学点概率论,打破认识误区
概率论是统计分析和机器学习的核心。掌握概率论对于理解和开发稳健的模型至关重要,因为数据科学家需要掌握概率论。本博客将带您了解概率论中的关键概念,从集合论的基础知识到高级贝叶斯推理,并提供详细的解释和实际示例。
目录
·简介
·基本集合论
·基本概率概念
·随机变量和期望
·边际、联合和条件概率
·概率规则:边际化和乘积
·贝叶斯定理
·概率分布
·使用概率进行学习
·贝叶斯推理
·在 Python 中实现概率概念
·玩具示例:抛硬币的贝叶斯推理
·结论
·行动呼吁
介绍
概率论是量化不确定性的数学框架。它使我们能够对随机现象进行建模和分析,在统计学、机器学习和数据科学中不可或缺。概率论帮助我们做出明智的决策、评估风险并建立预测模型。
基本集合论
首先,让我们定义几个关键术语。
集合(Set)是对象的集合。这些对象称为集合的元素。
集合a的子集b是其元素均为a的元素的集合,即𝑏 ⊂ 𝑎。
空间 S 是最大的集合;因此,所有其他集合都在考虑之中𝑠ᵢ ⊂ 𝑆。
空集 O 是空集或零集。O不 包含任何元素。
让我们将集合论的组成部分形象化。
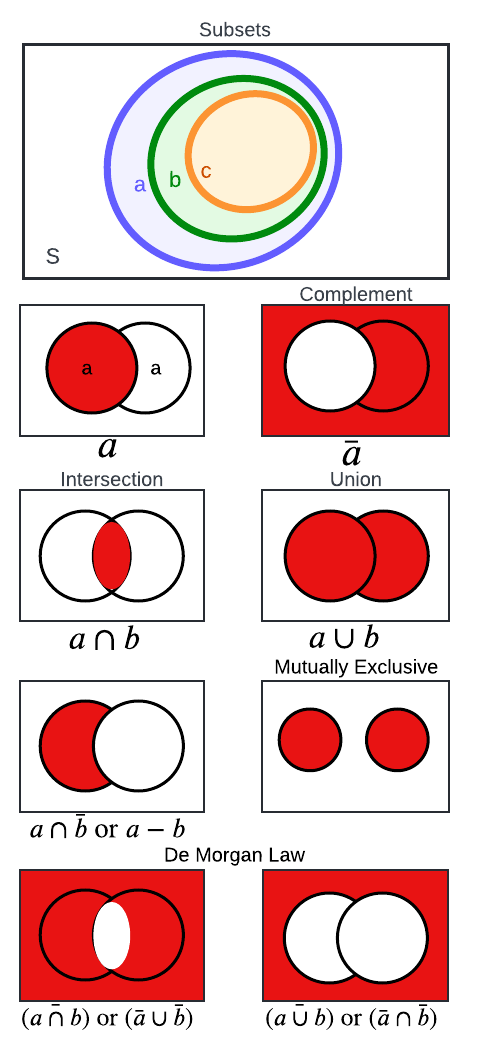
维恩图描绘了集合逻辑和运算。最上面的图显示样本空间S,其中集合A、B和C作为子集(即,B是A的子集,而C是B的子集;因此, C 是A的子集)。其余行描绘了两个集合,A和B。文本包含每个集合的描述和数学。作者创建了视觉效果。
上图描绘了我们在使用集合时遇到的各种场景。让我们来描述集合论的不同方面。鼓励读者在阅读定义和回顾数学表达式时参考每个小节后面的视觉图,以加深他们的直觉。
子集
子集𝑏 ⊂ 𝑎,或者集合a 包含b,如果b的所有元素也是a的元素,则𝑎 ⊃ 𝑏。也就是说,
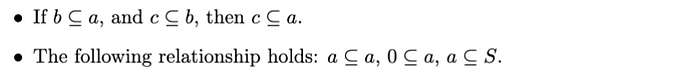
英文:语句“如果b ⊆ a,且c ⊆ b,则c ⊆ a ”表达了集合包含的传递性。如果集合b是集合a的子集,集合c是集合b的子集,则c也一定是a的子集。第二项“以下关系成立:a ⊆ a,0 ⊆ a,a ⊆ S ”强调了集合包含的基本性质。因此:
- a ⊆ a表示每个集合都是其自身的子集。
- 0⊆a表示空集是任意集合a的子集。
- a⊆S表示任意集合a都是全集S的子集。
集合运算
相等:两个集合相等,则a 的每个元素都必须在b中,而b的每个元素都必须在a中。从数学上来说:
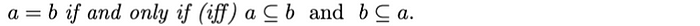
并集(和):两个集合a 和b的并集是由a或b 或两者的所有元素组成的集合。并集运算满足以下性质:
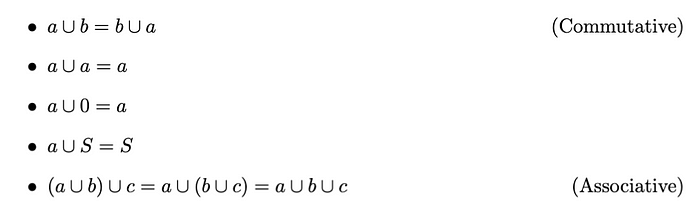
集合a 和b的交集(积)由集合a和b共有的所有元素组成。交集运算满足以下属性:
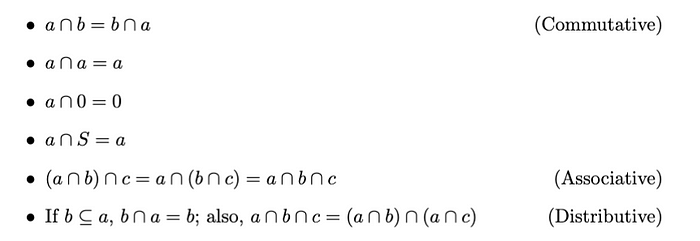
互斥集
如果两个集合a和b没有共同元素,我们称它们互斥或不相交,即

补充
集合 a 的补集 a 定义为由 S 中所有不属于 a 的元素组成的集合。补集满足以下性质:

两集合之差
a − b的差集是a中不属于b的元素的集合。差集满足以下性质:
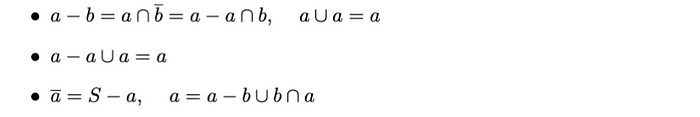
基本概率概念
样本空间(S):随机实验的所有可能结果的集合。
事件(E):样本空间的子集,包含特定结果或一组结果。
随机变量 (RV):可能值为随机现象的数值结果的变量。例如:人的身高、抛硬币或掷骰子的结果。
事件的概率
事件E的概率(即P(E))是衡量该事件发生可能性的指标。它满足以下性质:
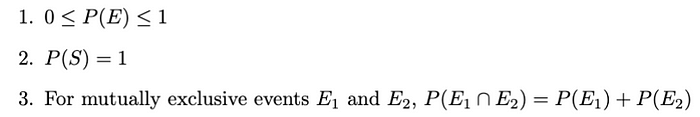
例子
考虑一个公平的六面骰子。样本空间为S = {1, 2, 3, 4, 5, 6}。掷出 3 的概率为 P({3}) = 1/6。掷出 1 或 3 呢?P({1, 3}) = 2/6 = 1/3。最后,掷出偶数呢?P({2, 4, 6}) = 3/6 = 1/2。
随机变量和期望
请注意,我们在本部分中使用了求和与积分。请参阅本系列的上一部分,其中涵盖了微积分和线性代数。
机器学习的基础数学
深入探究向量范数、线性代数、微积分
pub.towardsai.net
随机变量(RV)
RV 是一种变量,其值由随机实验的结果决定。有两种类型:离散随机变量(取可数个值)和连续随机变量(取不可数个值)。
例如离散随机变量的分布:
- 它可以取每个值的概率。
- 符号:P(X=xi)。
- 这些数字满足以下条件:
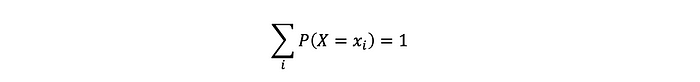
期望和方差
期望值(平均值):随机变量的平均值。
- 对于离散随机变量:
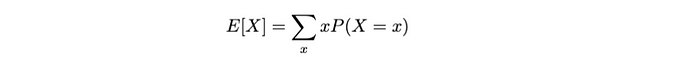
这个期望值(即平均值)是一个离散随机变量X 。因此,我们将其计算为所有可能值x乘以其各自概率P(X = x)的加权总和。
- 对于连续随机变量:
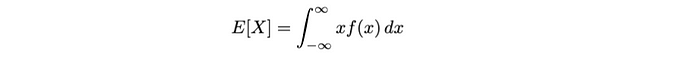
这个期望值(即平均值)是连续随机变量X的。我们将其计算为x乘以其概率密度函数f(x)在整个可能值范围内的积分。
总之:

方差:我们可以计算一个二阶统计测量,表示随机变量与预期值的偏离。
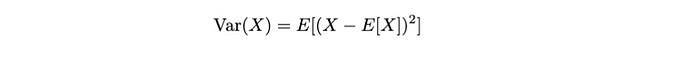
上述方程表示随机变量X的方差,测量X值围绕其均值E[X]的扩展或分散。
例子
对于一个公平的六面骰子,预期值是:
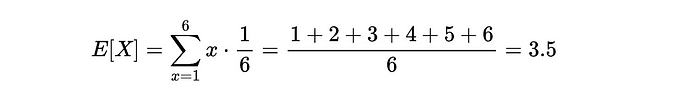
边际概率、联合概率和条件概率
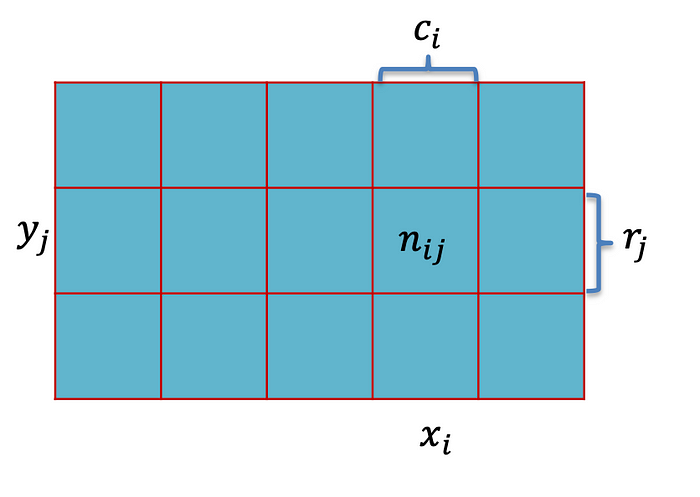
在本小节中,我们将使用一张图来解释边际概率、联合概率和条件概率。因此,表格是两个 RV 的联合概率分布,正如作者在此处所描绘的那样。
检查上面的图片。我们将使用这个视觉效果来学习概率论的基本概念:边际概率、联合概率和条件概率。这些概念对于理解随机变量之间的关系至关重要,尤其是在处理分类或计数数据时。
边际概率
边际概率是指在不考虑任何其他事件的情况下,单个事件发生的概率。在图中,p(X = xᵢ)表示它。然后,我们计算如下:

这表示随机变量X取特定值xᵢ的概率,该概率被边缘化为其他变量的所有可能值。因此,它有助于通过将该事件的联合概率与另一个变量的所有可能结果相加来找到单个事件的概率。
联合概率
联合概率是两个事件同时发生的概率。参考上图,它是概率p(X = xᵢ, Y = yⱼ),计算如下:
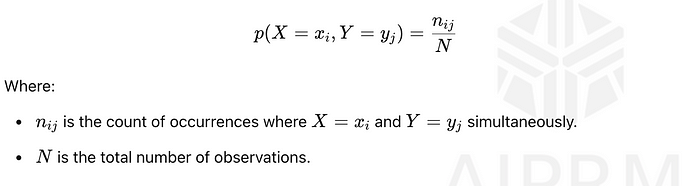
这个联合概率衡量两个事件X = xᵢ和Y = yⱼ同时发生的可能性。
条件概率
条件概率衡量在另一个事件已经发生的情况下,发生另一事件的概率。图像将其定义为p(Y = yⱼ | X = xᵢ),计算方法如下:
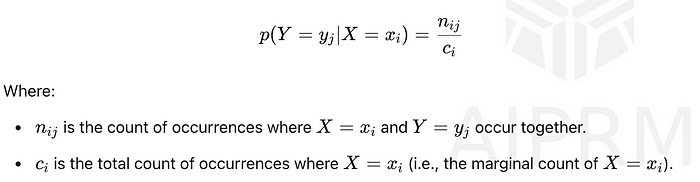
该公式显示在X = xᵢ已经发生的情况下,Y = yⱼ的可能性有多大。
概率规则:边缘化和产品
边缘化是概率论中用到的一个过程,用于从所有变量的联合概率分布中推导出与变量子集相关的事件的概率。
在这个等式中,我们通过对另一个变量Y的所有可能值求和来计算边际概率p(X = xᵢ):

乘积规则是概率中的一个基本概念,它使我们能够根据边际概率和条件概率来表示两个事件的联合概率。
该等式显示了联合概率p(X = xᵢ, Y = yⱼ)如何分解:
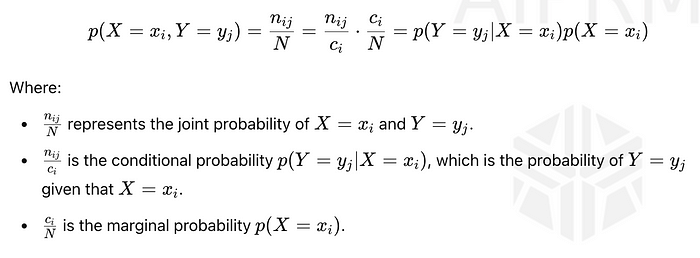
具体来说,用数学的方式表达,乘积法则允许使用一个事件的边际概率和在第一个事件的条件下另一个事件的条件概率来计算两个事件的联合概率。
概括
这些概念是概率论的基础,对于理解数据科学中更复杂的概率模型和推理技术至关重要。总结如下。
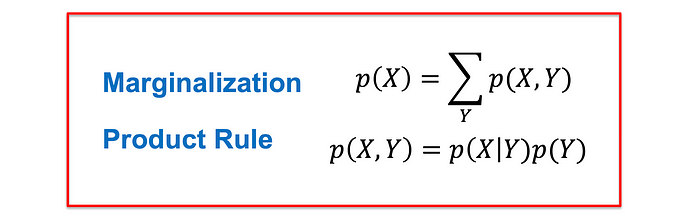
最后,如果P(Y | X) = P(Y) ,则𝑋和𝑌是独立的,这意味着P(Y | X) = P(Y)。这意味着P(𝑋, 𝑌) = P(X)P(Y)。
贝叶斯定理
贝叶斯定理是贝叶斯推理的基石,是一个强大的概率结构,它使我们能够将先验知识融入到我们的计算中。
回到条件概率并在此基础上构建:回想一下我们之前定义的p(Y = yⱼ | X = xᵢ)。我们可以使用事件A和B来概括这一点,并将其进一步扩展到贝叶斯。
因此,条件概率量化了在另一事件发生的情况下发生某事件的概率。因此,在事件B发生的情况下,事件 A的概率是A和B的联合概率与B的概率之比。我们将其表示为P(A | B),并定义为:
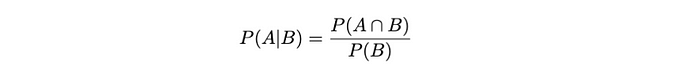
管道字符“|”在概率论中翻译为“给定”。
因此,贝叶斯定理将两个事件的条件概率关联如下:
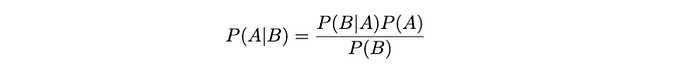
该术语根据似然P (B | A)、先验P(A)和边际概率P(B)来表达条件概率P(A | B) 。同样,这个构造是贝叶斯推理的基础,它使我们能够根据新证据更新我们的信念。
例子
假设我们对某种疾病进行测试,其概率如下:

利用贝叶斯定理,我们可以找到P(疾病|阳性):
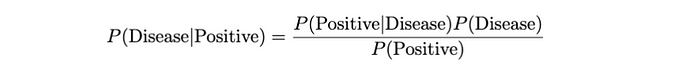
我们可以这样计算P(Positive) :
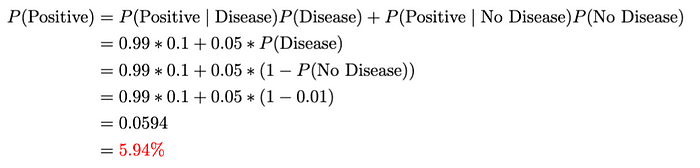
该方程表示考虑两种情况(即患有和不患有疾病)的检测呈阳性的总概率:直接应用总概率定律。
概率分布
典型趋势遵循已知分布。因此,一个常见的问题是假设一个特定的分布来拟合我们的数据。以下是离散和连续随机变量的几个分布。
离散分布
- 二项分布:描述固定次数的独立伯努利试验中的成功次数。
- 泊松分布:对固定时间间隔或空间内发生的事件数量进行建模。
连续分布
- 正态分布:以钟形曲线为特征,用平均值 μ 和标准差 σ 描述。
- 指数分布:描述泊松过程中事件之间的时间。
我们可以通过了解期望值、方差或其他统计指标来近似数据分布。以下备忘单总结了一些连续和离散 RV 的备忘单。
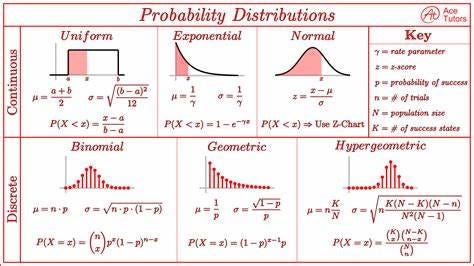
这是显示连续和离散概率分布的图表。每个分布都有其平均值、标准差和概率的公式——图片来源。
例子
让我们仔细看看正态分布的概率密度函数。从数学上讲,它表示如下:
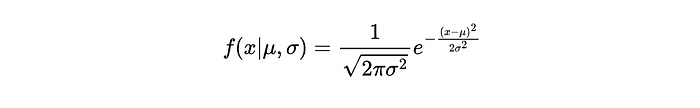
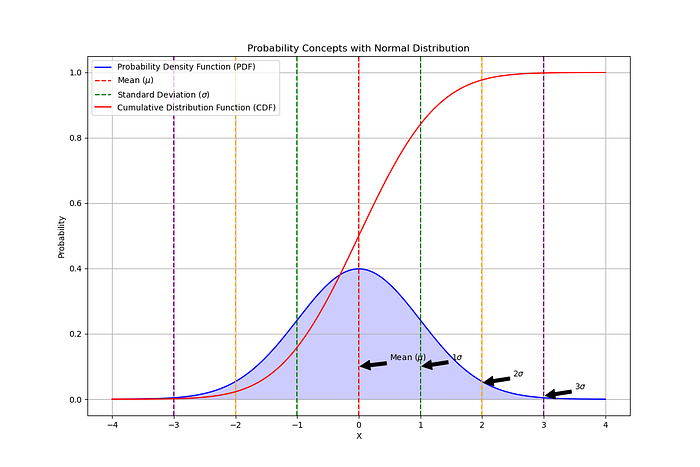
使用正态分布的概率概念可视化,显示概率密度函数 (PDF)、累积分布函数 (CDF)、平均值 (µ) 和标准差 (σ)。
该图以正态分布为基础,直观地展现了关键的概率概念。图中蓝色部分为概率密度函数 (PDF),表示分布中不同结果出现的可能性。PDF 曲线下方的面积表示随机变量落在特定范围内的概率。
累积分布函数 (CDF) 以红色显示。它从左到右累积概率,从 0 开始,渐近于 1。CDF 帮助我们确定随机变量小于或等于某个值的概率。
垂直虚线标记平均值 (μ) 和与平均值的标准差 (σ)。平均值在 x=0 处用红色虚线表示,而绿色、橙色和紫色虚线分别表示第一、第二和第三个标准差 (±1σ、±2σ、±3σ)。这些标准差说明了数据如何分布在平均值周围,其中约 68%、95% 和 99.7% 分别在平均值的 1σ、2σ 和 3σ 范围内。
图中的箭头有助于识别这些关键点,使视觉效果更易于理解。对于任何想要掌握概率基本概念的人来说,该图都是一个有用的工具,尤其是正态分布,它是统计分析和许多机器学习算法的基石。
使用概率进行学习
例如,在对垃圾邮件进行分类时,我们可以估计𝑃(𝑌 | 𝑉𝑖𝑎𝑔𝑎𝑟𝑎, 𝑙𝑜𝑡𝑡𝑒𝑟𝑦)。
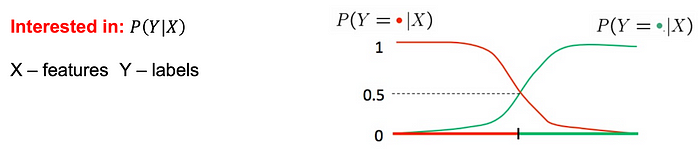
— 如果𝑃(𝑌 | 𝑋) <0.5 ,我们会将示例归类为垃圾邮件。 — 但是,对𝑃(𝑋 | 𝑌)
进行建模通常更容易。
这就给我们带来了最大似然法。
最大似然法

例如:抛硬币
根据n 次抛硬币的结果(其中h次都是正面),估计硬币掷出“正面”的概率p 。
数据的可能性:
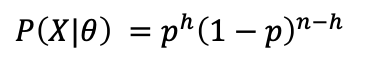
对数似然:
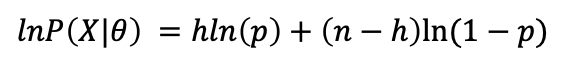
取导数并将其设置为 0:
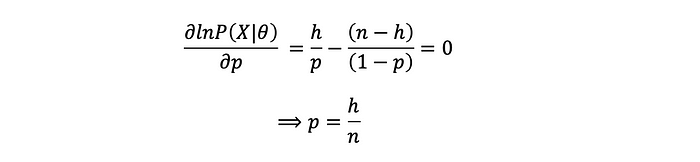
贝叶斯推理
贝叶斯推理是一种统计推断方法,其中贝叶斯定理用于随着更多证据的出现而更新假设的概率。
先验、似然和后验
- 先验(P(H)):对假设的初始信念。
- 可能性(P(E | H)):根据假设观察到证据的概率。
- 后验(P(H | E)):观察证据后对假设的更新信念。
贝叶斯推理中的贝叶斯定理:
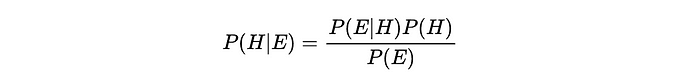
我们是如何得到这个结果的?让我们回到使用X和Y进行泛化。
根据乘积法则
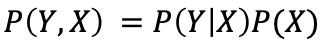
和
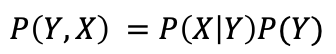
所以:
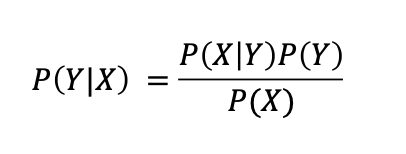
这被称为贝叶斯规则。
总之:

𝑷(𝑿) 可以计算为
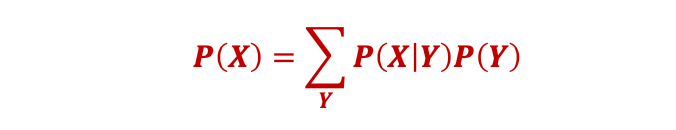
然而,推断标签并不重要。
例子
让我们回到我们的案例,我们正在接受罕见疾病的检测。这一次,我们的检测结果已经呈阳性。让我们使用贝叶斯来确定它是真阳性的概率(即使用贝叶斯检查测试是否为假阳性,即测试结果被错误地归类为真)。
- 在假阳性率为 5% 的测试中检测结果为阳性。
- 出现这种疾病的可能性有多大?
- 假设每 100 人中就有 1 人患有此病。这会有什么不同吗?
- 该测试的假阴性率为 10%;实际上,十分之一的错误预测是正确的。这可以用来改善我们的预测吗?
我们首先从视觉上看一下。
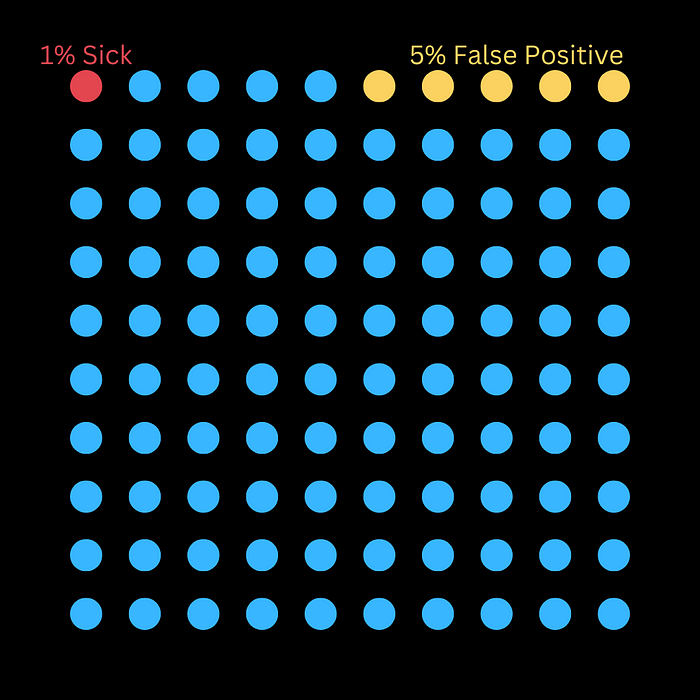
该图片显示,每 100 人中就有 5 人被错误地标记为患有该疾病(即假阳性),而 1 人确实患有该疾病。
让我们使用贝叶斯定理。
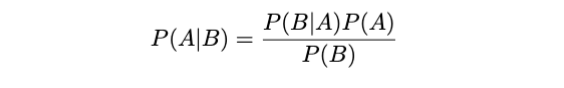
请查看《我们拥有什么和想要什么》。
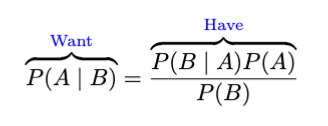
让我们进一步研究一下。

因此,先验(即分母中的P(B))由两个子集组成,我们可以将其表示为并集(或和)。
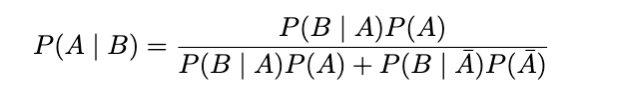
现在,插上电源并喝水:

因此,我们患病的概率为 15.4%!这比仅考虑假阳性率而不使用检测阳性和假阴性的百分比时原来的 95% 要好得多。
如果我们接受两次检测,每次都得到阳性结果,那会怎样?这种疾病存在的可能性有多大?
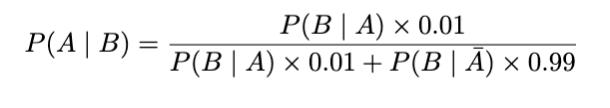
其中A患有该疾病,而B两次检测结果呈阳性。

请注意,即使经过两次测试,我们的机会仍然低于原来的 95%。
这就是贝叶斯的美妙之处:随着我们获得更多知识,我们可以将其融入到我们的数字理解中,从而提高概率的精确度!
在 Python 中实现概率概念
我们将使用该numpy库进行数值计算和scipy.stats概率分布。
示例:抛硬币模拟
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#007400"># 导入必要的库</span>
<span style="color:#aa0d91">import</span> numpy <span style="color:#aa0d91">as</span> np
<span style="color:#aa0d91">import</span> scipy.stats <span style="color:#aa0d91">as</span> stats
<span style="color:#aa0d91">import</span> matplotlib.pyplot <span style="color:#aa0d91">as</span> plt <span style="color:#007400"># 抛硬币次数</span>
n_flips = <span style="color:#1c00cf">100 </span>
<span style="color:#007400"># 模拟抛硬币(1 表示正面,0 表示反面)</span>coin_flips = np.random.binomial( <span style="color:#1c00cf">1</span> , <span style="color:#1c00cf">0.5</span> , n_flips) <span style="color:#007400"># 计算正面的次数</span>
n_heads = np.sum (coin_flips) <span style="color:#5c2699">print </span>
<span style="color:#5c2699">(</span> f <span style="color:#c41a16">"正面数量:<span style="color:#000000">{n_heads}</span> "</span> )
<span style="color:#007400"># 计算正面的概率</span>
p_heads = n_heads / n_flips
<span style="color:#5c2699">print</span> ( <span style="color:#c41a16">f"估计正面的概率:<span style="color:#000000">{p_heads: <span style="color:#1c00cf">.2</span> f}</span> "</span> )</span></span></span></span>输出:
正面次数:51
预计正面概率:0.51
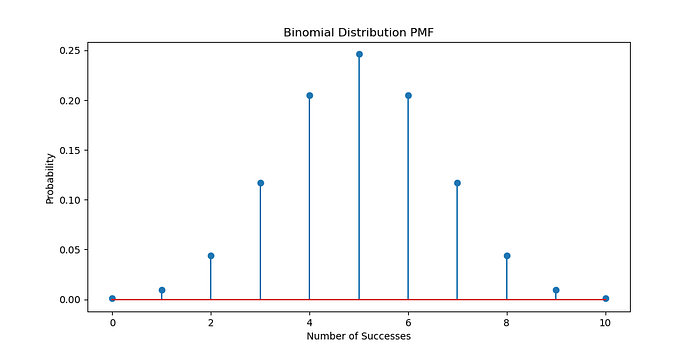
概率分布可视化
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#007400"># 绘制二项分布</span>
n_trials = <span style="color:#1c00cf">10</span>p_success = <span style="color:#1c00cf">0.5</span>x = np.arange( <span style="color:#1c00cf">0</span> , n_trials+ <span style="color:#1c00cf">1</span> )
binomial_pmf = stats.binom.pmf(x, n_trials, p_success) plt.figure(figsize=( <span style="color:#1c00cf">10</span> , <span style="color:#1c00cf">5</span> ))
plt.stem(x, binomial_pmf)
plt.title( <span style="color:#c41a16">'二项分布 PMF'</span> )
plt.xlabel( <span style="color:#c41a16">'成功次数'</span> )
plt.ylabel( <span style="color:#c41a16">'概率'</span> )
plt.show()</span></span></span></span>生成:
示例:硬币翻转的贝叶斯推理
我们将使用贝叶斯推理来估计有偏差的硬币出现正面的概率。
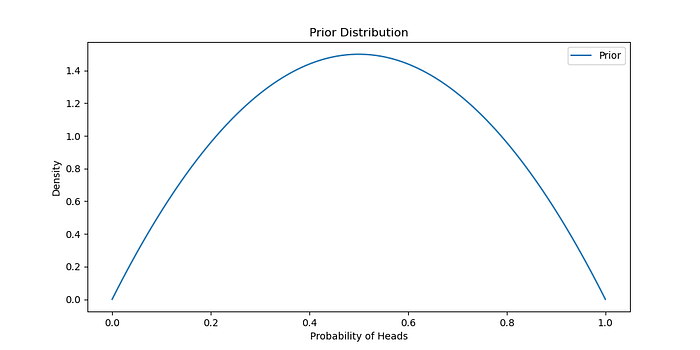
先前的信念
假设 Beta 先验分布的参数为 α = 2 和 β = 2,表示统一的先验信念。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#007400"># 定义先验分布</span>
alpha_prior = <span style="color:#1c00cf">2</span>beta_prior = <span style="color:#1c00cf">2</span>Prior = stats.beta(alpha_prior, beta_prior) <span style="color:#007400"># 绘制先验分布</span>
x = np.linspace( <span style="color:#1c00cf">0</span> , <span style="color:#1c00cf">1</span> , <span style="color:#1c00cf">100</span> )
plt.figure(figsize=( <span style="color:#1c00cf">10</span> , <span style="color:#1c00cf">5</span> ))
plt.plot(x, Prior.pdf(x), label= <span style="color:#c41a16">'Prior'</span> )
plt.title( <span style="color:#c41a16">'Prior Distribution'</span> )
plt.xlabel( <span style="color:#c41a16">'Probability of Heads'</span> )
plt.ylabel( <span style="color:#c41a16">'Density'</span> )
plt.legend()
plt.show()</span></span></span></span>生成:
似然和后验
使用观察到的数据(证据)更新先验以获得后验分布。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#007400"># 观察到的正面和反面的数量</span>
n_heads = <span style="color:#1c00cf">7</span>n_tails = <span style="color:#1c00cf">3 </span><span style="color:#007400"># 更新后验分布</span>
alpha_posterior = alpha_prior + n_heads
beta_posterior = beta_prior + n_tails
posterior = stats.beta(alpha_posterior, beta_posterior) <span style="color:#007400"># 绘制后验分布</span>
plt.figure(figsize=(
<span style="color:#1c00cf">10</span> , <span style="color:#1c00cf">5</span> ))
plt.plot(x, Prior.pdf(x), label= <span style="color:#c41a16">'Prior'</span> )
plt.plot(x, posterior.pdf(x), label= <span style="color:#c41a16">'Posterior'</span> , linestyle= <span style="color:#c41a16">'--'</span> )
plt.title( <span style="color:#c41a16">'先验和后验分布'</span> )
plt.xlabel( <span style="color:#c41a16">'正面的概率'</span> )
plt.ylabel( <span style="color:#c41a16">'密度'</span> )
plt.legend()
plt.show()</span></span></span></span>生成:
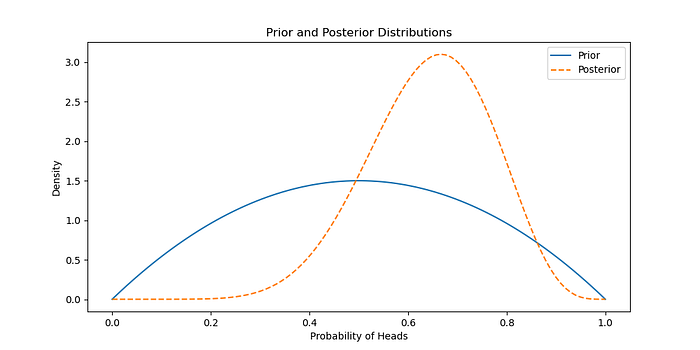
结论
概率论是支撑许多统计和机器学习技术的基本数据科学组成部分。本教程涵盖了概率的基本概念,从基本定义到高级贝叶斯推理,并提供了实际示例和 Python 实现。通过掌握这些概念,您可以构建更强大的模型,做出更好的决策,并从数据中获得更深入的见解。
尝试使用不同的概率分布、假设和数据集来探索概率论在数据科学项目中的广泛应用。
相关文章:
学点概率论,打破认识误区
概率论是统计分析和机器学习的核心。掌握概率论对于理解和开发稳健的模型至关重要,因为数据科学家需要掌握概率论。本博客将带您了解概率论中的关键概念,从集合论的基础知识到高级贝叶斯推理,并提供详细的解释和实际示例。 目录 简介 基本集合…...
NVIDIA AI Aerial
NVIDIA AI Aerial 适用于无线研发的 NVIDIA AI Aerial 基础模组Aerial CUDA 加速 RANAerial Omniverse 数字孪生Aerial AI 无线电框架 用例构建商业 5G 网络加速 5G生成式 AI 和 5G 数据中心 加速 6G 研究基于云的工具 优势100% 软件定义通过部署在数字孪生中进行测试6G 标准化…...

OpenCV 关键点定位
一、Opencv关键点定位介绍 关键点定位在计算机视觉领域占据着核心地位,它能够精准识别图像里物体的关键特征点。OpenCV 作为功能强大的计算机视觉库,提供了多种实用的关键点定位方法。本文将详细阐述关键点定位的基本原理,深入探讨 OpenCV 中…...

C++ 重构muduo网络库
本项目参考的陈硕老师的思想 1. 基础概念 进程里有 Reactor、Acceptor、Handler 这三个对象 Reactor 对象的作用是监听和分发事件;Acceptor 对象的作用是获取连接;Handler 对象的作用是处理业务; 先说说 阻塞I/O,非阻塞I/O&…...

SDHC接口协议底层传输数据是安全的
SDHC(Secure Digital High Capacity)接口协议在底层数据传输过程中确实包含校验机制,以确保数据的完整性和可靠性。以下是关键点的详细说明: 物理层与数据链路层的校验机制 物理层(Electrical Layer)&…...
arm_math.h、arm_const_structs.h 和 arm_common_tables.h
在 FOC(Field-Oriented Control,磁场定向控制) 中,arm_math.h、arm_const_structs.h 和 arm_common_tables.h 是 CMSIS-DSP 库的核心组件,用于实现高效的数学运算、预定义结构和查表操作。以下是它们在 FOC 控…...

buuctf sql注入类练习
BUU SQL COURSE 1 1 实例无法访问 / Instance cant be reached at that time | BUUCTF但是这个地方很迷惑就是这个 一个 # 我们不抓包就不知道这个是sql注入类的判断是 get 类型的sql注入直接使用sqlmap我们放入到1.txt中 目的是 优先检测 ?id1>python3 sqlmap.py -r 1.t…...

具身导航中的视觉语言注意力蒸馏!Vi-LAD:实现动态环境中的社会意识机器人导航
作者:Mohamed Elnoor 1 ^{1} 1, Kasun Weerakoon 1 ^{1} 1, Gershom Seneviratne 1 ^{1} 1, Jing Liang 2 ^{2} 2, Vignesh Rajagopal 3 ^{3} 3, and Dinesh Manocha 1 , 2 ^{1,2} 1,2单位: 1 ^{1} 1马里兰大学帕克分校电气与计算机工程系, 2…...

全局前置守卫与购物车页面鉴权
在很多应用里,并非所有页面都能随意访问。例如购物车页面,用户需先登录才能查看。这时可以利用全局前置守卫来实现这一鉴权功能。 全局前置守卫的书写位置在 router/index.js 文件中,在创建 router 对象之后,暴露 router 对象之前…...

vue3 ts 自定义指令 app.directive
在 Vue 3 中,app.directive 是一个全局 API,用于注册或获取全局自定义指令。以下是关于 app.directive 的详细说明和使用方法 app.directive 用于定义全局指令,这些指令可以用于直接操作 DOM 元素。自定义指令在 Vue 3 中非常强大࿰…...
layui 弹窗-调整窗口的缩放拖拽几次就看不到标题、被遮挡了怎么解决
拖拽几次,调整窗口的缩放,就出现了弹出的页面,右上角叉号调不出来了,窗口关不掉 废话不多说直入主题: 在使用layer.alert layer.confirm layer.msg 等等弹窗时,发现看不到弹窗,然后通过控制台检查代码发现…...

网络空间安全(57)K8s安全加固
一、升级K8s版本和组件 原因:K8s新版本通常会引入一系列安全功能,提供关键的安全补丁,能够补救已知的安全风险,减少攻击面。 操作:将K8s部署更新到最新稳定版本,并使用到达stable状态的API。 二、启用RBAC&…...

2025蓝桥杯C++A组省赛 题解
昨天打完蓝桥杯本来想写个 p y t h o n python python A A A 组的题解,结果被队友截胡了。今天上课把 C A CA CA 组的题看了,感觉挺简单的,所以来水一篇题解。 这场 B B B 是一个爆搜, C C C 利用取余的性质比较好写&#…...
论文学习:《通过基于元学习的图变换探索冷启动场景下的药物-靶标相互作用预测》
原文标题:Exploring drug-target interaction prediction on cold-start scenarios via meta-learning-based graph transformer 原文链接:https://www.sciencedirect.com/science/article/pii/S1046202324002470 药物-靶点相互作用(DTI&…...

【题解-洛谷】P1824 进击的奶牛
题目:P1824 进击的奶牛 题目描述 Farmer John 建造了一个有 N N N( 2 ≤ N ≤...

机械革命 无界15X 自带的 有线网卡 YT6801 debian12下 的驱动方法
这网卡是国货啊。。。 而且人家发了驱动程序 Motorcomm Microelectronics. YT6801 Gigabit Ethernet Controller [1f0a:6801] 网卡YT6801在Linux环境中的安装方法 下载网址 yt6801-linux-driver-1.0.29.zip 我不知道别的系统是否按照说明安装就行了 但是debian12不行&…...
十八、TCP多线程、多进程并发服务器
1、TCP多线程并发服务器 服务端: #include<stdio.h> #include <arpa/inet.h> #include<stdlib.h> #include<string.h> #include <sys/types.h> /* See NOTES */ #include <sys/socket.h> #include <pthread.h>…...

JAVA中正则表达式的入门与使用
JAVA中正则表达式的入门与使用 一,基础概念 正则表达式(Regex) 用于匹配字符串中的特定模式,Java 中通过 java.util.regex 包实现,核心类为: Pattern:编译后的正则表达式对象。 Matcher&#…...

AIGC-文生图与图生图
在之前的文章中,我们知道了如何通过Web UI和Confy UI两种SD工具来进行图片生成,今天进一步地讲解其中的参数用处及如何调节。 文生图 参数详解 所谓文生图,就是通过文字描述我们想要图片包含的内容。初学的话,还是以Web UI为例…...
量化交易 - 聚宽joinquant - 多因子入门研究 - 源码开源
先看一下我们的收益: JoinQuant直达这里看看 下面讲解原理和代码。 目录 一、是否为st 二、是否停牌 三、市值小、roe大 四、编写回测代码 今天来研究一下多因子回测模型,这里以‘市值’、‘roe’作为例子。 几个标准:沪深300里选股&am…...

本地缓存方案Guava Cache
Guava Cache 是 Google 的 Guava 库提供的一个高效内存缓存解决方案,适用于需要快速访问且不频繁变更的数据。 // 普通缓存 Cache<Key, Value> cache CacheBuilder.newBuilder().maximumSize(1000) // 最大条目数.expireAfterWrite(10, TimeUnit.MINUTES) /…...
)
虚拟列表react-virtualized使用(npm install react-virtualized)
1. 虚拟化列表 (List) // 1. 虚拟化列表 (List)import { List } from react-virtualized; import react-virtualized/styles.css; // 只导入一次样式// 示例数据 const list Array(1000).fill().map((_, index) > ({id: index,name: Item ${index},description: This is i…...

解释型语言和编译型语言的区别
Python 的执行过程通常涉及字节码,而不是直接将代码编译为机器码。以下是详细的解释: ### **Python 的执行过程** 1. **源代码到字节码**: - Python 源代码(.py 文件)首先被编译为字节码(.pyc 文件&…...

猫咪如厕检测与分类识别系统系列【三】融合yolov11目标检测
✅ 前情提要 家里养了三只猫咪,其中一只布偶猫经常出入厕所。但因为平时忙于学业,没法时刻关注牠的行为。我知道猫咪的如厕频率和时长与健康状况密切相关,频繁如厕可能是泌尿问题,停留过久也可能是便秘或不适。为了更科学地了解牠…...

sql server 字段逗号分割取后面的值
在 SQL Server 中,如果你有一个字段(字段类型通常是字符串),其中包含用逗号分隔的值,并且你想提取这些值中逗号后面的特定部分,你可以使用多种方法来实现这一点。这里我将介绍几种常见的方法: …...

FPGA 37 ,FPGA千兆以太网设计实战:RGMII接口时序实现全解析( RGMII接口时序设计,RGMII~GMII,GMII~RGMII 接口转换 )
目录 前言 一、设计流程 1.1 需求理解 1.2 模块划分 1.3 测试验证 二、模块分工 2.1 RGMII→GMII(接收方向,rgmii_rx 模块) 2.2 GMII→RGMII(发送方向,rgmii_tx 模块) 三、代码实现 3.1 顶层模块 …...

上篇:《排序算法的奇妙世界:如何让数据井然有序?》
个人主页:strive-debug 排序算法精讲:从理论到实践 一、排序概念及应用 1.1 基本概念 **排序**:将一组记录按照特定关键字(如数值大小)进行递增或递减排列的操作。 1.2 常见排序算法分类 - **简单低效型**ÿ…...

红宝书第三十四讲:零基础学会单元测试框架:Jest、Mocha、QUnit
红宝书第三十四讲:零基础学会单元测试框架:Jest、Mocha、QUnit 资料取自《JavaScript高级程序设计(第5版)》。 查看总目录:红宝书学习大纲 一、单元测试是什么? 就像给代码做“体检”,帮你检查…...

【JDBC-54.1】MySQL JDBC连接字符串常用参数详解
在Java应用程序中连接MySQL数据库时,JDBC连接字符串是建立连接的关键。一个配置得当的连接字符串不仅能确保连接成功,还能优化性能、增强安全性并处理各种连接场景。本文将深入探讨MySQL JDBC连接字符串的常用参数及其最佳实践。 1. 基本连接字符串格式…...

swagger 注释说明
一、接口注释核心字段 在 Go 的路由处理函数(Handler)上方添加注释,支持以下常用注解: 注解名称用途说明示例格式Summary接口简要描述Summary 创建用户Description接口详细说明Description 通过用户名和邮箱创建新用户Tags接口分…...