第二阶段:数据结构与函数
模块4:常用数据结构 (Organizing Lots of Data)
在前面的模块中,我们学习了如何使用变量来存储单个数据,比如一个数字、一个名字或一个布尔值。但很多时候,我们需要处理一组相关的数据,比如班级里所有学生的名字、一本书的所有章节标题、或者一个用户的各项配置信息。这时,就需要用到数据结构(Data Structures),它们是 Python 中用来组织和存储多个数据项的方式。
这个模块我们将学习 Python 中最常用的四种内置数据结构:列表(List)、元组(Tuple)、字典(Dictionary)和集合(Set)。
4.1 列表 (List): 最常用的“数据清单”
列表是 Python 中最常用、最灵活的数据结构。你可以把它想象成一个有序的、可以修改的清单。
- 有序 (Ordered): 列表中的每个元素都有一个固定的位置(索引),就像排队一样,顺序很重要。
- 可变 (Mutable): 你可以在创建列表后,随时添加、删除或修改里面的元素。
1. 创建列表
- 使用方括号
[],元素之间用逗号,分隔。 - 列表可以包含任何类型的元素,甚至混合类型。
- 创建一个空列表:
[]。
Python
# 一个包含数字的列表
numbers = [1, 2, 3, 4, 5]
print(numbers)# 一个包含字符串的列表
fruits = ["apple", "banana", "cherry"]
print(fruits)# 一个混合类型的列表
mixed_list = [10, "hello", 3.14, True, "banana"]
print(mixed_list)# 一个空列表
empty_list = []
print(empty_list)
2. 访问列表元素 (Indexing)
- 和字符串一样,通过索引访问列表中的元素,索引从
0开始。 - 也可以使用负数索引,
-1表示最后一个元素,-2表示倒数第二个,以此类推。
Python
colors = ["red", "green", "blue", "yellow"]first_color = colors[0] # 'red'
second_color = colors[1] # 'green'
last_color = colors[-1] # 'yellow'
second_last = colors[-2] # 'blue'print(f"第一个颜色是: {first_color}")
print(f"最后一个颜色是: {last_color}")# 如果索引超出范围,会报错 IndexError
# print(colors[4]) # 会导致 IndexError
3. 列表切片 (Slicing)
- 和字符串一样,使用
[start:stop:step]获取列表的一部分(子列表)。 - 包含
start索引处的元素,但不包含stop索引处的元素。 step是可选的步长。
Python
numbers = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]# 获取索引 1 到 4 (不含 4) 的元素
sub_list1 = numbers[1:4] # [1, 2, 3]
print(sub_list1)# 获取从索引 5 到末尾的元素
sub_list2 = numbers[5:] # [5, 6, 7, 8, 9]
print(sub_list2)# 获取从开头到索引 3 (不含 3) 的元素
sub_list3 = numbers[:3] # [0, 1, 2]
print(sub_list3)# 获取所有元素的一个副本
copy_list = numbers[:] # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(copy_list)# 获取步长为 2 的元素 (隔一个取一个)
step_list = numbers[0:10:2] # [0, 2, 4, 6, 8]
print(step_list)
4. 修改列表元素
因为列表是可变的,你可以直接通过索引来修改元素的值。
Python
my_list = [10, 20, 30, 40]
print(f"原始列表: {my_list}")# 修改索引为 1 的元素
my_list[1] = 25
print(f"修改后列表: {my_list}") # 输出: [10, 25, 30, 40]
5. 添加元素
append(item): 在列表末尾添加一个元素。insert(index, item): 在指定的索引位置插入一个元素,原来的元素及后面的元素会向后移动。
Python
hobbies = ["reading", "swimming"]
print(f"初始爱好: {hobbies}")# 在末尾添加
hobbies.append("coding")
print(f"添加后: {hobbies}") # ['reading', 'swimming', 'coding']# 在索引 1 的位置插入
hobbies.insert(1, "hiking")
print(f"插入后: {hobbies}") # ['reading', 'hiking', 'swimming', 'coding']
6. 删除元素
pop(index): 删除并返回指定索引位置的元素。如果省略index,默认删除并返回最后一个元素。remove(value): 删除列表中第一个出现的指定值。如果值不存在,会报错ValueError。del语句:通过索引删除元素或切片。
Python
items = ["pen", "pencil", "eraser", "ruler", "pencil"]
print(f"原始物品: {items}")# 删除并获取最后一个元素
last_item = items.pop()
print(f"被 pop 的元素: {last_item}") # 'pencil'
print(f"pop 后列表: {items}") # ['pen', 'pencil', 'eraser', 'ruler']# 删除索引为 1 的元素
removed_item = items.pop(1)
print(f"被 pop(1) 的元素: {removed_item}") # 'pencil'
print(f"pop(1) 后列表: {items}") # ['pen', 'eraser', 'ruler']# 删除第一个值为 "eraser" 的元素
items.remove("eraser")
print(f"remove 'eraser' 后列表: {items}") # ['pen', 'ruler']
# 如果 items.remove("notebook") 会报错 ValueError,因为 "notebook" 不存在# 使用 del 删除索引为 0 的元素
del items[0]
print(f"del items[0] 后列表: {items}") # ['ruler']# del 也可以删除切片
numbers = [1, 2, 3, 4, 5, 6]
del numbers[1:4] # 删除索引 1, 2, 3 的元素
print(f"del 切片后列表: {numbers}") # [1, 5, 6]
7. 常用列表方法
sort(): 对列表进行原地排序(直接修改原列表)。默认升序。如果列表元素不能互相比较(如数字和字符串混合),会报错TypeError。reverse(): 将列表中的元素原地反转。len(list): (这是一个内置函数,不是方法) 返回列表中的元素个数。count(value): 返回列表中某个值出现的次数。index(value): 返回列表中某个值首次出现的索引。如果值不存在,会报错ValueError。
Python
nums = [5, 1, 4, 2, 3, 1]
chars = ['c', 'a', 'b']
print(f"原始 nums: {nums}")
print(f"原始 chars: {chars}")# 获取长度
print(f"nums 的长度: {len(nums)}") # 6# 计数
print(f"nums 中 1 出现的次数: {nums.count(1)}") # 2# 查找索引
print(f"nums 中 4 的索引: {nums.index(4)}") # 2# 排序 (原地修改)
nums.sort()
chars.sort()
print(f"排序后 nums: {nums}") # [1, 1, 2, 3, 4, 5]
print(f"排序后 chars: {chars}") # ['a', 'b', 'c']# 降序排序
nums.sort(reverse=True)
print(f"降序排序后 nums: {nums}") # [5, 4, 3, 2, 1, 1]# 反转 (原地修改)
chars.reverse()
print(f"反转后 chars: {chars}") # ['c', 'b', 'a']
8. 列表推导式 (List Comprehensions) - 初步认识
列表推导式提供了一种更简洁、更高效的方式来创建列表,特别是基于现有列表或范围创建新列表时。
基本语法: [expression for item in iterable if condition]
expression: 对item进行处理的表达式,结果将是新列表的元素。for item in iterable: 循环遍历一个可迭代对象(如列表、range()等)。if condition: (可选) 只有当condition为True时,item才会被处理并添加到新列表中。
示例:
Python
# 1. 创建一个 0 到 9 的平方数的列表
squares = []
for x in range(10):squares.append(x**2)
print(f"传统方法创建平方数列表: {squares}")# 使用列表推导式
squares_comp = [x**2 for x in range(10)]
print(f"列表推导式创建平方数列表: {squares_comp}")# 2. 创建一个 0 到 9 中偶数的列表
evens = []
for x in range(10):if x % 2 == 0:evens.append(x)
print(f"传统方法创建偶数列表: {evens}")# 使用列表推导式
evens_comp = [x for x in range(10) if x % 2 == 0]
print(f"列表推导式创建偶数列表: {evens_comp}")# 3. 将一个字符串列表中的所有单词转为大写
words = ["hello", "world", "python"]
upper_words = [word.upper() for word in words]
print(f"单词转大写: {upper_words}") # ['HELLO', 'WORLD', 'PYTHON']
列表推导式非常强大且常用,刚开始可能觉得有点抽象,但多练习几次就会发现它的便利。
4.2 元组 (Tuple): 不可变的“数据清单”
元组和列表非常相似,也是有序的序列。但它们之间有一个关键区别:元组是不可变的 (Immutable)。一旦创建,你就不能修改元组中的元素(不能添加、删除或更改)。
1. 创建元组
- 使用圆括号
(),元素之间用逗号,分隔。 - 注意: 创建只包含一个元素的元组时,必须在该元素后面加上逗号
,,否则 Python 会把它当作普通的值。 - 创建空元组:
()。 - 在某些情况下,括号可以省略(比如赋值时),Python 也能识别它是元组。
Python
# 一个包含数字的元组
numbers_tuple = (1, 2, 3)
print(numbers_tuple)# 一个混合类型的元组
mixed_tuple = (10, "hello", 3.14)
print(mixed_tuple)# 创建单元素元组 - 注意逗号!
single_tuple = (99,)
not_a_tuple = (99)
print(f"这是一个元组: {single_tuple}, 类型: {type(single_tuple)}")
print(f"这不是元组: {not_a_tuple}, 类型: {type(not_a_tuple)}") # 这是 int 类型# 空元组
empty_tuple = ()
print(empty_tuple)# 省略括号创建元组
point = 10, 20 # 这也是一个元组 (10, 20)
print(point)
print(type(point))
2. 访问元组元素 (Indexing & Slicing)
- 和列表、字符串完全一样,使用索引
[]和切片[:]。
Python
my_tuple = ('a', 'b', 'c', 'd', 'e')
print(my_tuple[0]) # 'a'
print(my_tuple[-1]) # 'e'
print(my_tuple[1:3]) # ('b', 'c')
3. 不可变性 (Immutability)
这是元组的核心特性。尝试修改元组会引发 TypeError。
Python
immutable_tuple = (1, 2, 3)
# 下面的代码会报错 TypeError: 'tuple' object does not support item assignment
# immutable_tuple[0] = 100# 下面的代码也会报错 AttributeError: 'tuple' object has no attribute 'append'
# immutable_tuple.append(4)# 下面的代码也会报错 AttributeError: 'tuple' object has no attribute 'remove'
# immutable_tuple.remove(1)
4. 为什么使用元组?
既然列表那么灵活,为什么还需要不可变的元组呢?
-
性能: 元组通常比列表占用更少的内存,并且在某些操作上(如迭代访问)可能稍微快一点(尽管差异通常很小)。
-
安全性/数据保护: 不可变性确保了数据在创建后不会被意外修改,适用于存储不应改变的数据,如坐标点
(x, y)、RGB颜色值(r, g, b)等。 -
可以作为字典的键: 因为元组是不可变的,所以它可以作为字典的键(我们马上会学到字典),而列表不行。
-
元组解包 (Tuple Unpacking): 可以方便地将元组中的元素赋值给多个变量。
Pythoncoordinates = (10, 20, 30) x, y, z = coordinates # 解包 print(f"x={x}, y={y}, z={z}") # x=10, y=20, z=30
4.3 字典 (Dictionary / dict): 键值对应的“查找表”
字典是另一种非常有用的数据结构,它存储的是键值对 (Key-Value Pairs)。你可以把它想象成一本真实的字典或电话簿:
- 键 (Key): 就像字典里的单词或电话簿里的名字,用来查找信息。键必须是唯一的、不可变的 (通常使用字符串、数字或元组)。
- 值 (Value): 就像单词的释义或人对应的电话号码,是与键相关联的数据。值可以是任何数据类型,也可以重复。
字典在 Python 3.7+ 版本中是按插入顺序存储的,但在更早的版本中是无序的。字典查找速度非常快,特别适合需要通过某个唯一标识来快速获取对应信息的场景。
1. 创建字典
- 使用花括号
{},键值对之间用逗号,分隔,键和值之间用冒号:分隔。 - 创建空字典:
{}。
Python
# 一个存储学生信息的字典
student = {"name": "Alice","age": 20,"major": "Computer Science","is_graduated": False,"courses": ["Math", "Physics", "Programming"] # 值可以是列表
}
print(student)# 一个存储商品价格的字典
prices = {"apple": 5.5,"banana": 3.0,"orange": 4.5
}
print(prices)# 一个空字典
empty_dict = {}
print(empty_dict)
2. 访问字典的值
- 使用键放在方括号
[]中来访问对应的值。如果键不存在,会引发KeyError。 - 使用
get(key, default=None)方法访问值。如果键不存在,它会返回None(或者你指定的default值),而不会报错。这通常是更安全的方式。
Python
student = {"name": "Bob", "age": 22, "major": "Physics"}# 使用方括号访问
print(f"姓名: {student['name']}") # Bob
print(f"年龄: {student['age']}") # 22# 尝试访问不存在的键会报错 KeyError
# print(student['city'])# 使用 get() 方法访问
print(f"专业: {student.get('major')}") # Physics
print(f"城市: {student.get('city')}") # None (键不存在,返回 None)
print(f"城市 (带默认值): {student.get('city', 'Unknown')}") # Unknown (键不存在,返回指定的默认值 'Unknown')
3. 添加和修改键值对
- 直接给一个新键赋值,就可以添加新的键值对。
- 给一个已存在的键赋值,就会修改该键对应的值。
Python
student = {"name": "Charlie", "age": 19}
print(f"原始字典: {student}")# 修改 age
student['age'] = 20
print(f"修改年龄后: {student}")# 添加新的键值对 city
student['city'] = "London"
print(f"添加城市后: {student}") # {'name': 'Charlie', 'age': 20, 'city': 'London'}
4. 删除键值对
pop(key): 删除指定键的键值对,并返回对应的值。如果键不存在,会报错KeyError。del语句:通过键删除键值对。如果键不存在,也会报错KeyError。
Python
contact = {"name": "David", "phone": "123-456", "email": "david@example.com"}
print(f"原始联系人: {contact}")# 删除 email 并获取其值
removed_email = contact.pop("email")
print(f"被 pop 的 email: {removed_email}") # david@example.com
print(f"pop email 后: {contact}") # {'name': 'David', 'phone': '123-456'}# 使用 del 删除 phone
del contact["phone"]
print(f"del phone 后: {contact}") # {'name': 'David'}# 尝试删除不存在的键会报错
# del contact["address"] # KeyError
# contact.pop("city") # KeyError
5. 常用字典方法
keys(): 返回一个包含所有键的“视图对象”(可以像列表一样遍历)。values(): 返回一个包含所有值的“视图对象”。items(): 返回一个包含所有**(键, 值)**元组对的“视图对象”。
Python
student = {"name": "Eve", "age": 21, "major": "Biology"}# 获取所有键
keys = student.keys()
print(f"所有键: {keys}") # dict_keys(['name', 'age', 'major'])
print(list(keys)) # 可以转换为列表 ['name', 'age', 'major']# 获取所有值
values = student.values()
print(f"所有值: {values}") # dict_values(['Eve', 21, 'Biology'])
print(list(values)) # 可以转换为列表 ['Eve', 21, 'Biology']# 获取所有键值对
items = student.items()
print(f"所有项: {items}") # dict_items([('name', 'Eve'), ('age', 21), ('major', 'Biology')])
print(list(items)) # 可以转换为列表 [('name', 'Eve'), ('age', 21), ('major', 'Biology')]
6. 遍历字典
有几种常用的方式来遍历字典:
Python
student = {"name": "Frank", "age": 23, "major": "Chemistry"}# 遍历键 (默认方式)
print("\n遍历键:")
for key in student:print(f"键: {key}, 值: {student[key]}") # 通过键再次访问值# 遍历值
print("\n遍历值:")
for value in student.values():print(value)# 遍历键值对 (推荐方式)
print("\n遍历键值对 (使用 .items()):")
for key, value in student.items(): # 使用元组解包print(f"{key}: {value}")
4.4 集合 (Set): 无序且唯一的“元素包”
集合是一个无序的、包含不重复元素的集合。你可以把它想象成一个袋子,里面装的东西没有顺序,而且同样的东西只能装一个。
集合的主要用途:
- 去重 (Removing Duplicates): 快速去除列表或其他序列中的重复元素。
- 成员检测 (Membership Testing): 快速判断一个元素是否存在于集合中(比在列表中查找快得多)。
- 集合运算 (Set Operations): 进行数学上的集合运算,如交集、并集、差集等。
1. 创建集合
- 使用花括号
{},元素之间用逗号,分隔。 - 注意: 创建空集合必须使用
set()函数,因为{}创建的是空字典! - 可以直接从列表或其他可迭代对象创建集合,它会自动去重。
Python
# 创建一个包含数字的集合 (重复的 3 会被忽略)
numbers_set = {1, 2, 3, 4, 3, 2}
print(numbers_set) # 输出可能是 {1, 2, 3, 4} (顺序不固定)# 创建一个包含字符串的集合
fruits_set = {"apple", "banana", "cherry"}
print(fruits_set)# 创建空集合 - 必须用 set()
empty_set = set()
print(empty_set)
print(type(empty_set)) # <class 'set'># 从列表创建集合 (自动去重)
my_list = [1, 1, 2, 3, 4, 4, 4, 5]
my_set_from_list = set(my_list)
print(my_set_from_list) # {1, 2, 3, 4, 5}
2. 无序性
集合不保证元素的顺序,所以你不能像列表或元组那样使用索引来访问元素。
Python
my_set = {10, 20, 30}
# 下面的代码会报错 TypeError: 'set' object is not subscriptable
# print(my_set[0])
3. 唯一性
集合中不允许有重复的元素。如果你尝试添加一个已存在的元素,集合不会发生任何变化。
4. 添加和删除元素
add(element): 添加一个元素到集合中。如果元素已存在,则什么也不做。remove(element): 从集合中删除一个元素。如果元素不存在,会引发KeyError。discard(element): 从集合中删除一个元素。如果元素不存在,它不会报错,而是什么也不做。通常discard更安全。
Python
colors = {"red", "green"}
print(f"原始集合: {colors}")# 添加元素
colors.add("blue")
print(f"添加 blue 后: {colors}")colors.add("red") # 尝试添加已存在的元素
print(f"再次添加 red 后: {colors}") # 集合不变# 删除元素
colors.remove("green")
print(f"删除 green 后: {colors}")# 尝试 remove 不存在的元素会报错
# colors.remove("yellow") # KeyError# 使用 discard 删除存在的元素
colors.discard("blue")
print(f"discard blue 后: {colors}")# 使用 discard 删除不存在的元素 (不会报错)
colors.discard("yellow")
print(f"discard yellow 后: {colors}") # 集合不变
5. 集合运算
集合支持标准的数学集合运算:
- 成员检测 (
in): 判断元素是否在集合中(非常高效)。 - 并集 (
|或union()): 返回包含两个集合中所有元素的新集合。 - 交集 (
&或intersection()): 返回两个集合中共同存在的元素组成的新集合。 - 差集 (
-或difference()): 返回存在于第一个集合但不在第二个集合中的元素组成的新集合。 - 对称差集 (
^或symmetric_difference()): 返回存在于两个集合中,但不同时存在于两个集合中的元素(即并集减去交集)。
Python
set_a = {1, 2, 3, 4}
set_b = {3, 4, 5, 6}
print(f"集合 A: {set_a}")
print(f"集合 B: {set_b}")# 成员检测
print(f"2 在 A 中吗? {2 in set_a}") # True
print(f"5 在 A 中吗? {5 in set_a}") # False# 并集
union_set = set_a | set_b
# union_set = set_a.union(set_b)
print(f"并集 A | B: {union_set}") # {1, 2, 3, 4, 5, 6}# 交集
intersection_set = set_a & set_b
# intersection_set = set_a.intersection(set_b)
print(f"交集 A & B: {intersection_set}") # {3, 4}# 差集 (A 中有,B 中没有)
difference_set = set_a - set_b
# difference_set = set_a.difference(set_b)
print(f"差集 A - B: {difference_set}") # {1, 2}# 差集 (B 中有,A 中没有)
print(f"差集 B - A: {set_b - set_a}") # {5, 6}# 对称差集 (只在 A 或只在 B 中的元素)
sym_diff_set = set_a ^ set_b
# sym_diff_set = set_a.symmetric_difference(set_b)
print(f"对称差集 A ^ B: {sym_diff_set}") # {1, 2, 5, 6}
4.5 实践时间!
练习1:简单的学生成绩管理
- 创建一个列表,名为
students。这个列表将用来存储多个学生的信息。 - 列表中的每个元素都是一个字典,代表一个学生。每个学生字典至少包含以下键:
"name": 学生姓名 (字符串)"grades": 一个包含该学生各科成绩(数字)的列表。- 例如:
{"name": "Alice", "grades": [85, 90, 78]}
- 向
students列表中添加至少3个学生的信息。 - 编写代码,计算并打印出每个学生的平均成绩。你需要遍历
students列表,对于每个学生字典,再遍历其"grades"列表来计算总分和平均分。 - (可选)添加一个新功能:允许用户输入学生姓名,然后查找并打印该学生的成绩列表和平均分。如果学生不存在,则打印提示信息。
练习2:词频统计
- 定义一个包含一段文本的字符串变量(比如一句或几句话)。
- 预处理文本:
- 将文本全部转换为小写(使用字符串的
lower()方法)。 - (可选,简化处理)去除标点符号。你可以用
replace()方法将常见的标点符号(如.,,,?,!)替换为空格或空字符串。
- 将文本全部转换为小写(使用字符串的
- 分词: 使用字符串的
split()方法将处理后的文本分割成一个单词列表。默认情况下,split()会按空格分割。 - 统计词频:
- 创建一个空字典,名为
word_counts,用来存储每个单词出现的次数。 - 遍历你的单词列表。
- 对于列表中的每个单词:
- 检查这个单词是否已经是
word_counts字典的键。 - 如果是,将该键对应的值(计数)加 1。
- 如果不是,将这个单词作为新键添加到字典中,并将值设为 1。
- (提示:使用
get(word, 0)可以很方便地获取当前计数,如果单词不存在则返回0,然后加1即可:word_counts[word] = word_counts.get(word, 0) + 1)
- 检查这个单词是否已经是
- 创建一个空字典,名为
- 遍历
word_counts字典,打印出每个单词及其出现的次数。
模块5:函数——代码的复用
在我们之前的编程练习中,你可能已经注意到,有时我们会重复写几乎完全一样的代码块。比如,计算平均分的逻辑、打印特定格式信息的代码等。如果这样的代码很多,程序会变得冗长、难以阅读,而且一旦需要修改这部分逻辑,你就得找到所有重复的地方一一修改,非常麻烦且容易出错。
函数(Function)就是解决这个问题的利器!它可以让你把一段具有特定功能的代码打包起来,给它起一个名字,然后在需要执行这段代码的任何地方,简单地“调用”这个名字即可。
5.1 为什么需要函数?(DRY 原则)
使用函数的主要原因是为了遵循 DRY 原则:Don't Repeat Yourself(不要重复你自己)。
- 提高代码复用性: 定义一次,多次调用。
- 提高代码可读性: 将复杂的任务分解成小的、有明确功能的函数,让主程序逻辑更清晰。给函数起一个有意义的名字本身就是一种注释。
- 提高代码可维护性: 如果需要修改某项功能的逻辑,只需要修改对应的函数定义即可,所有调用该函数的地方都会自动生效。
- 方便协作: 不同的开发者可以分工编写不同的函数模块。
5.2 定义函数
使用 def 关键字来定义一个函数。
基本语法:
Python
def function_name(parameters):"""(可选) 函数文档字符串 (Docstring) - 解释函数的作用、参数和返回值。通常用三引号包裹。"""# 函数体 (缩进的代码块)# 这里是函数的具体逻辑statement1statement2# ...return value # (可选) 返回一个结果
def: 定义函数的关键字。function_name: 你给函数起的名字,遵循变量命名规则(snake_case)。(): 函数名后面的圆括号,必须有。parameters: (可选) 括号里的变量名,是函数接收的输入值(参数),多个参数用逗号分隔。如果没有参数,括号也是空的()。:: 圆括号后面必须有冒号。- Docstring: (可选但强烈推荐) 一个用三引号
"""Docstring goes here"""包裹的字符串,用于解释函数的功能。好的文档字符串对于理解和使用函数至关重要。 - 函数体: 缩进的代码块,包含函数的实际逻辑。
return value: (可选) 使用return关键字将函数的结果(值)发送回调用它的地方。如果函数没有return语句,或者return后面没有值,它默认返回None。
示例:一个简单的问候函数
Python
def greet():"""打印一句简单的问候语。"""print("Hello there! Welcome.")def greet_user(name):"""根据提供的名字打印个性化问候语。Args:name: 要问候的人的名字 (字符串)。"""print(f"Hello, {name}! Nice to meet you.")
5.3 调用函数
定义好函数后,你需要调用(Call 或 Invoke)它来执行函数体内的代码。调用函数的方法是写出函数名,后面跟上圆括号 (),并在括号内提供必要的参数(Arguments)。
Python
# 调用没有参数的函数
greet() # 输出: Hello there! Welcome.# 调用有参数的函数,需要提供参数值
greet_user("Alice") # 输出: Hello, Alice! Nice to meet you.
greet_user("Bob") # 输出: Hello, Bob! Nice to meet you.
当程序执行到函数调用时,它会“跳转”到函数的定义处,执行函数体内的代码,然后再“跳回”到函数被调用的地方继续执行。
5.4 参数 (Parameters) 与 实参 (Arguments)
这两个词经常互换使用,但严格来说:
- 参数 (Parameters): 定义函数时,写在圆括号里的变量名(如
greet_user函数中的name)。它们是函数内部使用的占位符。 - 实参 (Arguments): 调用函数时,传递给函数的实际值(如
greet_user("Alice")中的"Alice")。
Python 支持多种传递参数的方式:
1. 位置参数 (Positional Arguments)
最常见的方式。实参会按照它们在调用时出现的顺序,依次传递给函数定义中的参数。
Python
def describe_pet(animal_type, pet_name):"""显示宠物的信息。"""print(f"I have a {animal_type}.")print(f"My {animal_type}'s name is {pet_name.title()}.")describe_pet("hamster", "harry") # "hamster" 传给 animal_type, "harry" 传给 pet_name
describe_pet("dog", "willie")
注意:位置参数的顺序很重要,传错了会导致逻辑错误。 describe_pet("willie", "dog") 就会输出错误的信息。
2. 关键字参数 (Keyword Arguments)
调用函数时,你可以明确指定哪个实参传递给哪个参数,使用 参数名=值 的形式。这时,实参的顺序就不重要了。
Python
describe_pet(animal_type="cat", pet_name="whiskers")
describe_pet(pet_name="goldie", animal_type="fish") # 顺序不同,但结果正确
注意:在一个函数调用中,关键字参数必须跟在所有位置参数之后。
3. 默认参数值 (Default Parameter Values)
在定义函数时,可以为参数指定一个默认值。如果在调用函数时没有为该参数提供实参,那么就会使用这个默认值。
Python
def power(base, exponent=2): # exponent 参数默认值为 2"""计算 base 的 exponent 次方。"""result = base ** exponentprint(f"{base} 的 {exponent} 次方是 {result}")power(5) # 没有提供 exponent,使用默认值 2。输出: 5 的 2 次方是 25
power(3, 3) # 提供了 exponent,使用提供的值 3。输出: 3 的 3 次方是 27
power(base=4) # 也可以用关键字参数调用
power(base=2, exponent=5)
注意:在函数定义中,所有带默认值的参数必须放在所有不带默认值的参数之后。
4. 可变参数 (Variable-Length Arguments) - 初步认识
有时你希望函数能接受任意数量的参数。
-
Python*args(任意数量的位置参数): 在参数名前加一个星号*。这会将调用时提供的多余的位置参数收集到一个元组 (tuple) 中。参数名通常约定俗成用args,但也可以用别的名字(如*numbers)。def make_pizza(size, *toppings):"""概述要制作的比萨。Args:size: 比萨的尺寸。*toppings: 一个包含所有配料的元组。"""print(f"\nMaking a {size}-inch pizza with the following toppings:")if toppings: # 检查 toppings 元组是否为空for topping in toppings:print(f"- {topping}")else:print("- Plain cheese")make_pizza(12, "mushrooms") make_pizza(16, "mushrooms", "green peppers", "extra cheese") make_pizza(10) # toppings 会是一个空元组 -
Python**kwargs(任意数量的关键字参数): 在参数名前加两个星号**。这会将调用时提供的多余的关键字参数收集到一个字典 (dict) 中。参数名通常约定俗成用kwargs,但也可以用别的名字(如**user_info)。def build_profile(first, last, **user_info):"""创建一个字典,包含我们知道的有关用户的一切。Args:first: 名。last: 姓。**user_info: 包含其他信息的字典。"""profile = {}profile['first_name'] = firstprofile['last_name'] = lastfor key, value in user_info.items(): # 遍历 kwargs 字典profile[key] = valuereturn profile # 返回构建好的字典user_profile = build_profile('albert', 'einstein',location='princeton',field='physics') print(user_profile) # 输出: {'first_name': 'albert', 'last_name': 'einstein', 'location': 'princeton', 'field': 'physics'}user_profile2 = build_profile('marie', 'curie',field='physics', award='Nobel Prize') print(user_profile2)
注意:在函数定义中,参数的顺序通常是:普通位置参数 -> 默认参数 -> *args -> **kwargs。对于初学者,理解 *args 和 **kwargs 的基本概念(收集多余参数)即可。
5.5 返回值 (Return Values)
函数不仅可以执行操作(比如打印),还可以计算一个结果并将其“返回”给调用它的代码。这通过 return 语句实现。
- 当执行到
return语句时,函数立即停止执行,并将return后面的值作为结果返回。 - 调用函数的地方可以接收这个返回值,通常是赋给一个变量。
- 如果函数没有
return语句,或者return后面没有值,它默认返回特殊值None。 - 一个函数可以有多个
return语句(例如在不同的if分支里),但只要执行到任何一个return,函数就会结束。 - 可以返回任何类型的数据:数字、字符串、列表、字典,甚至另一个函数!
- 可以一次返回多个值,它们会被自动打包成一个元组。
Python
def add(x, y):"""计算两个数的和并返回结果。"""result = x + yreturn resultsum_result = add(5, 3)
print(f"5 + 3 = {sum_result}") # 输出: 5 + 3 = 8def get_name_parts(full_name):"""将全名分割成名和姓。"""parts = full_name.split() # 按空格分割if len(parts) >= 2:first_name = parts[0]last_name = " ".join(parts[1:]) # 处理可能有中间名的情况return first_name, last_name # 返回两个值 (打包成元组)elif len(parts) == 1:return parts[0], None # 如果只有一个部分,姓氏返回 Noneelse:return None, None # 如果输入为空,都返回 Nonefirst, last = get_name_parts("Albert Einstein")
print(f"First: {first}, Last: {last}") # First: Albert, Last: Einsteinfirst, last = get_name_parts("Marie Curie")
print(f"First: {first}, Last: {last}") # First: Marie, Last: Curiefirst, last = get_name_parts("Madonna")
print(f"First: {first}, Last: {last}") # First: Madonna, Last: Nonedef check_even(number):"""检查数字是否为偶数。"""if number % 2 == 0:return True # 如果是偶数,返回 True 并结束函数# 如果上面的 if 不满足,会执行到这里return Falseprint(f"4 是偶数吗? {check_even(4)}") # True
print(f"7 是偶数吗? {check_even(7)}") # Falsedef print_and_return_nothing(message):"""打印消息,但不显式返回值。"""print(message)result_none = print_and_return_nothing("Hello") # 会打印 Hello
print(f"函数返回值: {result_none}") # 输出: 函数返回值: None
5.6 函数的作用域 (Scope)
作用域指的是变量能够被访问的区域。
-
局部变量 (Local Variables): 在函数内部定义的变量(包括参数)是局部变量。它们只在函数被调用时创建,在函数执行结束时销毁。局部变量只能在函数内部访问,不能在函数外部访问。
Pythondef my_function():local_var = 10 # 局部变量print(f"函数内部: {local_var}")my_function() # 输出: 函数内部: 10 # 下面这行会报错 NameError: name 'local_var' is not defined # print(f"函数外部: {local_var}") -
全局变量 (Global Variables): 在所有函数外部定义的变量是全局变量。它们在程序的整个生命周期内都存在。全局变量可以在程序的任何地方(包括函数内部)被读取。
Pythonglobal_var = 100 # 全局变量def read_global():print(f"函数内部读取全局变量: {global_var}")def try_modify_global():# 试图直接修改全局变量 (不推荐,且可能产生 UnboundLocalError)# global_var = global_var + 1 # 这会报错,Python 认为你想创建一个新的局部变量print(f"函数内部尝试修改前读取: {global_var}") # 可以读取read_global() # 输出: 函数内部读取全局变量: 100 try_modify_global() print(f"函数外部: {global_var}") # 输出: 函数外部: 100 (全局变量未被修改) -
修改全局变量 (
Pythonglobal关键字): 如果确实需要在函数内部修改全局变量的值,需要使用global关键字明确声明。但通常不推荐这样做,因为它会破坏函数的封装性,使代码更难理解和调试。更好的做法是将需要修改的值作为参数传入,然后返回修改后的值。count = 0 # 全局变量def increment_global():global count # 声明要修改的是全局变量 countcount += 1print(f"函数内 count: {count}")increment_global() # 输出: 函数内 count: 1 increment_global() # 输出: 函数内 count: 2 print(f"函数外 count: {count}") # 输出: 函数外 count: 2
对于初学者,主要理解函数内部定义的变量是局部的,外部无法访问即可。尽量避免使用 global 关键字。
5.7 匿名函数 (lambda) - (可选/简要了解)
有时你需要一个非常简单的、只用一次的小函数,lambda 表达式提供了一种快速定义这种匿名函数(没有名字的函数)的方式。
语法: lambda arguments: expression
lambda: 关键字。arguments: 和普通函数的参数一样。:: 分隔符。expression: 一个表达式,它的计算结果就是函数的返回值(不需要return关键字)。Lambda 函数体只能包含一个表达式。
Python
# 普通函数定义
def add_regular(x, y):return x + y# 等效的 lambda 函数
add_lambda = lambda x, y: x + yprint(add_regular(5, 3)) # 8
print(add_lambda(5, 3)) # 8# 直接使用 lambda
result = (lambda a, b: a * b)(6, 7) # 定义并立即调用
print(result) # 42# lambda 常用于需要传入简单函数的地方,比如排序的 key
points = [(1, 2), (3, 1), (5, -4), (0, 8)]
# 按每个元组的第二个元素排序
points.sort(key=lambda point: point[1])
print(points) # [(5, -4), (3, 1), (1, 2), (0, 8)]
Lambda 对于初学者来说不是必需掌握的,了解有这样一种简洁写法即可,当你看到别人代码里用 lambda 时能大概理解它的意思就行。
5.8 实践时间!
练习1:将之前的练习改写成函数形式
- 重构闰年判断器:
- 定义一个函数
is_leap(year)。 - 它接收一个年份
year作为参数。 - 函数体包含之前判断闰年的逻辑。
- 函数应该返回
True(如果year是闰年)或False(如果不是)。 - 在主程序部分,获取用户输入,调用
is_leap()函数,并根据返回值打印结果。
- 定义一个函数
- 重构简单计算器:
- 定义一个函数
calculate(num1, num2, operator)。 - 接收两个数字
num1,num2和一个代表运算符的字符串operator('+','-','*',/) 作为参数。 - 根据
operator执行相应的计算。 - 返回计算结果。如果运算符无效或除数为零,可以考虑返回
None或打印错误信息并返回None。 - 在主程序部分,获取用户输入的两个数字和运算符,调用
calculate()函数,并打印结果(如果结果不是None)。
- 定义一个函数
练习2:编写工具函数 - 计算平均值
- 定义一个函数
calculate_average(numbers)。 - 它接收一个包含数字的列表
numbers作为参数。 - 函数应该计算并返回列表中所有数字的平均值。
- 考虑边界情况: 如果输入的列表
numbers是空的,直接计算平均值会报错(除以零)。在函数开始时检查列表是否为空 (if not numbers:或者if len(numbers) == 0:),如果为空,可以返回0或者None(并在文档字符串中说明)。 - 测试你的函数:创建一个数字列表,调用
calculate_average()并打印结果。也测试一下空列表的情况。
相关文章:

第二阶段:数据结构与函数
模块4:常用数据结构 (Organizing Lots of Data) 在前面的模块中,我们学习了如何使用变量来存储单个数据,比如一个数字、一个名字或一个布尔值。但很多时候,我们需要处理一组相关的数据,比如班级里所有学生的名字、一本…...

云函数采集架构:Serverless模式下的动态IP与冷启动优化
在 Serverless 架构中使用云函数进行网页数据采集,不仅能大幅降低运维成本,还能根据任务负载动态扩展。然而,由于云函数的无状态特性及冷启动问题,加上目标网站对采集行为的反制措施(如 IP 限制、Cookie 校验等&#x…...
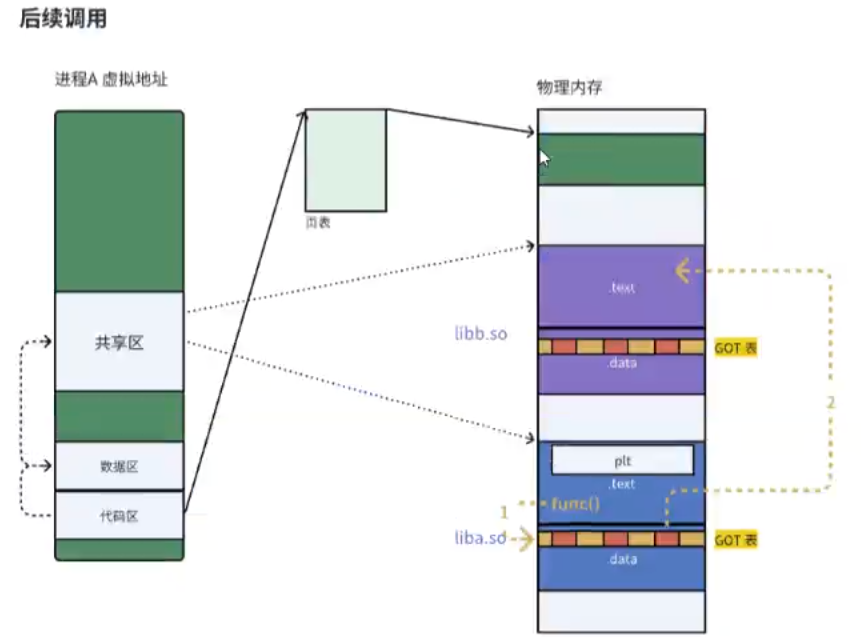
Linux笔记---动静态库(原理篇)
1. ELF文件格式 动静态库文件的构成是什么样的呢?或者说二者的内容是什么? 实际上,可执行文件,目标文件,静态库文件,动态库文件都是使用ELF文件格式进行组织的。 ELF(Executable and Linkable…...

string的模拟实现 (6)
目录 1.string.h 2.string.cpp 3.test.cpp 4.一些注意点 本篇博客就学习下如何模拟实现简易版的string类,学好string类后面学习其他容器也会更轻松些。 代码实现如下: 1.string.h #define _CRT_SECURE_NO_WARNINGS 1 #pragma once #include <…...
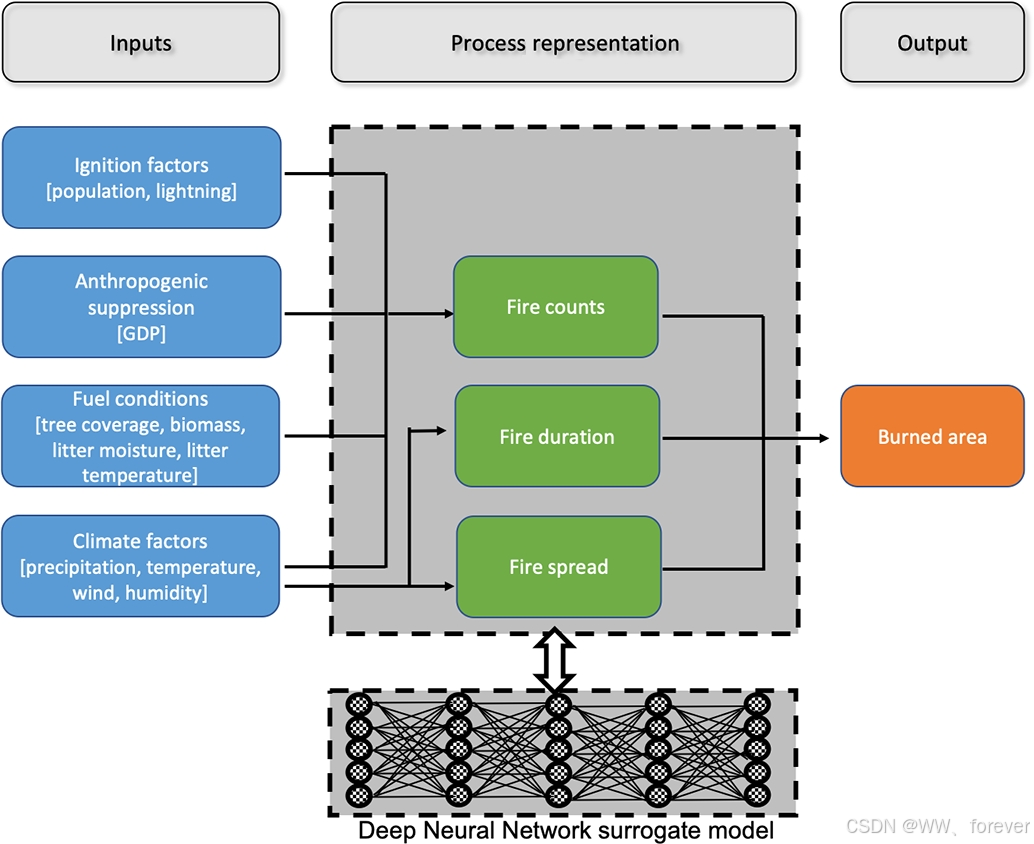
【野火模型】利用深度神经网络替代 ELMv1 野火参数化:机制、实现与性能评估
目录 一、ELMv1 野火过程表示法(BASE-Fire)关键机制野火模拟的核心过程 二、采用神经网络模拟野火过程三、总结参考 一、ELMv1 野火过程表示法(BASE-Fire) ELMv1 中的野火模型(称为 BASE-Fire)源自 Commun…...

红宝书第四十七讲:Node.js服务器框架解析:Express vs Koa 完全指南
红宝书第四十七讲:Node.js服务器框架解析:Express vs Koa 完全指南 资料取自《JavaScript高级程序设计(第5版)》。 查看总目录:红宝书学习大纲 一、框架定位:HTTP服务器的工具箱 共同功能: 快…...
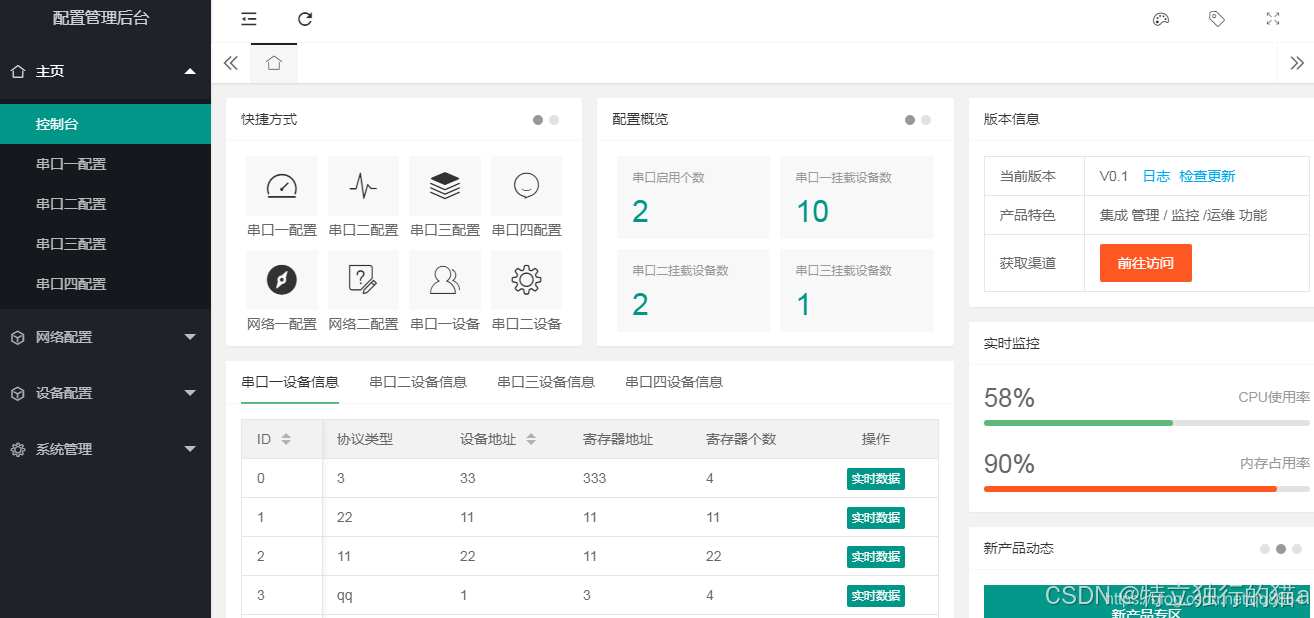
嵌入式Linux设备使用Go语言快速构建Web服务,实现设备参数配置管理方案探究
本文探讨,利用Go语言及gin框架在嵌入式Linux设备上高效搭建Web服务器,以实现设备参数的网页配置。通过gin框架,我们可以在几分钟内创建一个功能完善的管理界面,方便对诸如集中器,集线器等没有界面的嵌入式设备的管理。…...

【NLP 59、大模型应用 —— 字节对编码 bpe 算法】
目录 一、词表的构造问题 二、bpe(byte pair encoding) 压缩算法 算法步骤 示例: 步骤 1:初始化符号表和频率统计 步骤 2:统计相邻符号对的频率 步骤 3:合并最高频的符号对 步骤 4:重复合并直至终止条件 三、bpe在NLP中…...
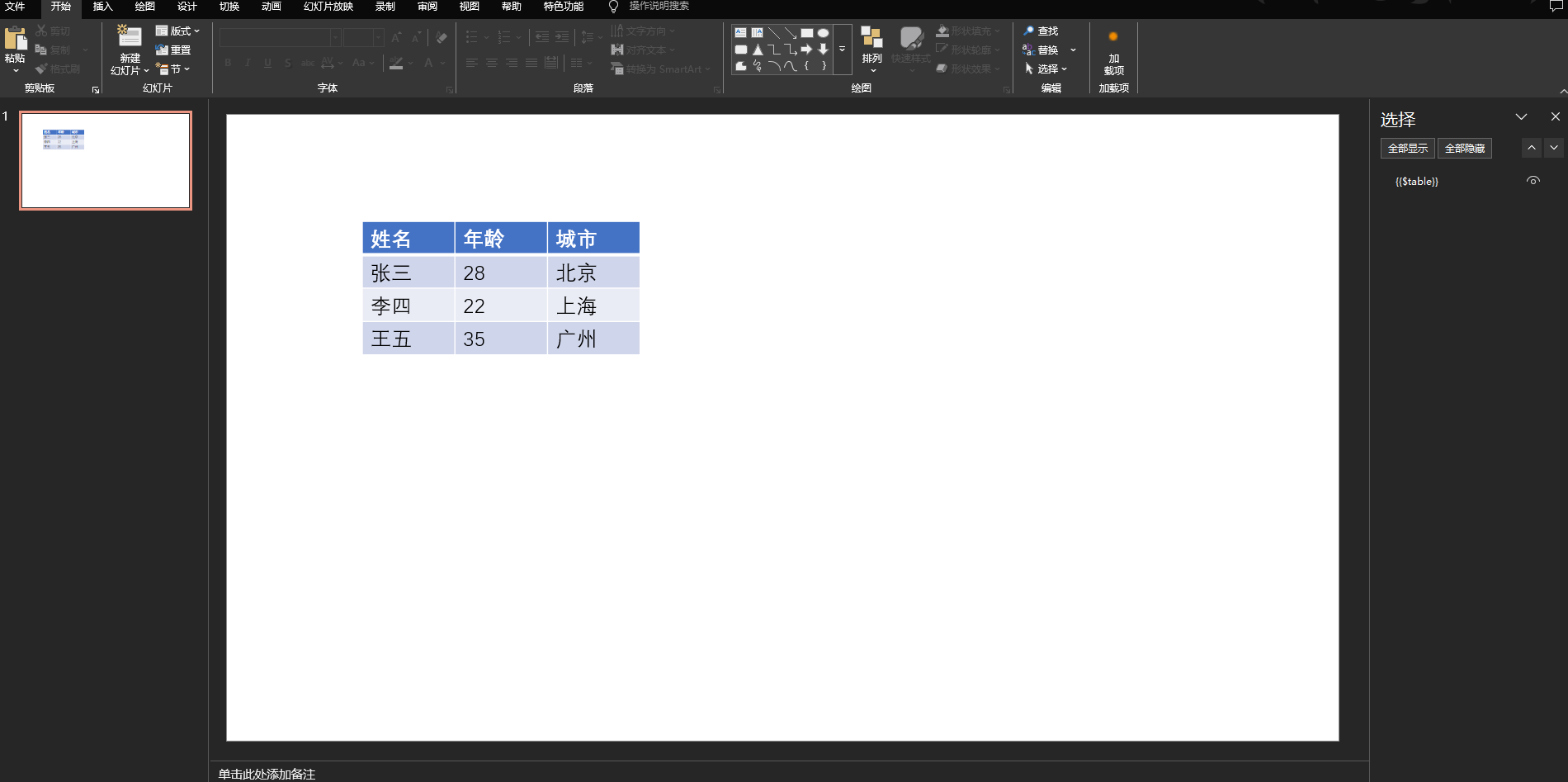
Python对ppt进行文本替换、插入图片、生成表格
目录 1. 安装pptx2. 文本替换和插入图片3. 生成表格 1. 安装pptx pip install python-pptx2. 文本替换和插入图片 文本通过占位符例如{{$xxx}}进行标记,然后进行替换;图片通过ppt中的图形和图片中的占位符进行标记ppt如下 具体实现 from pptx import …...
AI(学习笔记第一课) 在vscode中配置continue
文章目录 AI(学习笔记第一课) 在vscode中配置continue学习内容:1. 使用背景2. 在vscode中配置continue2.1 vscode版本2.2 在vscode中下载continue插件2.2.1 直接进行安装2.2.2 在左下角就会有continue的按钮2.2.3 可以移动到右上角2.2.3 使用的时候需要login 2.3 配…...

C++ (初始面向对象之继承,实现继承,组合,修饰权限)
初始面向对象之继承 根据面向对象的编程思路,我们可以把共性抽象出来封装成类,然后让不同的角色去继承这些类,从而避免大量重复代码的编写 实现继承 继承机制是面向对象程序设计中使代码可以复用的最重要的手段,它允许程序员在保…...
)
vmcore分析锁问题实例(x86-64)
问题描述:系统出现panic,dmesg有如下打印: [122061.197311] task:irq/181-ice-enp state:D stack:0 pid:3134 ppid:2 flags:0x00004000 [122061.197315] Call Trace: [122061.197317] <TASK> [122061.197318] __schedule0…...

21、c#中“?”的用途
在C#中,? 是一个多用途的符号,具有多种不同的用途,具体取决于上下文。以下是一些常见的用法: 1、可空类型(Nullable Types) ? 可以用于将值类型(如 int、bool 等)变为可空类型。…...
每日搜索--12月
12.1 1. urlencode是一种编码方式,用于将字符串以URL编码的形式进行转换。 urlencode也称为百分号编码(Percent-encoding),是特定上下文的统一资源定位符(URL)的编码机制。它适用于统一资源标识符(URI)的编码,也用于为application/x-www-form-urlencoded MIME准备数…...
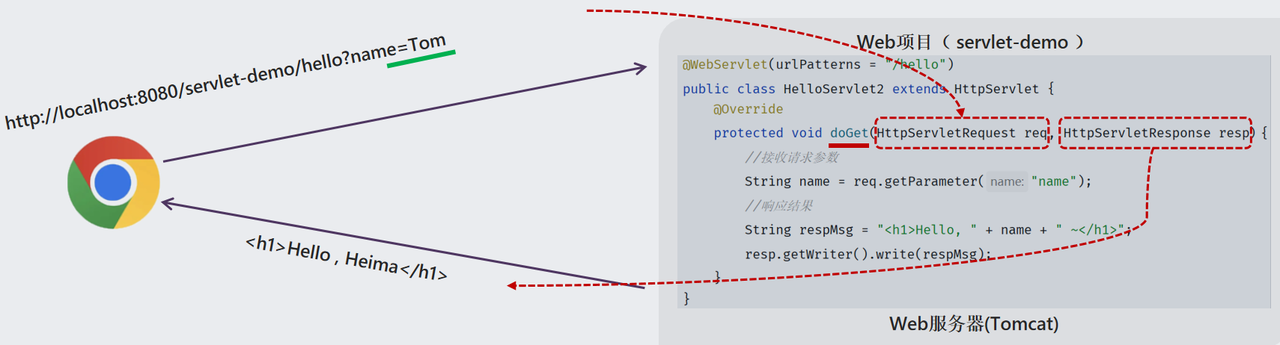
一天一个java知识点----Tomcat与Servlet
认识BS架构 静态资源:服务器上存储的不会改变的数据,通常不会根据用户的请求而变化。比如:HTML、CSS、JS、图片、视频等(负责页面展示) 动态资源:服务器端根据用户请求和其他数据动态生成的,内容可能会在每次请求时都…...

游戏报错?MFC140.dll怎么安装才能解决问题?提供多种MFC140.dll丢失修复方案
MFC140.dll 是 Microsoft Visual C 2015 运行库的重要组成部分,许多软件和游戏依赖它才能正常运行。如果你的电脑提示 "MFC140.dll 丢失" 或 "MFC140.dll 未找到",说明系统缺少该文件,导致程序无法启动。本文将详细介绍 …...

TDengine 3.3.6.3 虚拟表简单验证
涛思新出的版本提供虚拟表功能,完美解决了多值窄表查询时需要写程序把窄表变成宽表的处理过程,更加优雅。 超级表定义如下: CREATE STABLE st01 (ts TIMESTAMP,v0 INT,v1 BIGINT,v2 FLOAT,v3 BOOL) TAGS (device VARCHAR(32),vtype VARCHAR(…...

小白如何从0学习php
学习 PHP 可以从零开始逐步深入,以下是针对小白的系统学习路径和建议: 1. 了解 PHP 是什么 定义:PHP 是一种开源的服务器端脚本语言,主要用于 Web 开发(如动态网页、API、后台系统)。 用途:构建…...
常见的 14 个 HTTP 状态码详解
文章目录 一、2xx 成功1、200 OK2、204 No Content3、206 Partial Content 二、3xx 重定向1、301 Moved Permanently2、302 Found3、303 See Other注意4、Not Modified5、307 Temporary Redirect 三、4xx 客户端错误1、400 Bad Request2、401 Unauthorized3、403 Forbidden4、4…...

【Java学习笔记】DOS基本指令
DOS 基本指令 基本原理 接受指令 解析指令 执行指令 常用命令 查看当前目录有什么:dir 使用绝对路径查看特定目录下文件:dir 绝对路径 切换到其他盘:直接输入C: 或 D:直接切换到根目录 返回上一级目录:cd.. 切换到根目录…...
Linux Kernel 8
可编程中断控制器(Programmable Interrupt Controller,PIC) 支持中断(interrupt)的设备通常会有一个专门用于发出中断请求Interrupt ReQuest,IRQ的输出引脚(IRQ pin)。这些IRQ引脚连…...
原子操作CAS(Compare-And-Swap)和锁
目录 原子操作 优缺点 锁 互斥锁(Mutex) 自旋锁(Spin Lock) 原子性 单核单CPU 多核多CPU 存储体系结构 缓存一致性 写传播(Write Propagation) 事务串行化(Transaction Serialization&#…...

MySQL安装实战分享
一、在 Windows 上安装 MySQL 1. 下载 MySQL 安装包 访问 MySQL 官方下载页面。选择适合你操作系统的版本。一般推荐下载 MySQL Installer。 2. 运行安装程序 双击下载的安装文件(例如 mysql-installer-community-<version>.msi)。如果出现安全…...

C++ 编程指南35 - 为保持ABI稳定,应避免模板接口
一:概述 模板在 C 中是编译期展开的,不同模板参数会生成不同的代码,这使得模板类/函数天然不具备 ABI 稳定性。为了保持ABI稳定,接口不要直接用模板,先用普通类打个底,模板只是“外壳”,这样 AB…...
【WPF】 在WebView2使用echart显示数据
文章目录 前言一、NuGet安装WebView2二、代码部分1.xaml中引入webview22.编写html3.在WebView2中加载html4.调用js方法为Echarts赋值 总结 前言 为了实现数据的三维效果,所以需要使用Echarts,但如何在WPF中使用Echarts呢? 一、NuGet安装WebV…...

OpenCV 图像拼接
一、图像拼接的介绍 图像拼接是一种将多幅具有部分重叠内容的图像合并成一幅完整、无缝且具有更广阔视野或更高分辨率图像的技术。其目的是通过整合多个局部图像来获取更全面、更具信息价值的图像内容。 二、图像拼接的原理 图像拼接的核心目标是将多幅有重叠区域的图像进行准…...
数学建模AI智能体(4.16大更新)
别的不说就说下面这几点,年初内卷到现在,就现阶段AI水平,卷出了我比较满意的作品,这里分享给各位同学,让你们少走弯路: 1.轻松辅导学生 2.帮助学习 3.突破知识壁垒,缩短与大佬的差距 4.打破…...

音视频小白系统入门笔记-1
本系列笔记为博主学习李超老师课程的课堂笔记,仅供参阅 课程传送门:音视频小白系统入门课 音视频基础ffmpeg原理 往期课程笔记传送门:音视频小白系统入门笔记-0 课程实践代码仓库:传送门 音频采集 命令行采集 Android端音频…...

Flutter 强制横屏
在 Flutter 中,可以通过设置 SystemChrome 来强制应用横屏显示。以下是实现这一功能的详细步骤和代码示例: 步骤 1:导入必要的包 确保在文件顶部导入了 services.dart 包,因为 SystemChrome 类位于该包中。 import package:flut…...

量子安全邮件系统 —— NTRU算法邮件加密核心
目录 量子安全邮件系统 —— NTRU算法邮件加密核心一、项目背景与简介二、NTRU算法理论基础三、系统架构设计3.1 模块划分3.2 系统架构图(Mermaid示意图)四、邮件加密核心流程与关键技术4.1 密钥生成与公钥计算4.2 邮件加密4.3 邮件解密4.4 关键技术要点五、GUI设计与系统扩展…...