文件系统 软硬连接
🌻个人主页:路飞雪吖~
🌠专栏:Linux
目录
一、理解文件系统
🌠磁盘结构
二、软硬连接
🌟软硬链接
🌠软链接:
🌠硬链接:
🌟理解软硬链接的应用场景
✨软链接
✨硬链接
如若对你有帮助,记得关注、收藏、点赞哦~ 您的支持是我最大的动力🌹🌹🌹🌹!!!
若有误,望各位,在评论区留言或者私信我 指点迷津!!!谢谢 ヾ(≧▽≦*)o \( •̀ ω •́ )/
一、理解文件系统
🌠磁盘结构
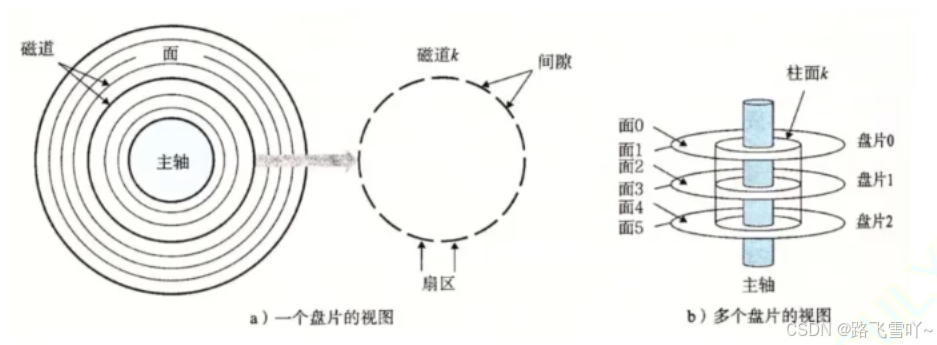
<1> 任何磁盘结构
磁盘由上亿的小磁铁构成【磁铁--南北极 --> 二进制】
(1) 磁盘物理结构:
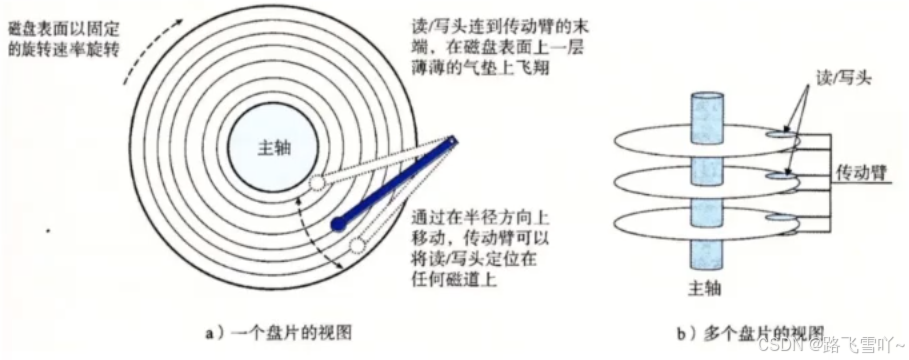
a. 磁盘在进行摆动旋转【磁头的左右摆动】:可以进行数据的寻址。
b. 磁头悬浮在盘片上【要求在真空环境中】。
(2) 磁盘存储结构:
a. 磁头在摆动的本质:定位磁道(柱面)
b. 磁头定位好一个磁道后,盘面在进行旋转时,就可以把各个不同的扇区,依次放在磁头的正下方,让磁头来确定一个扇区上面的 01 值;
c. 磁盘盘片旋转的本质:定位扇区。
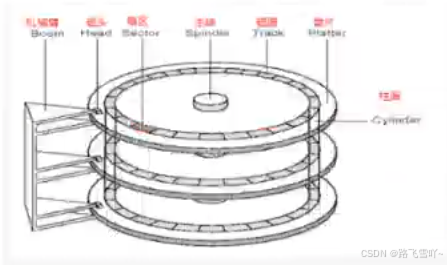
d. 扇区:是磁盘存储数据的基本单位,512字节,块设备;
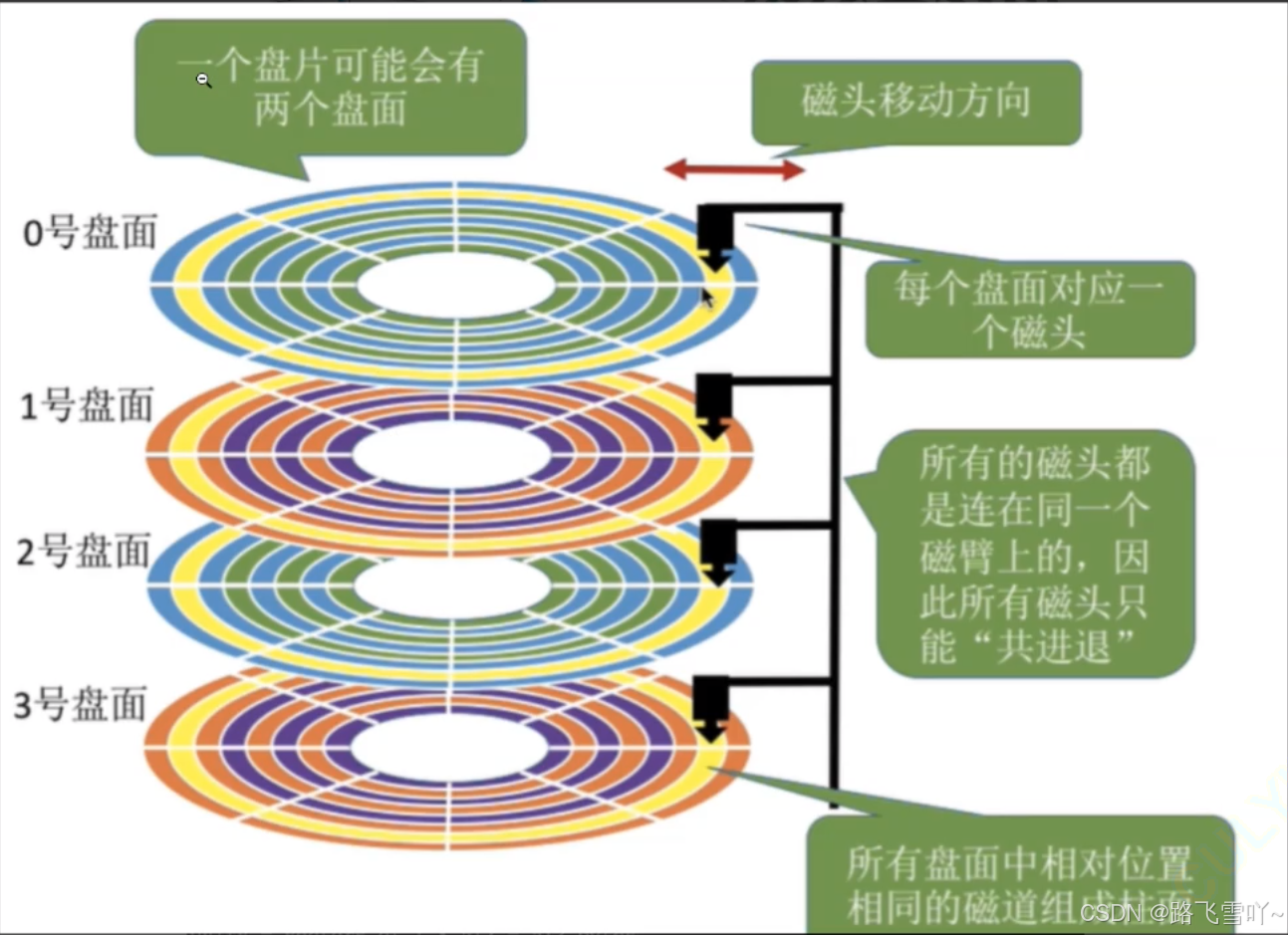
e. 磁盘,若有3片,就有6面,每一面都有一个磁头【h0~h5】;
f. 读写哪一个磁头,本质是读写哪一个面;
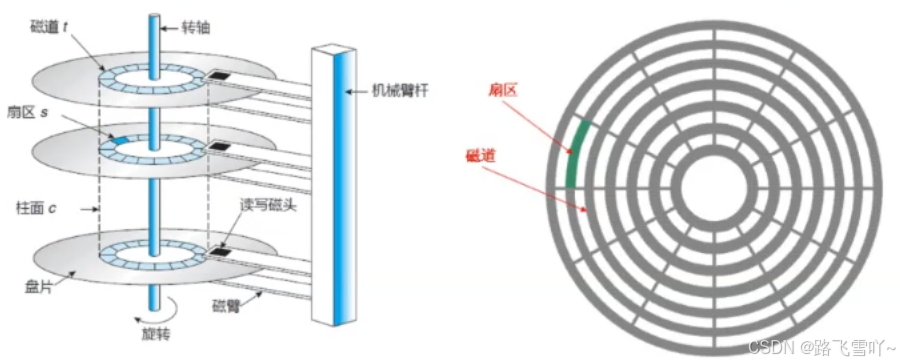
g. 如何定位一个扇区?【CHS地址定位法】
• 先定位磁头(header)
• 确定磁头要访问哪一个柱面(磁道)(cylinder)
• 定位一个扇区(sector)
h. 文件 = 内容 + 属性 这些都是数据,数据无非就是占据哪几个扇区的问题,能定位一个扇区,就能定位多个扇区了。
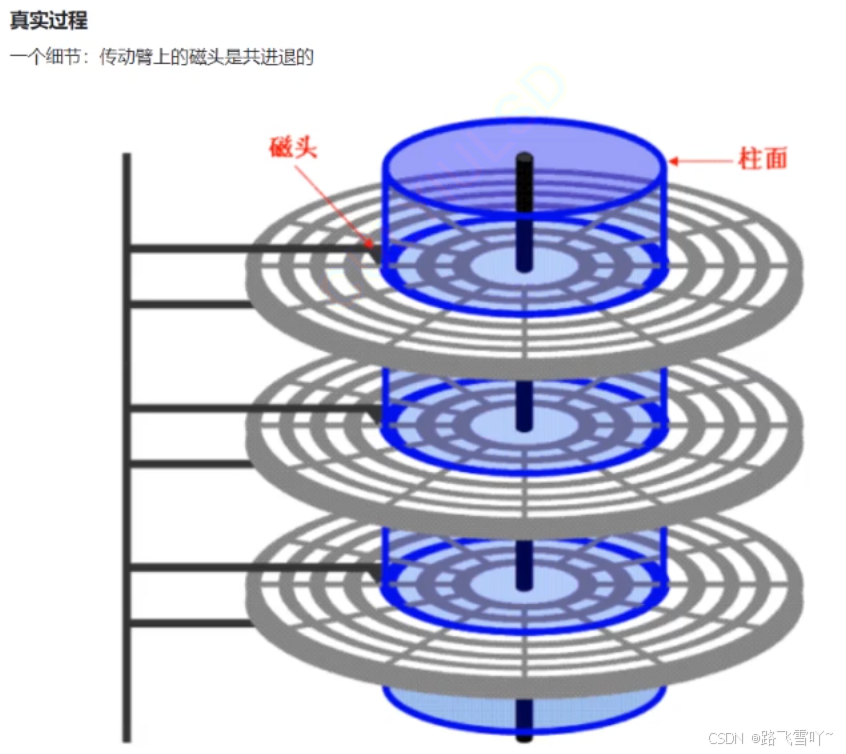
i. 传动臂上的磁头是共进退的!!!
(3) 磁盘逻辑结构:
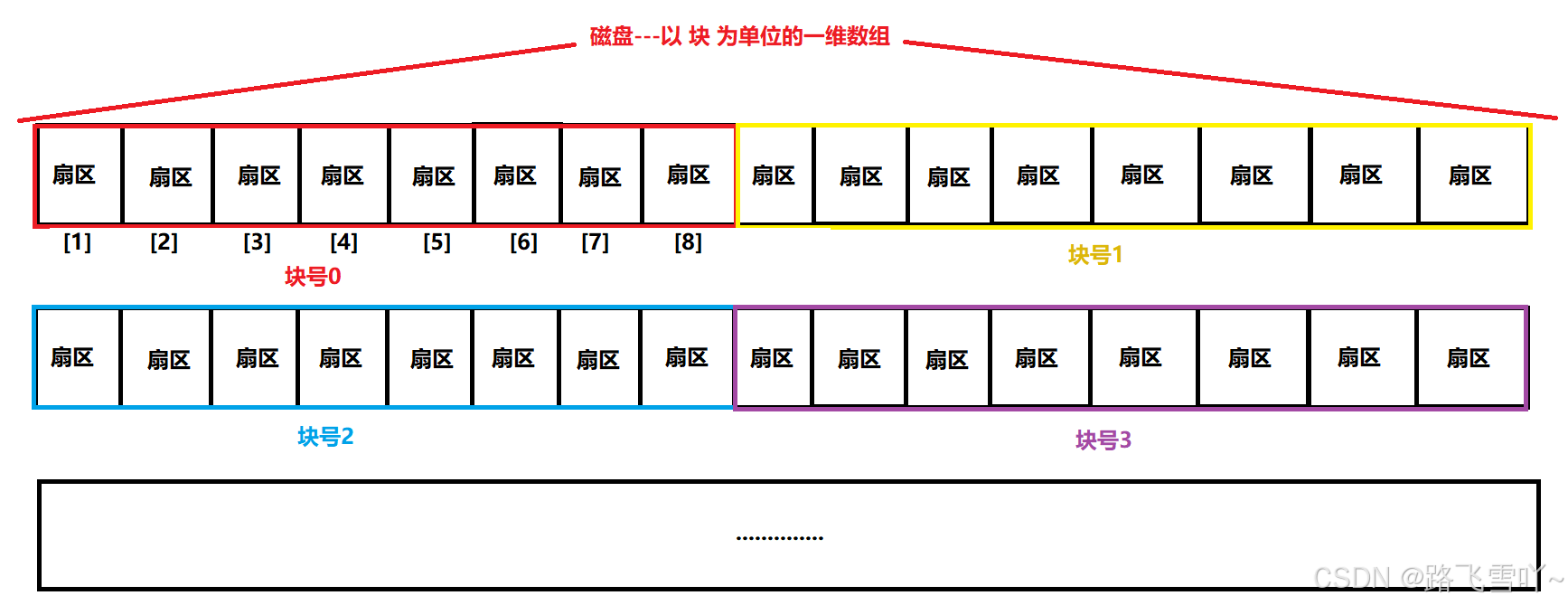
磁带上面可以储存数据,我们可以把磁带“拉直”,形成线性结构
磁盘本质上是硬质的,但是逻辑上我们可以把磁盘想象成为卷在一起的磁带,那么磁盘的逻辑存储结构就类似于:
这样每一个扇区,就有了一个线性地址(其实就是数组下标),这种地址叫做LBA
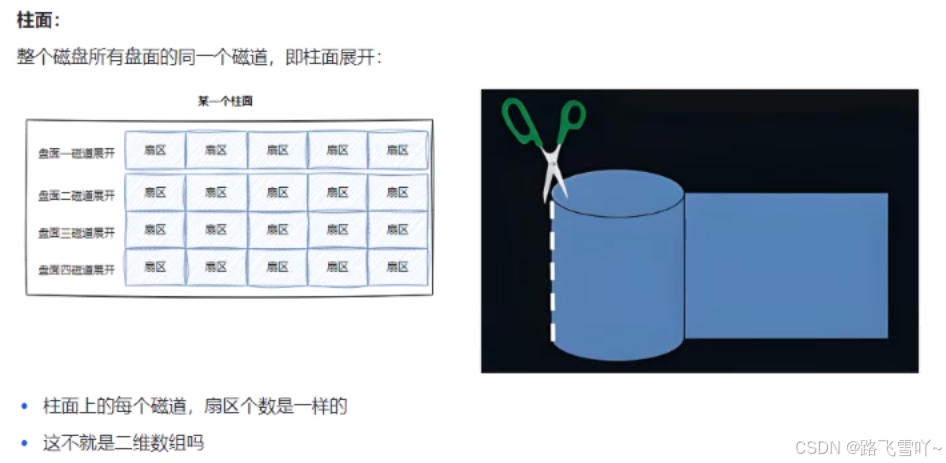
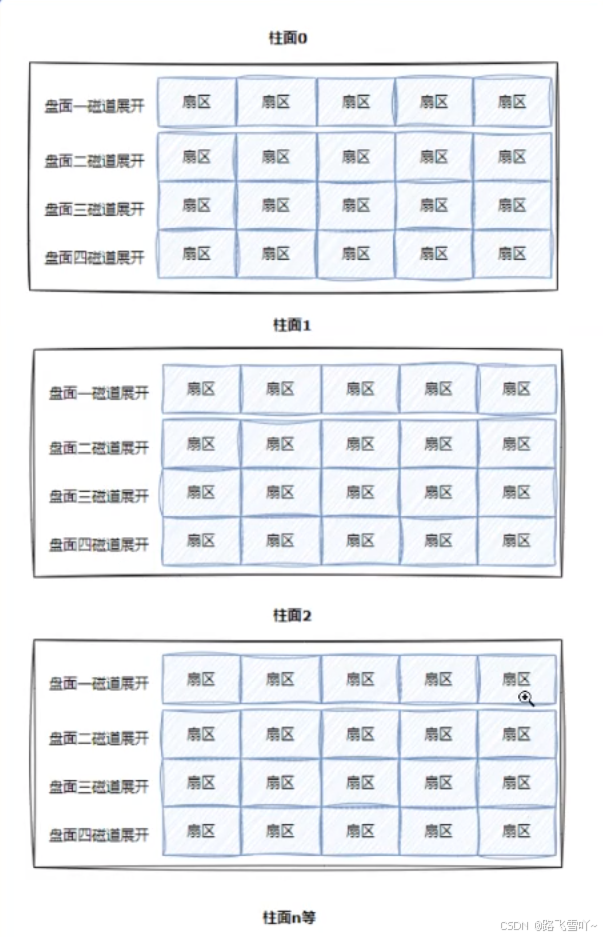
柱面是一个逻辑上的概念,其实就是每一个面上,相同半径的磁道逻辑上构成柱面。所以,磁盘物理上分了很多面,但是在我们看来,逻辑上,磁盘整体是由“柱面”卷起来的。
整盘:
整个磁盘不就是多张二维的扇区数组表(三维数组?)
所有,寻址一个扇区:先找到哪一个柱面(Cylinder),在确定柱面内哪一个磁道(其实就是磁头位置,Head),在确定扇区(Sector),所以就有了CHS。
我们之前学过C/C++的数组,在我们看来,其实全部都是一维数组:
所以,每一个扇区都有一个下标,我们叫做LBA(Logical Block Address)地址,其实就是线性地址。所以怎么计算得到这个LBA地址呢?
• 扇区的编号从1开始,LBA从0开始【数组下标】。
✨CHS转成LBA:
• 磁头数*每磁道扇区数 =单个柱面的扇区总数
• LBA = 柱面号C*单个柱面的扇区总数 + 磁头号H*每磁道扇区数 +扇区号S-1
• 即:LBA = 柱面号C*(磁头数*每磁道扇区数) + 磁头号H*每磁道扇区数+扇区号S-1
• 扇区号通常是从1开始的,而在LBA中,地址是从0开始的
• 柱面和磁道都是从0开始编号的
• 总柱面,磁道个数,扇区总数等信息,在磁盘内部会自动维护,上层开机的时候,会获取到这些参数。✨LBA转成CHS:
• 柱面号C = LBA //(磁头数*每磁道扇区数)【就是单个柱面的扇区总数】
• 磁头号H = (LBA %(磁头数*每磁道扇区数)) // 每磁道扇区数
• 扇区号S = (LBA % 每磁道扇区数)+1
• "//";表示除取整LBA地址 <--转换--> CHS地址,谁来做?磁盘自己来做!固件(硬件电路、伺服系统)
所以,从此往后,在磁盘使用者看来,根本就不关心CHS地址,而是直接使用LBA地址,磁盘内部自己转换。
所以,从现在开始,磁盘就是一个 元素为扇区 的一维数组,数组的下标就是每一个扇区的LBA地址。OS使用磁盘,就可以用一个数字访问磁盘扇区了。
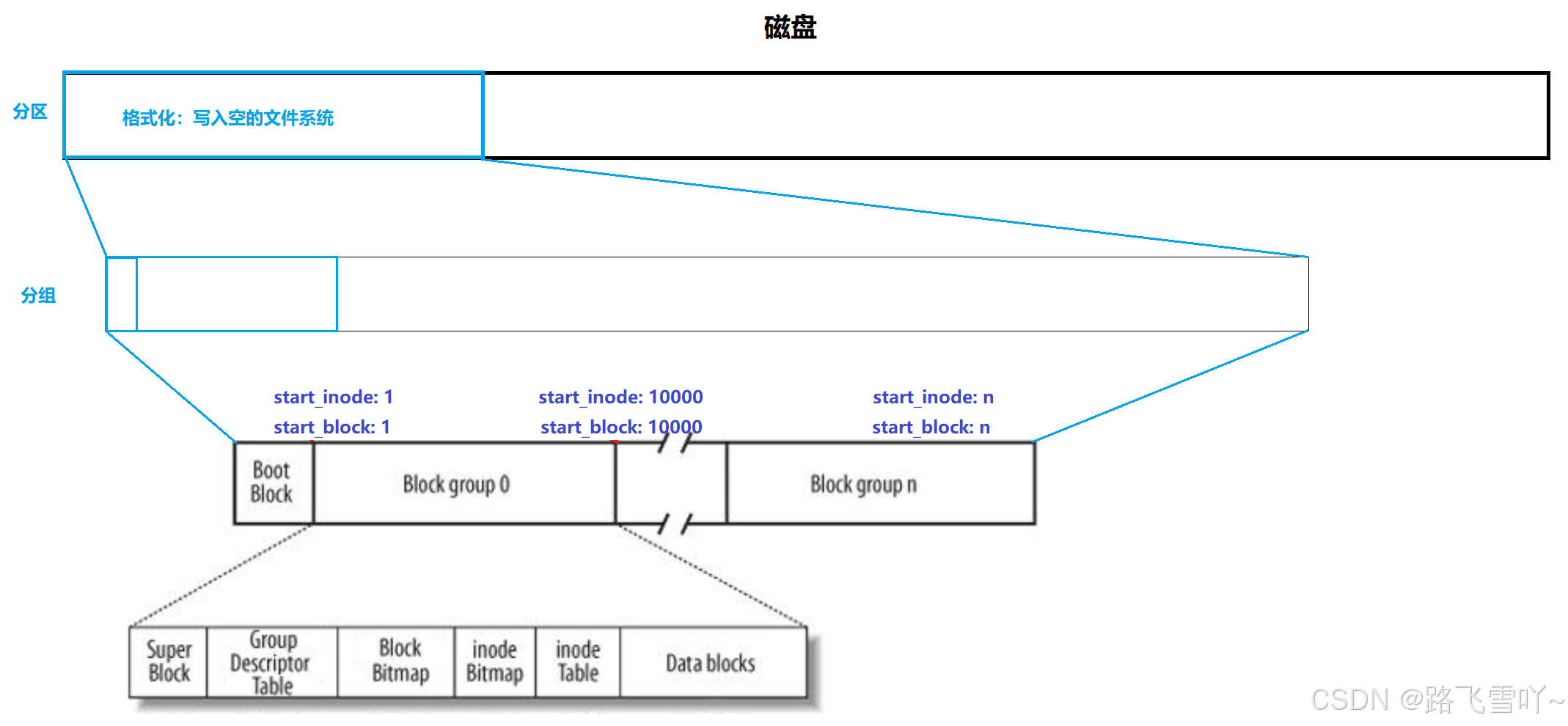
<2> 理解分区,格式化
OS和磁盘进行IO的时候,以扇区为基本单位,512字节,单次IO的数据量,1KB,2KB,3KB,4KB,8KB等,4KB数据块 ---- 8个扇区。
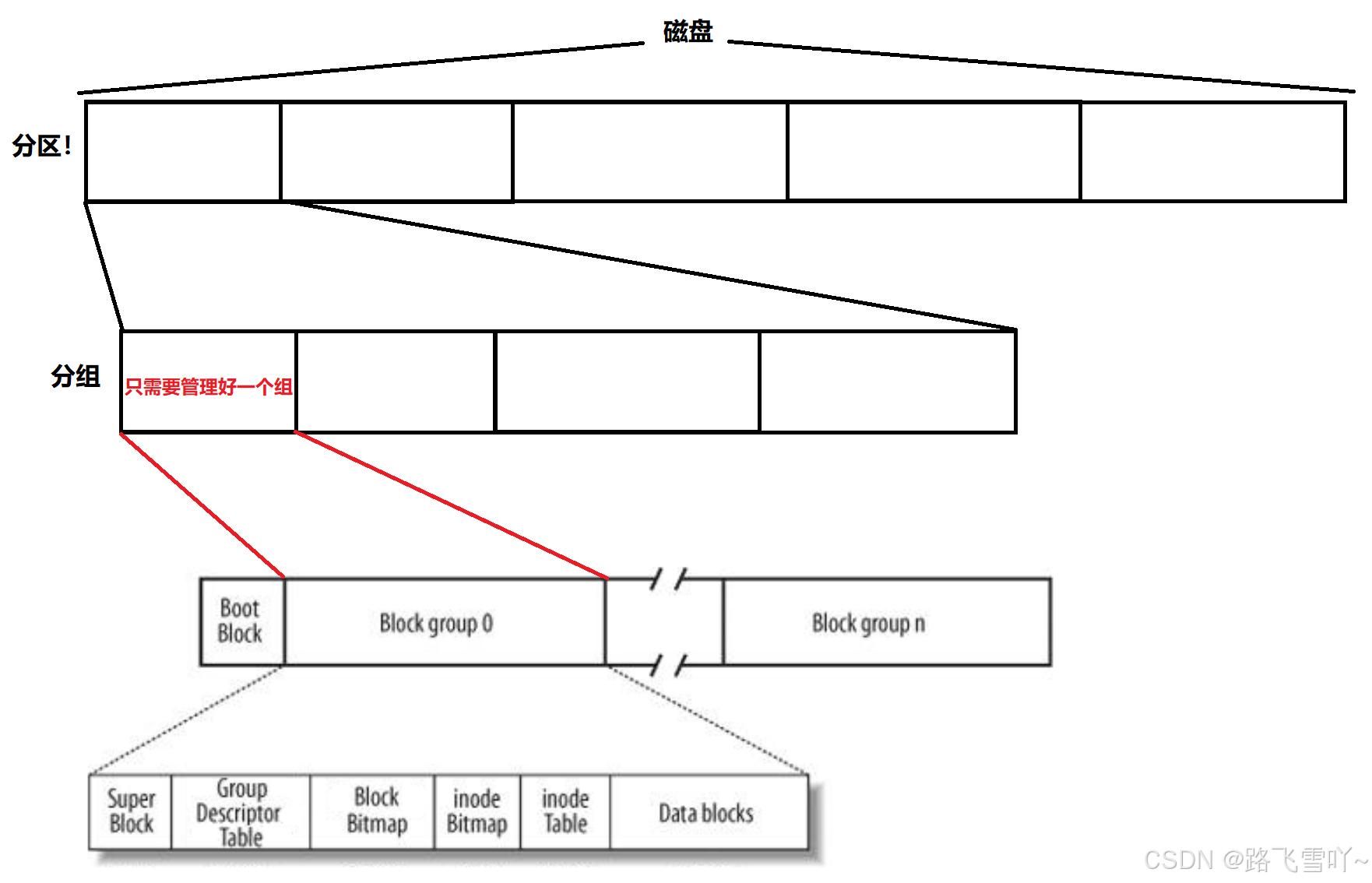
OS如何管理?分区!--> 分组 【分治思想】
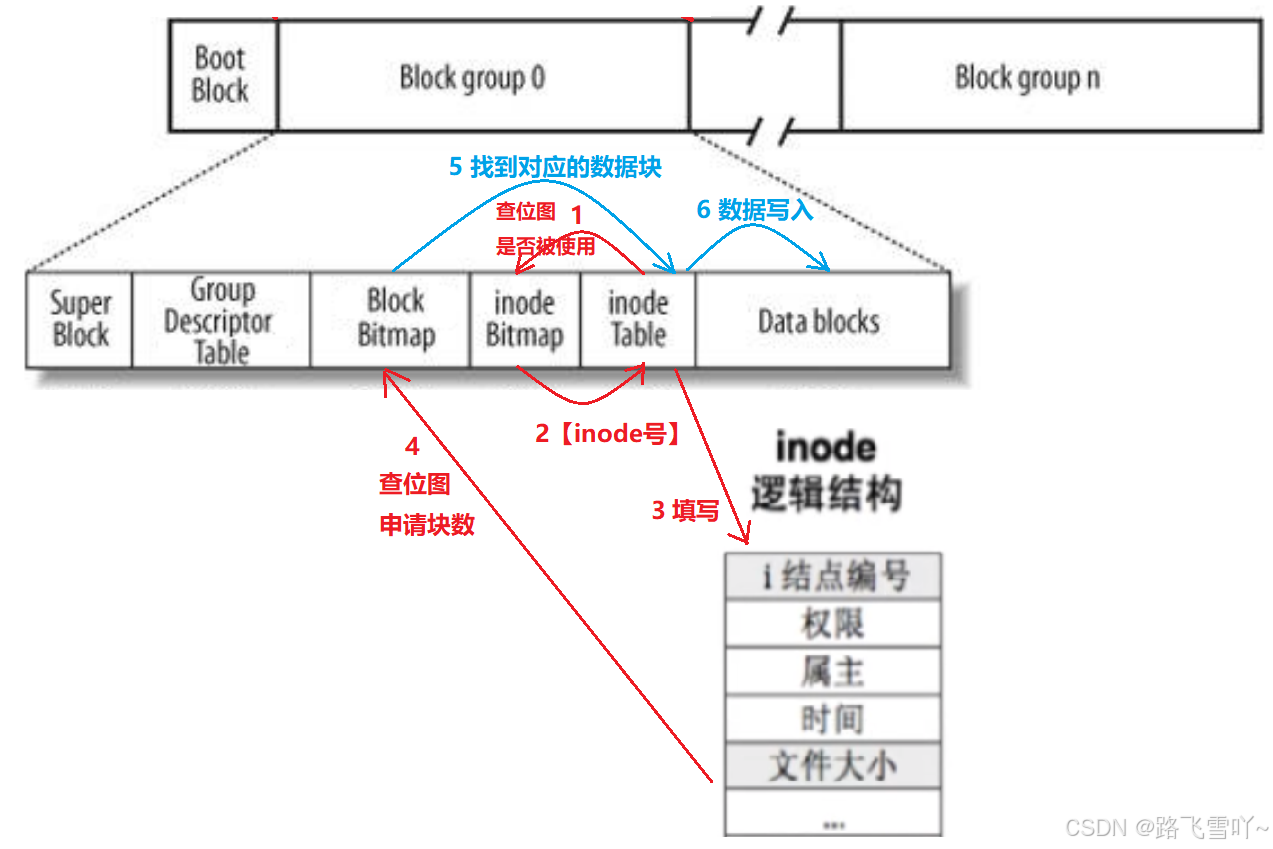
<3> Linux文件系统Ext*系列的文件系统,inode号和inode
• Block Group:ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成。政府管理各区的例子;
• 超级块(Super Block):【表示文件系统,管理整个分区】存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了;
• GDT,Group Descriptor Table:块组描述符,描述块组属性信息;
• 块位图(Block Bitmap):Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用;
• inode位图(inode Bitmap):每个bit表示一个inode是否空闲可用。
• i节点表:存放文件属性 如 文件大小,所有者,最近修改时间等;
• 数据区:存放文件内容 ;文件系统以分区为单位,一个分区一套文件系统;
分区和分区之间是互相独立的,不同的分区可以用不同的文件系统
🌠小贴士:
• 文件 = 内容 + 属性,文件属性也是数据,
• 在Linux当中会以结构体的方式构建出来【inode】,
• 一个文件只有一个inode,inode是文件属性数据的集合,
一个inode就是一个结构体【struct inode】
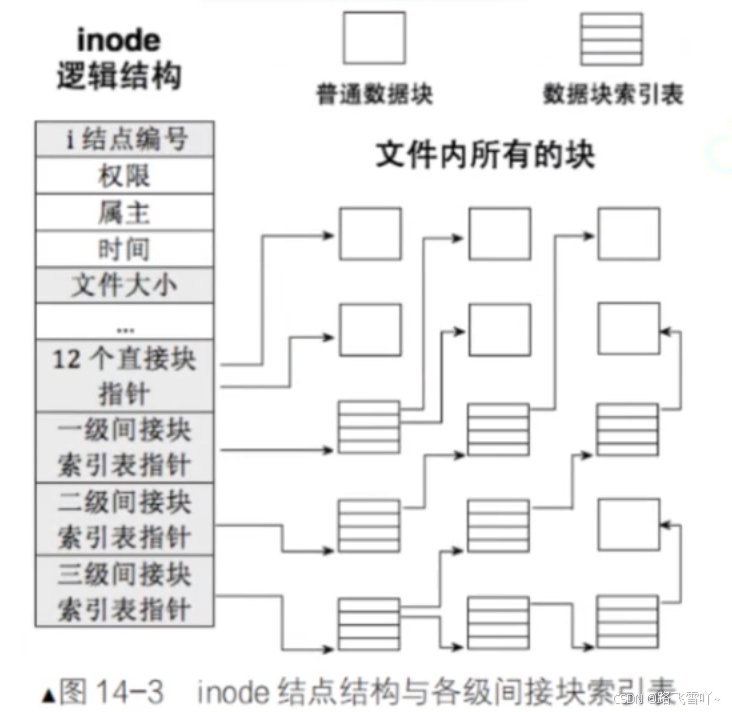
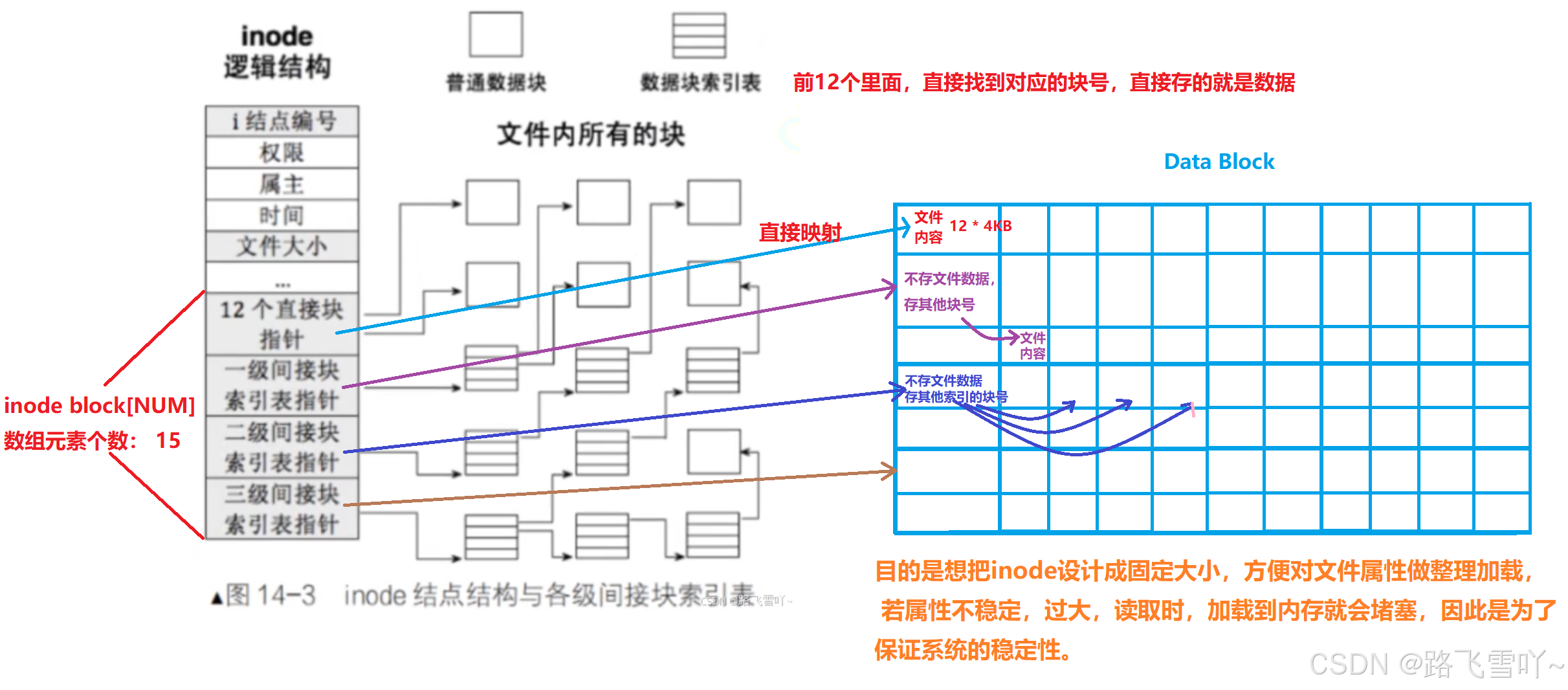
• inode的大小一般为128字节【跟系统有关】,一个块组中可能会存在100或1000个文件,就会存在100或1000个inode,文件系统会把当前你要新建的文件,文件的属性节点在内存里面定义出来【struct inode】,把属性值填入,接着把inode节点写入到磁盘当中指定的inode Table里面。
• OS在和磁盘进行IO交互的时,磁盘中一个块有4KB,那一个块就有 4KB/128字节 个inode,都存放在一个组当中的inode Table中,为此 每个文件都要有自己的文件编号【inode值】,inode彼此之间互不重复【有条件】
其中,在Linux系统中,文件名这个属性不在inode中保存!
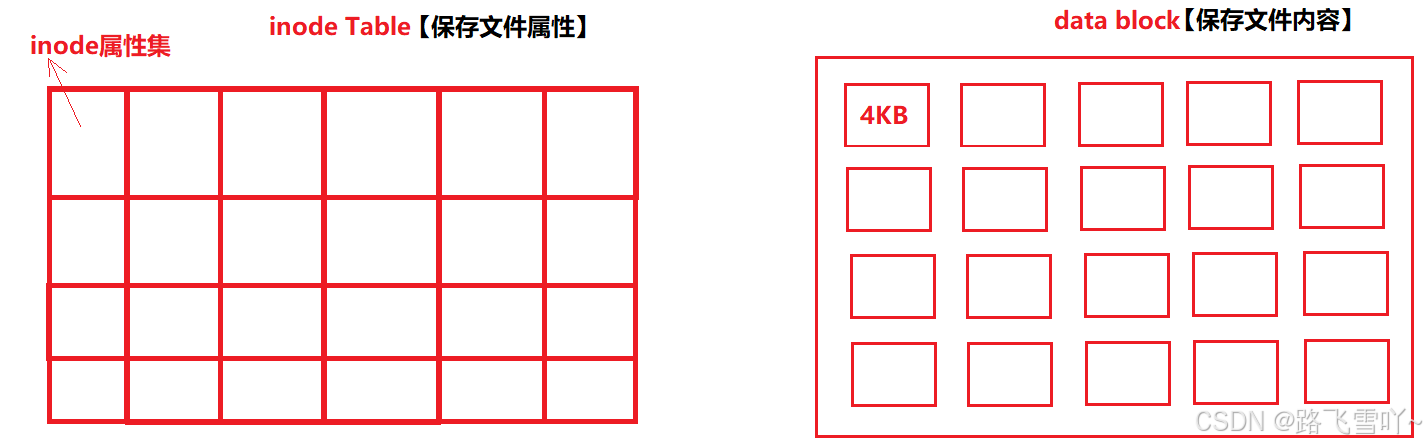
• inode Table 包含了当前组里面所有的文件属性集。
• data block 用来存放文件的内容,里面全是划分好的4KB大小的块,
Linux下,文件属性和文件内容是分开存储的!
✨如何找文件?
拿到对应的inode,接着在inode Table里面找到inode,inode属性里面还有inode映射表 【int block[NUM]】,数组里面记录了对应inode,所对应的数据在哪。
• inode Bitmap : inode Table有多少个inode,inoed Bitmap就需要有多少个比特位,当inode号为0,inode Bitmap对应的位图比特位就会记录下来【有效】,inode Bitmap会按比特位来检查inode号是否有效,有效才会去inode属性里面获取有效的inode属性。
• 对于inode Bitmap的一次进行修改,修改的原则:哪怕是一个Bite也要把4KB的数据全部放到内存里面,修改完成之后再写回磁盘去;
✨修改位图时:
磁盘当中是以扇区为单位的,当要修改时,先把要修改的扇区搬到内存里,以比特位修改位图,修改完成之后,直接写回到磁盘分组的 inode Bitmap 里面的位置。
✨在data block里面很多块号,我们怎么样才能知道哪些被占用/空闲?
black Bitmap也是一个位图,它的二进制位图中表明哪些被占用/空闲,因此在一个组当中,有了Block BItmap、inode Bitmap、inode Table、Data blocks后面这四块,我们就可以对一个分组的内容和属性进行基本的管理了。
有了inode Bitmap、inode Table这两张位图(有开始和结束),我们就可以清楚的知道,这两张位图所对应的区域,即inode Bitmap 和 inode Table 都有自己对应的编号(可以通过位图来得到)
✨过程:
新建一个文件并向这个文件写入"hello world"字符串,
• 新建一个文件,要在inode Table里面先分配一个inode,接着在inode Bitmap里面去查某一个对应的位图有没有被使用,没有被使用就会修改对应的位图【由0-->1】,接着在inode Table里面拿着对应的inode号,初始化节点编号、填写权限、属主、时间、文件大小.....,写入之后统计需要多少个块,就回去Block Bitmap里面查位图,申请所需的块数,申请完之后,把对应的“hello world”字符串写入到对应的块号里面,接着拿着这个块号返回到inode Bitmap找到inode Table里面的数组在里面写入块号(属性), 接着在inode Table中找到对应的data blocks进行数据的写入(内容)。
因此,我们只需要知道文件的inode编号就可以找到这个文件!!
• 在Linux中,删除的本质是设置inode和block无效!
删一个文件,可以恢复!!我们只需要把这个文件的inode Bitmap对应的【1/0 --置为--> 1】,接着再查找inode Table里面的块【int block[NUM];】所对应的块号,在Block Bitmap里面对应的块号【由0 ---> 1】,这个文件就会被恢复。
不小心删除了数据,不要随便操作,以免被删除的的inode和block被占用/覆盖,就恢复不了了。
✨如何评判当前块组【Block group 0】已经满了/放不下了呢?已经使用了多少/还剩多少?
因此每一个块组都有一个Group Descriptor Table【GDT】块组描述符。
✨Boot Block跟分组关系不大,【以磁盘硬件为单位】一般是整个磁盘里面最开始的一个小区域,与启动有关,一般保存这个磁盘里面的总容量是多少,【第一个分区开始和结束的扇区】启动信息、分区表、操作系统的内核所在的地址.....(不考虑)。
✨Super Block 表示的就是文件系统,对整个分区管理的数据结构【包括整个文件系统的文件系统名、什么文件系统】。在整个分区里面,不需要给每个分区里都保存Super Block,整个分区里面也不知是只有一个Super Block。混在组的内部里面,可能会存在两三份,并且里面的数据是完全一样的。【在整个分区里面,不是每个分组里面都有Super Block ,也绝不是只有其中一个分组里面有Super Block 】
✨为什么不是在整个分区里面保存一个Super Block呢?在一个分区里面,若Super Block挂掉了,整个分区的文件系统就全部都没了!!!分组情况都摸不清了,文件系统里面的整体情况都不知道了。所以会被打散到不同的分组里面,不一定每个分组都有,可能会同时存在两三份,因此一个Super Block坏掉/出现问题了,我们对应的文件系统就可以直接区其他块组里面去找对应的Super Block,把Super Block给覆盖回来,此时就能进行文件系统恢复了。
✨文件系统以分区为单位,一个分区,一套文件系统,不同的分区,可以写不同的文件系统。
✨格式化:写入空的文件系统
磁盘分区--->分组---> 在组里面划分好相关区域【inode Bitmap、Block Bitmap全部清零....】,划分的区域是多大... 写入文件信息
<4> 理解 文件、目录、文件系统
• 在一个块组里面 inode号的个数,block个数都是固定的!【这两个的占比是最多的】
• 存在 inode Table 用完【存的全部都是小文件】, Data Block没用完的情况
✨关于inode:
• inode只能在特定分区下有效,inode以分区为单位,一套inode;
• 在格式化分区的时候,要格式化出很多分组,其中在分组当中,inode在分配的时候,只需要确定起始inode即可;inode不能跨分区;inode里面有分组;每一个组里面的inode编号是固定的;这些值一般保存到GDT组描述符里面只需要记录起始inode即可。
Super Block 和 Group Descriptor Table 是两个固定的数据结构,大小也是固定的。
✨关于block:
• 整个分区块号也是统一编号的;【保存到GDT组描述符里面】
✨在一个组里面,我们是如何分配一个inode的?
• 在inode Bitmap一旦确定好开始和结束,起始的inode Bitmap里面是位图,位图里面记录的inode + 组里面分组好的起始inode值 = 新的inode; 这个inode在分区当中具有唯一性;
✨在一个组里面,我们是如何分配一个data block的?
• data block也是一样的,它的块号也是加上分组好的起始的block值,这些值都在GDT里面;
✨inode和data block都是全局建立的;
当块号不够的时候,可以进行跨组建立;
OS如何进行管理文件系统?OS对每个Super Block 和 Group Descriptor Table进行 先描述,再组织 来管理文件系统【内存级操作】;【Super Block 和 Group Descriptor Table的数据结构会被加载到内存里】
✨如何查找一个文件?
在一个分区里通过inode怎么找到对应的文件呢?根据inode,确定文件在哪个组里面,接着拿着inode减去start_inode,再查inode Bitmap,找到之后inode Table就找到inode,找到了inode就找到了文件的属性【inode结构】和 块的映射关系就有了,即就找到了块号,最终找到内容。
✨如何删除一个文件?
前提条件就是查找,找到之后,把inode Bitmap的位图直接【由1--置为-->0】,再找到inode属性和块的映射关系,拿到了块号,把 Block Bitmap的位图直接【由1--置为-->0】,inode就被释放了,GDT里面记录的已使用的inode就得减一,最后再把属性进行更新,就完成了删除。
✨如何修改一个文件?
前提条件就是查找,
修改要么是对属性进行修改,改掉文件对应的创建时间、文件的大小、文件权限...,拿着文件的inode,按照查找方式,找到文件,把inode加载到内存里,改完再写回对应的位置,
要么就是对内容进行修改,找到文件,把磁盘内容Data Block加载到内存里【文件的内核缓冲区】,改完之后写回磁盘,此时对文件的属性和内容就都能进行修改了。
✨如何新增一个文件?
首先要确定在哪一个组里面,操作系统由文件系统自动来进行确定, 遍历GDT去找,根据要新增文件的基本信息【新增文件的大小、文件名称、...】找到了对应的一个组,其中就要分配inode号,首先查位图,找到一个局部性的值【偏移量】,把inode Bitmap、Block Bitmap【由0--置为-->1】,最后给用户返回一个inode, start_inode + inode Bitmap里面的偏移量,即返回inode号。
✨inode 和 block 究竟是怎么映射的?
✨凭什么拿到inode?我们访问的好像都是文件名!!!【Linux,文件名不在inode中保存】,inode存在哪里?文件类型【文本文件、二进制、普通文件、目录】,存在自己所处的目录的数据块中【数据块存文件名和映射关系】,
✨如何理解目录文件?
目录 = inode + block = 属性 + 内容,内容也要有对应的数据块!目录的数据块里面,存的是文件名和 inode的映射关系,因此我们在查一个文件时,我们只要找到当前目录,根据目录的inode,找到目录的数据块【data block】,再根据文件名,进行inode映射,找到inode就可以找到属性和内容。
文件名 和 inode号 是互为映射的,任何目录不能存在同名文件,文件名 <--映射--> inode ,这就是为什么拿到文件名这个字符串就能找到文件,是因为拿着文件名,【ls命令】操作系统就会在当前目录下,打开当前目录,把当前目录的文件名按字符串查找,找到inode,根据inode号查一个文件,属性和内容就全有了。
🌠重新理解目录权限:rwx
• 当我们对一个目录没有 r 权限时,我们就查不了这个目录里面的内容,没有读权限,对目录没有读权限时,就无法读取目录的data block【内容】,操作系统不让读,就得不到文件名和inode的映射关系,拿不到inode就访问不到文件;
• 目录没有 w 权限,就不能在该目录新建文件,没有写权限就无法把文件名和inode的映射关系的字符串信息、文本信息,写到目录数据块当中。
• 目录没有 x 权限,就进不去,本质是打不开。
🌠文件类型【文本文件、二进制、普通文件、目录】,文件名和映射关系是保存在普通文件里面的,在磁盘级文件系统里面的inode Table、Data block、inode Bitmap、Block Bitmap这个层面上不区分文件是普通文件还是目录,不管是文件还是目录,在底层都叫inode、data block。
🌠在Linux中,找文件要用inode去找呢?文件名不在inode保存,是保存在当前所处的目录,所对应的数据块当中的!!!如果没有inode我们的文件名就存在属性里,这时查找文件时,都是按照文件名【字符串】来查找文件的,字符串可长可短,影响查找的效率,而inode是一个整数,效率更高。
🌠 命令"ls -l",在操作系统底层上干了什么?就会把当前目录在底层上给我们打开,接着遍历该目录对应的文件名和inode映射关系,把所有文件的inode全部拿到,接着把每个文件依次在文件系统当中进行查找,根据inode找到inode的值把属性和文件名进行罗列出来。
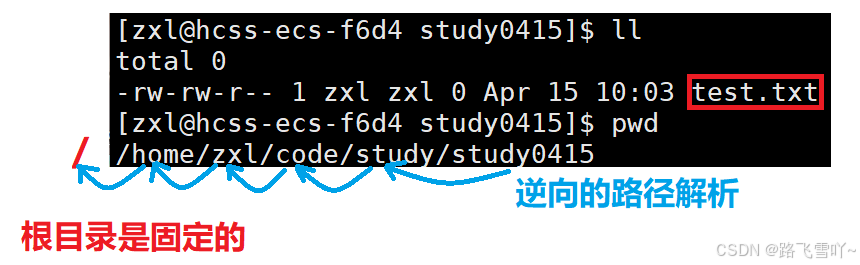
🌠 找到文件名,首先要打开当前目录,当前目录,也是文件!!也有文件名 ----> 逆向的路径解析,这就是为什么访问任何一个文件都要有路径,没有路径就根本不可能找到这个文件,文件名和inode的映射关系就建立不起来,必须要有全路径,才能在linux内部进行路径解析,才能找到最终文件名和inode的映射关系。
每一个进程都有一个CWD, 任何目标文件的路径都是进程给的!!在bash里做的任何操作,都是进程操作,所以进程内部保存了任何文件的CWD,保存了你所要找的CWD,不管你怎么访问绝对路径/相对路径,它都能拼成最终的完整路径,最终进行路径解析,方便查找。
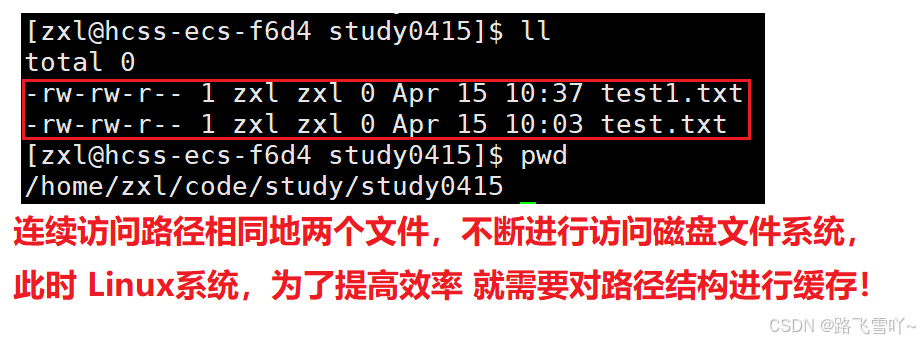
当我们连续对相同路径下的文件进行访问【即就是不断地进行访问磁盘文件系统】,此时Linux系统,需要进行对路径结构进行缓存【内存级缓存】!!
Linux系统,在磁盘上不需要维护任何的路径关系,只需要在数据块里记录这个目录里存的是什么文件和inode的映射关系, 在磁盘上没有路径地概念,只要inode、data block,根本就没有路径,那么此时路径是谁在维护呢?1.由进程提供,2.由对应的每个文件的 data block 给我们提供的映射关系,相当于在data block 构建了一张磁盘级简单的路径关系【多叉树】,跟文件系统没有关系。
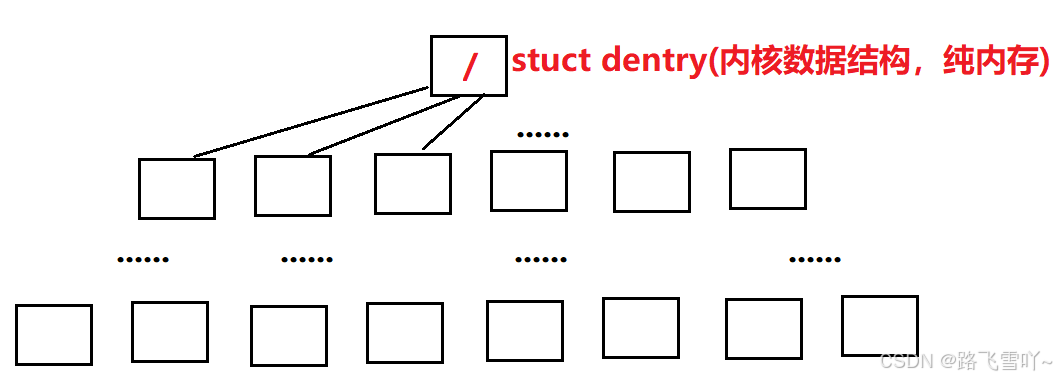
Linux要以什么样的数据结构来缓存路径呢?多叉树!!在Linux系统当中,在操作系统加载的时候只需要把根目录挂上,就能找到相应的路径, 构建的路径缓存【占磁盘级文件当中极少,会把用户曾经访问过的目录构建成节点缓存起来,没有访问过的目录就不需要了,所以这个缓存是一个内存级的缓存,这样我们在内存里就有一个对应的多叉树的路径了】,当第一次访问这个文件时,就构建好了路径树,第二次再访问时,不需要再进行访问磁盘了,直接查找缓存结构【树】。
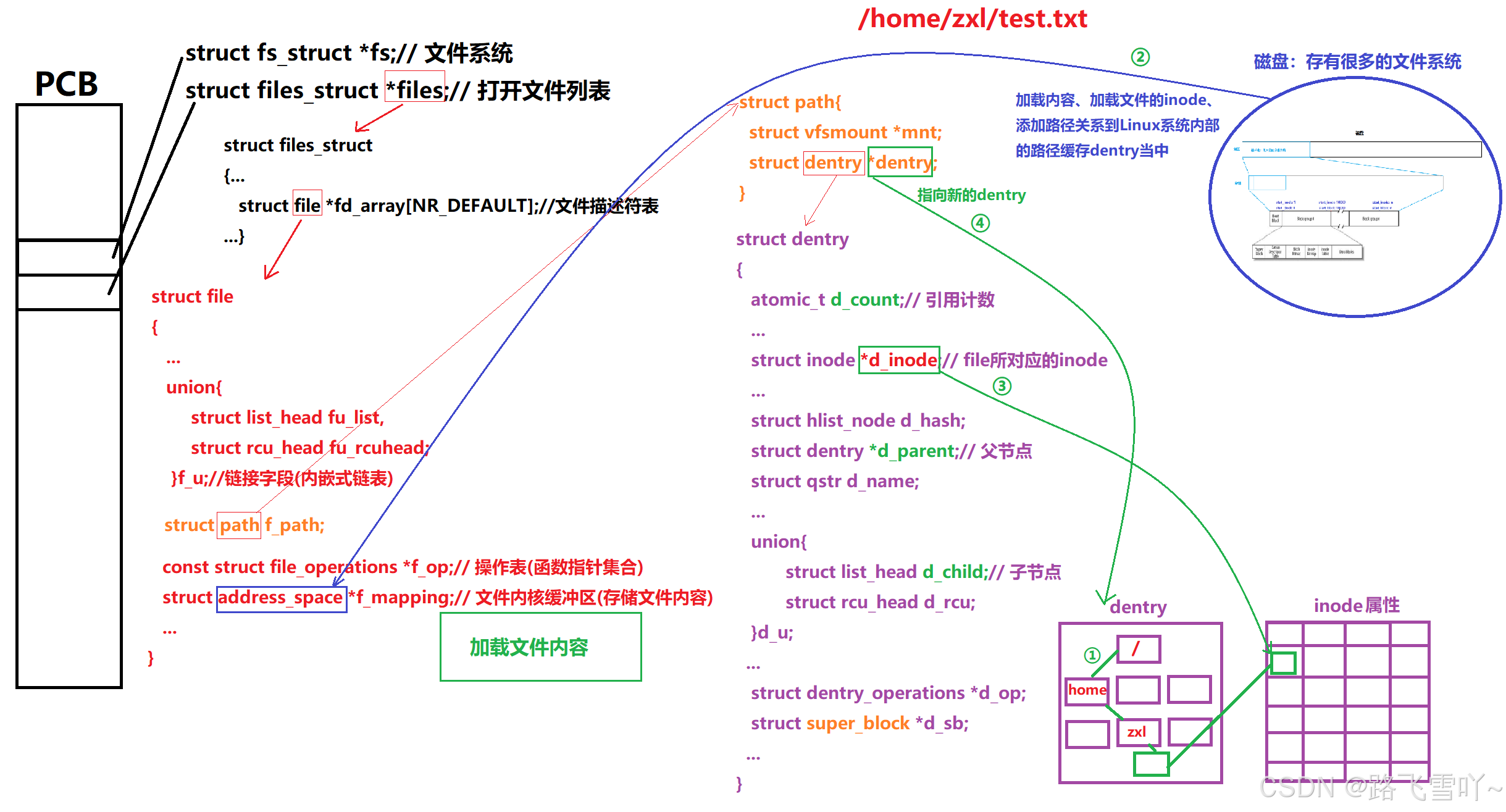
struct dentry,维护的是再Linux当中,帮我们维护一个dentry树,来进行路径缓存。
find /home -name test.txt ---- 在磁盘上找这个文件【根据文件路径去不断进行路径解析,去磁盘当中访问磁盘,从根目录开始】,find首次找会慢一点,第二次会快,第二次访问的时候,路径结构被缓存起来了,dentry会指导我们找到任何一个目录的inode和内容。
在Linux中,每一个文件【目录、普通文件....】都要配一个struct dentry{...},因为要把这个文件挂接在这个目录树里面,方便进行查找。
🌠宏观认识:
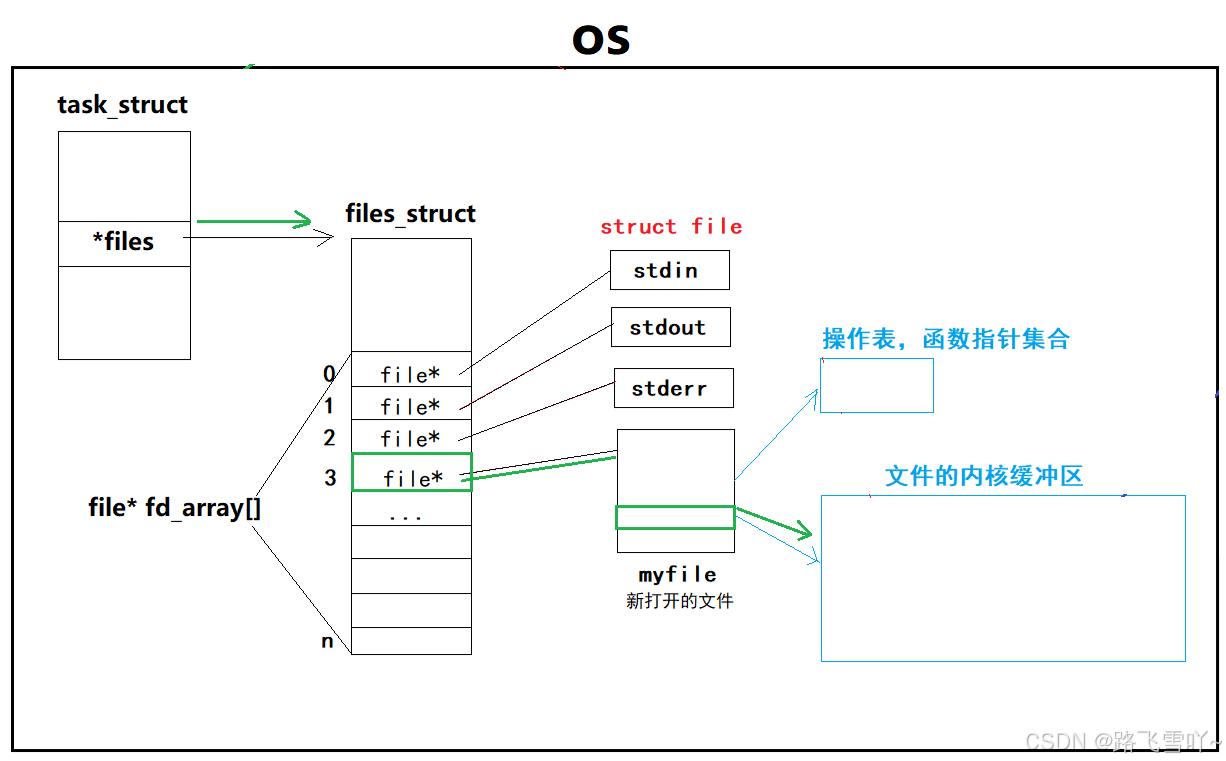
磁盘上存有很多的文件系统,Linux系统里,默认会在全局当中找到dentry里的根目录,当想要打开一个文件时,进程就必须给提供一个路径 【/home/zxl/test.txt】,Linux系统,根据根目录开始查dentry,dentry打开后,和路径里的字符串进行比较,找对应的字符串【home ,加载home所对应的属性inode和内容,在home所对应的内容里找zxl,此时就形成了路径/home/zxl,再打开zxl数据块的内容,得到test.txtx的内容和属性,得到test.txtx的文件名和inode的映射关系[1234]】,此时dentry就会根据路径所找到文件的inode,在磁盘指定的分区下找[1234]对应的inode,找到后加载到inode的文件属性里面【磁盘加载到内存】,在内核当中形成dentry结构,构建dentry节点【test.txt】, 最终用dentry构建节点【test.txt】指向inode属性,要打开【test.txtx】这个文件,内核就要创建struct_file,打开struct_file[文件描述符表]---> struct file ---> struct path f_path ---> struct dentry ---> 找到所对应的inode, 这个inode就指向加载到属性里面的inode,再让struct path里的dentry指向新建的dentry,最后再磁盘上把文件的内容加载到文件内核缓冲区里面【磁盘加载到内存】。
※操作系统内打开一个文件:
• 创建内核数据结构
• 再磁盘当中读取数据加载数据到内存,构建对应的映射关系
• 加载内容、加载文件的inode、添加路径关系到Linux系统内部的路径缓存dentry当中
<5> 做一个小实验
$ dd if=/dev/zero of=./disk.img bs=1M count=5 #制作⼀个⼤的磁盘块,就当做⼀个分区 $ mkfs.ext4 disk.img # 格式化写⼊⽂件系统 $ mkdir /mnt/mydisk # 建⽴空⽬录 $ df -h # 查看可以使⽤的分区 Filesystem Size Used Avail Use% Mounted on udev 956M 0 956M 0% /dev tmpfs 198M 724K 197M 1% /run /dev/vda1 50G 20G 28G 42% / tmpfs 986M 0 986M 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 986M 0 986M 0% /sys/fs/cgroup tmpfs 198M 0 198M 0% /run/user/0 tmpfs 198M 0 198M 0% /run/user/1002 $ sudo mount -t ext4 ./disk.img /mnt/mydisk/ # 将分区挂载到指定的⽬录 $ df -h Filesystem Size Used Avail Use% Mounted on udev 956M 0 956M 0% /dev tmpfs 198M 724K 197M 1% /run /dev/vda1 50G 20G 28G 42% / tmpfs 986M 0 986M 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 986M 0 986M 0% /sys/fs/cgroup tmpfs 198M 0 198M 0% /run/user/0 tmpfs 198M 0 198M 0% /run/user/1002 /dev/loop0 4.9M 24K 4.5M 1% /mnt/mydisk $ sudo umount /mnt/mydisk # 卸载分区 whb@bite:/mnt$ df -h Filesystem Size Used Avail Use% Mounted on udev 956M 0 956M 0% /dev tmpfs 198M 724K 197M 1% /run /dev/vda1 50G 20G 28G 42% / tmpfs 986M 0 986M 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 986M 0 986M 0% /sys/fs/cgroup tmpfs 198M 0 198M 0% /run/user/0 tmpfs 198M 0 198M 0% /run/user/1002怎么确认在哪一个分区里面?--> 访问任何一个文件都要有路径,路径的前缀就可以指明在哪一个分区上!!
多个分区 --> 一个分区包含/ --> 若干个普通目录 --> /a /b /c /d...
只要分区,该分区无法直接使用,分区必须经过“挂载”到目录上,分区才可以被用通过路径的方式进行访问!
✨任何一个分区,天然就有了基本的路径了!【路径一部分是挂载点提供的,一部分是自己产生的】








二、软硬连接
🌟软硬链接
🌠软链接:
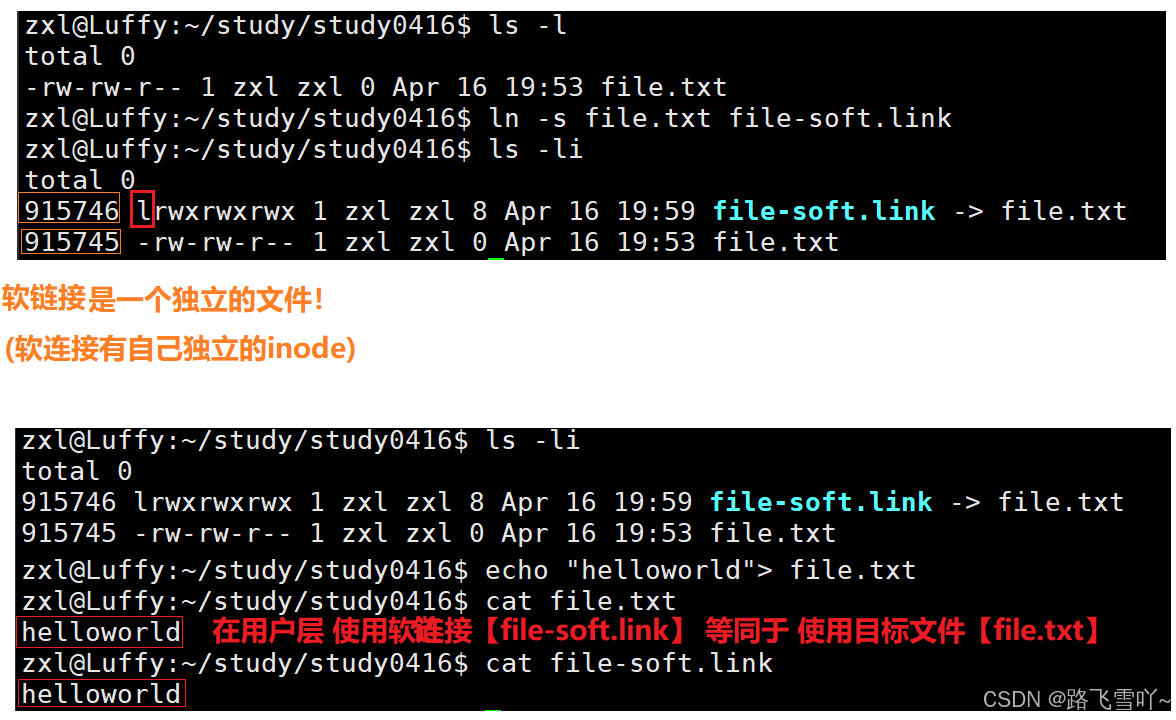
• 软连接是一个独立的文件,有独立的 inode,软链接内容上,保存的是目标文件的路径【window上的快捷方式】;
• 在用户层 使用软连接【file-soft.link】 等同于 使用目标文件【file.txt】
• ln -s file.txt file-soft.link 【后者去链接前者】
• 当我们建立软链接,就是在当前目录下新建一个软链接文件/快捷方式。
🌠硬链接:
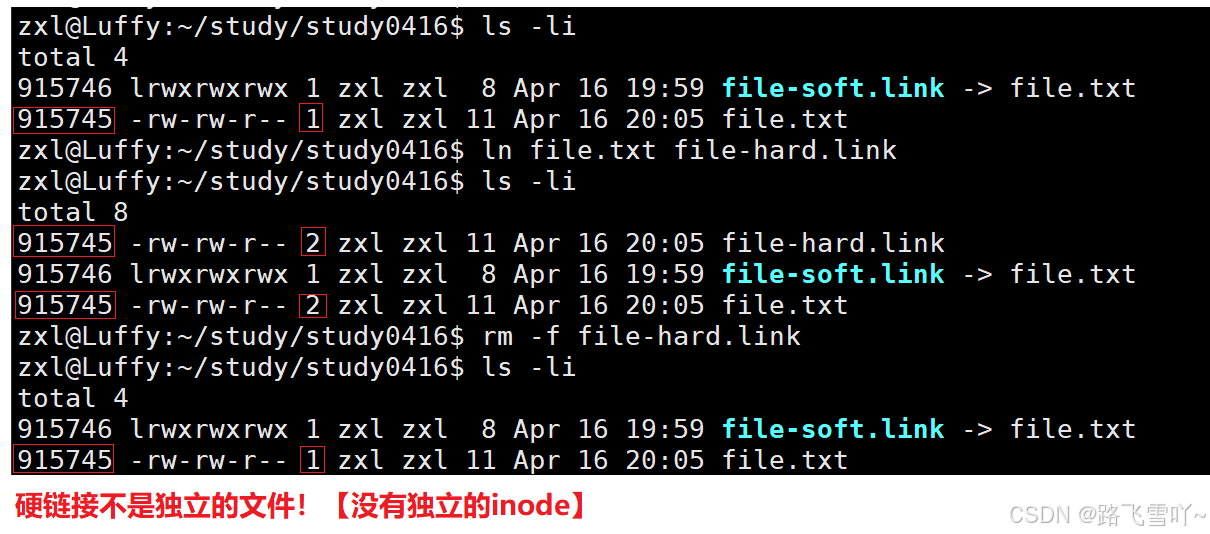
• 硬链接不是独立的文件!【没有独立的inode】,硬链接本质就是一组文件名和已经存在的文件的映射关系!
• ln file.txt file-hard.link 【后者去链接前者】
• 当我们建立一个硬链接,就是再当前目录所处的目录内部当中,新增一个新的文件名和inode对应的映射关系,所以硬链接所查到的 inode 和 目标文件的 inode 是一样的。
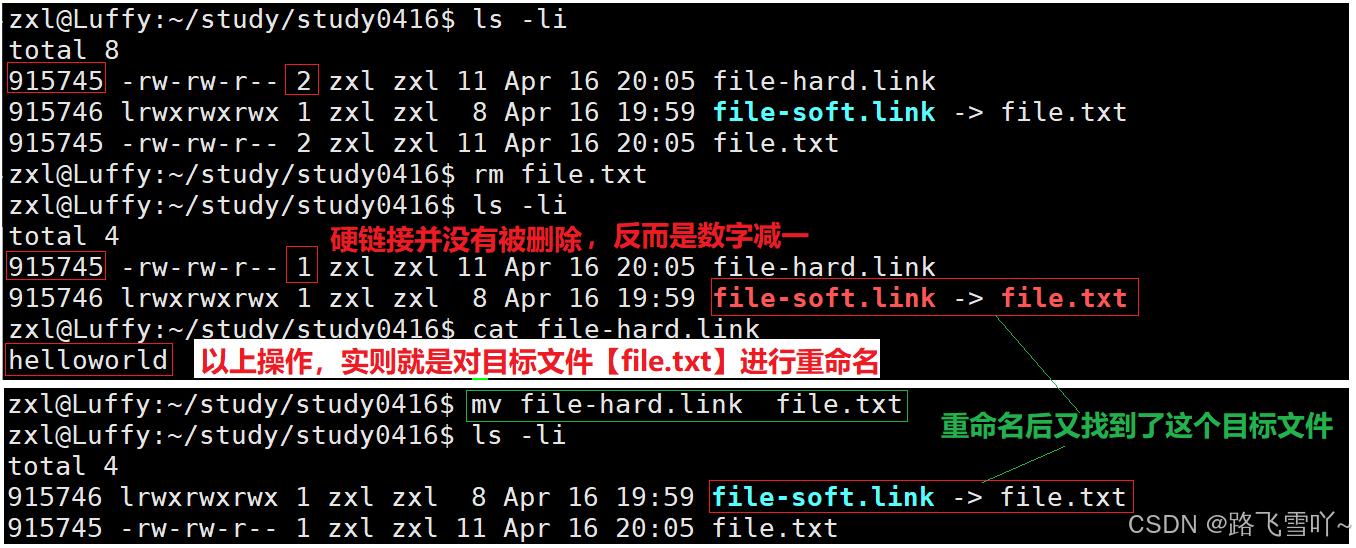
• 在当前目录下新建一个普通文件,普通文件的文件名在文件所处目录的内容中保存,硬链接会映射到同一个 inode【inode 特别像一个指针一样的东西】,当我们想使用文件名来找对应文件时,Linux是通过inode去找文件的,硬链接使得两个文件名指向同一个inode文件, 此时这个文件如何才算是删除呢?在整个系统里没有任何文件名字符串和这个文件inode有映射关系时,才算是被删除,我们如何知道有多少个文件名通过和inode号来产生对应的映射关系呢?在inode当中存在一个引用计数【atomic_t d_count;】硬链接数。
• 建立一个普通文件本质上就是在不断地进行建立硬链接【文件名和inode的映射关系只有一份,所以数字就会减一】
🌟理解软硬链接的应用场景
✨软链接
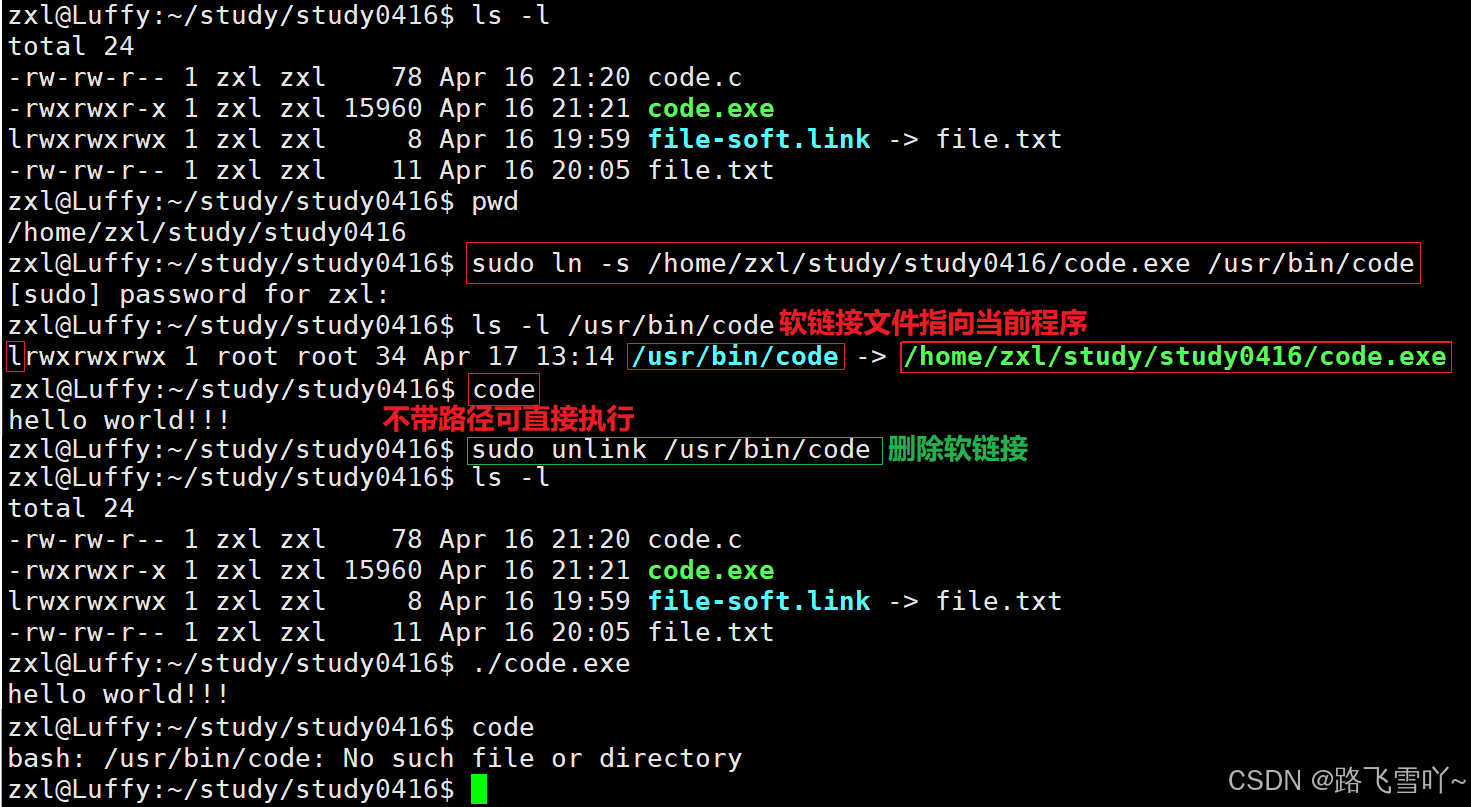
可执行文件在当前目录上,如何不带路径就可以直接执行文件呢?
1> 环境变量:把当前的所处的路径添加到系统环境变量里;
2> 把 .exe可执行文件,拷贝到系统的默认路径下;
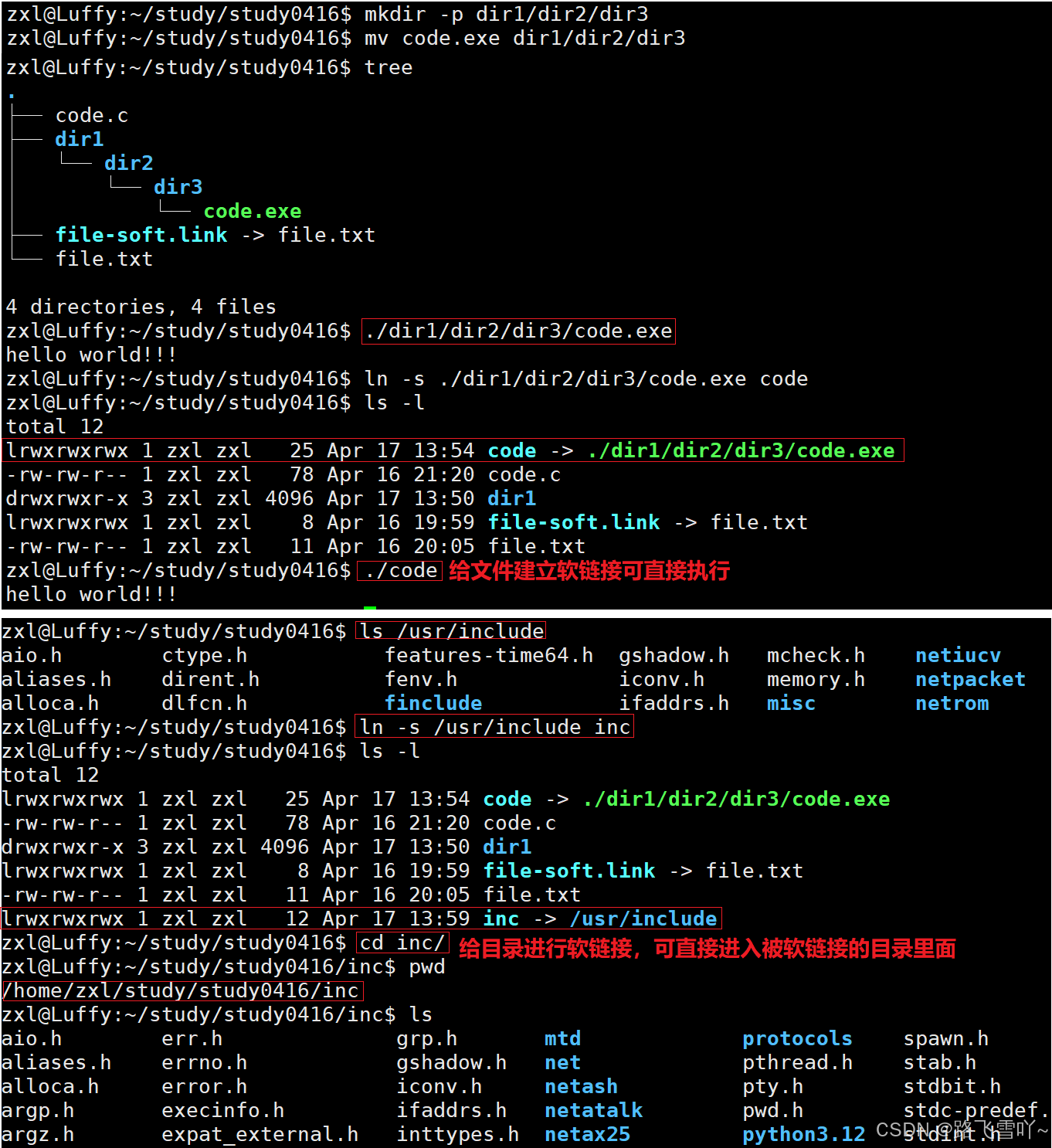
3> 给对应的可执行程序重新进行命名,建立软链接:
• 作用:当被执行的可执行程序放在比较深的目录下【路径很长】时,可以在深得路径下,建立软链接,也可以给目录进行软链接,直接一步进入想要进的目录里面。
主要是能让我们快速定位某一个文件,以最简单的方式进入。
一般在一个磁盘分区里面,软链接建在哪里都可以。
• 软链接:快捷方式,可以帮我们快速找到指令和对应的库。
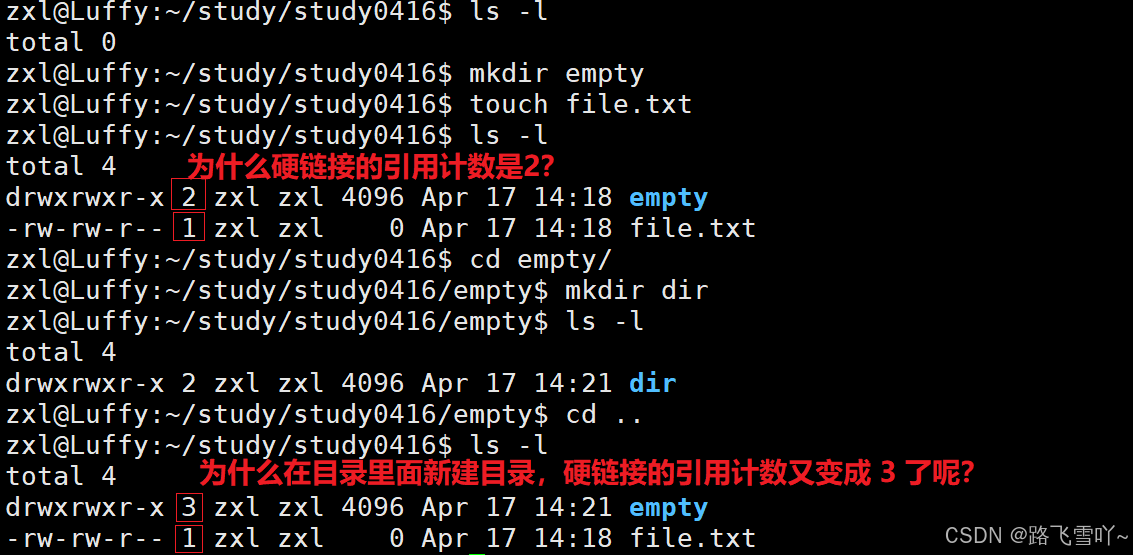
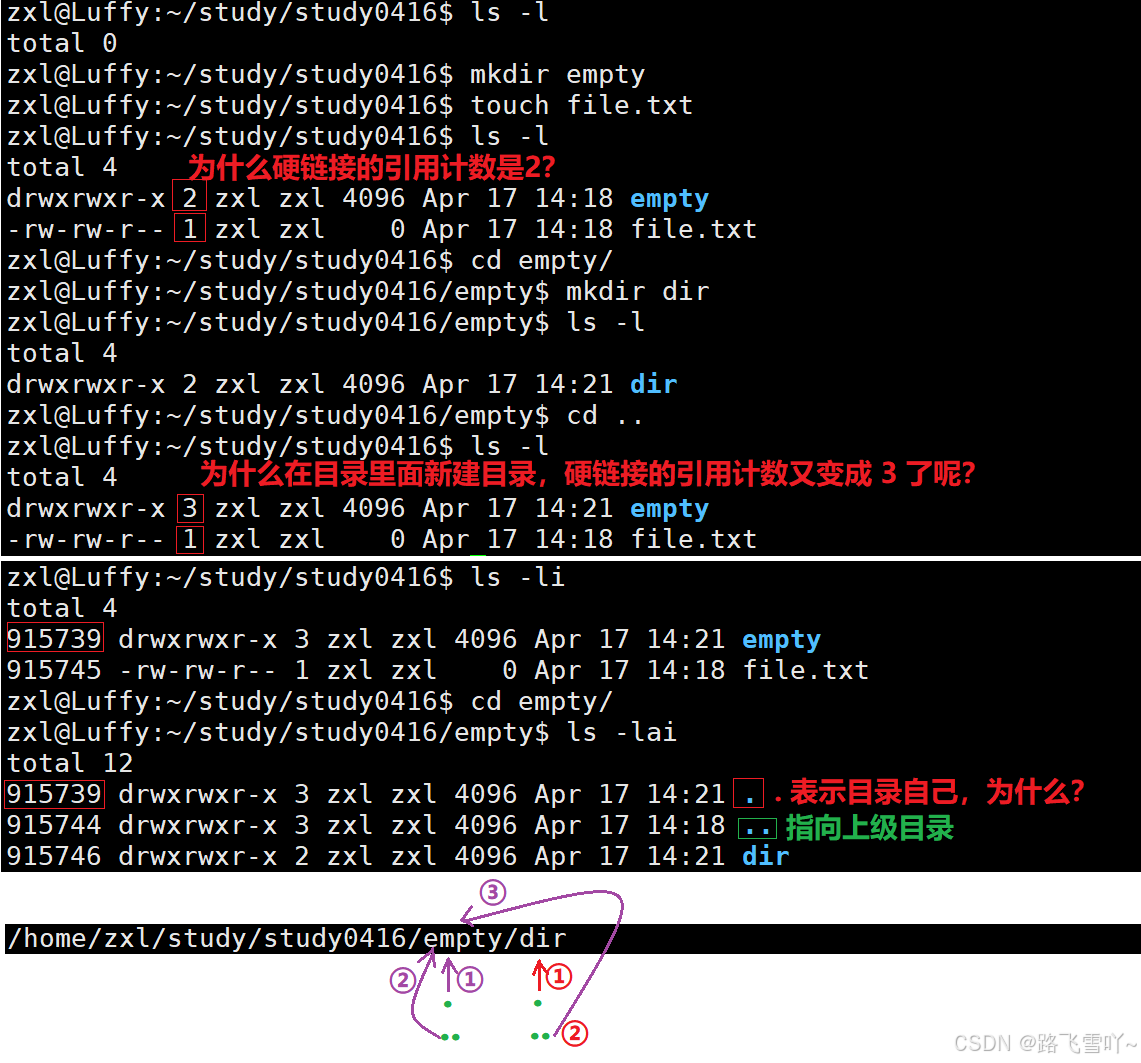
✨硬链接
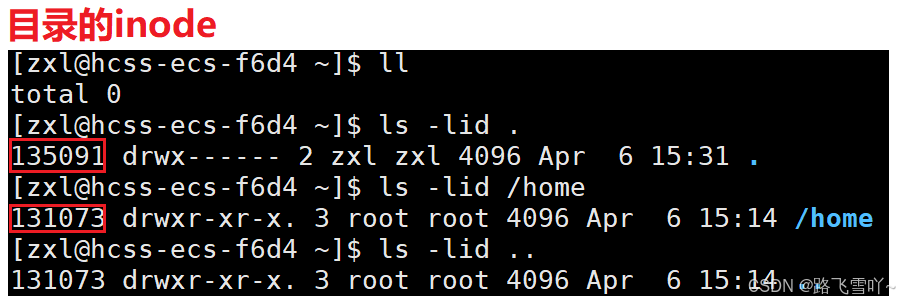
• “.” [文件名] 所映射的inode编号,和当前所处的【/empty】目录inode编号是一样的,文件名不同【. empty】但指向的inode是一样的,所以 “.” 就表示当前工作路径,所以在创建一个空目录时,一个是它自己【有一个文件名和inode有映射关系】。
“.”和 “..”目的是为了路径的快速切换,如何做到的呢?本质就是 文件所指向的inode就是上级路径,因此当 cd 切换路径时,要找到目标路径的inode,方便显式目标路径里面的文件。
• 文件备份!(就可以不用拷贝,也能找到内容)
• Linux下不允许对目录新建硬链接!!!【原因:怕进行硬链接之后,形成一些环状路径】
软链接【直接指向文件,里面保存的时路径字符串】,我们在进行查找软链接时,并不会对软链接做任何解析。
相关文章:
文件系统 软硬连接
🌻个人主页:路飞雪吖~ 🌠专栏:Linux 目录 一、理解文件系统 🌠磁盘结构 二、软硬连接 🌟软硬链接 🌠软链接: 🌠硬链接: 🌟理解软硬链接的应…...

Halcon-交互式处理图像模式
draw_rectangle1,这是halcon一个交互函数,当运行到这句话时,我们可以通过鼠标左键在图片上画一个矩形,然后通过鼠标右键结束交互过程。然后,我们就可以得到我们绘制矩形的左上角的点坐标,以及右下角的点坐标…...
计算机视觉——JPEG AI 标准发布了图像压缩新突破与数字图像取证的挑战及应对策略
概述 今年2月,经过多年旨在利用机器学习技术开发一种更小、更易于传输和存储且不损失感知质量的图像编解码器的研究后,JPEG AI国际标准正式发布。 来自JPEG AI官方发布流,峰值信噪比(PSNR)与JPEG AI的机器学习增强方法…...
Oracle 19c部署之数据库软件安装(二)
在完成了Oracle Linux 9的初始化配置之后,我们准备安装Oracle 19c数据库软件。 Oracle数据库支持两种主要的安装方式:图形化安装和静默安装。这两种方法各有优缺点,选择哪种取决于你的具体需求、环境配置以及个人偏好。 图形化安装 图形化安…...

音视频相关协议和技术内容
视频编解码: H264(AVC,MPEG-4 Part 10) 高压缩率,支持多种分辨率和帧率,用于在线流媒体、会议、数字电视 编码过程: 分块处理,将视频帧划分为宏块(16x16)使用帧预测和…...
在Vmware15(虚拟机免费) 中安装纯净win10详细过程
一、软件备选 1. VMware15.5.1 网盘下载地址 链接: https://pan.baidu.com/s/1y6GLJ2MG-1tomWblt3otsg?pwdim8e 提取码: im8e 2. windows镜像下载 去官网下载ios包 链接:https://www.microsoft.com/zh-cn/software-download/windows10 二、在VMware15.5.1下安装w…...

[Spark]深入解密Spark SQL源码:Catalyst框架如何优雅地解析你的SQL
本文内容组织形式 总结具体例子执行语句解析层优化层物理计划层执行层 猜你喜欢PS 总结 先写个总结,接下来会分别产出各个部分的源码解析,Spark SQL主要分为以下五个执行部分。 具体例子 接下来举个具体的例子来说明 执行语句 SELECT name, age FR…...
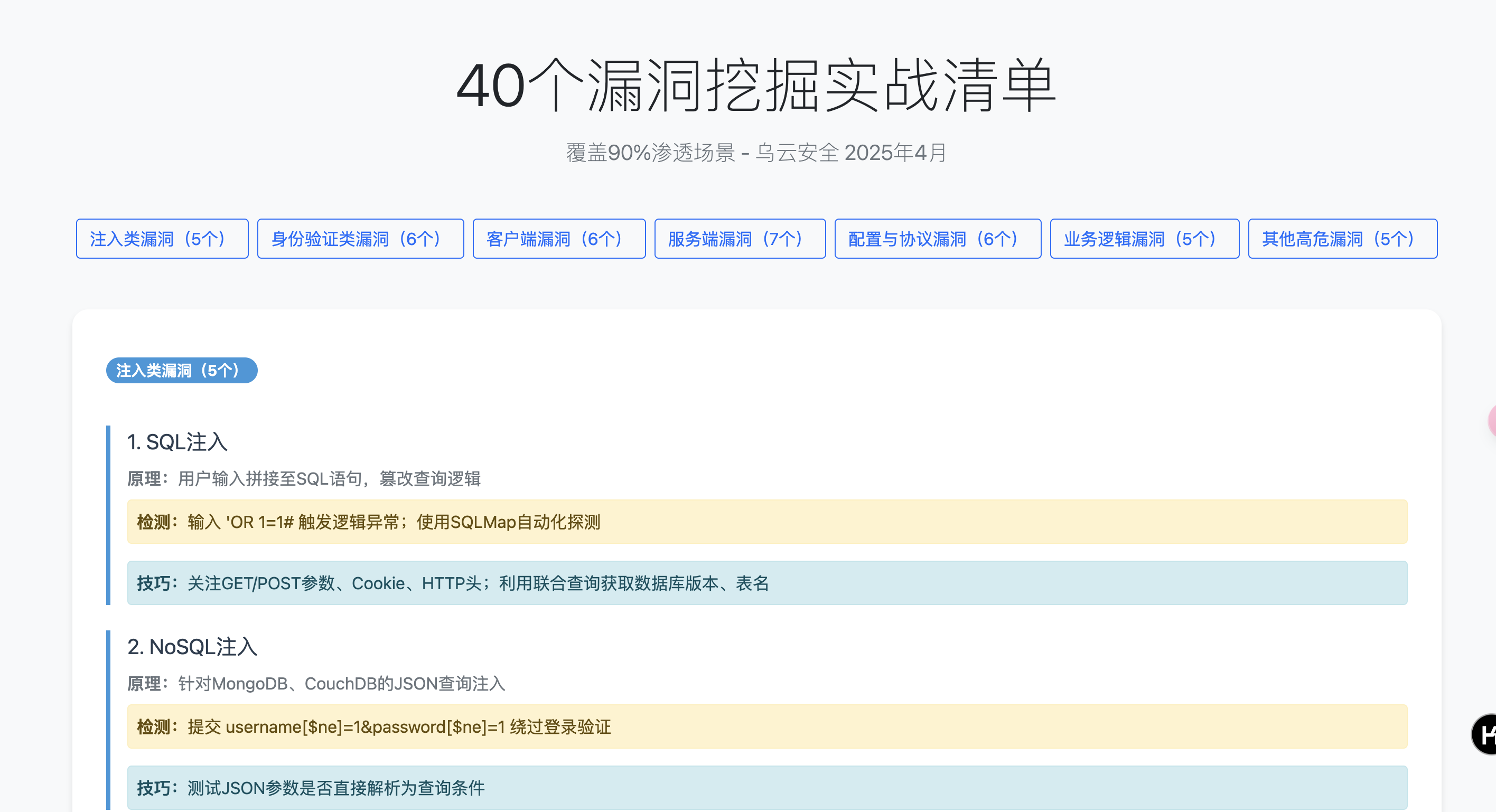
基于Flask的漏洞挖掘知识库系统设计与实现
基于Flask的漏洞挖掘知识库系统设计与实现 一、系统架构设计 1.1 整体架构 本系统采用经典的三层Web架构,通过Mermaid图展示的组件交互流程清晰呈现了以下核心模块: 前端展示层:基于Bootstrap5构建响应式界面业务逻辑层:Flask…...

ECharts散点图-散点图8,附视频讲解与代码下载
引言: ECharts散点图是一种常见的数据可视化图表类型,它通过在二维坐标系或其它坐标系中绘制散乱的点来展示数据之间的关系。本文将详细介绍如何使用ECharts库实现一个散点图,包括图表效果预览、视频讲解及代码下载,让你轻松掌握…...

四大wordpress模板站
WP汉主题 WP汉主题是一个专注于提供高质量WordPress中文主题的平台。它为中文用户提供了丰富的WordPress主题选择,包括但不限于企业网站模板、外贸建站模板等。WP汉主题致力于帮助用户轻松搭建专业的中文网站,无论是企业官网还是个人博客,都…...

DeepSeek在数据仓库的10大应用场景
一、智能数据集成与清洗 多源数据整合:DeepSeek能够从多种数据源中提取、转换和加载数据,实现跨系统数据的高效整合。 数据清洗与标准化:通过智能算法自动识别并纠正数据中的错误、不一致性和缺失值,提升数据质量。 二、数据仓…...

【Kubernetes基础--持久化存储原理】--查阅笔记5
目录 持久化存储机制PV 详解PV 关键配置参数PV 生命周期的各个阶段 PVC 详解PVC 关键配置参数PV 和 PVC 的生命周期 StorageClass 详解StorageClass 关键配置参数设置默认的 StorageClass 持久化存储机制 k8s 对于有状态的容器应用或对数据需要持久化的应用,不仅需…...

Langchain-构建向量数据库和检索器
向量数据库安装 pip install langchain-chroma 文档》向量存储》向量数据库。 和0416 提示词工程相同。 初始化 import osfrom langchain_chroma import Chroma from langchain_community.chat_message_histories import ChatMessageHistory from langchain_core.documents im…...

首席人工智能官(Chief Artificial Intelligence Officer,CAIO)的详细解析
以下是**首席人工智能官(Chief Artificial Intelligence Officer,CAIO)**的详细解析: 1. 职责与核心职能 制定AI战略 制定公司AI技术的长期战略,明确AI在业务中的应用场景和优先级,推动AI与核心业务的深度…...
2025华中杯数学建模B题完整分析论文(共42页)(含模型、数据、可运行代码)
2025华中杯大学生数学建模B题完整分析论文 目录 一、问题重述 二、问题分析 三、模型假设 四、 模型建立与求解 4.1问题1 4.1.1问题1解析 4.1.2问题1模型建立 4.1.3问题1样例代码(仅供参考) 4.1.4问题1求解结果(仅供参考&am…...

游戏引擎学习第231天
设定当天的主题 我们现在到了一个很少出现在直播中的阶段,但今天是那种需要解释计算机科学基础概念的日子。因此,今天我们将讨论这个内容,今天的重点是“大O表示法”(Order Notation),我将用黑板来解释这些…...

最快打包WPF 应用程序
在 Visual Studio 中右键项目选择“发布”,目标选“文件夹”,模式选“自包含”,生成含 .exe 的文件夹,压缩后可直接发给别人或解压运行,无需安装任何东西。 最简单直接的新手做法: 用 Visual Studio 的“…...

【模块化拆解与多视角信息6】自我评价:人设构建的黄金50字——从无效堆砌到精准狙击的认知升级
写在最前 作为一个中古程序猿,我有很多自己想做的事情,比如埋头苦干手搓一个低代码数据库设计平台(目前只针对写java的朋友),比如很喜欢帮身边的朋友看看简历,讲讲面试技巧,毕竟工作这么多年,也做到过高管,有很多面人经历,意见还算有用,大家基本都能拿到想要的offe…...

Linux网络编程实战:从字节序到UDP协议栈的深度解析与开发指南
网路通信的三大要素:协议,端口和IP 知识点1【字节序】 多字节在主机中的存放数据 把多字节看成一个整体存储的顺序。 为什么我们在文件中没有这个概念呢? 因为文件是字节流(流指针),流是以一个字节为操…...

【实战篇】导入dbc文件
目录 1 前言1.1 dbc文件简介1.2 dbc文件格式规范1.2.1 基础定义部分1.2.2 网络节点定义(BU_)1.2.3 报文定义(BO_)1.2.4 信号定义(SG_)1.2.5 扩展属性与注释1.2.6 数值表(VAL_)1.2.7 环境变量(EV_)1.2.8 DBC文件的典型结构示例2 步骤2.1 打开“输入文件”窗口2.2 点击…...

合成数据在自动驾驶中的实践:工作流、关键技术与评估体系全解析
目录 合成数据在自动驾驶中的实践:工作流、关键技术与评估体系全解析 一、为什么自动驾驶离不开合成数据? 二、自动驾驶合成数据的核心使用场景 三、典型合成数据工作流(架构图建议制作成PPT) 四、评估体系:合成数…...
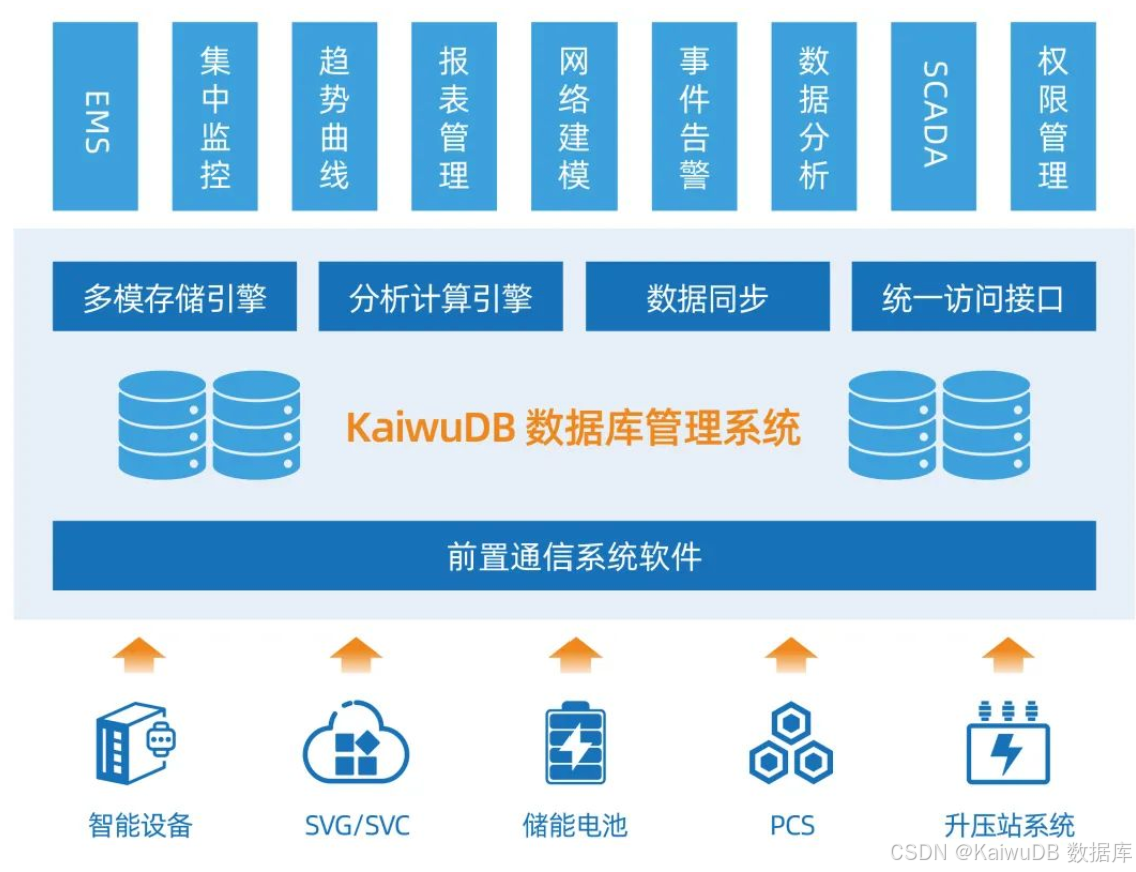
赋能能源 | 智慧数据,构建更高效智能的储能管理系统
行业背景 随着新能源产业的快速发展,大规模储能系统在电力调峰、调频及可再生能源消纳等领域的重要性日益凸显。 储能电站作为核心基础设施,其能量管理系统(EMS)需要处理海量实时数据,包括电池状态、功率变化、环境监…...

【音视频】音视频FLV合成实战
FFmpeg合成流程 示例本程序会⽣成⼀个合成的⾳频和视频流,并将它们编码和封装输出到输出⽂件,输出格式是根据⽂件扩展名⾃动猜测的。 示例的流程图如下所示。 ffmpeg 的 Mux 主要分为 三步操作: avformat_write_header : 写⽂件…...

猪行为视频数据集
猪行为数据集包含 23 天(超过 6 周)的日间猪行为视频,这些视频由近乎架空的摄像机拍摄。视频已配准颜色和深度信息。数据以每秒 6 帧的速度捕获,并以 1800 帧(5 分钟)为一批次进行存储。大多数帧显示 8 头猪。 这里可以看到颜色和深度图像的示例: 喂食器位于图片底部中…...
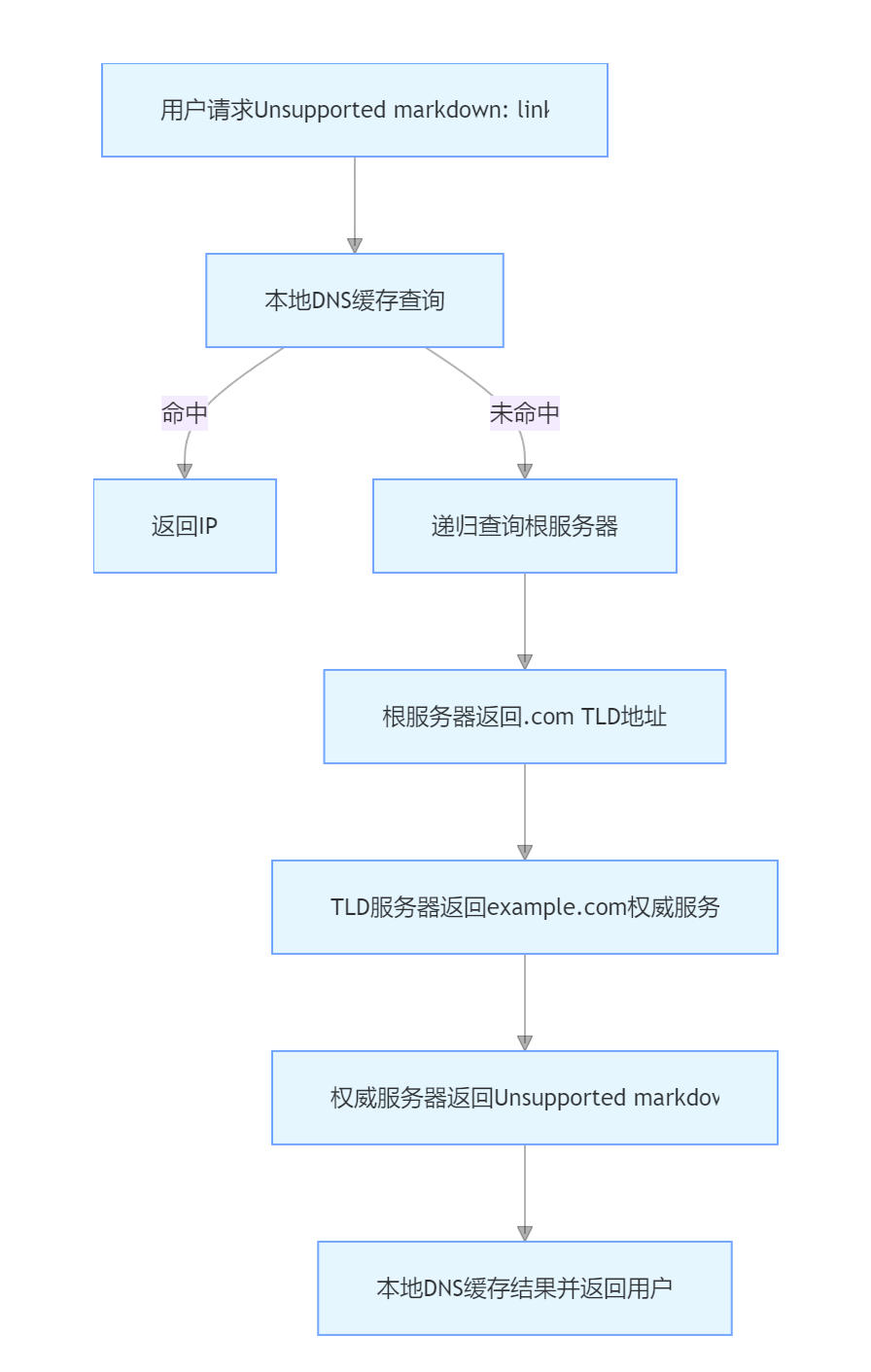
【网络技术_域名解析DNS】一、DNS 基础剖析及其原理
一、DNS 在互联网架构中的基石地位 当我们在浏览器地址栏输入www.baidu.com按下回车键的瞬间,一场跨越全球的 “数字寻址游戏” 便悄然启动。DNS(Domain Name System)作为互联网的核心基础设施,承担着将人类易读的域名转换为机…...

Java学习小册:Java并发容器与原子类
在Java并发编程中,并发容器和原子类是管理共享数据的重要工具。它们提供了线程安全的数据结构和原子操作,确保在多线程环境下数据的一致性和操作的正确性。本文将深入探讨Java中的并发容器和原子类,包括它们的基本概念、使用方法、关键类及其…...

摄影跟拍预定|基于java+vue的摄影跟拍预定管理系统(源码+数据库+文档)
摄影跟拍预定管理系统 目录 基于SprinBootvue的摄影跟拍预定管理系统 一、前言 二、系统设计 三、系统功能设计 1系统功能模块 2管理员功能模块 3摄影师功能模块 4用户功能模块 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获…...
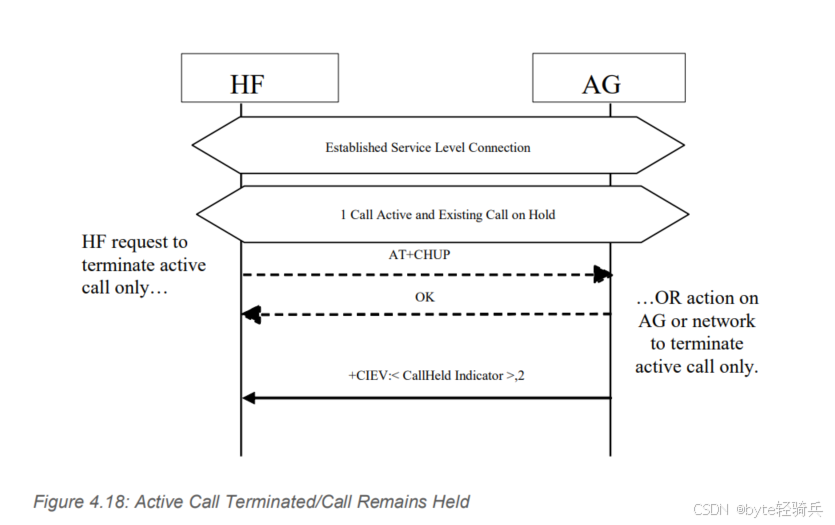
【HFP】深入解析蓝牙 HFP 协议中呼叫转移、呼叫建立及保持呼叫状态的机制
目录 一、核心指令概述 1.1 ATCMER:呼叫状态更新的 “总开关” 1.2 ATBIA:指示器的 “精准控制器” 1.3 指令对比 1.4 指令关系图示 二、CIEV 结果码:状态传递的 “信使” 2.1 工作机制 2.2 三类核心指示器 三、状态转移流程详解 3…...

从零开始学A2A三: A2A 能力发现与任务管理
A2A 能力发现与任务管理 学习目标 掌握智能体能力发现机制 理解 Agent Card 的结构和用途掌握能力注册和发现的流程学会管理智能体的生命周期 掌握 A2A 任务管理流程 学习任务创建和分发机制理解任务状态管理和监控掌握多智能体协作模式 理解与 MCP 的区别 对比两种架构的能…...

学习笔记十六——Rust Monad从头学
🧠 零基础也能懂的 Rust Monad:逐步拆解 三大定律通俗讲解 实战技巧 📣 第一部分:Monad 是什么? Monad 是一种“包值 链操作 保持结构”的代码模式,用来处理带上下文的值,并方便连续处理。 …...