【数据结构】之散列
一、定义与基本术语
(一)、定义
散列(Hash)是一种将键(key)通过散列函数映射到一个固定大小的数组中的技术,因为键值对的映射关系,散列表可以实现快速的插入、删除和查找操作。在这里分辨一下散列表和哈希表(Hash table和Hash Map):
- 散列表:可能是一个更通用的概念,不一定强调键值对的映射关系。
- 哈希表:通常强调键值对的映射关系,类似于
HashMap或Dictionary。
不过呢,散列表和哈希表在本质上是相同的,我们平时使用一般也不会做很详细的区分。都是基于散列函数的数据结构,用于高效地存储和查找数据。
(二)、基本术语
- 哈希函数(Hash Function):也叫散列函数,将键映射到散列表中的索引位置的函数。
哈希函数的作用是将键(key)转换为一个索引值,这个索引值用于在底层的数组(或其他数据结构)中定位存储值(value)的位置。这个过程可以概括为以下几个步骤:
键到哈希值的转换:哈希函数接收一个键作为输入,并输出一个哈希值。这个哈希值通常是整数。
哈希值到索引的映射:哈希值通过某种映射机制(如取模运算)转换成数组的索引。这个索引决定了键值对在哈希表中的具体存储位置。
存储和检索:在存储数据时,键值对被放置在由键通过哈希函数和映射机制确定的索引处。在检索数据时,同样的键通过哈希函数和映射机制计算出索引,然后直接访问该索引处的值。
常见的散列(哈希)函数:
- 除留余数法:
hash(key) = key % table_size。- 乘留余数法:
hash(key) = (key * A) % table_size,其中A是一个常数。- 平方取中法:适用于键是字符串的情况。
- 哈希冲突(Hash Collision):两个不同的键通过散列函数映射到同一个索引位置。
由于哈希值的范围通常远小于键的总数,不同的键可能会经过哈希函数计算后得到相同的索引值,这种现象称为哈希冲突。为了解决哈希冲突,常用的方法包括:
链地址法:在每个数组索引位置维护一个链表,所有映射到该索引的键值对都存储在这个链表中。(是不是可以想到操作系统里的地址表)
开放寻址法:当发生冲突时,使用某种探测序列在数组中寻找下一个空闲位置。
再哈希法:使用另一个哈希函数计算一个新的索引值。
- 负载因子(Load Factor):散列表中元素数量与表的容量的比值,衡量哈希表的空间利用率,>0.75会引发重哈希。
如果负载因子过高,意味着更多的键被映射到同一个桶中,这会增加哈希冲突的概率,降低哈希表的性能;
相反,如果负载因子过低,意味着哈希表的存储空间没有得到充分利用,导致额外的空间浪费。
实例 1:理想的哈希函数
假设我们有一个哈希表,总桶数量为10,哈希函数设计得非常完美,将5个键均匀地分布在这10个桶中。
-
已使用的桶的数量:5
-
总桶的数量:10
-
负载因子:105=0.5
在这种情况下,负载因子为0.5,表示哈希表的使用率为50%,冲突的概率较低,性能较好。
实例 2:不理想的哈希函数
假设我们有同样的哈希表,总桶数量为10,但哈希函数设计得不理想,将5个键都映射到了前5个桶中。
-
已使用的桶的数量:5
-
总桶的数量:10
-
负载因子:105=0.5
尽管负载因子仍然是0.5,但由于键的分布不均匀,实际上前5个桶已经满了,而后5个桶是空的。这种情况下,虽然负载因子显示哈希表的使用率不高,但实际上已经出现了性能问题。
实例 3:高负载因子
假设我们有一个哈希表,总桶数量为5,但存储了8个键。
-
已使用的桶的数量:8
-
总桶的数量:5
-
负载因子:8/5=1.6
在这种情况下,负载因子为1.6,表示哈希表的使用率超过了100%,这意味着平均每个桶中有两个键,哈希冲突非常频繁,性能会显著下降。
实例 4:动态扩容
假设我们有一个动态扩容的哈希表,初始总桶数量为10,存储了15个键。
-
已使用的桶的数量:15
-
总桶的数量:10
-
负载因子:15/10=1.5
当负载因子达到一定阈值(例如1.0)时,哈希表会自动扩容,比如将桶的数量增加到20。扩容后,原有的键会重新通过哈希函数计算新的桶位置,从而降低负载因子,减少冲突。
-
扩容后的总桶的数量:20
-
负载因子:15/20=0.75
通过动态扩容,负载因子降低,哈希表的性能得到改善。
二、特点
-
高效性:
- 平均时间复杂度为 O(1) 的插入、删除和查找操作。
- 在最坏情况下(如所有键都映射到同一索引),时间复杂度为 O(n)。
-
灵活性:
- 可以处理任意类型的键(如整数、字符串等)。
- 可以通过选择合适的散列函数和冲突解决方法优化性能。
-
空间利用率:
- 散列表通常需要预留一定的空间来降低冲突概率。
- 负载因子通常控制在 0.5 到 0.8 之间。
三、基本操作实现
基本操作就包括:
定义、插入,删除,查找
1. 散列表的基本操作
class HashTable{
private:vector<int> table;int size;// 哈希函数int hashFunction(int key) {return key % size;}public:// 构造函数HashTable(int s) : size(s) {table.resize(size, -1);}// 插入元素void insert(int key) {int index = hashFunction(key);while (table[index] != -1) {index = (index + 1) % size;}table[index] = key;}// 查找元素bool search(int key) {int index = hashFunction(key);int start = index;while (table[index] != -1) {if (table[index] == key) {return true;}index = (index + 1) % size;if (index == start) {break;}}return false;}// 删除元素void remove(int key) {int index = hashFunction(key);int start = index;while (table[index] != -1) {if (table[index] == key) {table[index] = -1;return;}index = (index + 1) % size;if (index == start) {break;}}}// 打印哈希表void printTable() {for (int i = 0; i < size; ++i) {cout << "Index " << i << ": ";if (table[i] != -1) {cout << table[i];} else {cout << "Empty";}cout << endl;}}
};int main() {HashTable hashTable(10);// 插入元素hashTable.insert(12);hashTable.insert(22);hashTable.insert(3);// 打印哈希表cout << "After insertion:" << endl;hashTable.printTable();// 查找元素cout << "\nSearching for 22: " << (hashTable.search(22) ? "Found" : "Not found") << endl;cout << "Searching for 10: " << (hashTable.search(10) ? "Found" : "Not found") << endl;// 删除元素hashTable.remove(22);cout << "\nAfter deletion of 22:" << endl;hashTable.printTable();return 0;
}2. 使用内置函数
以上都是为了帮助理解,在实际的代码中,std::unordered_map 和std::unordered_set 都属于标准库中的哈希表实现,借助它我们可以直接运用其内置函数来完成基本操作,无需手动实现哈希表。两者适用的问题不同:
std::unordered_map:存储的是键值对(key - value),每个元素由一个键和一个与之关联的值组成。键是唯一的,通过键可以快速查找对应的值。例如,我们可以用unordered_map来存储学生的学号和对应的姓名,学号作为键,姓名作为值。Leetcode例题参考:std::unordered_set:只存储单一的元素,每个元素都是唯一的。它更侧重于判断某个元素是否存在于集合中。例如可以用unordered_set来存储一组不重复的单词。Leetcode例题参考:202. 快乐数
具体来说,常用的内置函数包括:
1. 插入元素
insert:把键值对插入到unordered_map中。若键已存在,则不会插入新元素。emplace:原位构造并插入一个新元素,若键已存在,则不插入。operator[]:若键存在,返回对应的值;若键不存在,则插入该键,并默认初始化其值。2. 查找元素
find:查找指定键的元素,若找到则返回指向该元素的迭代器;若未找到,则返回end()迭代器。(所以我们判断指定键的元素在不在表中一般用的代码类似:if(seen.find(n)==seen.end()) )count:返回指定键的元素数量,由于unordered_map中键是唯一的,所以返回值要么是 0(键不存在),要么是 1(键存在)。3. 删除元素
erase:删除指定键的元素,可接受键或迭代器作为参数。4. 其他常用函数
size:返回表中元素的数量。empty:判断表是否为空。clear:清空表中的所有元素。
在这里也给出一个应用的例子:
#include <iostream>
#include <unordered_map>
#include <unordered_set>int main() {// 使用 std::unordered_mapstd::unordered_map<int, std::string> myMap;myMap[1] = "apple";myMap[2] = "banana";auto itMap = myMap.find(1);if (itMap != myMap.end()) {std::cout << "Value for key 1 in map: " << itMap->second << std::endl;}// 使用 std::unordered_setstd::unordered_set<std::string> mySet;mySet.insert("apple");mySet.insert("banana");auto itSet = mySet.find("apple");if (itSet != mySet.end()) {std::cout << "Element 'apple' found in set." << std::endl;}return 0;
}四、练习
1. 基本概念练习

首先明确单射、满射的含义:
理想的单射哈希函数:每个键都映射到一个唯一的索引,没有任何两个键共享同一个索引。这可以完全避免哈希冲突,使得每个键都可以直接映射到一个唯一的桶或数组位置。理想的满射哈希函数:所有的桶或数组索引至少被一个键映射到。这确保了数组的空间被充分利用,没有浪费的桶或索引。
但以上都属于理想情况,在实际设计哈希函数时,目标是尽量减少冲突(接近单射),同时尽可能均匀地分布键到所有可用的索引(接近满射)。
由此分析:
A:错误。由于 ∣A∣<∣S∣,即地址空间小于词条空间,不可能每个词条都映射到一个唯一的地址,因此 h 不可能是满射。
B:正确。从A的分析就能知道,由于 ∣A∣<∣S∣,不同的词条必须映射到相同的地址以避免某些词条无法映射,因此 h 不可能是单射。
C:错误。虽然 ∣A∣<∣S∣,但 h 仍然可以是满射,只要每个地址都至少被一个词条映射到。
D:错误。单射要求每个地址只能映射到一个词条。在哈希表中,由于冲突的存在,一个地址可能映射到多个词条,因此 h 不一定是单射。

我们从构造散列函数的目的进行分析,可以找出正确和错误的说法。
单射:在散列表的上下文中,单射并不是一个好的特性,因为不同的键映射到同一个索引是不可避免的,这是由于散列表的大小有限。
值域覆盖:一个好的散列函数应该尽可能覆盖散列表的所有地址,这样可以提高空间利用率和减少冲突。
一致性:同一个词条每次计算得到的哈希值应该是相同的,这样才能保证数据的一致性。
效率:散列函数的计算应该简单快速,以便于快速定位和检索数据。
均匀分布:散列函数应该能够将不同的词条均匀地分布在散列表中,避免某些区域过于拥挤,这有助于减少冲突。
冲突几率:一个好的散列函数应该设计得能够最小化冲突的概率,这样可以提高散列表的性能。

对于 h1(key)=key%12,计算每个元素的哈希值:
0%12=0
8%12=8
16%12=4
24%12=0 (与0冲突)
32%12=8 (与8冲突)
40%12=4 (与16冲突)
48%12=0 (与0, 24, 32冲突)
56%12=8 (与8, 32, 48冲突)
64%12=4 (与16, 40冲突)
不同的哈希值有:{0,4,8},共3个不同的元素。
对于 h2(key)=key%11,计算每个元素的哈希值:
0%11=0
8%11=8
16%11=5
24%11=2
32%11=10
40%11=7
48%11=4
56%11=1
64%11=9
所有的哈希值都是不同的,因此有9个不同的元素。

A. 错误。独立链法中,每个桶(数组的每个位置)都链接到一个链表,冲突的词条存放在对应的链表中,而不是桶数组内部。
B. 正确。开放定址法中,当发生冲突时,词条会尝试在数组中找到下一个空闲位置存放,因此实际存放位置可能与散列函数计算出的位置不同。
C. 错误。开放定址法不会使用链表存放词条,而是在数组中寻找下一个空闲位置。
D. 错误。即使散列函数设计得再好,由于散列表的大小有限,不同的键仍然可能映射到同一个索引,需要冲突解决策略。

h(4)=(3×4+5)%11=17%11=6
也就是说词条4应该被放在数组索引6的位置,但是我们发现索引6处非空闲,存储的是15,需要使用线性试探来寻找下一个空闲位置。线性试探的公式通常是 hi=(h+i)%size,其中 i 是探测次数,从0开始。
第一次试探:h0=6(已占用)
第二次试探:h1=(6+1)%11=7(已被26占用)
第三次试探:h2=(6+2)%11=8(空)
所以键4的实际存放位置是数组索引8的位置,即 A[8]。

开放定址法是一种处理哈希表冲突的方法,其中平方试探法是开放定址法的一种。在平方试探法中,如果发生冲突,我们按照 hi=(h+i2)%size 的公式来探测下一个可能的空槽位。
当使用平方试探法时,为了保证哈希表中至少有一个空槽位,装填因子load factor也就是负载因子不能超过 0.5。
这是因为在最坏的情况下,如果装填因子超过 0.5,那么在探测过程中可能会遇到一个“循环”,即所有的槽位都被占用,没有空槽位可以插入新的词条。

(1) H(9)=9%11=9
所以关键字为9的节点应该被存储在索引为9的位置。先对给出的散列表中元素进行插入:
给定的关键字已经按顺序插入散列表,我们先计算它们的哈希值并确定它们的存储位置:
15: 15%11=4 → 存储在位置 4
31: 31%11=9 → 存储在位置 9
27: 27%11=5 → 存储在位置 5
14: 14%11=3 → 存储在位置 3
10: 10%11=10 → 存储在位置 10
16: 16%11=5 → 与关键字 27 冲突,线性探测到位置 6
11: 11%11=0 → 存储在位置 0
查找后发现索引为9的位置已被占用,那就线性探测继续找下一个空位。
位置 10 已被关键字 10 占用
位置 11 为空
因此,关键字 9 将被存储在位置 11。
A={11,31,∗,14,∗,0,15,26,16,5,9,∗}
(2) 平均成功查找长度
15: 直接在位置 4 找到,长度为 1
31: 直接在位置 9 找到,长度为 1
27: 直接在位置 5 找到,长度为 1
14: 直接在位置 3 找到,长度为 1
10: 直接在位置 10 找到,长度为 1
16: 在位置 5 冲突,探测到位置 6,长度为 2
11: 直接在位置 0 找到,长度为 1
9: 在位置 9 冲突,探测到位置 11,长度为 2
总长度 = 1+1+1+1+1+2+1+2=10 ,关键字数量 = 8
ASL(成功) =10/8 =5/4
(3) 失败的平均查找长度
采用线性探测法处理冲突时,若该地址有元素,从该地址开始,依次探测下一个地址,直到找到空地址。将每个散列地址查找失败的比较次数相加,再除以散列地址的个数,就能得到失败的平均查找长度。
A={11,31,∗,14,∗,0,15,26,16,5,9,∗}
位置0:依次探测0,1,2,在索引为2处找到空桶,比较次数3;
位置1:依次探测1,2,在索引为2处找到空桶,比较次数2;
位置2:在索引为2处找到空桶,比较次数1;
位置3:依次探测3,4,在索引为4处找到空桶,比较次数2;
位置4:在索引为4处找到空桶,比较次数1;
位置5:依次探测5,6,7,8,9,10,11,在索引为11处找到空桶,比较次数为7;
位置6:依次探测6,7,8,9,10,11,在索引为11处找到空桶,比较次数为6;
位置7:依次探测7,8,9,10,11,在索引为11处找到空桶,比较次数为5;
位置8:依次探测8,9,10,11,在索引为11处找到空桶,比较次数为4;
位置9:依次探测9,10,11,在索引为11处找到空桶,比较次数为3;
位置10:依次探测10,11,在索引为11处找到空桶,比较次数为2;
位置11:在索引为11处找到空桶,比较次数为1;
总长度 = 3+2+1+2+1+7+6+5+4+3+2+1=11 空桶数量 = 3
ASL(失败) = 11
五、Leetcode练习题汇总
| 题号 | 题目名称 | 难度等级 | 关键词 |
|---|---|---|---|
| 1 | 两数之和 | 简单 | 哈希表、数组 |
| 202 | 快乐数 | 简单 | 哈希表、数学、双指针 |
| 217 | 存在重复元素 | 简单 | 哈希表、数组、排序 |
| 219 | 存在重复元素 II | 简单 | 哈希表、数组 |
| 242 | 有效的字母异位词 | 简单 | 哈希表、字符串、排序 |
| 349 | 两个数组的交集 | 简单 | 哈希表、双指针、二分查找、排序 |
| 350 | 两个数组的交集 II | 简单 | 哈希表、双指针、二分查找、排序 |
| 409 | 最长回文串 | 简单 | 哈希表、字符串、贪心 |
| 451 | 根据字符出现频率排序 | 中等 | 哈希表、字符串、排序、堆(优先队列) |
| 560 | 和为 K 的子数组 | 中等 | 哈希表、数组、前缀和 |
| 705 | 设计哈希集合 | 简单 | 哈希表、设计 |
| 706 | 设计哈希映射 | 简单 | 哈希表、设计 |
| 771 | 宝石与石头 | 简单 | 哈希表、字符串 |
| 811 | 子域名访问计数 | 简单 | 哈希表、字符串 |
| 953 | 验证外星语词典 | 简单 | 哈希表、字符串 |
| 1207 | 独一无二的出现次数 | 简单 | 哈希表、数组 |
| 1365 | 有多少小于当前数字的数字 | 简单 | 哈希表、数组、排序、计数 |
| 1481 | 不同整数的最少数目 | 中等 | 哈希表、贪心、排序、堆(优先队列) |
相关文章:
【数据结构】之散列
一、定义与基本术语 (一)、定义 散列(Hash)是一种将键(key)通过散列函数映射到一个固定大小的数组中的技术,因为键值对的映射关系,散列表可以实现快速的插入、删除和查找操作。在这…...
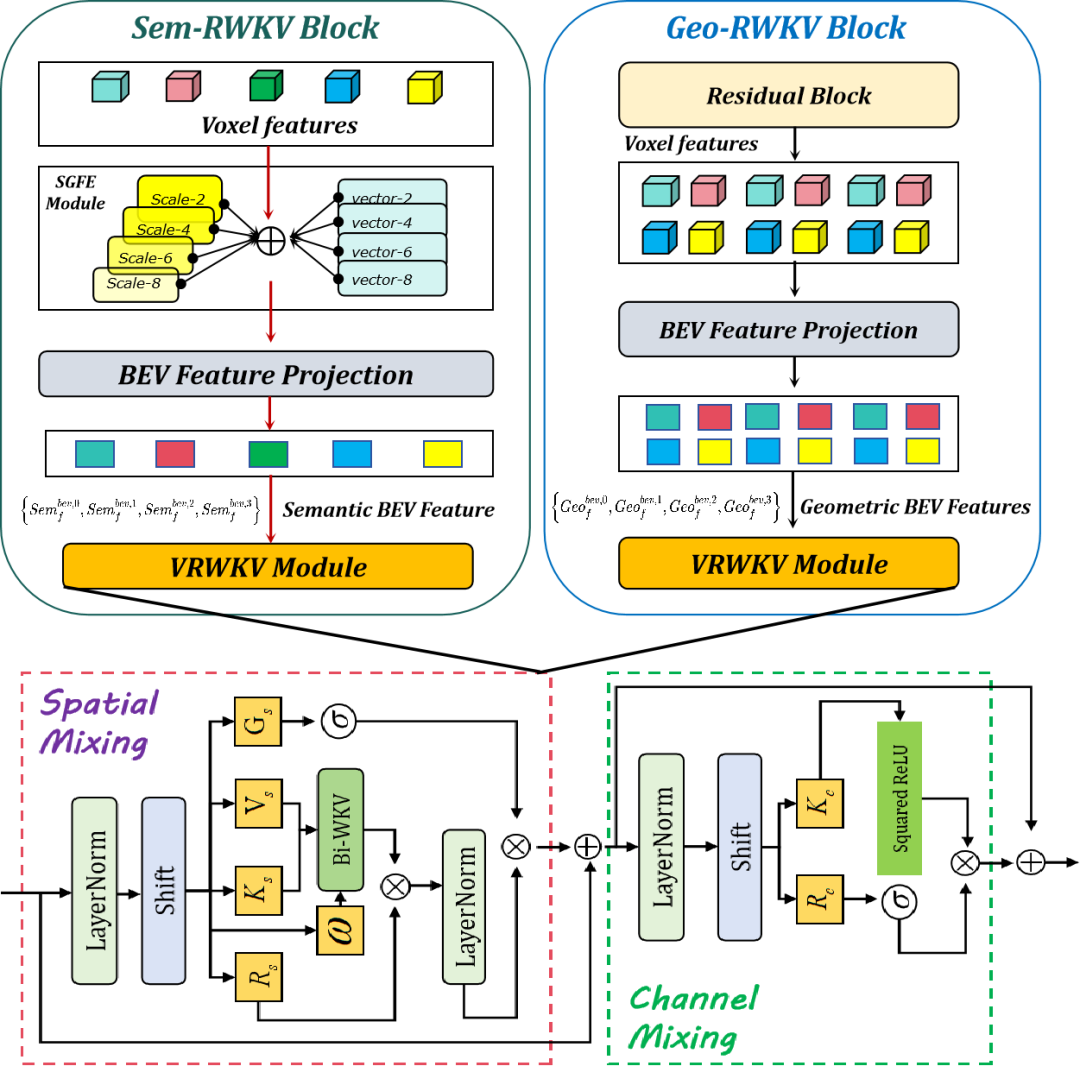
空地机器人在复杂动态环境下,如何高效自主导航?
随着空陆两栖机器人(AGR)在应急救援和城市巡检等领域的应用范围不断扩大,其在复杂动态环境中实现自主导航的挑战也日益凸显。对此香港大学王俊铭基于阿木实验室P600无人机平台自主搭建了一整套空地两栖机器人,使用Prometheus开源框架完成算法的仿真验证与…...
:Python 中 Lambda函数详解)
python小记(十二):Python 中 Lambda函数详解
Python 中 Lambda函数详解 Lambda函数详解:从入门到实战一、什么是Lambda函数?二、Lambda的核心语法与特点1. 基础语法2. 与普通函数对比 三、Lambda的六大应用场景(附代码示例)1. 基本数学运算2. 列表排序与自定义规则3. 数据映射…...
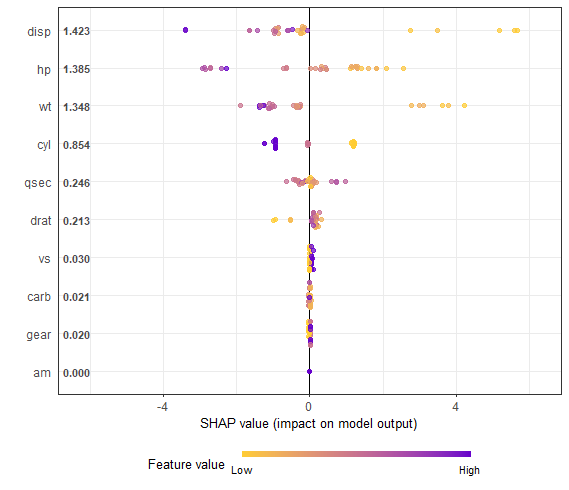
第二十一讲 XGBoost 回归建模 + SHAP 可解释性分析(利用R语言内置数据集)
下面我将使用 R 语言内置的 mtcars 数据集,模拟一个完整的 XGBoost 回归建模 SHAP 可解释性分析 实战流程。我们将以预测汽车的油耗(mpg)为目标变量,构建 XGBoost 模型,并用 SHAP 来解释模型输出。 🚗 示例…...
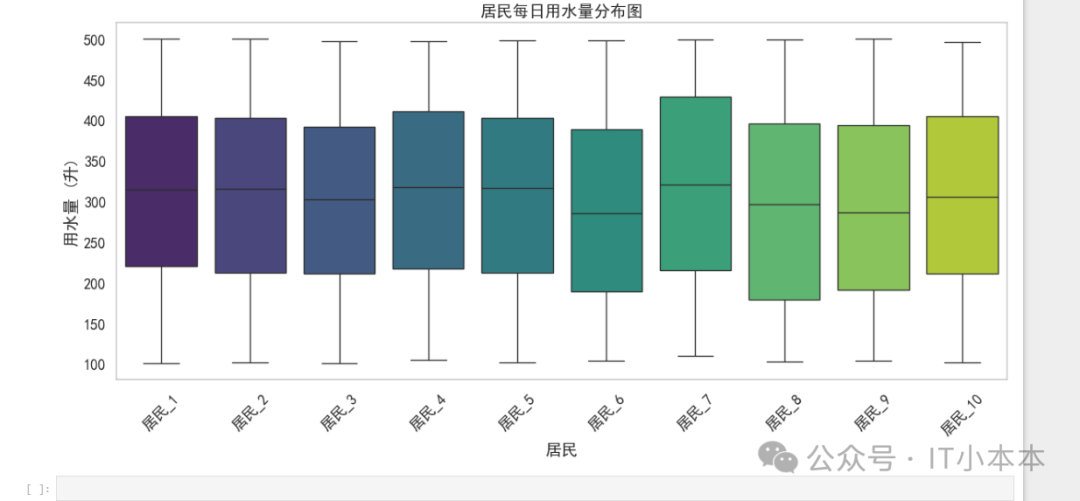
数据分析实战案例:使用 Pandas 和 Matplotlib 进行居民用水
原创 IT小本本 IT小本本 2025年04月15日 18:31 北京 本文将使用 Matplotlib 及 Seaborn 进行数据可视化。探索如何清理数据、计算月度用水量并生成有价值的统计图表,以便更好地理解居民的用水情况。 数据处理与清理 读取 Excel 文件 首先,我们使用 pan…...

Asp.NET Core WebApi 创建带鉴权机制的Api
构建一个包含 JWT(JSON Web Token)鉴权的 Web API 是一种常见的做法,用于保护 API 端点并验证用户身份。以下是一个基于 ASP.NET Core 的完整示例,展示如何实现 JWT 鉴权。 1. 创建 ASP.NET Core Web API 项目 使用 .NET CLI 或 …...

hash.
Redis 自身就是键值对结构 Redis 自身的键值对结构就是通过 哈希 的方式来组织的 哈希类型中的映射关系通常称为 field-value,用于区分 Redis 整体的键值对(key-value), 注意这里的 value 是指 field 对应的值,不是键…...
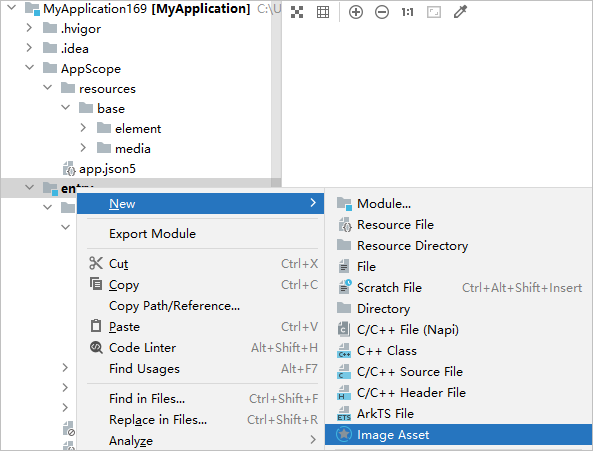
记录鸿蒙应用上架应用未配置图标的前景图和后景图标准要求尺寸1024px*1024px和标准要求尺寸1024px*1024px
审核报错【①应用未配置图标的前景图和后景图,标准要求尺寸1024px*1024px且需下载HUAWEI DevEco Studio 5.0.5.315或以上版本进行图标再处理、②应用在展开状态下存在页面左边距过大的问题, 应用在展开状态下存在页面右边距过大的问题, 当前页面左边距: 504 px, 当前页面右边距…...

golang-常见的语法错误
https://juejin.cn/post/6923477800041054221 看这篇文章 Golang 基础面试高频题详细解析【第一版】来啦~ 大叔说码 for-range的坑 func main() { slice : []int{0, 1, 2, 3} m : make(map[int]*int) for key, val : range slice {m[key] &val }for k, v : …...

Google最新《Prompt Engineering》白皮书全解析
近期有幸拿到了Google最新发布的《Prompt Engineering》白皮书,这是一份由Lee Boonstra主笔,Michael Sherman、Yuan Cao、Erick Armbrust、Antonio Gulli等多位专家共同贡献的权威性指南,发布于2025年2月。今天我想和大家分享这份68页的宝贵资…...
如何快速部署基于Docker 的 OBDIAG 开发环境
很多开发者对 OceanBase的 SIG社区小组很有兴趣,但如何将OceanBase的各类工具部署在开发环境,对于不少开发者而言都是比较蛮烦的事情。例如,像OBDIAG,其在WINDOWS系统上配置较繁琐,需要单独搭建C开发环境。此外&#x…...

[LeetCode 1306] 跳跃游戏3(Ⅲ)
题面: LeetCode 1306 思路: 只要能跳到其中一个0即可,和跳跃游戏1/2完全不同了,记忆化暴搜即可。 时间复杂度: O ( n ) O(n) O(n) 空间复杂度: O ( n ) O(n) O(n) 代码: dfs vector<…...
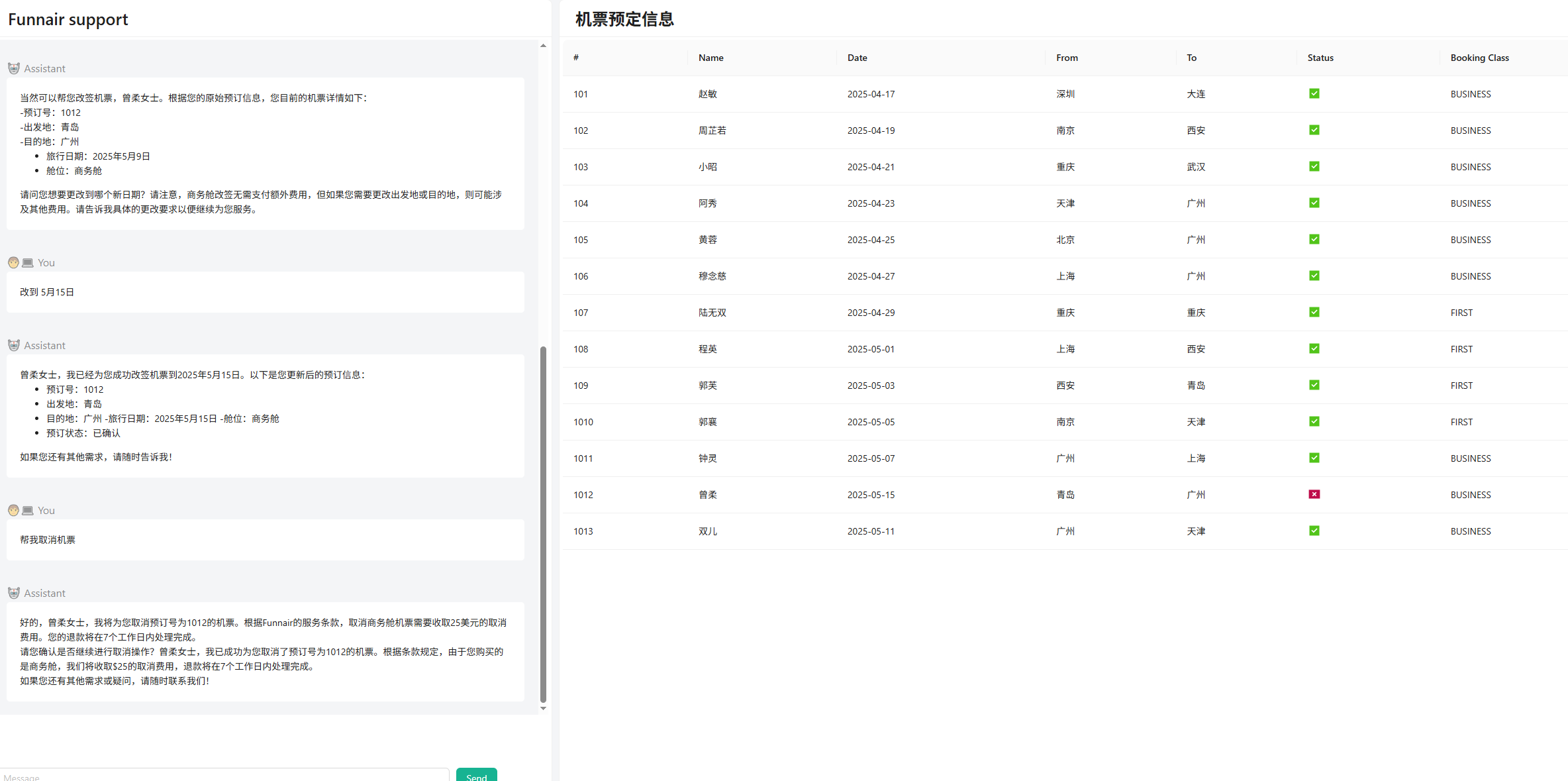
spring-ai-alibaba使用Agent实现智能机票助手
示例目标是使用 Spring AI Alibaba 框架开发一个智能机票助手,它可以帮助消费者完成机票预定、问题解答、机票改签、取消等动作,具体要求为: 基于 AI 大模型与用户对话,理解用户自然语言表达的需求支持多轮连续对话,能…...

STM32平衡车开发实战教程:从零基础到项目精通
STM32平衡车开发实战教程:从零基础到项目精通 一、项目概述与基本原理 1.1 平衡车工作原理 平衡车是一种基于倒立摆原理的两轮自平衡小车,其核心控制原理类似于人类保持平衡的过程。当人站立不稳时,会通过腿部肌肉的快速调整来维持平衡。平…...

使用DeepSeek AI高效降低论文重复率
一、论文查重原理与DeepSeek降重机制 1.1 主流查重系统工作原理 文本比对算法:连续字符匹配(通常13-15字符)语义识别技术:检测同义替换和结构调整参考文献识别:区分合理引用与不当抄袭跨语言检测:中英文互译内容识别1.2 DeepSeek降重核心技术 深度语义理解:分析句子核心…...

linux多线(进)程编程——(7)消息队列
前言 现在修真界大家的沟通手段已经越来越丰富了,有了匿名管道,命名管道,共享内存等多种方式。但是随着深入使用人们逐渐发现了这些传音术的局限性。 匿名管道:只能在有血缘关系的修真者(进程)间使用&…...
——ListView控件详解)
WinForm真入门(14)——ListView控件详解
一、ListView 控件核心概念与功能 ListView 是 WinForm 中用于展示结构化数据的多功能列表控件,支持多列、多视图模式及复杂交互,常用于文件资源管理器、数据报表等场景。 核心特点: 支持 5种视图模式:Details&…...

Python + Playwright:规避常见的UI自动化测试反模式
Python + Playwright:规避常见的UI自动化测试反模式 前言反模式一:整体式页面对象(POM)反模式二:具有逻辑的页面对象 - POM 的“越界”行为反模式三:基于 UI 的测试设置 - 缓慢且脆弱的“舞台搭建”反模式四:功能测试过载 - “试图覆盖一切”的测试反模式之间的关联与核…...
从服务器多线程批量下载文件到本地
1、客户端安装 aria2 下载地址:aria2 解压文件,然后将文件目录添加到系统环境变量Path中,然后打开cmd,输入:aria2c 文件地址,就可以下载文件了 2、服务端配置nginx文件服务器 server {listen 8080…...

循环神经网络 - 深层循环神经网络
如果将深度定义为网络中信息传递路径长度的话,循环神经网络可以看作既“深”又“浅”的网络。 一方面来说,如果我们把循环网络按时间展开,长时间间隔的状态之间的路径很长,循环网络可以看作一个非常深的网络。 从另一方面来 说&…...
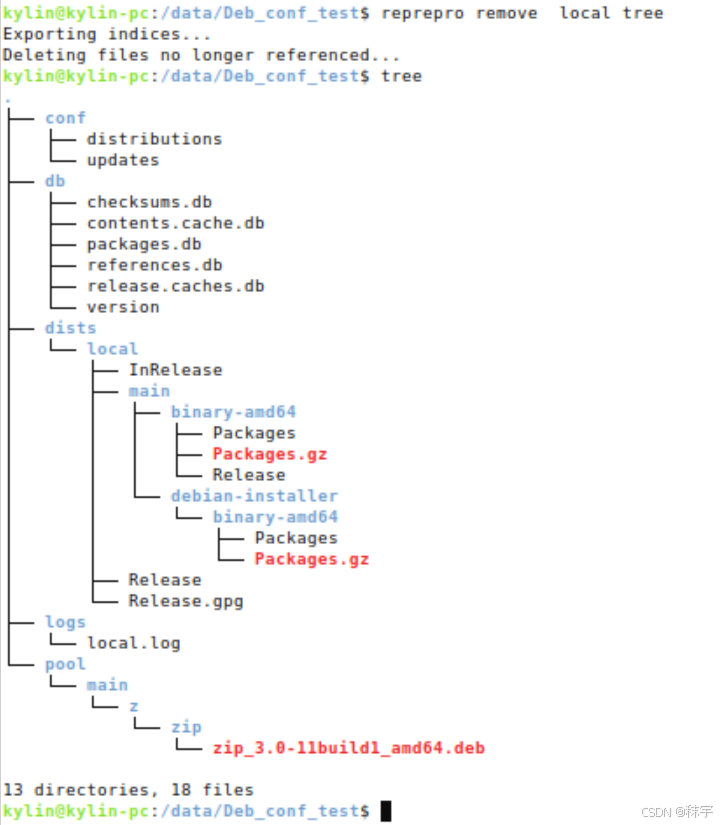
linux运维篇-Ubuntu(debian)系操作系统创建源仓库
适用范围 适用于Ubuntu(Debian)及其衍生版本的linux系统 例如,国产化操作系统kylin-desktop-v10 简介 先来看下我们需要创建出来的仓库目录结构 Deb_conf_test apt源的主目录 conf 配置文件存放目录 conf目录下存放两个配置文件&…...

深度学习之微积分
2.4.1 导数和微分 2.4.2 偏导数 
20242817李臻《Linux⾼级编程实践》第7周
20242817李臻《Linux⾼级编程实践》第7周 一、AI对学习内容的总结 第八章:多线程编程 8.1 多线程概念 进程与线程的区别: 进程是资源分配单位,拥有独立的地址空间、全局变量、打开的文件等。线程是调度单位,在同一进程内的线程…...

浙江大学:DeepSeek如何引领智慧医疗的革新之路?|48页PPT下载方法
导 读INTRODUCTION 随着人工智能技术的飞速发展,DeepSeek等大模型正在引领医疗行业进入一个全新的智慧医疗时代。这些先进的技术不仅正在改变医疗服务的提供方式,还在提高医疗质量和效率方面展现出巨大潜力。 想象一下,当你走进医院ÿ…...
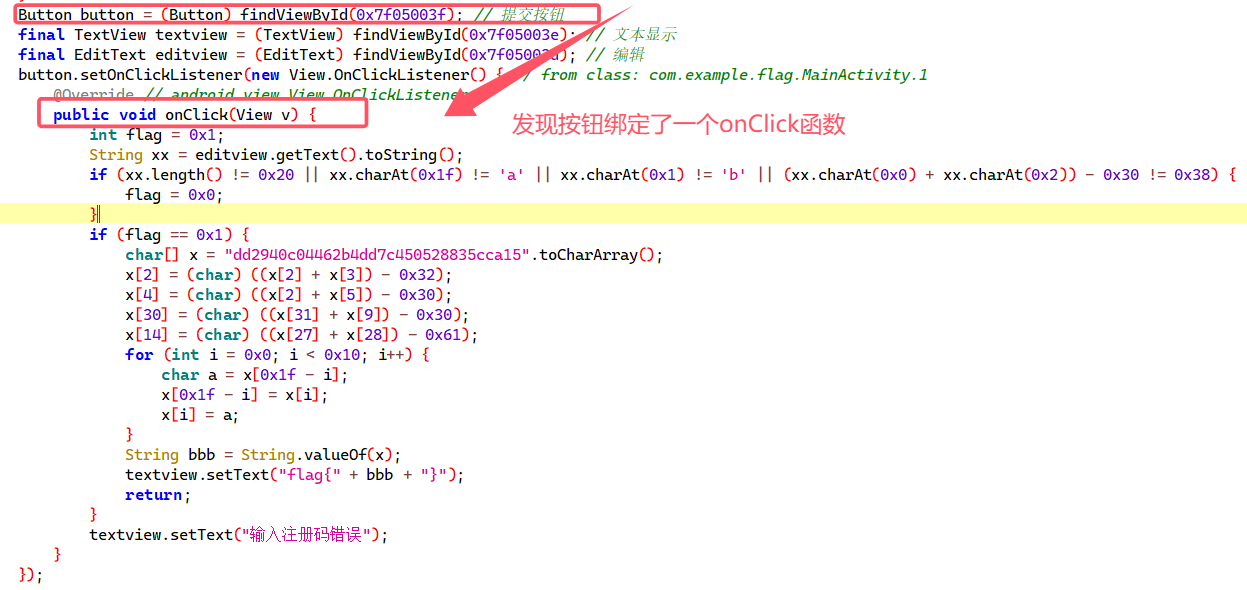
Android基础彻底解析-APK入口点,xml,组件,脱壳,逆向
第一章:引言与背景 Android逆向工程,作为一种深入分析Android应用程序的技术,主要目的就是通过分析应用的代码、资源和行为来理解其功能、结构和潜在的安全问题。它不仅仅是对应用进行破解或修改,更重要的是帮助开发者、研究人员和安全人员发现并解决安全隐患。 本文主要对…...
ubuntu 2204 安装 vcs 2018
安装评估 系统 : Ubuntu 22.04.1 LTS 磁盘 : ubuntu 自身占用了 9.9G , 按照如下步骤 安装后 , 安装后的软件 占用 13.1G 仓库 : 由于安装 libpng12-0 , 添加了一个仓库 安装包 : 安装了多个包(lsb及其依赖包 libpng12-0)安装步骤 参考 ubuntu2018 安装 vcs2018 安装该…...
详解:从零开始掌握(3))
Express中间件(Middleware)详解:从零开始掌握(3)
实用中间件模式25例 1. 基础增强模式 请求属性扩展 function extendRequest() {return (req, res, next) > {req.getClientLanguage () > {return req.headers[accept-language]?.split(,)[0] || en;};next();}; } 响应时间头 function responseTime() {return (r…...

深入理解微信小程序开发:架构、组件化与进阶实战
📘博文正文: 深入理解微信小程序开发:架构、组件化与进阶实战 微信小程序已成为移动互联网的重要入口。随着业务复杂度提升,仅靠入门知识已无法应对日常开发需求。本文将深入剖析小程序开发架构、组件化模式、状态管理、网络封装…...

逆向|中国产业政策大数据平台|请求体加密
2025-04-11 逆向地址:aHR0cDovL3poZW5nY2UuMmIuY24v 打开开发者工具出现debugger,直接注入脚本过掉无限debugger let aaa Function.prototype.constructor; Function.prototype.constructor function (params) { if(params ‘debugger’){ console.log(params); return null…...

在SpringBoot中访问 static 与 templates 目录下的内容
目录 步骤一:添加 Thymeleaf 依赖 (处理 Templates 目录)步骤二:配置静态资源路径 (可选但建议了解)步骤三:访问不同目录下的 HTML 文件访问 static 目录下的 HTML 文件访问 templates 目录下的 HTML 文件 总结 在使用 Spring Boot 开发 Web …...