再读bert(Bidirectional Encoder Representations from Transformers)
再读 BERT,仿佛在数字丛林中邂逅一位古老而智慧的先知。初次相见时,惊叹于它以 Transformer 架构为罗盘,在预训练与微调的星河中精准导航,打破 NLP 领域长久以来的迷雾。而如今,书页间跃动的不再仅是 Attention 机制精妙的数学公式,更是一场关于语言本质的哲学思辨 —— 它让我看见,那些被编码的词向量,恰似人类思维的碎片,在双向语境的熔炉中不断重组、淬炼,将离散的文字升华为可被计算的意义。BERT 教会我们,语言从来不是孤立的字符堆砌,而是承载着文化、逻辑与情感的多维载体,每一次模型的迭代与优化,都是人类向理解语言本质更深处的一次虔诚叩问,在这过程中,我们既是技术的创造者,也是语言奥秘的永恒探索者。
论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Github:https://github.com/google-research/bert?tab=readme-ov-file

1.引言与核心创新
-
背景:
现有预训练模型(如 ELMo、GPT)多基于单向语言模型,限制深层双向表征能力。
-
创新点:
(1)提出BERT,通过MLM和NSP预训练任务,实现真正的深层双向 Transformer 表征。
(2)证明预训练模型可通过简单微调(仅添加输出层)适配多任务,无需复杂架构设计。
2.模型架构与输入表征
-
模型结构:
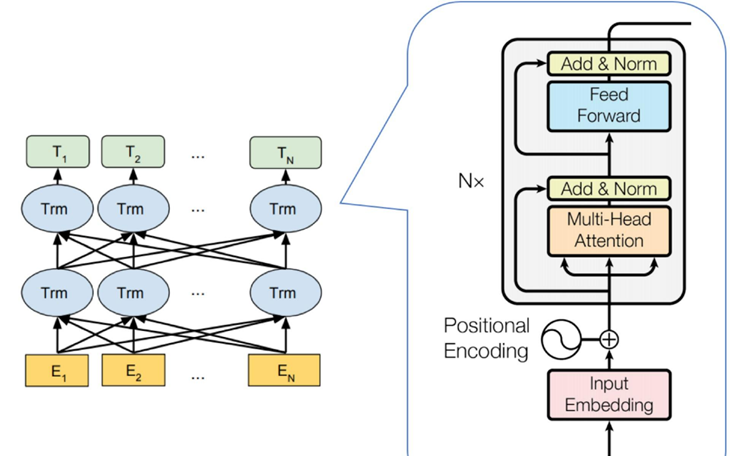
BERT(Bidirectional Encoder Representations from Transformers)由Google 提出并基于 Transformer 架构进行开发的预训练语言模型。如图所示, BERT 模型是由多个 Transformer 的编码器逐层叠加而成。 BERT 模型包括两种标准配置,其中 Base 版本包含 12 层 Transformer 编码器,而 Large版本包含 24 层 Transformer 编码器,其参数总数分别为 110M 和 340M。
BERT 模型的关键特点是能够全方位地捕捉上下文信息。与传统的单向模型(GPT-1 等自回归模型)相比, BERT 能够从两个方向考虑上下文,涵盖了某个词元之前和之后的信息。传统的模型往往只从一个固定的方向考虑上下文,这在处理复杂的语义关系和多变的句子结构时可能会遇到困难。例如,在问答系统中,单一方向可能导致模型不能完全理解问题的上下文,从而影响其回答的准确性。此外,在情感分析、关系抽取、语义角色标注、文本蕴涵和共指解析等任务中,单向方法可能无法充分捕获复杂的语义关系和上下文依赖,限制了其性能。为了应对这些挑战, BERT 通过预测遮蔽的词元来全面理解句子中的上下文,从而在许多 NLP 任务中实现了显著的性能增强。
-
Transformer 配置:
| 模型 | 层数 (L) | 隐层大小 (H) | 注意力头 (A) | 参数总量 |
| BERT BASE | 12 | 768 | 12 | 110M |
| BERT LARGE | 24 | 1024 | 16 | 340M |
-
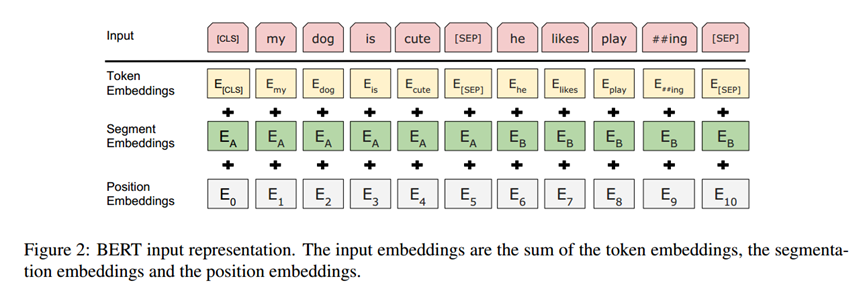
输入表征:
采用WordPiece 分词(30k 词汇表),添加特殊 token:
[CLS]:序列分类标识,对应隐层用于分类任务。
[SEP]:句子对分隔符,段嵌入(Sentence A/B)区分句子归属。
输入嵌入 = 词嵌入 + 段嵌入 + 位置嵌入。
3.训练任务设计
BERT 模型的训练过程通常分为预训练(Pre-training)与微调训练(Finetuning)等两部分。
3.1 预训练
在预训练阶段, BERT 模型在大量未标注的文本数据上进行训练,目标是学习文本之间的深层次关系和模式。具体来说,它使用了两种训练策略:
i)掩码语言模型 (Masked Language Model);
ii)预测下一句(Next Sentence Prediction)。
任务 1:掩码语言模型(MLM)
掩码策略:随机选择 15% tokens,其中:
80% 替换为[MASK](如my dog is [MASK]),
10% 替换为随机词(如my dog is apple),
10% 保留原词(如my dog is hairy)。
目标:通过双向注意力预测原词,缓解预训练与微调时[MASK]未出现的不匹配问题。
任务 2:下一句预测(NSP)
数据生成:50% 真实连续句对(标签 IsNext),50% 随机句对(标签 NotNext)。
目标:通过[CLS]隐层预测句对关系,提升句子级语义理解(如 QA、NLI 任务)。
3.2 微调
微调训练阶段是在预训练的 BERT 模型基础上,针对特定任务进行的训练。这一阶段使用具有标签的数据,如情感分析或命名实体识别数据。通过在预训练模型上加载特定任务的数据进行微调, BERT 能够在各种下游任务中达到令人满意的效果。
BERT 模型微调训练的目的是使其具备处理各种下游任务的能力,微调的任务包括:句子对分类任务、单句分类任务、问答任务和命名实体识别等。
微调训练中为了使 BERT 适应各种 NLP 任务,模型首先调整其输入和输出。例如,在基于句子对的分类任务中,假设要判断句子 A“这家餐厅的食物很美味。”和句子 B“菜品口味很棒,值得推荐。”之间的关系,模型的输入是这两个句子的组合,而输出可能是它们的关系分类,例如“相关”或“不相关”。而在命名实体识别任务中,如果输入句子为“任正非是华为的创始人”,输出则是每个词的实体类别,如“任正非”被标记为“PERSON”,“华为”被标记为“ORGANIZATION”。在针对不同的任务,如文本分类、实体识别或问答等,进行微调训练时,会在 BERT 模型上增添一个特定的输出层。这个输出层是根据特定任务的需求设计的。例如,如果是文本分类任务,输出层可能包含少量神经元,每个神经元对应一个类别。同时,通过反向传播对模型参数进行调整。微调的过程就像是对模型进行 “二次训练”。
4.实验结果与 SOTA 突破
-
GLUE 基准(11 任务)
| 任务 | BERT LARGE 得分 | 前 SOTA | 提升幅度 |
| MNLI(自然语言推理) | 86.7% | 82.1%(GPT) | +4.6% |
| QNLI(问答推理) | 92.7% | 87.4%(GPT) | +5.3% |
| SST-2(情感分析) | 94.9% | 91.3%(GPT) | +3.6% |
| 平均得分 | 82.1% | 75.1%(GPT) | +7.0% |
-
SQuAD 问答任务
v1.1(有答案):单模型 F1 值 93.2,ensemble 达 93.9,超过人类表现(91.2%)。
v2.0(无答案):F1 值 83.1,较前 SOTA 提升 5.1%,首次接近人类表现(89.5%)。
- SWAG 常识推理:BERT LARGE 准确率 86.3%,远超 GPT(78.0%)和人类专家(85.0%)。
5.消融研究与关键发现
-
NSP 任务的重要性
移除 NSP 后,MNLI 准确率从 84.4% 降至 83.9%,QNLI 从 88.4% 降至 84.9%,证明句子级关系建模对 QA 和 NLI 至关重要。
-
双向性 vs 单向性
单向模型(LTR,类似 GPT)在 SQuAD F1 值仅 77.8%,远低于 BERT BASE 的 88.5%;添加 BiLSTM 后提升至 84.9%,仍显著落后。
-
模型规模的影响
增大参数(如从 110M 到 340M)持续提升性能,即使在小数据集任务(如 MRPC,3.5k 训练例)中,BERT LARGE 准确率 70.1%,较 BASE 的 66.4% 提升 3.7%。
6.对比现有方法
-
与 GPT 对比:
- GPT 为单向 Transformer(仅左到右),BERT 通过 MLM 实现双向,且预训练数据多 3 倍(33 亿词 vs GPT 的 8 亿词)。
- BERT 在 GLUE 平均得分比 GPT 高 7.0%,证明双向性和 NSP 的关键作用。
-
与 ELMo 对比:
- ELMo 通过拼接单向 LSTM 输出实现双向,为特征基方法;BERT 为微调基,参数效率更高,且深层双向表征更优。
7.关键问题
问题 1:BERT 如何实现深层双向语义表征?
答案:BERT 通过 ** 掩码语言模型(MLM)和下一句预测(NSP)** 任务实现双向表征。MLM 随机掩码 15% 的输入 tokens(80% 替换为 [MASK]、10% 随机词、10% 保留原词),迫使模型利用左右语境预测原词,避免单向模型的局限性;NSP 任务通过判断句对是否连续,学习句子级语义关系,增强模型对上下文依赖的建模能力。
问题 2:BERT 在预训练中如何处理 “掩码 token 未在微调时出现” 的不匹配问题?
答案:BERT 采用混合掩码策略:在 15% 被选中的 tokens 中,仅 80% 替换为 [MASK],10% 随机替换为其他词,10% 保留原词。这种策略减少了预训练与微调时的分布差异,使模型在微调时更适应未出现 [MASK] 的真实场景,同时通过随机替换和保留原词,增强模型对输入噪声的鲁棒性。
问题 3:模型规模对 BERT 性能有何影响?
答案:增大模型规模(如从 BERT BASE 的 110M 参数到 LARGE 的 340M 参数)显著提升性能,尤其在小数据集任务中优势明显。实验显示,更大的模型在 GLUE 基准的所有任务中均表现更优,MNLI 准确率从 84.6% 提升至 86.7%,MRPC(3.5k 训练例)准确率从 66.4% 提升至 70.1%。这表明,足够的预训练后,更大的模型能学习更丰富的语义表征,即使下游任务数据有限,也能通过微调有效迁移知识。
相关文章:
再读bert(Bidirectional Encoder Representations from Transformers)
再读 BERT,仿佛在数字丛林中邂逅一位古老而智慧的先知。初次相见时,惊叹于它以 Transformer 架构为罗盘,在预训练与微调的星河中精准导航,打破 NLP 领域长久以来的迷雾。而如今,书页间跃动的不再仅是 Attention 机制精…...
uCOS3实时操作系统(系统架构和中断管理)
文章目录 系统架构中断管理ARM中断寄存器相关知识ucos中断机制 系统架构 ucos主要包含三个部分的源码: 1、OS核心源码及其配置文件(ucos源码) 2、LIB库文件源码及其配置文件(库文件,比如字符处理、内存管理࿰…...

图像预处理-图像噪点消除
一.基本介绍 噪声:指图像中的一些干扰因素,也可以理解为有那么一些点的像素值与周围的像素值格格不入。常见的噪声类型包括高斯噪声和椒盐噪声。 滤波器:也可以叫做卷积核 - 低通滤波器是模糊,高通滤波器是锐化 - 低通滤波器就…...
6.数据手册解读—运算放大器(二)
目录 6、细节描述 6.1预览 6.2功能框图 6.3 特征描述 6.3.1输入保护 6.3.1 EMI抑制 6.3.3 温度保护 6.3.4 容性负载和稳定性 6.3.5 共模电压范围 6.3.6反相保护 6.3.7 电气过载 6.3.8 过载恢复 6.3.9 典型规格与分布 6.3.9 散热焊盘的封装 6.3.11 Shutdown 6.4…...
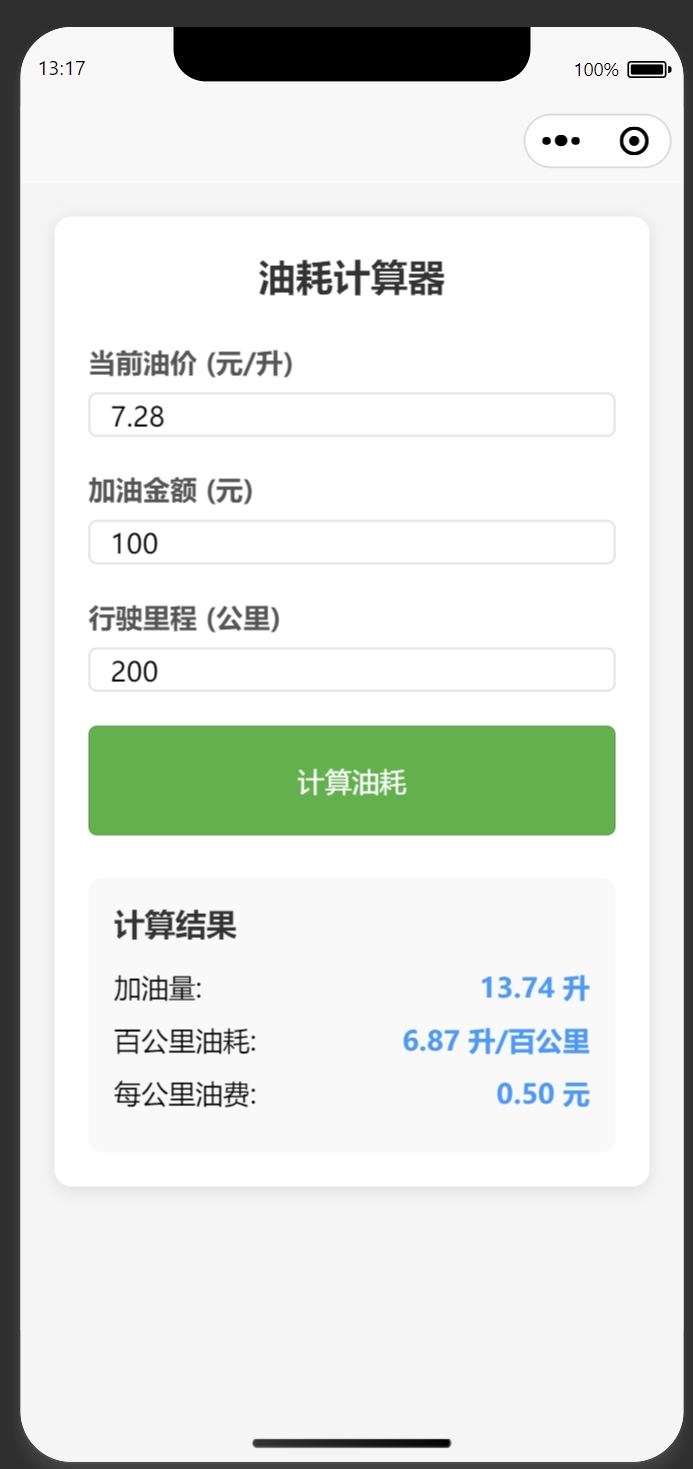
用 Deepseek 写的uniapp油耗计算器
下面是一个基于 Uniapp 的油耗计算器实现,包含 Vue 组件和页面代码。 1. 创建页面文件 在 pages 目录下创建 fuel-calculator 页面: <!-- pages/fuel-calculator/fuel-calculator.vue --> <template><view class"container"…...
thinkphp实现图像验证码
示例 服务类 app\common\lib\captcha <?php namespace app\common\lib\captcha;use think\facade\Cache; use think\facade\Config; use Exception;class Captcha {private $im null; // 验证码图片实例private $color null; // 验证码字体颜色// 默认配置protected $co…...
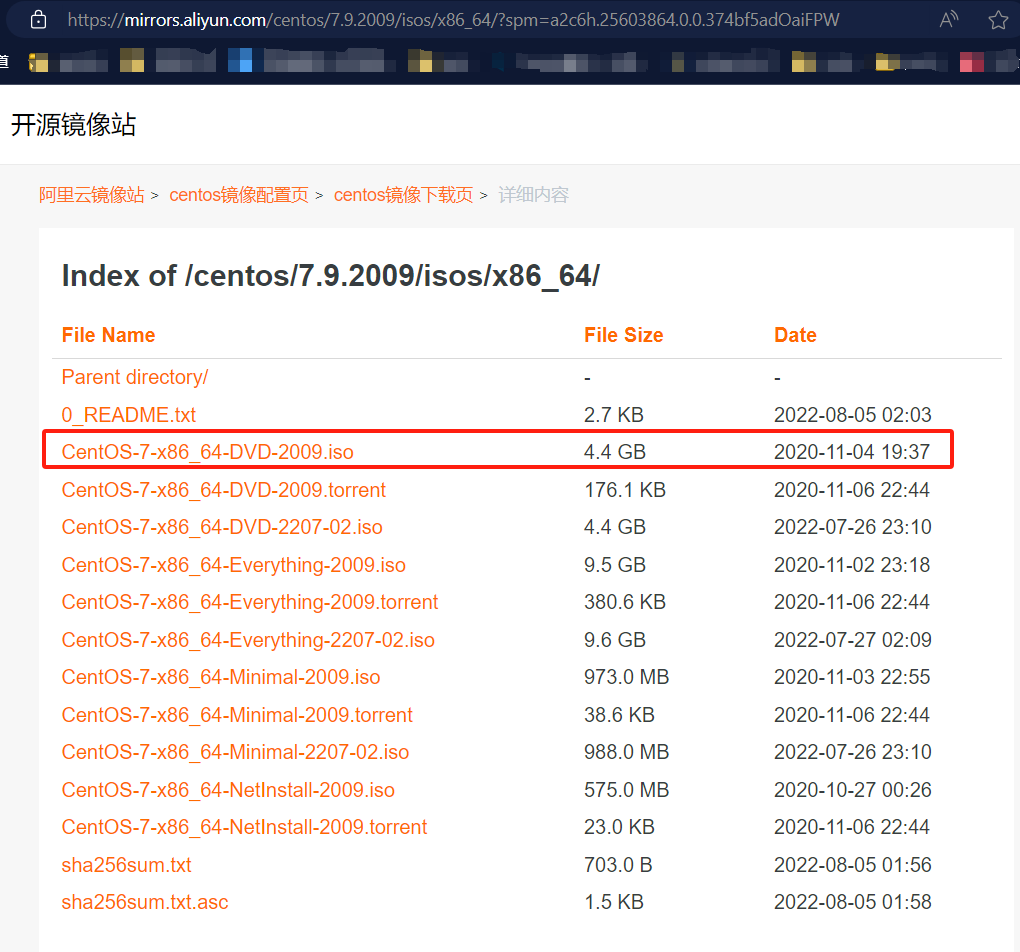
【k8s系列4】工具介绍
1、虚拟机软件 vmware workstation 2、shell 软件 MobaXterm 3、centos7.9 下载地址 (https://mirrors.aliyun.com/centos/7.9.2009/isos/x86_64/?spma2c6h.25603864.0.0.374bf5adOaiFPW) 4、上网软件...

微博辐射源和干扰机
微波辐射源和干扰机是电子战和通信领域中的两个重要概念,它们在军事、民用及科研中具有广泛应用。以下是两者的详细解析及其相互关系: 1. 微波辐射源 定义: 微波辐射源是指能够主动发射微波(频率范围通常为 300 MHz&…...

计算机网络——网络模型
一、OSI七层模型 (1)客户端发送请求时 OSI 七层模型的运作流程 应用层(Application Layer) 用户通过浏览器输入URL(如https://example.com),根据协议类型(HTTP/HTTPS)确…...
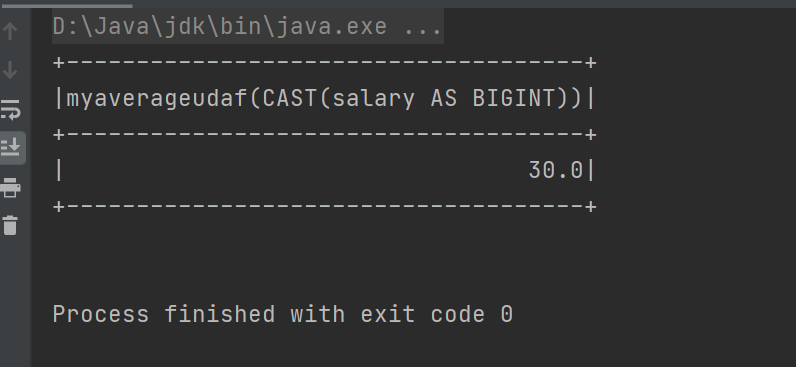
Spark-SQL核心编程2
路径问题 相对路径与绝对路径:建议使用绝对路径,避免复制粘贴导致的错误,必要时将斜杠改为双反斜杠。 数据处理与展示 SQL 风格语法:创建临时视图并使用 SQL 风格语法查询数据。 DSL 风格语法:使用 DSL 风格语法查询…...

Java 序列化与反序列化终极解析
Java 序列化与反序列化终极解析 1. 核心概念 (1) 什么是序列化? 定义:将对象转换为字节流的过程(对象 → 字节) 目的: 持久化存储(如保存到文件) 网络传输(如RPC调用)…...

STM32单片机入门学习——第41节: [12-1] Unix时间戳
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.18 STM32开发板学习——第41节: [12-1] Unix时间戳 前言开发板说明引用解答和科普一…...

无人机自主导航与路径规划技术要点!
一、自主导航与路径规划技术要点 1. 传感器融合 GPS/北斗定位:提供全局定位,但在室内或遮挡环境下易失效。 惯性测量单元(IMU)**:通过加速度计和陀螺仪实时追踪姿态,弥补GPS信号丢失时的定位空缺。 …...
AI绘画SD中,如何保持生成人物角色脸部一致?Stable Diffusion精准控制AI人像一致性两种实用方法教程!
在AI绘画StableDiffusion中,一直都有一个比较困难的问题,就是如何保证每次出图都是同一个人。今天就这个问题分享一些个人实践,大家和我一起来看看吧。 一. 有哪些实现方式 方式1:固定Seed种子值。 固定Seed种子值出来的图片人…...

java 设计模式 策略模式
简介 策略模式(Strategy Pattern)是一种行为设计模式,旨在定义一系列算法,并将每一个算法封装起来,使它们可以互相替换。策略模式让算法的变化独立于使用算法的客户端。换句话说,策略模式通过将不同的算法…...
)
std::set (C++)
std::set 1. 概述定义特点 2. 内部实现3. 性能特征4. 常用 API5. 使用示例6. 自定义比较器7. 注意事项与优化8. 使用建议 1. 概述 定义 template<class Key,class Compare std::less<Key>,class Allocator std::allocator<Key> > class std::set;特点 有…...

STM32 HAL 通用定时器延时函数
使用通用定时器TIM3,实现ms、us延时。 delay.c #include "delay.h" #include "stm32f1xx_hal.h"TIM_HandleTypeDef htim3;/*** brief 初始化定时器3用于延时* param 无* retval 无*/ void Delay_Init(void) {TIM_ClockConfigTypeDef sClock…...
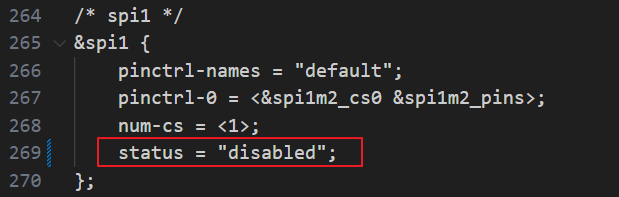
RK3588S开发板将SPI1接口改成GPIO
参考官方教程:ROC-RK3588S-PC 一.基本知识: 1.GPIO引脚计算: ROC-RK3588S-PC 有 5 组 GPIO bank:GPIO0~GPIO4,每组又以 A0~A7, B0~B7, C0~C7, D0~D7 作为编号区分,常用以下公式计算引脚:GPIO…...
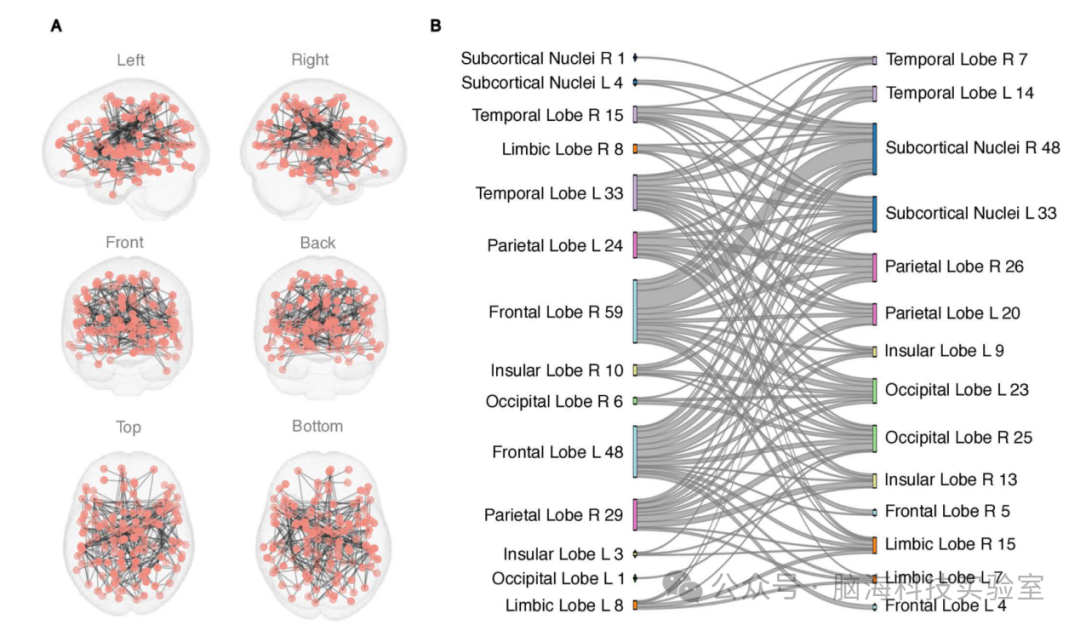
PLOS ONE:VR 游戏扫描揭示了 ADHD 儿童独特的大脑活动
在孩子的成长过程中,总有那么一些“与众不同”的孩子。他们似乎总是坐不住,课堂上小动作不断,注意力难以集中,作业总是拖拖拉拉……这些行为常常被家长和老师简单地归结为“淘气”“不听话”。然而,他们可能并不只是“…...
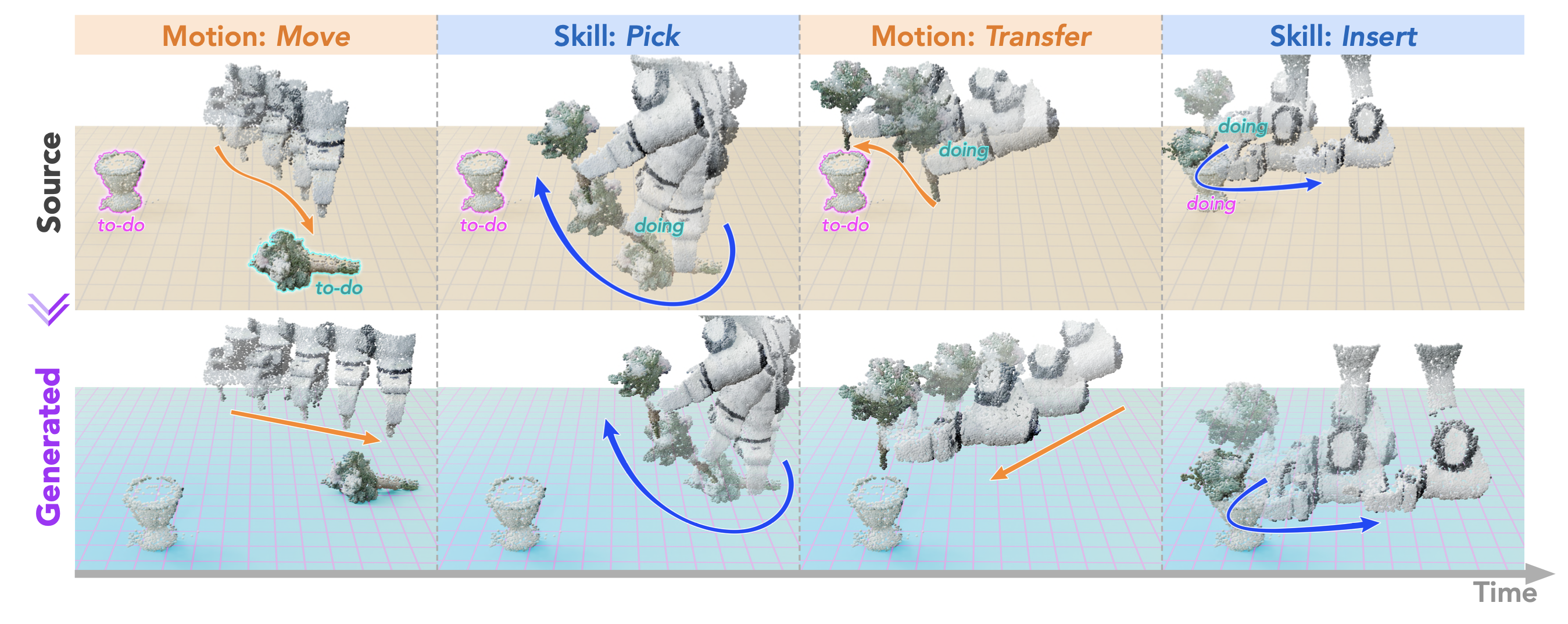
DemoGen:用于数据高效视觉运动策略学习的合成演示生成
25年2月来自清华、上海姚期智研究院和上海AI实验室的论文“DemoGen: Synthetic Demonstration Generation for Data-Efficient Visuomotor Policy Learning”。 视觉运动策略在机器人操控中展现出巨大潜力,但通常需要大量人工采集的数据才能有效执行。驱动高数据需…...

极狐GitLab 账号限制有哪些?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 账户和限制设置 (BASIC SELF) 默认项目限制 您可以配置新用户能在其个人命名空间中创建的默认最大项目数。此限制仅影响更改…...

@JsonView + 单一 DTO:如何实现多场景 JSON 字段动态渲染
JsonView 单一 DTO:如何实现多场景 JSON 字段动态渲染 JsonView 单一 DTO:如何实现多场景 JSON 字段动态渲染1、JsonView 注解产生的背景2、为了满足不同场景下返回对应的属性的做法有哪些?2.1 最快速的实现则是针对不同场景新建不同的 DTO…...

JVM之经典垃圾回收器
一、垃圾回收算法 1. 标记-清除(Mark-Sweep) 步骤: 标记:遍历对象图,标记所有存活对象。清除:回收未被标记的垃圾对象。 特点:简单,但会产生内存碎片。 2. 标记-复制(…...
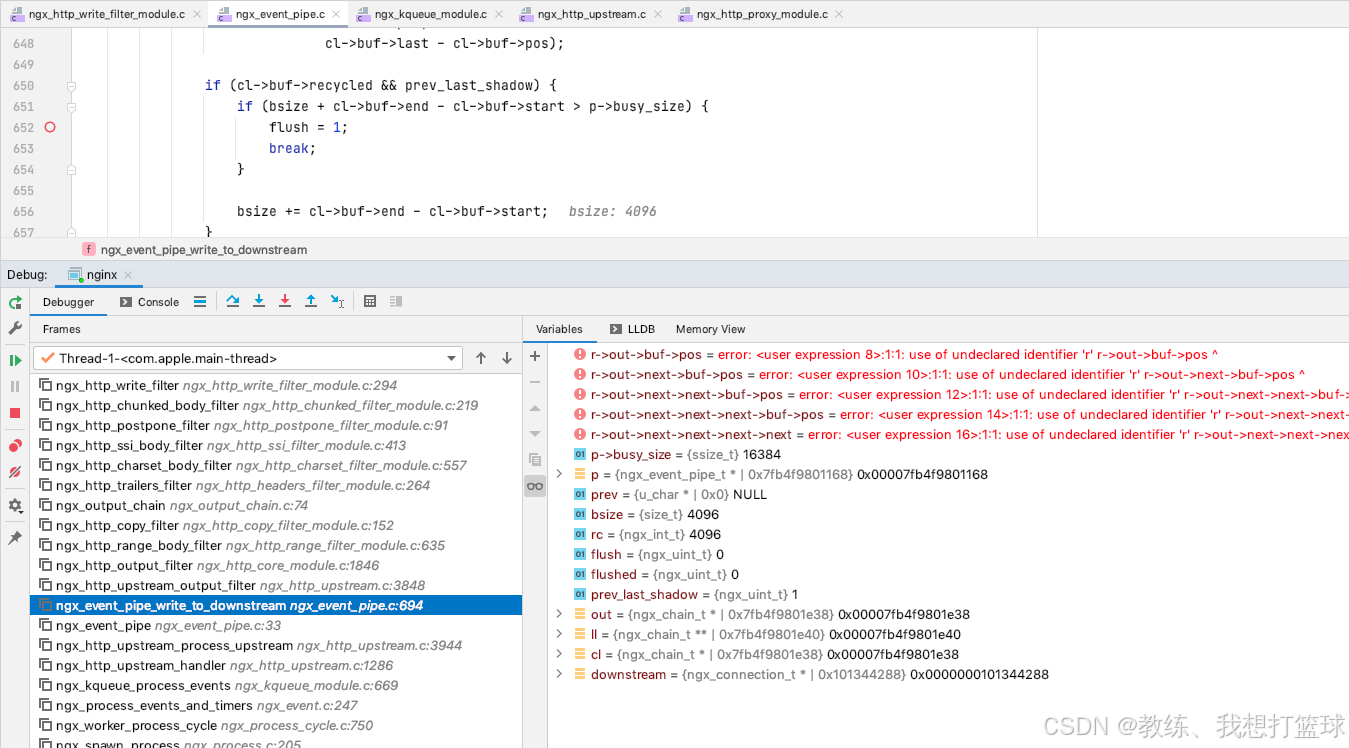
15 nginx 中默认的 proxy_buffering 导致基于 http 的流式响应存在 buffer, 以 4kb 一批次返回
前言 这也是最近碰到的一个问题 直连 流式 http 服务, 发现 流式响应正常, 0.1 秒接收到一个响应 但是 经过 nginx 代理一层之后, 就发现了 类似于缓冲的效果, 1秒接收到 10个响应 最终 调试 发现是 nginx 的 proxy_buffering 配置引起的 然后 更新 proxy_buffering 为…...
)
人工智能学习框架完全指南(2025年更新版)
一、核心框架分类与适用场景 人工智能框架根据功能可分为深度学习框架、机器学习框架、强化学习框架和传统工具库,以下是主流工具及选型建议: 1. 深度学习框架 (1)PyTorch 核心优势:动态计算图、灵活性强,适合科研与快速原型开发,支持多模态任务(如NLP、CV) 。技术生…...
安卓手机万能遥控器APP推荐
软件介绍 安卓手机也能当“家电总控台”?这款小米旗下的万能遥控器APP,直接把遥控器做成“傻瓜式操作”——不用配对,不连蓝牙,点开就能操控电视、空调、机顶盒,甚至其他品牌的电器!雷总这波操作直接封神&…...

颚式破碎机的设计
一、引言 颚式破碎机作为矿山、建材等行业的重要破碎设备,其性能优劣直接影响物料破碎效率与质量。随着工业生产规模的扩大和对破碎效率要求的提高,设计一款高效、稳定、节能的颚式破碎机具有重要意义。 二、设计需求分析 处理能力:根据目…...
PH热榜 | 2025-04-18
1. Wiza Monitor 标语:跟踪工作变动,接收Slack和电子邮件的提醒。 介绍:Wiza Monitor是一款用于追踪职位变动的工具,可以实时跟踪客户和潜在客户的工作变动,还可以通过电子邮件和Slack发送提醒,让你的客户…...

Android平台 Hal AIDL 系列文章目录
目录 1. Android Hal AIDL 简介2. AIDL 语言简介3. Android 接口定义语言 (AIDL)4. 定义AIDL 接口5. AIDL 中如何传递 Parcelable 对象6. 如何使用AIDL 定义的远程接口进行跨进程通信7. 适用于 HAL 的 AIDL8. Android Hal AIDL 编译调试9. 高版本Android (AIDL HAL) 沿用HIDL方…...
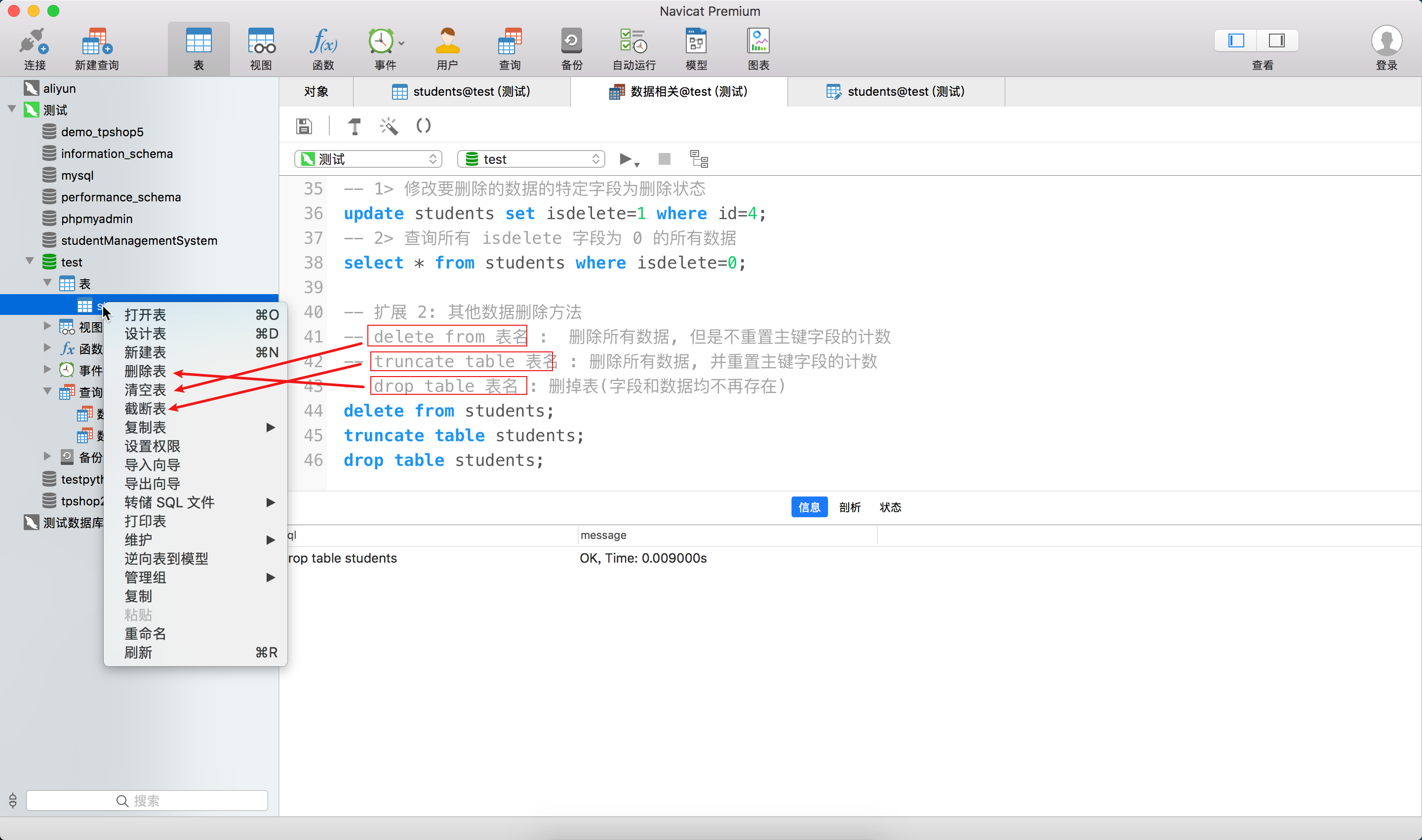
十、数据库day02--SQL语句01
文章目录 一、新建查询1.查询窗口的开启方法2. 单语句运行方法 二、数据库操作1.创建数据库2. 使用数据库3. 修改数据库4. 删除数据库和查看所有数据库5. 重点:数据库备份5.1 应用场景5.2 利用工具备份备份操作还原操作 5.3 扩展:使用命令备份 三、数据表…...