【NLP】 20. Attention 和 self-attention
1. 背景与基本概念
1.1 编码器-解码器模型的瓶颈问题
传统的序列到序列(Seq2Seq)模型主要依靠编码器生成单一固定长度的上下文向量,然后由解码器逐步生成输出。这个过程存在两个主要问题:
- 瓶颈问题:固定长度的上下文向量无法充分捕捉输入序列中所有信息,从而导致信息丢失,尤其对于长序列尤为明显。
- 难以并行化:由于解码器的每一步计算依赖前一步的输出(即“自回归”性质),导致整个生成过程难以并行计算,训练速度和推理效率受限。
为了解决这些问题,引入了注意力机制,使得每一步输出都能动态关注输入中最相关的信息。
1.2 注意力机制的基本思想
什么是 Attention?
Attention(注意力机制)模拟人类注意力集中的方式:
🧠 “我不是把全部输入都等量处理,而是关注最重要的信息。”
在 NLP 里,就是让模型在处理一个词时,自动找出它最该“注意”的其他词,并根据它们的相关性来生成当前的输出。
注意力机制(Attention)的核心思想是:
对于每个生成的输出步骤,通过对输入序列中的所有隐藏向量进行加权求和,计算出一个“上下文向量”,该向量能更有针对性地帮助生成当前输出。
图示:
输入序列隐藏状态: h₁, h₂, ..., hₙ
解码器当前状态: sᵢ注意力过程:
1. 根据当前解码器状态 sᵢ 和输入隐藏状态 hⱼ 计算注意力分数 eᵢⱼ;
2. 对分数 eᵢⱼ 进行归一化(通常使用 softmax)得到权重 αᵢⱼ;
3. 对输入隐藏状态加权求和:cᵢ = Σⱼ αᵢⱼ hⱼ;
4. 将上下文向量 cᵢ 与 sᵢ 结合用于生成输出。
2. 公式推导与实现细节
在这个教程中,我们讨论多种注意力机制以及它们背后的数学公式与实现细节。下面分段说明各类注意力的计算过程及公式。
2.1 基本注意力计算过程
- 隐藏向量表示
假设输入序列经过编码器得到隐藏状态:
H = { h 1 , h 2 , … , h n } H = \{h_1, h_2, \dots, h_n\} H={h1,h2,…,hn}
每个隐藏向量 h j ∈ R d h h_j \in \mathbb{R}^{d_h} hj∈Rdh 表示输入的第 j 个时刻的信息。 - 当前输出时刻的隐藏向量
对于解码器deocer当前时刻 i 的状态 s i s_i si 表示,我们需要得到一个与输入序列中最相关的上下文向量。 - 注意力分数计算
计算方式可以有多种,我们一般记得统一格式如下:- 点积注意力(Dot-Product Attention):
e i j = s i ⊤ h j e_{ij} = s_i^\top h_j eij=si⊤hj - 缩放点积注意力(Scaled Dot-Product Attention):
为了避免维度过高导致点积数值过大,使用缩放因子:
e i j = s i ⊤ h j d k e_{ij} = \frac{s_i^\top h_j}{\sqrt{d_k}} eij=dksi⊤hj 其中 dk 为键(Key)的维度。 - 乘性注意力(Multiplicative Attention/Bilinear Attention):
在此方法中,可以允许 si 和 hj 的维度不同,使用一个可学习的矩阵 W:
e i j = s i ⊤ W h j e_{ij} = s_i^\top W h_j eij=si⊤Whj - 降秩乘性注意力(Reduced-Rank Multiplicative Attention):
为了提高效率,矩阵 W 可以分解为低秩矩阵的乘积,减少参数量。
e = s T ( U T V ) h = ( s U ) T ( V h ) e = s^T(U^TV)h = (sU)^T(Vh) e=sT(UTV)h=(sU)T(Vh) - 加性注意力(Additive / Feedforward Attention):
通过一个前馈神经网络来计算注意力分数,其形式为:
e i j = b tanh ( W 1 h + W 2 s ) e_{ij} = b \tanh(W_1h+ W_2s ) eij=btanh(W1h+W2s) 其中 v,Ws,Wh 和 b 均为可学习参数,加性注意力能提供更大的非线性和灵活性。
- 点积注意力(Dot-Product Attention):
- 分数归一化
得到注意力分数后,一般通过 softmax 对所有输入的分数进行归一化,得到权重 - 加权平均计算上下文向量
根据得到的注意力权重,计算加权平均: c i = ∑ j = 1 n α i j h j c_i = \sum_{j=1}^{n} \alpha_{ij} h_j ci=j=1∑nαijhj
这就是传统注意力机制的完整计算流程。 这解决了瓶颈问题,而没有引入许多额外的参数
Attention ≠ Self-Attention
它们是一个大类里的不同类型,我们先来理清楚:
🧠 Attention 是大类,Self-Attention 是其中一种特例:
| 类型 | 描述 |
|---|---|
| 普通 Attention | Query 来自一个序列,Key/Value 来自另一个序列。 典型场景:机器翻译(Decoder 对 Encoder 做 Attention)。 |
| Self-Attention | Query、Key、Value 都来自同一个序列。 用于模型理解当前序列内部各部分的关系。 |
🔁 举个例子来对比!
🎯 普通 Attention(Cross-Attention):
用在 Seq2Seq 机器翻译里。
比如你在翻译:
arduinoCopyEdit英文(输入):"I love you"
法文(输出):"Je t'aime"
此时:
- Encoder 处理英文句子,生成 Key 和 Value;
- Decoder 在生成法文单词时,用 Query 去和 Encoder 的 Key 做匹配;
- 然后从 Value 中取出最相关的“语义”来帮助生成下一个词。
所以:
Query ← Decoder 生成的当前状态
Key, Value ← Encoder 的输出
👉 这种 Attention 就是 Cross-Attention
🔄 Self-Attention:
处理一个序列(比如句子)时,模型希望:
“我处理一个词的时候,也考虑它在句子里跟谁最相关。”
比如句子是:
"The animal didn't cross the street because it was too tired."
模型要弄清楚 “it” 指的是 “the animal” 还是 “the street”——这就靠 Self-Attention。
此时:
- Query、Key、Value 都来自这个句子本身;
- 每个词都对整个句子中的其他词做注意力运算;
- 得到一个加权的表示向量。
💬 总结类比一句话:
| 类比 | Attention 像什么? |
|---|---|
| Cross-Attention | 你问别人问题(Query)→ 去他们的记忆(Key/Value)中找答案 |
| Self-Attention | 你自己脑内思考一个词时,把整个句子所有词都考虑一遍 |
3. 自注意力(Self-Attention)与位置编码
3.1 自注意力的动机及实现
在自注意力机制中,输入自身被用来构造查询(Query)、键(Key)和值(Value),即:
- 查询(Query):由当前时刻或位置的输入生成
- 键(Key):代表所有输入信息
- 值(Value):包含需要传递给后续层的信息
自注意力使每个词的表示能够综合考虑上下文中所有其他词的影响,从而生成具有更高层次语义信息的表示。其计算与前文相似,不过所有向量均来自于同一输入序列。
计算步骤如下:
- 初始词向量 xi
- 变换为 Query, Key, Value
利用可学习的线性变换: q i = W Q x i , k i = W K x i , v i = W V x i q_i = W^Q x_i,\quad k_i = W^K x_i,\quad v_i = W^V x_i qi=WQxi,ki=WKxi,vi=WVxi - 计算注意力分数
使用缩放点积: e i j = q i ⊤ k j d k e_{ij} = \frac{q_i^\top k_j}{\sqrt{d_k}} eij=dkqi⊤kj - 归一化分数:
α i j = exp ( e i j ) ∑ l = 1 n exp ( e i l ) \alpha_{ij} = \frac{\exp(e_{ij})}{\sum_{l=1}^{n} \exp(e_{il})} αij=∑l=1nexp(eil)exp(eij) - 计算加权平均得到新的表示:
z i = ∑ j = 1 n α i j v j z_i = \sum_{j=1}^{n} \alpha_{ij} v_j zi=j=1∑nαijvj
以上步骤可以堆叠多层以获得更复杂的表示。
3.2 非线性与位置表示
单纯的线性组合容易丢失非线性特征,因此**添加前馈层(Feedforward Layer)**非常关键:
- 前馈层通常在每个自注意力层后添加,公式如下: FFN ( z ) = max ( 0 , z W 1 + b 1 ) W 2 + b 2 \text{FFN}(z) = \max(0, zW_1 + b_1)W_2 + b_2 FFN(z)=max(0,zW1+b1)W2+b2其中使用了 ReLU 激活函数(当然也可以使用其他非线性激活函数)。
位置编码(Positional Encoding)用于注入序列中位置信息,由于自注意力机制本质上不涉及位置顺序,需要人为提供位置信息。常见两种方法:
-
固定位置编码
使用正余弦函数:P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i d ) PE(pos, 2i) = \sin\left(\frac{pos}{10000^{\frac{2i}{d}}}\right) PE(pos,2i)=sin(10000d2ipos) P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i d ) PE(pos, 2i+1) = \cos\left(\frac{pos}{10000^{\frac{2i}{d}}}\right) PE(pos,2i+1)=cos(10000d2ipos)
其中 pospospos 表示位置,iii 表示维度索引,ddd 是词向量维度。
-
学习位置编码
为每个位置学习一个向量,这种方法能更好地适应训练数据,但存在不能泛化到训练过程中未出现的长度问题。
Rotary Positional Embeddings也是一种较新方法,其核心思想是利用旋转变换使得词向量在不同位置呈现出不同的特征,同时保持词之间的余弦相似度不变,从而能够更好地捕捉不同位置间的关系。
3.3 模型优化与并行计算改进
针对传统RNN计算步骤依赖前一步的限制,Attention/自注意力机制能够“剪断循环边缘”,实现并行计算:
- 解决瓶颈问题:
利用注意力机制,系统在不引入大量额外参数的情况下,能够从输入序列中提取出对当前输出决策最有用的信息。 - 并行性增强:
自注意力允许所有位置之间的计算并行化,大大提高训练效率,尤其在Transformer模型中表现显著。
例如,在解码器中,为了避免输出提前“窥探”未来的信息,计算注意力分数时采用屏蔽(masking)策略:
e i j = { q i ⊤ k j , j ≤ i − ∞ , j > i e_{ij} = \begin{cases} q_i^\top k_j, & j \le i \\ -\infty, & j > i \end{cases} eij={qi⊤kj,−∞,j≤ij>i
屏蔽掉未来的信息保证生成时仅使用过去和当前的信息。
4. 实践案例与进一步讨论
4.1 示例:机器翻译中的注意力
在机器翻译中,注意力机制常被用来捕捉源语言词语与目标语言词语之间的对齐关系。例如:
- 输入句子:
“我 爱 自然 语言 处理” - 编码器生成隐藏状态:
每个单词对应的隐藏向量 h1,h2,…,h5h_1, h_2, …, h_5h1,h2,…,h5 - 目标输出:
当解码器生成目标单词时,通过注意力计算获得当前词最相关的源语言词汇,然后结合生成时的隐藏状态产生翻译结果。实践中观察到注意力权重矩阵往往捕捉到了词语对齐,即某个目标词权重最高的源词常常就是对应翻译的词。
值得注意的是,“the”等常见词在注意力机制中的处理往往较为特殊。由于其频率极高,可能在统计上贡献较小或者干扰信息,因此很多模型会采用词嵌入降权、词频削弱或加入专门的正则化项来降低这些高频词对整体注意力分布的影响,使得模型更关注那些信息量更大的关键词。
4.2 自注意力替代RNN
由于RNN难以并行化的缺陷,Transformer引入了自注意力作为主要构件。详细步骤如下:
- 初始词向量:
xi - 线性变换生成 Query, Key, Value:
qi=WQxi,ki=WKxi,vi=WVxi q i = W Q x i , k i = W K x i , v i = W V x i q_i = W^Q x_i,\quad k_i = W^K x_i,\quad v_i = W^V x_i qi=WQxi,ki=WKxi,vi=WVxi - 计算注意力分数(缩放点积形式):
e i j = q i ⊤ k j d k e_{ij} = \frac{q_i^\top k_j}{\sqrt{d_k}} eij=dkqi⊤kj - Softmax归一化
- 加权求和:
z i = ∑ j = 1 n α i j v j z_i = \sum_{j=1}^{n} \alpha_{ij} v_j zi=j=1∑nαijvj - 非线性映射(前馈层)
- 加入位置信息:
初始输入中直接加入位置编码:
x i = x i + p i x_i = x_i + p_i xi=xi+pi 或在后续层与原始信息进行融合,如拼接或逐层加入。
这种设计既保留了RNN捕捉序列相关性的优势,也显著提升了计算效率和并行计算能力。
🧠 传统 RNN + Attention vs 纯 Attention
最开始 Attention 是加在 RNN / LSTM / GRU 上的
后来有人问:我们能不能只靠 Attention,不要 RNN?
答案就是 ——
✅ Yes!这就是 Transformer(2017 Vaswani 等人的论文)
💥 为什么 RNN 不需要了?
RNN 有个主要的“限制”:
它是顺序处理的!每个词要等前面的处理完才能计算。
而 Attention 机制 + Position Embedding 可以做到:
一次性并行处理整句,每个词同时看全句的上下文,不再“排队等处理”。
🔧 如何做到没有 RNN,还能处理序列?
🧩 1. 全靠 Self-Attention
Transformer 用多个 Self-Attention 层堆叠,每一层都能理解词之间的关系:
- 每个词作为 Query;
- 关注整个句子的 Key / Value;
- 自我关联。
🧩 2. 加上 Positional Encoding
因为没有 RNN 的顺序感知能力,Transformer 加了位置编码
👉 把位置信息通过正余弦函数 encode,加入词向量中。
🧬 总结结构对比:
| 模型类型 | 是否用 RNN | 是否用 Attention | 能否并行 | 能否捕捉长依赖 |
|---|---|---|---|---|
| LSTM | ✅ 是 | ❌ 无(默认) | ❌ 否 | ✅ 有点困难 |
| LSTM + Attention | ✅ 是 | ✅ 是 | ❌ 否 | ✅ 强一些 |
| Transformer | ❌ 否 | ✅ Self-Attention | ✅ 是 | ✅ 非常强 |
相关文章:

【NLP】 20. Attention 和 self-attention
1. 背景与基本概念 1.1 编码器-解码器模型的瓶颈问题 传统的序列到序列(Seq2Seq)模型主要依靠编码器生成单一固定长度的上下文向量,然后由解码器逐步生成输出。这个过程存在两个主要问题: 瓶颈问题:固定…...

vue3+element-plus实现省市区三级地址多选
目录 背景实现功能点遗留问题完整代码参考 背景 需要实现:选择省级地址时,回传节点为 [ 省级地址 id], 选择市级地址时,回传节点为 [ 省级地址 id,市级地址 id], 选择区县地址时,回传节点为 [ …...

centos部署的openstack发布windows虚拟机
CentOS上部署的OpenStack可以发布Windows虚拟机。在CentOS上部署OpenStack后,可以通过OpenStack平台创建和管理Windows虚拟机。以下是具体的步骤和注意事项: 安装和配置OpenStack: 首先,确保系统满足OpenStack的最低硬件…...

Linux : 进程等待以及进程终止
进程控制之进程等待 (一)fork函数1*fork函数返回值2.父子进程的写时拷贝 (二)进程终止1.进程退出码2.进程常见退出方法(1)_exit(2)exit(3)return 3.进程的异常…...
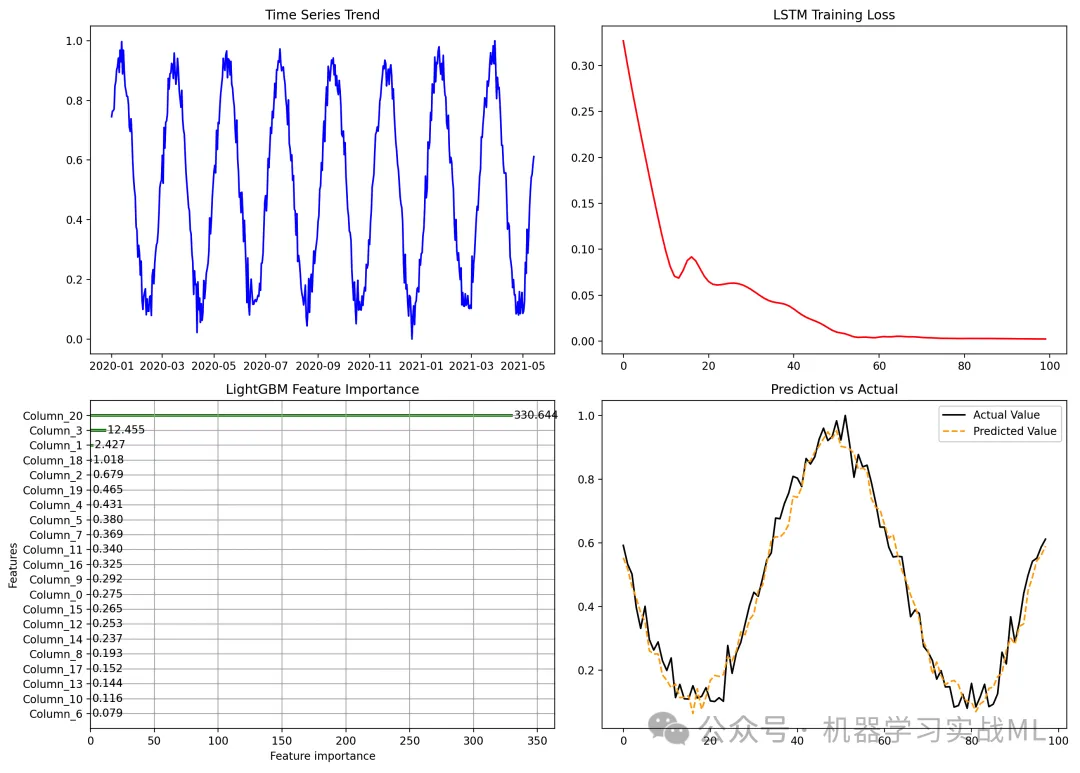
LSTM结合LightGBM高纬时序预测
1. LSTM 时间序列预测 LSTM 是 RNN(Recurrent Neural Network)的一种变体,它解决了普通 RNN 训练时的梯度消失和梯度爆炸问题,适用于长期依赖的时间序列建模。 LSTM 结构 LSTM 由 输入门(Input Gate)、遗…...

详细解释MCP项目中安装命令 bunx 和 npx区别
详细解释 bunx 和 npx 1. bunx bunx 是 Bun 的一个命令行工具,用于自动安装和运行来自 npm 的包。它是 Bun 生态系统中类似于 npx 或 yarn dlx 的工具。以下是 bunx 的主要特点和使用方法: 自动安装和运行: bunx 会自动从 npm 安装所需的包…...
【统信UOS操作系统】python3.11安装numpy库及导入问题解决
一、安装Python3.11.4 首先来安装Python3.11.4。所用操作系统:统信UOS 前提是准备好Python3.11.4的安装包(可从官网下载(链接)),并解压到本地: 右键,选择“在终端中打开”ÿ…...

【中间件】nginx反向代理实操
一、说明 nginx用于做反向代理,其目标是将浏览器中的请求进行转发,应用场景如下: 说明: 1、用户在浏览器中发送请求 2、nginx监听到浏览器中的请求时,将该请求转发到网关 3、网关再将请求转发至对应服务 二、具体操作…...

嵌入式硬件篇---加法减法积分微分器
文章目录 前言1. 加法器(Summing Amplifier)结构反相加法器同相加法器 特点反相输出虚地特性 应用 2. 减法器(差分放大器)结构特点差分放大共模抑制比 应用 3. 积分器结构特点直流漂移问题应用 4. 微分器结构特点应用关键注意事项…...

Spring Cloud Gateway 的执行链路详解
Spring Cloud Gateway 的执行链路详解 🎯 核心目标 明确 Spring Cloud Gateway 的请求处理全过程(从接收到请求 → 到转发 → 到返回响应),方便你在合适的生命周期节点插入你的逻辑。 🧱 核心执行链路图(执…...
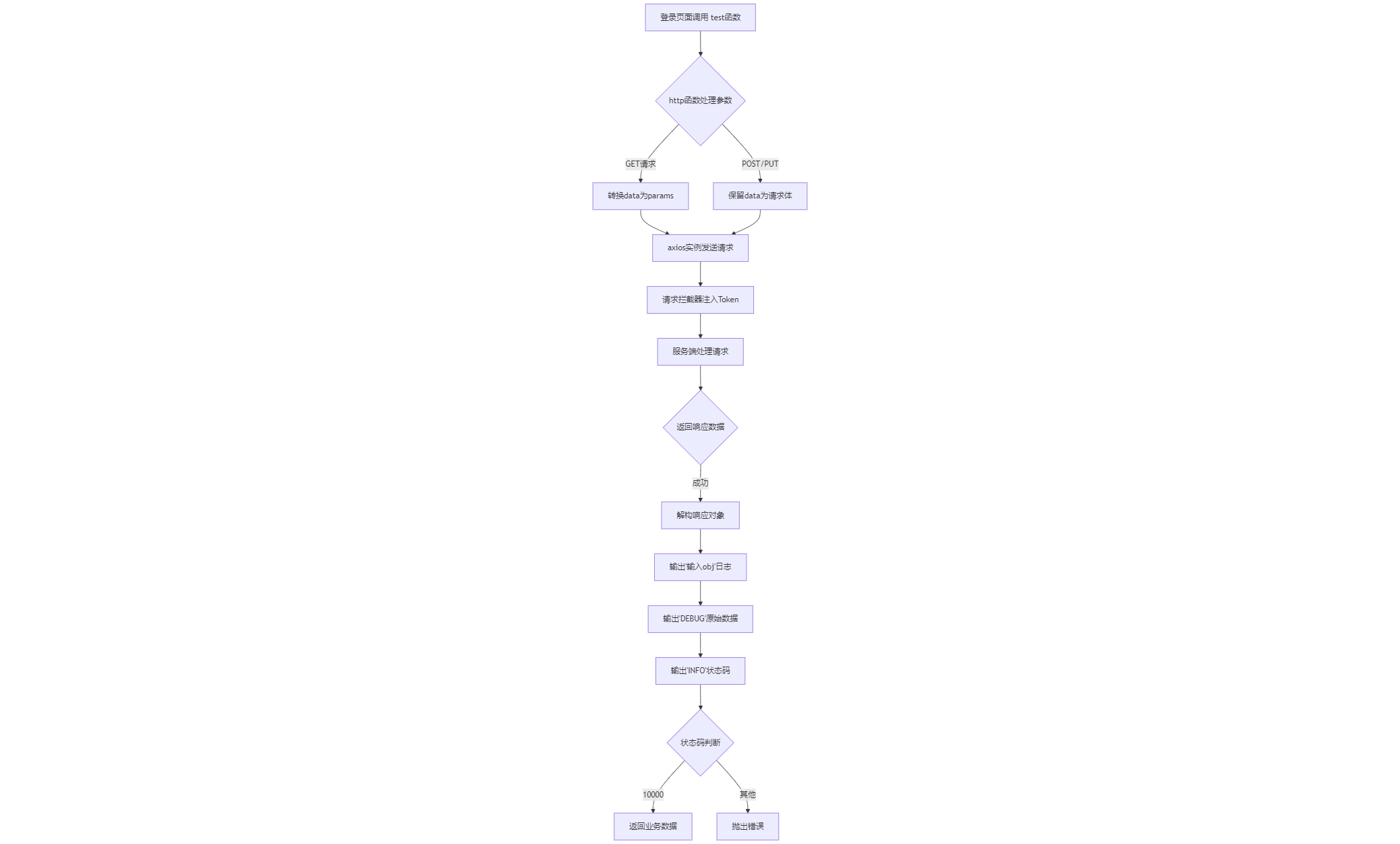
鸿蒙应用(医院诊疗系统)开发篇2·Axios网络请求封装全流程解析
一、项目初始化与环境准备 1. 创建鸿蒙工程 src/main/ets/ ├── api/ │ ├── api.ets # 接口聚合入口 │ ├── login.ets # 登录模块接口 │ └── request.ets # 网络请求核心封装 └── pages/ └── login.ets # 登录页面逻辑…...
突发重磅消息!!!CVE项目将被取消?
突发重磅消息!!!CVE项目将被取消?突发!来自可靠消息来源。MITRE 对 CVE 项目的支持将于明天到期。附件信件已发送给 CVE 董事会成员。https://mp.weixin.qq.com/s/N3qkiHaDfzDuBMK3JbBCjw...
详解与FTP服务器相关操作
目录 什么是FTP服务器 搭建FTP服务器相关 编辑 Unity中与FTP相关的类 上传文件到FTP服务器 使用FTP服务器上传文件的关键点 开始上传 从FTP服务器下载文件到客户端 使用FTP下载文件的关键点 开始下载 关于FTP服务器的其他操作 将文件的上传,下载&…...

远程登录一个Linux系统,如何用命令快速知道该系统属于Linux的哪个发行版,以及该服务器的各种配置参数,运行状态?
远程登录一个Linux系统,如何用命令快速知道该系统属于Linux的哪个发行版,以及该服务器的各种配置参数,运行状态? 查看Linux发行版信息 查看发行版名称和版本: cat /etc/*-release或 lsb_release -a查看内核版本&#…...

解决 .Net 6.0 项目发布到IIS报错:HTTP Error 500.30
今天在将自己开发许久的项目上线的时候,发现 IIS 发布后请求后端老是报一个 HTTP Error 500.30 的异常,如下图所示。 后来仔细调查了一下发现是自己的程序中写了 UseStaticFiles 的依赖注入,这个的主要作用就是发布后端后,想…...

STM32F103_HAL库+寄存器学习笔记16 - 监控CAN发送失败(轮询方式)
导言 《STM32F103_HAL库寄存器学习笔记15 - 梳理CAN发送失败时,涉及哪些寄存器》从上一章节看到,当CAN消息发送失败时,CAN错误状态寄存器ESR的TEC会持续累加,LEC等于0x03(ACK错误)。本次实验的目的是编写一…...

Java并发-AQS框架原理解析与实现类详解
什么是AQS? AQS(AbstractQueuedSynchronizer)是Java并发包(JUC)的核心基础框架,它为构建锁和同步器提供了高效、灵活的底层支持。本文将从设计原理、核心机制及典型实现类三个维度展开,帮助读者…...

实现定长的内存池
池化技术 所谓的池化技术,就是程序预先向系统申请过量的资源,然后自己管理起来,以备不时之需。这个操作的价值就是,如果申请与释放资源的开销较大,提前申请资源并在使用后并不释放而是重复利用,能够提高程序…...
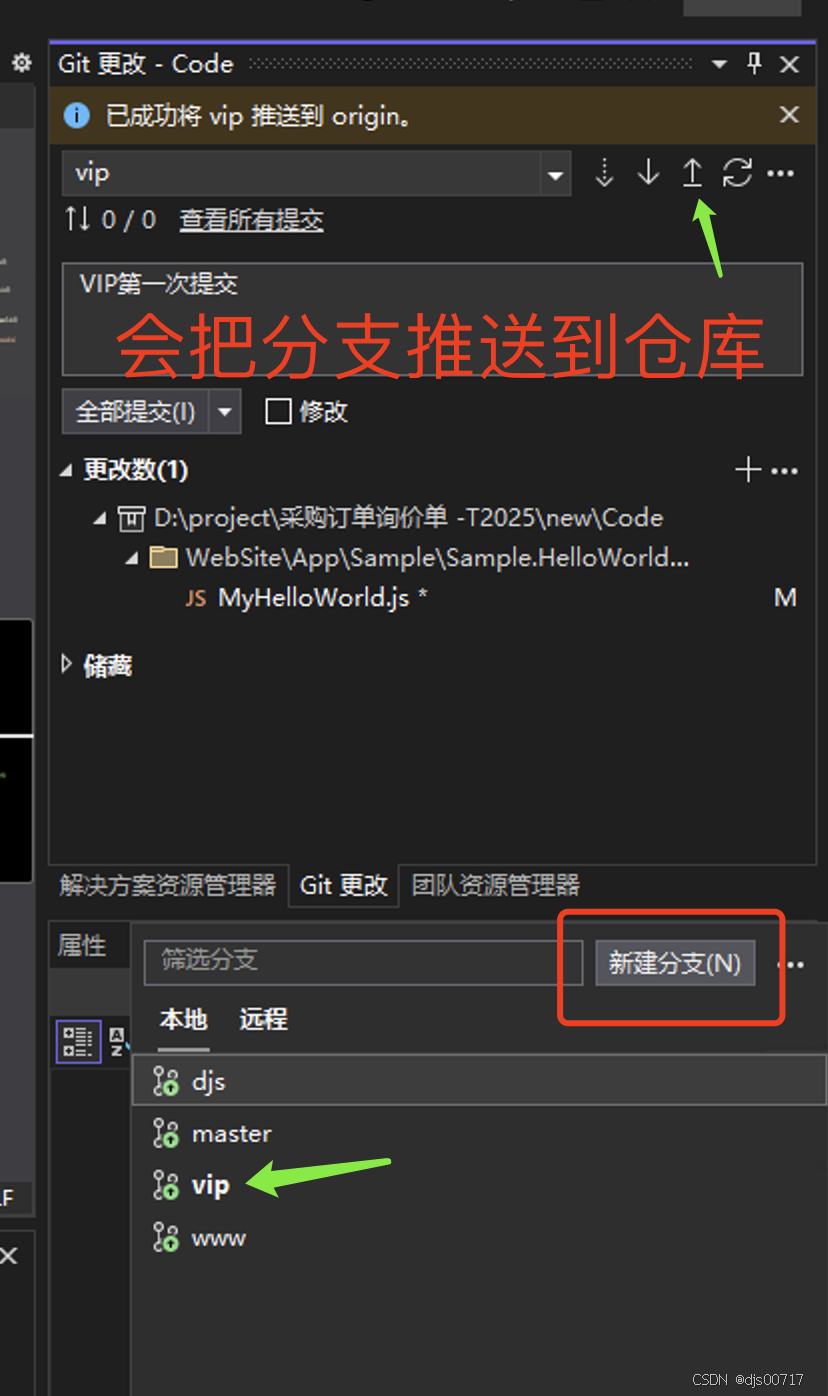
vs2022使用git方法
1、创建git 2、在cmd下执行 git push -f origin master ,会把本地代码全部推送到远程,同时会覆盖远程代码。 3、需要设置【Git全局设置】,修改的代码才会显示可以提交,否则是灰色的不能提交。 4、创建的分支,只要点击…...

Mysql中表的使用(3)
目录 1.updata的使用 2.delete(删除表中数据)drop(删除表) 数据库的约束 1.NOT NULL 指定列不能为空 2.UNIQUE指定列唯一 3.DEFAULT(默认值) 4.PRIMARY KEY 5.自增主键 1.updata的使用 1.0update 表名 set 列名x where 列名y; 2.0update 表名 s…...
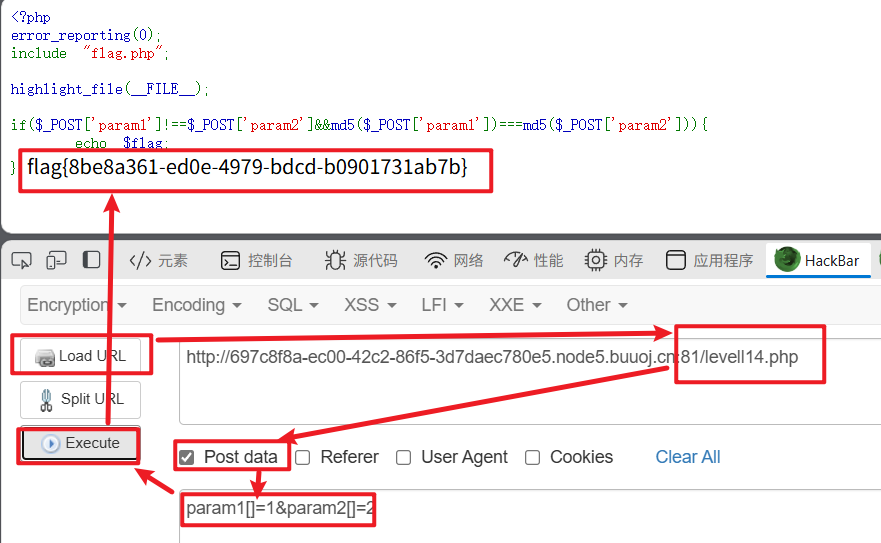
BUUCTF-Web(1-20)
目录 一.SQL注入 (1)[极客大挑战 2019]EasySQL 万能密码 (7)[SUCTF 2019]EasySQL 堆叠注入 解一: 解二: (10)[强网杯 2019]随便注 堆叠注入 解一: 解二: 解三: (8)[极客大挑战 2019]LoveSQL 联…...

Uniapp:确认框
目录 一、 出现场景二、 效果展示三、具体使用 一、 出现场景 在项目的开发中,会经常出现删除数据的情况,如果直接删除的话,可能会存在误删,用户体验不好,所以需要增加一个消息提示,提醒用户是否删除。 二…...

【前端网络请求入门】XMLHttpRequest与Fetch保姆级教程
新手学前端时,经常会被「如何让网页和服务器说话」难住。今天我们用最通俗的语言,把浏览器最常用的两种网络请求方式——XMLHttpRequest和Fetch讲清楚,还会带完整的代码示例,跟着敲一遍就能上手! 一、先搞懂「网络请求…...
)
力扣热题100—滑动窗口(c++)
3.无重复字符的最长子串 给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串 的长度。 unordered_set<char> charSet; // 用于保存当前窗口的字符int left 0; // 窗口左指针int maxLength 0; // 最长子串的长度for (int right 0; right < s.siz…...
实验四 中断实验
一、实验目的 掌握中断服务程序的编写。 二、实验电路 三、实验内容 1.实验用PC机内部的中断控制器8259A,中断源用TPC-ZK实验箱上的单脉冲电路,将单脉冲电路的输出接中断请求信号IRQ,每按一次单脉冲按键产生一次…...

腾势品牌欧洲市场冲锋,科技豪华席卷米兰
在时尚与艺术的交汇点,米兰设计周的舞台上,一场汽车界的超级风暴正在酝酿,腾势品牌如一头勇猛无畏的雄狮,以雷霆万钧之势正式向欧洲市场发起了冲锋。其最新力作——腾势Z9GT的登场,仿佛是一道闪电划破夜空,…...

第五阶段:项目实践与后续学习指引
模块 10:综合项目实践 在这个模块中,我们将通过实际项目来综合运用前面所学的 Python 知识。我们会选择一个命令行记事本应用作为主要示例,同时简要介绍其他项目的思路。 项目:命令行记事本应用 1. 项目规划 良好的项目规划是…...

MoogDB数据库日常维护技巧与常见问题解析
在当今的数据驱动世界中,数据库作为信息存储与管理的核心组件,扮演着举足轻重的角色。MoogDB作为一款高性能、易扩展的数据库解决方案,越来越受到开发者和企业的青睐。为了确保MoogDB的稳定性与高性能,定期的日常维护及对常见问题…...

Java 中的各种锁详解
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/literature?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,…...

多店铺商城_多商户商城系统源码_免费开源!
在电商行业快速发展的今天,多店铺商城系统(B2B2C模式)已成为企业实现平台化运营的核心工具,就像我们平时用的淘宝,京东那样。如果你想做一个电商平台就需要这种多店铺商城系统。 本文将深入探讨多商户商城系统的核心功…...