索引下推(Index Condition Pushdown, ICP)
概念
索引下推是一种数据库查询优化技术,通过在存储引擎层面应用部分WHERE条件来减少不必要的数据读取。它特别适用于复合索引的情况,因为它可以在索引扫描阶段就排除不符合全部条件的数据行,而不是将所有可能匹配的记录加载到服务器层再进行筛选。这样可以显著减少I/O操作和内存使用量,从而提升查询性能。
原理详解
当执行一个查询时,如果查询中包含可以利用现有索引来评估的部分条件,则这些条件可以在存储引擎层面直接应用于索引扫描过程。这意味着:
- 减少I/O操作:只读取符合全部条件的数据行,而不是所有可能匹配的行。
- 降低内存使用:减少了需要加载到内存中的数据量。
- 提高查询性能:特别是在大型表和复合索引场景中,效果尤为明显。
例如,假设有一个复合索引(col1, col2),对于查询SELECT * FROM table WHERE col1 = 'value1' AND col2 > 10;,如果没有ICP,数据库会首先找到所有col1 = 'value1'的行,然后在服务器层筛选出col2 > 10的行。而有ICP时,这两个条件都可在索引扫描阶段应用,直接过滤掉不符合col2 > 10的行。
让我们用一个更贴近生活的例子来解释索引下推(Index Condition Pushdown, ICP),以便更容易理解。想象一下你正在水果市场买苹果
假设你要买的是“红色的、直径大于8厘米的苹果”。水果市场非常大,有成千上万的苹果。没有索引下推的情况下,你的购买过程可能如下:
-
传统方式:首先,你会去到所有卖苹果的地方(相当于数据库中的全表扫描),然后挑选出所有看起来是红色的苹果(第一次筛选)。接下来,你需要一个接一个地测量这些红苹果的直径,找出那些直径大于8厘米的苹果(第二次筛选)。
-
使用索引下推的方式:现在想象一下,有一个特别聪明的助手帮你。当你告诉助手你想要的条件后(红色且直径大于8厘米),他不是直接带你去看所有的苹果,而是先根据他的知识和经验(相当于数据库中的索引)直接找到可能是红色并且直径较大的苹果区域。在这个区域内,他进一步检查每个苹果是否真正符合你的两个条件(红色且直径大于8厘米)。这样,你不需要在一开始就看遍所有的苹果,也不需要对每一个初步选出来的红苹果都进行测量。
在数据库查询中的应用
-
没有ICP:数据库引擎会先通过索引找到所有满足部分条件的数据(比如只考虑了颜色为红色的苹果),然后从表中读取这些记录的完整信息(相当于把苹果拿起来仔细检查其大小),再根据剩余的条件(如直径大于8厘米)过滤数据。
-
有ICP:当使用索引下推时,数据库可以在利用索引的同时应用更多的条件(例如,既考虑颜色也考虑尺寸),这样就可以在访问实际数据之前排除掉不满足所有条件的记录。这减少了需要读取的数据量,从而加快了查询速度。
总结
索引下推就像是给数据库增加了一个智能助手,这个助手能够在查找数据时就考虑到尽可能多的过滤条件,而不是先把所有看起来有可能的数据找出来之后再逐一检查。这样一来,数据库就能更快地给出最终结果,因为很多不必要的数据处理步骤被省略了。
更详细的代码示例
下面是一个更详细的MySQL例子,演示如何使用ICP:
-- 创建测试表
create table sales (id int not null auto_increment,product_name varchar(255) not null,sale_date date,price decimal(10,2),primary key(id),key(product_name, sale_date)
);-- 插入测试数据
insert into sales (product_name, sale_date, price) values
('laptop', '2025-01-01', 999.99),
('tablet', '2025-02-01', 499.99),
('smartphone', '2025-03-01', 799.99);-- 使用索引下推的查询
explain select * from sales where product_name = 'laptop' and sale_date > '2024-12-31';在这个例子中,我们创建了一个名为sales的表,并为product_name和sale_date字段创建了复合索引。当我们执行查询并使用explain命令查看查询计划时,可以看到是否启用了索引下推。若启用,数据库将在索引(product_name, sale_date)上应用这两个条件,在存储引擎层面完成过滤。
EXPLAIN输出分析
在MySQL中执行上述EXPLAIN命令后,你将看到类似以下的输出结果(请注意,实际输出可能根据你的MySQL版本和配置有所不同):
+----+-------------+--------+------------+------+--------------------------+--------------------------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+--------------------------+--------------------------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | sales | NULL | ref | product_name | product_name | 767 | const | 1 | 100.00 | Using index condition |
+----+-------------+--------+------------+------+--------------------------+--------------------------+---------+-------+------+----------+-----------------------+输出字段解释:
- id: 查询标识符。
- select_type: 表示查询的类型,这里为
SIMPLE,意味着这是一个简单的SELECT查询。 - table: 表示正在访问的表名,在这里是
sales。 - type: 访问类型,这里显示的是
ref,表示基于索引的等值匹配。 - possible_keys: 可能使用的索引列表,这里列出了
product_name。 - key: 实际使用的索引,这里应该是
product_name(即复合索引的第一个部分)。 - key_len: 索引使用的长度,对于
product_name这个VARCHAR(255),其长度取决于字符集。 - ref: 显示哪个列或常量与索引比较,这里是
const,因为product_name是常量值'laptop'。 - rows: 估计需要检查的行数,这里为1,意味着只需要扫描一行。
- filtered: 表示被过滤后的行数百分比。
- Extra: 提供了额外的信息,“Using index condition”表明启用了索引下推。
结论
在这个例子中,通过EXPLAIN命令我们可以看到,MySQL确实利用了索引下推技术来优化查询。具体来说,它在索引(product_name, sale_date)上应用了product_name = 'laptop' AND sale_date > '2024-12-31'这两个条件,尽可能地在存储引擎层面完成过滤,从而减少了不必要的I/O操作和内存占用。
注意事项与最佳实践扩展
-
版本兼容性检查:
- 确保使用的数据库版本支持ICP。例如,MySQL自5.6版开始支持此功能。可以通过官方文档确认当前使用的数据库版本是否支持该特性。
-
合理设计复合索引:
- 正确设计复合索引是关键。需考虑哪些列最常用于查询条件及其顺序。通常,应将选择性较高的列放在前面。此外,避免过多或过少的索引,以免影响插入和更新性能。
-
保持统计信息最新:
- 定期更新表和索引的统计信息,以帮助查询优化器做出最佳决策。可以使用
analyze table命令更新统计信息。
- 定期更新表和索引的统计信息,以帮助查询优化器做出最佳决策。可以使用
-
复杂查询优化:
- 对于复杂的查询或特定的数据分布情况,ICP的效果可能会有所不同。有时候调整查询逻辑或重新考虑索引策略可能是必要的。例如,避免在索引列上使用函数或运算符,因为这可能导致无法使用索引。
-
实际测试与验证:
- 通过
EXPLAIN命令分析查询执行计划,了解查询是如何执行的以及是否有效利用了索引下推。不同的环境设置(如硬件配置)也可能影响最终的性能表现。务必在你的环境中进行充分的测试和验证。
- 通过
-
监控与调优:
- 使用数据库提供的监控工具跟踪查询性能,并根据实际情况调整索引策略或其他优化措施。持续监控有助于发现潜在问题并及时解决。
相关文章:
)
索引下推(Index Condition Pushdown, ICP)
概念 索引下推是一种数据库查询优化技术,通过在存储引擎层面应用部分WHERE条件来减少不必要的数据读取。它特别适用于复合索引的情况,因为它可以在索引扫描阶段就排除不符合全部条件的数据行,而不是将所有可能匹配的记录加载到服务器层再进行…...
Transformer模型在自然语言处理中的实战应用
基于BERT的文本分类实战:从原理到部署 一、Transformer与BERT核心原理 Transformer模型通过自注意力机制(Self-Attention)突破了RNN的顺序计算限制,BERT(Bidirectional Encoder Representations from Transformers)作为其典型代表,具有两大创新: 双向上下文编码:通过…...

stm32week11
stm32学习 八.stm32基础 2.stm32内核和芯片 F1系统架构:4个主动单元和4个被动单元 AHB是内核高性能总线,APB是外围总线 总线矩阵将总线和各个主动被动单元连到一起 ICode总线直接连接Flash接口,不需要经过总线矩阵 AHB:72MHz&am…...

ConcurrentHashMap 源码分析
摘要 介绍线程安全集合类 ConcurrentHashMap 源码,包括扩容,协助扩容,红黑树节点读写线程同步,插入元素后累加键值对数量操作原子性实现。 1 成员变量及其对应的数据结构 底层由数组红黑树链表实现volatile long baseCount 和 v…...

Python数据可视化:从脚本到海报级图表
Python数据可视化:从脚本到海报级图表 引言 在数据分析和科学计算领域,Python 是一种强大且灵活的工具。本文将带您了解如何使用 Python 进行数据可视化,从简单的脚本到生成高质量的海报级图表。我们将重点介绍如何使用 Matplotlib 库来创建、保存和优化图表,以便在各种场…...

【Python语言基础】19、垃圾回收
文章目录 1. 垃圾回收1.1 引用计数-日常检查货物标签1.2 标记-清除算法:处理互相依赖的货物1.3 分代回收:根据货物新旧安排清理频率 2. 特殊方法2.1 构造和析构方法2.2 字符串表示方法2.3 比较方法2.4 容器相关方法2.5 可调用对象方法 1. 垃圾回收 计算…...
开发与应用(二))
用户自定义函数(UDF)开发与应用(二)
五、UDF 在不同平台的应用 5.1 数据库中的 UDF 应用(如 MySQL、PostgreSQL) 在数据库领域,UDF 为开发者提供了强大的扩展能力,使得数据库可以完成一些原本内置函数无法实现的复杂操作。 以 MySQL 为例,假设我们有一…...
从三次方程到复平面:复数概念的奇妙演进(二)
注:本文为 “复数 | 历史 / 演进” 相关文章合辑。 因 csdn 篇幅限制分篇连载,此为第二篇。 生料,不同的文章不同的点。 机翻,未校。 History of Complex Numbers 复数的历史 The problem of complex numbers dates back to …...

深入剖析缓存一致性问题:延时双删的利弊与替代方案
在当今的分布式系统架构中,缓存凭借其快速的数据读取能力,成为提升系统性能和响应速度的关键组件。然而,缓存的引入也带来了缓存一致性问题,这一问题成为开发者在系统设计与维护中必须攻克的难关。缓存一致性问题聚焦于数据更新时…...

基于视觉语言模型的机器人实时探索系统!ClipRover:移动机器人零样本视觉语言探索和目标发现
作者:Yuxuan Zhang 1 ^{1} 1, Adnan Abdullah 2 ^{2} 2, Sanjeev J. Koppal 3 ^{3} 3, and Md Jahidul Islam 4 ^{4} 4单位: 2 , 4 ^{2,4} 2,4佛罗里达大学电气与计算机工程系RoboPI实验室, 1 , 3 ^{1,3} 1,3佛罗里达大学电气与计算机工程系F…...
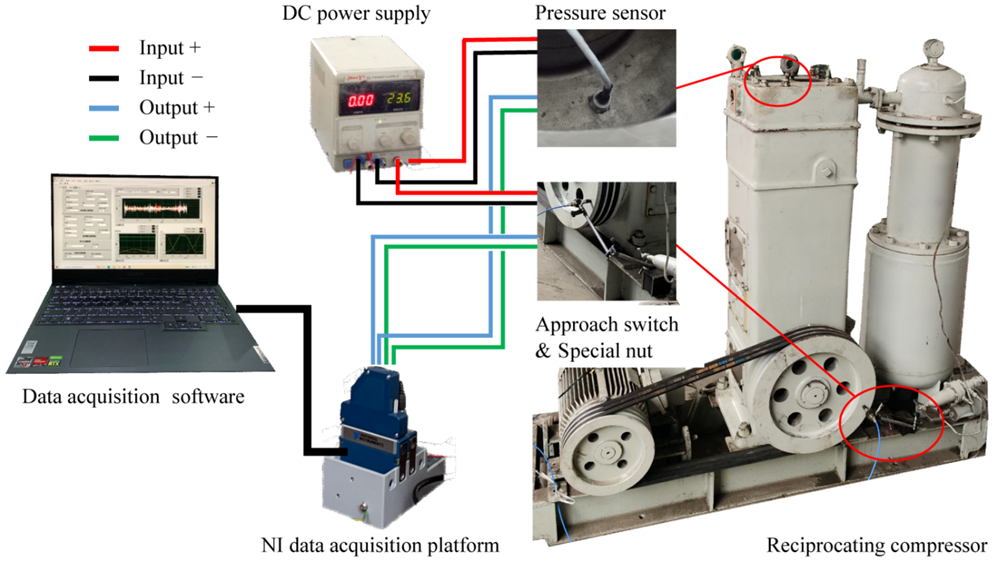
LabVIEW往复式压缩机管路故障诊断系统
往复式压缩机作为工业领域的关键设备,广泛应用于石油化工、能源等行业,承担着气体压缩的重要任务。然而,其管路故障频发,不仅降低设备性能、造成能源浪费,还可能引发严重安全事故。因此,开发精准高效的管路…...
)
wsl下编译eXosip和osip库(Ubuntu 22.04)
1.下载eXosip和osip osip下载路径 Index of /mirror/gnu.org/savannah/osip eXosip下载路径 Index of /nongnu/exosip 我选的osip和eXosip版本为 5.2.0 2.编译osip库 tar -zxvf libosip2-5.2.0.tar.gz cd libosip2-5.2.0 ./configure make make install 在编译…...
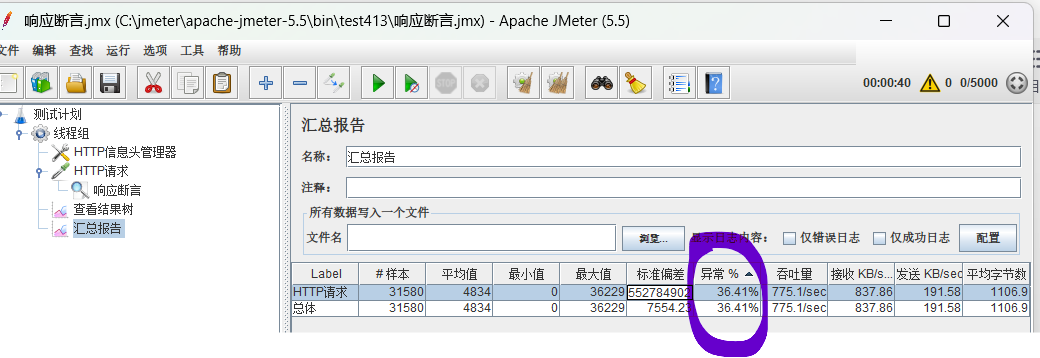
springboot 项目 jmeter简单测试流程
测试内容为 主机地址随机数 package com.hainiu.example;import lombok.extern.slf4j.Slf4j; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestMethod; import org.springframework.web.bind.annotat…...
:解锁行业术语,开启专业交流之门)
程序化广告行业(82/89):解锁行业术语,开启专业交流之门
程序化广告行业(82/89):解锁行业术语,开启专业交流之门 在程序化广告这个充满活力与挑战的行业里,持续学习是我们不断进步的动力源泉。一直以来,我都期望能和大家一起深入探索这个领域,共同成长…...
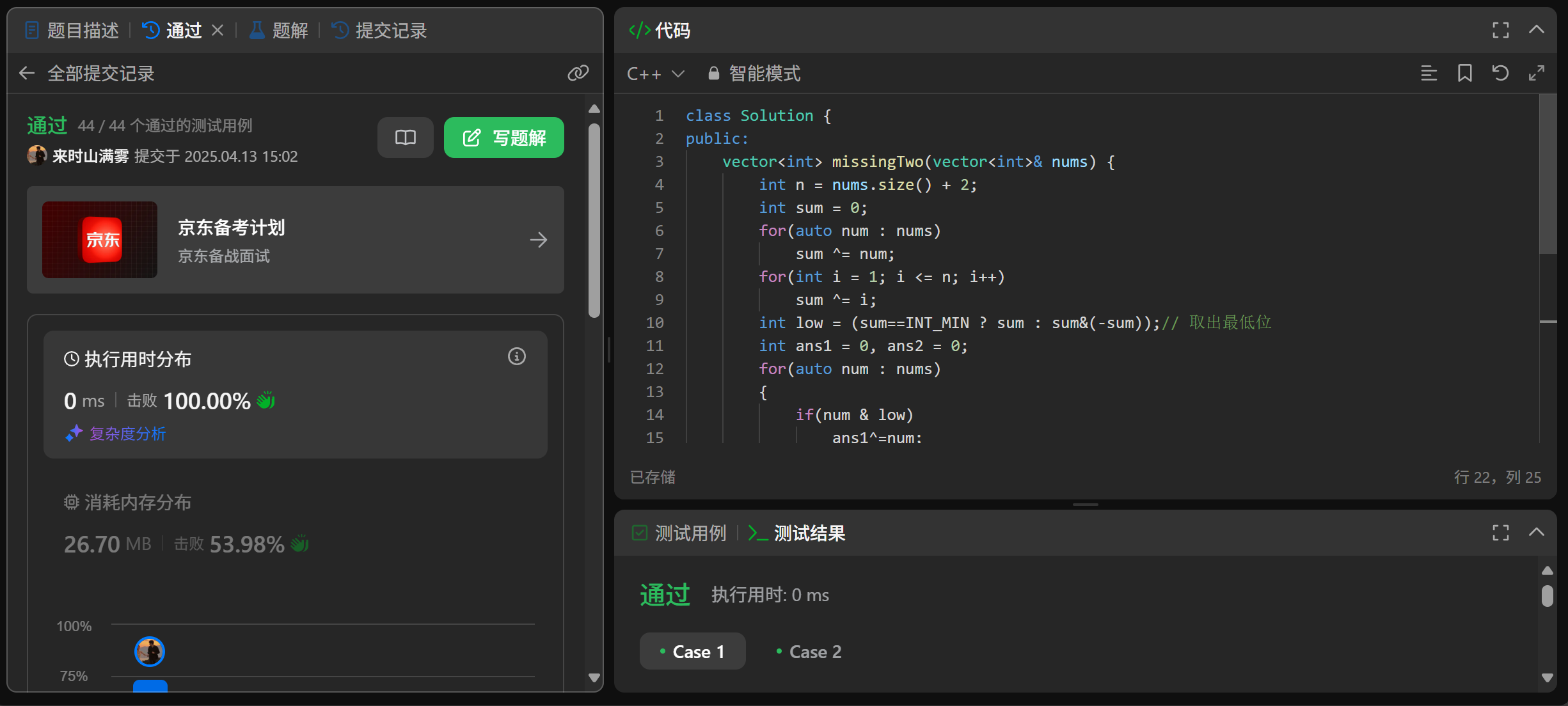
算法思想之位运算(二)
欢迎拜访:雾里看山-CSDN博客 本篇主题:算法思想之位运算(二) 发布时间:2025.4.13 隶属专栏:算法 目录 滑动窗口算法介绍六大基础位运算符常用模板总结 例题判定字符是否唯一题目链接题目描述算法思路代码实现 汉明距离题目链接题目…...

Collection vs Collections:核心区别与面试指南
Collection vs Collections:核心区别与面试指南 一、本质区别(核心记忆点) 维度CollectionCollections身份集合框架的根接口操作集合的工具类包位置java.utiljava.util是否可实例化❌ 接口✅ 类(但构造器私有,不可实…...

win10中快速访问部分外网的快捷设置方法
目的 不翻墙而访问一些本来访问很慢的网站。 具体操作 例如想要访问 github 网站,首先在终端(Terminal,cmd或powershell)中通过 ping github.com 判断网站是否可以被ping到: 若返回 Request time out. 则说明本方法不可用。若收到Reply&am…...
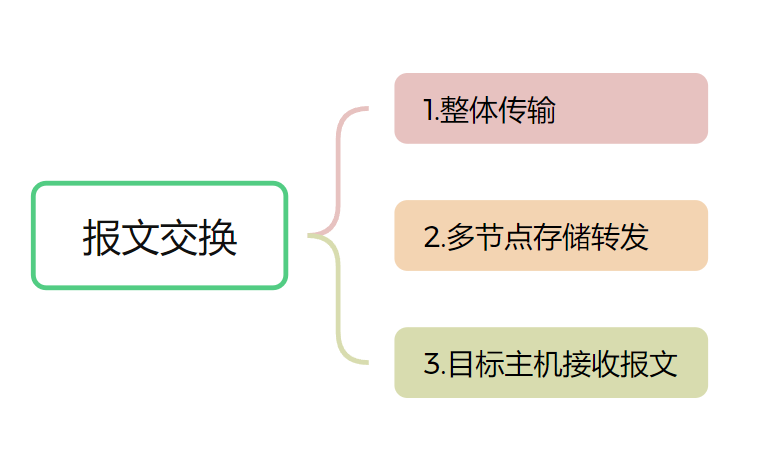
【计网】网络交换技术之报文交换(复习自用,了解,重要3)
复习自用的,处理得比较草率,复习的同学或者想看基础的同学可以看看,大佬的话可以不用浪费时间在我的水文上了 另外两种交换技术可以直接点击链接访问相关笔记: 电路交换 分组交换 一、报文交换的定义 报文交换(Me…...

【Web功能测试】Web商城搜索模块测试用例设计深度解析
Web商城的搜索模块功能测试用例设计 1.搜索功能设计 1.1 搜索框设计 位置显眼:通常置于页面顶部中央,符合用户习惯。 智能提示(Autocomplete):输入时实时推荐关键词、商品或分类(如“手机 苹果”&#x…...

穿梭在数字王国:Python进制转换奇遇记
穿梭在数字王国:Python进制转换奇遇记 想象一下,你是一位勇敢的探险家,正在穿越神秘的"数字王国"。在这个王国里,不同的地区使用着不同的语言(或者说,进制)。二进制村的居民只懂"0"和"1";八进制镇的人们使用0到7的数字;而十六进制城的…...

【动态规划】深入动态规划:背包问题
文章目录 前言01背包例题一、01背包二、分割等和子集三、目标和四、最后一块石头的重量|| 完全背包例题一、完全背包二、 零钱兑换三、零钱兑换||四、完全平方数 前言 什么是背包问题,怎么解决算法中的背包问题呢? 背包问题 (Knapsack problem) 是⼀种组…...
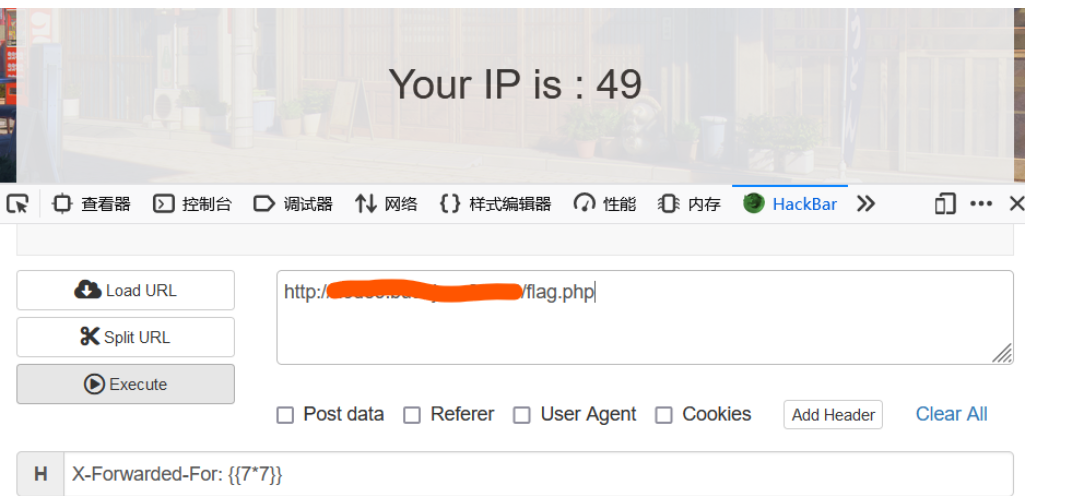
BUUCTF-web刷题篇(25)
34.the mystery of ip 给出链接,输入得到首页: 有三个按钮,flag点击后发现页面窃取客户端的IP地址,通过给出的github代码中的php文件发现可以通过XFF或Client-IP传入值。使用hackbar或BP 使用XSS,通过github给出的目录…...
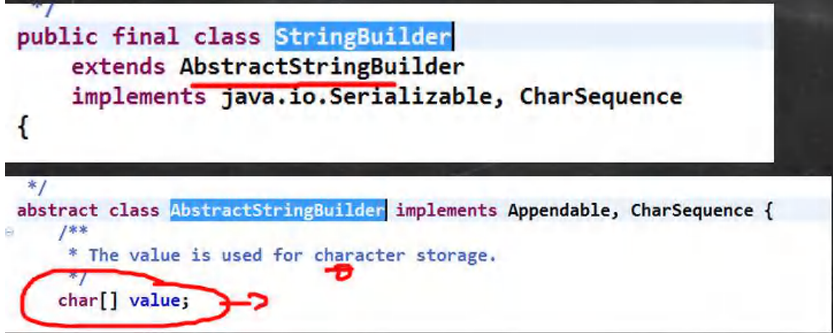
StringBuilder类基本使用
文章目录 1. 基本介绍2. StringBuilder常用方法3. String、StringBuffer 和 StringBuilder 的比较4. String、StringBuffer 和 StringBuilder 的效率测试5. String、StringBuffer 和 StringBuilder 的选择 1. 基本介绍 一个可变的字符序列。此类提供一个与StringBuffer兼容的A…...
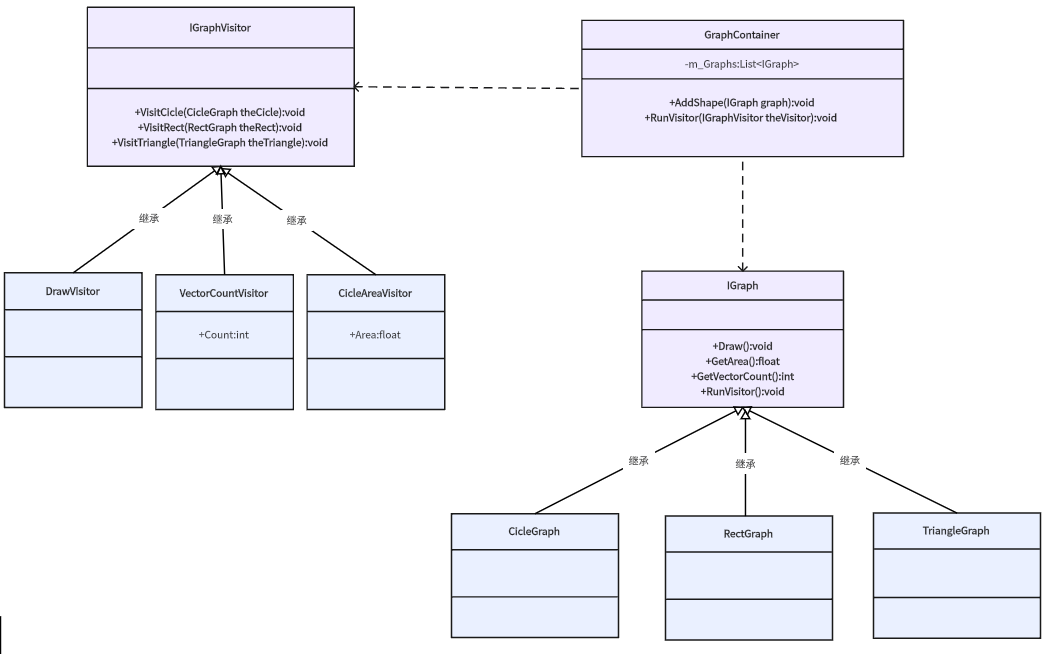
设计模式 --- 访问者模式
访问者模式是一种行为设计模式,它允许在不改变对象结构的前提下,定义作用于这些对象元素的新操作。 优点: 1.符合开闭原则:新增操作只需添加新的访问者类,无需修改现有对象结构。 2.操作逻辑集中管理&am…...

常用AI辅助编程工具及平台介绍
在当今快速发展的技术领域,AI编程工具已经成为提升开发效率和代码质量的重要手段。这些工具利用人工智能技术来帮助开发者提高编程效率、生成代码建议、自动完成功能,并识别错误。接下来,我们将详细介绍几款主流的AI编程工具及其特点,以帮助你选择最适合自己的开发需求的工…...
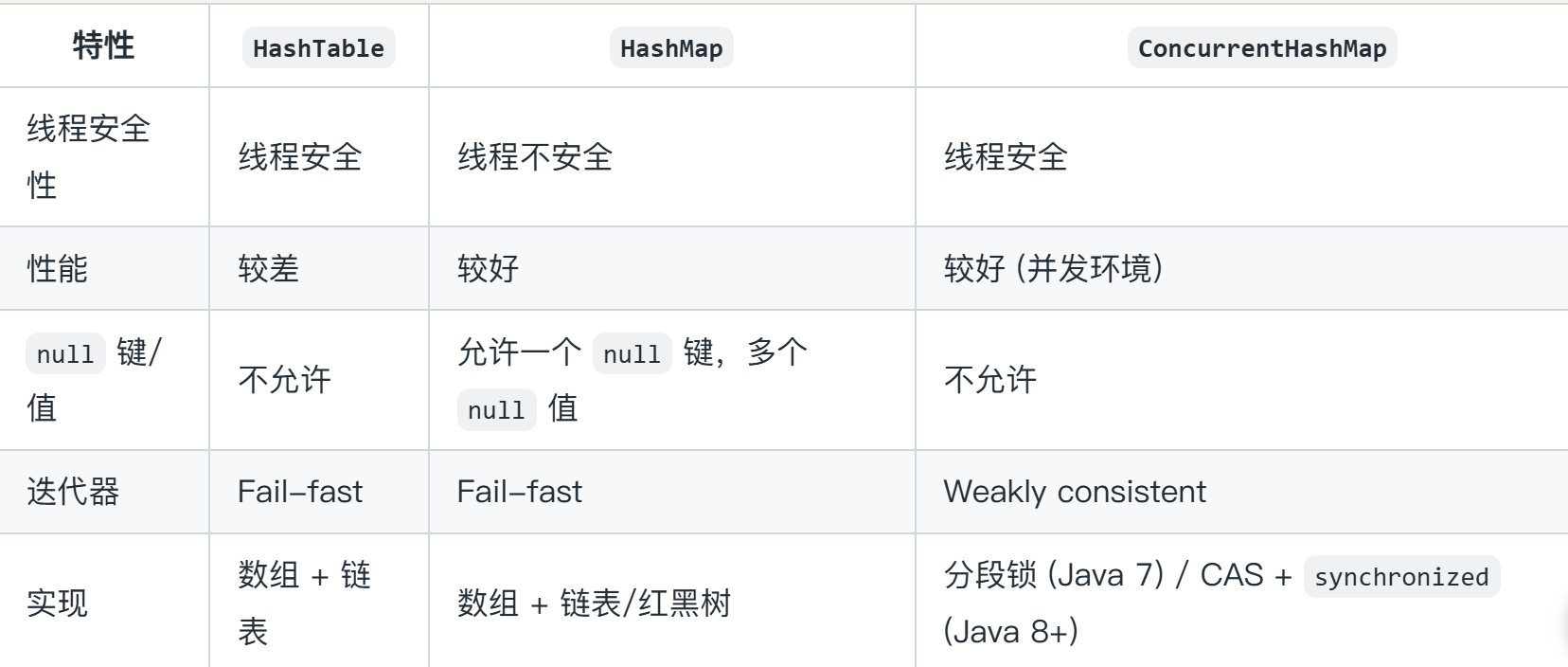
HashTable,HashMap,ConcurrentHashMap之间的区别
文章目录 线程安全方面性能方面总结 线程安全方面 HashMap线程不安全,HashMap的方法没有进行同步,多个线程同时访问HashMap,并至少有一个线程修改了其内容,则必须手动同步。 HashTable是线程安全的,在HashMap的基础上…...

LeetCode.225. 用队列实现栈
用队列实现栈 题目解题思路1. push2. pop3. empty CodeQueue.hQueue.cStack.c 题目 225. 用队列实现栈 请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。 实现…...

LVGL AnalogClock控件和Dclock控件详解
LVGL AnalogClock控件和Dclock控件详解 一、AnalogClock控件详解1. 概述2. 创建模拟时钟2.1 函数2.2 参数2.3 返回值 3. 设置时间3.1 函数3.2 参数 4. 获取时间4.1 函数4.2 参数 5. 设置样式5.1 常用样式属性5.2 示例代码 6. 更新时间6.1 定时器回调示例6.2 创建定时器 7. 示例…...

通过分治策略解决内存限制问题完成大型Hive表数据的去重的PySpark代码实现
在Hive集群中,有一张历史交易记录表,要从这张历史交易记录表中抽取一年的数据按某些字段进行Spark去重,由于这一年的数据超过整个集群的内存容量,需要分解成每个月的数据,分别用Spark去重,并保存为Parquet文…...

深入解析 HTML 中 `<script>` 标签的 async 和 defer 属性
一、背景与问题 在网页性能优化中,脚本的加载和执行方式直接影响页面渲染速度和用户体验。传统 <script> 标签的阻塞行为可能导致页面“白屏”,而 async 和 defer 属性提供了非阻塞的解决方案。本周重点研究二者的差异、适用场景及实际应用。 二、…...