go 通过汇编分析函数传参与返回值机制
文章目录
- 概要
- 一、前置知识
- 二、汇编分析
- 2.1、示例
- 2.2、汇编
- 2.2.1、 寄存器传值的汇编
- 2.2.2、 栈内存传值的汇编
- 三、拓展
- 3.1 了解go中的Duff’s Device
- 3.2 go tool compile
- 3.2 call 0x46dc70 & call 0x46dfda
概要
在上一篇文章中,我们研究了go函数调用时的栈布局,观察到了其函数参数和返回值一般通过AX、BX等通用寄存器传递,但是函数示例的传参和返回值个数都很少,自然会想到,如果函数参数和返回值很多,怎么办?毕竟CPU的寄存器数量是有限的,而go函数参数数量可没限制。
调试环境:Centos Linux 7 ,CPU AMD x86_64,Go version 1.24
先说结论:当函数参数和返回值过多时,多余的值直接通过栈来传递,下面就让我们通过go汇编来验证下吧。
一、前置知识
AMD x86_64 CPU 常见寄存器:
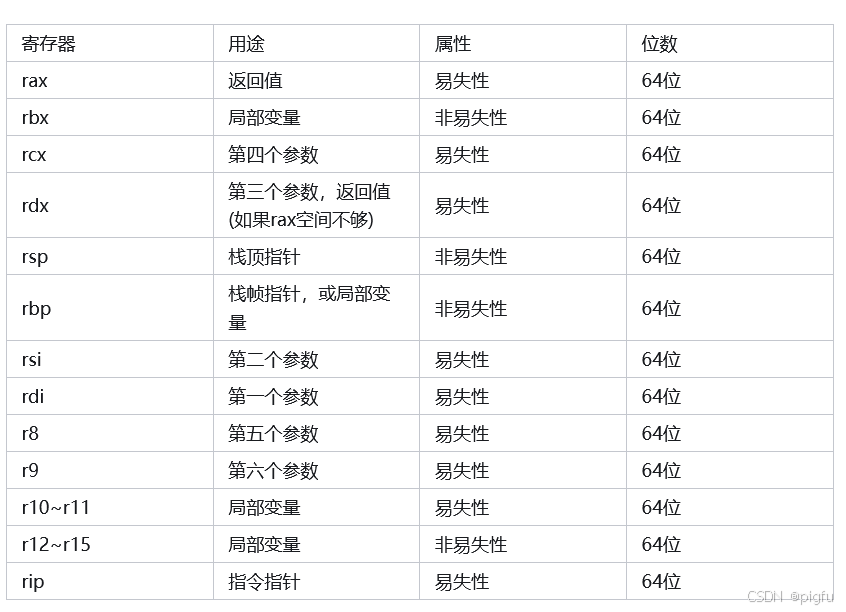
另外还有8个专为Steraming SIMD Extensions(SSE——多指令多数据流扩展)准备的寄存器(128位):xmm0~xmm15。
对于AX系列寄存器,在16位下是ax、32位下是eax、64位下是rax,如果在64位cpu下使用eax,表示只用该寄存器前32位,其他同理。
二、汇编分析
2.1、示例
1 package main23 func main() { // 探索栈布局4 x := int64(6)5 callMaxTest(x)6 rv := returnMax()7 x = rv.Id58 }910 func callMaxTest(z int64) {11 d := MaxData{12 Id: 1,13 Id1: 2,14 Id2: 3,15 Id3: z,16 Id4: 5,17 Id5: 6,18 Id6: 7,19 Id7: 8,20 Id8: 9,21 }22 d.Id = callMax(d) //过大的传参数据,寄存器不够用,所以会用过栈内存传递数据23 }2425 func callMax(md MaxData) int64 {26 a, b := md.Id2, md.Id527 return a + b28 }2930 func returnMax() MaxData { //过大的返回数据,寄存器不够用,所以会用过栈内存传递数据31 y := int64(7)32 md := MaxData{33 Id: 1,34 Id1: 2,35 Id2: 3,36 Id3: 4,37 Id4: 5,38 Id5: 6,39 Id6: 7,40 Id7: 8,41 Id8: 9,42 }43 md.Id5 = y44 return md45 }4647 type MaxData struct { //x86_6448 Id int64 //AX49 Id1 int64 //BX50 Id2 int64 //CX51 Id3 int64 //DI52 Id4 int64 //SI53 Id5 int64 //R854 Id6 int64 //R955 Id7 int64 //R1056 Id8 int64 //R1157 //Id9 int64 //导致寄存器不足, 编译器判定使用栈内存传递数据58 }通过调整MaxData结构体字段个数,得到9个字段是是否使用寄存器传参的极限。
2.2、汇编
通过寄存器传值和栈内存传值两种模式分析。
仍然使用dlv debug 来调试。
2.2.1、 寄存器传值的汇编
即MaxData结构体字段个数是9个的情况下的汇编,由于本文只分析函数传参和返回值,所以我们只研究callMaxTest和returnMax的汇编。
TEXT main.callMaxTest(SB) /home/gofunc/ret.goret.go:10 0x470be0 4c8d6424e0 lea r12, ptr [rsp-0x20]ret.go:10 0x470be5 4d3b6610 cmp r12, qword ptr [r14+0x10]ret.go:10 0x470be9 0f86c0000000 jbe 0x470cafret.go:10 0x470bef 55 push rbpret.go:10 0x470bf0 4889e5 mov rbp, rsp
=> ret.go:10 0x470bf3* 4881ec98000000 sub rsp, 0x98ret.go:10 0x470bfa 48898424a8000000 mov qword ptr [rsp+0xa8], rax#令rsp+0xa8地址保存参数zret.go:20 0x470c02 48c744244801000000 mov qword ptr [rsp+0x48], 0x1#开始设置各个字段的值,令字段Id=1ret.go:20 0x470c0b 48c744245002000000 mov qword ptr [rsp+0x50], 0x2ret.go:20 0x470c14 48c744245803000000 mov qword ptr [rsp+0x58], 0x3ret.go:20 0x470c1d 48c744246000000000 mov qword ptr [rsp+0x60], 0x0#令字段Id3=0ret.go:20 0x470c26 48c744246805000000 mov qword ptr [rsp+0x68], 0x5ret.go:20 0x470c2f 48c744247006000000 mov qword ptr [rsp+0x70], 0x6ret.go:20 0x470c38 48c744247807000000 mov qword ptr [rsp+0x78], 0x7ret.go:20 0x470c41 48c784248000000008000000 mov qword ptr [rsp+0x80], 0x8ret.go:20 0x470c4d 48c784248800000009000000 mov qword ptr [rsp+0x88], 0x9#令字段Id8=9ret.go:15 0x470c59 488bbc24a8000000 mov rdi, qword ptr [rsp+0xa8]#开始设置参数,令RDX传递字段Id3的值ret.go:15 0x470c61 48897c2460 mov qword ptr [rsp+0x60], rdi#令字段Id3等于参数zret.go:22 0x470c66 488b442448 mov rax, qword ptr [rsp+0x48]#令RAX传递字段Id的值ret.go:22 0x470c6b 488b5c2450 mov rbx, qword ptr [rsp+0x50]ret.go:22 0x470c70 488b4c2458 mov rcx, qword ptr [rsp+0x58]ret.go:22 0x470c75 488b742468 mov rsi, qword ptr [rsp+0x68]ret.go:22 0x470c7a 4c8b442470 mov r8, qword ptr [rsp+0x70]ret.go:22 0x470c7f 4c8b4c2478 mov r9, qword ptr [rsp+0x78]ret.go:22 0x470c84 4c8b942480000000 mov r10, qword ptr [rsp+0x80]ret.go:22 0x470c8c 4c8b9c2488000000 mov r11, qword ptr [rsp+0x88]#令R11传递字段Id8的值ret.go:22 0x470c94 e847000000 call $main.callMaxret.go:22 0x470c99 4889842490000000 mov qword ptr [rsp+0x90], raxret.go:22 0x470ca1 4889442448 mov qword ptr [rsp+0x48], raxret.go:23 0x470ca6 4881c498000000 add rsp, 0x98ret.go:23 0x470cad 5d pop rbpret.go:23 0x470cae c3 retret.go:10 0x470caf 4889442408 mov qword ptr [rsp+0x8], raxret.go:10 0x470cb4 e847acffff call $runtime.morestack_noctxtret.go:10 0x470cb9 488b442408 mov rax, qword ptr [rsp+0x8]ret.go:10 0x470cbe 6690 data16 nopret.go:10 0x470cc0 e91bffffff jmp $main.callMaxTest
TEXT main.returnMax(SB) /home/gofunc/ret.goret.go:30 0x470d40 4c8d6424e0 lea r12, ptr [rsp-0x20]ret.go:30 0x470d45 4d3b6610 cmp r12, qword ptr [r14+0x10]ret.go:30 0x470d49 0f86fe000000 jbe 0x470e4dret.go:30 0x470d4f 55 push rbpret.go:30 0x470d50 4889e5 mov rbp, rsp
=> ret.go:30 0x470d53* 4881ec98000000 sub rsp, 0x98ret.go:30 0x470d5a 440f113c24 movups xmmword ptr [rsp], xmm15#令rsp+0x0地址值等于0ret.go:30 0x470d5f 440f117c2408 movups xmmword ptr [rsp+0x8], xmm15ret.go:30 0x470d65 440f117c2418 movups xmmword ptr [rsp+0x18], xmm15ret.go:30 0x470d6b 440f117c2428 movups xmmword ptr [rsp+0x28], xmm15ret.go:30 0x470d71 440f117c2438 movups xmmword ptr [rsp+0x38], xmm15ret.go:31 0x470d77 48c744244807000000 mov qword ptr [rsp+0x48], 0x7#令变量y=7ret.go:41 0x470d80 48c744245001000000 mov qword ptr [rsp+0x50], 0x1#开始设置各个字段的值,令字段Id=1ret.go:41 0x470d89 48c744245802000000 mov qword ptr [rsp+0x58], 0x2ret.go:41 0x470d92 48c744246003000000 mov qword ptr [rsp+0x60], 0x3ret.go:41 0x470d9b 48c744246804000000 mov qword ptr [rsp+0x68], 0x4ret.go:41 0x470da4 48c744247005000000 mov qword ptr [rsp+0x70], 0x5ret.go:41 0x470dad 48c744247806000000 mov qword ptr [rsp+0x78], 0x6#令字段Id5=6ret.go:41 0x470db6 48c784248000000007000000 mov qword ptr [rsp+0x80], 0x7ret.go:41 0x470dc2 48c784248800000008000000 mov qword ptr [rsp+0x88], 0x8ret.go:41 0x470dce 48c784249000000009000000 mov qword ptr [rsp+0x90], 0x9#令字段Id8=9ret.go:43 0x470dda 488b542448 mov rdx, qword ptr [rsp+0x48]#令RDX等于变量yret.go:43 0x470ddf 4889542478 mov qword ptr [rsp+0x78], rdx#令字段Id5等于RDX,即等于变量yret.go:44 0x470de4 488b542450 mov rdx, qword ptr [rsp+0x50]#令RDX等于字段Idret.go:44 0x470de9 48891424 mov qword ptr [rsp], rdx#令rsp地址等于RDX,即等于字段Idret.go:44 0x470ded 0f10442458 movups xmm0, xmmword ptr [rsp+0x58] #将XMM0寄存器(16字节)等于rsp+0x58地址到rsp+0x58+16字节地址之间的内容,即将字段Id1和字段Id2的值设给XMM0寄存器ret.go:44 0x470df2 0f11442408 movups xmmword ptr [rsp+0x8], xmm0#将字段Id1和字段Id2的值依次设置给地址rsp+0x8 和 rsp+0x10ret.go:44 0x470df7 0f10442468 movups xmm0, xmmword ptr [rsp+0x68]ret.go:44 0x470dfc 0f11442418 movups xmmword ptr [rsp+0x18], xmm0ret.go:44 0x470e01 0f10442478 movups xmm0, xmmword ptr [rsp+0x78]ret.go:44 0x470e06 0f11442428 movups xmmword ptr [rsp+0x28], xmm0ret.go:44 0x470e0b 0f10842488000000 movups xmm0, xmmword ptr [rsp+0x88]ret.go:44 0x470e13 0f11442438 movups xmmword ptr [rsp+0x38], xmm0ret.go:44 0x470e18 488b0424 mov rax, qword ptr [rsp]#开始处理返回值,RAX等于rsp地址,即等于字段Id, 则是令RAX返回字段Id的值ret.go:44 0x470e1c 488b5c2408 mov rbx, qword ptr [rsp+0x8]#RBX 返回字段Id1的值ret.go:44 0x470e21 488b4c2410 mov rcx, qword ptr [rsp+0x10]#RCX 返回字段Id2的值ret.go:44 0x470e26 488b7c2418 mov rdi, qword ptr [rsp+0x18]ret.go:44 0x470e2b 488b742420 mov rsi, qword ptr [rsp+0x20]ret.go:44 0x470e30 4c8b442428 mov r8, qword ptr [rsp+0x28]ret.go:44 0x470e35 4c8b4c2430 mov r9, qword ptr [rsp+0x30]ret.go:44 0x470e3a 4c8b542438 mov r10, qword ptr [rsp+0x38]ret.go:44 0x470e3f 4c8b5c2440 mov r11, qword ptr [rsp+0x40]#R11 返回字段Id8的值ret.go:44 0x470e44 4881c498000000 add rsp, 0x98ret.go:44 0x470e4b 5d pop rbpret.go:44 0x470e4c c3 retret.go:30 0x470e4d e8aeaaffff call $runtime.morestack_noctxtret.go:30 0x470e52 e9e9feffff jmp $main.returnMax
可以看到寄存器RAX、RBX、RCX、RDI、RSI、R8、R9、R10、R11这9个寄存器都参与了函数参数和返回值的传递。
2.2.2、 栈内存传值的汇编
此时需要将结构体MaxData的Id9字段放出来,即10个字段时可以触发函数之间通过栈内存传值,参数和返回值在函数之间的传递原理一样的,所以这里只分析returnMax返回值的传递。
TEXT main.main(SB) /home/gofunc/ret.goret.go:3 0x470b00 4c8d6424d0 lea r12, ptr [rsp-0x30]ret.go:3 0x470b05 4d3b6610 cmp r12, qword ptr [r14+0x10]ret.go:3 0x470b09 765e jbe 0x470b69ret.go:3 0x470b0b 55 push rbpret.go:3 0x470b0c 4889e5 mov rbp, rsp
=> ret.go:3 0x470b0f* 4881eca8000000 sub rsp, 0xa8ret.go:4 0x470b16 48c744245006000000 mov qword ptr [rsp+0x50], 0x6#设置变量x=6ret.go:5 0x470b1f b806000000 mov eax, 0x6 #设置EAX等与变量x的值6,用于调用callMaxTest函数传参ret.go:5 0x470b24 e857000000 call $main.callMaxTestret.go:6 0x470b29 e852010000 call $main.returnMax#调用returnMax函数ret.go:6 0x470b2e 488d7c2458 lea rdi, ptr [rsp+0x58]ret.go:6 0x470b33 4889e6 mov rsi, rspret.go:6 0x470b36 660f1f840000000000 nop word ptr [rax+rax*1], axret.go:6 0x470b3f 90 nopret.go:6 0x470b40 48896c24f0 mov qword ptr [rsp-0x10], rbpret.go:6 0x470b45 488d6c24f0 lea rbp, ptr [rsp-0x10]ret.go:6 0x470b4a e88bd4ffff call 0x46dfda#跳到0x46dfda地址处,执行相应机器码,作用是将rsp+0x8到rsp+0x8+80字节(rsp+0x58)地址之间的内容依次复制到rsp+0x58到rsp+0x58+80字节之间地址上。结合returnMax逻辑,可知,main函数栈rsp+0x58到rsp+0x58+80字节(rsp+0xa8)地址之间的栈内存用于保存returnMax函数返回值。rsp+0x58 = rv.Id,rsp+0x60 = rv.Id1 依次类推。ret.go:6 0x470b4f 488b6d00 mov rbp, qword ptr [rbp]ret.go:7 0x470b53 488b8c2480000000 mov rcx, qword ptr [rsp+0x80]#取rv.Id5值放到RCXret.go:7 0x470b5b 48894c2450 mov qword ptr [rsp+0x50], rcx#令x=rv.Id5ret.go:8 0x470b60 4881c4a8000000 add rsp, 0xa8ret.go:8 0x470b67 5d pop rbpret.go:8 0x470b68 c3 retret.go:3 0x470b69 e892adffff call $runtime.morestack_noctxtret.go:3 0x470b6e eb90 jmp $main.main
TEXT main.returnMax(SB) /home/gofunc/ret.goret.go:30 0x470c80 55 push rbpret.go:30 0x470c81 4889e5 mov rbp, rsp
=> ret.go:30 0x470c84* 4883ec58 sub rsp, 0x58ret.go:30 0x470c88 488d7c2468 lea rdi, ptr [rsp+0x68]#给call 0x46dc70对应函数用的,这里rsp+0x68就是main函数的rsp+0x8位置了ret.go:30 0x470c8d 488d7fd0 lea rdi, ptr [rdi-0x30]#这里减少48字节很奇怪,莫名其妙ret.go:30 0x470c91 660f1f840000000000 nop word ptr [rax+rax*1], axret.go:30 0x470c9a 660f1f440000 nop word ptr [rax+rax*1], axret.go:30 0x470ca0 48896c24f0 mov qword ptr [rsp-0x10], rbpret.go:30 0x470ca5 488d6c24f0 lea rbp, ptr [rsp-0x10]ret.go:30 0x470caa e8c1cfffff call 0x46dc70 #跳到0x46dc70地址处,执行相应机器码,作用是将rsp+0x68 到rsp+0x68+80字节(MaxData结构体大小)之间地址置为0ret.go:30 0x470caf 488b6d00 mov rbp, qword ptr [rbp]ret.go:31 0x470cb3 48c7042407000000 mov qword ptr [rsp], 0x7 #令变量y=7ret.go:41 0x470cbb 488d7c2408 lea rdi, ptr [rsp+0x8]#给call 0x46dfda函数用的ret.go:41 0x470cc0 488d35b9dd0100 lea rsi, ptr [rip+0x1ddb9]#给call 0x46dfda函数用的ret.go:41 0x470cc7 48896c24f0 mov qword ptr [rsp-0x10], rbpret.go:41 0x470ccc 488d6c24f0 lea rbp, ptr [rsp-0x10]ret.go:41 0x470cd1 e804d3ffff call 0x46dfda#跳到0x46dfda地址处,执行相应机器码,作用是将rip+0x1ddb9到rip+0x1ddb98+80字节地址之间的内容依次复制到rsp+0x8到rsp+0x8+80字节之间地址上。即将变量md的值从数据区复制到returnMax函数的栈上。ret.go:41 0x470cd6 488b6d00 mov rbp, qword ptr [rbp]ret.go:43 0x470cda 488b0424 mov rax, qword ptr [rsp]#令RAX等于变量yret.go:43 0x470cde 4889442430 mov qword ptr [rsp+0x30], rax#令md.Id5=yret.go:44 0x470ce3 488d7c2468 lea rdi, ptr [rsp+0x68]#rsp+0x60是main函数的栈顶ret.go:44 0x470ce8 488d742408 lea rsi, ptr [rsp+0x8]ret.go:44 0x470ced 660f1f840000000000 nop word ptr [rax+rax*1], axret.go:44 0x470cf6 660f1f840000000000 nop word ptr [rax+rax*1], axret.go:44 0x470cff 90 nopret.go:44 0x470d00 48896c24f0 mov qword ptr [rsp-0x10], rbpret.go:44 0x470d05 488d6c24f0 lea rbp, ptr [rsp-0x10]ret.go:44 0x470d0a e8cbd2ffff call 0x46dfda#跳到0x46dfda地址处,执行相应机器码,作用是将rsp+0x8到rsp+0x8+80字节地址之间的内容依次复制到rsp+0x68到rsp+0x68+80字节之间地址上。即将变量md的值从returnMax函数的栈复制到main函数栈上,实现栈内存传递值。ret.go:44 0x470d0f 488b6d00 mov rbp, qword ptr [rbp]ret.go:44 0x470d13 4883c458 add rsp, 0x58ret.go:44 0x470d17 5d pop rbpret.go:44 0x470d18 c3 ret
看到这里读者就清晰的知道栈内存传值的原理了,就是caller开辟栈空间(参数和返回值都是caller开辟)时专门多申请一部分内存接收callee的返回值,callee执行时会将返回值直接写入到caller栈上,朴素而又好用吧。
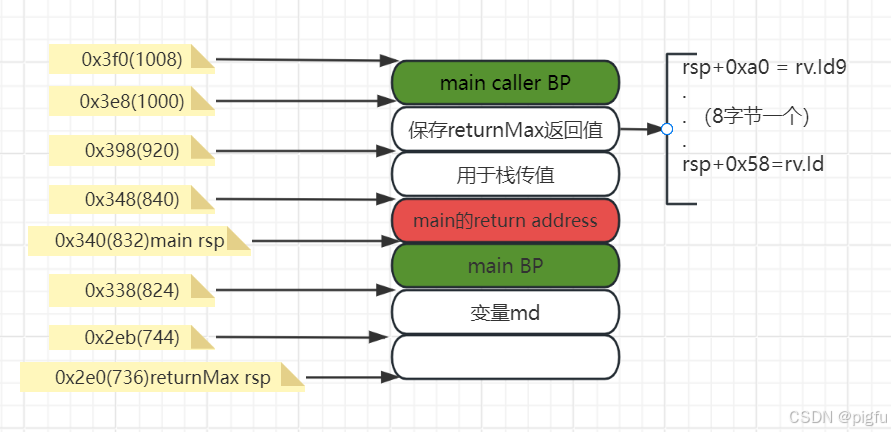
假设main函数的BP是0x3f0(1008),则main和returnMax的栈结构如下(注意此时MaxData大小是80字节):
三、拓展
在2.2.2小节,可以看到我对call 0x46dc70和call 0x46dfda两个汇编指令一长串的注释,怎么得来的呢?
3.1 了解go中的Duff’s Device
Duff’s Device就是将循环展开,减少判断次数来提升性能的一种机制。
在runtime/mkduff.go中,可以看到在amd x86_64下的两个Duff函数:runtime.duffzero() 【高效将某段连续内存清零】和runtime·duffcopy【高效将某段连续内存内容复制到另一段内存中】
func zeroAMD64(w io.Writer) {// X15: zero// DI: ptr to memory to be zeroed 通过DI寄存器确定要清零内存得低地址的一侧起始地址// DI is updated as a side effect.fmt.Fprintln(w, "TEXT runtime·duffzero<ABIInternal>(SB), NOSPLIT|NOFRAME, $0-0")for i := 0; i < 16; i++ {fmt.Fprintln(w, "\tMOVUPS\tX15,(DI)")fmt.Fprintln(w, "\tMOVUPS\tX15,16(DI)")fmt.Fprintln(w, "\tMOVUPS\tX15,32(DI)")fmt.Fprintln(w, "\tMOVUPS\tX15,48(DI)")fmt.Fprintln(w, "\tLEAQ\t64(DI),DI") // We use lea instead of add, to avoid clobbering flagsfmt.Fprintln(w)}fmt.Fprintln(w, "\tRET")
}
func copyAMD64(w io.Writer) {// SI: ptr to source memory SI寄存器指向源内存地址// DI: ptr to destination memory DI寄存器指向目的内存地址// SI and DI are updated as a side effect.// This is equivalent to a sequence of MOVSQ but for some reason that is 3.5x slower than this code.fmt.Fprintln(w, "TEXT runtime·duffcopy<ABIInternal>(SB), NOSPLIT|NOFRAME, $0-0")for i := 0; i < 64; i++ {fmt.Fprintln(w, "\tMOVUPS\t(SI), X0")fmt.Fprintln(w, "\tADDQ\t$16, SI")fmt.Fprintln(w, "\tMOVUPS\tX0, (DI)")fmt.Fprintln(w, "\tADDQ\t$16, DI")fmt.Fprintln(w)}fmt.Fprintln(w, "\tRET")
}
具体内容可以到runtime/duff_amd64.s文件中看对应汇编内容。
runtime·duffzero就是16个
MOVUPS X15,(DI) #4字节 [44 0f 11 3f] 汇编对应的机器码
MOVUPS X15,16(DI) #5字节 [44 0f 11 7f 10]
MOVUPS X15,32(DI) #5字节 [44 0f 11 7f 20]
MOVUPS X15,48(DI) #5字节 [44 0f 11 7f 30]
LEAQ 64(DI),DI #4字节 [48 8d 7f 40]
依次展开,一次循环的指令是23字节,留意这个数字。
runtime·duffcopy就是64个
MOVUPS (SI), X0 #3字节
ADDQ $16, SI #4字节
MOVUPS X0, (DI) #3字节
ADDQ $16, DI #4字节
依次展开,一次循环的指令是14字节,留意这个数字。
3.2 go tool compile
我们go tool compile -S -N -l ret.go看看其plan9汇编,选取returnMax函数关键部分,与2.2.2小节returnMax函数汇编对比,可以发现
call 0x46dc70 对应 DUFFZERO $336
call 0x46dfda 对应 DUFFCOPY $826
lea rsi, ptr [rip+0x1ddb9] 对应 LEAQ main…stmp_1(SB), SI
那么[DUFFZERO $336]表示跳到在代码区相对runtime·duffzero第一个机器码偏移336个字节的机器码;
那么[DUFFCOPY $826]表示跳到在代码区相对runtime·duffcopy第一个机器码偏移826个字节的机器码;
程序内存一般分为代码区(程序编译后的机器码)、数据区(常量、全局变量等)、堆区、栈区。
main.returnMax STEXT nosplit size=153 args=0x50 locals=0x60 funcid=0x0 align=0x0#...省略0x000d 00013 (/home/gofunc/ret.go:30) LEAQ -48(DI), DI0x0011 00017 (/home/gofunc/ret.go:30) NOP0x0020 00032 (/home/gofunc/ret.go:30) DUFFZERO $3360x0033 00051 (/home/gofunc/ret.go:31) PCDATA $0, $-10x0033 00051 (/home/gofunc/ret.go:31) MOVQ $7, main.y(SP)0x003b 00059 (/home/gofunc/ret.go:41) LEAQ main.md+8(SP), DI0x0040 00064 (/home/gofunc/ret.go:41) LEAQ main..stmp_1(SB), SI0x0047 00071 (/home/gofunc/ret.go:41) PCDATA $0, $-20x0047 00071 (/home/gofunc/ret.go:41) DUFFCOPY $826#...省略 0x0098 00152 (/home/gofunc/ret.go:44) RET
main..stmp_1 SRODATA static size=80 #数据区,returnMax函数变量md对应的值(只读,80字节)0x0000 01 00 00 00 00 00 00 00 02 00 00 00 00 00 00 00 ................0x0010 03 00 00 00 00 00 00 00 04 00 00 00 00 00 00 00 ................0x0020 05 00 00 00 00 00 00 00 06 00 00 00 00 00 00 00 ................0x0030 07 00 00 00 00 00 00 00 08 00 00 00 00 00 00 00 ................0x0040 09 00 00 00 00 00 00 00
LEAQ main…stmp_1(SB), SI表示将在数据区存储的returnMax函数变量md对应的值的起始地址装在到SI寄存器中,即方便后面通过DUFFCOPY函数将数据拷贝到returnMax函数栈内存中。
在dlv debug ret.go中,可以通过si命令进入call 0x46dc70和call 0x46dfda的函数中。
3.2 call 0x46dc70 & call 0x46dfda
(dlv) si
> runtime.duffzero() /usr/local/go/src/runtime/duff_amd64.s:95 (PC: 0x46dc70)
Warning: debugging optimized functionduff_amd64.s:89 0x46dc59 440f117f30 movups xmmword ptr [rdi+0x30], xmm15duff_amd64.s:90 0x46dc5e 488d7f40 lea rdi, ptr [rdi+0x40]duff_amd64.s:92 0x46dc62 440f113f movups xmmword ptr [rdi], xmm15duff_amd64.s:93 0x46dc66 440f117f10 movups xmmword ptr [rdi+0x10], xmm15duff_amd64.s:94 0x46dc6b 440f117f20 movups xmmword ptr [rdi+0x20], xmm15
=> duff_amd64.s:95 0x46dc70 440f117f30 movups xmmword ptr [rdi+0x30], xmm15 #从本指令开始执行 ,这里在rdi+0x30 基础上操作的,也解释了2.2.2小节汇编中lea rdi, ptr [rsp+0x68]之后为啥强行来一个lea rdi, ptr [rsp-0x30]了duff_amd64.s:96 0x46dc75 488d7f40 lea rdi, ptr [rdi+0x40]duff_amd64.s:98 0x46dc79 440f113f movups xmmword ptr [rdi], xmm15duff_amd64.s:99 0x46dc7d 440f117f10 movups xmmword ptr [rdi+0x10], xmm15duff_amd64.s:100 0x46dc82 440f117f20 movups xmmword ptr [rdi+0x20], xmm15duff_amd64.s:101 0x46dc87 440f117f30 movups xmmword ptr [rdi+0x30], xmm15duff_amd64.s:102 0x46dc8c 488d7f40 lea rdi, ptr [rdi+0x40]duff_amd64.s:104 0x46dc90 c3 ret #函数执行结束
显示,call 0x46dc70是从runtime.duffzero()函数的中间某个位置开始执行的,即duff_amd64.s:95位置,为什么?
在3.1小节中知道runtime·duffzero一个循环的机器码是23字节,ret指令占1字节,那么runtime·duffzero函数的机器码是16*23+1=369字节,
在3.2小节中得知call 0x46dc70 对应 DUFFZERO $336,即偏移了336字节,则369-336=33字节,从duff_amd64.s:95位置的机器码开始算,到duff_amd64.s:104的机器码正好33字节,这下知道为什么从duff_amd64.s:95位置的机器码开始执行了吗?
我们在前置知识中了解到XMM系列寄存器是16字节,那么movups一次就操作16字节:
duff_amd64.s:95
duff_amd64.s:98
duff_amd64.s:99
duff_amd64.s:100
duff_amd64.s:101
这5次清零操作刚好是16*5=80字节,等于结构体MaxData大小了,都是go编译器精密计算好的。
【call 0x46dfda】汇编如下:
> runtime.duffcopy() /usr/local/go/src/runtime/duff_amd64.s:402 (PC: 0x46dfda)
Warning: debugging optimized functionduff_amd64.s:395 0x46dfc8 4883c710 add rdi, 0x10duff_amd64.s:397 0x46dfcc 0f1006 movups xmm0, xmmword ptr [rsi]duff_amd64.s:398 0x46dfcf 4883c610 add rsi, 0x10duff_amd64.s:399 0x46dfd3 0f1107 movups xmmword ptr [rdi], xmm0duff_amd64.s:400 0x46dfd6 4883c710 add rdi, 0x10
=> duff_amd64.s:402 0x46dfda 0f1006 movups xmm0, xmmword ptr [rsi] #从本机器码开始duff_amd64.s:403 0x46dfdd 4883c610 add rsi, 0x10duff_amd64.s:404 0x46dfe1 0f1107 movups xmmword ptr [rdi], xmm0duff_amd64.s:405 0x46dfe4 4883c710 add rdi, 0x10duff_amd64.s:407 0x46dfe8 0f1006 movups xmm0, xmmword ptr [rsi]duff_amd64.s:408 0x46dfeb 4883c610 add rsi, 0x10duff_amd64.s:409 0x46dfef 0f1107 movups xmmword ptr [rdi], xmm0duff_amd64.s:410 0x46dff2 4883c710 add rdi, 0x10duff_amd64.s:412 0x46dff6 0f1006 movups xmm0, xmmword ptr [rsi]duff_amd64.s:413 0x46dff9 4883c610 add rsi, 0x10duff_amd64.s:414 0x46dffd 0f1107 movups xmmword ptr [rdi], xmm0duff_amd64.s:415 0x46e000 4883c710 add rdi, 0x10duff_amd64.s:417 0x46e004 0f1006 movups xmm0, xmmword ptr [rsi]duff_amd64.s:418 0x46e007 4883c610 add rsi, 0x10duff_amd64.s:419 0x46e00b 0f1107 movups xmmword ptr [rdi], xmm0duff_amd64.s:420 0x46e00e 4883c710 add rdi, 0x10duff_amd64.s:422 0x46e012 0f1006 movups xmm0, xmmword ptr [rsi]duff_amd64.s:423 0x46e015 4883c610 add rsi, 0x10duff_amd64.s:424 0x46e019 0f1107 movups xmmword ptr [rdi], xmm0duff_amd64.s:425 0x46e01c 4883c710 add rdi, 0x10duff_amd64.s:427 0x46e020 c3 ret
有兴趣的朋友可以在评论区说出其偏移原理了。
相关文章:
go 通过汇编分析函数传参与返回值机制
文章目录 概要一、前置知识二、汇编分析2.1、示例2.2、汇编2.2.1、 寄存器传值的汇编2.2.2、 栈内存传值的汇编 三、拓展3.1 了解go中的Duff’s Device3.2 go tool compile3.2 call 0x46dc70 & call 0x46dfda 概要 在上一篇文章中,我们研究了go函数调用时的栈布…...

解决Ubuntu Desktop 24.04 VMware中安装后不能全屏显示,只能居中的问题
Ubuntu Desktop 24.04 VMware中安装后不能全屏显示,只能居中。 sudo apt-get install open-vm-tools sudo apt-get install open-vm*...
【笔记ing】AI大模型-04逻辑回归模型
一个神经网络结构,其中的一个神经网络层,本质就是一个逻辑回归模型 深度神经网络的本质就是多层逻辑回归模型互相连接或采用一定的特殊连接的方式连接在一起构成的。其中每一个层本质就是一个逻辑回归模型。 逻辑回归模型基本原理 逻辑回归࿰…...

分布式ID生成方案的深度解析与Java实现
在分布式系统中,生成全局唯一的ID是一项核心需求,广泛应用于订单编号、用户信息、日志追踪等场景。分布式ID不仅需要保证全局唯一性,还要满足高性能、高可用性以及一定的可读性要求。本文将深入探讨分布式ID的概念、设计要点、常见生成方案&a…...

AF3 ProteinDataModule类解读
AlphaFold3 protein_datamodule 模块 ProteinDataModule 类继承自 PyTorch Lightning 数据模块(LightningDataModule),负责 ProteinFlow 数据的准备、加载、拆分、变换等逻辑封装在一起,便于训练过程中的统一管理和复现。 这个类承担了 AlphaFold3 训练和评估过程中的 数据…...

如何将一个8s的接口优化到500ms以下
最近换了个工作,刚入职就接了个活--优化公司自营app的接口性能,提升用户体验。 刚开始还以为是1s优化到500ms这种,或者500ms优化到200ms的接口,感觉还挺有挑战的。下好app体验了一下。好家伙,那个慢已经超过了我的忍耐…...
记录学习的第二十五天
今天终于又开始更新了。实在是星期六的蓝桥杯给了我一个大大的打击,今天终于好不容易缓过来了,可以好好学算法了。 还是老规划,力扣的每日一题。不过今天的每日一题我之前做过了,就又提交了一次来签到。 之后三道哈希表题目。 我一…...
linux电源管理(二),内核的CPUFreq(DVFS)和ARM的SCPI
更多linux系统电源管理相关的内容请看:https://blog.csdn.net/u010936265/article/details/146436725?spm1011.2415.3001.5331 1 简介 CPUFreq子系统位于drivers/cpufreq目录下,负责进行运行过程中CPU频率和电压的动态调整,即DVFS (Dynami…...

【LeetCode 热题 100】哈希 系列
📁1. 两数之和 本题就是将通过两层遍历优化而成的,为什么需要两层遍历,因为遍历 i 位置时,不知道i-1之前的元素是多少,如果我们知道了,就可以通过两数相加和target比较即可。 因为本题要求返回下标…...

ES6学习04-数组扩展:扩展运算符、新增方法
一、扩展运算符 1. 2. eg: 3. 二、新增方法 1. arguments 元素组合 类似数组对象 2....

Redis存储“大数据对象”的常用策略及StackOverflowError错误解决方案
Hi,大家好,我是灰小猿! 在一些功能的开发中,我们一般会有一些场景需要将得到的数据先暂时的存储起来,以便后面的接口或业务使用,这种场景我们一般常用的场景就是将数据暂时存储在缓存中,之后再…...

在轨道交通控制系统中如何实现μs级任务同步
轨道交通作为现代城市化进程中的重要支柱,承载着数以亿计的乘客出行需求,同时也是城市经济运行的命脉。无论是地铁、轻轨还是高速铁路,其控制系统的稳定性和可靠性直接关系到运营安全和效率。在这样一个高风险、高复杂度的环境中,任何微小的失误都可能导致灾难性后果。因此…...

嵌入式程序设计英语
实际要求:认识最基本的英文单词即可,(总计几百个) IDE 集成开发环境 fatal error fatal 致命的,error 错误,fatal error 致命的错误 main 主要的 include 包含 io input 输入,output 输出,input output …...
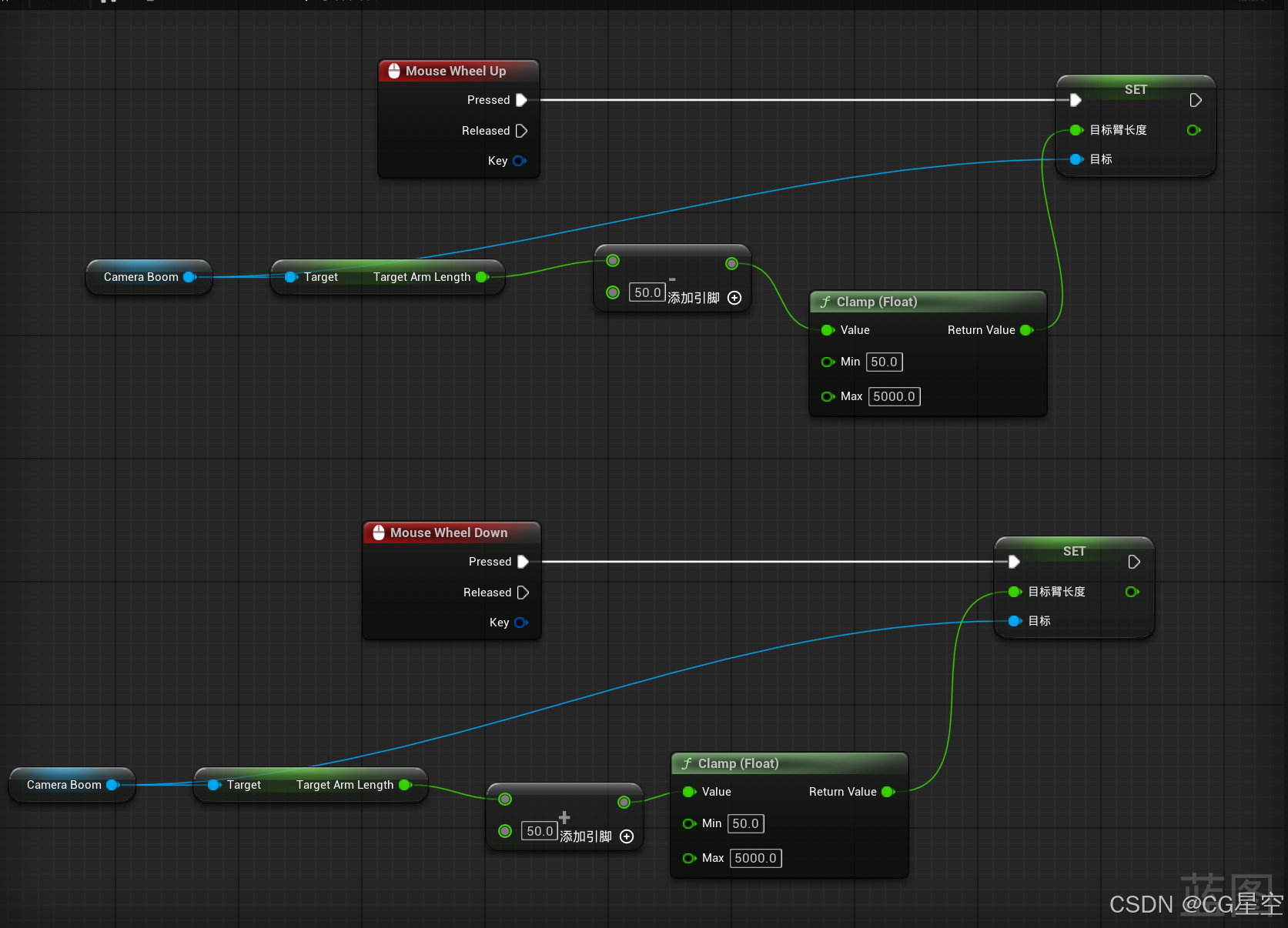
滚轮控制目标臂长度调整相机距离
通过鼠标滚轮来控制摄像机目标臂长度 , 调整相机距离 看图就行,不多说,照着连就完事了...
FireCrawl爬虫工具, Craw4ai
FireCrawl是一款开源的AI爬虫工具,专门用于Web数据提取,并将其转换为Markdown格式或其他结构化数据。FireCrawl特别适合处理使用JavaScript动态生成的网站,能够自动抓取网站及其所有可访问的子页面内容,并将其转换为适合大语言…...
pyenv库应用入门与Ubuntu端安装实践
pyenv库应用入门与Ubuntu端安装实践 pyenv概述virtualenv、pyvenv、pyenvvirtualenvpyvenvpyenv Ubuntu端安装pyenv实践安装依赖报错解决安装pyenv配置环境变量更换pyenv源地址 pyenv基本用法安装成功服务器部署scrapyd pyenv概述 pyenv 是一个用于管理多个 Python 版本的工具…...

CS5346 - Annotation in Visualization (可视化中的注释)
文章目录 Annotation 的重要性Levels of Annotation (注释的层级)Headings and IntroductionHeadings(标题)陈述型(Statement):突出结论或有趣发现疑问型(Question)&…...
如何开发一套场外个股期权交易系统?个股期权交易软件包含:询价,报价,交易,持仓,行权,账户盈亏统计等
一、场外个股期权的定义与特点 场外个股期权(Over-the-Counter Equity Option)是一种由交易双方私下协商的非标准化金融衍生品合约,以特定个股为标的资产。与交易所上市的标准化期权不同,其合约条款(如行权价、到期日…...
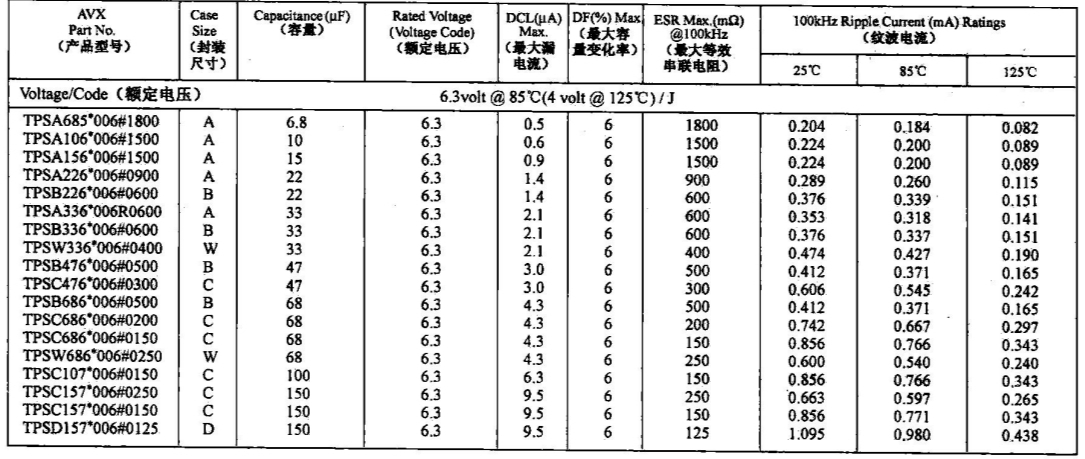
高速电路中的电阻、电容的选型及应用
2.1 电阻的应用 2.1.1 与电阻相关的经典案例 如果说芯片是电路的骨架,那么电阻就是在芯片之间起连接作用的关节。电阻的阻值、布放位置等,对设计的成功起着至关重要的作用。 【案例2.1】串联电阻过大,导致板间告警失败 某产品由业务板和主…...

六、adb通过Wifi连接
背景 收集是荣耀X40,数据线原装全新的,USB连上之后,老是断,电脑一直叮咚叮咚的响个不停,试试WIFI 连接是否稳定,需要手机和电脑用相同的WIFI. 连接 1.通过 USB 连接手机和电脑(打开USB调试等这些都略过) adb device…...

Java新手村第二站:泛型、集合与IO流初探
文章目录 Java新手村第二站:泛型、集合与IO流初探泛型包装类集合IO流函数式接口和Lambda表达式 Java新手村第二站:泛型、集合与IO流初探 泛型 泛型的概念与作用: 核心目的:在编译期提供类型安全检查,避免运行时的 Cla…...

AT_abc398_e [ABC398E] Tree Game 题解
题目传送门 题目大意 题目描述 本题是一道交互题(你的程序需要通过输入输出与评测系统进行交互)。 给定一棵包含 N N N 个顶点的树 G G G,顶点编号为 1 1 1 至 N N N。第 i i i 条边连接顶点 U i U_i Ui 和 V i V_i Vi。 你和…...

CSI-external-provisioner
main() 这段Go代码是一个CSI(容器存储接口)Provisioner(供应器)的实现,用于在Kubernetes集群中动态提供持久卷。代码涉及多个组件和步骤,下面是对关键部分的解释: 初始化和配置 命令行标志和…...

android中dp和px的关系
关于android的dp和px的关系是我刚开始学习android的第一个知识点,不知不觉学安卓也有一年了,但是偶然间我发现我理解的dp和px的关系一直是错的,真的是有一点搞笑,今天特意写一篇博客纪念一下这个我理解错一年的知识点。 dp和px之间…...

DeepSeek模型在非图形智能体的应用中是否需要GPU
答:不一定 概念 1、是否需要GPU与应用是否图形处理应用无关 2、文本内容智能体大多也需要GPU来提供更好的性能 3、DeepSeek模型在非图形智能体的应用中是否需要GPU取决于具体的模型版本和部署环境 不需要GPU的模型版本 DeepSeek-R1-1.5B: 这…...

4.14代码随想录第四十三天打卡
图论理论基础 https://www.programmercarl.com/kamacoder/%E5%9B%BE%E8%AE%BA%E7%90%86%E8%AE%BA%E5%9F%BA%E7%A1%80.html 98. 所有可达路径 (1)题目描述: (2)解题思路: #include <iostream> #include <vector> #include <list> using namespace std;vec…...
【视频目标分割论文集】Efficient Track Anything0000
github 摘要 视频对象分割和追踪任意目标领域出现了强大的工具——分割任意模型 2(SAM 2)。SAM 2 实现令人印象深刻的视频对象分割性能的关键组成部分包括用于帧特征提取的大型多阶段图像编码器,以及存储过去帧记忆上下文以辅助当前帧分割的…...

码率自适应(ABR)决策的直播场景
直播场景 1. 直播场景的普遍框架与工作原理 主播端:即各类主播(游戏、网红歌手、户外达人等),通过手机端或者个人电脑在线直播录制个人活动。 编码服务器:主播端上传视频流以后,编码服务器根据相应的编码转…...

SCP-Firmware安全通告:CVE-2024-11863和CVE-2024-11864
安全之安全(security)博客目录导读 目录 一、概述 二、CVE详情 三、受影响产品 四、修复建议 五、致谢 六、版本历史 一、概述 在SCP固件(SCP-Firmware)中发现两处安全漏洞,可能允许普通世界特权软件(normal world privileged softwareÿ…...
)
Redis高频面试题(含答案)
当然可以,Redis 是面试中非常常见的高频考点,尤其在后台开发、分布式系统、缓存设计等方向,面试官常常通过 Redis 来考察你的高并发处理能力、系统设计能力和对缓存一致性理解。 以下是一些典型 Redis 的面试场景题目类型和你可以如何回答的思路: ✅ 一、基础使用类问题 …...