Java中的经典排序算法:插入排序、希尔排序、选择排序、堆排序与冒泡排序(如果想知道Java中有关插入排序、希尔排序、选择排序、堆排序与冒泡排序的知识点,那么只看这一篇就足够了!)
前言:排序算法是计算机科学中的基础问题之一,它在数据处理、搜索算法以及各种优化问题中占有重要地位,本文将详细介绍几种经典的排序算法:插入排序、选择排序、堆排序和冒泡排序。
✨✨✨这里是秋刀鱼不做梦的BLOG
✨✨✨想要了解更多内容可以访问我的主页秋刀鱼不做梦-CSDN博客

先让我们看一下本文大致的讲解内容:

对于每个排序算法,我们都会从算法简介、其原理与步骤、代码实现、时间复杂度分析、空间复杂度分析与该排序算法的应用场景这几个方面来进行讲解。
目录
1.插入排序(InsertSort)
(1)算法简介
(2)原理与步骤
(3)Java代码实现
(4)时间复杂度 + 空间复杂度分析
(5)应用场景
2.希尔排序(Shell Sort)
(1)算法简介
(2)算法步骤
(3)代码实现
(4)时间复杂度 + 空间复杂度分析
(5)应用场景
3.选择排序(Selection Sort)
(1)算法简介
(2)算法步骤
(3)代码实现
(4)时间复杂度 + 空间复杂度分析
(5)应用场景
4.堆排序(Heap Sort)
(1)算法简介
(2)算法步骤
(3)代码实现
(4)时间复杂度 + 空间复杂度分析
(5)应用场景
5.冒泡排序(Bubble Sort)
(1)算法简介
(2)算法步骤
(3)代码实现
(4)时间复杂度 + 空间复杂度分析
(5)应用场景
1.插入排序(InsertSort)
(1)算法简介
在开始学习插入排序算法之前,先让我们来看一下该算法的概念:
——插入排序是一种简单直观的排序算法,通常用于对少量元素的排序。其基本思想是构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
(2)原理与步骤
了解了插入排序算法的概念之后,让我们看一下实现该排序算法的几个核心步骤:
-
从第一个元素开始,该元素可以认为已经被排序。
-
取出下一个元素,在已经排序的元素序列中从后向前扫描。
-
如果已排序的元素大于新元素,将该元素向右移动。
-
重复步骤3,直到找到已排序的元素小于或等于新元素的位置。
-
将新元素插入到该位置中。
-
重复步骤2~5。
读者可以根据上述的描述先简要的了解一些插入排序的核心思路,接下来让我们使用代码来进行对其的实现。
(3)Java代码实现
现在我们使用代码来实现一下插入排序算法:
public class InsertionSort {public void insertSort(int[] array) {for (int i = 1; i < array.length; i++) {int key = array[i];int j = i - 1;while (j >= 0 && array[j] > key) {array[j + 1] = array[j];j = j - 1;}array[j + 1] = key;}}
}
注释解释:
1.外层
for循环:
从第二个元素(索引为1)开始遍历,因为第一个元素本身已经是一个排序好的子数组。
2.保存当前元素:
使用
temp变量保存当前要插入的元素。3.内层
for循环:
从当前元素的前一个位置开始向前检查,如果已排序部分的元素大于
temp,就将该元素向后移动一位。如果找到的元素小于或等于
temp,则跳出循环,说明找到了插入位置。4.插入元素:
在找到的位置将
temp插入到数组中。
这样我们就大致的了解了如何去实现插入排序算法了!
(4)时间复杂度 + 空间复杂度分析
对于插入排序,其最坏时间复杂度为O(n^2),当数据完全逆序时,需进行最多的比较和移动操作。平均情况下的时间复杂度也是O(n^2),但在最好的情况下(数据已经有序),时间复杂度为O(n)。
插入排序是一个原地排序算法,只需要常数级别的额外空间,因此空间复杂度为O(1)。
(5)应用场景
插入排序常常用于小规模数据集,特别是在数组几乎有序的情况下非常高效。它的稳定性也是其一个优点,在某些需要稳定排序的应用中有着广泛应用。
——通过上边对插入排序的简单讲解,我们就大致的了解了插入排序算法了!
2.希尔排序(Shell Sort)
了解完了插入排序之后,让我们看一下根据其优化的算法——希尔排序。
(1)算法简介
——希尔排序(Shell Sort)是插入排序的改进版,它通过分组的方式减少插入排序的移动次数,从而提高排序效率。希尔排序通过一个间隔序列(gap sequence)将数组分成若干子序列,每个子序列进行插入排序,然后逐步减小间隔,最终完成排序。
(2)算法步骤
了解了希尔排序的基本概念之后,让我们看一下如何去实现希尔排序:
-
选择初始间隔(通常为数组长度的一半)。
-
对每个间隔下的子序列进行插入排序。
-
减小间隔,重复步骤2,直到间隔为1。
——那么接下来让我们使用代码来进行对其的实现。
(3)代码实现
以下为实现希尔排序算法的代码:
public void shellSort(int[] array) {// 初始间隔设置为数组长度int gap = array.length;// 当间隔大于1时,继续进行希尔排序while (gap > 1) {// 更新间隔,通常将间隔除以2gap /= 2;// 使用当前间隔进行插入排序shellInsertSort(gap, array);}
}private void shellInsertSort(int gap, int[] array) {// 从间隔后的第一个元素开始遍历for (int i = gap; i < array.length; i++) {// 保存当前要插入的元素int temp = array[i];// 从当前元素的前一个间隔位置开始向前检查int j = i - gap;// 将当前元素与前面间隔的元素进行比较// 如果前面间隔的元素大于当前元素,则将前面间隔的元素向后移动一位// 否则,找到正确的位置for (; j >= 0; j -= gap) {if (array[j] > temp) {array[j + gap] = array[j]; // 移动元素} else {break; // 找到插入位置}}// 将当前元素插入到找到的位置array[j + gap] = temp;}
}
注释解释:
shellSort方法:
初始化间隔:设置初始间隔为数组的长度。
更新间隔:通过将间隔除以2来逐步减小间隔,直到间隔小于等于1。
调用插入排序:使用当前的间隔值调用
shellInsertSort方法对数组进行插入排序。
shellInsertSort方法:
遍历数组:从当前间隔位置的第一个元素开始遍历数组。
保存当前元素:将当前元素保存到
temp中。检查并插入:从当前元素的前一个间隔位置开始向前检查,如果前面的元素大于当前元素,则将前面的元素向后移动一位,直到找到适合插入的位置。
插入元素:将当前元素
temp插入到找到的位置。
这样我们就大致的了解了如何去实现希尔排序算法了!
(4)时间复杂度 + 空间复杂度分析
希尔排序的时间复杂度取决于选择的间隔序列。常见的间隔序列有Shell增量(n/2, n/4, …, 1)和Hibbard增量(1, 3, 7, 15, …)。时间复杂度通常介于O(n)和O(n^2)之间,最坏情况下为O(n^2)。
希尔排序也是一种原地排序算法,空间复杂度为O(1)。
(5)应用场景
希尔排序适用于中小规模的数据集,特别是在内存较为紧张且需要较高排序效率的场景下表现优异。
——通过上边对希尔排序的简单讲解,我们就大致的了解了希尔排序算法了!
3.选择排序(Selection Sort)
接下来让我们学习选择排序算法。
(1)算法简介
——选择排序(Selection Sort)是一种简单的排序算法。它的基本思想是每次从未排序部分中选择最小的元素,放到已排序部分的末尾。选择排序的特点是每次交换位置时,都能确定一个元素的最终位置,因此它的交换次数较少。
(2)算法步骤
在了解完了选择排序算法的概念之后,让我们看一下实现其算法的核心步骤:
-
从数组中找到最小的元素,将其与数组的第一个元素交换位置。
-
在剩下的未排序部分中重复上述步骤,直到所有元素都已排序。
这样,我们就了解了选择排序的核心思路了,接下来让我们使用代码对其进行实现。
(3)代码实现
以下为实现选择排序算法的代码:
public void selectSort(int[] array) {// 遍历数组的每一个元素for (int i = 0; i < array.length - 1; i++) {// 假设当前元素是最小值int minIndex = i;// 在未排序部分中寻找最小值的索引for (int j = i + 1; j < array.length; j++) {// 如果找到比当前最小值还小的元素,则更新最小值的索引if (array[j] < array[minIndex]) {minIndex = j;}}// 将当前元素与找到的最小值交换位置swap(array, i, minIndex);}
}private void swap(int[] array, int pos1, int pos2) {// 交换数组中两个位置的元素int temp = array[pos1];array[pos1] = array[pos2];array[pos2] = temp;
}
注释解释:
selectSort方法:
遍历数组:通过外层循环遍历数组的每个元素,作为当前排序的起始位置。
寻找最小值:假设当前元素是最小值,并使用内层循环在未排序部分中寻找更小的值。
更新最小值索引:如果找到比当前最小值更小的元素,则更新
minIndex为这个元素的位置。交换元素:调用
swap方法,将当前元素与找到的最小值元素交换位置,使得最小值元素放置在当前排序的位置上。
swap方法:
交换位置:使用临时变量
temp来交换数组中两个指定位置的元素。
这样我们就大致的了解了如何去实现选择排序算法了!
(4)时间复杂度 + 空间复杂度分析
时间复杂度:
- 最坏情况:O(n^2)
- 最好情况:O(n^2)
- 平均情况:O(n^2)
空间复杂度:
选择排序也是一种原地排序算法,空间复杂度为O(1)。
(5)应用场景
选择排序适用于对内存写操作次数敏感的场景,因为它的交换次数较少。此外,选择排序在数据量不大且对排序效率要求不高的场合中表现良好。
——通过上边对选择排序的简单讲解,我们就大致的了解了选择排序算法了!
4.堆排序(Heap Sort)
接下来让我们学习堆排序算法。
(1)算法简介
——堆排序(Heap Sort)是一种基于堆这种数据结构的排序算法。堆是一种近似完全二叉树的结构,分为大顶堆和小顶堆。堆排序通过构建一个大顶堆或小顶堆,将根节点与末尾元素交换,逐步减少堆的大小,最终完成排序。
(2)算法步骤
在了解完了堆排序算法的概念之后,让我们看一下实现其算法的核心步骤:
构建一个最大堆。
将堆顶元素(最大值)与最后一个元素交换,将堆的大小减1。
调整堆结构,使其重新满足最大堆性质。
重复步骤2和3,直到堆的大小为1。
接下来让我们使用代码来进行对其的实现。
(3)代码实现
以下为实现堆排序算法的代码:
public void heapSort(int[] array) {// 将数组转换为大根堆// 从最后一个非叶子节点开始,向上调整堆for (int parent = (array.length - 1 - 1) / 2; parent >= 0; parent--) {makeHeap(array, parent, array.length);}// 交换堆顶(最大值)和最后一个元素,重新调整堆int end = array.length - 1;while (end > 0) {// 交换堆顶和当前堆的最后一个元素swap(array, 0, end);// 调整新的堆顶makeHeap(array, 0, end);end--;}
}private void makeHeap(int[] array, int parent, int length) {// 左子节点的索引int child = 2 * parent + 1;while (child < length) {// 如果右子节点存在且大于左子节点,则将子节点设置为右子节点if (child + 1 < length && array[child] < array[child + 1]) {child++;}// 如果父节点小于子节点,则交换父节点和子节点if (array[parent] < array[child]) {swap(array, parent, child);// 更新父节点为刚交换过的子节点parent = child;// 更新子节点为新的左子节点child = 2 * parent + 1;} else {break;}}
}private void swap(int[] array, int pos1, int pos2) {// 交换数组中两个位置的元素int temp = array[pos1];array[pos1] = array[pos2];array[pos2] = temp;
}
注释解释:
heapSort方法:
构建大根堆:从最后一个非叶子节点开始(计算公式
(array.length - 1 - 1) / 2),对每个节点调用makeHeap方法来调整堆,使整个数组成为一个大根堆。排序过程:将堆顶(最大值)与当前堆的最后一个元素交换,并对新的堆顶进行调整。每次调整后减少堆的有效长度
end,直到end为0,即整个数组已经排序完毕。
makeHeap方法:
调整堆:从父节点开始,检查并维护大根堆的性质。如果子节点存在且大于父节点,则交换父节点和子节点,更新父节点为子节点并继续调整。直到堆的性质被维护好或者没有需要调整的地方。
swap方法:
交换位置:使用临时变量
temp来交换数组中两个指定位置的元素
这样我们就大致的了解了如何去实现堆排序算法了!
(4)时间复杂度 + 空间复杂度分析
堆排序的时间复杂度主要来自于构建最大堆和调整堆的过程:
- 最坏情况:O(n log n)
- 最好情况:O(n log n)
- 平均情况:O(n log n)
由于堆的调整涉及到树的高度,而树的高度为log n,因此每次调整堆的复杂度为O(log n),总的时间复杂度为O(n log n)。
堆排序是原地排序算法,不需要额外的存储空间,空间复杂度为O(1)。
(5)应用场景
堆排序适用于需要高效且稳定的排序场景,尤其在需要排序较大数据集的情况下,堆排序表现良好,由于其时间复杂度在最坏情况下仍然保持O(n log n),堆排序在处理大量数据时非常有用。
——通过上边对堆排序的简单讲解,我们就大致的了解了堆排序算法了!
5.冒泡排序(Bubble Sort)
最后,让我们学习一下冒泡排序算法。
(1)算法简介
——冒泡排序(Bubble Sort)是一种最简单的排序算法之一。它的基本思想是通过多次遍历数组,每次都将相邻的两个元素进行比较,并根据大小关系交换它们的位置。这样,较大的元素逐步“冒泡”到数组的末尾。尽管冒泡排序的效率较低,但它的概念简单,容易理解和实现。
(2)算法步骤
了解了冒泡排序算法的概念之后,让我们看一下实现该排序算法的几个核心步骤:
-
从数组的起始位置开始,逐个比较相邻的两个元素。
-
如果前一个元素比后一个元素大,则交换它们的位置。
-
对整个数组进行多次遍历,直到没有元素需要交换为止。
接下来我们使用代码对其进行实现。
(3)代码实现
以下为实现冒泡排序算法的代码:
public void bubbleSort(int[] array) {// 外层循环控制排序的轮数for (int i = 0; i < array.length - 1; i++) {// 标志位,用于检测是否有交换发生boolean flag = true;// 内层循环进行相邻元素的比较和交换for (int j = 0; j < array.length - 1 - i; j++) {// 如果当前元素大于下一个元素,则交换它们if (array[j] > array[j + 1]) {flag = false; // 设置标志位为 false,表示发生了交换swap(array, j, j + 1);}}// 如果在某一轮排序中没有发生交换,说明数组已经有序,提前退出循环if (flag) {break;}}
}private void swap(int[] array, int pos1, int pos2) {// 交换数组中两个位置的元素int temp = array[pos1];array[pos1] = array[pos2];array[pos2] = temp;
}
注释解释:
bubbleSort方法:
外层循环:控制排序的轮数,总共需要
array.length - 1轮。在每一轮中,最大的元素会被移动到数组的末尾。标志位
flag:在每一轮开始时,假设数组已经有序。如果在该轮中没有发生任何交换,flag会保持为true,表明数组已经完全排序好,可以提前结束排序。内层循环:比较相邻的元素,如果当前元素大于下一个元素,则交换它们,并将
flag设置为false,表示发生了交换。每次比较和交换的范围逐渐减小,因为每轮排序都会将最大元素移到末尾。
swap方法:
交换位置:使用临时变量
temp来交换数组中两个指定位置的元素。
这样我们就大致的了解了如何去实现冒泡排序算法了!
(4)时间复杂度 + 空间复杂度分析
时间复杂度:
- 最坏情况:O(n^2)(数组为逆序)
- 最好情况:O(n)(数组已经有序)
- 平均情况:O(n^2)
在最坏和平均情况下,冒泡排序的时间复杂度都是O(n^2),但在最佳情况下,当数组已经有序时,冒泡排序的复杂度可以降为O(n)。
空间复杂度:
冒泡排序是原地排序算法,不需要额外的存储空间,空间复杂度为O(1)。
(5)应用场景
冒泡排序适用于小规模数据集或数据基本有序的情况。尽管冒泡排序的效率较低,但其实现简单,常用于教学演示或一些对效率要求不高的应用场景。
——通过上边对堆排序的简单讲解,我们就大致的了解了堆排序算法了!
以上就是本篇文章的全部内容了~~~
相关文章:
Java中的经典排序算法:插入排序、希尔排序、选择排序、堆排序与冒泡排序(如果想知道Java中有关插入排序、希尔排序、选择排序、堆排序与冒泡排序的知识点,那么只看这一篇就足够了!)
前言:排序算法是计算机科学中的基础问题之一,它在数据处理、搜索算法以及各种优化问题中占有重要地位,本文将详细介绍几种经典的排序算法:插入排序、选择排序、堆排序和冒泡排序。 ✨✨✨这里是秋刀鱼不做梦的BLOG ✨✨✨想要了解…...

K8S+Prometheus+Consul+alertWebhook实现全链路服务自动发现与监控、告警配置实战
系列文章目录 k8s服务注册到consul prometheus监控标签 文章目录 系列文章目录前言一、环境二、Prometheus部署1.下载2.部署3.验证 三、kube-prometheus添加自定义监控项1.准备yaml文件2.创建新的secret并应用到prometheus3.将yaml文件应用到集群4.重启prometheus-k8s pod5.访…...
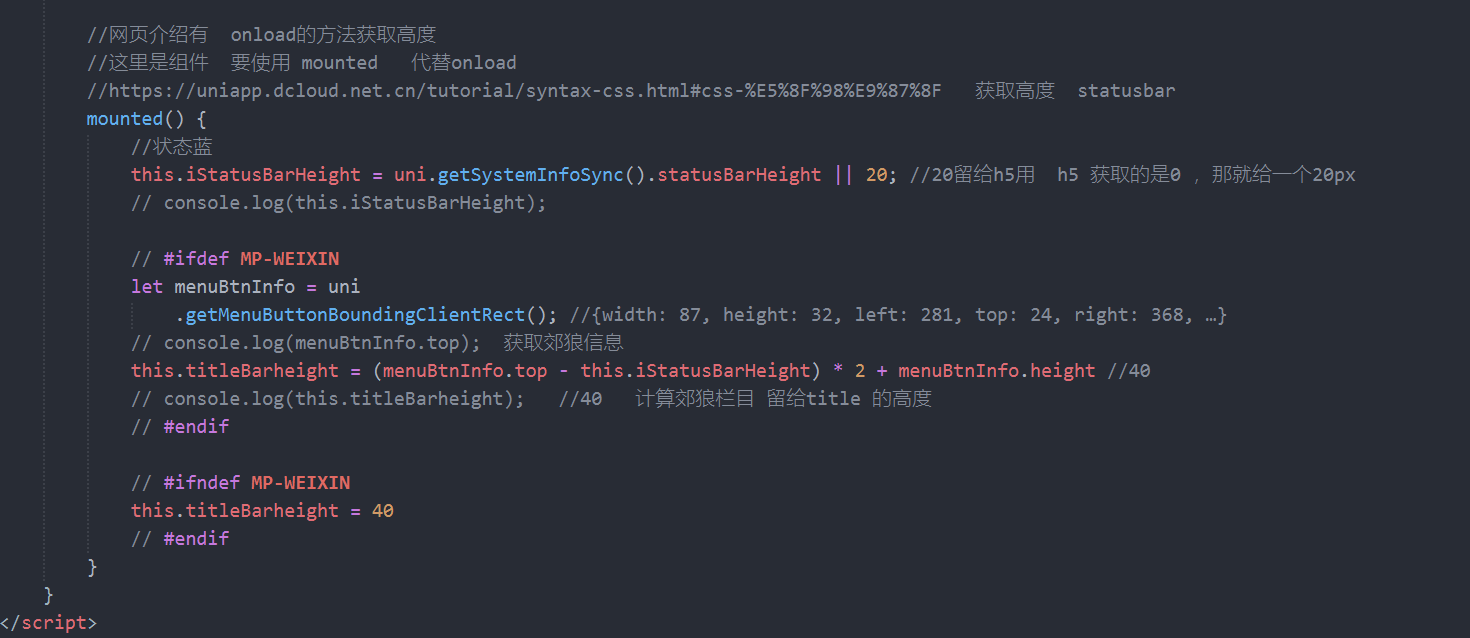
uniapp-商城-25-顶部模块高度计算
计算高度: 使用computed进行顶部模块的计算。 总高度:bartotalHeight log 介绍--收款码这一条目 也就是上一章节的title的高度计算 bodybarheight。 在该组件中: js部分的代码: 包含了导出的名字: shop-head…...

Proxmox VE 网络配置命令大全
如果对 Proxmox VE 全栈管理感兴趣,可以关注“Proxmox VE 全栈管理”专栏,后续文章将围绕该体系,从多个维度深入展开。 概要:Proxmox VE 网络配置灵活,满足虚拟化组网需求。基础靠桥接实现虚拟机与物理网络互联&#x…...

非关系型数据库(NoSQL)与 关系型数据库(RDBMS)的比较
非关系型数据库(NoSQL)与 关系型数据库(RDBMS)的比较 一、引言二、非关系型数据库(NoSQL)2.1 优势 三、关系型数据库(RDBMS)3.1 优势 四、结论 💖The Begin💖…...

WPF 图标原地旋转
如何使元素原地旋转 - WPF .NET Framework | Microsoft Learn <ButtonRenderTransformOrigin"0.5,0.5"HorizontalAlignment"Left">Hello,World<Button.RenderTransform><RotateTransform x:Name"MyAnimatedTransform" Angle"…...
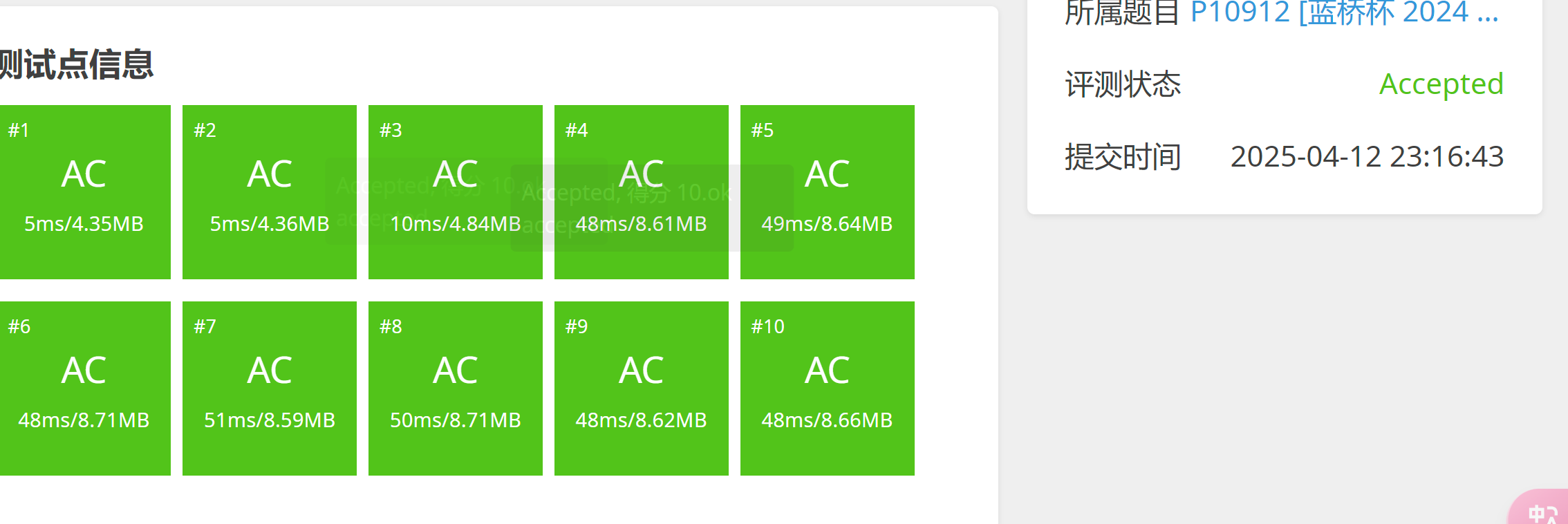
蓝桥杯2024国B数星星
小明正在一棵树上数星星,这棵树有 n 个结点 1,2,⋯,n。他定义树上的一个子图 G 是一颗星星,当且仅当 G 同时满足: G 是一棵树。G 中存在某个结点,其度数为 ∣VG∣−1。其中 ∣VG∣ 表示这个子图含有的结点数。 两颗星星不相…...

Ubuntu 系统上通过终端安装 Google Chrome 浏览器
使用终端安装前,需要配置好终端使用了代理。 参考文章:https://blog.csdn.net/yangshuo1281/article/details/147262633?spm1011.2415.3001.5331 转自 风车 首先,添加 Google Chrome 的软件源和密钥: # 下载并添加 Google 的签…...

中科院1区顶刊Expert Systems with Applications ESO:增强型蛇形算法,性能不错
Snake Optimizer(SO)是一种优化效果良好的新颖算法,但由于自然规律的限制,在探索和开发阶段参数更多是固定值,因此SO算法很快陷入局部优化并慢慢收敛。本文通过引入新颖的基于对立的学习策略和新的动态更新机制&#x…...
实现分布式锁)
zk(Zookeeper)实现分布式锁
Zookeeper实现分布式锁 1,zk中锁的种类: 读锁:大家都可以读,要想上读锁的前提:之前的锁没有写锁 写锁:只有得到写锁的才能写。要想上写锁的前提是:之前没有任何锁 2,zk如何上读锁 创…...

自我生成,自我训练:大模型用合成数据实现“自我学习”机制实战解析
目录 自我生成,自我训练:大模型用合成数据实现“自我学习”机制实战解析 一、什么是自我学习机制? 二、实现机制:如何用合成数据实现自我训练? ✅ 方式一:Prompt强化生成 → 自我采样再训练 ✅ 方式二…...

【Vue】从 MVC 到 MVVM:前端架构演变与 Vue 的实践之路
个人博客:haichenyi.com。感谢关注 一. 目录 一–目录二–架构模式的演变背景三–MVC:经典的分层起点四–MVP:面向接口的解耦尝试五–MVVM:数据驱动的终极形态六–Vue:MVVM 的现代化实践 二. 架构模…...

prototype`和`__proto__`有什么区别?如何手动修改一个对象的原型?
在 JavaScript 中,prototype 和 __proto__ 都与原型链相关,但它们的角色和用途有本质区别: 1. prototype 和 __proto__ 的区别 特性prototype__proto__归属对象仅函数对象拥有(如构造函数)所有对象默认拥有࿰…...

Flask+Influxdb+grafna构建电脑性能实时监控系统
Influx下载地址,这里下载了以下版本influxdb-1.8.5_windows_amd64.zip 运行前需要先启动Influx数据库: 管理员方式运行cmd->F:->cd F:\influxdb\influxdb-1.8.5-1->influxd -config influxdb.conf,以influxdb.conf配置文件启动数…...

关于链接库
在 C# 中,链接库主要分为两种类型:托管链接库和非托管链接库,以下为你详细介绍它们的特点和导入方式: 托管链接库 特点 托管链接库通常是用 .NET 兼容的语言(如 C#、VB.NET 等)编写的,运行在…...

若伊微服务版本教程(自参)
第一步 若伊官网下载源码 https://ruoyi.vip/ RuoYi-Cloud: 🎉 基于Spring Boot、Spring Cloud & Alibaba的分布式微服务架构权限管理系统,同时提供了 Vue3 的版本 git clone 到 本地 目录如下: 第二部 参考官网 运行部署说明 环境部署…...
_分布式优化思路01_yxy)
数据库性能优化(sql优化)_分布式优化思路01_yxy
数据库性能优化_分布式优化思路01 1 分布式数据库的独特挑战2 分布式新增操作符介绍2.1 数据交换操作符(ESEND/ERECV):2.2 数据迭代操作符GI:3 核心优化策略(一)_分区裁剪优化3.1 普通分区裁剪3.2 动态分区裁剪1 分布式数据库的独特挑战 在分布式数据库系统中,核心为数据被…...
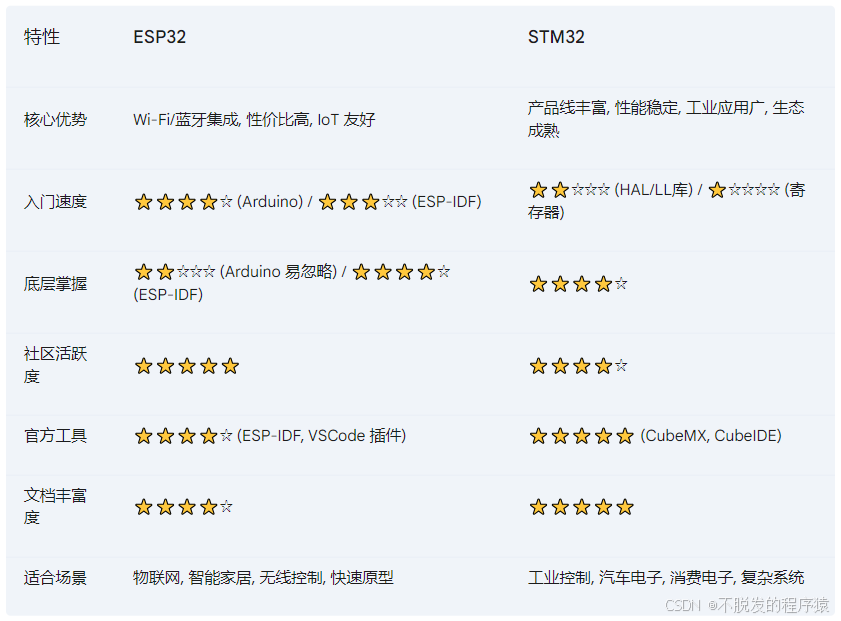
ESP32与STM32哪种更适合初学者?
目录 1、ESP32:物联网时代的“网红” 2、STM32:工业界的“常青树” 3、到底谁更容易? 无论是刚入坑的小白,还是想扩展技术栈的老鸟,在选择主力 MCU 时,学习曲线绝对是重要的考量因素。ESP32 以其强大的 …...
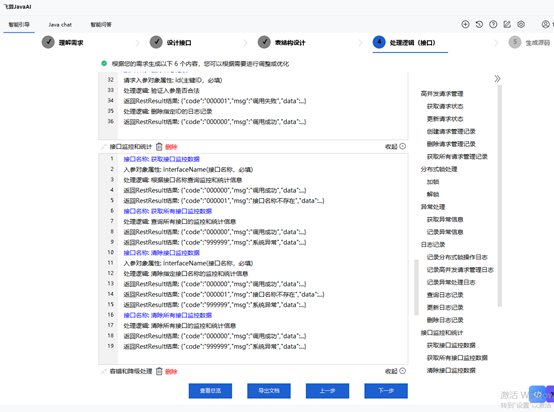
秒杀秒抢系统开发:飞算 JavaAI 工具如何应对高并发难题?
秒杀、秒抢活动已成为电商促销与吸引流量的常用手段。然而,此类活动所带来的高并发访问,对系统性能构成了巨大挑战。如何确保系统在高并发场景下依然能够稳定、高效运行,成为开发者亟待解决的关键问题。飞算 JavaAI 工具作为一款功能强大的开…...

未启用CUDA支持的PyTorch环境** 中使用GPU加速解决方案
1. 错误原因分析 根本问题:当前安装的PyTorch是CPU版本,无法调用GPU硬件加速。当运行以下代码时会报错:model YOLO("yolov8n.pt").to("cuda") # 或 .cuda()2. 解决方案步骤 步骤1:验证CUDA可用性 在Pyth…...
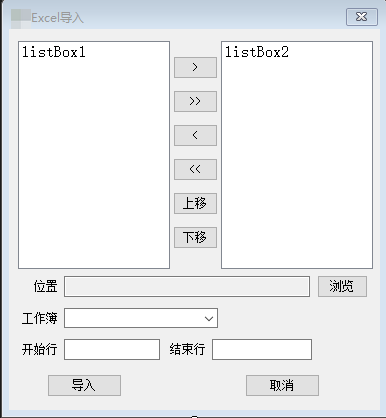
C# 将Excel格式文件导入到界面中,用datagridview显示
界面按钮不做介绍。 主要代码: //用于获取从上一个页面传过来datagridview标题 public DataTable GetHeader { get; set; } private void UI_EXPINFO_Load(object sender, EventArgs e) { //页面加载显示listbox1中可…...
Spring Boot整合难点?AI一键生成全流程解决方案
在当今的软件开发领域,Spring Boot 凭借其简化开发流程、快速搭建项目的优势,成为了众多开发者的首选框架。然而,Spring Boot 的整合过程并非一帆风顺,常常会遇到各种难点。而飞算 JavaAI 的出现,为解决这些问题提供了…...

分享一下这几天在公司学到的东西
这几天我学到了很多东西 (1)我自己原来写项目,前后端联调用的都是postman,然后直接测试接口,然后连一下就完了。这几天我接触到了apifox的Mock这个东西!我知道了一个前端工程师进行前后端链条的时候&#…...
:Slice解密)
Java转Go日记(一):Slice解密
1.切片通过函数,传的是什么? package mainimport ("fmt""reflect""unsafe" )func main() {s : make([]int, 5, 10)PrintSliceStruct(&s)test(s) }func test(s []int) {PrintSliceStruct(&s) }func PrintSliceStr…...
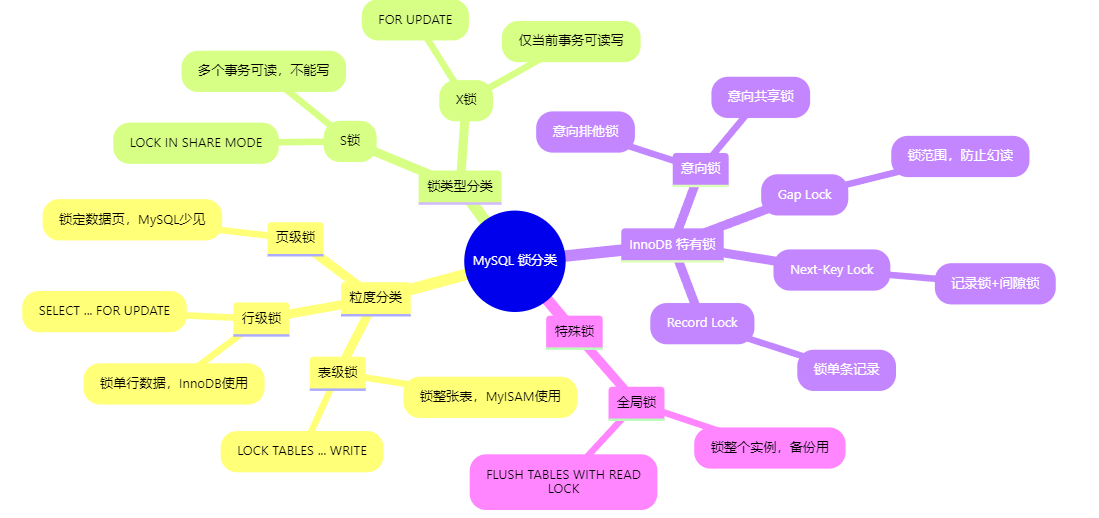
MySQL 锁机制全景图:分类、粒度与示例一图掌握
✅ 一、按粒度分类(锁的范围大小) 1. 表级锁(Table Lock) 锁住整张表粒度大,开销小,并发性差常见于:MyISAM 引擎 📌 示例: LOCK TABLES user WRITE; -- 会锁住整个 u…...
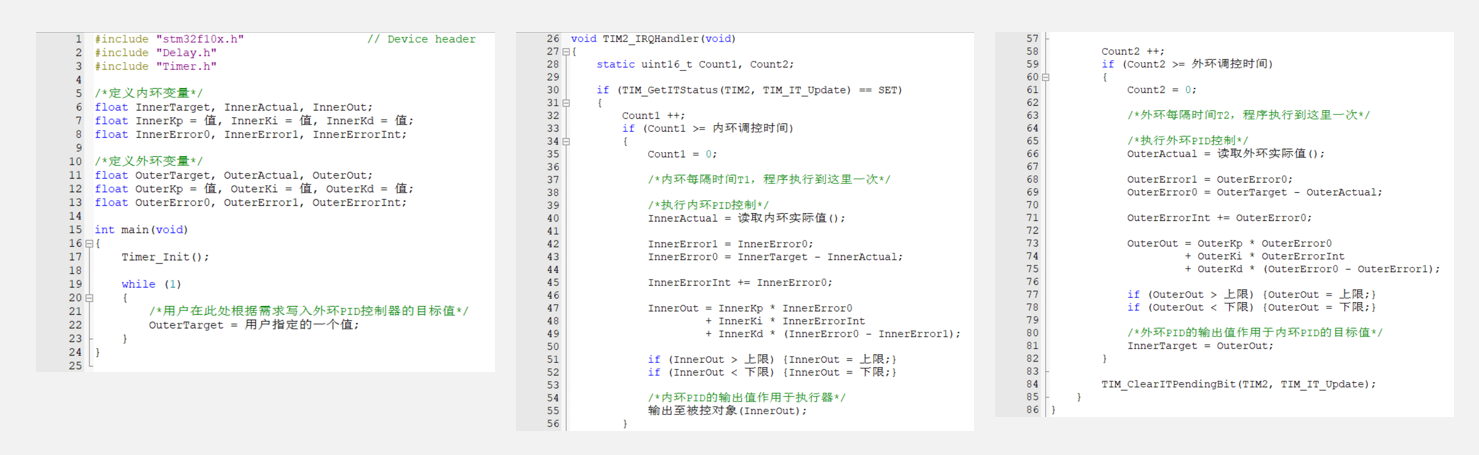
STM32江科大----------PID算法
声明:本人跟随b站江科大学习,本文章是观看完视频后的一些个人总结和经验分享,也同时为了方便日后的复习,如果有错误请各位大佬指出,如果对你有帮助可以点个赞小小鼓励一下,本文章建议配合原视频使用❤️ 如…...
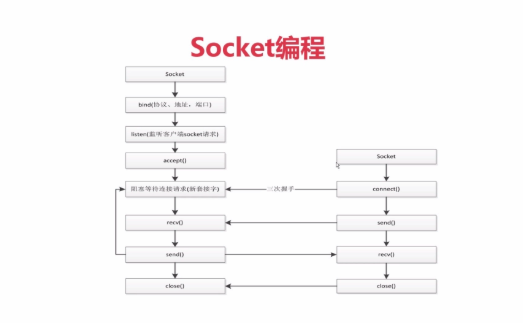
架构师面试(二十九):TCP Socket 编程
问题 今天考察网络编程的基础知识。 在基于 TCP 协议的网络 【socket 编程】中可能会遇到很多异常,在下面的相关描述中说法正确的有哪几项呢? A. 在建立连接被拒绝时,有可能是因为网络不通或地址错误或 server 端对应端口未被监听&#x…...
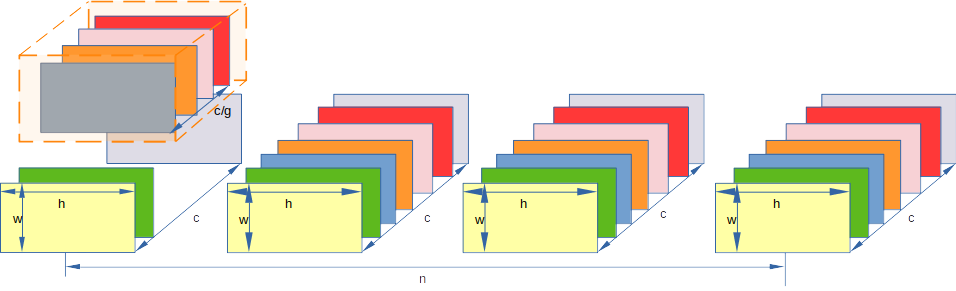
基础学习(4): Batch Norm / Layer Norm / Instance Norm / Group Norm
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言1 batch normalization(BN)2 Layer normalization (LN)3 instance normalization (IN)4 group normalization (GN)总结 前言 对 norm/batch/instance/group 这…...

局域网内Docker镜像共享方法
在局域网内将Docker镜像构建并传输到另一台电脑,可以通过以下几种方法实现。以下是具体步骤及注意事项,结合不同场景的适用方案: 方法一:使用 docker save 和 docker load 传输镜像文件 步骤说明 在构建机上保存镜像 通过 docker…...
Idea集成AI:CodeGeeX开发
当入职新公司,或者调到新项目组进行开发时,需要快速熟悉项目代码 而新的项目代码,可能有很多模块,很多的接口,很复杂的业务逻辑,更加有与之前自己的代码风格不一致的现有复杂代码 更别提很多人写代码不喜…...