文献总结:ECCV2022-BEVFormer
BEVFormer
- 一、文章基本信息
- 二、文章背景
- 三、BEVFormer架构
- (1) BEV 查询
- (2) 空间交叉注意力机制
- (3) 时间自注意力机制
- (4) BEV应用
- (5) 实施细节
- 四、实验
- 五、总结
一、文章基本信息
| 标题 | BEVFormer: Learning Bird’s-Eye-view Representation from Multi-camera images via spatiotemporal transformers |
|---|---|
| 会议 | ECCV (European Conference on Computer Vision) |
| 作者 | Zhiqi Li;Wenhai Wang;Hongyang Li;Enze Xie;Chonghao Sima;Tong Lu;Yu Qiao;Jifeng Dai |
| 主要单位 | Nanjing University;Shanghai AI Laboratory |
| 日期 | v1: 31 Mar 2022;v2: 13 July 2022 |
| 论文地址 | https://arxiv.org/abs/2203.17270 |
| 项目地址 | https://github.com/fundamentalvision/BEVFormer |
本会议论文扩展后被2025年TPAMI第三期收录,增加了点云数据模态,本文主要分享ECCV版本,对期刊版本感兴趣的朋友可以自行查看。

文章摘要:3D视觉感知任务,包括基于多摄像头图像的3D检测和地图分割,对于自动驾驶系统至关重要。在这项工作中,我们提出了一个名为BEVFormer的新框架,它通过时空Transformer学习统一的鸟瞰视图(BEV)表示,可以支持多种自动驾驶感知任务。简而言之,BEVFormer通过预定义的网格状BEV查询与空间和时间维度进行交互,从而利用空间和时间信息。为了聚合空间信息,我们设计了空间交叉注意力机制,使每个BEV查询能够从跨摄像头视图的感兴趣区域中提取空间特征。对于时间信息,我们提出了时间自注意力机制,以循环融合历史BEV信息。我们的方法在nuScenes测试集上,以NDS指标衡量达到了56.9% 的最新最优水平,比之前的最佳方法高出9.0个百分点,与基于激光雷达的基线性能相当。我们进一步表明,BEVFormer显著提高了在低能见度条件下速度估计的准确性(velocity estimation)和物体的召回率。代码可在 https://github.com/ zhiqi-li/BEVFormer获取。 |
二、文章背景
3D空间的感知任务对于自动驾驶、机器人而言是十分重要的应用。尽管基于激光雷达的方法取得了较大的进步,但基于相机的方法今年来也获得了较大的关注,因为其有如下几个优点:
- 部署成本低(low cost for deployment)
- 更远的检测距离(detect long-range distance objects)
- 可以识别视觉化的路侧单元(identify vision-based road elements)
自动驾驶的环境感知是希望能从多个相机给出的2D提示中,来预测3D检测框或语义地图。目前最直接的方法包括基于单目相机框架和多相机后处理的方法。该框架的下游是分别地处理不同视角,不能捕捉多个相机的信息,从而导致较低的精度和效率。
BEV视图为多相机图像提供了一个更好的融合空间,可以清晰地获取目标的位置和大小,适合自动驾驶的不同任务(感知与规划)。尽管地图语义分割已经证明了BEV的效率,但在3D目标检测中还没展现出具体的优势。最主要的原因在于:3D目标检测任务需要更多的BEV特征来实现检测框的预测,然而,从2D平面生成BEV特征是一个病态问题(ill-posed)。有名的基于深度信息生成BEV特征的框架十分受欢迎,但是,该范式对于深度值或深度分布是敏感的。因此,作者们有了第一个motivation: 不依赖于深度信息来生成BEV特征,而是直接学习BEV特征。Transformer利用注意力机制来动态融合有价值的特征,刚好满足需要。
另一个motivation是想要通过BEV特征来联合时间与空间。在人类感知系统中,时间信息扮演了一个重要的角色,可以帮助我们捕捉物体的运动和识别遮挡,然而很少有研究关注时间信息。重大挑战在于自动驾驶对时间要求极高,且场景中的物体变化迅速,因此简单地堆叠跨时间戳的鸟瞰图(BEV)特征会带来额外的计算成本和干扰信息,这可能并不理想。作者受RNN的启发:利用BEV特征从过去时刻循环发送时间信息到现在时刻,有点像RNN的隐藏状态。
出于这个考量,本文提出了一个基于注意力机制的BEV编码器,叫做BEVFormer,该模块能有效融合多视图相机和BEV历史特征的时空特征。从BEVFormer获取的BEV特征可以有效地应用于多个3D感知任务,例如:3D目标检测、地图划分;如下图所示,BEVFormer包括3个关键的设计:
- 通过灵活的注意力机制来融合空间和时间特征的网格形状BEV查询器 (grid-shaped BEV queries)
- 从多个相机的图片融合空间特征的空间交叉注意力模块(spatial cross-attention module)
- 从历史BEV特征中提取时间信息的时间自注意力模块(temporal self-attention)

这些设计有助于移动目标的速度估计和严重遮挡目标的检测,并且只会带来微不足道的计算增加。
三、BEVFormer架构
BEVFormer的整体架构如下图所示,相当于每个相机视角有一个encoder,每一个encoder包括一个grid-shaped BEV queries, temporal self-attention and spatial cross-attention
- 首先,通过时间自注意力机制来,使用BEV查询获取 B t − 1 B_{t-1} Bt−1
- 其次,通过空间交叉注意力机制,使用BEV查询来获取多相机视图的空间信息
- 最后,在经过一个前馈网络之后,编码器输出重新定义的BEV特征

(1) BEV 查询
预定义了一组网格状的可学习参数作为BEVFormer的查询 Q ∈ R H × W × C Q\in R^{H \times W\times C} Q∈RH×W×C,其中网格的形状是 H × W H \times W H×W。
- 具体来说,位于 Q Q Q中 p = ( x , y ) p = (x, y) p=(x,y) 处的查询 Q p ∈ R 1 × C Q_{p} \in \mathbb{R}^{1×C} Qp∈R1×C 负责BEV平面中对应的网格单元区域。 每个BEV平面的单元都和真实事件的尺寸对应。
- 默认下,BEV特征得中心对应自车的位置。
(2) 空间交叉注意力机制
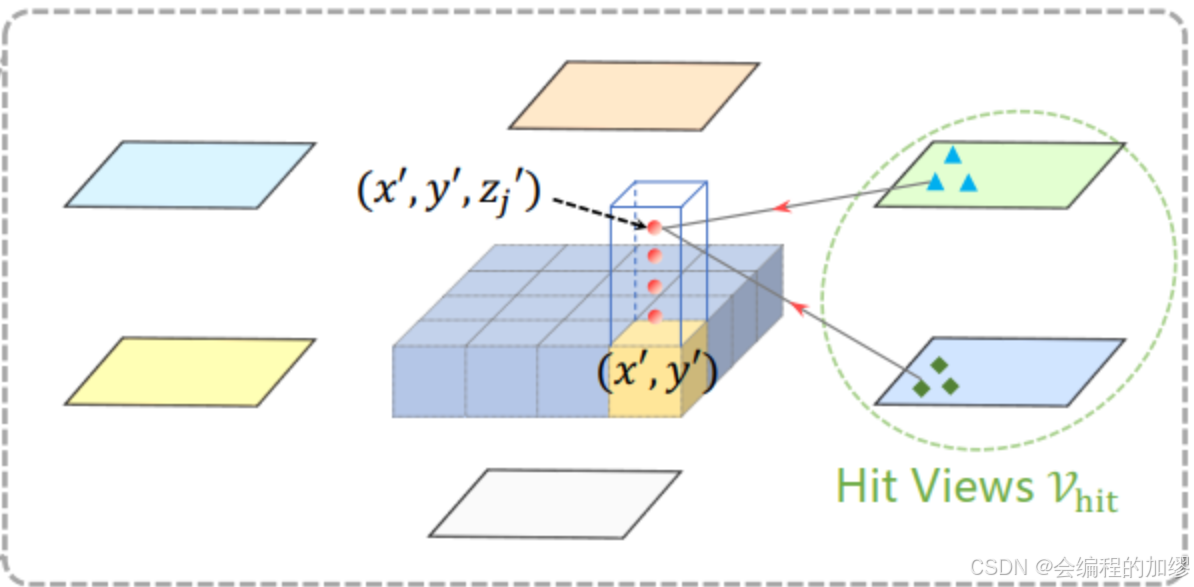
因为之前普通的全局注意力,对于6个视角的图像而言计算负担太大了,所以作者采用了deformable attention的思想,但是该思想起源于2D感知,要应用于3D必须得做一些修改:
对于一个BEV查询,投影后的2D点只能落在某些视图上,而其他视图不会被投影:这些被投影到的视图被成为 V h i t V_{hit} Vhit,将这些2D点视为查询 Q p Q_{p} Qp的参考点,并从这些被投影到的 V h i t V_{hit} Vhit视图中围绕这些参考点采样特征。最后,对采样特征进行加权求和。时空交叉注意力机制被列为下式:
S C A ( Q p , F t ) = 1 ∣ V h i t ∣ ∑ i ∈ V h i t ∑ j = 1 N r e f D e f o r m A t t n ( Q p , P ( p , i , j ) , F t i ) SCA(Q_{p},F_{t})=\frac{1}{|V_{hit}|}\sum_{i\in V_{hit}}\sum_{j=1}^{N_{ref}}DeformAttn(Q_{p}, P(p, i, j),F_{t}^i) SCA(Qp,Ft)=∣Vhit∣1i∈Vhit∑j=1∑NrefDeformAttn(Qp,P(p,i,j),Fti)
- i i i 表示相机视图的索引
- j j j 表示参考点的索引
- N r e f N_{ref} Nref是每个BEV查询的总参考点数
- F t i F_{t}^i Fti 是第 i i i个相机视图的特征
- 对于每个BEV查询 Q p Q_{p} Qp,采用投影函数 P ( p , i , j ) P(p, i, j) P(p,i,j)来获取第 i i i 个视图图像上的第 j j j 个参考点
如何实现投影函数 P ( p , i , j ) P(p, i, j) P(p,i,j)呢?
-
计算 p = ( x , y ) p=(x, y) p=(x,y)点处的查询 Q p Q_{p} Qp相对应的真实世界位置 ( x ′ , y ′ ) (x', y') (x′,y′), 如图
x ′ = ( x − W 2 ) × s ; y ′ = ( y − H 2 ) × s x' = (x-\frac{W}{2})\times s; \ y'=(y-\frac{H}{2}) \times s x′=(x−2W)×s; y′=(y−2H)×s -
在3D空间中,位于 ( x ′ , y ′ ) (x', y') (x′,y′)上的目标会在z轴上具有一个 z ′ z' z′的高度,所以预定义一组锚点高度 { z j ’ } j = 1 N r e f \{{z_{j}’}\}_{j=1}^{N_{ref}} {zj’}j=1Nref来确保能获取不同高度的线索
-
通过这种方式,每一个查询 Q p Q_{p} Qp,我们可以获得一个3D参考点柱体 ( x ′ , y ′ , z j ′ ) j = 1 N r e f (x',y',z_{j}')_{j=1}^{N_{ref}} (x′,y′,zj′)j=1Nref
-
最后,通过相机的投影矩阵,来获得不同视图的参考点 ( x ′ , y ′ , z j ′ ) (x', y',z'_{j}) (x′,y′,zj′)
(3) 时间自注意力机制
本文作者设计了一个时间自注意力模块(temporal self-attention),它是通过历史BEV特征表现出的当前环境。
给定当前时刻 t t t 的BEV查询 Q Q Q, 和 t − 1 t-1 t−1 时刻保留的历史BEV特征 B t − 1 B_{t-1} Bt−1 :
- 根据自车的运动来对齐 t − 1 t-1 t−1时刻的BEV特征与 Q Q Q查询,使得特征在与相同真实世界位置关联的BEV网格中
- 因为真实世界中,不同时刻相同目标在BEV特征中可能有偏差,所以通过时间自注意力机制(temporal self-attention, TSA)来对这种时间关联进行建模
T S A ( Q p , { Q , B t − 1 ′ } ) = ∑ V ∈ { Q , B t − 1 ′ } D e f o r m A t t n ( Q p , p , V ) TSA(Q_{p}, \{Q, B_{t-1}'\})=\sum_{V\in\{Q,B_{t-1}'\}}DeformAttn(Q_{p},p,V) TSA(Qp,{Q,Bt−1′})=V∈{Q,Bt−1′}∑DeformAttn(Qp,p,V)
- Q p Q_{p} Qp表示在 p = ( x , y ) p=(x, y) p=(x,y)点处的BEV查询
不同于普通的deformable attention,时间自注意力机制中的偏差 Δ p \Delta p Δp,通过一连串的 Q Q Q和 B t − 1 ′ B_{t-1}' Bt−1′来预测。特别地,每一个序列的第一个样本,自动退化为没有时间信息的自注意力机制,通过重复的BEV查询 { Q , Q } \{Q,Q\} {Q,Q}来取代 { Q , B t − 1 ′ } \{Q, B_{t-1}'\} {Q,Bt−1′}。
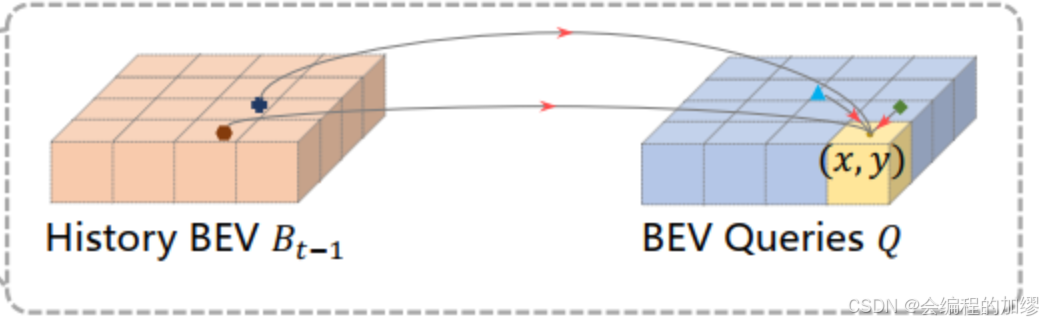
与简单堆叠的BEV模型相比,我们的时空自注意力机制能更加有效地建模长时间依赖
(4) BEV应用
BEV特征 B t ∈ R H × W × C B_{t} \in R^{H\times W\times C} Bt∈RH×W×C是一个多功能的2D特征图(versatile 2D feature map),可以被用于不同的自动驾驶感知任务。
- 3D目标检测—>用的2D detector Deformable DETR
- 地图分割 —>用的2D segmentation method Panoptic SegFormer
(5) 实施细节
训练阶段
对于时间戳 t t t的每个样本,我们从过去2秒的连续序列中随机抽取另外3个样本,(这三个随机选择的样本并不是连续的,因为2秒内不止3张图片)这种随机采样策略可以增加自车运动的多样性[57]。我们将这四个样本的时间戳分别记为 t − 3 t - 3 t−3、 t − 2 t - 2 t−2、 t − 1 t - 1 t−1和 t t t。前三个时间戳的样本用于循环生成BEV特征 { B t − 3 , B t − 2 , B t − 1 } \{B_{t - 3}, B_{t - 2}, B_{t - 1}\} {Bt−3,Bt−2,Bt−1},此阶段不需要计算梯度。对于时间戳 t − 3 t - 3 t−3的第一个样本,由于没有之前的BEV特征,时间自注意力会退化为自注意力。在时间 t t t时,模型基于多摄像头输入和之前的BEV特征 B t − 1 B_{t - 1} Bt−1生成BEV特征 B t B_{t} Bt,这样 B t B_{t} Bt就包含了跨越这四个样本的时空线索。最后,我们将BEV特征 B t B_{t} Bt输入到检测头和分割头中,并计算相应的损失函数。
推理阶段
在推理阶段,我们按时间顺序评估视频序列的每一帧。前一个时间戳的BEV特征会被保存下来并用于下一次推理,这种在线推理策略高效且符合实际应用场景。尽管我们利用了时间信息,但我们的推理速度仍与其他方法相当。
四、实验
数据集
- nuScenes Dataset: 1000个持续20帧的训练场景
- Waymo Open Dataset: 798个训练序列、202个测试序列
实验设置
采用了两类主干网络:
- ResNet101-DCN (用了FCOS3D的权重文件来初始化)
- VoVnet-99 (用DD3D的权重文件来初始化)
用从不同尺寸的FPS来输出多尺度特征:
在nuScenes数据集上进行实验时,BEV查询的默认大小为200×200,X轴和Y轴的感知范围均为[-51.2米, 51.2米],BEV网格的分辨率 s s s为0.512米。我们对BEV查询采用可学习的位置嵌入。BEV编码器包含6个编码层,在每一层中不断细化BEV查询。每个编码层的输入BEV特征 B t − 1 B_{t - 1} Bt−1相同且不需要计算梯度。对于每个局部查询,在由可变形注意力机制实现的空间交叉注意力模块中,它对应于3D空间中4个具有不同高度的目标点,预定义的高度锚点是从-5米到3米均匀采样得到的。对于2D视图特征上的每个参考点,每个注意力头在该参考点周围使用四个采样点。默认情况下,我们使用24个epoch、学习率为 2 × 1 0 − 4 2×10^{-4} 2×10−4来训练模型。
在Waymo数据集上进行实验时,我们更改了一些设置。由于Waymo的摄像头系统无法捕捉到自车周围的完整场景,BEV查询的默认空间形状为300×220,X轴的感知范围是[35.0米, 75.0米],Y轴的感知范围是[75.0米, 75.0米]。每个网格的分辨率S为0.5米。在BEV视图中,自车的位置是(70, 150) 。
消融实验
对比了不同的注意力机制和提取BEV的骨干网络
- BEV骨干网络
- VPN
- List-Splat
- Attention
- Global
- Points
- Local

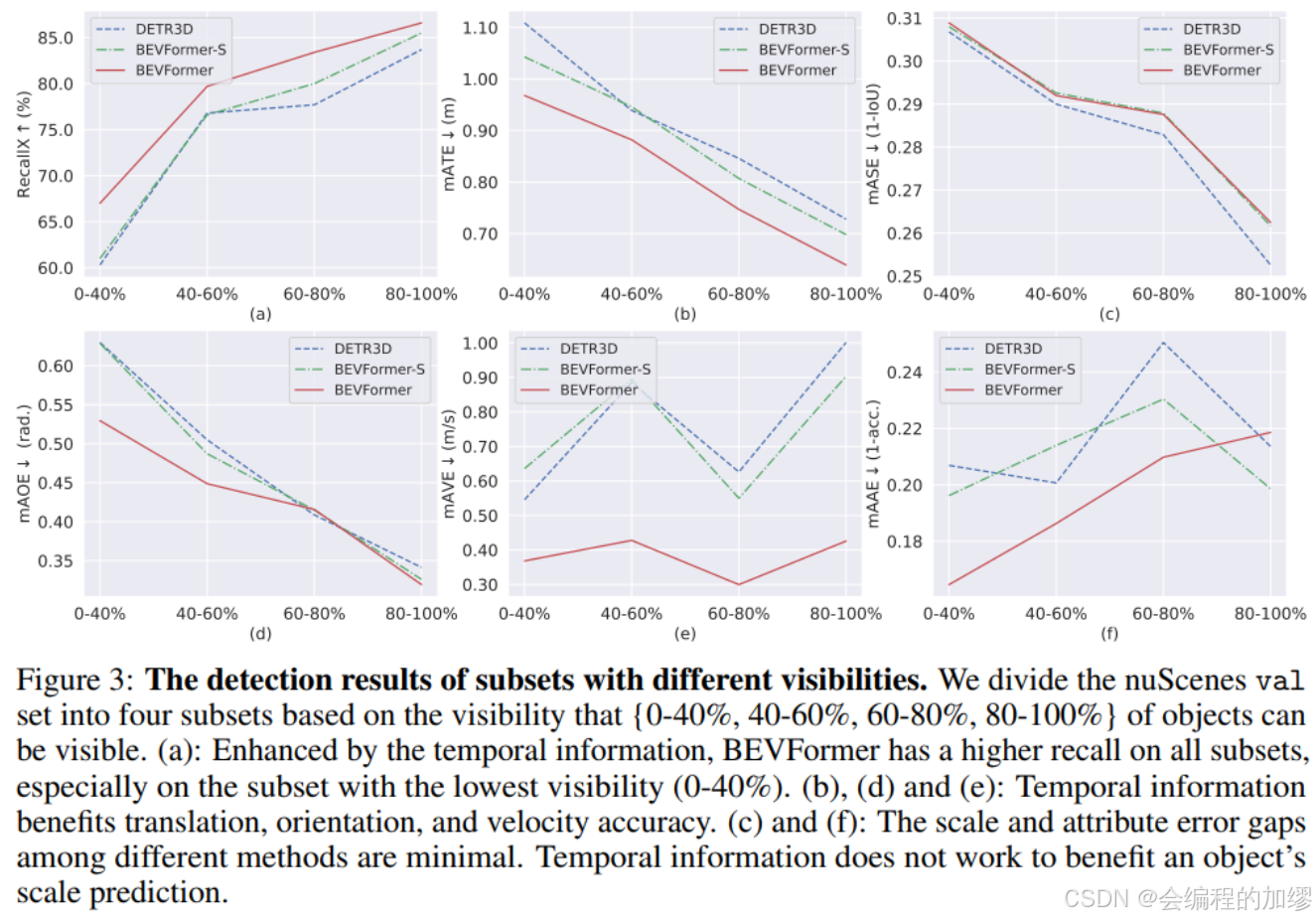
同时为了验证时间自注意力的效果,作者对比了不同遮挡等级的模型效果,可以明显看到的是BEVFormer的召回率更高:
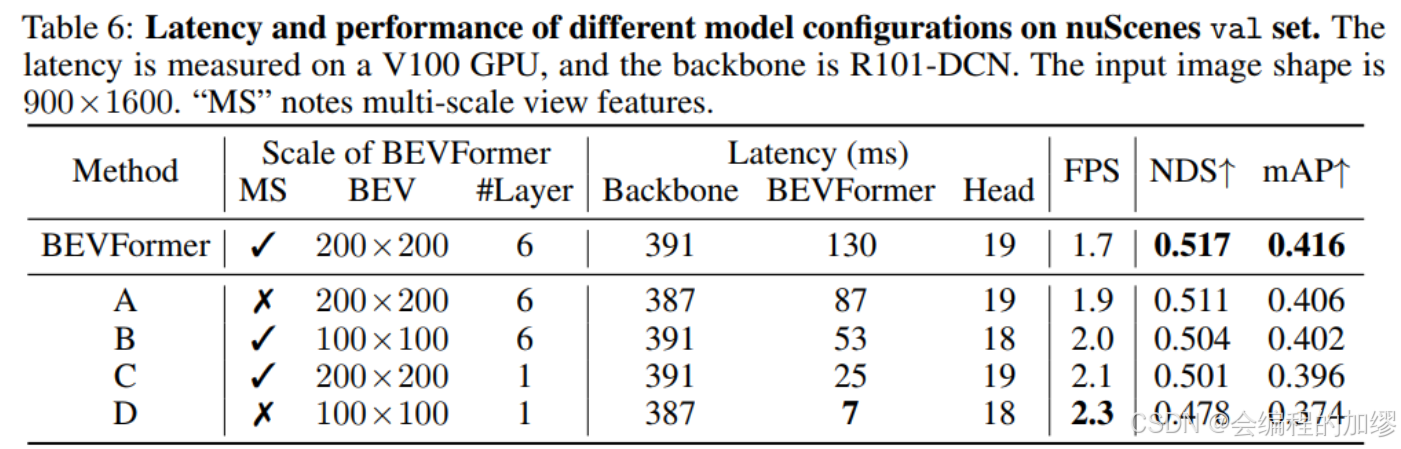
与此同时,作者还对比了不同模型参数设置下的推理速度:
五、总结
总结:在这项工作中,我们提出了BEVFormer,用于从多摄像头输入中生成鸟瞰图特征。BEVFormer能够高效地聚合空间和时间信息,并生成强大的鸟瞰图(BEV)特征,这些特征可同时支持3D目标检测和地图分割任务。 |
相关文章:
文献总结:ECCV2022-BEVFormer
BEVFormer 一、文章基本信息二、文章背景三、BEVFormer架构(1) BEV 查询(2) 空间交叉注意力机制(3) 时间自注意力机制(4) BEV应用(5) 实施细节 四、实验五、总结 一、文章基本信息 标题BEVFormer: Learning Bird’s-Eye-view Representation from Multi-camera images via spa…...
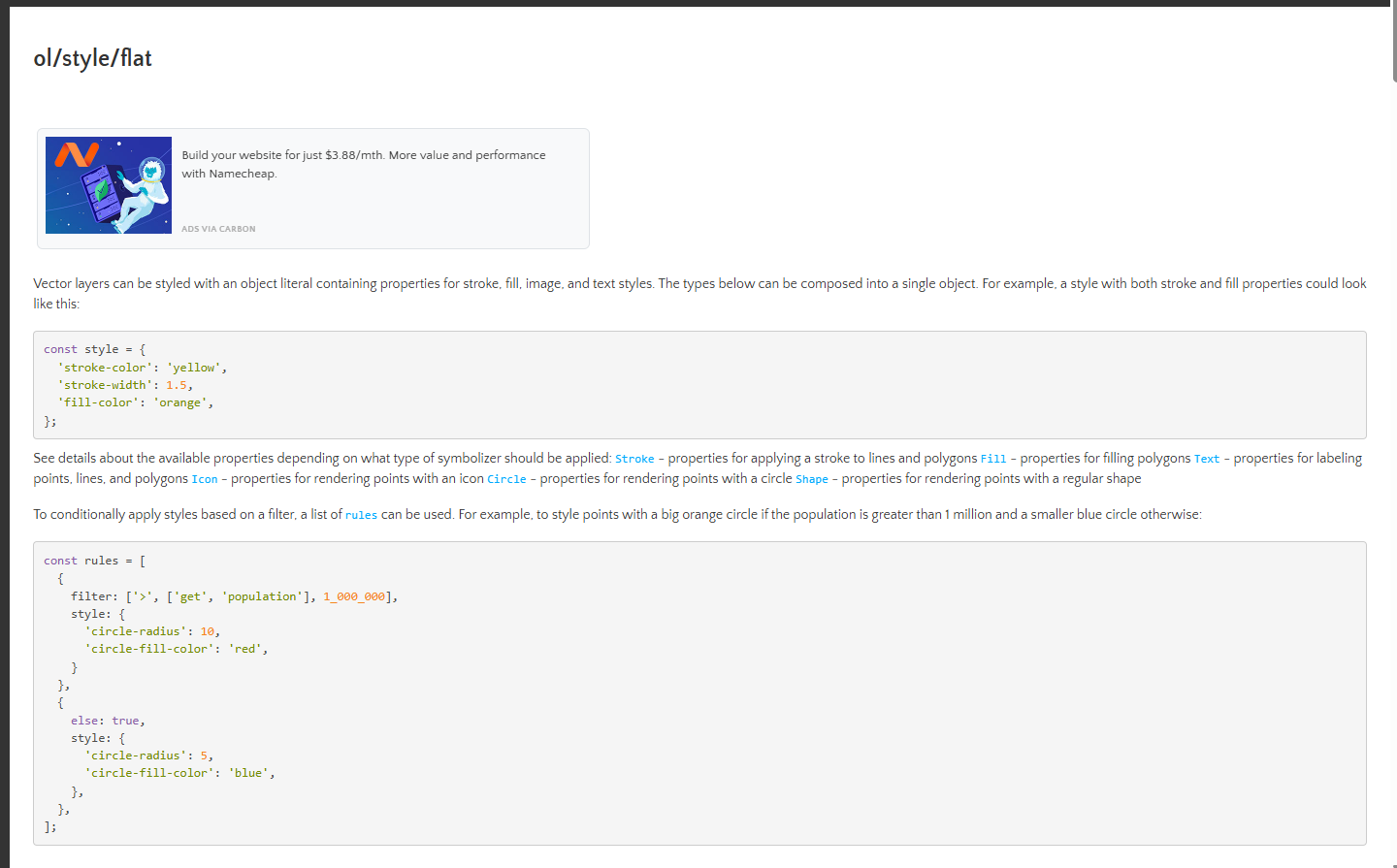
Openlayers:海量图形渲染之WebGL渲染
最近由于在工作中涉及到了海量图形渲染的问题,因此我开始研究相关的解决方案。我在网络上寻找相关的解决方案时发现许多的文章都提到利用Openlayers中的WebGLPointsLayer类,可以实现渲染海量的点,之后我又了解到利用WebGLVectorLayer类可以渲…...
RCE漏洞学习
1,What is RCE? 在CTF(Capture The Flag)竞赛中,RCE漏洞指的是远程代码执行漏洞(Remote Code Execution)。这类漏洞允许攻击者通过某种方式在目标系统上执行任意代码,从而完全控制目…...

如何将网页保存为pdf
要将网页保存为PDF,可以按照以下几种方法操作: 1. 使用浏览器的打印功能 大多数现代浏览器(如Chrome、Firefox、Edge等)都支持将网页保存为PDF文件。步骤如下: 在 Google Chrome 中: 打开你想保存为PDF…...

什么是继承?js中有哪儿些继承?
1、什么是继承? 继承是面向对象软件技术中的一个概念。 2、js中有哪儿些继承? js中的继承有ES6的类class的继承、原型链继承、构造函数继承、组合继承、寄生组合继承。 2.1 ES6中类的继承 class Parent {constructor() {this.age 18;} }class Chil…...
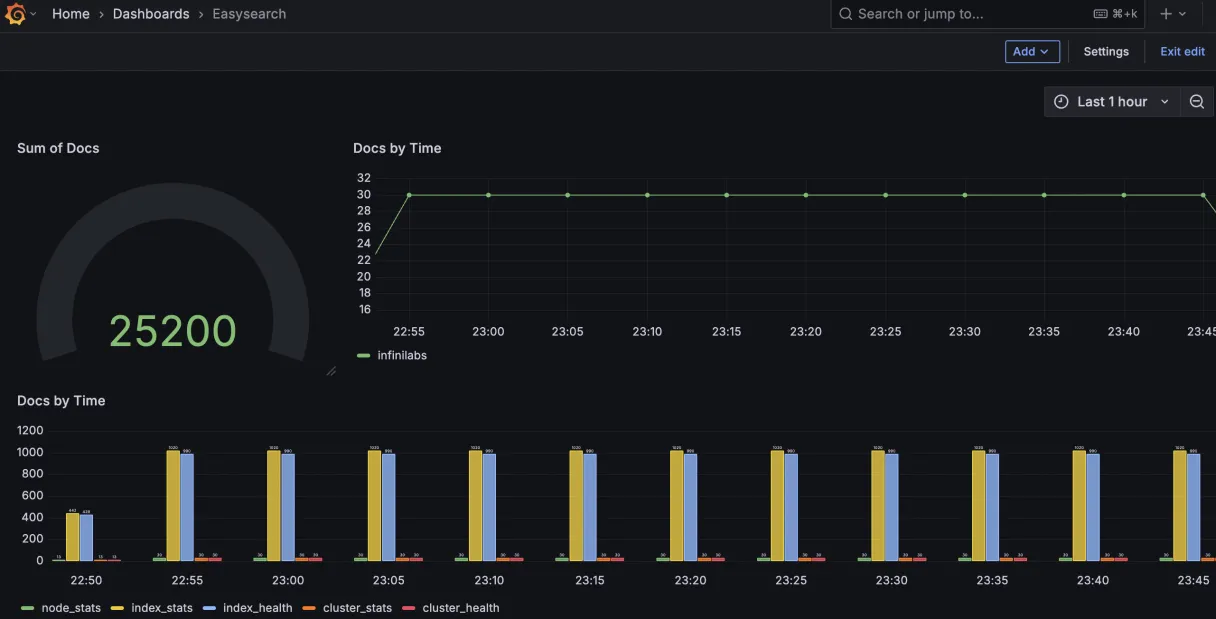
如何使用 Grafana 连接 Easyearch
Grafana 介绍 Grafana 是一款开源的跨平台数据可视化与监控分析工具,专为时序数据(如服务器性能指标、应用程序日志、业务数据等)设计。它通过直观的仪表盘(Dashboards)帮助用户实时监控系统状态、分析趋势࿰…...
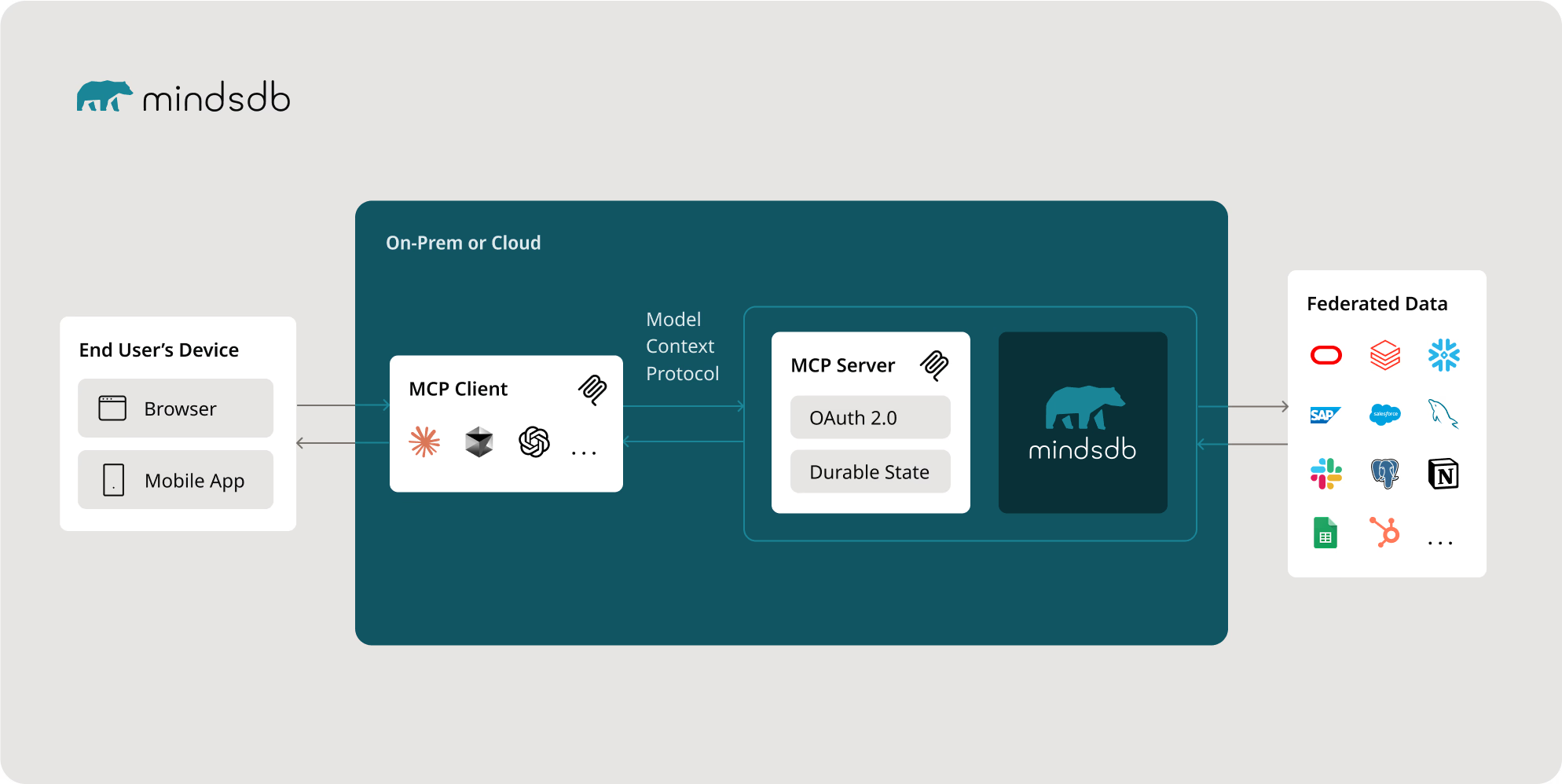
mindsdb AI 开源的查询引擎 - 用于构建 AI 的平台,该平台可以学习和回答大规模联合数据的问题。
一、软件介绍 文末提供源码和程序下载学习 MindsDB 是一种解决方案,使人类、AI、代理和应用程序能够以自然语言和 SQL 查询数据,并在不同的数据源和类型中获得高度准确的答案。此开源程序是一个联合查询引擎,可以整理您的数据蔓延混乱&#…...

802.11a ofdm 过程了解
ofdm_demo.py import numpy as np from scipy import interpolate import commpy as cpy import ofdm_debug as ofdm_debug class OFDMSystem:def __init__(self, K64, CPNone, P8, pilotValue33j, Modulation_typeQAM16, channel_typerandom, SNRdb25,debugFalse):# 设置OFDM…...

BOTA六维力矩传感器如何打通机器人AI力控操作的三层架构?感知-决策-执行全链路揭秘
想象一下,你对着一个机器人说:“请帮我泡杯茶。”然后,它就真的开始行动了:找茶壶、烧水、取茶叶、泡茶……这一切看似简单,但背后却隐藏着复杂的AI技术。今天,我们就来揭秘BOTA六维力矩传感器在机器人操控…...

HDF5文件格式:数据类型与读写功能详解
HDF5文件格式:数据类型与读写功能详解 HDF5简介 HDF5(Hierarchical Data Format version 5)是一种用于存储和管理大量科学数据的文件格式和库。它由美国国家高级计算应用中心(NCSA)开发,具有以下特点&…...
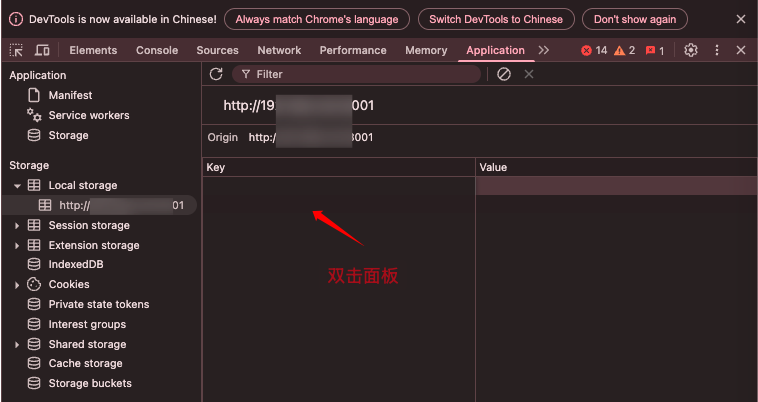
macOS Chrome - 打开开发者工具,设置 Local storage
文章目录 macOS Chrome - 打开开发者工具设置 Local storage macOS Chrome - 打开开发者工具 方式2:右键点击网页,选择 检查 设置 Local storage 选择要设置的 url,显示右侧面板 双击面板,输入要添加的内容 2025-04-08ÿ…...

使用Vscode排除一些子文件搜索
打开用户/工作区设置 全局生效:打开命令面板(CtrlShiftP 或 CmdShiftP),搜索并选择 Preferences: Open User Settings (JSON)。 仅当前项目生效:在项目根目录下创建 .vscode/settings.json 文件(如果不存在…...

kubernetes 入门篇之架构介绍
经过前段时间的学习和实践,对k8s的架构有了一个大致的理解。 1. k8s 分层架构 架构层级核心组件控制平面层etcd、API Server、Scheduler、Controller Manager工作节点层Kubelet、Kube-proxy、CRI(容器运行时接口)、CNI(网络插件&…...

如何绕过WAF实现SQL注入攻击?
引言 在渗透测试中,SQL注入(SQLi)始终是Web安全的核心漏洞之一。然而,随着企业广泛部署Web应用防火墙(WAF),传统的注入攻击往往会被拦截。本文将分享一种绕过WAF检测的SQL注入技巧…...
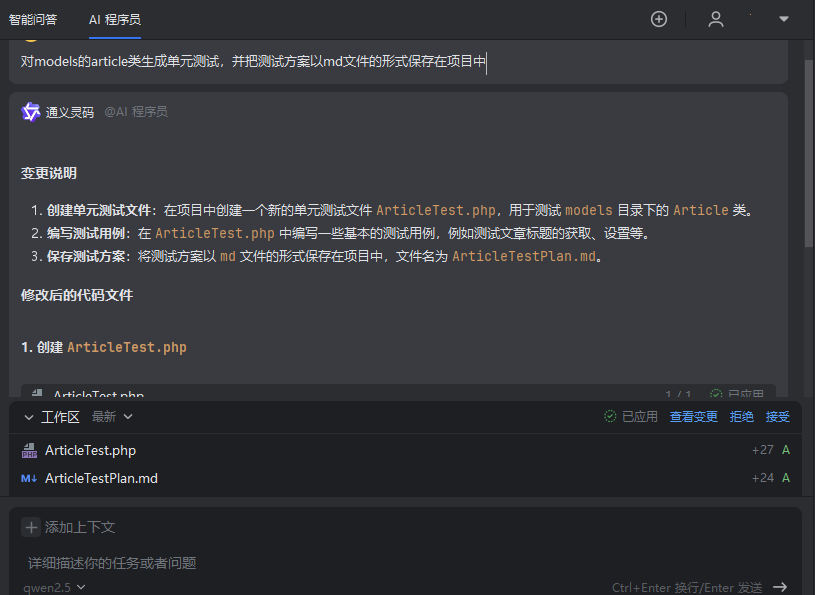
如何使用通义灵码完成PHP单元测试 - AI辅助开发教程
一、引言 在软件开发过程中,测试是至关重要的一环。然而,在传统开发中,测试常常被忽略或草草处理,很多时候并非开发人员故意为之,而是缺乏相应的测试思路和方法,不知道如何设计测试用例。随着 AI 技术的飞…...
pig 权限管理开源项目学习
pig 源码 https://github.com/pig-mesh/pig 文档在其中,前端在文档中,官方视频教学也在文档中有。 第一次搭建,建议直接去看单体视频,照着做即可,需 mysql,redis 基础。 文章目录 项目结构Maven 多模块项…...

设计模式:依赖倒转原则 - 依赖抽象,解耦具体实现
一、为什么用依赖倒转原则? 在软件开发中,类与类之间的依赖关系是架构设计中的关键。如果依赖过于紧密,系统的扩展性和维护性将受到限制。为了应对这一挑战,依赖倒转原则(Dependency Inversion Principle,…...

探秘Transformer系列之(26)--- KV Cache优化 之 PD分离or合并
探秘Transformer系列之(26)— KV Cache优化 之 PD分离or合并 文章目录 探秘Transformer系列之(26)--- KV Cache优化 之 PD分离or合并0x00 概述0x01 背景知识1.1 自回归&迭代1.2 KV Cache 0x02 静态批处理2.1 调度策略2.2 问题…...

鸿蒙5.0 非桌面页面,设备来电后挂断,自动返回桌面
1.背景 其实在Android上面打开一个应用,然后设备来电后挂断应该是返回到前面打开的这个应用的,但是在鸿蒙里面现象是直接返回桌面,设计如此 2.分析 这个分析需要前置知识,鸿蒙的任务栈页面栈,具体参考如下链接: zh-cn/application-dev/application-models/page-missio…...
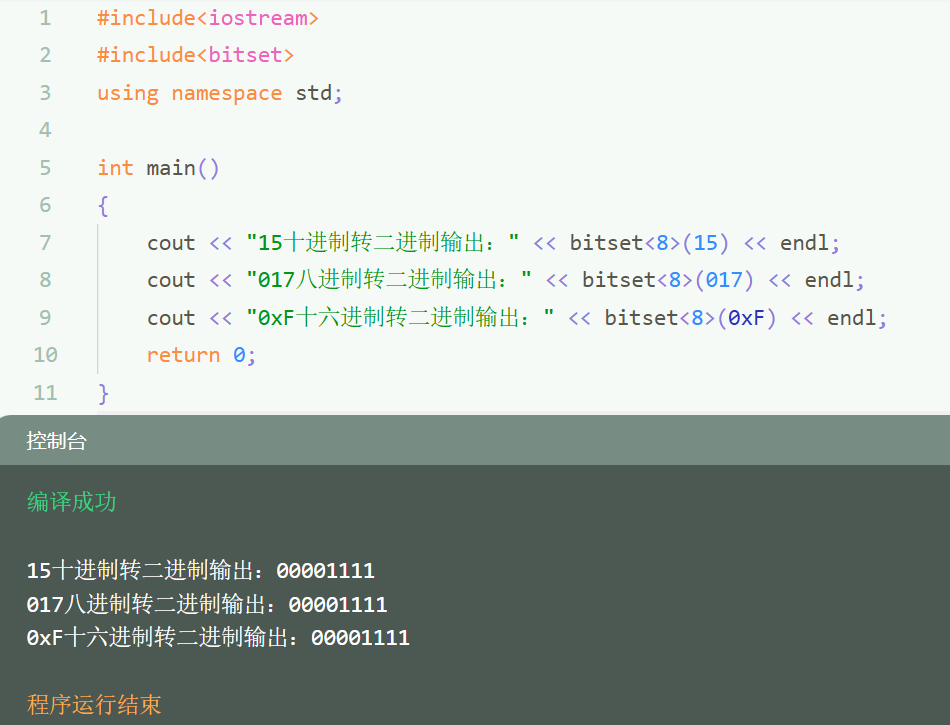
C++语言程序设计——02 变量与数据类型
目录 一、变量与数据类型(一)变量的数据类型(二)变量命名规则(三)定义变量(四)变量赋值(五)查看数据类型 二、ASCII码三、进制表示与转换(一&…...
Model Context Protocol (MCP) - 尝试创建和测试一下MCP Server
1.简单介绍 MCP是Model Context Protocol的缩写,是Anthropic开源的一个标准协议。MCP使得大语言模型可以和外部的数据源,工具进行集成。当前MCP在社区逐渐地流行起来了。同时official C# SDK(仓库是csharp-sdk) 也在不断更新中,目前最新版本…...

十四种逻辑器件综合对比——《器件手册--逻辑器件》
目录 逻辑器件 简述 按功能分类 按工艺分类 按电平分类 特殊功能逻辑器件 应用领域 详尽阐述 1 逻辑门 一、基本概念 二、主要类型 三、实现方式 四、应用领域 2 反相器 工作原理 基本功能 主要应用 常见类型 特点 未来发展趋势 3 锁存器 基本概念 工作原理 主要类型…...

将已有 SVN 服务打包成 Docker 镜像的详细步骤
将已有 SVN 服务打包成 Docker 镜像的详细步骤 一、服务器环境准备 在开始将 SVN 服务打包成 Docker 镜像之前,我们需要确保目标服务器的环境满足一定条件。 首先要确保目标服务器已安装 Docker。同时服务器可以连接互联网,可以通过以下简单命令来验证…...

python文件打包无法导入ultralytics模块
💥打包的 .exe 闪退了?别慌!教你逐步排查 PyInstaller 打包的所有错误! 🛠 运行 .exe 查看报错信息✅ 正确姿势: ⚠ importlib 动态导入导致打包失败❓什么是动态导入?✅ 解决方式: …...

AMBA-CHI协议详解(二十六)
AMBA-CHI协议详解(一)- Introduction AMBA-CHI协议详解(二)- Channel fields / Read transactions AMBA-CHI协议详解(三)- Write transactions AMBA-CHI协议详解(四)- Other transactions AMBA-CHI协议详解(五)- Transaction identifier fields AMBA-CHI协议详解(六…...

Go小技巧易错点100例(二十六)
本期分享: 1. string转[]byte是否会发生内存拷贝 2. Go程序获取文件的哈希值 正文: string转[]byte是否会发生内存拷贝 在Go语言中,字符串转换为字节数组([]byte)确实会发生内存拷贝。这是因为在Go中,字…...
FPGA_BD Block Design学习(一)
PS端开发流程详细步骤 1.第一步:打开Vivado软件,创建或打开一个工程。 2.第二步:在Block Design中添加arm核心,并将其配置为IP核。 3.第三步:配置arm核心的外设信息,如DDR接口、时钟频率、UART接口等。 …...
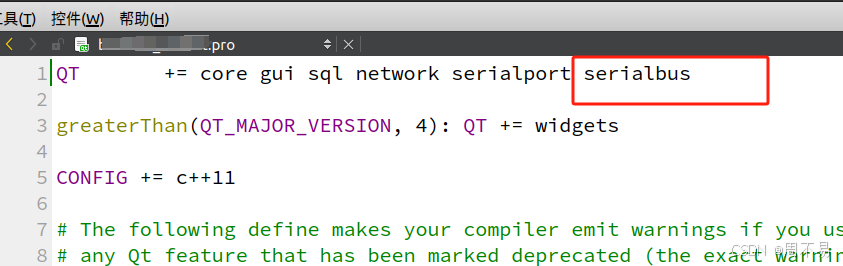
ubuntu20.04+qt5.12.8安装serialbus
先从官网https://download.qt.io/archive/qt/5.12/5.12.8/submodules/ 下载 qtserialbus-everywhere-src-5.12.8.tar.xz 有需要其他版本的点击返回上一级自行寻找对应版本。 也可从 https://download.csdn.net/download/zhouhui1982/90595810 下载 在终端中依次输入以下命令…...

银河麒麟V10 Ollama+ShellGPT打造Shell AI助手——筑梦之路
环境说明 1. 操作系统版本: 银河麒麟V10 2. CPU架构:X86 3. Python版本:3.12.9 4. 大模型:mistral:7b-instruct 准备工作 1. 编译安装python 3.12 # 下载python 源码wget https://www.python.org/ftp/python/3.12.9/Python-3.12.9.tg…...

python求π近似值
【问题描述】用公式π/4≈1-1/31/5-1/7..1/(2*N-1).求圆周率PI的近似值。 从键盘输入一个整数N值,利用上述公式计算出π的近似值,然后输出π值,保留小数后8位。 【样例输入】1000 【样例输出】3.14059265 def countpi(N):p0040nowid0for i i…...