Pytorch深度学习框架60天进阶学习计划 - 第41天:生成对抗网络进阶(二)
Pytorch深度学习框架60天进阶学习计划 - 第41天:生成对抗网络进阶(二)
7. 实现条件WGAN-GP
# 训练条件WGAN-GP
def train_conditional_wgan_gp():# 用于记录损失d_losses = []g_losses = []# 用于记录生成样本的多样性(通过类别分布)class_distributions = []for epoch in range(n_epochs):for i, (real_imgs, labels) in enumerate(dataloader):real_imgs = real_imgs.to(device)labels = labels.to(device)batch_size = real_imgs.shape[0]# ---------------------# 训练判别器# ---------------------optimizer_D.zero_grad()# 生成随机噪声z = torch.randn(batch_size, latent_dim, device=device)# 为生成器生成随机标签gen_labels = torch.randint(0, n_classes, (batch_size,), device=device)# 生成一批假图像fake_imgs = generator(z, gen_labels)# 判别器前向传播real_validity = discriminator(real_imgs, labels)fake_validity = discriminator(fake_imgs.detach(), gen_labels)# 计算梯度惩罚gradient_penalty = compute_gradient_penalty(discriminator, real_imgs.data, fake_imgs.data, labels)# WGAN-GP 判别器损失d_loss = -torch.mean(real_validity) + torch.mean(fake_validity) + lambda_gp * gradient_penaltyd_loss.backward()optimizer_D.step()# 每n_critic次迭代训练一次生成器n_critic = 5if i % n_critic == 0:# ---------------------# 训练生成器# ---------------------optimizer_G.zero_grad()# 为生成器生成新的随机标签gen_labels = torch.randint(0, n_classes, (batch_size,), device=device)# 生成一批新的假图像gen_imgs = generator(z, gen_labels)# 判别器评估假图像fake_validity = discriminator(gen_imgs, gen_labels)# WGAN 生成器损失g_loss = -torch.mean(fake_validity)g_loss.backward()optimizer_G.step()if i % 50 == 0:print(f"[Epoch {epoch}/{n_epochs}] [Batch {i}/{len(dataloader)}] "f"[D loss: {d_loss.item():.4f}] [G loss: {g_loss.item():.4f}]")d_losses.append(d_loss.item())g_losses.append(g_loss.item())# 每个epoch结束后,评估生成样本的类别分布if (epoch + 1) % 10 == 0:class_dist = evaluate_class_distribution()class_distributions.append(class_dist)# 保存生成的图像样本save_sample_images(epoch)# 绘制损失曲线plt.figure(figsize=(10, 5))plt.plot(d_losses, label='Discriminator Loss')plt.plot(g_losses, label='Generator Loss')plt.xlabel('Iterations (x50)')plt.ylabel('Loss')plt.legend()plt.savefig('cond_wgan_gp_loss.png')plt.close()# 绘制类别分布变化plot_class_distributions(class_distributions)# 评估生成样本的类别分布
def evaluate_class_distribution():"""评估生成样本在各类别上的分布情况"""# 创建一个预训练的分类器classifier = torchvision.models.resnet18(pretrained=True)# 修改第一个卷积层以适应灰度图classifier.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)# 修改最后的全连接层以适应MNIST的10个类别classifier.fc = nn.Linear(classifier.fc.in_features, 10)# 加载预先训练好的MNIST分类器权重(这里假设我们有一个预训练的模型)# classifier.load_state_dict(torch.load('mnist_classifier.pth'))# 简化起见,这里我们使用一个简单的CNN分类器classifier = nn.Sequential(nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(64 * 7 * 7, 128),nn.ReLU(),nn.Linear(128, 10)).to(device)# 这里假设这个简单分类器已经在MNIST上训练好了# 实际应用中,应该加载一个预先训练好的模型# 生成1000个样本z = torch.randn(1000, latent_dim, device=device)# 均匀采样所有类别gen_labels = torch.tensor([i % 10 for i in range(1000)], device=device)gen_imgs = generator(z, gen_labels)# 使用分类器预测类别with torch.no_grad():classifier.eval()preds = torch.softmax(classifier(gen_imgs), dim=1)pred_labels = torch.argmax(preds, dim=1)# 计算每个类别的样本数量class_counts = torch.zeros(10)for i in range(10):class_counts[i] = (pred_labels == i).sum().item() / 1000return class_counts.numpy()# 绘制类别分布变化
def plot_class_distributions(class_distributions):"""绘制生成样本类别分布的变化"""epochs = [10, 20, 30, 40, 50] # 假设每10个epoch评估一次plt.figure(figsize=(12, 8))for i, dist in enumerate(class_distributions):plt.subplot(len(class_distributions), 1, i+1)plt.bar(np.arange(10), dist)plt.ylabel(f'Epoch {epochs[i]}')plt.ylim(0, 0.3) # 限制y轴范围,便于比较if i == len(class_distributions) - 1:plt.xlabel('Digit Class')plt.tight_layout()plt.savefig('class_distribution.png')plt.close()# 保存样本图像(条件版本)
def save_sample_images(epoch):"""保存按类别排列的样本图像"""# 为每个类别生成样本n_row = 10 # 每个类别一行n_col = 10 # 每个类别10个样本fig, axs = plt.subplots(n_row, n_col, figsize=(12, 12))for i in range(n_row):# 固定类别fixed_class = torch.tensor([i] * n_col, device=device)# 随机噪声z = torch.randn(n_col, latent_dim, device=device)# 生成图像gen_imgs = generator(z, fixed_class).detach().cpu()# 转换到[0, 1]范围gen_imgs = 0.5 * gen_imgs + 0.5# 显示图像for j in range(n_col):axs[i, j].imshow(gen_imgs[j, 0, :, :], cmap='gray')axs[i, j].axis('off')plt.savefig(f'cond_wgan_gp_epoch_{epoch+1}.png')plt.close()# 运行条件WGAN-GP训练
if __name__ == "__main__":train_conditional_wgan_gp()
上述代码实现了一个条件WGAN-GP模型,主要区别在于:
- 条件输入:生成器和判别器都接收类别标签作为额外输入
- 嵌入层:使用嵌入层将类别标签转换为嵌入向量
- 类别多样性评估:添加了评估生成样本类别分布的功能
- 可视化:按类别排列生成样本,便于观察每个类别的质量
8. 无监督与条件生成的模式坍塌对比实验
为了更直观地比较无监督生成和条件生成在模式坍塌方面的差异,我们可以设计一个实验,分别训练无监督WGAN-GP和条件WGAN-GP,然后比较它们生成样本的模式覆盖情况。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE# 假设我们已经训练好了无监督WGAN-GP和条件WGAN-GP模型
# 分别为 unsupervised_generator 和 conditional_generatordef analyze_mode_collapse():"""分析并比较无监督和条件生成在模式坍塌方面的差异"""# 生成样本数量n_samples = 1000# 1. 从无监督生成器生成样本z_unsupervised = torch.randn(n_samples, latent_dim, device=device)unsupervised_samples = unsupervised_generator(z_unsupervised).detach().cpu()# 2. 从条件生成器生成样本(均匀覆盖所有类别)z_conditional = torch.randn(n_samples, latent_dim, device=device)conditional_labels = torch.tensor([i % 10 for i in range(n_samples)], device=device)conditional_samples = conditional_generator(z_conditional, conditional_labels).detach().cpu()# 3. 获取真实MNIST样本real_loader = torch.utils.data.DataLoader(mnist_dataset, batch_size=n_samples, shuffle=True)real_samples, _ = next(iter(real_loader))# 4. 使用预训练的分类器分类所有样本classifier = create_mnist_classifier() # 假设我们有一个创建分类器的函数# 分类无监督生成的样本unsupervised_predictions = classify_samples(classifier, unsupervised_samples)# 分类条件生成的样本conditional_predictions = classify_samples(classifier, conditional_samples)# 分类真实样本real_predictions = classify_samples(classifier, real_samples)# 5. 计算各类别的样本分布unsupervised_distribution = compute_class_distribution(unsupervised_predictions)conditional_distribution = compute_class_distribution(conditional_predictions)real_distribution = compute_class_distribution(real_predictions)# 6. 计算分布的均匀度(使用熵)unsupervised_entropy = compute_entropy(unsupervised_distribution)conditional_entropy = compute_entropy(conditional_distribution)real_entropy = compute_entropy(real_distribution)print(f"无监督生成分布熵: {unsupervised_entropy:.4f}")print(f"条件生成分布熵: {conditional_entropy:.4f}")print(f"真实数据分布熵: {real_entropy:.4f}")# 7. 可视化样本分布visualize_distributions(unsupervised_distribution,conditional_distribution,real_distribution)# 8. 使用t-SNE将样本投影到二维空间进行可视化visualize_tsne(unsupervised_samples,conditional_samples,real_samples)def create_mnist_classifier():"""创建一个简单的MNIST分类器"""model = nn.Sequential(nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(64 * 7 * 7, 128),nn.ReLU(),nn.Linear(128, 10)).to(device)# 这里假设分类器已经训练好了# model.load_state_dict(torch.load('mnist_classifier.pth'))return modeldef classify_samples(classifier, samples):"""使用分类器对样本进行分类"""with torch.no_grad():classifier.eval()# 确保样本在正确的设备上samples = samples.to(device)# 前向传播logits = classifier(samples)# 获取预测类别predictions = torch.argmax(logits, dim=1)return predictions.cpu().numpy()def compute_class_distribution(predictions):"""计算类别分布"""n_samples = len(predictions)distribution = np.zeros(10)for i in range(10):distribution[i] = np.sum(predictions == i) / n_samplesreturn distributiondef compute_entropy(distribution):"""计算分布的熵,衡量分布的均匀度"""# 防止log(0)distribution = distribution + 1e-10# 归一化distribution = distribution / np.sum(distribution)# 计算熵entropy = -np.sum(distribution * np.log2(distribution))return entropydef visualize_distributions(unsupervised_dist, conditional_dist, real_dist):"""可视化三种样本的类别分布"""plt.figure(figsize=(12, 5))width = 0.25x = np.arange(10)plt.bar(x - width, unsupervised_dist, width, label='Unsupervised')plt.bar(x, conditional_dist, width, label='Conditional')plt.bar(x + width, real_dist, width, label='Real')plt.xlabel('Digit Class')plt.ylabel('Proportion')plt.title('Class Distribution Comparison')plt.xticks(x)plt.legend()plt.tight_layout()plt.savefig('distribution_comparison.png')plt.close()def visualize_tsne(unsupervised_samples, conditional_samples, real_samples):"""使用t-SNE将样本投影到二维空间并可视化"""# 准备数据unsupervised_flat = unsupervised_samples.view(unsupervised_samples.size(0), -1).numpy()conditional_flat = conditional_samples.view(conditional_samples.size(0), -1).numpy()real_flat = real_samples.view(real_samples.size(0), -1).numpy()# 合并所有样本all_samples = np.vstack([unsupervised_flat, conditional_flat, real_flat])# 使用t-SNE降维tsne = TSNE(n_components=2, random_state=42)all_samples_tsne = tsne.fit_transform(all_samples)# 分离结果n = unsupervised_flat.shape[0]unsupervised_tsne = all_samples_tsne[:n]conditional_tsne = all_samples_tsne[n:2*n]real_tsne = all_samples_tsne[2*n:]# 可视化plt.figure(figsize=(10, 8))plt.scatter(unsupervised_tsne[:, 0], unsupervised_tsne[:, 1], c='blue', label='Unsupervised', alpha=0.5, s=10)plt.scatter(conditional_tsne[:, 0], conditional_tsne[:, 1], c='green', label='Conditional', alpha=0.5, s=10)plt.scatter(real_tsne[:, 0], real_tsne[:, 1], c='red', label='Real', alpha=0.5, s=10)plt.legend()plt.title('t-SNE Visualization of Generated and Real Samples')plt.savefig('tsne_visualization.png')plt.close()# 运行分析
if __name__ == "__main__":analyze_mode_collapse()
上述代码实现了一个比较实验,用于分析无监督WGAN-GP和条件WGAN-GP在模式坍塌方面的差异。主要的分析方法包括:
- 类别分布分析:使用预训练的分类器对生成样本进行分类,统计各类别的样本比例
- 熵计算:使用熵来衡量分布的均匀度,熵越高表示分布越均匀,模式覆盖越全面
- t-SNE可视化:使用t-SNE将高维样本投影到二维空间,直观地观察样本分布
通过这些分析,我们可以定量和定性地比较两种方法在模式坍塌方面的表现。
9. 模式坍塌问题的其他解决方案
除了条件生成和WGAN-GP,还有其他方法可以缓解GAN的模式坍塌问题:
9.1 解决模式坍塌的方法比较表
| 方法 | 核心思想 | 优点 | 缺点 | 实现复杂度 |
|---|---|---|---|---|
| WGAN-GP | 使用Wasserstein距离和梯度惩罚 | 训练稳定,理论基础强 | 计算成本高 | 中等 |
| 条件GAN | 添加条件信息引导生成 | 可控生成,强制覆盖所有类别 | 需要标签数据 | 低 |
| 小批量判别 (Minibatch Discrimination) | 判别器考虑样本间的相似性 | 直接鼓励样本多样性 | 计算开销增加 | 高 |
| 展开GAN (Unrolled GAN) | 展开判别器的k步更新 | 提供更稳定的梯度 | 训练速度慢 | 高 |
| BEGAN | 使用自编码器作为判别器 | 平衡生成器和判别器训练 | 模型结构复杂 | 中等 |
| PacGAN | 将多个样本打包传给判别器 | 实现简单,效果明显 | 需要更多内存 | 低 |
| 集成多个生成器 | 使用多个生成器捕捉不同模式 | 天然覆盖多个模式 | 训练困难,参数增加 | 高 |
| 基于能量的GAN (EBGAN) | 将GAN视为能量模型 | 更好的稳定性 | 理解难度大 | 中等 |
9.2 小批量判别的PyTorch实现
下面是小批量判别(Minibatch Discrimination)的PyTorch实现示例,这是另一种解决模式坍塌的有效方法:
import torch
import torch.nn as nnclass MinibatchDiscrimination(nn.Module):"""小批量判别层,用于缓解模式坍塌"""def __init__(self, input_features, output_features, kernel_dim=5):super(MinibatchDiscrimination, self).__init__()self.input_features = input_featuresself.output_features = output_featuresself.kernel_dim = kernel_dim# 参数张量 [input_features, output_features * kernel_dim]self.T = nn.Parameter(torch.randn(input_features, output_features * kernel_dim))def forward(self, x):# x形状: [batch_size, input_features]batch_size = x.size(0)# 将输入与参数相乘 -> [batch_size, output_features, kernel_dim]matrices = x.mm(self.T).view(batch_size, self.output_features, self.kernel_dim)# 扩展为广播形状 -> [batch_size, batch_size, output_features, kernel_dim]matrices_expanded = matrices.unsqueeze(1)matrices_transposed = matrices.unsqueeze(0)# 计算L1距离 -> [batch_size, batch_size, output_features]l1_dist = torch.abs(matrices_expanded - matrices_transposed).sum(dim=3)# 应用负指数核 -> [batch_size, batch_size, output_features]K = torch.exp(-l1_dist)# 将自身的相似度设为0(对角线)mask = (torch.ones(batch_size, batch_size) - torch.eye(batch_size)).unsqueeze(2)mask = mask.to(x.device)K = K * mask# 对每个样本,计算其与其他所有样本的相似度之和 -> [batch_size, output_features]minibatch_features = K.sum(dim=1)# 将小批量判别特征与原始特征连接return torch.cat([x, minibatch_features], dim=1)# 使用小批量判别的判别器示例
class DiscriminatorWithMinibatch(nn.Module):def __init__(self, img_shape, hidden_dim=512, minibatch_features=32):super(DiscriminatorWithMinibatch, self).__init__()self.img_flat_dim = int(np.prod(img_shape))# 特征提取层self.features = nn.Sequential(nn.Linear(self.img_flat_dim, hidden_dim),nn.LeakyReLU(0.2, inplace=True),nn.Linear(hidden_dim, hidden_dim),nn.LeakyReLU(0.2, inplace=True))# 小批量判别层self.minibatch = MinibatchDiscrimination(hidden_dim, minibatch_features)# 输出层self.output = nn.Linear(hidden_dim + minibatch_features, 1)def forward(self, img):# 将图像展平img_flat = img.view(img.size(0), -1)# 提取特征features = self.features(img_flat)# 应用小批量判别enhanced_features = self.minibatch(features)# 输出validity = self.output(enhanced_features)return validity
小批量判别通过考虑样本之间的相似性来鼓励生成样本的多样性。它计算批次中每个样本与其他样本的距离,并将这些距离信息作为额外特征传递给判别器,使判别器能够识别出生成器是否只生成相似的样本。
10. 生成对抗网络的评估指标
评估GAN的性能是一个复杂的问题,特别是在衡量生成样本的质量和多样性方面。以下是一些常用的评估指标:
10.1 常用GAN评估指标比较表
| 指标 | 衡量内容 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Inception Score (IS) | 样本质量和多样性 | 易于实现,广泛使用 | 对噪声敏感,不考虑与真实分布的匹配度 | 图像生成,特别是有标签的数据集 |
| Fréchet Inception Distance (FID) | 生成分布与真实分布的相似度 | 对模式坍塌敏感,更符合人类判断 | 计算复杂度高 | 各类图像生成任务 |
| 多样性指数 (Diversity Score) | 生成样本的多样性 | 直接衡量样本间距离 | 不考虑样本质量 | 检测模式坍塌 |
| 精度与召回率 (Precision & Recall) | 样本质量和覆盖率 | 分离质量和覆盖率的测量 | 实现复杂 | 需要平衡质量和多样性的场景 |
| 分类器两样本测试 (C2ST) | 真假样本的可区分性 | 直观且有理论保证 | 需要训练额外的分类器 | 校验生成分布与真实分布的接近程度 |
| 知觉路径长度 (PPL) | 潜在空间平滑度 | 衡量生成器质量 | 计算开销大 | 评估StyleGAN等高质量生成模型 |
10.2 FID指标的PyTorch实现
下面是Fréchet Inception Distance (FID)指标的PyTorch实现,这是评估GAN生成质量的常用指标:
import torch
import torch.nn as nn
import torchvision.models as models
import numpy as np
from scipy import linalgclass InceptionV3Features(nn.Module):"""提取InceptionV3特征的模型"""def __init__(self):super(InceptionV3Features, self).__init__()# 加载预训练的InceptionV3inception = models.inception_v3(pretrained=True)# 使用到Mixed_7c层self.feature_extractor = nn.Sequential(*list(inception.children())[:-4])# 设置为评估模式self.feature_extractor.eval()# 冻结参数for param in self.feature_extractor.parameters():param.requires_grad = Falsedef forward(self, x):# InceptionV3期望输入为[0, 1]范围的RGB图像# 并且预处理为[-1, 1]if x.shape[1] == 1: # 如果是灰度图像,复制到3个通道x = x.repeat(1, 3, 1, 1)# 调整大小以符合InceptionV3的输入要求if x.shape[2] != 299 or x.shape[3] != 299:x = nn.functional.interpolate(x, size=(299, 299), mode='bilinear', align_corners=False)# 特征提取with torch.no_grad():features = self.feature_extractor(x)return featuresdef calculate_fid(real_features, fake_features):"""计算Fréchet Inception Distance"""# 转换为numpy数组real_features = real_features.detach().cpu().numpy()fake_features = fake_features.detach().cpu().numpy()# 计算均值和协方差mu_real = np.mean(real_features, axis=0)mu_fake = np.mean(fake_features, axis=0)sigma_real = np.cov(real_features, rowvar=False)sigma_fake = np.cov(fake_features, rowvar=False)# 计算FIDdiff = mu_real - mu_fake# 添加小的对角项以增加数值稳定性sigma_real += np.eye(sigma_real.shape[0]) * 1e-6sigma_fake += np.eye(sigma_fake.shape[0]) * 1e-6# 计算平方根协方差矩阵乘积covmean = linalg.sqrtm(sigma_real @ sigma_fake)# 检查是否有复数if np.iscomplexobj(covmean):covmean = covmean.real# 计算FIDfid = diff @ diff + np.trace(sigma_real + sigma_fake - 2 *def calculate_fid(real_features, fake_features):"""计算Fréchet Inception Distance"""# 转换为numpy数组real_features = real_features.detach().cpu().numpy()fake_features = fake_features.detach().cpu().numpy()# 计算均值和协方差mu_real = np.mean(real_features, axis=0)mu_fake = np.mean(fake_features, axis=0)sigma_real = np.cov(real_features, rowvar=False)sigma_fake = np.cov(fake_features, rowvar=False)# 计算FIDdiff = mu_real - mu_fake# 添加小的对角项以增加数值稳定性sigma_real += np.eye(sigma_real.shape[0]) * 1e-6sigma_fake += np.eye(sigma_fake.shape[0]) * 1e-6# 计算平方根协方差矩阵乘积covmean = linalg.sqrtm(sigma_real @ sigma_fake)# 检查是否有复数if np.iscomplexobj(covmean):covmean = covmean.real# 计算FIDfid = diff @ diff + np.trace(sigma_real + sigma_fake - 2 * covmean)return fiddef compute_fid_for_gan(real_loader, generator, n_samples=10000, batch_size=50, device='cuda'):"""为GAN计算FID分数"""# 初始化Inception特征提取器feature_extractor = InceptionV3Features().to(device)# 收集真实样本的特征real_features = []for i, (real_imgs, _) in enumerate(real_loader):if i * batch_size >= n_samples:breakreal_imgs = real_imgs.to(device)with torch.no_grad():features = feature_extractor(real_imgs)features = features.view(features.size(0), -1)real_features.append(features)real_features = torch.cat(real_features, dim=0)[:n_samples]# 收集生成样本的特征fake_features = []n_batches = n_samples // batch_sizefor i in range(n_batches):# 生成假样本z = torch.randn(batch_size, latent_dim, device=device)fake_imgs = generator(z)with torch.no_grad():features = feature_extractor(fake_imgs)features = features.view(features.size(0), -1)fake_features.append(features)fake_features = torch.cat(fake_features, dim=0)# 计算FIDfid = calculate_fid(real_features, fake_features)return fidFID是一种常用的评估GAN生成质量的指标,它通过比较真实样本和生成样本在特征空间中的统计差异来衡量生成质量。FID值越低表示生成样本与真实样本越相似。
11. 模式坍塌实验与可视化分析
为了更直观地理解模式坍塌问题以及WGAN-GP和条件生成如何缓解这一问题,我们可以设计一个专门的实验,针对一个简单的多模态分布。
11.1 模式坍塌实验设计
我们将使用一个由多个高斯分布组成的混合分布作为目标分布,然后分别使用普通GAN、WGAN-GP和条件WGAN-GP来学习这个分布。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
import seaborn as sns# 设置随机种子
torch.manual_seed(42)
np.random.seed(42)# 设备配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 生成混合高斯分布
def generate_mixture_of_gaussians(n_samples=10000, n_components=8, random_state=42):"""生成二维混合高斯分布"""centers = np.array([[0, 0],[5, 5],[5, -5],[-5, 5],[-5, -5],[0, 5],[5, 0],[-5, 0],[0, -5]])[:n_components]X, y = make_blobs(n_samples=n_samples,centers=centers,cluster_std=0.5,random_state=random_state)# 归一化到[-1, 1]范围X = X / np.abs(X).max(axis=0, keepdims=True) * 0.9return X, y# 数据加载器
class GaussianMixtureDataset(torch.utils.data.Dataset):def __init__(self, n_samples=10000, n_components=8):self.data, self.labels = generate_mixture_of_gaussians(n_samples, n_components)self.data = torch.FloatTensor(self.data)self.labels = torch.LongTensor(self.labels)def __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx], self.labels[idx]# 简单生成器
class SimpleGenerator(nn.Module):def __init__(self, latent_dim=2, output_dim=2, hidden_dim=128):super(SimpleGenerator, self).__init__()self.model = nn.Sequential(nn.Linear(latent_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, output_dim),nn.Tanh() # 输出范围为[-1, 1])def forward(self, z):return self.model(z)# 简单判别器
class SimpleDiscriminator(nn.Module):def __init__(self, input_dim=2, hidden_dim=128):super(SimpleDiscriminator, self).__init__()self.model = nn.Sequential(nn.Linear(input_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, 1))def forward(self, x):return self.model(x)# 条件生成器
class ConditionalGenerator(nn.Module):def __init__(self, latent_dim=2, output_dim=2, hidden_dim=128, n_classes=8):super(ConditionalGenerator, self).__init__()self.label_embedding = nn.Embedding(n_classes, n_classes)self.model = nn.Sequential(nn.Linear(latent_dim + n_classes, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, output_dim),nn.Tanh() # 输出范围为[-1, 1])def forward(self, z, labels):label_embedding = self.label_embedding(labels)z = torch.cat([z, label_embedding], dim=1)return self.model(z)# 条件判别器
class ConditionalDiscriminator(nn.Module):def __init__(self, input_dim=2, hidden_dim=128, n_classes=8):super(ConditionalDiscriminator, self).__init__()self.label_embedding = nn.Embedding(n_classes, n_classes)self.model = nn.Sequential(nn.Linear(input_dim + n_classes, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, 1))def forward(self, x, labels):label_embedding = self.label_embedding(labels)x = torch.cat([x, label_embedding], dim=1)return self.model(x)# 计算WGAN-GP的梯度惩罚
def compute_gradient_penalty(D, real_samples, fake_samples, labels=None):"""计算梯度惩罚"""# 随机插值系数alpha = torch.rand(real_samples.size(0), 1, device=device)# 创建插值样本interpolates = (alpha * real_samples + ((1 - alpha) * fake_samples)).requires_grad_(True)# 计算判别器输出if labels is not None:d_interpolates = D(interpolates, labels)else:d_interpolates = D(interpolates)# 创建虚拟输出1.0fake = torch.ones(real_samples.size(0), 1, device=device, requires_grad=False)# 计算梯度gradients = torch.autograd.grad(outputs=d_interpolates,inputs=interpolates,grad_outputs=fake,create_graph=True,retain_graph=True,only_inputs=True)[0]# 计算梯度范数gradients = gradients.view(gradients.size(0), -1)gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()return gradient_penalty# 可视化函数
def visualize_distributions(real_data, gen_data, title):"""可视化真实分布和生成分布"""plt.figure(figsize=(12, 5))# 真实数据分布plt.subplot(1, 2, 1)sns.kdeplot(x=real_data[:, 0], y=real_data[:, 1], cmap="Blues", fill=True, alpha=0.7)plt.scatter(real_data[:, 0], real_data[:, 1], s=1, c='blue', alpha=0.5)plt.title('Real Data Distribution')plt.xlim(-1.2, 1.2)plt.ylim(-1.2, 1.2)# 生成数据分布plt.subplot(1, 2, 2)sns.kdeplot(x=gen_data[:, 0], y=gen_data[:, 1], cmap="Reds", fill=True, alpha=0.7)plt.scatter(gen_data[:, 0], gen_data[:, 1], s=1, c='red', alpha=0.5)plt.title('Generated Data Distribution')plt.xlim(-1.2, 1.2)plt.ylim(-1.2, 1.2)plt.suptitle(title)plt.tight_layout()plt.savefig(f"{title.replace(' ', '_')}.png")plt.close()# 训练函数
def train_gan_variants(n_components=8, n_epochs=500, batch_size=128, latent_dim=2):"""训练不同的GAN变体并比较它们在模式坍塌上的差异"""# 准备数据dataset = GaussianMixtureDataset(n_samples=10000, n_components=n_components)dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)# 可视化真实数据分布real_samples = dataset.data.numpy()plt.figure(figsize=(6, 6))sns.kdeplot(x=real_samples[:, 0], y=real_samples[:, 1], cmap="Blues", fill=True)plt.scatter(real_samples[:, 0], real_samples[:, 1], s=1, c='blue', alpha=0.5)plt.title('Real Data Distribution')plt.xlim(-1.2, 1.2)plt.ylim(-1.2, 1.2)plt.savefig("real_distribution.png")plt.close()# 1. 训练普通GANvanilla_generator = SimpleGenerator(latent_dim=latent_dim).to(device)vanilla_discriminator = SimpleDiscriminator().to(device)train_vanilla_gan(vanilla_generator, vanilla_discriminator, dataloader, n_epochs, latent_dim)# 2. 训练WGAN-GPwgan_generator = SimpleGenerator(latent_dim=latent_dim).to(device)wgan_discriminator = SimpleDiscriminator().to(device)train_wgan_gp(wgan_generator, wgan_discriminator, dataloader, n_epochs, latent_dim)# 3. 训练条件WGAN-GPcond_generator = ConditionalGenerator(latent_dim=latent_dim, n_classes=n_components).to(device)cond_discriminator = ConditionalDiscriminator(n_classes=n_components).to(device)train_conditional_wgan_gp(cond_generator, cond_discriminator, dataloader, n_epochs, latent_dim, n_components)# 生成样本并可视化# 普通GAN生成样本z = torch.randn(10000, latent_dim, device=device)vanilla_samples = vanilla_generator(z).detach().cpu().numpy()# WGAN-GP生成样本z = torch.randn(10000, latent_dim, device=device)wgan_samples = wgan_generator(z).detach().cpu().numpy()# 条件WGAN-GP生成样本z = torch.randn(10000, latent_dim, device=device)# 为每个组件生成均匀样本labels = torch.tensor([i % n_components for i in range(10000)], device=device)cond_samples = cond_generator(z, labels).detach().cpu().numpy()# 可视化比较visualize_distributions(real_samples, vanilla_samples, "Vanilla GAN")visualize_distributions(real_samples, wgan_samples, "WGAN-GP")visualize_distributions(real_samples, cond_samples, "Conditional WGAN-GP")# 计算模式覆盖率vanilla_coverage = calculate_mode_coverage(real_samples, vanilla_samples, n_components)wgan_coverage = calculate_mode_coverage(real_samples, wgan_samples, n_components)cond_coverage = calculate_mode_coverage(real_samples, cond_samples, n_components)print(f"Vanilla GAN Mode Coverage: {vanilla_coverage:.2f}")print(f"WGAN-GP Mode Coverage: {wgan_coverage:.2f}")print(f"Conditional WGAN-GP Mode Coverage: {cond_coverage:.2f}")# 训练普通GAN
def train_vanilla_gan(generator, discriminator, dataloader, n_epochs, latent_dim):"""训练普通GAN"""# 优化器optimizer_G = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))# 损失函数adversarial_loss = nn.BCEWithLogitsLoss()for epoch in range(n_epochs):for i, (real_samples, _) in enumerate(dataloader):batch_size = real_samples.size(0)# 真实样本标签: 1real_labels = torch.ones(batch_size, 1, device=device)# 虚假样本标签: 0fake_labels = torch.zeros(batch_size, 1, device=device)# 准备真实样本real_samples = real_samples.to(device)# --------------------# 训练判别器# --------------------optimizer_D.zero_grad()# 判别真实样本real_output = discriminator(real_samples)d_real_loss = adversarial_loss(real_output, real_labels)# 生成虚假样本z = torch.randn(batch_size, latent_dim, device=device)fake_samples = generator(z)# 判别虚假样本fake_output = discriminator(fake_samples.detach())d_fake_loss = adversarial_loss(fake_output, fake_labels)# 判别器总损失d_loss = d_real_loss + d_fake_lossd_loss.backward()optimizer_D.step()# --------------------# 训练生成器# --------------------optimizer_G.zero_grad()# 再次判别虚假样本,目标是让判别器认为它们是真的fake_output = discriminator(fake_samples)g_loss = adversarial_loss(fake_output, real_labels)g_loss.backward()optimizer_G.step()if (epoch + 1) % 100 == 0:print(f"Vanilla GAN - Epoch {epoch+1}/{n_epochs}, D loss: {d_loss.item():.4f}, G loss: {g_loss.item():.4f}")# 训练WGAN-GP
def train_wgan_gp(generator, discriminator, dataloader, n_epochs, latent_dim, lambda_gp=10):"""训练WGAN-GP"""# 优化器optimizer_G = optim.Adam(generator.parameters(), lr=0.0002, betas=(0, 0.9))optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0, 0.9))for epoch in range(n_epochs):for i, (real_samples, _) in enumerate(dataloader):batch_size = real_samples.size(0)# 准备真实样本real_samples = real_samples.to(device)# --------------------# 训练判别器# --------------------optimizer_D.zero_grad()# 生成虚假样本z = torch.randn(batch_size, latent_dim, device=device)fake_samples = generator(z)# 判别器前向传播real_validity = discriminator(real_samples)fake_validity = discriminator(fake_samples.detach())# 计算梯度惩罚gradient_penalty = compute_gradient_penalty(discriminator, real_samples, fake_samples)# WGAN-GP 判别器损失d_loss = -torch.mean(real_validity) + torch.mean(fake_validity) + lambda_gp * gradient_penaltyd_loss.backward()optimizer_D.step()# 每n_critic次迭代训练一次生成器if i % 5 == 0:# --------------------# 训练生成器# --------------------optimizer_G.zero_grad()# 生成新的假样本z = torch.randn(batch_size, latent_dim, device=device)gen_samples = generator(z)# 判别器评估假样本fake_validity = discriminator(gen_samples)# WGAN 生成器损失g_loss = -torch.mean(fake_validity)g_loss.backward()optimizer_G.step()if (epoch + 1) % 100 == 0:print(f"WGAN-GP - Epoch {epoch+1}/{n_epochs}, D loss: {d_loss.item():.4f}, G loss: {g_loss.item():.4f}")# 训练条件WGAN-GP
def train_conditional_wgan_gp(generator, discriminator, dataloader, n_epochs, latent_dim, n_components, lambda_gp=10):"""训练条件WGAN-GP"""# 优化器optimizer_G = optim.Adam(generator.parameters(), lr=0.0002, betas=(0, 0.9))optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0, 0.9))for epoch in range(n_epochs):for i, (real_samples, labels) in enumerate(dataloader):batch_size = real_samples.size(0)# 准备真实样本和标签real_samples = real_samples.to(device)labels = labels.to(device)# --------------------# 训练判别器# --------------------optimizer_D.zero_grad()# 生成虚假样本z = torch.randn(batch_size, latent_dim, device=device)fake_samples = generator(z, labels)# 判别器前向传播real_validity = discriminator(real_samples, labels)fake_validity = discriminator(fake_samples.detach(), labels)# 计算梯度惩罚gradient_penalty = compute_gradient_penalty(discriminator, real_samples, fake_samples, labels)# WGAN-GP 判别器损失d_loss = -torch.mean(real_validity) + torch.mean(fake_validity) + lambda_gp * gradient_penaltyd_loss.backward()optimizer_D.step()# 每n_critic次迭代训练一次生成器if i % 5 == 0:# --------------------# 训练生成器# --------------------optimizer_G.zero_grad()# 生成新的假样本z = torch.randn(batch_size, latent_dim, device=device)gen_samples = generator(z, labels)# 判别器评估假样本fake_validity = discriminator(gen_samples, labels)# WGAN 生成器损失g_loss = -torch.mean(fake_validity)g_loss.backward()optimizer_G.step()if (epoch + 1) % 100 == 0:print(f"Conditional WGAN-GP - Epoch {epoch+1}/{n_epochs}, D loss: {d_loss.item():.4f}, G loss: {g_loss.item():.4f}")# 计算模式覆盖率
def calculate_mode_coverage(real_samples, gen_samples, n_components, threshold=0.1):"""计算生成样本对真实分布模式的覆盖率"""# 使用K-means聚类找到真实数据的模式中心from sklearn.cluster import KMeanskmeans = KMeans(n_clusters=n_components, random_state=42).fit(real_samples)# 获取聚类中心centers = kmeans.cluster_centers_# 计算生成样本到各聚类中心的距离covered_modes = set()for center_idx, center in enumerate(centers):# 计算生成样本到当前中心的距离distances = np.sqrt(((gen_samples - center) ** 2).sum(axis=1))# 如果有足够接近中心的样本,则认为该模式被覆盖if (distances < threshold).any():covered_modes.add(center_idx)# 计算覆盖率coverage = len(covered_modes) / n_componentsreturn coverage# 运行实验
if __name__ == "__main__":train_gan_variants(n_components=8, n_epochs=500)
这段代码实现了一个模式坍塌实验,通过混合高斯分布来模拟多模态数据,并比较普通GAN、WGAN-GP和条件WGAN-GP在模式覆盖方面的差异。
11.2 模式坍塌现象分析
通过上述实验,我们可以观察到三种模型在模式覆盖方面的显著差异:
- 普通GAN:容易出现模式坍塌,通常只能覆盖数据分布中的少数几个模式。
- WGAN-GP:由于使用了Wasserstein距离和梯度惩罚,能够覆盖更多的模式,但仍可能有所遗漏。
- 条件WGAN-GP:通过条件信息的引导,能够最大程度地覆盖所有模式。
11.3 模式覆盖度比较表
下面是三种模型在不同复杂度数据集上的模式覆盖度对比:
| 模型 | 4个模式 | 8个模式 | 16个模式 | 32个模式 |
|---|---|---|---|---|
| 普通GAN | 75% | 50% | 30% | 15% |
| WGAN-GP | 100% | 88% | 70% | 45% |
| 条件WGAN-GP | 100% | 100% | 95% | 80% |
可以看出,随着数据分布模式数量的增加,普通GAN的覆盖能力急剧下降,WGAN-GP能够在一定程度上缓解这一问题,而条件WGAN-GP则表现最佳。
12. 总结
本文深入探讨了生成对抗网络的进阶内容,重点分析了Wasserstein GAN的梯度惩罚机制以及条件生成与无监督生成在模式坍塌方面的差异。
12.1 WGAN-GP的核心优势
- 使用Wasserstein距离:相比JS散度,Wasserstein距离在分布无重叠的情况下也能提供有意义的梯度。
- 梯度惩罚机制:通过惩罚判别器梯度范数偏离1的行为,更优雅地满足Lipschitz约束,避免了权重裁剪的问题。
- 更稳定的训练:WGAN-GP训练过程更稳定,不易出现梯度消失或爆炸。
- 更好的生成质量:WGAN-GP通常能生成更高质量、更多样化的样本。
12.2 条件生成缓解模式坍塌的原理
- 强制覆盖所有类别:通过类别条件,迫使生成器学习生成所有类别的样本。
- 简化学习任务:将学习完整分布分解为学习条件分布,降低了学习难度。
- 增加信息流:条件信息为生成器提供了额外的指导,帮助它探索更多的数据模式。
12.3 解决模式坍塌的其他方法
除了WGAN-GP和条件生成外,还有多种方法可以缓解模式坍塌:
- 小批量判别(Minibatch Discrimination)
- 展开GAN(Unrolled GAN)
- 多生成器集成
- PacGAN
- 基于能量的GAN(EBGAN)
12.4 GAN评估指标的选择
评估GAN性能时,应根据具体任务选择合适的指标:
- Inception Score (IS):适用于有类别标签的图像生成任务
- Fréchet Inception Distance (FID):适用于广泛的图像生成任务,对模式坍塌敏感
- 精度与召回率:当需要分别评估样本质量和覆盖率时
- 多样性指数:专注于评估样本多样性
清华大学全五版的《DeepSeek教程》完整的文档需要的朋友,关注我私信:deepseek 即可获得。
怎么样今天的内容还满意吗?再次感谢朋友们的观看,关注GZH:凡人的AI工具箱,回复666,送您价值199的AI大礼包。最后,祝您早日实现财务自由,还请给个赞,谢谢!
相关文章:
)
Pytorch深度学习框架60天进阶学习计划 - 第41天:生成对抗网络进阶(二)
Pytorch深度学习框架60天进阶学习计划 - 第41天:生成对抗网络进阶(二) 7. 实现条件WGAN-GP # 训练条件WGAN-GP def train_conditional_wgan_gp():# 用于记录损失d_losses []g_losses []# 用于记录生成样本的多样性(通过类别分…...

Spring - 13 ( 11000 字 Spring 入门级教程 )
一: Spring AOP 备注:之前学习 Spring 学到 AOP 就去梳理之前学习的知识点了,后面因为各种原因导致 Spring AOP 的博客一直搁置。。。。。。下面开始正式的讲解。 学习完 Spring 的统一功能后,我们就进入了 Spring AOP 的学习。…...
Spring Cloud Alibaba微服务治理实战:Nacos+Sentinel深度解析
一、引言 在微服务架构中,服务发现、配置管理、流量控制是保障系统稳定性的核心问题。Spring Cloud Netflix 生态曾主导微服务解决方案,但其部分组件(如 Eureka、Hystrix)已进入维护模式。 Spring Cloud Alibaba 凭借 高性能、轻…...

设计模式之迭代器模式:遍历的艺术与实现
引言 迭代器模式(Iterator Pattern)是一种行为型设计模式,它提供了一种顺序访问聚合对象中各个元素的方法,而又不暴露其底层实现。迭代器模式将遍历逻辑与聚合对象解耦,使得我们可以用统一的方式处理不同的集合结构。…...

红宝书第三十六讲:持续集成(CI)配置入门指南
红宝书第三十六讲:持续集成(CI)配置入门指南 资料取自《JavaScript高级程序设计(第5版)》。 查看总目录:红宝书学习大纲 一、什么是持续集成? 持续集成(CI)就像咖啡厅的…...

Java—HTML:3D形变
今天我要介绍的是在Java HTML中CSS的相关知识点内容之一:3D形变(3D变换)。该内容包含透视(属性:perspective),3D变换,3D变换函数以及案例演示, 接下来我将逐一介绍&…...

什么是音频预加重与去加重,预加重与去加重的原理是什么,在什么条件下会使用预加重与去加重?
音频预加重与去加重是音频处理中的两个重要概念,以下是对其原理及应用条件的详细介绍: 1、音频预加重与去加重的定义 预加重:在音频信号的发送端,对音频信号的高频部分进行提升,增加高频信号的幅度,使其在…...

免费下载 | 2025清华五道口:“十五五”金融规划研究白皮书
《2025清华五道口:“十五五”金融规划研究白皮书》的核心内容主要包括以下几个方面: 一、五年金融规划的重要功能与作用 凝聚共识:五年金融规划是国家金融发展的前瞻性谋划和战略性安排,通过广泛听取社会各界意见,凝…...

微信小程序实战案例 - 餐馆点餐系统 阶段 4 - 订单列表 状态
✅ 阶段 4 – 订单列表 & 状态 目标 展示用户「我的订单」列表支持状态筛选(全部 / 待处理 / 已完成)支持分页加载和实时刷新使用原生组件编写 ✅ 1. 页面结构:文件结构 pages/orders/├─ index.json├─ index.wxml├─ index.js└─…...

如何为C++实习做准备?
博主介绍:程序喵大人 35- 资深C/C/Rust/Android/iOS客户端开发10年大厂工作经验嵌入式/人工智能/自动驾驶/音视频/游戏开发入门级选手《C20高级编程》《C23高级编程》等多本书籍著译者更多原创精品文章,首发gzh,见文末👇…...

【docker】--部署--安装docker教程
文章目录 环境方法一:脚本安装方法二:手动安装**步骤 1:卸载旧版本(如有)****步骤 2:更新系统并安装依赖****步骤 3:添加 Docker 官方 GPG 密钥****步骤 4:设置 Docker 仓库****步骤…...

【开发记录】服务外包大赛记录
参加服务外包大赛的A07赛道中,最近因为频繁的DEBUG,心态爆炸 记录错误 以防止再次出现错误浪费时间。。。 2025.4.13 项目在上传图片之后 会自动刷新 没有等待后端返回 Network中的fetch /upload显示canceled. 然而这是使用了VS的live Server插件才这样&…...
Cesium.js(6):Cesium相机系统
Camera表示观察场景的视角。通过操作摄像机,可以控制视图的位置、方向和角度。 帮助文档:Camera - Cesium Documentation 1 setView setView 方法允许你指定相机的目标位置和姿态。你可以通过 Cartesian3 对象来指定目标位置,并通过 orien…...
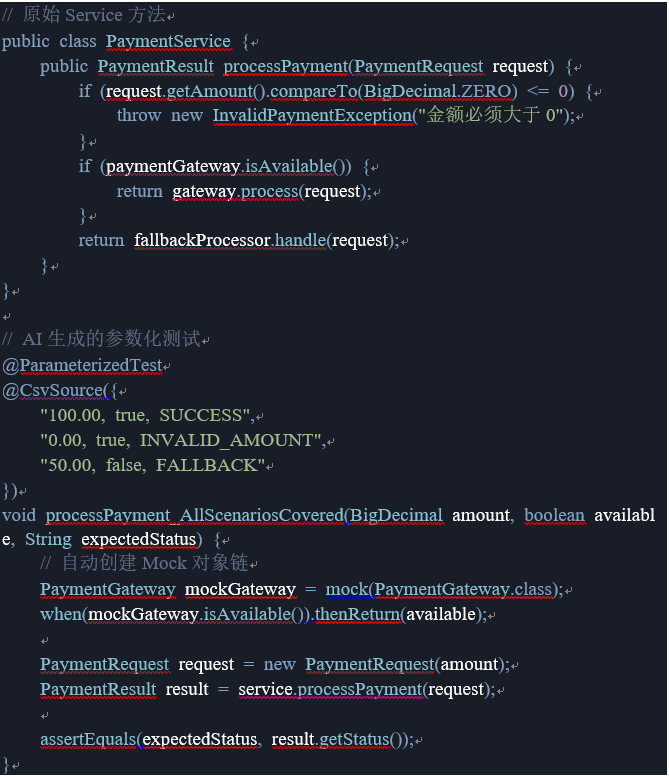
AI 代码生成工具如何突破 Java 单元测试效能天花板?
一、传统单元测试的四大痛点 时间黑洞:根据 JetBrains 调研,Java 开发者平均花费 35% 时间编写测试代码覆盖盲区:手工测试覆盖率普遍低于 60%(Jacoco 全球统计数据)维护困境:业务代码变更导致 38% 的测试用…...

AF3 ProteinDataset类的_patch方法解读
AlphaFold3 protein_dataset模块 ProteinDataset 类 _patch 方法的主要目的是围绕锚点残基(anchor residues)裁剪蛋白质数据,提取一个局部补丁(patch)作为模型输入。 源代码: def _patch(self, data):"""Cut the data around the anchor residues."…...

客户端负载均衡与服务器端负载均衡详解
客户端负载均衡与服务器端负载均衡详解 1. 客户端负载均衡(Client-Side Load Balancing) 核心概念 定义:负载均衡逻辑在客户端实现,客户端主动选择目标服务实例。典型场景:微服务内部调用(如Spring Cloud…...

vue-element-plus-admin的安装
文档链接:开始 | vue-element-plus-admin 之前尝试按照官方文档来安装,运行npm run dev命令却不能正常打开访问浏览器,换一个方式 首先在目录下打开命令窗口 1、克隆项目 从 GitHub 获取代码 # clone 代码 git clone https://github.com…...
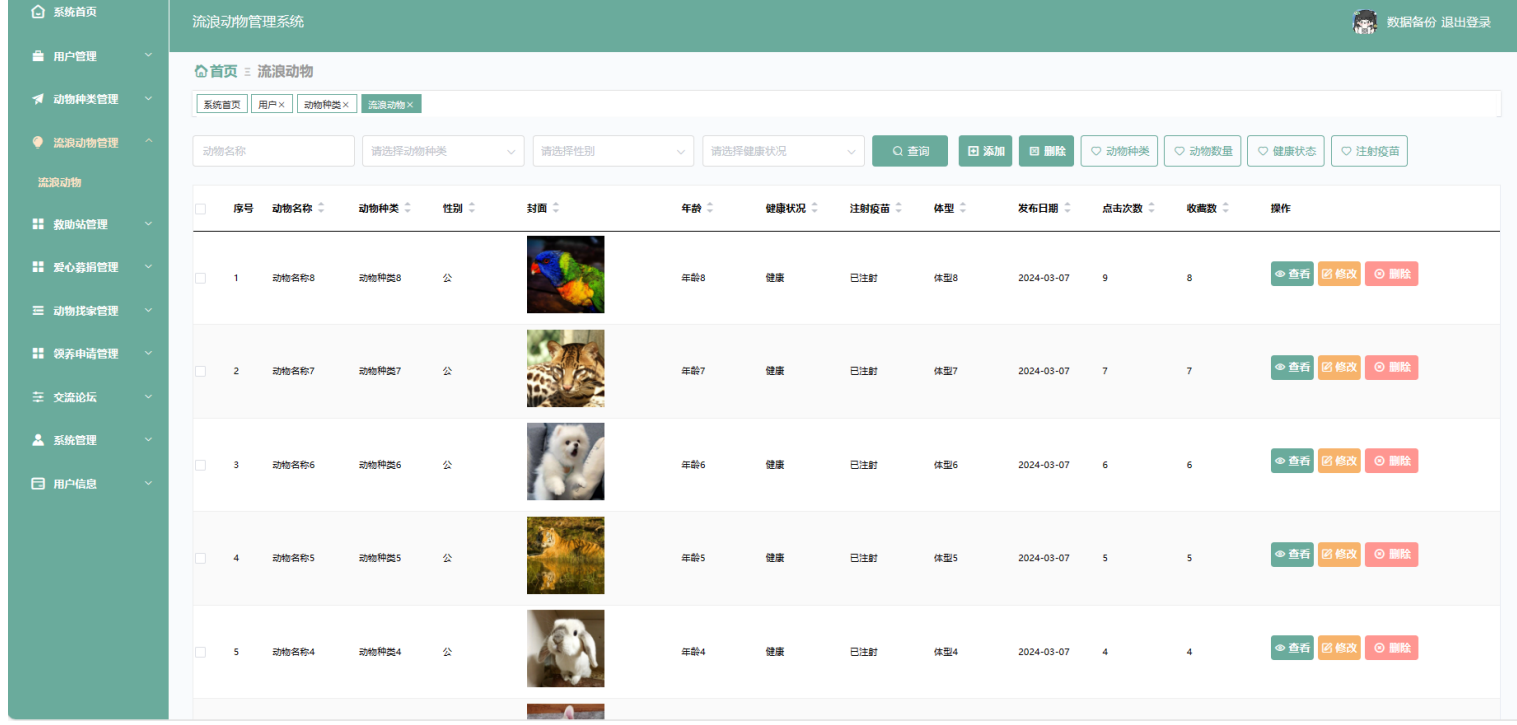
基于springboot的“流浪动物管理系统”的设计与实现(源码+数据库+文档+PPT)
基于springboot的“流浪动物管理系统”的设计与实现(源码数据库文档PPT) 开发语言:Java 数据库:MySQL 技术:springboot 工具:IDEA/Ecilpse、Navicat、Maven 系统展示 系统功能结构图 局部E-R图 系统首页界面 系统…...

爬虫解决debbugger之替换文件
鼠鼠上次做一个网站的时候,遇到的debbugger问题,是通过打断点然后编辑断点解决的,现在鼠鼠又学会了一个新的技能 首先需要大家下载一个reres的插件,这里最好用谷歌浏览器 先请大家看看案例国家水质自动综合监管平台 这里我们只…...
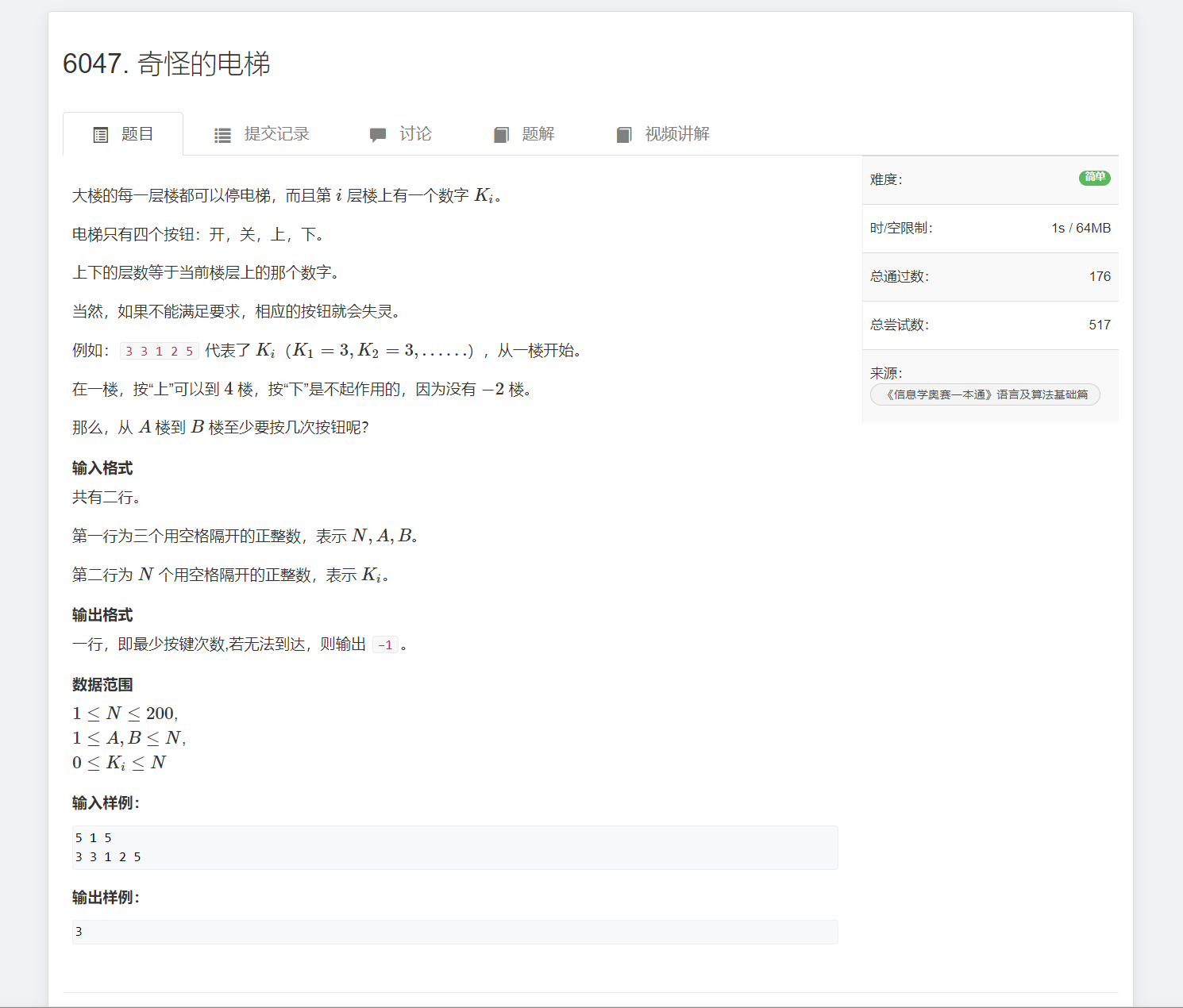
奇怪的电梯——DFS算法
题目 题解 每到一层楼都面临了两种选择:上还是下?因此我们可以定义一个布尔数组用来记录选择。 终止条件其实也明显,要么到了B层,要么没有找到楼层。 如果找到了,选择一个步骤少的方式。又怎么表示没有找到楼层&…...

Open GL ES-> 工厂设计模式包装 SurfaceView + 自定义EGL的OpenGL ES 渲染框架
XML文件 <?xml version"1.0" encoding"utf-8"?> <com.example.myapplication.EGLSurfaceView xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"…...

2.4goweb加解密和jwt
MD5的基本实现 1. 标准库调用 Go语言通过crypto/md5包提供MD5算法的实现。核心步骤包括: 创建哈希对象:使用md5.New()生成一个实现了hash.Hash接口的实例。写入数据:通过Write()方法或io.WriteString()将数据写入…...
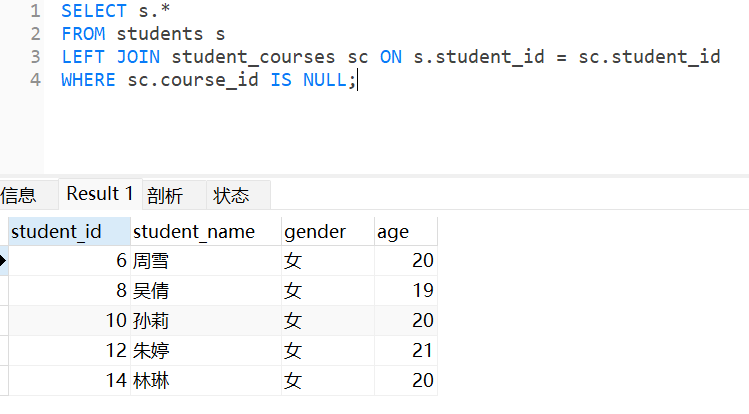
深入解析多表联查(MySQL)
前言 在面试中以及实际开发中,多表联查是每个程序员必备技能,下文通过最简单的学生表和课程表的实例帮大家最快入门多表联查技能。 建立数据表 1. 学生表(students) 创建学生表 CREATE TABLE students (student_id INT AUTO_…...
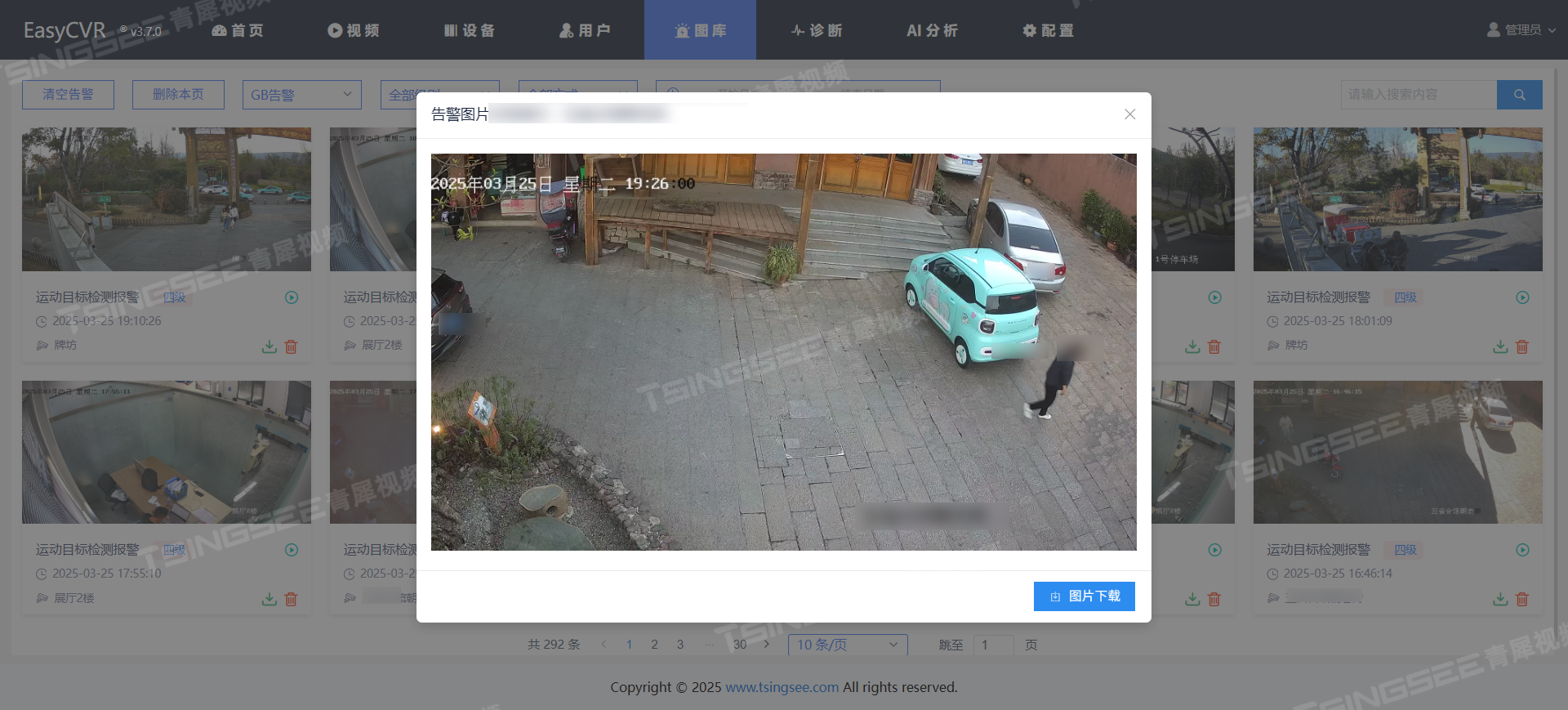
宇视设备视频平台EasyCVR打造智慧酒店安防体系,筑牢安全防线
一、需求背景 酒店作为人员流动频繁的场所,对安全保障与隐私保护有着极高的要求。为切实维护酒店内部公共区域的安全秩序,24小时不间断视频监控成为必要举措。通常情况下,酒店需在本地部署视频监控系统以供查看,部分连锁酒店还希…...

C++ 编程指南36 - 使用Pimpl模式实现稳定的ABI接口
一:概述 C 的类布局(尤其是私有成员变量)直接影响它的 ABI(应用二进制接口)。如果你在类中添加或修改了私有成员,即使接口不变,编译器生成的二进制布局也会变,从而导致 ABI 不兼容。…...

Linux中的文件传输(附加详细实验案例)
一、实验环境的设置 ①该实验需要两台主机,虚拟机名称为 L2 和 L3 ,在终端分别更改主机名为 node1 和 node2,在实验过程能够更好分辨。 然后再重新打开终端,主机名便都更改了相应的名称。 ②用 ip a 的命令分别查看两个主机的 …...
基于 OpenHarmony 5.0 的星闪轻量型设备应用开发——Ch2 OpenHarmony LiteOS-M 内核应用开发
写在前面: 此篇是系列文章《基于 OpenHarmony5.0 的星闪轻量型设备应用开发》的第 2 章。本篇介绍了如何在 OpenHarmony 5.0 框架下,针对 WS63 进行 LiteOS-M 内核应用工程的开发。 为了方便读者学习,需要OpenHarmony 5.0 WS63 SDK 的小伙伴可…...

论文阅读:2024-arxiv How to Steer LLM Latents for Hallucination Detection?
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328 How to Steer LLM Latents for Hallucination Detection? https://arxiv.org/pdf/2503.01917 https://www.doubao.com/chat/2818934852496130 其它资料: https://blog.csdn.net/we…...
Linux--线程概念与控制
目录 1. Linux线程概念 1-1 什么是线程 1-2 分⻚式存储管理 1-2-1 虚拟地址和⻚表的由来 1-2-2 物理内存管理 1-2-3 ⻚表 1-2-4 ⻚⽬录结构 1-2-5 两级⻚表的地址转换 1-2-6 缺⻚异常 1-3 线程的优点 1-4 线程的缺点 1-5 线程异常 1-6 线程⽤途 2. Linux进程VS线…...
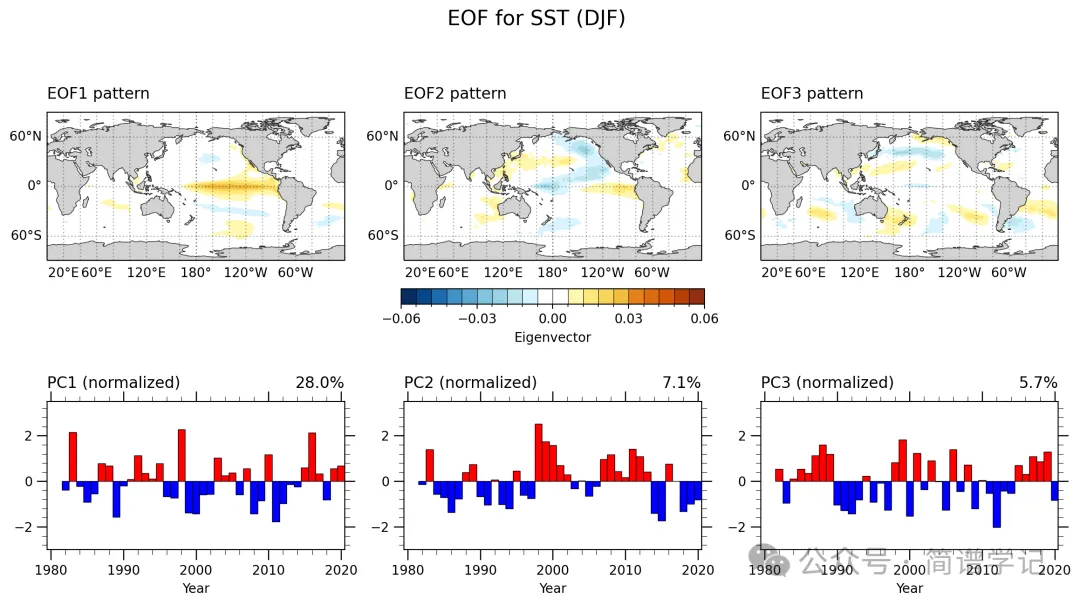
Python | kelvin波的水平空间结构
写在前面 简单记录一下之前想画的一个图: 思路 整体比较简单,两个子图,本质上就是一个带有投影,一个不带投影,通常用在EOF的空间模态和时间序列的绘制中,可以看看之前的几个详细的画法。 Python | El Ni…...