机器学习(3)——决策树
文章目录
- 1. 决策树基本原理
- 1.1. 什么是决策树?
- 1.2. 决策树的基本构成:
- 1.3. 核心思想
- 2. 决策树的构建过程
- 2.1. 特征选择
- 2.1.1. 信息增益(ID3)
- 2.1.2. 基尼不纯度(CART)
- 2.1.3. 均方误差(MSE)
- 2.2. 节点划分
- 2.3. 停止条件:
- 3. 决策树的剪枝(防止过拟合)
- 4. 决策树的优缺点
- 5. 常见决策树算法
- 6. 样例代码:
- 7. 归纳
1. 决策树基本原理
1.1. 什么是决策树?
决策树(Decision Tree)是一种非参数的监督学习算法,适用于分类和回归任务。其核心思想是通过一系列规则(if-then结构)对数据进行递归划分,最终形成一棵树形结构,实现预测或分类。
1.2. 决策树的基本构成:
- 根节点(Root Node):代表整个数据集,选择第一个最优特征进行分裂。
- 内部节点(Internal Nodes):代表对某个特征的判断,用来决定如何分裂数据。
- 叶子节点(Leaf Nodes):存放最终的预测结果,表示分类或回归结果。
1.3. 核心思想
- 目标:构建一棵树,使得每个分支节点代表一个特征判断,每个叶子节点代表一个预测结果。
- 关键问题:
- 如何选择划分特征?(特征选择准则)
- 何时停止划分?(防止过拟合)
2. 决策树的构建过程
决策树的构建是一个递归分割(Recursive Partitioning)的过程
2.1. 特征选择
选择最佳特征:在每一步分裂中,算法会选择一个最优的特征来进行数据划分。
常用的准则:
- 信息增益(Information Gain, ID3算法)
- 信息增益比(Gain Ratio, C4.5算法)
- 基尼不纯度(Gini Impurity, CART算法)
- 均方误差(MSE, 回归树)
2.1.1. 信息增益(ID3)
-
衡量使用某特征划分后信息不确定性减少的程度。
-
计算公式: 信息增益 = H ( D ) − H ( D ∣ A ) 信息增益=H(D)−H(D∣A) 信息增益=H(D)−H(D∣A)
- H(D):数据集的熵(不确定性)。
- H(D∣A):在特征 A划分后的条件熵。
2.1.2. 基尼不纯度(CART)
-
衡量数据集的不纯度,越小越好,表示数据集越纯。
-
计算公式:
Gini ( D ) = 1 − ∑ k = 1 K p k 2 \text{Gini}(D) = 1 - \sum_{k=1}^{K} p_k^2 Gini(D)=1−k=1∑Kpk2- p k p_k pk :数据集中第 k k k 类样本的比例。
2.1.3. 均方误差(MSE)
-
用于回归问题,计算预测值与真实值的差异。
-
计算公式: M S E = 1 n ∑ ( y i − y ^ i ) 2 MSE= \frac {1}{n}\sum(y_i − \hat y_i) ^2 MSE=n1∑(yi−y^i)2
- y i y_i yi是实际值, y ^ i \hat y_i y^i 是预测值。
2.2. 节点划分
- 分类任务:选择使信息增益最大(或基尼不纯度最小)的特征进行划分。
- 回归任务:选择使均方误差(MSE)最小的特征进行划分。
2.3. 停止条件:
- 当前节点所有样本属于同一类别(纯度100%)。
- 所有特征已用完,或继续划分无法显著降低不纯度。
- 达到预设的最大深度(max_depth)或最小样本数(min_samples_split)。
3. 决策树的剪枝(防止过拟合)
决策树容易过拟合(训练集表现好,测试集差)。为了防止过拟合,我们通常会使用剪枝技术。
-
预剪枝(Pre-pruning):在训练时提前停止(如限制树深度)。
-
后剪枝(Post-pruning):先训练完整树,再剪掉不重要的分支(如C4.5的REP方法)。
4. 决策树的优缺点
- ✅ 优点
- 可解释性强:规则清晰,易于可视化(if-then结构)。
- 无需数据标准化:对数据分布无严格要求。
- 可处理混合类型数据(数值型+类别型)。
- 适用于小规模数据。
- ❌ 缺点
- 容易过拟合(需剪枝或限制树深度)。
- 对噪声敏感(异常值可能导致树结构不稳定)。
- 不稳定性:数据微小变化可能导致完全不同的树。
- 不适合高维稀疏数据(如文本数据)。
5. 常见决策树算法
| 算法 | 适用任务 | 特征选择准则 | 特点 |
|---|---|---|---|
| ID3 | 分类 | 信息增益 | 只能处理离散特征,容易过拟合 |
| C4.5 | 分类 | 信息增益比 | 可处理连续特征,支持剪枝 |
| CART | 分类/回归 | 基尼不纯度(分类) 均方误差(回归) | 二叉树结构,Scikit-learn默认实现 |
| CHAID | 分类 | 卡方检验 | 适用于类别型数据 |
6. 样例代码:
# 导入必要的库
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree# 加载鸢尾花数据集
data = load_iris()
X = data.data
y = data.target# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建决策树分类器
clf = DecisionTreeClassifier(criterion='gini', max_depth=3, random_state=42)# 训练决策树
clf.fit(X_train, y_train)# 预测测试集
y_pred = clf.predict(X_test)# 输出准确率
print(f"Accuracy: {accuracy_score(y_test, y_pred):.4f}")# 可视化决策树
plt.figure(figsize=(12, 8))
plot_tree(clf, filled=True, feature_names=data.feature_names, class_names=data.target_names)
plt.show()7. 归纳
决策树的核心:递归划分数据,选择最优特征,构建树结构。
-
关键问题:
- 如何选择划分特征?(信息增益、基尼不纯度)
- 如何防止过拟合?(剪枝、限制树深度)
-
适用场景:
-
需要可解释性的任务(如金融风控)。
-
小规模、低维数据分类/回归
-
相关文章:
——决策树)
机器学习(3)——决策树
文章目录 1. 决策树基本原理1.1. 什么是决策树?1.2. 决策树的基本构成:1.3. 核心思想 2. 决策树的构建过程2.1. 特征选择2.1.1. 信息增益(ID3)2.1.2. 基尼不纯度(CART)2.1.3. 均方误差(MSE&…...

Redis常用数据结构和应用场景
一、前言 Redis提供了多种数据结构,每种结构对应不同的应用场景。本文对部分常用的核心数据结构和典型使用场景作出介绍。 二、String(字符串) 特点:二进制安全,可存储文本、数字、序列化对象等。场景: 缓…...
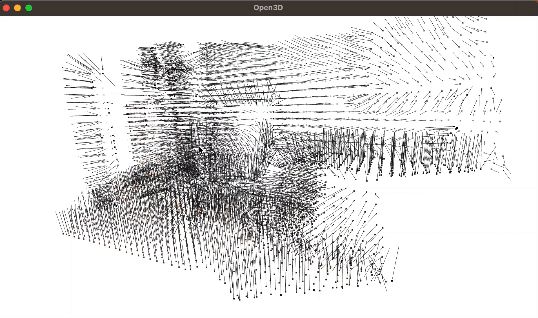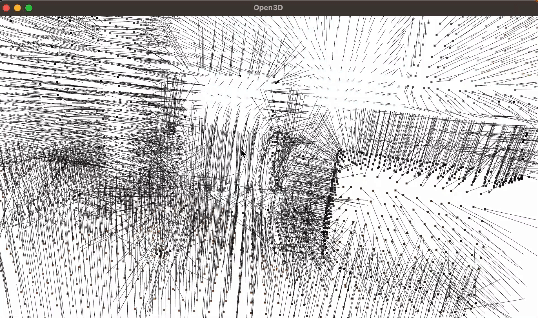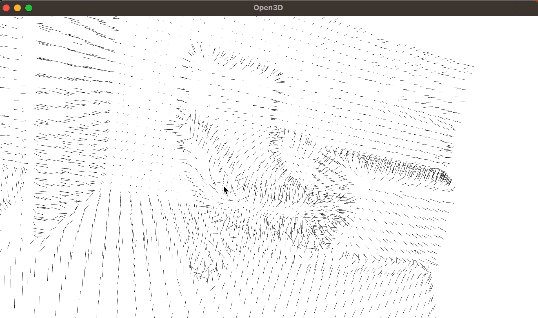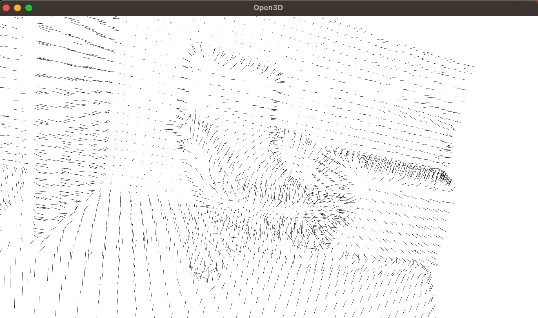
【转载翻译】使用Open3D和Python进行点云处理
转自个人博客:【转载翻译】使用Open3D和Python进行点云处理 转载自:Point Cloud Processing with Open3D and Python 本文由 Carlos Melo 发布于2024年2月12日 本文很适合初学者对三维处理、点云处理以及Open3D库进行初步了解 另外,本文是基于…...
用户登录不上linux服务器
一般出现这种问题,重新用root用户修改lsy用户的密码即可登录,但是当修改了还是登录不了的时候,去修改一个文件用root才能修改, 然后在最后添加上改用户的名字,例如 原本是只有user的,现在我加上了lsy了&a…...

SQL 全文检索原理
全文检索(Full-Text Search)是SQL中用于高效搜索文本数据的技术,与传统的LIKE操作或简单字符串比较相比,它能提供更强大、更灵活的文本搜索能力。 基本概念 全文检索的核心思想是将文本内容分解为可索引的单元(通常是词或词组),然后建立倒排…...

dcsdsds
我将为您在页面顶部添加欢迎内容,同时保持整体风格的一致性。以下是修改后的代码,主要修改了模板部分和对应的样式: vue 复制 <template><div class"main-wrapper"><!-- 新增欢迎部分 --><div class"…...

FISCO BCOS区块链Postman接口测试:高级应用与实战技巧 [特殊字符]
引言:为什么Postman是FISCO BCOS测试的利器? 在区块链开发领域,接口测试是确保系统稳定性和安全性的关键环节。作为国产领先的联盟链平台,FISCO BCOS在金融、政务、供应链等多个领域得到广泛应用。而Postman作为一款功能强大的API测试工具,凭借其直观的图形界面和丰富的测…...

KWDB创作者计划—KWDB场景化创新实践:多模态数据融合与边缘智能的突破性应用
引言:AIoT时代的数据库范式重构 在工业物联网设备数量突破千亿、边缘计算节点覆盖率达75%的2025年,传统数据库面临多模态数据处理效率低下、边缘端算力利用率不足、跨域数据协同困难等核心挑战。KWDB(KaiwuDB Community Edition)通…...

风暴之眼:在AI重构的数字世界重绘职业坐标系
硅谷的某个深夜,GitHub Copilot在程序员的注视下自动生成出完美代码,这个场景正在全球数百万开发者的屏幕上同步上演。当AI生成的代码通过图灵测试,当机器学习模型开始理解业务需求,一个根本性命题浮出水面:在人类亲手…...

主机协议端口安全
FTP RDP SSH Rsync 渗透基础 | 黑客常用端口利用总结 - ZM思 - 博客园 (cnblogs.com)...
matplotlib数据展示
目录 一、绘制直方图 1、简单直方图 2、绘制横向直方图 3、绘制堆叠直方图 4、对比直方图 二、折线图与散点图 三、绘制饼图 四、雷达图 1、简单雷达图 2、多层雷达图 五、总和 在前面的学习中,我们能够使用一些库进行数据的整合,收集&#x…...

MySQL 面经
1、什么是 MySQL? MySQL 是一个开源的关系型数据库,现在隶属于 Oracle 公司。是我们国内使用频率最高的一种数据库,我本地安装的是比较新的 8.0 版本。 1.1 怎么删除/创建一张表? 可以使用 DROP TABLE 来删除表,使用…...

vLLM实战:多机多卡大模型分布式推理部署全流程指南
1. 环境准备与基础配置 1.1 系统要求 依赖组件: # 基础工具安装 sudo apt-get install -y lsof git-lfs nvidia-cuda-toolkit1.2 虚拟环境配置 使用conda创建隔离环境,避免依赖冲突: conda create -n vllm python3.10 -y conda activate…...

贪心算法 day08(加油站+单调递增的数字+坏了的计算机)
目录 1.加油站 2.单调递增的数字 3.坏了的计算器 1.加油站 链接:. - 力扣(LeetCode) 思路: gas[index] - cost[index],ret 表示的是在i位置开始循环时剩余的油量 a到达的最大路径假设是f那么我们可以得出 a b …...
String类基本使用
文章目录 1. String类的理解和创建对象2. 创建String对象的两种方式3. 两种创建String对象的区别4. 测试5. 字符串的特性6. String 类的常见方法 1. String类的理解和创建对象 String 对象用于保存字符串,也就是一组字符序列字符串常量对象是用双引号括起的字符序列…...
华为机试—火车进站
题目 火车站一共有 n 辆火车需要入站,每辆火车有一个编号,编号为 1 到 n。 同时,也有火车需要出站,由于火车站进出共享一个轨道,所以后入站的火车需要先出站。换句话说,对于某一辆火车,只有在它…...
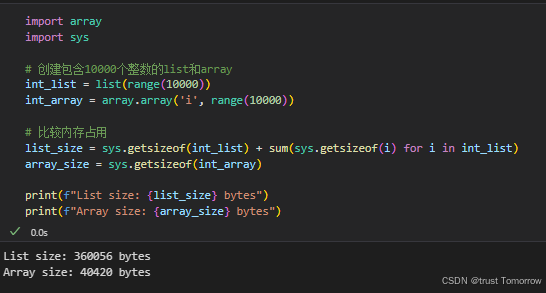
Python数组(array)学习之旅:数据结构的奇妙冒险
Python数组学习之旅:数据结构的奇妙冒险 第一天:初识数组的惊喜 阳光透过窗帘缝隙洒进李明的房间,照亮了他桌上摊开的笔记本和笔记本电脑。作为一名刚刚转行的金融分析师,李明已经坚持学习Python编程一个月了。他的眼睛因为昨晚熬夜编程而微微发红,但脸上却挂着期待的微…...
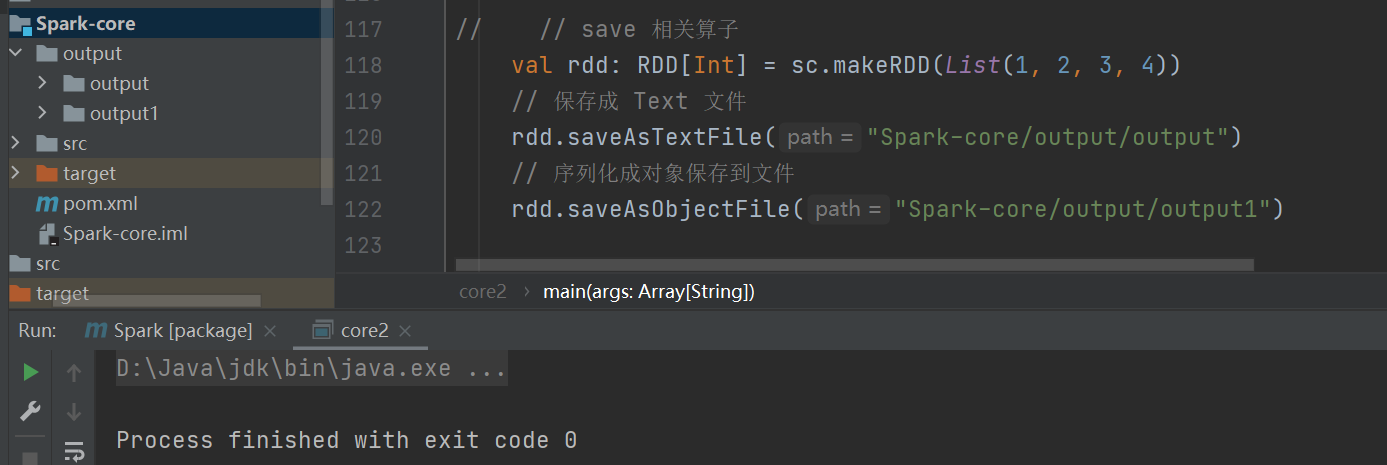
spark-core编程2
Key-Value类型: foldByKey 当分区内计算规则和分区间计算规则相同时,aggregateByKey 就可以简化为 foldByKey combineByKey 最通用的对 key-value 型 rdd 进行聚集操作的聚集函数(aggregation function)。类似于aggregate()&…...
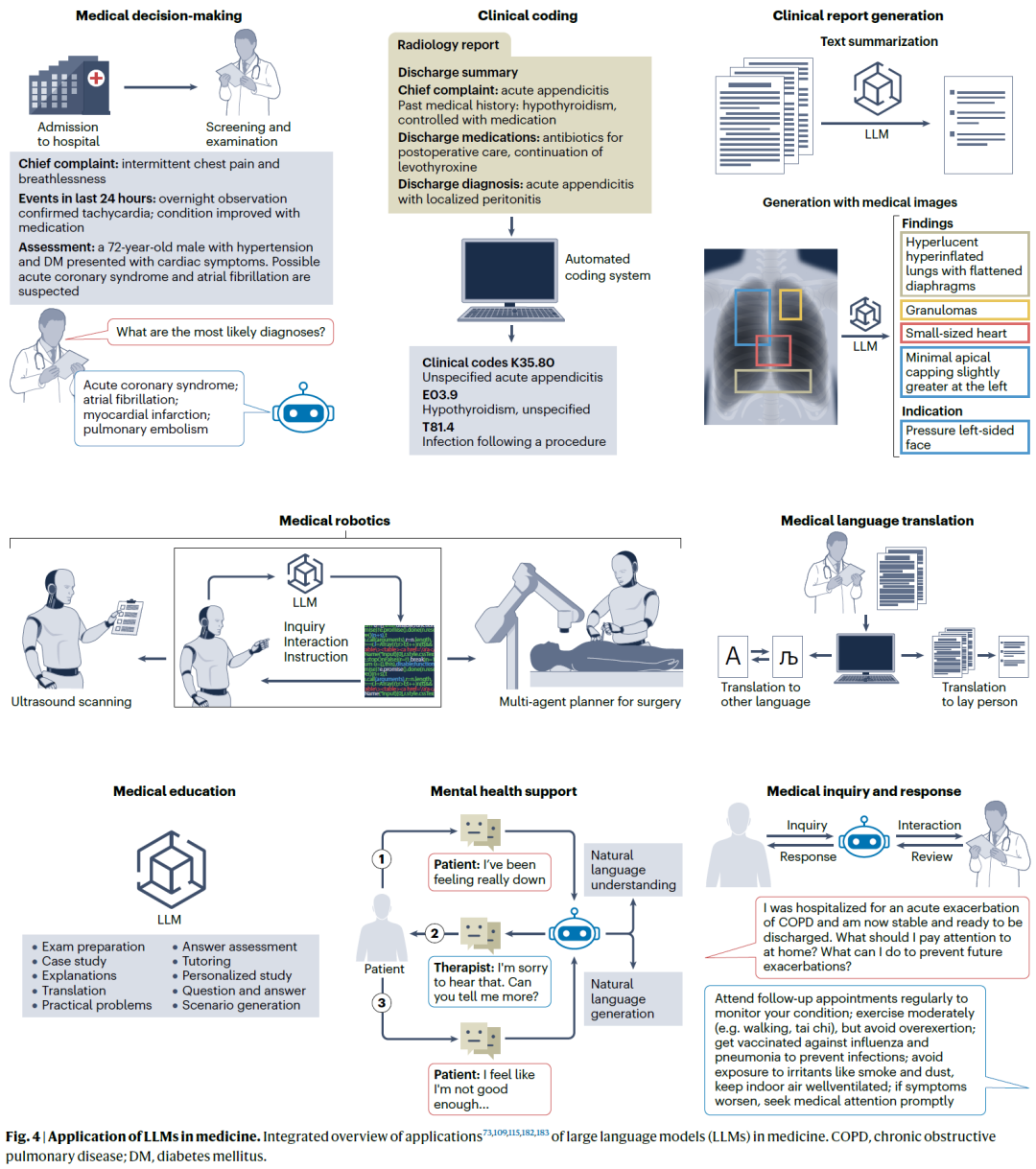
AIDD-人工智能药物设计-大语言模型在医学领域的革命性应用
Nat. Rev. Bioeng. | 大语言模型在医学领域的革命性应用 大型语言模型(LLMs),如 ChatGPT,因其对人类语言的理解与生成能力而备受关注。尽管越来越多研究探索其在临床诊断辅助、医学教育等任务中的应用,但关于其发展、…...
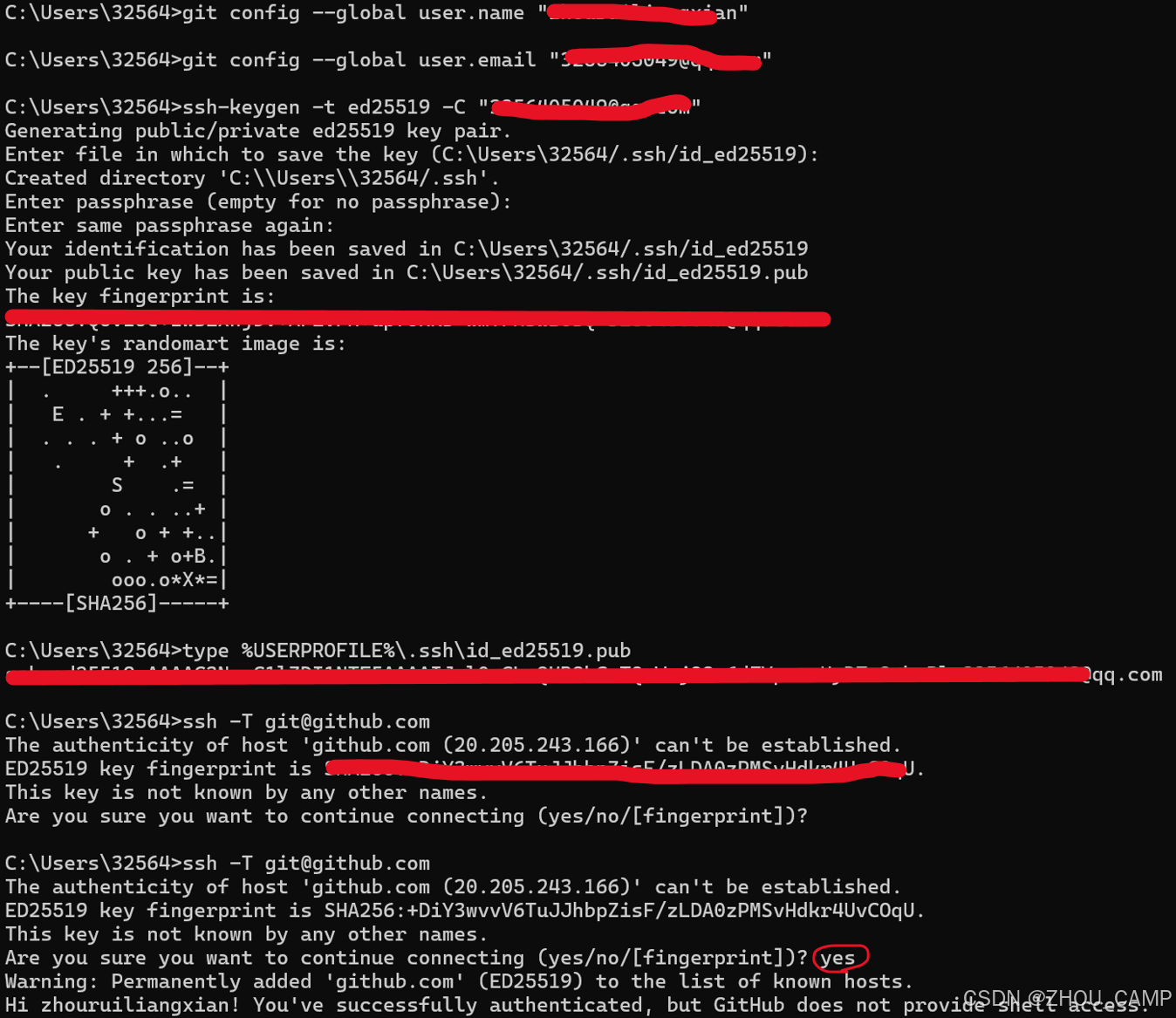
Windows 系统中安装 Git 并配置 GitHub 账户
由于电脑重装系统,重新配置了git. 以下是在 Windows 系统中安装 Git 并配置 GitHub 账户的详细步骤: 1. 安装 Git 访问 Git 官网下载页面下载 Windows 版本的 Git 安装程序运行安装程序,使用默认选项即可 2. 配置 Git 用户信息 打开命令…...
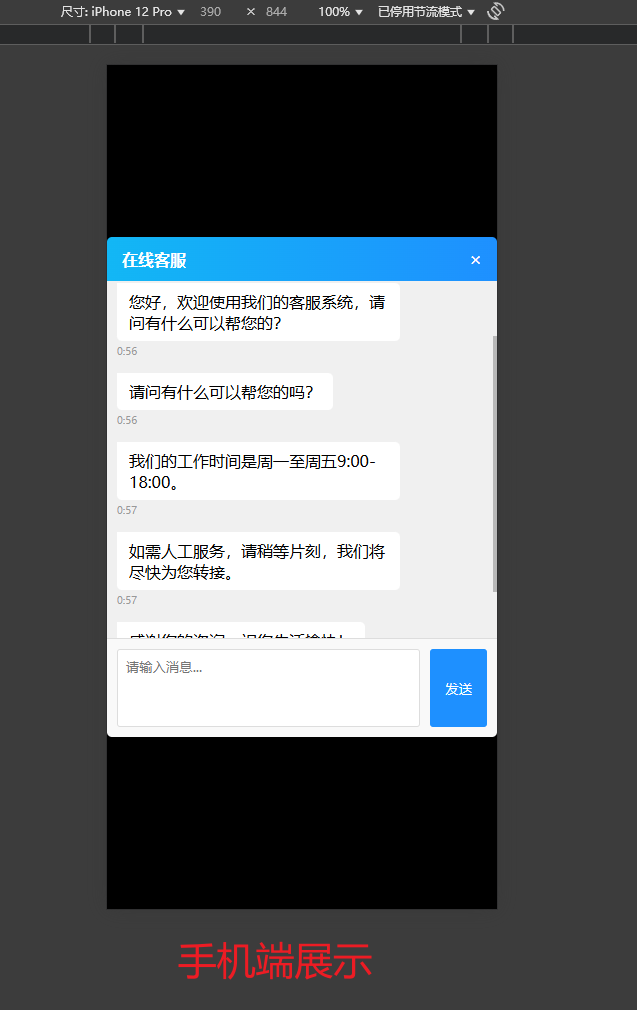
QQ风格客服聊天窗口
QQ风格客服聊天窗口 展示引入方式 展示 引入方式 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title&g…...

fastadmin后端添加页面,自主控制弹出框关闭,关闭父页面弹框
Form.api.bindevent($(“form[roleform]”), (data, ret) > { 重写绑定事件,返回false即可 注意:只有返回code1才能拦截,其他值不进行拦截 add: function () {//获取当前search里面的type值var type location.search.split(type)[1];Form.api.bindevent($("form[role…...

leetcode572 另一棵树的子树
1.与100、101解法相同 递归: class Solution { private:bool compare(TreeNode* p, TreeNode* q){if(!p && !q) return true;else if(!p || !q) return false;else if(p->val ! q->val) return false;bool leftside compare(p->left, q->lef…...

MCU刷写——Hex文件格式详解及Python代码
工作之余来写写关于MCU的Bootloader刷写的相关知识,以免忘记。今天就来聊聊Hex这种文件的格式,我是分享人M哥,目前从事车载控制器的软件开发及测试工作。 学习过程中如有任何疑问,可底下评论! 如果觉得文章内容在工作学习中有帮助到你,麻烦点赞收藏评论+关注走一波!感谢…...

ubnetu 服务器版本常用端口和开放的端口对应的应用
1. 使用 netstat 查看端口与进程 netstat 是查看网络连接和监听端口的常用工具。通过以下命令可以列出所有开放的TCP/UDP端口及其关联的进程: sudo netstat -tulnp参数解析: -t:显示TCP端口。 -u:显示UDP端口。 -l࿱…...

汇舟问卷:国外问卷调查技巧有哪些,具体该怎么操作
大家好,我是汇舟问卷,今天咱们就聊聊国外问卷答题的技巧和操作步骤,保你听完立马能上手! 一、答题前先创建人设 1,进题时先瞄两眼问题,快速判断问卷主题,再定人设。比如遇到奶粉问卷ÿ…...

DeepSeek的神经元革命:穿透搜索引擎算法的下一代内容基建
DeepSeek的神经元革命:穿透搜索引擎算法的下一代内容基建 ——从语义网络到价值共识的范式重构 一、搜索引擎的“内容饥渴症”与AI的基建使命 2024年Q1数据显示,百度索引网页总数突破3500亿,但用户点击集中在0.78%的高价值页面。这种“数据…...
C++标识符:检查是否和保留字冲突
1. 基础知识 最基本的要求: 字母、数字、下划线组成, 并且不能是数字开头。 禁忌1: C 关键字不能用做标识符。 它们是: alignas alignof asm auto bool break case catch char char16_t char32_t class const constexpr const_…...
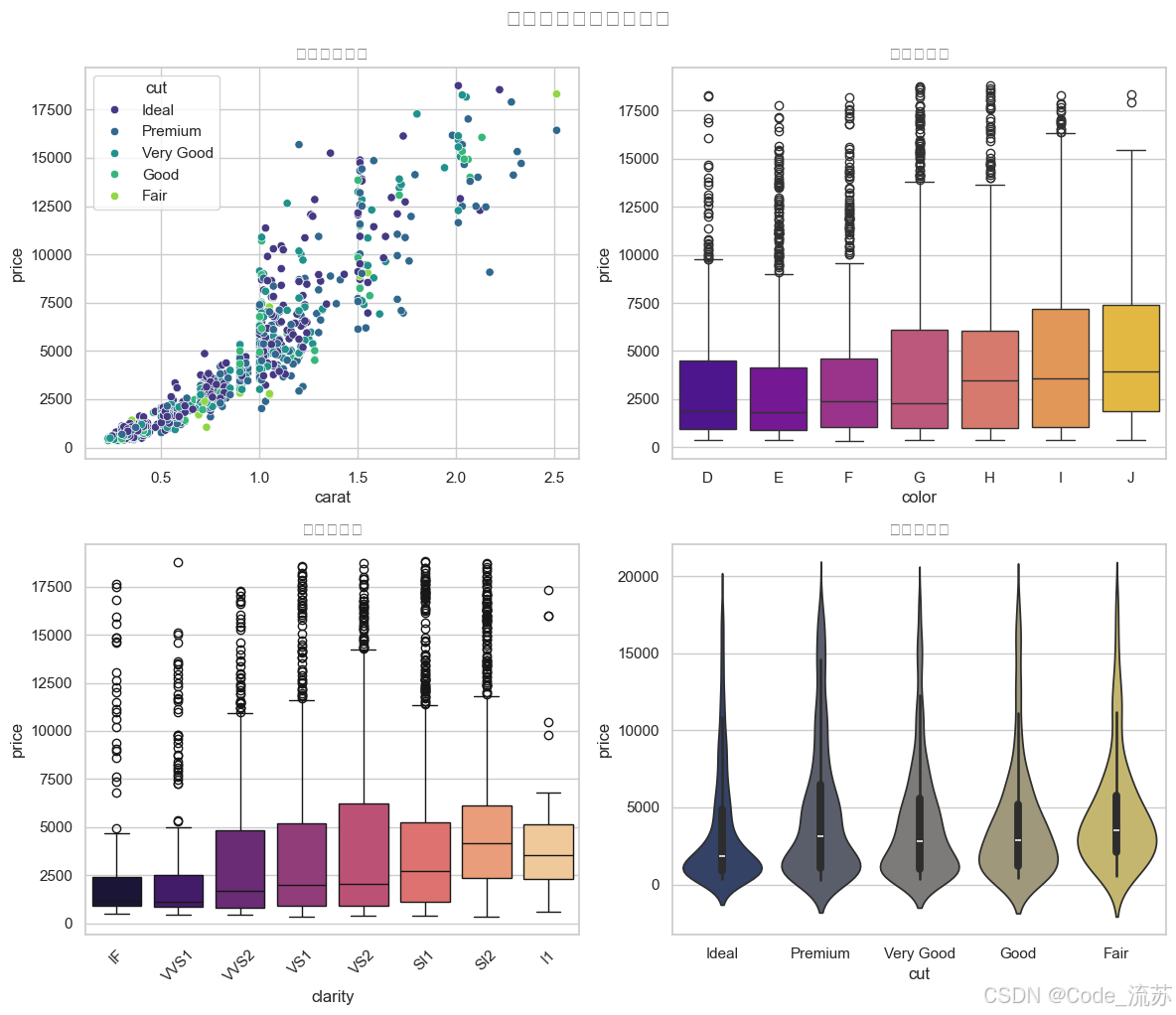
《Python星球日记》第27天:Seaborn 可视化
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏:《Python星球日记》,限时特价订阅中ing 目录 一、Seabor…...
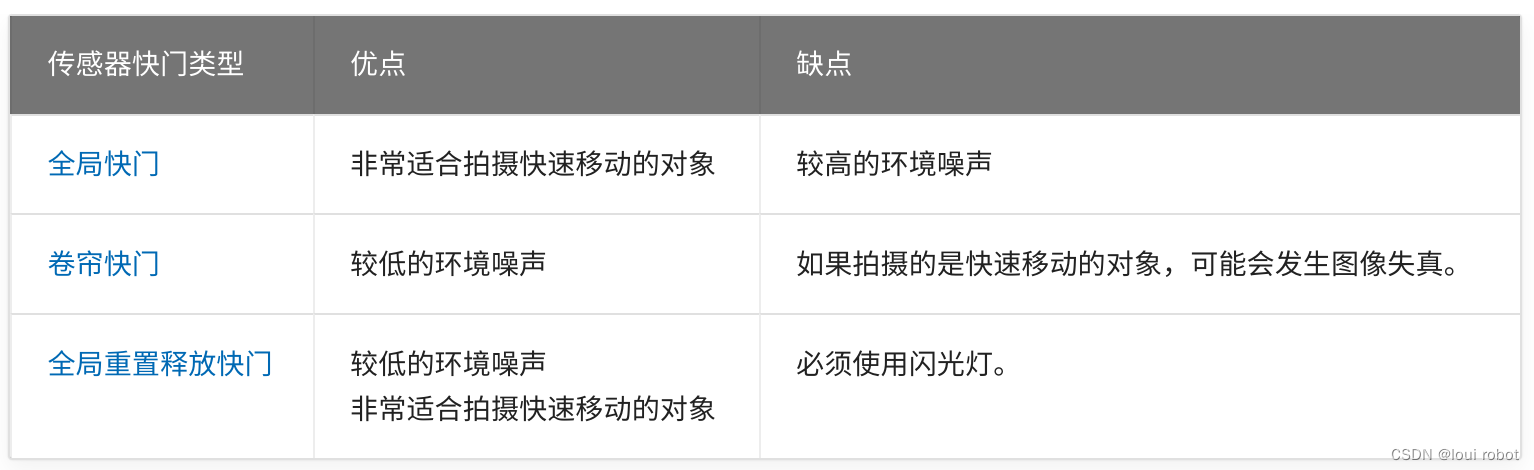
自动驾驶技术-相机_IMU时空标定
自动驾驶技术-相机_IMU时空标定 时间延迟 时间延迟 参考链接1、2 相机主要分为全局和卷帘快门相机,从触发到成像的过程包括:复位时间、AE()曝光时间、读出时间 全局快门如下图所示 卷帘快门如下图所示 相机录制视频时,为了保持固定频率&am…...