【4.1.-4.20学习周报】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 摘要
- Abstract
- 一、方法介绍
- 1.1HippoRAG
- 1.2HippoRAG2
- 二、实验
- 2.1实验概况
- 2.2实验代码
- 2.3实验结果
- 总结
摘要
本博客介绍了论文《From RAG to Memory: Non-Parametric Continual Learning for
Large Language Models》提出HippoRAG 2框架,以解决现有检索增强生成(RAG)系统在模拟人类长期记忆方面的局限。首先分析了持续学习LLMs的挑战及RAG方法的不足,如无法捕捉长期记忆的意义构建和关联性。接着介绍HippoRAG 2的离线索引和在线检索流程,通过密集 - 稀疏集成、深度上下文关联和识别记忆等改进,增强了与人类记忆机制的契合度。实验表明,HippoRAG 2在事实、意义构建和关联记忆任务上全面超越标准RAG方法,为LLMs的非参数持续学习开辟了新途径。
之前的周报我也有提到HippoRAG,HippoRAG 2是对HippoRAG进行升级和改进
Abstract
This blog presents the paper From RAG to Memory: Non-Parametric Continual Learning for Large Language Models proposes the HippoRAG 2 framework to address the limitations of existing Retrieval Enhancement Generation (RAG) systems in simulating human long-term memory. Firstly, the challenges of continuous learning LLMs and the shortcomings of RAG methods, such as the inability to capture the meaning-making and correlation of long-term memory, were analyzed. Next, the offline indexing and online retrieval process of HippoRAG 2 is introduced, which enhances the fit with human memory mechanisms through improvements such as dense-sparse integration, deep context association, and recognition memory. Experiments show that HippoRAG 2 surpasses the standard RAG method in fact, meaning construction and associative memory tasks, opening up a new way for nonparametric continuous learning of LLMs
一、方法介绍
最近提出了几个RAG框架,这些框架使用LLM来显式地构建其检索语料库,以解决这些限制。为了增强意义构建,这种结构增强RAG方法允许LLM生成摘要或知识图(KG)结构连接不同但相关的段落组,从而提高RAG系统理解更长的更复杂的话语的能力。
为了解决联想性差距,HippoRAG使用了个性化PageRank算法和LLM自动构建KG并赋予检索过程多跳推理能力的能力。
尽管这些方法在这两种更具挑战性的记忆任务中表现出了强大的性能,但要使RAG真正接近人类的长期记忆,还需要在更简单的记忆任务中进行非业务操作。为了了解这些系统是否能够实现这样的业务,研究者进行了全面的实验,不仅通过多跳QA大规模语篇理解同时评估它们的联想性和意义构建能力,还通过简单的QA任务测试它们的事实记忆能力。
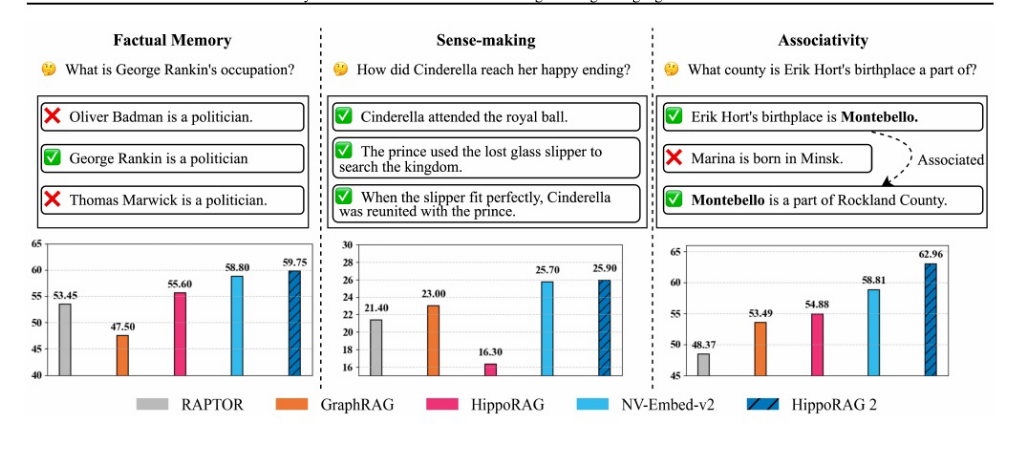
如上图所示,,在所有三种基准类型上,与最强的基于嵌入的RAG方法相比,所有先前的结构增强方法都表现不佳。
研究者提出的方法,HippoRAG 2,利用HippoRAG的OpenIE和个性化PageRank (PPR)方法的优势,同时通过将段落整合到PPR图搜索过程中,解决了基于查询的上下文化限制。在KG三元组的选择中更深入地涉及查询,并在在线检索过程中使用LLM来识别检索到的三元组何时不相关。
1.1HippoRAG
在这里对之前看过的HippoRAG做一个简单的复习。HippoRAG是是一个受神经生物学启发的llm长期记忆框架,每个组件都旨在模拟人类记忆的各个方面。该框架由三个主要部分组成:人工新皮层(LLM),海马旁区(PHR编码器)和人工海马(开放KG)。这些组成部分协作复制了人类长期记忆中观察到的相互作用。
对于HippoRAG离线索引,LLM将pass -sages处理成KG三元组,然后将其合并到工海马索引中。同时,PHR负责检测同义词以实现信息互连。对于HippoRAG在线检索,LLM新皮层从查询中提取命名实体,而PHR编码器将这些实体链接到海马体索引。然后,在KG上进行个性化PageRank (personal - personalisedPageRank, PPR)算法,进行基于上下文的检索。尽管HippoRAG试图从非参数RAG构建记忆,但其有效性受到一个关键缺陷的阻碍:以实体为中心的方法会导致索引和推理过程中的上下文丢失,以及语义匹配困难。
1.2HippoRAG2
基于HippoRAG中提出的神经生物学启发的长期记忆框架,HippoRAG 2的结构遵循类似的两阶段过程:离线索引和在线检索.
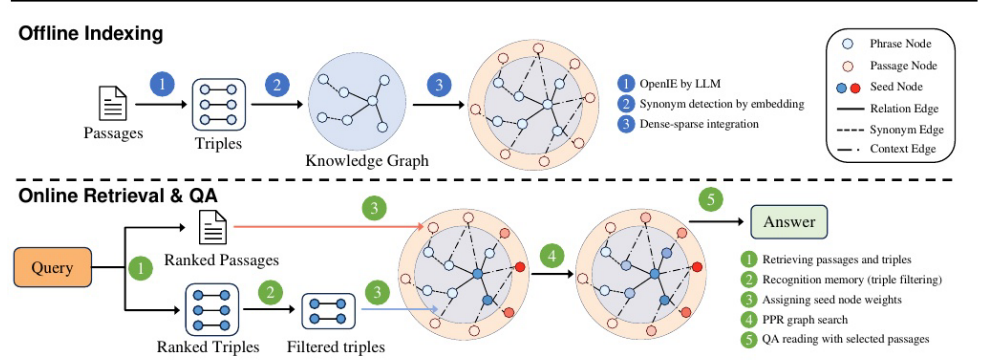 HippoRAG 2方法。对于离线索引,使用LLM从段落中提取开放的KG三元组,并将同义词检测应用于短语节点。这些短语和段落一起构成了开放式的KG。对于在线检索,嵌入模型对段落和三元组进行评分,以识别个性化PageRank (PPR)算法的两种类型的种子节点。识别记忆使用LLM过滤最上面的三元组。然后,PPR算法在KG上执行基于上下文的检索,为最终的QA任务提供最相关的段落。上面KG节点的不同颜色反映了它们的概率质量;深色表示PPR过程引起的可能性较高。
HippoRAG 2方法。对于离线索引,使用LLM从段落中提取开放的KG三元组,并将同义词检测应用于短语节点。这些短语和段落一起构成了开放式的KG。对于在线检索,嵌入模型对段落和三元组进行评分,以识别个性化PageRank (PPR)算法的两种类型的种子节点。识别记忆使用LLM过滤最上面的三元组。然后,PPR算法在KG上执行基于上下文的检索,为最终的QA任务提供最相关的段落。上面KG节点的不同颜色反映了它们的概率质量;深色表示PPR过程引起的可能性较高。
HippoRAG2在原有的基础上通过引入以下几个层面来增强与人类长期记忆的关联,:1)它在开放的KG中无缝地集成了概念和上下文信息,增强了构建索引的全面性和原子性。2)通过利用KG结构超越孤立的KG节点,它促进了更多的上下文感知检索。3)它结合了识别记忆,以改进图搜索的种子节点选择。
受人脑中观察到的密集-稀疏整合的启发,研究者将短语节点作为提取概念的稀疏编码形式,同时将密集编码纳入我们的KG中,以表示这些概念产生的上下文。首先,采用了一种编码方法——类似于短语的编码方式,使用嵌入模型。然后在KG中以特定的方式集成这两种类型的编码。与HippoRAG中的文档集成(简单地从图搜索嵌入匹配中聚合分数)不同,通过引入通道节点来增强KG,实现上下文信息的更无缝集成。这种方法保留了与HippoRAG相同的离线索引过程,同时在构建过程中使用与通道相关的附加节点和边来丰富图结构。具体来说,语料库中的每个段落都被视为一个段落节点,上下文边缘标记为“contains”,将该段落与从该段落衍生出来的所有短语连接起来。
Recognition Memory:回忆和识别是人类记忆检索中的两个互补过程。回忆涉及在没有外部线索的情况下主动检索信息,而识别则依赖于在外部刺激的帮助下识别信息。受此启发,我们将查询到三重检索建模为一个两步过程。1) Query to Triple:使用嵌入模型检索图的top-k个三元组T。2)三重过滤:使用llm来过滤检索到的T并生成三元组T′⊆T。
二、实验
2.1实验概况
研究者选择了三种比较方法作为基线:1)经典寻回犬BM25 (、和GTR (Ni et al., 2022)。2)在BEIR排行榜上表现良好的大型嵌入模型、,包括阿里巴巴- nlp /GTE-Qwen2-7B-Instruct 、、GritLM/GritLM- 7b 、和nvidia/NV-Embed-v2 、。3)结构增强RAG方法,包括RAPTOR 、GraphRAG 、LightRAG ()和Hip-poRAG 。
数据集:为了评估RAG系统在增强联想性和意义构建的同时保留
事实记忆的能力,选择了对应于三种关键挑战类型的数据集:1)简单QA主要评估准确回忆和检索事实知识的能力。2)多跳QA(Multi-hop QA)通过要求模型连接多
个信息来得出答案来衡量关联性。3)话语理解(discourseunderstanding)通过测试的方法来评估意义构建对冗长、复杂的叙述进行解释和推理的能力。

2.2实验代码
完整项目代码:实验代码
以下展示HippoRAG2的关键实现代码:
import torch
from transformers import AutoModel, AutoTokenizer, pipeline
import networkx as nx
import numpy as np# Load models
llm_model_name = "meta-llama/Llama-3.3-70B-Instruct"
encoder_model_name = "nvidia/NV-Embed-v2"
llm_tokenizer = AutoTokenizer.from_pretrained(llm_model_name)
llm_model = AutoModel.from_pretrained(llm_model_name)
encoder_tokenizer = AutoTokenizer.from_pretrained(encoder_model_name)
encoder_model = AutoModel.from_pretrained(encoder_model_name)# Offline Indexing
def offline_indexing(corpus):"""Build the knowledge graph from the corpus during offline indexing.Args:corpus (list): List of text passages.Returns:kg (nx.DiGraph): Knowledge graph with phrase and passage nodes.phrase_to_passage (dict): Mapping of phrases to passage IDs."""kg = nx.DiGraph()phrase_to_passage = {}for passage_id, passage in enumerate(corpus):# Extract triples using LLMtriples = extract_triples(passage)for triple in triples:subject, relation, object_ = triplekg.add_edge(subject, object_, relation=relation)phrase_to_passage[subject] = passage_idphrase_to_passage[object_] = passage_id# Add passage node and connect to phrasespassage_node = f"passage_{passage_id}"kg.add_node(passage_node, type="passage", content=passage)for triple in triples:kg.add_edge(passage_node, triple[0], relation="contains")kg.add_edge(passage_node, triple[2], relation="contains")# Synonym detectionphrases = [node for node in kg.nodes if not node.startswith("passage_")]if phrases:phrase_embeddings = get_embeddings(phrases)for i in range(len(phrases)):for j in range(i + 1, len(phrases)):similarity = cosine_similarity(phrase_embeddings[i], phrase_embeddings[j])if similarity > 0.8: # Synonym thresholdkg.add_edge(phrases[i], phrases[j], relation="synonym")kg.add_edge(phrases[j], phrases[i], relation="synonym")return kg, phrase_to_passagedef extract_triples(passage):"""Extract triples from a passage using an LLM (simplified placeholder).Args:passage (str): Text passage.Returns:list: List of (subject, relation, object) triples."""# Placeholder: In practice, use OpenIE with LLMreturn [("example_subject", "example_relation", "example_object")]def get_embeddings(texts):"""Generate embeddings for a list of texts using the encoder.Args:texts (list): List of text strings.Returns:torch.Tensor: Embeddings tensor."""inputs = encoder_tokenizer(texts, return_tensors="pt", padding=True, truncation=True)with torch.no_grad():embeddings = encoder_model(**inputs).last_hidden_state.mean(dim=1)return embeddingsdef cosine_similarity(a, b):"""Compute cosine similarity between two vectors.Args:a (np.ndarray): First vector.b (np.ndarray): Second vector.Returns:float: Cosine similarity score."""return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))# Online Retrieval
def online_retrieval(query, kg, phrase_to_passage, corpus):"""Perform online retrieval for a given query.Args:query (str): User query.kg (nx.DiGraph): Knowledge graph.phrase_to_passage (dict): Mapping of phrases to passage IDs.corpus (list): List of text passages.Returns:str: Generated answer."""# Query to triplesquery_embedding = get_embeddings([query])[0]triples = [(s, o, d['relation']) for s, o, d in kg.edges(data=True) if d['relation'] != "contains" and d['relation'] != "synonym"]if triples:triple_texts = [f"{s} {r} {o}" for s, r, o in triples]triple_embeddings = get_embeddings(triple_texts)similarities = [cosine_similarity(query_embedding, emb) for emb in triple_embeddings]top_k_indices = np.argsort(similarities)[-5:][::-1] # Top-5 triplestop_k_triples = [triples[i] for i in top_k_indices]else:top_k_triples = []# Recognition memory filteringfiltered_triples = filter_triples(query, top_k_triples)# Personalized PageRankif filtered_triples:seed_phrases = set()for triple in filtered_triples:seed_phrases.add(triple[0])seed_phrases.add(triple[2])seed_passages = [node for node in kg.nodes if node.startswith("passage_")]seed_nodes = list(seed_phrases) + seed_passages# Assign reset probabilitiesreset_probabilities = {}phrase_total = len(seed_phrases)passage_total = len(seed_passages)for node in seed_phrases:reset_probabilities[node] = 0.95 / phrase_total if phrase_total > 0 else 0for node in seed_passages:reset_probabilities[node] = 0.05 / passage_total if passage_total > 0 else 0ppr_scores = nx.pagerank(kg, personalization=reset_probabilities, alpha=0.5)ranked_passages = sorted([(node, score) for node, score in ppr_scores.items() if node.startswith("passage_")],key=lambda x: x[1],reverse=True)top_passage_ids = [int(node.split("_")[1]) for node, _ in ranked_passages[:5]]else:# Fallback to embedding-based retrievalpassage_embeddings = get_embeddings(corpus)similarities = [cosine_similarity(query_embedding, emb) for emb in passage_embeddings]top_passage_ids = np.argsort(similarities)[-5:][::-1]# Generate answercontext = " ".join([corpus[i] for i in top_passage_ids])answer = generate_answer(query, context)return answerdef filter_triples(query, triples):"""Filter triples based on relevance to the query using LLM (simplified placeholder).Args:query (str): User query.triples (list): List of (subject, relation, object) triples.Returns:list: Filtered list of triples."""# Placeholder: In practice, use LLM with prompts as in Appendix Areturn triples # Simplified: return all triplesdef generate_answer(query, context):"""Generate an answer using the LLM based on query and context (simplified placeholder).Args:query (str): User query.context (str): Retrieved context.Returns:str: Generated answer."""# Placeholder: In practice, use LLM for QAreturn "Generated answer based on context"# Example usage
if __name__ == "__main__":corpus = ["Example passage 1 about some topic.","Example passage 2 with related information.",# Add more passages as needed]kg, phrase_to_passage = offline_indexing(corpus)query = "What is the topic discussed in the passages?"answer = online_retrieval(query, kg, phrase_to_passage, corpus)print(f"Query: {query}")print(f"Answer: {answer}")
2.3实验结果
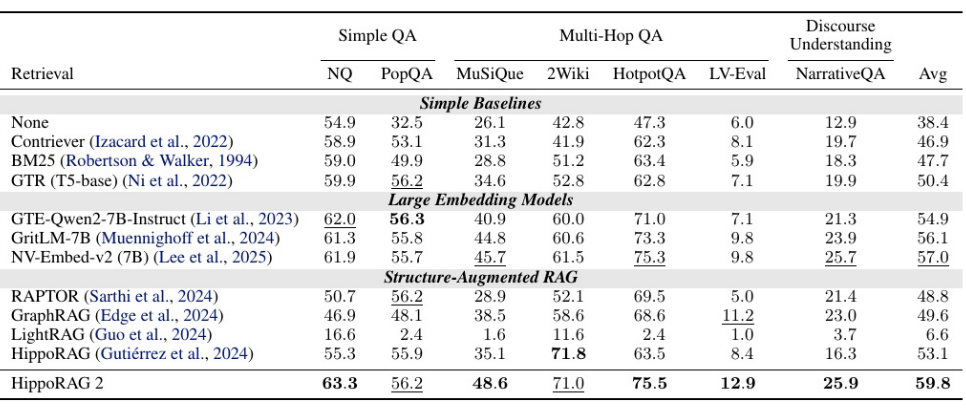
可以从上图看到,hippoRAG2在所有QA数据集上的表现均超过了基线模型以及之前的hippoRAG。
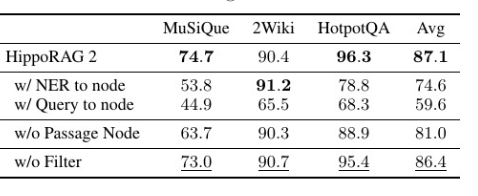
研究者针对所提出的连接方法、图构建方法和三重滤波方法设计了烧蚀实验,结果如上图所示。每个引入的机制都促进了HippoRAG 2。首先,具有更深上下文化的
链接方法带来了显著的性能提升。值得注意的是,没有对ner_to -node或查询to-node方法应用过滤过程;然而,无论是否应用过滤,查询到三重方法的性能始
终优于其他两种链接策略。与ner_to -node相比,查询-to-triple平均提高Recall12.5%。此外,查询到节点并不比ner_to -node具有优势,因为查询和KG节点在不
同的粒度级别上操作,而NER结果和KG节点都对应于短语级表示。
总结
基于HippoRAG,引入深度段落整合、上下文感知检索和识别记忆机制,使知识图谱更好融合概念与上下文信息。
在多类记忆任务上超越现有方法,尤其在联想记忆任务上比先进嵌入模型提升7%。
识别记忆中三元组过滤的精度有提升空间,部分样本过滤后无匹配短语或无三元组,需依赖密集检索结果。
个性化PageRank图搜索组件在部分样本中表现不佳,虽识别关键短语,但难以返回理想结果。
相关文章:
【4.1.-4.20学习周报】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 摘要Abstract一、方法介绍1.1HippoRAG 1.2HippoRAG2二、实验2.1实验概况2.2实验代码2.3实验结果 总结 摘要 本博客介绍了论文《From RAG to Memory: Non-Parametri…...

MySQL 临时表介绍
在 MySQL 数据库中,临时表是一种特殊类型的表,它在数据库会话期间存在,会话结束时自动删除。临时表为处理特定的、临时性的数据操作任务提供了一种高效且便捷的方式。 一、临时表的创建 使用CREATE TEMPORARY TABLE语句来创建临时表。其语法…...
 与type erase)
Rust : 关于*const () 与type erase
*const () 可以替代泛型,更加灵活。下面举了两个完全不一样的数据结构Foo和Bar;以及不同的函数,来说明。 一、 代码 trait Work {fn process(&self); } struct Foo(String);impl Work for Foo {fn process(&self) {println!("p…...

python学习—合并多个word文档
系列文章目录 python学习—合并TXT文本文件 python学习—统计嵌套文件夹内的文件数量并建立索引表格 python学习—查找指定目录下的指定类型文件 python学习—年会不能停,游戏抽签抽奖 python学习—循环语句-控制流 python学习—合并多个Excel工作簿表格文件 pytho…...

Java LinkedList深度解析:双向链表的实现艺术与实战指南
在Java集合框架中,LinkedList以其独特的双向链表结构和灵活的操作特性,成为处理动态数据的重要工具。本文将从底层实现、核心方法、性能优化到企业级应用场景,全方位解析这一经典数据结构的设计哲学与实战技巧。 一、LinkedList的设计定位与核心特性 1. 双向链表的本质 Lin…...

c#内存泄露的原因和解决办法
内存泄漏的原因 不正确的对象引用:最常见的原因是对象不再需要时未被垃圾回收器回收。例如,如果一个对象被一个不再使用的变量引用,它将不会被垃圾回收。事件订阅者未取消:如果订阅了一个事件但没有在对象不再需要时取消订阅&…...

android如何在生产环境中做到详实的日志收集而不影响性能?
在Android应用的生命周期中,日志收集贯穿于开发、测试到生产环境的每一个阶段。特别是在生产环境中,当应用部署到成千上万的用户设备上时,开发者无法直接访问用户的运行环境,也无法像在开发阶段那样通过调试工具实时查看代码执行情况。这时,日志就成为连接开发者与用户设备…...

MySQL安装实战:从零开始搭建你的数据库环境
MySQL作为全球最流行的开源关系型数据库,是开发者、运维人员及数据管理者的核心工具之一。本文将通过多平台安装指南、关键配置解析及常见问题排查三个维度,手把手带你完成MySQL环境搭建。 一、多平台安装指南 1. Linux系统(以Ubuntu为例&am…...

[Python] UV工具入门使用指南——小试牛刀
背景 MCP开发使用到了uv,简单记录一下: 为什么MCP更推荐使用uv进行环境管理? MCP 依赖的 Python 环境可能包含多个模块,uv 通过 pyproject.toml 提供更高效的管理方式,并且可以避免 pip 的一些依赖冲突问题。…...
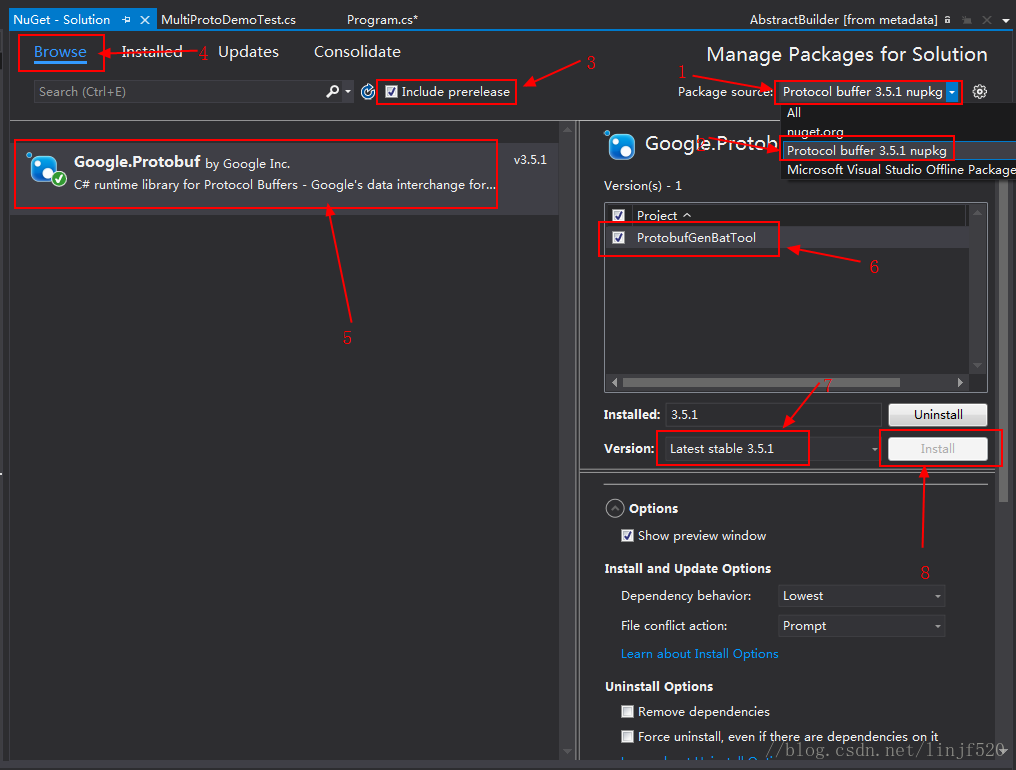
PclSharp ——pcl的c#nuget包
简介: NuGet Gallery | PclSharp 1.8.1.20180820-beta07 下载.NET Framework 4.5.2 Developer Pack: 下载 .NET Framework 4.5.2 Developer Pack Offline Installer 离线安装nupkg: nupkg是visual studio 的NuGet Package的一个包文件 安…...
)
多任务响应1(Qt)
多任务响应1 1. 架构概述2. 代码示例3. 说明 当系统的一些任务都是同一个对象产生,但需要交由不同对象进行响应。 比如:系统有多个按键,这些按键的共用一个槽函数,但不同的按键对应不同的功能响应。 推荐采用命令模式分散响应的思…...

1. k8s的简介
Kubernetes(k8s)简介 1. 产生背景 随着云计算和微服务架构的兴起,传统的单体应用逐渐被拆分为多个小型、松耦合的服务(微服务)。这种架构虽然提升了开发灵活性和可维护性,但也带来了新的挑战:…...

单片机 | 基于51单片机的倾角测量系统设计
以下是一个基于51单片机的倾角测量系统设计详解,包含原理、公式和完整代码: 一、系统原理 核心器件:MPU6050(集成3轴加速度计+陀螺仪) 主控芯片:STC89C52RC(51单片机) 显示模块:LCD1602液晶 工作原理: 通过MPU6050采集XYZ三轴加速度数据,利用重力加速度分量计算俯仰…...
和view(微信小程序专用组件)的主要区别体)
div(HTML标准元素)和view(微信小程序专用组件)的主要区别体
div(HTML标准元素)和view(微信小程序专用组件)的主要区别体现在以下方面: 一、应用场景与开发框架 适用平台不同 div是HTML/CSS开发中通用的块级元素,用于Web页面布局;view是微信小程序专…...

MGR实现mysql高可用性
一。MGR和PXC的区别 1. PXC的消息广播机制是在节点间循环的,需要所有节点都确认消息,因此只要有一个节点故障,则会导致整个PXC都发生故障。而MGR则是多数派投票模式,个别少数派节点故障时,一般不影响整体的可用性。这…...

新型多机器人协作运输系统,轻松应对复杂路面
受到鱼类、鸟类和蚂蚁等微小生物体协作操纵的启发,研究人员开发了多机器人协作运输系统(Multirobot Cooperative Transportation Systems,MRCTS)运输单个机器人无法处理的重型超大物体,可用于搜救行动、灾难响应、军事…...

汇编获取二进制
文章目录 AT&Tasm Intel AT&T mov_test.s mov $0,%r8dgcc -c mov_test.s 输出 mov_test.o,objdump -D mov_test.o 查看 mov_test.o: mov_test.o: file format elf64-x86-64Disassembly of section .text:0000000000000000 <.text>:0: 41 b8 00 00 00 00 …...

【秣厉科技】LabVIEW工具包——OpenCV 教程(19):拾遗 - imgproc 基础操作(上)
文章目录 前言imgproc 基础操作(上)1. 颜色空间2. 直方图3. 二值化4. 腐蚀、膨胀、开闭运算5. 梯度与轮廓6. 简易绘图7. 重映射 总结 前言 需要下载安装OpenCV工具包的朋友,请前往 此处 ;系统要求:Windows系统&#x…...

学习笔记:金融经济学 第3讲
学习笔记:金融经济学 第3讲 注:A本金,n时间(比如年),r利率一、 计算习惯1. 单息(新产生的利息不算进本金重新计算利息,收款额A(1nr) )2. 复利(新产生的利息算进本金重新计…...

NVIDIA RTX™ GPU 低成本启动零售 AI 场景开发
零售行业正在探索应用 AI 升级客户体验,同时优化内部流程。面对多重应用场景以及成本优化压力,团队可采用成本相对可控的方案,来应对多重场景的前期项目预演和落地,避免短期内大规模投入造成的资源浪费。 客户体验 AI 场景的研究…...
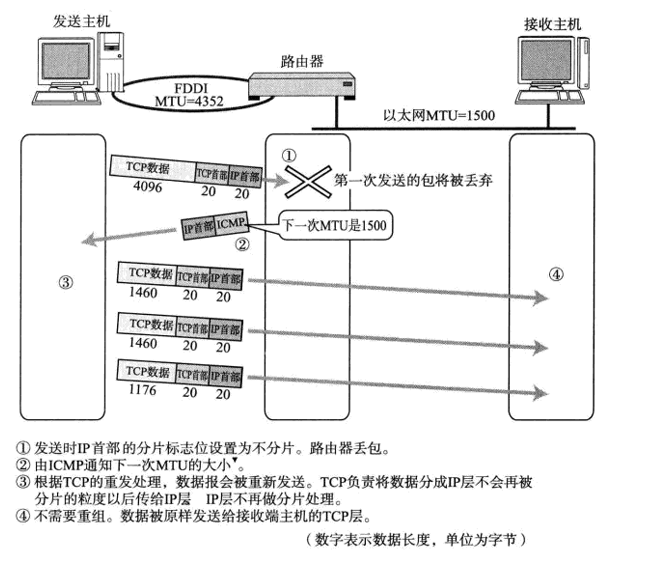
【网络】IP层的重要知识
目录 1.IP层的作用 2.主机和节点 3.网络层和数据链路层的关系 4.路由控制 4.1.路由控制的过程 4.2. IP地址与路由控制 4.3.路由控制表的聚合 4.4.静态路由和动态路由 4.5.动态路由的基础 5.数据链路的抽象化 5.1.数据链路不同,MTU则相异 5.2.路径MTU发…...
综论与跨学科应用)
数理逻辑(Mathematical Logic)综论与跨学科应用
李升伟 整理 数理逻辑(Mathematical Logic)是现代逻辑学与数学交叉的核心学科,以严格的数学方法研究逻辑推理的形式与规律。其发展深刻影响了数学基础、计算机科学、语言哲学等领域。以下从多个维度综论数理逻辑: 1. 核心分支 命…...

OpenCV 模板匹配方法详解
文章目录 1. 什么是模板匹配?2. 模板匹配的原理2.1数学表达 3. OpenCV 实现模板匹配3.1基本步骤 4. 模板匹配的局限性5. 总结 1. 什么是模板匹配? 模板匹配(Template Matching)是计算机视觉中的一种基础技术,用于在目…...
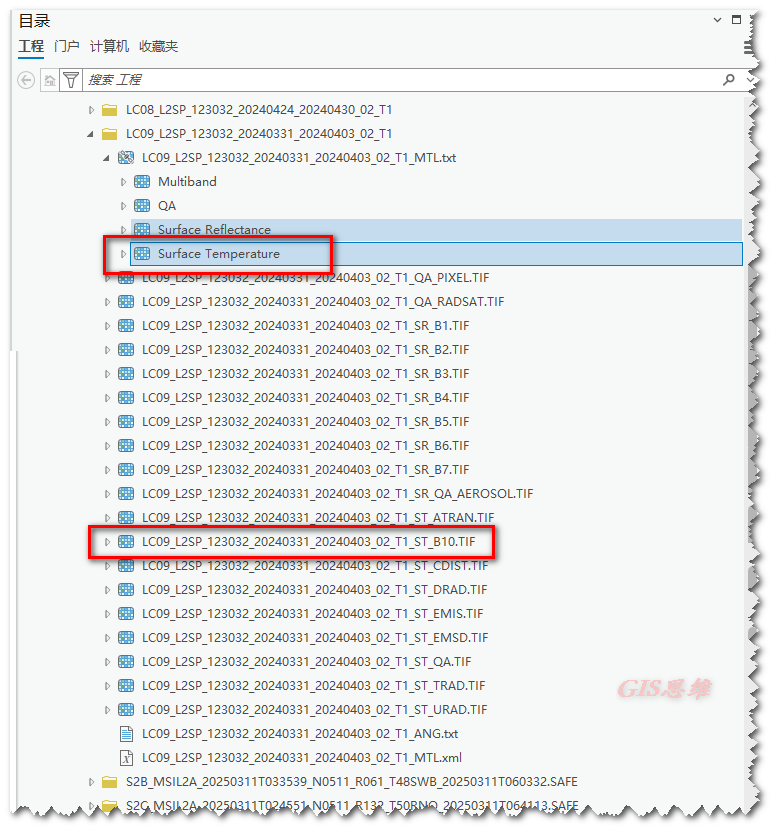
一键解锁Landsat 9地表温度计算!ENVI与ArcGIS Pro全流程详解(无需NASA大气校正)
为什么选择Landsat 9的L2SP数据? 之前:《ArcGIS与ENVI——基于landsat与Modis影像的遥感技术的生态环境质量评价》,基于Landsat前期的产品计算温度反演数据需要一系列复杂的步骤。 现在: Landsat 8-9的Collection 2 Level-2&…...
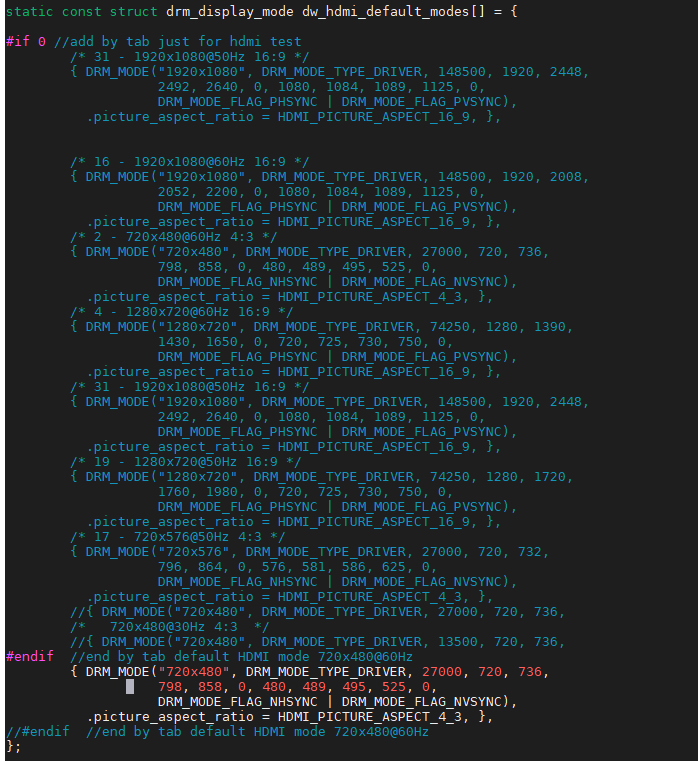
RK3588的linux下实现HDMI输出分辨率及帧率的裁剪
bug反馈:客户现场反馈hdmi接显示屏出现概率性闪黑屏,排除线材,显示屏及GND等外部因素后,提出尝试降低hdmi的输出分辨率和帧率对比测试看看。 Step1:先直接在linux的sdk中找到板卡编译生成后的dts找到hdmi节点 然后找到…...

XR技术赋能艺术展演|我的宇宙推动东方美学体验化
本次广州展览现场引入我的宇宙XR体验模块,通过空间计算与动作捕捉技术,让观众在潮玩艺术氛围中体验虚拟互动,打造“看得懂也玩得动”的展演新场景。 作为科技与文化融合的推动者,我的宇宙正在以“体验科技”为媒介,为潮…...
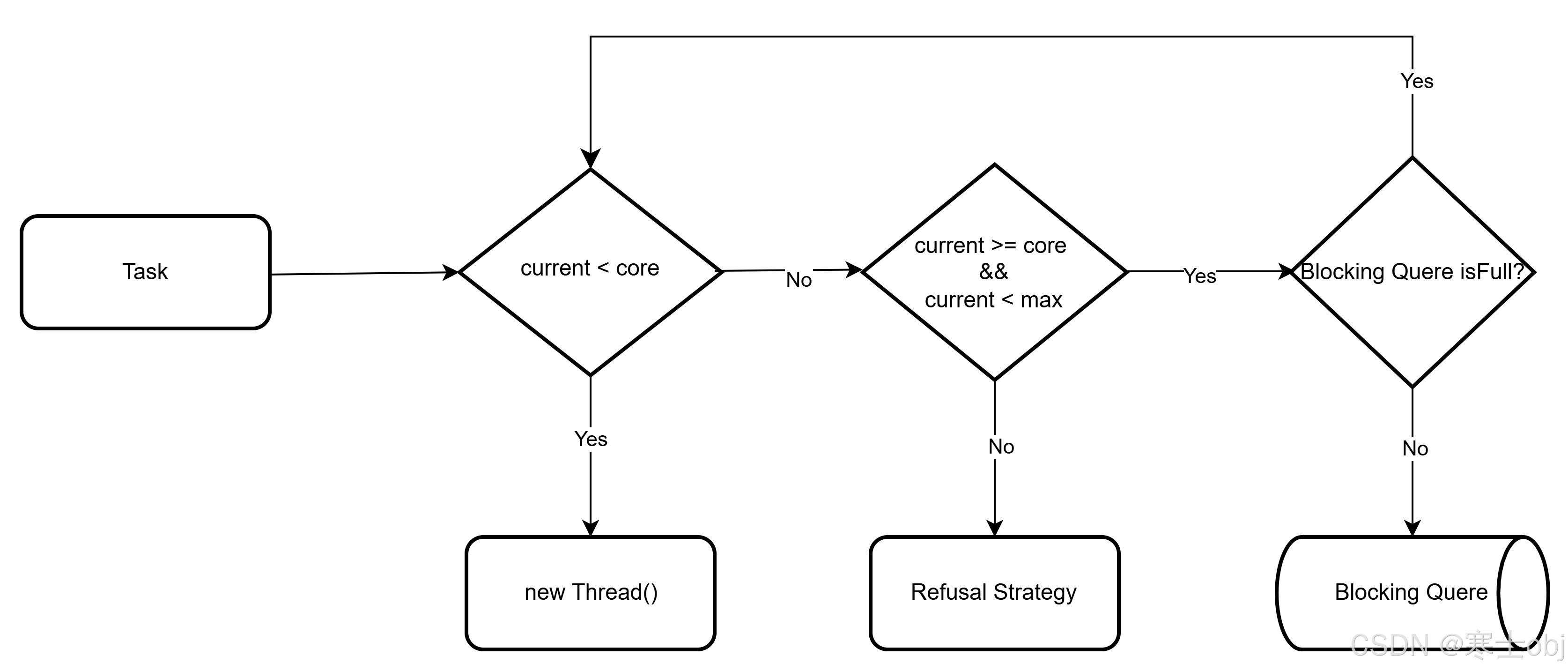
多线程进阶知识篇(二)
文章目录 一、Synchronized 锁二、ReentrantLock 锁三、两阶段终止阶段一:通知终止阶段二:响应中断 四、线程池为什么要使用线程池?如何创建线程池?ExecutorsThreadPoolExecutor 线程池的基本参数 五、线程池处理任务的流程 一、S…...

Python深度学习基础——深度神经网络(DNN)(PyTorch)
张量 数组与张量 PyTorch 作为当前首屈一指的深度学习库,其将 NumPy 数组的语法尽数吸收,作为自己处理张量的基本语法,且运算速度从使用 CPU 的数组进步到使用 GPU 的张量。 NumPy 和 PyTorch 的基础语法几乎一致,具体表现为&am…...

简单实现单点登录
单点登录 单点登录(Single Sign-On, SSO) SSO是一种统一身份认证技术,用户只需在认证平台登录一次,即可访问所有关联的应用程序或网站,无需重复输入凭据。例如,企业员工登录内部系统后,可直接…...

c++基础三
1.继承 继承表示,子类可以获取父类的属性和方法,然后可以写子类独有的属性和方法,或者修改父类的方法。类可以继承父类的公共成员(public),但不能继承私有成员(private),私有成员只能在父类内部访问。 1.1 案例一单继承 #include <iostream>using namespace …...