大数据面试问答-批处理性能优化
1. 数据存储角度
1.1 存储优化
列式存储格式:使用Parquet/ORC代替CSV/JSON,减少I/O并提升压缩率。
df.write.parquet("hdfs://path/output.parquet")
列式存储减少I/O的核心机制:
列裁剪(Column Pruning)
原理:查询时只读取需要的列,跳过无关列。
示例:
若执行 SELECT AVG(Age) FROM users,只需读取Age列的数据块,而无需加载Name、City等列。
节省效果:假设表有100列,仅读取1列时,I/O量减少99%。
高效压缩(Compression)
数据局部性:同一列的数据类型和值域相似,压缩效率更高。
数值型数据(如Age):可使用Delta Encoding(存储差值)或Run-Length Encoding(连续重复值压缩)。
字符串数据(如City):可使用字典编码(如NY→1, SF→2)。
1.2 小文件合并
Spark任务使用coalesce或repartition合并任务输出的小文件,
Hive需手动执行ALTER TABLE COMPACT
1.3 分区和分桶
| 特性 | 分区(Partitioning) | 分桶(Bucketing) |
|---|---|---|
| 目的 | 减少扫描范围(按目录过滤) | 优化JOIN、采样、数据局部性 |
| 实现方式 | 按字段值划分目录(如/date=20230101/) | 按字段哈希值分到固定数量的文件(桶) |
| 语法 | PARTITIONED BY (date STRING) | CLUSTERED BY (user_id) INTO 10 BUCKETS |
| 适用场景 | 高基数字段(如日期、地域) | 低基数字段(如用户ID、分类ID) |
分桶的核心价值:通过物理存储的预分区,将相同 Key 的数据聚集到同一位置,使得 Hive 可以在 Map 阶段直接完成 JOIN,跳过 Shuffle 和 Reduce。
本质区别:
分区(Partitioning)是 粗粒度过滤(按目录剪枝),减少数据扫描范围。
分桶(Bucketing)是 细粒度分布(按哈希分片),优化数据计算效率。
适用场景:高频大表 JOIN、数据倾斜缓解、高效采样。
2. 计算角度
2.1 join优化
使用Broadcast Join小表广播与分桶优化Join ,具体可看大数据面试问答-Hadoop/Hive/HDFS/Yarn中的2.3章节
2.2 数据倾斜
2.2.1 加盐处理
对倾斜的Key添加随机前缀,分散数据
-- 原始SQL
SELECT user_id, COUNT(*) FROM logs GROUP BY user_id;-- 加盐优化后
SELECT user_id, SUM(cnt) FROM (SELECT CONCAT(user_id, '_', FLOOR(RAND()*10)) AS salted_key, COUNT(*) AS cnt FROM logs GROUP BY salted_key
) GROUP BY user_id;
使用两阶段聚合(加盐后局部聚合,再去盐全局聚合)
# 原始代码(存在倾斜)
rdd.groupByKey().mapValues(sum)# 优化后(两阶段聚合)
# 1. 加盐并局部聚合
salted_rdd = rdd.map(lambda x: (f"{x[0]}_{random.randint(0,9)}", x[1]))
partial_sum = salted_rdd.reduceByKey(lambda a, b: a + b)
# 2. 去盐并全局聚合
unsalted_rdd = partial_sum.map(lambda x: (x[0].split("_")[0], x[1]))
final_sum = unsalted_rdd.reduceByKey(lambda a, b: a + b)
2.2.2 增加分区
当某些 Key 的数据量极大时,默认的分区数(如 spark.sql.shuffle.partitions=200)可能导致这些 Key 的数据集中在少数分区中,造成长尾任务。
增加分区数(如设置为 1000)可以将原本集中在少量分区的数据分散到更多分区,降低单个分区的数据量,从而缓解倾斜。
例如:假设一个 Key 的数据量占整体的 50%,当分区数从 200 增加到 1000 时,该 Key 的数据会被 Hash 分配到更多分区(但实际效果受 Hash 算法影响,可能仍不均匀)。
适用场景:
数据倾斜由多个不同的 Key 导致(如多个热 Key),而非单个超大 Key。
分区数不足导致部分分区负载过高(如默认分区数远小于实际 Key 的基数)。
局限性:
对单个超大 Key(如某个 Key 占 90% 数据量)无效,因为该 Key 的所有数据仍会被 Hash 到同一个分区。
此时必须使用 加盐(如为 Key 附加随机前缀,强制分散数据)。
示例:Spark 中的分区优化
# 增加 Shuffle 分区数(全局配置)
spark.conf.set("spark.sql.shuffle.partitions", "1000")# 或在特定操作中重新分区
df.repartition(1000, "key").groupBy("key").count()
示例:Hive 中的优化
-- 增加 Reduce 任务数
SET mapred.reduce.tasks = 1000;-- 两阶段聚合(自动处理倾斜)
SET hive.groupby.skewindata = true;-- 手动加盐处理单个超大 Key
SELECT key_salted, SUM(value)
FROM (SELECT CONCAT(key, '_', CAST(RAND() * 10 AS INT)) AS key_salted, valueFROM input_table
) tmp
GROUP BY key_salted;
2.2.3 过滤无效数据
提前剔除无意义的空值或默认值,减少无效计算
2.2.4 单独处理
拆分倾斜Key单独处理
2.3 算子优化
减少Shuffle:
避免不必要的groupByKey,优先用reduceByKey。
3. 资源角度
Executor配置
# 单个Executor资源
--executor-memory 16G # 内存(留20%给堆外内存)
--executor-cores 4 # CPU核心
--num-executors 20 # Executor数量# 动态资源分配(应对数据波动)
spark.dynamicAllocation.enabled=true
内存管理:
调整内存分配比例:spark.memory.fraction=0.6(默认0.6,Execution和Storage共享)。
堆外内存优化:spark.executor.memoryOverhead=2G(防止OOM)。
相关文章:

大数据面试问答-批处理性能优化
1. 数据存储角度 1.1 存储优化 列式存储格式:使用Parquet/ORC代替CSV/JSON,减少I/O并提升压缩率。 df.write.parquet("hdfs://path/output.parquet")列式存储减少I/O的核心机制: 列裁剪(Column Pruning) …...

浅析数据库面试问题
以下是关于数据库的一些常见面试问题: 一、基础问题 什么是数据库? 数据库是按照数据结构来组织、存储和管理数据的仓库。SQL 和 NoSQL 的区别是什么? SQL 是关系型数据库,使用表结构存储数据;NoSQL 是非关系型数据库,支持多种数据模型(如文档型、键值对型等)。什么是…...

Android 12.0 framework实现对系统语言切换的功能实现
1.前言 在12.0的系统rom定制化开发过程中,在定制某些接口的过程中,需要通过系统提供接口,然后实现对系统语言的切换 功能实现,接下来分析下系统中关于系统语言切换的相关功能 2.framework实现对系统语言切换的功能实现的核心类 frameworks/base/core/java/android/app/IA…...
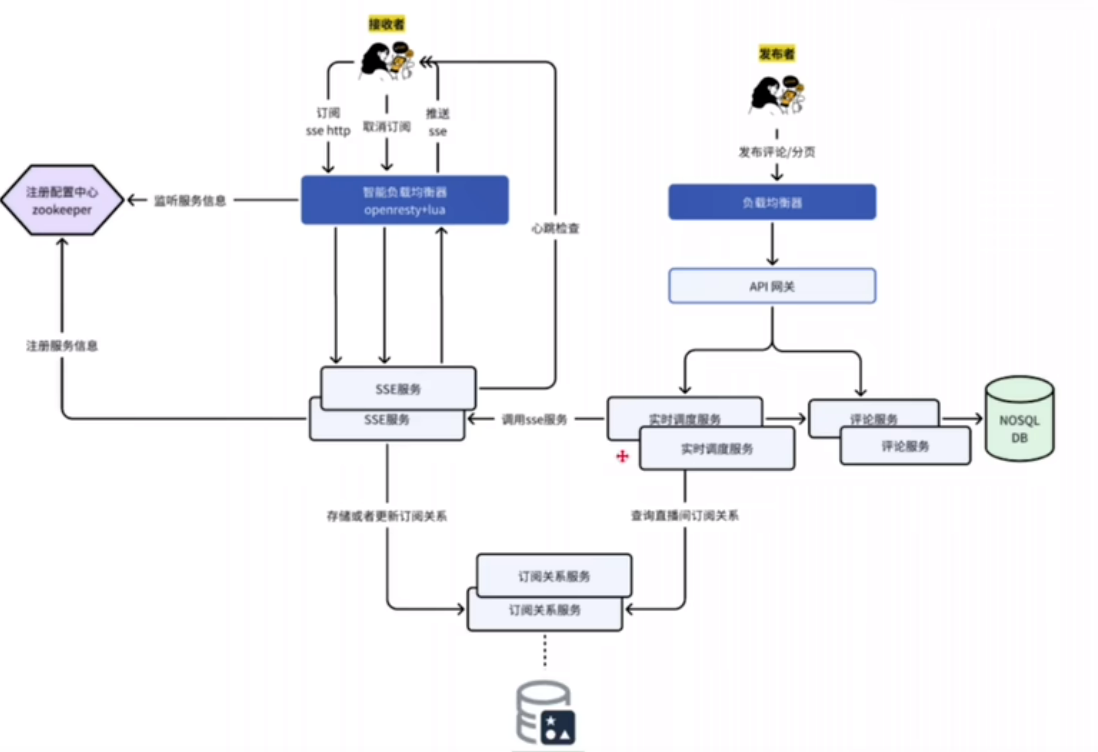
实时直播弹幕系统设计
整个服务读多写少,读写比例大概几百比1. 如果实时性要求高的话,可以采用长连接模式(轮询的话,时效性不好,同时对于评论少的直播间可能空转) websocket 和 SSE架构 只要求服务端推送的话,可以…...
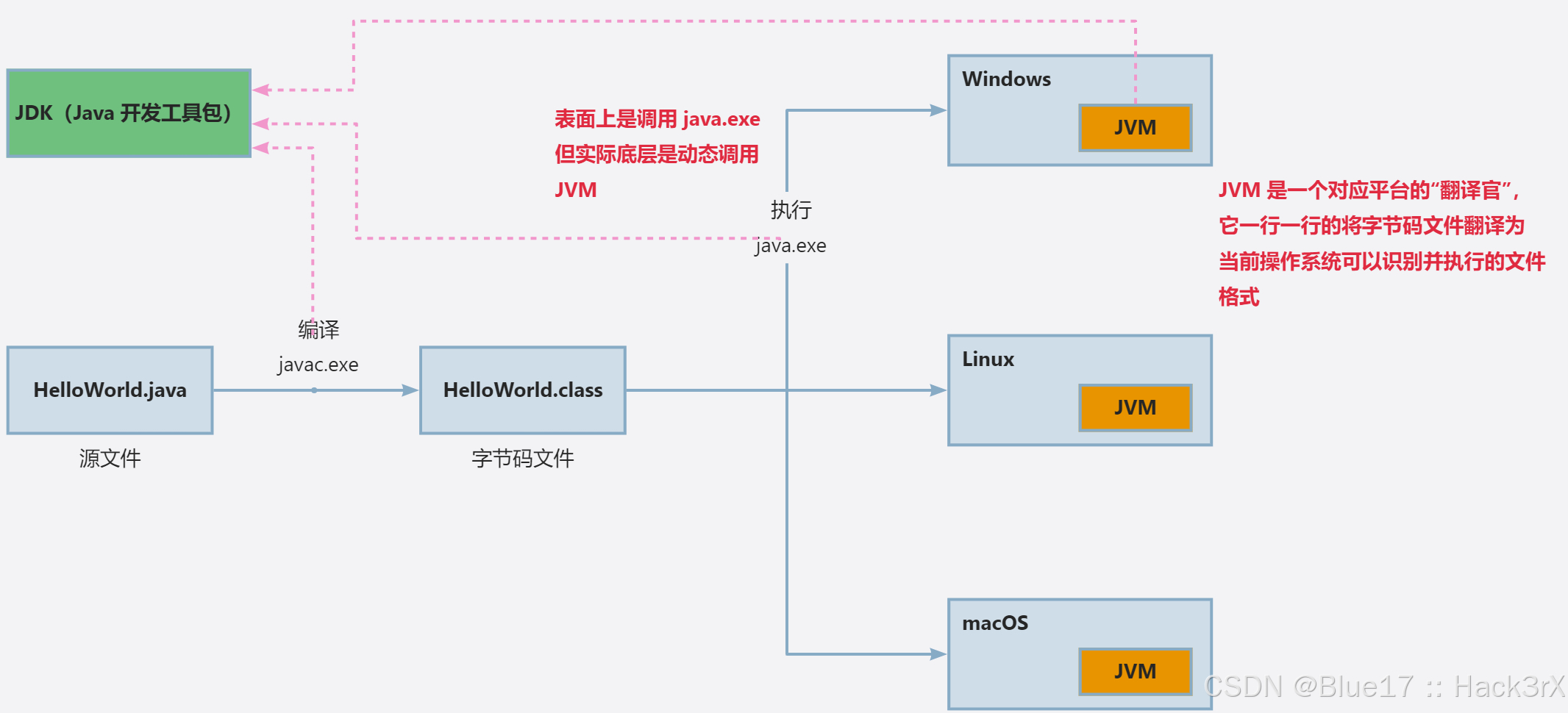
[Java · 初窥门径] Java 语言初识
🌟 想系统化学习 Java 编程?看看这个:[编程基础] Java 学习手册 0x01:Java 编程语言简介 Java 是一种高级计算机编程语言,它是由 Sun Microsystems 公司(已被 Oracle 公司收购)于 1995 年 5 …...
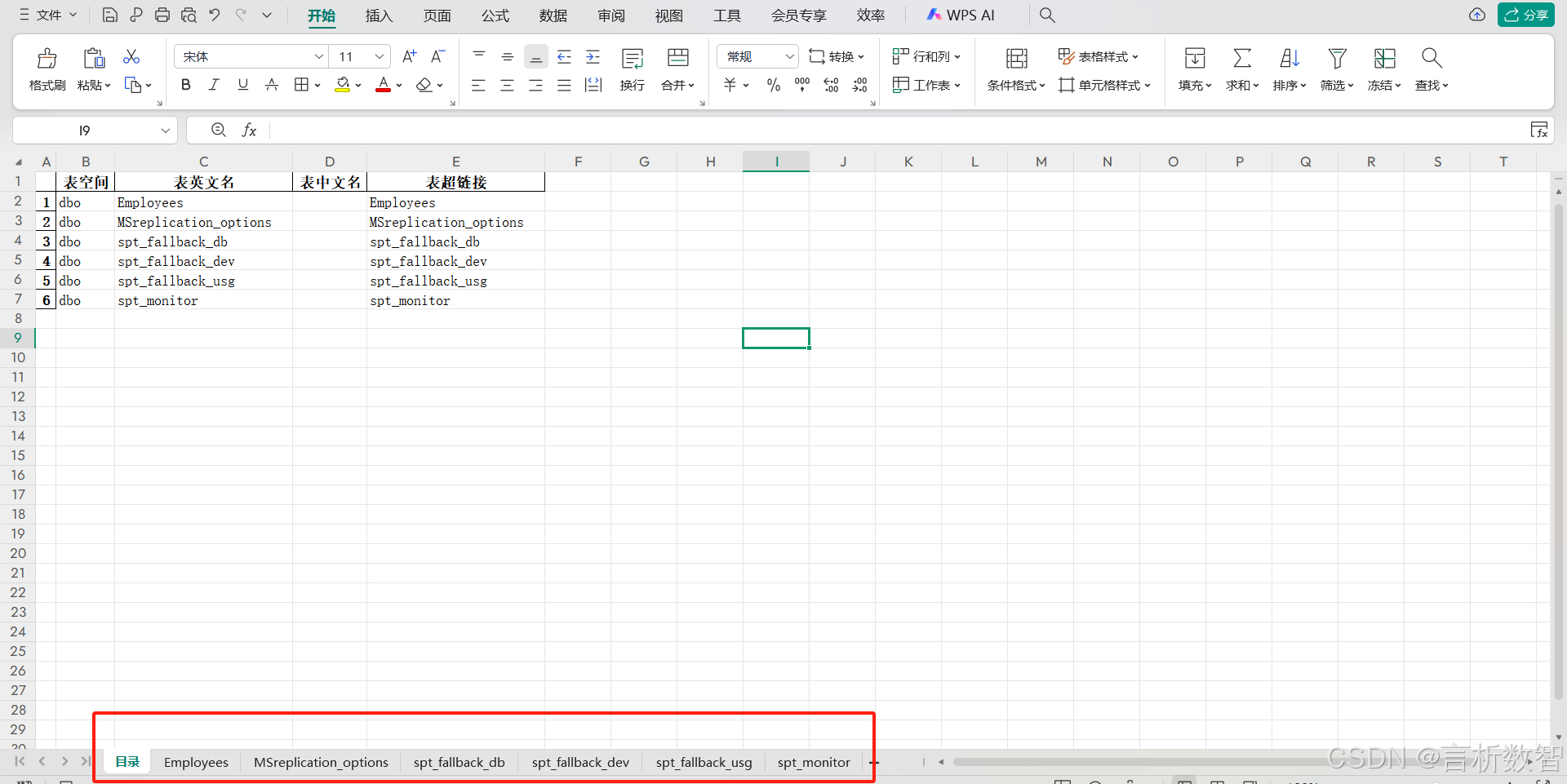
【SQL Server】数据探查工具1.0研发可行性方案
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 想抢先解锁数据自由的宝子,速速戳我!评论区蹲一波 “蹲蹲”,揪人唠唠你的超实用需求! 【SQL Server】数据探查工具1.0研发可行性方案…...

谓词——C++
1.一元谓词 1.定义 2.案例 查找容器有没有大于五的数字 #include<stdio.h> using namespace std; #include<string> #include<vector> #include<set> #include <iostream> class myfind { public:bool operator()(int a){return a > 5;} …...
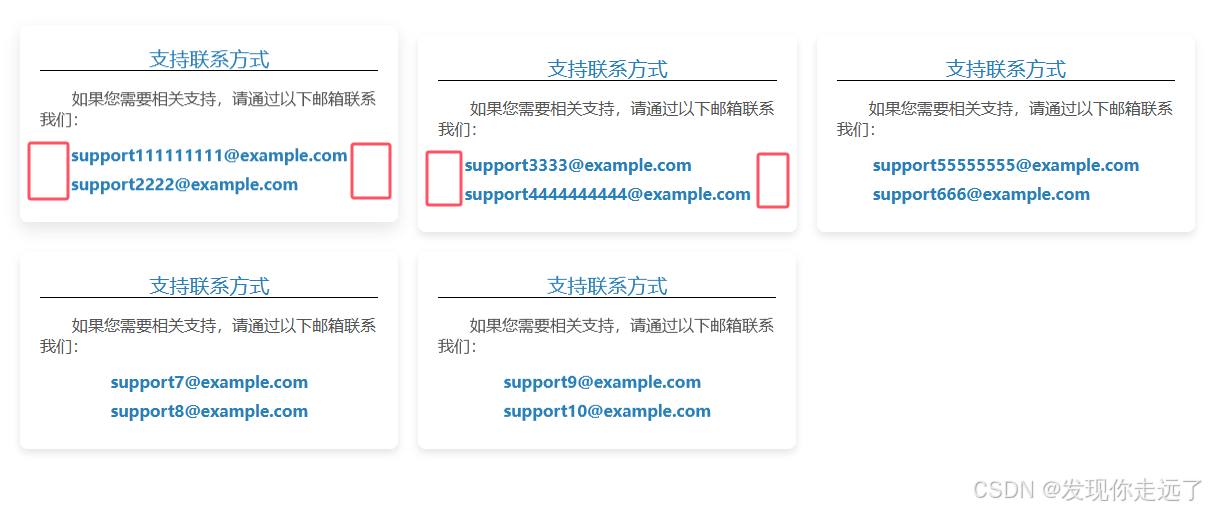
『前端样式分享』联系我们卡片式布局 自适应屏幕 hover动效 在wikijs中使用 (代码拿来即用)
目录 预览效果分析要点响应式网格布局卡片样式:阴影和过渡效果 代码优化希望 长短不一的邮箱地址在左右居中的同时,做到左侧文字对齐(wikijs可用)总结 欢迎关注 『前端布局样式』 专栏,持续更新中 欢迎关注 『前端布局样式』 专栏,持续更新中…...

Python PDF 转 Markdown 工具库对比与推荐
根据最新评测及开源社区实践,以下为综合性能与适用场景的推荐方案: 1. Marker 特点: 转换速度快,支持表格、公式(转为 LaTeX)、图片提取,适配复杂排版文档。依赖 PyTorch,…...

MySQL 缓存机制全解析:从磁盘 I/O 到性能优化
MySQL 缓存机制全解析:从磁盘 I/O 到性能优化 MySQL 的缓存机制是提升数据库性能的关键部分,它通过多级缓存减少磁盘 I/O 和计算开销,从而提高查询和写入的效率。 1. 为什么需要缓存? 数据库的性能瓶颈通常集中在磁盘 I/O 上。…...

1.1 设置电脑开机自动用户登录exe开机自动启动
本文介绍两个事情: 1.Windows如何开机自动登录系统(不用输密码) 2. 应用程序(.exe)如何开机自动启动 详细解释如下: 一、Windows如何开机自动登录系统(不用输密码) 设备上的工控机,如果开机后都需要操作人员输入密码&…...
基于 Python 和 OpenCV 技术的疲劳驾驶检测系统(2.0 全新升级,附源码)
大家好,我是徐师兄,一个有着7年大厂经验的程序员,也是一名热衷于分享干货的技术爱好者。平时我在 CSDN、掘金、华为云、阿里云和 InfoQ 等平台分享我的心得体会。 🍅文末获取源码联系🍅 2025年最全的计算机软件毕业设计…...

axios 模拟实现
axios 模拟实现 包含发送请求,拦截器,取消请求 第一步 , axios模拟发送请求 //使用 xhr 发送请求function xhr_adpter(config){return new Promise(function handle(resolve,reject){let xhr new XMLHttpRequest();xhr.open(config.method, config.url,true);xhr.onreadysta…...

学术AI工具推荐
一、基础信息对比 维度知网研学AI(研学智得AI)秘塔AIWOS AI开发公司同方知网(CNKI)上海秘塔网络科技Clarivate Analytics是否接入DeepSeek✅ 深度集成(全功能接入DeepSeek-R1推理服务)✅ 通过API接入DeepS…...
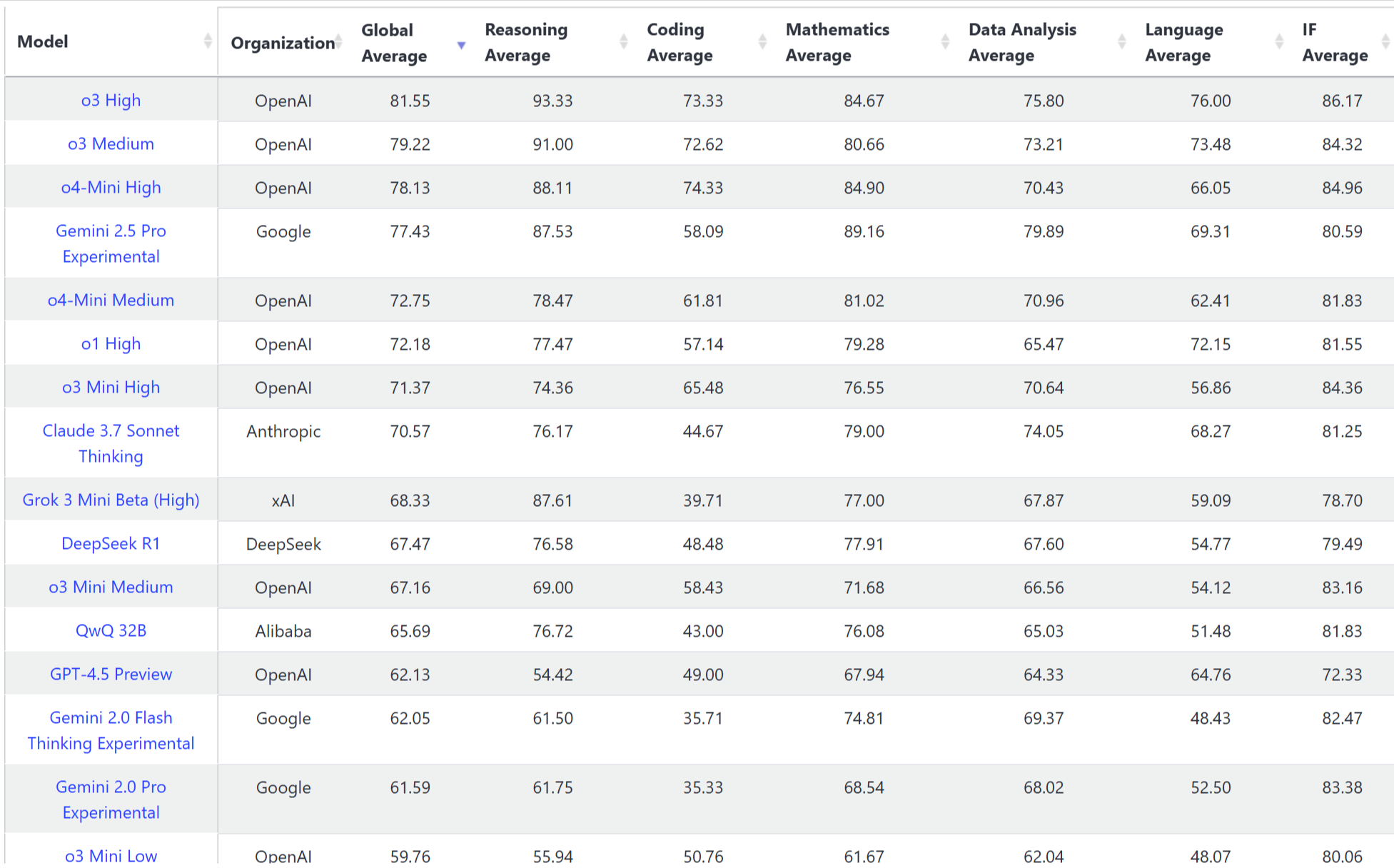
OpenAI重返巅峰:o3与o4-mini引领AI推理新时代
引言 2025年4月16日,OpenAI发布了全新的o系列推理模型:o3和o4-mini,这两款模型被官方称为“迎今为止最智能、最强大的大语言模型(LLM)”。它们不仅在AI推理能力上实现了质的飞跃,更首次具备了全面的工具使…...

Unity3d 6(6000.*.*)版本国区下载安装参考
前言 Unity3d 6.是最新的版本,是与来自世界各地的开发者合作构建、测试和优化的成果,现在可以完全投入生产,是我们迄今为止性能最出色、最稳定的 Unity 版本。Unity 6 有许多令人兴奋的新工具和功能:端到端多人游戏工作流程将加速…...
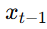
第 3 期:逆过程建模与神经网络的作用(Reverse Process)
一、从正向扩散到逆向去噪:生成的本质 在上期中我们讲到,正向扩散是一个逐步加入噪声的过程,从原始图像 x_0到接近高斯分布的 x_T: 而我们真正关心的,是从纯噪声中逐步还原原图的过程,也就是逆过程&…...

健康养生:开启活力生活新篇章
在当代社会,熬夜加班、久坐不动、外卖快餐成为许多人的生活常态,随之而来的是各种亚健康问题。想要摆脱身体的疲惫与不适,健康养生迫在眉睫,它是重获活力、拥抱美好生活的关键。 应对不良饮食习惯带来的健康隐患,饮…...

50个Excel常用公式
方法 1:使用 VLOOKUP 函数查找对应值 假设: Sheet1 的 K 列包含需要查找的 IP 地址。Sheet2 的 A 列是所有 IP 地址,B 列是对应的 MAC 地址。你想在 Sheet1 的 L 列显示对应的 MAC 地址。 在 Sheet1 的 L 列输入公式: 在 Sheet1…...
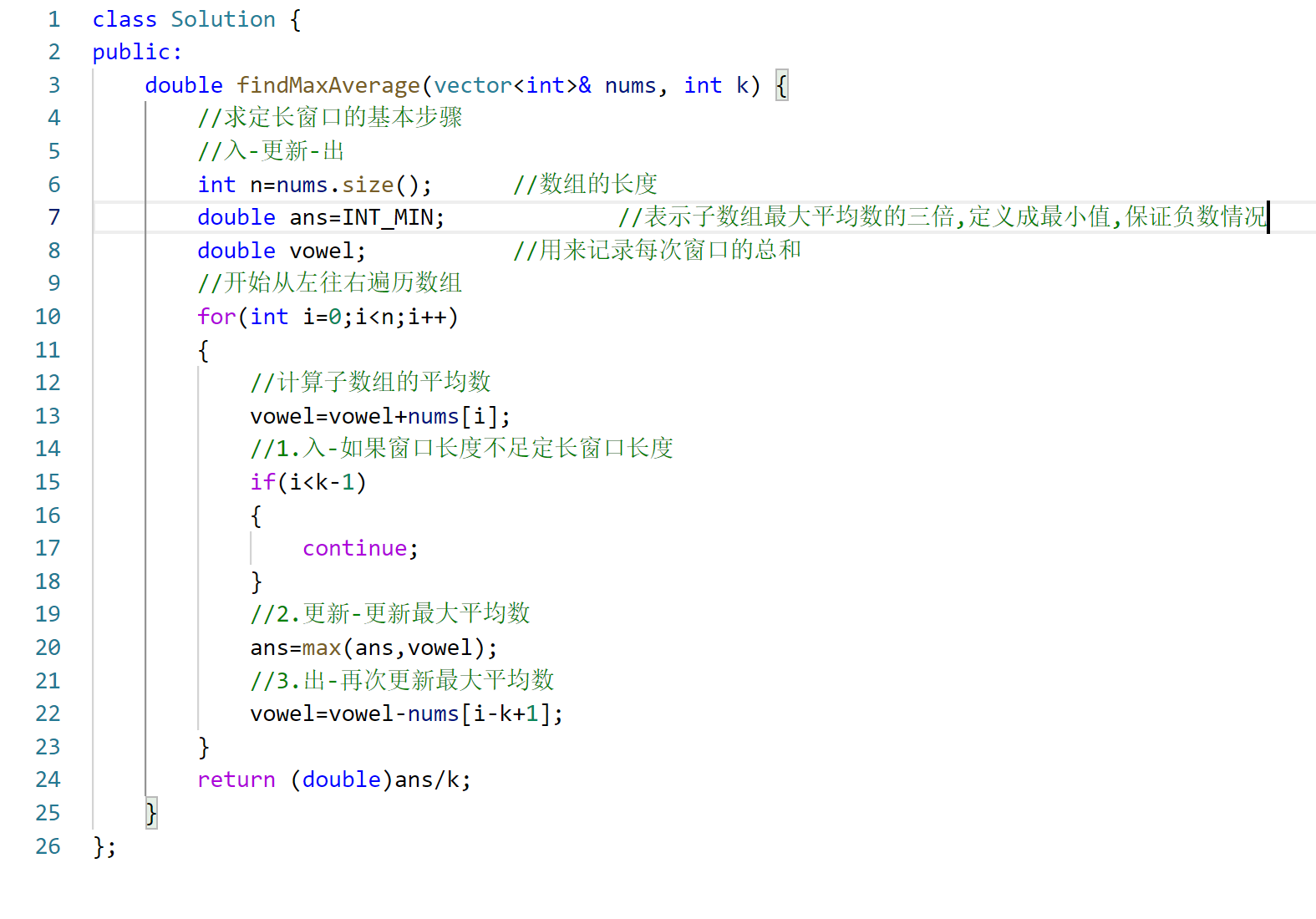
记录学习的第二十九天
还是力扣每日一题。 本来想着像昨天一样两个循环搞定的,就下面👇🏻 不过,结果肯定是超时啦,中等题是吧。 正确答案是上面的。 之后就做了ls题单第一部分,首先是定长滑窗问题 这种题都是有套路的࿰…...
Express学习笔记(六)——前后端的身份认证
目录 1. Web 开发模式 1.1 服务端渲染的 Web 开发模式 1.2 服务端渲染的优缺点 1.3 前后端分离的 Web 开发模式 1.4 前后端分离的优缺点 1.5 如何选择 Web 开发模式 2. 身份认证 2.1 什么是身份认证 2.2 为什么需要身份认证 2.3 不同开发模式下的身份认证 3. Sessio…...

Ubuntu 修改语言报错Failed to download repository information
1.进入文件(ps:vim可能出现无法修改sources.list文件的问题) sudo gedit /etc/apt/sources.list2.修改(我是直接增添以下内容在其原始源前面,没有删原始内容)文件并保存,这里会替换原文件 deb http://mirrors.aliyun.com/ubuntu/ focal mai…...
leetcode 309. Best Time to Buy and Sell Stock with Cooldown
目录 题目描述 第一步,明确并理解dp数组及下标的含义 第二步,分析并理解递推公式 1.求dp[i][0] 2.求dp[i][1] 3.求dp[i][2] 第三步,理解dp数组如何初始化 第四步,理解遍历顺序 代码 题目描述 这道题与第122题的区别就是卖…...
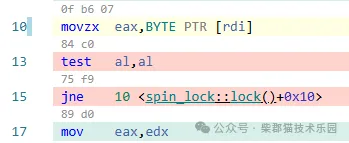
优化自旋锁的实现
在《C11实现一个自旋锁》介绍了分别使用TAS和CAS算法实现自旋锁的方案,以及它们的优缺点。TAS算法虽然实现简单,但是因为每次自旋时都要导致一场内存总线流量风暴,对全局系统影响很大,一般都要对它进行优化,以降低对全…...
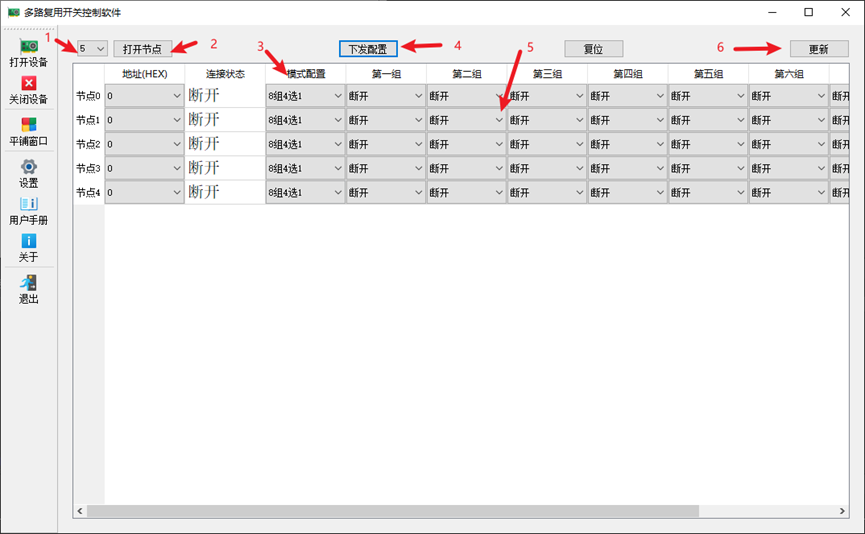
SS25001-多路复用开关板
1 概述 1.1 简介 多路复用开关板是使用信号继电器实现2线制的多路复用开关板卡;多路复用开关是一种可以将一个输入连接到多个输出或一个输出连接到多个输入的拓扑结构。这种拓扑通常用于扫描,适合将一系列通道自动连接到公共线路的的设备。多路复用开…...

thanos sidecar和receive区别?
Thanos Sidecar 和 Thanos Receive 是 Thanos 生态系统中两个关键组件,但它们在架构中的作用和功能上有明显的区别。以下是它们的主要区别: 1. Thanos Sidecar 功能: 与 Prometheus 集成: Sidecar 是一个部署在每个 Prometheus…...

string函数的应用
字符串查找 find 方法 实例 string s "Hello World,C is awesome!";//查找子串 size_t pos1 s.find("World"); //pos16 size_t pos2 s.find("Python"); //pos2string::npos//查找字符 size_tpos3s.find(c); //pos313//从指定位置开始查找 size…...

【AI News | 20250418】每日AI进展
AI Repos 1、exa-mcp-server AI助手通过Exa获得实时网络信息获取的能力,提供结构化的搜索结果,返回包括标题、URL以及内容片段在内的结构化结果;会把最近的搜索结果缓存为资源,下次再搜索相同的内容时可以直接使用缓存࿱…...
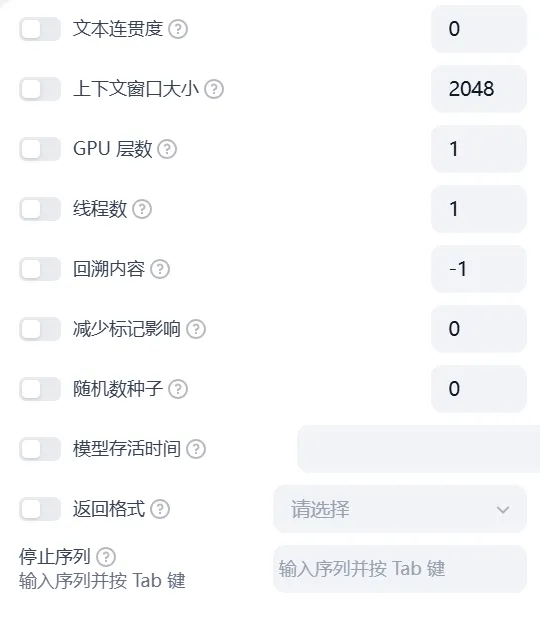
Dify LLM大模型参数(一)
深入了解大语言模型(LLM)的参数设置 模型的参数对模型的输出效果有着至关重要的影响。不同的模型会拥有不同的参数,而这些参数的设置将直接影响模型的生成结果。以下是 DeepSeek 模型参数的详细介绍: 温度(Tempera…...

展示数据可视化的魅力,如何通过图表、动画等形式让数据说话
在当今信息爆炸的时代,数据的量级和复杂性不断增加。如何从海量数据中提取有价值的信息,并将其有效地传达给用户,成为了一个重要的课题。数据可视化作为一种将复杂数据转化为直观图形、图表和动画的技术,能够帮助用户快速理解数据…...