交叉熵在机器学习中的应用解析
文章目录
- 核心概念
- 香农信息量(自信息)
- 熵(Entropy)
- KL散度(Kullback-Leibler Divergence)
- 交叉熵
- 在机器学习中的应用
- 作为损失函数
- 对于二分类(Binary Classification):
- 对于多分类(Multiclass Classification):
- 多标签分类(Multi-label Classification)
- 其他应用场景
- 实例
- 手撸计算
- 实现示例(PyTorch)
- 注意事项
- 直观解释
- 为什么用交叉熵?
- 变体与改进
交叉熵(Cross-Entropy)是信息论和机器学习中的一个重要概念,用于衡量两个概率分布之间的差异。它在分类任务(如逻辑回归、神经网络)中常作为损失函数使用。
核心概念
香农信息量(自信息)
对于一个具有概率 P ( x ) P(x) P(x) 的事件 x x x,其信息量 I ( x ) I(x) I(x) 定义为:
I ( x ) = − log b P ( x ) I(x) = -\log_b P(x) I(x)=−logbP(x)
其中:
- log b \log_b logb 是以 b b b 为底的对数,常用的底数有:
- b = 2 b = 2 b=2:信息量单位为比特(bit)。
- b = e b = e b=e:信息量单位为奈特(nat)。
- b = 10 b = 10 b=10:信息量单位为哈特(hart)。
- 信息量 I ( x ) I(x) I(x) 表示事件 x x x 发生时所携带的信息的多少,概率越低的事件信息量越大。
熵(Entropy)
熵(平均信息量)
熵是随机变量不确定性的度量,定义为信息量的期望:
H ( X ) = − ∑ x ∈ X P ( x ) log b P ( x ) H(X) = -\sum_{x \in X} P(x) \log_b P(x) H(X)=−x∈X∑P(x)logbP(x)
对于连续随机变量,熵可以表示为:
H ( X ) = − ∫ − ∞ ∞ p ( x ) log b p ( x ) d x H(X) = -\int_{-\infty}^{\infty} p(x) \log_b p(x) \, dx H(X)=−∫−∞∞p(x)logbp(x)dx
其中 ( p(x) ) 是概率密度函数。
表示一个概率分布自身的不确定性。对于离散分布 P P P,熵定义为:
H ( P ) = − ∑ i P ( x i ) log P ( x i ) H(P) = -\sum_{i} P(x_i) \log P(x_i) H(P)=−i∑P(xi)logP(xi)
- 熵越大,不确定性越高。
KL散度(Kullback-Leibler Divergence)
衡量两个分布 P P P(真实分布)和 Q Q Q(预测分布)的差异:
D K L ( P ∥ Q ) = ∑ i P ( x i ) log P ( x i ) Q ( x i ) D_{KL}(P \| Q) = \sum_{i} P(x_i) \log \frac{P(x_i)}{Q(x_i)} DKL(P∥Q)=i∑P(xi)logQ(xi)P(xi)
- KL散度非负,且不对称。
- 当 P = Q P = Q P=Q 时,交叉熵最小,等于 P P P 的熵。
交叉熵
交叉熵是熵与KL散度的组合:
H ( P , Q ) = H ( P ) + D K L ( P ∥ Q ) = − ∑ i P ( x i ) log Q ( x i ) H(P, Q) = H(P) + D_{KL}(P \| Q) = -\sum_{i} P(x_i) \log Q(x_i) H(P,Q)=H(P)+DKL(P∥Q)=−i∑P(xi)logQ(xi)
- 当 P P P 是真实分布(如one-hot标签), Q Q Q 是模型预测时,最小化交叉熵等价于最小化KL散度。
在机器学习中的应用
作为损失函数
对于二分类(Binary Classification):
- 公式
L = − 1 N ∑ i = 1 N [ y i log ( p i ) + ( 1 − y i ) log ( 1 − p i ) ] L = -\frac{1}{N} \sum_{i=1}^N \left[ y_i \log(p_i) + (1-y_i) \log(1-p_i) \right] L=−N1i=1∑N[yilog(pi)+(1−yi)log(1−pi)]
其中 y i ∈ { 0 , 1 } y_i \in \{0,1\} yi∈{0,1} 是真实标签, p i p_i pi 是模型预测为正类的概率。 - 场景
逻辑回归、神经网络二分类输出层(如Sigmoid激活)。
对于多分类(Multiclass Classification):
- 公式(分类交叉熵,Categorical Cross-Entropy)
L = − 1 N ∑ i = 1 N ∑ c = 1 C y i , c log ( p i , c ) L = -\frac{1}{N} \sum_{i=1}^N \sum_{c=1}^C y_{i,c} \log(p_{i,c}) L=−N1i=1∑Nc=1∑Cyi,clog(pi,c)- y i , c y_{i,c} yi,c:样本 i i i 属于类别 c c c 的真实标签(one-hot编码)。
- p i , c p_{i,c} pi,c:模型预测样本 i i i 属于类别 c c c 的概率。
- 场景
Softmax输出层配合交叉熵(如ResNet、Transformer的分类头)。
多标签分类(Multi-label Classification)
- 特点:每个样本可能属于多个类别,使用二元交叉熵对每个类别独立计算损失。
- 公式:
L = − 1 N ∑ i = 1 N ∑ c = 1 C [ y i , c log ( p i , c ) + ( 1 − y i , c ) log ( 1 − p i , c ) ] L = -\frac{1}{N} \sum_{i=1}^N \sum_{c=1}^C \left[ y_{i,c} \log(p_{i,c}) + (1-y_{i,c}) \log(1-p_{i,c}) \right] L=−N1i=1∑Nc=1∑C[yi,clog(pi,c)+(1−yi,c)log(1−pi,c)]
其他应用场景
- 生成模型:GAN中判别器的损失函数常使用交叉熵衡量真实/生成分布的差异。
- 语言模型:预测下一个词的概率分布(如BERT、GPT的预训练目标)。
- 强化学习:策略梯度方法中优化策略分布与最优分布的交叉熵。
实例
手撸计算
假设真实分布 P = [ 1 , 0 ] P = [1, 0] P=[1,0](类别1),模型预测 Q = [ 0.8 , 0.2 ] Q = [0.8, 0.2] Q=[0.8,0.2]:
H ( P , Q ) = − 1 ⋅ log ( 0.8 ) − 0 ⋅ log ( 0.2 ) ≈ 0.223 H(P, Q) = -1 \cdot \log(0.8) - 0 \cdot \log(0.2) \approx 0.223 H(P,Q)=−1⋅log(0.8)−0⋅log(0.2)≈0.223
若预测更差(如 $ Q = [0.3, 0.7] $):
H ( P , Q ) = − 1 ⋅ log ( 0.3 ) ≈ 1.203 H(P, Q) = -1 \cdot \log(0.3) \approx 1.203 H(P,Q)=−1⋅log(0.3)≈1.203
实现示例(PyTorch)
import torch.nn as nn# 二分类
loss_fn = nn.BCELoss() # 需手动Sigmoid
loss_fn = nn.BCEWithLogitsLoss() # 内置Sigmoid# 多分类
loss_fn = nn.CrossEntropyLoss() # 输入为logits(无需Softmax)
注意事项
- 数值稳定性:计算 log ( p ) \log(p) log(p)时可能溢出,通常框架会自动处理(如添加微小偏移 ϵ \epsilon ϵ)。
- 概率归一化:确保模型输出符合概率分布(如通过Softmax或Sigmoid)。
直观解释
- 当预测概率 Q Q Q 与真实分布 P P P 一致时,交叉熵最小(等于 P P P 的熵)。
- 预测越偏离真实,交叉熵越大。
为什么用交叉熵?
- 梯度友好性:
- 对于Softmax输出,交叉熵的梯度为 ∂ L ∂ z i = p i − y i \frac{\partial L}{\partial z_i} = p_i - y_i ∂zi∂L=pi−yi,避免了均方误差(MSE)的梯度消失问题(当 p i p_i pi接近0或1时,MSE梯度极小)。
- 概率解释:直接优化模型输出的概率分布与真实分布的差异,与最大似然估计(MLE)等价。天然适配分类任务的概率输出。
- 处理不平衡数据:可通过加权交叉熵(Weighted Cross-Entropy)调整类别权重。
变体与改进
- 标签平滑(Label Smoothing):防止模型对标签过度自信,将真实标签从1调整为 1 − ϵ 1-\epsilon 1−ϵ,其余类别分配 ϵ / ( C − 1 ) \epsilon/(C-1) ϵ/(C−1)。
- Focal Loss:解决类别不平衡问题,降低易分类样本的权重:
L = − α t ( 1 − p t ) γ log ( p t ) L = -\alpha_t (1-p_t)^\gamma \log(p_t) L=−αt(1−pt)γlog(pt)
( γ \gamma γ 为调节因子, α t \alpha_t αt 为类别权重)。
理解交叉熵的关键是掌握其与熵、KL散度的关系,以及如何通过最小化它来使模型逼近真实分布。
相关文章:

交叉熵在机器学习中的应用解析
文章目录 核心概念香农信息量(自信息)熵(Entropy)KL散度(Kullback-Leibler Divergence)交叉熵 在机器学习中的应用作为损失函数对于二分类(Binary Classification):对于多…...

ARM Cortex汇编指令
在ARM架构的MCU开发中,汇编指令集是底层编程的核心。以下是针对Cortex-M系列(如M0/M3/M4/M7/M85)的指令集体系、分类及查询方法的详细说明: 一、指令集体系与核心差异 1. 架构版本与指令集特性 处理器架构指令集特点典型应用场…...
数据结构——二叉树(中)
接上一篇,上一篇主要讲解了关于二叉树的基本知识,也是为了接下来讲解关于堆结构和链式二叉树结构打基础,其实无论是堆结构还是链式二叉树结构,都是二叉树的存储结构,那么今天这一篇主要讲解关于堆结构的实现与应用 堆…...

InnoDB的MVCC实现原理?MVCC如何实现不同事务隔离级别?MVCC优缺点?
概念 InnoDB的MVCC(Multi-Version Concurrency Control)即多版本并发控制,是一种用于处理并发事务的机制。它通过保存数据在不同时间点的多个版本,让不同事务在同一时刻可以看到不同版本的数据,以此来减少锁竞争&…...

UDP目标IP不存在时的发送行为分析
当网络程序使用UDP协议发送数据时,如果目标IP不存在,发送程序的行为取决于网络环境和操作系统的处理机制。以下是详细分析: 1. UDP的无连接特性 UDP是无连接的传输协议,发送方不会预先建立连接,也不会收到对方是否存在…...

WHAT - 动态导入模块遇到版本更新解决方案
文章目录 一、动态导入模块二、常见原因与解决方案1. 模块 URL 错误2. 开发人员发版用户停留在旧页面问题背景解决方案思路1. 监听错误,提示用户刷新2. 使用缓存控制策略:强制刷新3. 动态模块加载失败时兜底4. 使用 import.meta.glob() 或 webpack 的 __…...
02-MySQL 面试题-mk
文章目录 1.mysql 有哪些存储引擎、区别是什么?1.如何定位慢查询?2.SQL语句执行很慢,如何分析?3.索引概念以及索引底层的数据结构4.什么是聚簇索引什么是非聚簇索引?5.知道什么叫覆盖索引嘛 ?6.索引创建原则有哪些?7.什么情况下索引会失效 ?8.谈一谈你对sql的优化的经验…...

#include<bits/stdc++.h>
#include<bits/stdc.h> 是 C 中一个特殊的头文件,其作用如下: 核心作用 包含所有标准库头文件 该头文件会自动引入 C 标准库中的几乎全部头文件(如 <iostream>、<vector>、<algorithm> 等)&…...

PostgreSQL:逻辑复制与物理复制
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c=1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编程,高并发设计,Springboot和微服务,熟悉Linux,ESXI虚拟化以及云原生Docker和K8s,热衷于探…...
在企业级部署中如何优化NVIDIA GPU和容器环境配置:最佳实践与常见误区20250414
在企业级部署中如何优化NVIDIA GPU和容器环境配置:最佳实践与常见误区 引言 随着AI和深度学习技术的迅速发展,企业对GPU加速计算的需求愈加迫切。在此过程中,如何高效地配置宿主机与容器化环境,特别是利用NVIDIA GPU和相关工具&…...

iphone各个机型尺寸
以下是苹果(Apple)历代 iPhone 机型 的屏幕尺寸、分辨率及其他关键参数汇总(截至 2023年10月,数据基于官方发布信息): 一、标准屏 iPhone(非Pro系列) 机型屏幕尺寸(英寸…...

栈的学习笔记
使用数组实现一个栈 #include <stdio.h>#define MAX_SIZE 101int A[MAX_SIZE]; int top -1; //栈顶指针,初始为-1,表示栈为空 void push(int x) {if (top MAX_SIZE - 1){printf("栈已满,无法入栈\n");return;}A[top] x;…...
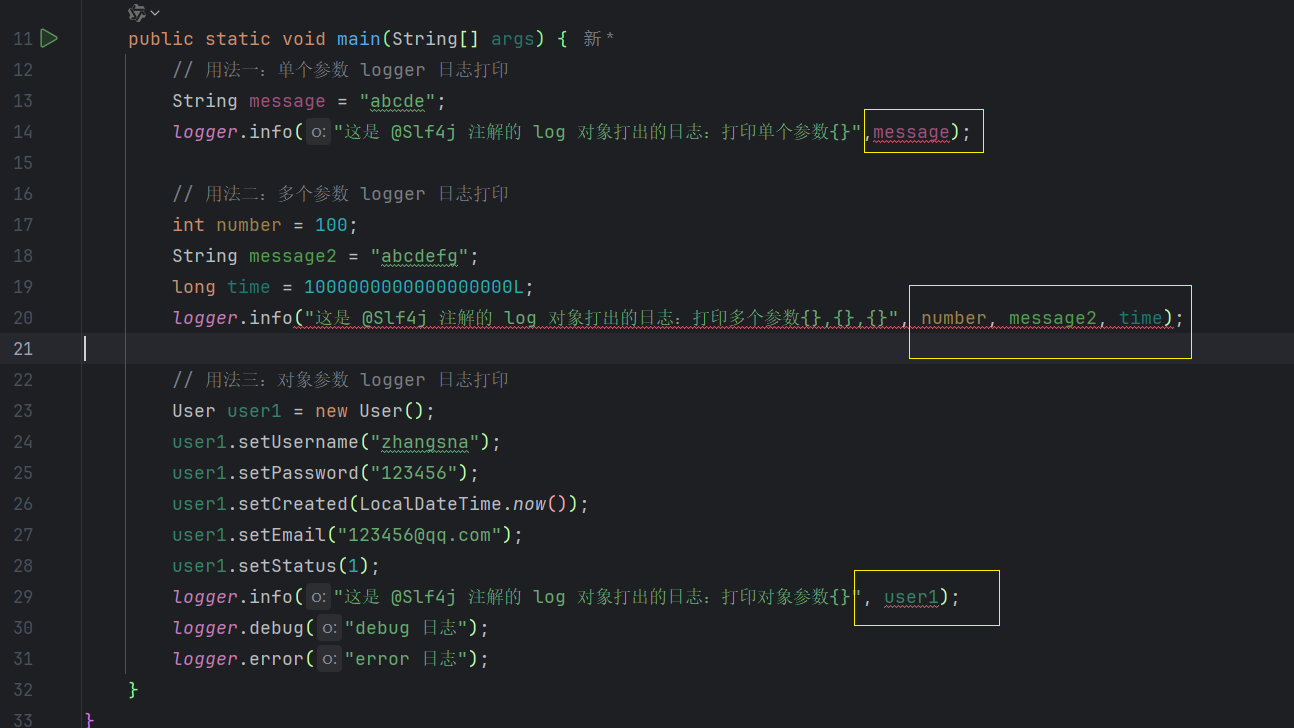
Spring Boot 项目三种打印日志的方法详解。Logger,log,logger 解读。
目录 一. 打印日志的常见三种方法? 1.1 手动创建 Logger 对象(基于SLF4J API) 1.2 使用 Lombok 插件的 Slf4j 注解 1.3 使用 Spring 的 Log 接口(使用频率较低) 二. 常见的 Logger,logger,…...

按键精灵安卓/ios脚本辅助工具开发教程:如何把界面配置保存到服务器
在使用按键精灵工具辅助的时候,多配置的情况下,如果保存现有的配置,并且读取,尤其是游戏中多种任务并行情况下,更是需要界面进行保存,简单分享来自紫猫插件的配置保存服务器写法。 界面例子: …...

[react]Next.js之自适应布局和高清屏幕适配解决方案
序言 阅读前首先了解即将要用到的两个包的作用 1.postcss-pxtorem 自动将 CSS 中的 px 单位转换为 rem 单位按照设计稿尺寸直接写 px 值,由插件自动计算 rem 值 2.amfe-flexible 动态设置根元素的 font-size(即 1rem 的值)根据设备屏幕宽度和…...
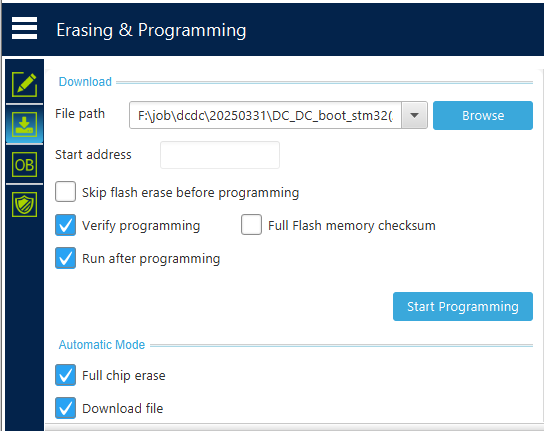
STM32H503CB升级BootLoader
首先,使用SWD接口,ST-LINK连接电脑和板子。 安装SetupSTM32CubeProgrammer_win64 版本2.19。 以下是接线和软件操作截图。...
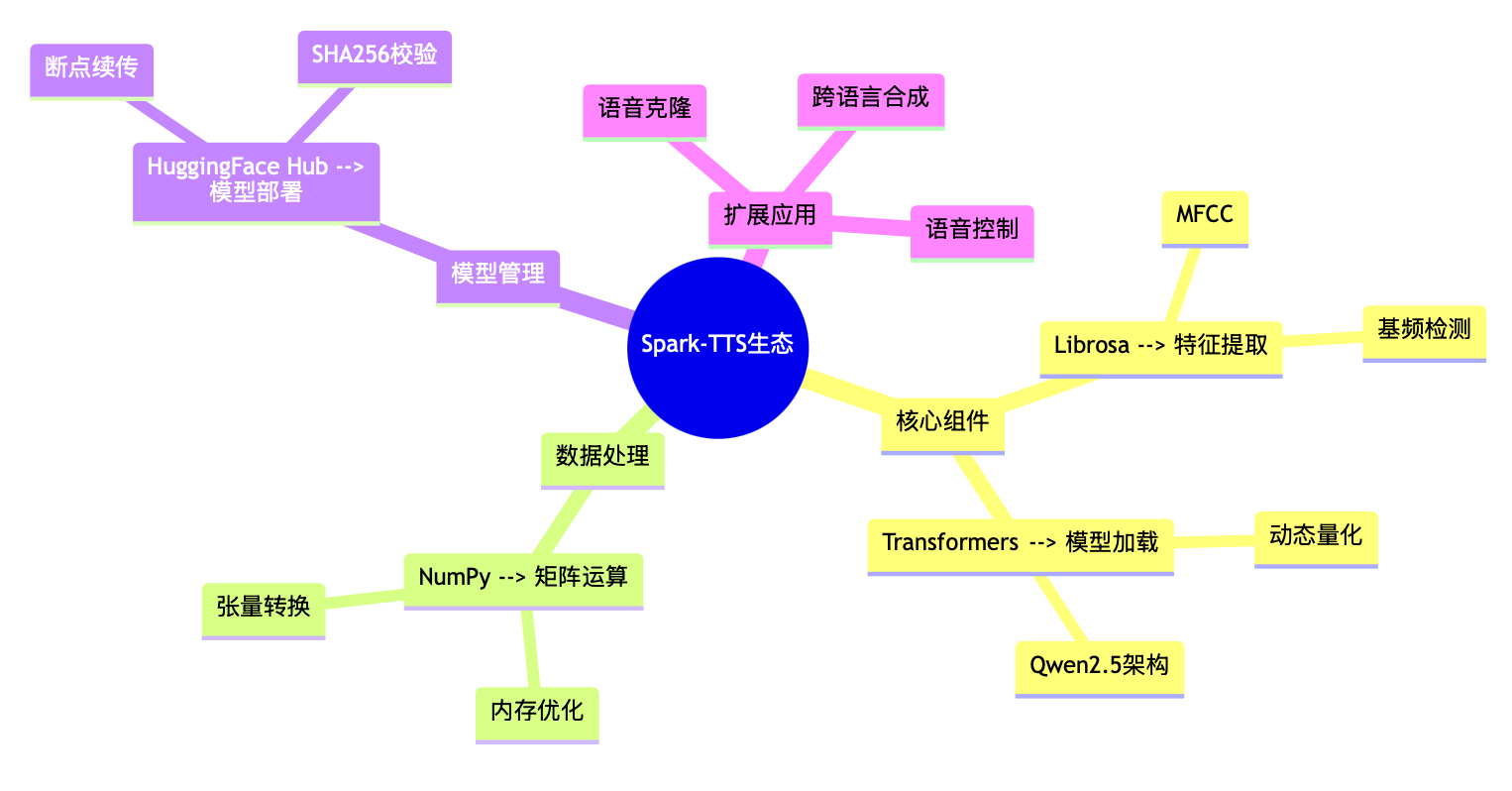
在Apple Silicon上部署Spark-TTS:四大核心库的技术魔法解析!!!
在Apple Silicon上部署Spark-TTS:四大核心库的技术魔法解析 🚀 (M2芯片实测|Python 3.12.9PyTorch 2.6.0全流程解析) 一、核心库功能全景图 🔍 在Spark-TTS的部署过程中,pip install numpy li…...
VMWare 16 PRO 安装 Rocky8 并部署 MySQL8
VMWare 16 PRO 安装 Rocky8 并部署 MySQL8 一.Rocky OS 下载1.官网二.配置 Rocky1.创建新的虚拟机2.稍后安装系统3.选择系统模板4.设置名字和位置5.设置大小6.自定义硬件设置核心、运存和系统镜像7.完成三.启动安装1.上下键直接选择安装2.回车安装3.设置分区(默认即可)和 roo…...
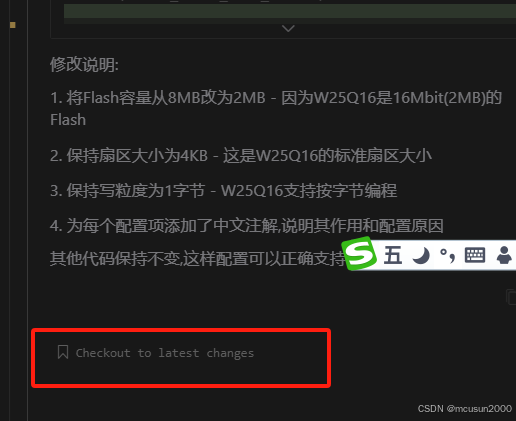
cursor如何回退一键回退多个文件的修改
当我们使用 Cursor 写代码时,起初可能操作得很顺利,但某次更改或许会让代码变得面目全非。这时候如果没有使用 Git 该怎么办呢?别担心,Cursor 已经为我们考虑到了。 具体的操作如下: 当我们要取消某次操作时…...

基于RV1126开发板的口罩识别算法开发
1. 口罩识别简介 口罩识别是一种基于深度学习的判断人员有没有戴口罩的分类算法,能广泛的用于安防、生产安全等多种场景。本算法先基于人脸检测和人脸标准化获取的标准人脸,然后输入到口罩识别分类算法进行识别。 本人脸检测算法在数据集表现如下所示&am…...

PyCharm显示主菜单和工具栏
显示主菜单 新版 PyCharm 是不显示主菜单的,要想显示主菜单和工具栏,则通过 “视图” → “外观” ,勾选 “在单独的工具栏中显示主菜单” 和 “工具栏” 即可。 设置工具栏 此时工具栏里并没有什么工具,因此我们需要自定义工具…...

Java工程行业管理软件源码 - 全面的项目管理工具 - 工程项目模块与功能一览
工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离构建工程项目管理系统 项目背景 随着公司的快速发展,企业人员和经营规模不断壮大。为了提高工程管理效率、减轻劳动强度、提高信息处理速度和准确性,公司对内部工程管理的提升提…...
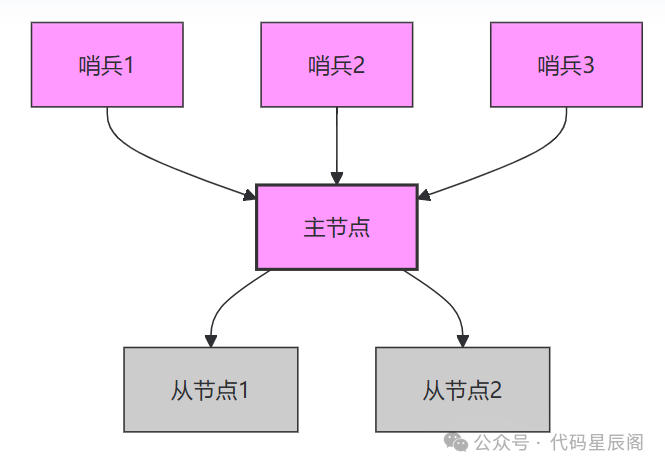
Redis 高可用集群搭建与优化实践
在分布式系统中,缓存技术用于提升性能和响应速度。 Redis 作为一款高性能的键值存储系统,广泛应用于缓存、消息队列和会话管理等场景。随着业务规模的扩大,单机 Redis 的性能和可用性逐渐无法满足需求。 因此,搭建高可用的 Redis 集群可以解决这一问题。我将详细介绍 Red…...

利用多GPU计算探索量子无序及AI拓展
量子无序系统的领域是凝聚态物理学中一个引人入胜的前沿。与它们完全有序的对应物不同,这些材料表现出量子力学和内在随机性的复杂相互作用,导致了许多令人着迷且常常难以理解的行为。量子自旋玻璃就是一个典型的例子,在这种系统中࿰…...
【AI大模型】基于阿里百炼大模型进行调用
目录 一、认识阿里云百炼 模型广场 创建自己的模型 二、AI扩图示例 1、开头服务、设置秘钥 2、选择HTTP方式调用流程 3、创建任务请求示例 4、发送http请求提交任务 5、查看任务进度的流程设计 6、后端查看任务进度代码 三、总结 大家好,我是jstart千语…...

【神经网络结构的组成】深入理解 转置卷积与转置卷积核
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀《深度学习理论直觉三十讲》_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 …...

数据战略新范式:从中台沉淀到服务觉醒,SQL2API 如何重塑数据价值链条?
一、数据中台退烧:从 “战略神话” 到 “现实拷问” 曾几何时,数据中台被视为企业数字化转型的 “万能解药”,承载着统一数据资产、打破业务壁垒的厚望。然而,大量实践暴露出其固有缺陷:某零售企业投入 500 万元建设中…...

Docker 代理配置全攻略:从入门到企业级实践
Docker 代理配置终极指南:从原理到实践 在企业环境中,Docker 的网络访问常常需要通过代理来完成,例如拉取镜像或在容器内访问外部网络。本文将从核心流程、配置方法到验证步骤,全面解析 Docker 代理的配置方式,助你轻…...

MyBatis-plus笔记 (上)
简介 [MyBatis-Plus](简称 MP)是一个 [MyBatis]的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。 mybatis-plus总结: 注意:mybatis-puls仅局限于单表操作。 自动生成单表的C…...
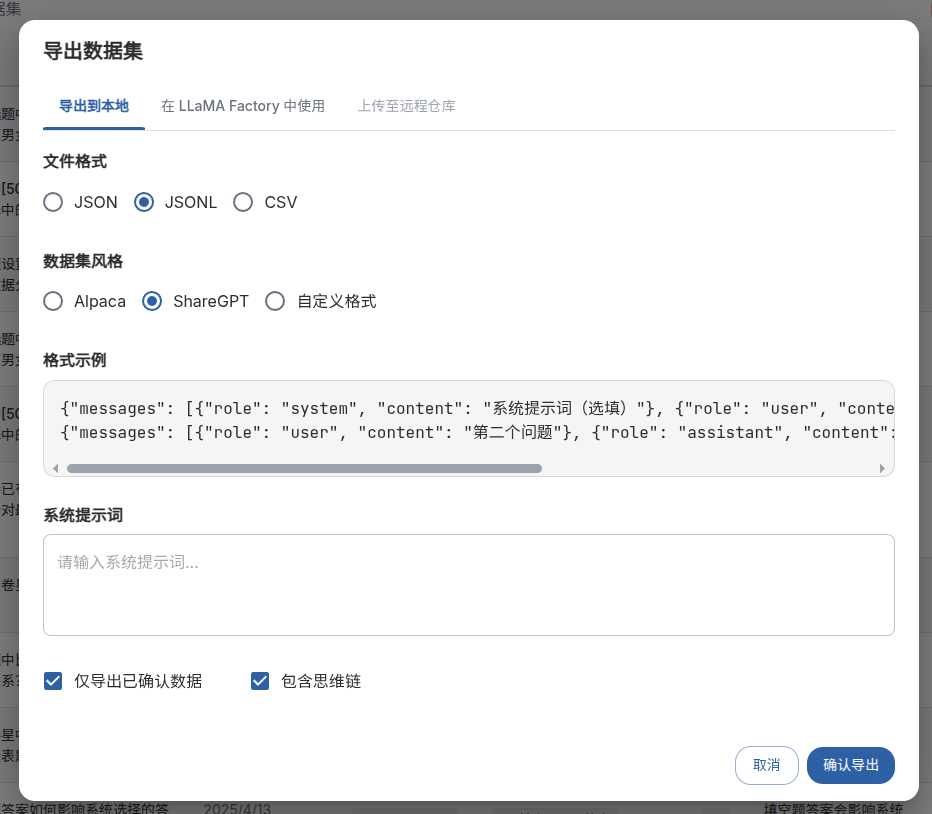
大模型微调数据集怎么搞?基于easydataset实现文档转换问答对json数据集!
微调的难点之一在与数据集。本文介绍一种将文档转换为问答数据集的方法,超级快! 上图左侧是我的原文档,右侧是我基于文档生成的数据集。 原理是通过将文档片段发送给ollama本地模型,然后本地模型生成有关问题,并基于文…...