Causal Attention的底层原理
Causal Attention
Transformer的Decoder中最显著的结构是Casual Attention。
通过本篇文章,你将学会
Casual Attention的机制原理
Casual Attention在TensorFlow中的实现原理
如何快速地保存并打印TensorFlow中模型已经训练好的参数
如何实现Transformer的Decoder的前向传播
1、训练阶段
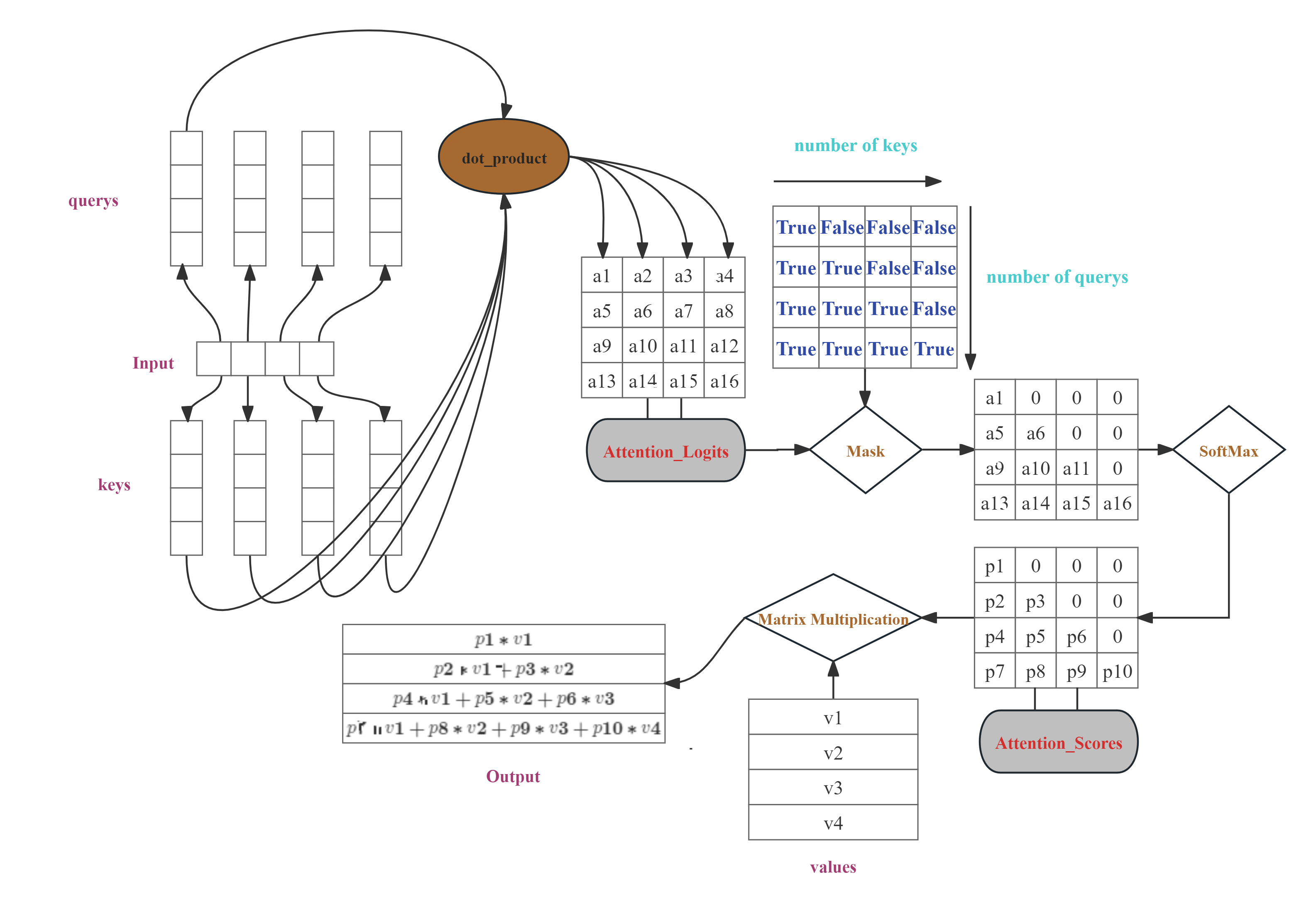
图1
Decoder和RNN一样,是串行地生成Token的。Casual Attention是带掩码的Attention——在标准的注意力分数矩阵上乘了一个下三角因果掩码矩阵,使得最终的输出具备了时序因果性——t时刻Token的预测过程不会受到t时刻之后的Key,Value以及Query的影响。因为Casual Attention这种独特掩码机制,使得Decoder在训练时可以进行并行训练,而非RNN那样只能串行训练。
2、推理阶段
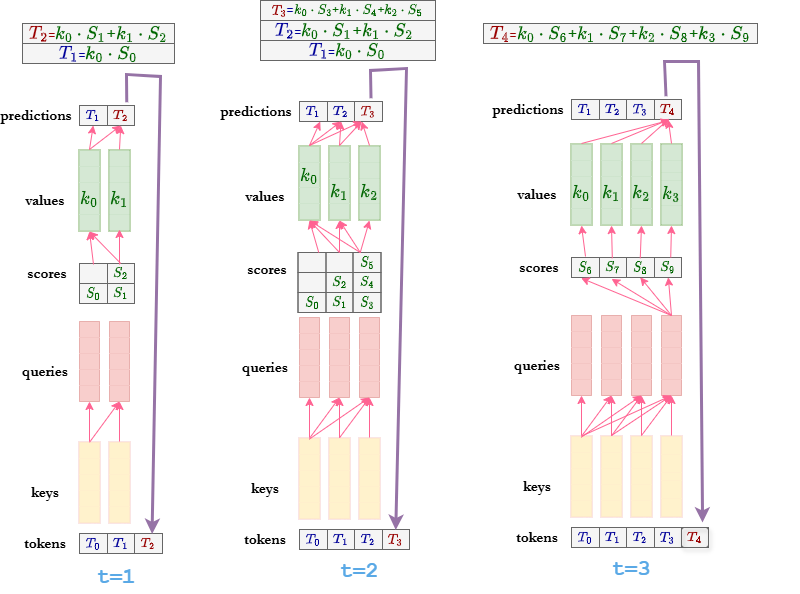
图2
Decoder在推理时是依时序串行生成Token的,这是所有Casual Attention 的作用结果。
每个Casual Atention 在推理时和训练时是一样的,t时刻上的query只会与t时刻及t时刻之前的key计算点积,t时刻上的value只会与t时刻及t时刻之前的value进行加权相加。
其中有一个关键点值得注意。如果decoder在推理时采取和训练时一样的运算流程,那么在每个时间步上,t时刻之前的value,key,query都会被重复计算。
为了提高计算效率,就有了K-V缓存技术。
3、Key-Value缓存
Key-Value缓存是运用在Decoder推理时的技术,它需要缓存每个时间步上所有Causal Attention的Key和Value。如此就可以让Decoder在下一时间步无需再计算之前的Keys和Values了,只需要得到当前的Key和Value,再将当前的Query与所有Key计算注意力分数,接着合并所有Value就行了,合并后的Value再经过预测头,就可以生产新的Token了。
Key-Value缓存能够让Decoder中所有Causal Attention在每个一时间步只需计算上一时间步预测出来的Token的Key,Value和Query。如图2,t=2时刻,2之前的Keys和Values均已缓存,只需要计算Token的Key,Value和Query;t=3时刻,只需要计算Token
的Key,Value和Query。
每个时刻上的query是不需要缓存的,这是因为每个Casual Attention缓存了t时刻之前的value后,t时刻之前的query在t时刻就没用了,且t+1时刻的预测token只与t时刻的query以及t+1时刻之前所有value和key有关。query是有时效性的,无需缓存。
4、Casual Attention在Tensorflow中的实现原理
用Tensorflow训练一个Decoder并保存其模型结构和参数
import tensorflow as tf# 词汇表
vocabulary_table = {1: "今", 2: "天", 3: "气", 4: "好", 5: "真"}class Model(tf.keras.Model):def __init__(self, **kwargs):super().__init__(**kwargs)self.embedding = tf.keras.layers.Embedding(input_dim=6, output_dim=64, name="Embedding")self.casual_attention = tf.keras.layers.MultiHeadAttention(num_heads=2, key_dim=64, name="Casual_Attention")self.dense = tf.keras.layers.Dense(6, activation="softmax", name="output_dense")def call(self, inputs, training=None, mask=None):x = self.embedding(inputs)x = self.casual_attention(value=x,key=x,query=x,use_causal_mask=True)x = self.dense(x)return xclass ExportModel(tf.Module):def __init__(self, model):self.model = model@tf.function(input_signature=[tf.TensorSpec(shape=[1, 5], dtype=tf.float32)])def __call__(self, inputs):# training=False表明模型工作在推理模式result = self.model(inputs, training=False)return resultmodel = Model(name="Decoder")
# 今天天气真好
tokens = tf.constant([[1., 2., 2., 3., 5., 4.]])
Decoder_input = tokens[:, :-1]
print(Decoder_input)
Decoder_output = tokens[:, 1:]
print(Decoder_output)model.compile(optimizer="adam", loss=tf.keras.losses.sparse_categorical_crossentropy)
model.fit(x=Decoder_input,y=Decoder_output,epochs=164
)
# 只保存模型参数, 模型结构需要手动构建(前向传播)
model.save_weights("Decoder_weights.h5", save_format="h5")# 模型结构与参数全部保存
model = ExportModel(model)
tf.saved_model.save(model, "Decoder")读取已训练好的权重参数,并手动实现Decoder的前向传播(这里的实现过程并没有使用K-V缓存)。
注意:在计算完query向量和key向量的点积后,一定要除以向量维数的平方根!
这是因为在Transformer模型中,注意力机制是核心组件。它通过query向量和key向量的点积来计算注意力分数。但当向量维度很高时,点积结果会变得非常大,这可能导致以下问题:
数值不稳定:大值在Softmax函数中会被放大,导致注意力过于集中,分布不均。
训练困难:梯度可能爆炸,影响模型稳定性。
为了解决这些问题,Transformer模型中引入了缩放注意力分数的技巧。具体来说,就是在点积后除以向量维度的平方根。这样做的好处有:
控制数值大小:将点积结果缩小到一个适中的范围,保持数值稳定。
优化Softmax表现:避免生成过于极端的概率分布,使注意力更平滑,模型学习更均匀。
训练更稳定:梯度不会因为指数函数放大而爆炸,收敛速度更快。
import tensorflow as tf
import h5py
import numpy as np# tokens(Batch_size, num_tokens)
def forward(tokens):# model.save_weights()仅保存模型权重, 保存格式为.h5文件, 需要用h5py库进行读取# 读取模型参数文件weights = h5py.File("Decoder_weights.h5")# 打印Embedding层参数# (6, 64), 词汇表大小为5, 再加上一个空白词(Padding 0), 总共6个Embedding.embeddings_table = weights["Embedding/Decoder/Embedding/embeddings:0"][:]# 打印Causal Attention层参数# kernel : (input_dim=64, num_heads=2, key_dim=64)# bias : (num_heads=2, key_dim=64)key_dense_kernel = weights["Casual_Attention/Decoder/Casual_Attention/key/kernel:0"][:]key_dense_bias = weights["Casual_Attention/Decoder/Casual_Attention/key/bias:0"][:]# kernel : (input_dim=64, num_heads=2, query_dim=64)# bias : (num_heads=2, query_dim=64)query_dense_kernel = weights["Casual_Attention/Decoder/Casual_Attention/query/kernel:0"][:]query_dense_bias = weights["Casual_Attention/Decoder/Casual_Attention/query/bias:0"][:]# kernel : (input_dim=64, num_heads=2, value_dim=64)# bias : (num_heads=2, value_dim=64)value_dense_kernel = weights["Casual_Attention/Decoder/Casual_Attention/value/kernel:0"][:]value_dense_bias = weights["Casual_Attention/Decoder/Casual_Attention/value/bias:0"][:]# kernel : (num_heads=2, value_dim=64, output_dim=64)# bias : (value_dim=64,)attention_output_kernel = weights["Casual_Attention/Decoder/Casual_Attention/attention_output/kernel:0"][:]attention_output_bias = weights["Casual_Attention/Decoder/Casual_Attention/attention_output/bias:0"][:]# 打印最后一层密集层的参数# (64, 6)output_dense_kernel = weights["output_dense/Decoder/output_dense/kernel:0"][:]# (6,)output_dense_bias = weights["output_dense/Decoder/output_dense/bias:0"][:]B = tf.shape(tokens)[0]embeddings_table = tf.tile(embeddings_table[tf.newaxis], [B, 1, 1])# (Batch_size, num_tokens, embeddings_dim)embeddings = tf.gather_nd(embeddings_table, tokens[:, :, tf.newaxis], batch_dims=1)# 将embeddings分别映射成key, query, valuekey = tf.einsum("abc,cde->abde", embeddings, key_dense_kernel) + key_dense_biasquery = tf.einsum("abc,cde->abde", embeddings, query_dense_kernel) + query_dense_biasvalue = tf.einsum("abc,cde->abde", embeddings, value_dense_kernel) + value_dense_bias# 计算注意力分数,# 计算query和key的数量积时, 一定要除以一个dim--query最后一个维度的长度# 因为query和key的维度很高时, 它两的数量积往往很大, 几个很大的数经过SoftMax后会产生饱和状态dim = tf.cast(tf.shape(query)[-1], dtype=tf.float32)# 生成一个下三角的掩码矩阵, 下三角是0, 上三角是一个负无穷数(-1e11)query_length = tf.shape(query)[1]key_length = tf.shape(key)[1]attention_mask = (1 - np.tri(N=query_length, M=key_length)) * -1e11# query和key的数量积矩阵加上attention_mask后,# 上三角全变为负无穷, 负无穷数的指数接近于0, 使得上三角的数量积在softmax中不起作用scores = tf.math.softmax(tf.einsum("aecd, abcd -> acbe", key, query / tf.sqrt(dim)) + attention_mask, axis=-1)# 利用注意力分数将value进行加权相加.stacked_value = tf.einsum("acbe,aecd->abcd", scores, value)# Causal Attention输出映射attention_output = tf.einsum("abcd, cde -> abe", stacked_value, attention_output_kernel) + attention_output_bias# 预测映射prediction = tf.math.softmax(tf.einsum("abc, cd -> abd", attention_output, output_dense_kernel) + output_dense_bias, axis=-1)return predictionif __name__ == '__main__':# [1., 2., 2., 3., 5., 4.]tokens = tf.constant([[1, 2, 2, 3, 5]], dtype=tf.int32)Decoder = tf.saved_model.load("Decoder")print(forward(tokens)[:, -1])print(Decoder(tf.cast(tokens, dtype=tf.float32))[:, -1])
最后检验上述的前向传播是否实现成功,
if __name__ == '__main__':# [1., 2., 2., 3., 5., 4.]tokens = tf.constant([[1, 2, 2, 3, 5]], dtype=tf.int32)Decoder = tf.saved_model.load("Decoder")print(forward(tokens)[:, -1])print(Decoder(tf.cast(tokens, dtype=tf.float32))[:, -1])最终打印结果为:
tf.Tensor(
[[1.4004541e-09 2.9884575e-10 1.6915389e-29 9.1038288e-13 9.9929798e-017.0196530e-04]], shape=(1, 6), dtype=float32)
tf.Tensor(
[[1.4004541e-09 2.9884575e-10 1.6915389e-29 9.1038288e-13 9.9929798e-017.0196530e-04]], shape=(1, 6), dtype=float32)
两者结果一致,且在索引4处的概率值最大,表明下一个token的预测结果为4,符合真实值。
相关文章:
Causal Attention的底层原理
Causal Attention Transformer的Decoder中最显著的结构是Casual Attention。 通过本篇文章,你将学会 Casual Attention的机制原理 Casual Attention在TensorFlow中的实现原理 如何快速地保存并打印TensorFlow中模型已经训练好的参数 如何实现Transformer的Dec…...

深入理解类:ArkTS面向对象编程的核心概念
# 深入理解类:ArkTS面向对象编程的核心概念 在编程世界里,面向对象编程(OOP)是一种强大的编程范式,而类则是OOP的核心构建块。在ArkTS语言中,类的设计和使用对于构建复杂、可维护的应用程序至关重要。今天…...

AI 驱动下的后端开发架构革命:从智能协同体系
AI 驱动下的后端开发架构革命:从智能协同体系 一、引言:AI 重构后端开发范式 在 2025 年的企业级技术演进中,人工智能正从辅助工具升级为核心架构要素。根据 Gartner《2025 智能技术栈成熟度报告》,传统 "人力编码 硬规则…...

vue3 Ts axios 封装
vue3 Ts axios 封装 axios的封装 import axios, { AxiosError, AxiosInstance, InternalAxiosRequestConfig, AxiosResponse, AxiosRequestConfig, AxiosHeaders } from axios import qs from qs import { config } from ./config import { ElMessage } from element-plus// …...
CyberAgentAILab 开源数字人项目TANGO,heygen的开源版来了~
简介 TANGO 是 CyberAgentAILab 开源的一项前沿研究成果,其初衷在于探索高效生成模型在实际应用场景中的表现。项目诞生于 CyberAgent 在整合创意与人工智能的实践中,旨在为数字内容生成、交互和实时渲染等领域提供一个高性能、模块化、可扩展的解决方案…...
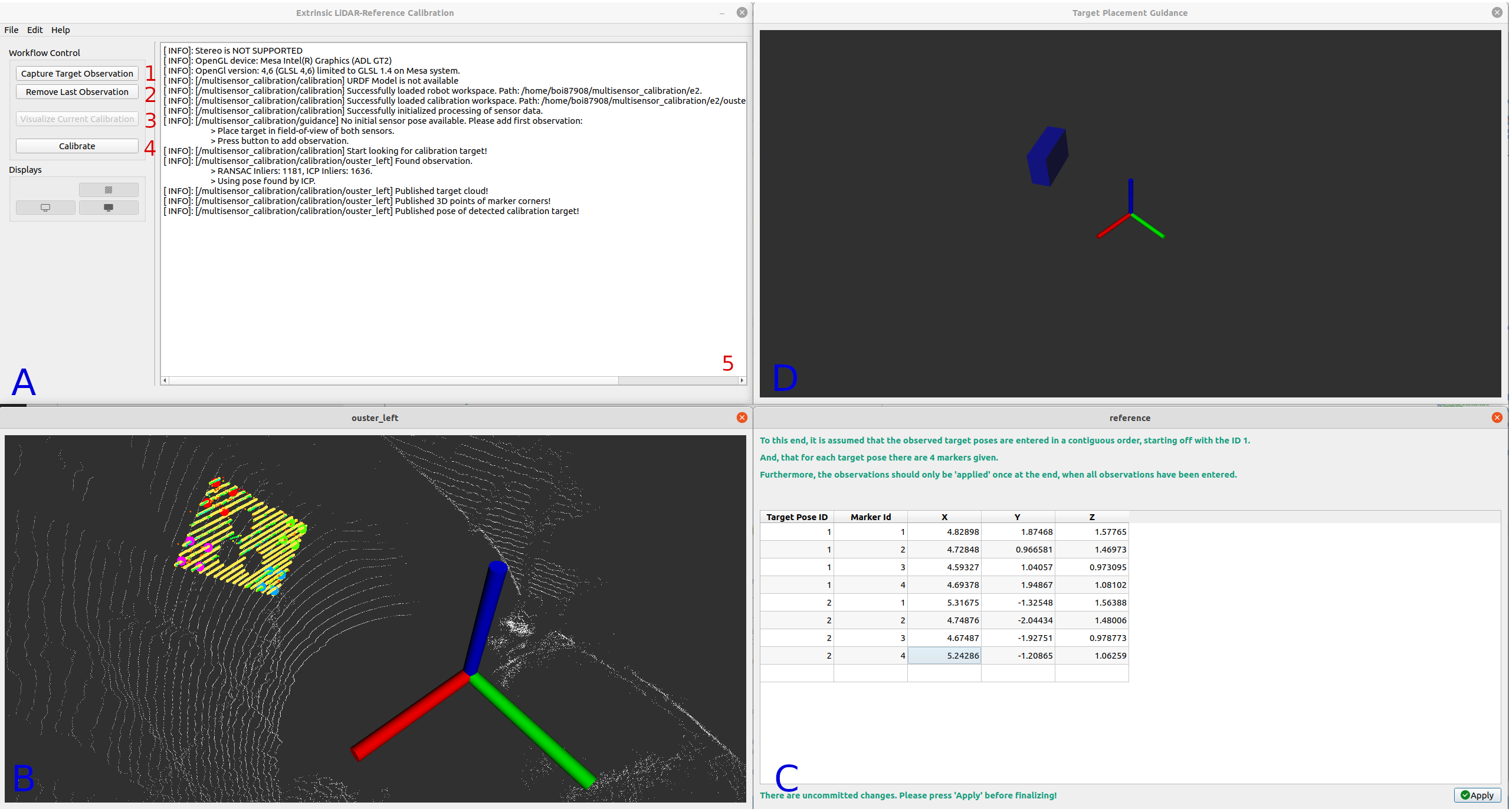
ROS ROS2 机器人深度相机激光雷达多传感器标定工具箱入门教程(一)
系列文章目录 目录 系列文章目录 前言 一、安装 1.1 ROS 2 官方软件包 二、教程 2.1 标定配置器 2.1.1 机器人选项 2.1.2.1 外参相机-激光雷达标定 2.1.2.2 外参激光雷达-激光雷达标定 2.1.2.3 外参相机参照标定 2.1.2.4 外参激光雷达-参考标定 2.2 外参照相机-激…...
:ながら 一边。。一边)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(6):ながら 一边。。一边
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(6):ながら 一边。。一边 1、前言(1)情况说明(2)工程师的信仰 2、知识点(1)ながら1)一边。。一边2࿰…...

从EOF到REOF:如何用旋转经验正交函数提升时空数据分析精度?
目录 1. 基本概念与原理2. 应用场景3. 与传统EOF的区别4. 技术实现5. 其他领域中的“REOF”参考资料 REOF 的输入是多个地区在不同时间的气候数据(如温度或降雨量),它的作用是通过旋转计算找出这些数据中最主要的变化规律,输出则是…...
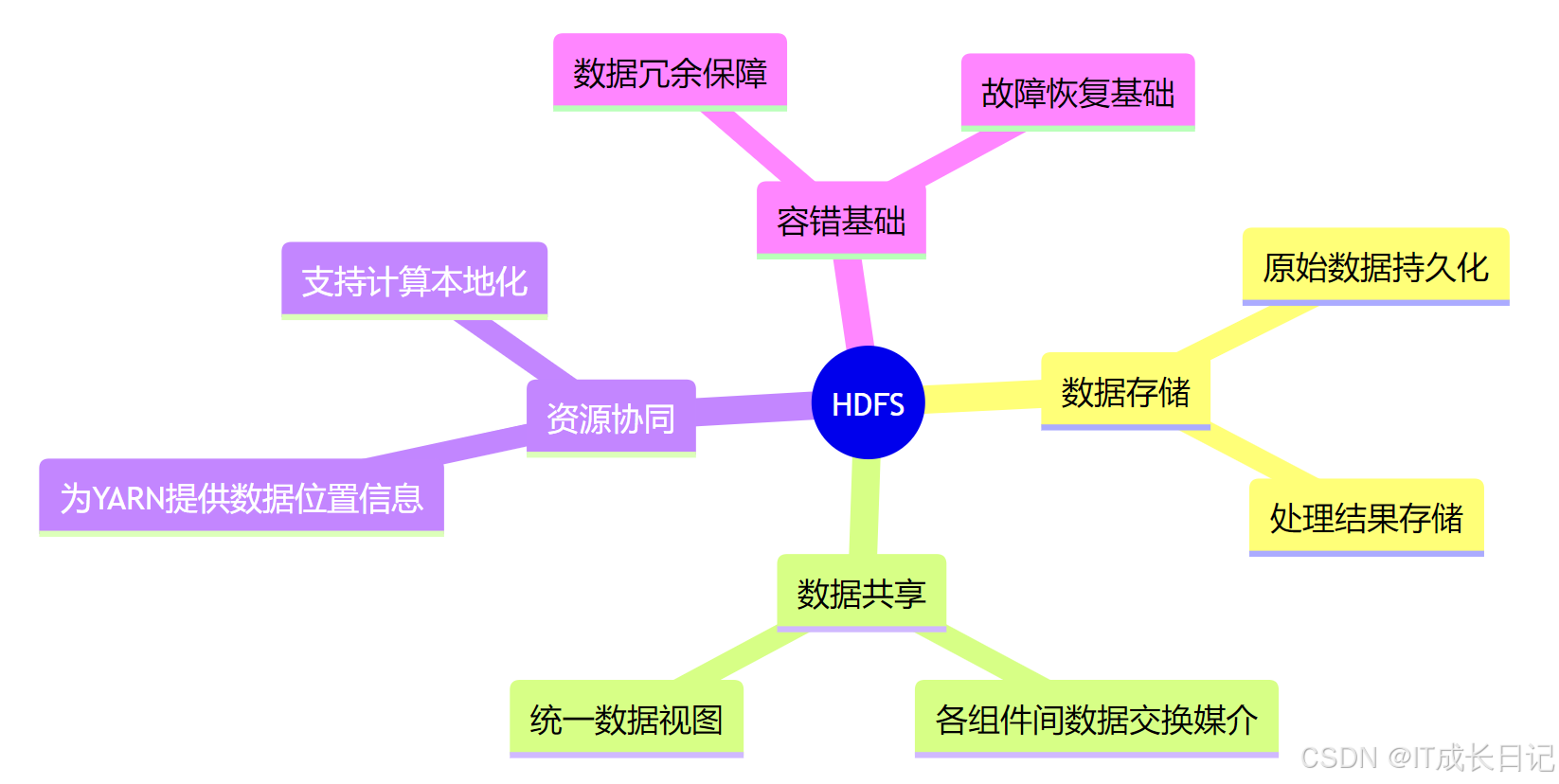
【HDFS入门】HDFS与Hadoop生态的深度集成:与YARN、MapReduce和Hive的协同工作原理
目录 引言 1 HDFS核心架构回顾 2 HDFS与YARN的集成 3 HDFS与MapReduce的协同 4 HDFS与Hive的集成 4.1 Hive架构与HDFS交互 4.2 Hive数据组织 4.3 Hive查询执行流程 5 HDFS在生态系统中的核心作用 6 性能优化实践 7 总结 引言 在大数据领域,Hadoop生态系统…...
用 AI 十天开发小程序:探秘 “幸运塔塔屋” 之 “解惑指南书” 功能
在当今软件开发领域,AI 技术正以前所未有的速度改变着我们的开发方式。我仅用十天时间,借助 AI 成功开发出 “幸运塔塔屋” 小程序,其中 “解惑指南书” 功能别具一格。今天,就为大家详细剖析这个功能从构思到落地的全过程。 十天…...
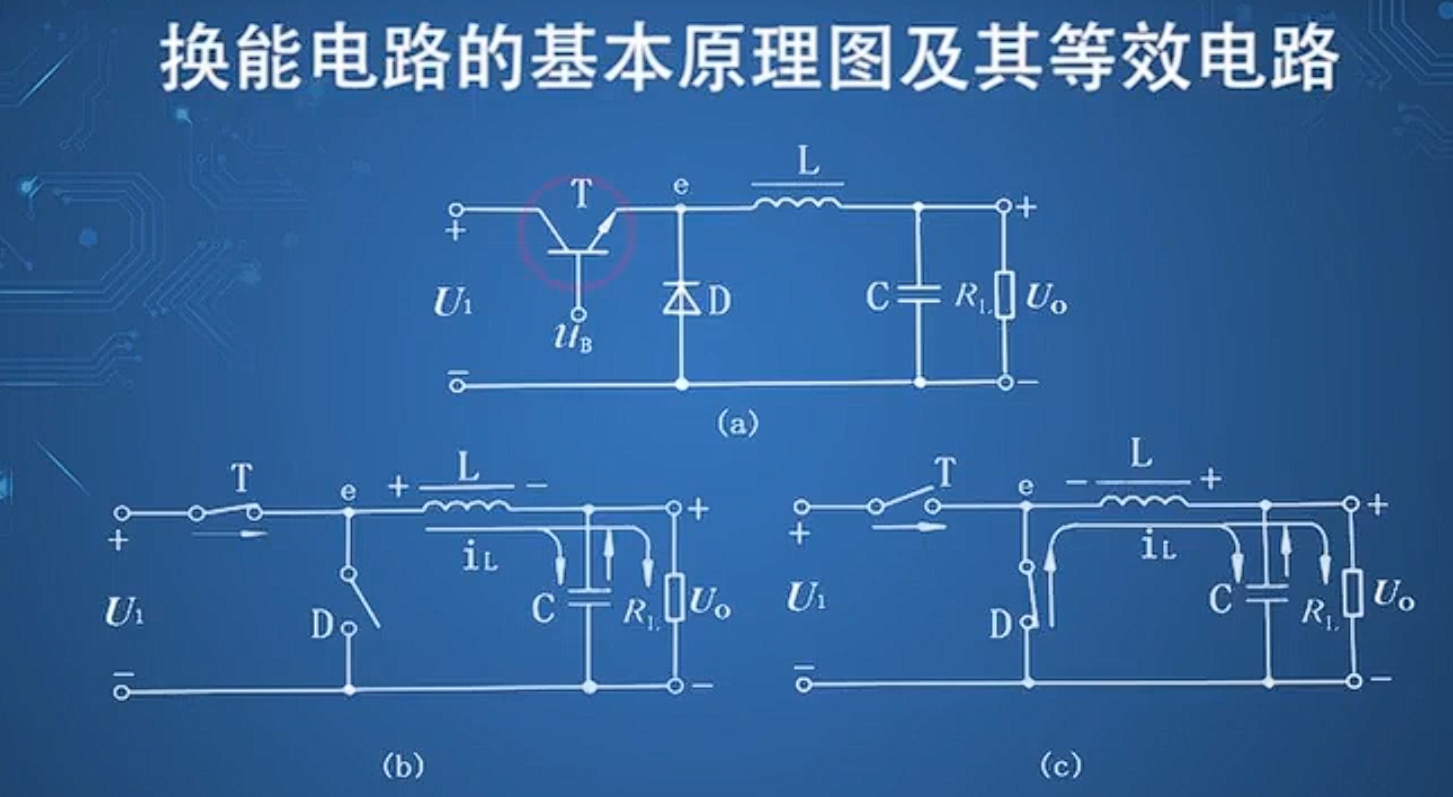
直流电源基本原理
整流电路 在构建整流电路时,要选择合适参数的二极管 If是二极管能够通过电流的能力,也是最大整流的平均电流。 还要考虑二极管的反向截至电压。 脉动系数电压交流幅值/直流平均电压(越小越好) 三相整流电路优点: …...

osu ai 论文笔记 DQN
e https://theses.liacs.nl/pdf/2019-2020-SteeJvander.pdf Creating an AI for the Rhytm Game osu! 20年的论文 用监督学习训练移动模型100首歌能达到95准确率 点击模型用DQN两千首歌65准确率 V抖用的居然不是强化学习? 5,6星打96准确度还是有的东西的 这是5.…...

MapReduce实验:分析和编写WordCount程序(对文本进行查重)
实验环境:已经部署好的Hadoop环境 Hadoop安装、配置与管理_centos hadoop安装-CSDN博客 实验目的:对输入文件统计单词频率 实验过程: 1、准备文件 test.txt文件,它是你需要准备的原始数据文件,存放在你的 Linux 系…...
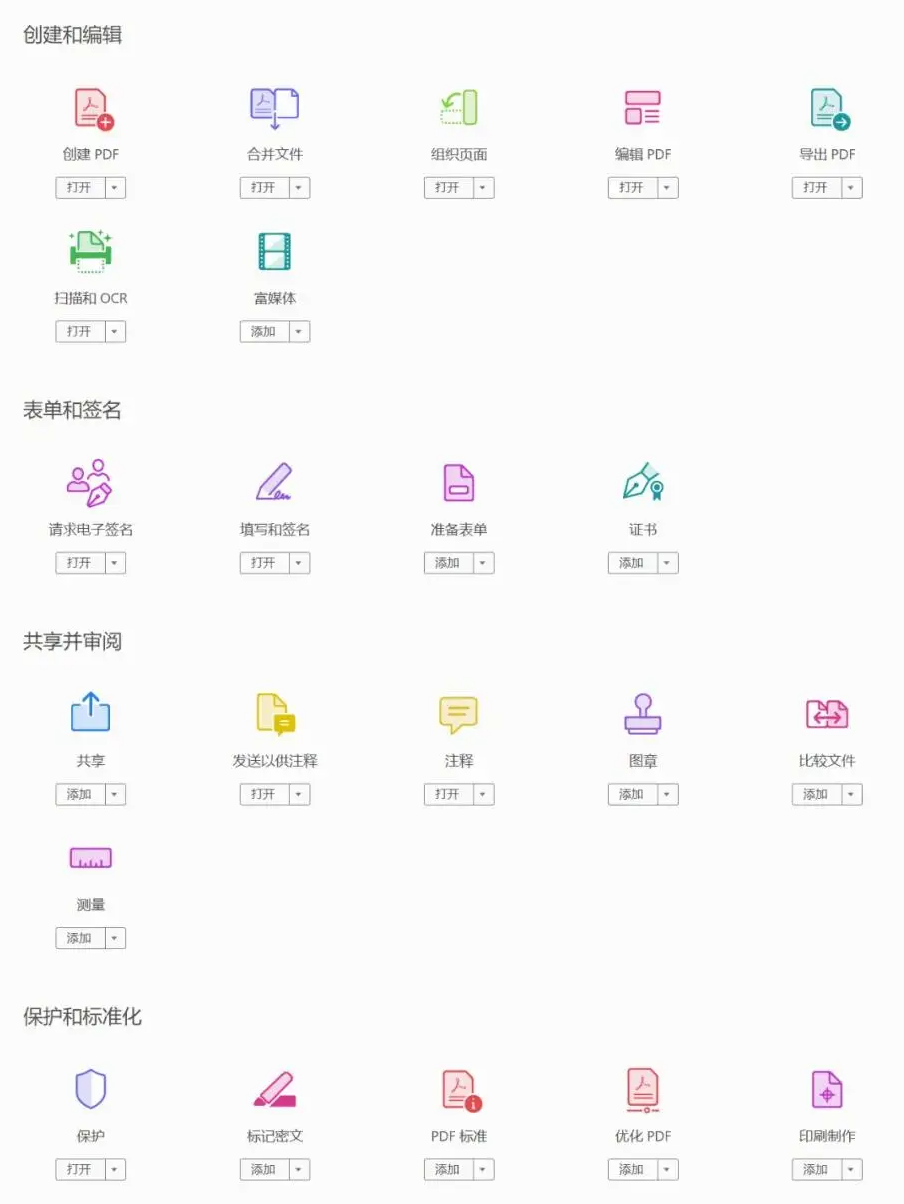
Windows Acrobat Pro DC-v2025.001.20435-x64-CN-Portable便携版
Windows Acrobat Pro 链接:https://pan.xunlei.com/s/VOO1nMjQ1Qf53dyISGne0c_9A1?pwdsfgn# Acrobat Pro 2024 专业增强版特色 ● 创建和编辑 PDF 文件:可以将各种类型的文档转换为 PDF 格式,并进行编辑和修改。 ● 合并和拆分 PDF&#…...

二十、FTP云盘
1、服务端 #include <stdio.h> #include <string.h> #include <stdlib.h> #include <sys/types.h> #include <unistd.h> #include <sys/types.h> /* See NOTES */ #include <sys/socket.h> #include <netinet/in.h>…...

【4】k8s集群管理系列--harbor镜像仓库本地化搭建
一、harbor基本概念 Harbor是一个由VMware开源的企业级Docker镜像仓库解决方案,旨在解决企业在容器化应用部署中的痛点,提供镜像存储、管理、安全和分发的全生命周期管理。Harbor扩展了Docker Registry,增加了企业级功能,如…...

Oracle 12.1.0.2补丁安装全流程
第一步,先进行备份 tar -cvf u01.tar /u01 第二步,更新OPatch工具包 根据补丁包中readme信息汇总提示的信息,下载对应版本的OPatch工具包,本次下载的版本为: p6880880_122010_Linux-x86-64.zip opatch版本为最新的…...

【AAOS】【源码分析】Car UX Restrictions
AAOS UX的核心理念:安全驾驶是驾驶员的首要责任。汽车制造商和应用程序开发人员的所有设计都必须反映这一优先事项。 AAOS平台允许设备制造商(OEM)对不同驾驶状态下的限制进行定制。 驾驶员分心指南 只有符合Driver Distraction Guidelines的应用才可以在驾驶过程中运行。…...

解读《人工智能指数报告 2025》:洞察 AI 发展新态势
美国斯坦福大学 “以人为本人工智能研究院”(HAI)近日发布的第八版《人工智能指数报告》(AI Index Report 2025)备受全球瞩目。自 2017 年首次发布以来,该报告一直为政策制定者、研究人员、企业高管和公众提供准确、严…...

【SpringBoot+Vue自学笔记】003 SpringBoot Controll
跟着这位老师学习的:https://www.bilibili.com/video/BV1nV4y1s7ZN?vd_sourceaf46ae3e8740f44ad87ced5536fc1a45 这段话的意思其实是:Spring Boot 简化了传统 Web 项目的搭建流程,让你少折腾配置,直接开搞业务逻辑。 ὒ…...

探索Web3平台的数据安全和保护机制
在数字化时代,Web3 平台以其去中心化、透明性和用户主权等特点,正逐渐成为互联网技术的新宠。然而,随着数据价值的日益凸显,Web3 平台的数据安全和保护机制变得尤为重要。本文将深入探讨 Web3 平台的数据安全和保护机制࿰…...

基于ssh密钥访问远程Linux
1、在本地机器上生成密钥对(默认保存在 ~/.ssh/) ssh-keygen -t ed25519 或使用 RSA(兼容性更好): ssh-keygen -t rsa -b 4096 2、 将公钥上传到远程主机 方法一:使用 ssh-copy-id ssh-copy-id -i ~/.ssh/id_ed25519.pub us…...

《基于神经网络实现手写数字分类》
《基于神经网络实现手写数字分类》 一、主要内容: 1、通过B站陈云霁老师的网课,配合书本资料,了解神经网络的基本组成和数学原理。 2、申请云平台搭建实验环境 3、基于5个不同的实验模块逐步理解实验操作步骤,并实现不同模块代码…...
1 cline 提示词工程指南-架构篇
cline 提示词工程指南-架构篇 本篇是 cline 提示词工程指南的学习和扩展,可以参阅: https://docs.cline.bot/improving-your-prompting-skills/prompting 前言 cline 是 vscode 的插件,用来在 vscode 里实现 ai 编程。 它使得你可以接入…...
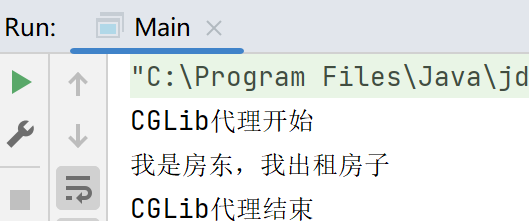
代理模式简述
目录 一、主要角色 二、类型划分 三、静态代理 示例 缺点 四、动态代理 JDK动态代理 示例 缺点 CGLib动态代理 导入依赖 示例 五、Spring AOP 代理模式是一种结构型设计模式,通过代理对象控制对目标对象的访问,可在不改变目标对象情况下增强…...
:Hello World)
Operator 开发入门系列(一):Hello World
背景 我们公司最近计划将产品迁移到 Kubernetes 环境。 为了更好地管理和自动化我们的应用程序,我们决定使用 Kubernetes Operator。 本系列博客将记录我们学习和开发 Operator 的过程,希望能帮助更多的人入门 Operator 开发。 目标读者 对 Kubernete…...
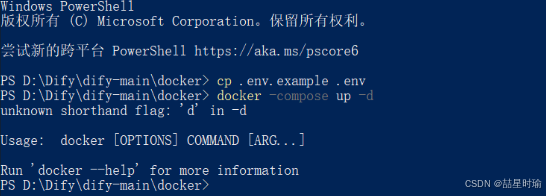
【Docker】运行错误提示 unknown shorthand flag: ‘d‘ in -d ----详细解决方法
使用docker拉取Dify的时候遇到错误 错误提示 unknown shorthand flag: d in -dUsage: docker [OPTIONS] COMMAND [ARG...]错误原因解析 出现 unknown shorthand flag: d in -d 的根本原因是 Docker 命令格式与当前版本不兼容,具体分为以下两种情况: 新…...

【AI插件开发】Notepad++ AI插件开发实践:实现对话窗口功能
引言 之前的文章已经介绍实现了AI对话窗口,但只有个空壳,没有实现功能。本次将集中完成对话窗口的功能,主要内容为: 模型动态切换:支持运行时加载配置的AI模型列表交互式输入处理:实现多行文本输入与Ctrl…...
在激烈竞争下B端HMI设计怎样打造独特用户体验?
在当今数字化高度发展的时代,B 端市场竞争愈发激烈。对于 B 端 HMI(人机界面)设计而言,打造独特的用户体验已成为在竞争中脱颖而出的关键因素。B 端用户在复杂的工作场景中,对 HMI 设计有着独特的需求和期望࿰…...
【Netty篇】Handler Pipeline 详解
目录 一、 Handler & Pipeline——流水线上的“特种部队”与“生产线”1、 ChannelHandler —— 流水线上的“特种兵”👮♂️2、 ChannelPipeline —— 生产线上的“接力赛跑”🏃♀️🏃♂️ 二、 代码实例1、 服务端代码示例2、 客…...