(小白0基础) 微调deepseek-8b模型参数详解以及全流程——训练篇
本篇参考bilibili如何在本地微调DeepSeek-R1-8b模型_哔哩哔哩_bilibili
上篇:(小白0基础) 租用AutoDL服务器进行deepseek-8b模型微调全流程(Xshell,XFTP) —— 准备篇
初始变量
max_seq_length = 2048
dtype = None
load_in_4bit = True
- 单批次最大处理模型大小
- dype 参数的数据精度,包括各种矩阵中的数据的精例如 float32(高精度)、float16(半精度),选择None则是自动选择精度
- 4bit量化,可以将模型部署在消费级的显卡上,而不损失大量的精度
model, tokenizer = FastLanguageModel.from_pretrained(model_name = "unsloth/DeepSeek-R1-Distill-Llama-8B",max_seq_length = max_seq_length,dtype = dtype,load_in_4bit = load_in_4bit,token = hf_token,
)
- 解包操作,对于该方法复制给两个变量
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"## 模型输入
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")outputs = model.generate(input_ids=inputs.input_ids,attention_mask=inputs.attention_mask,max_new_tokens=1200,use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
- input_ids这里是将字符转换为token
- max_new_tokens 生成的最大长度
- use_cache 缓存开启,也就是保存之前的键值对(这里还不太懂)
- attention_mask 指的是 Padding Mask 指的是忽略输入文本长度,针对样本不同的token填充例如[PAD],在矩阵中赋值为0
model = FastLanguageModel.get_peft_model(model,r=16,target_modules=["q_proj","k_proj","v_proj","o_proj","gate_proj","up_proj","down_proj",],lora_alpha=16,lora_dropout=0,bias="none",use_gradient_checkpointing="unsloth", # True or "unsloth" for very long contextrandom_state=3407,use_rslora=False,loftq_config=None,
)
-
Lora的基本概念,通过分解detw的值ΔW=A⋅B
-
r 分解矩阵的秩的大小:d×r+r×k
-
lora_alpha, LoRA缩放因子(ΔW = α * A*B)通常为r的倍数
-
lora_dropout 丢弃率,防止过拟合
-
bias 偏置项,减少训练量 wx+b的b
-
andom_state,用来确保实验可以复现(保存初始化元素)
-
use_rslora lora变体
-
use_gradient_checkpointing 梯度检查点
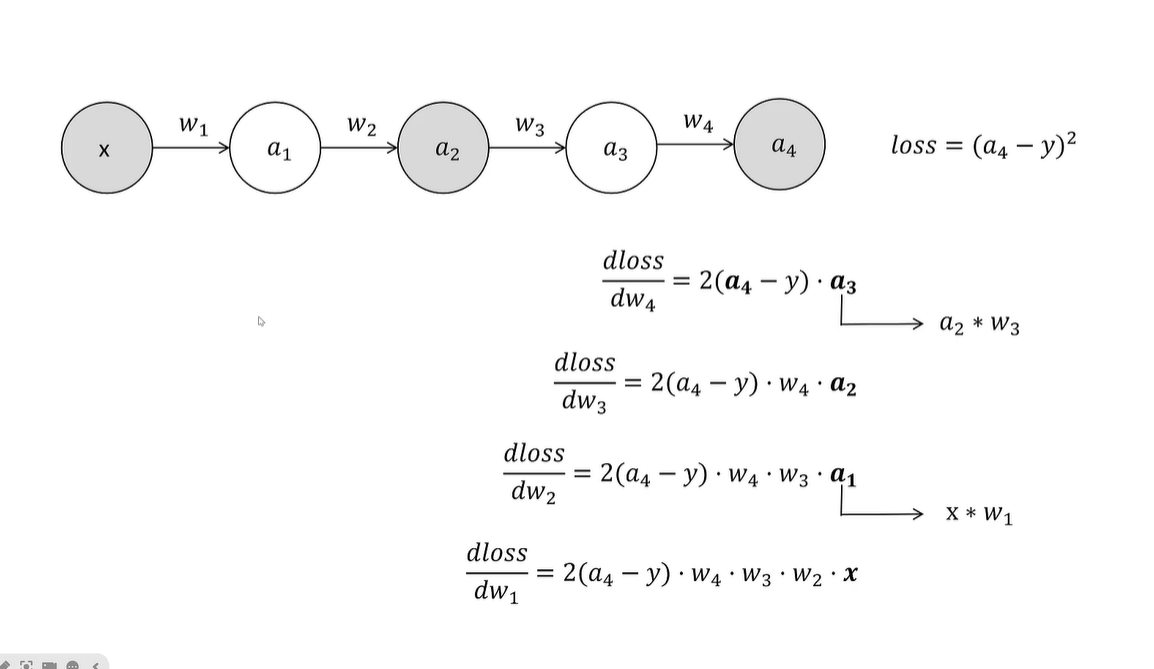
Forward: [Layer1-5 → 检查点 → Layer6-10 → 检查点 → …] 仅存储检查点激活
Backward:-
从最后一个检查点重计算 Layer6-10
-
计算 Grad10-6
-
从中间检查点重计算 Layer1-5
-
计算 Grad5-1
具体来说,就是删除其中一些向量a,我们在反向传播的时候要用到的a通过再次前向传输进行计算输出
用空间换时间
-
trainer = SFTTrainer(model=model,tokenizer=tokenizer,train_dataset=dataset,dataset_text_field="text",max_seq_length=max_seq_length,dataset_num_proc=2,args=TrainingArguments(per_device_train_batch_size=2,gradient_accumulation_steps=4,# Use num_train_epochs = 1, warmup_ratio for full training runs!warmup_steps=5,max_steps=60,learning_rate=2e-4,fp16=not is_bfloat16_supported(),bf16=is_bfloat16_supported(),logging_steps=10,optim="adamw_8bit",weight_decay=0.01,lr_scheduler_type="linear",seed=3407,output_dir="outputs",),
)-
SFTTrainer是trl库中专门用于对语言模型进行监督式微调(Supervised Fine-Tuning)的训练器,通常用于指令微调(Instruction Tuning)。 -
dataset_num_proc=2
作用: 指定在预处理数据集(例如,进行分词)时使用的 CPU 进程数量。
-
per_device_train_batch_size=2 Batch Size 是指在单次模型权重更新前,模型处理的样本数量。
-
gradient_accumulation_steps=4 小批次反向传播
-
warmup_steps 在训练开始的前
warmup_steps步(这里是 5 步),学习率会从一个很小的值(通常是 0)逐渐线性增加到设定的learning_rate。这有助于在训练初期稳定模型,避免因初始梯度过大导致训练发散。- max_steps=60 训练将在执行了 60 次权重更新后停止,无论处理了多少数据或完成了多少轮(Epoch)。如果同时设置了
num_train_epochs,max_steps会覆盖它。这里设置为 60,表明这是一个非常短的训练过程,可能用于快速验证代码或流程是否正常。注释提示完整训练应使用num_train_epochs。
- max_steps=60 训练将在执行了 60 次权重更新后停止,无论处理了多少数据或完成了多少轮(Epoch)。如果同时设置了
-
num_train_epochs = 1 删除
max_steps=60,设置num_train_epochs = 1作为 -
fp16=not is_bfloat16_supported(), 数据精度问题
bf16=is_bfloat16_supported(), -
logging_steps=10 设置记录训练指标(如损失、学习率等)的频率
-
optim=“adamw_8bit” adam优化器
-
-
weight_decay=0.01 权重衰减是一种正则化技术,通过在损失函数中添加一个与权重平方和成正比的惩罚项,来防止模型权重变得过大,有助于减少过拟合。区别(L2)
-
lr_scheduler_type=“linear” 学习率调度器负责在训练过程中动态调整学习率,这里是线性增加
这里的学习处理的一些参数设置关系
训练开始 (Step 0 -> Step 5):
- Warmup 控制:
warmup_steps=5生效。 - Scheduler (Linear) 配合: 学习率从 0 开始线性增加。
- Optimizer (AdamW_8bit) 执行: 在每一步使用这个逐渐增大的学习率和计算出的梯度来更新模型权重。
预热结束 (Step 5):
- 学习率达到峰值
learning_rate=2e-4。
训练继续 (Step 6 -> Step 60):
- Scheduler (Linear) 控制:
lr_scheduler_type="linear"生效。学习率从2e-4开始线性下降,目标是在第 60 步时降到 0。 - Optimizer (AdamW_8bit) 执行: 在每一步使用这个逐渐减小的学习率和计算出的梯度来更新模型权重。
训练结束 (Step 60):
- 学习率理论上降到 0,训练停止。
wandb图标观察
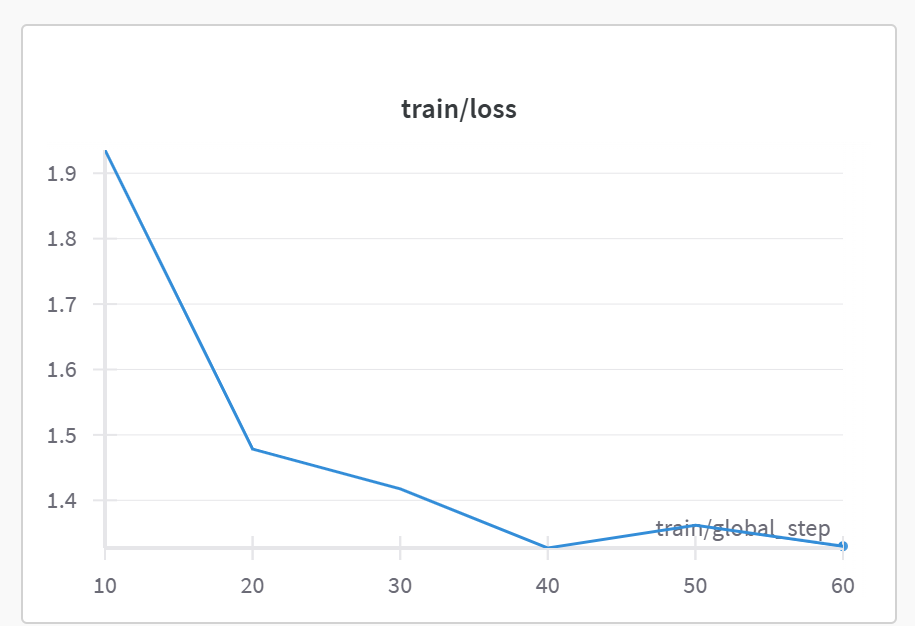
train/loss(训练损失)
-
X 轴:
train/global_step- 训练进行的全局步数(优化器更新次数),从 10 到 60。 -
Y 轴: Loss (损失值) - 模型在训练数据上计算出的损失函数值。这个值越低通常表示模型拟合训练数据越好。
-
曲线解读: 图表显示损失值从训练开始(第 10 步之后)的较高值(约 1.9)迅速下降,然后在后续步骤中(20 到 60 步)下降速度减缓,最终达到约 1.35 左右。
-
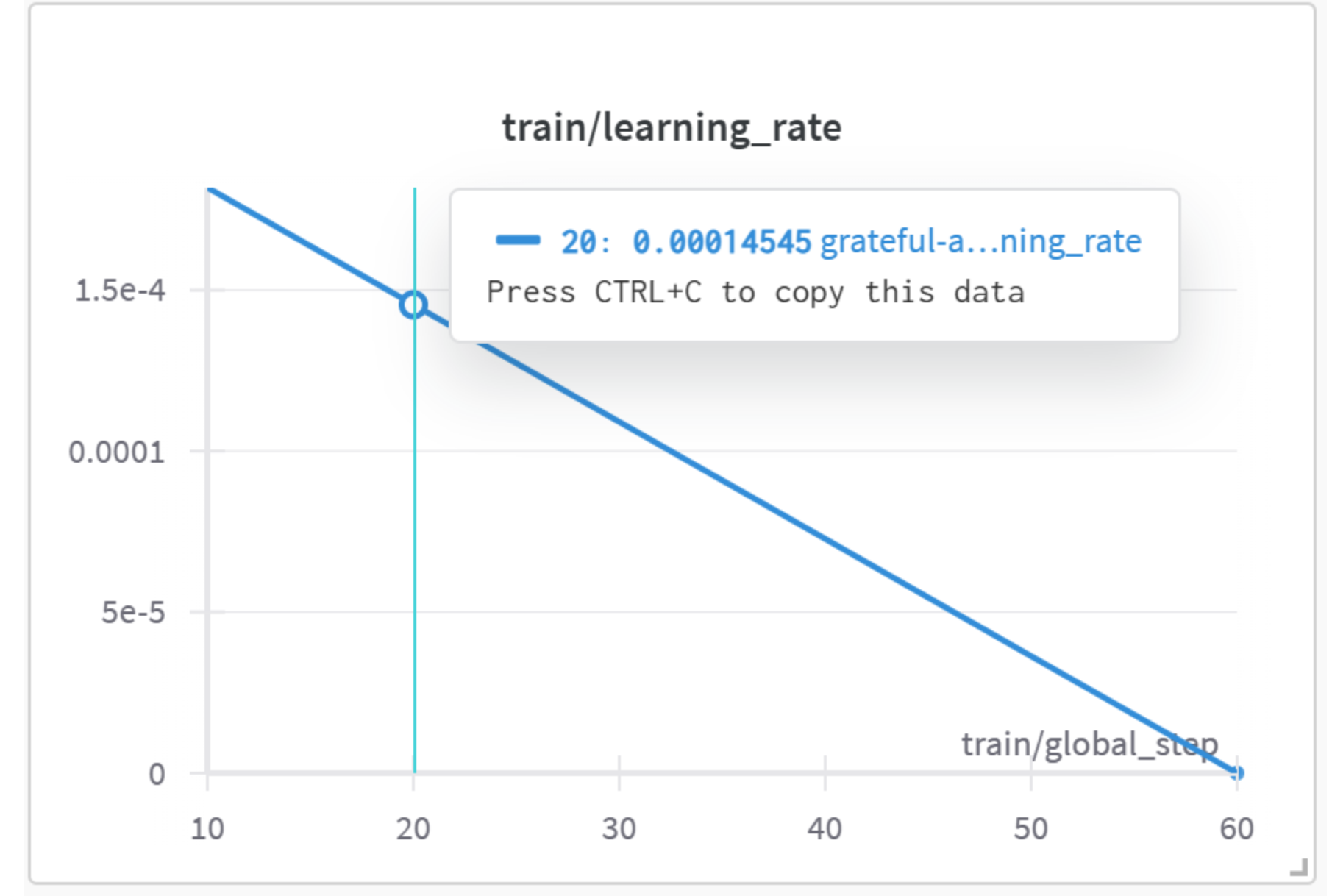
train/learning_rate(训练学习率)
- X 轴:
train/global_step- 全局步数 (10 到 60)。 - Y 轴: Learning Rate (学习率) - 优化器在每一步实际使用的学习率。
- 曲线解读: 学习率从第 10 步时的一个较高值(接近你设置的峰值
2e-4,这里显示约 1.6e-4 可能是因为记录点和实际峰值点略有偏差或 warmup 刚结束)开始,随着步数增加线性下降,在第 60 步接近 0。 - 意义: 这个图完美地验证了你的学习率调度设置:
warmup_steps=5(前 5 步预热,图中未完全显示,因为 x 轴从 10 开始) 和lr_scheduler_type="linear"以及max_steps=60。学习率在预热后达到峰值,然后线性衰减至训练结束。
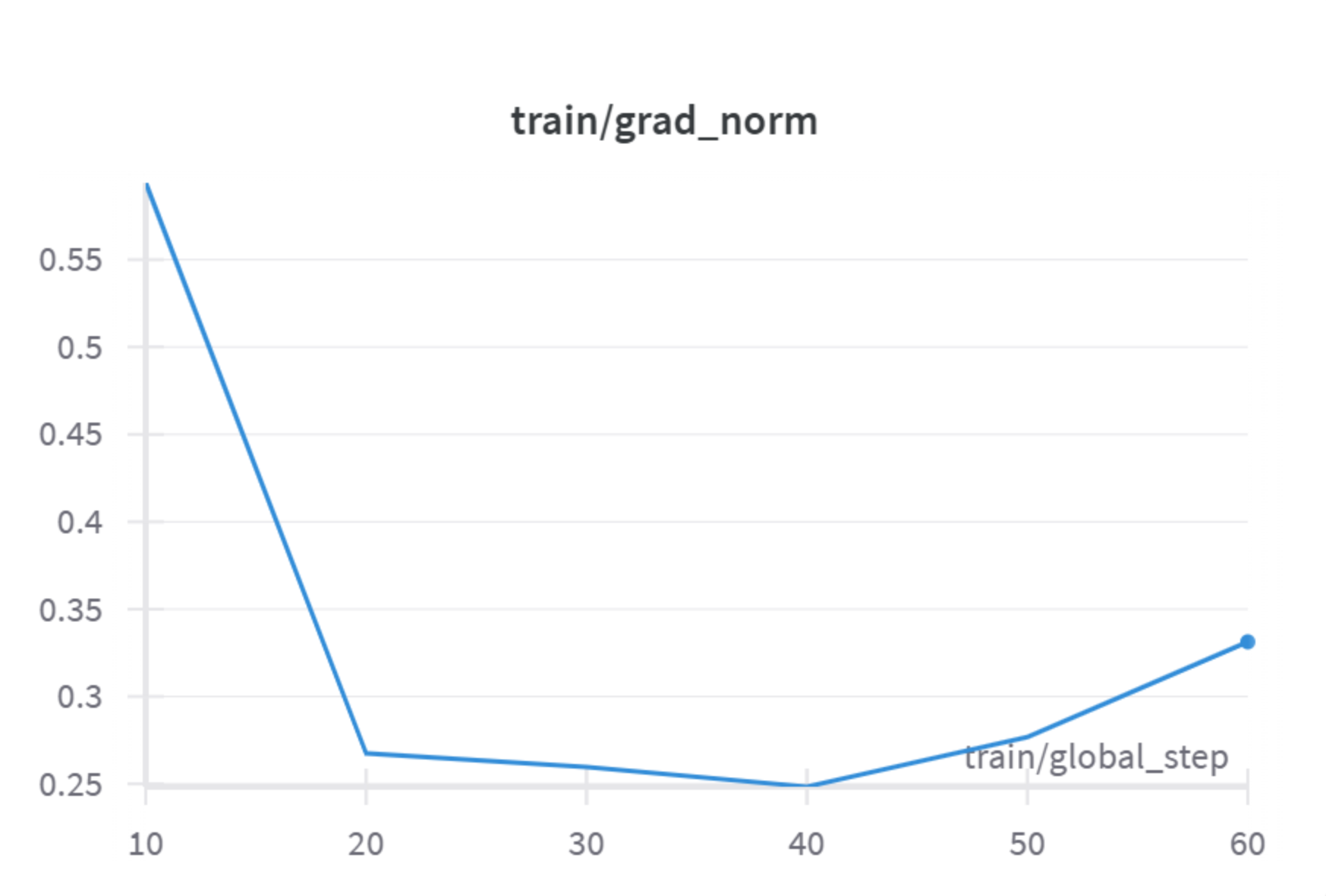
train/grad_norm(训练梯度范数)- X 轴:
train/global_step- 全局步数 (10 到 60)。 - Y 轴: Grad Norm (梯度范数) - 模型所有参数梯度组成的向量的长度(范数)。它衡量了梯度的大小。
- 曲线解读: 梯度范数在训练早期(第 10 步)相对较高(约 0.58),然后迅速下降到 0.3 左右(第 20 步),之后趋于稳定,最后略有回升到 0.35 左右。
- 意义: 梯度范数可以帮助诊断训练稳定性。初始值较高表明模型离最优解较远,需要较大调整。迅速下降表明模型快速进入损失较低的区域。后续稳定或轻微波动是正常的。需要警惕的是梯度范数爆炸(变得非常大)或消失(变得非常接近 0),这两种情况都可能阻碍训练。你图中的值看起来在合理范围内。
- X 轴:
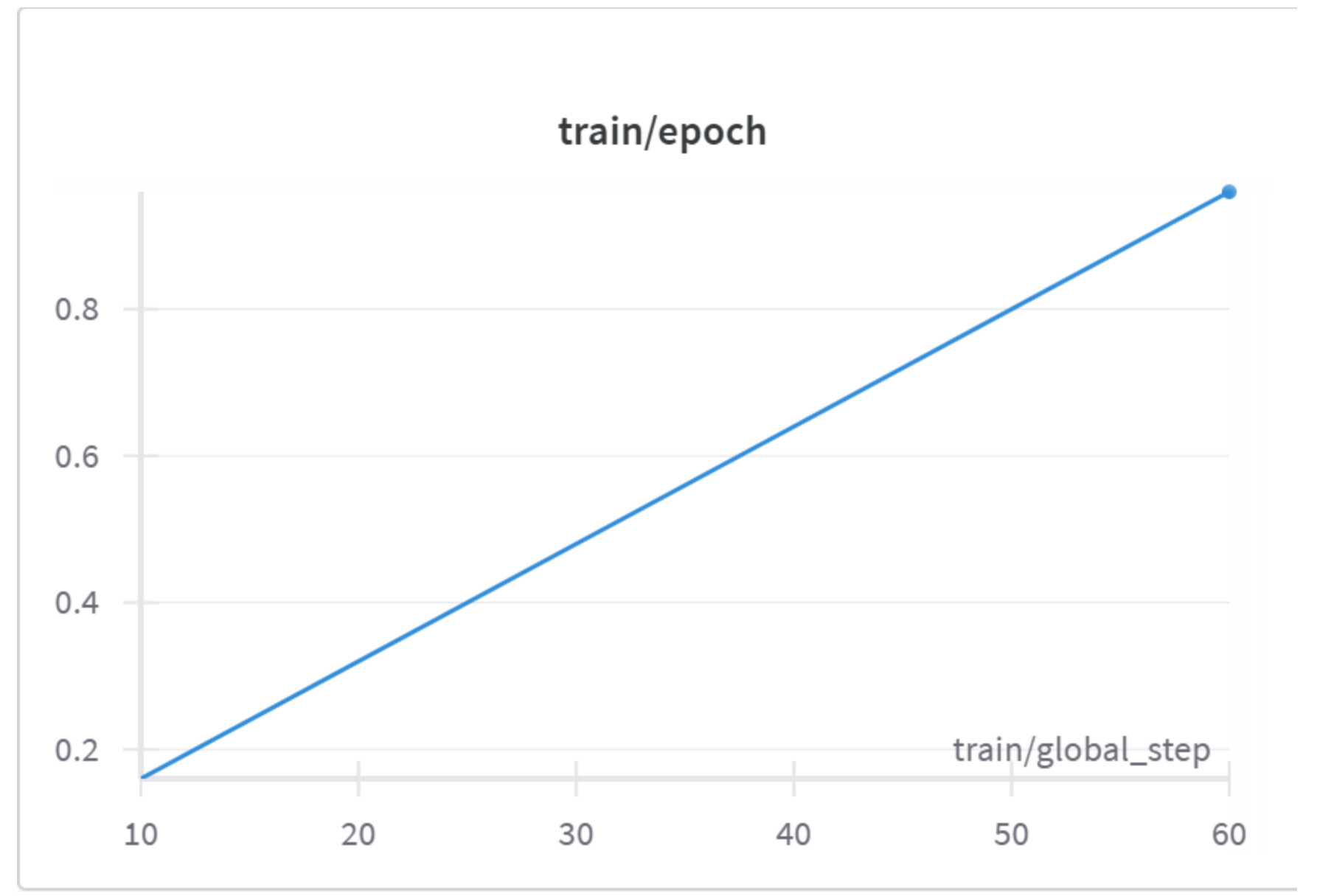
train/epoch(训练轮数)- X 轴:
train/global_step- 全局步数 (10 到 60)。 - Y 轴: Epoch - 当前训练进度相当于遍历了整个训练数据集的多少比例。
- 曲线解读: Epoch 值随着全局步数的增加而线性增加,从第 10 步的约 0.15 增加到第 60 步的约 0.9。
- X 轴:
完整代码
pip install unsloth # 安装unsloth库
pip install bitsandbytes unsloth_zoo # 安装工具库import torch # 加载torch库
from unsloth import FastLanguageModel # ############## 加载模型和分词器#####################
# 超参数设置
max_seq_length = 2048 #模型的上下文长度,可以任意选择,内部提供了RoPE Scaling 技术支持
dtype = None # 通常设置为None,使用Tesla T4, V100等GPU时可用Float16,使用Ampere+时用Bfloat16
load_in_4bit = True # 以4位量化进行微调# 基于unsloth加载deepseek的蒸馏模型
model, tokenizer = FastLanguageModel.from_pretrained(model_name = "unsloth/DeepSeek-R1-Distill-Llama-8B",max_seq_length = max_seq_length,dtype = dtype,load_in_4bit = load_in_4bit,token = hf_token,
)# ################# 提示模板 #######################
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""# ##################### 微调前推理示例 #######################
question = "一个患有急性阑尾炎的病人已经发病5天,腹痛稍有减轻但仍然发热,在体检时发现右下腹有压痛的包块,此时应如何处理?"FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")outputs = model.generate(input_ids=inputs.input_ids,attention_mask=inputs.attention_mask,max_new_tokens=1200,use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])# ###################### 更新提示模板 #######################
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""# ####################### 处理函数 #########################
EOS_TOKEN = tokenizer.eos_token # 末尾必须加上 EOS_TOKENdef formatting_prompts_func(examples):inputs = examples["Question"]cots = examples["Complex_CoT"]outputs = examples["Response"]texts = []for input, cot, output in zip(inputs, cots, outputs):text = train_prompt_style.format(input, cot, output) + EOS_TOKENtexts.append(text)return {"text": texts,}# ################### 加载数据集 ##########################
from datasets import load_dataset
dataset = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT", 'zh', split = "train[0:500]", trust_remote_code=True)
print(dataset.column_names)dataset = dataset.map(formatting_prompts_func, batched = True)
print(dataset["text"][0])# ################## 微调参数设置 #####################
model = FastLanguageModel.get_peft_model(model,r=16, # 选择任何数字 > 0 !建议 8、16、32、64、128微调过程的等级。#数字越大,占用的内存越多,速度越慢,但可以提高更困难任务的准确性。太大也会过拟合target_modules=["q_proj","k_proj","v_proj","o_proj","gate_proj","up_proj","down_proj",], # 选择所有模块进行微调lora_alpha=16, # 微调的缩放因子,建议将其等于等级 r,或将其加倍。lora_dropout=0, # 将其保留为 0 以加快训练速度!可以减少过度拟合,但不会那么多。bias="none", # 将其保留为 0 以加快训练速度并减少过度拟合!use_gradient_checkpointing="unsloth", # True or "unsloth" for very long contextrandom_state=3407, # 随机种子数use_rslora=False, # 支持等级稳定的 LoRA,高级功能可自动设置 lora_alpha = 16loftq_config=None, # 高级功能可将 LoRA 矩阵初始化为权重的前 r 个奇异向量。#可以在一定程度上提高准确性,但一开始会使内存使用量激增。
)# ################# 训练参数设置 #######################
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supportedtrainer = SFTTrainer(model=model,tokenizer=tokenizer,train_dataset=dataset,dataset_text_field="text",max_seq_length=max_seq_length,dataset_num_proc=2,args=TrainingArguments(per_device_train_batch_size=2,gradient_accumulation_steps=4,# Use num_train_epochs = 1, warmup_ratio for full training runs!warmup_steps=5,max_steps=60,learning_rate=2e-4,fp16=not is_bfloat16_supported(),bf16=is_bfloat16_supported(),logging_steps=10,optim="adamw_8bit",weight_decay=0.01,lr_scheduler_type="linear",seed=3407,output_dir="outputs",),
)# ################### 模型训练 #################
trainer_stats = trainer.train()# ################### 模型保存 ##################
new_model_local = "DeepSeek-R1-Medical-COT"
model.save_pretrained(new_model_local) # 本地模型保存
tokenizer.save_pretrained(new_model_local) # 分词器保存# 将模型和分词器以合并的方式保存到指定的本地目录
model.save_pretrained_merged(new_model_local, tokenizer, save_method = "merged_16bit",) # model.push_to_hub("your_name/lora_model", token = "...") # Online saving
# tokenizer.push_to_hub("your_name/lora_model", token = "...") # Online saving
相关文章:
(小白0基础) 微调deepseek-8b模型参数详解以及全流程——训练篇
本篇参考bilibili如何在本地微调DeepSeek-R1-8b模型_哔哩哔哩_bilibili 上篇:(小白0基础) 租用AutoDL服务器进行deepseek-8b模型微调全流程(Xshell,XFTP) —— 准备篇 初始变量 max_seq_length 2048 dtype None load_in_4bit True单批次最大处理模型大小dy…...

调用LLM的api
目录 chatgptdemo可选模型 chatgpt demo import openai openai.api_key xxxxxxxxx # 自己的api key openai.api_base https://api.feidaapi.com/v1 # 中转非直连 # response openai.ChatCompletion.create( # model"gpt-4o", # messages[ # {"rol…...
关于汽车辅助驾驶不同等级、技术对比、传感器差异及未来发展方向的详细分析
以下是关于汽车辅助驾驶不同等级、技术对比、传感器差异及未来发展方向的详细分析: 一、汽车辅助驾驶等级详解 根据SAE(国际自动机工程师学会)的标准,自动驾驶分为 L0到L5 六个等级: 1. L0(无自动化&…...

windows安卓子系统wsa隐藏应用列表的安装激活使用
Windows 11 安卓子系统应用部署全攻略 windows安卓子系统wsa隐藏应用列表的安装激活使用|过检测核心前端 在 Windows 11 系统中,安卓子系统为用户带来了在电脑上运行安卓应用的便利。经过一系列的操作,我们已经完成了 Windows 11 安卓子系统的底层和前端…...
mongodb7日志特点介绍:日志分类、级别、关键字段(下)
#作者:任少近 上篇《mongodb7日志特点介绍:日志分类、级别、关键字段(上)》 链接: link 文章目录 4.日志会输出F/E/W/I四种情况5.日志关键字段6.日志量验证情况7.总结 4.日志会输出F/E/W/I四种情况 在MongoDB7中,日志输出按照严重性分为四种…...
word中插入图片显示不完整,怎么处理让其显示完整?
在WORD里插入图片后,选择嵌入式发现插入的图片显示不正常,只能显示底部一部分,或者遮住文字。出现此故障的原因有可能是设置为固定值的文档行距小于图形的高度,从而导致插入的图形只显示出了一部分。 1.选中图片,然后点…...

SAP S4HANA embedded analytics
SAP S4HANA embedded analytics...

大模型在胃十二指肠溃疡预测及治疗方案制定中的应用研究
目录 一、引言 1.1 研究背景与意义 1.2 国内外研究现状 1.3 研究目的与方法 二、胃十二指肠溃疡概述 2.1 疾病定义与分类 2.2 流行病学特征 2.3 病因与发病机制 2.4 临床表现与诊断方法 三、大模型技术原理与应用现状 3.1 大模型基本概念与架构 3.2 在医疗领域的应…...

macos下 ~/.zshrc~ 和 ~/.zshrc
macos下 ~/.zshrc~ 和 ~/.zshrc ~/.zshrc通常是备份文件或临时文件,可能由编辑器(如vim)创建,通常可以安全删除,不会影响系统运行。 在Mac下,这种带~后缀的备份文件通常是由以下情况产生: 常…...

【C语言基础】双指针在qsort函数中的应用
在C语言中使用 qsort 对字符串数组(如 char* 数组)排序时,必须转换为双指针(char**),这是由字符串数组的内存结构和 qsort 的工作原理决定的。以下是详细解释: 一、底层原理分析 1. 字符串数组…...

Android组件刷新
Android中刷新View的方法有以下几种: 调用invalidate()方法,该方法会使View树中的所有视图无效或脏,等待下一次绘制时重新绘制。例如: mCustomView.invalidate(); 调用postInvalidate()方法,该方法类似于invalidate()…...
JavaWeb开发 Servlet底层 Servlet 过滤器 过滤器和拦截器 手写一个限制访问路径的拦截器
目录 万能图 过滤器自我理解 案例 实现Filter 接口 配置文件 web.xml 将过滤器映射到 servlet 用处 拦截器 手写案例 重写 preHandle() 方法 拦截处理 重写 postHandle() 方法 后处理 重写 afterHandle() 方法 完成处理 代码 如何配置拦截器 万能图 还是看一下这张…...

QT中多线程写法
转自个人博客:QT中多线程写法 1. QThread及moveToThread() 使用情况: 多使用于需要将有着复杂逻辑或需要一直占用并运行的类放入子线程中执行的情况,moveToThread是将整个类的对象移入子线程。 优缺点: 优点:更符合…...

0415-批量删除操作
关于删除的全部代码: <!DOCTYPE html> <html> <head> <meta charset"UTF-8"> <title>Insert title here</title> <script src"js/jquery-3.7.1.min.js"></script> <srcipt src"js/jqu…...

Day08 【基于余弦相似度实现的表示型文本匹配】
基于余弦相似度实现的表示型文本匹配 目标数据准备参数配置数据处理初始化方法加载数据编码句子补齐与截断重写父类两个方法采样策略加载词表和方案 模型构建SentenceEncoder类SiameseNetwork类优化器配置 主程序验证与评估推理预测测试结果 目标 本文基于给定的词表ÿ…...

【leetcode hot 100 72】编辑距离
解法一:递归 解法二:(动态规划)①定义:dp[i][j]为word1中前i个字符转化为word2中前j个字符所需操作数;dp[m1][n1] ②初始状态:dp[0][j]j(0变为j,需要j步),dp[i][0]i(i变为0ÿ…...

Dubbo、HTTP、RMI之间的区别
Dubbo、HTTP、RMI之间的区别如下: 表格 复制 特性DubboHTTPRMI通信机制基于Netty的NIO异步通信,采用长连接,支持多种序列化方式基于标准的HTTP协议,无状态,每次请求独立基于Java原生的RMI机制,支持Java对…...
Java练习——day1(反射)
文章目录 练习1练习2练习3思考封装原则与反射合理使用反射“破坏”封装的场景 练习1 编写代码,通过反射获取String类的所有公共方法名称,并按字母顺序打印。 示例代码: import java.lang.reflect.Method; import java.util.Arrays;public …...

golang的slice扩容过程
Go 语言中的切片扩容机制是 Go 运行时的一个关键部分,它确保切片在动态增加元素时能够高效地管理内存。这个机制是在 Go 运行时内部实现的,涉及了内存分配、数据拷贝和容量调整。扩容的实现主要体现在 runtime.growslice 函数中。下面我们将深入分析 Go …...

Swift —— delegate 设计模式
一、什么是 delegate 模式 所谓 delegate 就是代理模式。简单来说,delegate 模式就是在类的函数里运行完一段代码后,你可以通过一个符合某个代理协议的属性来调代理的方法。其中,代理方法就是回调函数。 二、delegate 模式与闭包比的优势 …...

Docker 安装 Elasticsearch 8.x
Docker 安装 Elasticsearch 8.x 前言一、准备工作二、设置容器的目录结构三、启动一个临时的容器来复制配置文件四、复制配置文件到本地目录五、删除临时容器六、创建并运行容器,挂载本地目录七、修改文件配置监听端口八、端口配置:Host 网络模式 vs Por…...
Vue工程化开发脚手架Vue CLI
开发Vue有两种方式 核心包传统开发模式:基于html / css / js 文件,直接引入核心包,开发 Vue。工程化开发模式:基于构建工具(例如:webpack)的环境中开发Vue。 脚手架Vue CLI Vue CLl 是 Vue 官方…...

开源智慧巡检——无人机油田AI视频监控的未来之力
油田巡检,关乎能源命脉,却常受困于广袤地形、高危环境和人工效率瓶颈。管道泄漏、设备故障、非法闯入——这些隐患稍有疏忽,便可能酿成大患。传统巡检已无法满足现代油田对安全与效率的需求,而无人机油田巡检系统正以智能化之力重…...
)
数字ic后端设计从入门到精通(含fusion compiler, tcl教学)
pin 在集成电路设计中,特别是在使用工具如 Fusion Compiler 时,理解“引脚”(pin)的基础知识对于设计、优化和验证电路至关重要。以下是从 Fusion Compiler 的角度出发,关于引脚(pin)的基础知识…...
Django从零搭建卖家中心登陆与注册实战
在电商系统开发中,卖家中心是一个重要的组成部分,而用户注册与登陆则是卖家中心的第一步。本文将详细介绍如何使用Django框架从零开始搭建一个功能完善的卖家注册页面,包括前端界面设计和后端逻辑实现。 一、项目概述 我们将创建一个名为sel…...

MySQL表的使用(4)
首先回顾一下之前所学的增删查改,这些覆盖了平时使用的80% 我们上节课中学习到了MySQL的约束 其中Primary key 是主键约束,我们今天要学习的是外键约束 插入一个表 外键约束 父表 子表 这条记录中classid为5时候,不能插入; 删除…...
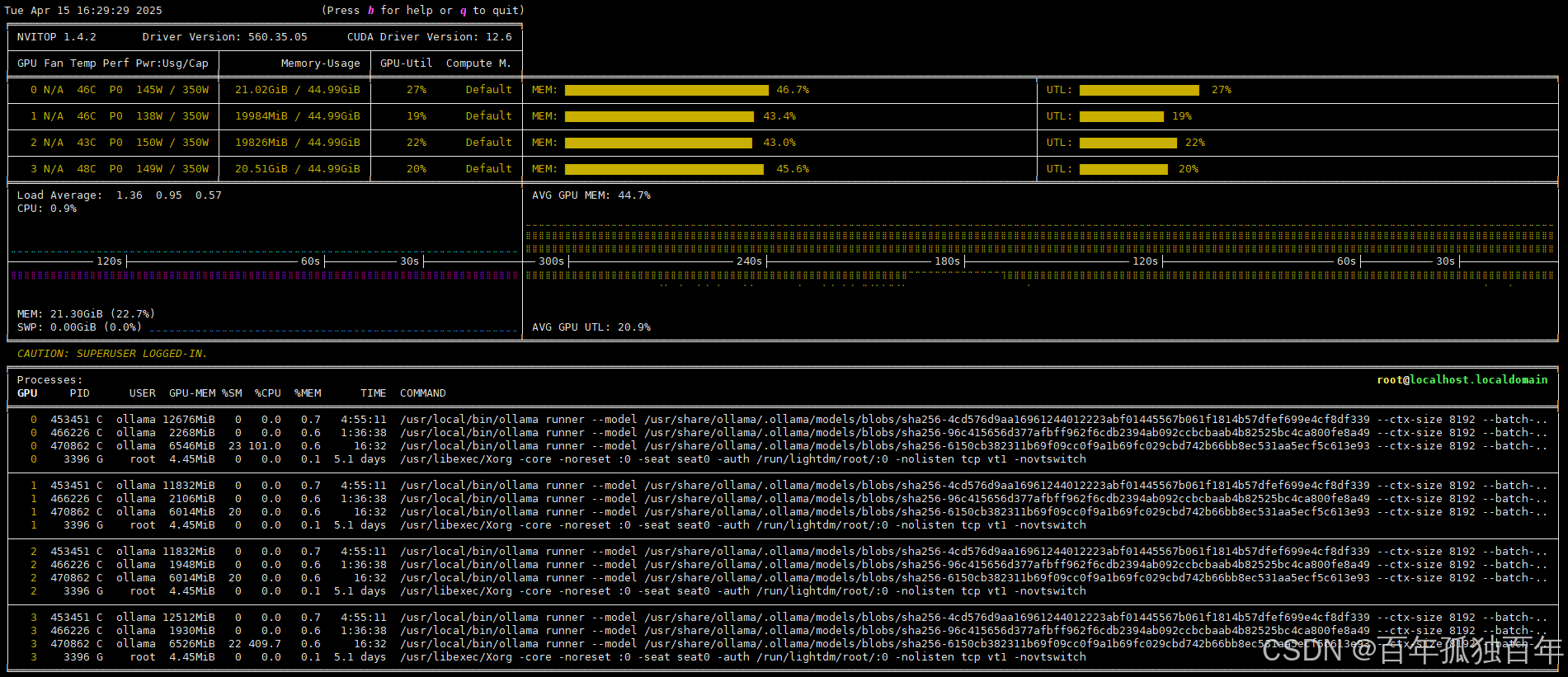
ollama修改配置使用多GPU,使用EvalScope进行模型压力测试,查看使用负载均衡前后的性能区别
文章目录 省流结论机器配置不同量化模型占用显存1. 创建虚拟环境2. 创建测试jsonl文件3. 新建测试脚本3. 默认加载方式,单卡运行模型3.1 7b模型输出213 tok/s3.1 32b模型输出81 tok/s3.1 70b模型输出43tok/s 4. 使用负载均衡,多卡运行4.1 7b模型输出217t…...

深入定制 QSlider——实现精准点击跳转与拖拽区分
在使用 Qt 编写界面应用时,QSlider 是一个常用的滑动控件。但你可能会注意到,默认情况下点击滑轨(groove)区域时,滑块并不会直接跳到鼠标点击的位置,而是按照内部的分页步进(page step)行为响应。此外,垂直 Slider 在点击最底部时还存在 releaseEvent(或 sliderRelea…...

Dijkstra算法求解最短路径—— 从零开始的图论讲解(2)
前言 在本系列第一期:从零开始的图论讲解(1)——图的概念,图的存储,图的遍历与图的拓扑排序-CSDN博客 笔者给大家介绍了 图的概念,如何存图,如何简单遍历图,已经什么是图的拓扑排序 按照之前的学习规划,今天笔者将继续带大家深入了解图论中的一个核心问题&#x…...

Java Spring Cloud框架使用及常见问题
Spring Cloud作为基于Spring Boot的分布式微服务框架,显著简化了微服务架构的开发与管理。其核心优势包括集成Eureka、Ribbon、Hystrix等组件,提供一站式服务发现、负载均衡、熔断容错等解决方案,支持动态配置与消息总线,实现高效…...