2025最新版微软GraphRAG 2.0.0本地部署教程:基于Ollama快速构建知识图谱
一、前言
微软近期发布了知识图谱工具 GraphRAG 2.0.0,支持基于本地大模型(Ollama)快速构建知识图谱,显著提升了RAG(检索增强生成)的效果。本文手把手教你如何从零部署,并附踩坑记录和性能实测!
二、环境准备
1. 创建虚拟环境
推荐使用 Python 3.12.4(亲测兼容性较佳):
conda create -n graphrag200 python=3.12.4
conda activate graphrag2002. 拉取源码
建议通过Git下载最新代码(Windows用户需提前安装Git):
git clone https://github.com/microsoft/graphrag.git
cd graphrag(附:若直接下载压缩包解压,解压完后需创建一个仓库,不然后续会报错)
创建仓库方法:
git init git add . git commit -m "Initial commit"
3. 安装依赖
一键安装所需依赖包:
pip install -e .4. 创建输入文件夹
用于存放待处理的文档(Windows可以直接手动创建):
mkdir -p ./graphrag_ollama/input将数据集放入input目录即可。
三、关键配置修改
1. 初始化项目
执行初始化命令(注意与旧版参数不同):
python -m graphrag init --root ./graphrag_ollama2. 修改settings.yaml
核心配置项(需按需调整):
-
模型设置:使用Ollama本地模型
注意修改一下圈出的几个地方
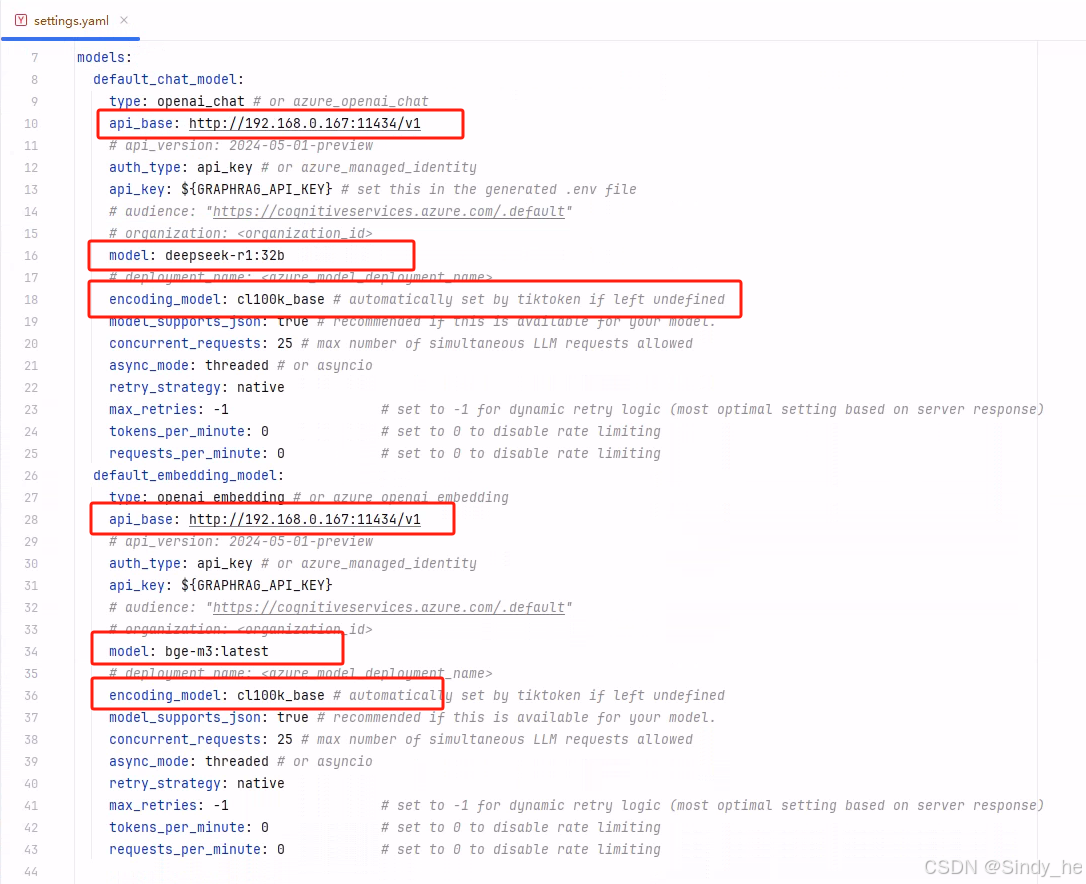
测试小文件时,建议把chunks改小:
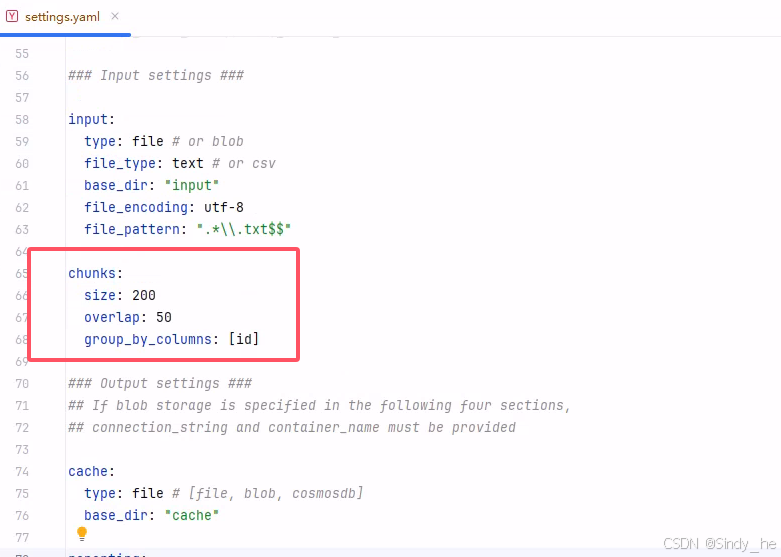
修改结果如下:
-
### This config file contains required core defaults that must be set, along with a handful of common optional settings. ### For a full list of available settings, see https://microsoft.github.io/graphrag/config/yaml/### LLM settings ### ## There are a number of settings to tune the threading and token limits for LLM calls - check the docs.models:default_chat_model:type: openai_chat # or azure_openai_chatapi_base: http://192.168.0.167:11434/v1# api_version: 2024-05-01-previewauth_type: api_key # or azure_managed_identityapi_key: ${GRAPHRAG_API_KEY} # set this in the generated .env file# audience: "https://cognitiveservices.azure.com/.default"# organization: <organization_id>model: deepseek-r1:32b# deployment_name: <azure_model_deployment_name>encoding_model: cl100k_base # automatically set by tiktoken if left undefinedmodel_supports_json: true # recommended if this is available for your model.concurrent_requests: 25 # max number of simultaneous LLM requests allowedasync_mode: threaded # or asyncioretry_strategy: nativemax_retries: -1 # set to -1 for dynamic retry logic (most optimal setting based on server response)tokens_per_minute: 0 # set to 0 to disable rate limitingrequests_per_minute: 0 # set to 0 to disable rate limitingdefault_embedding_model:type: openai_embedding # or azure_openai_embeddingapi_base: http://192.168.0.167:11434/v1# api_version: 2024-05-01-previewauth_type: api_key # or azure_managed_identityapi_key: ${GRAPHRAG_API_KEY}# audience: "https://cognitiveservices.azure.com/.default"# organization: <organization_id>model: bge-m3:latest# deployment_name: <azure_model_deployment_name>encoding_model: cl100k_base # automatically set by tiktoken if left undefinedmodel_supports_json: true # recommended if this is available for your model.concurrent_requests: 25 # max number of simultaneous LLM requests allowedasync_mode: threaded # or asyncioretry_strategy: nativemax_retries: -1 # set to -1 for dynamic retry logic (most optimal setting based on server response)tokens_per_minute: 0 # set to 0 to disable rate limitingrequests_per_minute: 0 # set to 0 to disable rate limitingvector_store:default_vector_store:type: lancedbdb_uri: output\lancedbcontainer_name: defaultoverwrite: Trueembed_text:model_id: default_embedding_modelvector_store_id: default_vector_store### Input settings ###input:type: file # or blobfile_type: text # or csvbase_dir: "input"file_encoding: utf-8file_pattern: ".*\\.txt$$"chunks:size: 200overlap: 50group_by_columns: [id]### Output settings ### ## If blob storage is specified in the following four sections, ## connection_string and container_name must be providedcache:type: file # [file, blob, cosmosdb]base_dir: "cache"reporting:type: file # [file, blob, cosmosdb]base_dir: "logs"output:type: file # [file, blob, cosmosdb]base_dir: "output"### Workflow settings ###extract_graph:model_id: default_chat_modelprompt: "prompts/extract_graph.txt"entity_types: [organization,person,geo,event]max_gleanings: 1summarize_descriptions:model_id: default_chat_modelprompt: "prompts/summarize_descriptions.txt"max_length: 500extract_graph_nlp:text_analyzer:extractor_type: regex_english # [regex_english, syntactic_parser, cfg]extract_claims:enabled: falsemodel_id: default_chat_modelprompt: "prompts/extract_claims.txt"description: "Any claims or facts that could be relevant to information discovery."max_gleanings: 1community_reports:model_id: default_chat_modelgraph_prompt: "prompts/community_report_graph.txt"text_prompt: "prompts/community_report_text.txt"max_length: 2000max_input_length: 8000cluster_graph:max_cluster_size: 10embed_graph:enabled: false # if true, will generate node2vec embeddings for nodesumap:enabled: false # if true, will generate UMAP embeddings for nodes (embed_graph must also be enabled)snapshots:graphml: falseembeddings: false### Query settings ### ## The prompt locations are required here, but each search method has a number of optional knobs that can be tuned. ## See the config docs: https://microsoft.github.io/graphrag/config/yaml/#querylocal_search:chat_model_id: default_chat_modelembedding_model_id: default_embedding_modelprompt: "prompts/local_search_system_prompt.txt"global_search:chat_model_id: default_chat_modelmap_prompt: "prompts/global_search_map_system_prompt.txt"reduce_prompt: "prompts/global_search_reduce_system_prompt.txt"knowledge_prompt: "prompts/global_search_knowledge_system_prompt.txt"drift_search:chat_model_id: default_chat_modelembedding_model_id: default_embedding_modelprompt: "prompts/drift_search_system_prompt.txt"reduce_prompt: "prompts/drift_search_reduce_prompt.txt"basic_search:chat_model_id: default_chat_modelembedding_model_id: default_embedding_modelprompt: "prompts/basic_search_system_prompt.txt"四、构建知识图谱
执行索引命令(算力警告:亲测4090-24G显卡处理2万字需3小时):
python -m graphrag index --root ./graphrag_ollama五、知识图谱查询
支持多种查询方式,按需选择:
-
方法 命令示例 用途 全局查询 python -m graphrag query --method global --query "知识图谱定义"跨文档综合分析 局部查询 python -m graphrag query --method local --query "知识图谱定义"单文档精准检索 DRIFT查询 python -m graphrag query --method drift --query "知识图谱定义"动态漂移分析 基础查询 python -m graphrag query --method basic --query "知识图谱定义"传统RAG检索
六、注意事项
-
模型路径:确保Ollama服务已启动,且模型名称与配置一致(如
deepseek-r1:32b需提前拉取)。 -
算力需求:小规模数据集建议使用GPU加速,CPU模式耗时可能成倍增加。
-
文件编码:输入文档需为UTF-8编码,否则可能报错。
-
配置备份:修改
settings.yaml前建议备份原始文件。
七、总结
GraphRAG 2.0.0大幅优化了知识图谱的构建效率,结合本地模型可实现隐私安全的行业级应用。若遇到部署问题,欢迎在评论区留言交流!
相关资源:
GraphRAG GitHub仓库
Ollama模型库
原创声明:本文为作者原创,未经授权禁止转载。如需引用请联系作者。
点赞关注,技术不迷路! 👍
你的支持是我更新的最大动力! ⚡
相关文章:
2025最新版微软GraphRAG 2.0.0本地部署教程:基于Ollama快速构建知识图谱
一、前言 微软近期发布了知识图谱工具 GraphRAG 2.0.0,支持基于本地大模型(Ollama)快速构建知识图谱,显著提升了RAG(检索增强生成)的效果。本文手把手教你如何从零部署,并附踩坑记录和性能实测…...
)
泛型算法——只读算法(一)
在 C 标准库中,泛型算法的“只读算法”指那些 不会改变它们所操作的容器中的元素,仅用于访问或获取信息的算法,例如查找、计数、遍历等操作。 accumulate std::accumulate()是 C 标准库**numeric**头文件中提供的算法,用于对序列…...

Redis的常见数据类型
Redis 提供了多种数据类型,以满足不同的应用场景。以下是 Redis 的主要数据类型及其应用场景: 字符串(String): 描述:最基本的数据类型,存储单个键值对,值可以是字符串、整数或浮点数…...
层几种传参方式)
Mybatis中dao(mapper)层几种传参方式
一、SQL语句中接收参数的方式有两种: 1、 #{}预编译 (可防止sql注入) 2、${}非预编译(直接拼接sql,不能防止sql注入) #{}和${}的区别是什么? #{} 占位符,相当于?,sql预编译&…...

网络安全知识点2
1.虚拟专用网VPN:VPN用户在此虚拟网络中传输私网流量,在不改变网络现状的情况下实现安全,可靠的连接 2.VPN技术的基本原理是利用隧道技术,对传输报文进行封装,利用VPN骨干网建立专用数据传输通道,实现报文…...

libevent服务器附带qt界面开发(附带源码)
本章是入门章节,讲解如何实现一个附带界面的服务器,后续会完善与优化 使用qt编译libevent源码演示视频qt的一些知识 1.主要功能有登录界面 2.基于libevent实现的服务器的业务功能 使用qt编译libevent 下载这个,其他版本也可以 主要是github上…...
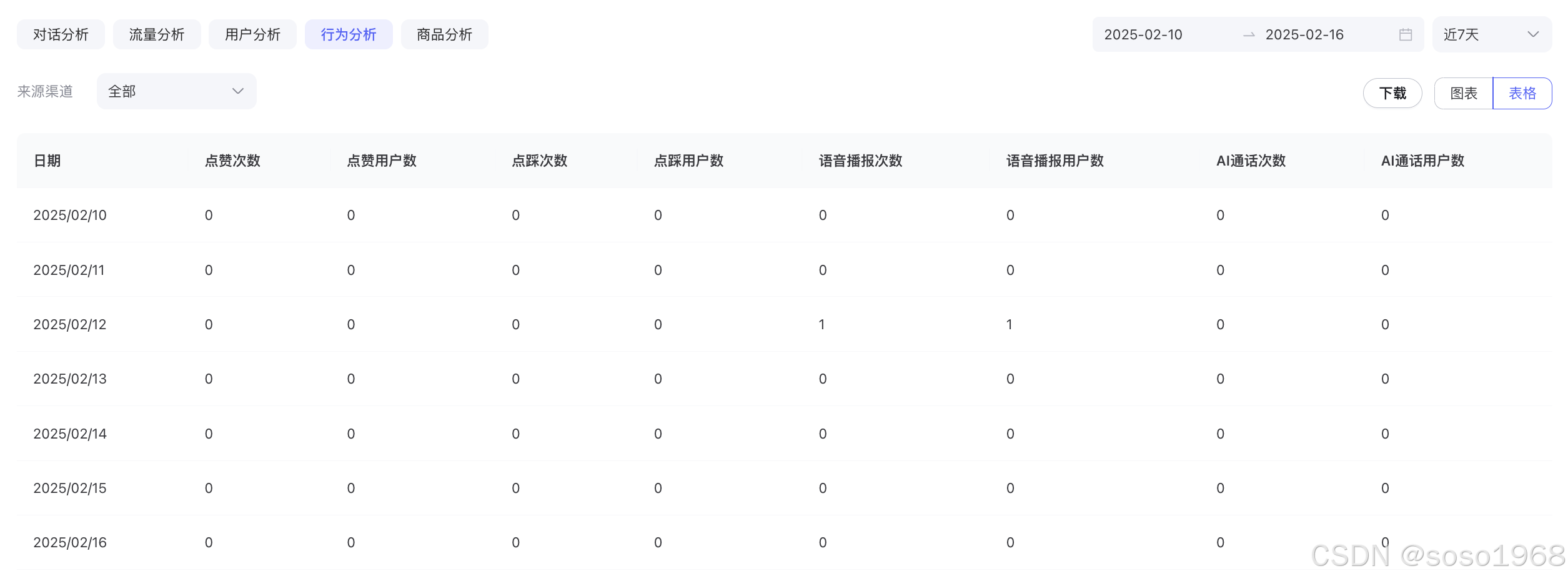
智能体数据分析
数据概览: 展示智能体的累计对话次数、累计对话用户数、对话满意度、累计曝光次数。数据分析: 统计对话分析、流量分析、用户分析、行为分析数据指标,帮助开发者完成精准的全面分析。 ps:数据T1更新,当日12点更新前一天…...
原理解析:容器背后的存储技术)
[特殊字符] UnionFS(联合文件系统)原理解析:容器背后的存储技术
🔍 UnionFS(联合文件系统)原理解析:容器背后的存储技术 💡 什么是 UnionFS? UnionFS(联合文件系统) 是一种可以将多个不同来源的文件系统“合并”在一起的技术。它的核心思想是&am…...
STM32(M4)入门: 概述、keil5安装与模板建立(价值 3w + 的嵌入式开发指南)
前言:本教程内容源自信盈达教培资料,价值3w,使用的是信盈达的405开发版,涵盖面很广,流程清晰,学完保证能从新手入门到小高手,软件方面可以无基础学习,硬件学习支持两种模式ÿ…...

采用若依vue 快速开发系统功能模块
文章目录 运行若依项目 科室管理科室查询-后端代码实现科室查询-前端代码实现科室名称状态搜索科室删除-后端代码实现科室删除-前端代码实现科室新增-后端代码实现科室新增-前端代码实现科室修改-后端代码实现前端代码实现角色权限实现 运行若依项目 运行redis 创建数据库 修改…...
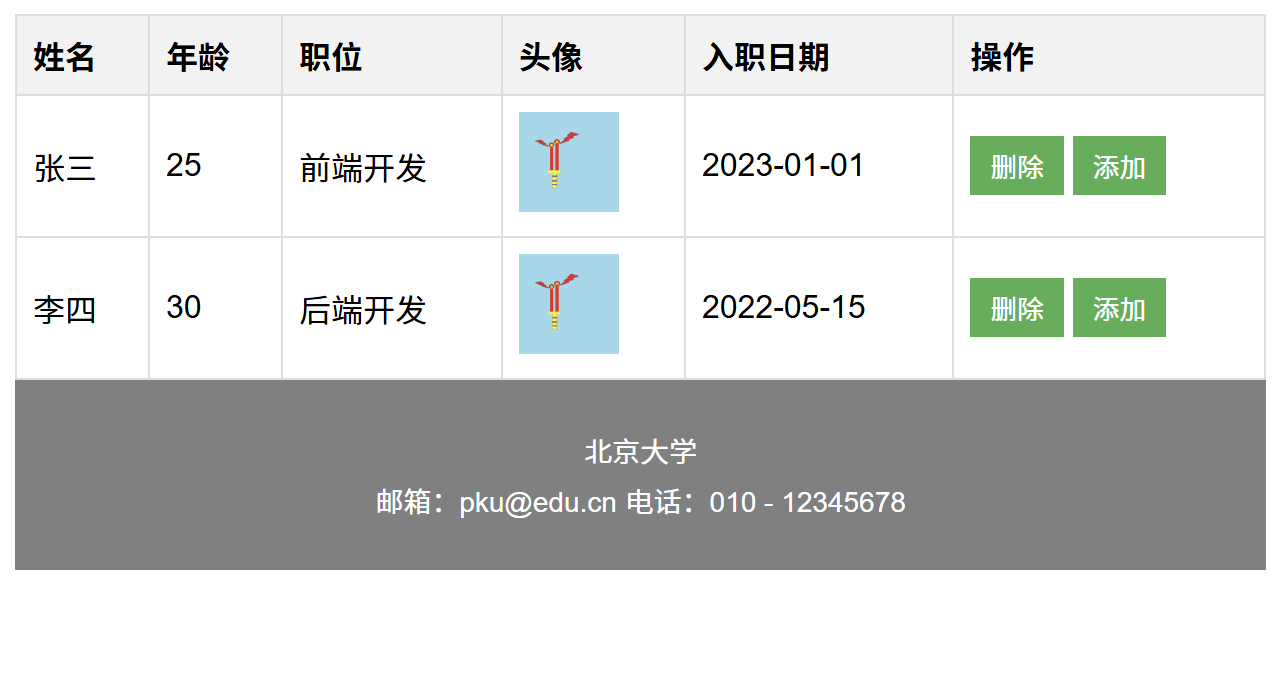
HTML:表格数据展示区
<!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>人员信息表</title><link rel"styl…...

WIN11运行游戏时出现“ms-gamingoverlay”弹框的问题
针对WIN11运行游戏时出现“ms-gamingoverlay”弹框的问题,以下是经过验证的多种解决方法,结合不同场景需求提供对应方案: 一、关闭系统内置的游戏录制功能 禁用Xbox Game Bar及游戏录制 • 进入系统设置(WinI)→ 左侧选…...
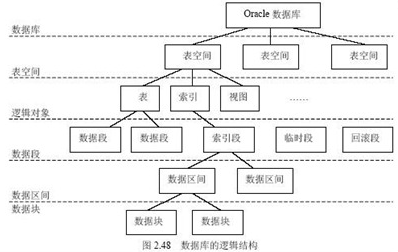
Oracle测试题目及笔记(单选)
所有题目来自于互联网搜索 当 Oracle 服务器启动时,下列哪种文件不是必须的(D)。 A.数据文件 B.控制文件 C.日志文件 D.归档日志文件 数据文件、日志文件-在数据库的打开阶段使用 控制文件-在数…...

Jmeter创建使用变量——能够递增递减的计数器
Jmeter创建使用变量——能够递增递减的计数器 如下图所示,创建一个 取值需限定为0 2 4这三个值内的变量。 Increment:每次迭代后 递增的值,给计数器增加的值 Maximum value:计数器的最大值,如果超过最大值࿰…...

【LeetCode基础算法】滑动窗口与双指针
定长滑动窗口 总结:入-更新-出。 入:下标为 i 的元素进入窗口,更新相关统计量。如果 i<k−1 则重复第一步。 更新:更新答案。一般是更新最大值/最小值。 出:下标为 i−k1 的元素离开窗口,更新相关统计量…...
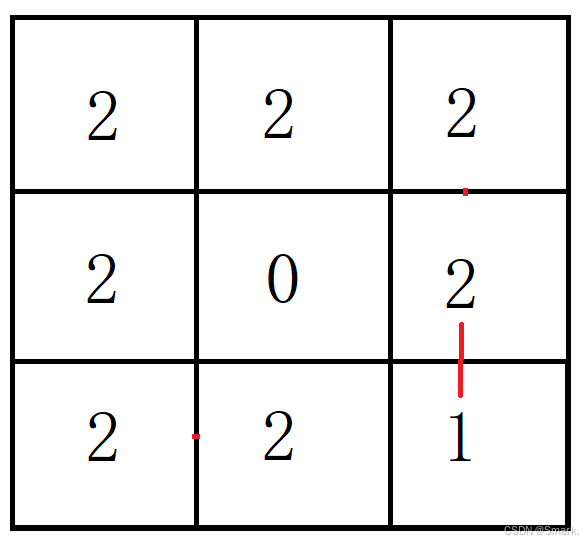
数据结构之BFS广度优先算法(腐烂的苹果)
队列这个数据结构在很多场景下都有使用,比如在实现二叉树的层序遍历,floodfill问题(等等未完成)中,都需要借助队列的先进先出特性,下面给出这几个问题的解法 经典的二叉树的层序遍历 算法图示,以下图所示的二叉树为例…...

道可云人工智能每日资讯|首届世界人工智能电影节在法国尼斯举行
道可云元宇宙每日简报(2025年4月15日)讯,今日元宇宙新鲜事有: 杭州《西湖区打造元宇宙产业高地的扶持意见》发布 杭州西湖区人民政府印发《西湖区打造元宇宙产业高地的扶持意见》。该意见已于4月4日正式施行,有效期至…...
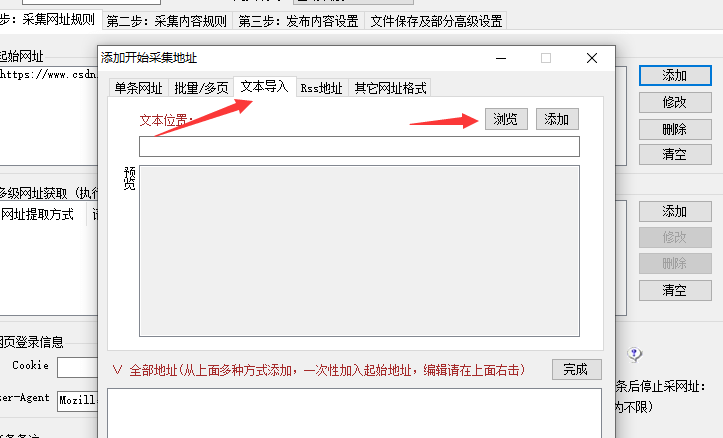
火车头采集动态加载Ajax数据(无分页瀑布流网站)
为了先填充好数据在上线,在本地搭建了一个网站,并用火车头采集数据填充到里面。 开始很上手,因为找的网站的分类中是有分页的。很快捷的找到页面标识。 但是问题来了,如今很多网站都是采用的Ajax加载数据,根本没有分…...

Android Jetpack是什么与原生android 有什么区别
Android Jetpack是什么 Android Jetpack是Google推出的一套开发组件工具集,旨在帮助开发者更高效地构建高质量的Android应用。它包含多个库和工具,被分为架构、用户界面、行为和基础四大类。以下是一些Android Jetpack的示例: 架构组件 ViewModel:用于以生命周期的方式管理…...
)
Android Retrofit 框架适配器模块深入源码分析(五)
Android Retrofit 框架适配器模块深入源码分析 一、引言 在 Android 开发中,网络请求是一个常见且重要的功能。Retrofit 作为一个强大的网络请求框架,以其简洁的 API 和高度的可定制性受到了广泛的欢迎。适配器模块(CallAdapter)…...
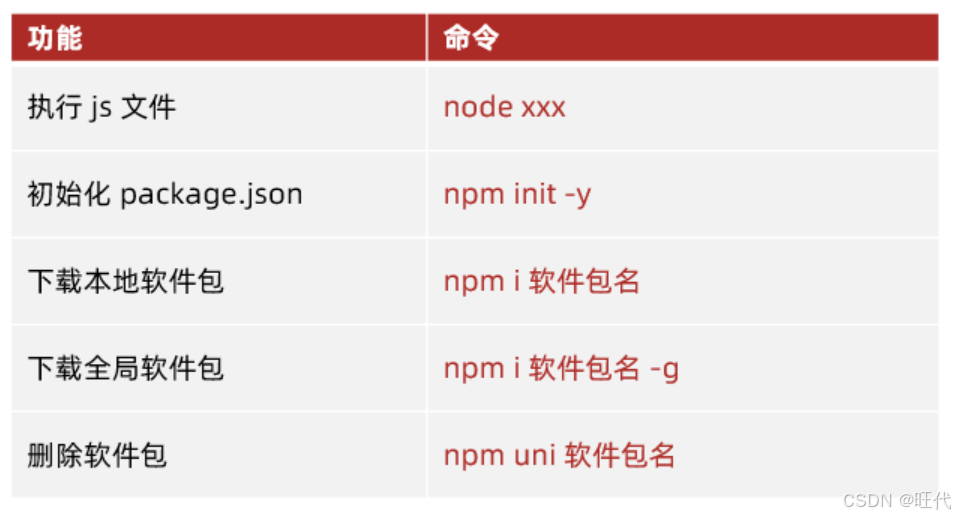
Node.js模块化与npm
目录 一、模块化简介 二、CommonJS 规范 1. 基本语法 2. 导出模块 3. 导入模块 三、ECMAScript 标准(ESM) 1. 启用 ESM 一、默认导出与导入 1. 基本语法 2. 默认导出(每个模块仅一个) 3. 默认导入 二、命名导出与导入…...

nginx中的代理缓存
1.缓存存放路径 对key取哈希值之后,设置cache内容,然后得到的哈希值的倒数第一位作为第一个子目录,倒数第三位和倒数第二位组成的字符串作为第二个子目录,如图。 proxy_cache_path /xxxx/ levels1:2 2.文件名哈希值...

【前端vue生成二维码和条形码——MQ】
前端vue生成二维码和条形码——MQ 前端vue生成二维码和条形码——MQ一、安装所需要的库1、安装qrcode2、安装jsbarcode 二、使用步骤1、二维码生成2、条形码生成 至此,大功告成! 前端vue生成二维码和条形码——MQ 一、安装所需要的库 1、安装qrcode 1…...
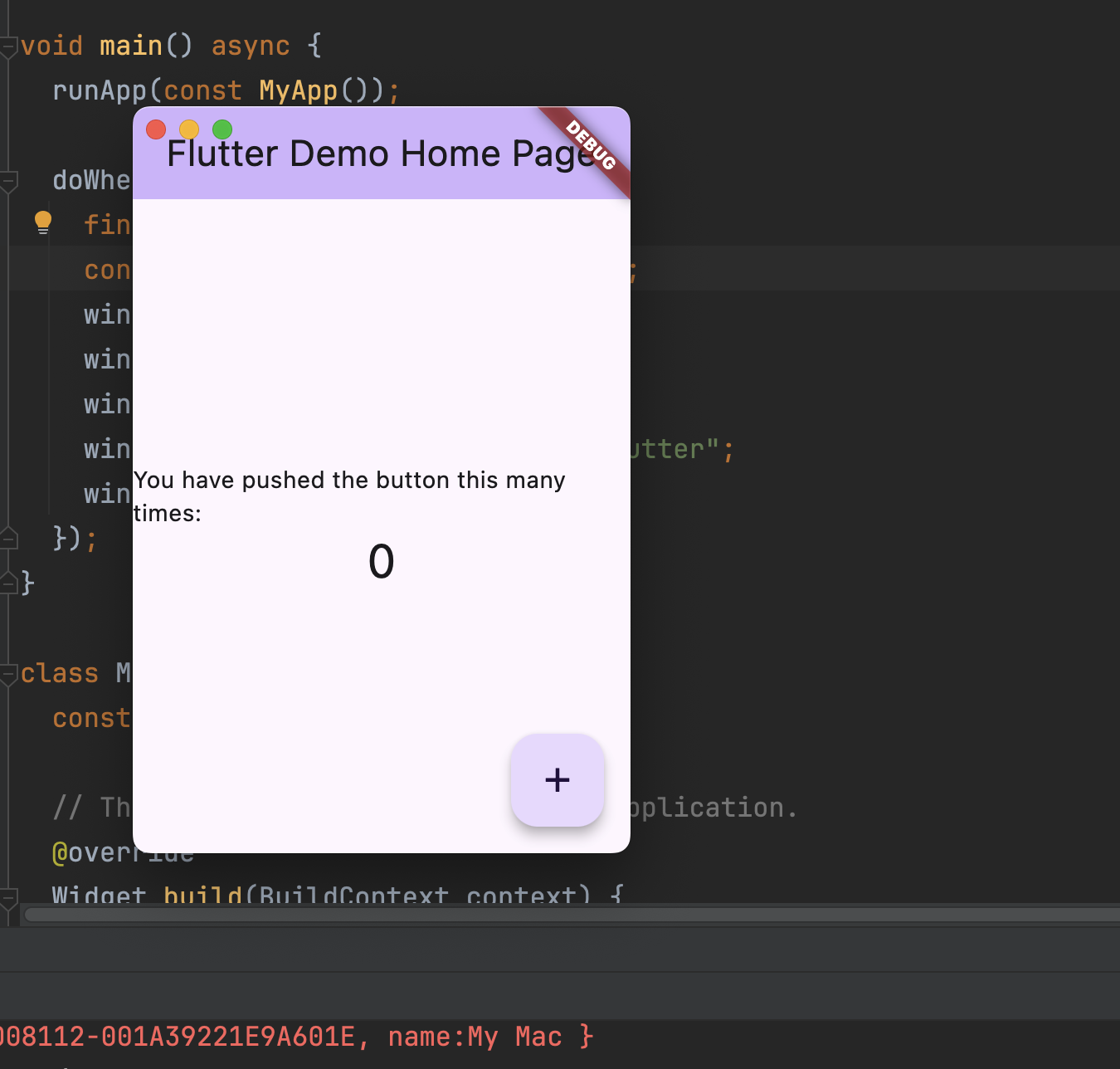
flutter 桌面应用之窗口自定义
在开发桌面软件的时候我们经常需要配置软件的窗口的大小以及位置 我们有两个框架选择:window_manager和bitsdojo_window 对比bitsdojo_window 特性bitsdojo_windowwindow_manager自定义标题栏✅ 支持❌ 不支持控制窗口行为(大小/位置)✅(基本…...

华为OD机试真题——MELON的难题(2025A卷:200分)Java/python/JavaScript/C++/C语言/GO六种最佳实现
2025 A卷 200分 题型 本文涵盖详细的问题分析、解题思路、代码实现、代码详解、测试用例以及综合分析; 并提供Java、python、JavaScript、C、C语言、GO六种语言的最佳实现方式! 2025华为OD真题目录全流程解析/备考攻略/经验分享 华为OD机试真题《MELON的…...

【C++】深入浅出之继承
目录 继承的概念及定义继承的定义继承方式和访问限定符protected与private的区别 默认继承方式继承类模板基类和派生类对象赋值兼容转换继承中的作⽤域(隐藏关系)相关面试题⭐ 派生类的默认成员函数⭐构造函数拷贝构造赋值重载析构函数 继承与友元继承与静态成员继承的方式菱形…...
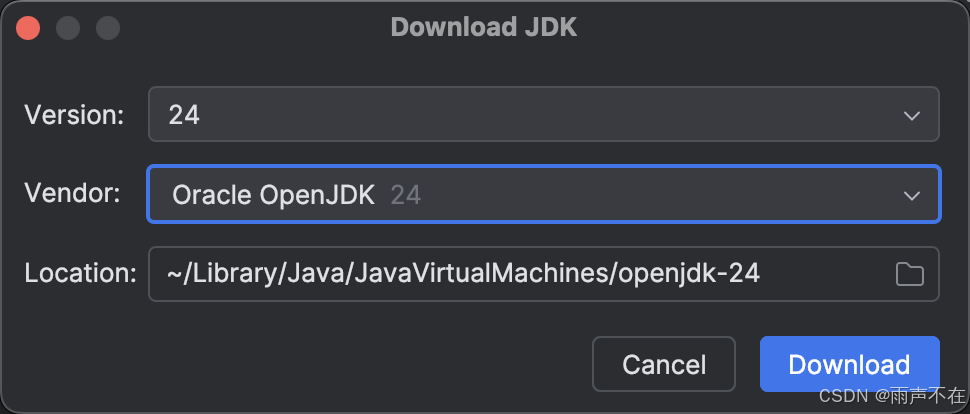
在 macOS 上切换默认 Java 版本
下载javasdk 打开android studio -> setting -> build.execution,dep -> build tools -> gradle -> Gradle JDK -> download JDK… 点击下载,就下载到了 ~/Library/Java/JavaVirtualMachines/ 安装 jenv brew install jenv将 jenv 集成到 Shell …...
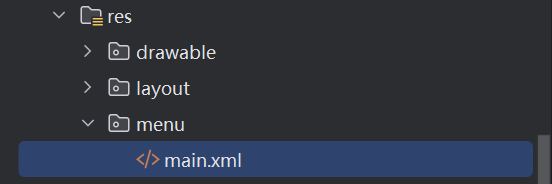
【安卓开发】【Android Studio】Menu(菜单栏)的使用及常见问题
一、菜单栏选项 在项目中添加顶部菜单栏的方法: 在res目录下新建menu文件夹,在该文件夹下新建用于菜单栏的xml文件: 举例说明菜单栏的写法,只添加一个选项元素: <?xml version"1.0" encoding"ut…...

2025.04.17【Stacked area】| 生信数据可视化:堆叠区域图深度解析
文章目录 生信数据可视化:堆叠区域图深度解析堆叠面积图简介为什么使用堆叠面积图如何使用R语言创建堆叠面积图安装和加载ggplot2包创建堆叠面积图的基本步骤示例代码 解读堆叠面积图堆叠面积图的局限性实际应用案例示例:基因表达量随时间变化 结论 生信…...

【NLP】 22. NLP 现代教程:Transformer的训练与应用全景解读
🧠 NLP 现代教程:Transformer的训练与应用全景解读 一、Transformer的使用方式(Training and Use) 如何使用Transformer模型? Transformer 模型最初的使用方式有两种主要方向: 类似 RNN 编码-解码器的架…...