深度学习-torch,全连接神经网路
3. 数据集加载案例
通过一些数据集的加载案例,真正了解数据类及数据加载器。
3.1 加载csv数据集
代码参考如下
import torch from torch.utils.data import Dataset, DataLoader import pandas as pd class MyCsvDataset(Dataset):def __init__(self, filename):df = pd.read_csv(filename)# 删除文字列df = df.drop(["学号", "姓名"], axis=1)# 转换为tensordata = torch.tensor(df.values)# 最后一列以前的为data,最后一列为labelself.data = data[:, :-1]self.label = data[:, -1]self.len = len(self.data) def __len__(self):return self.len def __getitem__(self, index):idx = min(max(index, 0), self.len - 1)return self.data[idx], self.label[idx] def test001():excel_path = r"./大数据答辩成绩表.csv"dataset = MyCsvDataset(excel_path)dataloader = DataLoader(dataset, batch_size=4, shuffle=True)for i, (data, label) in enumerate(dataloader):print(i, data, label) if __name__ == "__main__":test001()
练习:上述示例数据构建器改成TensorDataset
def build_dataset(filepath):df = pd.read_csv(filepath)df.drop(columns=['学号', '姓名'], inplace=True)data = df.iloc[..., :-1]labels = df.iloc[..., -1] x = torch.tensor(data.values, dtype=torch.float)y = torch.tensor(labels.values) dataset = TensorDataset(x, y) return dataset def test001():filepath = r"./大数据答辩成绩表.csv"dataset = build_dataset(filepath)dataloader = DataLoader(dataset, batch_size=4, shuffle=True)for i, (data, label) in enumerate(dataloader):print(i, data, label)
3.2 加载图片数据集
参考代码如下:只是用于文件读取测试
import torch from torch.utils.data import Dataset, DataLoader import os # 导入opencv import cv2 class MyImageDataset(Dataset):def __init__(self, folder):# 文件存储路径列表self.filepaths = []# 文件对应的目录序号列表self.labels = []# 指定图片大小self.imgsize = (112, 112)# 临时存储文件所在目录名dirnames = [] # 递归遍历目录,root:根目录路径,dirs:子目录名称,files:子文件名称for root, dirs, files in os.walk(folder):# 如果dirs和files不同时有值,先遍历dirs,然后再以dirs的目录为路径遍历该dirs下的files# 这里需要在dirs不为空时保存目录名称列表if len(dirs) > 0:dirnames = dirs for file in files:# 文件路径filepath = os.path.join(root, file)self.filepaths.append(filepath)# 分割root中的dir目录名classname = os.path.split(root)[-1]# 根据目录名到临时目录列表中获取下标self.labels.append(dirnames.index(classname))self.len = len(self.filepaths) def __len__(self):return self.len def __getitem__(self, index):# 获取下标idx = min(max(index, 0), self.len - 1)# 根据下标获取文件路径filepath = self.filepaths[idx]# opencv读取图片img = cv2.imread(filepath)# 图片缩放,图片加载器要求同一批次的图片大小一致img = cv2.resize(img, self.imgsize)# 转换为tensorimg_tensor = torch.tensor(img)# 将图片HWC调整为CHWimg_tensor = torch.permute(img_tensor, (2, 0, 1))# 获取目录标签label = self.labels[idx] return img_tensor, label def test02():path = os.path.join(os.path.dirname(__file__), 'dataset')# 转换为相对路径path = os.path.relpath(path)dataset = MyImageDataset(path) dataloader = DataLoader(dataset, batch_size=8, shuffle=True) for img, label in dataloader:print(img.shape)print(label) if __name__ == "__main__":test02()
练习:1.重写上述代码,如果不对图片进行缩放会产生什么结果?2.在遍历图片的代码中打印图片查看图片效果(打印一批次即可)
# 导入opencv
import cv2
class MyDataset(Dataset):def __init__(self, folder):
dirnames = []self.filepaths = []self.labels = []
for root, dirs, files in os.walk(folder):if len(dirs) > 0:dirnames = dirs
for file in files:filepath = os.path.join(root, file)self.filepaths.append(filepath)classname = os.path.split(root)[-1]if classname in dirnames:self.labels.append(dirnames.index(classname))else:print(f'{classname} not in {dirnames}')
self.len = len(self.filepaths)
def __len__(self):return self.len
def __getitem__(self, index):idx = min(max(index, 0), self.len - 1)filepath = self.filepaths[idx]img = cv2.imread(filepath)print(img.shape)# 不做图片缩放,报:RuntimeError: stack expects each tensor to be equal size, but got [3, 1333, 2000] at entry 0 and [3, 335, 600] at entry 1img = cv2.resize(img, (112, 112))t_img = torch.tensor(img)t_img = torch.permute(t_img, (2, 0, 1))
label = self.labels[idx]return t_img, label
def test02():path = os.path.join(os.path.dirname(__file__), 'dataset')dataset = MyDataset(path)dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
for img, label in dataloader:
print(img.shape, label)for i in range(img.shape[0]):im = torch.permute(img[i], (1, 2, 0))plt.imshow(im)plt.show()
break
if __name__ == "__main__":test02()
优化:使用ImageFolder加载图片集
ImageFolder 会根据文件夹的结构来加载图像数据。它假设每个子文件夹对应一个类别,文件夹名称即为类别名称。例如,一个典型的文件夹结构如下:
root/class1/img1.jpgimg2.jpg...class2/img1.jpgimg2.jpg......
在这个结构中:
-
root是根目录。 -
class1、class2等是类别名称。 -
每个类别文件夹中的图像文件会被加载为一个样本。
ImageFolder构造函数如下:
torchvision.datasets.ImageFolder(root, transform=None, target_transform=None, is_valid_file=None)
参数解释
-
root:字符串,指定图像数据集的根目录。 -
transform:可选参数,用于对图像进行预处理。通常是一个torchvision.transforms的组合。 -
target_transform:可选参数,用于对目标(标签)进行转换。 -
is_valid_file:可选参数,用于过滤无效文件。如果提供,只有返回True的文件才会被加载。
import torch from torchvision import datasets, transforms import os from torch.utils.data import DataLoader from matplotlib import pyplot as plt torch.manual_seed(42) def load():path = os.path.join(os.path.dirname(__file__), 'dataset')print(path) transform = transforms.Compose([transforms.Resize((112, 112)),transforms.ToTensor()]) dataset = datasets.ImageFolder(path, transform=transform)dataloader = DataLoader(dataset, batch_size=1, shuffle=True) for x,y in dataloader:x = x.squeeze(0).permute(1, 2, 0).numpy()plt.imshow(x)plt.show()print(y[0])break if __name__ == '__main__':load()
3.3 加载官方数据集
在 PyTorch 中官方提供了一些经典的数据集,如 CIFAR-10、MNIST、ImageNet 等,可以直接使用这些数据集进行训练和测试。
数据集:Datasets — Torchvision 0.21 documentation
常见数据集:
-
MNIST: 手写数字数据集,包含 60,000 张训练图像和 10,000 张测试图像。
-
CIFAR10: 包含 10 个类别的 60,000 张 32x32 彩色图像,每个类别 6,000 张图像。
-
CIFAR100: 包含 100 个类别的 60,000 张 32x32 彩色图像,每个类别 600 张图像。
-
COCO: 通用对象识别数据集,包含超过 330,000 张图像,涵盖 80 个对象类别。
torchvision.transforms 和 torchvision.datasets 是 PyTorch 中处理计算机视觉任务的两个核心模块,它们为图像数据的预处理和标准数据集的加载提供了强大支持。
transforms 模块提供了一系列用于图像预处理的工具,可以将多个变换组合成处理流水线。
datasets 模块提供了多种常用计算机视觉数据集的接口,可以方便地下载和加载。
参考如下:
import torch from torch.utils.data import Dataset, DataLoader import torchvision from torchvision import transforms, datasets def test():transform = transforms.Compose([transforms.ToTensor(),])# 训练数据集data_train = datasets.MNIST(root="./data",train=True,download=True,transform=transform,)trainloader = DataLoader(data_train, batch_size=8, shuffle=True)for x, y in trainloader:print(x.shape)print(y)break # 测试数据集data_test = datasets.MNIST(root="./data",train=False,download=True,transform=transform,)testloader = DataLoader(data_test, batch_size=8, shuffle=True)for x, y in testloader:print(x.shape)print(y)break def test006():transform = transforms.Compose([transforms.ToTensor(),])# 训练数据集data_train = datasets.CIFAR10(root="./data",train=True,download=True,transform=transform,)trainloader = DataLoader(data_train, batch_size=4, shuffle=True, num_workers=2)for x, y in trainloader:print(x.shape)print(y)break# 测试数据集data_test = datasets.CIFAR10(root="./data",train=False,download=True,transform=transform,)testloader = DataLoader(data_test, batch_size=4, shuffle=False, num_workers=2)for x, y in testloader:print(x.shape)print(y)break if __name__ == "__main__":test()test006()
1. 神经网络基础
1.1 生物神经元与人工神经元
神经网络的设计灵感来源于生物神经元。生物神经元通过树突接收信号,细胞核处理信号,轴突传递信号,突触连接不同的神经元。人工神经元模仿了这一过程,接收多个输入信号,经过加权求和和非线性激活函数处理后,输出结果。
1.2 人工神经元的组成
人工神经元由以下几个部分组成:
- 输入(Inputs):代表输入数据,通常用向量表示。
- 权重(Weights):每个输入数据都有一个权重,表示该输入对最终结果的重要性。
- 偏置(Bias):一个额外的可调参数,用于调整模型的输出。
- 加权求和:将输入乘以对应的权重后求和,再加上偏置。
- 激活函数(Activation Function):将加权求和后的结果转换为输出结果,引入非线性特性。
数学表示如下:
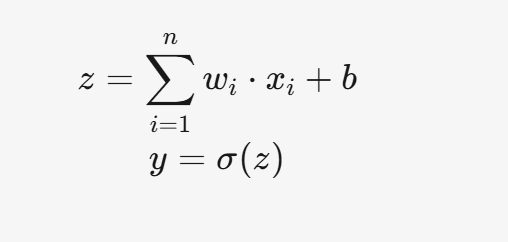
其中,σ(z) 是激活函数。
2. 神经网络结构
2.1 基本结构
神经网络由以下三层构成:
- 输入层(Input Layer):接收外部数据,不进行计算。
- 隐藏层(Hidden Layer):位于输入层和输出层之间,进行特征提取和转换。隐藏层可以有多层,每层包含多个神经元。
- 输出层(Output Layer):产生最终的预测结果或分类结果。
2.2 全连接神经网络
全连接神经网络(Fully Connected Neural Network,FCNN)是前馈神经网络的一种,每一层的神经元与上一层的所有神经元全连接。全连接神经网络常用于图像分类、文本分类等任务。
2.2.1 特点
- 权重数量大:由于全连接的特点,权重数量较大,计算量大。
- 学习能力强:能够学习输入数据的全局特征,但对高维数据的局部特征捕捉能力较弱。
2.2.2 计算步骤
- 数据传递:输入数据逐层传递到输出层。
- 激活函数:每一层的输出通过激活函数处理。
- 损失计算:计算预测值与真实值之间的差距。
- 反向传播:通过反向传播算法更新权重以最小化损失。
3. 激活函数
激活函数在神经网络中引入非线性,使网络能够处理复杂的任务。以下是几种常见的激活函数及其特点。
3.1 Sigmoid
3.1.1 公式
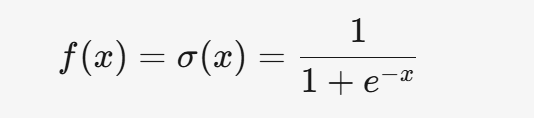
3.1.2 特点
- 将输入映射到 (0, 1) 之间,适合处理概率问题。
- 梯度消失问题严重,容易导致训练速度变慢。
- 计算成本较高。
3.1.3 应用场景
- 一般用于二分类问题的输出层。
3.2 Tanh
3.2.1 公式
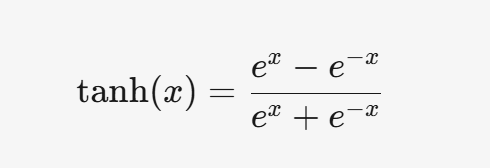
3.2.2 特点
- 输出范围为 (-1, 1),是零中心的,有助于加速收敛。
- 对称性较好,适合隐藏层。
- 仍然存在梯度消失问题。
3.2.3 应用场景
- 适用于隐藏层,但不如 ReLU 常用。
3.3 ReLU
3.3.1 公式
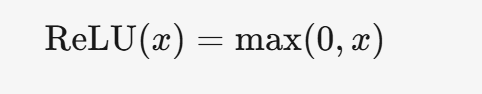
3.3.2 特点
- 计算简单,适合大规模数据训练。
- 缓解梯度消失问题,适合深层网络。
- 存在神经元死亡问题,即某些神经元可能永远不被激活。
3.3.3 应用场景
- 深度学习中最常用的激活函数,适用于隐藏层。
3.4 Leaky ReLU
3.4.1 公式
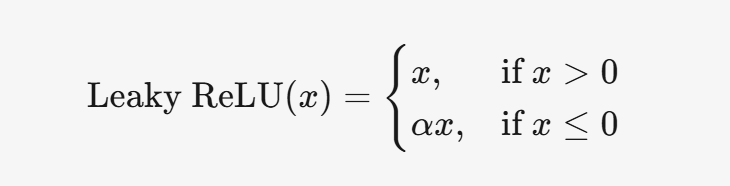
3.4.2 特点
- 解决了 ReLU 的神经元死亡问题。
- 计算简单,但需要调整超参数 α。
3.4.3 应用场景
- 适用于隐藏层,尤其是 ReLU 效果不佳时。
3.5 Softmax
3.5.1 公式
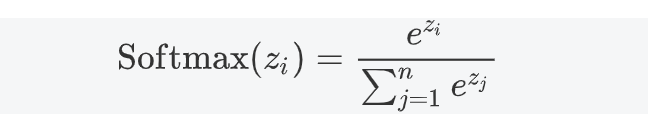

3.5.2 特点
- 将输出转化为概率分布,适合多分类问题。
- 放大差异,使概率最大的类别更突出。
- 存在数值不稳定性问题,需进行数值调整。
3.5.3 应用场景
- 用于多分类问题的输出层。
4. 激活函数的选择
4.1 隐藏层
- 优先选择 ReLU。
- 如果 ReLU 效果不佳,尝试 Leaky ReLU 或其他激活函数。
- 避免使用 Sigmoid,可以尝试 Tanh。
4.2 输出层
- 二分类问题选择 Sigmoid。
- 多分类问题选择 Softmax。
5. 总结
神经网络是深度学习的核心,理解其结构和激活函数的作用至关重要。人工神经元是神经网络的基本单元,通过加权求和和激活函数实现非线性变换。全连接神经网络是最基本的神经网络结构,广泛应用于各类任务。激活函数在神经网络中引入非线性,增强了网络的表达能力。不同激活函数适用于不同的场景,合理选择激活函数可以显著提升模型性能。
相关文章:
深度学习-torch,全连接神经网路
3. 数据集加载案例 通过一些数据集的加载案例,真正了解数据类及数据加载器。 3.1 加载csv数据集 代码参考如下 import torch from torch.utils.data import Dataset, DataLoader import pandas as pd class MyCsvDataset(Dataset):def __init__(self, fil…...

SQL注入相关知识
一、布尔盲注 1、布尔盲简介 布尔盲注是一种SQL注入攻击技术,用于在无法直接获取数据库查询结果的情况下,通过页面的响应来判断注入语句的真假,从而获取数据库中的敏感信息 2、布尔盲注工作原理 布尔盲注的核心在于利用SQL语句的布尔逻辑…...

Codex CLI - 自然语言命令行界面
本文翻译整理自:https://github.com/microsoft/Codex-CLI 文章目录 一、关于 Codex CLI相关链接资源 二、安装系统要求安装步骤 三、基本使用1、基础操作2、多轮模式 四、命令参考五、提示工程与上下文文件自定义上下文 六、故障排查七、FAQ如何查询可用OpenAI引擎&…...
实现窗口函数
java 实现窗口函数 public class SlidingWin {public static void main(String[] args) {SlidingWin slidingWin new SlidingWin();double v slidingWin.SlidWin(2);System.out.println(v);}public double SlidWin(int k){int [] array new int[]{2,4,5,6,9,10,12,23,1,3,8…...

pycharm中怎么解决系统cuda版本高于pytorch可以支持的版本的问题?
在PyCharm中安装与系统CUDA版本不一致的PyTorch是可行的。以下是解决方案的步骤: 1. 确认系统驱动兼容性 检查NVIDIA驱动支持的CUDA版本:运行 nvidia-smi,右上角显示的CUDA版本是驱动支持的最高版本。只要该版本不低于PyTorch所需的CUDA版本…...

Day57 | 79. 单词搜索、89. 格雷编码
79. 单词搜索 题目链接:79. 单词搜索 - 力扣(LeetCode) 题目难度:中等 代码: class Solution {public boolean exist(char[][] board, String word) {char[] wordsword.toCharArray();for(int i0;i<board.lengt…...
清华《数据挖掘算法与应用》K-means聚类算法
使用k均值聚类算法对表4.1中的数据进行聚类。代码参考P281。 创建一个名为 testSet.txt 的文本文件,将以下内容复制粘贴进去保存即可: 0 0 1 2 3 1 8 8 9 10 10 7 表4.1 # -*- coding: utf-8 -*- """ Created on Thu Apr 17 16:59:58 …...
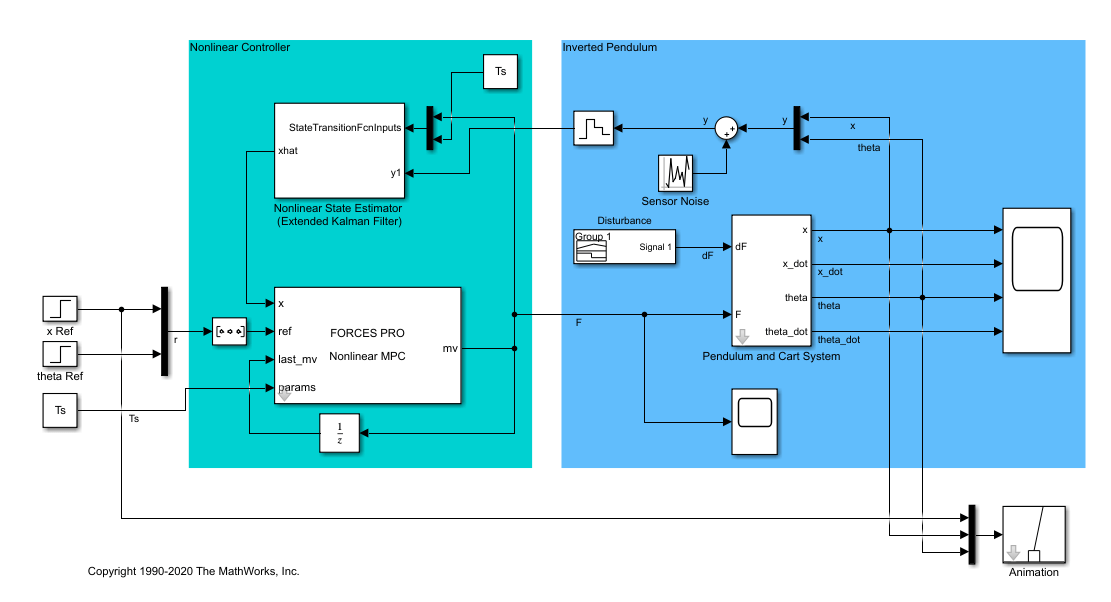
MATLAB - 小车倒立摆的非线性模型预测控制(NMPC)
系列文章目录 目录 系列文章目录 前言 一、摆锤/小车组件 二、系统方程 三、控制目标 四、控制结构 五、创建非线性 MPC 控制器 六、指定非线性设备模型 七、定义成本和约束 八、验证非线性 MPC 控制器 九、状态估计 十、MATLAB 中的闭环仿真 十一、使用 MATLAB 中…...

深入解析进程与线程:区别、联系及Java实现
引言 在现代操作系统中,进程和线程是并发编程的两大核心概念。理解它们的区别与联系对开发高性能、高可靠性的程序至关重要。本文将通过原理分析和Java代码示例,深入探讨这两个关键概念。 一、基本概念 1.1 进程(Process) 定义&…...

【Flutter深度解析】多线程编程
Flutter作为单线程模型的框架,在处理复杂计算时可能会遇到性能瓶颈。本文将全面剖析Flutter中的多线程编程方案,帮助你充分利用设备的多核性能,构建流畅的Dart应用。 一、Flutter线程模型基础 1. Dart的单线程事件循环 Flutter应用运行在单…...
HAL库配置RS485+DMA+空闲中断收发数据
前言: (1)DMA是单片机集成在芯片内部的一个数据搬运工,它可以代替单片机对数据进行传输、存储,节约CPU资源。一般应用场景,ADC多通道采集,串口收发(频繁进入接收中断)&a…...

【java实现+4种变体完整例子】排序算法中【计数排序】的详细解析,包含基础实现、常见变体的完整代码示例,以及各变体的对比表格
以下是计数排序的详细解析,包含基础实现、常见变体的完整代码示例,以及各变体的对比表格: 一、计数排序基础实现 原理 通过统计每个元素的出现次数,按顺序累加得到每个元素的最终位置,并填充到结果数组中。 代码示…...
嵌入式单片机开发 - Keil MDK 编译与烧录程序
Keil MDK 编译程序 1、Keil MDK 编译按钮 Build 按钮:重新编译整个工程的所有源文件,无论它们是否被修改过 Rebuild 按钮:仅编译修改过的文件及其依赖项,未修改的文件直接使用之前的编译结果 2、Keil MDK 编译结果 linking... …...

裂项法、分式分解法——复杂分式的拆解
目录 一、裂项法 1. 核心思想 2. 适用场景 3. 步骤 4. 例题 二、分式分解 1. 核心思想 2. 适用场景 3. 步骤 4.例题 一、裂项法 1. 核心思想 将一项拆解为多项之差,使得在求和时中间项相互抵消,最终仅剩首尾少数项。 2. 适用场景 级数求和…...

黑马点评秒杀优化
异步优化秒杀业务 回顾之前的内容黑马点评 秒杀优惠券集群下一人一单超卖问题-CSDN博客,为了处理并发情况下的线程安全和数据一致性的问题,我们已经完成了查询优惠券信息、判断秒杀是否开始和结束、检查库存、用户ID加锁、创建订单和扣减库存。 尽管之前…...
JavaScript 的演变:2023-2025 年的新特性解析
随着Web技术的飞速发展,ECMAScript(简称ES)作为JavaScript的语言标准,也在不断进化。 本文将带你学习 ECMAScript 2023-2025 的新特性。 一、ECMAScript 2023 新特性 1.1 数组的扩展 Array.prototype.findLast()/Array.protot…...
[Java · 初窥门径] Java 注释符
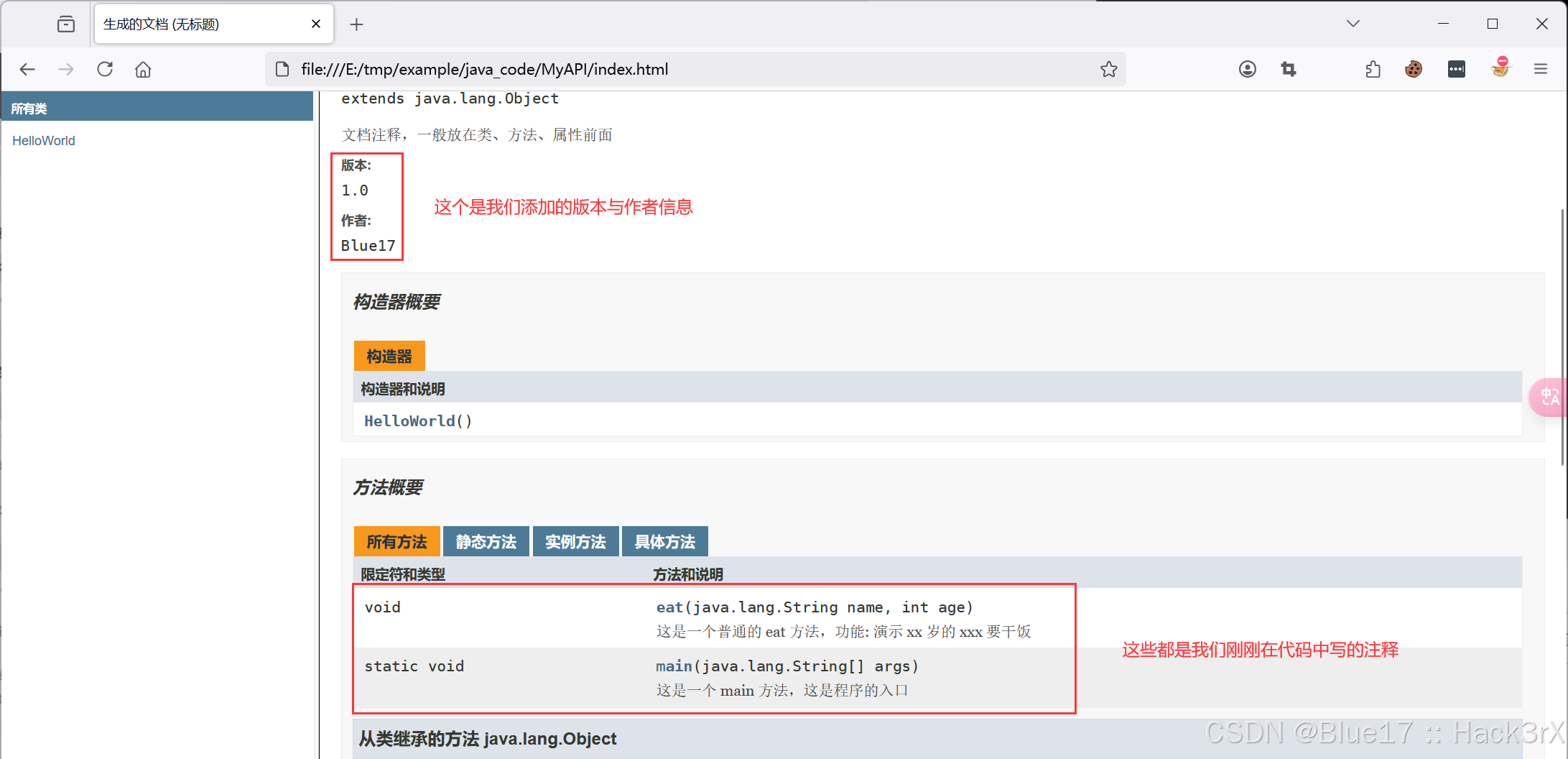
🌟 想系统化学习 Java 编程?看看这个:[编程基础] Java 学习手册 0x01:Java 注释符简介 在编写程序时,为了使代码易于理解,通常会为代码加一些注释。Java 注释就是用通俗易懂的语言对代码进行描述或解释&a…...

Spring MVC 全栈指南:RESTful 架构、核心注解与 JSON 实战解析
目录 RESTful API 设计规范Spring MVC 核心注解解析静态资源处理策略JSON 数据交互全解高频问题与最佳实践 一、RESTful API 设计规范 1.1 核心原则 原则说明示例 URI资源为中心URI 使用名词(复数形式)/users ✔️ /getUser ❌HTTP 方法语义化GET&…...

【web服务_负载均衡Nginx】三、Nginx 实践应用与高级配置技巧
一、Nginx 在 Web 服务器场景中的深度应用 1.1 静态网站部署与优化 在 CentOS 7 系统中,使用 Nginx 部署静态网站是最基础也最常见的应用场景。首先,准备网站文件,在/var/www/html目录下创建index.html文件: sudo mkdir -p…...

Docker环境下SpringBoot程序内存溢出(OOM)问题深度解析与实战调优
文章目录 一、问题背景与现象还原**1. 业务背景****2. 故障特征****3. 核心痛点****4. 解决目标** 二、核心矛盾点分析**1. JVM 与容器内存协同失效****2. 非堆内存泄漏****3. 容器内存分配策略缺陷** 三、系统性解决方案**1. Docker 容器配置**2. JVM参数优化(容器…...

【计算机网络】网络基础(协议,网络传输流程、Mac/IP地址 、端口号)
目录 1.协议简述2.网络分层结构2.1 软件分层2.2 网络分层为什么? 是什么?OSI七层模型TCP/IP五层(或四层)结构 3. 网络与操作系统之间的关系4.从语言角度理解协议5.网络如何传输局域网通信(同一网段) 不同网…...

【Mysql】mysql数据库占用空间查询
Mysql数据库操作 数据库大小查询 # 查询 每一个 数据库大小 SELECT table_schema AS 数据库名,SUM(data_length index_length) / 1024 / 1024 AS 数据库大小(MB) FROM information_schema.TABLES GROUP BY table_schema;# 查询 数据库占用磁盘大小 SELECT SUM(data_length …...
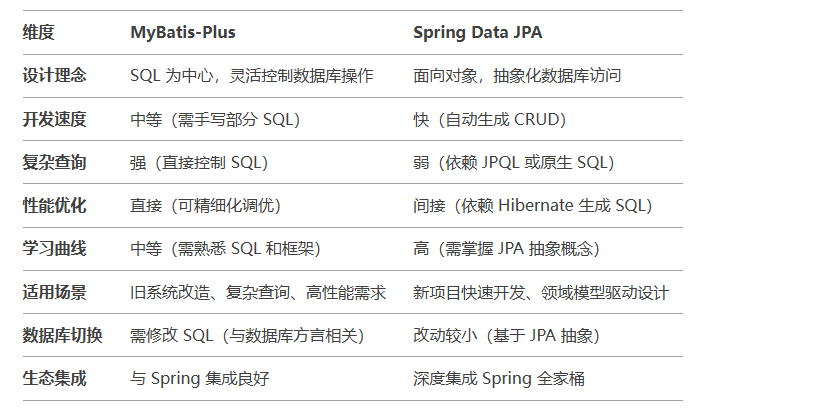
pgsql中使用jsonb的mybatis-plus和jps的配置
在pgsql中使用jsonb类型的数据时,实体对象要对其进行一些相关的配置,而mybatis和jpa中使用各不相同。 在项目中经常会结合 MyBatis-Plus 和 JPA 进行开发,MyBatis_plus对于操作数据更灵活,jpa可以自动建表,两者各取其…...

使用MetaGPT 创建智能体(2)多智能体
先给上个文章使用MetaGPT 创建智能体(1)入门打个补丁: 补丁1: MeteGTP中Role和Action的关联和区别?这是这两天再使用MetaGPT时候心中的疑问,这里做个记录 Role(角色)和 Action&…...
C# 使用.NET内置的 IObservable<T> 和 IObserver<T>-观察者模式
核心概念 IObservable<T> 表示 可观察的数据源(如事件流、实时数据)。 关键方法:Subscribe(IObserver<T> observer),用于注册观察者。 IObserver<T> 表示 数据的接收者,响应数据变化。 三个核心…...
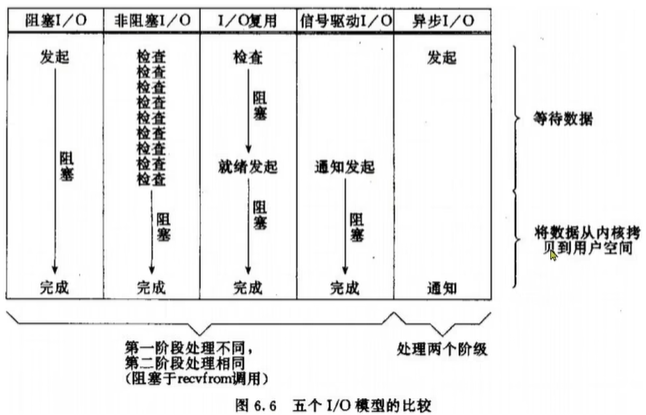
Redis——网络模型之IO讲解
目录 前言 1.用户空间和内核空间 1.2用户空间和内核空间的切换 1.3切换过程 2.阻塞IO 3.非阻塞IO 4.IO多路复用 4.1.IO多路复用过程 4.2.IO多路复用监听方式 4.3.IO多路复用-select 4.4.IO多路复用-poll 4.5.IO多路复用-epoll 4.6.select poll epoll总结 4.7.IO多…...

【dify实战】chatflow结合deepseek实现基于自然语言的数据库问答、Echarts可视化展示、Excel报表下载
dify结合deepseek实现基于自然语言的数据库问答、Echarts可视化展示、Excel报表下载 观看视频,您将学会 在dify下如何快速的构建一个chatflow,来完成数据分析工作;如何在AI的回复中展示可视化的图表;如何在AI 的回复中加入Excel报…...

vue3 传参 传入变量名
背景: 需求是:在vue框架中,接口传参我们需要穿“变量名”,而不是字符串 通俗点说法是:在网络接口请求的时候,要传属性名 效果展示: vue2核心代码: this[_keyParam] vue3核心代码&…...

裸金属服务器有什么用途?
裸金属服务器可以直接在硬件上运行应用程序和操作系统,不需要虚拟化层,裸金属服务器还会为企业提供一种高性能、高可靠性和高安全性的计算资源,通常运用在需要大量计算能力和数据处理能力的应用场景中,下面介绍一下裸金属服务器的…...

旅游特种兵迪士尼大作战:DeepSeek高精准路径优化
DeepSeek大模型高性能核心技术与多模态融合开发 - 商品搜索 - 京东 随着假期的脚步日渐临近,环球影城等备受瞩目的主题游乐场,已然成为大人与孩子们心中不可或缺的节日狂欢圣地。然而,随之而来的庞大客流,却总让无数游客在欢乐的…...