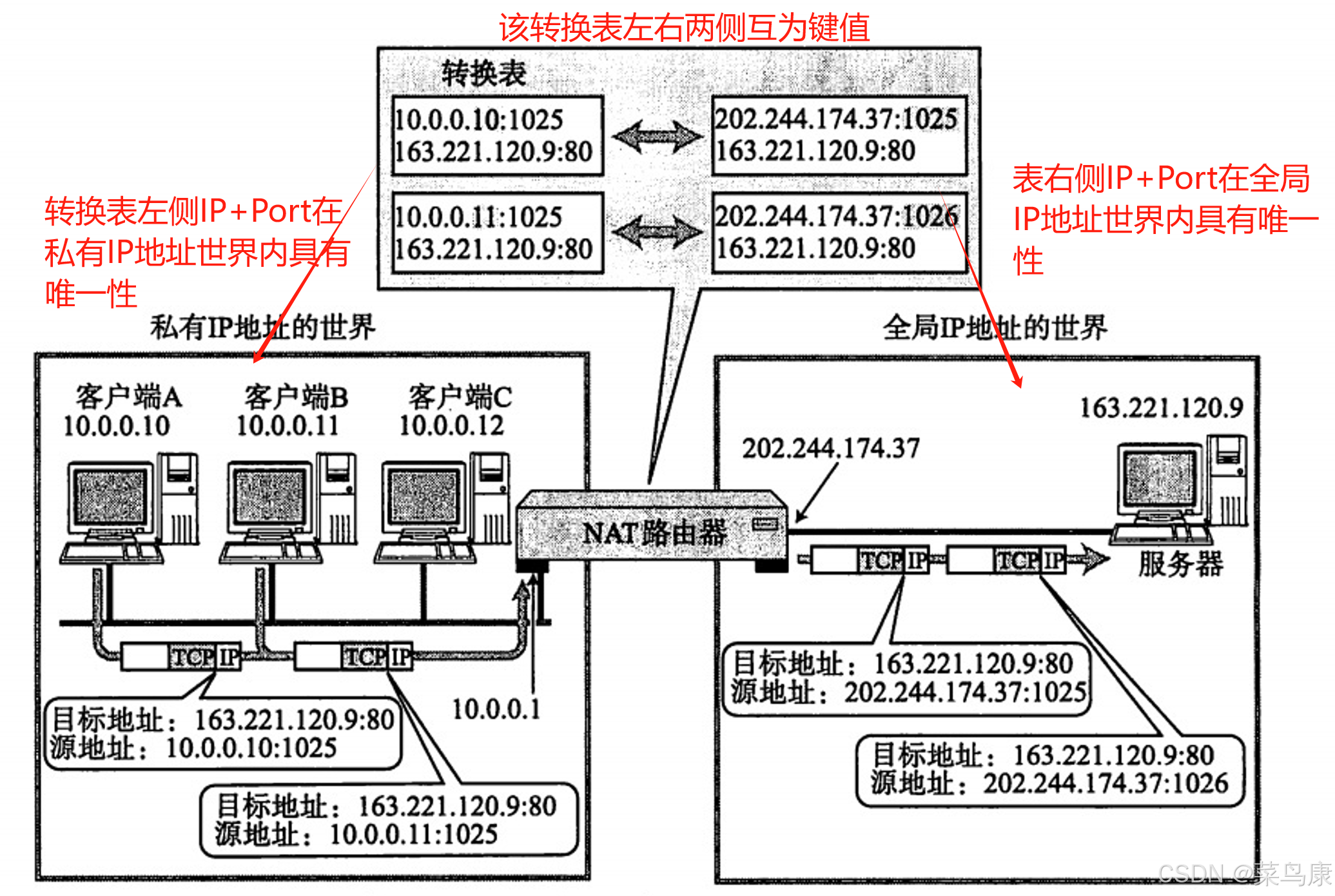
Linux网络编程——数据链路层详解,以太网、MAC地址、MTU、ARP、DNS、NAT、代理服务器......
目录 一、前言 二、以太网 二、以太网帧格式 三、 MAC地址 四、MTU 1、数据链路层的数据分片 2、MTU对UDP协议的影响 3、MTU对TCP协议的影响 五、ARP协议 1、什么是ARP 2、ARP的作用 3、ARP协议的工作流程 4、ARP缓存表 5、ARP请求报文 6、中间人 六、DNS&…...

MySQL 5.7.30 Linux 二进制安装包详解及安装指南
MySQL 5.7.30 Linux 安装包详解 mysql-5.7.30-linux-glibc2.12-x86_64.tar 是 MySQL 服务器 5.7.30 版本的 Linux 二进制发行包。 mysql-5.7.30-linux-glibc2.12-x86_64.tar 安装包下载 链接:https://pan.quark.cn/s/2943cd209ca5 包信息 版本: MySQL 5.7.30 平…...

基于springboot+vue的秦皇岛旅游景点管理系统
开发语言:Java框架:springbootJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包:Maven3.3.9 系统展示 用户登录 旅游路…...
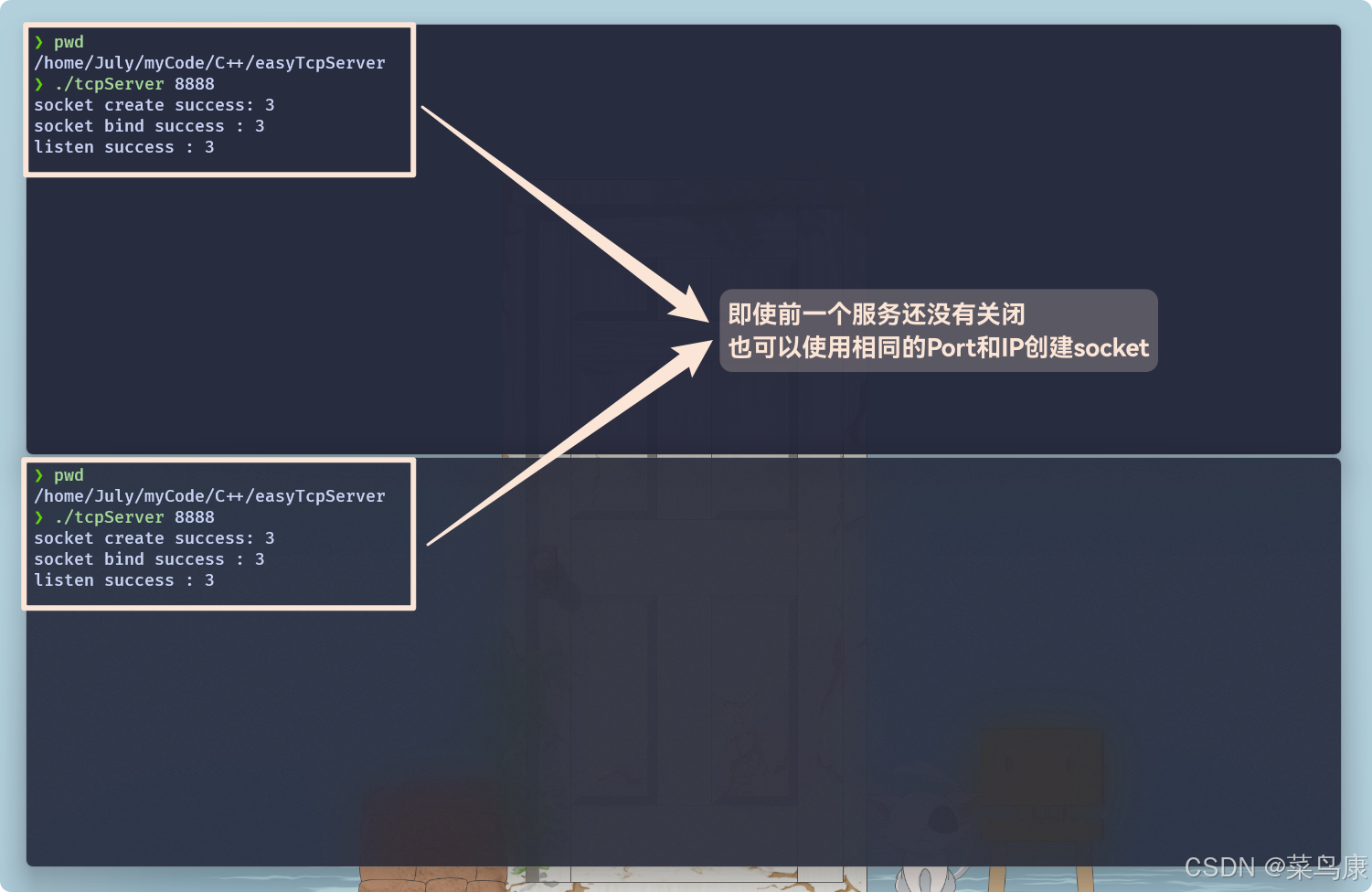
Linux网络编程——TCP通信的四次挥手
一、前言 上篇文章讲到了TCP通信建立连接的“三次握手”的一些细节,本文再对TCP通信断开连接的“四次挥手”的过程做一些分析了解。 二、TCP断开连接的“四次挥手” 我们知道TCP在建立连接的时需要“三次握手”,三次握手完后就可以进行通信了。而在通…...

634SJBH苏州旅游网站
1 绪论 1.1 课题的提出、研究现状及研究意义 旅游业具有“无烟产业”和“永远的朝阳产业”的美称,它已经和石油业、汽车业并列为世界三大产业;根据WTTC的统计,它每年产出4.7万亿美金的收入,直接或间接地为2亿700万人提供了就业机…...

计算机视觉算法实现——SAM实例分割:原理、实现与应用全景
✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连✨ 1. 实例分割领域概述 实例分割(Instance Segmentation)是计算机视觉领域最具挑战性的任务之一,…...

基于SpringBoot的宠物健康咨询系统(源码+数据库+万字文档)
502基于SpringBoot的宠物健康咨询系统,系统包含三种角色:管理员、用户,顾问主要功能如下。 【用户功能】 1. 首页:查看系统主要信息和最新动态。 2. 公告:浏览系统发布的公告信息。 3. 顾问:浏览可提供咨询…...
vue2 el-element中el-select选中值,数据已经改变但选择框中不显示值,需要其他输入框输入值才显示这个选择框才会显示刚才选中的值
项目场景: <el-table-column label"税率" prop"TaxRate" width"180" align"center" show-overflow-tooltip><template slot-scope"{row, $index}"><el-form-item :prop"InquiryItemList. …...
、except(差集)、intersect(交集))
pgsql:关联查询union(并集)、except(差集)、intersect(交集)
pgsql:关联查询union(并集)、except(差集)、intersect(交集)_pgsql except-CSDN博客...

CCF CSP 第35次(2024.09)(2_字符串变换_C++)(哈希表+getline)
CCF CSP 第35次(2024.09)(2_字符串变换_C) 解题思路:思路一(哈希表getline): 代码实现代码实现(思路一(哈希表getline)): …...

PostgreSQL 的 COPY 命令
PostgreSQL 的 COPY 命令 PostgreSQL 的 COPY 命令是高效数据导入导出的核心工具,性能远超常规 INSERT 语句。以下是 COPY 命令的深度解析: 一 COPY 命令基础 1.1 基本语法对比 命令类型语法示例执行位置文件访问权限服务器端COPYCOPY table FROM /p…...

Docker--利用dockerfile搭建mysql主从集群和redis集群
Docker镜像制作的命令 链接 Docker 镜像制作的注意事项 链接 搭建mysql主从集群 mysql主从同步的原理 MySQL主从同步(Replication)是一种实现数据冗余和高可用性的技术,通过将主数据库(Master)的变更操作同步到一个…...

Context的全面解析:在不同技术应用中的通用作用与差异
Context的全面解析:在不同技术应用中的通用作用与差异 引言: 在软件开发中,“Context”这个概念被广泛使用。它不仅限于某个特定的技术或编程语言,实际上,Context 作为一种抽象的设计模式,贯穿在许多开发领…...
蓝桥杯嵌入式考前模块总结
一.RTC 使用RTC直接再cubeMX中配置启动时钟和日历 如第六届省赛 想要让RTC的秒每隔一秒递增1需要在时钟树界面观察RTC的主频 由于RTC时钟主频为32KHZ将异步预分频计数器的值设为31,将同步预分频计数器的值设为999这样就可以将RTC的时钟信号分频为1HZ达到1秒自增的…...

关于举办“2025年第五届全国大学生技术创新创业大赛“的通知
赛事含金量 大赛获奖即可有机会为你的大学里的“创新创业”加分!这是每个大学要求必须修满的学分! 中国“互联网+”大学生创新创业大赛磨刀赛!“挑战杯”中国大学生创业计划大赛必参赛! 国赛获奖,“互联…...

spark安装过程问题
1. Spark-local模式 - 适用于单节点环境,无需启动Hadoop集群。 - 实验步骤包括解压文件、启动Local环境、运行命令行工具、提交测试应用等。 - 通过bin/spark-shell启动本地环境,通过sc.textFile等命令测试功能。 - 提交应用时使用--master loca…...
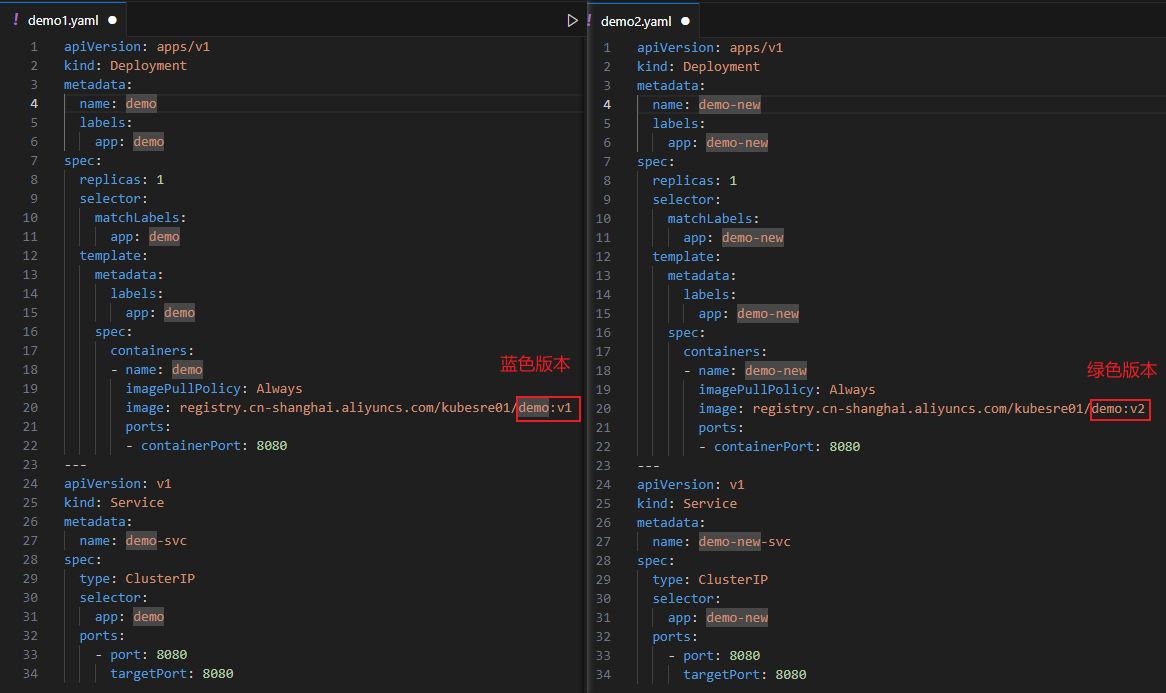
Ingress蓝绿发布
Ingress蓝绿发布 Ingress常用注解说明yaml资源清单绿色版本yml资源清单蓝色版本yaml资源清单 主Ingress金丝雀Ingress基于客户端请求头的流量切分结果验证 基于客户端来源IP的流量切分结果验证 基于服务权重的流量切分结果验证 基于IP来源区域来切分IP---方案未验证基于User-Ag…...