Oracle数据库数据编程SQL<01. 课外关注:数据库查重方法全面详解>
查重是数据库管理和数据分析中的常见需求,以下是各种查重方法的全面总结,涵盖不同场景和技术手段。
更多Oracle学习内容请查看:Oracle保姆级超详细系列教程_Tyler先森的博客-CSDN博客
目录
一、基础SQL查重方法
1. 使用GROUP BY和HAVING
2. 使用窗口函数
3. 使用自连接
二、高级查重技术
1. 模糊查重(相似度匹配)
1.1 使用SOUNDEX函数(语音相似)
1.2 使用Levenshtein距离(编辑距离)
1.3 使用UTL_MATCH包(Oracle)
2. 大数据量查重优化
2.1 使用HASH值比较
2.2 分区查重
3. 跨表查重
三、数据库特定查重方法
1. Oracle查重技术
1.1 使用分析函数
1.2 使用Oracle GoldenGate或Data Compare工具
2. MySQL查重技术
2.1 使用临时表删除重复
2.2 使用INSERT IGNORE
3. SQL Server查重技术
3.1 使用MERGE语句
3.2 使用SSIS数据流任务
四、程序化查重方法
1. Python + Pandas
2. Java查重示例
3. 使用Apache Spark(大数据场景)
五、数据质量工具集成
1. 专业数据质量工具
2. 开源工具
六、查重后的处理策略
1. 删除重复数据
2. 合并重复记录
3. 标记重复记录
七、预防重复数据的策略
1. 数据库约束
2. 使用序列/自增ID
3. 应用层校验
4. 使用MERGE/UPSERT
八、特殊数据类型查重
1. JSON数据查重
2. 时空数据查重
3. 图像/二进制数据查重
九、性能优化建议
十、行业特定查重案例
1. 金融行业(反洗钱)
2. 电商行业(刷单检测)
3. 医疗行业(重复就诊)
一、基础SQL查重方法
1. 使用GROUP BY和HAVING
-- 单列查重
SELECT column_name, COUNT(*)
FROM table_name
GROUP BY column_name
HAVING COUNT(*) > 1;-- 多列组合查重
SELECT column1, column2, COUNT(*)
FROM table_name
GROUP BY column1, column2
HAVING COUNT(*) > 1;2. 使用窗口函数
-- 使用ROW_NUMBER()标记重复行
SELECT *,ROW_NUMBER() OVER(PARTITION BY column1, column2 ORDER BY id) AS rn
FROM table_name;-- 提取重复记录
WITH dup_check AS (SELECT *,ROW_NUMBER() OVER(PARTITION BY column1, column2 ORDER BY id) AS rnFROM table_name
)
SELECT * FROM dup_check WHERE rn > 1;3. 使用自连接
-- 查找完全重复的行
SELECT a.*
FROM table_name a
JOIN table_name b
ON a.column1 = b.column1
AND a.column2 = b.column2
AND a.id <> b.id; -- 排除自连接二、高级查重技术
1. 模糊查重(相似度匹配)
1.1 使用SOUNDEX函数(语音相似)
SELECT a.name, b.name
FROM customers a, customers b
WHERE a.id < b.id -- 避免重复比较
AND SOUNDEX(a.name) = SOUNDEX(b.name);1.2 使用Levenshtein距离(编辑距离)
-- Oracle需要自定义函数
CREATE OR REPLACE FUNCTION levenshtein( s1 IN VARCHAR2, s2 IN VARCHAR2 )
RETURN NUMBER IS [...];SELECT a.name, b.name
FROM products a, products b
WHERE a.id < b.id
AND levenshtein(a.name, b.name) <= 3; -- 允许3个字符差异1.3 使用UTL_MATCH包(Oracle)
SELECT a.name, b.name, UTL_MATCH.JARO_WINKLER_SIMILARITY(a.name, b.name) AS similarity
FROM customers a, customers b
WHERE a.id < b.id
AND UTL_MATCH.JARO_WINKLER_SIMILARITY(a.name, b.name) > 90; -- 相似度>90%2. 大数据量查重优化
2.1 使用HASH值比较
-- 创建哈希列
ALTER TABLE large_table ADD hash_value RAW(16);-- 更新哈希值(组合关键列)
UPDATE large_table
SET hash_value = DBMS_CRYPTO.HASH(UTL_I18N.STRING_TO_RAW(column1||column2||column3, 'AL32UTF8'),2); -- 2=MD4算法-- 查找重复哈希
SELECT hash_value, COUNT(*)
FROM large_table
GROUP BY hash_value
HAVING COUNT(*) > 1;2.2 分区查重
-- 按日期分区查重
SELECT user_id, action_date, COUNT(*)
FROM user_actions
PARTITION (p_2023_01) -- 指定分区
GROUP BY user_id, action_date
HAVING COUNT(*) > 1;3. 跨表查重
-- 查找两个表中都存在的记录
SELECT a.*
FROM table1 a
WHERE EXISTS (SELECT 1 FROM table2 bWHERE a.key_column = b.key_column
);-- 使用INTERSECT
SELECT key_column FROM table1
INTERSECT
SELECT key_column FROM table2;三、数据库特定查重方法
1. Oracle查重技术
1.1 使用分析函数
-- 查找重复并保留最新记录
SELECT *
FROM (SELECT t.*,ROW_NUMBER() OVER(PARTITION BY id_number, name ORDER BY create_date DESC) AS rnFROM persons
)
WHERE rn = 1; -- 只保留每组最新记录1.2 使用Oracle GoldenGate或Data Compare工具
专业工具提供可视化比较和同步功能。
2. MySQL查重技术
2.1 使用临时表删除重复
-- 创建临时表存储唯一记录
CREATE TABLE temp_table AS
SELECT DISTINCT * FROM original_table;-- 替换原表
RENAME TABLE original_table TO old_table, temp_table TO original_table;2.2 使用INSERT IGNORE
-- 跳过重复记录插入
INSERT IGNORE INTO target_table
SELECT * FROM source_table;3. SQL Server查重技术
3.1 使用MERGE语句
MERGE INTO target_table t
USING source_table s
ON t.key_column = s.key_column
WHEN NOT MATCHED THENINSERT (col1, col2) VALUES (s.col1, s.col2);3.2 使用SSIS数据流任务
SQL Server Integration Services提供图形化查重组件。
四、程序化查重方法
1. Python + Pandas
import pandas as pd# 读取数据
df = pd.read_sql("SELECT * FROM table_name", engine)# 简单查重
duplicates = df[df.duplicated(subset=['col1', 'col2'], keep=False)]# 模糊查重(使用fuzzywuzzy)
from fuzzywuzzy import fuzz
dupe_pairs = []
for i, row1 in df.iterrows():for j, row2 in df.iterrows():if i < j and fuzz.ratio(row1['name'], row2['name']) > 85:dupe_pairs.append((i, j))2. Java查重示例
// 使用内存哈希集查重
Set<String> uniqueKeys = new HashSet<>();
List<Record> duplicates = new ArrayList<>();for (Record record : records) {String compositeKey = record.getField1() + "|" + record.getField2();if (!uniqueKeys.add(compositeKey)) {duplicates.add(record);}
}3. 使用Apache Spark(大数据场景)
val df = spark.read.jdbc(...) // 从数据库读取// 精确查重
val duplicates = df.groupBy("col1", "col2").count().filter("count > 1")// 近似查重(使用MinHash)
import org.apache.spark.ml.feature.MinHashLSH
val mh = new MinHashLSH().setInputCol("features").setOutputCol("hashes")
val model = mh.fit(featurizedData)
val dupCandidates = model.approxSimilarityJoin(featurizedData, featurizedData, 0.8)五、数据质量工具集成
1. 专业数据质量工具
- Informatica Data Quality
- IBM InfoSphere QualityStage
- Talend Data Quality
- Oracle Enterprise Data Quality
2. 开源工具
- OpenRefine:强大的数据清洗和查重工具
- DataCleaner:提供可视化查重规则配置
- Dedupe.io:基于机器学习的智能去重
六、查重后的处理策略
1. 删除重复数据
-- Oracle使用ROWID删除重复
DELETE FROM table_name
WHERE ROWID NOT IN (SELECT MIN(ROWID)FROM table_nameGROUP BY column1, column2
);-- MySQL使用临时表
CREATE TABLE temp_table AS SELECT DISTINCT * FROM original_table;
TRUNCATE TABLE original_table;
INSERT INTO original_table SELECT * FROM temp_table;
DROP TABLE temp_table;2. 合并重复记录
-- 合并重复客户记录
UPDATE customers c1
SET (address, phone) = (SELECT COALESCE(c1.address, c2.address),COALESCE(c1.phone, c2.phone)FROM customers c2WHERE c1.email = c2.emailAND c2.ROWID = (SELECT MIN(ROWID) FROM customers c3 WHERE c3.email = c1.email)
)
WHERE c1.ROWID <> (SELECT MIN(ROWID) FROM customers c4 WHERE c4.email = c1.email
);3. 标记重复记录
-- 添加重复标记列
ALTER TABLE customers ADD is_duplicate NUMBER(1) DEFAULT 0;-- 标记重复记录
UPDATE customers c
SET is_duplicate = 1
WHERE EXISTS (SELECT 1 FROM customers c2WHERE c.email = c2.emailAND c.ROWID > c2.ROWID
);七、预防重复数据的策略
1. 数据库约束
-- 唯一约束
ALTER TABLE products ADD CONSTRAINT uk_product_code UNIQUE (product_code);-- 复合唯一约束
ALTER TABLE orders ADD CONSTRAINT uk_order_item UNIQUE (order_id, product_id);2. 使用序列/自增ID
-- Oracle序列
CREATE SEQUENCE customer_id_seq START WITH 1 INCREMENT BY 1;-- MySQL自增
CREATE TABLE customers (id INT AUTO_INCREMENT PRIMARY KEY,...
);3. 应用层校验
// Java示例-插入前检查
public boolean isCustomerExist(String email) {String sql = "SELECT 1 FROM customers WHERE email = ?";try (Connection conn = dataSource.getConnection();PreparedStatement stmt = conn.prepareStatement(sql)) {stmt.setString(1, email);try (ResultSet rs = stmt.executeQuery()) {return rs.next();}}
}4. 使用MERGE/UPSERT
-- Oracle MERGE
MERGE INTO customers t
USING (SELECT 'john@example.com' email, 'John' name FROM dual) s
ON (t.email = s.email)
WHEN NOT MATCHED THENINSERT (email, name) VALUES (s.email, s.name)
WHEN MATCHED THENUPDATE SET t.name = s.name;八、特殊数据类型查重
1. JSON数据查重
-- PostgreSQL JSONB查重
SELECT json_column->>'id', COUNT(*)
FROM json_table
GROUP BY json_column->>'id'
HAVING COUNT(*) > 1;-- Oracle JSON查重
SELECT JSON_VALUE(json_column, '$.id'), COUNT(*)
FROM json_table
GROUP BY JSON_VALUE(json_column, '$.id')
HAVING COUNT(*) > 1;2. 时空数据查重
-- 地理位置相近查重(PostGIS)
SELECT a.id, b.id
FROM locations a, locations b
WHERE a.id < b.id
AND ST_DWithin(a.geom, b.geom, 100); -- 100米范围内视为重复-- 时间范围重叠查重
SELECT a.event_id, b.event_id
FROM events a, events b
WHERE a.event_id < b.event_id
AND a.end_time > b.start_time
AND a.start_time < b.end_time;3. 图像/二进制数据查重
-- 使用哈希比较图像
SELECT image_hash, COUNT(*)
FROM images
GROUP BY image_hash
HAVING COUNT(*) > 1;-- Oracle使用DBMS_CRYPTO
SELECT DBMS_CRYPTO.HASH(image_data, 2) AS img_hash
FROM images;九、性能优化建议
- 索引优化:为查重字段创建合适索引
CREATE INDEX idx_customer_email ON customers(email); - 分批处理:大数据集分批次查重
-- 按时间范围分批 SELECT * FROM orders WHERE order_date BETWEEN TO_DATE('2023-01-01') AND TO_DATE('2023-01-31') GROUP BY customer_id, product_id HAVING COUNT(*) > 1; - 物化视图:预计算重复数据
CREATE MATERIALIZED VIEW duplicate_orders_mv REFRESH COMPLETE ON DEMAND AS SELECT customer_id, product_id, COUNT(*)FROM ordersGROUP BY customer_id, product_idHAVING COUNT(*) > 1; - 并行查询:
SELECT /*+ PARALLEL(4) */ column1, COUNT(*) FROM large_table GROUP BY column1 HAVING COUNT(*) > 1; -
使用NoSQL解决方案:对于超大规模数据,考虑Redis或MongoDB等方案
十、行业特定查重案例
1. 金融行业(反洗钱)
-- 查找同一天多笔大额交易
SELECT customer_id, transaction_date, COUNT(*), SUM(amount)
FROM transactions
GROUP BY customer_id, transaction_date
HAVING COUNT(*) > 3 AND SUM(amount) > 100000;2. 电商行业(刷单检测)
-- 检测相同IP短时间内下单
SELECT ip_address, COUNT(DISTINCT user_id), COUNT(*)
FROM orders
WHERE order_time > SYSDATE - 1/24 -- 最近1小时
GROUP BY ip_address
HAVING COUNT(DISTINCT user_id) > 3 OR COUNT(*) > 5;3. 医疗行业(重复就诊)
-- 查找同一患者相同诊断重复挂号
SELECT patient_id, diagnosis, visit_date, COUNT(*)
FROM medical_records
GROUP BY patient_id, diagnosis, TRUNC(visit_date)
HAVING COUNT(*) > 1;以上方法涵盖了从基础到高级的各种查重技术,实际应用中应根据数据特点、系统环境和业务需求选择合适的方法组合。对于关键业务系统,建议建立常态化的数据质量检查机制,而不仅仅是临时查重。
相关文章:

Oracle数据库数据编程SQL<01. 课外关注:数据库查重方法全面详解>
查重是数据库管理和数据分析中的常见需求,以下是各种查重方法的全面总结,涵盖不同场景和技术手段。 更多Oracle学习内容请查看:Oracle保姆级超详细系列教程_Tyler先森的博客-CSDN博客 目录 一、基础SQL查重方法 1. 使用GROUP BY和HAVING …...

开源技术如何助力中小企业实现财务管理自主化?
中小企业的数字化困境与开源机遇 国际数据公司(IDC)研究显示,全球67%的中小企业因高昂的软件成本和僵化的功能设计,未能有效推进数字化转型。传统商业软件常面临三大矛盾: 功能冗余与核心需求缺失:标准化系…...

边缘计算与隐私计算的融合:构建数据经济的“隐形护盾“
在数据成为核心生产要素的今天,边缘计算与隐私计算的交汇正在重塑技术生态。这并非简单的技术叠加,而是一场关于数据主权、算力分配与信任机制的深度博弈。本文将从"数据流动的拓扑学"视角,探讨二者融合如何重构数字社会的基础设施…...
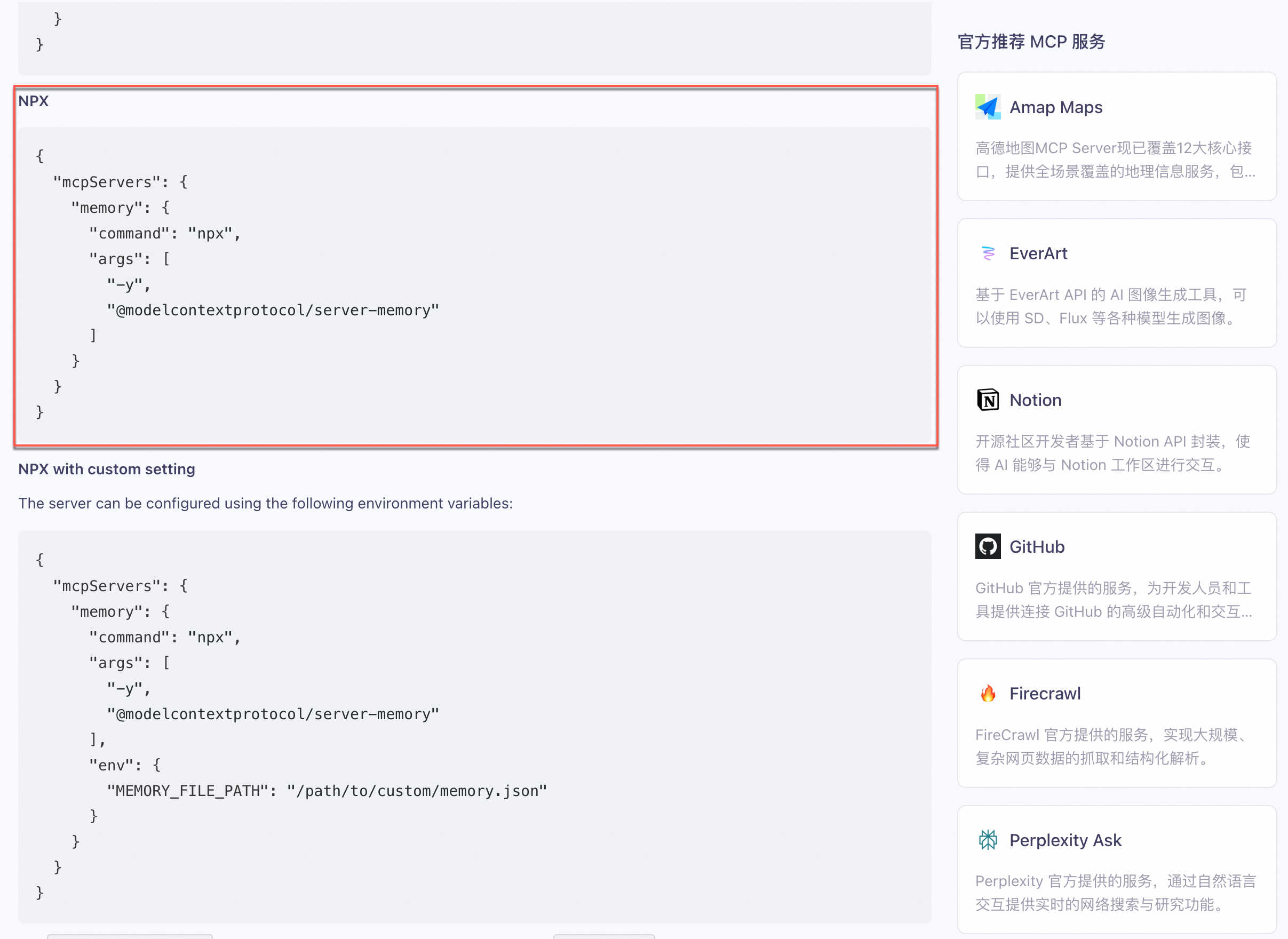
【大模型实战篇】--阿里云百炼搭建MCP Agent
MCP协议(Model Communication Protocol,模型通信协议)是大语言模型(LLM)与外部系统或其他模型交互时的一种标准化通信框架,旨在提升交互效率、安全性和可扩展性。 目录 1.阿里云百炼--MCP 1.1.MCP 服务接…...
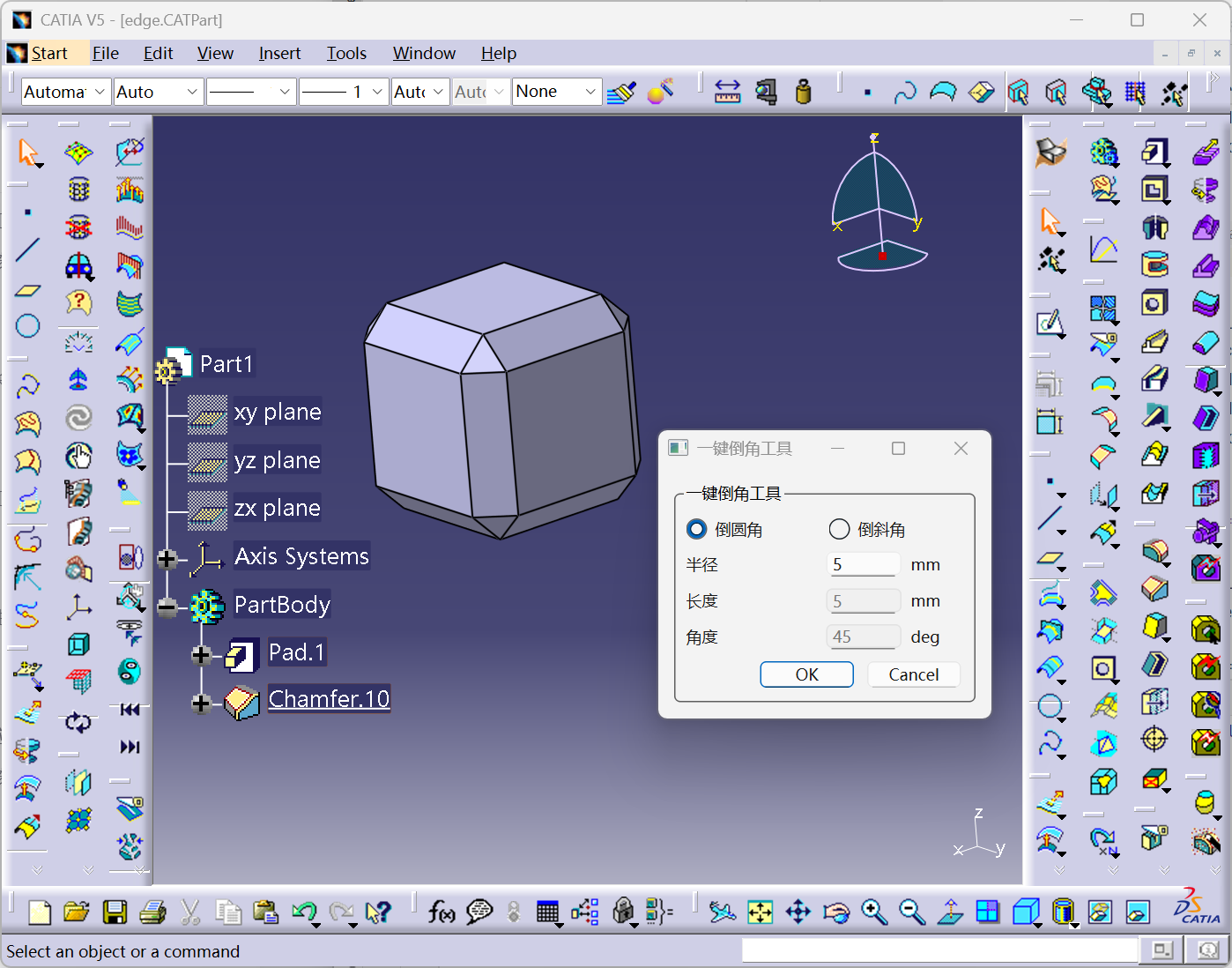
基于PySide6与pycatia的CATIA智能倒角工具开发全解析
引言:工业设计中的倒角革命 在机械设计领域,倒角操作是零件加工前的必要工序。传统手动操作效率低下且易出错本文基于PySide6pycatia技术栈,提出一种支持批量智能倒角、参数动态校验、跨层级操作的自动化方案,其核心突破体现在&a…...
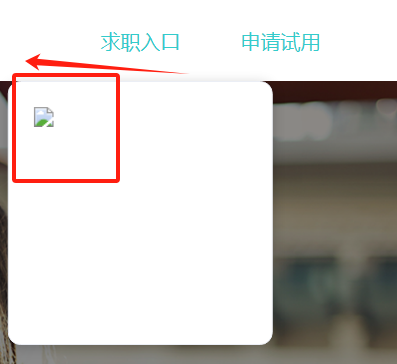
css 二维码始终显示在按钮的正下方,并且根据不同的屏幕分辨率自动调整位置
一、需求 “求职入口” 下面的浮窗位置在其正下方,并且浏览器分辨的改变(拖动浏览器),位置依旧在最下方 二、实现 <div class"btn_box"><div class"btn_link id"js-apply">求职入口<di…...

串口接收的使用-中断
1、引言 单片机串口、按键等等这种外部输入的, 用轮询的方式非常浪费资源,所以最好的方法就是使用中断接收数据。 2、串口 对于串口中断, 使用的非常频繁。 1. 基本原理 串口中断接收通过以下方式工作: 当串口接收到一个字节…...
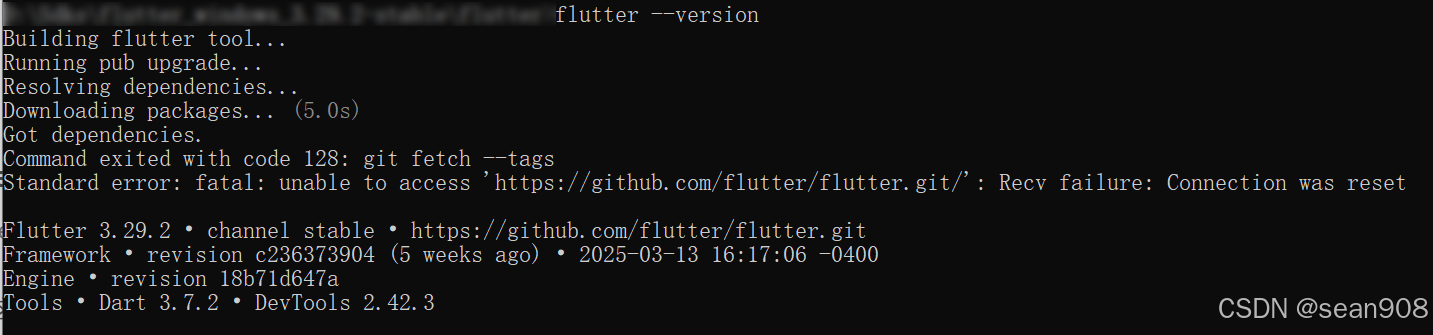
处理 Flutter 没有反应
现象 有以下几种 VS Code 中 Initializing the Flutter SDK. This may take a few minutes. 会一直维持在这个右下角提示窗, 但是无后续动作 Flutter CMD flutter_console.bat 执行 --version 或者 doctor [-v] 没有任何输出, 命令卡住 解决办法 参考官方说明 管理员身份…...

Linux-服务器负载评估方法
在 Linux 服务器中,top 命令显示的 load average(平均负载)反映了系统在特定时间段内的负载情况。它通常显示为三个数值,分别代表过去 1 分钟、5 分钟和 15 分钟的平均负载。 1. 什么是 Load Average? Load average …...

入门51单片机(1)-----点灯大师梦开始的地方
前言 这一次的博客主要是要记录一下学习的记录的,方便以后去复习一下的,当然这篇博客还是针于零基础的伙伴萌,看完这篇博客,大家就可以学会点灯了。 安装软件 方法一下一下来教!!萌新宝贝萌可以学会的!帮…...
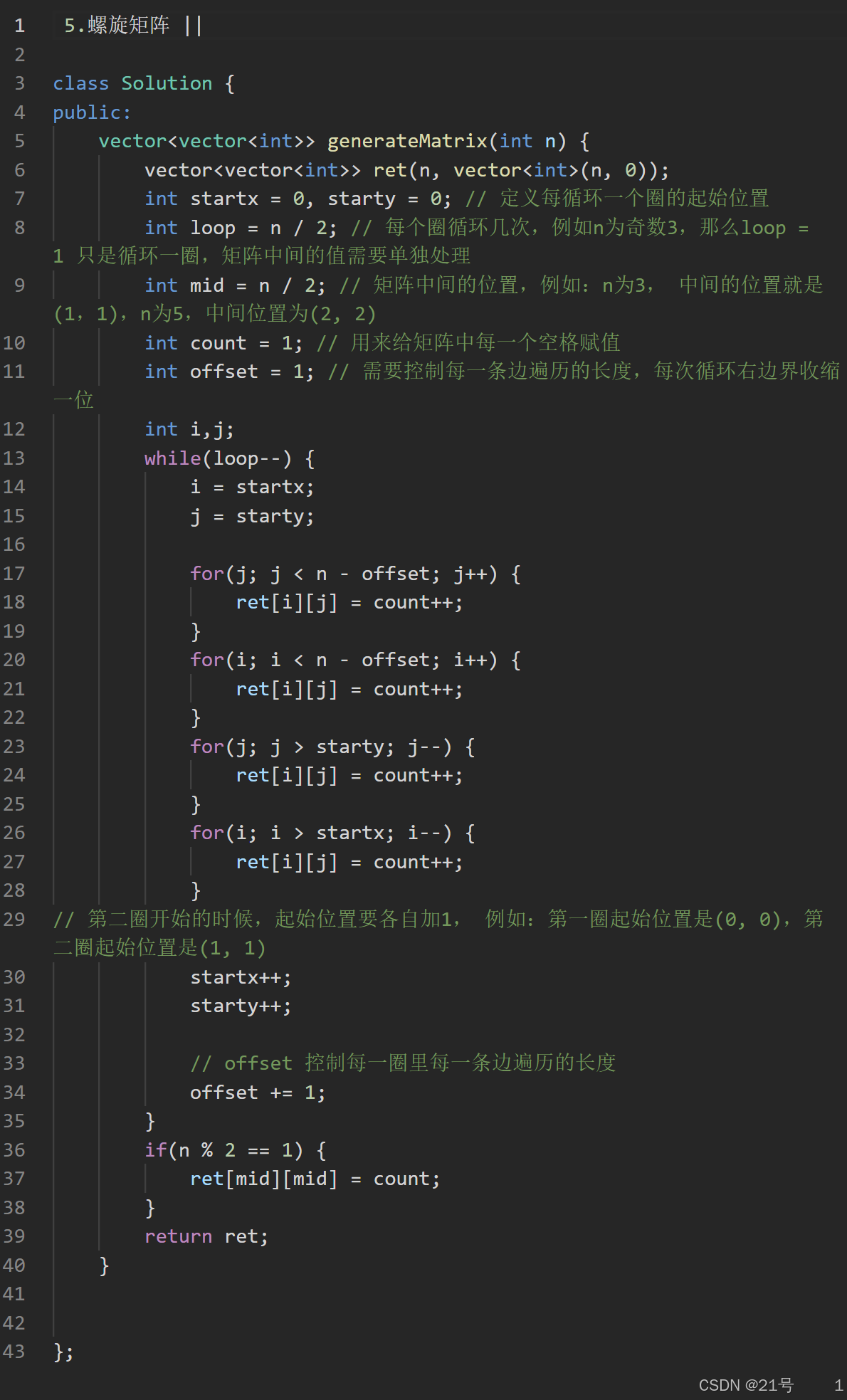
3.数组(随想录)
1.二分查找 *2.移除元素 还有一个小优化(可以不看) 3.有序数组的平方 *4.长度最小的子数组 (3种解法) 5.螺旋矩阵 ||...

解决import pyqtgraph.opengl报错
在使用pyqtgraph时,出现没有OpenGL模块的报错 报错信息 ModuleNotFoundError: No module named OpenGL 解决方案 该环境下没有安装OpenGL库导致,输入以下代码进行安装: pip install PyOpenGL conda install -c conda-forge pyopengl 安…...
?)
大模型面经 | 请你介绍一下ReAct(Reasoning and Acting)?
大家好,我是皮先生!! 今天给大家分享一些关于大模型面试常见的面试题,希望对大家的面试有所帮助。 往期回顾: 大模型面经 | 春招、秋招算法面试常考八股文附答案(RAG专题一) 大模型面经 | 春招、秋招算法面试常考八股文附答案(RAG专题二) 大模型面经 | 春招、秋招算法…...
C#设计模式-状态模式
状态模式案例解析:三态循环灯的实现 案例概述 本案例使用 状态模式(State Pattern) 实现了一个 三态循环灯 的功能。每点击一次按钮,灯的状态会按顺序切换(状态1 → 状态2 → 状态3 → 状态1...)ÿ…...

LLM实现text2SQL实战总结
LLM在组织内部应用的一类重要场景就是利用LLM的NL2SQL能力,简化用户对数据库的访问。本文主要介绍如何使用LLM生成SQL语句,不涉及到如何训练提升LLM的SQL生成能力。 开启正文之前,我们先明确一下这类功能在组织内服务的目标群体。我们将服务目…...

字节跳动开源 LangManus:不止是 Manus 平替,更是下一代 AI 自动化引擎
当 “AI 自动化” 成为科技领域最炙手可热的关键词,我们仿佛置身于一场激动人心的变革前夜。各行各业都在翘首以盼,期待 AI 技术能够真正解放生产力,将人类从繁琐重复的工作中解脱出来。在这个充满无限可能的时代,字节跳动悄然发布…...
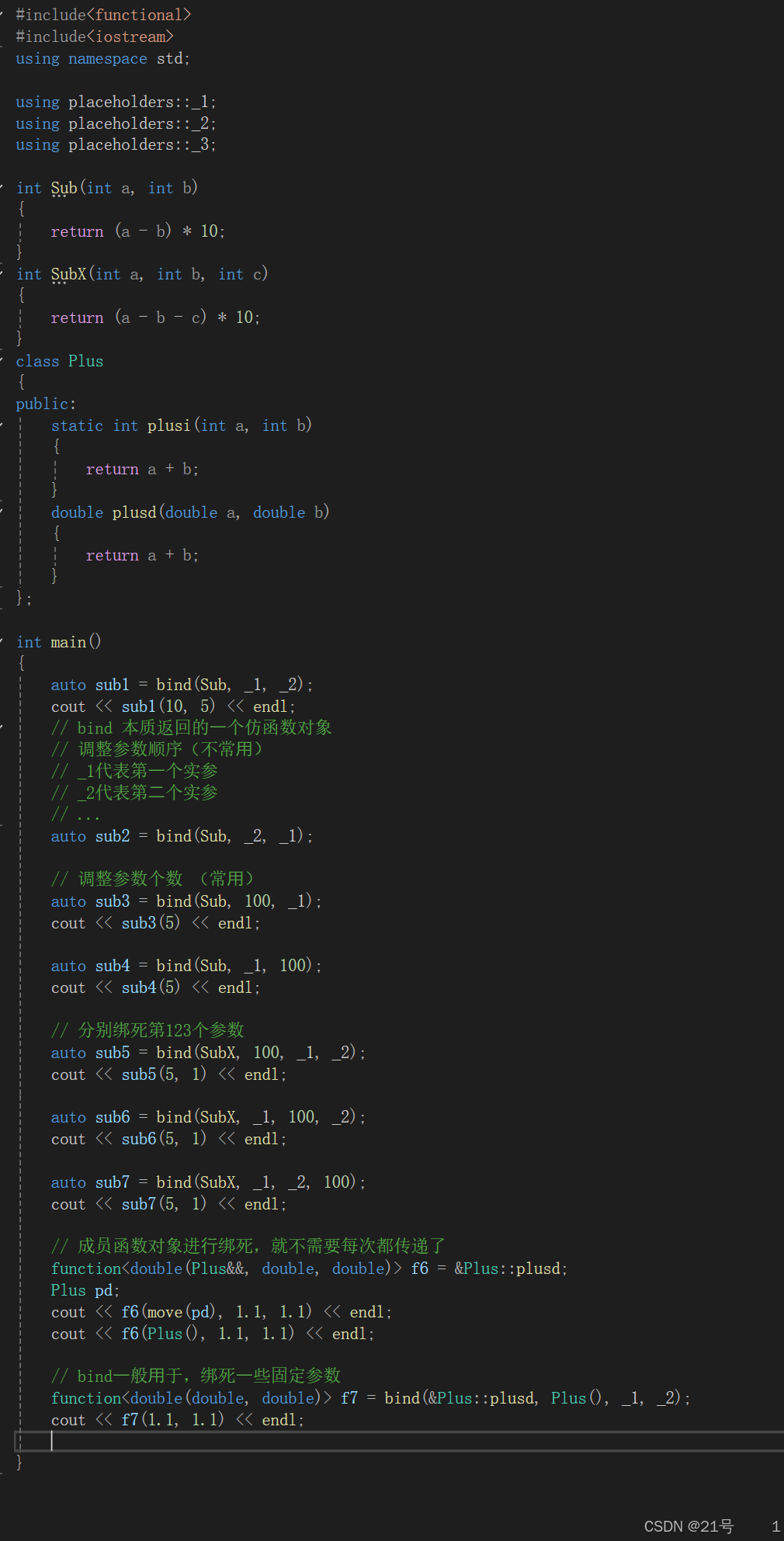
21.C++11
1.列表初始化 1.1C11中的{} •C11以后想统⼀初始化⽅式,试图实现⼀切对象皆可⽤{}初始化,{}初始化也叫做列表初始化。 • 内置类型⽀持,⾃定义类型也⽀持,⾃定义类型本质是类型转换,中间会产⽣临时对象,最…...
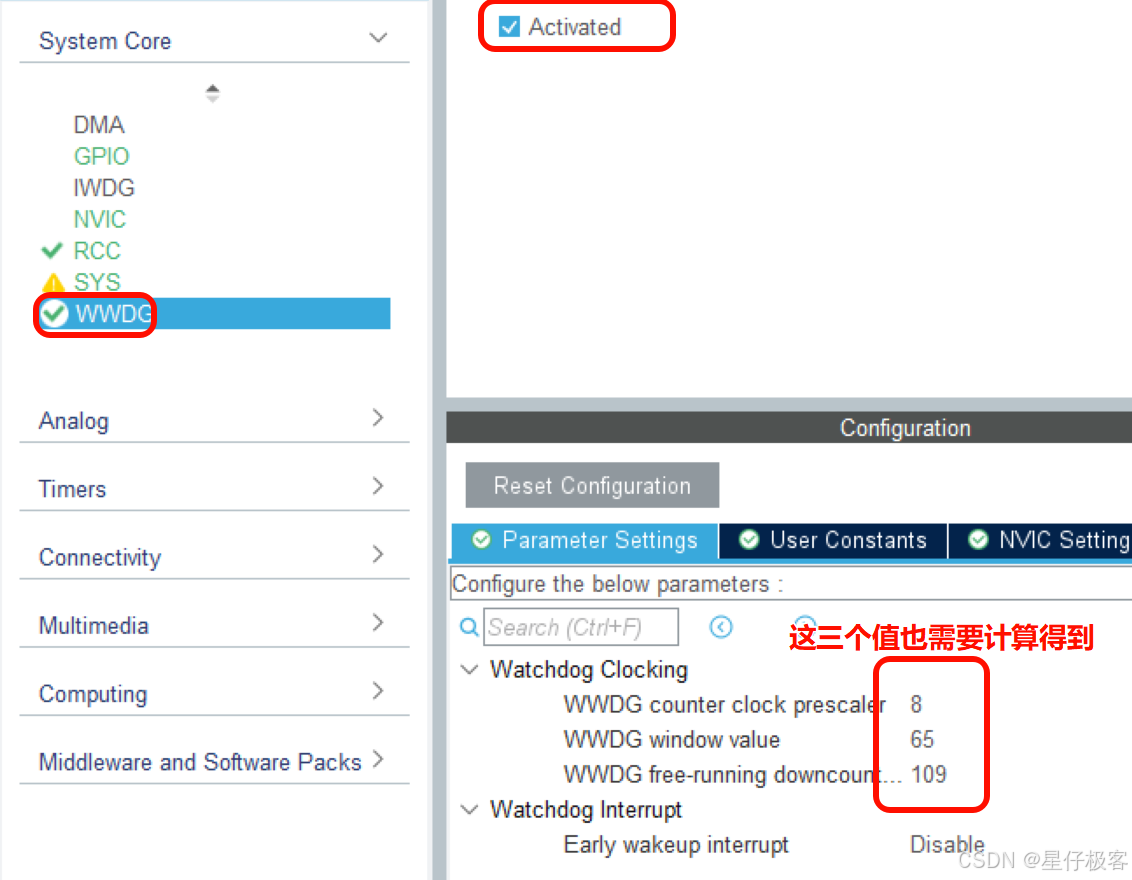
STM32 HAL库之WDG示例代码
独立看门狗(IWDG) 初始化独立看门狗,在main.c中的 MX_IWDG_Init();,也就是iwdg.c中的初始化代码 void MX_IWDG_Init(void) {/* USER CODE BEGIN IWDG_Init 0 *//* USER CODE END IWDG_Init 0 *//* USER CODE BEGIN IWDG_Init 1 …...
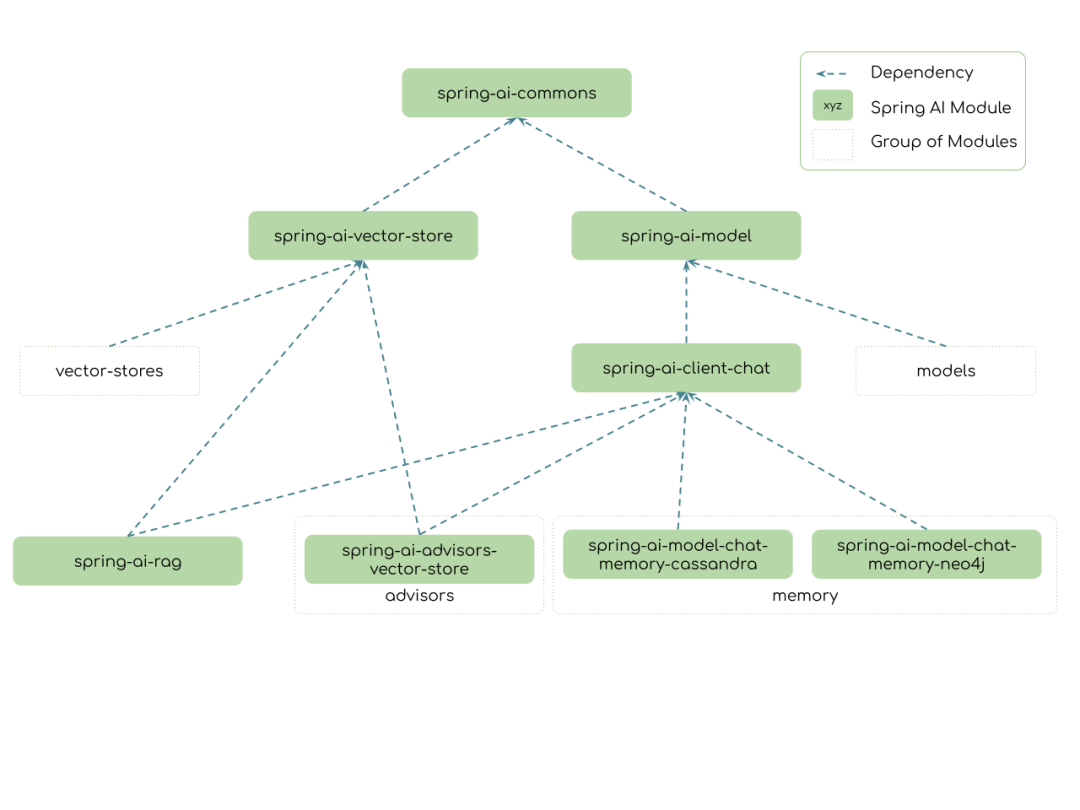
Spring AI 发布了它的 1.0.0 版本的第七个里程碑(M7)
Spring AI 发布了它的 1.0.0 版本的第七个里程碑(M7),下个月就是 RC1,紧接着就是 GA!,对于我们 Java 开发者来说,这绝对是个值得关注的好消息! 但是对于 Java 学习者来说,…...
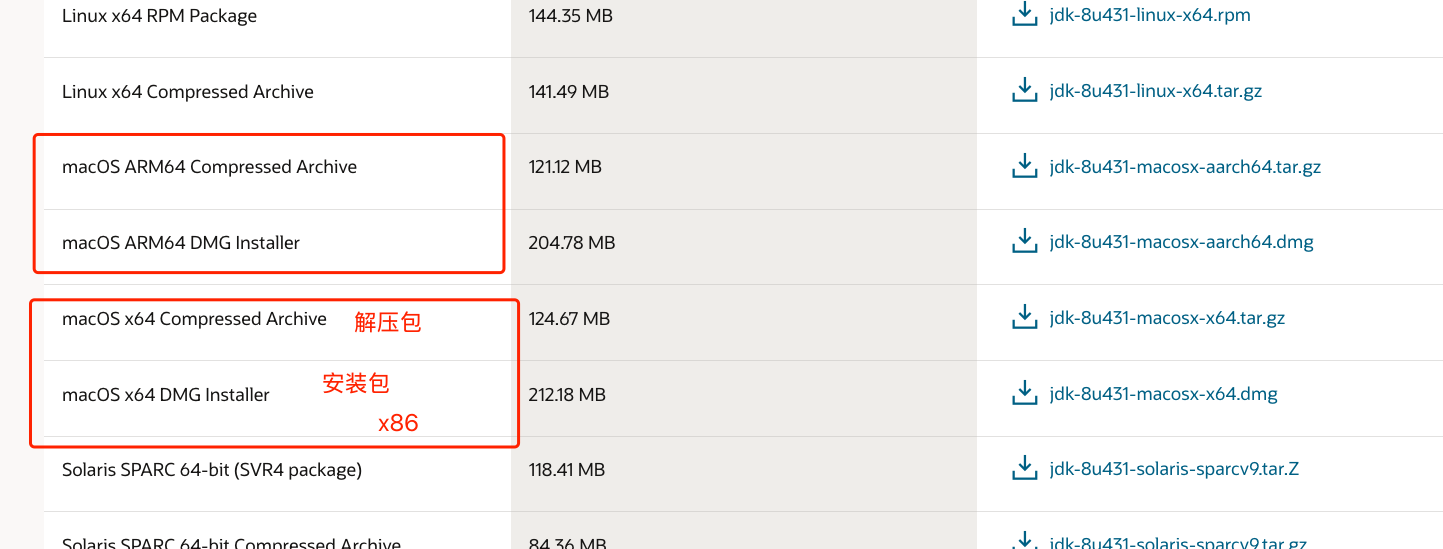
jdk 安装
oracle官网 : Java Archive | Oracle 中国 export JAVA_HOME/Users/xxxxx/app/services/x86jdk/jdk1.8.0_431.jdk/Contents/Home export PATH$JAVA_HOME/bin:$PATH 华为镜像网站:Index of java-local/jdk...

Windows服务器组建与综合服务部署技术方案
目录 一、项目背景与需求分析 1.1 企业网络架构 1.2 核心服务需求矩阵 二、Active Directory与权限管理体系 2.1 用户账户标准化 2.2 文件服务器纵深防御 三、高可用服务集群构建 3.1 分布式文件服务(DFS) 3.2 打印服务高可用方案 四、安全加固与审计体系 4.1 本地安…...

3.2.2.2 Spring Boot配置视图控制器
在Spring Boot中配置视图控制器可以简化页面跳转跳逻辑。通过实现WebMvcConfigurer接口的addViewControllers方法,可以直接将URL映射到特定的视图,而无需编写控制器类。例如,将根路径"/"映射到welcome.html视图,当访问应…...

华为OD机试真题——找出两个整数数组中同时出现的整数(2025A卷:100分)Java/python/JavaScript/C++/C语言/GO六种最佳实现
2025 A卷 100分 题型 本文涵盖详细的问题分析、解题思路、代码实现、代码详解、测试用例以及综合分析; 并提供Java、python、JavaScript、C++、C语言、GO六种语言的最佳实现方式! 华为OD机试真题《找出两个整数数组中同时出现的整数》: 目录 题目名称:找出两个整数数组中同…...

Go 1.24 新方法:编写性能测试用例方法 testing.B.Loop 介绍
Go 开发者在使用 testing包编写基准测试用例时,如果不注意,可能会遇到各种陷阱。这些陷阱,导致基准测试结果不准确。Go1.24 版本引入了一种新的基准测试编写方式,它同样易用,并且可以帮助规避编写基准测试时的一些坑。…...
烽火ai场控接入deepseek自动回复话术软件
要将烽火AI场控软件与DeepSeek自动回复话术软件进行对接,实现直播间自动互动功能,需通过API接口或脚本工具完成数据互通。以下是具体操作步骤及注意事项: 确认兼容性与准备工作 软件支持检查 确认烽火AI场控是否开放API接口(一般需…...

Spring AOP 学习笔记 之 Advice详解
学习材料:https://docs.spring.io/spring-framework/reference/core/aop/ataspectj/advice.html 1. 什么是 Advice(通知) 定义:Advice 是 AOP 的核心概念之一,表示在特定的连接点(Join Point)上…...
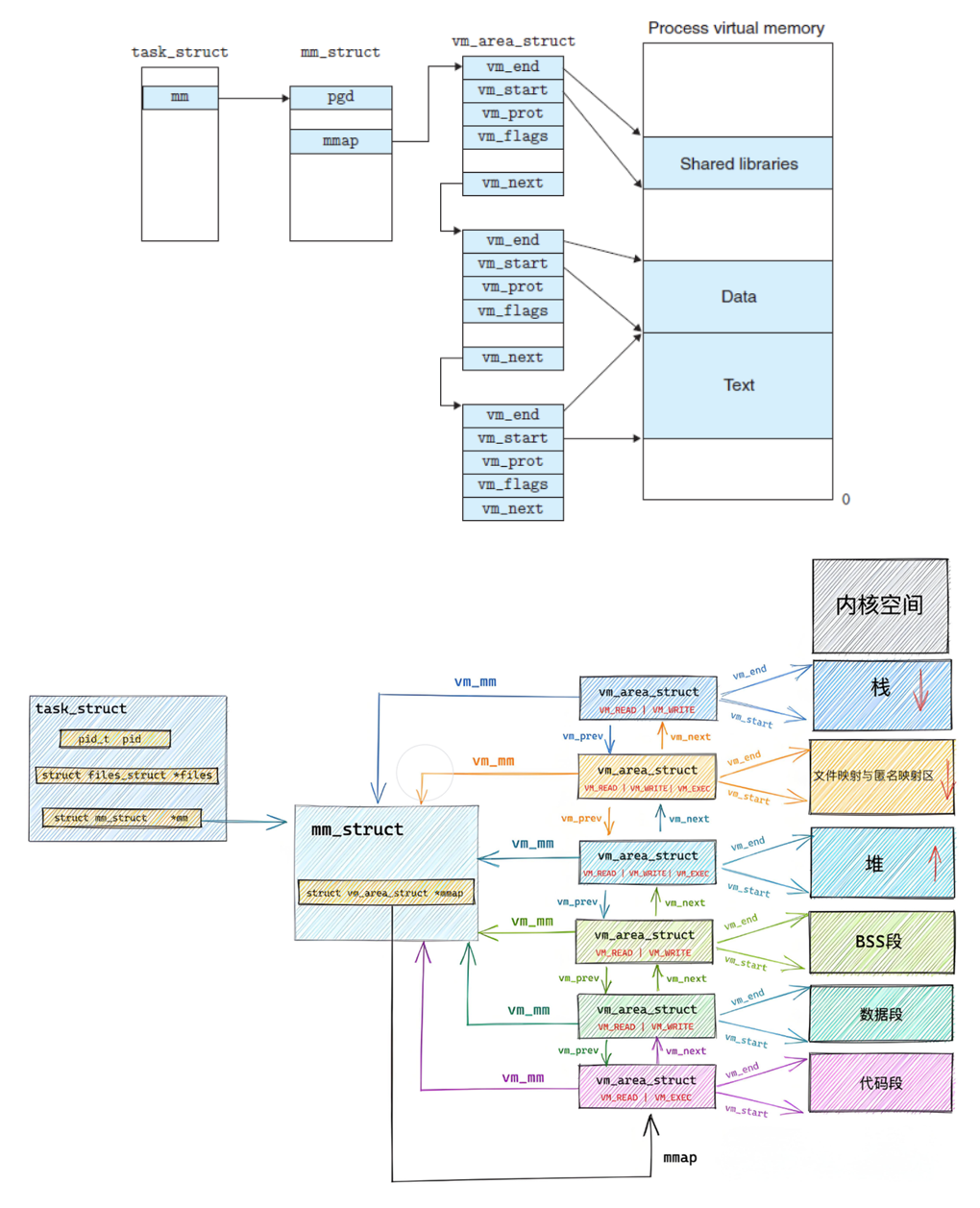
【Linux系统】进程地址空间
命令行参数 int main (int argc, char* argv[]) 命令行参数列表 argc:参数的个数argv:参数的清单 int main (int argc, char* argv[]) {printf("argc: %d\n",argc);for(int i 0; i < argc; i){printf("argv[%d] : %s \n", i…...
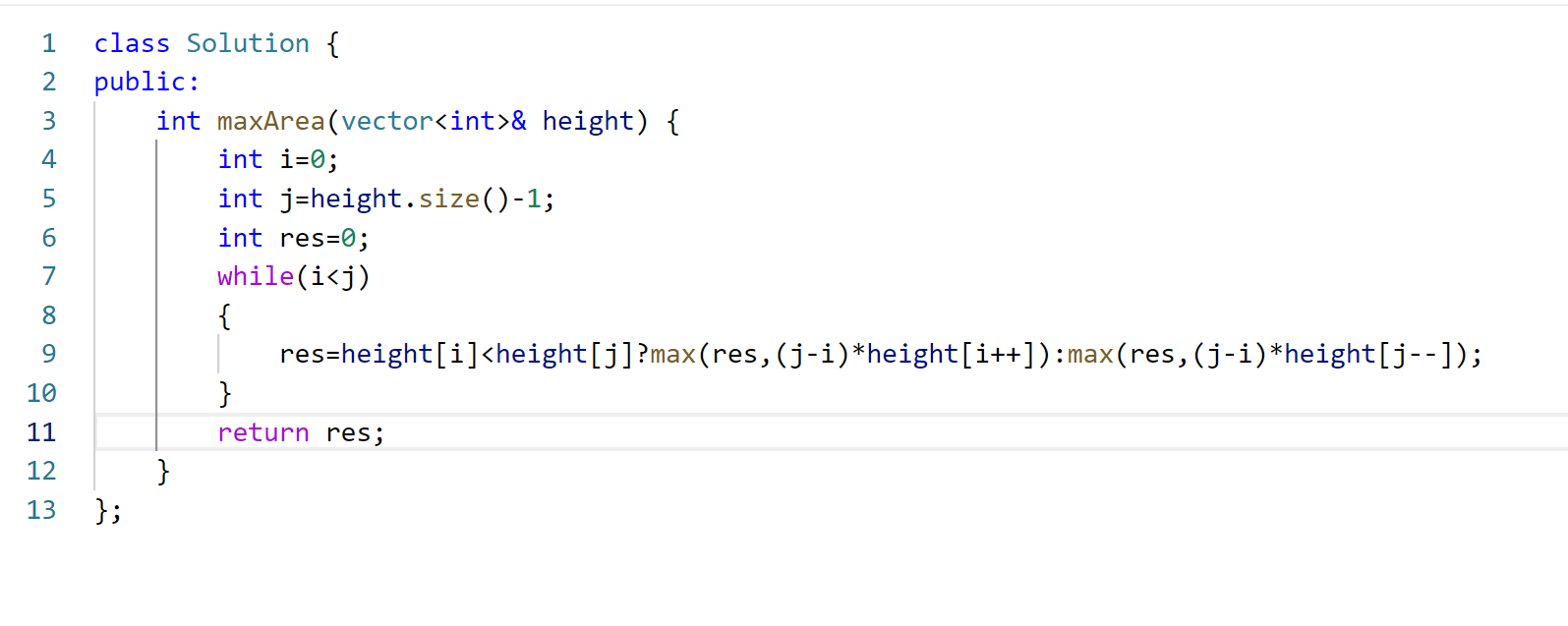
记录学习的第二十六天
还是每日一题。 今天这道题有点难度,我看着题解抄的。 之后做了两道双指针问题。 这道题本来是想用纯暴力做的,结果出错了。😓...

python成功解决AttributeError: can‘t set attribute ‘lines‘
文章目录 报错信息与原因分析解决方法示例代码代码解释总结 报错信息与原因分析 在使用 matplotlib绘图时,若尝试使用 ax.lines []来清除图表中的线条,会遇到AttributeError: can’t set attribute错误。这是因为 ax.lines是一个只读属性,不…...

测试 认识bug
一、软件测试生命周期与测试模型 1. 软件(开发)生命周期:包括需求分析、计划、设计、编码、测试、运行维护阶段。需求分析是起始点,明确用户需求,后续阶段依此展开 。例如开发电商软件,需求分析阶段确定商品…...