面试算法高频08-动态规划-02
动态规划练习题
题目描述
给定两个字符串 text1 和 text2,要求返回这两个字符串的最长公共子序列。例如对于字符串 “ABAZDC” 和 “BACBAD”,需找出它们最长的公共子序列。子序列是指在不改变其余字符相对位置的情况下,从原始字符串中删除某些字符(也可以不删除)后形成的新字符串。
最优解(Python)
def longestCommonSubsequence(text1, text2):m, n = len(text1), len(text2)dp = [[0] * (n + 1) for _ in range(m + 1)]for i in range(1, m + 1):for j in range(1, n + 1):if text1[i - 1] == text2[j - 1]:dp[i][j] = dp[i - 1][j - 1] + 1else:dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])return dp[m][n]
解析
- 动态规划思路:本题采用动态规划方法,核心是通过分析子问题的解来构建最终问题的解。
- 状态定义:定义二维数组
dp[i][j]表示text1的前i个字符和text2的前j个字符的最长公共子序列长度。 - 状态转移方程:
- 当
text1[i - 1] == text2[j - 1]时,说明当前字符相等,此时dp[i][j]等于dp[i - 1][j - 1] + 1,即在前i - 1和前j - 1个字符最长公共子序列基础上长度加1。 - 当
text1[i - 1] != text2[j - 1]时,dp[i][j]取dp[i - 1][j]和dp[i][j - 1]中的较大值,因为此时最长公共子序列要么是text1前i - 1个字符与text2前j个字符的最长公共子序列,要么是text1前i个字符与text2前j - 1个字符的最长公共子序列。
- 当
- 边界条件:
dp[0][j] = 0表示text1为空字符串时,最长公共子序列长度为0;dp[i][0] = 0表示text2为空字符串时,最长公共子序列长度为0 。 - 时间复杂度:由于使用了两层嵌套循环遍历两个字符串,时间复杂度为 O ( m × n ) O(m \times n) O(m×n),其中 m m m 和 n n n 分别是
text1和text2的长度。 - 空间复杂度:使用了一个二维数组
dp存储中间结果,空间复杂度为 O ( m × n ) O(m \times n) O(m×n) ,不过可以通过滚动数组优化为 O ( m i n ( m , n ) ) O(min(m, n)) O(min(m,n)) 。
题目描述
题目链接为https://leetcode-cn.com/problems/climbing-stairs/description/ ,假设你正在爬楼梯,需要 n 阶才能到达楼顶。每次你可以爬 1 或 2 个台阶,要求计算有多少种不同的方法可以爬到楼顶 。其中,n 是一个正整数,且满足 1 <= n <= 45 。例如:
- 当输入
n = 2时,输出为2,因为有两种方法可以爬到楼顶,分别是 “1 阶 + 1 阶” 和 “2 阶” 。 - 当输入
n = 3时,输出为3,因为有三种方法可以爬到楼顶,分别是 “1 阶 + 1 阶 + 1 阶” 、“1 阶 + 2 阶” 、“2 阶 + 1 阶” 。
最优解(Python)
def climbStairs(n):if n <= 2:return na, b = 1, 2for _ in range(2, n):a, b = b, a + breturn b
解析
- 动态规划思路:本题可采用动态规划的方法求解。动态规划的核心是将原问题分解为多个子问题,通过求解子问题并保存结果来避免重复计算,最终得到原问题的解。
- 状态定义:定义
f(n)表示爬到第n阶楼梯的不同方法数。 - 状态转移方程:因为每次可以爬
1阶或2阶,所以爬到第n阶的方法数等于爬到第n - 1阶的方法数加上爬到第n - 2阶的方法数,即f(n) = f(n - 1) + f(n - 2)。这是一个类似斐波那契数列的递推关系。 - 边界条件:当
n = 1时,只有一种方法(爬1阶),即f(1) = 1;当n = 2时,有两种方法(两次爬1阶或一次爬2阶) ,即f(2) = 2。 - 代码实现细节:代码中使用了两个变量
a和b分别表示f(n - 2)和f(n - 1),通过不断更新这两个变量来计算f(n)。循环从n = 2开始,每次迭代更新a和b的值,最终b存储的就是爬到第n阶的方法数。 - 复杂度分析:
- 时间复杂度:代码中只进行了一次循环,循环次数为
n - 2次,每次循环的操作都是常数时间的,所以时间复杂度为 O ( n ) O(n) O(n) 。 - 空间复杂度:只使用了常数个额外变量(
a和b),所以空间复杂度为 O ( 1 ) O(1) O(1) 。 这种空间复杂度为常数的实现方式是对动态规划空间优化后的结果,相较于使用数组存储所有子问题结果(空间复杂度为 O ( n ) O(n) O(n) )更为高效。
- 时间复杂度:代码中只进行了一次循环,循环次数为
题目描述
题目链接为https://leetcode-cn.com/problems/triangle/description/ ,给定一个三角形 triangle ,它是一个二维列表,其中 triangle[i] 表示三角形第 i 行的数字列表。要求找到从三角形顶部到底部的最小路径和。在每一步只能移动到下一行中相邻的节点上。例如,对于三角形 [[2],[3,4],[6,5,7],[4,1,8,3]] ,从顶部到底部的最小路径和是 11(路径为 2→3→5→1 )。
最优解(Python)
def minimumTotal(triangle):n = len(triangle)# 从倒数第二行开始向上遍历for i in range(n - 2, -1, -1):for j in range(len(triangle[i])):# 状态转移:选择下方相邻两个数中较小的,加上当前数triangle[i][j] += min(triangle[i + 1][j], triangle[i + 1][j + 1])return triangle[0][0]解析
- 动态规划思路:采用动态规划来解决此问题。动态规划的关键在于将问题分解为多个子问题,并利用子问题的解来构建最终问题的解。
- 状态定义:把
triangle[i][j]看作状态,表示从三角形第i行第j列这个位置到底部的最小路径和。 - 状态转移方程:对于第
i行第j列的元素,它下一步可以移动到下一行的第j列或者第j + 1列。所以triangle[i][j]的最小路径和等于当前位置的值加上下一行相邻两个位置中较小的那个位置的最小路径和,即triangle[i][j] += min(triangle[i + 1][j], triangle[i + 1][j + 1])。 - 遍历顺序:从三角形的倒数第二行开始向上遍历,因为最底层的元素到底部的最小路径和就是其自身的值,以此为基础向上递推。
- 边界条件:最底层的元素不需要进行额外计算,其自身值就是从它到底部的最小路径和(因为已经是最底层了)。
- 复杂度分析:
- 时间复杂度:使用了两层嵌套循环,外层循环遍历行数,内层循环遍历每行的元素,总的时间复杂度为 O ( n 2 ) O(n^2) O(n2) ,其中 n n n 是三角形的行数。
- 空间复杂度:直接在原三角形数组上进行操作,没有使用额外的与问题规模相关的空间,所以空间复杂度为 O ( 1 ) O(1) O(1) 。 这种在原数据结构上直接修改来保存中间结果的方式,有效避免了额外的空间开销。
题目描述
链接:https://leetcode-cn.com/problems/maximum-subarray/ 。
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。例如,输入 nums = [-2,1,-3,4,-1,2,1,-5,4] ,输出为 6 ,因为连续子数组 [4,-1,2,1] 的和最大,为 6 。
最优解(Python)
def maxSubArray(nums):n = len(nums)if n == 0:return 0dp = [0] * ndp[0] = nums[0]max_sum = dp[0]for i in range(1, n):dp[i] = max(nums[i], dp[i - 1] + nums[i])max_sum = max(max_sum, dp[i])return max_sum解析
- 动态规划思路:本题运用动态规划方法。动态规划的核心是将复杂问题分解为多个相互关联的子问题,通过求解子问题并保存结果,避免重复计算,从而高效地解决原问题。
- 状态定义:定义
dp[i]表示以nums[i]结尾的连续子数组的最大和 。 - 状态转移方程:对于
dp[i],它有两种情况。一种是只取nums[i]这一个元素作为子数组,另一种是将nums[i]加入到以nums[i - 1]结尾的连续子数组中。所以状态转移方程为dp[i] = max(nums[i], dp[i - 1] + nums[i])。 - 边界条件:当
i = 0时,dp[0] = nums[0],因为此时以nums[0]结尾的连续子数组就是它本身。 - 求解过程:在循环中,每计算出一个
dp[i],就更新max_sum,max_sum记录的是到当前位置为止,所有以不同元素结尾的连续子数组中的最大和。 - 复杂度分析:
- 时间复杂度:代码中只有一层循环,循环次数为数组的长度
n,每次循环内的操作都是常数时间的,所以时间复杂度为 O ( n ) O(n) O(n) 。 - 空间复杂度:使用了一个长度为
n的数组dp来保存中间结果,所以空间复杂度为 O ( n ) O(n) O(n) 。不过,还可以进一步优化,将空间复杂度降为 O ( 1 ) O(1) O(1) ,即不使用dp数组,而是用一个变量来记录以当前元素结尾的最大子数组和。优化后的代码如下:
- 时间复杂度:代码中只有一层循环,循环次数为数组的长度
def maxSubArray(nums):n = len(nums)if n == 0:return 0cur_sum = nums[0]max_sum = nums[0]for i in range(1, n):cur_sum = max(nums[i], cur_sum + nums[i])max_sum = max(max_sum, cur_sum)return max_sum
此时,只使用了几个额外的变量,空间复杂度为 O ( 1 ) O(1) O(1) 。
题目描述(另一题,链接:https://leetcode-cn.com/problems/maximum-product-subarray/description/ )
给定一个整数数组 nums ,找出一个乘积最大的连续子数组。子数组最少包含一个元素。例如,输入 nums = [2,3,-2,4] ,输出为 6 ,因为子数组 [2,3] 有最大乘积 6 。
最优解(Python)
def maxProduct(nums):n = len(nums)if n == 0:return 0max_ending_here = min_ending_here = res = nums[0]for i in range(1, n):# 暂存当前的最大值,用于计算新的最小值temp_max = max_ending_heremax_ending_here = max(nums[i], max_ending_here * nums[i], min_ending_here * nums[i])min_ending_here = min(nums[i], temp_max * nums[i], min_ending_here * nums[i])res = max(res, max_ending_here)return res解析
- 动态规划思路:同样采用动态规划策略。由于数组中存在负数,负数与负数相乘可能得到更大的乘积,所以不能简单地用与最大子数组和类似的方法。需要同时记录以当前元素结尾的最大乘积子数组和最小乘积子数组。
- 状态定义:定义
max_ending_here表示以当前元素nums[i]结尾的最大乘积子数组的乘积,min_ending_here表示以当前元素nums[i]结尾的最小乘积子数组的乘积 。 - 状态转移方程:
- 对于
max_ending_here,它的取值可能是当前元素nums[i],也可能是当前元素与之前的max_ending_here相乘,还可能是当前元素与之前的min_ending_here相乘(因为负负得正,可能得到更大的值),即max_ending_here = max(nums[i], max_ending_here * nums[i], min_ending_here * nums[i])。 - 对于
min_ending_here,它的取值可能是当前元素nums[i],也可能是当前元素与之前的max_ending_here相乘(得到较小的值),还可能是当前元素与之前的min_ending_here相乘,即min_ending_here = min(nums[i], temp_max * nums[i], min_ending_here * nums[i])。这里的temp_max是暂存的上一轮的max_ending_here,用于计算新的min_ending_here。
- 对于
- 边界条件:当
i = 0时,max_ending_here = min_ending_here = nums[0]。 - 求解过程:在循环中,每次更新
max_ending_here和min_ending_here后,都用res记录到当前位置为止的最大乘积,最后返回res。 - 复杂度分析:
- 时间复杂度:只有一层循环,循环次数为数组长度
n,每次循环内操作是常数时间,所以时间复杂度为 O ( n ) O(n) O(n) 。 - 空间复杂度:只使用了几个额外变量,空间复杂度为 O ( 1 ) O(1) O(1) 。
- 时间复杂度:只有一层循环,循环次数为数组长度
题目描述
题目链接为https://leetcode-cn.com/problems/coin-change/description/ 。给定不同面额的硬币 coins 列表和一个总金额 amount ,编写一个函数来计算可以凑成总金额所需的最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。假设每种硬币的数量是无限的。例如:
- 输入
coins = [1, 2, 5],amount = 11,输出为3,因为11 = 5 + 5 + 1,最少需要3枚硬币。 - 输入
coins = [2],amount = 3,输出为-1,因为无法用面额为2的硬币凑出金额3。
最优解(Python)
def coinChange(coins, amount):dp = [amount + 1] * (amount + 1)dp[0] = 0for i in range(1, amount + 1):for coin in coins:if coin <= i:dp[i] = min(dp[i], dp[i - coin] + 1)return dp[amount] if dp[amount] != amount + 1 else -1解析
- 动态规划思路:本题使用动态规划来解决。动态规划的核心在于将问题分解为多个子问题,通过求解子问题并保存结果,避免重复计算,最终得到原问题的解。
- 状态定义:定义
dp[i]表示凑成金额i所需的最少硬币个数。 - 状态转移方程:对于金额
i,遍历所有硬币面额coin,如果coin <= i,那么dp[i]可以由dp[i - coin] + 1得到(dp[i - coin]是凑成金额i - coin所需的最少硬币个数,加上一枚面额为coin的硬币就可以凑成金额i),并且取dp[i]和dp[i - coin] + 1中的较小值,即dp[i] = min(dp[i], dp[i - coin] + 1)。 - 边界条件:
dp[0] = 0,表示凑成金额0不需要任何硬币。初始化dp数组其他元素为amount + 1,这是一个不可能达到的较大值,用于后续比较更新。 - 求解过程:通过两层循环,外层循环遍历从
1到amount的所有金额,内层循环遍历所有硬币面额,不断更新dp数组。最后,如果dp[amount]仍然是初始的amount + 1,说明无法凑出该金额,返回-1;否则返回dp[amount]。 - 复杂度分析:
- 时间复杂度:有两层循环,外层循环次数为
amount次,内层循环次数为硬币种类数(假设为m),所以时间复杂度为 O ( m × a m o u n t ) O(m \times amount) O(m×amount) 。 - 空间复杂度:使用了一个长度为
amount + 1的数组dp来保存中间结果,所以空间复杂度为 O ( a m o u n t ) O(amount) O(amount) 。
- 时间复杂度:有两层循环,外层循环次数为
相关文章:

面试算法高频08-动态规划-02
动态规划练习题 题目描述 给定两个字符串 text1 和 text2,要求返回这两个字符串的最长公共子序列。例如对于字符串 “ABAZDC” 和 “BACBAD”,需找出它们最长的公共子序列。子序列是指在不改变其余字符相对位置的情况下,从原始字符串中删除…...

PyTorch逻辑回归总结
目录 PyTorch逻辑回归总结神经网络基础基本结构学习路径 线性回归简单线性回归多元线性回归 逻辑回归核心原理损失函数 梯度下降法基本思想关键公式学习率影响 PyTorch实现数据准备模型构建代码优化 核心概念对比 PyTorch逻辑回归总结 神经网络基础 基本结构 输入节点隐藏节…...

使用 Vue 开发登录页面的完整指南
一、项目搭建与基础配置 环境准备 使用 Vue CLI 或 Vite 创建项目,推荐组合:Vue3 Element Plus Vue Router npm create vuelatest npm install element-plus element-plus/icons-vue vue-router 全局配置(main.js) import { c…...
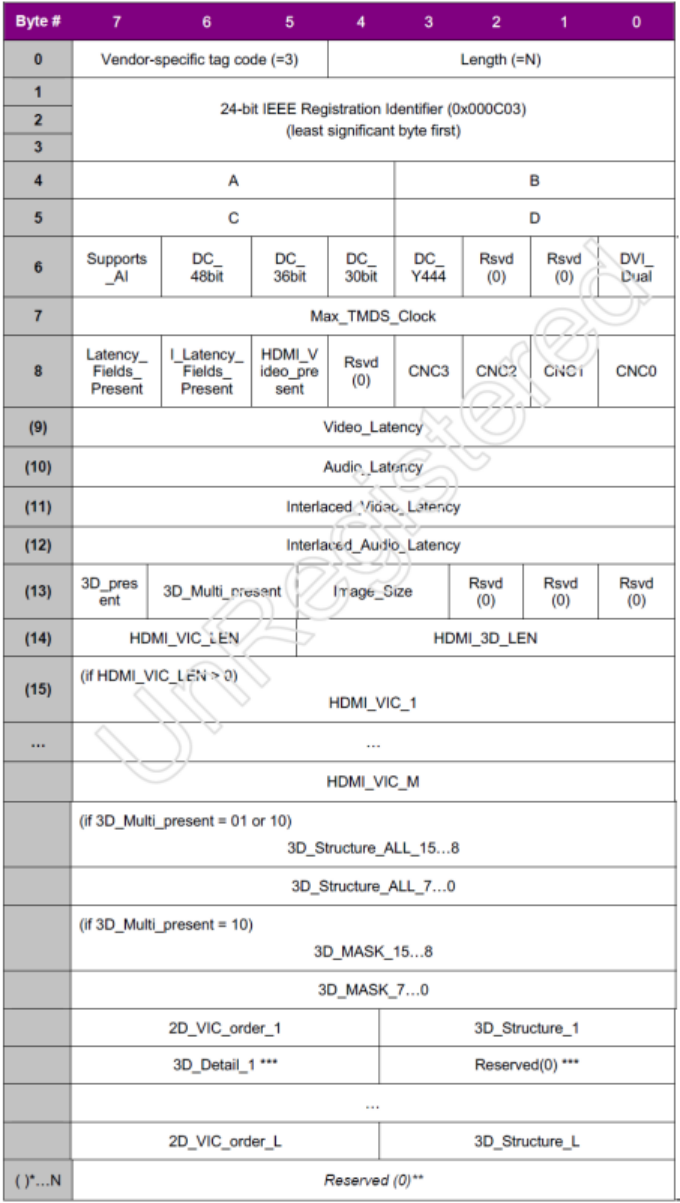
EDID结构
EDID DDC通讯中传输显示设备数据 VGA , DVI 的EDID由128字节组成,hdmi的EDID增加扩展块128字节。扩展快的内容主要是和音频属性相关的,DVI和vga没有音频,hdmi自带音频,扩展快数据规范按照cea-861x标准。 Edid为了让pc或其他的图像…...

文件包含(详解)
文件包含漏洞是一种常见的Web安全漏洞,其核心在于应用程序未对用户控制的文件路径或文件名进行严格过滤,导致攻击者能够包含并执行任意文件(包括本地或远程恶意文件)。 1. 文件包含原理 动态文件包含机制 开发者使用动态包含函数…...

《SpringBoot中@Scheduled和Quartz的区别是什么?分布式定时任务框架选型实战》
🌟 大家好,我是摘星! 🌟 今天为大家带来的是Scheduled和Quartz对比分析: 新手常见困惑: 刚学SpringBoot时,我发现用Scheduled写定时任务特别简单。但当我看到同事在项目里用Quartz时&…...

安装fvm可以让电脑同时管理多个版本的flutter、flutter常用命令、vscode连接模拟器
打开 PowerShellfvm安装 dart pub global activate fvm安装完成后,如果显示FVM无法识别,那么需要去添加环境变量path添加这个:C:\Users\Administrator\AppData\Local\Pub\Cache\bin 常用命令 fvm releases 查看用户可以装的flutter版本fvm l…...

UNION和UNION ALL的主要区别
UNION和UNION ALL的主要区别在于处理重复数据和排序的方式。 UNION和UNION ALL都是SQL语言中用于合并两个或多个SELECT语句结果集的关键字。它们的主要区别如下: 1、对重复结果的处理:UNION在进行表链接后会筛选掉重复的记录,而UNION ALL不会…...

Kafka系列之:计算kafka集群topic占的存储大小
Kafka系列之:计算kafka集群topic占的存储大小 topic存储数据格式统计topic存储大小定时统计topic存储大小topic存储数据格式 单位是字节大小 size_bytes{directory="/data/datum/kafka/optics-all" } 782336计算topic存储大小脚本逻辑是: 计算指定目录或文件的大小…...

[密码学实战]Java使用Bouncy Castle实现Base64编码解码:完整指南
Java使用Bouncy Castle实现Base64编码解码:完整指南 摘要 本文将深入讲解如何通过Bouncy Castle(BC)加密库实现Base64编码解码,包含核心API使用、流式处理、与加密算法集成三大实战场景,提供5种代码实现方案和3种性能优化技巧。 一、Base64基础原理 1.1 编码机制 Bas…...

智谱AI大模型免费开放:开启AI创作新时代
文章摘要:近日,国内领先的人工智能公司智谱AI宣布旗下多款大模型服务免费开放,这一举措标志着大模型技术正式迈入普惠阶段。本文将详细介绍智谱AI此次开放的GLM-4 等大模型,涵盖其主要功能、技术特点、使用步骤以及应用场景&#…...

为什么要给单片机植入操作系统
给单片机植入操作系统(通常是实时操作系统,RTOS)主要是为了在资源有限的环境中实现更高效、更可靠的多任务管理和系统调度。以下是主要原因和优势: 1. 多任务并行处理 背景:单片机通常需要同时处理多个任务࿰…...
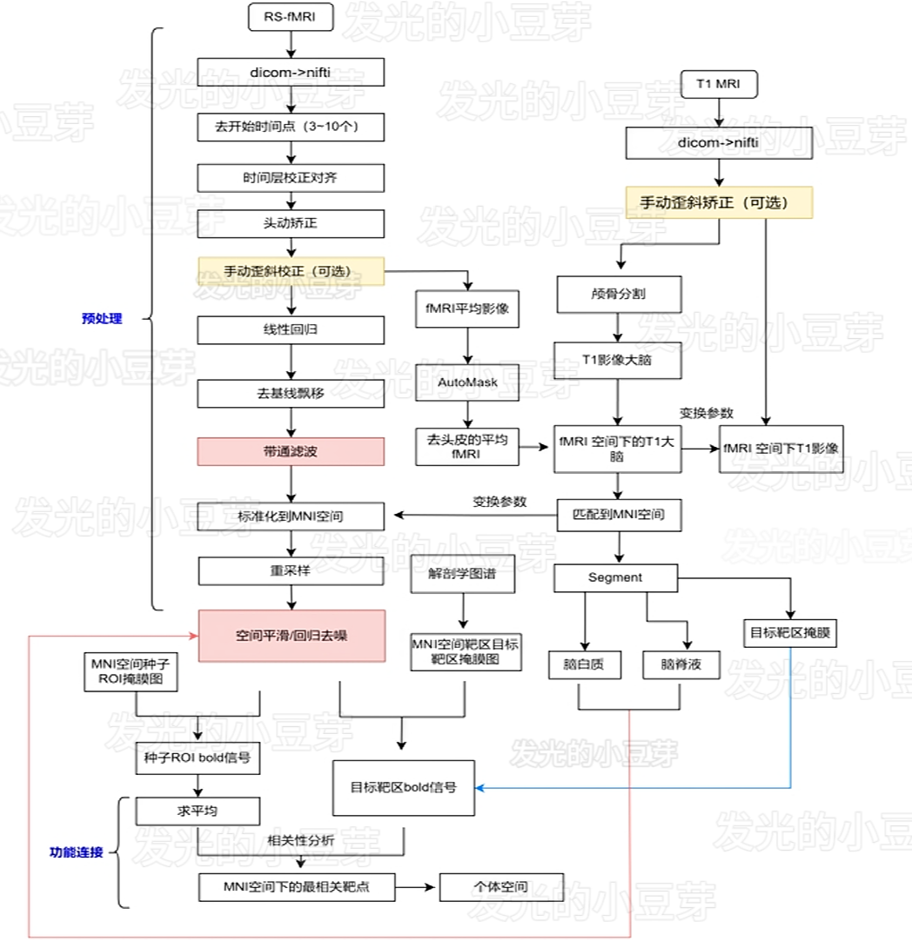
T1结构像+RS-fMRI影像处理过程记录(数据下载+Matlab工具箱+数据处理)
最近需要仿真研究T1结构像RS-fMRI影像融合处理输出目标坐标的路线可行性。就此机会记录下来。 为了完成验证目标处理,首先需要有数据,然后需要准备对应的处理平台和工具箱,进行一系列。那么开始记录~ 前言: 为了基于种子点的功能连…...
【前端基础】--- HTML
个人主页 : 9ilk 专栏 : 前端基础 文章目录 🏠 初识HTML🏠 HTML结构认识HTML标签HTML文件基本结构标签层次结构快速生成代码框架 🏠 HTML常见标签注释标签标题标签 h1-h6段落标签 p换行标签 br格式化标签图片标签 img超链接标签…...

黑马V11版 最新Java高级软件工程师课程-JavaEE精英进阶课
课程大小:60.2G 课程下载:https://download.csdn.net/download/m0_66047725/90615581 更多资源下载:关注我 阶段一 中台战略与组件化开发专题课程 阶段二 【物流行业】品达物流TMS 阶段三 智牛股 阶段四 千亿级电商秒杀解决方案专题 …...
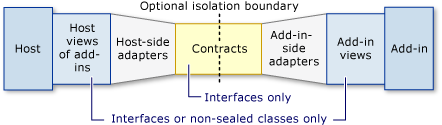
C#插件与可扩展性
外接程序为主机应用程序提供了扩展功能或服务。.net framework提供了一个编程模型,开发人员可以使用该模型来开发加载项并在其主机应用程序中激活它们。该模型通过在主机和外接程序之间构建通信管道来实现此目的。该模型是使用: System.AddIn, System.AddIn.Hosting, System.…...

CVPR‘25 | 高文字渲染精度的商品图文海报生成
本文分享阿里妈妈智能创作与AI应用团队在图文广告创意方向上提出的商品图文海报生成模型,通过构建字符级视觉表征作为控制信号,可以实现精准的图上中文逐像素生成。基于该项工作总结的论文已被 CVPR 2025录用,并在阿里妈妈业务场景落地&#…...

Golang|抽奖相关
文章目录 抽奖核心算法生成抽奖大转盘抽奖接口实现 抽奖核心算法 我们可以根据 单商品库存量/总商品库存量 得到每个商品被抽中的概率,可以想象这样一条 0-1 的数轴,数轴上的每一段相当于一种商品,概率之和为1。 抽奖时,我们会生…...

RT-Thread开发文档合集
瑞萨VisionBoard开发实践指南 RT-Thread 文档中心 RT-Thread-【RA8D1-Vision Board】 RA8D1 Vision Board上的USB实践RT-Thread问答社区 - RT-Thread 【开发板】环境篇:05烧录工具介绍_哔哩哔哩_bilibili 【RA8D1-Vision Board】基于OpenMV 实现图像分类_哔哩哔哩_…...

rulego-server是一个开源程序,是一个轻量级、无依赖性的工作流自动化平台。支持 iPaaS、流式计算和 AI 能力。
一、软件介绍 文末提供程序和源码下载学习 RuleGo-Server 是一个基于 RuleGo 构建的轻量级、高性能、模块化和集成友好的自动化工作流程平台。可用于自动化编排、iPaaS(集成平台即服务)、API 编排、应用编排、AI 编排、数据处理、IoT 规则引擎、AI 助手…...

鸿蒙系统开发状态更新字段区别对比
在鸿蒙系统开发中,状态管理是构建响应式UI的核心机制,主要通过装饰器(Decorators)实现字段的状态观测与更新。根据鸿蒙的版本(V1稳定版和V2试用版),支持的装饰器及其特性有所不同。以下是主要状…...

抽象的https原理简介
前言 小明和小美是一对好朋友,他们分隔两地,平时经常写信沟通,但是偶然被小明发现他回给小美的信好像被人拆开看过,甚至偷偷被篡改过。 对称加密算法 开头的通信过程比较像HTTP服务器与客户端的通信过程,全明文传输…...

HTML理论题
1.什么是HTML? 超文本标记语言(英语:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。 2.DOCTYPE 的作用是什么?标准与兼容模式(混杂模式)各有什么区别? DOCTYPE 的作用是告知浏览器的解析器用什么文档标准解析这个文档。 标准模式:用于…...
)
nginx-基础知识(二)
目录 虚拟主机 虚拟主机的功能 虚拟主机的划分方式 基于IP地址进行划分 基于域名进行划分 正向/反向代理 正向代理 反向代理 正向代理和反向代理的区别 负载均衡 负载均衡的类型 负载均衡的作用 nginx并发量比较高的原因 负载均衡的算法 会话保持 虚拟主机 虚拟…...

Ubuntu上安装Mysql
步骤 1:安装 MySQL Server sudo apt update sudo apt install mysql-server -y这将安装最新版本的 MySQL 8.0 以及所有依赖组件。 步骤 2:检查安装是否成功 mysql --version sudo systemctl status mysql如果状态是 active (running),说明成…...
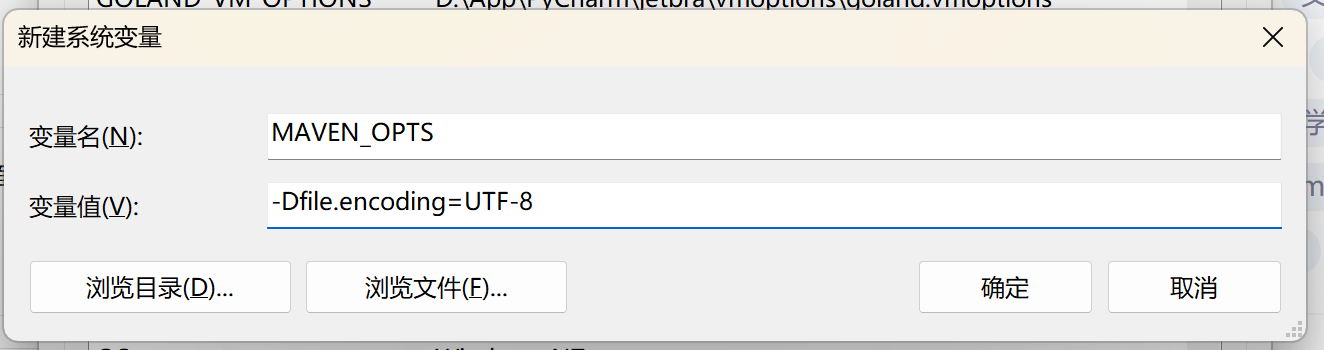
idea maven 命令后控制台乱码
首先在idea中查看maven的编码方式 执行mvn -v命令 查看编码语言是GBK C:\Users\13488>mvn -v Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f) Maven home: D:\maven\apache-maven-3.6.3\bin\.. Java version: 1.8.0_202, vendor: Oracle Corporation, runt…...
C# dll 打包进exe
Framework4.x推荐使用 Costura.Fody 1. 安装 NuGet 包 Install-Package Costura.Fody工程自动生成packages文件夹,300M左右。生成FodyWeavers.xml、FodyWeavers.xsd文件。 2. 自动嵌入 编译后,所有依赖的 DLL 会被自动嵌入到 EXE 中。 运行时自动解压…...

【数据融合实战手册·实战篇】二维赋能三维的5种高阶玩法:手把手教你用Mapmost打造智慧城市标杆案例
在当今数字化时代,二三维数据融合技术的重要性不言而喻。二三维数据融合通过整合二维数据的结构化优势与三维数据的直观性,打破了传统数据在表达和分析上的局限,为各行业提供了更全面、精准的数据分析手段。从智慧城市建设到工业智能制造&…...

ValueError: model.embed_tokens.weight doesn‘t have any device set
ValueError: model.embed_tokens.weight doesn’t have any device set model.embed_tokens.weight 通常在深度学习框架(如 PyTorch)中使用,一般是在处理自然语言处理(NLP)任务时,用于指代模型中词嵌入层(Embedding layer)的权重参数。下面详细解释: 词嵌入层的作用 …...
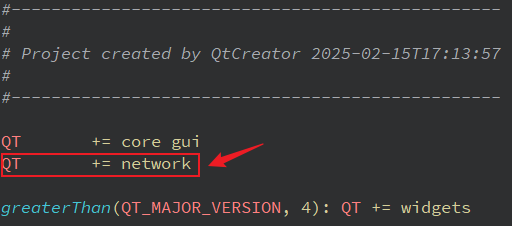
解决:QTcpSocket: No such file or directory
项目场景: 使用QTcpSocket进行网络编程: 调用connectToHost连接服务器,调用waitForConnected判断是否连接成功,连接信号readyRead槽函数,异步读取数据,调用waitForReadyRead,阻塞读取数据。 问题描述 找不…...