PG,TRPO,PPO,GRPO,DPO原理梳理
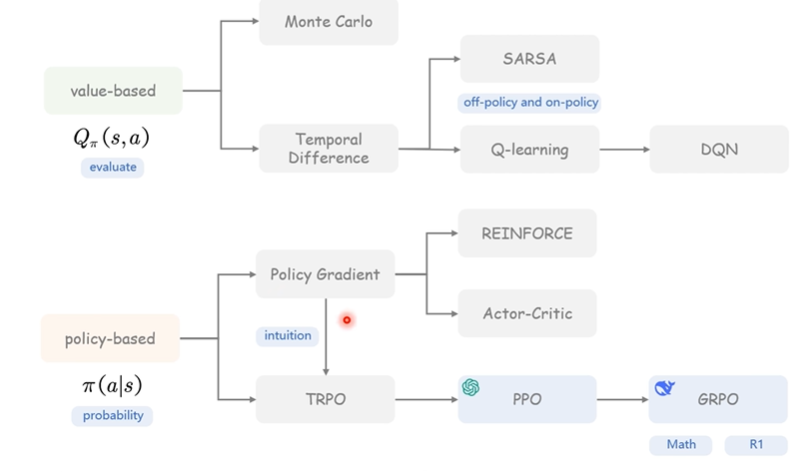
强化学习方法的分类
一、基础概念
-
Policy Model(Actor Model):根据输入文本,预测下一个token的概率分布,输出下一个token也即Policy模型的“动作”。该模型需要训练,是我们最终得到的模型,并由上一步的SFT初始化而来。
-
Value Model(Critic Model):用于预估当前模型回复的每一个token的收益。接着,还会进一步计算累积收益,累加每一个token的收益时不仅局限于当前token的质量,还需要衡量当前token对后续tokens生成的影响。这个累积收益一般是称为优势,用于衡量当前动作的好坏,也即模型本次回复的好坏,计算的方法一般使用GAE(广义优势估计,generalized advantage estimation))该模型同样需要训练
-
Reward Model:对Policy Model的输出整体进行打分,评估模型对于当前输出的即时收益。该模型训练过程不进行更新。
-
Reference Model:与 Policy Model是一样的模型,但在训练过程中不进行更新。其作用主要是与Policy Model计算KL散度(可以理解为两者的预测token概率分布差距)来作为约束,防止PolicyModel在更新过程中出现过大偏差,即每一次参数更新不要与Reference Model相差过于大。
二、PG(策略梯度)
策略梯度方法的核心思想是直接对策略函数(policy function)进行参数化,通过梯度上升(gradient ascent)的方法来优化策略参数,使得智能体在环境中获得的累积奖励最大化。
三、TRPO(Trust Region Policy Optimization)
在PG的基础上,加上了与参考模型的约束,限制策略的更新幅度。
优势函数 A(s,a) 衡量了在状态 s 下采取动作 a 相比于按照当前策略平均表现所能获得的额外奖励。

1.TRPO 在优化策略时加入了约束条件,即要求新旧策略之间的 KL 散度(衡量两个概率分布差异的指标)不超过某个阈值。
2.TRPO 的优化目标是在满足 KL 散度约束的条件下,最大化策略在优势函数下的期望值。它尝试在策略改进和策略变化幅度之间找到一个平衡,既让策略能够朝着获得更高奖励的方向更新,又不至于因更新幅度过大而破坏了策略的稳定性。
四、PPO(Proximal Policy Optimization)

PPO 的核心思想是在策略更新时,限制新旧策略之间的差异,防止更新幅度过大导致策略性能不稳定。为此,它提出了两种实现方式:PPO-penalty 和 PPO-clip。
PPO-penalty:在目标函数中添加了一个惩罚项,该惩罚项基于新旧策略之间的KL散度。
PPO-clip:对策略比率 进行裁剪,使其在 [1 - ϵ, 1 + ϵ] 范围内。这样可以限制新策略与旧策略的偏离程度,避免更新幅度过大。
TRPO 通过严格的数学推导来保证策略更新的稳定性,但其实现较为复杂,计算成本较高。因为不知道下一步的策略到底是什么。
PPO 则在保证策略更新稳定性的基础上,通过更简单的方式(惩罚项或裁剪策略比率)实现了类似的效果,同时提高了算法的效率和易用性。
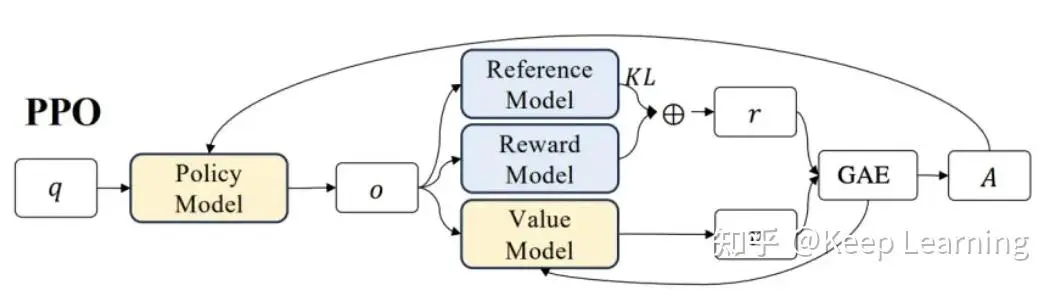
4.1 流程
-
采样动作:在当前状态sₜ下(即未更新前的策略模型π旧和价值模型V旧),对一个样本的提示q,使用策略模型(Actor Model)进行一次采样生成动作aₜ,即一次“动作”。
-
计算即时奖励:使用奖励模型计算动作aₜ的分数,同时计算参考模型与当前策略模型的KL散度,将两者结合起来作为即时奖励r。
-
计算当前收益:使用价值模型(Critic Model)来计算每一个token的收益,记为V旧。
-
计算优势A:根据即时奖励和后续tokens的分数影响,计算本次采样的优势(累积收益)。优势A结合了当前token的分数和后续tokens的影响。
-
策略更新比例:策略模型对q进行一次新的生成π(aₜ|sₜ),计算与旧策略π旧相比的更新比例:rₜ(θ)=π(aₜ|sₜ)/π旧(aₜ|sₜ)。
-
调整更新比例:当优势A>0时,表示本次采样的动作是正收益的(质量较好),尽量提升rₜ(θ);反之当A<0时,尽量降低rₜ(θ)。
-
裁剪更新比例:为了避免训练不稳定,对rₜ(θ)进行裁剪,上下限控制在一个合理范围内(类似梯度裁剪):Lclip(πθ)=E[min(rₜ(θ)Aₜ,clip(rₜ(θ),1−ε,1+ε)Aₜ)]。
-
更新值函数:价值模型对新的采样π(aₜ|sₜ)进行价值评估V新,并使其尽量靠近参考奖励R=A+V旧。同样进行裁剪:L(Vφ)=E[max[(V新−R)², (clip(V新,V旧−ε,V旧+ε)−R)²]]。
-
更新模型:使用两个损失函数分别更新策略模型πθ和价值模型Vφ。
-
完成本轮训练:循环步骤5-9,完成本轮PPO训练:用新的策略模型和价值模型替换旧的,即π旧←πθ,V旧←V新。
-
进入下一批次训练:使用更新后的策略模型和价值模型开始下一批次的训练。
4.2 广义优势估计(GAE)

在估计下一步策略时,并不知道下一步到底是什么,目前有蒙特卡洛和时序差分方法,前者对每一步进行模拟,后者走一步看一步。

GAE通过引入参数 λ,将不同步数的优势估计进行加权求和,从而在方差和偏差之间取得平衡。当 λ=0 时,GAE退化为单步时序差分估计;当 λ→1 时,GAE接近蒙特卡洛估计。通过调整 λ 的值,可以在降低方差和增加偏差之间进行权衡。

4.3 RM的训练

五、GRPO(Group Relative Policy Optimization)
GRPO 的核心思想是通过组内相对奖励来估计基线(baseline),从而避免使用额外的价值函数模型。

策略函数跟PPO-clip一样。
5.1 流程
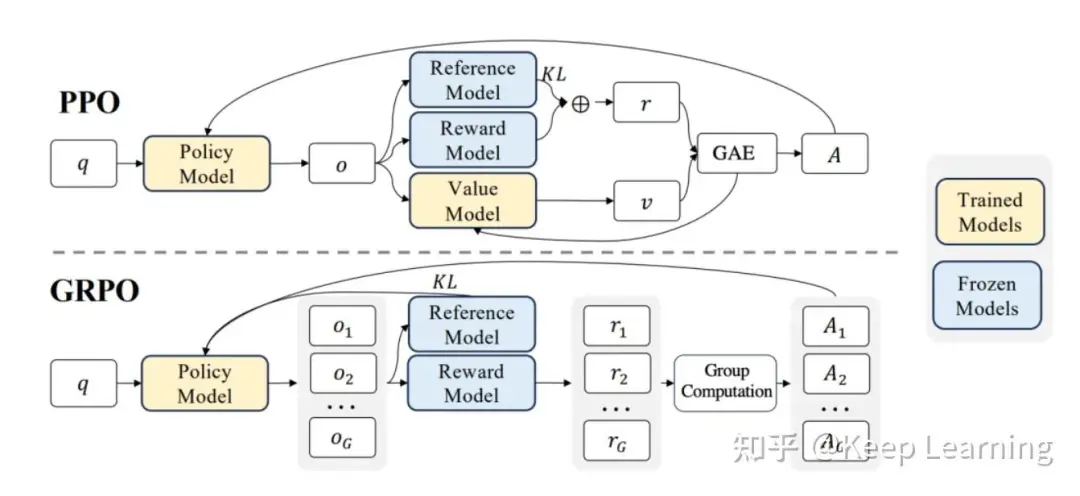
1.对一个样本的Prompt q,使用Policy Model进行G次生成
2.同样地,也进行G次生成,与Policy Model进行KL散度计算,KL散度可以理解为两者的预测token概率分布差距,跟其他方法都是类似作用,避免Policy Model训练不稳定
3.再使用Reward Model对Policy Model的这G次生成进行打分。参考DeepSeek-R1的做法,甚至可以不需要Reward Model,只需要奖励函数,比如代码问题,可以根据模型生成的代码是否能够运行,有标准答案的数学问题,从模型的生成中提取的答案是否正确,来给予一定的奖励分数
4.最后平均的KL散度和奖励分数作为Loss去更新Policy Model
六、DPO(Direct Preference Optimization)

- 训练数据是与上述奖励模型一样的偏好对数据。
- Policy Model的目标是尽量拉开chosen(preferred)样本与rejected(dispreferred)样本的token概率差距。
- 同时Policy Model的概率差距与Reference Model的概率差距不要太过于大,避免训练不稳定。
- Policy Model在DPO中,其实也是充当了Reward Model的角色,概率差可以认为是对应的应得奖励收益。

参考文献
【【大白话04】一文理清强化学习PPO和GRPO算法流程 | 原理图解】 https://www.bilibili.com/video/BV15cZYYvEhz/?share_source=copy_web&vd_source=29af710704ae24d166ca951b4c167d53
https://blog.csdn.net/Ever_____/article/details/139304624
https://mp.weixin.qq.com/s/UClxnbCMKP8IRa0OMWPPtw
相关文章:
PG,TRPO,PPO,GRPO,DPO原理梳理
强化学习方法的分类 一、基础概念 Policy Model(Actor Model):根据输入文本,预测下一个token的概率分布,输出下一个token也即Policy模型的“动作”。该模型需要训练,是我们最终得到的模型,并由上…...
Cursor新版0.49.x发布
小子看到 Cursor 0.49.x 版本正式发布,截止今天已经有两个小patch版本!本次更新聚焦于 自动化Rules生成、改进的 Agent Terminal 以及 MCP 图像支持,并带来了一系列旨在提升编码效率和协作能力的改进与修复。 以下是本次更新的详细内容&…...

ZLMediaKit 和 SRS的区别,哪个更好用?
ZLMediaKit 和 SRS(Simple RTMP Server)是两个主流的开源流媒体服务器框架,各自在功能、性能、适用场景等方面存在显著差异。以下是两者的对比分析及选择建议: 一、核心差异对比 协议支持 ZLMediaKit:支持更广泛的流媒…...

每日算法-250419
每日算法 - 2024年4月19日 记录今天完成的LeetCode算法题。 1710. 卡车上的最大单元数 题目描述 思路 贪心 解题过程 目标是最大化卡车可以装载的单元总数。根据贪心策略,我们应该优先装载单位体积(每个箱子)包含单元数 (numberOfUnitsPerB…...
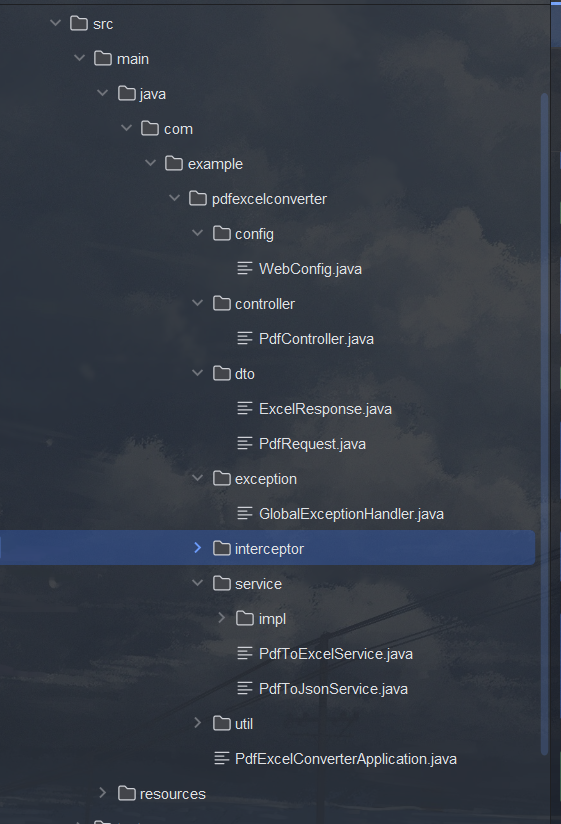
PDF转excel+json ,vue3+SpringBoot在线演示+附带源码
在线演示地址:Vite Vuehttp://www.xpclm.online/pdf-h5 源码gitee前后端地址: javapdfexcel: javaPDF转excelhttps://gitee.com/gaiya001/javapdfexcel.git 盖亚/vuepdfhttps://gitee.com/gaiya001/vuepdf.git 后续会推出 前端版本跟nestjs版本 识别复…...

如何高效使用 Text to SQL 提升数据分析效率?四个关键应用场景解析
数据分析师和业务人员常常面临这样的困境:有大量数据等待分析,但 SQL 编写却成为效率瓶颈。即使对于经验丰富的数据分析师来说,编写复杂 SQL 查询也需要耗费大量时间;而对于不具备 SQL 专业知识的业务人员,数据分析则更…...
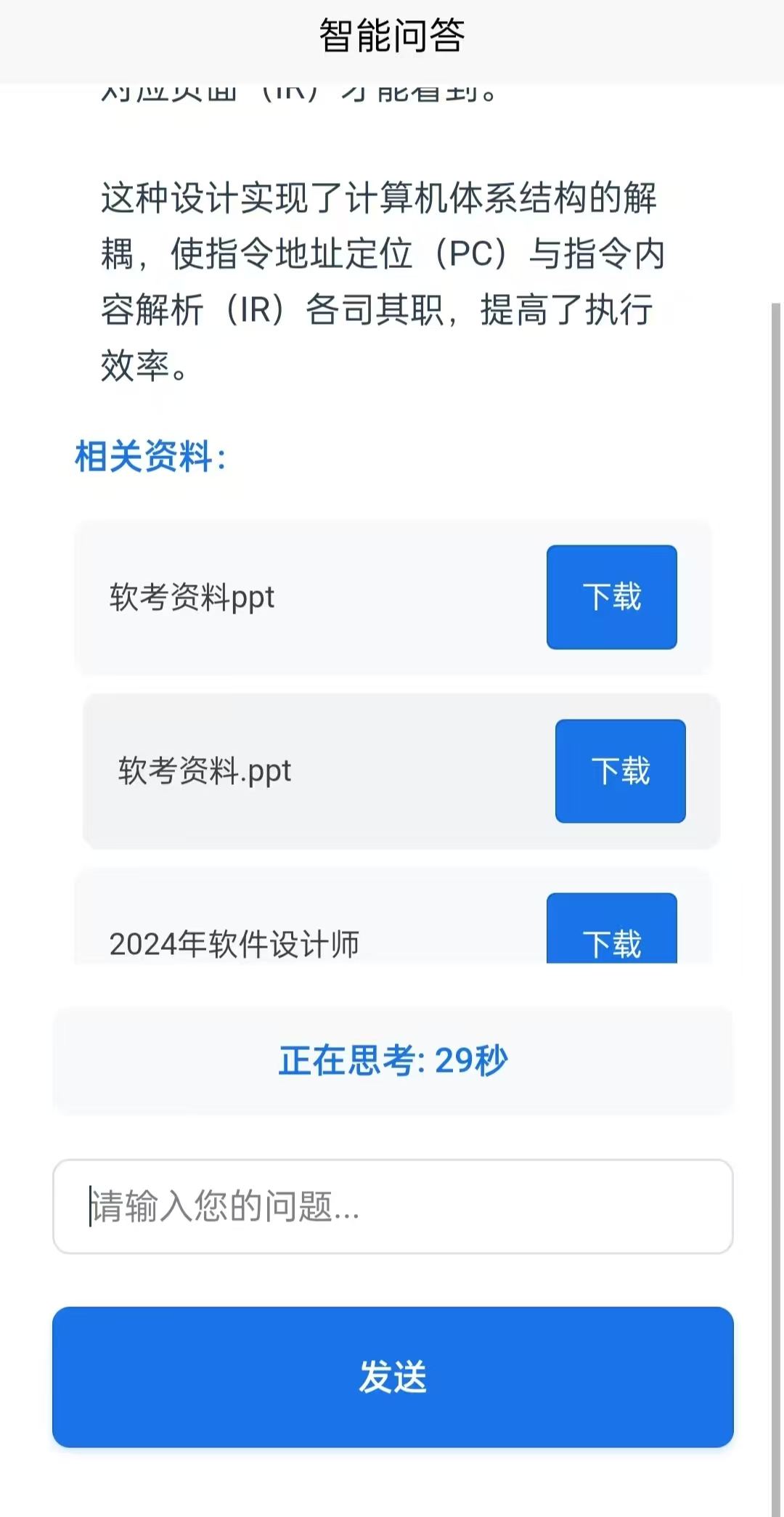
分享一个DeepSeek+自建知识库实现人工智能,智能回答高级用法。
这个是我自己搞的DeepSeek大模型自建知识库相结合到一起实现了更强大的回答问题能力还有智能资源推荐等功能。如果感兴趣的小伙伴可以联系进行聊聊,这个成品已经有了实现了,所以可以融入到你的项目,或者毕设什么的还可以去参加比赛等等。 1.项…...

突破速率瓶颈:毫米波技术如何推动 5G 网络迈向极限?
突破速率瓶颈:毫米波技术如何推动 5G 网络迈向极限? 引言 5G 网络的普及,已经让我们告别了“加载中”时代,实现了更快的数据传输、更低的延迟和更高的设备连接密度。而在 5G 技术的核心中,毫米波(mmWave&…...
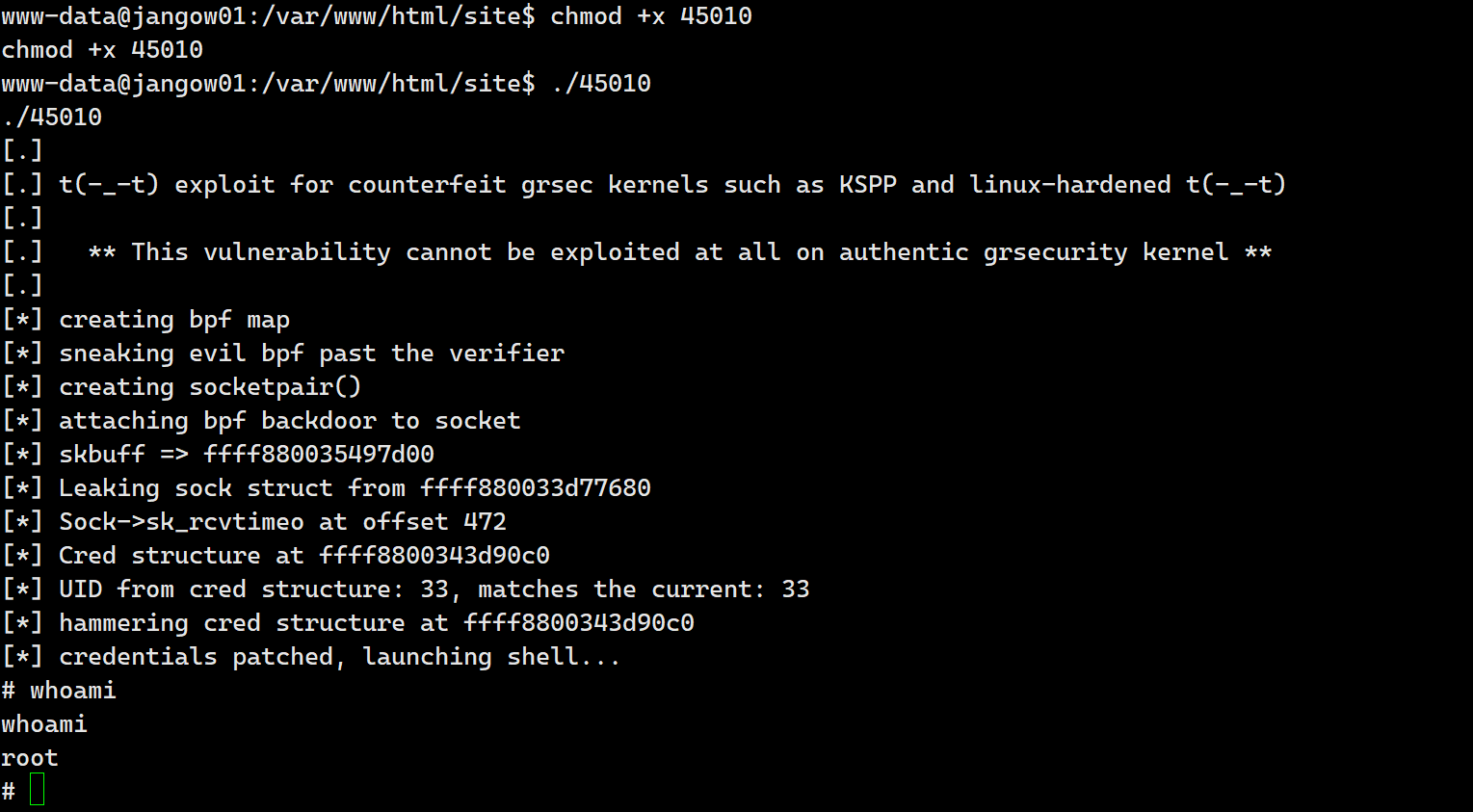
jangow靶机笔记(Vulnhub)
环境准备: 靶机下载地址: https://download.vulnhub.com/jangow/jangow-01-1.0.1.ova kali地址:192.168.144.128 靶机(jangow)地址:192.168.144.180 一.信息收集 1.主机探测 使用arp-scan进行主机探…...
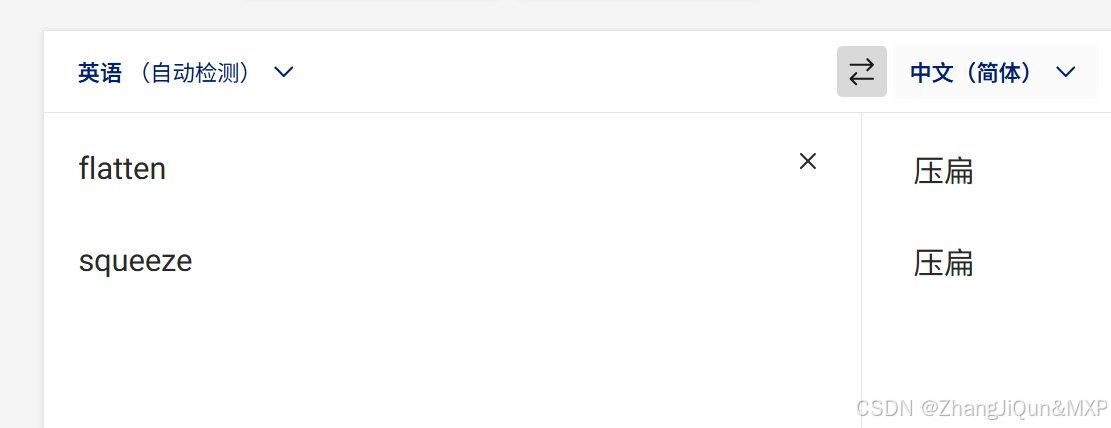
PyTorch `flatten()` 和 `squeeze()` 区别
PyTorch flatten() 和 squeeze() 区别 在 PyTorch 里,flatten() 和 squeeze(0) 是两个不同的张量操作, 1. flatten() 方法 flatten() 方法用于把一个多维张量展开成一维张量。它会将张量里的所有元素按顺序排列成一个一维序列。 语法 torch.flatten(input, start_dim=...

洛谷P1312 [NOIP 2011 提高组] Mayan 游戏
题目 #算法/进阶搜索 思路: 根据题意,我们可以知道,这题只能枚举,剪枝,因此,我们考虑如何枚举,剪枝. 首先,我们要定义下降函数down(),使得小木块右移时,能够下降到最低处,其次,我们还需要写出判断函数,判断矩阵内是否有小木块没被消除.另外,我们还需要消除函数,将矩阵内三个相连…...

thinkphp6 + oracle 数据库连接 表名、字段名大小写和字符集
之前一直用tp6连接的都是mysql数据,近期一个项目需要连接oracle数据,理论上thinkphp是支持oracle数据库的,但是由于oracle的数据库编码方式和字段表名大小写与mysql不一样。首先oracle的表名默认是全大写的,可是如果使用tp6连接的…...
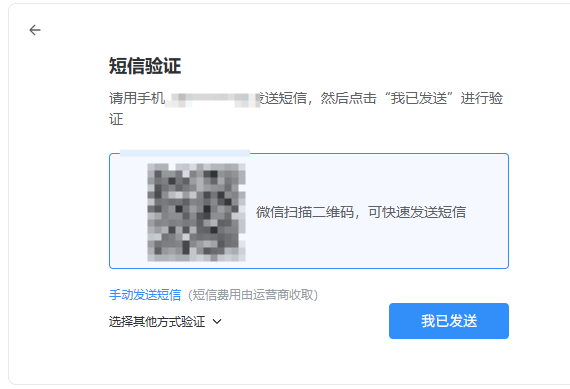
wordpress SMTP配置qq邮箱发送邮件,新版QQ邮箱授权码获取方法
新版的QQ邮箱界面不同了,以下是新版的设置方法: 1. 进入邮箱后,点右上角的设置图标: 2. 左下角的菜单里,选择“账号与安全” : 3. 然后如下图,开启SMTP 服务: 4. 按提示验证短信&am…...

Django 实现服务器主动给客户端发送消息的几种常见方式及其区别
Django Channels 原理 :Django Channels 是 Django 的一个扩展,它通过使用 WebSockets 等协议来处理长连接,使服务器能够与客户端建立持久连接,从而实现双向通信。一旦连接建立,服务器可以随时主动向客户端发送消息。…...

2025年最新版 Git和Github的绑定方法,以及通过Git提交文件至Github的具体流程(详细版)
文章目录 Git和Github的绑定方法与如何上传至代码仓库一. 注册 GitHub 账号二.如何创建自己的代码仓库:1.登入Github账号,完成登入后会进入如下界面:2.点击下图中红色框选的按钮中的下拉列表3.选择New repostitory4.进入创建界面后࿰…...

基于LSTM-AutoEncoder的心电信号时间序列数据异常检测(PyTorch版)
心电信号(ECG)的异常检测对心血管疾病早期预警至关重要,但传统方法面临时序依赖建模不足与噪声敏感等问题。本文使用一种基于LSTM-AutoEncoder的深度时序异常检测框架,通过编码器-解码器结构捕捉心电信号的长期时空依赖特征&#…...
JavaScript中的Event事件对象详解
一、事件对象(Event)概述 1. 事件对象的定义 event 对象是浏览器自动生成的对象,当用户与页面进行交互时(如点击、键盘输入、鼠标移动等),事件触发时就会自动传递给事件处理函数。event 对象包含了与事件…...

极狐GitLab 用户 API 速率限制如何设置?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 用户 API 速率限制 (BASIC SELF) 您可以为对 Users API 的请求配置每个用户的速率限制。 要更改速率限制: 1.在…...

王牌学院,25西电通信工程学院(考研录取情况)
1、通信工程学院各个方向 2、通信工程学院近三年复试分数线对比 学长、学姐分析 由表可看出: 1、信息与通信工程25年相较于24年上升5分、军队指挥学25年相较于24年上升30分 2、新一代电子信息技术(专硕)25年相较于24年下降25分、通信工程&…...
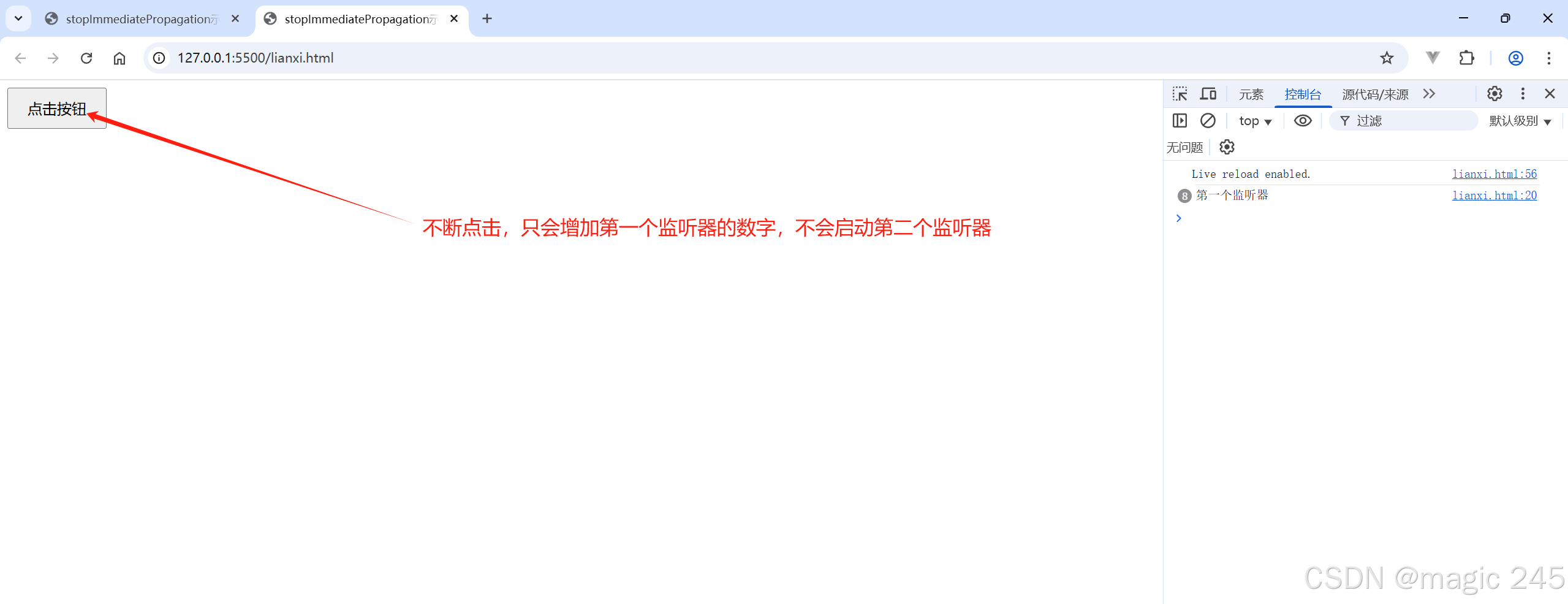
深入理解 Java 多线程:锁策略与线程安全
文章目录 一、常见的锁策略1. 乐观锁&&悲观锁2. 读写锁3. 重量级锁&&轻量级锁4. 自旋锁5. 公平锁&&不公平锁6. 可重入锁 && 不可重入锁 二、CAS1. 什么是 CAS2. CAS 是怎么实现的3.CAS 有哪些应用1) 实现原子类2) 实现自旋锁 4. CAS 的 ABA 问…...

Java数据结构——ArrayList
Java中ArrayList 一 ArrayList的简介二 ArrayList的构造方法三 ArrayList常用方法1.add()方法2.remove()方法3.get()和set()方法4.index()方法5.subList截取方法 四 ArrayList的遍历for循环遍历增强for循环(for each)迭代器遍历 ArrayList问题及其思考 前言 ArrayList是一种 顺…...
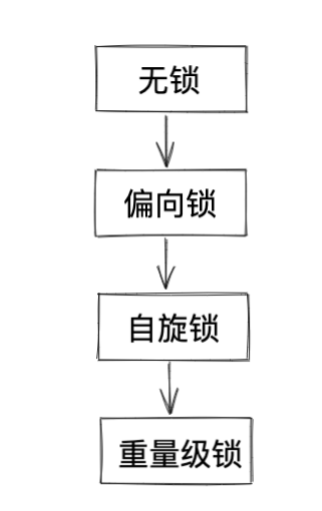
科学量化AI对品牌产品印象 首个AI印象(AII)指数发布
2025年4月18日,营销传播数据研究领先机构四度传播研究院(SAC),正式推出了量化AI大模型对产品整体印象的AI印象,简称AII(ARTIFICIAL INTELLIGENCE IMPRESSIONS),同时发布了首个“汽车AI印象榜”。为企业和消…...

Python语法系列博客 · 第8期[特殊字符] Lambda函数与高阶函数:函数式编程初体验
上一期小练习解答(第7期回顾) ✅ 练习1:找出1~100中能被3或5整除的数 result [x for x in range(1, 101) if x % 3 0 or x % 5 0]✅ 练习2:生成字符串长度字典 words ["apple", "banana", "grape…...
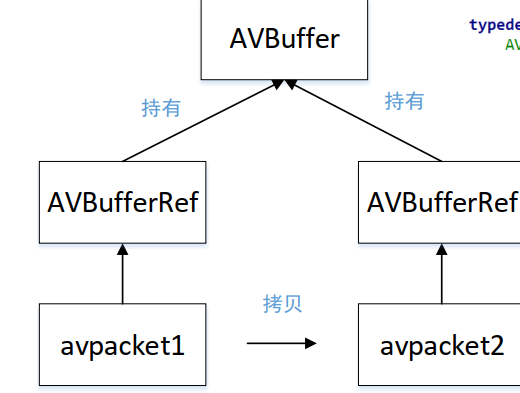
FFmpeg 硬核指南:从底层架构到播放器全链路开发实战 基础
目录 1.ffmpeg的基本组成2.播放器的API2.1 复用器阶段2.1.1 分配解复用上下文2.1.2 文件信息操作2.1.3 综合示例 2. 2 编解码部分2.2.1 分配解码器上下文2.2.2编解码操作2.2.3 综合示例 3 ffmpeg 内存模型3.1 基本概念3.2API 1.ffmpeg的基本组成 模块名称功能描述主要用途AVFo…...

大数据建模与评估
文章目录 实战案例:电商用户分群与价值预测核心工具与库总结一、常见数据挖掘模型原理及应用(一)决策树模型(二)随机森林模型(三)支持向量机(SVM)模型(四)K - Means聚类模型(五)K - Nearest Neighbors(KNN)模型二、运用Python机器学习知识实现数据建模与评估(一…...
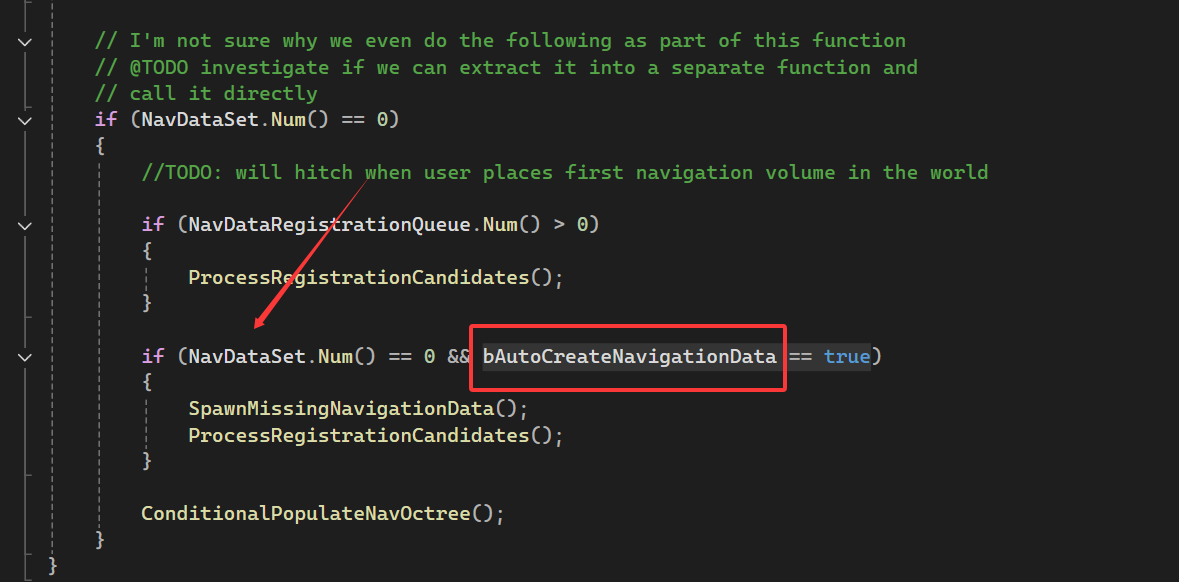
UE5有些场景的导航生成失败解决方法
如果导航丢失,就在项目设置下将: 即可解决问题: 看了半个小时的导航生成代码发现,NavDataSet这个数组为空,导致异步构建导航失败。 解决 NavDataSet 空 无法生成如下: 当 NavDataSet 为空的化 如果 bAut…...

MCP(Model Context Protocol 模型上下文协议)科普
MCP(Model Context Protocol,模型上下文协议)是由人工智能公司 Anthropic 于 2024年11月 推出的开放标准协议,旨在为大型语言模型(LLM)与外部数据源、工具及服务提供标准化连接,从而提升AI在实际…...

健康养生指南
在快节奏的现代生活中,健康养生成为人们关注的焦点。它不仅关乎身体的强健,更是提升生活质量、预防疾病的关键。掌握科学的养生方法,能让我们在岁月流转中始终保持活力。 饮食是健康养生的基础。遵循 “均衡膳食” 原则,每日饮食需…...

Linux系统:进程终止的概念与相关接口函数(_exit,exit,atexit)
本节目标 理解进程终止的概念理解退出状态码的概念以及使用方法掌握_exit与exit函数的用法以及区别atexit函数注册终止时执行的函数相关宏 一、进程终止 进程终止(Process Termination)是指操作系统结束一个进程的执行,回收其占用的资源&a…...
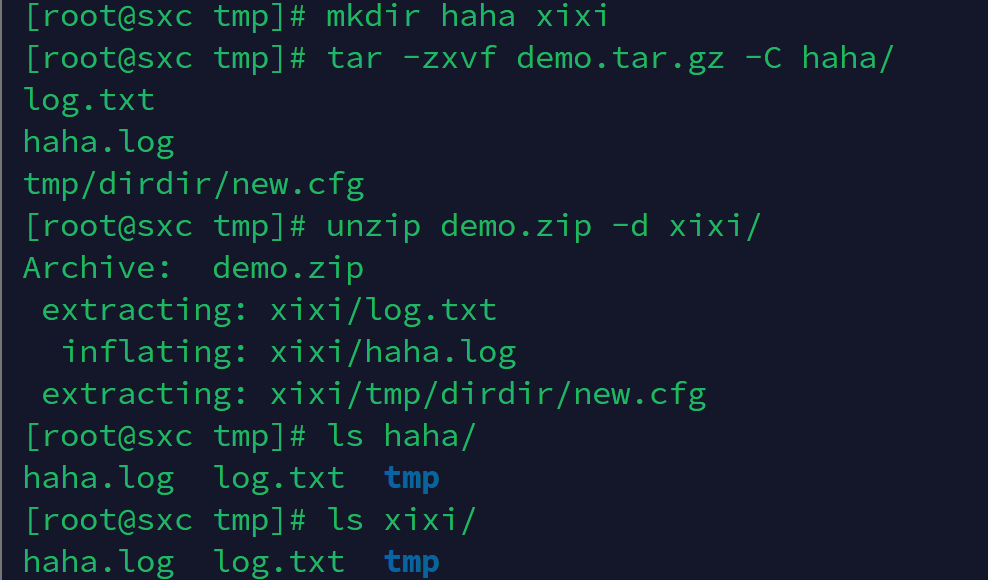
Linux下 文件的查找、复制、移动和解压缩
1、在/var/log目录下创建一个hehe.log的文件,其文件内容是: myhostname ghl mydomain localdomain relayhost [smtp.qq.com]:587 smtp_use_tls yes smtp_sasl_auth_enable yes smtp_sasl_security_options noanonymous smtp_sasl_tls_security_opt…...