排序(java)
一.概念
排序:对一组数据进行从小到大/从大到小的排序
稳定性:即使进行排序相对位置也不受影响如:

如果再排序后 L 在 i 的前面则稳定性差,像图中这样就是稳定性好。
二.常见的排序
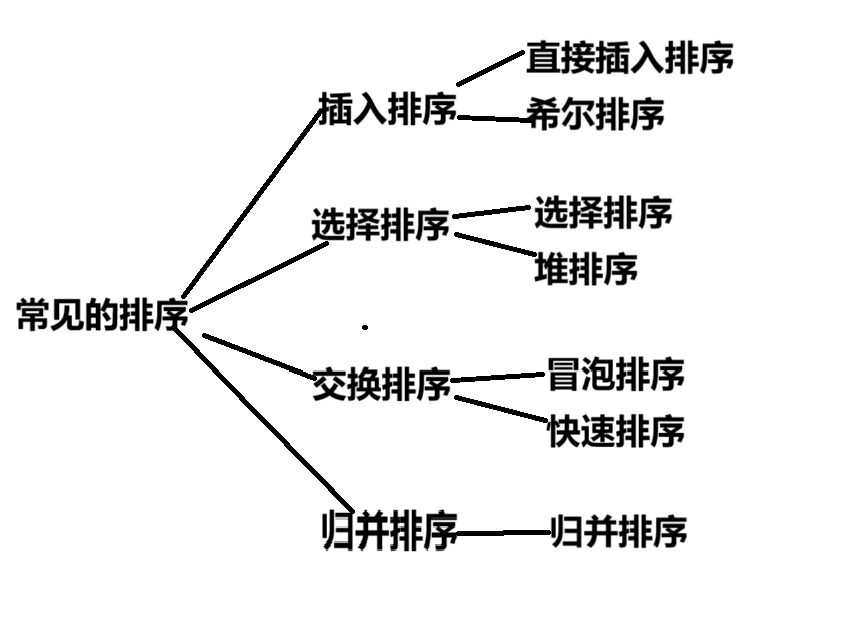
三.常见算法的实现
1.插入排序
1.1 直接插入排序
时间复杂度
最好情况:数据完全有序的时候O(N)
最坏的情况:数据完全逆序的时候O(N^2)
当前数据越有序越快
空间复杂度:O(1)
稳定性:稳定
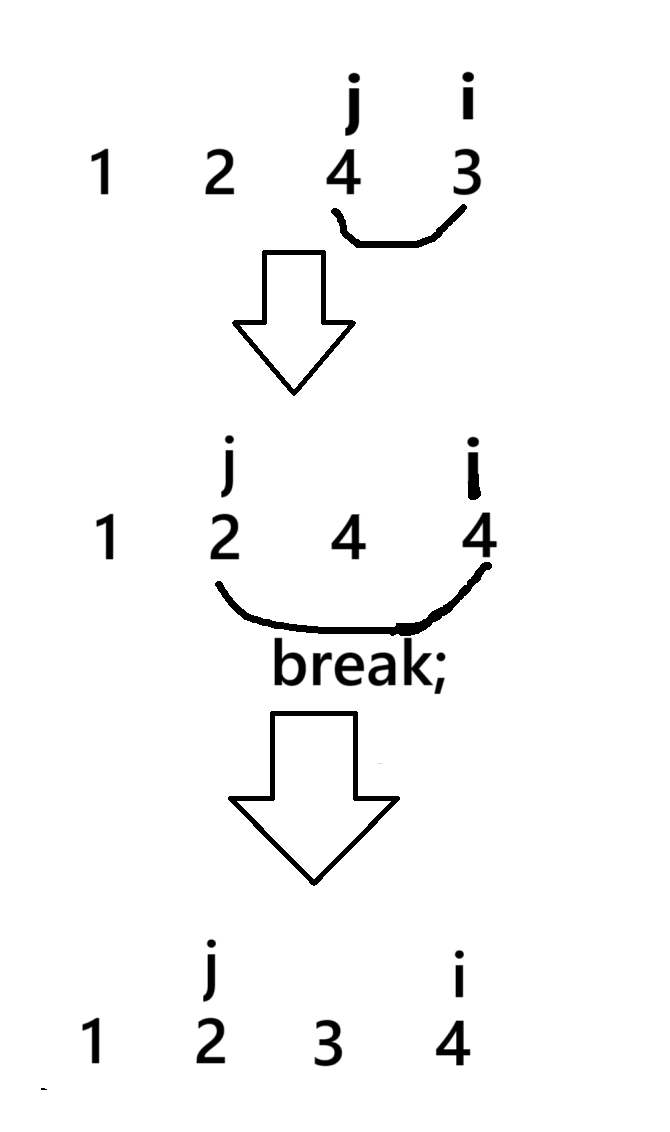
public static void insertSort(int[] array) {for (int i = 1; i < array.length; i++) {int tmp = array[i];int j = i - 1;for (; j >= 0; j--) {if (array[j] > tmp) {array[j + 1] = array[j];} else {break;}}array[j + 1] = tmp;}}该排序就是从第二个数据开始进行比较,以第4个数据进行举例,假设第三个数据大于第四个数据则第一个数据的值就改为第三个数据,第二个数据不大于第四个数据循环结束,当前第二个数据后面的数据就是当时第四个数据的值。
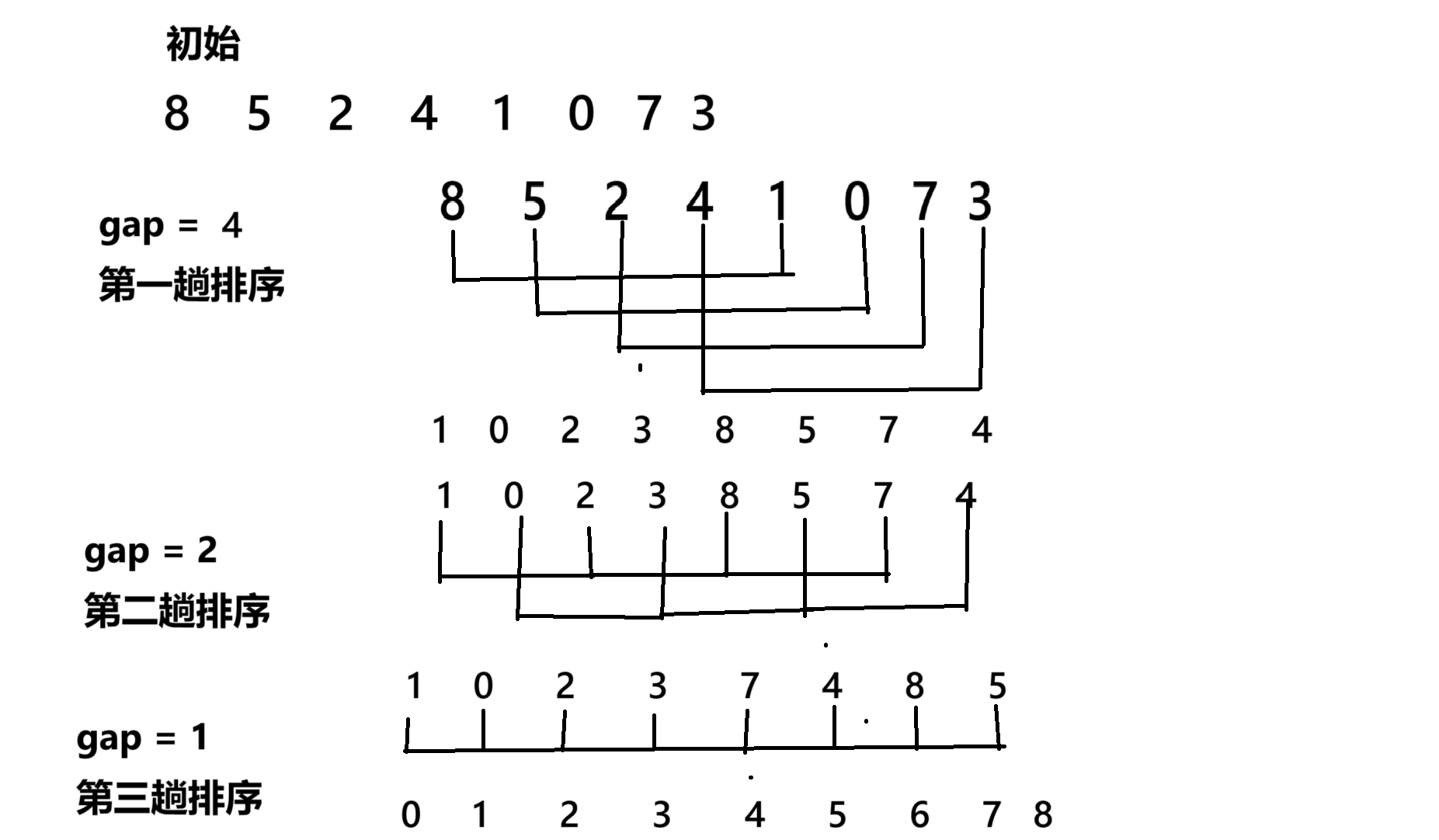
1.2 希尔排序
public static void shellSort(int[] array) {int gap = array.length;while (gap > 1) {gap /= 2;shell(array, gap);}}private static void shell(int[] array, int gap) {for (int i = gap; i < array.length; i += gap) {int tmp = array[i];int j = i - gap;for (; j >= 0; j -= gap) {if (array[j] > tmp) {array[j + gap] = array[j];} else {break;}}array[j + gap] = tmp;}}
c ,
通过对数据分成多个组,随着组数越来越多,组的大小越来越小,数据也越归于有序,通常gap大小都是gap/=2,这种方法是对于插入算法的优化,但是因为gap不固定所以时间复杂度不固定。
稳定性:不稳定
2.选择排序
基本思想:每次都从元素中找一个最大/最小的值,放在初始/末尾位置。
2.1直接选择排序
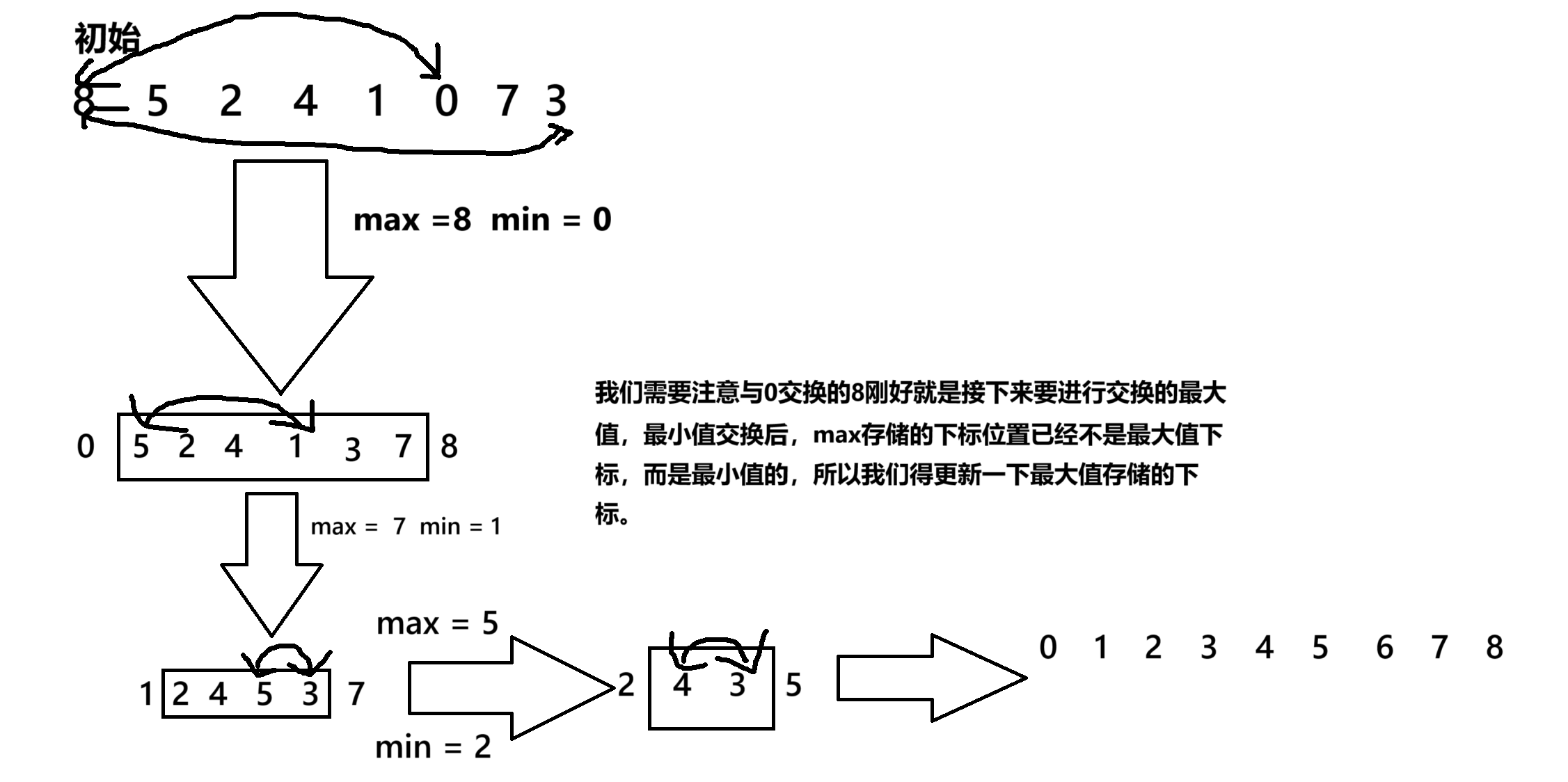
方法一:
public static void selectSort(int[] array) {for (int i = 0; i < array.length; i++) {int minIndex = i;for (int j = i + 1; j < array.length ; j++){if (array[j] < array[minIndex]) {minIndex = j;}}swap(array, minIndex, i);}
}方法一就是找到一个最小的值放在初始位置。
方法二:
public static void selsectSort2(int[] array){int left = 0;int right = array.length - 1;while (left < right){int minIndex = left;int maxIndex = left;for (int j = left + 1; j <= right; j++) {if (array[minIndex] > array[j]){minIndex = j;}if (array[maxIndex] < array[j]) {maxIndex = j;}}swap(array,left,minIndex);if(maxIndex == left){maxIndex =minIndex;}swap(array,right,maxIndex);left++;right--;}}方法二就是找到最大值和最小值,然后进行交换,需要注意的是我们在进行最小值交换的时候。如果与最小值交换的元素刚好就是最大值,我们就需要进行判断一下。 然后将最大值的下标更新一下。
1.时间复杂度: O(N^2)
2.空间复杂度:O(1)
3.稳定性:不稳定
2.2堆排序
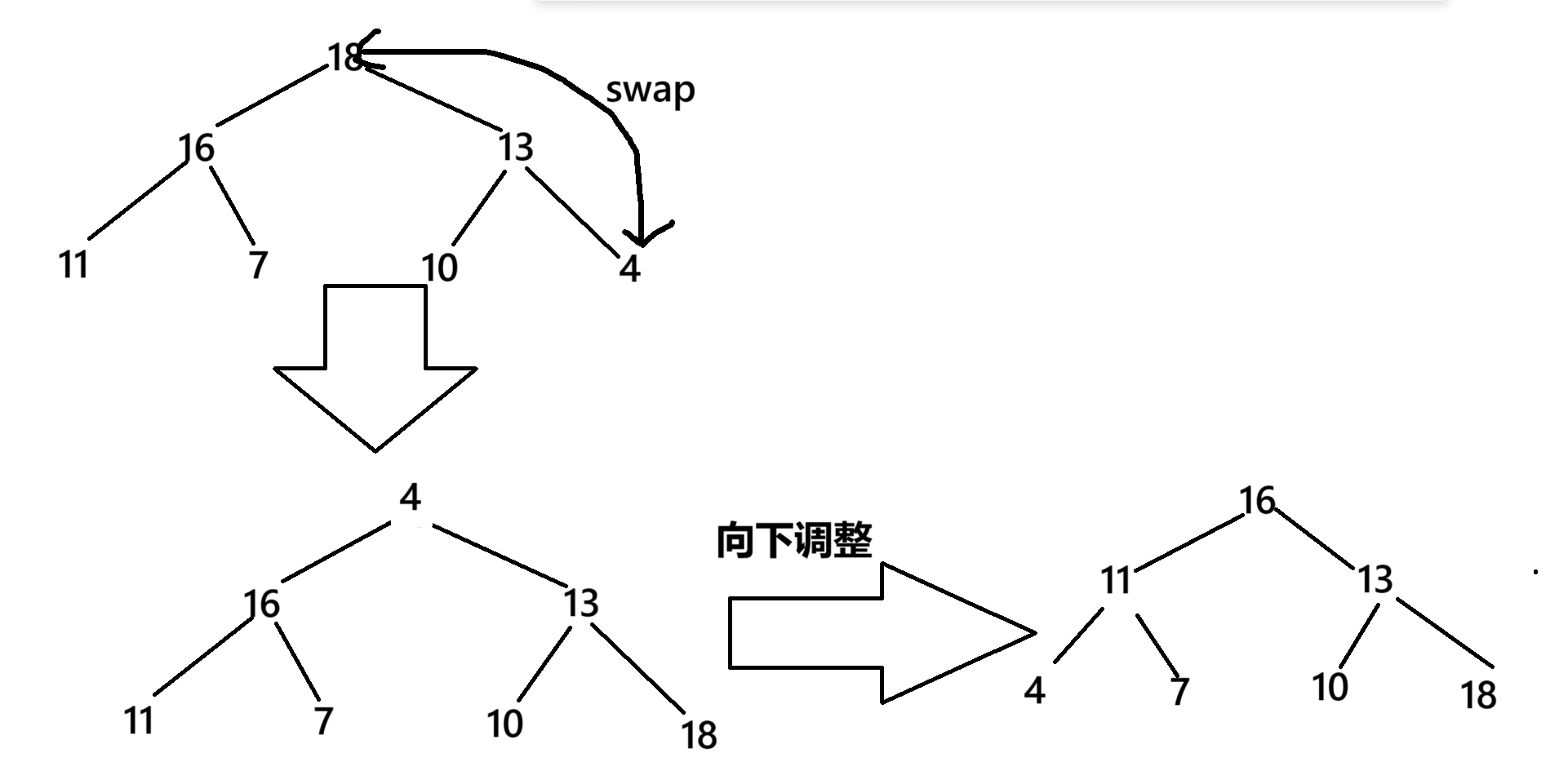
在使用堆时,我们已经知道可以根据创建一个大根堆来实现对于元素的排序,这种方法是因为大根堆的根结点是最大的,所以我们可以将它和最后一个交换位置,然后对排序元素个数减一后进行向下排序,此时可以确定的是最后一个元素是最大的。
public static void heapSort(int[] array){creatBigHeap(array);int end = array.length - 1;while(end > 0){swap(array,0 ,end);end--;siftDown(0,array,end);}}public static void creatBigHeap(int[] arrray){for (int parent = (arrray.length - 1 - 1)/2; parent >= 0 ; parent--) {siftDown(parent, arrray,arrray.length);}}private static void siftDown(int parent,int[] array,int end) {int child = 2*parent + 1;while(child < end){if(child + 1 < end && array[child] < array[child+1]){child++;}if(array[child] > array[parent]){swap(array,child,parent);parent = child;child = parent*2 + 1;}else{break;}}}时间复杂度:O(n*logN)
空间复杂度:O(1)
稳定性:不稳定的
3.交换排序
概念:通过比较大小来交换元素,元素大的向后走,元素小的向前走。
3.1冒泡排序
冒泡排序就是通过遍历来进行前后比较,来进行排序,通过这种方法,数组的末尾总是当前的最大值,所以我们在进行遍历比较是时,应该减去我们我们进行整体排序的次数,之所以给外循环的上限减去一,是因为我们在对n个数据进行在整体排序时,我们只需要排序n-1次就好,因为最后一个数据应该也是有序,没必要再进行排序。
时间复杂度:O(N^2)
空间复杂度: O(1)
稳定性:稳定
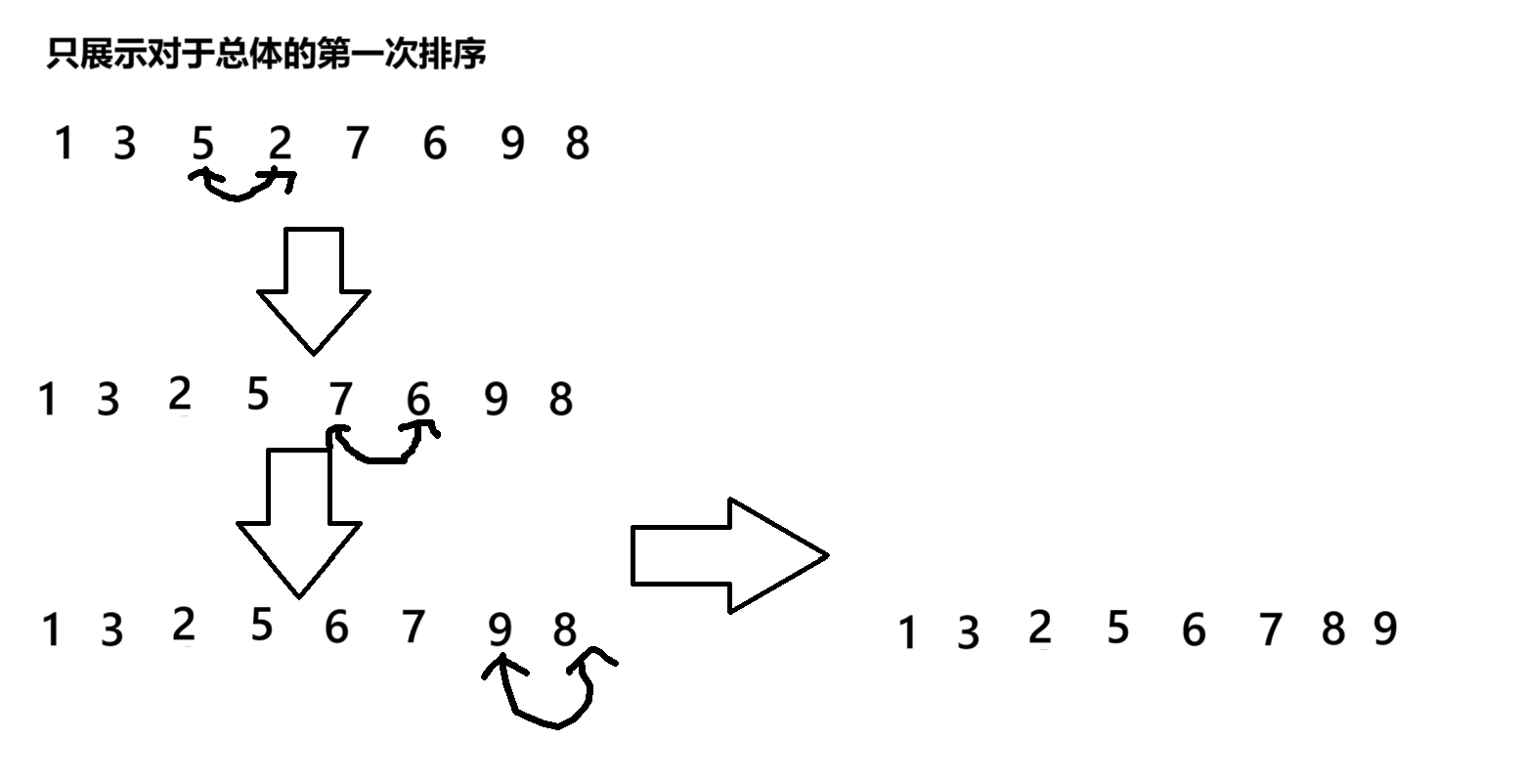
public static void popSort(int[] array){boolean flag = false;for (int i = 0; i < array.length - 1; i++) {for (int j = 0; j < array.length - 1 -i ; j++) {if (array[j] > array[j+1]) {swap(array, j, j + 1);flag = true;}}if (flag == false){break;}}}3.2快速排序
基本思想就是取一个基准值,将当前数据分为大于基准值和小于基准值两个部分,然后再对这两个部分进行同样的操作,直到所有的元素都有序为止。
最好情况:O(N*logN) 满二叉树/完全二叉树
最坏情况:O(N^2) 单分支的树
空间复杂度:
最好情况:O(logN) 满二叉树/完全二叉树
最坏情况:O(N) 单分支的树
稳定性:不稳定
3.2.1递归版
private static void quick(int[] array,int start,int end) {if(start >= end){return;}int pivot = partition3(array,start,end);quick(array,start,pivot - 1);quick(array,pivot+1,end);}3.2.1.1 Hoare版
private static int parttionHoare(int[] array,int left,int right){int key = array[left];int i = left;while(left < right){while(left < right && array[right] >= key){right--;}while(left < right && array[left] <= key){left++;}swap(array,left,right);}swap(array,left,i);return left;}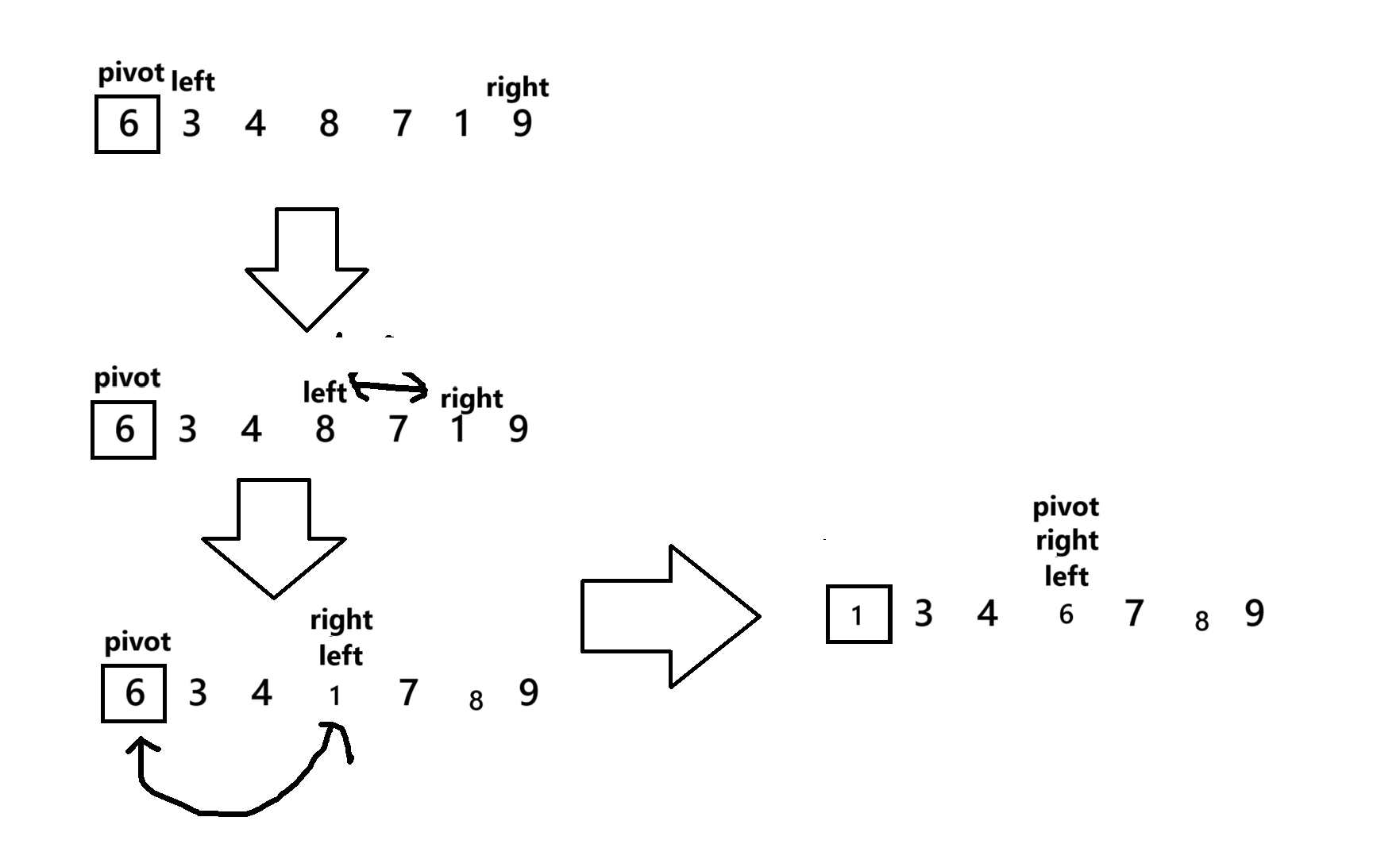
Hoare版的快速排序就是从两边进行调整,左边一碰到大于基准的值就停下来,右边碰到小于基准的值就停下来,然后进行交换,就这样进行下去知道left >= right,最后我们left所停留的位置就是基准应该再的位置,但是基准开始被设为就是left,所以我们提前存的left就有了价值了,让他俩交换,就完成了一次快排。
3.2.1.2挖坑法
private static int parttion2(int[] array,int left,int right){int key = array[left];while(left < right){while(left < right && array[right] >= key){right--;}array[left] = array[right];while(left < right && array[left] <= key){left++;}array[right] = array[left];}array[left] = key;return left;}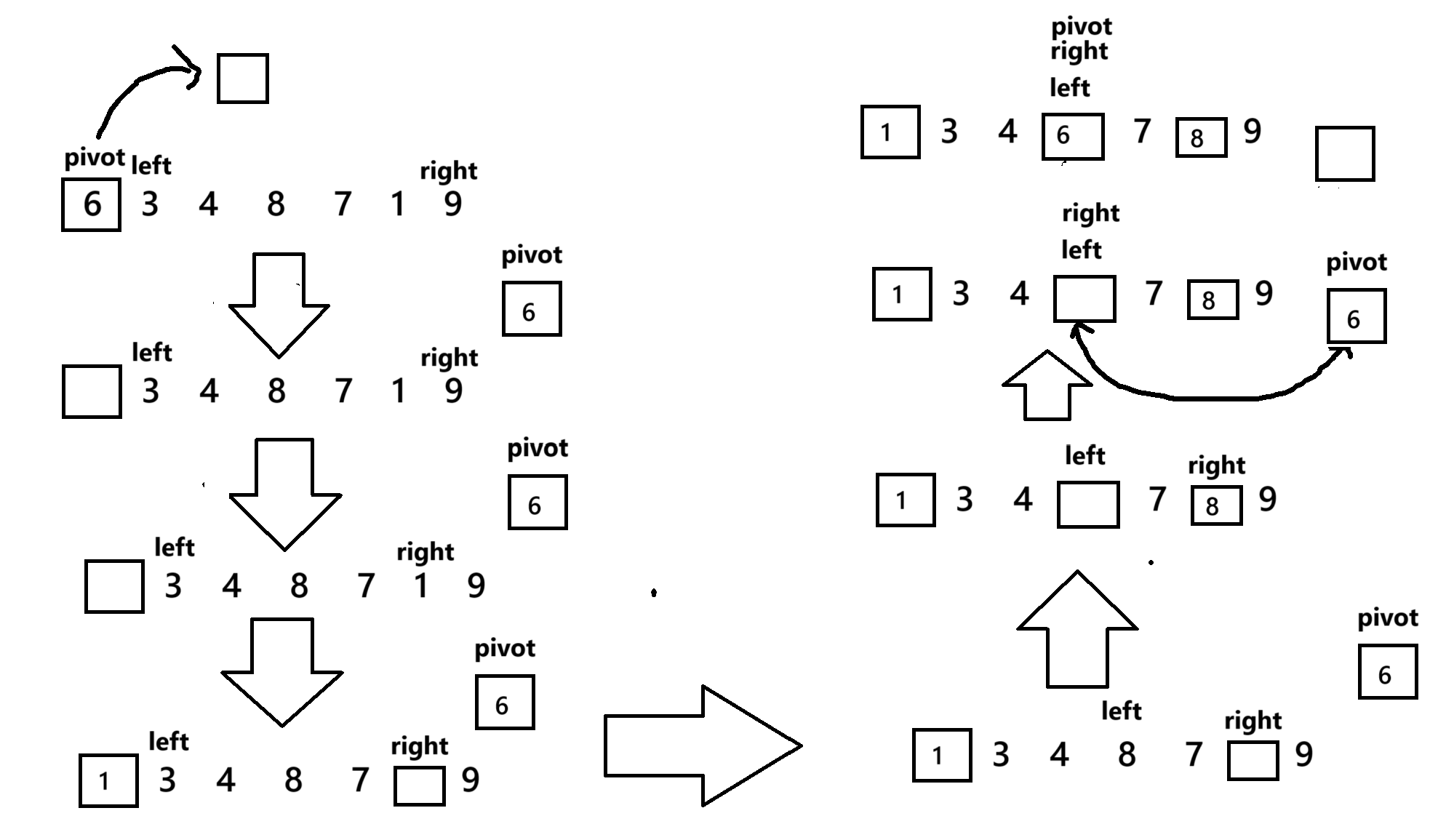
挖坑法就是先挖个坑让右边小于基准的值给填进去,这样右边就也有个坑了,然后再在左边找,找到一个大于基准的数,填满右边的坑,之后肯定有一个坑是空的,这就是我们要找的基准位置。
3.2.1.3 双指针法
private static int partition3(int[] array, int left, int right) {int prev = left;int pcur = left + 1;while(pcur <= right){if (array[left] > array[pcur] && array[++prev] != array[pcur]){swap(array,prev,pcur);}pcur++;}swap(array,left,prev);return prev;}我们会以左边第一个元素为基准,如果碰到比基准小的值,我们会用用pcur来进行记录,而prev移动的条件就是当pcur遇到小的值时,而prev的下一个元素也必然时大于基准的,因为当前这个元素不大于基准pcur不能走。我们来画图举例:
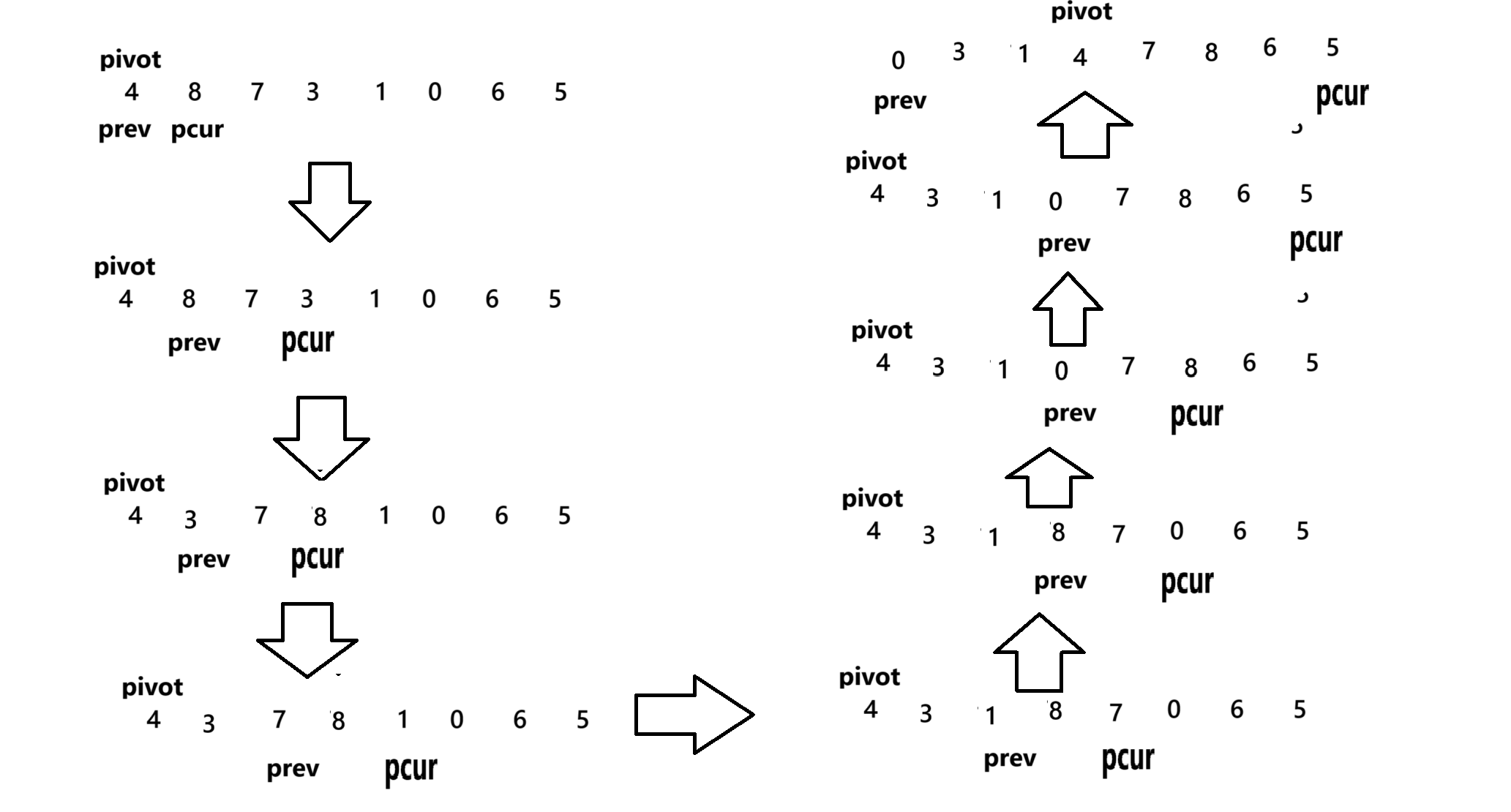
3.2.2 非递归
public static void quickSortNor(int[] array){Stack<Integer> stack = new Stack<>();int left = 0;int right = array.length - 1;int pivot = parttionHoare(array,left,right);if(pivot - 1 > left) {stack.push(left);stack.push(pivot - 1);}if(pivot + 1 < right) {stack.push(pivot+1);stack.push(right);}while(!stack.isEmpty()){right = stack.pop();left = stack.pop();pivot = parttionHoare(array,left,right);if(pivot - 1 > left){stack.push(left);stack.push(pivot - 1);}if(pivot + 1 < right){stack.push(pivot + 1);stack.push(right);}}}非递归使用了栈,首先将元素分为大于基准和小于基准两组,然后重复进行操作,通过HOare操作来对数组进行排序。
快速排序优化
private static void insertSortRange(int[] array,int begain,int end) {for (int i = begain + 1; i <= end; i++) {int tmp = array[i];int j = i - 1;for (; j >= begain; j--) {if (array[j] > tmp) {array[j + 1] = array[j];} else {break;}}array[j + 1] = tmp;}}private static void quick(int[] array,int start,int end) {if(start >= end){return;}if (end - start + 1 <= 15){//插入排序insertSortRange(array,start,end);return;}//三数取中int index = midOfThree(array,start,end);swap(array,index,start);int pivot = parttionHoare(array,start,end);quick(array,start,pivot - 1);quick(array,pivot+1,end);}当我们遇到小的区间可以用插入排序来解决,在选择基准时我们可以尽量选择取中间值来进行排序,所以我们又有了一个方法就是三数取中。
4.归并排序
基本思想:将一组数据分成两组,然后对分开的组在进行分组,直到分为一个组,然后进行合并,在合并过程中进行排序,开始时一 一排序,然后是二二,知道全部组都合并为一个组。
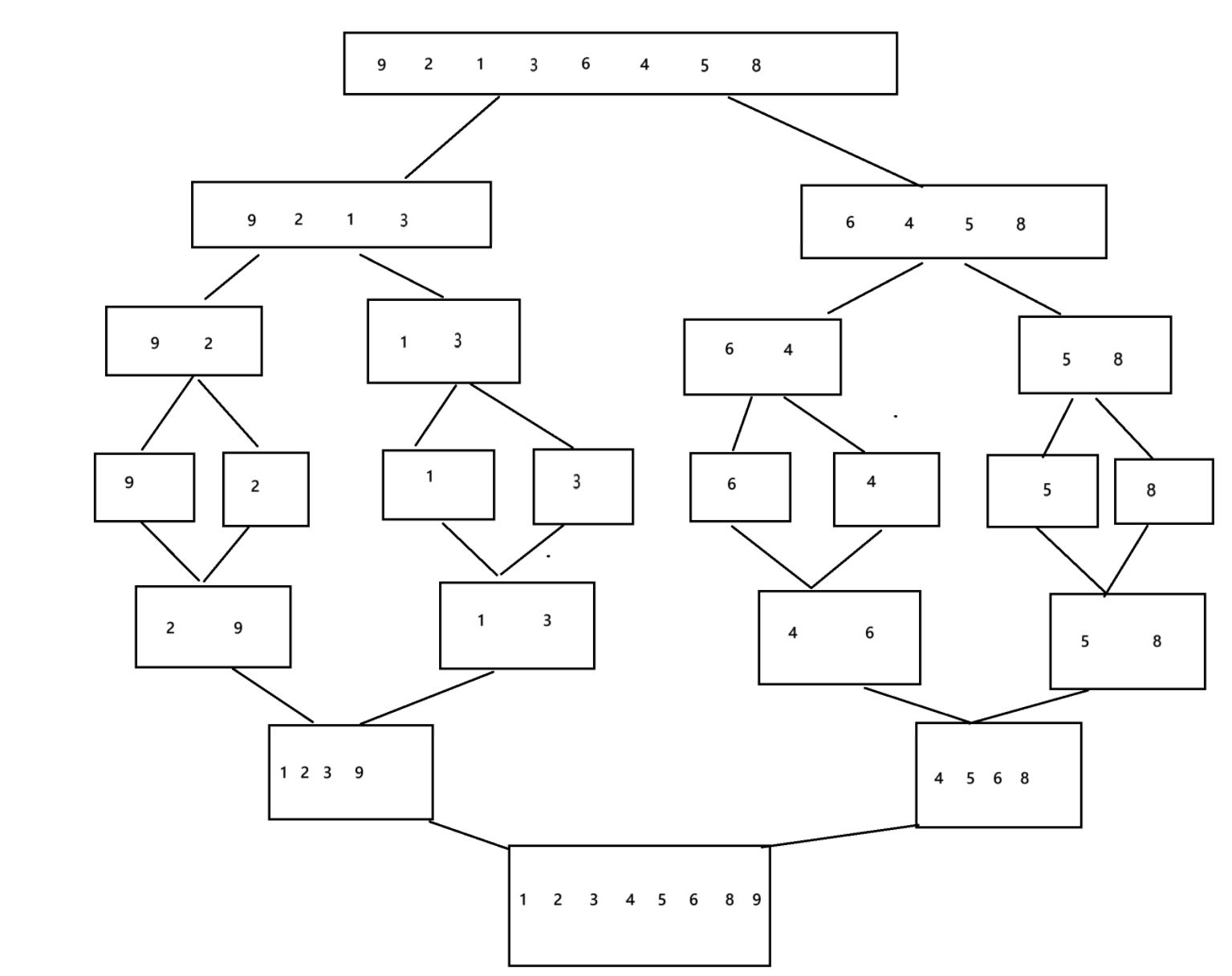
归并排序总结
1.归并排序缺点在于时间复杂度过高,因为占用外部空间来排序很多。
2.时间复杂度:O(N*logN)
3.空间复杂度:O(N)
4.稳定性:稳定
代码实现
public static void mergeSort(int[] array){mergeSortFunc(array,0,array.length - 1);}private static void mergeSortFunc(int[] array, int left, int right) {if(left >= right){return ;}int mid = (left + right) / 2;mergeSortFunc(array,left,mid);mergeSortFunc(array,mid + 1,right);merge(array,left,right,mid);}private static void merge(int[] array, int left, int right, int mid) {int s1 = left;int s2 = mid + 1;int[] tmpArr = new int[right - left + 1];int k = 0;while(s1 <= mid && s2 <= right){if (array[s2] <= array[s1]){tmpArr[k++] = array[s2++];}else{tmpArr[k++] = array[s1++];}}while (s1 <= mid){tmpArr[k++] = array[s1++];}while(s2 <= right){tmpArr[k++] = array[s2++];}for (int i = 0; i < tmpArr.length; i++) {array[i + left ] = tmpArr[i];}}
非递归实现
public static void mergeSortNor(int[] array){int gap = 1;while(gap < array.length ){for (int i = 0; i < array.length; i += 2*gap ) {int left = i;int mid = left + gap - 1;int right = mid + gap;if (mid >= array.length){mid = array.length - 1;}if (right >= array.length){right = array.length - 1;}merge(array,left,right,mid);}gap*=2;}}在这七大排序中稳定的只有归并排序,冒泡排序,插入排序,其中归并排序,快速排序,插入排序应当作为重点。
其他排序
计数排序
public static void countSort(int[] array){int minVal = array[0];int maxVal = array[0];for (int i = 1; i < array.length; i++) {if (array[i] < minVal){minVal = array[i];}if (array[i] > maxVal){maxVal = array[i];}}int[] count = new int[maxVal - minVal + 1];for (int i = 0; i < array.length; i++) {count[array[i] - minVal]++;}int index = 0;for (int i = 0; i < count.length; i++) {while(count[i] > 0){array[index] = i+minVal;index++;count[i]--;}}}通过对相同元素出现的次数来进行排序。
相关文章:
排序(java)
一.概念 排序:对一组数据进行从小到大/从大到小的排序 稳定性:即使进行排序相对位置也不受影响如: 如果再排序后 L 在 i 的前面则稳定性差,像图中这样就是稳定性好。 二.常见的排序 三.常见算法的实现 1.插入排序 1.1 直…...
内存管理补充版)
嵌入式C语言进阶(二+)内存管理补充版
C语言内存管理:从小白到大神的完全指南 前言:为什么需要理解内存管理 C语言以其高效性和灵活性著称,但这也意味着程序员需要手动管理内存。与Java、Python等高级语言不同,C语言没有自动垃圾回收机制,内存管理的重担完全落在开发者肩上。理解C语言的内存管理机制不仅能帮…...
【HDFS入门】HDFS副本策略:深入浅出副本机制
目录 1 HDFS副本机制概述 2 HDFS副本放置策略 3 副本策略的优势 4 副本因子配置 5 副本管理流程 6 最佳实践与调优 7 总结 1 HDFS副本机制概述 Hadoop分布式文件系统(HDFS)的核心设计原则之一就是通过数据冗余来保证可靠性,而这一功能正是通过副本策略实现的…...

Excel自定义函数取拼音首字母
1.启动Excel 2003(其它版本请仿照操作),打开相应的工作表; 2.执行“工具 > 宏 > Visual Basic编辑器”命令(或者直接按“AltF11”组合键),进入Visual Basic编辑状态; 3.执行“…...
智能 GitHub Copilot 副驾驶® 更新升级!
智能 GitHub Copilot 副驾驶 迎来重大升级!现在,所有 VS Code 用户都能体验支持 Multi-Context Protocol(MCP)的全新 Agent Mode。此外,微软还推出了智能 GitHub Copilot 副驾驶 Pro 订阅计划,提供更强大的…...

Android ViewPager使用预加载机制导致出现页面穿透问题
缘由 在应用中使用ViewPager,并且设置预加载页面。结果出现了一些异常的现象。 我们有4个页面,分别是4个Fragment,暂且称为FragmentA、FragmentB、FragmentC、FragmentD,ViewPager在MainActivity中,切换时&#x…...

【今日三题】添加字符(暴力枚举) / 数组变换(位运算) / 装箱问题(01背包)
⭐️个人主页:小羊 ⭐️所属专栏:每日两三题 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 添加字符(暴力枚举)数组变换(位运算)装箱问题(01背包) 添加字符(暴力枚举) 添加字符 当在A的开头或结尾添加字符直到和B长度…...
)
【AIoT】智能硬件GPIO通信详解(二)
前言 上一篇我们深入解析了智能硬件GPIO通信原理(传送门:【AIoT】智能硬件GPIO通信详解(一))。接下来,我们将结合无人售货机控制场景,通过具体案例进一步剖析物联网底层通信机制的实际应用。 在智能零售领域,无人售货机通过AI技术升级为智能柜,其设备控制的底层通信…...
Python中JSON的妙用:详解序列化与反序列化原理及实战案例)
Python(18)Python中JSON的妙用:详解序列化与反序列化原理及实战案例
目录 一、背景:为什么Python需要JSON?二、核心技术解析:序列化与反序列化2.1 核心概念2.2 类型映射对照表 三、Python操作JSON的四大核心方法3.1 基础方法库3.2 方法详解1. json.dumps()2. json.loads()3. json.dump()4. json.load() 四、实战…...

【Python进阶】字典:高效键值存储的十大核心应用
目录 前言:技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块技术选型对比 二、实战演示环境配置要求核心代码实现(10个案例)案例1:基础操作案例2:字典推导式…...
的轨迹仿真,主要用于模拟升力体在不同飞行阶段(初始滑翔段、滑翔段、下压段)的运动轨迹)
MATLAB脚本实现了一个三自由度的通用航空运载器(CAV-H)的轨迹仿真,主要用于模拟升力体在不同飞行阶段(初始滑翔段、滑翔段、下压段)的运动轨迹
%升力体:通用航空运载器CAV-H %读取数据1 升力系数 alpha = [10 15 20]; Ma = [3.5 5 8 10 15 20 23]; alpha1 = 10:0.1:20; Ma1 = 3.5:0.1:23; [Ma1, alpha1] = meshgrid(Ma1, alpha1); CL = readmatrix(simulation.xlsx, Sheet, Sheet1, Range, B2:H4); CL1 = interp2(…...
 函数)
多角度分析Vue3 nextTick() 函数
nextTick() 是 Vue 3 中的一个核心函数,它的作用是延迟执行某些操作,直到下一次 DOM 更新循环结束之后再执行。这个函数常用于在 Vue 更新 DOM 后立即获取更新后的 DOM 状态,或者在组件渲染完成后执行某些操作。 官方的解释是,当…...

Linux——消息队列
目录 一、消息队列的定义 二、相关函数 2.1 msgget 函数 2.2 msgsnd 函数 2.3 msgrcv 函数 2.4 msgctl 函数 三、消息队列的操作 3.1 创建消息队列 3.2 获取消息队列并发送消息 3.3 从消息队列接收消息recv 四、 删除消息队列 4.1 ipcrm 4.2 msgctl函数 一、消息…...
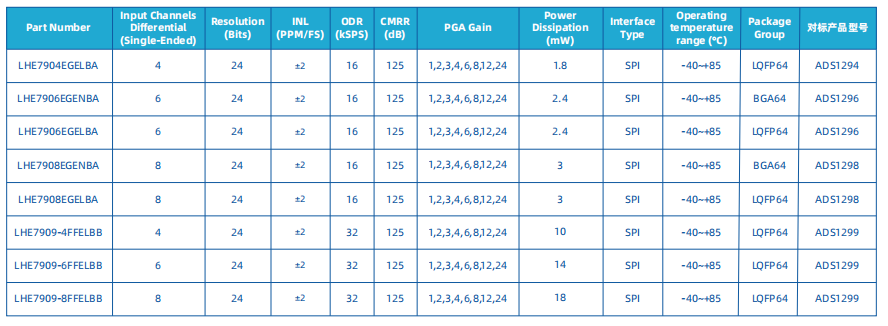
领慧立芯LHE7909可兼容替代TI的ADS1299
LHE7909是一款由领慧立芯(Legendsemi)推出的24位高精度Δ-Σ模数转换器(ADC),主要面向医疗电子和生物电势测量应用,如脑电图(EEG)、心电图(ECG)等设备。以下是…...

在PyTorch中,使用不同模型的参数进行模型预热
在PyTorch中,使用不同模型的参数进行模型预热(Warmstarting)是一种常见的迁移学习和加速训练的策略。以下是结合多个参考资料总结的实现方法和注意事项: 1. 核心机制:load_state_dict()与strict参数 • 部分参数加载&…...

conda 创建、激活、退出、删除环境命令
参考博客:Anaconda创建环境、删除环境、激活环境、退出环境 使用起来觉得有些不方便可以改进,故写此文。 1. 创建环境 使用 -y 跳过确认 conda create -n 你的环境名 -y 也可以直接选择特定版本 python 安装,以 3.10 为例: co…...

Redis核心数据类型在实际项目中的典型应用场景解析
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 Redis作为高性能的键值存储系统,在现代软件开发中扮演着重要角色。其多样化的数据结构为开发者提供了灵活的解决方案,本文将通过真实项…...
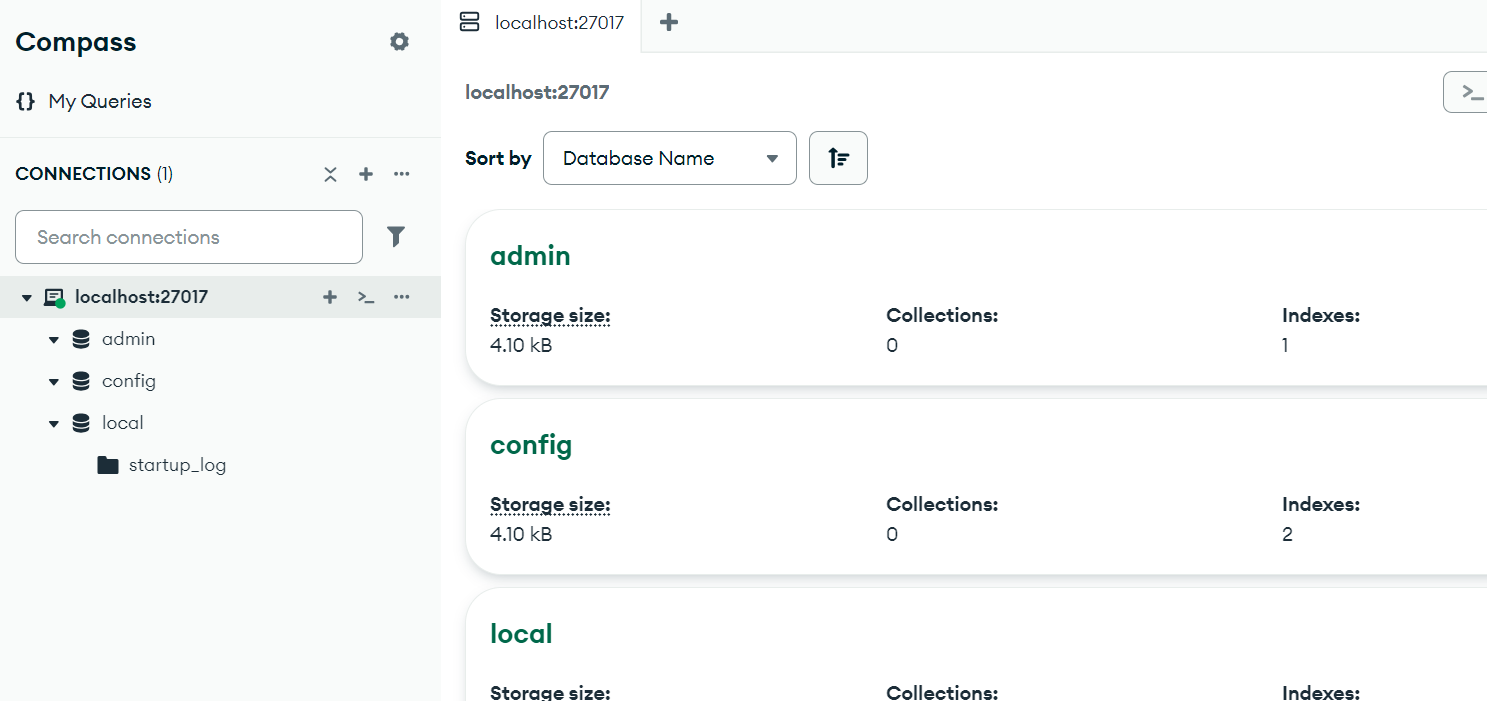
MongoDB简单用法
图片中 MongoDB Compass 中显示了默认的三个数据库: adminconfiglocal 如果在 .env 文件中配置的是: MONGODB_URImongodb://admin:passwordlocalhost:27017/ MONGODB_NAMERAGSAAS💡 一、为什么 Compass 里没有 RAGSAAS 数据库?…...

如何学习嵌入式
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.16 请各位前辈能否给我提点建议,或者学习路线指导一下 STM32单片机学习总…...

【AI】IDEA 集成 AI 工具的背景与意义
一、IDEA 集成 AI 工具的背景与意义 随着人工智能技术的迅猛发展,尤其是大语言模型的不断演进,软件开发行业也迎来了智能化变革的浪潮。对于开发者而言,日常工作中面临着诸多挑战,如代码编写的重复性劳动、复杂逻辑的实现、代码质…...
uniapp-商城-26-vuex 使用流程
为了能在所有的页面都实现状态管理,我们按照前面讲的页面进行状态获取,然后再进行页面设置和布局,那就是重复工作,vuex 就会解决这样的问题,如同类、高度提炼的接口来帮助我们实现这些重复工作的管理。避免一直在造一样的轮子。 https://vuex.vuejs.org/zh/#%E4%BB%80%E4…...
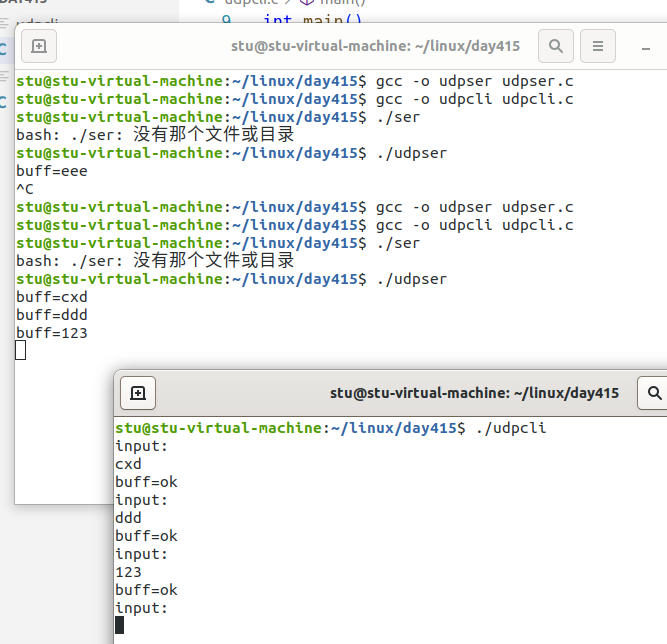
UDP概念特点+编程流程
UDP概念编程流程 目录 一、UDP基本概念 1.1 概念 1.2 特点 1.2.1 无连接性: 1.2.2 不可靠性 1.2.3 面向报文 二、UDP编程流程 2.1 客户端 cli.c 2.2 服务端ser.c 一、UDP基本概念 1.1 概念 UDP 即用户数据报协议(User Datagram Protocol &…...

celery rabbitmq 配置 broker和backend
在使用Celery和RabbitMQ作为消息代理和结果后端时,你需要正确配置Celery以便它们可以有效地通信。以下是如何配置Celery以使用RabbitMQ作为broker(消息代理)和backend(结果后端)的步骤: 安装必要的库 首先…...
)
vue+electron ipc+sql相关开发(三)
在 Electron 中使用 IPC(Inter-Process Communication)与 SQLite 数据库进行通信是一个常见的模式,特别是在需要将数据库操作从渲染进程(Vue.js)移到主进程(Electron)的情况下。这样可以更好地管理数据库连接和提高安全性。下一篇介绍结合axios写成通用接口形式,虽然没…...

[特殊字符] PostgreSQL MCP 开发指南
简介 🚀 PostgreSQL MCP 是一个基于 FastMCP 框架的 PostgreSQL 数据库交互服务。它提供了一套简单易用的工具函数,让你能够通过 API 方式与 PostgreSQL 数据库进行交互。 功能特点 ✨ 🔄 数据库连接管理与重试机制🔍 执行 SQL…...

GD32裸机程序-SFUD接口文件记录
SFUD gitee地址 SFUD spi初始化 /********************************************************************************* file : bsp_spi.c* author : shchl* brief : None* version : 1.0* attention : None* date : 25-…...
Flutter项目之设置页
目录: 1、实现效果图2、实现流程2.1、引入依赖2.2、封装弹窗工具类2.3、设置页2.4、路由中注册设置页面 1、实现效果图 2、实现流程 2.1、引入依赖 2.2、封装弹窗工具类 import package:fluttertoast/fluttertoast.dart;class CommontToast {static showToast(Str…...

【Pandas】pandas DataFrame tail
Pandas2.2 DataFrame Indexing, iteration 方法描述DataFrame.head([n])用于返回 DataFrame 的前几行DataFrame.at快速访问和修改 DataFrame 中单个值的方法DataFrame.iat快速访问和修改 DataFrame 中单个值的方法DataFrame.loc用于基于标签(行标签和列标签&#…...

通过GO后端项目实践理解DDD架构
最近在工作过程中重构的项目要求使用DDD架构,在网上查询资料发现教程五花八门,并且大部分内容都是长篇的概念讲解,晦涩难懂,笔者看了一些github上入门的使用DDD的GO项目,并结合自己开发中的经验,谈谈自己对…...
:解锁数据驱动的商业成功密码)
精益数据分析(2/126):解锁数据驱动的商业成功密码
精益数据分析(2/126):解锁数据驱动的商业成功密码 大家好!在如今这个数据爆炸的时代,数据就像一座蕴含无限宝藏的矿山,等待着我们去挖掘和利用。最近我在深入研读《精益数据分析》这本书,收获了…...