论文阅读VACE: All-in-One Video Creation and Editing
code:https://github.com/ali-vilab/VACE
核心

- 单个模型同时处理多种视频生成和视频编辑任务
- 通过VCU(视频条件单元)进行实现
方法
视频任务
所有的视频相关任务可以分为4类
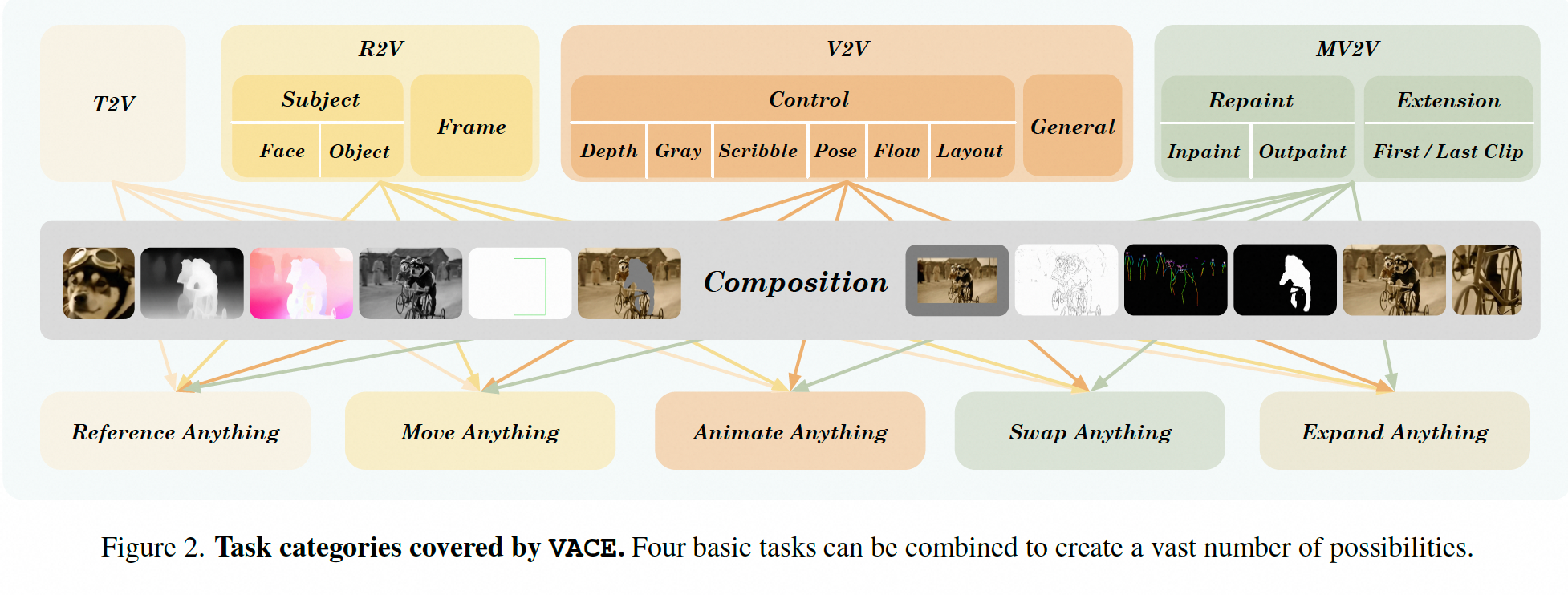
文本生视频
参考图片生视频
视频生视频
视频+mask生视频
VCU
对上述4个任务,制定一个统一的输入范式。text,frame以及mask。
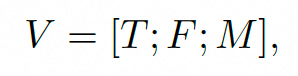
对于每一个不同的任务,text不用变,主要变化F以及M。对于参考图+视频,无非是多了l个参考图的输入。mask对应设置如下表所示。
这样就统一了不同类型任务的输入。

结构
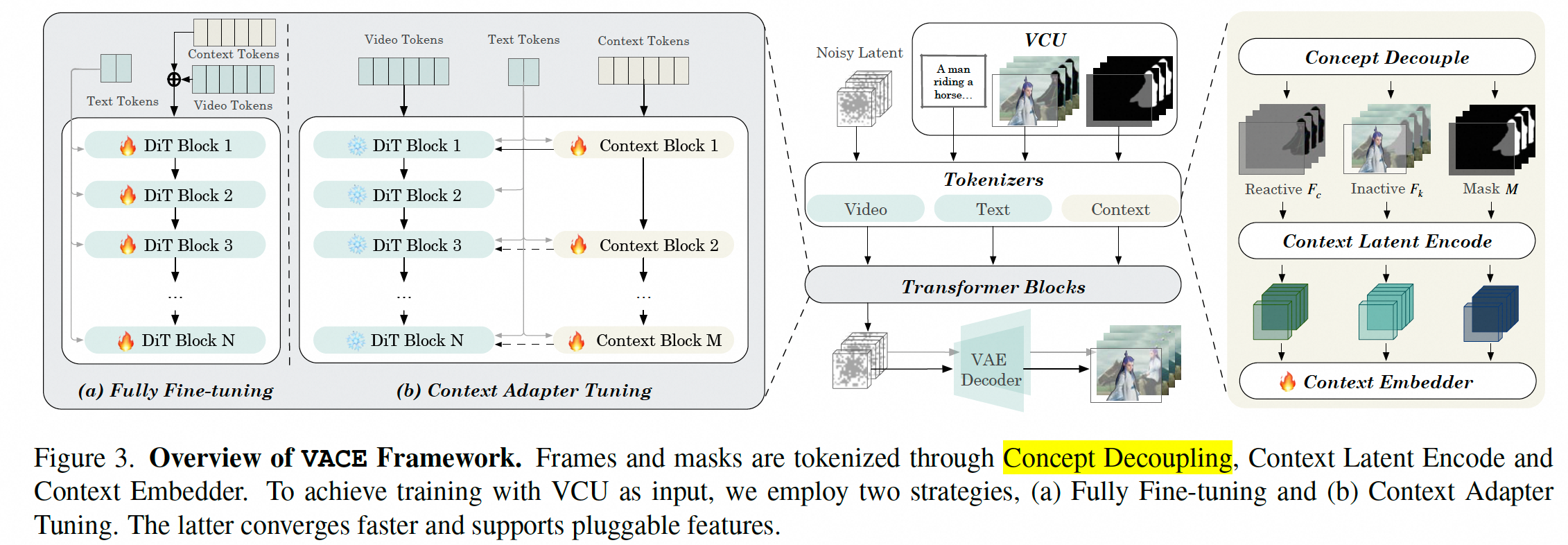
重构了DiT模型用于VACE
Context Tokenization
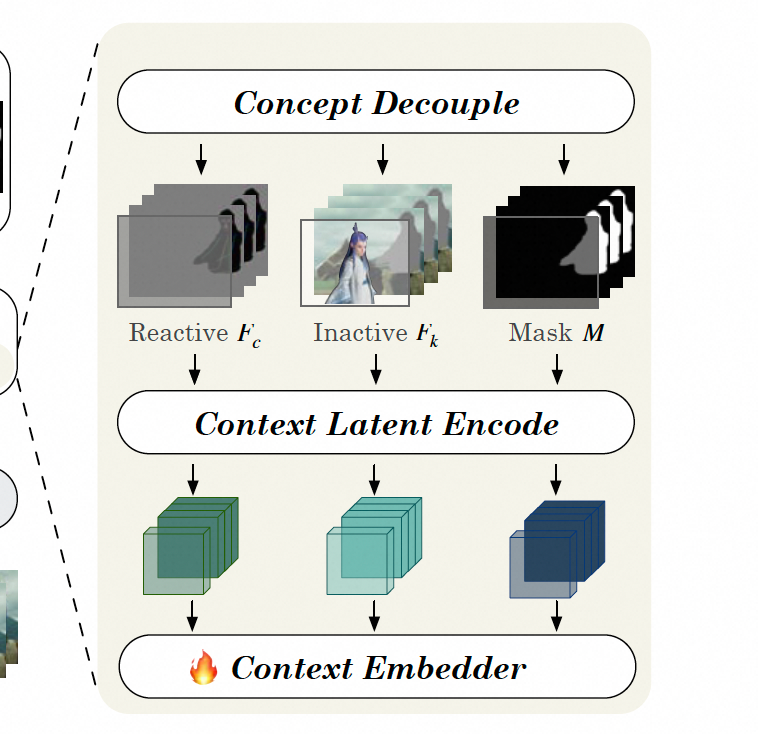
- 概念解耦。主要是将视频分为了2部分,一部分是和mask有交互的,需要重新生成;一部分和mask无交互的,需要保持不变。
- Context Latent Encoding.解藕的两部分以及原始视频、mask分别encoder到latent空间,shape保持一致
- Context Embedder 将上述3个concat一起输入到transformer中
代码如下:
def vace_encode_frames(self, frames, ref_images, masks=None):if ref_images is None:ref_images = [None] * len(frames)else:assert len(frames) == len(ref_images)if masks is None:latents = self.vae.encode(frames)else:inactive = [i * (1 - m) + 0 * m for i, m in zip(frames, masks)]reactive = [i * m + 0 * (1 - m) for i, m in zip(frames, masks)]inactive = self.vae.encode(inactive)reactive = self.vae.encode(reactive)latents = [torch.cat((u, c), dim=0) for u, c in zip(inactive, reactive)]cat_latents = []for latent, refs in zip(latents, ref_images):if refs is not None:if masks is None:ref_latent = self.vae.encode(refs)else:ref_latent = self.vae.encode(refs)ref_latent = [torch.cat((u, torch.zeros_like(u)), dim=0) for u in ref_latent]assert all([x.shape[1] == 1 for x in ref_latent])latent = torch.cat([*ref_latent, latent], dim=1)cat_latents.append(latent)return cat_latents
3.3.2. Fully Fine-Tuning and Context Adapter Tuning
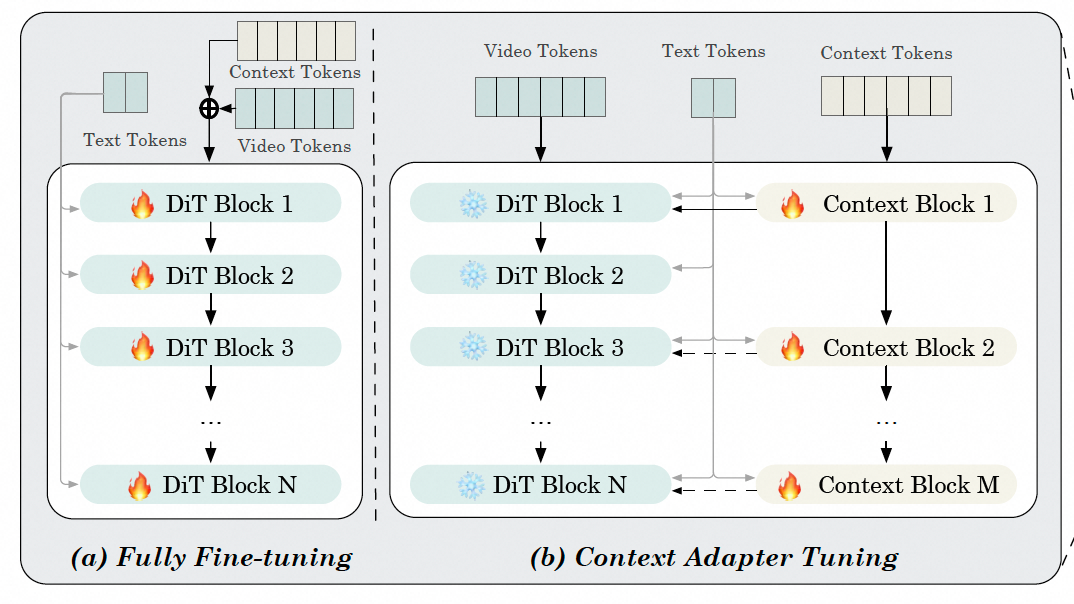 作者设计了两种训练方式。
作者设计了两种训练方式。
- 全训练。直接将video tokens和context tokens相加,然后训练整个DiT
- Context Adapter Tuning。直训练context Block和context Embed。DiT不动,cotext作为一个控制信号注入到DiT。参考了Res-tuning,也有点controlnet到结构。
后文也有提到Context Adapter Tuning的效果更好,所以关注这个就可以。
结果
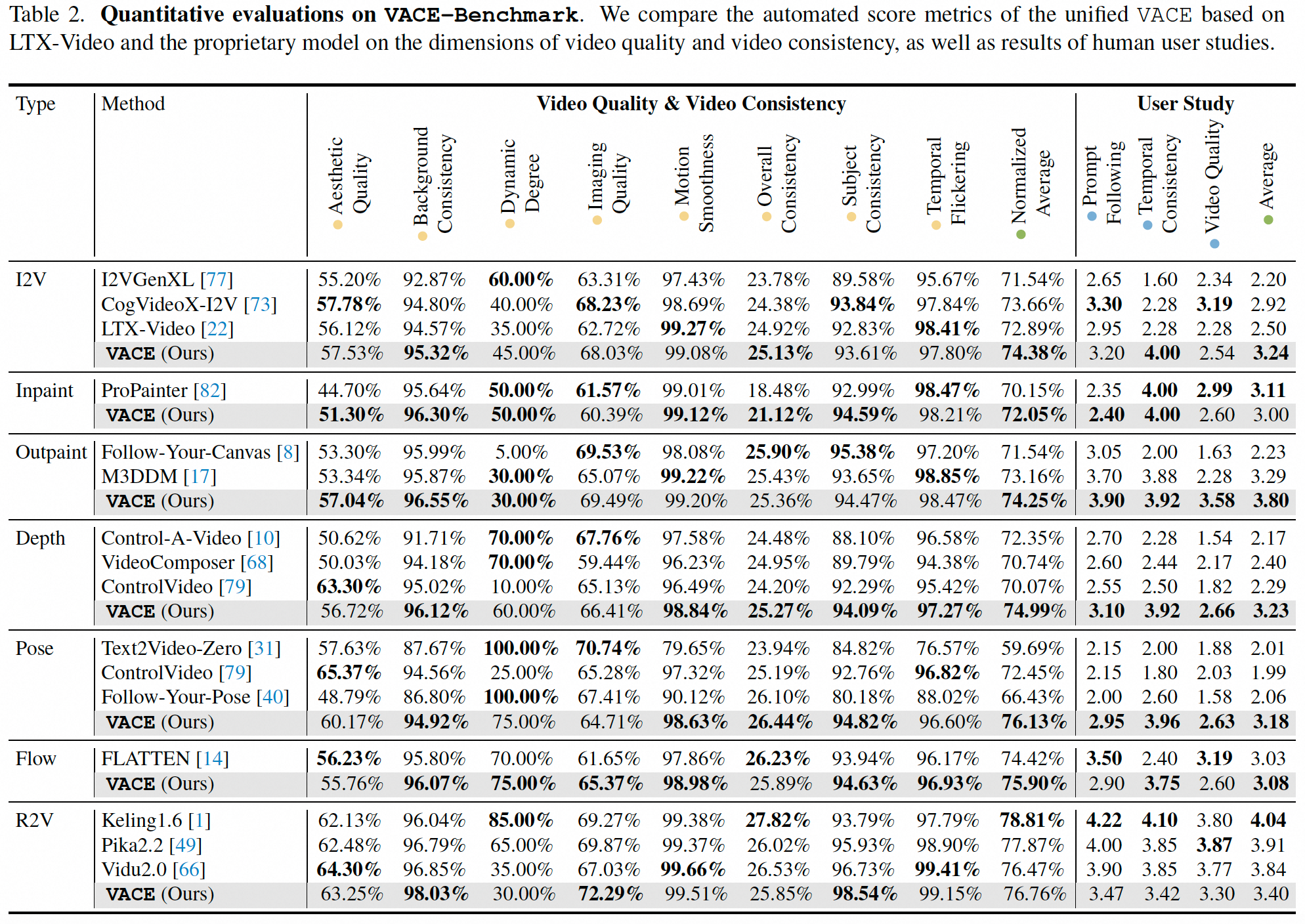
作者自己构建了一个新的数据集,用于评估多类视频任务。
定量
多个任务上的性能超过了sota,特别是在视频质量和视频一致性方面。例如,在图像到视频(I2V)任务中,VACE在多个指标上优于I2VGenXL、CogVideoX-I2V和LTX-Video-I2V等方法。
但是在R2V任务上,keling更胜一筹
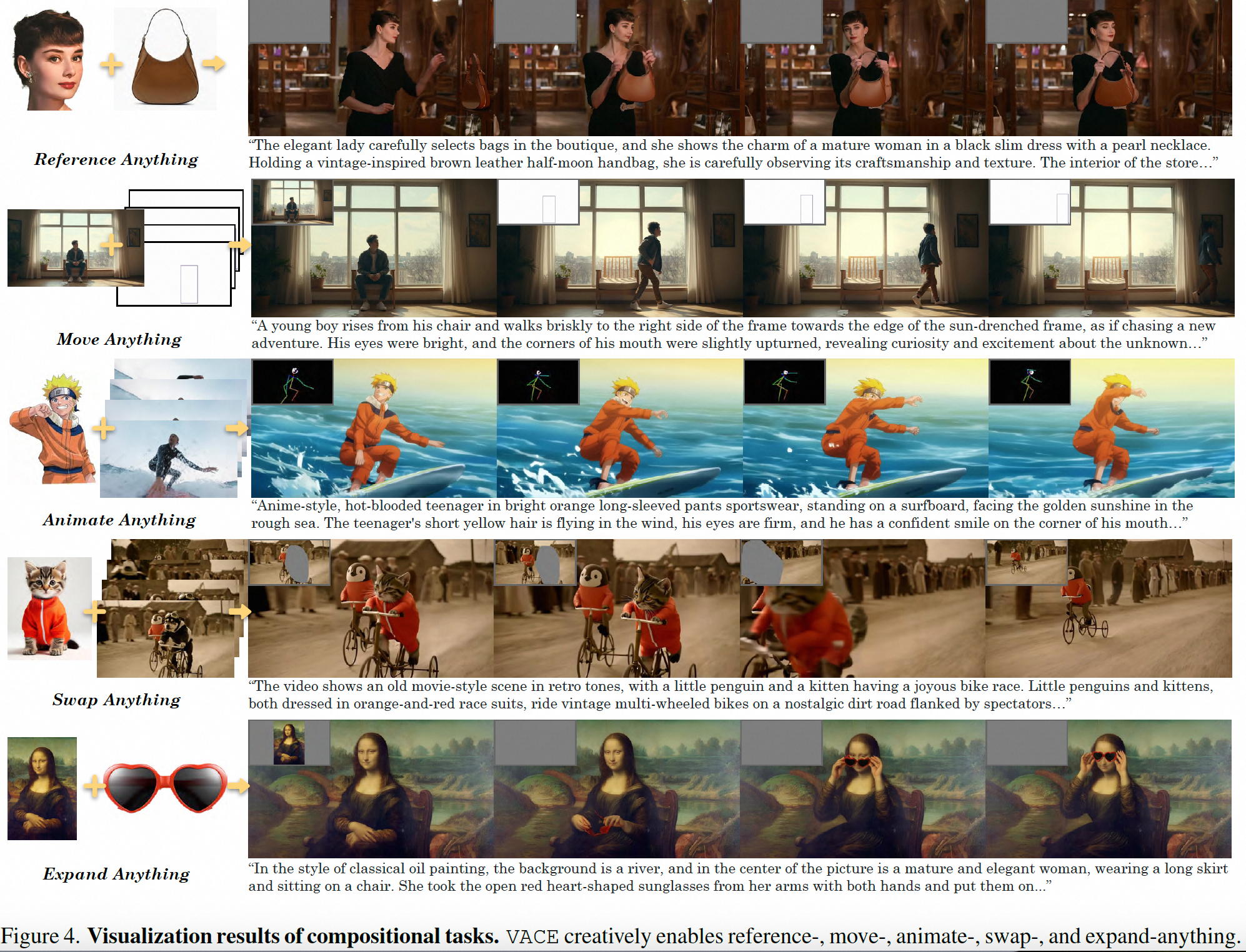
定性
消融实验
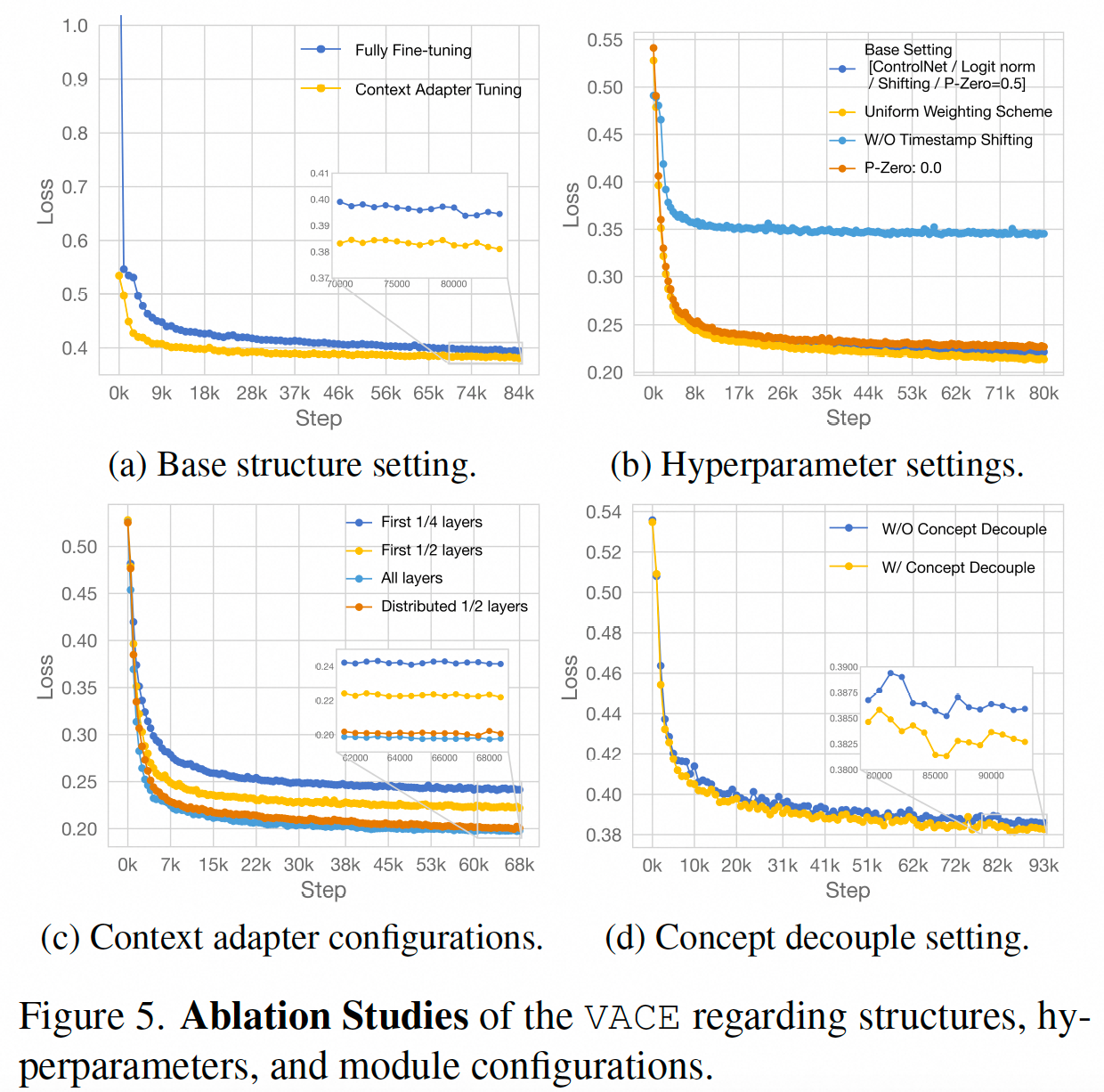
- Context Adapter Tuning的训练方式更好
- 超参数设置Uniform最好
- Context Adapter设置所有layers最好
- Concept 解耦更好一点
局限(C.1. Limitations)
- 生成的质量和风格受基础模型的影响。小模型快,但是质量和连贯性不好。例如身份一致性差,对输入的控制能力较弱。大模型慢,质量高。
- VACE的训练数据不足,训练时间不足
- 用户使用起来更复杂一些(对比单一任务模型)
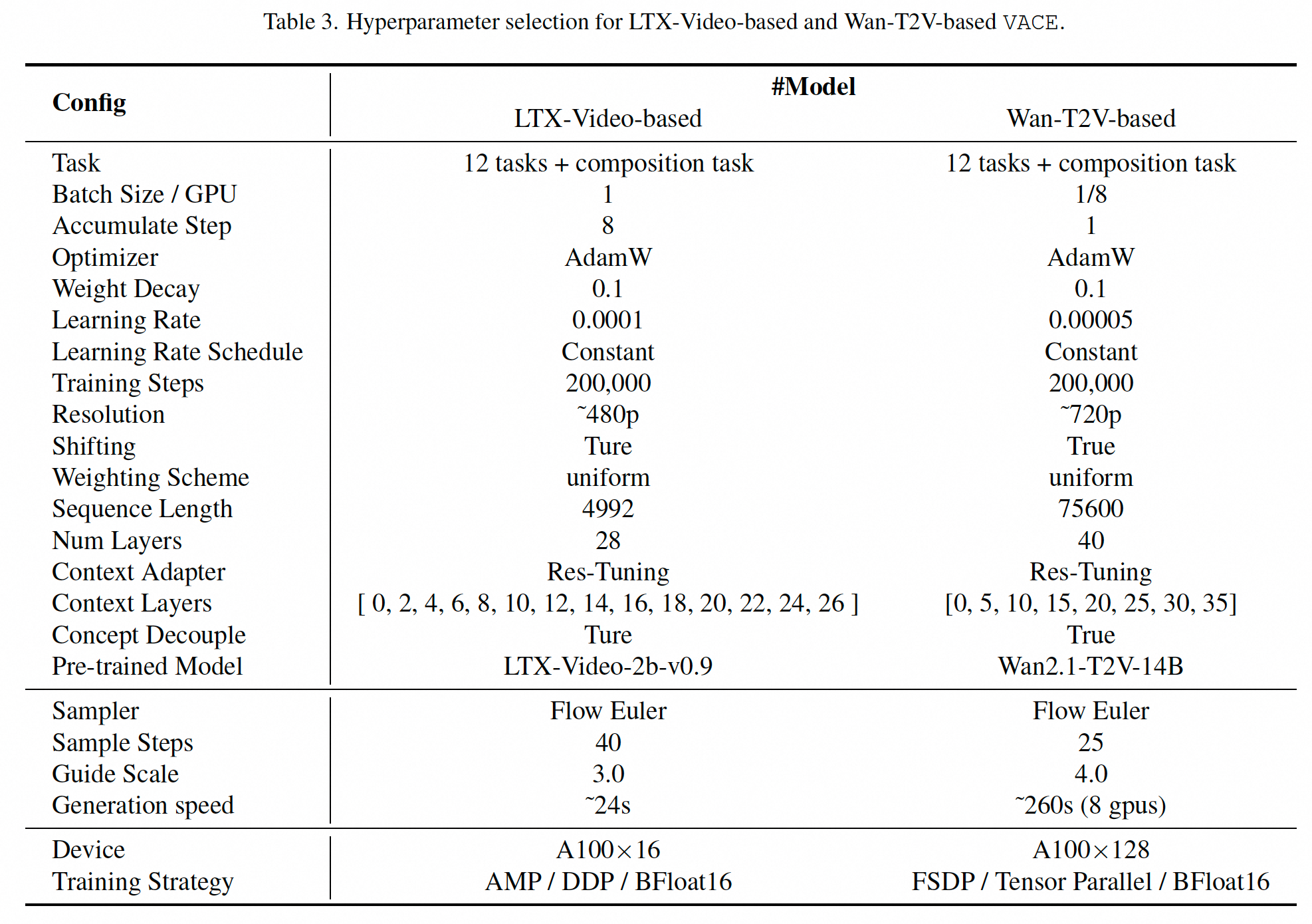
细节
基础模型
在LTX-Video-2B和WAN-T2V-14B两个模型基础上训练
训练卡数:16张A100/128张A100
训练分为3个阶段
- 基础任务训练,作为构建更复杂任务的基石。具体任务为视频修复和视频扩展
- 任务扩展训练,扩展模型的能力。包括单输入参考帧到多输入参考帧和单一任务到组合任务
- 质量提升训练,提升模型生成视频的质量,特别是在高分辨率和长视频序列上的表现。
训练参数
总结
主要是统一了多个不同的视频任务,使得单一模型拥有复杂的能力。创新点注意围绕着接口设计、训练设计。模型核心结构未变。
相关文章:
论文阅读VACE: All-in-One Video Creation and Editing
code:https://github.com/ali-vilab/VACE 核心 单个模型同时处理多种视频生成和视频编辑任务通过VCU(视频条件单元)进行实现 方法 视频任务 所有的视频相关任务可以分为4类 文本生视频 参考图片生视频 视频生视频 视频mask生视频 VCU …...
JavaSE学习(前端初体验)
文章目录 前言一、准备环境二、创建站点(创建一个文件夹)三、将站点部署到编写器中四、VScode实用小设置五、案例展示 前言 首先了解前端三件套:HTML、CSS、JS HTML:超文本标记语言、框架层、描述数据的; CSS…...

AlmaLinux 9.2 安装 snmp 后 sshd 服务无法启动
问题 AlmaLinux 9.2 安装 net-snmp 后导致 sshd 无法启动,SSH 无法正常连接。并且在日志中发现OpenSSL version mismatch. Built against 30000010, you have 30200020错误。 问题排查 AlmaLinux 9.2 初始安装 openssl 的版本为 3.0.7。软件包为openssl-3.0.7-6。…...

前端渲染pdf文件解决方案
一、前言 在当今数字化信息传播的时代,PDF文档作为一种常见的文件格式扮演着重要的角色。对于前端开发者而言,实现在网页上渲染和展示PDF文件是一项常见但也具有挑战性的任务。幸运的是,现在有一个强大的工具——react-pdf-viewer,…...

Kubernetes(K8S)内部功能总结
Kubernetes(K8S)是云技术的最核心的部分,也是构建是云原生的基石 K8S K8S,是Kubernetes的缩写,是Google开发的容器编排平台,现在由云原生计算基金会(CNCF)进行维护。 K8Sÿ…...

蓝桥杯日期的题型
做题思路 一般分为3个步骤,首先要定义一个结构体来存储月份的天数,第一循环日期,第二判断日期是否为闰年,第三就是题目求什么 结构体 static int[] ds{0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31}; 判断是否闰年的函数 public static void f(int m,int d){//被4整…...
【计算机网络】3数据链路层①
这篇笔记专门讲数据链路层的功能。 2.功能 数据链路层的主要任务是让帧在一段链路上或一个网络中传输。 2.1.封装成帧(组帧) 解决的问题:①帧定界②帧同步③透明传输 实现组帧的方法通常有以下种。 2.1.1.字符计数法 原理:在每个帧开头,用一个定长计数字段来记录该…...

Mysql--基础知识点--93--两阶段提交
1 两阶段提交 以update语句的具体执行过程为例: 具体更新一条记录 UPDATE t_user SET name ‘xiaolin’ WHERE id 1;的流程如下: 1.执行器负责具体执行,会调用存储引擎的接口,通过主键索引树搜索获取 id 1 这一行记录&#…...
Nginx底层架构(非常清晰)
目录 前言: 场景带入: HTTP服务器是什么? 反向代理是什么? 模块化网关能力: 1.配置能力: 2.单线程: 3.多worker进程 4.共享内存: 5.proxy cache 6.master进程 最后&…...

期货数据API对接实战指南
一、期货数据接口概述 StockTV提供全球主要期货市场的实时行情与历史数据接口,覆盖以下品种: 商品期货:原油、黄金、白银、铜、天然气、农产品等金融期货:股指期货、国债期货特色品种:马棕油、铁矿石等区域特色期货 …...

网页图像优化:现代格式与响应式技巧
网页图像优化:现代格式与响应式技巧 网页图像如果处理不好,很容易拖慢加载速度,影响用户体验。这篇文章聊聊怎么用现代图像格式和响应式技巧,让你的网站图片加载更快、效果更好。 推荐的图像格式 选对图像格式,能在保…...
Docker 设置镜像源后仍无法拉取镜像问题排查
#记录工作 Windows系统 在使用 Docker 的过程中,许多用户会碰到设置了国内镜像源后,依旧无法拉取镜像的情况。接下来,记录了操作要点以及问题排查方法,帮助我们顺利解决这类问题。 Microsoft Windows [Version 10.0.27823.1000…...

设计模式实践:模板方法、观察者与策略模式详解
目录 1 模板方法1.1 模板方法基本概念1.2 实验1.2.1 未使用模板方法实现代码1.2.2 使用模板方法的代码 2 观察者模式2.1 观察者模式基本概念2.2 实验 3 策略模式3.1 策略模式基本概念3.2 实验 1 模板方法 1.1 模板方法基本概念 定义:一个操作中的算法的骨架 &…...

Rockchip 显示架构
对于 Rockchip 平台,主要有以下几种显示架构可供选择: Qt + WaylandQt + EGLFSEGL program + X11WaylandNone多窗口的功能需求,选择: X11Wayland桌面的功能需求,选择: X114K 视频播放 + 全屏:Qt + WaylandQt + EGLFSX11Wayland4K 视频播放 + 多窗口: X11Qt + WaylandWa…...

Edge 浏览器推出 Copilot Vision:免费实时解析屏幕内容;Aqua Voice:极速 AI 语音输入工具丨日报
开发者朋友们大家好 这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 技术 」、「有亮点的 产品 」、「有思考的 文章 」、「有态度的 观点 」、「有看…...

async-profiler火焰图找出耗CPU方法
事情起于开发应用对依赖的三方包(apache等等)进行了升级后(主要是升级spring),CPU的使用率较原来大幅提升,几个应用提升50%-100%。 查找半天,对比每次版本的cpu火焰图,看不出有什么…...
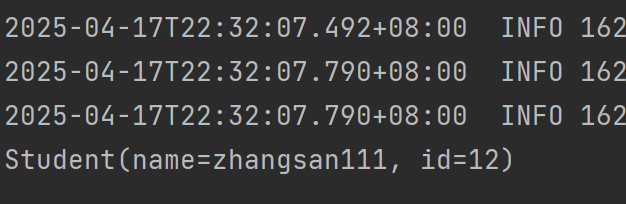
@Autowird 注解与存在多个相同类型对象的解方案
现有一个 Student 类,里面有两个属性,分别为 name 和 id;有一个 StuService 类,里面有两个方法,返回值均为类型为 Student 的对象;还有一个 StuController 类,里面有一个 Student 类型的属性&am…...

WordPiece 详解与示例
WordPiece详解 1. 定义与背景 WordPiece 是一种子词分词算法,由谷歌于2012年提出,最初用于语音搜索系统,后广泛应用于机器翻译和BERT等预训练模型。其核心思想是将单词拆分为更小的子词单元(如词根、前缀/后缀),从而解决传统分词方法面临的词汇表过大和未知词(OOV)处…...
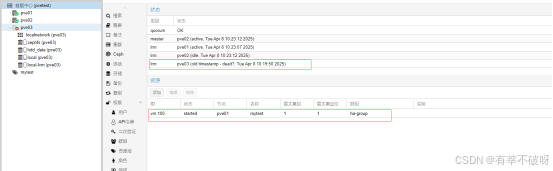
PVE+CEPH+HA部署搭建测试
一、基本概念介绍 Proxmox VE Proxmox Virtual Environment (Proxmox VE) 是一款开源的虚拟化管理平台,基于 Debian Linux 开发,支持虚拟机和容器的混合部署。它提供基于 Web 的集中管理界面,简化了计算、存储和网络资源的配置与监控。P…...

【Leetcode 每日一题 - 补卡】1534. 统计好三元组
问题背景 给你一个整数数组 a r r arr arr,以及 a 、 b 、 c a、b 、c a、b、c 三个整数。请你统计其中好三元组的数量。 如果三元组 ( a r r [ i ] , a r r [ j ] , a r r [ k ] ) (arr[i], arr[j], arr[k]) (arr[i],arr[j],arr[k]) 满足下列全部条件ÿ…...

ROS ROS2 机器人深度相机激光雷达多传感器标定工具箱
系列文章目录 目录 系列文章目录 前言 三、标定目标 3.1 使用自定义标定目标 四、数据处理 4.1 相机数据中的标定目标检测 4.2 激光雷达数据中的标定目标检测 输入过滤器: 正常估算: 区域增长: 尺寸过滤器: RANSAC&a…...
android rtsp 拉流h264 h265,解码nv12转码nv21耗时卡顿问题及ffmpeg优化
一、 背景介绍及问题概述 项目需求需要在rk3568开发板上面,通过rtsp协议拉流的形式获取摄像头预览,然后进行人脸识别 姿态识别等后续其它操作。由于rtsp协议一般使用h.264 h265视频编码格式(也叫 AVC 和 HEVC)是不能直接用于后续处…...
熊海cms代码审计
目录 sql注入 1. admin/files/login.php 2. admin/files/columnlist.php 3. admin/files/editcolumn.php 4. admin/files/editlink.php 5. admin/files/editsoft.php 6. admin/files/editwz.php 7. admin/files/linklist.php 8. files/software.php 9. files…...

滑动窗口209. 长度最小的子数组
1.题目 给定一个含有 n 个正整数的数组和一个正整数 target 。 找出该数组中满足其总和大于等于 target 的长度最小的 子数组 [numsl, numsl1, ..., numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,返回 0 。 示例 1: 输入&…...
:INSERT INTO SELECT与SELECT INTO,选数据出来,放到另一个表中)
SQL(8):INSERT INTO SELECT与SELECT INTO,选数据出来,放到另一个表中
INSERT INTO SELECT 语句从一个表复制数据,然后把数据插入到一个已存在的表中; SELECT INTO 语句从一个表复制数据,然后把数据插入到另一个新表中 想象一下你有两个本子(数据库里的表): 本子A (源头)&…...

DeepSeek 与开源:肥沃土壤孕育 AI 硕果
当 DeepSeek 以低成本推理、多模态能力惊艳全球时,人们惊叹于国产AI技术的「爆发力」,却鲜少有人追问:这份爆发力的根基何在? 答案,藏在中国开源生态二十余年的积淀中。 从倪光南院士呼吁「以开源打破垄断」…...

2025高频面试算法总结篇【动态规划】
文章目录 直接刷题链接直达编辑距离最长回文子串完全平方数最长递增子序列正则表达式匹配零钱兑换鸡蛋掉落单词拆分 直接刷题链接直达 动态规划(Dynamic Programming, DP)是一种通过拆解子问题并利用子问题的最优解来构建整体问题的最优解的方法&#x…...
Maven中clean、compil等操作介绍和Pom.xml中各个标签介绍
文章目录 前言Maven常用命令1.clean2.vaildate3.compile4.test5.package6.verify7.install8.site9.deploy pom.xml标签详解格式<?xml version"1.0" encoding"UTF-8"?>(xml版本和编码)modelVersion(xml版本)groupIdÿ…...
力扣刷题-热题100题-第35题(c++、python)
146. LRU 缓存 - 力扣(LeetCode)https://leetcode.cn/problems/lru-cache/?envTypestudy-plan-v2&envIdtop-100-liked 双向链表哈希表 内置函数 对于c有list可以充当双向链表,unordered_map充当哈希表;python有OrderedDic…...

Nautilus 正式发布:为 Sui 带来可验证的链下隐私计算
作为 Sui 安全工具包中的强大新成员,Nautilus 现已上线 Sui 测试网。它专为 Web3 开发者打造,支持保密且可验证的链下计算。Nautilus 应用运行于开发者自主管理的可信执行环境(Trusted Execution Environment,TEE)中&a…...