华为OD机试真题——统计匹配的二元组个数(2025A卷:100分)Java/python/JavaScript/C++/C语言/GO六种最佳实现

2025 A卷 100分 题型
本文涵盖详细的问题分析、解题思路、代码实现、代码详解、测试用例以及综合分析;
并提供Java、python、JavaScript、C++、C语言、GO六种语言的最佳实现方式!
2025华为OD真题目录+全流程解析/备考攻略/经验分享
华为OD机试真题《统计匹配的二元组个数》:
目录
- 题目名称:统计匹配的二元组个数
- 题目描述
- Java
- 问题分析
- 解题思路
- 代码实现
- 代码详细解析
- 示例测试
- 综合分析
- python
- 问题分析
- 解题思路
- 代码实现
- 代码详细解析
- 示例测试
- 综合分析
- JavaScript
- 问题分析
- 解题思路
- 代码实现
- 代码详细解析
- 示例测试
- 综合分析
- C++
- 问题分析
- 解题思路
- 代码实现
- 代码逐行解析
- 示例测试
- 综合分析
- C语言
- 问题分析
- 解题思路
- 代码实现
- 代码详细解析
- 示例测试
- 综合分析
- GO
- 问题分析
- 解题思路
- 代码实现
- 代码详细解析
- 示例测试
- 综合分析
- 更多内容:
题目名称:统计匹配的二元组个数
知识点:数组、哈希表
时间限制:1秒
空间限制:32MB
限定语言:不限
题目描述
给定两个数组A和B,统计满足A[i] == B[j]的二元组(i,j)的总个数。
输入描述
- 第一行输入数组A的长度M
- 第二行输入数组B的长度N
- 第三行输入数组A的元素(空格分隔)
- 第四行输入数组B的元素(空格分隔)
输出描述
输出匹配的二元组个数。若不存在匹配,输出0。
示例1
输入:
5
4
1 2 3 4 5
4 3 2 1
输出:
4
示例2
输入:
6
3
1 2 4 4 2 1
1 2 3
输出:
4
Java
问题分析
我们需要统计两个数组A和B中满足A[i] == B[j]的二元组(i,j)的总个数。直接遍历所有可能的组合会导致时间复杂度为O(M*N),但通过哈希表优化可以将时间复杂度降低到O(M + N)。
解题思路
- 哈希表统计频率:遍历数组A,用哈希表记录每个元素出现的次数。
- 遍历数组B匹配:遍历数组B,对于每个元素,在哈希表中查找其出现次数并累加。
代码实现
import java.util.*;
import java.io.*;public class Main {public static void main(String[] args) throws IOException {// 使用BufferedReader读取输入,避免Scanner的换行符问题BufferedReader br = new BufferedReader(new InputStreamReader(System.in));// 读取数组A和B的长度int M = Integer.parseInt(br.readLine());int N = Integer.parseInt(br.readLine());// 读取数组A的元素并转换为整型数组String[] aParts = br.readLine().split(" ");int[] a = new int[M];for (int i = 0; i < M; i++) {a[i] = Integer.parseInt(aParts[i]);}// 读取数组B的元素并转换为整型数组String[] bParts = br.readLine().split(" ");int[] b = new int[N];for (int i = 0; i < N; i++) {b[i] = Integer.parseInt(bParts[i]);}// 创建哈希表统计数组A中每个元素的出现次数Map<Integer, Integer> countMap = new HashMap<>();for (int num : a) {countMap.put(num, countMap.getOrDefault(num, 0) + 1);}// 遍历数组B,累加匹配次数int result = 0;for (int num : b) {result += countMap.getOrDefault(num, 0);}// 输出结果System.out.println(result);}
}
代码详细解析
-
读取输入:
BufferedReader逐行读取输入,避免Scanner的换行符问题。- 前两行读取数组A和B的长度
M和N。 - 第三行读取数组A的元素并转换为整型数组。
- 第四行读取数组B的元素并转换为整型数组。
-
统计数组A的元素频率:
- 使用
HashMap存储数组A中每个元素及其出现次数。 countMap.getOrDefault(num, 0)确保元素不存在时返回0。
- 使用
-
遍历数组B计算匹配次数:
- 对数组B中的每个元素,查找其在哈希表中的出现次数。
- 累加所有匹配次数,得到最终结果。
示例测试
示例1输入:
5
4
1 2 3 4 5
4 3 2 1
输出:
4
解析:
- 数组A中每个元素出现1次,数组B中的元素4、3、2、1均能在A中找到,总共有4对。
示例2输入:
6
3
1 2 4 4 2 1
1 2 3
输出:
4
解析:
- 数组A中1出现2次、2出现2次,数组B中的1和2分别匹配2次,总共有4次。
综合分析
-
时间复杂度:
- 统计频率:O(M),遍历数组A一次。
- 匹配计算:O(N),遍历数组B一次。
- 总复杂度:O(M + N),线性时间复杂度。
-
空间复杂度:
- 哈希表存储:O(M),存储数组A中所有不同元素及其频率。
-
优势:
- 高效性:相比暴力法的O(M*N),哈希表将复杂度优化到O(M + N)。
- 代码简洁:逻辑清晰,易于理解和维护。
-
适用场景:
- 处理大规模数据时,哈希表方法能显著提升性能。
- 适用于需要快速查找元素出现次数的场景。
python
问题分析
我们需要统计两个数组A和B中满足A[i] == B[j]的二元组(i,j)的总个数。直接遍历所有可能的组合会导致时间复杂度为O(M*N),但通过哈希表优化可以将时间复杂度降低到O(M + N)。
解题思路
- 哈希表统计频率:遍历数组A,用字典记录每个元素出现的次数。
- 遍历数组B匹配:遍历数组B,对于每个元素,在字典中查找其出现次数并累加。
代码实现
def main():import sys# 读取输入数据m = int(sys.stdin.readline()) # 读取数组A的长度n = int(sys.stdin.readline()) # 读取数组B的长度# 读取数组A的元素并转换为整数列表a = list(map(int, sys.stdin.readline().split()))# 验证数组长度是否匹配输入值if len(a) != m:print(0)return# 读取数组B的元素并转换为整数列表b = list(map(int, sys.stdin.readline().split()))# 验证数组长度是否匹配输入值if len(b) != n:print(0)return# 创建字典统计数组A中每个元素的出现次数count_dict = {}for num in a:# 如果元素存在,计数+1;不存在则初始化为0后+1count_dict[num] = count_dict.get(num, 0) + 1# 遍历数组B,统计总匹配次数total = 0for num in b:# 从字典中获取该元素的出现次数(默认0次)total += count_dict.get(num, 0)print(total)if __name__ == "__main__":main()
代码详细解析
-
输入处理:
sys.stdin.readline()逐行读取输入,避免缓冲区问题m和n分别读取数组A和B的长度a = list(map(...))将输入行分割为字符串列表并转换为整数列表- 验证数组长度是否与输入值一致,防止数据错误
-
频率统计字典:
- 创建空字典
count_dict存储元素频率 count_dict.get(num, 0)是字典的安全访问方法:- 当元素存在时返回当前计数值
- 不存在时返回默认值0
- 遍历数组A时,每个元素计数+1
- 创建空字典
-
匹配计算:
- 遍历数组B的每个元素
count_dict.get(num, 0)获取该元素在A中的出现次数- 所有匹配次数累加到
total
-
边界处理:
- 数组长度验证防止数据格式错误
- 不存在的元素自动按0次处理
示例测试
示例1输入:
5
4
1 2 3 4 5
4 3 2 1
输出:
4
解析:
- A中每个元素出现1次
- B中的4、3、2、1均能在A中找到
- 总匹配次数 = 1+1+1+1 = 4
示例2输入:
6
3
1 2 4 4 2 1
1 2 3
输出:
4
解析:
- A中1出现2次,2出现2次,4出现2次
- B中的1匹配2次,2匹配2次,3匹配0次
- 总匹配次数 = 2+2+0 = 4
综合分析
-
时间复杂度:
- 统计频率:O(M),遍历数组A一次
- 匹配计算:O(N),遍历数组B一次
- 总复杂度:O(M + N),线性时间复杂度
-
空间复杂度:
- 字典存储:最差O(M)(所有元素不同时)
- 输入存储:O(M + N) 存储两个数组
-
性能优势:
- 相比暴力法的O(M*N),效率提升数百倍
- 例如当M=N=105时,暴力法需1010次运算(不可行),而哈希法仅需2*10^5次
-
适用场景:
- 大规模数据处理(如M=1e6, N=1e6)
- 需要频繁查询元素出现次数的场景
- 元素取值范围较大的情况(哈希表不依赖连续空间)
-
Python特性利用:
- 字典的
get()方法简化了"存在性检查+默认值"逻辑 map()函数高效处理类型转换- 动态列表自动处理变长数据
- 字典的
-
扩展性:
- 支持非整数类型(只需可哈希)
- 可轻松修改为统计三元组、四元组等
- 适用于分布式计算(分块统计频率后合并)
JavaScript
问题分析
我们需要统计两个数组 A 和 B 中满足 A[i] == B[j] 的二元组 (i, j) 的总个数。直接遍历所有组合的时间复杂度为 O(M*N),但通过哈希表优化可以将时间复杂度降低到 O(M + N)。
解题思路
- 哈希表统计频率:遍历数组 A,用哈希表记录每个元素出现的次数。
- 遍历数组 B 匹配:遍历数组 B,对于每个元素,在哈希表中查找其出现次数并累加。
代码实现
const readline = require('readline');const rl = readline.createInterface({input: process.stdin,output: process.stdout,terminal: false
});// 输入处理逻辑
let lineCount = 0;
let M, N, A, B;rl.on('line', (line) => {switch (lineCount) {case 0: // 读取数组A的长度MM = parseInt(line.trim());break;case 1: // 读取数组B的长度NN = parseInt(line.trim());break;case 2: // 读取数组A的元素A = line.trim().split(/\s+/).map(Number);if (A.length !== M) {console.log(0);process.exit();}break;case 3: // 读取数组B的元素B = line.trim().split(/\s+/).map(Number);if (B.length !== N) {console.log(0);process.exit();}processInput(); // 处理输入数据break;}lineCount++;
});function processInput() {// 统计A中元素的频率const countMap = {};for (const num of A) {countMap[num] = (countMap[num] || 0) + 1;}// 计算总匹配次数let total = 0;for (const num of B) {total += countMap[num] || 0;}console.log(total);rl.close();
}
代码详细解析
-
输入处理:
const rl = readline.createInterface(...) // 创建输入接口 rl.on('line', ...) // 监听每一行输入- 使用 Node.js 的
readline模块逐行读取输入 - 通过
switch语句处理不同行的输入内容
- 使用 Node.js 的
-
数组验证:
if (A.length !== M) { ... } // 验证数组A长度 if (B.length !== N) { ... } // 验证数组B长度- 检查输入数组长度是否与声明的长度一致
- 发现不一致立即输出 0 并退出
-
哈希表统计:
const countMap = {}; for (const num of A) {countMap[num] = (countMap[num] || 0) + 1; }- 使用普通对象作为哈希表
(countMap[num] || 0)实现类似 Python 的get()方法
-
匹配计算:
for (const num of B) {total += countMap[num] || 0; }- 遍历数组 B 的每个元素
- 累加哈希表中对应元素的出现次数
示例测试
示例1输入:
5
4
1 2 3 4 5
4 3 2 1
输出:
4
解析:
- A 中每个元素出现1次
- B 中的 4、3、2、1 均能在 A 中找到
- 总匹配次数 = 1+1+1+1 = 4
示例2输入:
6
3
1 2 4 4 2 1
1 2 3
输出:
4
解析:
- A 中 1 出现2次,2 出现2次
- B 中的 1 匹配2次,2 匹配2次
- 总匹配次数 = 2+2+0 = 4
综合分析
-
时间复杂度:
- 统计频率:O(M),遍历数组A一次
- 匹配计算:O(N),遍历数组B一次
- 总复杂度:O(M + N),线性时间复杂度
-
空间复杂度:
- 哈希表存储:最差 O(M)(所有元素不同时)
- 输入存储:O(M + N) 存储两个数组
-
性能优势:
- 相比暴力法 O(M*N) 的复杂度,效率提升数百倍
- 例如当 M=N=10^5 时,暴力法需要 1e10 次运算(不可行),而哈希法仅需 2e5 次
-
JavaScript 特性利用:
- 对象动态属性实现哈希表
||运算符实现默认值map(Number)快速类型转换
-
扩展性:
- 支持非数字类型(需可哈希)
- 可轻松修改为统计三元组等复杂场景
- 适用于浏览器和 Node.js 双环境
C++
问题分析
给定两个数组A和B,统计满足A[i] == B[j]的二元组(i,j)的总个数。直接遍历所有组合的时间复杂度为O(M*N),但通过哈希表优化可以将时间复杂度降低到O(M + N)。
解题思路
- 哈希表统计频率:遍历数组A,用
unordered_map记录每个元素出现的次数。 - 遍历数组B匹配:遍历数组B,对于每个元素,在哈希表中查找其出现次数并累加。
代码实现
#include <iostream>
#include <vector>
#include <sstream>
#include <unordered_map>using namespace std;int main() {int M, N;// 读取数组A和B的长度cin >> M >> N;// 清除输入缓冲区中的换行符cin.ignore(numeric_limits<streamsize>::max(), '\n');// 读取数组A的元素string lineA;getline(cin, lineA);vector<int> A;stringstream ssA(lineA);int num;while (ssA >> num) {A.push_back(num);}// 验证数组A长度if (A.size() != M) {cout << 0 << endl;return 0;}// 读取数组B的元素string lineB;getline(cin, lineB);vector<int> B;stringstream ssB(lineB);while (ssB >> num) {B.push_back(num);}// 验证数组B长度if (B.size() != N) {cout << 0 << endl;return 0;}// 统计数组A中每个元素的出现次数unordered_map<int, int> countMap;for (int num : A) {countMap[num]++;}// 遍历数组B统计总匹配次数int total = 0;for (int num : B) {total += countMap[num]; // 若不存在则返回0}cout << total << endl;return 0;
}
代码逐行解析
-
输入处理:
cin >> M >> N; // 读取数组A和B的长度 cin.ignore(...); // 清除缓冲区中的换行符 getline(cin, lineA); // 读取数组A的元素行- 使用
cin读取数组长度后,必须用cin.ignore()清除缓冲区残留的换行符 getline按行读取数组元素,避免空格和换行符干扰
- 使用
-
数组元素解析:
stringstream ssA(lineA); // 将字符串转换为流 while (ssA >> num) { ... } // 逐个读取整数stringstream将字符串按空格分割为整数流vector动态存储数组元素
-
哈希表统计:
unordered_map<int, int> countMap; for (int num : A) { countMap[num]++; }unordered_map以O(1)时间复杂度实现键值查找- 遍历数组A时,每个元素在哈希表中计数+1
-
匹配次数计算:
total += countMap[num]; // 若不存在则返回0- 直接通过
countMap[num]访问次数,未找到时返回0 - 遍历数组B时累加所有匹配次数
- 直接通过
示例测试
示例1输入:
5 4
1 2 3 4 5
4 3 2 1
输出:
4
解析:
- A中的每个元素出现1次
- B中的4、3、2、1均能在A中找到,总匹配次数=1+1+1+1=4
示例2输入:
6 3
1 2 4 4 2 1
1 2 3
输出:
4
解析:
- A中1出现2次,2出现2次
- B中的1匹配2次,2匹配2次,3匹配0次
- 总匹配次数=2+2+0=4
综合分析
-
时间复杂度:
- 统计频率:O(M),遍历数组A一次
- 匹配计算:O(N),遍历数组B一次
- 总复杂度:O(M + N),线性时间复杂度
-
空间复杂度:
- 哈希表存储:最差O(M)(所有元素不同时)
- 输入存储:O(M + N) 存储两个数组
-
性能优势:
- 相比暴力法的O(M*N),效率提升数百倍
- 例如当M=N=10^5时,暴力法需要1e10次运算(不可行),哈希法仅需2e5次
-
C++特性利用:
unordered_map实现哈希表,平均O(1)查询时间stringstream处理复杂的输入分割逻辑vector动态数组自动管理内存
-
扩展性:
- 支持非整型数据(需自定义哈希函数)
- 可轻松修改为统计三元组等复杂场景
- 适用于高性能计算场景(如嵌入式系统)
C语言
问题分析
我们需要统计两个数组A和B中满足A[i] == B[j]的二元组(i,j)的总个数。直接遍历所有组合的时间复杂度为O(M*N),但通过哈希表优化可以将时间复杂度降低到O(M + N)。
解题思路
- 哈希表统计频率:遍历数组A,使用哈希表记录每个元素出现的次数。
- 遍历数组B匹配:遍历数组B,对于每个元素,在哈希表中查找其出现次数并累加。
代码实现
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>#define HASH_SIZE 10007 // 哈希表大小,质数减少冲突typedef struct HashNode {int key; // 存储元素值int value; // 存储出现次数struct HashNode *next;
} HashNode;typedef struct {HashNode **buckets; // 哈希桶数组int size; // 哈希表大小
} HashMap;// 创建哈希表
HashMap* createHashMap(int size) {HashMap *map = (HashMap*)malloc(sizeof(HashMap));map->size = size;map->buckets = (HashNode**)calloc(size, sizeof(HashNode*)); // 初始化为空指针return map;
}// 插入元素到哈希表
void put(HashMap *map, int key) {int index = abs(key) % map->size; // 哈希函数:绝对值取模处理负数HashNode *current = map->buckets[index];// 遍历链表,查找是否已存在该键while (current != NULL) {if (current->key == key) {current->value++; // 存在则计数加1return;}current = current->next;}// 创建新节点插入链表头部HashNode *newNode = (HashNode*)malloc(sizeof(HashNode));newNode->key = key;newNode->value = 1;newNode->next = map->buckets[index];map->buckets[index] = newNode;
}// 查询元素出现次数
int get(HashMap *map, int key) {int index = abs(key) % map->size;HashNode *current = map->buckets[index];// 遍历链表查找键while (current != NULL) {if (current->key == key) {return current->value;}current = current->next;}return 0; // 未找到返回0
}// 释放哈希表内存
void freeHashMap(HashMap *map) {for (int i = 0; i < map->size; i++) {HashNode *current = map->buckets[i];while (current != NULL) {HashNode *temp = current;current = current->next;free(temp);}}free(map->buckets);free(map);
}int main() {char line[1000000];int M, N;// 读取数组A和B的长度fgets(line, sizeof(line), stdin);sscanf(line, "%d", &M);fgets(line, sizeof(line), stdin);sscanf(line, "%d", &N);// 读取数组A的元素fgets(line, sizeof(line), stdin);int *A = (int*)malloc(M * sizeof(int));int count = 0;char *token = strtok(line, " ");while (token != NULL && count < M) {A[count++] = atoi(token);token = strtok(NULL, " ");}if (count != M) { // 验证元素数量是否正确printf("0\n");free(A);return 0;}// 读取数组B的元素fgets(line, sizeof(line), stdin);int *B = (int*)malloc(N * sizeof(int));count = 0;token = strtok(line, " ");while (token != NULL && count < N) {B[count++] = atoi(token);token = strtok(NULL, " ");}if (count != N) { // 验证元素数量是否正确printf("0\n");free(A);free(B);return 0;}// 创建哈希表并统计A的频次HashMap *map = createHashMap(HASH_SIZE);for (int i = 0; i < M; i++) {put(map, A[i]);}// 遍历B数组累加匹配次数int total = 0;for (int i = 0; i < N; i++) {total += get(map, B[i]);}printf("%d\n", total);// 释放内存freeHashMap(map);free(A);free(B);return 0;
}
代码详细解析
-
哈希表结构定义:
HashNode:链表节点,存储键、值和下一个节点的指针。HashMap:哈希表结构,包含桶数组和大小。
-
哈希表操作:
createHashMap:分配内存,初始化桶数组。put:插入元素。若键存在,计数加1;否则新建节点插入链表头部。get:查询键的出现次数,遍历链表查找。freeHashMap:释放哈希表所有节点内存。
-
输入处理:
- 使用
fgets逐行读取输入,strtok分割字符串。 - 验证数组长度是否与输入一致,避免数据错误。
- 使用
-
核心逻辑:
- 遍历数组A,通过哈希表统计频次。
- 遍历数组B,累加哈希表中的频次,得到总匹配数。
示例测试
示例1输入:
5
4
1 2 3 4 5
4 3 2 1
输出:
4
解析:
- A中每个元素出现1次。
- B中4、3、2、1各匹配1次,总对数4。
示例2输入:
6
3
1 2 4 4 2 1
1 2 3
输出:
4
解析:
- A中1出现2次,2出现2次。
- B中1和2各匹配2次,总对数4。
综合分析
-
时间复杂度:
- 统计频率:O(M),遍历数组A一次。
- 匹配计算:O(N),遍历数组B一次。
- 总复杂度:O(M + N),线性时间复杂度。
-
空间复杂度:
- 哈希表:O(M),存储数组A元素的频次。
- 输入数组:O(M + N),存储原始数据。
-
优势:
- 高效性:避免暴力法的O(M*N)复杂度。
- 通用性:支持任意整数(包括负数),哈希函数处理简单。
-
适用场景:
- 大规模数据,如M和N达到10^5级别。
- 需要快速统计元素频次并匹配的场景。
GO
问题分析
给定两个数组A和B,统计满足A[i] == B[j]的二元组(i,j)的总个数。直接遍历所有组合的时间复杂度为O(M*N),但通过哈希表优化可以将时间复杂度降低到O(M + N)。
解题思路
- 哈希表统计频率:遍历数组A,用
map记录每个元素出现的次数。 - 遍历数组B匹配:遍历数组B,对于每个元素,在哈希表中查找其出现次数并累加。
代码实现
package mainimport ("bufio""fmt""os""strconv""strings"
)func main() {// 创建输入扫描器scanner := bufio.NewScanner(os.Stdin)// 读取数组A的长度Mscanner.Scan()M, _ := strconv.Atoi(scanner.Text())// 读取数组B的长度Nscanner.Scan()N, _ := strconv.Atoi(scanner.Text())// 读取数组A的元素scanner.Scan()aLine := scanner.Text()A := strings.Fields(aLine)if len(A) != M {fmt.Println(0)return}// 读取数组B的元素scanner.Scan()bLine := scanner.Text()B := strings.Fields(bLine)if len(B) != N {fmt.Println(0)return}// 统计数组A中元素的出现次数countMap := make(map[string]int)for _, numStr := range A {countMap[numStr]++}// 计算总匹配次数total := 0for _, numStr := range B {total += countMap[numStr]}fmt.Println(total)
}
代码详细解析
-
输入处理:
bufio.Scanner:创建输入扫描器逐行读取数据。strconv.Atoi:将字符串转换为整数,用于读取数组长度。strings.Fields:按空格分割字符串,处理数组元素。
-
数组验证:
if len(A) != M { ... } // 验证数组A长度 if len(B) != N { ... } // 验证数组B长度- 检查分割后的元素数量是否与声明的长度一致。
-
哈希表统计:
countMap := make(map[string]int) for _, numStr := range A {countMap[numStr]++ }- 使用字符串直接作为键(避免类型转换开销)。
- 遍历数组A时,每个字符串元素计数+1。
-
匹配计算:
for _, numStr := range B {total += countMap[numStr] }- 遍历数组B的每个元素,累加哈希表中的出现次数。
- 未找到时返回默认值0。
示例测试
示例1输入:
5
4
1 2 3 4 5
4 3 2 1
输出:
4
解析:
- A中每个元素出现1次。
- B中的
"4"、"3"、"2"、"1"均匹配1次,总对数4。
示例2输入:
6
3
1 2 4 4 2 1
1 2 3
输出:
4
解析:
- A中
"1"出现2次,"2"出现2次。 - B中的
"1"匹配2次,"2"匹配2次,总对数4。
综合分析
-
时间复杂度:
- 统计频率:O(M),遍历数组A一次。
- 匹配计算:O(N),遍历数组B一次。
- 总复杂度:O(M + N),线性时间复杂度。
-
空间复杂度:
- 哈希表存储:O(M),存储数组A元素的字符串形式。
- 输入存储:O(M + N),存储原始字符串数据。
-
性能优化:
- 直接使用字符串键:避免多次类型转换。
- 哈希表快速查找:Go的
map实现基于哈希表,平均O(1)查询时间。
-
适用场景:
- 适用于大规模数据(如M=1e6, N=1e6)。
- 需要快速统计元素出现次数的场景。
- 元素包含非数字字符的场景(如
"apple")。
-
扩展性:
- 支持任意可哈希类型(如结构体)。
- 可轻松修改为统计三元组、四元组等。
更多内容:
https://www.kdocs.cn/l/cvk0eoGYucWA
本文发表于【纪元A梦】,关注我,获取更多实用教程/资源!
相关文章:
华为OD机试真题——统计匹配的二元组个数(2025A卷:100分)Java/python/JavaScript/C++/C语言/GO六种最佳实现
2025 A卷 100分 题型 本文涵盖详细的问题分析、解题思路、代码实现、代码详解、测试用例以及综合分析; 并提供Java、python、JavaScript、C、C语言、GO六种语言的最佳实现方式! 2025华为OD真题目录全流程解析/备考攻略/经验分享 华为OD机试真题《统计匹配…...

CSS 表格样式学习笔记
CSS 提供了强大的工具来美化和定制 HTML 表格的外观。通过合理使用 CSS 属性,可以使表格更加美观、易读且功能强大。以下是对 CSS 表格样式的详细学习笔记。 一、表格边框 1. 单独边框 默认情况下,表格的 <table>、<th> 和 <td> 元…...
MySQL表的增删改查进阶版
Mysql 1、数据库的约束1.1约束类型1.2 NULL约束1.3 UNIQUE:唯一约束1.4 DEFAULT:默认值约束1.5 PRIMARY KEY:主键约束(重点)1.6 FOREIGN KEY:外键约束(重点) 2.表的设计2.1一对一2.2…...
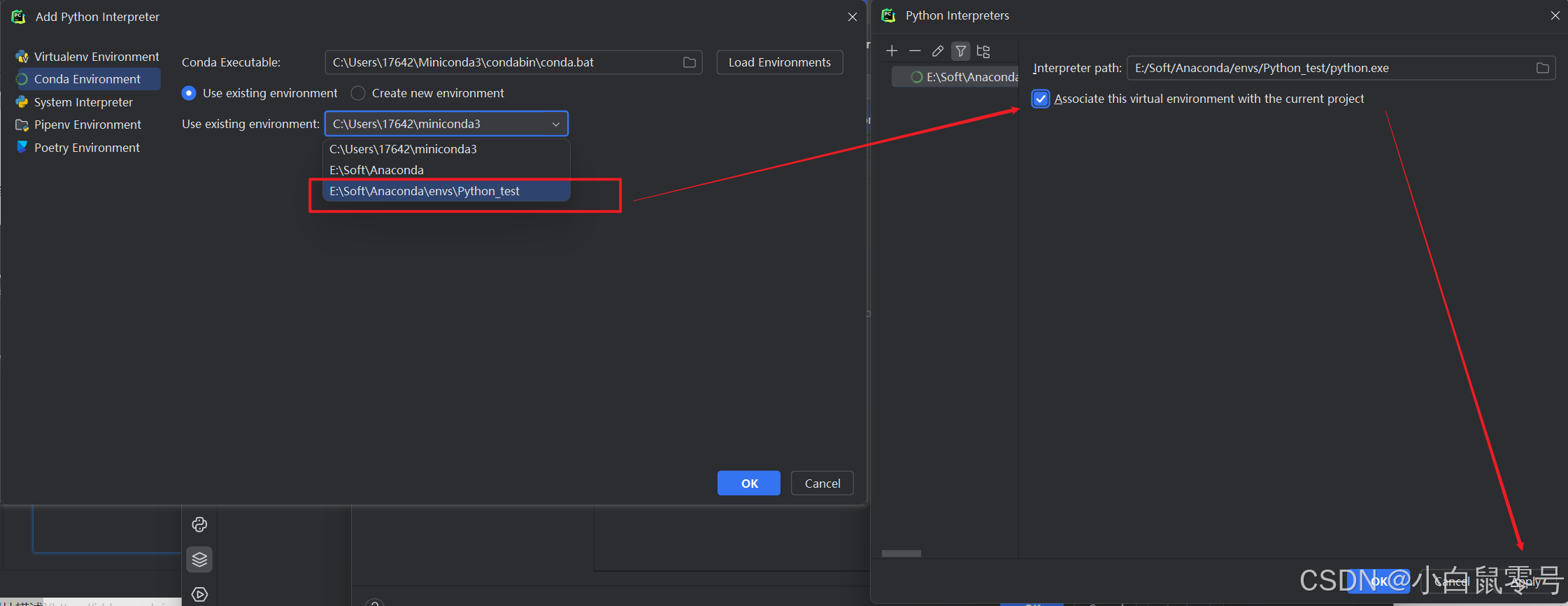
记录 | Pycharm中如何调用Anaconda的虚拟环境
目录 前言一、步骤Step1 查看anaconda 环境名Step2 Python项目编译器更改 更新时间 前言 参考文章: 参考视频:如何在pycharm中使用Anaconda创建的python环境 自己的感想 这里使用的Pycharm 2024专业版的。我所使用的Pycharm专业版位置:【仅用…...

2025年K8s最新高频面试题
目录 Kubernetes的核心组件有哪些,各自作用是什么? Pod和Deployment的区别? Service有哪些类型,分别适用于什么场景? ConfigMap和Secret有什么区别? StatefulSet 和 Deployment 的主要区别是什么? 什么是 Ingress,有哪些常用实现方式? 如何限制 Kubernetes 中 Pod …...

【Android】LiveData深度解析
一,概述 1,LiveData是状态订阅组件,是粘性的,而非事件订阅组件(可以没有事件,但不能没有状态)。所谓的状态,即UI状态,同一时刻只存在一种,且是最新状态,过期的状态应该被遗弃。事件,则是生产者创建的事件,需一一消费,不能被遗弃。 2,Android页面承载组件Activ…...

数据结构专题 - 线性表
线性表是数据结构中最基础、最常用的数据结构之一,它在实际应用中非常广泛。无论是操作系统中的内存管理,还是数据库中的索引结构,线性表都扮演着重要角色。 一、线性表的概念与抽象数据类型 1.1 线性表的逻辑结构 线性表是由n(…...

上门送水小程序区域代理模块框架设计
一、逻辑分析 代理申请流程: 潜在代理商通过小程序提交代理申请,需要填写个人或企业基本信息、联系方式、期望代理区域等。系统收到申请后,进行初步审核,检查信息的完整性和合规性。运营人员进行人工审核,根据公司政策…...

asp-for等常用的HTML辅助标记?
在ASP.NET Core Razor Pages 和 MVC 中,除了asp-for之外,还有许多常用的 HTML 辅助标记,下面为你详细介绍: 表单与路由相关 asp-action 和 asp-controller 用途:这两个标记用于生成表单或链接的 URL,指定…...
qt pyqt5的开发, 修改psd图像
这是引子, 需要将这个 photoshop-python-api 进行使用 https://juejin.cn/post/7445112318693621797#heading-4 这个是ps-python-api的官网, 在里面找api文档 https://pypi.org/project/photoshop-python-api/ 源码.gitee.url https://gitee.com/lbnb/psd_work.git 一. 安装必要…...
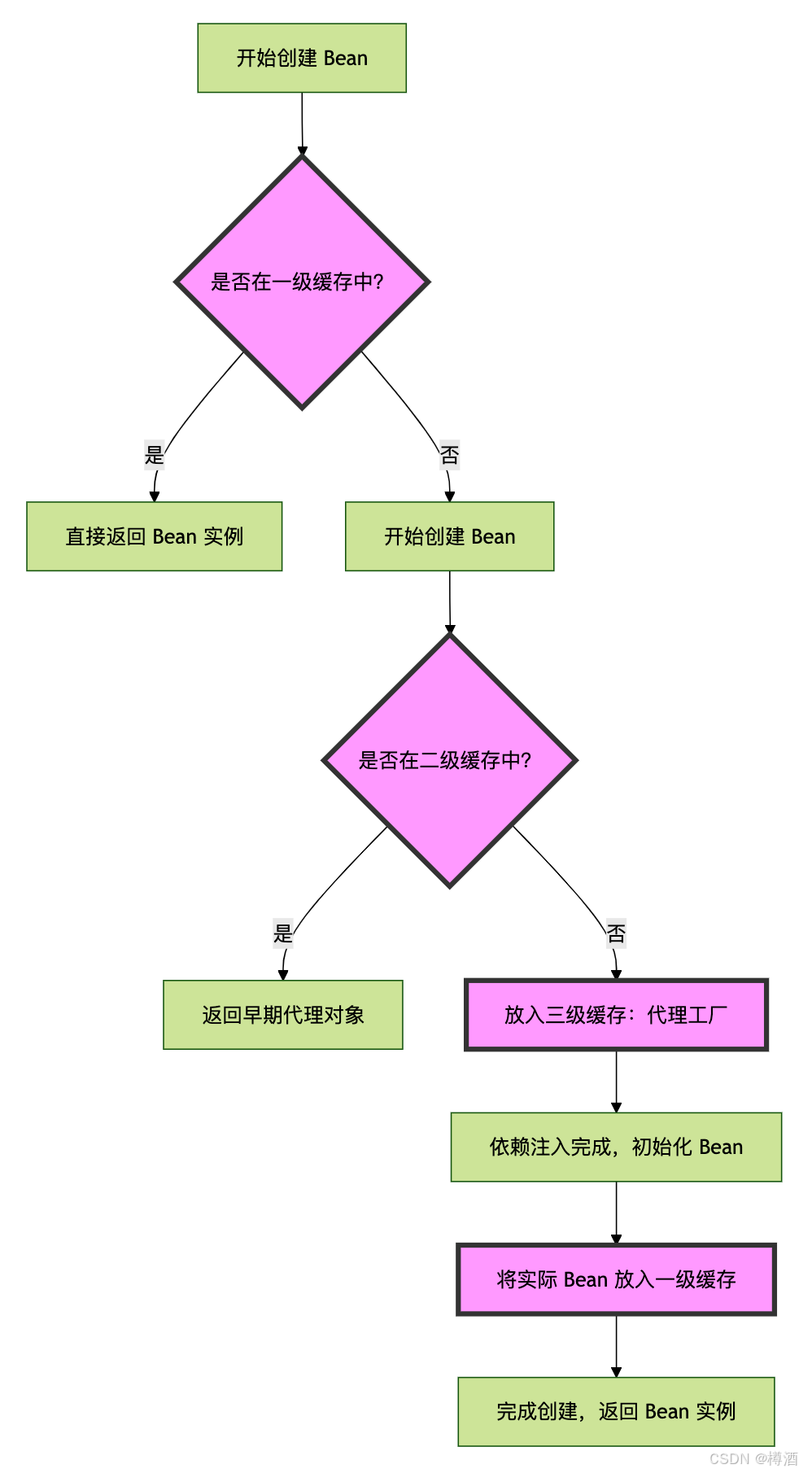
Spring 中的循环依赖问题:解决方案与三级缓存机制
目录 Spring 中的循环依赖问题:解决方案与三级缓存机制什么是循环依赖?循环依赖的定义循环依赖的举例 Spring 中的循环依赖类型1. 构造器注入引发的循环依赖2. Setter 注入引发的循环依赖3. 字段注入(Autowired)引发的循环依赖 Sp…...
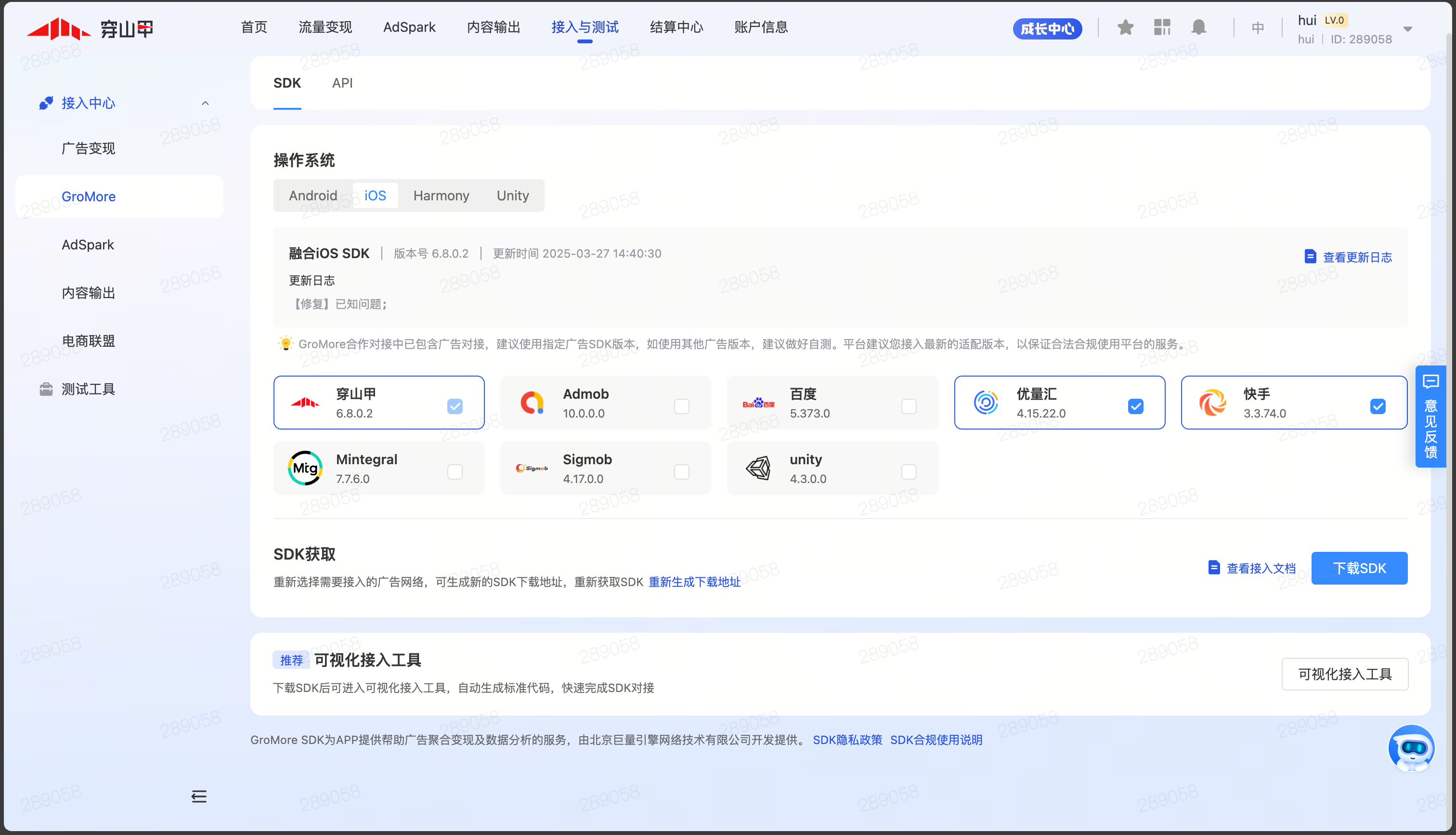
ios接入穿山甲【Swift】
1.可接入的广告,点击右下角查看接入文档 https://www.csjplatform.com/union/media/union/download/groMore 2.进入接入文档,选择最新版本进行接入 pod Ads-CN-Beta,6.8.0.2pod GMGdtAdapter-Beta, 4.15.22.0pod GDTMobSDK,4.15.30pod KSAdSDK,3.3.74.0p…...

蓝桥杯大模板
init.c void System_Init() {P0 0x00; //关闭蜂鸣器和继电器P2 P2 & 0x1f | 0xa0;P2 & 0x1f;P0 0x00; //关闭LEDP2 P2 & 0x1f | 0x80;P2 & 0x1f; } led.c #include <LED.H>idata unsigned char temp_1 0x00; idata unsigned char temp_old…...

电脑一直不关机会怎么样?电脑长时间不关机的影响
现代生活中,许多人会让自己的电脑24小时不间断运行,无论是为了持续的工作、娱乐,还是出于忘记关机的习惯。然而,电脑长时间不关机,除了提供便利之外,也可能对设备的健康产生一系列影响。本文将为大家介绍电…...

vue3 当页面显示了 p/span/div 标签 想要转换成正常文字
返回值有标签出现时,使用v-html 解决 <p>{{ item.content }}</p> //页面直接显示接口返回的带标签的数据 <p v-html"item.content "></p> //转换成html文件 显示正常文字各种样式 问题: 解决:v-html 显…...
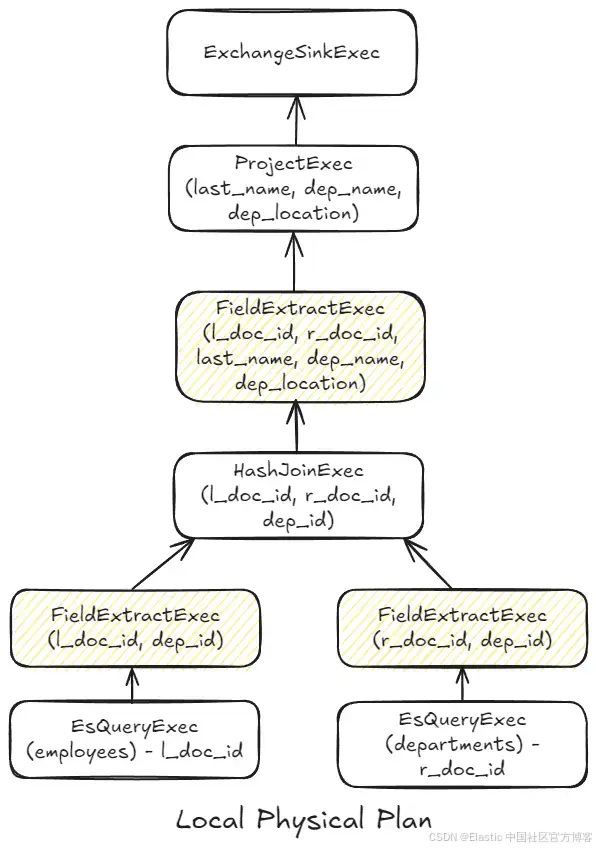
Elasticsearch 8.18 中提供了原生连接 (Native Joins)
作者:来自 Elastic Costin Leau 探索 LOOKUP JOIN,这是一条在 Elasticsearch 8.18 的技术预览中提供的新 ES|QL 命令。 很高兴宣布 LOOKUP JOIN —— 这是一条在 Elasticsearch 8.18 的技术预览中提供的新 ES|QL 命令,旨在执行左 joins 以进行…...

java CountDownLatch用法简介
CountDownLatch倒计数锁存器 CountDownLatch:用于协同控制一个或多个线程等待在其他线程中执行的一组操作完成,然后再继续执行 CountDownLatch用法 构造方法:CountDownLatch(int count),count指定等待的条件数(任务…...
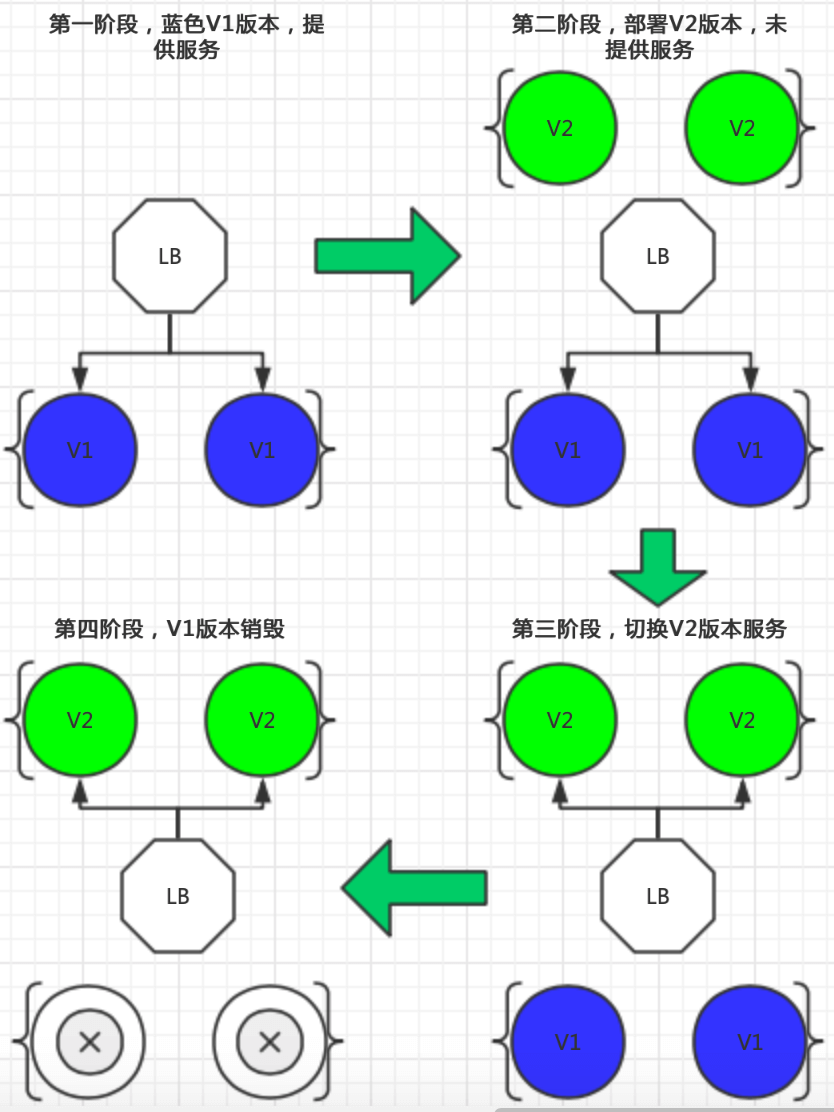
k8s蓝绿发布
k8s蓝绿发布 什么是蓝绿部署K8S中如何实现蓝绿部署k8s蓝绿部署流程图 什么是蓝绿部署 参考: https://youtu.be/CLq_hA0lAd0 https://help.coding.net/docs/cd/best-practice/blue-green.html 蓝绿部署最早是由马丁福勒 2010年在他的博客中提出. 蓝绿部署是一种软件部署策略,用…...

链接世界:计算机网络的核心与前沿
计算机网络引言 在数字化时代,计算机网络已经成为我们日常生活和工作中不可或缺的基础设施。从简单的局域网(LAN)到全球互联网,计算机网络将数以亿计的设备连接在一起,推动了信息交换、资源共享以及全球化的进程。 什…...
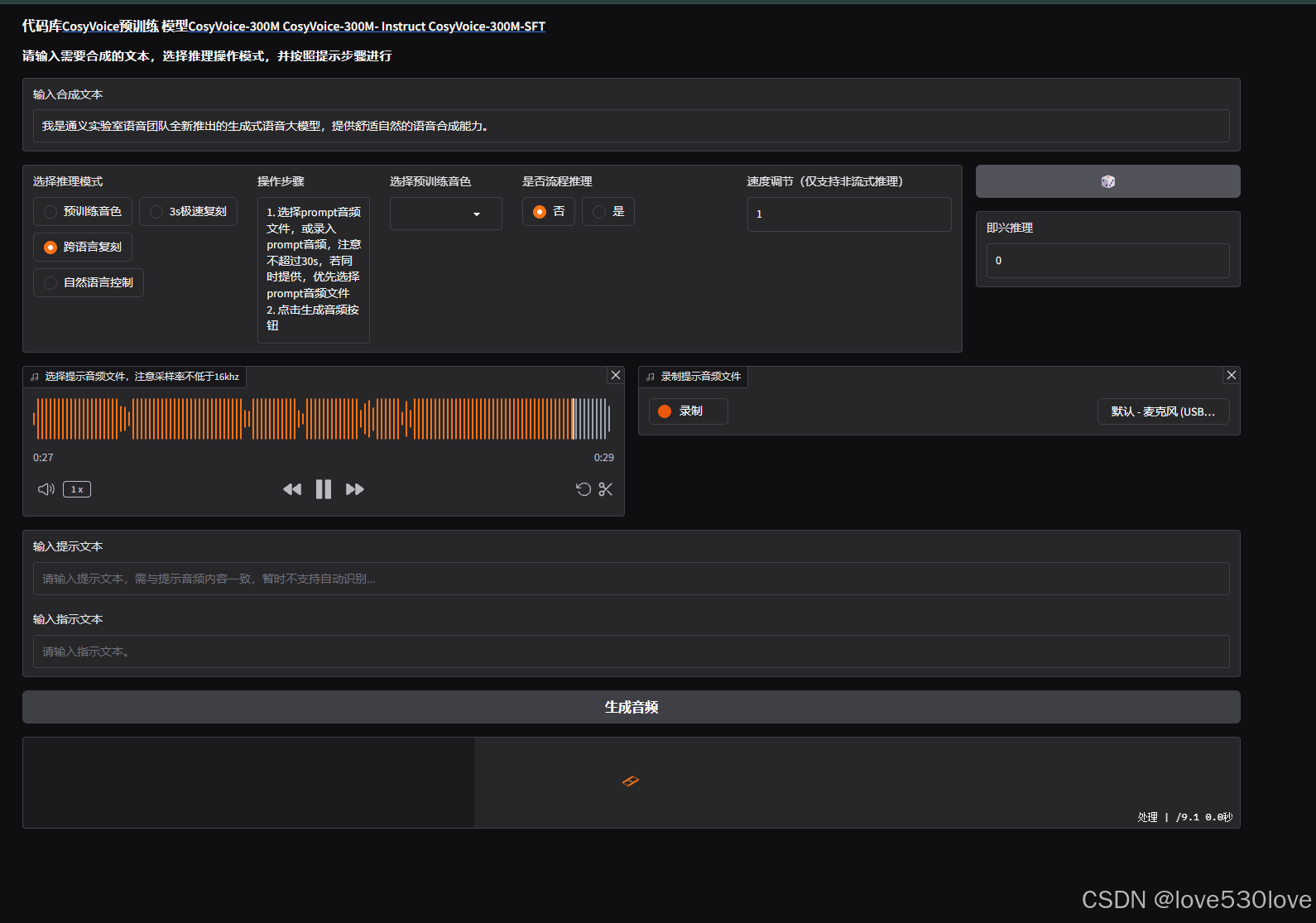
记录Docker部署CosyVoice V2.0声音克隆
#记录工作 CosyVoice 是由 FunAudioLLM 团队开发的一个开源多语言大规模语音生成模型,提供了从推理、训练到部署的全栈解决方案。 项目地址: https://github.com/FunAudioLLM/CosyVoice.git 该项目目前从v1.0版本迭代到v2.0版本,但是在Wind…...

MCU刷写——HEX与S19文件互转详解及Python实现
工作之余来写写关于MCU的Bootloader刷写的相关知识,以免忘记。今天就来聊聊Hex与S19这这两种文件互相转化,我是分享人M哥,目前从事车载控制器的软件开发及测试工作。 学习过程中如有任何疑问,可底下评论! 如果觉得文章内容在工作学习中有帮助到你,麻烦点赞收藏评论+关注走…...

全链路开源数据平台技术选型指南:六大实战工具链解析
在数字化转型加速的背景下,开源技术正重塑数据平台的技术格局。本文深度解析数据平台的全链路架构,精选六款兼具创新性与实用性的开源工具,涵盖数据编排、治理、实时计算、联邦查询等核心场景,为企业构建云原生数据架构提供可落地…...

C++学习:六个月从基础到就业——面向对象编程:封装、继承与多态
C学习:六个月从基础到就业——面向对象编程:封装、继承与多态 本文是我C学习之旅系列的第九篇技术文章,主要讨论C中面向对象编程的三大核心特性:封装、继承与多态。这些概念是理解和应用面向对象设计的关键。查看完整系列目录了解…...

Golang Event Bus 最佳实践:使用 NSQite 实现松耦合架构
Go Event Bus 最佳实践:使用 NSQite 实现松耦合架构 什么是 Event Bus? Event Bus(事件总线)是一种消息传递模式,它允许应用程序的不同组件通过发布/订阅机制进行通信,而不需要直接相互依赖。这种模式特别…...

独家!美团2025校招大数据题库
推荐阅读文章列表 2025最新大数据开发面试笔记V6.0——试读 我的大数据学习之路 面试聊数仓第一季 题库目录 Java 1.写一个多线程代码 2.写一个单例代码 3.LinkedBlockingQueue原理 4.模板设计模式 5.如何设计一个 生产者-消费者队列 6.堆内存和栈内存 7.ThreadLo…...

用 C++ 模拟客户端渲染中的分步数据加载
用 C++ 模拟客户端渲染中的分步数据加载 引言 在前端开发中,客户端渲染是一种常见的技术,它允许页面在加载后动态地更新内容。通常,页面会先展示一个基本的骨架,然后再逐步加载和渲染具体的数据。本文将介绍如何使用 C++ 编写一个简单的程序来模拟客户端渲染中的这种分步…...

Dify智能体平台源码二次开发笔记(5) - 多租户的SAAS版实现(2)
目录 前言 用户的查询 controller层 添加路由 service层 用户的添加 controller层 添加路由 service层-添加用户 service层-添加用户和租户关系 验证结果 结果 前言 完成租户添加功能后,下一步需要实现租户下的用户管理。基础功能包括:查询租…...

Linux的目录结构(介绍,具体目录结构)
目录 介绍 具体目录结构 简洁的目录解释 详细的目录解释 介绍 Linux的文件系统是采用级层式的树状目录结构,在此结构的最上层是根目录“/”。Linux的世界中,一切皆文件(比如:Linux会把硬件映射成文件来管理) 具体目…...
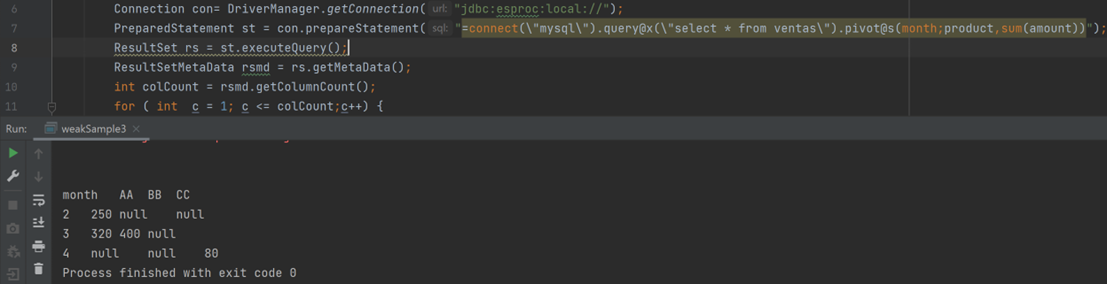
如何用 esProc 补充数据库 SQL 的缺失能力
某些数据库 SQL 缺失必要的能力,通常要编写大段的代码,才能间接实现类似的功能,有些情况甚至要改用存储过程,连结构都变了。常见的比如:生成时间序列、保持分组子集、动态行列转换、自然序号、相对位置、按序列和集合生…...

晶晨线刷工具下载及易错点说明:Key文件配置错误/mac剩余数为0解决方法
晶晨线刷工具下载及易错点说明:Key文件配置错误/mac剩余数为0解决方法 各种版本晶晨线刷工具下载: 晶晨线刷工具易出错点故障解决方法: 1、晶晨线刷工具加载固件的时候提示mac红字且剩余数为0的解决办法 很多同学可能会与遇到加…...