从零开始学java--线性表
数据结构基础
目录
数据结构基础
线性表
顺序表
链表
顺序表和链表的区别:
栈
队列
线性表
线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表中的元素个数就是线性表的长度,表的起始位置称为表头,结束位置称为表尾,当一个线性表中没有元素时称为空表。
线性表是一种在实际中广泛使用的数据结 构,常见的线性表:顺序表、链表、栈、队列...
线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的,线性表在物理上存储时,通常以数组和链式结构的形式存储。
顺序表
顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储。在数组上完成数据的增删查改。
我们存放数据还是使用数组,但是为其编写一些额外的操作来强化为线性表,像这样底层依然采用顺序存储实现的线性表称为顺序表:
public class ArrayList <E>{ //泛型E,因为表中要存的具体数据类型待定private int size=0; //当前已经存放的元素数量private int capacity=10; //当前顺序表的容量private Object[]array=new Object[capacity]; //底层存放的数组
}当插入元素时需要将插入位置腾出来,也就是将后面所有元素向后移;
如果要删除元素,需要将所有元素向前移动。
顺序表是紧凑的,不能出现空位。
插入方法(把元素放入顺序表):
public class ArrayList <E>{private int size=0;private int capacity=10;private Object[]array=new Object[capacity];public void add(E element,int index){ //插入方法需要支持在指定下标位置插入if(index<0||index>size)throw new IndexOutOfBoundsException("插入位置非法,合法的插入位置为:0-"+size);//在插入前判断,允许插入的位置只有[0,size]for (int i = size; i >index ; i--) //从后往前一个一个搬运元素array[i]=array[i-1];array[index]=element; //腾出位置后插入元素放到对应的位置上size++; //插入完成后将size自增(扩大)}//重写toString方法打印当前存放的元素public String toString(){StringBuilder builder=new StringBuilder();for (int i = 0; i < size; i++) builder.append(array[i]).append(" ");return builder.toString();}
}public class Main {public static void main(String[] args) {ArrayList<String>list=new ArrayList<>();list.add("aaa",0);list.add("bbb",1);System.out.println(list);}
}
//输出aaa bbb扩容操作:
public void add(E element,int index){if(index<0||index>size)throw new IndexOutOfBoundsException("插入位置非法,合法的插入位置为:0-"+size);if(size>=capacity) {int newCapacity=capacity+(capacity>>1); //原本容量的1.5倍Object[]newArray=new Object[newCapacity]; //创建一个新数组来存放更多的元素System.arraycopy(array,0,newArray,0,size); //使用arraycopy快递拷贝原数组内容到新的数组array=newArray; //更换为新的数组capacity=newCapacity; //容量变成扩容之后的}删除操作:
可删除的范围只可能是[0,size)
@SuppressWarnings("unchecked") //屏蔽未经检查警告public E remove(int index){ //删除对应位置上的元素,注意需要返回被删除的元素if(index<0||index>size-1)throw new IndexOutOfBoundsException("删除位置非法,合法的删除位置为:0-"+(size-1));E e=(E)array[index]; //因为存放的是Object类型,需要强制类型转换为Efor (int i = index; i <size ; i++) //从前往后,挨个往前搬一位array[i]=array[i+1];size--;return e;}获取指定下标位置上的元素:
@SuppressWarnings("unchecked")public E get(int index){if(index<0||index>size-1)throw new IndexOutOfBoundsException("查询位置非法,合法位置为:0"+(size-1));return (E) array[index];}判断某位置是否为空:
public boolean isEmpty(){return size==0;}System.out.println(list.get(2));链表
顺序表的缺陷:
ArrayList底层使用数组来存储元素:由于其底层是一段连续空间,当在ArrayList任意位置插入或者删除元素时,就需要将后序元素整体往前或者往后搬移,时间复杂度为O(n),效率比较低,因此ArrayList不适合做任意位置插入和删除比较多的场景。因此:java 集合中又引入了LinkedList,即链表结构。
链表是一种物理存储结构上非连续存储结构,数据元素的逻辑顺序是通过链表中的引用链接次序实现的 。在逻辑结构上连续,但在物理上不一定连续。
实际中链表的结构非常多样:
1. 单向或者双向
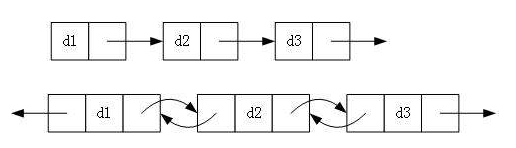
2. 带头或者不带头

3. 循环或者非循环
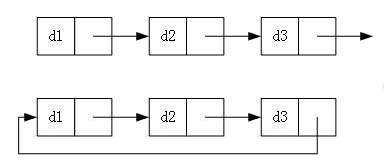
无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。这种结构在笔试面试中出现很多。
无头双向链表:在Java的集合框架库中LinkedList底层实现就是无头双向循环链表。
带头单向链表:
public class LinkedList <E>{//链表的头结点,用于连接之后的所有结点private final Node<E>head=new Node<>(null);private int size; //存当前元素数量,方便后续操作private static class Node<E>{ //结点类,仅供内部使用private E element; //每个结点都存放元素private Node<E> next; //以及指向下一个结点的引用public Node(E e){this.element=e;}}
}链表的插入:
public void add(E element,int index){if(index<0||index>size)throw new IndexOutOfBoundsException("插入位置非法,合法的插入位置为:0-"+size);//先找到对应位置的前驱结点Node<E>prev=head; for (int i = 0; i < index; i++) prev =prev.next;Node<E>node=new Node<>(element); //创建新的结点node.next=prev.next; //新的结点指向原本在这个位置上的结点prev.next=node; //让前驱结点指向当前结点size++; //更新size}toString方法:
@Overridepublic String toString(){StringBuilder builder=new StringBuilder();Node<E> node=head.next; //从第一个结点开始,一个一个遍历,遍历一个就拼接到字符串上去while (node!=null){builder.append(node.element).append(" ");node=node.next;}return builder.toString();}删除操作:
public E remove(int index){if(index<0||index>size-1)throw new IndexOutOfBoundsException("删除位置非法,合法的删除位置为:0-"+(size-1));Node<E>prev=head;for (int i = 0; i < index; i++) //找到前驱结点prev=prev.next;E e=prev.next.element; //先把待删除结点存放的元素取出来prev.next=prev.next.next;size--;return e;}获取对应位置上的元素: (有点蒙,做个标记)
public E get(int index){if(index<0||index>size-1)throw new IndexOutOfBoundsException("查询位置非法,合法位置为:0"+(size-1));Node<E>node=head;while (index-->=0) //这里直接让index减到-1为止node=node.next;return node.element;}public int size(){return size;}顺序表和链表的区别:
| 不同点 | ArrayList | LinkedList |
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定连续 |
| 随机访问 | 支持O(1) | 不支持:O(N) |
| 头插 | 需要搬移元素,效率低O(N) | 只需修改引用的指向,时间复杂度为O(1) |
| 插入 | 空间不够时需要扩容 | 没有容量的概念 |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置插入和删除频繁 |
栈
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。
压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
出栈:栈的删除操作叫做出栈。出数据在栈顶。
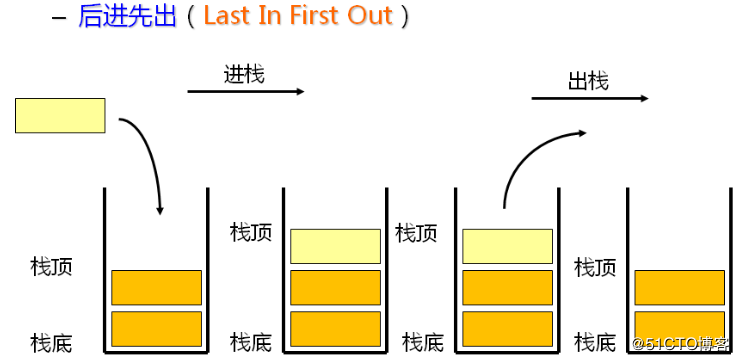
栈可以使用顺序表实现,也可以使用链表实现,使用链表会更加方便。我们可以直接将头结点指向栈顶结点,而栈顶结点连接后续的栈内结点。
入栈操作:
当有新的元素入栈,只需要在链表头部插入新的结点即可。
public class LinkedStack <E>{private final Node<E> head=new Node<>(null);public void push(E element){Node<E>node=new Node<>(element); //直接创建新结点node.next=head.next; //新结点的下一个变成原本的栈顶结点head.next=node; //头结点的下一个改成新的结点}public boolean isEmpty(){return head.next==null;}private static class Node<E>{private E element;private Node<E> next;public Node(E e){this.element=e;}}
}出栈操作:
public E pop(){if(isEmpty()){ //如果栈没有元素了无法取throw new NoSuchElementException("栈为空");}E e=head.next.element; //先把待出栈元素取出来head.next=head.next.next; //直接让头结点的下一个指向下一个的下一个return e;} public static void main(String[] args) {LinkedStack<String>stack=new LinkedStack<>();stack.push("A");stack.push("B");stack.push("C");stack.push("D");while (!stack.isEmpty()){System.out.println(stack.pop());}}
//输出
D
C
B
A队列
队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出FIFO(First In First Out)
入队列:进行插入操作的一端称为队尾(Tail/Rear)
出队列:进行删除操作的一端称为队头 (Head/Front)
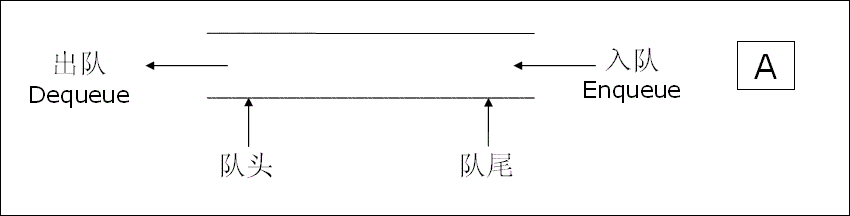
当有新的元素入队时,只需要拼在队尾就可以了,同时队尾指针也要后移一位。
出队时,只需要移除队首指向的下一个元素即可。
public class LinkedQuene <E>{private final Node<E> head=new Node<>(null);//入队操作public void offer(E element){Node<E>tail=head;while (tail.next!=null) //入队直接放到最后一个结点的后面tail=tail.next;tail.next=new Node<>(element);}//出队操作public E poil(){if(isEmpty()) //若队列没有元素了无法取出throw new NoSuchElementException("队列为空");E e=head.next.element;head.next=head.next.next; //直接从队首取出return e;}//仅获取不移除队首public E peak(){if(isEmpty())throw new NoSuchElementException("队列为空");return head.next.element;}public boolean isEmpty(){return head.next==null;}private static class Node<E>{private E element;private Node<E> next;public Node(E e){this.element=e;}}
}相关文章:
从零开始学java--线性表
数据结构基础 目录 数据结构基础 线性表 顺序表 链表 顺序表和链表的区别: 栈 队列 线性表 线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表中的元素个数就是线性表的长度,表的起始位置称为表头&am…...
AD917X系列JESD204B MODE7使用
MODE7特殊在F8,M4使用2个复数通道 CH0_NCO10MHz CH1_NCO30MHZ DP_NCO50MHz DDS1偏移20MHz DDS2偏移40MHz...
Spring Cloud之远程调用OpenFeign最佳实践
目录 OpenFeign最佳实践 问题引入 Feign 继承方式 创建Module 引入依赖 编写接口 打Jar包 服务提供方 服务消费方 启动服务并访问 Feign 抽取方式 创建Module 引入依赖 编写接口 打Jar包 服务消费方 启动服务并访问 服务部署 修改pom.xml文件 观察Nacos控制…...

【Python爬虫】详细入门指南
目录 一、简单介绍 二、详细工作流程以及组成部分 三、 简单案例实现 一、简单介绍 在当今数字化信息飞速发展的时代,数据的获取与分析变得愈发重要,而网络爬虫技术作为一种能够从互联网海量信息中自动抓取所需数据的有效手段,正逐渐走入…...

Win11系统 VMware虚拟机 安装教程
Win11系统 VMware虚拟机 安装教程 一、介绍 Windows 11是由微软公司(Microsoft)开发的操作系统,应用于计算机和平板电脑等设备 。于2021年6月24日发布 ,2021年10月5日发行 。 Windows 11提供了许多创新功能,增加了新…...
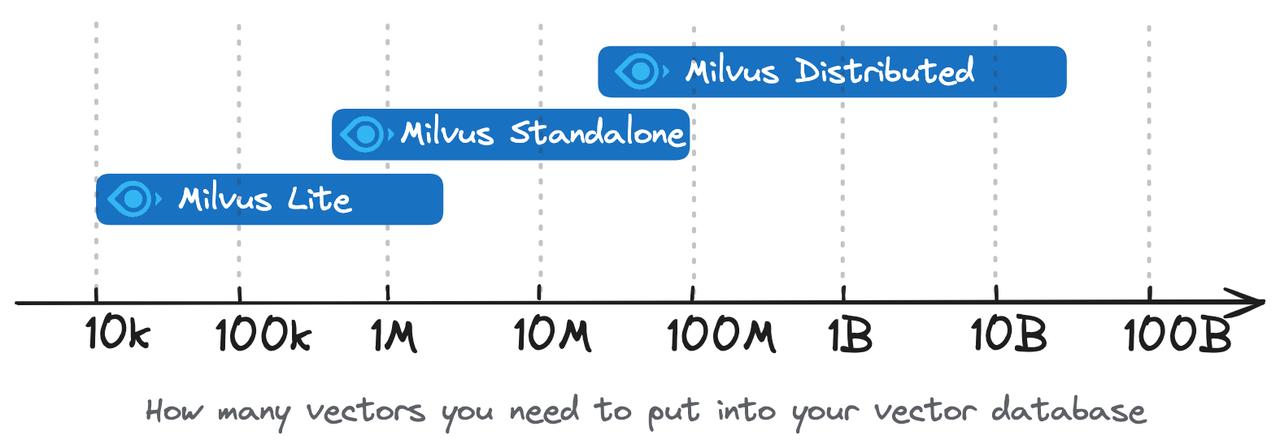
打造AI应用基础设施:Milvus向量数据库部署与运维
目录 打造AI应用基础设施:Milvus向量数据库部署与运维1. Milvus介绍1.1 什么是向量数据库?1.2 Milvus主要特点 2. Milvus部署方案对比2.1 Milvus Lite2.2 Milvus Standalone2.3 Milvus Distributed2.4 部署方案对比表 3. Milvus部署操作命令实战3.1 Milv…...

对于客户端数据存储方案——SQLite的思考
SQLite 比较适合进行本地小型数据的存储,在功能丰富性和并发能力上不如 MySQL。 数据类型差异 SQLite 使用动态类型系统:只有 5 种基本存储类 (NULL, INTEGER, REAL, TEXT, BLOB) 类型亲和性:SQLite 会将声明的列类型映射到最接近的存储类 …...
【深度学习与大模型基础】第11章-Bernoulli分布,Multinoulli分布
一、Bernoulli分布 1. 基本概念 想象你抛一枚硬币: 正面朝上(记为 1)概率是 p(比如 0.6)。 反面朝上(记为 0)概率是 1-p(比如 0.4)。 这就是一个Bernoulli分布&…...
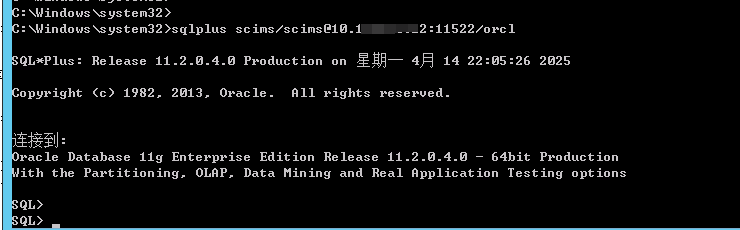
基于Windows通过nginx代理访问Oracle数据库
基于Windows通过nginx代理访问Oracle数据库 环境说明: 生产环境是一套一主一备的ADG架构服务器,用户需要访问生产数据,基于安全考虑,生产IP地址不能直接对外服务,所以需要在DMZ部署一个前置机,并在该前置机…...
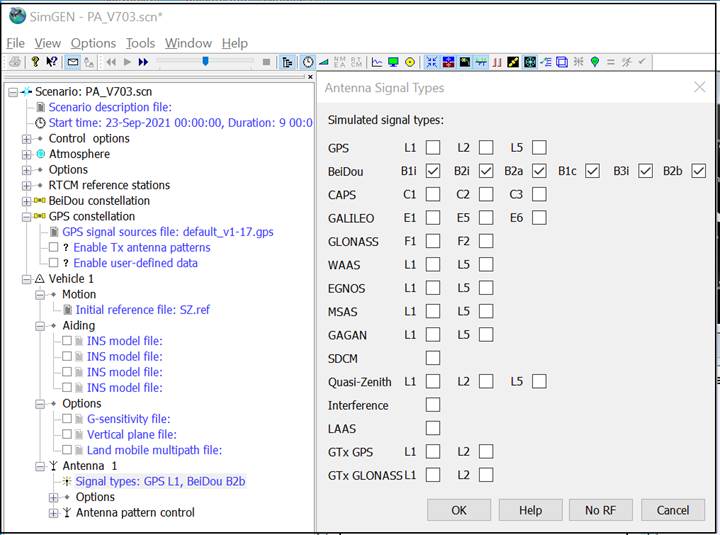
北斗和GPS信号频率重叠-兼容与互操作
越来越多的同学们发现北斗三代信号的B1C,B2a信号居然和美国GPS L1,L5处在同样频率上? 为什么美国会允许这样的事情发生?同频率难道不干扰彼此的信号吗? 思博伦卫星导航技术支持文章TED 这事得从2006年联合国成立全球卫星导航系统…...
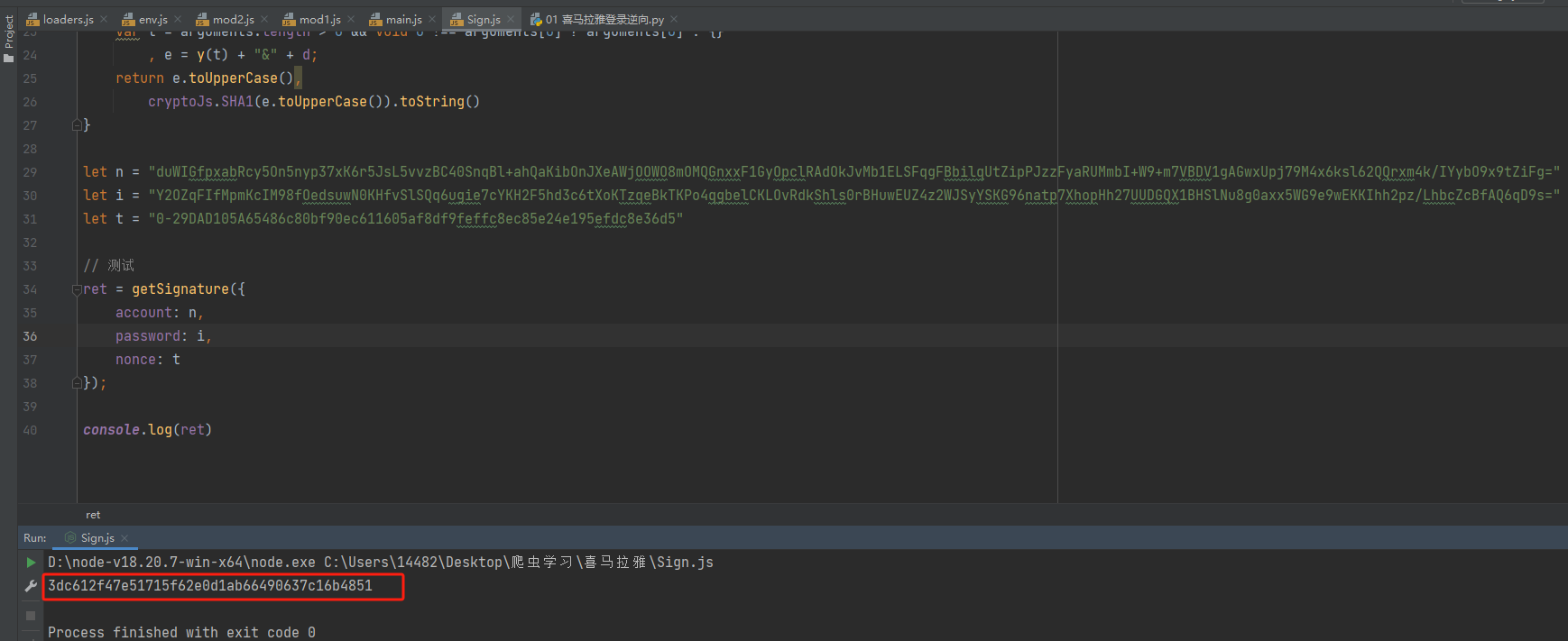
python爬虫:喜马拉雅案例(破解sign值)
声明: 本文章中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 根据上一篇文章,我们破解了本网站的,手机号和密码验证&#x…...

如何高效查询订单销售情况与售罄率:从SQL到架构优化的全流程设计
在电商平台、SaaS多租户系统中,订单数据作为核心数据之一,承载了关键的运营指标,如销售额、商品售罄率、订单转化等。随着数据量的持续增长,如何在大数据量条件下快速、稳定地获取统计信息,成为系统设计的重点之一。 本文将从查询目标分析入手,结合数据库设计优化与典型…...

机器学习:让数据开口说话的科技魔法
在人工智能飞速发展的今天,「机器学习」已成为推动数字化转型的核心引擎。无论是手机的人脸解锁、网购平台的推荐系统,还是自动驾驶汽车的决策能力,背后都离不开机器学习的技术支撑。那么,机器学习究竟是什么?它又有哪…...

51单片机波特率与溢出率的关系
1. 波特率与溢出率的基本关系 波特率(Baud Rate)表示串口通信中每秒传输的位数(bps),而溢出率是定时器每秒溢出的次数。在51单片机中,波特率通常通过定时器的溢出率来生成。 公式关系: 波特率=溢出率/分频系数 其中,分频系数与定时器的工作模…...

Java 8 CompletableFuture:异步编程的利器与最佳实践
目录 1. 创建异步任务 1.1 使用默认线程池 1.2 使用自定义线程池 2. 异步回调处理 2.1 thenApply 和 thenApplyAsync 2.2 thenAccept 和 thenAcceptAsync 2.3 thenRun 和 thenRunAsync 3. 异常处理 3.1 whenComplete 和 whenCompleteAsync 3.2 handle 和 handleAsync…...

Podman与行业趋势分析 ——兼论与Docker的对比及未来发展方向
1. Podman核心概念与架构解析 1.1 定义与定位 Podman(Pod Manager)是由Red Hat主导开发的开源容器引擎,遵循OCI(Open Container Initiative)标准,专注于提供无守护进程(Daemonless)…...

摄影测量——单像空间后方交会
空间后方交会的求解是一个非线性问题,通常采用最小二乘法进行迭代解算。下面我将详细介绍具体的求解步骤: 1. 基本公式(共线条件方程) 共线条件方程是后方交会的基础: 复制 x - x₀ -f * [m₁₁(X-Xₛ) m₁₂(Y-…...

ros2_01
note01 ROS2和ROS最大的区别中间件 中间件: 介于某两个或者多个节点中间的组件;提供多个节点中间通信; ROS1:中间件是ROS组织自己基于TCP机制建立的,随着现在传感器的升级,数据量越来越大,原…...

C++中的高阶函数
C中的高阶函数 高阶函数是指可以接受其他函数作为参数或返回函数作为结果的函数。在C中,有几种方式可以实现高阶函数的功能: 1. 函数指针 #include <iostream>int add(int a, int b) { return a b; } int subtract(int a, int b) { return a -…...

计算机视觉与深度学习 | 钢筋捆数识别
===================================================== github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 ===================================================== 钢筋捆数 1、初始结果2、处理效果不佳时的改进方法1、预处理增强2、后…...
)
L3-027 可怜的复杂度(纯暴力)
暴力解答,肯定超时,因为我刚开始把所有答案,存到了ans这个vector里面了,然后进行枚举情况,后面发现因为这个阶数很高的时候,就会直接炸内存,所以我直接选择了在dfs里面进行统计答案,…...

基于RV1126开发板的人脸姿态估计算法开发
1. 人脸姿态估计简介 人脸姿态估计是通过对一张人脸图像进行分析,获得脸部朝向的角度信息。姿态估计是多姿态问题中较为关键的步骤。一般可以用旋转矩阵、旋转向量、四元数或欧拉角表示。人脸的姿态变化通常包括上下俯仰(pitch)、左右旋转(yaw)以及平面内角度旋转(r…...
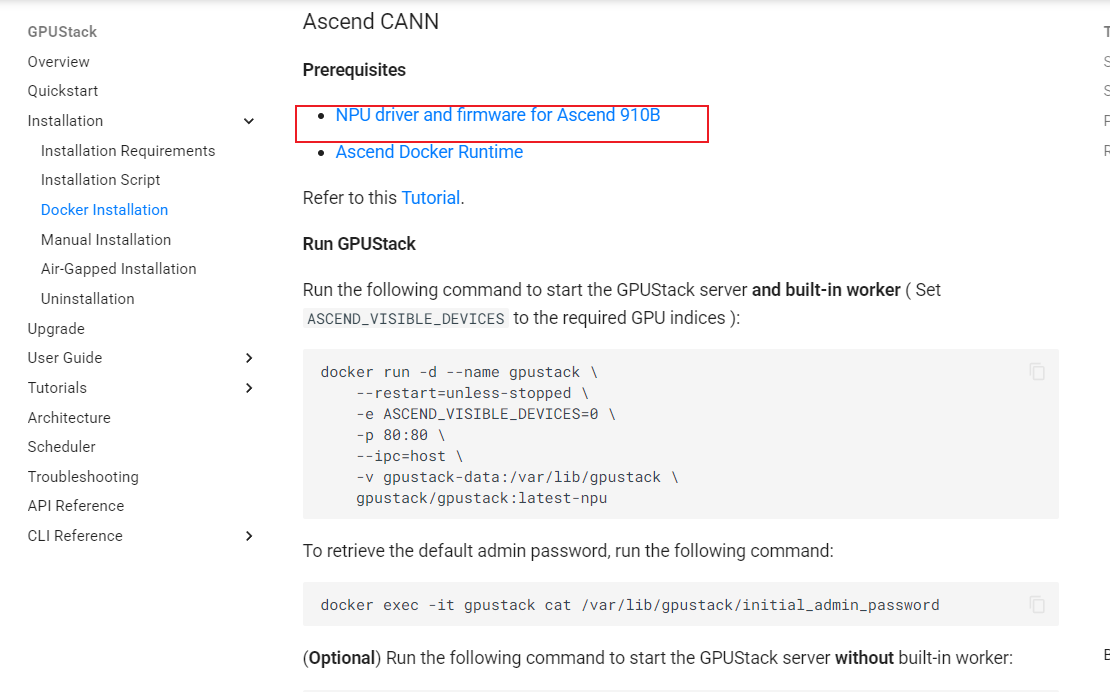
鲲鹏+昇腾部署集群管理软件GPUStack,两台服务器搭建双节点集群【实战详细踩坑篇】
前期说明 配置:2台鲲鹏32C2 2Atlas300I duo,之前看网上文档,目前GPUstack只支持910B芯片,想尝试一下能不能310P也部署试试,毕竟华为的集群软件要收费。 系统:openEuler22.03-LTS 驱动:24.1.rc…...

【C#】CAN通信的使用
在C#中实现CAN通信通常需要借助第三方库或硬件设备的驱动程序,因为C#本身并没有直接内置支持CAN通信的功能。以下是一个关于如何使用C#实现CAN通信的基本指南,包括所需的步骤和常用工具。 1. 硬件准备 要进行CAN通信,首先需要一个支持CAN协…...

火山引擎旗下的产品
用户问的是火山引擎旗下的产品,我需要详细列出各个类别下的产品。首先,我得确认火山引擎有哪些主要业务领域,比如云计算、大数据、人工智能这些。然后,每个领域下具体有哪些产品呢?比如云计算方面可能有云服务器、容器…...

Elasticsearch 故障转移及水平扩容
一、故障转移 Elasticsearch 的故障转移(Failover)机制是其高可用性的核心,通过分布式设计、自动检测和恢复策略确保集群在节点故障时持续服务。 1.1 故障转移的核心组件 组件作用Master 节点管理集群状态(分片分配、索引创建&…...

机器学习中 提到的张量是什么?
在机器学习中, 张量(Tensor) 是一个核心数学概念,用于表示和操作多维数据。以下是关于张量的详细解析: 一、数学定义与本质 张量在数学和物理学中的定义具有多重视角: 多维数组视角 传统数学和物理学中,张量被定义为多维数组,其分量在坐标变换时遵循协变或逆变规则。例…...

edge 更新到135后,Clash 打开后,正常网页也会自动跳转
发现了一个有意思的问题:edge 更新135后,以前正常使用的clash出现了打开deepseek也会自动跳转: Search Resultshttps://zurefy.com/zu1.php#gsc.tab0&gsc.qdeepseek ,也就是不需要梯子的网站打不开了,需要的一直正…...

prime 1 靶场笔记(渗透测试)
环境说明: 靶机prime1和kali都使用的是NAT模式,网段在192.168.144.0/24。 Download (Mirror): https://download.vulnhub.com/prime/Prime_Series_Level-1.rar 一.信息收集 1.主机探测: 使用nmap进行全面扫描扫描,找到目标地址及…...

实验一 字符串匹配实验
一、实验目的 1.熟悉汇编语言编程环境和DEBUG调试程序的使用。 2.掌握键盘输入字符串的方法和分支程序的设计。 二、实验内容 编程实现:从键盘分别输入两个字符串,然后进行比较,若两个字符串的长度…...